1. Introduction
Over the last hundred years, biochemical discoveries have made it increasingly possible to characterize the metabolic pathways in our bodies, develop new drugs, and monitor human nutrition and lifestyle. Though our knowledge is increasingly broad, it remains divided into specific areas, such as the characterization of genetic make-up or transcriptional factors underlying the expression of essential proteins involved in specific physiological or pathophysiological processes. In this context, metabolomics has come into its own to mend the cracks between the different disciplines hitherto used to study our biochemical mechanisms [
1]. Considering that a single change in a DNA base can lead to the observation of alterations in metabolite concentrations of up to 10,000-fold changes [
2], metabolomics represents a highly sensitive probe for depicting our phenotype. Helped by the development of new analytical technologies for obtaining and processing biochemistry data, metabolomics as an omics discipline is under constant development. In the last 20 years alone, more than 5000 papers have been published on the subject, making it one of the fastest-growing disciplines [
3].
The most used analytical platforms in metabolomics are chromatography-mass spectrometry (LC–MS, GC–MS, CE–MS, and IMS–MS) and NMR spectroscopy. As reported in many papers, these two methodologies have several features that make them complementary [
4]. For example, MS techniques are highly sensitive and allow for the detection of thousands of features at different concentration ranges, potentially expanding the description of a metabolic profile in detail with just a few microliters of sample. However, the identification of compounds by MS is a more complex process than by NMR. Indeed, the metabolite identity is solved by measuring the mass-to-charge ratio (
m/
z) of the ionized molecule and/or its ionized molecular fragments and then comparing them with reference spectra and/or using analytical standards [
5]. Furthermore, not all MS techniques have the same degree of reproducibility; this is mainly the case for LC–MS measurements, which yield less reliable metabolite quantifications [
6].
Unlike mass spectrometry, NMR is not a destructive technique and, in many cases, requires minimal sample preparation. The ability to determine the identity of a compound with a single analysis (
1H-NMR) can be very accurate and fast for concentrated compounds or those that give signals in non-crowded regions of the spectrum. However, it has a lower sensitivity than MS [
3], making it possible to only quantify a portion of the metabolome.
Thus far, few studies have described a combined use of both techniques, and these have directed their attention towards the development of statistical methods for weighing the two datasets [
4] or for the structure determination of new compounds in commonly studied biofluids [
7]. However, given the high complementarity of the two techniques, it should be beneficial to combine the data separately obtained with NMR and MS to improve the ability to classify and quantify the “metabotypes” under investigation [
8].
One of the main limitations of using NMR is the relatively low number of accurately quantifiable metabolites in particularly complex mixtures like urine. For example, a study performed at two different fields (600 and 700 MHz) starting from a list of 151 metabolites that are potentially quantifiable in urine showed that only 50 presented data strongly correlated between the values obtained at the two magnetic fields [
9]. This result represents a limit of quantifiable compounds in urine using NMR, and most studies in the literature have used a dataset of this size [
10,
11,
12,
13,
14,
15]. However, in one case, it was possible to reach 209 quantified metabolites [
16], but only a fraction was detected in more than 80% of the samples.
Simultaneously identifying a metabolite by both NMR and MS would maximize the advantages for biomarker discovery by increasing the number of quantified metabolites in all samples and the accuracy of the measured concentrations. In our opinion, the method that has best combined MS data with NMR is the one developed by Nicholson et al. [
17]. The authors named this strategy Statistical Heterospectroscopy (SHY) and showed that it is possible to correlate chemical shift and
m/
z data when a cohort of samples is considered. This concept revealed a new perspective to cross-reference NMR and MS data and to get the best of both techniques. However, the correlation was attempted with regions of the NMR spectrum, limiting the number of identifiable metabolites and obtaining only relative levels instead of concentrations. Our idea is to use the SHY concept to develop a novel strategy of the MS-assisted deconvolution of NMR spectra to extend the number of urinary metabolites quantified in their absolute rather than relative levels. We show how the synergistic use of both analytical methodologies can help to achieve this goal, taking the determination of metabolite concentrations in human urine as a specific case. We call this approach:
SYnergic use of NMR and HRMS for
METabolomics (SYNHMET). Using SYNHMET, it was possible to obtain a complete dataset comprising 165 urinary metabolite concentrations for nine controls, six patients affected by chronic cystitis, and thirty-one bladder cancer patients.
3. Discussion
The value of combining the two most commonly used techniques in metabolomics, NMR and MS, was recently recognized and addressed in a review by Marshall and Powers [
8]. However, no method has attempted to directly correlate an NMR chemical shift with an MS
m/
z value of a single sample because there is no specific information to indicate that these two features belong to the same molecule [
8]. MS intensities belonging to a cohort of samples were cross-correlated with NMR spectral regions to overcome this limitation [
17]. The correlation that does not exist in one sample exists in all of them as a group because, at this point, it is the distribution of intensities that determines whether a given chemical shift belongs to a molecule signal presenting a certain
m/
z. The so-called Statistical Heterospectroscopy approach, however, led to the identification of a reduced number of metabolites. The major drawback of this approach is, in our opinion, that the correlation was attempted between intensities of compounds whose levels are measured separately by HPLC–MS with regions of the NMR spectrum whose intensities result from the simultaneous contributions of many metabolites. A clear correlation between the MS and the NMR bin intensities can only be expected for strongly dominating metabolites because of their concentration in the region’s shape.
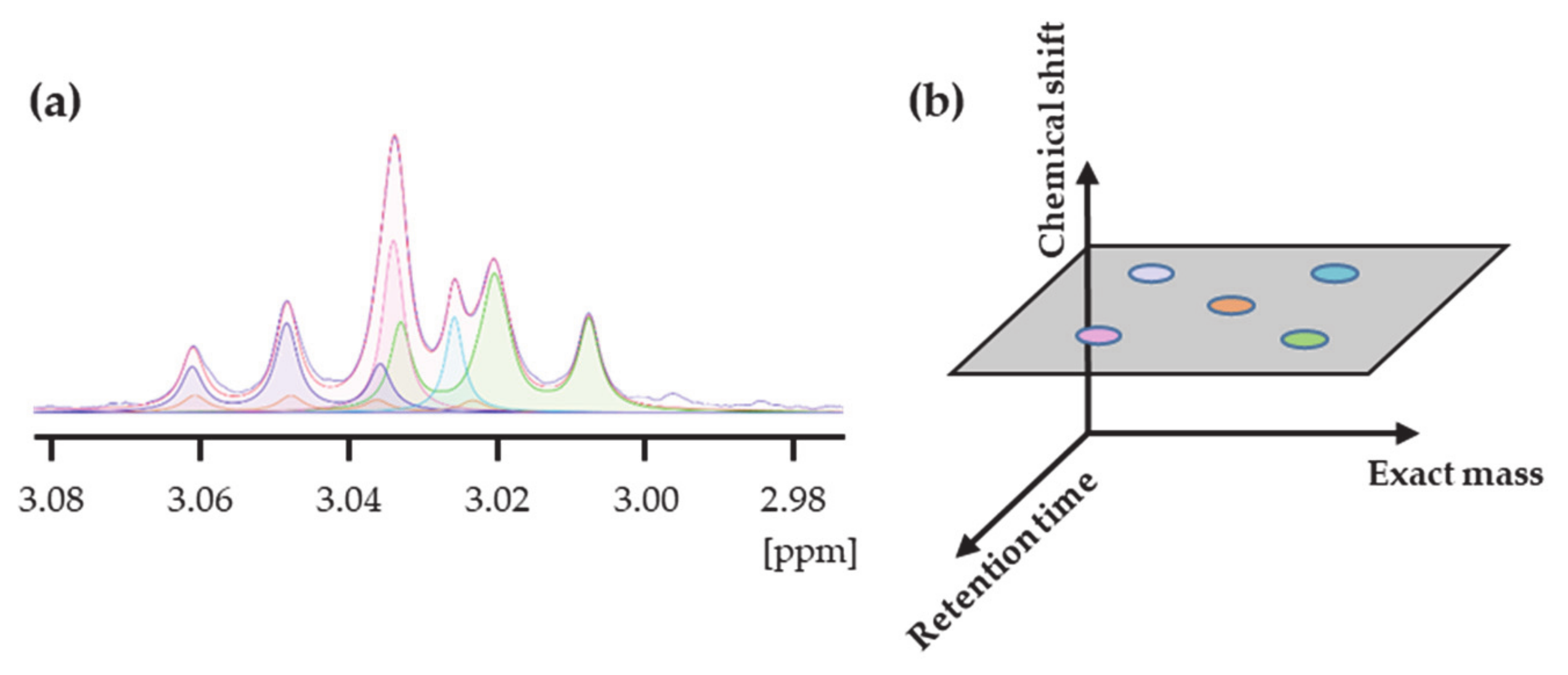
Differently, SYNHMET uses the resolution power of NMR to separate most of the different signals contributing to the spectrum profile, coupled to that of UHPLC–HRMS. The deconvolution strategy was used to extract more than 200 metabolite concentrations from urine [
16], a result not reproduced in any further study to the best of our knowledge. The difficulty associated with this methodology lies mainly in the extraction of levels for not concentrated metabolites or those presenting signals in crowded regions. These areas only provide the sum of the contributions of the various compounds, and without further information, there are many ways to combine the positions and intensities of the mixture components to reproduce the experimental shape of the NMR spectrum. The simultaneous use of UHPLC–HRMS intensities provides the key to obtain a single solution because it adds two new features to calculate the relative contribution of metabolites to a profile: the molecular weight and the chromatographic resolution. The latter is not practical in NMR measurements due to a combination of low sensitivity and long acquisition times. In this way, the correct proportions are extracted by combining NMR and UHPLC–HRMS, which transforms the experiment used for metabolite identification/quantification from monodimensional (chemical shift) into three-dimensional (by adding retention time and exact mass). Globally, the mechanism by which this method operates can be defined as an MS-assisted NMR deconvolution, improving the quality and quantity of the obtained data compared to that expected when exclusively using NMR (
Scheme 2).
According to the Metabolomics Standard Initiative, a definite metabolite identification, called level 1, needs a direct comparison of experimental data with an authentic reference standard [
27]. It was argued that NMR metabolite identification of compounds in mixtures achieved by comparing with a spectra database approaches level 1 identification [
27]. In the SYNHMET strategy, we added parameters characterizing a compound (chemical shift, multiplicity, and the number of signals) and the elemental composition provided by the correlation with the MS data to the NMR. This additional information limits the possible structures to the existing isomers, constituting a very restricted chemical space for low molecular weight compounds. The probability that two isomers show the same NMR parameters is extremely low, if even possible. For all these reasons, the confidence in the SYNHMET identification should be considered, in our opinion, similar to that in level 1.
Applying SYNHMET enabled us to quantify a large number of metabolites in urine. Many papers have supported the concept that the utility of a given approach is directly proportional to the measurable number of metabolite levels. However, this is only one of the two essential parameters in defining the value of a dataset for metabolomics studies. The other is the completeness of the matrix because if there are too many missing values, the classification ability or the detection of correlations between metabolites becomes weaker [
28]. In our experience and from analyzing the literature on NMR urine metabolomics, the maximum number of metabolites quantified in at least 80% of samples is around 50–60 [
10,
11,
12,
13,
14,
15]. This number is far from that achieved in LC-MS studies, which have reached more than a thousand [
29]. However, the identity of many of these metabolites is only putative because it is only supported by fragmentation spectra.
In our scheme, both the reproducibility and accuracy of the results are mainly supported by the characteristics of NMR. It is commonly accepted that these are two main robust features of NMR, which involve the possibility of obtaining the same instrumental response even when different spectrometers are used. These characteristics have favored constructing a community-built reference calibration line, with the participation of twenty-three laboratories, including ours [
30]. We foresee that a similar calibration line can be produced among laboratories keen to prove the validity of the SYNHMET approach, allowing for the scientific community to obtain more robust results in metabolomics. However, the number of samples analyzed in this work did not allow for a definitive answer, and further studies will be needed to assess the limits in terms of precision and accuracy.
A compelling application of SYNHMET is the possibility of generating a detailed personalized profile of urinary metabolites. The main way to get a reliable profile is the election of an effective way to normalize the metabolites’ concentrations to correct the variation induced by the subject hydration status. Usually, concentrations are normalized by the total urine volume collected during 24 h or the urinary creatinine level. These two normalization strategies present advantages and drawbacks. In case of using the total urine volume for 24 h, the incomplete collection is the main problem [
22]. On the other hand, creatinine concentration is affected by several factors that are not directly related to the glomerular filtration rate, like muscle mass, diet, age, sex, and race [
31,
32]. Creatinine is also secreted from the renal tubules, which is not desirable for a glomerular filtration marker. A study comparing the uncertainties related to standardization of urine samples with volume and creatinine concentration showed that the latter introduces a 19–35% error [
22]. However, if compared with the total volume normalization, this is partially counteracted by the higher risk that the sample is incomplete in collecting voids during a 24-h time interval. More recently, a study showed that normalization with urinary creatinine is better than volume in rats under controlled preclinical conditions, even when compared to a more recently proposed normalizer, cystatin C [
33].
Our study used creatinine to normalize the metabolite concentrations, mainly because almost all the available normal ranges found in the literature are expressed in μM/mM of creatinine [
34]. Independently on the used strategy, the profile of normalized metabolite concentrations constitutes a personalized urinary picture, which can be used to expand the current capability of classical biochemical tests to determine aperson’s health status. This approach is very different from classical metabolomics, which seeks to find universal biomarkers of a disease or drug effects. The concept of personalized medicine grew up from the scientific evidence that there is high interindividual variability in the metabolic response to any change in the health status or the response to a drug. Therefore, expanding the number of metabolites that can be routinely monitored in biofluids can define a more accurate picture to be used in clinical practice [
35]. At the heart of this analysis is the concept that a person’s metabolic profile can reflect an individual’s overall health status. Nowadays, physicians only capture a tiny fraction of the information contained in the metabolome, mainly due to its high complexity and the lack of robust and efficient analytical methods to determine the absolute instead of the relative level of a large number of chemical compounds in biofluids. Routine analyses only evaluate a very restricted number of compounds, such as glucose level for monitoring diabetes, cholesterol and low/high-density lipoproteins for cardiovascular health, or urea and creatinine for renal disorders. Simultaneously determining the absolute concentration of hundreds of molecules will open up new scenarios towards more accurate personalized medicine and increase the predictive value of such analyses.
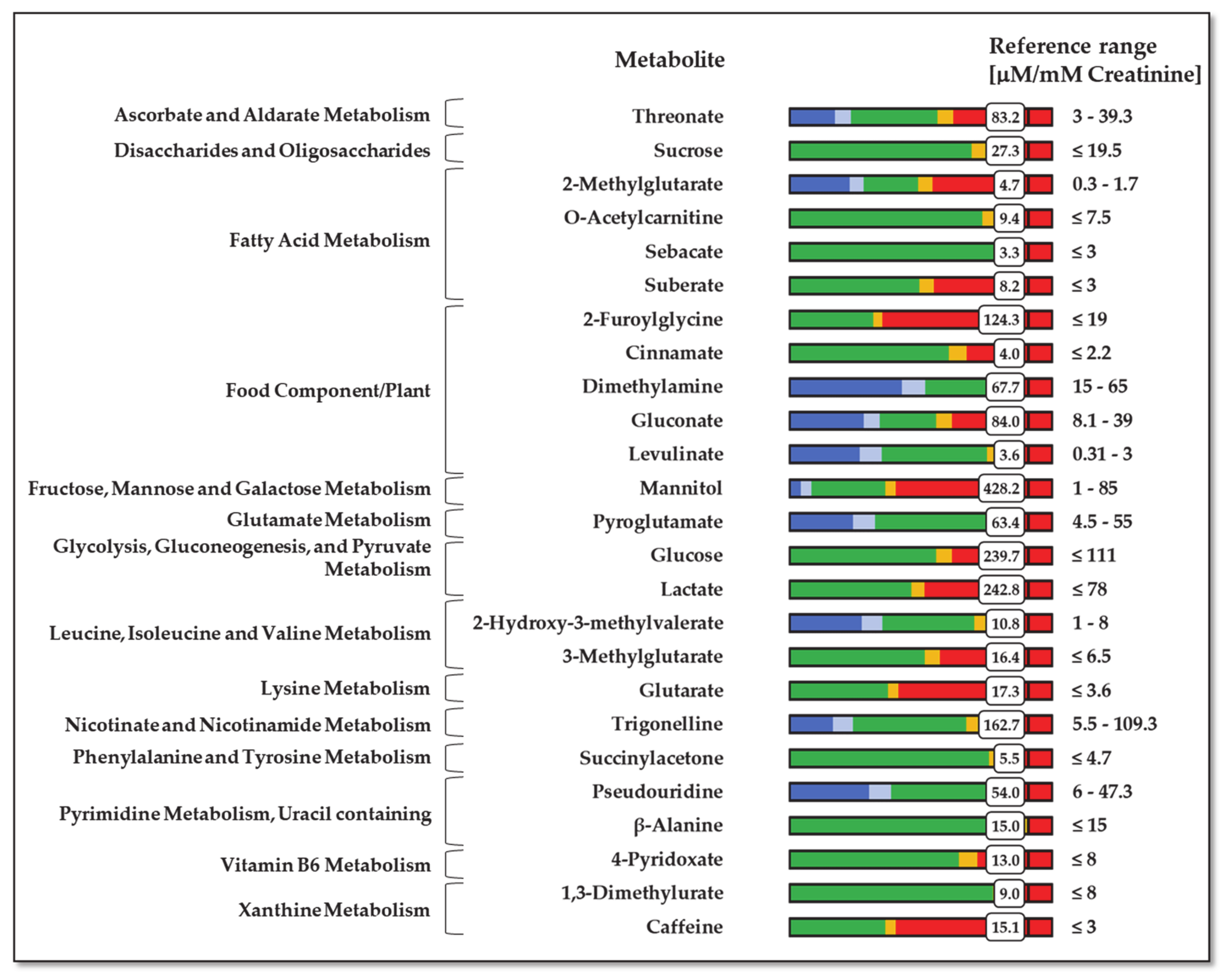
For example, a patient suffering from BC showed a urinary profile with significant abnormal values for metabolites belonging to galactose/starch sucrose, caffeine, and lysine metabolisms (
Figure 5). A recent study about recognizing different stages of BC using machine learning identified the first two as the main dysregulated metabolisms in early stages, whereas lysine metabolism was found to be unbalanced in late stages [
36]. The case of caffeine metabolism is remarkable. Along with one of its metabolites, 1,3-dimethylurate, caffeine is processed by a P450 family cytochrome acting in the liver, CYP1A2 [
37]. The connection between caffeine metabolism, exposure to tobacco compounds, and urinary mutagenicity has been known for a long time [
38]. Significantly, cigarette smoking is the leading risk factor for BC, accounting for 50% of the total [
39]. In addition to this patient, urine caffeine levels were significantly elevated in six other subjects with BC.
This patient also presented significant comorbidity due to cardiovascular pathologies, particularly severe myocardial ischemia. We observed different altered metabolisms related to cardiopathies, like those corresponding to branched-chain amino acids, lactate, and fatty acid metabolism [
40]. They are the consequences of increased fatty acid metabolism, decreased glucose metabolism, and impaired branched-chain amino acid catabolism. Finally, the patient showed chronic pancreatitis, probably related to past alcohol abuse. The malfunction of the pancreas should explain the very high level of glucose in the urine, as in diabetic subjects.
4. Materials and Methods
4.1. Chemicals and Reagents
All used solvents and reagents were LC–MS grade. Water (H2O), acetonitrile (ACN), formic acid (FA), and ammonium formate (CAS 540-69-2) were obtained from Sigma Aldrich (St. Louis, MO, USA). The stable isotope-labeled (SIL) internal standard 13C15N2-8-hydroxy-2′-deoxyguanosine (13C15N2-8-OH-dG) was obtained from Toronto Research Chemicals (Toronto, ON, Canada). 15N4-hypoxanthine (15N4-Hyp), L-tyrosine-(phenyl-d4) (d4-L-Tyr), and 15N4-inosine (15N4-I) were purchased from Cambridge Isotope Laboratories, Inc., (Tewksbury, MA, USA). L-kynurenine sulfate: H2O (ring-d4, 3,3-d2) (d6-KYN) and D2O were acquired from Cambridge Isotope Laboratories, Inc. (Andover, MA, USA). Anthranilic acid-ring-13C6 (13C6-AA) and 3-(trimethylsilyl)-2,2,3,3-d propionic acid (TSP) were purchased from Sigma Aldrich (Schnelldorf, Germany). 15N,13C2-3-Hydroxy-DL-kynurenine (15N-13C2-OH-KYN) was obtained from AMRI (Albany, NY, USA).
4.2. Urine Collection
Urine samples were obtained from the Urological Research Institute (URI) of San Raffaele Hospital (Milan, Italy). Caucasian patients aged between 32 and 90 years were recruited. The dataset comprised 46 samples: 31 bladder cancer (BC) patients, nine healthy controls, and six with chronic cystitis. BC patients with concomitant or previous prostate, renal, or upper excretory tract cancer; urinary tract infections; or kidney failure were excluded. Urine samples were collected before the surgical intervention and processed soon after. The samples were centrifuged at 300 g for 5 min, aliquoted, and stored at –80 °C until use.
4.3. UHPLC–High Resolution Mass Spectrometry Analysis
4.3.1. SIL-Stock and Working Solution Preparation
Stock solutions were prepared from the independent weight of compounds and stored at −20 °C. d6-KYN and 13C6-AA were prepared in H2O/DMSO (1/1, v/v) at 1.5 and 5.0 mg/mL, respectively. 15N-13C2-OH-KYN was prepared in H2O/DMSO (1/19, v/v) at 2.0 mg/mL. 13C15N2-8-OH-dG, 15N4-Hyp, d4-L-Tyr, and 15N4-I were prepared in water at 1.0 mg/mL.
Internal Standard Working Solutions (IS-WS) were prepared by adding appropriate volumes of the stock solutions to 50 mL of ultrapure H2O (ISWS-A) and ACN (ISWS-B) to reach a final concentration of 200 ng/mL for all the standards. The solutions were maintained at 4 °C and freshly prepared every week.
4.3.2. Urine Normalization by Specific Gravity
Specific gravity (SG) measurements were made with a portable digital refractometer (Atago UG-α, Tokyo, Japan). The refractometer had a urinary SG range from 1.000 to 1.060 with a resolution of 0.001. Urine samples were thawed at room temperature in an ultrasonic bath for 10 min and then centrifuged (4000 rpm). An aliquot of urine (100 µL) was placed upon the lens of the refractometer previously calibrated with LC–MS-grade water to measure SG values. Samples were then split into two aliquots. Urinary metabolite levels were normalized by SG-diluting each aliquot with water or ACN:H2O in variable amounts for RP and HILIC analysis, respectively. Dilutions were performed to bring all samples to the same specific gravity value.
4.3.3. Urine Samples Preparation
All samples were further diluted by 3-fold with ISWS-A for RP analysis or ISWS-B for HILIC analysis. Samples were vortexed and centrifuged (13,000 g for 10 min), and the supernatant (350 μL) was transferred to a 96-well plate and randomized for LC–MS analyses.
4.3.4. Quality Control Samples and Blanks Preparation
Two different types of quality control (QC) samples were prepared: pooled QCs made by mixing equal volumes (5 μL) from each sample previously normalized for the specific gravity and dilution QCs prepared by 2, 4, and 8-fold diluting the pooled QCs with LC–MS-grade water. All QCs were further diluted by 3-fold with ISWS-A for RP analysis or ISWS-B for HILIC analysis. Pooled QC samples were injected first (n = 20) to condition the LC–MS system and obtain stable retention times and MS response. Subsequently, pooled QCs were injected every six true samples (n = 8 in total) to perform intra-batch signal drift corrections. Dilution QCs were analyzed four times and were regularly incorporated along the sample list to verify the linear response of the MS signal. Blanks consisted of LC–MS-grade water for RP analysis and ACN: H2O 80:20 (v/v) for HILIC analysis. Blank injection (n = 3) was performed at the beginning of the batch to collect a background signal excluded from the dataset.
4.3.5. HILIC and RP Chromatography
The used UHPLC system was an Ultimate 3000™ liquid chromatographic system (Thermo Scientific™, MA, USA) coupled to an Orbitrap Q Exactive™ mass spectrometer (Thermo Scientific™, MA, USA) equipped with a HESI source operating in the positive and negative ion modes. HILIC chromatographic separation was accomplished using a BEH-HILIC column, 130 Å, 1.7 μm, and 2.1 × 100 mm (Waters, Milford, MA, USA). The used mobile phases were: 20 mM ammonium formate along with 0.1% FA at pH 3.7 (mobile phase A) and ACN (mobile phase B). The gradient consisted of a linear increase of mobile phase B from 5% to 35% over 8.5 min, followed by an additional increase to 50% in 1 min. Phase B was kept constant for 1.5 min and then decreased to 5% in 0.5 min and kept stable for 3.5 min for column re-equilibration (total run time of 15 min). The used flow rate was 0.300 mL/min, the injection volume was 2 µL, and the column was kept at 35 °C.
RP chromatographic separation was achieved using an HSS-T3 column, 100 Å, 1.7 μm, and 2.1 × 100 mm (Waters, Milford, MA, USA). The mobile phases were: 0.1% FA in H2O (mobile phase A) and 0.1% FA in ACN (mobile phase B). The gradient ramp consisted of a linear increase to 10% of mobile phase B over 6 min and to 35% in 2 min. Mobile phase B was further increased to 98% in 2 min, kept constant for 0.5 min, and finally decreased to 0% in 0.5 min and kept stable for 3 min for column re-equilibration (total run time of 15 min). The flow rate was 0.300 mL/min from 0 to 8.0 min, increased to 0.4 mL/min from 8.0 to 12.0 min for column washing, and brought back to 0.3 mL/min from 12.0 to 15.0 min. The injection volume was 2 µL, and the column was kept at 35 °C. During LC–MS analysis, samples were kept in the autosampler at 8 °C.
4.3.6. High-Resolution Mass Spectrometry
Mass spectra were acquired on an Orbitrap QExactive™ mass spectrometer (Thermo Scientific™, MA, USA) operating in both the positive and negative ion modes. The HESI parameters were: 3.20 kV (pos)/–3.20 kV (neg) electrospray voltage, 280 °C heated capillary temperature, 50 (pos)/–50 (neg) S-lens RF level, sheath gas (N2) flow of 50 a.u., auxiliary gas (N2) flow of 10 a.u., and gas temperature of 300 °C. The acquisition range was set from m/z 60 to 900 at a resolution of 70,000 FWHM at m/z 200. All data were acquired in profile mode using Xcalibur™ 3.1.66.10. The QExactive™ mass spectrometer was calibrated for the positive and negative modes before sample analysis using the calibration solution provided by the manufacturer (Pierce LTQ ESI Positive Calibration Solution and Pierce LTQ ESI Negative Calibration Solution). For the mass calibration of the instrument, a custom list that included lower masses than the default calibration provided with the instrument was used to ensure that accurate masses were detected at low molecular weights.
4.3.7. Raw Data Processing by Compound Discoverer
The raw files obtained in the positive and negative ion modes were separately processed using Compound Discoverer™ 2.0 (Thermo Scientific™). Four output tables (RP+, RP-, HILIC+, and HILIC-) were generated, including m/z, retention time, and peak intensity, for all the analyzed samples. An untargeted metabolomics workflow for retention time alignment, component detection, elemental composition prediction, and gap-filling was used. The workflow tree included the following nodes: input files, select spectra, align retention times, detect unknown compounds, group unknown compounds, fill gaps, normalization areas, and mark background compounds. The raw files were aligned with an adaptive curve setting with a 5 ppm mass tolerance and a 0.4 min retention time shift. Unknown compounds were detected with a 5 ppm mass tolerance, signal to noise ratio of 3, 30% of relative intensity tolerance for isotope search, and 10,000 minimum peak intensity, and then they were grouped with 5 ppm mass and 0.3 min retention time tolerances. A procedural blank sample was used for background subtraction and noise removal during the pre-processing step. Peaks were removed from the list if they showed less than a 3-fold increase compared to blank samples or if they were detected in less than 50% of QCs and/or with relative standard deviation (%RSD) of the QCs greater than 50%. To balance differences in intensities that may have arisen from instrument instability, a normalized area across all samples was provided for each detected metabolic feature by normalization to the periodically analyzed QC samples (pooled QC).
Finally, the hit intensities of each sample were multiplied by the dilution factor used for pre-normalization. Thus, un-normalized data were used to ensure a better degree of correlation between NMR and MS.
4.4. H-NMR Spectroscopy
4.4.1. Sample Preparation
The urine samples, previously stored at –80° C, were thawed on ice and centrifuged at 4000 rpm for 10 min at 4 °C; then, 500 µL of supernatant were collected. Then, 50 µL of phosphate buffer solution [
41] (1.5 M K
2HPO
4/NaH
2PO
4, 30 mM NaN
3, and 5.5 mM TSP, pH 7.4 in D
2O) were added, and 50 µL of the final solution were transferred to a 1.7 mm thin-walled glass NMR tube for subsequent NMR analysis.
4.4.2. Spectra Acquisition
1H-NMR experiments were performed on Bruker Avance 600 MHz equipped with a SampleJet autosampler using a noesypr1d sequence, mixing time of 100 ms, a spectral window of 12 ppm, acquisition time of 2 s, relaxing time of 3 s, 516 scans, 4 dummy scans, and T = 298 K. This sequence has become the best choice for NMR-based metabolomics studies [
42] for several reasons. Firstly, the quality of water suppression is very high without the need for extensive optimization. Secondly, an increasing number of well-established groups utilize the sequence, reflecting its consistency [
43]. Finally, the library of Chenomx used in this study to quantify metabolite concentrations is optimized for this sequence and compensates for incomplete relaxation.
4.4.3. H-NMR Data Analysis
All the spectra were processed using 0.5 Hz of line-broadening followed by manual phase and baseline correction. Chenomx NMRSuite 8.5 (Chenomx Inc.) was used to quantify the concentrations of the metabolites. The spectra database in this software allows for the manual deconvolution of different signals and determines the concentration of the compounds that form the mixture. TSP was set as an internal standard at 0.5 mM.
4.5. SYNHMET Method
The starting spectrum profile for deconvolution is defined using the average concentrations of urine metabolites [
16]. The chemical shifts and levels of all compounds are then varied to reproduce the profile observed in each experimental NMR spectrum. The matching between the calculated and experimental spectral profiles is never perfect. The source of this inequality can be understood by analyzing all variables contributing to the spectrum intensity at a given chemical shift (
Ik) (Equation (1)):
where
k is the chemical shift,
i represents one assigned metabolite,
n is the total number of assigned metabolites,
Ki,k is a known factor accounting for the shape of assigned metabolites,
j represents one unassigned metabolite,
m is the total number of unassigned metabolites,
Uj,k is an unknown factor considering the shape of unidentified metabolites,
ai and
bj are the metabolite concentrations, and
Nk is a random factor representing the noise.
In parallel, the exact mass of each metabolite is searched in the MS dataset, creating a list of linked MS features for most compounds. The number of MS peaks associated with each metabolite varies from zero to more than twenty. Detecting more than one peak with the same exact mass turns the identification based solely on the molecular weight uncertain unless using labeled standards. In the SYNHMET method, combining the concentrations measured for a cohort of samples simultaneously by MS and NMR can solve this ambiguity in an alternative way. We considered that a certain MS-detected chromatographic peak showing the accurate mass of a metabolite can be attributed to it when it is the only one showing a significant correlation between the distributions of the MS peak intensities and NMR concentrations. The intensities of the selected peak are then converted into concentrations by multiplying them with the slope of the best fit solution. The initial spectrum profile is then adjusted, inserting the values of the peak or peaks averaged to those measured by NMR for each metabolite. Conversely, concentrations of compounds not represented by any MS feature or showing multiple or no correlations are not updated for the following phase.
During the next profiling step, all compounds’ signal positions and concentrations defining the updated profile are varied to obtain the best accordance between the calculated and experimental profiles. After completion, a new correlation test is accomplished, possibly increasing the number of identified and consequently quantified metabolites. This process is iteratively repeated until no further information is added. The final matrix contains concentrations of metabolites that are determined by a combination of MS and NMR measurements.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}