
Short-Term Prediction of Multi-Energy Loads Based on Copula Correlation Analysis and Model Fusions


Abstract
:1. Introduction
- (1)
- A two-stage approach to load feature identification and extraction is proposed. To address the challenges associated with the cumbersome and intricate threshold selection in the conventional DP algorithm, which is difficult to quantify and necessitates adaptive adjustments for different original datasets, the DP algorithm is improved by a fuzzy optimization threshold. After the initial feature extraction, the concept of statistical frequency distribution is applied to perform a secondary extraction of the collective characteristics of this load curve cluster to enhance the process of load feature identification and extraction.
- (2)
- Through the utilization of dynamically optimized Copula correlation measures, the input feature set of the multi-energy short-term forecasting model can be expanded. This integration ensures the thorough inclusion of interrelated characteristics among multi-energy loads into the predictive model, thereby effectively supplementing the model’s input information.
- (3)
- A multi-energy load forecasting model based on a model fusion framework is proposed. A Bayesian regularization (BR)-NARX (BR-NARX) neural network is used for the first prediction step, which uses BR to further optimize the performance of the traditional NARX model. Subsequently, a secondary forecasting model builds on the output of the primary model, utilizing a GA-optimized extreme learning machine (ELM) for separate multi-energy, short-term predictions of electricity, heat, and cooling loads. This approach ensures the comprehensive exploration of multi-energy load characteristics and elevates the accuracy of multi-energy, short-term load forecasting.
2. Materials and Methods
2.1. Two-Stage Optimization Method for Features and Extraction for Multi-Energy Loads
2.1.1. Initial Feature Extraction Based on a Fuzzy Optimization-Enhanced DP Algorithm
Average Matching Degree
Average Compression Ratio
Proportion Coefficients a and b
2.1.2. Secondary Feature Extraction Based on Statistical Frequency Distribution
2.2. Analysis of Multi-Energy Load Correlation Characteristics Based on the Copula Method
2.2.1. Definition of the Copula Function
2.2.2. Correlation Analysis Based on Copula Functions
2.2.3. Analysis of Multi-Energy Load Characteristics Based on Copula Methods
- Multi-energy load data are normalized in the [0, 1] interval to ensure data uniformity.
- The kernel density estimation function is calculated using the MLK method, which determines the marginal density function of the variable sequence.
- To obtain static correlation coefficients, the marginal density copula functions are used to calculate the extreme points of the likelihood function.
- To obtain dynamic correlation coefficients, the dynamic copula distributions are used to construct the likelihood function considering the corresponding evolution equation parameters (, , and ).
- Once the maximum likelihood estimates and the corresponding evolution equation parameters are obtained, they are substituted into the evolution equation parameters to calculate the required time-varying cross-correlation coefficients.
- Simultaneously, the selected copula functions are optimized based on the maximum likelihood estimate, and later the optimal copula model is obtained by comparing the corresponding AIC indexes.
2.3. Short-Term Forecasting Framework for Multi-Energy Loads Based on Model Fusion
2.3.1. BR-NARX Model
2.3.2. Combined Genetic Algorithm and Extreme Learning Machine Model
2.3.3. Overall Modeling Framework
3. Results and Discussion
3.1. Copula-Related Characteristic Analysis Based on Multi-Energy Loads
3.2. Model Parameter
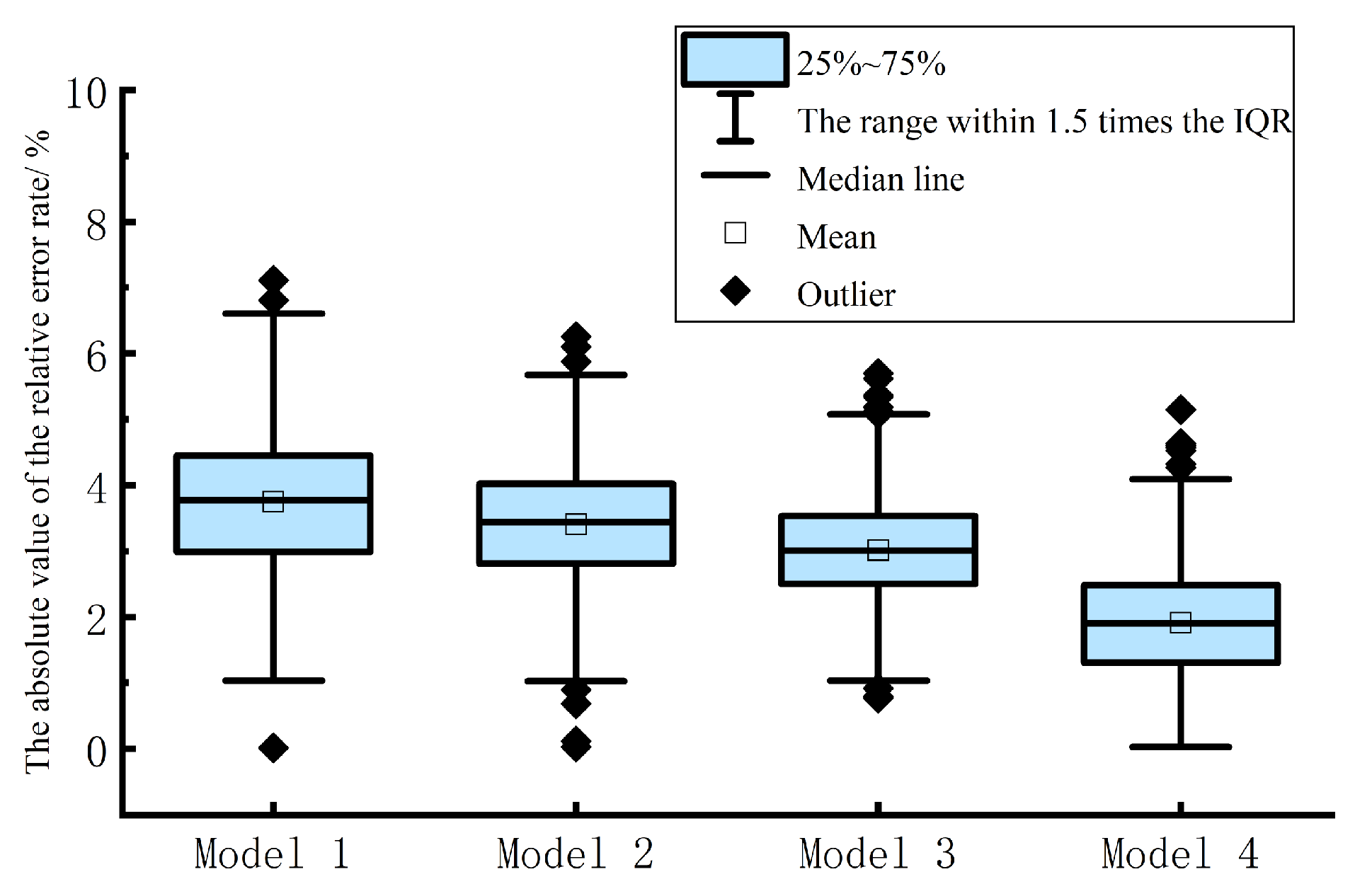
3.3. Evaluation of the Model Performance
3.4. Results
4. Conclusions
- (1)
- At present, the existing short-term multi-energy load prediction research is mostly modeled from the perspective of a single energy form output, and in future comprehensive energy system multi-energy load forecasting research, the multi-objective prediction should be studied accordingly, so as to better link the coupling characteristics between multi-energy loads to improve the corresponding prediction effect.
- (2)
- The multi-energy load represented by the intelligent building building is transmitted, distributed and converted by the energy topology network architecture and energy coupling conversion device equipment in the park, so there are not only correlation characteristics at the time scale, but also correlation characteristics at the spatial scale, and the next step is to analyze the load characteristics from the perspective of spatiotemporal correlation to more accurately characterize the coupling conversion characteristics of multi-energy loads.
- (3)
- The existing short-term multi-energy load forecasting research has less analysis and less consideration from the perspective of multi-energy marketization. In the new environment of the development of a multi-energy market mechanism, how to consider the characteristics of multi-energy load brought by marketization will be the next meaningful research direction.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Nti, I.K.; Teimeh, M.; Nyarko-Boateng, O.; Adekoya, A.F. Electricity load forecasting: A systematic review. J. Electr. Syst. Inf. Technol. 2020, 7, 13. [Google Scholar] [CrossRef]
- Hammad, M.A.; Jereb, B.; Rosi, B.; Dragan, D. Methods and models for electric load forecasting: A comprehensive review. Logist. Supply Chain. Sustain. Glob. Chall. 2020, 11, 51–76. [Google Scholar] [CrossRef]
- Kim, J.H.; Seong, N.C.; Choi, W. Cooling load forecasting via predictive optimization of a non-linear autoregressive exogenous (NARX) neural network model. Sustainability 2019, 11, 6535. [Google Scholar] [CrossRef]
- Fu, G. Deep belief network based ensemble approach for cooling load forecasting of air-conditioning system. Energy 2018, 148, 269–282. [Google Scholar] [CrossRef]
- Li, F.; Zheng, H.; Li, X.; Yang, F. Day-ahead city natural gas load forecasting based on decomposition-fusion technique and diversified ensemble learning model. Appl. Energy 2021, 303, 117623. [Google Scholar] [CrossRef]
- Lu, H.; Azimi, M.; Iseley, T. Short-term load forecasting of urban gas using a hybrid model based on improved fruit fly optimization algorithm and support vector machine. Energy Rep. 2019, 5, 666–677. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Y.; Cao, L.; Si, H. A forecasting method of district heat load based on improved wavelet neural network. J. Energy Resour. Technol. 2020, 142, 1–29. [Google Scholar] [CrossRef]
- Kannari, L.; Kiljander, J.; Piira, K.; Piippo, J.; Koponen, P. Building heat demand forecasting by training a common machine learning model with physics-based simulator. Forecasting 2021, 3, 290–302. [Google Scholar] [CrossRef]
- Zhu, J.; Dong, H.; Zheng, W.; Li, S.; Huang, Y.; Xi, L. Review and prospect of data-driven techniques for load forecasting in integrated energy systems. Appl. Energy 2022, 321, 119269. [Google Scholar] [CrossRef]
- Ahmad, T.; Chen, H. Short and medium-term forecasting of cooling and heating load demand in building environment with data-mining based approaches. Energy Build. 2018, 166, 460–476. [Google Scholar] [CrossRef]
- Tan, Z.; De, G.; Li, M.; Lin, H.; Yang, S.; Huang, L.; Tan, Q. Combined electricity-heat-cooling-gas load forecasting model for integrated energy system based on multi-task learning and least square support vector machine. J. Clean. Prod. 2019, 248, 119252. [Google Scholar] [CrossRef]
- Zhang, L.; Shi, J.; Wang, L.; Xu, C. Electricity, heat, and gas load forecasting based on deep multitask learning in industrial-park integrated energy system. Entropy 2020, 22, 1355. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, Z.; Song, Z. A comparative study of the data-driven day-ahead hourly provincial load forecasting methods: From classical data mining to deep learning. Renew Sustain. Energy Rev. 2020, 119, 109632. [Google Scholar] [CrossRef]
- Chen, J.; Li, T.; Zou, Y.; Wang, G.; Ye, H.; Lv, F. An ensemble feature selection method for short-term electrical load forecasting. In Proceedings of the 2019 IEEE 3rd Conference on Energy Internet and Energy System Integration, Changsha, China, 8–10 October 2019; Volume EI2, pp. 1429–1432. [Google Scholar] [CrossRef]
- Salami, M.; Sobhani, F.M.; Ghazizadeh, M.S. A hybrid short-term load forecasting model developed by factor and feature selection algorithms using improved grasshopper optimization algorithm and principal component analysis. Electr. Eng. 2020, 102, 437–460. [Google Scholar] [CrossRef]
- Yahaya, A.S.; Javaid, N.; Latif, K.; Rehman, A. An enhanced very short-term load forecasting scheme based on activation function. In Proceedings of the International Conference on Computer and Information Sciences (ICCIS), Aljouf, Saudi Arabia, 3–4 April 2019; IEEE Publications: New York, NY, USA, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Kalkstein, L.S.; Tan, G.; Skindlov, J.A. An evaluation of three clustering procedures for use in synoptic climatological classification. J. Clim. Appl. Meteor. 1987, 26, 717–730. [Google Scholar] [CrossRef]
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartographica 1973, 10, 112–122. [Google Scholar] [CrossRef]
- Visvalingam, M.; Whyatt, J.D. The Douglas-Peucker algorithm for line simplification: Re-evaluation through visualization. Comput Graph Forum. 1990, 9, 213–225. [Google Scholar] [CrossRef]
- Hershberger, J.; Snoeyink, J. Speeding up the Douglas-Peucker line simplification algorithm. In Proceedings of the 5th International Syrnposium on Spatial Data Handling, Charleston, SC, USA, 3–7 August 1992; pp. 134–143. [Google Scholar]
- Hershberger, J.; Snoeyink, J. An O(n log n) implementation of the Douglas-Peucker algorithm for line simplification. In Proceedings of the 10th Annual Symposium on Computational Geometry, New York, NY, USA, 6–8 June 1994; pp. 383–384. [Google Scholar]
- van der Vlist, R.; Taal, C.; Heusdens, R. Tracking recurring patterns in time series using dynamic time warping. In Proceedings of the 27th European Signal Processing Conference (EUSIPCO), A Coruña, Spain, 2–6 September 2019; IEEE: New York, NY, USA, 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Luo, M.; Tian, Y.; Li, C.; Chen, Y. The non-linear test and empirically study on the financial crisis contagion based on copula method. In Proceedings of the 2nd International Conference on Artificial Intelligence, Management Science and Electronic Commerce (AIMSEC), Zhengzhou, China, 8–10 August 2011; IEEE: New York, NY, USA, 2011; pp. 2587–2591. [Google Scholar]
- Xu, Y.; Yuan, Y. Analysis of aggregated wind power dependence based on optimal vine copula. In Proceedings of the IEEE Innovative Smart Grid Technologies, Gramado, Brazil, 15–18 September 2019; Asia Publishing: Hong Kong, China, 2019; pp. 1788–1792. [Google Scholar] [CrossRef]
- Patton, A.J. Modelling asymmetric exchange rate dependence. Int. Econ. Rev. 2006, 47, 527–556. [Google Scholar] [CrossRef]
- Patton, A.J. Estimation of multivariate models for time series of possibly different lengths. J. Appl. Econ. 2006, 21, 147–173. [Google Scholar] [CrossRef]
- Leontaritis, I.J.; Billings, S.A. Input-output parametric models for non-linear systems part I: Deterministic non-linear systems. Int. J. Control. 1985, 41, 303–328. [Google Scholar] [CrossRef]
- Leontaritis, I.J.; Billings, S.A. Input-output parametric models for non-linear systems part II: Stochastic non-linear systems. Int. J. Control. 1985, 41, 329–344. [Google Scholar] [CrossRef]
- Wang, H.; Yeung, D.Y. Towards Bayesian deep learning: A framework and some existing methods. IEEE Trans. Knowl. Data Eng. 2016, 28, 3395–3408. [Google Scholar] [CrossRef]
- Mackay, D.J.C. Bayesian interpolation. Neural Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Copula Function | AIC | Maximum Likelihood Estimate |
|---|---|---|
| Static N-copula | 553.458 | −311.165 |
| Dynamic N-copula | −1725.336 | 851.325 |
| Static T-copula | 366.878 | −197.563 |
| Dynamic T-copula | −1935.928 | 937.112 |
| Static Clayton copula | 627.436 | −407.601 |
| Dynamic Clayton copula | −2817.727 | 1329.752 |
| Static SJC copula | −1622.901 | 677.244 |
| Dynamic SJC copula | −3284.187 | 1648.263 |
| Data | The Content of the Data |
|---|---|
| Sampling interval of load data | The sampling interval is 15 min, and the daily load curve is composed of 96 load points from 00:0 to 23:45. |
| Factors affecting the load | (1) Meteorological information Daily temperature, humidity, air pressure, wind direction and wind speed (2) Working days, rest days and holidays information |
| Training set | 80% of the previous data |
| Testing set | 20% of the previous data |
| The reference input of the load at time t to be predicted |
(1) The load at time t of the preceding 3 days with the same load category (considering similar days) (2) The load at time t − 7 to t − 1 (considering the relevant time) (3) Other energy load characteristic information from similar days (4) Meteorological information and day type rule information for both similar days and forecasted days |
| Model | Parameter | Parameter Settings |
|---|---|---|
| BR-NARX | Total number of layers | 3 |
| Number of neurons in hidden layer | 18 | |
| Order of time delay | 7 | |
| GA | Population size | 40 |
| Number of iterations | 200 | |
| Crossover probability | 0.85 | |
| Mutation probability | 0.1 | |
| ELM | Number of neurons in input layer | 190 |
| Number of neurons in hidden layer | 25 | |
| Number of neurons in output layer | 96 |
| Evaluation Index | ERMSE (Electrical/Heating/Cooling) (MW) | EMAPE (Electrical/Heating/Cooling) (%) | ESUMMAPE (%) | AccSUM (%) | |
|---|---|---|---|---|---|
| Prediction Model | |||||
| Group 1 | 1.077/0.066/1.816 | 3.280/4.212/3.411 | 3.519 | 96.329 | |
| Group 2 | 1.078/0.065/1.761 | 3.340/4.137/3.301 | 3.484 | 96.381 | |
| Group 3 | 0.928/0.053/1.533 | 2.831/3.411/2.905 | 2.977 | 96.892 | |
| Group 4 | 0.747/0.047/1.101 | 2.268/2.962/1.998 | 2.299 | 97.544 | |
| Evaluation Index | ERMSE (Electrical/Heating/Cooling) (MW) | EMAPE (Electrical/Heating/Cooling) (%) | ESUMMAPE (%) | AccSUM (%) | |
|---|---|---|---|---|---|
| Prediction Model | |||||
| Group 1 | 1.390/0.078/2.044 | 4.811/4.751/4.596 | 4.713 | 95.199 | |
| Group 2 | 1.320/0.070/1.669 | 4.590/4.267/3.667 | 4.156 | 95.760 | |
| Group 3 | 0.975/0.074/1.488 | 3.308/4.483/3.276 | 3.530 | 96.371 | |
| Group 4 | 0.816/0.053/0.870 | 2.725/3.189/1.705 | 2.410 | 97.431 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, M.; Lin, S.; Dong, K.; Zhang, S. Short-Term Prediction of Multi-Energy Loads Based on Copula Correlation Analysis and Model Fusions. Entropy 2023, 25, 1343. https://doi.org/10.3390/e25091343
Xie M, Lin S, Dong K, Zhang S. Short-Term Prediction of Multi-Energy Loads Based on Copula Correlation Analysis and Model Fusions. Entropy. 2023; 25(9):1343. https://doi.org/10.3390/e25091343
Chicago/Turabian StyleXie, Min, Shengzhen Lin, Kaiyuan Dong, and Shiping Zhang. 2023. "Short-Term Prediction of Multi-Energy Loads Based on Copula Correlation Analysis and Model Fusions" Entropy 25, no. 9: 1343. https://doi.org/10.3390/e25091343
APA StyleXie, M., Lin, S., Dong, K., & Zhang, S. (2023). Short-Term Prediction of Multi-Energy Loads Based on Copula Correlation Analysis and Model Fusions. Entropy, 25(9), 1343. https://doi.org/10.3390/e25091343