
Three-Dimensional Object Recognition and Registration for Robotic Grasping Systems Using a Modified Viewpoint Feature Histogram



Abstract
:1. Introduction
2. System Architecture
2.1. Hardware Setup
2.2. Algorithm for the Robotic Grasping System
2.3. Database for Object Recognition and Registration
3. Object Recognition and Registration
3.1. Pre-Processing
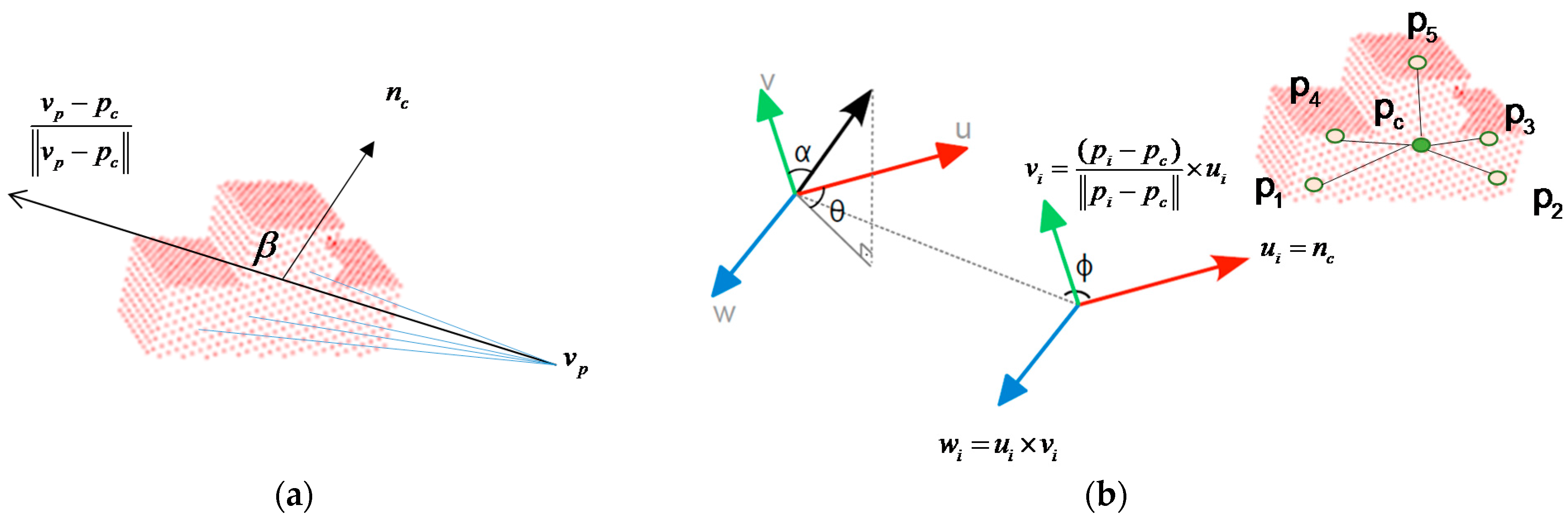
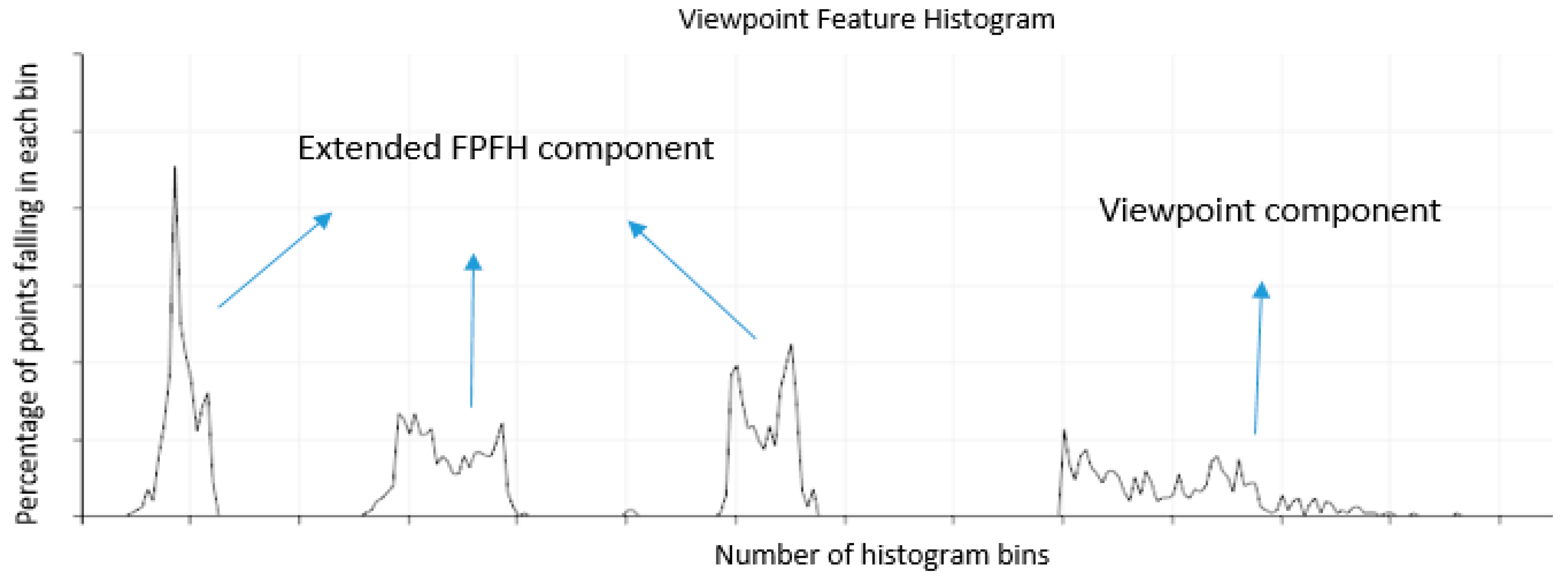
3.2. Gobal Descriptor Estimation
3.3. MVFH
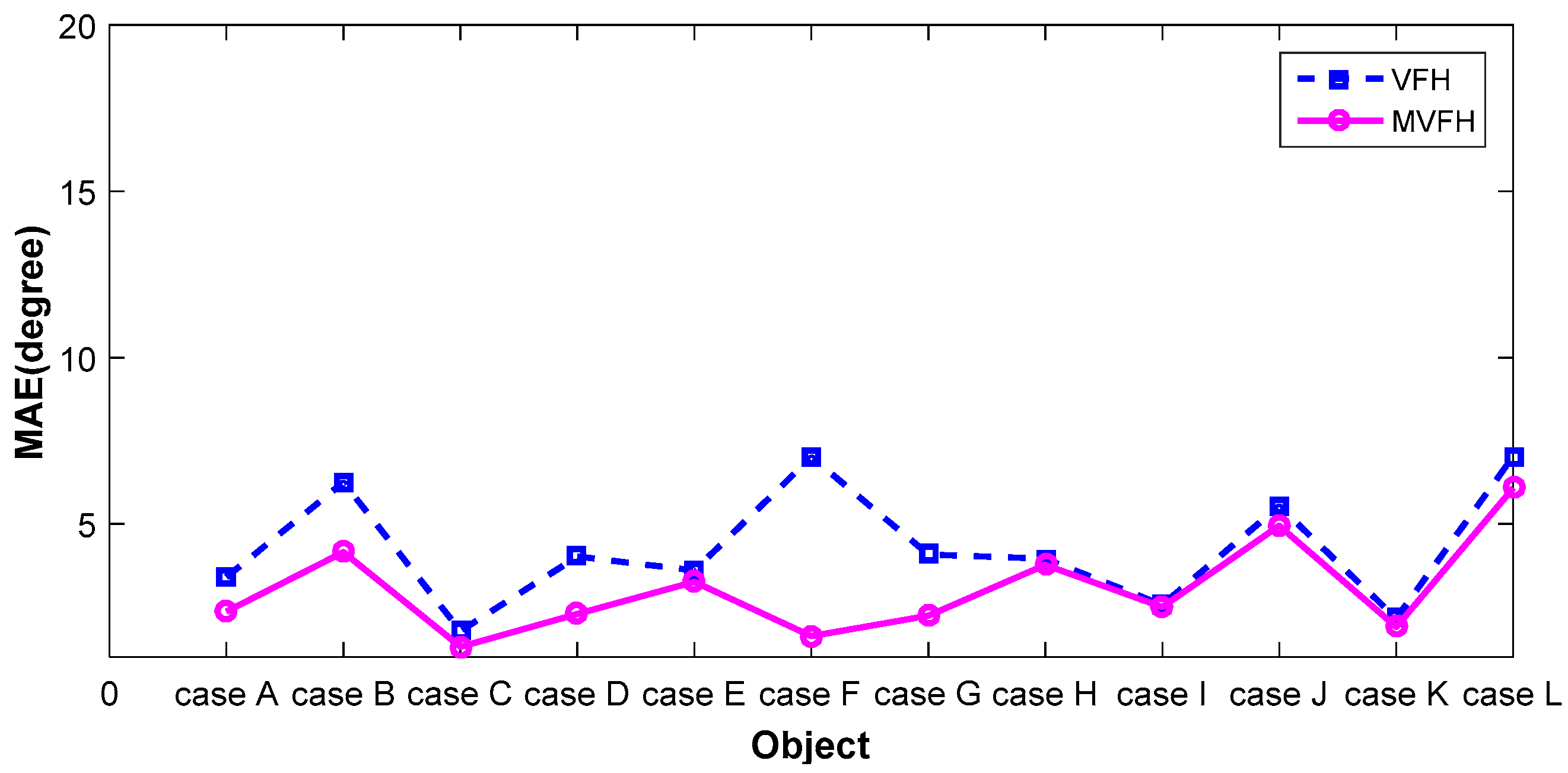
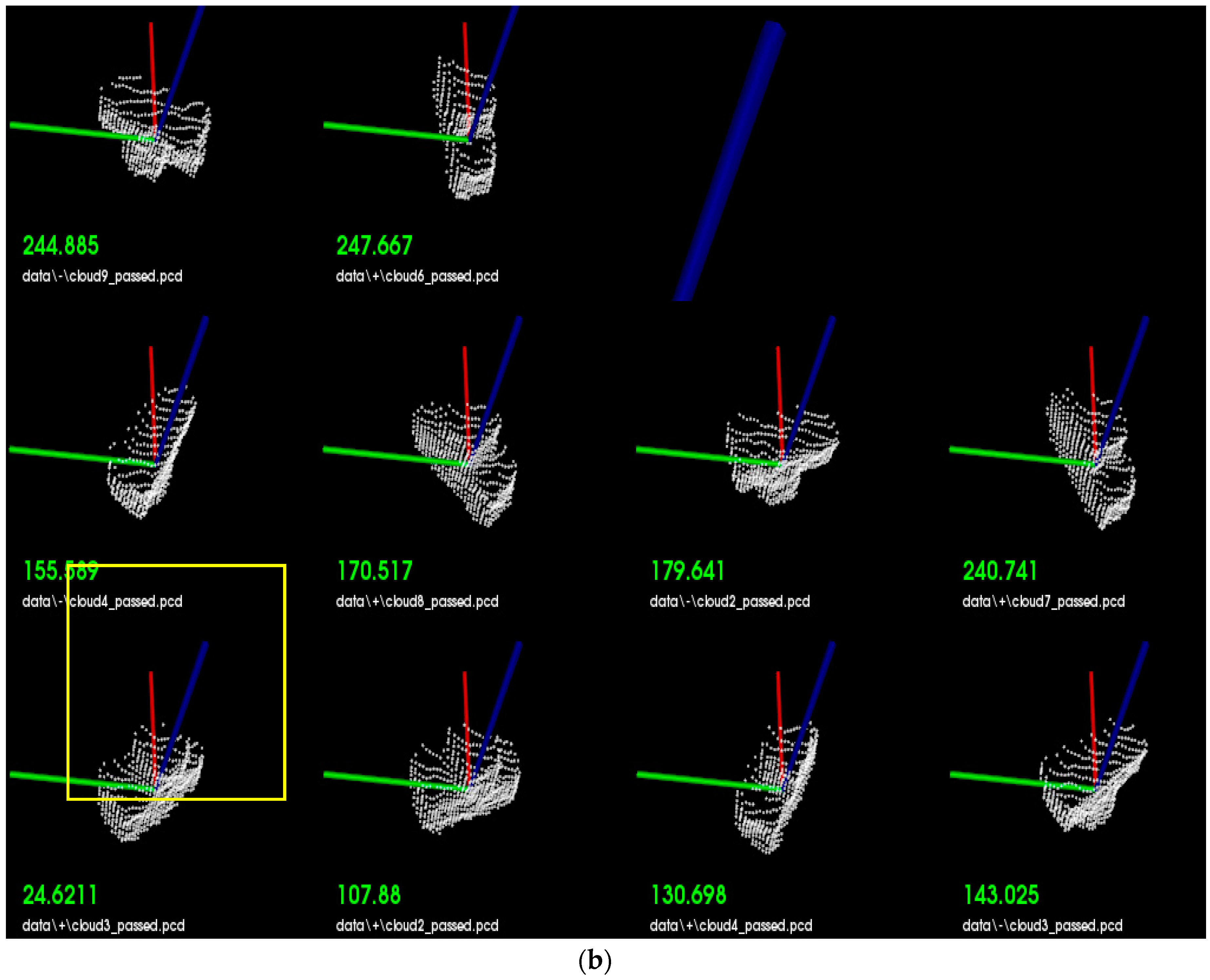
4. Experimental Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3D recognition and pose using the viewpoint feature histogram. In Proceedings of the 2010 IEEE/RSJ International Conference on the Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 2155–2162.
- Rusu, R.B.; Holzbach, A.; Beetz, M. Detecting and Segmenting Objects for Mobile Manipulation. In Proceedings of the IEEE Workshop on Search in 3D and Video (S3DV), Held in Conjunction with the 12th IEEE international Conference on Computer Vision (iCCV), Kyoto, Japan, 27 September–4 October 2009.
- Aldoma, A.A.; Vincze, M.; Blodow, N.; Gossow, D.; Gedikli, S.; Rusu, R.B.; Bradski, G. CAD-model recognition and 6DOF pose estimation using 3D cues. In Proceedings of the 2011 IEEE International Conference Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 585–592.
- Tombari, F.; Salti, S.; di Stefano, L. Unique signatures of histograms for local surface description. In Computer Vision–ECCV 2010; Springer: Berlin, Germany, 2010; pp. 356–369. [Google Scholar]
- Haselirad, A.; Neubert, J. A novel Kinect-based system for 3D moving object interception with a 5-DOF robotic arm. In Proceedings of the IEEE International Conference on Robotics and Automation, Gothenburg, Sweden, 24–28 August 2015.
- Luo, R.C.; Kuo, C.W. A Scalable Modular Architecture of 3D Object Acquisition for Manufacturing Automation. In Proceedings of 2015 IEEE 13th International Conference on the Industrial Informatics (INDIN), Cambridge, UK, 22–24 July 2015; pp. 269–274.
- Aldoma, A.; Tombari, F.; Rusu, R.B.; Vincze, M. OUR-CVFH–Oriented, unique and repeatable clustered viewpoint feature histogram for object recognition and 6DOF pose estimation. In Pattern Recognition; Springer: Berlin, Germany, 2012. [Google Scholar]
- Canny, J.F. Finding Edges and Lines in Images. Master’s Thesis, M.I.T. Artificial Intell. Lab., Cambridge, MA, USA, 1983. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- PCL Pass through Filter. Available online: http://pointclouds.org/documentation/tutorials/passthrough.php (accessed on 25 May 2016).
- PCL RANSAC Plane Segmentation. Available online: http://pointclouds.org/documentation/tutorials/planar_segmentation.php (accessed on 25 May 2016).
- PCL Statistical Outlier Removal. Available online: http://pointclouds.org/documentation/tutorials/statistical_outlier.php (accessed on 25 May 2016).
- PCL Down-Sampling. Available online: http://pointclouds.org/documentation/tutorials/voxel_grid.php (accessed on 25 May 2016).
- PCL Kdtree Search. Available online: http://pointclouds.org/documentation/tutorials/kdtree_search.php (accessed on 25 May 2016).
- Besl, P.J.; McKay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Singh, A.; Sha, J.; Narayan, K.S.; Achim, T.; Abbeel, P. Bigbird: (Big) Berkeley Instance Recognition Dataset. Available online: http://rll.berkeley.edu/bigbird/ (accessed on 20 September 2016).




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Average Computation Time |
|---|---|
| VFH | 0.01691 |
| With VFH + ICP | 0.25634 |
| MVFH | 0.02162 |
| With MVFH + ICP | 0.22179 |
| Method | Average Computation Time |
|---|---|
| With MVFH + ICP | 0.4948 |
| With VFH + ICP | 0.6019 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.-S.; Chen, P.-C.; Hsu, C.-M. Three-Dimensional Object Recognition and Registration for Robotic Grasping Systems Using a Modified Viewpoint Feature Histogram. Sensors 2016, 16, 1969. https://doi.org/10.3390/s16111969
Chen C-S, Chen P-C, Hsu C-M. Three-Dimensional Object Recognition and Registration for Robotic Grasping Systems Using a Modified Viewpoint Feature Histogram. Sensors. 2016; 16(11):1969. https://doi.org/10.3390/s16111969
Chicago/Turabian StyleChen, Chin-Sheng, Po-Chun Chen, and Chih-Ming Hsu. 2016. "Three-Dimensional Object Recognition and Registration for Robotic Grasping Systems Using a Modified Viewpoint Feature Histogram" Sensors 16, no. 11: 1969. https://doi.org/10.3390/s16111969
APA StyleChen, C. -S., Chen, P. -C., & Hsu, C. -M. (2016). Three-Dimensional Object Recognition and Registration for Robotic Grasping Systems Using a Modified Viewpoint Feature Histogram. Sensors, 16(11), 1969. https://doi.org/10.3390/s16111969