
Towards an Autonomous Vision-Based Unmanned Aerial System against Wildlife Poachers




Abstract
:1. Introduction
2. Related Works
2.1. Computer Vision Using Aerial Images
2.1.1. Visual Tracking
2.1.2. Face Detection
2.2. Vision as the Sensor for Control Applications in Robotics
2.3. Vision-Based UAV Control
3. Related Actions against Poachers
4. Adaptive Visual Animal Tracking Using Aerial Images
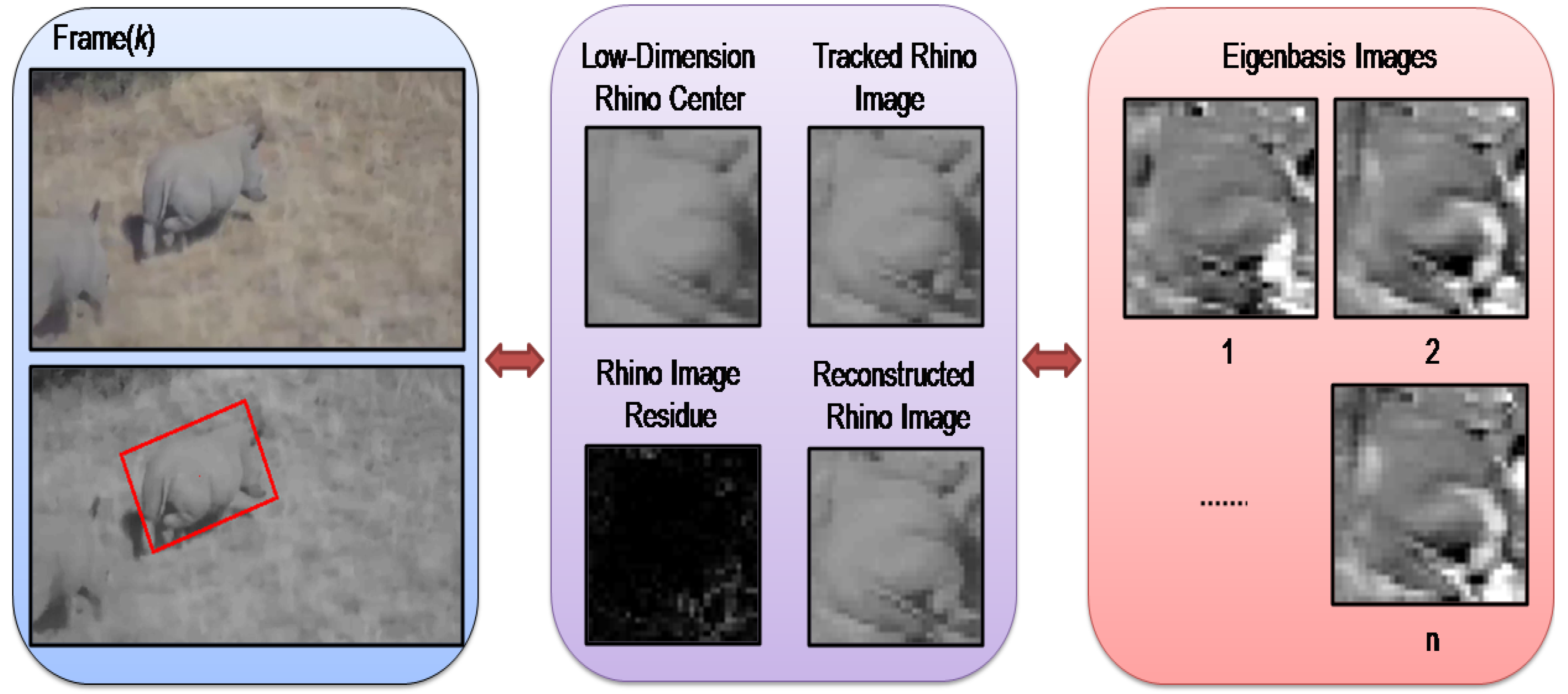
4.1. Adaptive Visual Animal Tracking Algorithm

4.1.1. Dynamic Model

4.1.2. Observation Model
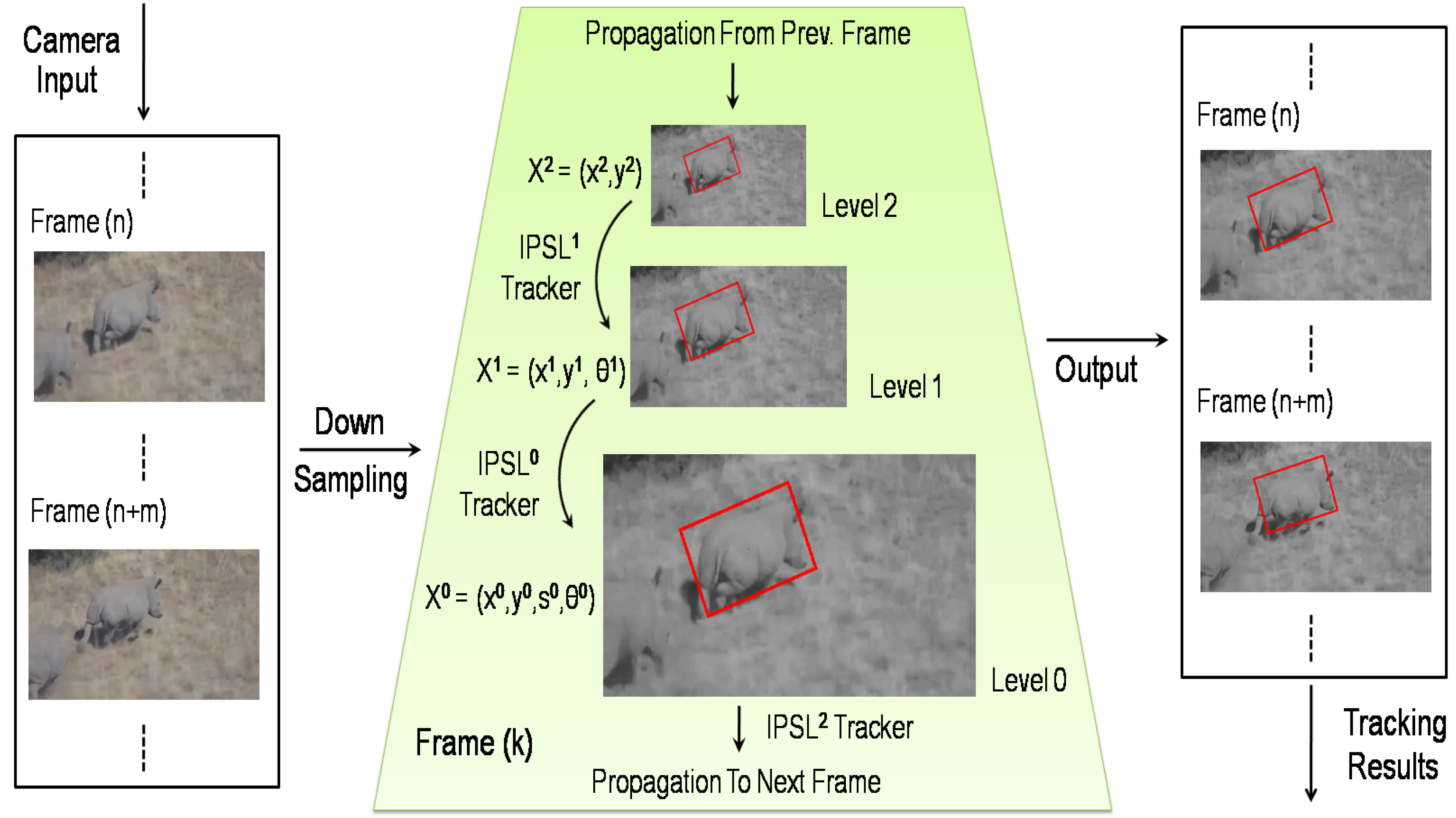
4.2. Hierarchy Tracking Strategy

4.3. Hierarchical Structure
4.4. Particle Filter Setup
- , i.e.,
- , i.e., +
- , i.e.,
4.5. Motion Model Propagation
4.6. Block Size Recursion
5. Visual Animal Tracking Evaluation and Discussion
5.1. Ground Truth Generation

5.2. Real Test of Visual Animal Tracking
5.2.1. Test 1: Rhino Tracking

5.2.2. Test 2: Rhino Tracking

5.2.3. Test 3: Elephant Tracking

5.2.4. Test 4: Elephant Tracking

6. Face Detection Using Aerial Images for Poachers’ Detection and Identification
6.1. Face Detection Approach
- It is easy to calculate integral features
- It uses machine learning using AdaBoost
- It leverages the cascade system for speed optimization
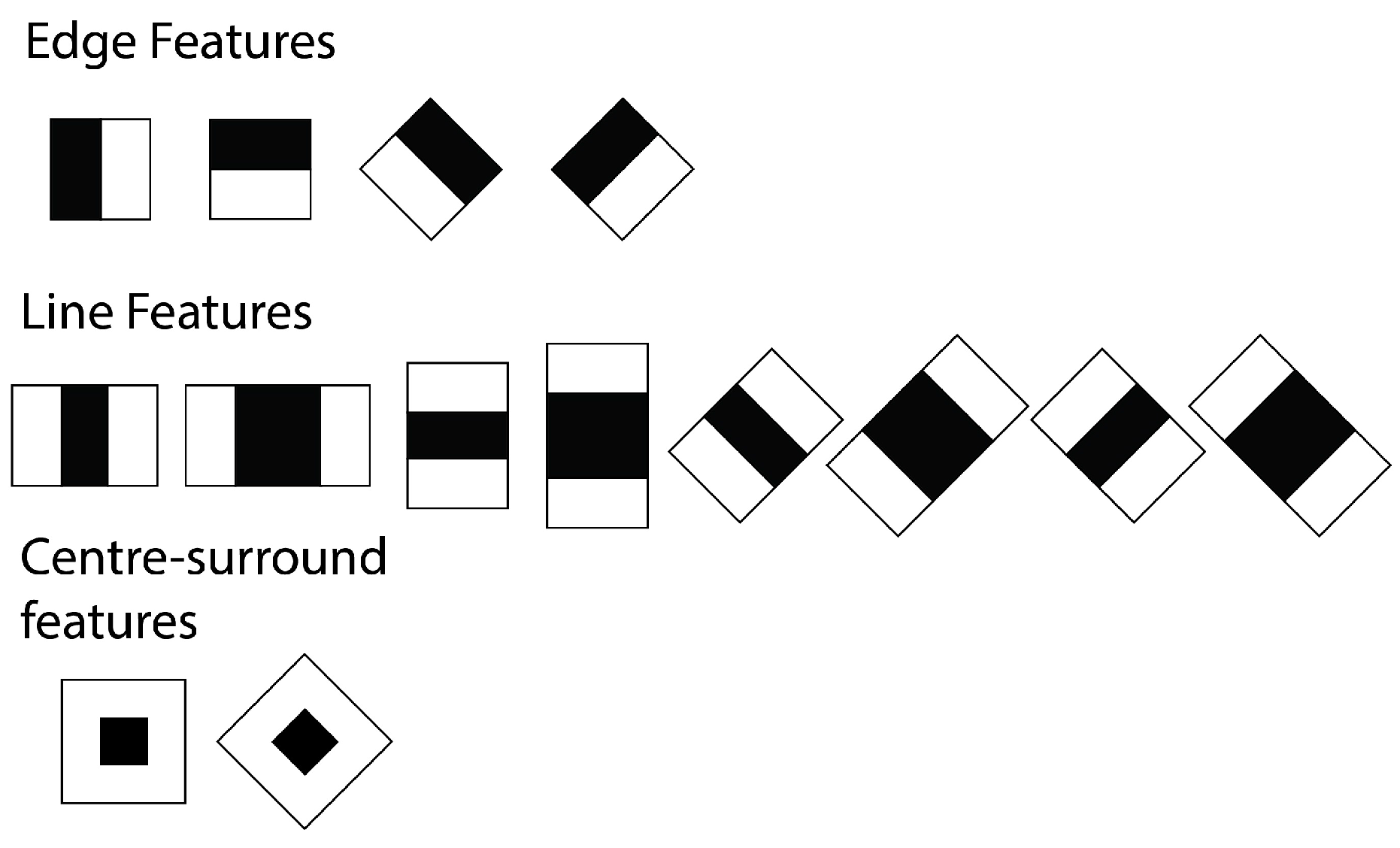
6.1.1. Feature Detection



6.1.2. AdaBoost
6.1.3. Cascade System
6.2. Implementation
- Cascade: OpenCV comes with a number of different face detection cascade systems. For this research, haarcascade_frontalface_alt_tree.xml has been selected.
- scaleFactor= : The algorithm scans the input image in multiple iterations, each time increasing the detection window by a scaling factor. A smaller scaling factor increases the number of detections, but also increases the processing time.
- minNeighbors = 3: This refers to the number of times a face needs to be detected before it is accepted. Higher values reduce the number of false detections.
- Flags: There a number of additional flags in existence. In this particular case, the flag CV_HAAR_DO_CANNY_PRUNING is used because it helps to reduce the number of false detections and it also improves the speed of the detection.
- minSize and maxSize: These parameters limit the size of the search window. With fixed cameras, this is beneficial to improve speed, but in this case, these values are set very broadly because the distance from the subjects is constantly changing.
6.3. Drone Setup

6.4. Experiments
- Standing in the shadow: Faces are well exposed, and there are no harsh shadows. The face detection works well under these conditions, even during direction changes of the drone. One frame of this test is shown in Figure 13.
- Direct sunlight: When filming people standing in direct sunlight, the harsh shadows make the detection more difficult (Figure 14). In this case, the detection is not as consistent as in the previous test, but it still manages to detect all of the faces at some point. In Figure 14, it also shows how the system is able to detect a person who is standing in the shadow (left), even though the camera was not exposed for those lighting conditions, and it is difficult for humans eyes to even detect the body of this person.
- Fly-over: For the last experiment, the UAV was set to fly over a group of moving people. An example frame of this footage can be seen in Figure 15. Due to the close proximity to the subjects, this tests required the detection of a lot of faces of different sizes. The proximity also makes the motion blur on the subjects stronger. Because of the wide angle of the lens, lens distortion can also cause problems with closer subjects. In this case, the detection also works well, mainly because of the large size of the faces.



6.5. Calculation Speed
6.6. Limitations
7. Vision-Based Control Approach for Vehicle Following and Autonomous Landing
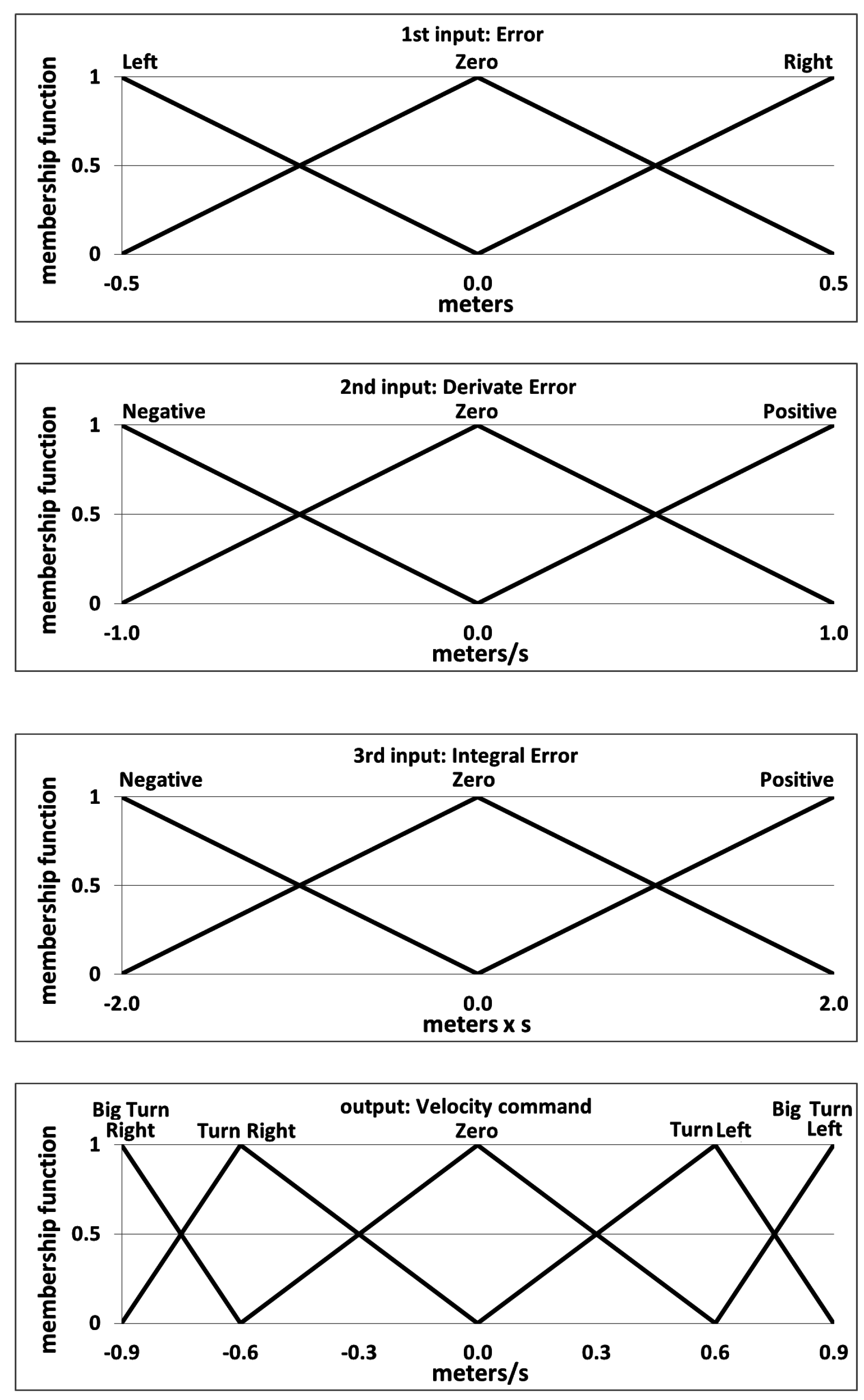
7.1. Vision-Based Fuzzy Control System Approach


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Controller Weight | Lateral | Longitudinal | Vertical | Heading |
|---|---|---|---|---|
| Error | 0.3 | 0.3 | 1.0 | 1.0 |
| Derivative of the error | 0.5 | 0.5 | 1.0 | 1.0 |
| Integral of the error | 0.1 | 0.1 | 1.0 | 1.0 |
| Output | 0.4 | 0.4 | 0.4 | 0.16 |
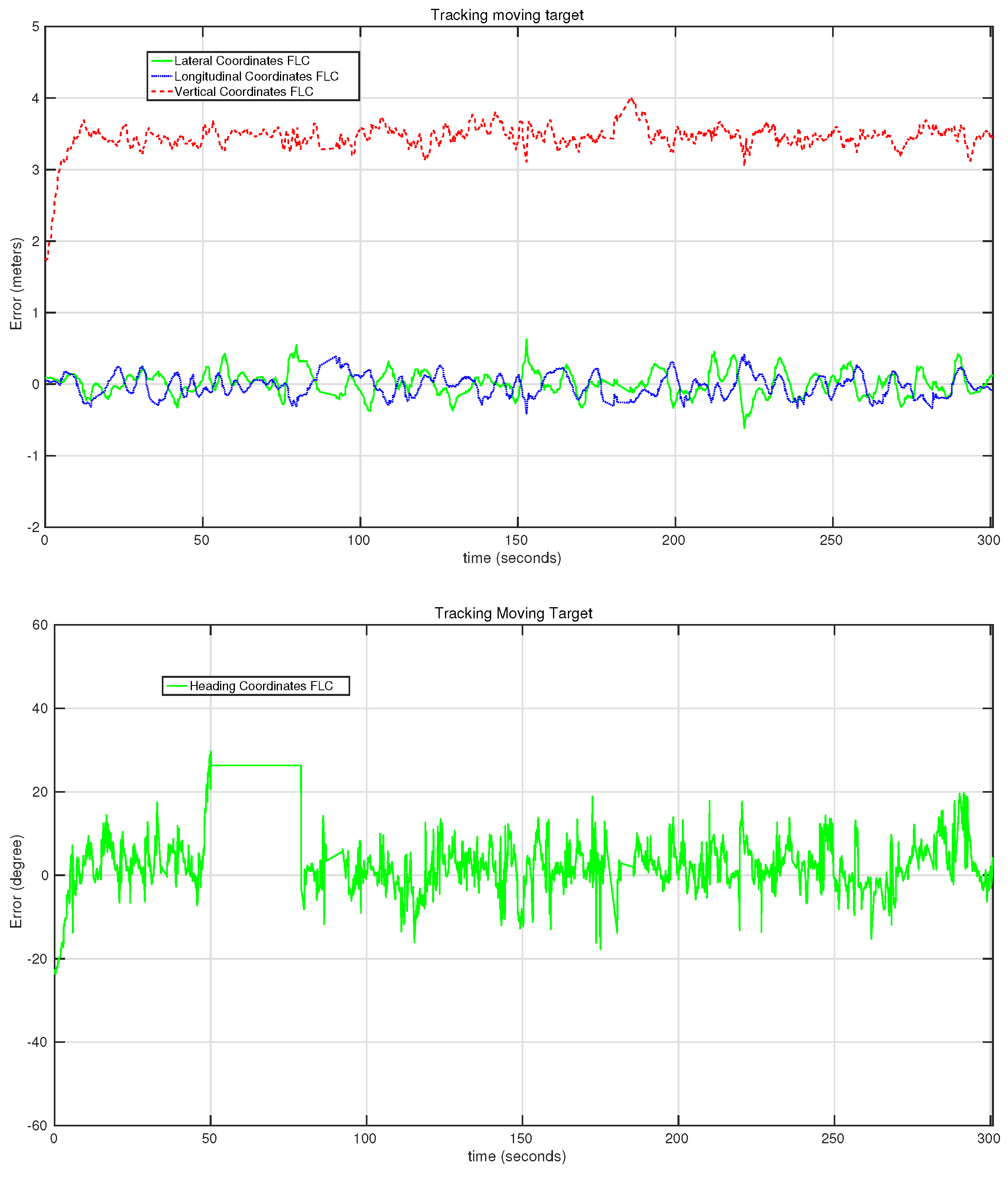
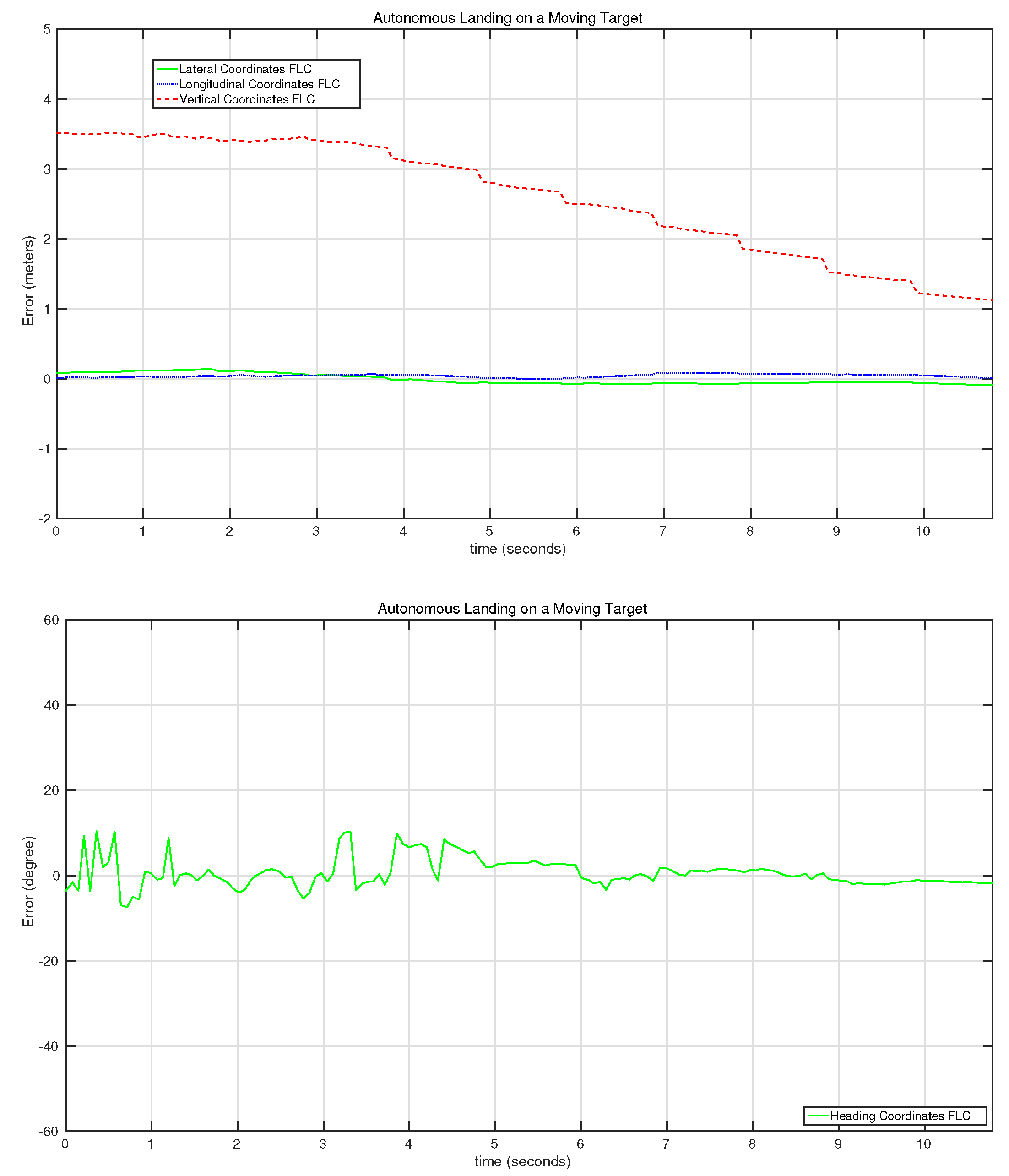
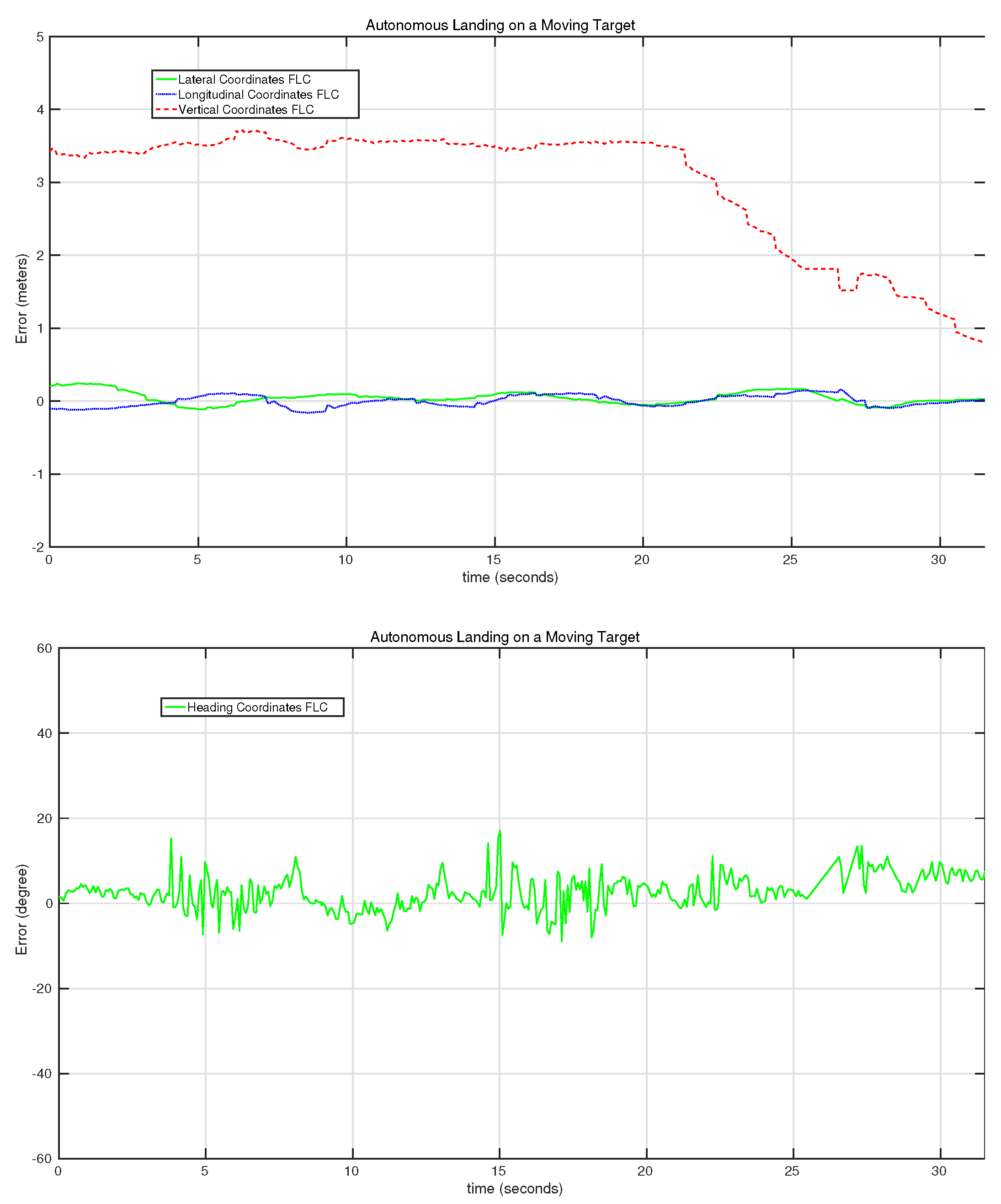
7.2. Experiments

| Controller | Lateral | Longitudinal | Vertical | Heading | time |
|---|---|---|---|---|---|
| Experiment | (RMSE, m) | (RMSE, m) | (RMSE, m) | (RMSE, Degrees) | (s) |
| Following #1 | 0.1702 | 0.1449 | 0.1254 | 10.3930 | 300 |
| Following #2 | 0.0974 | 0.1071 | 0.1077 | 8.6512 | 146 |
| Following #3 | 0.1301 | 0.1073 | 0.1248 | 5.2134 | 135 |
| Following #4 | 0.1564 | 0.1101 | 0.0989 | 12.3173 | 144 |
| Landing #1 | 0.1023 | 0.0.096 | 1.1634 | 4.5843 | 12 |
| Landing #2 | 0.0751 | 0.0494 | 1.1776 | 3.5163 | 11 |
| Landing #3 | 0.0969 | 0.0765 | 0.9145 | 4.6865 | 31 |




8. Conclusions and Future Works
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Olivares-Mendez, M.A.; Bissyandé, T.F.; Somasundar, K.; Klein, J.; Voos, H.; le Traon, Y. The NOAH project: Giving a chance to threatened species in Africa with UAVs. In Proceedings of the Fifth International EAI Conference on e-Infrastructure and e-Services for Developing Countries, Blantyre, Malawi, 25–27 November 2013; pp. 198–208.
- SPOTS-Air Rangers. Available online: http://www.spots.org.za/ (accessed on 15 October 2013).
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking: A survey. ACM Comput. Surv. 2006, 38. [Google Scholar] [CrossRef]
- Smeulder, A.; Chu, D.; Cucchiara, R.; Calderara, S.; Deghan, A.; Shah, M. Visual Tracking: An Experimental Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1442–1468. [Google Scholar]
- Fotiadis, E.P.; Garzon, M.; Barrientos, A. Human Detection from a Mobile Robot Using Fusion of Laser and Vision Information. Sensors 2013, 13, 11603–11635. [Google Scholar] [CrossRef] [PubMed]
- Mondragon, I.; Campoy, P.; Martinez, C.; Olivares-Mendez, M. 3D pose estimation based on planar object tracking for UAVs control. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation (ICRA), Anchorage, Alaska, 3–7 May 2010; pp. 35–41.
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Martinez, C.; Mondragon, I.; Campoy, P.; Sanchez-Lopez, J.; Olivares-Mendez, M. A Hierarchical Tracking Strategy for Vision-Based Applications On-Board UAVs. J. Intell. Robot. Syst. 2013, 72, 517–539. [Google Scholar] [CrossRef]
- Martinez, C.; Richardson, T.; Thomas, P.; du Bois, J.L.; Campoy, P. A vision-based strategy for autonomous aerial refueling tasks. Robot. Auton. Syst. 2013, 61, 876–895. [Google Scholar] [CrossRef]
- Sanchez-Lopez, J.; Saripalli, S.; Campoy, P.; Pestana, J.; Fu, C. Toward visual autonomous ship board landing of a VTOL UAV. In Proceedings of the 2013 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 28–31 May 2013; pp. 779–788.
- Fu, C.; Suarez-Fernandez, R.; Olivares-Mendez, M.; Campoy, P. Real-time Adaptive Multi-Classifier Multi-Resolution Visual Tracking Framework for Unmanned Aerial Vehicles. In Proceedings of the 2013 2nd International Workshop on Research, Education and Development of Unmanned Aerial Systems (RED-UAS), Compiegne, France, 20–22 November 2013; pp. 532–541.
- Babenko, B.; Yang, M.H.; Belongie, S. Robust Object Tracking with Online Multiple Instance Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1619–1632. [Google Scholar] [CrossRef] [PubMed]
- Fu, C.; Carrio, A.; Olivares-Mendez, M.; Suarez-Fernandez, R.; Campoy, P. Robust Real-time Vision-based Aircraft Tracking from Unmanned Aerial Vehicles. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 5441–5446.
- Black, M.; Jepson, A. EigenTracking: Robust Matching and Tracking of Articulated Objects Using a View-Based Representation. Int. J. Comput. Vis. 1998, 26, 63–84. [Google Scholar] [CrossRef]
- Murase, H.; Nayar, S. Visual learning and recognition of 3-d objects from appearance. Int. J. Comput. Vis. 1995, 14, 5–24. [Google Scholar] [CrossRef]
- Belhumeur, P.; Kriegman, D. What is the set of images of an object under all possible lighting conditions? Computer Vision and Pattern Recognition, 1996. In Proceedings of the 1996 IEEE Computer Society Conference on CVPR ’96, San Francisco, CA, USA, 18–20 June 1996; pp. 270–277.
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; Volume 2, pp. 506–513.
- Arulampalam, M.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Sign. Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Yang, M.H.; Kriegman, D.J.; Ahuja, N. Detecting faces in images: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 34–58. [Google Scholar] [CrossRef]
- Leung, T.K.; Burl, M.C.; Perona, P. Finding faces in cluttered scenes using random labeled graph matching. In Proceedings of the Fifth International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 1995; pp. 637–644.
- Lanitis, A.; Taylor, C.J.; Cootes, T.F. Automatic face identification system using flexible appearance models. Image Vis. Comput. 1995, 13, 393–401. [Google Scholar] [CrossRef]
- Rowley, H.; Baluja, S.; Kanade, T. Neural network-based face detection. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 23–38. [Google Scholar] [CrossRef]
- Rajagopalan, A.N.; Kumar, K.S.; Karlekar, J.; Manivasakan, R.; Patil, M.M.; Desai, U.B.; Poonacha, P.; Chaudhuri, S. Finding faces in photographs. In Proceedings of the Sixth International Conference on Computer Vision, 1998, Bombay, India, 4–7 January 1998; pp. 640–645.
- Osuna, E.; Freund, R.; Girosi, F. Training support vector machines: An application to face detection. In Proceedings of the 1997 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 17–19 Jun 1997; pp. 130–136.
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. I511–I518.
- Shirai, Y.; Inoue, H. Guiding a robot by visual feedback in assembling tasks. Pattern Recognit. 1973, 5, 99–108. [Google Scholar] [CrossRef]
- Sanderson, A.C.; Weiss, L.E. Adaptative visual servo control of robots. In Robot Vision; Pugh, A., Ed.; Springer: Berlin, Germany; Heidelberg, Germany, 1983; pp. 107–116. [Google Scholar]
- Campoy, P.; Correa, J.; Mondragón, I.; Martínez, C.; Olivares, M.; Mejías, L.; Artieda, J. Computer Vision Onboard UAVs for Civilian Tasks. J. Intell. Robot. Syst. 2009, 54, 105–135. [Google Scholar] [CrossRef] [Green Version]
- Ding, W.; Gong, Z.; Xie, S.; Zou, H. Real-time vision-based object tracking from a moving platform in the air. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; pp. 681–685.
- Teuliere, C.; Eck, L.; Marchand, E. Chasing a moving target from a flying UAV. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 4929–4934.
- Ruffier, F.; Franceschini, N. Visually guided micro-aerial vehicle: Automatic take off, terrain following, landing and wind reaction. In Proceedings of the 2004 IEEE International Conference on Robotics and Automation (ICRA’04), New Orleans, LA, USA, 26 April –1 May 2004; pp. 2339–2346.
- Lee, D.; Ryan, T.; Kim, H. Autonomous landing of a VTOL UAV on a moving platform using image-based visual servoing. In Proceedings of the 2012 IEEE International Conference onRobotics and Automation (ICRA), St Paul, MN, USA, 14–18 May 2012; pp. 971–976.
- Zengin, U.; Dogan, A. Cooperative target pursuit by multiple UAVs in an adversarial environment. Robot. Auton. Syst. 2011, 59, 1049–1059. [Google Scholar] [CrossRef]
- Egbert, J.; Beard, R.W. Low-altitude road following using strap-down cameras on miniature air vehicles. In Proceedings of the 2007 American Control Conference, New York, NY, USA, 9–13 July 2011; pp. 831–843.
- Rodríguez-Canosa, G.R.; Thomas, S.; del Cerro, J.; Barrientos, A.; MacDonald, B. A Real-Time Method to Detect and Track Moving Objects (DATMO) from Unmanned Aerial Vehicles (UAVs) Using a Single Camera. Remote Sens. 2012, 4, 1090–1111. [Google Scholar] [CrossRef]
- Cesetti, A.; Frontoni, E.; Mancini, A.; Zingaretti, P.; Longhi, S. A Vision-Based Guidance System for UAV Navigation and Safe Landing using Natural Landmarks. J. Intell. Robot. Syst. 2010, 57, 233–257. [Google Scholar] [CrossRef]
- De Wagter, C.; Mulder, J. Towards Vision-Based UAV Situation Awareness. In Proceedings of the AIAA Guidance, Navigation, and Control Conference and Exhibit, San Francisco, CA, USA, 17 August 2005.
- Fucen, Z.; Haiqing, S.; Hong, W. The object recognition and adaptive threshold selection in the vision system for landing an Unmanned Aerial Vehicle. In Proceedings of the 2009 International Conference on Information and Automation (ICIA ’09), Zhuhai/Macau, China, 22–25 June 2009; pp. 117–122.
- Saripalli, S.; Sukhatme, G.S. Landing a helicopter on a moving target. In Proceedings of the IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 2030–2035.
- Saripalli, S.; Montgomery, J.F.; Sukhatme, G.S. Visually-Guided Landing of an Unmanned Aerial Vehicle. IEEE Trans. Robot. Autom. 2003, 19, 371–381. [Google Scholar] [CrossRef]
- Saripalli, S.; Montgomery, J.; Sukhatme, G. Vision-based autonomous landing of an unmanned aerial vehicle. In Proceedings of the 2002 IEEE International Conference on Robotics and Automation (ICRA’02), Washinton, DC, USA, 11–15 May 2002; Volume 3, pp. 2799–2804.
- Merz, T.; Duranti, S.; Conte, G. Autonomous Landing of an Unmanned helicopter Based on Vision and Inbertial Sensing. In Proceedings of the The 9th International Symposium on Experimental Robotics (ISER 2004), Singapore, 18–21 June 2004.
- Merz, T.; Duranti, S.; Conte, G. Autonomous landing of an unmanned helicopter based on vision and inertial sensing. In Experimental Robotics IX; Ang, M., Khatib, O., Eds.; Springer Berlin: Heidelberg, Germany, 2006; Volume 21, pp. 343–352. [Google Scholar]
- Hermansson, J. Vision and GPS Based Autonomous Landing of an Unmanned Aerial Vehicle. Ph.D. Thesis, Linkoping University, Department of Electrical Engineering, Automatic Control, Linkoping, Sweeden, 2010. [Google Scholar]
- Lange, S.; Sünderhauf, N.; Protzel, P. Autonomous landing for a multirotor UAV using vision. In Proceedings of the SIMPAR International Conference on Simulation, Modeling and Programming for Autonomous Robots, Venice, Italy, 3–7 November 2008; pp. 482–491.
- Voos, H. Nonlinear landing control for quadrotor UAVs. In Autonome Mobile Systeme 2009; Dillmann, R., Beyerer, J., Stiller, C., ZÃűllner, J., Gindele, T., Eds.; Springer: Berlin, Germany; Heidelberg, Germany, 2009; pp. 113–120. [Google Scholar]
- Voos, H.; Bou-Ammar, H. Nonlinear Tracking and Landing Controller for Quadrotor Aerial Robots. In Proceedings of the 2010 IEEE International Conference on Control Applications (CCA), Yokohama, Japan, 8–10 September 2010; pp. 2136–2141.
- Chitrakaran, V.; Dawson, D.; Chen, J.; Feemster, M. Vision Assisted Autonomous Landing of an Unmanned Aerial Vehicle. In Proceedings of the 2005 44th IEEE Conference on Decision and Control European Control Conference (CDC-ECC’05), Seville, Spain, 12–15 December 2005; pp. 1465–1470.
- Nonami, K.; Kendoul, F.; Suzuki, S.; Wang, W.; Nakazawa, D.; Nonami, K.; Kendoul, F.; Suzuki, S.; Wang, W.; Nakazawa, D. Guidance and navigation systems for small aerial robots. In Autonomous Flying Robots; Springer: Tokyo, Japan, 2010; pp. 219–250. [Google Scholar]
- Wenzel, K.; Masselli, A.; Zell, A. Automatic Take Off, Tracking and Landing of a Miniature UAV on a Moving Carrier Vehicle. J. Intell. Robot. Syst. 2011, 61, 221–238. [Google Scholar] [CrossRef]
- Venugopalan, T.; Taher, T.; Barbastathis, G. Autonomous landing of an Unmanned Aerial Vehicle on an autonomous marine vehicle. Oceans 2012, 2012, 1–9. [Google Scholar]
- Kendoul, F. Survey of Advances in Guidance, Navigation, and Control of Unmanned Rotorcraft Systems. J. Field Robot. 2012, 29, 315–378. [Google Scholar] [CrossRef]
- Chao, H.; Cao, Y.; Chen, Y. Autopilots for small unmanned aerial vehicles: A survey. Int. J. Control Autom. Syst. 2010, 8, 36–44. [Google Scholar] [CrossRef]
- Zulu, A.; John, S. A Review of Control Algorithms for Autonomous Quadrotors. Open J. Appl. Sci. 2014, 4, 547–556. [Google Scholar] [CrossRef]
- Martinez, S.E.; Tomas-Rodriguez, M. Three-dimensional trajectory tracking of a quadrotor through PVA control. Rev. Iberoam. Autom. Inform. Ind. RIAI 2014, 11, 54–67. [Google Scholar]
- Shadowview. Available online: http://www.shadowview.org (accessed on 15 October 2013).
- Wildlife Conservation UAV Challenge. Available online: http://www.wcuavc.com (accessed on 23 August 2015).
- Li, G.; Liang, D.; Huang, Q.; Jiang, S.; Gao, W. Object tracking using incremental 2D-LDA learning and Bayes inference. In Proceedings of the 2008 15th IEEE International Conference on Image Processing (ICIP 2008), San Diego, CA, USA, 12–15 October 2008; pp. 1568–1571.
- Wang, T.; Gu, I.H.; Shi, P. Object Tracking using Incremental 2D-PCA Learning and ML Estimation. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2007), Honolulu, HI, USA, 15–20 April 2007; Volume 1, pp. 933–936.
- Wang, D.; Lu, H.; wei Chen, Y. Incremental MPCA for color object tracking. In Proceedings of the 2010 20th International Conference on Pattern Recognition (ICPR), Istanbul, Turkey, 23–26 August 2010; pp. 1751–1754.
- Hu, W.; Li, X.; Zhang, X.; Shi, X.; Maybank, S.; Zhang, Z. Incremental Tensor Subspace Learning and Its Applications to Foreground Segmentation and Tracking. Int. J. Comput. Vis. 2011, 91, 303–327. [Google Scholar] [CrossRef]
- Ross, D.A.; Lim, J.; Lin, R.S.; Yang, M.H. Incremental Learning for Robust Visual Tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Juan, L.; Gwon, O. A Comparison of SIFT, PCA-SIFT and SURF. Int. J. Image Process. IJIP 2009, 3, 143–152. [Google Scholar]
- Levey, A.; Lindenbaum, M. Sequential Karhunen-Loeve basis extraction and its application to images. IEEE Trans. Image Process. 2000, 9, 1371–1374. [Google Scholar] [CrossRef] [PubMed]
- Hall, P.; Marshall, D.; Martin, R. Adding and subtracting eigenspaces with eigenvalue decomposition and singular value decomposition. Image Vis. Comput. 2002, 20, 1009–1016. [Google Scholar] [CrossRef]
- Hartley, R.I.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, United Kingdom, 2004. [Google Scholar]
- Automation & Robotics Research Group at SnT—University of Luxembourg. Available online: http://wwwen.uni.lu/snt/research/automation_research_group/projects#MoRo (accessed on 28 November 2015).
- Davis, N.; Pittaluga, F.; Panetta, K. Facial recognition using human visual system algorithms for robotic and UAV platforms. In Proceedings of the 2013 IEEE International Conference on Technologies for Practical Robot Applications (TePRA), Woburn, MA, USA, 22–23 April 2013; pp. 1–5.
- Gemici, M.; Zhuang, Y. Autonomous Face Detection and Human Tracking Using ar Drone Quadrotor; Cornell University: Ithaca, NY, USA, 2011. [Google Scholar]
- Pan, Y.; Ge, S.; He, H.; Chen, L. Real-time face detection for human robot interaction. In Proceedings of the 18th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN 2009), Toyama, Japan, 27 September–2 October 2009; pp. 1016–1021.
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A general framework for object detection. In Proceedings of the 1998 Sixth International Conference on Computer vision, Bombay, India, 4–7 January 1998; pp. 555–562.
- Lienhart, R.; Kuranov, A.; Pisarevsky, V. Empirical analysis of detection cascades of boosted classifiers for rapid object detection. In Pattern Recognition; Springer: Berlin, Germany, 2003; pp. 297–304. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications, 1st ed.; Springer-Verlag New York, Inc.: New York, NY, USA, 2010. [Google Scholar]
- Garrido-Jurado, S.; Munoz-Salinas, R.; Madrid-Cuevas, F.; Marin-Jimenez, M. Automatic generation and detection of highly reliable fiducial markers under occlusion. Pattern Recognit. 2014, 47, 2280–2292. [Google Scholar] [CrossRef]
- Briod, A.; Zufferey, J.C.; Floreano, D. Automatically calibrating the viewing direction of optic-flow sensors. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), St Paul, MN, USA, 14–18 May 2012; pp. 3956–3961.
- Sa, I.; Hrabar, S.; Corke, P. Inspection of Pole-Like Structures Using a Visual-Inertial Aided VTOL Platform with Shared Autonomy. Sensors 2015, 15, 22003–22048. [Google Scholar] [CrossRef] [PubMed]
- Mondragón, I.; Olivares-Méndez, M.; Campoy, P.; Martínez, C.; Mejias, L. Unmanned aerial vehicles UAVs attitude, height, motion estimation and control using visual systems. Auton. Robot. 2010, 29, 17–34. [Google Scholar] [CrossRef] [Green Version]
- Rohmer, E.; Singh, S.; Freese, M. V-REP: A versatile and scalable robot simulation framework. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 1321–1326.
- Olivares-Mendez, M.; Kannan, S.; Voos, H. Vision based fuzzy control autonomous landing with UAVs: From V-REP to real experiments. In Proceedings of the 2015 23th Mediterranean Conference on Control and Automation (MED), Torremolinos, Spain, 16–19 June 2015; pp. 14–21.
- Ar.Drone Parrot. Available online: http://ardrone.parrot.com (accessed on 1 March 2012).
- KUKA Youbot. Available online: http://www.kuka-robotics.com/en/products/education/youbot/ (accessed on 17 July 2015).
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Olivares-Mendez, M.A.; Fu, C.; Ludivig, P.; Bissyandé, T.F.; Kannan, S.; Zurad, M.; Annaiyan, A.; Voos, H.; Campoy, P. Towards an Autonomous Vision-Based Unmanned Aerial System against Wildlife Poachers. Sensors 2015, 15, 31362-31391. https://doi.org/10.3390/s151229861
Olivares-Mendez MA, Fu C, Ludivig P, Bissyandé TF, Kannan S, Zurad M, Annaiyan A, Voos H, Campoy P. Towards an Autonomous Vision-Based Unmanned Aerial System against Wildlife Poachers. Sensors. 2015; 15(12):31362-31391. https://doi.org/10.3390/s151229861
Chicago/Turabian StyleOlivares-Mendez, Miguel A., Changhong Fu, Philippe Ludivig, Tegawendé F. Bissyandé, Somasundar Kannan, Maciej Zurad, Arun Annaiyan, Holger Voos, and Pascual Campoy. 2015. "Towards an Autonomous Vision-Based Unmanned Aerial System against Wildlife Poachers" Sensors 15, no. 12: 31362-31391. https://doi.org/10.3390/s151229861
APA StyleOlivares-Mendez, M. A., Fu, C., Ludivig, P., Bissyandé, T. F., Kannan, S., Zurad, M., Annaiyan, A., Voos, H., & Campoy, P. (2015). Towards an Autonomous Vision-Based Unmanned Aerial System against Wildlife Poachers. Sensors, 15(12), 31362-31391. https://doi.org/10.3390/s151229861