
K-mer Content Changes with Node Degree in Promoter–Enhancer Network of Mouse ES Cells


Abstract
:1. Introduction
2. Results
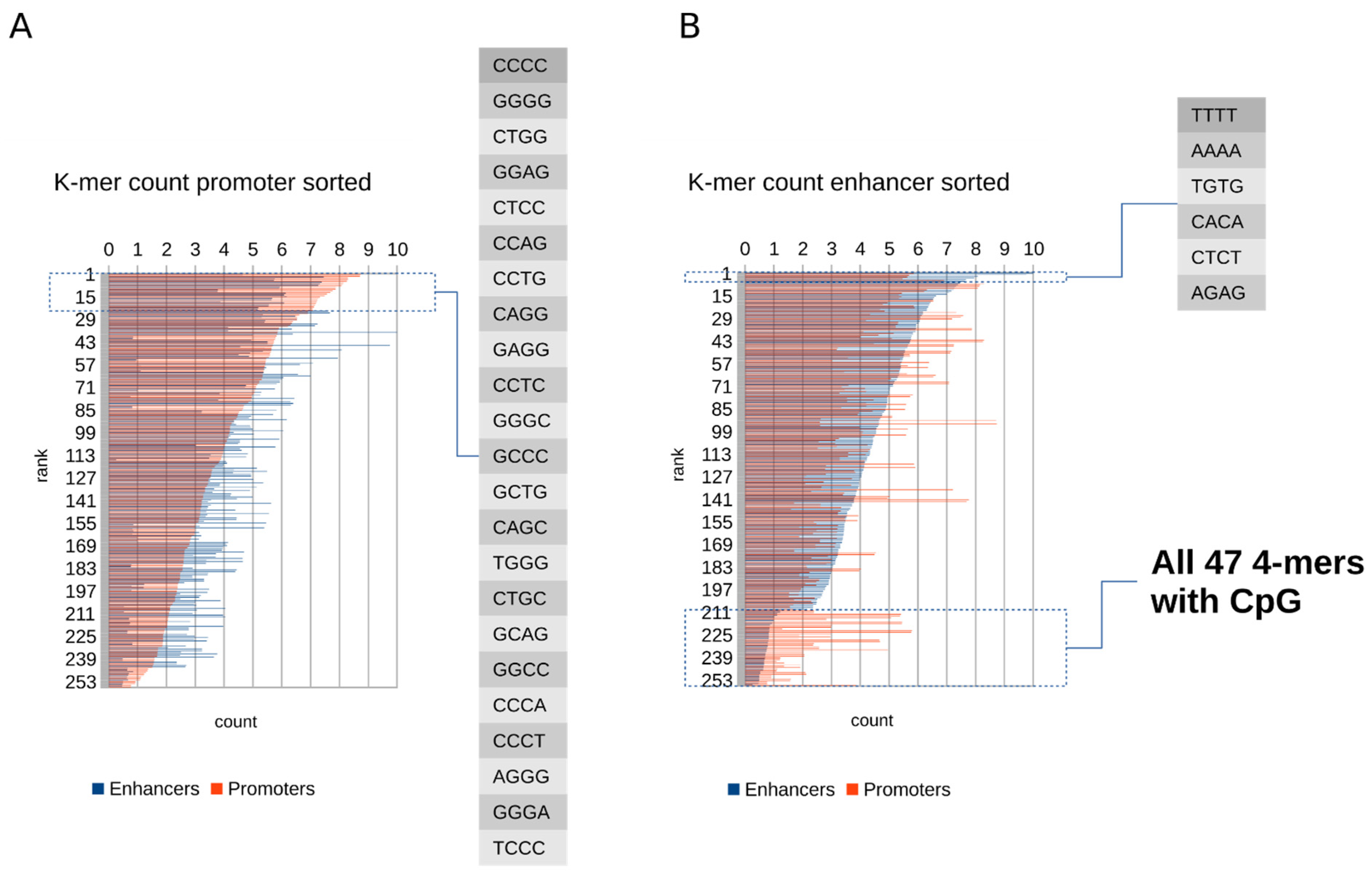
2.1. Promoters Contain More GC-Rich k-mers, While Enhancers Have Reduced Content of All k-mers Containing CpG
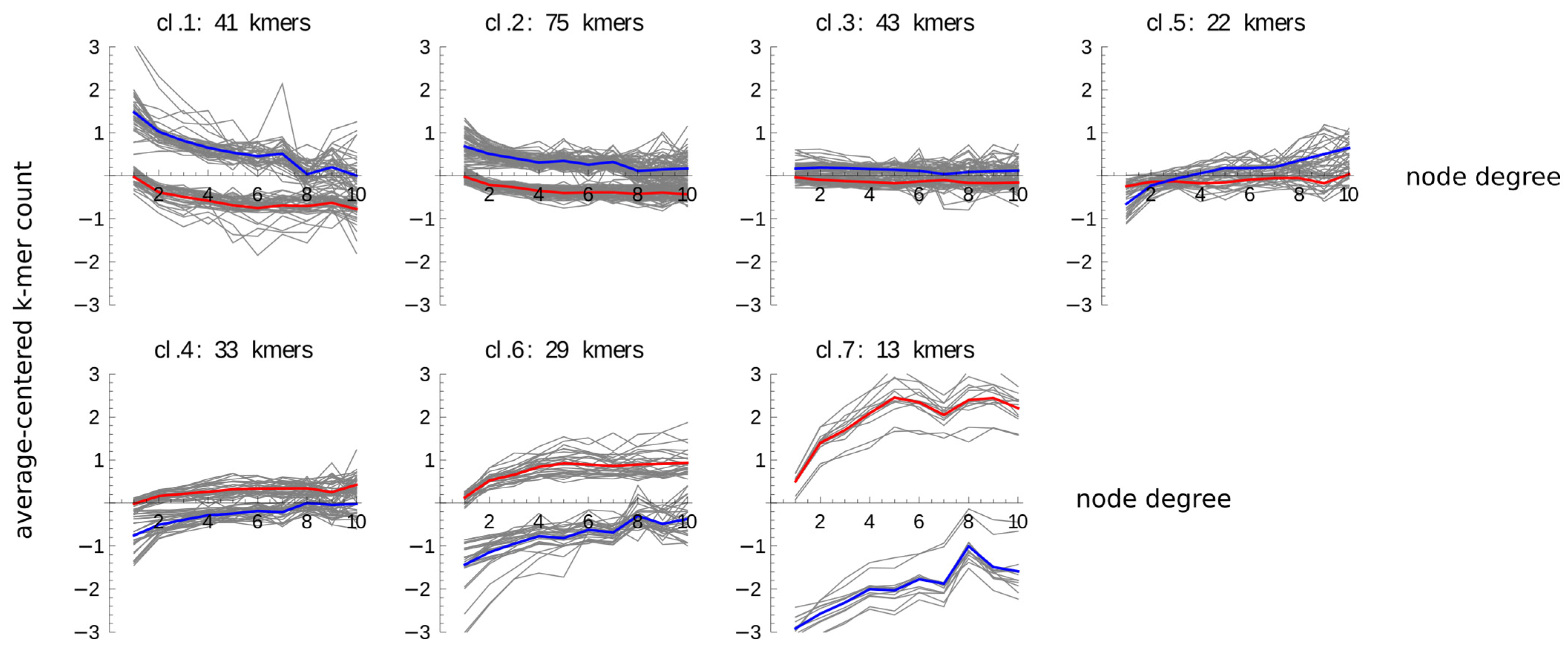
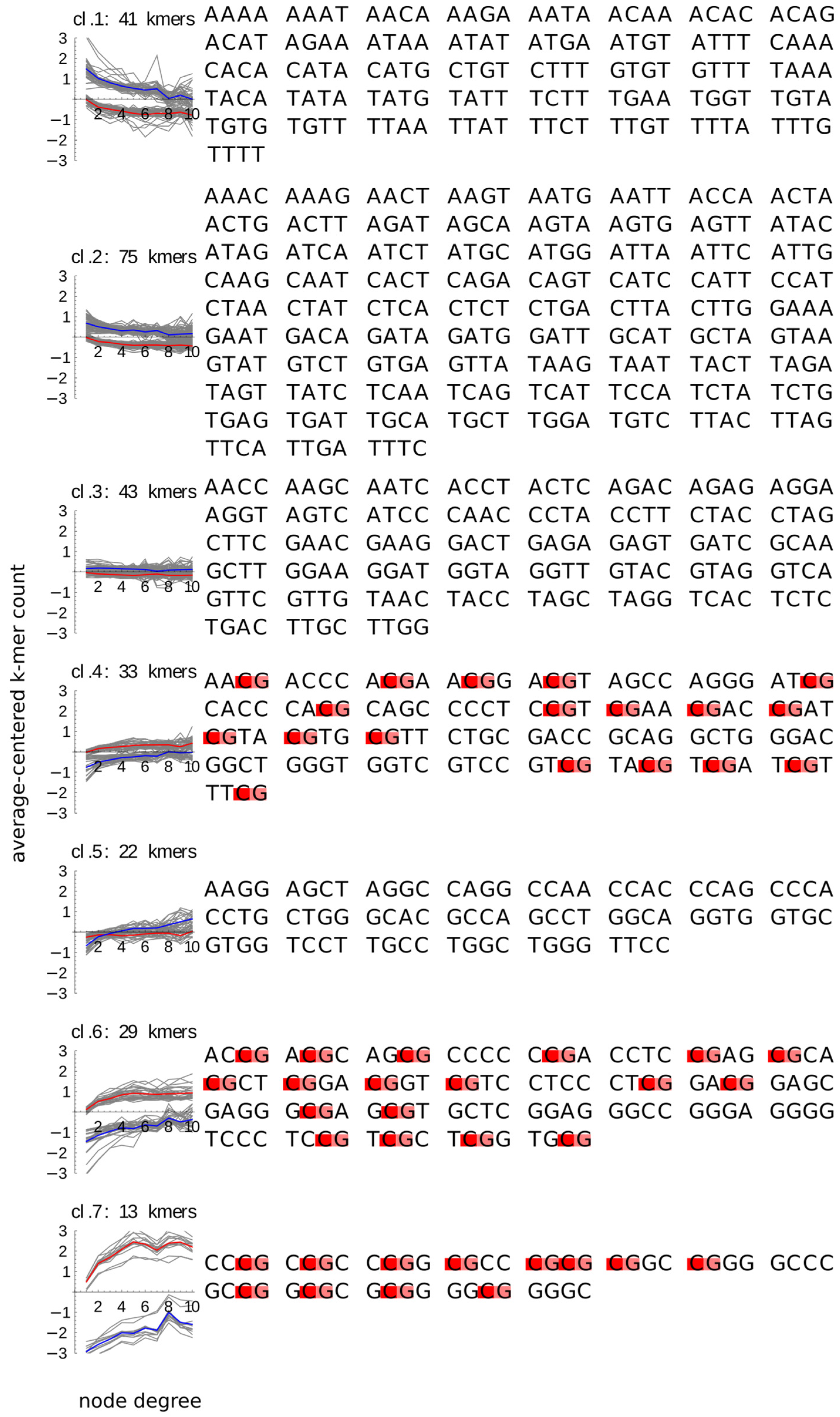
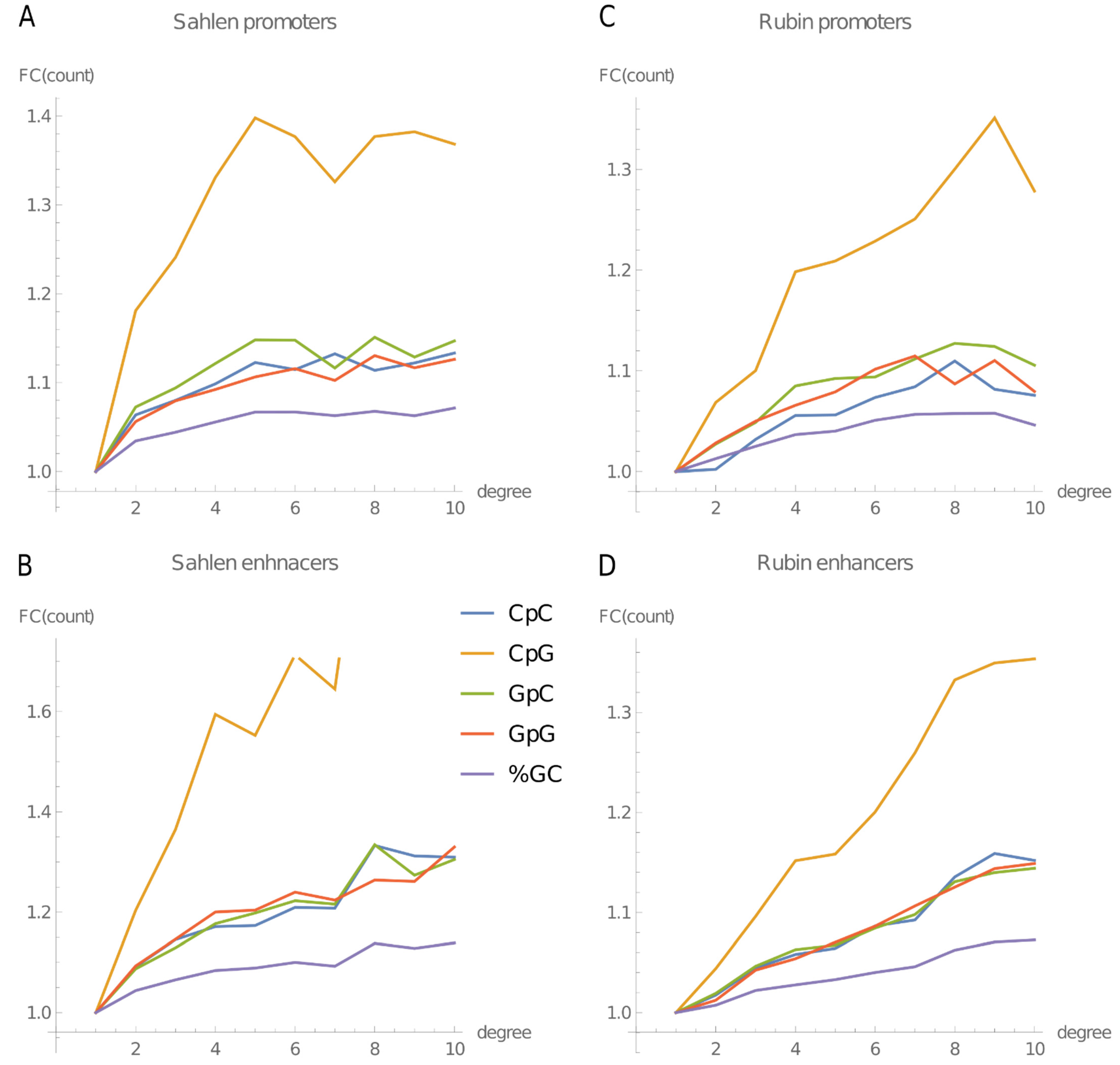
2.2. Content of All 4-mers Containing CpG and of GC-Rich 4-mers Increases with the Node Degree in Both Promoters and Enhancers
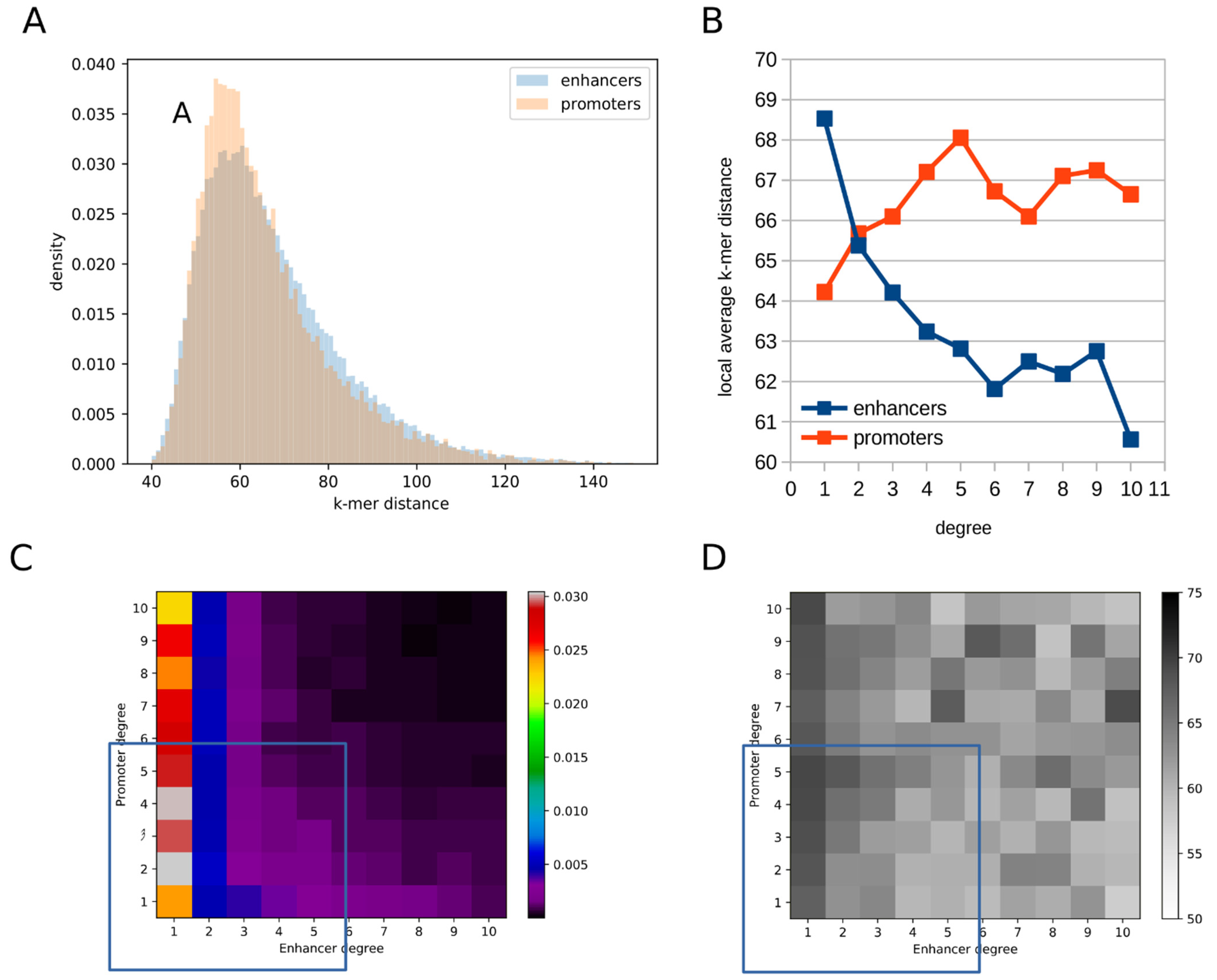
2.3. Promoters Are More Similar to Their Interacting Enhancers Than Vice-Versa
2.4. Higher-Degree Enhancers Are More Similar to the Promoters They Interact with, While the Reverse Is True for Promoters
2.5. GC and CpG Content Increases with the Node Degree in Mouse ES Cells and Also in Human Keratinocytes
3. Discussion
4. Materials and Methods
4.1. Data
4.2. K-mer Count
4.3. Local Average k-mer Distance
4.4. Code Availability
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Langdon, S.D.; Kaufman, R.E. Gamma-Globin Gene Promoter Elements Required for Interaction with Globin Enhancers. Blood 1998, 91, 309–318. [Google Scholar] [CrossRef] [PubMed]
- Alberts, B.; Johnson, A.; Lewis, J.; Raff, M.; Roberts, K.; Walter, P. Molecular Biology of the Cell, 4th ed.; Garland Science: New York, NY, USA, 2002; ISBN 978-0-8153-3218-3. [Google Scholar]
- Lieberman-Aiden, E.; van Berkum, N.L.; Williams, L.; Imakaev, M.; Ragoczy, T.; Telling, A.; Amit, I.; Lajoie, B.R.; Sabo, P.J.; Dorschner, M.O.; et al. Comprehensive Mapping of Long-Range Interactions Reveals Folding Principles of the Human Genome. Science 2009, 326, 289–293. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sahlén, P.; Abdullayev, I.; Ramsköld, D.; Matskova, L.; Rilakovic, N.; Lötstedt, B.; Albert, T.J.; Lundeberg, J.; Sandberg, R. Genome-Wide Mapping of Promoter-Anchored Interactions with Close to Single-Enhancer Resolution. Genome Biol. 2015, 16, 156. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schoenfelder, S.; Javierre, B.-M.; Furlan-Magaril, M.; Wingett, S.W.; Fraser, P. Promoter Capture Hi-C: High-Resolution, Genome-Wide Profiling of Promoter Interactions. J. Vis. Exp. 2018, 136, 57320. [Google Scholar] [CrossRef]
- Novo, C.L.; Javierre, B.-M.; Cairns, J.; Segonds-Pichon, A.; Wingett, S.W.; Freire-Pritchett, P.; Furlan-Magaril, M.; Schoenfelder, S.; Fraser, P.; Rugg-Gunn, P.J. Long-Range Enhancer Interactions Are Prevalent in Mouse Embryonic Stem Cells and Are Reorganized upon Pluripotent State Transition. Cell Rep. 2018, 22, 2615–2627. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, D.; Karchin, R.; Beer, M.A. Discriminative Prediction of Mammalian Enhancers from DNA Sequence. Genome Res. 2011, 21, 2167–2180. [Google Scholar] [CrossRef] [Green Version]
- Herman-Izycka, J.; Wlasnowolski, M.; Wilczynski, B. Taking Promoters out of Enhancers in Sequence Based Predictions of Tissue-Specific Mammalian Enhancers. BMC Med. Genom. 2017, 10, 34. [Google Scholar] [CrossRef] [Green Version]
- Colbran, L.L.; Chen, L.; Capra, J.A. Short DNA Sequence Patterns Accurately Identify Broadly Active Human Enhancers. BMC Genom. 2017, 18, 536. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Zhang, R.; Singh, S.; Ma, J. Exploiting Sequence-Based Features for Predicting Enhancer-Promoter Interactions. Bioinformatics 2017, 33, i252–i260. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zeng, W.; Wu, M.; Jiang, R. Prediction of Enhancer-Promoter Interactions via Natural Language Processing. BMC Genom. 2018, 19, 84. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.; Yang, Y.; Póczos, B.; Ma, J. Predicting Enhancer-Promoter Interaction from Genomic Sequence with Deep Neural Networks. Quant. Biol. 2019, 7, 122–137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lecellier, C.-H.; Wasserman, W.W.; Mathelier, A. Human Enhancers Harboring Specific Sequence Composition, Activity, and Genome Organization Are Linked to the Immune Response. Genetics 2018, 209, 1055–1071. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gu, Z.; Jin, K.; Crabbe, M.J.C.; Zhang, Y.; Liu, X.; Huang, Y.; Hua, M.; Nan, P.; Zhang, Z.; Zhong, Y. Enrichment Analysis of Alu Elements with Different Spatial Chromatin Proximity in the Human Genome. Protein Cell 2016, 7, 250–266. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Andersson, R.; Gebhard, C.; Miguel-Escalada, I.; Hoof, I.; Bornholdt, J.; Boyd, M.; Chen, Y.; Zhao, X.; Schmidl, C.; Suzuki, T.; et al. An Atlas of Active Enhancers across Human Cell Types and Tissues. Nature 2014, 507, 455–461. [Google Scholar] [CrossRef] [PubMed]
- Larsen, F.; Gundersen, G.; Lopez, R.; Prydz, H. CpG Islands as Gene Markers in the Human Genome. Genomics 1992, 13, 1095–1107. [Google Scholar] [CrossRef]
- Rubin, A.J.; Barajas, B.C.; Furlan-Magaril, M.; Lopez-Pajares, V.; Mumbach, M.R.; Howard, I.; Kim, D.S.; Boxer, L.D.; Cairns, J.; Spivakov, M.; et al. Lineage-Specific Dynamic and Pre-Established Enhancer-Promoter Contacts Cooperate in Terminal Differentiation. Nat. Genet. 2017, 49, 1522–1528. [Google Scholar] [CrossRef] [PubMed]
- Illingworth, R.S.; Bird, A.P. CpG Islands—‘A Rough Guide’. FEBS Lett. 2009, 583, 1713–1720. [Google Scholar] [CrossRef] [Green Version]
- Fenouil, R.; Cauchy, P.; Koch, F.; Descostes, N.; Cabeza, J.Z.; Innocenti, C.; Ferrier, P.; Spicuglia, S.; Gut, M.; Gut, I.; et al. CpG Islands and GC Content Dictate Nucleosome Depletion in a Transcription-Independent Manner at Mammalian Promoters. Genome Res. 2012, 22, 2399–2408. [Google Scholar] [CrossRef] [Green Version]
- Narwade, N.; Patel, S.; Alam, A.; Chattopadhyay, S.; Mittal, S.; Kulkarni, A. Mapping of Scaffold/Matrix Attachment Regions in Human Genome: A Data Mining Exercise. Nucleic Acids Res. 2019, 47, 7247–7261. [Google Scholar] [CrossRef] [Green Version]
- Sahlén, P.; Spalinskas, R.; Asad, S.; Mahapatra, K.D.; Höjer, P.; Anil, A.; Eisfeldt, J.; Srivastava, A.; Nikamo, P.; Mukherjee, A.; et al. Chromatin Interactions in Differentiating Keratinocytes Reveal Novel Atopic Dermatitis- and Psoriasis-Associated Genes. J. Allergy Clin. Immunol. 2021, 147, 1742–1752. [Google Scholar] [CrossRef]
- Podgornaya, O.I.; Ostromyshenskii, D.I.; Enukashvily, N.I. Who Needs This Junk, or Genomic Dark Matter. Biochemistry 2018, 83, 450–466. [Google Scholar] [CrossRef]
- Elbarbary, R.A.; Lucas, B.A.; Maquat, L.E. Retrotransposons as Regulators of Gene Expression. Science 2016, 351, aac7247. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bajic, V.B.; Tan, S.L.; Christoffels, A.; Schönbach, C.; Lipovich, L.; Yang, L.; Hofmann, O.; Kruger, A.; Hide, W.; Kai, C.; et al. Mice and Men: Their Promoter Properties. PLoS Genet. 2006, 2, e54. [Google Scholar] [CrossRef] [PubMed]
- Thomson, J.P.; Skene, P.J.; Selfridge, J.; Clouaire, T.; Guy, J.; Webb, S.; Kerr, A.R.W.; Deaton, A.; Andrews, R.; James, K.D.; et al. CpG Islands Influence Chromatin Structure via the CpG-Binding Protein Cfp1. Nature 2010, 464, 1082–1086. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clouaire, T.; Webb, S.; Skene, P.; Illingworth, R.; Kerr, A.; Andrews, R.; Lee, J.-H.; Skalnik, D.; Bird, A. Cfp1 Integrates Both CpG Content and Gene Activity for Accurate H3K4me3 Deposition in Embryonic Stem Cells. Genes Dev. 2012, 26, 1714–1728. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- van de Lagemaat, L.N.; Flenley, M.; Lynch, M.D.; Garrick, D.; Tomlinson, S.R.; Kranc, K.R.; Vernimmen, D. CpG Binding Protein (CFP1) Occupies Open Chromatin Regions of Active Genes, Including Enhancers and Non-CpG Islands. Epigenetics Chromatin 2018, 11, 59. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hurst, L.D.; Sachenkova, O.; Daub, C.; Forrest, A.R.R.; Huminiecki, L. FANTOM consortium A Simple Metric of Promoter Architecture Robustly Predicts Expression Breadth of Human Genes Suggesting That Most Transcription Factors Are Positive Regulators. Genome Biol. 2014, 15, 413. [Google Scholar] [CrossRef]
- Steinhaus, R.; Gonzalez, T.; Seelow, D.; Robinson, P.N. Pervasive and CpG-Dependent Promoter-like Characteristics of Transcribed Enhancers. Nucleic Acids Res. 2020, 48, 5306–5317. [Google Scholar] [CrossRef]
- Serfling, E.; Jasin, M.; Schaffner, W. Enhancers and Eukaryotic Gene Transcription. Trends Genet. 1985, 1, 224–230. [Google Scholar] [CrossRef]
- Kim, T.-K.; Shiekhattar, R. Architectural and Functional Commonalities between Enhancers and Promoters. Cell 2015, 162, 948–959. [Google Scholar] [CrossRef] [Green Version]
- Marçais, G.; Kingsford, C. A Fast, Lock-Free Approach for Efficient Parallel Counting of Occurrences of k-Mers. Bioinformatics 2011, 27, 764–770. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the Number of Clusters in a Data Set via the Gap Statistics. J. R. Statist. Soc. B 2002, 63, 411–423. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset and Type | Correlation | p-Value | Slope |
|---|---|---|---|
| Sahlén promoters | |||
| GG | 0.1580 | 2.28 × 10−89 | 0.3456 |
| CC | 0.1621 | 4.9 × 10−94 | 0.3702 |
| GC | 0.1824 | 4.68 × 10−119 | 0.3497 |
| CG | 0.2073 | 6.51 × 10−154 | 0.5035 |
| %GC | 0.1934 | 7.08 × 10−134 | 0.1285 |
| Sahlén enhancers | |||
| GG | 0.1392 | 2.29 × 10−308 | 2.1587 |
| CC | 0.1337 | 3.62 × 10−284 | 2.1534 |
| GC | 0.1579 | 0 | 1.6845 |
| CG | 0.1345 | 1.27 × 10−287 | 1.1236 |
| %GC | 0.1696 | 0 | 0.7159 |
| Rubin promoters | |||
| GG | 0.0743 | 4.66 × 10−25 | 0.1355 |
| CC | 0.0722 | 9.51 × 10−24 | 0.1490 |
| GC | 0.0957 | 1.66 × 10−40 | 0.1970 |
| CG | 0.1203 | 3.28 × 10−63 | 0.2834 |
| %GC | 0.0851 | 2.15 × 10−32 | 0.0649 |
| Rubin enhancers | |||
| GG | 0.1118 | 1.54 × 10−157 | 0.9189 |
| CC | 0.1107 | 1.55 × 10−154 | 0.8581 |
| GC | 0.1292 | 6.36 × 10−210 | 0.6348 |
| CG | 0.1309 | 1.36 × 10−215 | 0.3858 |
| %GC | 0.1292 | 3.68 × 10−210 | 0.3121 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Szyman, K.; Wilczyński, B.; Dąbrowski, M. K-mer Content Changes with Node Degree in Promoter–Enhancer Network of Mouse ES Cells. Int. J. Mol. Sci. 2021, 22, 8067. https://doi.org/10.3390/ijms22158067
Szyman K, Wilczyński B, Dąbrowski M. K-mer Content Changes with Node Degree in Promoter–Enhancer Network of Mouse ES Cells. International Journal of Molecular Sciences. 2021; 22(15):8067. https://doi.org/10.3390/ijms22158067
Chicago/Turabian StyleSzyman, Kinga, Bartek Wilczyński, and Michał Dąbrowski. 2021. "K-mer Content Changes with Node Degree in Promoter–Enhancer Network of Mouse ES Cells" International Journal of Molecular Sciences 22, no. 15: 8067. https://doi.org/10.3390/ijms22158067
APA StyleSzyman, K., Wilczyński, B., & Dąbrowski, M. (2021). K-mer Content Changes with Node Degree in Promoter–Enhancer Network of Mouse ES Cells. International Journal of Molecular Sciences, 22(15), 8067. https://doi.org/10.3390/ijms22158067