


Maturity Stage Discrimination of Camellia oleifera Fruit Using Visible and Near-Infrared Hyperspectral Imaging

Abstract
:1. Introduction
2. Material and Methods
2.1. Sample Preparation
2.2. Hyperspectral Image Acquisition and Calibration
2.3. Reference Analysis
2.4. Extraction of Spectra
2.5. Spectral Pre-Processing
2.6. Modeling Methods and Assessment
2.7. Dimensionality Reduction Methods
3. Results and Discussion
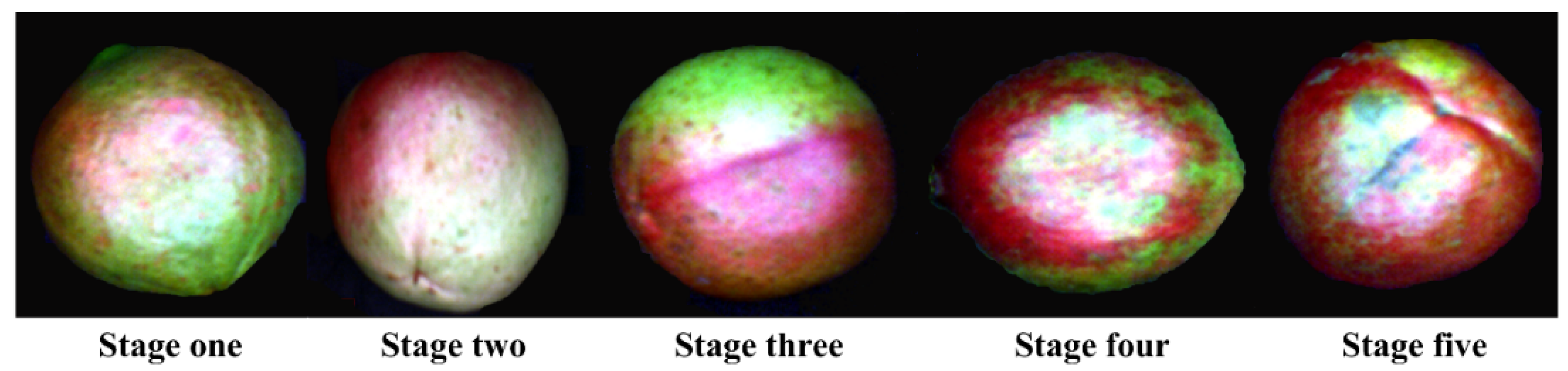
3.1. Statistical Characterization of Samples at Different Maturity Stages
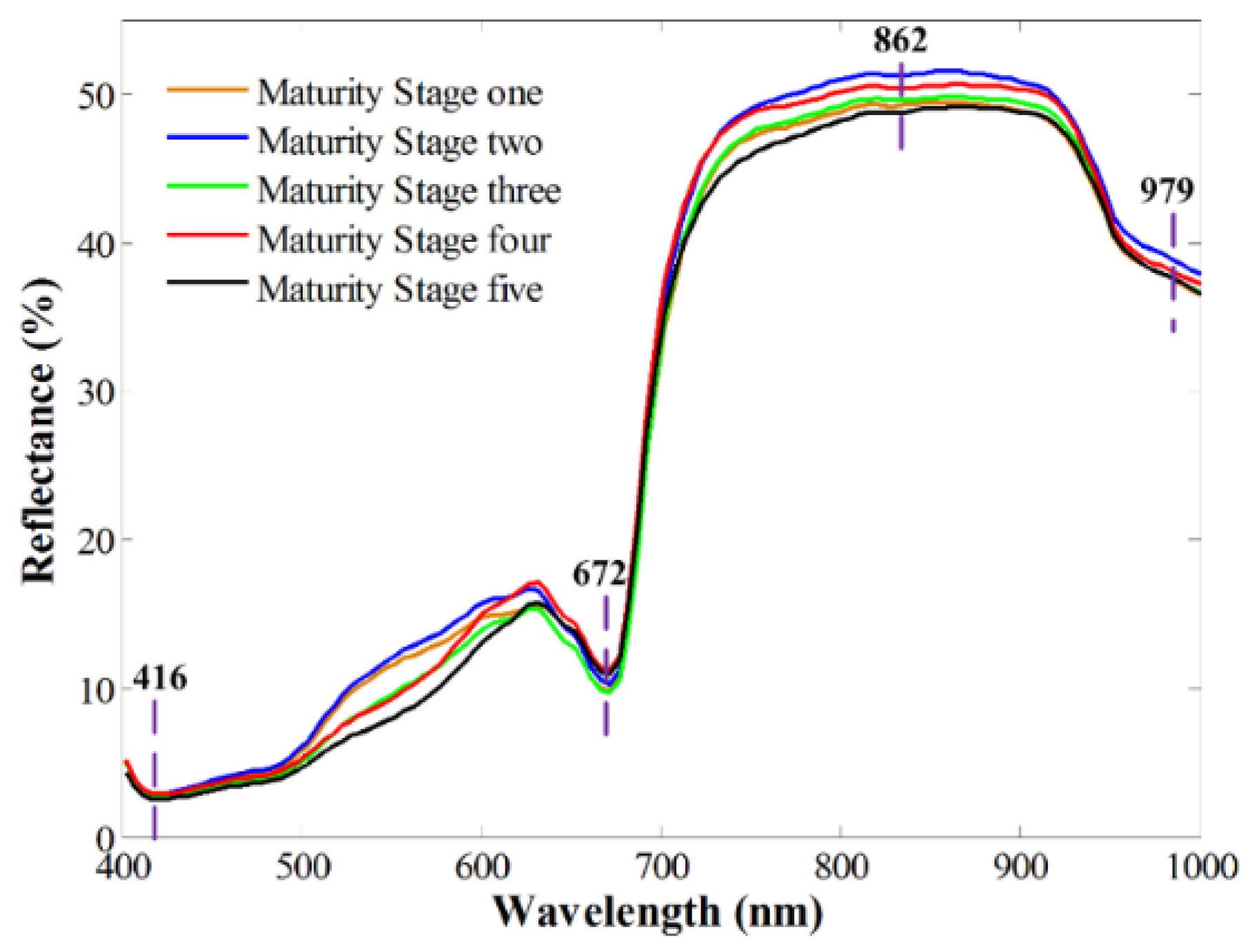
3.2. Spectral Profiles
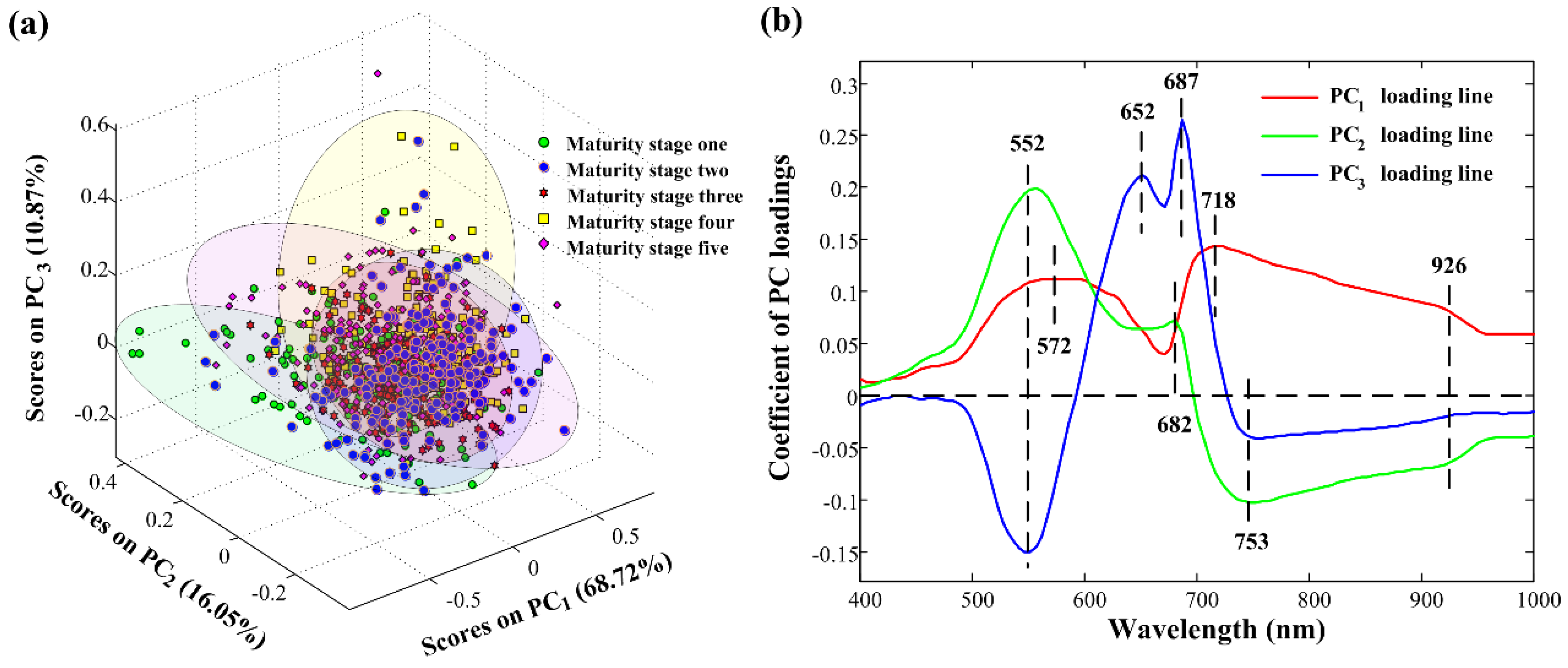
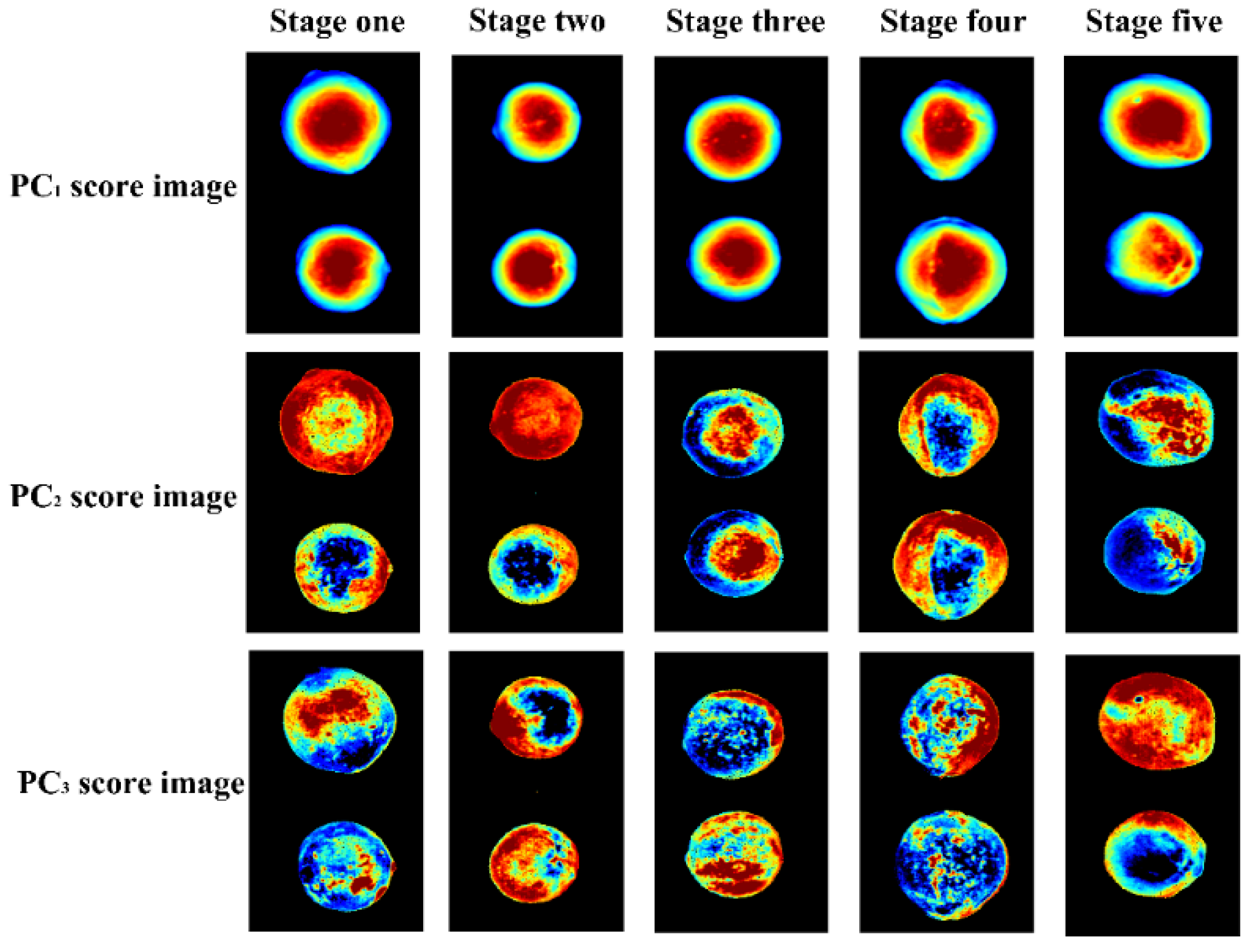
3.3. Principal Component Analysis
3.4. Model Development, Based on Full Spectra
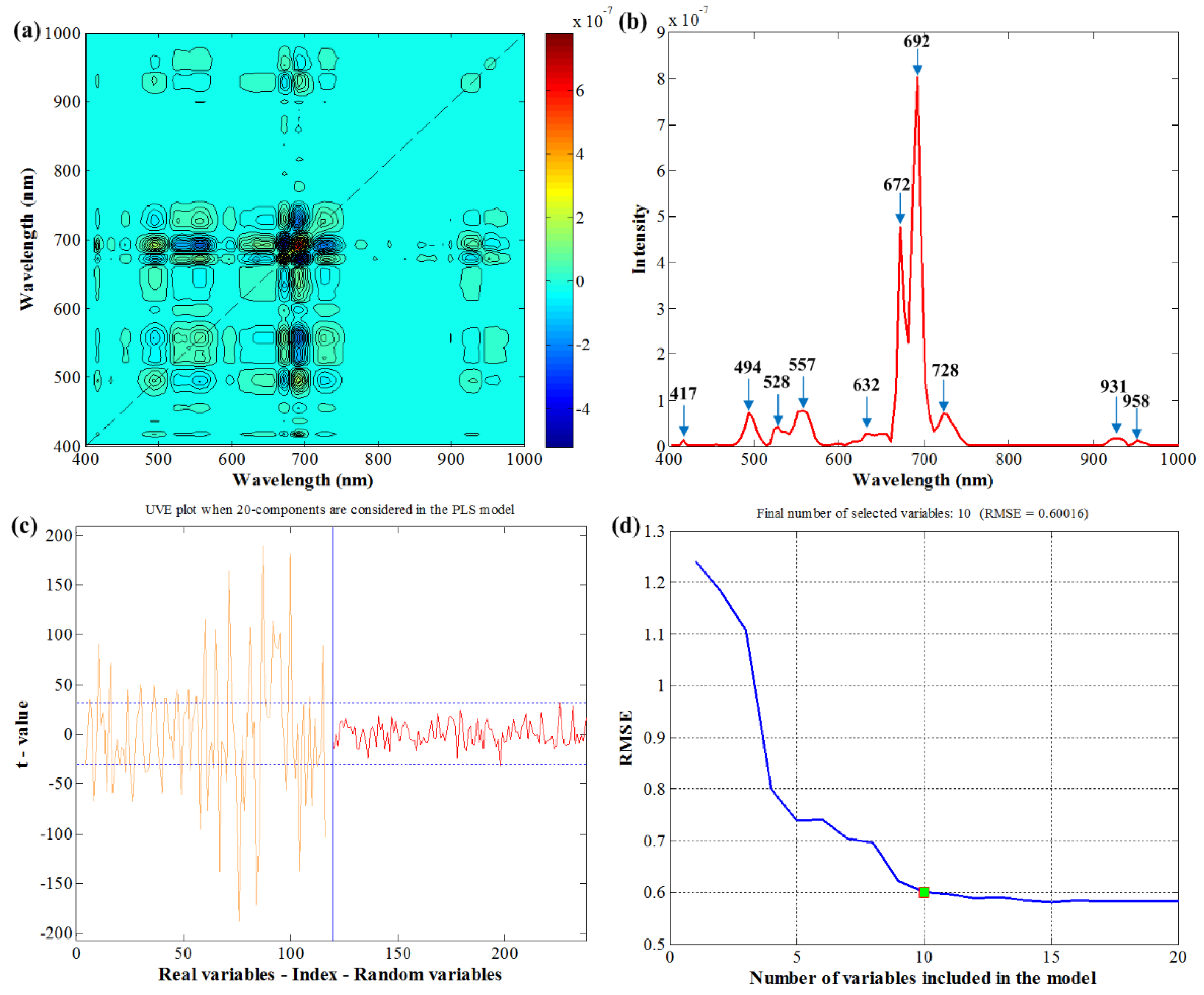
3.5. Effective Wavelengths Selection
3.6. Establishment of PLS-DA Models, Based on Selected Wavelengths
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xie, Y.; Ge, S.; Jiang, S.; Liu, Z.; Chen, L.; Wang, L.; Chen, J.; Qin, L.; Peng, W. Study on biomolecules in extractives of Camellia oleifera fruit shell by GC–MS. Saudi J. Biol. Sci. 2018, 25, 234–236. [Google Scholar] [CrossRef]
- Wu, B.; Ruan, C.; Han, P.; Dong, R.; Xiong, C.W.; Ding, J.; Liu, S. Comparative transcriptomic analysis of high- and low-oil Camellia oleifera reveals a coordinated mechanism for the regulation of upstream and downstream multigenes for high oleic acid accumulation. 3 Biotech 2019, 9, 257. [Google Scholar] [CrossRef] [PubMed]
- Zhu, G.; Liu, H.; Xie, Y.; Liao, Q.; Lin, Y.; Liu, Y.; Xiao, H.; Gao, Z.; Hu, S. Postharvest processing and storage methods for Camellia oleifera seeds. Food Rev. Int. 2020, 36, 319–339. [Google Scholar] [CrossRef]
- Shah, S.S.A.; Zeb, A.; Qureshi, W.S.; Arslan, M.; Malik, A.U.; Alasmary, W.; Alanazi, E. Towards fruit maturity estimation using NIR spectroscopy. Infrared Phys. Technol. 2020, 111, 103479. [Google Scholar] [CrossRef]
- Lovász, T.; Merész, P.; Salgó, A. Application of near infrared transmission spectroscopy for the determination of some quality parameters of apples. J. Near Infrared Spectrosc. 1994, 2, 213–221. [Google Scholar] [CrossRef]
- Surya Prabha, D.; Satheesh Kumar, J. Assessment of banana fruit maturity by image processing technique. J. Food Sci. Technol. 2015, 52, 1316–1327. [Google Scholar] [CrossRef]
- Wang, A.; Fu, X.; Xie, L. Application of visible/near-infrared spectroscopy combined with machine vision technique to evaluate the ripeness of melons (Cucumis melo L.). Food Anal. Methods 2015, 8, 1403–1412. [Google Scholar] [CrossRef]
- Castro, W.; Oblitas, J.; De-La-Torre, M.; Cotrina, C.; Bazán, K.; Avila-George, H. Classification of cape gooseberry fruit according to its level of ripeness using machine learning techniques and different color spaces. IEEE Access 2019, 7, 27389–27400. [Google Scholar] [CrossRef]
- Fadilah, N.; Mohamad-Saleh, J.; Halim, Z.A.; Ibrahim, H.; Ali, S.S.S. Intelligent color vision system for ripeness classification of oil palm fresh fruit bunch. Sensors 2012, 12, 14179–14195. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Chen, Y. Tender Leaf Identification for Early-Spring Green Tea Based on Semi-Supervised Learning and Image Processing. Agronomy 2022, 12, 1958. [Google Scholar] [CrossRef]
- Guo, Y.-Q.; Chen, G.; Wang, Y.-N.; Zha, X.-M.; Xu, Z.-D. Wildfire Identification Based on an Improved Two-Channel Convolutional Neural Network. Forests 2022, 13, 1302. [Google Scholar] [CrossRef]
- Zhu, H.; Tang, H.; Hu, Y.; Tao, H.; Xie, C. Lightweight Single Image Super-Resolution with Selective Channel Processing Network. Sensors 2022, 22, 5586. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez-Saona, L.E.; Fry, F.S.; McLaughlin, M.A.; Calvey, E.M. Rapid analysis of sugars in fruit juices by FT-NIR spectroscopy. Carbohydr. Res. 2001, 336, 63–74. [Google Scholar] [CrossRef]
- Larraín, M.; Guesalaga, A.R.; Agosín, E. A multipurpose portable instrument for determining ripeness in wine grapes using NIR spectroscopy. IEEE Trans. Instrum. Meas. 2008, 57, 294–302. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, D.; Liu, Y.; Zhou, H.; Sun, Y. Measurement of Early Disease Blueberries Based on Vis/NIR Hyperspectral Imaging System. Sensors 2020, 20, 5783. [Google Scholar] [CrossRef] [PubMed]
- Ni, C.; Li, Z.; Zhang, X.; Sun, X.; Huang, Y.; Zhao, L.; Zhu, T.; Wang, D. Online sorting of the film on cotton based on deep learning and hyperspectral imaging. IEEE Access 2020, 8, 93028–93038. [Google Scholar] [CrossRef]
- Zhang, H.; Ge, Y.; Xie, X.; Atef, A.; Wijewardane, N.K.; Thapa, S. High throughput analysis of leaf chlorophyll content in sorghum using RGB, hyperspectral, and fluorescence imaging and sensor fusion. Plant Methods 2022, 18, 60. [Google Scholar] [CrossRef]
- Huang, Y.; Yang, Y.; Sun, Y.; Zhou, H.; Chen, K. Identification of apple varieties using a multichannel hyperspectral imaging system. Sensors 2020, 20, 5120. [Google Scholar] [CrossRef]
- Wei, X.; Liu, F.; Qiu, Z.; Shao, Y.; He, Y. Ripeness classification of astringent persimmon using hyperspectral imaging technique. Food Bioprocess Technol. 2014, 7, 1371–1380. [Google Scholar] [CrossRef]
- Guo, C.; Liu, F.; Kong, W.; He, Y.; Lou, B. Hyperspectral imaging analysis for ripeness evaluation of strawberry with support vector machine. J. Food Eng. 2016, 179, 11–18. [Google Scholar]
- Zou, S.; Tseng, Y.C.; Zare, A.; Rowland, D.L.; Tillman, B.L.; Yoon, S.C. Peanut maturity classification using hyperspectral imagery. Biosyst. Eng. 2019, 188, 165–177. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Bian, B.; Wang, X.; Chen, S.; Li, Y.; Sun, Y. Identification of tomato maturity based on multinomial logistic regression with kernel clustering by integrating color moments and physicochemical indices. J. Food Process Eng. 2020, 43, e13504. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, H.; Fei, Y.; Liu, Y.; Zhang, X. Research on the prediction of green plum acidity based on improved XGBoost. Sensors 2021, 21, 930. [Google Scholar] [CrossRef]
- AOAC. Official Methods of Analysis, 13th ed.; Association of Official Analytical Chemists: Washington, DC, USA, 1980. [Google Scholar]
- Mishra, P.; Rutledge, D.N.; Roger, J.M.; Wali, K.; Khan, H.A. Chemometric pre-processing can negatively affect the performance of near-infrared spectroscopy models for fruit quality prediction. Talanta 2021, 229, 122303. [Google Scholar] [CrossRef] [PubMed]
- Barnes, R.J.; Dhanoa, M.S.; Lister, S.J. Standard normal variate transformation and de-trending of near-infrared diffuse reflectance spectra. Appl. Spectrosc. 1989, 43, 772–777. [Google Scholar] [CrossRef]
- Jiang, H.; Yoon, S.C.; Zhuang, H.; Wang, W.; Yang, Y. Evaluation of factors in development of Vis/NIR spectroscopy models for discriminating PSE, DFD and normal broiler breast meat. Br. Poult. Sci. 2017, 58, 673–680. [Google Scholar] [CrossRef]
- Swierenga, H.; De Weijer, A.P.; Van Wijk, R.J.; Buydens, L.M.C. Strategy for constructing robust multivariate calibration models. Chemom. Intell. Lab. Syst. 1999, 49, 1–17. [Google Scholar] [CrossRef]
- Granato, D.; Santos, J.S.; Escher, G.B.; Ferreira, B.L.; Maggio, R.M. Use of principal component analysis (PCA) and hierarchical cluster analysis (HCA) for multivariate association between bioactive compounds and functional properties in foods: A critical perspective. Trends Food Sci. Technol. 2018, 72, 83–90. [Google Scholar] [CrossRef]
- Lasalvia, M.; Capozzi, V.; Perna, G. A Comparison of PCA-LDA and PLS-DA Techniques for Classification of Vibrational Spectra. Appl. Sci. 2022, 12, 5345. [Google Scholar] [CrossRef]
- Guo, Z.; Guo, C.; Chen, Q.; Ouyang, Q.; Shi, J.; El-Seedi, H.R.; Zou, X. Classification for Penicillium expansum spoilage and defect in apples by electronic nose combined with chemometrics. Sensors 2020, 20, 2130. [Google Scholar] [CrossRef]
- Zou, X.; Zhao, J.; Povey, M.; Holmes, M.; Mao, H. Variables selection methods in near-infrared spectroscopy. Anal. Chim. Acta 2010, 667, 14–32. [Google Scholar]
- Centner, V.; Massart, D.L.; de Noord, O.E.; de Jong, S.; Vandeginste, B.M.; Sterna, C. Elimination of uninformative variables for multivariate calibration. Anal. Chem. 1996, 68, 3851–3858. [Google Scholar] [CrossRef] [PubMed]
- Araújo, M.C.U.; Saldanha, T.C.B.; Galvao, R.K.H.; Yoneyama, T.; Chame, H.C.; Visani, V. The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. Syst. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Ye, S.; Wang, D.; Min, S. Successive projections algorithm combined with uninformative variable elimination for spectral variable selection. Chemom. Intell. Lab. Syst. 2008, 91, 194–199. [Google Scholar] [CrossRef]
- Noda, I. Generalized two-dimensional correlation method applicable to infrared, Raman, and other types of spectroscopy. Appl. Spectrosc. 1993, 47, 1329–1336. [Google Scholar] [CrossRef]
- Jiang, H.; Jiang, X.; Ru, Y.; Chen, Q.; Li, X.; Xu, L.; Zhou, H.; Shi, M. Rapid and non-destructive detection of natural mildew degree of postharvest Camellia oleifera fruit based on hyperspectral imaging. Infrared Phys. Technol. 2022, 123, 104169. [Google Scholar] [CrossRef]
- Walsh, K.B.; Blasco, J.; Zude-Sasse, M.; Sun, X. Visible-NIR ‘point’spectroscopy in postharvest fruit and vegetable assessment: The science behind three decades of commercial use. Postharvest Biol. Technol. 2020, 168, 111246. [Google Scholar] [CrossRef]
- Liu, D.; Wang, E.; Wang, G.; Ma, G. Nondestructive determination of soluble solids content, firmness, and moisture content of “Longxiang” pears during maturation using near-infrared spectroscopy. J. Food Process. Preserv. 2022, 46, e16332. [Google Scholar] [CrossRef]
- Xiao, H.; Li, A.; Li, M.; Sun, Y.; Tu, K.; Wang, S.; Pan, L. Quality assessment and discrimination of intact white and red grapes from Vitis vinifera L. at five ripening stages by visible and near-infrared spectroscopy. Sci. Hortic. 2018, 233, 99–107. [Google Scholar] [CrossRef]
- Yun, Y.H.; Bin, J.; Liu, D.L.; Xu, L.; Yan, T.L.; Cao, D.S.; Xu, Q.S. A hybrid variable selection strategy based on continuous shrinkage of variable space in multivariate calibration. Anal. Chim. Acta 2019, 1058, 58–69. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maturity Stages | Height (mm) | Diameter (mm) | Fruit Mass (g) | Seeds Mass (g) | Seeds Yield (%) | Oil Content (%) | Pericarp Moisture (%) |
|---|---|---|---|---|---|---|---|
| S1 | 40.32 ± 0.35 | 40.08 ± 0.15 | 28.40 ± 1.32 | 10.27 ± 0.43 | 36.16 ± 3.13 | 22.31 ± 0.93 | 70.19 ± 4.56 |
| S2 | 40.45 ± 0.32 | 40.21 ± 0.14 | 27.32 ± 1.56 | 10.36 ± 0.36 | 37.92 ± 4.77 | 24.03 ± 0.73 | 70.23 ± 5.69 |
| S3 | 40.53 ± 0.33 | 40.39 ± 0.15 | 29.60 ± 2.03 | 11.30 ± 0.35 | 38.18 ± 4.31 | 27.46 ± 1.02 | 68.97 ± 5.35 |
| S4 | 41.12 ± 0.36 | 40.96 ± 0.18 | 30.21 ± 2.13 | 12.98 ± 0.42 | 42.97 ± 5.10 | 32.27 ± 1.12 | 69.12 ± 6.21 |
| S5 | 41.24 ± 0.35 | 41.03 ± 0.25 | 30.64 ± 1.89 | 11.85 ± 0.41 | 38.67 ± 3.95 | 35.54 ± 1.13 | 68.65 ± 5.36 |
| Control | 41.16 ± 0.42 | 41.65 ± 0.21 | 30.55 ± 2.77 | 12.64 ± 0.48 | 41.37 ± 4.32 | 35.06 ± 0.84 | 66.39 ± 3.13 |
| Modeling Methods | Pre-Processings | Correction Classification Rate | Parameters | ||
|---|---|---|---|---|---|
| Calibration Set | Cross-Validation Set | Prediction Set | |||
| PLS-DA | None | 93.9% | 92.9% | 82.8% | LV = 18 |
| SNV | 97.9% | 96.5% | 95.6% | LV = 19 | |
| Normalization | 98.7% | 96.7% | 95.6% | LV = 19 | |
| 1st derivative | 95.2% | 93.6% | 88.0% | LV = 19 | |
| 2nd derivative | 99.2% | 98.4% | 97.6% | LV = 16 | |
| PCA-DA | None | 90.3% | 88.5% | 80.8% | PC = 20 |
| SNV | 89.1% | 87.1% | 83.2% | PC = 20 | |
| Normalization | 95.7% | 94.7% | 91.2% | PC = 20 | |
| 1st derivative | 86.4% | 84.0% | 79.6% | PC = 20 | |
| 2nd derivative | 94.9% | 93.9% | 91.6% | PC = 18 | |
| Methods | Numbers | Selected Wavelengths (nm) |
|---|---|---|
| PC loadings | 8 | 552, 572, 652, 682, 687, 718, 753, 926 |
| 2DCOS | 10 | 417, 494, 528, 557, 632, 672, 692, 728, 931, 958 |
| UVE+SPA | 10 | 572, 622, 652, 753, 774, 821, 862, 873, 894, 963 |
| Model. | LVs | Correction Classification Rate (%) | ||
|---|---|---|---|---|
| Calibration Set | Cross-Validation Set | Prediction Set | ||
| PC-PLS-DA | 7 | 57.9 | 56.1 | 55.6 |
| 2DCOS-PLS-DA | 9 | 68.8 | 66.9 | 54.0 |
| UVE-SPA-PLS-DA | 9 | 83.6 | 82.1 | 81.2 |
| Actual Stages | Predicted Stages | CCR | Sensitivity | Specificity | Precision | ||||
|---|---|---|---|---|---|---|---|---|---|
| S1 | S2 | S3 | S4 | S5 | |||||
| S1 | 49 | 1 | 0 | 0 | 0 | 98.0% | 0.98 | 0.95 | 0.83 |
| S2 | 8 | 37 | 1 | 1 | 3 | 74.0% | 0.74 | 0.95 | 0.80 |
| S3 | 2 | 2 | 40 | 4 | 2 | 80.0% | 0.80 | 0.94 | 0.78 |
| S4 | 0 | 4 | 7 | 33 | 6 | 66.0% | 0.66 | 0.97 | 0.85 |
| S5 | 0 | 2 | 3 | 1 | 44 | 88.0% | 0.88 | 0.94 | 0.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, H.; Hu, Y.; Jiang, X.; Zhou, H. Maturity Stage Discrimination of Camellia oleifera Fruit Using Visible and Near-Infrared Hyperspectral Imaging. Molecules 2022, 27, 6318. https://doi.org/10.3390/molecules27196318
Jiang H, Hu Y, Jiang X, Zhou H. Maturity Stage Discrimination of Camellia oleifera Fruit Using Visible and Near-Infrared Hyperspectral Imaging. Molecules. 2022; 27(19):6318. https://doi.org/10.3390/molecules27196318
Chicago/Turabian StyleJiang, Hongzhe, Yilei Hu, Xuesong Jiang, and Hongping Zhou. 2022. "Maturity Stage Discrimination of Camellia oleifera Fruit Using Visible and Near-Infrared Hyperspectral Imaging" Molecules 27, no. 19: 6318. https://doi.org/10.3390/molecules27196318
APA StyleJiang, H., Hu, Y., Jiang, X., & Zhou, H. (2022). Maturity Stage Discrimination of Camellia oleifera Fruit Using Visible and Near-Infrared Hyperspectral Imaging. Molecules, 27(19), 6318. https://doi.org/10.3390/molecules27196318