1. Introduction
Research on biodiversity conservation involves a wide range of scientific studies with the goal of comprehending and safeguarding Earth’s biodiversity [
1]. Its scope encompasses the examination, control, and safeguarding of ecosystems, species, and genetic diversity to ensure the long-term sustainability and functioning of natural systems [
2]. This field, which combines various scientific disciplines such as ecology, genetics, behavior, statistics, and environmental sciences, aims to collect and analyze information about the distribution, abundance, and trends of populations, communities, and ecosystems [
3]. These data drive conservation planning and decision-making processes, enabling the implementation of effective strategies for biodiversity conservation [
4].
Technological advancements have significantly expanded the horizons and capabilities of biodiversity conservation research. The utilization of geographic information systems (GIS), remote sensing, and DNA sequencing techniques has revolutionized data collection, analysis, and monitoring [
5,
6]. These technologies empower scientists to gather, analyze, and interpret vast datasets, enabling more accurate and comprehensive assessments of biodiversity and associated threats.
Moreover, the integration of statistical models and computational tools has markedly improved the precision and the efficacy of data analysis in biodiversity conservation research [
4,
7]. The application of these tools has paved the way for the development of sophisticated algorithms, facilitating species distribution modeling, population viability analysis, and spatial planning [
8]. Through the utilization of these algorithms, researchers can forecast species’ habitat suitability, assess the likelihood of population persistence, and pinpoint critical areas for targeted conservation interventions. This information is crucial for guiding management and policy decisions as well as strategically allocating limited conservation resources [
4].
R is a programming language and software environment specifically designed for statistical computing, data analysis, and graphical representation (
https://www.r-project.org, accessed on 12 September 2022). It was initially developed by Ross Ihaka and Robert Gentleman at the University of Auckland, New Zealand in the early 1990s [
9]. R is open-source software released under the GNU General Public License. This means that anyone can use, modify, and distribute R without any licensing costs. The availability of a free and open-source platform makes R accessible to scientists worldwide, including those with limited resources or in developing countries. R has a vast collection of user-contributed packages available on the Comprehensive R Archive Network (CRAN) and other repositories. Researchers can leverage these packages to access specialized functions and algorithms, expanding the capabilities of R for their specific scientific analyses. R enables researchers to conduct sophisticated analyses, produce compelling visualizations, and share their work transparently, making it a preferred language for scientific research and data analysis [
10,
11].
Academic journals are commonly used by scientists to disseminate their research findings within the academic community and to the wider public. To assess the overall usage of R in various scientific fields, the frequency of its use in published papers within this domain can serve as a useful indicator. Although extensively employed in biodiversity conservation research, the overarching trends in R and R packages use, and patterns within this realm, remain unexplored. While a previous study examined the use of R in ecology and highlighted its increasing popularity from 2008 to 2017 [
12], there remains a significant gap in our understanding of its application in biodiversity conservation research despite some overlapping journals between the two fields. Assessing the extent of R’s usage within the discipline of biodiversity conservation holds a considerable number of potential benefits. It can offer valuable insights for both novice R users who may be contemplating its integration into their research methodologies and for researchers actively engaged in developing R packages for future use by their peers. By shedding light on the role of R in biodiversity conservation research, this exploration has the potential to facilitate more comprehensive and efficient data analysis within the discipline, ultimately driving further advancements in conservation efforts.
In this study, we meticulously analyzed a comprehensive dataset comprising over 24,100 research articles published in the top eight biodiversity conservation journals spanning the period from 2008 to 2022. Our primary objective is to evaluate the prevalence of R and its associated packages within these articles, aiming to discern notable trends and patterns in their adoption as well as the popularity of specific packages. Through this analysis, our aim is to enhance our understanding of the advantages of employing R in biodiversity conservation research. Ultimately, our findings hold the potential to guide researchers and practitioners in the field of biodiversity conservation, enabling them to make well-informed decisions about integrating R and its packages into their work.
3. Results
3.1. Trends in the Utilization of R
Through meticulous efforts, we curated a comprehensive dataset comprising 24,158 research articles sourced from eight selected biodiversity conservation journals covering a fifteen-year span from 2008 to 2022.
Among these articles, 10,220 papers, accounting for approximately 42.3% of the total, explicitly mentioned using R as statistical software for data analysis. This finding underscores the widespread adoption of R in biodiversity conservation research. Over the years, the percentage of articles reporting the utilization of R has steadily increased, starting at 11.1% in 2008 and soaring to a remarkable 70.6% in 2022 (
Figure 1). Furthermore, a strong correlation between the percentage of R utilization and years was observed with a coefficient of r = 0.99 (
p < 0.001).
It is noteworthy that, since 2016, over half of the research papers (ranging from 51.1% in 2016 to 70.6% in 2022) have incorporated R as their statistical analysis tool. These statistics emphasize the growing prevalence and the strong endorsement of R as a preferred and valuable piece of statistical software in the field of biodiversity conservation research. This trend not only highlights the adaptability of R but also its capacity to meet the evolving analytical needs of researchers in this field. Consequently, R has made significant contributions to advancements in biodiversity conservation efforts.
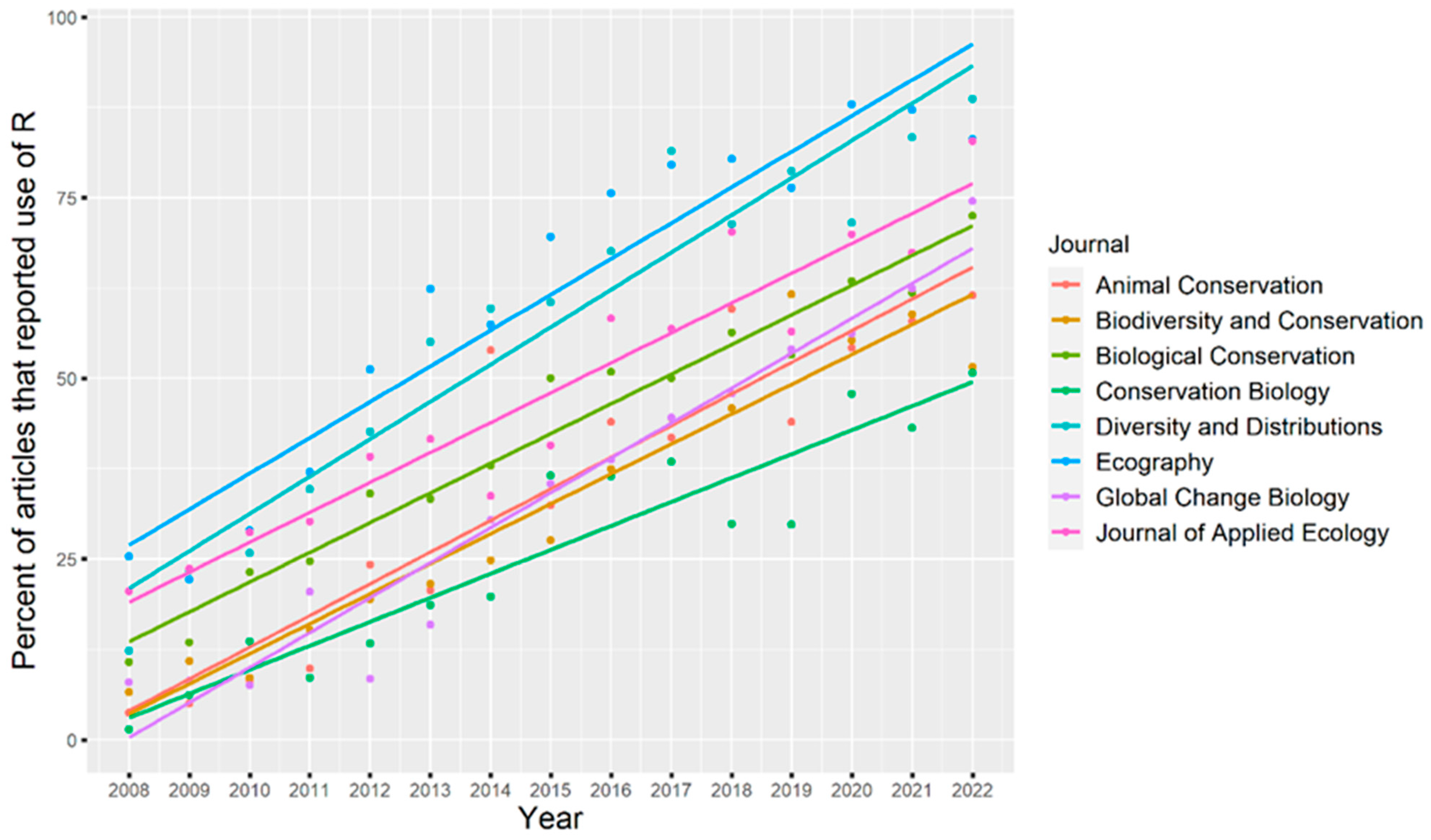
In our comprehensive analysis spanning from 2008 to 2022, a clear upward trend is evident in the percentage of articles utilizing R for data analysis in the selected journals, as illustrated in
Figure 2. However, it is essential to emphasize that specific journals showed notable fluctuations, and the growth rate of R usage varied among them (
Figure 2).
Notably, Ecography has distinguished itself for its exceptional commitment to utilizing R, achieving an impressive usage rate of 64.1% (1244 out of 1940) over a fifteen-year period. In 2008, Ecography already demonstrated a substantial R usage rate of 25.3%, experiencing average annual growth of 4.8%. By 2020, the R usage rate within Ecography had surged to an astonishing 87.8%. While there was a slight decline in both 2021 (87.1%) and 2022 (83%), this underscores that the use of the R language has reached its peak and stabilized, underscoring a consistent preference for R in this journal.
Diversity and Distributions closely tracked behind, sustaining an average R usage rate of 60.8% (1148 out of 1888). Remarkably, Diversity and Distributions showcased the most rapid growth trend in R usage among all journals with an average annual increase of 5.2%. It underwent a significant ascent from a 12.3% R usage rate in 2008 to an impressive 88.6% in 2022, marking the highest R usage among all journals in 2022. We believe it is likely to enter a stable phase moving forward.
Journal of Applied Ecology initiated the period with an R usage rate of 20.5% in 2008, demonstrating an average annual growth of 4.1%. By 2022, the R usage rate in Journal of Applied Ecology had risen to 82.8%. Consequently, Journal of Applied Ecology secured the third position in the overall 15-year average R usage ratio, standing at 50.6% (1502 out of 2917).
In contrast, Biodiversity Conservation, Global Change Biology, Animal Conservation, and Biodiversity and Conservation exhibited moderately positioned fifteen-year average R usage percentages at 42.5%, 38.9%, 37.3%, and 32.1%, respectively. These four journals started with relatively low R usage rates in 2008 with figures of 10.7%, 7.9%, 3.7%, and 6.6%, respectively. The final journal, Conservation Biology, displayed the lowest levels of R language use, boasting a 15-year average of only 23.5% and an initial point of merely 1.4% in 2008. It also reported the lowest annual growth rate at only 3.3%. Therefore, the overall lowest R usage rate in Conservation Biology is not surprising.
3.2. Patterns of R Package Utilization
In our comprehensive analysis of research articles, we recorded that researchers employed a diverse array of over 1450 R packages to facilitate their data analysis efforts. Notably, 26 packages emerged as prominent choices, featuring in more than 100 articles (
Figure 3). Leading the list was the “
vegan” package, recognized for its versatility and widespread use, particularly in multivariate analysis in community ecology [
14]. Following closely in the second position was “
lme4”, a versatile package well known for its extensive utility in fitting and dissecting linear mixed models [
15]. The usage frequencies of the two packages significantly surpassed those of others (see
Figure 3). In the third position was “
MuMIn”, a valuable package that greatly simplifies information theoretic model selection and averaging based on information criteria [
16]. Following closely in fourth place was “
nlme”, a versatile package frequently used for modeling both linear and nonlinear mixed models [
17]. Securing the fifth position was the “
mgcv” package, renowned for its pivotal role in generalized additive models [
18,
19]. Rounding out the top ten were
raster,
MASS,
ggplot2,
car, and
dismo. For detailed information of the 26 most frequently used packages, one can refer to
Supplementary Materials.
The diverse focuses within various journals naturally led to the adoption of distinct sets of frequently used R packages (
Figure 4). Among these, the “
vegan” package prominently emerged as the top choice for
Ecography,
Biodiversity and Conservation, and
Diversity and Distributions. Particularly in
Biodiversity and Conservation, “
vegan” maintained a substantial lead, with its usage exceeding that of the second-ranked “
lme4” by more than double, establishing “
vegan” as the preferred package across all journals, as highlighted in
Figure 3. However, the “
lme4” package, despite claiming the title of the most frequently utilized package in the remaining five journals, found itself in the second spot in the overall usage frequency rankings due to the relatively lower proportion of R usage in these journals. Meanwhile, the “
MuMIn” package secured the second position in one journal (
Animal Conservation), the third position in two journals (
Biodiversity and Conservation and
Biological Conservation), the fourth position in three journals (
Conservation Biology,
Ecography, and
Journal of Applied Ecology), and the fifth position in two journals (
Biodiversity and Distributions and
Global Change Biology). This diverse placement underscores the extensive application of the “
MuMIn” package in biodiversity conservation research, ultimately earning it third position in the overall rankings.
This diversity in package usage reflects the remarkable versatility of the R language, which can effectively cater to a vast array of research requirements. Furthermore, this diversity underscores the vital role played by specific packages in advancing various aspects of data analysis within the realm of biodiversity conservation research. Each package serves as a specialized tool contributing to the multifaceted needs of researchers in this field, and, collectively, they form a robust toolkit for addressing the complex challenges and questions that arise in the study of biodiversity and conservation. In essence, these package choices are a testament to the dynamic and ever-evolving nature of data analysis in this field, where researchers continually seek and apply the best-suited tools for their specific research goals.
4. Discussion
In recent years, advancements in data collection technologies have led to the accumulation of extensive datasets in biodiversity [
20]. The processing and analysis of these big datasets have become routine tasks for contemporary biodiversity conservation researchers [
21]. The handling of such abundant data relies heavily on statistical models and software [
4]. With the continuous progress of computing technology, researchers now have access to a variety of statistical software options, each with its unique strengths and limitations [
4]. A noteworthy trend is the substantial increase in the adoption of R as the primary statistical tool in research articles published in eight distinguished biodiversity conservation journals. This adoption rate has experienced remarkable growth, surging from a mere 11.1% in 2008 to a significant 70.6% in 2022. This impressive evolution serves as a clear indicator of the growing importance of the R language as a pivotal instrument for data analysis in contemporary biodiversity conservation research. These patterns are consistent with the discoveries of other bibliometric studies in related fields such as ecology [
12] and photosynthesis [
22]. The prominence of R in these studies can be attributed to its robust statistical capabilities, its advanced data visualization tools, its unwavering support from a dynamic and engaged community, its open-source nature, and its accessibility. Collectively, these qualities establish R as the compelling first choice for data analysis and research across diverse domains, including the realm of biodiversity conservation.
The popularity of the R language in
Ecography and
Diversity and Distributions can be attributed to the close alignment of these journals with the field of macroecology. Macroecology involves the comprehensive exploration of ecological patterns and processes on a grand scale—both spatially and temporally [
2,
23,
24]. Consequently, macroecology typically entails the meticulous management of extensive datasets and the application of numerous models, which are primarily conducted on computers [
3]. The expansive and inclusive nature of the R language renders it particularly well-suited for meeting the intricate data analysis needs inherent in macroecology [
23,
24]. Consequently, the two journals have gravitated towards adopting R as their primary statistical software. Conversely, the limited adoption of R in
Conservation Biology can be linked to a stronger emphasis on biodiversity conservation theory and practices, exploring the social, ecological, and philosophical dimensions of the conservation of biological diversity. This field may not necessitate the extensive data-intensive analysis that R excels in, thus resulting in a lower R adoption rate.
Journal of Applied Ecology is a journal that focuses on the interface between ecological science and the management of biological resources. Therefore, it is also included in categories of both “Biodiversity Conservation” and “Ecology” on the Web of Science. The higher use of R in this journal stems primarily from the fact that the field of ecology represents a data-intensive area of study, often demanding advanced computational skills [
25,
26,
27].
Although Biodiversity Conservation, Animal Conservation, and Biodiversity and Conservation are included in the category of biodiversity conservation in the Web of Science, many articles in these three journals involve data-driven research spanning the realms of both macroecology and conservation biology. Consequently, the utilization of R in these journals exists at a moderate level. Global Change Biology primarily focuses on publishing research related to the interface between biological systems and global environmental changes. Despite the initial low adoption rate of the R language in this journal during early stages, there has been a substantial and swift surge in its usage over time. This significant growth trend serves as a clear indicator of the mounting popularity and the widespread acceptance of the R language as an indispensable tool within the realm of global change research.
The substantial statistical capabilities of R receive significant augmentation from its extensive library of packages, a fundamental element contributing to the refinement of R’s analytical proficiency and adaptability. When scrutinizing the patterns of package utilization as observed in 30 ecology journals between 2008 to 2017 [
12], the two most frequently employed packages, “
lme4” and “
vegan”, remain consistent with eight biodiversity conservation journals. However, disparities in their rankings underscore distinctions between the fields of ecology and biodiversity conservation. In 30 ecology journals, as expected, “
lme4” claims the top position due to its specific design in addressing the prevalent issue of non-independence frequently encountered in ecological data [
28,
29,
30,
31]. Ecological data often involves intricate relationships, hierarchies, and repeated measurements [
32], rendering “
lme4” well-suited to handle these complex scenarios. Conversely, in the realm of biodiversity conservation, where the central focus is on biodiversity, the analytical emphasis leans more towards multivariate analysis. This makes “
vegan” particularly well-suited to biodiversity conservation research. This observation underscores both shared and distinctive characteristics in statistical analysis between ecology and biodiversity conservation, reflecting the specialized needs and nuances of each discipline. In addition to the ten previously mentioned packages widely employed in biodiversity conservation research, there are specific R packages tailored for biodiversity research that deserve the attention of conservation ecologists. These include data download packages such as “
rgbif” [
33], “
genesysr” [
34], and “
spocc” [
35], while “
taxize” [
36] facilitates taxonomic naming. The “
CoordinateCleaner” package [
37] proves instrumental in addressing data cleaning and coordinat quality assurance. In the domain of species distribution modeling, crucial packages encompass “
sdm” [
38], “
maxnet” [
39], “
wallace” [
40], “
BiodiversityR” [
41], and “
GapAnalysis” [
42]. The inclusion of these packages significantly enriches the toolkit available to researchers actively involved in biodiversity conservation studies.
Reproducibility is imperative across diverse research domains within contemporary natural sciences [
43]. The R language emerges as a crucial facilitator in enhancing research reproducibility by providing a transparent, standardized, and well-documented platform for data statistical analysis [
44]. Its extensive adoption not only ensures uniformity but also enhances transparency, fostering an environment where research findings can undergo independent validation and verification by fellow scientists [
45]. The R language’s popularity in prominent biodiversity conservation journals carries significant implications for advancing the field as an open science initiative. By collectively embracing R as a common tool, researchers in biodiversity conservation science pledge to uphold transparency, consistency, and collaborative efforts. This shared commitment not only fortifies the scientific rigor of biodiversity conservation research but also extends an invitation to a wider audience for the assessment, validation, and expansion of existing findings. Ultimately, the prevalence of the R language in biodiversity conservation journals cultivates an ethos of open science, propelling scientific progress and fostering innovation within the field.
Despite the numerous benefits that R offers to biodiversity conservation research, it is crucial to recognize that its comprehensive utilization encounters specific challenges. These challenges encompass computational demands, steep learning curves, and the intricacies associated with integrating diverse data sources [
10]. Meeting the computational requirements of handling extensive biodiversity conservation datasets poses another significant challenge. Given the intricate, large-scale nature of data in biodiversity conservation research [
46], optimizing R to efficiently manage big data becomes imperative.
The future of R use in biodiversity conservation research should focus on several key areas. Firstly, enhancing usability is paramount. This involves making R accessible to a broad spectrum of users through intuitive and user-friendly interfaces. By doing so, researchers with diverse backgrounds and technical expertise can effectively employ R in their biodiversity conservation studies. Secondly, reinforcing its capacity to handle big data efficiently is crucial. As datasets continue to grow in size and complexity, optimizing R’s capabilities to process and analyze large-scale data efficiently becomes critical. This can be achieved through the development of improved algorithms, efficient memory management, and leveraging parallel processing to expedite computations. By enhancing R’s performance in these areas, it can better address the data-intensive requirements of biodiversity conservation research. Finally, fostering interdisciplinary collaborations is of paramount importance. Biodiversity conservation research spans multiple fields and disciplinary perspectives [
46]. Encouraging collaboration among researchers from different fields enables the further development and customization of R packages to meet the specific needs of biodiversity conservation science. This approach positions R as a more versatile and widely used tool in biodiversity conservation research that is better equipped to tackle the intricate and multifaceted challenges inherent to modern biodiversity conservation research. With these advancements, R can play a pivotal role in supporting biodiversity conservation research and facilitating scientific progress in this critical field.
As our literature survey was primarily dedicated to evaluating the prevalence of R usage, we faced a constraint in quantifying trends related to other computer programs in biodiversity conservation journals. It is crucial to recognize that this an inherent limitation in our present study. Future research endeavors should consider conducting a more comprehensive analysis that extends beyond R usage. This approach would permit a thorough exploration of the broader spectrum of computer programs utilized in biodiversity conservation research. Such an analysis would contribute to an enhanced understanding of the diverse tools employed in the field, providing a more holistic perspective on computational approaches within the domain of biodiversity conservation.



{kind=link}
{kind=link}
{kind=link}
{kind=link}



