Study on Effect of Extraction Techniques and Seed Coat on Proteomic Distribution and Cheese Production from Soybean Milk




Abstract
:1. Introduction
2. Results and Discussion
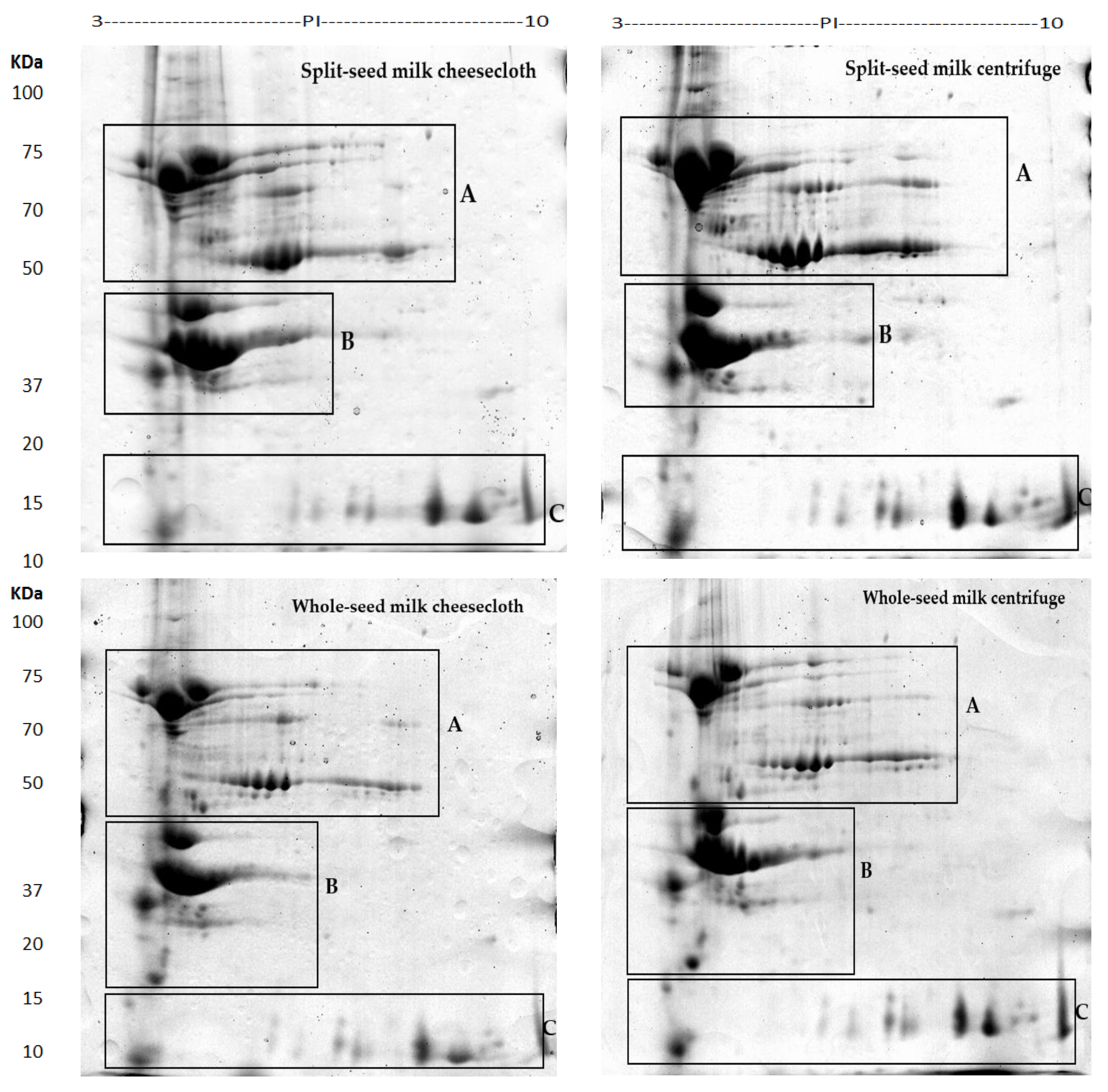
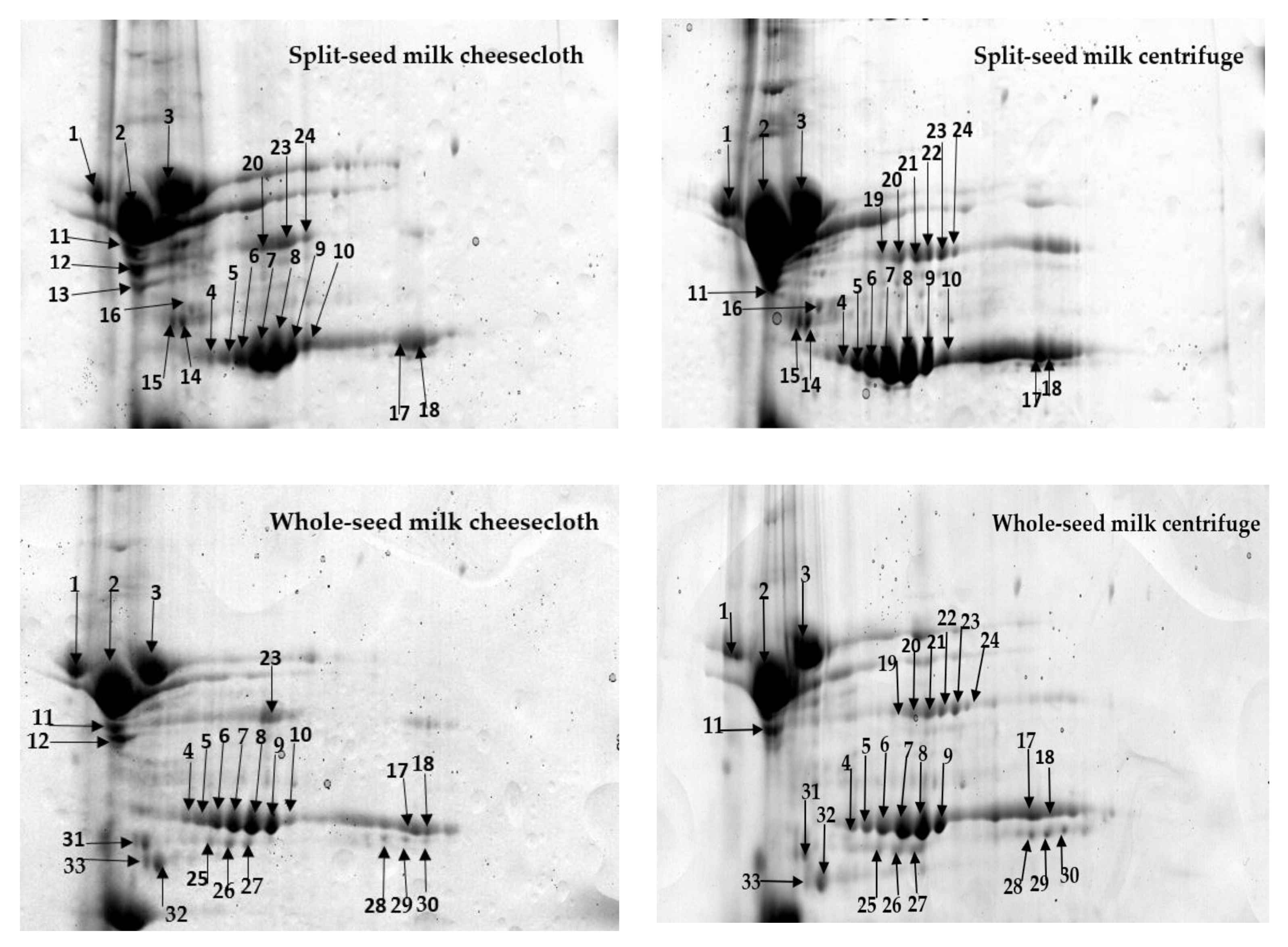
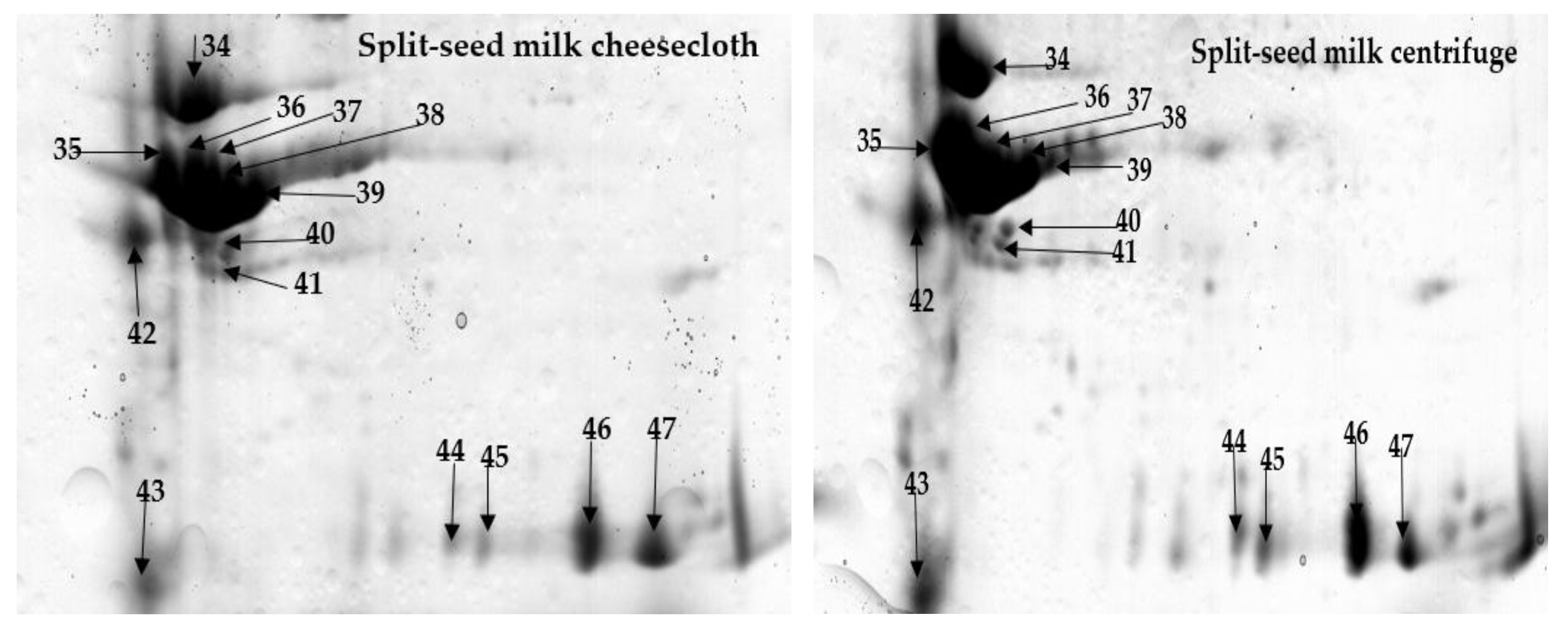
2.1. Comprehensive Protein Profile of Soybean Milk
2.2. Influence of Separation Techniques and Seed Coat on Protein Extractability Form Soybean Milk
2.2.1. Separation Techniques
2.2.2. Seed Type (Split vs. Whole)
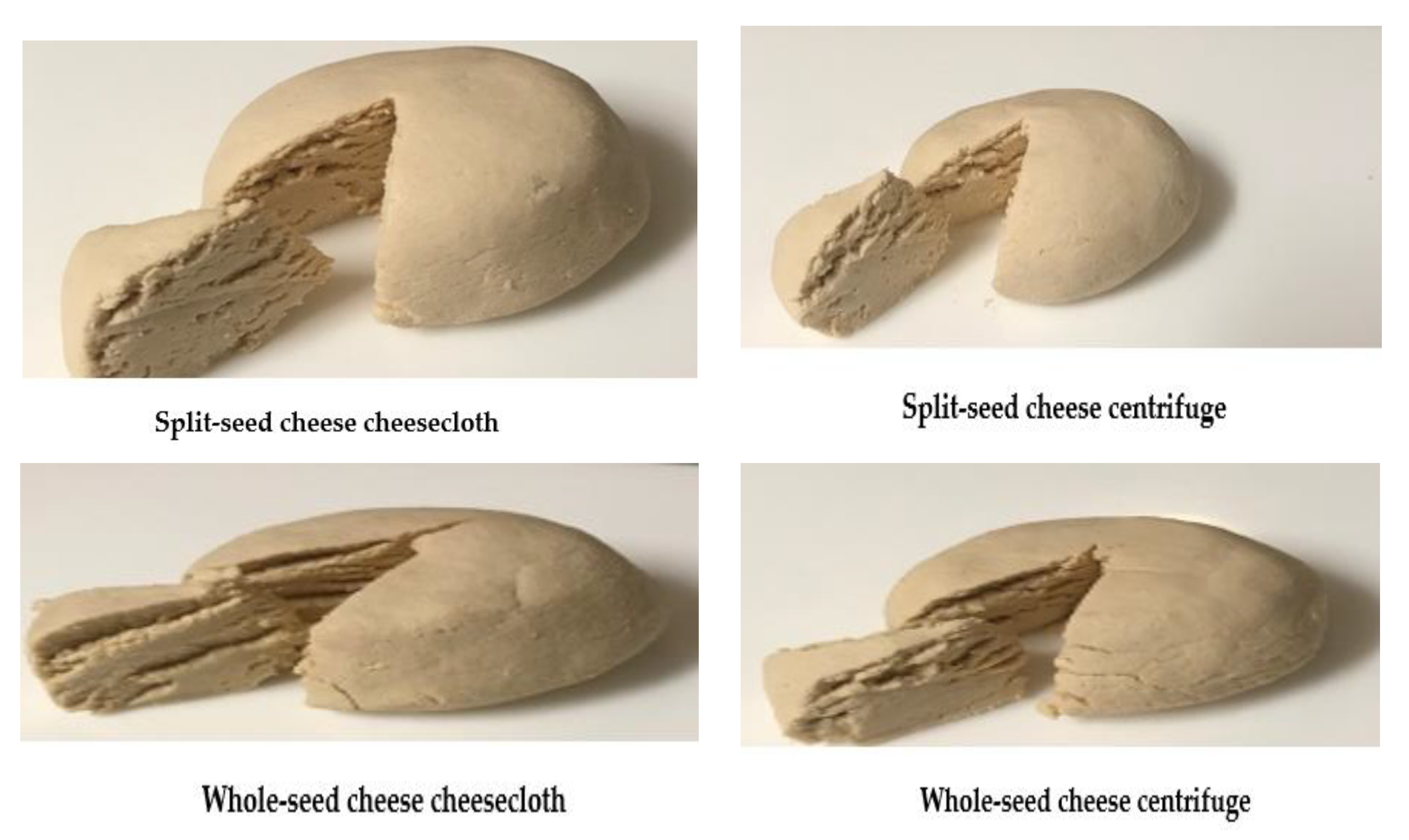
2.3. Evaluation of Cheese Production
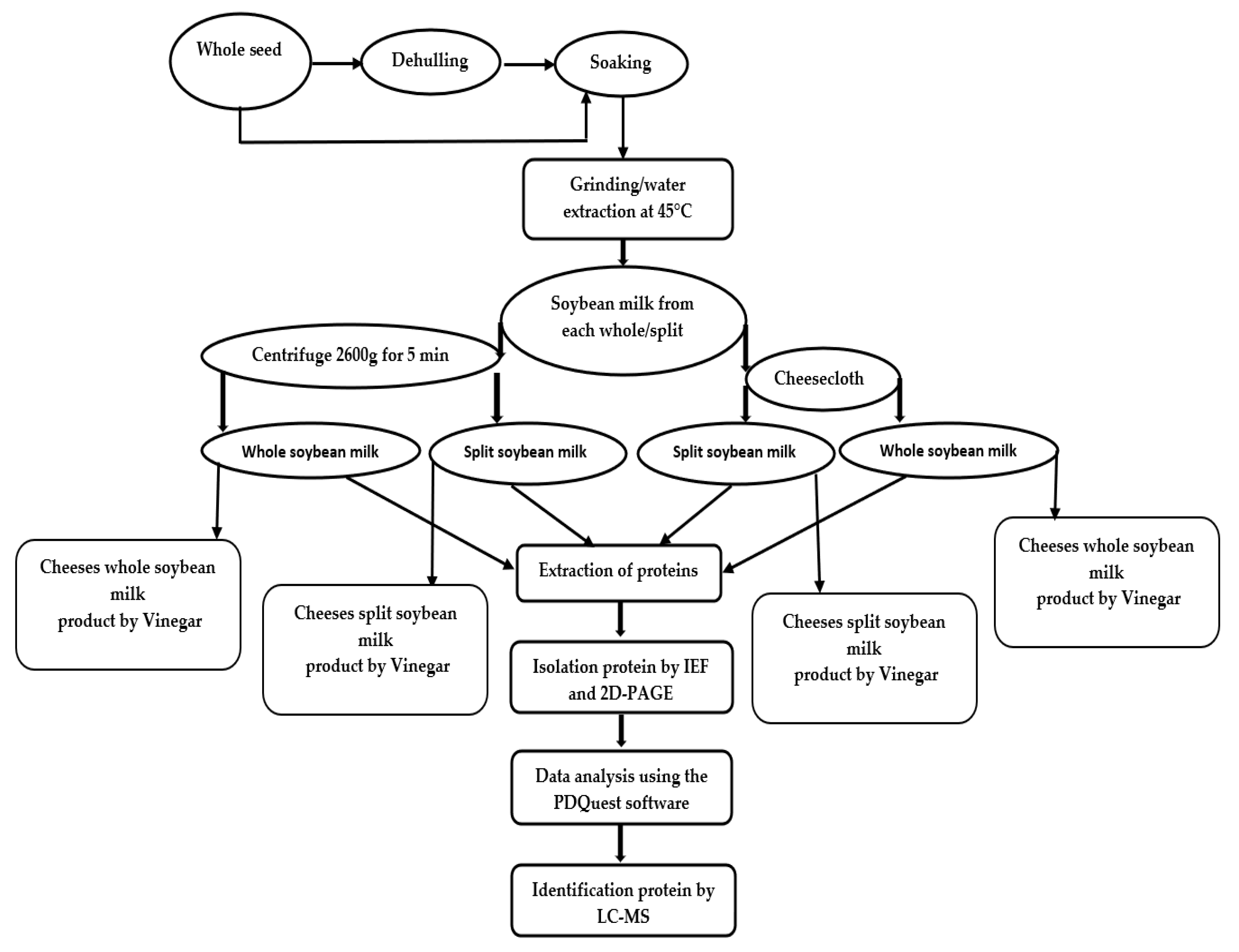
3. Materials and Methods
3.1. Chemicals
3.2. Plant Materials and Preparation of Soybean Milk
3.3. Extraction of Protein
3.4. Two-Dimensional Gel Electrophoresis and Data Analysis
3.5. Identification of Protein
3.6. Determination of Acetic Acid Volume in Vinegar
3.7. Fermentation of Milk to Obtain Soybean Cheeses
3.8. Determination of Curd Yield of Cheese
- X1 = Volume (mL) of soybean milk
- X2 = Weight (g) of protein coagulant (soybean curd)
3.9. Determination of Total Protein in Soybean Milk and Cheese
3.10. Sensory Evaluation
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hosken, B. Advances in Soybean Processing and Utilization; Aspen Pub Inc.: Frederick, MD, USA, 1999. [Google Scholar]
- Ginn, P.; Hosken, R.; Cole, S.; Ashton, J. Physicochemical and sensory evaluation of selected Australian UHT processed soy beverages. Food Aust. 1998, 50, 347–351. [Google Scholar]
- Omoni, A.O.; E Aluko, R. Soybean Foods and Their Benefits: Potential Mechanisms of Action. Nutr. Rev. 2005, 63, 272–283. [Google Scholar] [CrossRef] [PubMed]
- Rijavec, T.; Zupin, Ž. Soybean Protein Fibres (SPF), Recent Trends for Enhancing the Diversity and Quality of Soybean Products, Prof. Dora Krezhova Ed. 2011. Available online: http://www.intechopen.com/books/recent-trends-for-enhancing-the-diversity-and-quality-ofsoybean-products/soybean-protein-fibres-spf (accessed on 5 June 2020).
- Zhang, L.; Zeng, M. Proteins as Sources of Materials; Elsevier BV: Oxford, UK, 2008; pp. 479–493. [Google Scholar]
- Yasuda, M. Fermented Tofu, Tofuyo, Soybean—Biochemistry, Chemistry and Physiology, Prof. Tzi-Bun Ng Ed. 2011. Available online: http://www.intechopen.com/books/soybean-biochemistry-chemistry-and-physiology/fermented-tofu-tofuyo (accessed on 5 June 2020).
- Friedman, M.; Brandon, D.L. Nutritional and Health Benefits of Soy Proteins†. J. Agric. Food Chem. 2001, 49, 1069–1086. [Google Scholar] [CrossRef] [PubMed]
- Hajduch, M.; Ganapathy, A.; Stein, J.W.; Thelen, J.J. A Systematic Proteomic Study of Seed Filling in Soybean. Establishment of High-Resolution Two-Dimensional Reference Maps, Expression Profiles, and an Interactive Proteome Database1[w]. Plant. Physiol. 2005, 137, 1397–1419. [Google Scholar] [CrossRef] [Green Version]
- Natarajan, S.; Xu, C.; Caperna, T.J.; Garrett, W.M. Comparison of protein solubilization methods suitable for proteomic analysis of soybean seed proteins. Anal. Biochem. 2005, 342, 214–220. [Google Scholar] [CrossRef] [Green Version]
- Natarajan Analysis of Soybean Embryonic Axis Proteins by Two-Dimensional Gel Electrophoresis and Mass Spectrometry. J. Basic Appl. Sci. 2013, 9, 302–308. [CrossRef]
- Natarajan, S.S.; Krishnan, H.B.; Lakshman, S.; Garrett, W.M. An efficient extraction method to enhance analysis of low abundant proteins from soybean seed. Anal. Biochem. 2009, 394, 259–268. [Google Scholar] [CrossRef]
- Aghaei, K.; Ehsanpour, A.A.; Shah, A.H.; Komatsu, S. Proteome analysis of soybean hypocotyl and root under salt stress. Amino Acids 2008, 36, 91–98. [Google Scholar] [CrossRef]
- Natarajan, S.S. Analysis of Soybean Seed Proteins Using Proteomics. J. Data Min. Genom. Proteom. 2014, 5, 1. [Google Scholar] [CrossRef]
- Bazinet, L.; Ippersiel, D.; Labrecque, R.; Lamarche, F. Effect of Temperature on the Separation of Soybean 11 S and 7 S Protein Fractions during Bipolar Membrane Electroacidification. Biotechnol. Prog. 2000, 16, 292–295. [Google Scholar] [CrossRef]
- Konieczny, P.; Uchman, W. Comparative characterization of surface hydrophobicity and other physico-chemical properties of selected protein preparations. Electronic Journal of Polish Agricultural Universities. Series Food Sci. Technol. 2002, 5. [Google Scholar]
- Hojilla-Evangelista, M.P.; Sessa, D.J.; Mohamed, A. Functional properties of soybean and lupin protein concentrates produced by ultrafiltration-diafiltration. J. Am. Oil Chem. Soc. 2004, 81, 1153–1157. [Google Scholar] [CrossRef]
- Ugochi, N.F.; Chukwuma, U.M.; Nwanneoma, O.J.; Ndako; Jummai, K.; Nwabugo, M.A. Nutrient and Sensory Quality of Soymilk Produced from Different Improved Varieties of Soybean. Pak. J. Nutr. 2015, 14, 898–906. [Google Scholar] [CrossRef] [Green Version]
- Rinaldoni, A.N.; Palatnik, D.R.; Zaritzky, N.; Campderr?s, M.E. Soft cheese-like product development enriched with soy protein concentrates. LWT 2014, 55, 139–147. [Google Scholar] [CrossRef]
- Obiegbuna James, E.; Morah Grace, N.; Ishiwu Charles, N. Comparison of Yields and Physicochemical Properties of Lime Juice with Acetic Acid and Calcium Chloride Coagulated Soybean Curds. J. Food Nutr. Sci. 2014, 2, 58. [Google Scholar] [CrossRef]
- Saio, K.; Watanabe, T. Differences In Functional Properties of 7S and 11S Soybean Proteins. J. Texture Stud. 1978, 9, 135–157. [Google Scholar] [CrossRef]
- Nielsen, N.C.; Dickinson, C.D.; Cho, T.J.; Thanh, V.H.; Scallon, B.J.; Fischer, R.L.; Sims, T.L.; Drews, G.N.; Goldberg, R.B. Characterization of the glycinin gene family in soybean. Plant. Cell 1989, 1, 313–328. [Google Scholar] [CrossRef]
- Gonzalez-Perez, S.; Arellano, J.B. Vegetable protein isolates. In Handbook of Hydrocolloids; Elsevier BV: New Delhi, India, 2009; pp. 383–419. [Google Scholar]
- Grimes, H.D.; Overvoorde, P.J.; Ripp, K.; Franceschi, V.R.; Hitz, W.D. A 62-kD sucrose binding protein is expressed and localized in tissues actively engaged in sucrose transport. Plant. Cell 1992, 4, 1561–1574. [Google Scholar] [CrossRef] [Green Version]
- Overvoorde, P.J.; Chao, W.S.; Grimes, H. A Plasma Membrane Sucrose-binding Protein That Mediates Sucrose Uptake Shares Structural and Sequence Similarity with Seed Storage Proteins but Remains Functionally Distinct. J. Boil. Chem. 1997, 272, 15898–15904. [Google Scholar] [CrossRef] [Green Version]
- Martínez-Maqueda, D.; Hernández-Ledesma, B.; Amigo, L.; Miralles, B.; Gomez-Ruiz, J.A. Extraction/Fractionation Techniques for Proteins and Peptides and Protein Digestion. In Proteomics in Foods; Springer Science and Business Media LLC, Springer: Boston, MA, USA, 2012; pp. 21–50. [Google Scholar]
- Mooney, B.P.; Thelen, J.J. High-throughput peptide mass fingerprinting of soybean seed proteins: Automated workflow and utility of UniGene expressed sequence tag databases for protein identification. Phytochemistry 2004, 65, 1733–1744. [Google Scholar] [CrossRef]
- Al-Saedi, N.; Agarwal, M.; Ma, W.-J.; Islam, S.; Ren, Y. Proteomic Characterisation of Lupin (Lupinus angustifolius) Milk as Influenced by Extraction Techniques, Seed Coat and Cultivars. Molecules 2020, 25, 1782. [Google Scholar] [CrossRef]
- Krishnan, H.B.; Pueppke, S.G. Heat shock triggers rapid protein phosphorylation in soybean seedings. Biochem. Biophys. Res. Commun. 1987, 148, 762–767. [Google Scholar] [CrossRef]
- Dust, J.M.; Gajda, A.; Flickinger, E.A.; Burkhalter, T.M.; Merchen, N.R.; Fahey, G.C. Extrusion Conditions Affect Chemical Composition and in Vitro Digestion of Select Food Ingredients. J. Agric. Food Chem. 2004, 52, 2989–2996. [Google Scholar] [CrossRef] [PubMed]
- Saio, K. Tofu-relationships between texture and fine structure. Cereal Foods World MN USA 1979, 24, 342–354. [Google Scholar]
- Natarajan, S.S.; Xu, C.; Bae, H.; Caperna, T.J.; Garrett, W.M. Characterization of Storage Proteins in Wild (Glycine soja) and Cultivated (Glycine max) Soybean Seeds Using Proteomic Analysis. J. Agric. Food Chem. 2006, 54, 3114–3120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schuler, M.A.; Schmitt, E.S.; Beachy, R.N. Closely related families of genes code for the ? and ?‘ subunits of the soybean 7S storage protein complex. Nucleic Acids Res. 1982, 10, 8225–8244. [Google Scholar] [CrossRef] [Green Version]
- Maruyama, N.; Adachi, M.; Takahashi, K.; Yagasaki, K.; Kohno, M.; Takenaka, Y.; Okuda, E.; Nakagawa, S.; Mikami, B.; Utsumi, S. Crystal structures of recombinant and native soybean β-conglycinin β homotrimers. JBIC J. Boil. Inorg. Chem. 2001, 268, 3595–3604. [Google Scholar] [CrossRef]
- Wilson, S.; Blaschek, K.; De Mejia, E.G. Allergenic Proteins in Soybean: Processing and Reduction of P34 Allergenicity. Nutr. Rev. 2005, 63, 47–58. [Google Scholar] [CrossRef]
- Bringans, S.; Eriksen, S.; Kendrick, T.; Gopalakrishnakone, P.; Livk, A.; Lock, R.; Lipscombe, R. Proteomic analysis of the venom ofHeterometrus longimanus (Asian black scorpion). Proteomics 2008, 8, 1081–1096. [Google Scholar] [CrossRef]
- Association of Official Analytical Chemists. Official Methods of Analysis of the Association of Official Analytical Chemists, AOAC Official Method 930.35, 16th ed.; Association of Official Analytical Chemists: Arlington, VA, USA, 1995; Volume 1. [Google Scholar]
- Association of Official Analytical Chemists. Official Methods of Analysis: Changes in Official Methods of Analysis Made at the Annual Meeting; Association of Official Analytical Chemists: Arlington, VA, USA, 1991. [Google Scholar]
- Seleet, F.L.; Kassem, J.; Bayomim, H.M.; Abd-Rabou, N.; Ahmed, N.S. Production of Functional Spreadable Processed Cheese Analogue Supplemented with Chickpea. Int. J. Dairy Sci. 2014, 9, 1–14. [Google Scholar] [CrossRef]
Sample Availability: Samples of the compounds are not available from the authors. |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Soybean Seeds to Make Milk | Separation Method | Total Protein (g/100 mL) Mean ± SD (n = 3) | Spots Numbers Mean ± SD (n = 3) |
|---|---|---|---|
| Split | cheesecloth | 2.03 ± 0.15 | 73 ± 1.70 |
| Split | centrifuge | 2.56 ± 1.00 | 80 ± 1.50 |
| Whole | cheesecloth | 2.60 ± 0.10 | 81 ± 1.52 |
| Whole | centrifuge | 2.97 ± 0.05 | 93 ± 0.50 |
| Split-Soybean Milk | Whole-Soybean Milk | ||||
|---|---|---|---|---|---|
| Cheesecloth | Centrifuge | Cheesecloth | Centrifuge | ||
| Spot No | SSP | Mean ± SD (n = 3) | Mean ± SD (n = 3) | Mean ± SD (n = 3) | Mean ± SD (n = 3) |
| 1 | 2701 | 207.91 ± 1.00 | 279.66 ± 0.20 | 136.77 ± 0.93 | 236.62 ± 0.61 |
| 2 | 2706 | 1275.11 ± 1.00 | 1539.53 ± 2.05 | 70.51 ± 0.61 | 403.36 ± 0.75 |
| 3 | 3704 | 226.53 ± 1.03 | 620.87 ± 0.56 | 207.06 ± 0.52 | 446.47 ± 1.42 |
| 4 | 4501 | 72.46 ± 0.18 | 150.61 ± 0.54 | 69.47 ± 0.56 | 60.13 ± 0.14 |
| 5 | 4502 | 136.92 ± 0.61 | 188.12 ± 0.99 | 115.00 ± 0.58 | 90.60 ± 0.54 |
| 6 | 4503 | 185.06 ± 0.25 | 334.73 ± 0.17 | 122.41 ± 0.38 | 58.98 ± 0.05 |
| 7 | 4507 | 181.52 ± 0.51 | 648.99 ± 4.93 | 59.93 ± 0.14 | 178.55 ± 0.50 |
| 8 | 5509 | 573.21 ± 0.19 | 694.61 ± 0.60 | 253.94 ± 0.57 | 57.89 ± 0.10 |
| 9 | 5510 | 111.06 ± 0.56 | 257.23 ± 0.21 | 50.55 ± 0.49 | 81.47 ± 0.43 |
| 10 | 5507 | 185.45 ± 0.40 | 266.56 ± 0.47 | 20.03 ± 0.61 | 34.26 ± 1.74 |
| 11 | 2707 | 20.40 ± 0.01 | 177.26 ± 0.54 | 25.81 ± 0.56 | 132.56 ± 1.00 |
| 12 | 2704 | 58.40 ± 0.01 | ND | 137.48 ± 0.59 | ND |
| 13 | 2601 | 43.20 ± 1.16 | ND | ND | ND |
| 14 | 3601 | 81.29 ± 0.58 | 38.97 ± 0.57 | ND | ND |
| 15 | 3603 | 73.72 ± 0.02 | 69.60 ± 0.43 | ND | ND |
| 16 | 3602 | 31.74 ± 1.74 | 24.20 ± 0.56 | ND | ND |
| 17 | 6503 | 115.94 ± 0.97 | 144.84 ± 0.56 | 44.06 ± 1.02 | 126.23 ± 1.08 |
| 18 | 6504 | 245.25 ± 0.99 | 304.51 ± 1.15 | 97.22 ± 0.59 | 152.83 ± 0.57 |
| 19 | 5703 | ND | 85.52 ± 0.05 | ND | 21.72 ± 0.62 |
| 20 | 5704 | 60.31 ± 0.01 | 98.30 ± 0.05 | ND | 112.29 ± 0.05 |
| 21 | 5701 | ND | 284.05 ± 0.60 | ND | 58.51 ± 0.05 |
| 22 | 5702 | ND | 171.01 ± 0.58 | ND | 80.54 ± 0.01 |
| 23 | 5705 | 85.42 ± 0.01 | 263.02 ± 0.58 | 38.40 ± 0.05 | 84.06 ± 0.57 |
| 24 | 5706 | 49.85 ± 0.44 | 137.67 ± 0.01 | ND | 28.25 ± 0.57 |
| 25 | 4508 | ND | ND | 20.40 ± 0.01 | 30.06 ± 1.02 |
| 26 | 4504 | ND | ND | 38.48 ± 0.59 | 77.38 ± 0.60 |
| 27 | 4501 | ND | ND | 26.54 ± 0.58 | 41.96 ± 0.91 |
| 28 | 6506 | ND | ND | 18.80 ± 0.21 | 49.43 ± 0.58 |
| 29 | 6507 | ND | ND | 21.43 ± 0.57 | 47.36 ± 0.01 |
| 30 | 6508 | ND | ND | 20.50 ± 0.63 | 39.69 ± 0.27 |
| 31 | 3501 | ND | ND | 202.99 ± 0.56 | 102.19 ± 0.57 |
| 32 | 3404 | ND | ND | 89.65 ± 0.05 | 77.24 ± 0.22 |
| 33 | 3502 | ND | ND | 75.21 ± 0.57 | 47.53 ± 0.57 |
| 34 | 3402 | 163.15 ± 0.15 | 41.74 ± 0.56 | 287.28 ± 1.15 | 44.96 ± 0.59 |
| 35 | 2302 | 526.88 ± 0.58 | 17.55 ± 0.28 | ND | ND |
| 36 | 2308 | 661.08 ± 0.87 | 75.98 ± 0.01 | 200.21 ± 0.37 | 184.68 ± 0.68 |
| 37 | 2309 | 393.39 ± 0.35 | 42.43 ± 0.49 | 320.79 ± 0.29 | 97.55 ± 0.07 |
| 38 | 3309 | 1408.00 ± 1.15 | 151.47 ± 0.56 | 657.14 ± 0.14 | 183.00 ± 1.12 |
| 39 | 3308 | 997.10 ± 0.57 | 231.30 ± 1.61 | 828.98 ± 0.57 | 668.05 ± 0.04 |
| 40 | 3306 | 66.04 ± 0.60 | 109.10 ± 0.58 | 93.06 ± 0.02 | 150.44 ± 0.58 |
| 41 | 3305 | 25.56 ± 0.05 | 132.41 ± 0.58 | 44.71 ± 0.35 | 140.45 ± 0.04 |
| 42 | 2301 | 551.87 ± 0.58 | 667.58 ± 0.72 | 691.18 ± 0.59 | 959.22 ± 0.02 |
| 43 | 2207 | 23.44 ± 0.01 | 82.64 ± 0.58 | 45.44 ± 0.05 | 86.03 ± 0.58 |
| 44 | 6302 | 68.52 ± 0.02 | 195.52 ± 0.05 | 40.93 ± 0.58 | 156.74 ± 0.58 |
| 45 | 6301 | 31.26 ± 0.56 | 169.77 ± 0.37 | 20.87 ± 0.67 | 31.10 ± 0.55 |
| 46 | 7301 | 731.75 ± 0.57 | 838.44 ± 0.57 | 497.53 ± 0.55 | 1123.50 ± 0.62 |
| 47 | 7208 | 486.16 ± 0.57 | 690.42 ± 0.01 | 24.18 ± 0.34 | 751.49 ± 0.57 |
| 48 | 2304 | ND | ND | 235.98 ± 0.58 | 364.00 ± 0.61 |
| 49 | 3302 | ND | ND | 59.61 ± 0.01 | 88.25 ± 0.49 |
| Type of Seeds to Make Milk | Separation Techniques | Present Only in Cheesecloth Separation | Higher Level of Abundance in Cheesecloth Separation * | Present Only in a Centrifuge | Higher Level of Abundance in Centrifuge Separation * |
|---|---|---|---|---|---|
| Split | Cheesecloth versus centrifuge | 12 [Mutant glycinin A3B4] 13 [Uncharacterized protein] | 14–16, 42 [β-Subunit of β-Conglycinin] 34 [Glyg5_SoybnGlycinin] 35 [Uncharacterized protein] 36–39 [Mutant glycinin Subunit A1aB1b] | 19 [Glyso Sucrose-binding protein] 21, 22 [Sucrose binding protein homolog S-64] | 1–3 [α-Subunit of β-Conglycinin] 4–11, 17, 18, 24, 42 [β-Subunit of β-Conglycinin] 20, 23 [Glyso Sucrose-binding protein] 40, 41 [Glyso Lectin] 45 [Glyso Glycinin] 46, 47 [Glycinin G4 subunit] 44 [Mutant glycinin A3B4] 43 [Uncharacterized protein] |
| Whole | cheesecloth versus centrifuge | 12 [Mutant glycinin A3B4] | 4–6, 8, 11 [β-Subunit of β-Conglycinin] 31, 32 [α-Subunit of β-Conglycinin] 33 [Glycinin A3B4 subunit] 34 [Glyg5_SoybnGlycinin] 36–39 [Mutant glycinin Subunit A1aB1b] 21 [Sucrose binding protein homolog S-64] | 19 [Glyso Sucrose-binding protein] 21, 22 [Sucrose binding protein homolog S-64] 24 [β-Subunit of β-Conglycinin] | 1–3, 26 [α-Subunit of β-Conglycinin] 7, 9, 10, 17, 18, 25, 27–30, 42 [β-Subunit of β-Conglycinin] 20, 23, 49 [Glyso Sucrose-binding protein] 40, 41 [Glyso Lectin] 45 [Glyso Glycinin] 46, 47 [Glycinin G4 subunit] 44 [Mutant glycinin A3B4] 43, 48 [Uncharacterized protein] |
| Type of Seeds to Make Milk | Separation Techniques | Present Only in Split-Seed Extractions | Higher Level of Abundance in Split-Seed Extraction * | Present Only in Whole-Seed Extractions | Higher Level of Abundance in Whole-Seed Extractions * |
|---|---|---|---|---|---|
| Split versus whole | Cheesecloth | 14, 15, 16, 24 [β-Subunit of β-Conglycinin] 20, 23 [Glyso Sucrose-binding protein] 13, 35 [Uncharacterized protein] | 1–3 [α-Subunit of β-Conglycinin] 4–10, 17, 18 [β-Subunit of β-Conglycinin] 46, 47 [Glycinin G4 subunit] 36–39 [Mutant glycinin Subunit A1aB1b] | 25, 27–29 [β-Subunit of β-Conglycinin] 21, 26, 30-32 [α-Subunit of β-Conglycinin] 33 [Glycinin A3B4 subunit] 48 [Uncharacterized protein] 49 [Glyso Sucrose-binding protein] | 11, 42 [β-Subunit of β-Conglycinin] 41, 40 [Glyso Lectin] 34 [Glyg5_SoybnGlycinin] 45 [Glyso Glycinin] 12, 44 [Mutant glycinin A3B4] 43 [Uncharacterized protein] |
| Split versus whole | Centrifuge | 14, 15, 16 [β-Subunit of β-Conglycinin] 35 [Uncharacterized protein] | 4–11, 17, 18, 24 [β-Subunit of β-Conglycinin] 1–3 [α-Subunit of β-Conglycinin] 23 [Glyso Sucrose-binding protein] 21, 22 [Sucrose binding protein homolog S-64] 44 [Mutant glycinin A3B4] 45 [Glyso Glycinin] | 25, 27–29 [β-Subunit of β-Conglycinin] 26, 30–32 [α-Subunit of β-Conglycinin] 33 [Glycinin A3B4 subunit] 48 [Uncharacterized protein] 49 [Glyso Sucrose-binding protein] | 42 [β-Subunit of β-Conglycinin] 20 [Glyso Sucrose-binding protein] 34 [Glyg5_SoybnGlycinin] 36–39 [Mutant glycinin Subunit A1aB1b] 41, 40 [Glyso Lectin] 43 [Uncharacterized protein] 46, 47 [Glycinin G4 subunit] |
| Type of Soybean Seeds to Make Cheese | Separation Method | Total Protein (g/100 g of Cheese) Mean ± SD (n = 3) |
|---|---|---|
| Split | cheesecloth | 21.26 ± 0.11 |
| Split | centrifuge | 26.80 ± 1.00 |
| Whole | cheesecloth | 27.62 ± 0.02 |
| Whole | centrifuge | 30.63 ± 0.20 |
| Milk | Separation Methods | Yield (%) | Appearance | Color | Flavor | Texture | Overall Acceptability |
|---|---|---|---|---|---|---|---|
| Split | Cheesecloth | 17.00 ± 0.70 | 3.66 ± 0.67 | 3.41 ± 0.68 | 3.55 ± 0.68 | 3.55 ± 0.57 | 3.76 ± 0.57 |
| Split | Centrifuge | 14.25 ± 0.35 | 2.97 ± 0.61 | 2.97 ± 0.61 | 3.00 ± 0.69 | 3.20 ± 0.66 | 3.31 ± 0.68 |
| Whole | Cheesecloth | 16.25 ± 0.33 | 2.60 ± 0.49 | 2.37 ± 0.49 | 2.40 ± 0.49 | 2.37 ± 0.49 | 2.60 ± 0.62 |
| Whole | Centrifuge | 13.50 ± 0.70 | 2.43 ± 0.50 | 2.53 ± 0.50 | 2.45 ± 0.49 | 2.30 ± 0.46 | 2.77 ± 0.67 |
| cow’s milk | NSM | 17.50 ± 0.70 | 4.17 ± 0.46 | 3.80 ± 0.48 | 3.83 ± 0.53 | 3.87 ± 0.57 | 4.07 ± 0.69 |
| NO | Protein | NCBI Accession Number | Database Theoretical * MW/PI | Sequence Coverage % | MOWES Score | Peptides |
|---|---|---|---|---|---|---|
| 1 | α-Subunit of β-Conglycinin (Glycine max) | gi|111278867 | 69,845/5.43 | 36 | 803 | MITLAIPVNK, FNLRSRDPIY, ELAFPGSAKD, PGRFESFFLS, SYNLQSGDAL, STQAQQSYLQ, TPEKNPQLRD, RVPAGTTYYV, LDVFLSVVDM, VNPDNDENLR, NEGALFLPHF, VISQIPSQVQ |
| 2 | α-Subunit of β-Conglycinin (Glycine max) | gi|39718 | 70,263/5.12 | 32 | 927 | NENLRLITLA, SEDKPFNLRS, LLPHFNSKAI, IPVNKPGRFE, EEGQQQGEQR, SFFLSSTEAQ, LQESVIVEIS, SGDALRVPSG, PQLRDLDIFL, DEDEDEEQDE, TTYYVVNPDN, SIVDMNEGAL |
| 3 | α-Subunit of β-Conglycinin (Glycine max) | gi|74271743 | 69,845/5.43 | 34 | 967 | LFKNQYGHVR, MITLAIPVNK, NSKAIVVLVI, HGGKGSEEEQ, PGRFESFFLS, SNKLGKLFEI, NEGEANIELV, STQAQQSYLQ, TPEKNPQLRD, GFSKNILEAS, LDVFLSVVDM, VNPDNDENLR, YDTKFEEINK, VISQIPSQVQ, NEGALFLPHF |
| 4 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 39 | 999 | NNFGKFFEIT, PEKNPQLRDL, DIFLSSVDIN, NFLAGEKDNV, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, NLRSRNPIYS, LAFPGSAQDV |
| 5 | β-Subunit of β-Conglycinin (Glycine Max) | gi|341603993 | 49,987/6.14 | 54 | 949 | GRAILTLVNN, KFFEITPEKN, PQLRDLDIFL, AQPQQKEEGS, DYRIVQFQSK, GDAQRIPAGT, SSVDINEGAL, NNPFYFRSSN, PNTILLPHHA, TYYLVNPHDH, SEDEPFNLRS, SFQTLFENQN, DADFLLFVLS, RNPIYSNNFG |
| 6 | β-Subunit of β-Conglycinin (Glycine Max) | gi|21465631 | 47,947/5.67 | 56 | 888 | IVQFQSKPNT, QRIPAGTTYY, QGFSHNILET, LSSVDINEGA, FYFRSSNSFQ, ILLPHHADAD, LVNPHDHQNL, SFHSEFEEIN, SSEDEPFNLR, FLLFVLSGRA, ILTLVNNDDR, PQLENLRDYR, DSYNLHPGDA, SSTQAQQSYL, NPQLRDLDIF |
| 7 | β-Subunit of β-Conglycinin (Glycine Max) | gi|341603993 | 49,987/6.14 | 48 | 911 | GRAILTLVNN, KFFEITPEKN, DDRDSYNLHP, PQLRDLDIFL, AQPQQKEEGS, GDAQRIPAGT, SSVDINEGAL, NNPFYFRSSN, PNTILLPHHA, TYYLVNPHDH, SFQTLFENQN, DADFLLFVLS |
| 8,9 | β-Subunit of β-Conglycinin (Glycine Max) | gi|341603993 | 49,987/6.14 | 57 | 1074 | GRAILTLVNN, KFFEITPEKN, DDRDSYNLHP, PQLRDLDIFL, AQPQQKEEGS, DYRIVQFQSK, SSVDINEGAL, NNPFYFRSSN, PNTILLPHHA, TYYLVNPHDH, SEDEPFNLRS, SFQTLFENQN, DADFLLFVLS, VLFGEEEEQR, RNPIYSNNFG |
| 10 | β-Subunit of β-Conglycinin (Glycine Max) | NP_0012368722 | 50,411/5.88 | 56 | 1058 | GRAILTLVNN, EEQRQQEGVI, PEKNPQLRDL, YFVDAQPQQK, NNFGKFFEIT, KRSPQLENLR, DDRDSYNLHP, DYRIVQFQSK, DIFLSSVDIN, PNTILLPHHA, TYYLVNPHDH, KTISSEDEPF, SFQTLFENQN, DADFLLFVLS, NLRSRNPIYS, LAFPGSAQDV |
| 11 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 52 | 1532 | GRAILTLVNN, EEQRQQEGVI, NNFGKFFEIT, DDRDSYNLHP, PEKNPQLRDL, YFVDAQPQQK, GDAQRIPAGT, DIFLSSVDIN, NFLAGEKDNV, NNPFYLRSSN, PNTILLPHHA, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, SFQTLFENQN, NLRSRNPIYS |
| 12 | Mutant glycinin A3B4 (Glycine Max) | gi|223649560 | 60,002/5.65 | 14 | 568 | PGVPYWTYNT, GDEPVVAISL, IVTVEGGLSV, LDTSNFNNQL, DQNPRVFYLA, GFSKHFLAQS, FNEGDVLVIP, FNTNEDTAEK |
| 13 | Uncharacterized protein (Glycine max) | gi|947119133 | 54,647/5.30 | 24 | 560 | WMYNNEDTPV, DSGAIVTVKG, VAVSIIDTNS, QEEENEGSNI, LENQLDQMPR, LSGFAPEFLK, RFYLAGNQEQ, EAFGVNMQIV, LIAVPTGVAW, RNLQGENEEE |
| 14 | β-Subunit of β-Conglycinin (Glycine Max) | gi|341603993 | 49,987/6.14 | 56 | 1308 | GRAILTLVNN, QQEGVIVELS, KFFEITPEKN, DDRDSYNLHP, PQLRDLDIFL, AQPQQKEEGS, SSVDINEGAL, NNPFYFRSSN, PNTILLPHHA, PNTILLPHHA, TYYLVNPHDH, TYYLVNPHDH, SEDEPFNLRS, SFQTLFENQN, DADFLLFVLS, RNPIYSNNFG |
| 15 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 58 | 1498 | GRAILTLVNN, EEQRQQEGVI, NNFGKFFEIT, DDRDSYNLHP, PEKNPQLRDL, GDAQRIPAGT, DIFLSSVDIN, NFLAGEKDNV, NNPFYLRSSN, PNTILLPHHA, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, DADFLLFVLS, NLRSRNPIYS, LAFPGSAQDV |
| 16 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 56 | 1294 | GRAILTLVNN, EEQRQQEGVI, NNFGKFFEIT, KRSPQLENLR, DDRDSYNLHP, PEKNPQLRDL, Y FVDAQPQQK, GDAQRIPAGT, NFLAGEKDNV, PNTILLPHHA, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, NLRSRNPIYS, LAFPGSAQDV |
| 17 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 33 | 762 | LFKNQYGHVR, MITLAIPVNK, FNLRSRDPIY, ELAFPGSAKD, PGRFESFFLS, SYNLQSGDAL, STQAQQSYLQ, TPEKNPQLRD, RVPAGTTYYV, LDVFLSVVDM, LDVFLSVVDM, RNFLAGSKDN, VNPDNDENLR, NEGALFLPHF, VISQIPSQVQ, |
| 18 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 37 | 913 | RQFPFPRPPH, NENLRLITLA, SEDKPFNLRS, LLPHFNSKAI, PSQVQELAFP, IPVNKPGRFE, EEGQQQGEQR, RDPIYSNKLG, SFFLSSTEAQ, LQESVIVEIS, ESEDSELRRH, SGDALRVPSG, PQLRDLDIFL, DEDEDEEQDE, TTYYVVNPDN, SIVDMNEGAL |
| 19 | Glyso sucrose-binding protein (Glycine Soja) | gi|1169100901 | 57,954/6.08 | 43 | 933 | AILEARAHTF, LSAFSWNVLQ, WWPFGGESKP, PSYHRISSDL, FAGKDNIVSS, VSPRHFDSEV, KPGMVFVVPP, LAMLHIPVSV, VGPDDDEKSW, LLQGIENFRL, GPGGRDPESV, GHPFVTIASN |
| 20 | Glyso sucrose-binding protein (Glycine Soja) | gi|1169100901 | 57,954/6.08 | 46 | 986 | AILEARAHTF, LSAFSWNVLQ, WWPFGGESKP, PSYHRISSDL, FAGKDNIVSS, VSPRHFDSEV, KPGMVFVVPP, LAMLHIPVSV, VGPDDDEKSW, LLQGIENFRL, GPGGRDPESV, GHPFVTIASN |
| 21 | Sucrose binding protein homolog S-64 (Glycine Max) | gi|6179947 | 57,954/6.08 | 39 | 934 | AILEARAHTF, HIPAGTPLYI, LSAFSWNVLQ, PSYHRISSDL, FAGKDNIVSS, VSPRHFDSEV, IHYNSHATKI, LDNVAKELAF, NYPSEMVNGV, LAMLHIPVSV, LGLVSESETE, STPGKFEEFF, FDRKESFFFP, LLQGIENFRL, KITLEPGDMI, GPGGRDPESV |
| 22 | Sucrose binding protein homolog S-64 (Glycine Max) | gi|6179947 | 55,799/6.32 | 22 | 476 | SPRHFDSEVV, QTPKGKLERL, SHATKIALVM, GKFEEFFGPG, LQGNENFRLA, ITLEPGDMIH, GRDPESVLSA, ILEARAHTFV, FSWNVLQAAL, NIVSSLDNVA, QRSMSTIHYN |
| 23 | Glyso Sucrose-binding protein (Glycine Soja) | gi|1169100901 | 57,954/6.08 | 44 | 1135 | AILEARAHTF, HIPAGTPLYI, LSAFSWNVLQ, VSPRHFDSEV, LDNVAKELAF, NYPSEMVNGV, LGLVSESETE, VGPDDDEKSW, FDRKESFFFP, LLQGIENFRL, KITLEPGDMI, GPGGRDPESV, GPGGRDPESV, FELPREERGR |
| 24 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 58 | 1441 | GRAILTLVNN, EEQRQQEGVI, NNFGKFFEIT, DDRDSYNLHP, PEKNPQLRDL, DIFLSSVDIN, NFLAGEKDNV, NNPFYLRSSN, PNTILLPHHA, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, SFQTLFENQN, DADFLLFVLS, NLRSRNPIYS, LAFPGSAQDV |
| 25 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,445/5.88 | 42 | 952 | NNFGKFFEIT, DDRDSYNLHP, PEKNPQLRDL, YFVDAQPQQK, GDAQRIPAGT, DIFLSSVDIN, NFLAGEKDNV, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, NLRSRNPIYS, LAFPGSAQDV |
| 26 | α-Subunit of β-Conglycinin (Glycine max) | gi|111278867 | 69,845/5.43 | 15 | 349 | FNLRSRDPIY, ELAFPGSAKD, PGRFESFFLS, IENLIKSQSE, QLQNLRDYRI, STQAQQSYLQ, RNFLAGSKDN, GFSKNILEAS, YDTKFEEINK, RKTISSEDKP, VISQIPSQVQ |
| 27 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 37 | 858 | GRAILTLVNN, PVNKPGRYDD, EEQRQQEGVI, NNFGKFFEIT, KRSPQLENLR, DDRDSYNLHP, YFVDAQPQQK, GDAQRIPAGT, DIFLSSVDIN, EEEPLEVQRY, NFLAGEKDNV, EGALLLPHFN |
| 28 | β-Subunit of β-Conglycinin (Glycine Max) | gi|341603993 | 49,987/6.14 | 48 | 1155 | GRAILTLVNN, KFFEITPEKN, DDRDSYNLHP, PQLRDLDIFL, DYRIVQFQSK, SSVDINEGAL, NNPFYFRSSN, PNTILLPHHA, SEDEPFNLRS, DADFLLFVLS, VLFGEEEEQR, RNPIYSNNFG |
| 29 | β-Subunit of β-Conglycinin (Glycine Max) | gi|341603993 | 49,987/6.14 | 42 | 578 | GRAILTLVNN, KFFEITPEKN, NIELVGIKEQ, DDRDSYNLHP, PQLRDLDIFL, GDAQRIPAGT, SSVDINEGAL, PNTILLPHHA, TYYLVNPHDH, LLPHFNSKAI, DADFLLFVLS, VILVINEGDA |
| 30 | α-Subunit of β-Conglycinin (Glycine max) | gi|111278867 | 69,845/5.43 | 31 | 861 | LFKNQYGHVR, MITLAIPVNK, VLFGREEGQQ, PGRFESFFLS, QGEERLQESV, STQAQQSYLQ, TPEKNPQLRD, GFSKNILEAS, LDVFLSVVDM, VNPDNDENLR, YDTKFEEINK, NEGALFLPHF |
| 31 | α-Subunit of β-Conglycinin (Glycine max) | gi|111278867 | 69,845/5.43 | 29 | 839 | MITLAIPVNK, VLFGREEGQQ, FNLRSRDPIY, ELAFPGSAKD, QGEERLQESV, QLQNLRDYRI, SYNLQSGDAL, RVPAGTTYYV, LDVFLSVVDM, QEEQPLEVRK, VNPDNDENLR, YDTKFEEINK, RKTISSEDKP, NEGALFLPHF, VISQIPSQVQ |
| 32 | α-Subunit of β-Conglycinin (Glycine max) | gi|15425633 | 72,431/5.32 | 25 | 695 | DALRVPSGTT, YYVVNPDNNE, NLRLITLAIP, DKPFNLRSRD, VNKPGRFESF, GQQQGEQRLQ, FLSSTEAQQS, ESVIVEISKE, FEITPEKNPQ |
| 33 | Glycinin A3B4 subunit (Glycine Max) | gi|126144646 | 57,663/5.78 | 31 | 629 | MQQQQQQKSH, LRSPDDERKQ, HEDDEDEDEE, GGRKQGQHQQ, IVTVEGGLSV, EDQPRPDHPP, QEEEGGSVLS, QRPSRPEQQE, LHLPSYSPYP, GFSKHFLAQS, QMIIVVQGKG, GNPDIEHPET |
| 34 | Glyg5_SoybnGlycinin (Glycine max) | gi|121280 | 57,921/5.60 | 26 | 445 | MQQQQQQKSH, LRSPDDERKQ, EDEEEDQPRP, SHLPSYLPYP, SHGKHEDDED, GGRKQGQHRQ, IVTVEGGLSV, DHPPQRPSRP, LQDSHQKIRH, QMIIVVQGKG, GNPDIEHPET, FNTNEDTAEK |
| 35 | Uncharacterized protein (Glycine Max) | gi|947119133 | 54,647/5.30 | 24 | 560 | WMYNNEDTPV, DSGAIVTVKG, VAVSIIDTNS, QEEENEGSNI, LENQLDQMPR, LSGFAPEFLK, RFYLAGNQEQ, EAFGVNMQIV, LIAVPTGVAW, RNLQGENEEE |
| 36 | Mutant glycinin Subunit A1aB1b (Glycine Max) | gi|254029113 | 43,495/5.51 | 24 | 359 | GHQSQKGKHQ, DKGAIVTVKG, QEEENEGGSI, GQSSRPQDRH, LSGFTLEFLE, RFYLAGNQEQ, HAFSVDKQIA, EFLKYQQEQG, KNLQGENEGE |
| 37 | Mutant glycinin Subunit A1aB1b (Glycine Max) | gi|254029113 | 43,495/5.51 | 27 | 402 | GHQSQKGKHQ, DKGAIVTVKG, QEEENEGGSI, GQSSRPQDRH, LSGFTLEFLE, RPSYTNGPQE, RFYLAGNQEQ, EFLKYQQEQG, KNLQGENEGE |
| 38 | Mutant glycinin Subunit A1aB1b (Glycine Max) | gi|254029113 | 43,495/5.51 | 24 | 430 | GHQSQKGKHQ, DKGAIVTVKG, QEEENEGGSI, GQSSRPQDRH, LSGFTLEFLE, RFYLAGNQEQ, EFLKYQQEQG, KNLQGENEGE |
| 39 | Mutant glycinin Subunit A1aB1b (Glycine Max) | gi|254029113 | 43,495/5.51 | 39 | 591 | WMYNNEDTPV, GHQSQKGKHQ, VAVSIIDTNS, QEEENEGGSI, GQSSRPQDRH, LENQLDQMPR, LSGFTLEFLE, RPSYTNGPQE, RFYLAGNQEQ, LIAVPTGVAW, EFLKYQQEQG, KNLQGENEGE |
| 40 | Glyso Lectin (Glycine Soja) | gi|1236589326 | 309,009/5.65 | 39 | 545 | ILQGDAIVTS, DASTSLLVAS, SGKLQLNKVD, RNSWDPPNPH, LVYPSQRTSN, ENGTPKPSSL, IGINVNSIRS, ILSDVVDLKT, IKTTSWDLAN, NKVAKVLITY |
| 41 | Glyso Lectin (Glycine Soja) | gi|1236589326 | 309,009/5.65 | 37 | 546 | ILQGDAIVTS, DASTSLLVAS, RNSWDPPNPH, LVYPSQRTSN, IGINVNSIRS, ILSDVVDLKT, GRALYSTPIH, IKTTSWDLAN, NKFVPKQPNM, NKVAKVLITY |
| 42 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1149122548 | 26,223/4.75 | 14 | 162 | TQPGGASSVM, QSAATRNEQA, NPDATATPGG, VAASVAAAAR |
| 43 | Uncharacterized protein (Glycine Max) | gi|356535993 | 68,164/5.94 | 20 | 406 | IVILMVTEGE, AQDIENLIKN, GKFYEITPEK, ANIELVGLKE, QRESYFADAQ, NPQLRDFDIL, QQQGEETREV, LNTVDINEGG, LLLPHYNSKA, VKELAFPAGS |
| 44 | Mutant glycinin A3B4 (Glycine Max) | gi|734345445 | 59,013/5.79 | 36 | 438 | RLRQNIGQNS, VAAKSQSDNF, SPDIYNPQAG, EYVSFKTNDR, FSFLVPPQES, SITTATSLDF, PSIGNLAGAN, PALWLLKLSA, RVFDGELQEG, SLLNALPEEV, QYGSLRKNAM, GVLIVPQNFA, IQHTFNLKSQ |
| 45 | Glyso Glycinin (Glyso Soja) | gi|734345446 | 55,783/5.95 | 28 | 520 | PALSWLRLSA, RVFDGELQEG, SLLNALPEEV, EFGSLRKNAM, FVPHYNLNAN, VAARSQSDNF, SIIYALNGRA, EYVSFKTNDT, FKFLVPPQES, PMIGTLAGAN |
| 46 | Glycinin G4 Subunit (Glycine Max) | gi|255224 | 63,641/5.38 | 9 | 264 | VFKTHHNAVT, TLNSLTLPAL, PSEVLAHSYN, NNNPFSFLVP, GLLWGASKLV, QATKDDLTVY |
| 47 | Glycinin G4 subunit (Glycine Max) | gi|255224 | 63,641/5.38 | 7 | 209 | FYNPKAGRIS, PKESQRRVVA, TLNSLTLPAL, SYLKDVFRAI, PSEVLAHSYN, NNNPFSFLVP |
| 48 | Uncharacterized protein (Glycine Max) | gi|947119133 | 54,647/5.30 | 10 | 260 | DSGAIVTVKG, QEEENEGSNI, LSGFAPEFLK, RFYLAGNQEQ, EAFGVNMQIV, RNLQGENEEE |
| 49 | Glyso sucrose-binding protein (Glycine Soja) | gi|1169100901 | 57,954/6.08 | 43 | 933 | AILEARAHTF, LSAFSWNVLQ, WWPFGGESKP, PSYHRISSDL, FAGKDNIVSS, VSPRHFDSEV, KPGMVFVVPP, LAMLHIPVSV, VGPDDDEKSW, LLQGIENFRL, GPGGRDPESV, GHPFVTIASN |
| 50 | Glyso Sucrose-binding protein (Glycine Soja) | gi|1169100901 | 69,845/5.43 | 46 | 986 | AILEARAHTF, HIPAGTPLYI, LSAFSWNVLQ, PSYHRISSDL, FAGKDNIVSS, VSPRHFDSEV, IHYNSHATKI, LDNVAKELAF, NYPSEMVNGV, LAMLHIPVSV, LGLVSESETE, STPGKFEEFF, FDRKESFFFP, LLQGIENFRL, KITLEPGDMI, GPGGRDPESV |
| 51 | GlysoSucrose-binding protein (Glycine Soja) | gi|1174098436 | 50,411/5.88 | 45 | 1237 | GRAILTLVNN, EEQRQQEGVI, NNFGKFFEIT, DDRDSYNLHP, PEKNPQLRDL, YFVDAQPQQK, GDAQRIPAGT, DIFLSSVDIN, NFLAGEKDNV, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, NLRSRNPIYS, SFQTLFENQN |
| 52 | Glyso sucrose-binding protein (Glycine Soja) | gi|1169100901 | 57,954/6.08 | 44 | 1135 | AILEARAHTF, HIPAGTPLYI, LSAFSWNVLQ, VSPRHFDSEV, LDNVAKELAF, NYPSEMVNGV, LGLVSESETE, VGPDDDEKSW, FDRKESFFFP, LLQGIENFRL, KITLEPGDMI, GPGGRDPESV, GPGGRDPESV, FELPREERGR |
| 53 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 58 | 1441 | GRAILTLVNN, EEQRQQEGVI, NNFGKFFEIT, DDRDSYNLHP, PEKNPQLRDL, DIFLSSVDIN, NFLAGEKDNV, NNPFYLRSSN, PNTILLPHHA, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, SFQTLFENQN, DADFLLFVLS, NLRSRNPIYS, LAFPGSAQDV |
| 54 | β-Subunit of β-Conglycinin (Glycine Max) | gi|111278867 | 69,845/5.43 | 36 | 803 | MITLAIPVNK, FNLRSRDPIY, ELAFPGSAKD, PGRFESFFLS, SYNLQSGDAL, STQAQQSYLQ, TPEKNPQLRD, RVPAGTTYYV, LDVFLSVVDM, VNPDNDENLR, NEGALFLPHF, VISQIPSQVQ |
| 55 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 56 | 1294 | GRAILTLVNN, EEQRQQEGVI, NNFGKFFEIT, KRSPQLENLR, DDRDSYNLHP, PEKNPQLRDL, YFVDAQPQQK, GDAQRIPAGT, NFLAGEKDNV, PNTILLPHHA, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, NLRSRNPIYS, LAFPGSAQDV |
| 56 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 58 | 1498 | GRAILTLVNN, EEQRQQEGVI, NNFGKFFEIT, DDRDSYNLHP, PEKNPQLRDL, GDAQRIPAGT, DIFLSSVDIN, NFLAGEKDNV, NNPFYLRSSN, PNTILLPHHA, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, DADFLLFVLS, NLRSRNPIYS, LAFPGSAQDV |
| 57 | β-Subunit of β-Conglycinin (Glycine Max) | gi|341603993 | 49,987/6.14 | 38 | 1308 | GRAILTLVNN, QQEGVIVELS, KFFEITPEKN, DDRDSYNLHP, PQLRDLDIFL, AQPQQKEEGS, SSVDINEGAL, NNPFYFRSSN, PNTILLPHHA, TYYLVNPHDH, TYYLVNPHDH, SEDEPFNLRS, SFQTLFENQN, DADFLLFVLS, RNPIYSNNFG |
| 58 | β-Subunit of β-Conglycinin (Glycine max) | gi|1174098436 | 50,411/5.88 | 60 | 1554 | GRAILTLVNN, EEQRQQEGVI, NNFGKFFEIT, DDRDSYNLHP, PEKNPQLRDL, YFVDAQPQQK, GDAQRIPAGT, DIFLSSVDIN, NFLAGEKDNV, NNPFYLRSSN, PNTILLPHHA, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, SFQTLFENQN, NLRSRNPIYS |
| 59 | β-Subunit of β-Conglycinin (Glycine max) | gi|1174098436 | 50,411/5.88 | 45 | 1237 | GRAILTLVNN, EEQRQQEGVI, NNFGKFFEIT, DDRDSYNLHP, PEKNPQLRDL, YFVDAQPQQK, GDAQRIPAGT, DIFLSSVDIN, NFLAGEKDNV, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, NLRSRNPIYS, SFQTLFENQN |
| 60 | Mutant glycinin A3B4 (Glycine Max) | gi|223649560 | 60,002/5.65 | 14 | 368 | PGVPYWTYNT, GDEPVVAISL, IVTVEGGLSV, LDTSNFNNQL, DQNPRVFYLA, GFSKHFLAQS, FNEGDVLVIP, FNTNEDTAEK |
| 61 | Uncharacterized protein (Glycine max) | gi|947119133 | 54,647/5.30 | 24 | 560 | WMYNNEDTPV, DSGAIVTVKG, VAVSIIDTNS, QEEENEGSNI, LENQLDQMPR, LSGFAPEFLK, RFYLAGNQEQ, EAFGVNMQIV, LIAVPTGVAW, RNLQGENEEE |
| 62 | Glyso Glycinin (Glycine Soja) | gi|734345446 | 55,783/5.95 | 20 | 478 | GGSQSQKGKH, EDKGAIVTVK, QQEEENEGGS, GQSSRPQDRH, ILSGFTLEFL, RPSYTNGPQE, RFYLAGNQEQ, EHAFSVDKQI, PDNRIESEGG, IYIQQGKGIF, AKNLQGENEG |
| 63 | Uncharacterized protein (Glycine max) | gi|947119133 | 54,647/5.30 | 18 | 501 | DSGAIVTVKG, QEEENEGSNI, GQSSRPQDRH, LSGFAPEFLK, CQIQKLNALK, QKIYNFREGD, RFYLAGNQEQ, EAFGVNMQIV, RNLQGENEEE, PDNRIESEGG |
| 64 | Uncharacterized protein (Glycine max) | gi|947119133 | 54,647/5.30 | 16 | 459 | DSGAIVTVKG, QEEENEGSNI, LSGFAPEFLK, EAFGVNMQIV, RFYLAGNQEQ, EAFGVNMQIV, RNLQGENEEE, EFLKYQQQQQ, PDNRIESEGG |
| 65 | Uncharacterized protein (Glycine max) | gi|351726399 | 27,863/6.92 | 35 | 361 | FIGGTGYIGK, YPSEFGNDVD, FIVEASAKAG, RTHAVEPAKS, HPTFLLVRES, AFATKAKVRR, LGDGNPKAVF, ERIYVPEEQL |
| 66 | Glyso Glycinin (Glycine Soja) | gi|734345446 | 55,783/5.95 | 20 | 478 | GGSQSQKGKH, EDKGAIVTVK, QQEEENEGGS, GQSSRPQDRH, ILSGFTLEFL, RPSYTNGPQE, RFYLAGNQEQ, EHAFSVDKQI, PDNRIESEGG, IYIQQGKGIF, AKNLQGENEG |
| 67 | Glyso Glycinin (Glycine Soja) | gi|734345446 | 55,783/5.95 | 17 | 410 | PALSWLRLSA, RVFDGELQEG, SLLNALPEEV, RVLIVPQNFV, IQHTFNLKSQ, VAARSQSDNF, EYVSFKTNDT, FKFLVPPQES |
| 68 | Glyso Glycinin (Glycine Soja) | gi|734345446 | 55,783/5.95 | 25 | 517 | PALSWLRLSA, RVFDGELQEG, SLLNALPEEV, EFGSLRKNAM, FVPHYNLNAN, VAARSQSDNF, SIIYALNGRA, EYVSFKTNDT, FKFLVPPQES, PMIGTLAGAN |
| 69 | Glyso Glycinin (Glycine Soja) | gi|734345445 | 59,013/5.79 | 24 | 446 | RLRQNIGQNS, VAAKSQSDNF, SPDIYNPQAG, EYVSFKTNDR, FSFLVPPQES, SITTATSLDF, PSIGNLAGAN, PALWLLKLSA, RVFDGELQEG, SLLNALPEEV, QYGSLRKNAM, GVLIVPQNFA, IQHTFNLKSQ |
| 70 | α-Subunit of β-Conglycinin (Glycine max) | gi|111278867 | 69,845/5.43 | 32 | 762 | LFKNQYGHVR, MITLAIPVNK, FNLRSRDPIY, ELAFPGSAKD, PGRFESFFLS, SYNLQSGDAL, STQAQQSYLQ, TPEKNPQLRD, RVPAGTTYYV, LDVFLSVVDM, LDVFLSVVDM, RNFLAGSKDN, VNPDNDENLR, NEGALFLPHF, VISQIPSQVQ |
| 71 | α-Subunit of β-Conglycinin (Glycine max) | gi|74271743 | 70,263/5.12 | 38 | 913 | RQFPFPRPPH, NENLRLITLA, SEDKPFNLRS, LLPHFNSKAI, PSQVQELAFP, IPVNKPGRFE, EEGQQQGEQR, RDPIYSNKLG, SFFLSSTEAQ, LQESVIVEIS, ESEDSELRRH, SGDALRVPSG, PQLRDLDIFL, DEDEDEEQDE, TTYYVVNPDN, SIVDMNEGAL |
| 72 | α-Subunit of β-Conglycinin (Glycine max) | gi|111278867 | 69,845/5.43 | 36 | 803 | MITLAIPVNK, FNLRSRDPIY, ELAFPGSAKD, PGRFESFFLS, SYNLQSGDAL, STQAQQSYLQ, TPEKNPQLRD, RVPAGTTYYV, LDVFLSVVDM, VNPDNDENLR, NEGALFLPHF, VISQIPSQVQ |
| 73 | Glyso Sucrose-binding protein (Glycine Soja) | gi|1169100901 | 57,954/6.08 | 33 | 761 | AILEARAHTF, LSAFSWNVLQ, FAGKDNIVSS, VSPRHFDSEV, AALQTPKGKL, VFFNIKGRAV, LAMLHIPVSV, LGLVSESETE, STPGKFEEFF, VGPDDDEKSW, LLQGIENFRL, GPGGRDPESV, FELPREERGR |
| 74 | Glyso Sucrose-binding protein (Glycine Soja) | gi|1169100901 | 57,954/6.08 | 44 | 577 | QHEEQDENPY, AILEARAHTF, HIPAGTPLYI, LSAFSWNVLQ, FAGKDNIVSS, IFEEDKDFET, IHYNSHATKI, KPGMVFVVPP, GHPFVTIASN, LGLVSESETE, VGPDDDEKSW, LLQGIENFRL, KITLEPGDMI, GPGGRDPESV, FELPREERGR |
| 75 | Glyso Sucrose-binding protein (Glycine Soja) | gi|1169100901 | 57,954/6.08 | 31 | 817 | QHEEQDENPY, AILEARAHTF, LSAFSWNVLQ, FAGKDNIVSS, IFEEDKDFET, AALQTPKGKL, IHYNSHATKI, LDNVAKELAF, LGLVSESETE, LLQGIENFRL, FELPREERGR, SIFAISREQV |
| 76 | Glyso Sucrose-binding protein (Glycine Soja) | gi|1169100901 | 57,954/6.08 | 24 | 585 | AILEARAHTF, LSAFSWNVLQ, FAGKDNIVSS, LDNVAKELAF, NYPSEMVNGV, LGLVSESETE, LLQGIENFRL, GPGGRDPESV |
| 77 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 50 | 1093 | EEQRQQEGVI, NNFGKFFEIT, EGDANIELVG, KRSPQLENLR, DDRDSYNLHP, PEKNPQLRDL, GDAQRIPAGT, DIFLSSVDIN, NFLAGEKDNV, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, SKAIVILVIN, LAFPGSAQDV |
| 78 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 55 | 1100 | GRAILTLVNN, EEQRQQEGVI, NNFGKFFEIT, KRSPQLENLR, DDRDSYNLHP, PEKNPQLRDL, DIFLSSVDIN, NFLAGEKDNV, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, SFQTLFENQN, SKAIVILVIN, LAFPGSAQDV |
| 79 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 46 | 797 | GRAILTLVNN, PVNKPGRYDD, EEQRQQEGVI, NNFGKFFEIT, GDAQRIPAGT, DIFLSSVDIN, NFLAGEKDNV, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, NLRSRNPIYS, LAFPGSAQDV |
| 80 | β-Subunit of β-Conglycinin (Glycine Max) | gi|1174098436 | 50,411/5.88 | 45 | 880 | GRAILTLVNN, EEQRQQEGVI, DDRDSYNLHP, PEKNPQLRDL, DIFLSSVDIN, NFLAGEKDNV, PNTILLPHHA, TYYLVNPHDH, KTISSEDEPF, EGALLLPHFN, SFQTLFENQN, DADFLLFVLS |
| 81 | β-Subunit of β-Conglycinin (Glycine Max) | gi|341603993 | 49,987/6.14 | 56 | 912 | GRAILTLVNN, QQEGVIVELS, NIELVGIKEQ, DDRDSYNLHP, PQLRDLDIFL, QQKQKQEEEP, GDAQRIPAGT, NNPFYFRSSN, PNTILLPHHA, TYYLVNPHDH, LLPHFNSKAI, SFQTLFENQN, DADFLLFVLS, VLFGEEEEQR, VILVINEGDA |
| 82 | β-Subunit of β-Conglycinin (Glycine Max) | gi|341603993 | 49,987/6.14 | 52 | 896 | GRAILTLVNN, QQEGVIVELS, KFFEITPEKN, NIELVGIKEQ, DDRDSYNLHP, PQLRDLDIFL, QQKQKQEEEP, GDAQRIPAGT, NNPFYFRSSN, TYYLVNPHDH, LLPHFNSKAI, SFQTLFENQN, VLFGEEEEQR, VILVINEGDA, GSAQDVERLL |
| 83 | GlysoGlycininA3B4subunit (Glycine Soja) | gi|126144646 | 57,663/5.78 | 25 | 566 | LRSPDDERKQ, HEDDEDEDEE, IVTVEGGLSV, EDQPRPDHPP, QEEEGGSVLS, QRPSRPEQQE, LQDSHQKIRH, GFSKHFLAQS, GNPDIEHPET, FNTNEDTAEK |
| 84 | GlysoGlycininA3B4subunit (Glycine Soja) | gi|126144646 | 57,663/5.78 | 37 | 695 | PGVPYWTYNT, LRSPDDERKQ, HEDDEDEDEE, GFSKHFLAQS, GDEPVVAISL, IVTVEGGLS, EDQPRPDHPP, LDTSNFNNQL, QEEEGGSVLS, QRPSRPEQQE, LHLPSYSPYP, DQNPRVFYLA, FNEGDVLVIP, GNPDIEHPET, FNTNEDTAEK |
| 85 | Uncharacterized protein (Glycine max) | gi|947119133 | 54,647/5.30 | 22 | 596 | GGSQSQKGKQ, DSGAIVTVKG, QEEENEGSNI, GLRVTAPAMR, LSGFAPEFLK, RPSYTNGPQE, RFYLAGNQEQ, EAFGVNMQIV, EFLKYQQQQQ, RNLQGENEEE |
| 86 | Uncharacterized protein (Glycine max) | gi|947119133 | 54,647/5.30 | 18 | 475 | DSGAIVTVKG, GGSQSQKGKQ, GLRVTAPAMR, RPSYTNGPQE, RFYLAGNQEQ, EAFGVNMQIV, RNLQGENEEE, EFLKYQQQQQ, IYIQQGKGIF, PDNRIESEGG |
| 87 | Uncharacterized protein (Glycine max) | gi|947119133 | 54,647/5.30 | 29 | 828 | WMYNNEDTPV, DSGAIVTVKG, VAVSIIDTNS, QEEENEGSNI, LENQLDQMPR, LSGFAPEFLK, RPSYTNGPQE, RFYLAGNQEQ, EAFGVNMQIV, LIAVPTGVAW, RNLQGENEEE, PDNRIESEGG |
| 88 | Glyso Glycinin (Glycine Soja) | gi|734345446 | 55,783/5.95 | 19 | 539 | EDKGAIVTVK, QQEEENEGGS, ILSGFTLEFL, RPSYTNGPQE, CQIQKLNALK, RPSYTNGPQE, RFYLAGNQEQ, EHAFSVDKQI, IYIQQGKGIF, EFLKYQQQQQ, AKNLQGENEG |
| 89 | Glyso Glycinin (Glycine Soja) | gi|734345446 | 55,783/5.95 | 18 | 473 | EDKGAIVTVK, QQEEENEGGS, ILSGFTLEFL, RPSYTNGPQE, RFYLAGNQEQ, EHAFSVDKQI, PDNRIESEGG, IYIQQGKGIF, AKNLQGENEG |
| 90 | Glyso Glycinin (Glycine Soja) | gi|734345446 | 55,783/5.95 | 27 | 427 | WMYNNEDTPV, EDKGAIVTVK, VAVSIIDTNS, QQEEENEGGS, LENQLDQMPR, ILSGFTLEFL, RPSYTNGPQE, RFYLAGNQEQ, LIAVPTGVAW, EFLKYQQQQQ, AKNLQGENEG |
| 91 | Glyso Elongation Factor (Glycine Soja) | gi|734402136 | 24,973/4.42 | 20 | 266 | ASGLKKLDEY, IDALLRISGV, EESVRSVQME, LLPRSYITGY, GLLWGASKLV, QATKDDLTVY, PVGYGIKKLQ |
| 92 | Uncharacterized protein (Glycine max) | gi|947119133 | 54,647/5.30 | 13 | 274 | DSGAIVTVKG, QEEENEGSNI, LSGFAPEFLK, RFYLAGNQEQ, EAFGVNMQIV, RNLQGENEEE |
| 93 | Glycinin G4 subunit (Glycine Max) | gi|255224 | 63,641/5.38 | 9 | 264 | VFKTHHNAVT, TLNSLTLPAL, PSEVLAHSYN, NNNPFSFLVP |
| 94 | Glyso Glycinin (Glycine Soja) | gi|734345446 | 55,783/5.95 | 23 | 436 | SLLNALPEEV, RVFDGELQEG, EFGSLRKNAM, RVLIVPQNFV, IQHTFNLKSQ, FVPHYNLNAN, VAARSQSDNF, SIIYALNGRA, EYVSFKTNDT, PMIGTLAGAN |
| 95 | Uncharacterized protein (Glycine max) | gi|356535993 | 68,164/5.94 | 30 | 409 | IVILMVTEGE, AQDIENLIKN, GKFYEITPEK, ANIELVGLKE, QRESYFADAQ, NPQLRDFDIL, QQQGEETREV, LNTVDINEGG, LLLPHYNSKA, VKELAFPAGS, QEEENEGSNI |
| 96 | β-Subunit of β-Conglycinin (Glycine max) | gi|341603993 | 49,987/6.14 | 38 | 1035 | MITLAIPVNK, VLFGREEGQQ, FNLRSRDPIY, ELAFPGSAKD, PGRFESFFLS, QGEERLQESV, NEGEANIELV, SYNLQSGDAL, STQAQQSYLQ, TPEKNPQLRD, GIKEQQQRQQ, LDVFLSVVDM |
| 97 | β-Subunit of β-Conglycinin (Glycine max) | gi|1174098436 | 50,411/5.88 | 39 | 1035 | NENLRLITLA, EEINKVLFSR, SEDKPFNLRS, PSQVQELAFP, IPVNKPGRFE, EEGQQQGEQR, SFFLSSTEAQ, LQESVIVEIS, SGDALRVPSG, QSYLQGFSRN, PQLRDLDIFL, QQEQQQEEQP |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Saedi, N.; Agarwal, M.; Ma, W.; Islam, S.; Ren, Y. Study on Effect of Extraction Techniques and Seed Coat on Proteomic Distribution and Cheese Production from Soybean Milk. Molecules 2020, 25, 3237. https://doi.org/10.3390/molecules25143237
Al-Saedi N, Agarwal M, Ma W, Islam S, Ren Y. Study on Effect of Extraction Techniques and Seed Coat on Proteomic Distribution and Cheese Production from Soybean Milk. Molecules. 2020; 25(14):3237. https://doi.org/10.3390/molecules25143237
Chicago/Turabian StyleAl-Saedi, Nadia, Manjree Agarwal, Wujun Ma, Shahidul Islam, and Yonglin Ren. 2020. "Study on Effect of Extraction Techniques and Seed Coat on Proteomic Distribution and Cheese Production from Soybean Milk" Molecules 25, no. 14: 3237. https://doi.org/10.3390/molecules25143237
APA StyleAl-Saedi, N., Agarwal, M., Ma, W., Islam, S., & Ren, Y. (2020). Study on Effect of Extraction Techniques and Seed Coat on Proteomic Distribution and Cheese Production from Soybean Milk. Molecules, 25(14), 3237. https://doi.org/10.3390/molecules25143237