1. Introduction
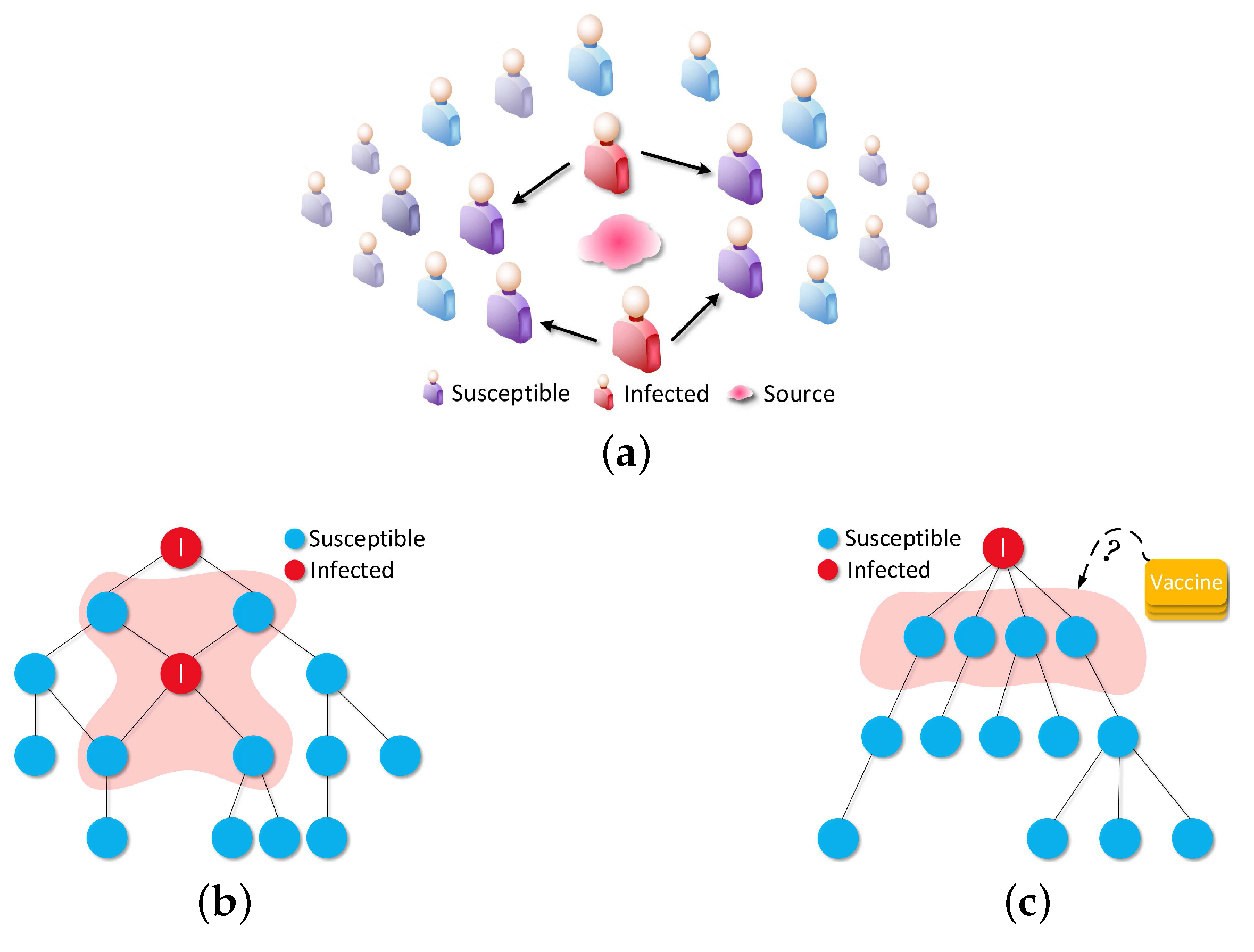
To what extent have you been bothered by the outbreak of undesirable things, a contagious disease, computer virus, or malicious rumor, and gone through a difficult time to wait for the constraint of the outbreak? Minimizing the spread of undesirable things is a major problem in Centers for Disease Control, Kaspersky, Twitter and Facebook, etc., where management and staff undertake much more responsibility for discovering and controlling the contamination. Many organizations are looking to address this problem with the distribution of vaccines/patches in the relevant network with a limited budget [
1,
2,
3]. For example, before the outbreak of H1N1 Flu, American Centers for Disease Control and Prevention(CDC) had centralized the distribution of vaccines for nearly 150,000 sites (hospitals, clinics, health departments), and it had been based on a cautious strategy of distributing the limited budget of vaccines to protect more people from being infected. Current placement strategies of vaccines/patches, however, are assuming that the initially infected nodes are randomly appearing [
4,
5,
6,
7]. Almost all cases, however, are such that the initially infected nodes are unevenly distributed. For example, in a city, some susceptible individuals are at high risk of getting an infection from a particular infectious disease (e.g., poultry farmers who are easily exposed to bird flu). Similarly, once a computer virus was made, it is aiming at the servers which lack specific precautions rather than randomly attack servers, and the propagation of this virus will start from those servers, obviously. Knowing the initially infected nodes as a prior information is also indispensable for the rumor control of social network companies. They could send an official alert message to limited people to prevent the rumor from developing into a public affair. With the help of a reliable node protection strategy, the related social network applications also can be extended to other hot topics, such as minimizing the error message propagation in Cyber-Physical Systems [
8,
9,
10,
11,
12,
13,
14], which already attracts a lot of attention from the academic field and industry areas [
15,
16,
17,
18,
19]. Besides, the dissemination of data in a network [
20,
21,
22,
23,
24] can also be guaranteed in a better way.
Minimizing the influence of undesirable things under prior information has been recently proposed [
25,
26] and the key part of solving this problem is to propose a greedy vaccines placement algorithm. Researchers try to improve protection performance of their algorithm by modifying heuristic idea since the problem is
NP-hard [
27] and even computing the influence between each node is a
#p problem [
28]. However, underlying their solutions is an assumption that all vaccines need to be deployed at once, which does not relate well to the facts. The saving number of one vaccine may have a notable difference at a different time with various network structures. Thus, the immunization strategy should take the benefit of each vaccine at different time slot into consideration so that we can maximize the utilization of every vaccine. This paper introduces Dancing with the propagation virus (DWPV), a dynamic vaccines placement strategy combines the time division into our solution. In line with common practice in selecting vaccines set [
25,
26,
29,
30], DWPV adopts Independent Cascade (IC) model [
27] as virus propagation model. To get the placement position of vaccines, the propagation model is a basic function to analyze the influence of immunizing those candidate nodes. The challenge of our problem, however, is to identify where and when the vaccines should be distributed.
Unlike past approaches [
6,
7], which consider delaying the placement time as detrimental, DWPV exploits the postponement of vaccine distribution to protect healthy nodes from being infected. Specifically, the benefit of putting one vaccine in a specific position on the network is always changed by the dynamic network structure. Hence, if we can ensure that a higher benefit of vaccines can be obtained from other transmission time slot (as shown in
Figure 1), then we postpone the placement time of those vaccines to next time slot to save more nodes.
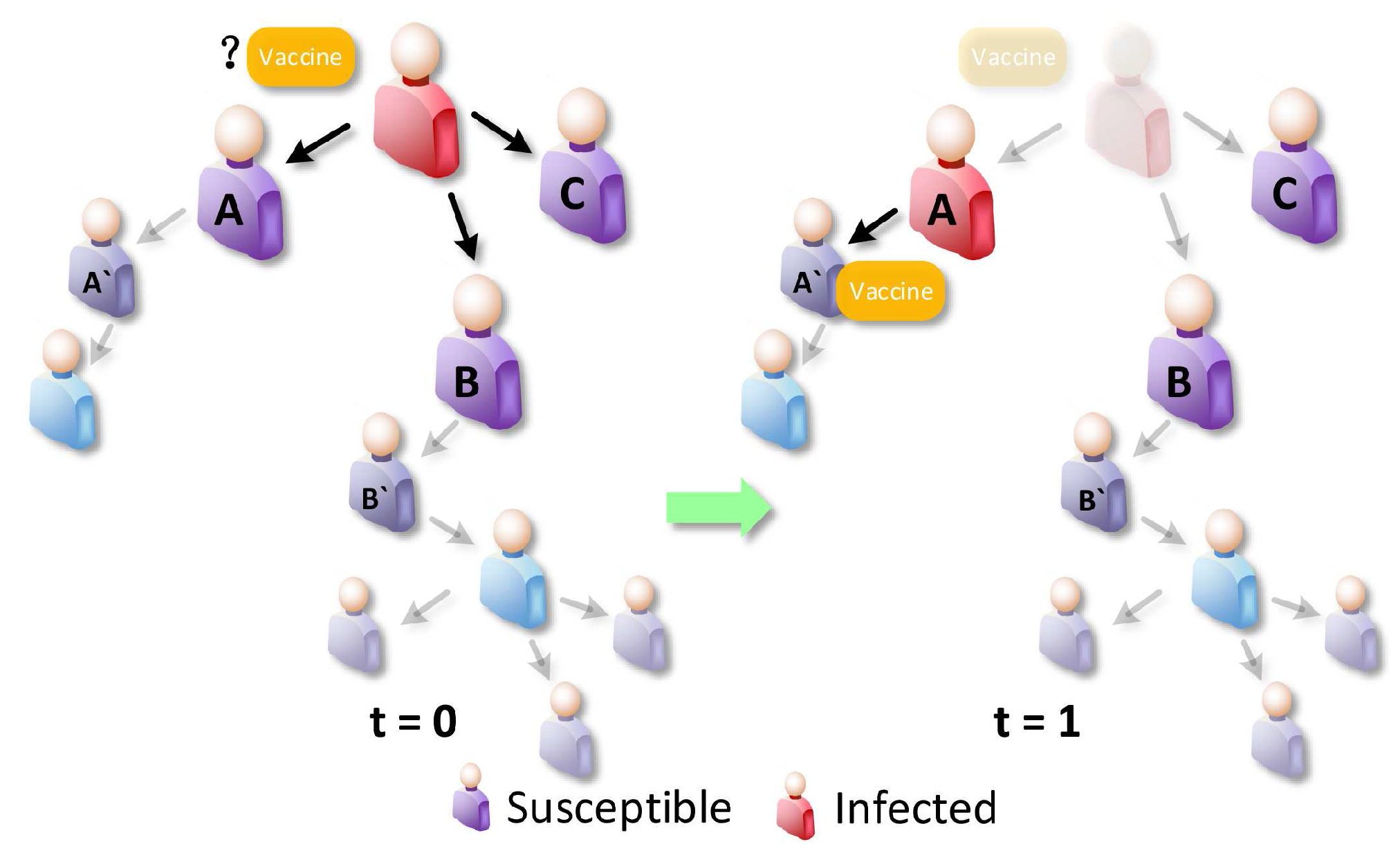
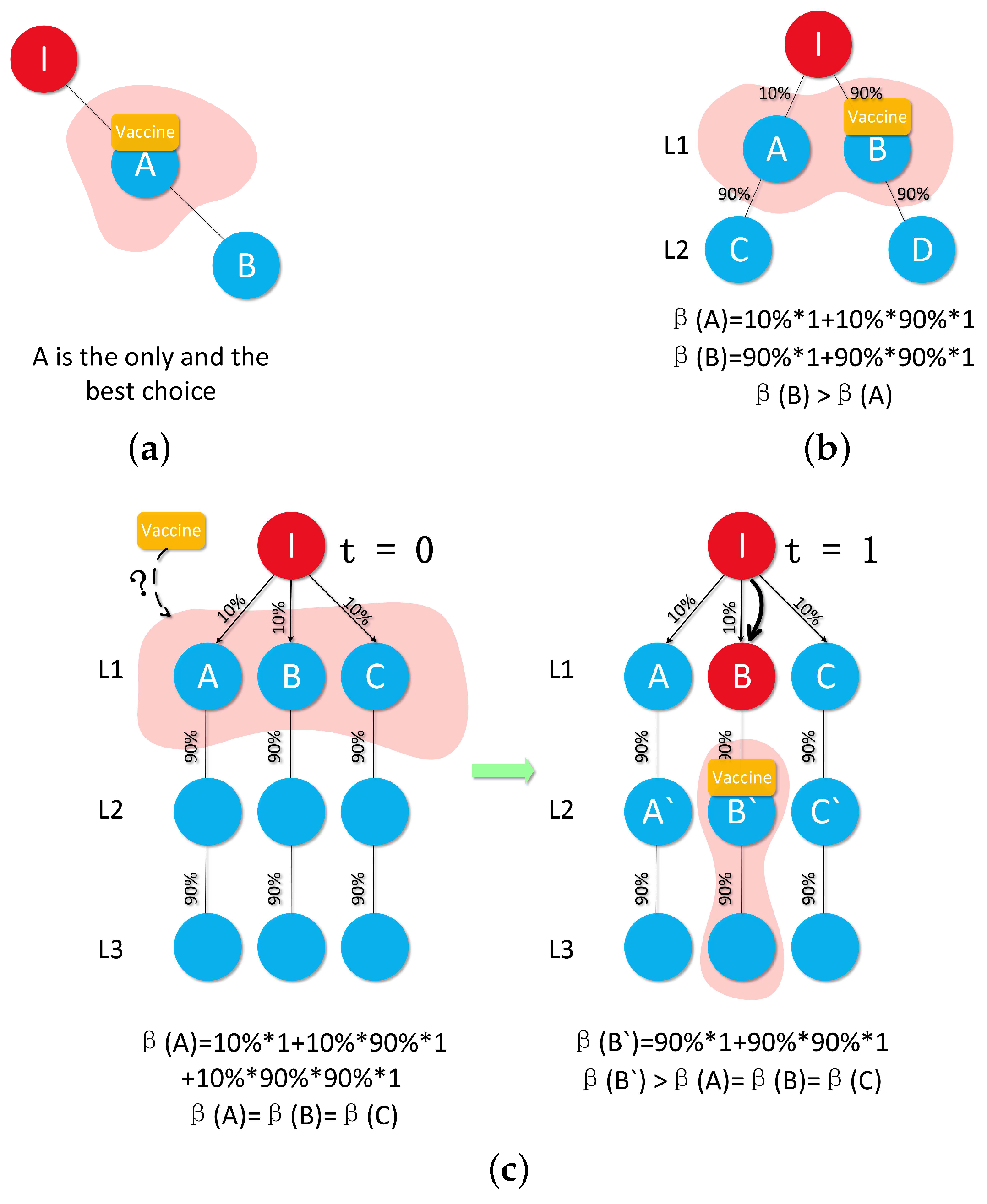
To illustrate DWPV’s approach,
Figure 2 shows a toy example with some susceptible nodes and one infected node, where the infected node is surrounded by three neighbors A, B and C, and the virus propagation probability is 0.2. As the figure shows, the idle vaccine, like the yellow one, may have a very limited benefit from the neighbors of the infected node at time slot 1 as we are not really sure who will be infected in the next time slot. However, this vaccine tends to have significantly different benefit from being distributed at time slot 2, e.g., putting the vaccine on A’. Hence, one needs to consider the full-time series benefits of vaccines; one-time slot alone, like the benefit from time slot 1, can be invalidated. To see this more clearly, we can use the standard metric [
25] to measure the effectiveness of putting vaccine on the each node of
Figure 2.
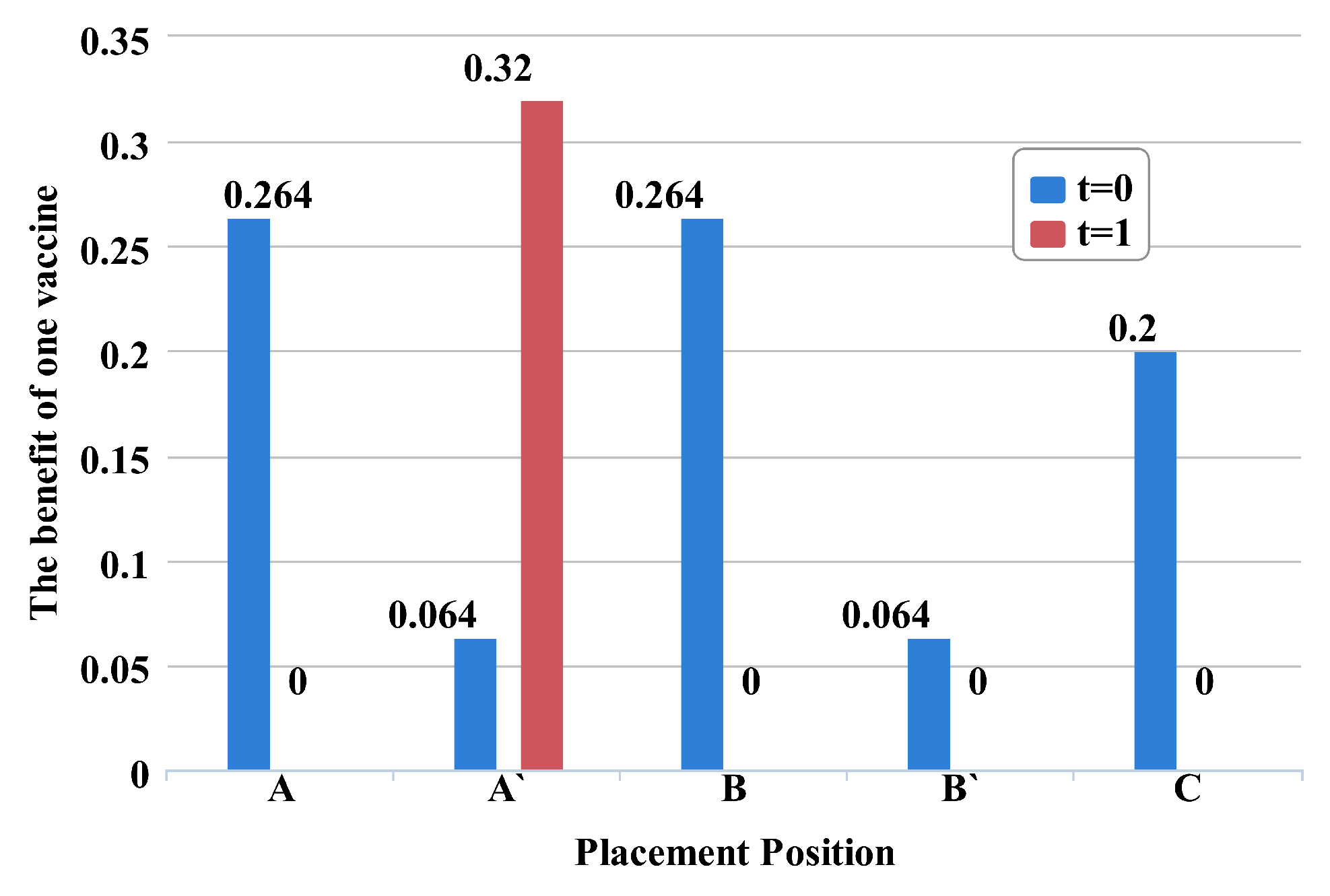
Figure 1 shows the obtained benefit from each node of
Figure 2 at t = 0 and t = 1. It is clear from this figure that looking at the neighbors of initially infected alone—i.e., A, B and C at t = 0—would wrongly indicate that vaccinating node B is the best choice, while looking at t = 1 allows us to realize that vaccinating node A’ at t = 1 has more benefit than vaccinating node B at t = 0. Thus, a robust vaccine placement strategy needs to compare the node’s benefit at different time slots by quantifying how much difference there is between putting vaccines on the current time slot and next time slot.
So how can we automatically quantify the changes across the benefit of different time slots? To do so, we need to estimate the influence of nodes’ benefit in different time slots. In contrast to the illustrative example, however, real-world networks always have many potential propagation events, which may change differently depending on the number of initially infected nodes and the propagation probability of each node. Further, different scale of networks typically has a different complexity of relationship between each node, causing the benefit of nodes to be changed frequently. In designing a technique that finds the most suitable node and its placement time despite these changes, we are inspired by the baseline strategy [
25], which without consideration the placement time of vaccines, in using the dominator tree to approximately represent the relationship between each node of the network. Given an arbitrary graph and trying to figure out the relation between each node is a
#p problem to us, we need to approximately represent the dominating relation to finding the dominator node that we can put a vaccine on there to release the most infecting pressure of other nodes. In graph theory, a graph is converted to a dominator tree following the rules that if the status of A is donated by B then we define it as B denote A. Namely, we can directly point out the dominating node after we translate the original graph into a tree structure and merge the initially infected nodes as the root node. As opposed to only converting the original graph into the dominator tree and point out the key node, DWPV analyzes the transmission probability of each root node’s neighbor, which nodes are treated as the best candidate nodes in previous works, by using a binary tree to figure out the expected benefit of these nodes in current time slot and next time slot. Furthermore, we propose a Monte Carlo sampling method as a substitute method to suit the limited computation application. We present the design in
Section 4 and we have theoretically proved that the strategy of ours, which combine the time division into the placement of vaccine, has an advantage over previous works in controlling the propagation of the virus.
Finally, while we could obtain a set of position to put the vaccines and its corresponding placement time, there will always be many changes in the propagation process of the virus, since all analysis results are based on a probabilistic model. For this reason, DWPV decides to put one vaccine on the graph only if a neighbor of the candidate node is infected. This design broadens the assurance of the effectiveness of vaccines (up to 30%), and in case of some vaccines, they become invalid as their neighbors are always safe during the propagation of the virus.
This paper makes the following contributions:
It presents a vaccine placement strategy that exploits the changes of vaccine’s benefit in different time slots to get the highest benefit of one vaccine. As a result, the design delivers high-level protection to keep more healthy nodes from being infected.
It also demonstrates the capability of the dominator tree to select out the candidate immunization nodes in a dynamic scenario, and we successfully use it to protect more healthy nodes in an infected network than the static one. While our design and results are presented in the social network, the basic idea can be extended to other communication problems.
It presents an accurate method to evaluate the possible benefit from other time slots by using binary tree and its simplified version with lower computation complex by using Monte Carlo method.
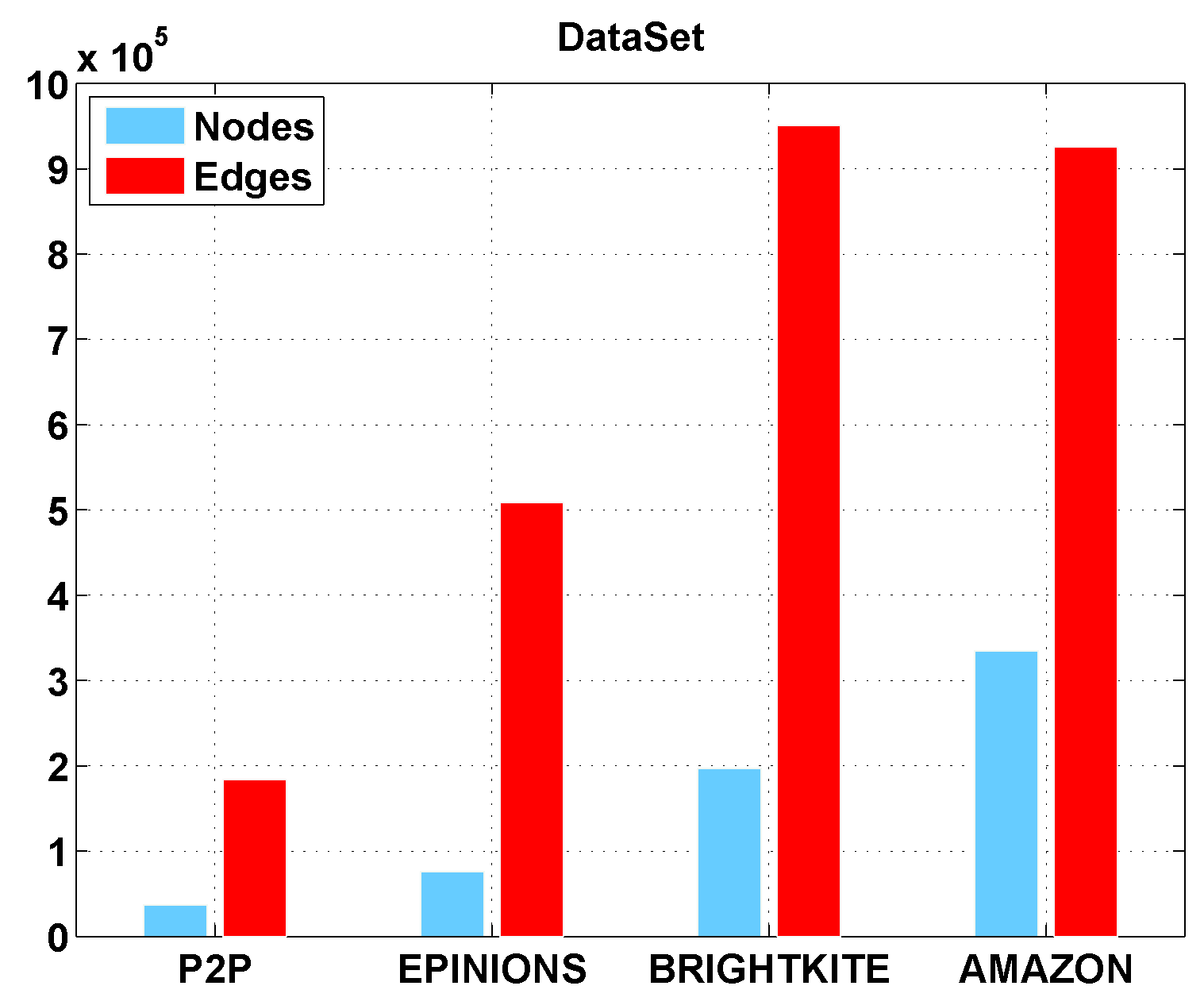
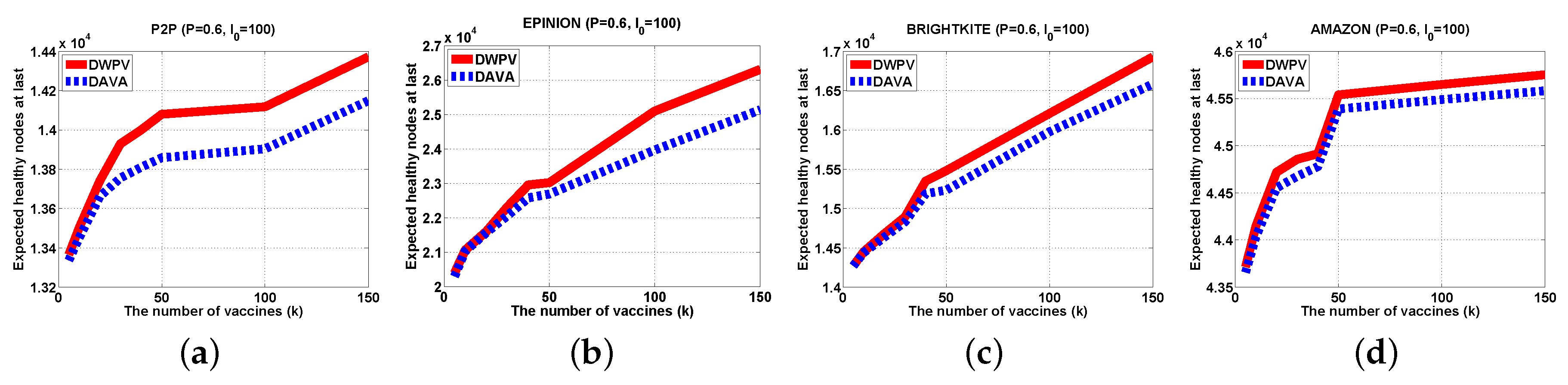
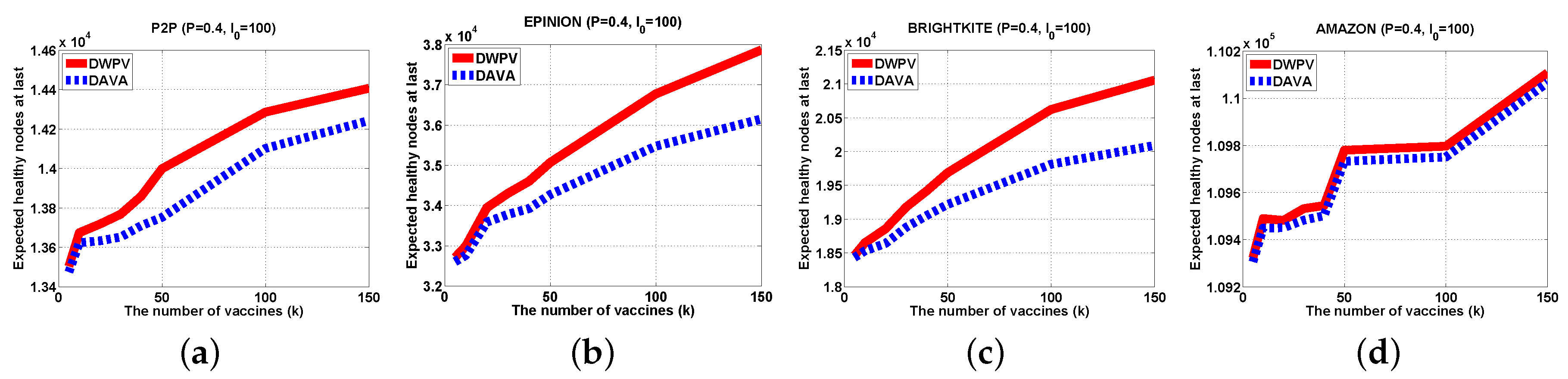
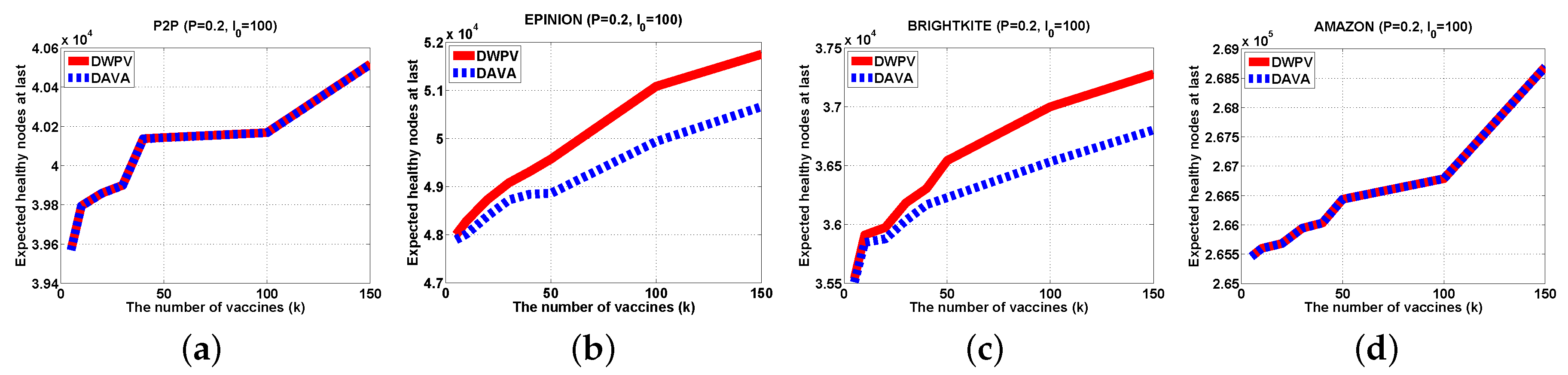
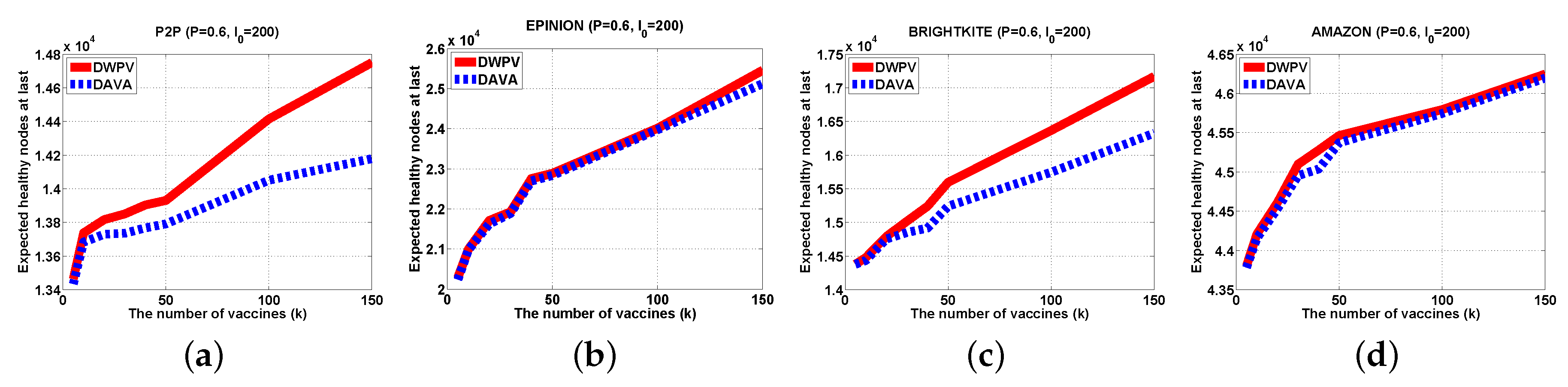
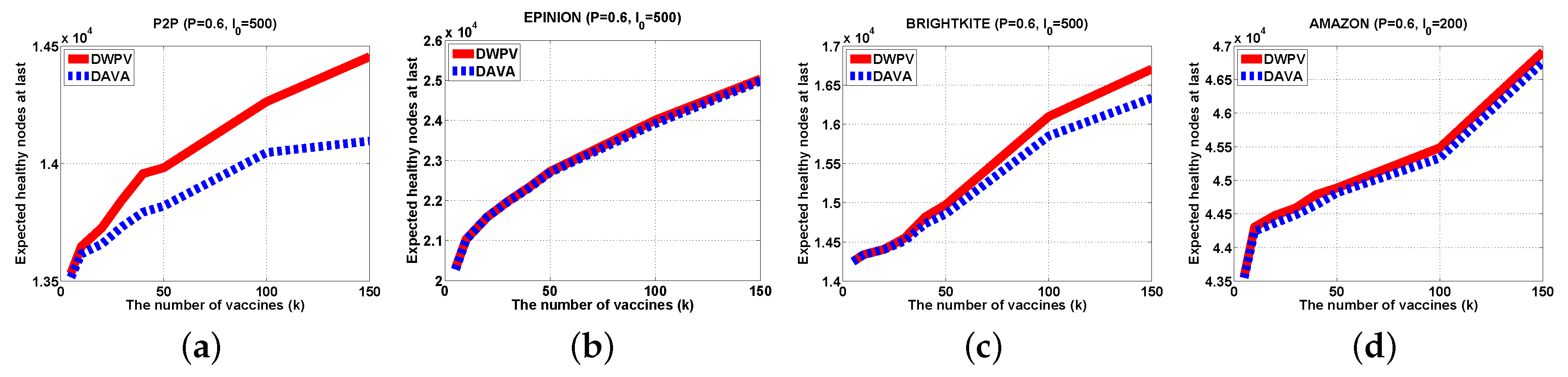
It has been evaluated in some real-world large-scale data sets.
The rest of the paper is organized as follows.
Section 2 introduces our preliminaries.
Section 3 define our problem as vaccines placement problem and we present our solution in
Section 4.
Section 5 shows our experiment results with open-resource datasets.
Section 6 is the related work about this paper and we have a conclusion of this paper in
Section 7.
2. Preliminaries
The information propagation model is the first thing we have to understand for knowing the method of restricting the malicious things communication in the social network, which is depicting the propagation process of information (bad/good) in a discrete way. The Susceptible/Infected/Recovered (SIR) Model [
1] and Independent cascade (IC) model [
27] are two popular models about malicious information communication which have been well studied for quite a long time. Compare to the SHIR (Susceptible-Hidden-Infected-Recovered), SIS(Susceptible-Infected-Susceptible) and LT (Linear Threshold), those two models are more widely used. In this paper, we introduce our method in IC model first, and we transfer the IC model into SIR model later. Meanwhile, notations list is shown in
Table 1.
SIR Model is a comprehensive description model of disease spreading, which has been well studied for many decades. As shown in
Figure 3, initial infected nodes
are already in the graph
. Besides, the weight of each edge,
(
), is used to represent the
transmission probability between
u and
v. Here, if one node gets infected at step
t, then that node will try to infect its neighbors (
susceptible) in
at step
. The status of each node will be updated in every time slot and it is notable that the recovered nodes will be removed from
. It is not until there is no infectious node in the
that the transmission processing of virus is over. Besides, once a node gets infected, that node will try to transform its status from
infected to
recovery (something like a man has antibodies) and the probability of this transformation is determined by
.
In general, in order to concentrate on the propagation process of the undesirable thing, we always use IC model to instead of SIR model [
31,
32,
33]. Compared to SIR model, IC model omits the process of recovery (
) and every infected node has only one chance to infect its neighbors. In this paper, we adopt IC model as our basic model too, and we will introduce how to transform IC to SIR in
Section 4.
4. Placement Strategy of Vaccines
Immunization time of limited vaccines, as we already knew, is an important key to satisfied our nodes protecting need. However, as the network structure is difficult enough that we can not get the immunization time and position easily from the original graph. Naturally, we need some basic tools of graph theory to initialize our network so that the structure can be simplified to meet the demand of analyzing the influence of each candidate node’s position. Once we get the easy network, we could propose our heuristic idea of the VP problem and verify its advantages over previous static version.
4.1. Network Initialize
The VP problem has been proved to be an NP-hard problem in the previous section and it needs a heuristic method to be solved. As mentioned before, the essence of our problem is a graph problem. However, knowing the influence relationship between two nodes is a #p problem, and we need to design a method to solve our problem in polynomial time. Hence, we initialize the network to simplify our problem. In this section, we will introduce the initialize methods, like dominator tree and super infected nodes.
4.1.1. Dominator Tree
For solving VP problem, after being given a graph
with initial infected nodes set
, the selection process of
not only need to find out the
Most Influence Node Set (MINS) but also need to take the relationship between
and MINS into consideration. Meanwhile, getting the relationship between each node is a
#p problem, then we need an approximate method to represent the relationship. Luckily, the Dominator Tree (DT, as shown in
Figure 4c that is a tree with infected root) has the power to convert a graph into tree structure with a dominating relation in linear-time, e.g., if node
u wants to infect
v, all the path between
u and
v need to pass
m, then we define it as
m dom
v (or
). After having a tree structure to represent
, then we just need to treat those nodes, which are in the
Most Dominating Layer (MDL) of DT (the first layer after the root node, e.g., the pink area as shown in
Figure 4c, as the best candidates.
Definition 1 (Most Dominating Layer)
. After being given a DT with infected root, then we define the first layer after the root node as the Most Dominating Layer (MDL). MDL is a node set that nodes in this layer not only has the highest probability to be infected by the infectious root node of all other nodes but also can determine if their children will be infected or not. Obviously, |MDL| < k is always true, otherwise we can easily stop the propagation of virus just by removing all direct suspectable nodes.
4.1.2. Benefit of One Node
Calculating the influence of removing one node in
is a
#p problem problem, which has been proved by [
28]. However, in DT, we can calculate out the value of influence (we define it as
benefit) with an easy method since each branch of a tree structure is mutually independent. Thus, we can treat
benefit as an estimation metric to estimate the value of candidate nodes so that we can make a better choice from those nodes.
Definition 2 (Metric for Estimating the Value of Removed Node)
. In DT, every node has a benefit which is used to represent the expected benefit of removing itself from G(V, E), and that is defined as a metric for estimating the value of the removed node. As every branch in DT is independent, the calculation of the benefit is a linear time algorithm and the details has been shown in Algorithm 1.
In Algorithm 1,
is calculated by a recursion function. Line 3–5 depict that the calculating process will be kept until it down to the leaf node. In DT, as for each branch is independent, the complexity of this algorithm is
. Meanwhile, a vivid instance of Algorithm 1 is shown in
Figure 5.
| Algorithm 1 Benefit of one candidate vaccine. |
| Input: One candidate vaccine i, Pu,v and a dominator tree with infected root node I0 |
| Output: The benefit of node i and it is stated as β(i) |
| Function Cal-Benefit (node i) |
- 1:
if i is not a leaf node then - 2:
- 3:
for each child j of node i do - 4:
- 5:
end for - 6:
else - 7:
- 8:
end if - 9:
return
|
| EndFunction |
Then, we can transform our target function (Equation (1)) into
Here, we use the calculation of the maximum summation of expected benefit
to stands the selection of
. Moreover, as
, we can constrain our target into calculating the value of
,
4.2. The Heuristic Idea of VP Problem
From the point of adding time division into our solution, heuristically, we should compare the advantage of vaccines in each time slots and decide which slots is the best immunization time finally. Moreover, we discover that can be obtained from other layers of DT by waiting for some time slots, rather than just from the MDL.
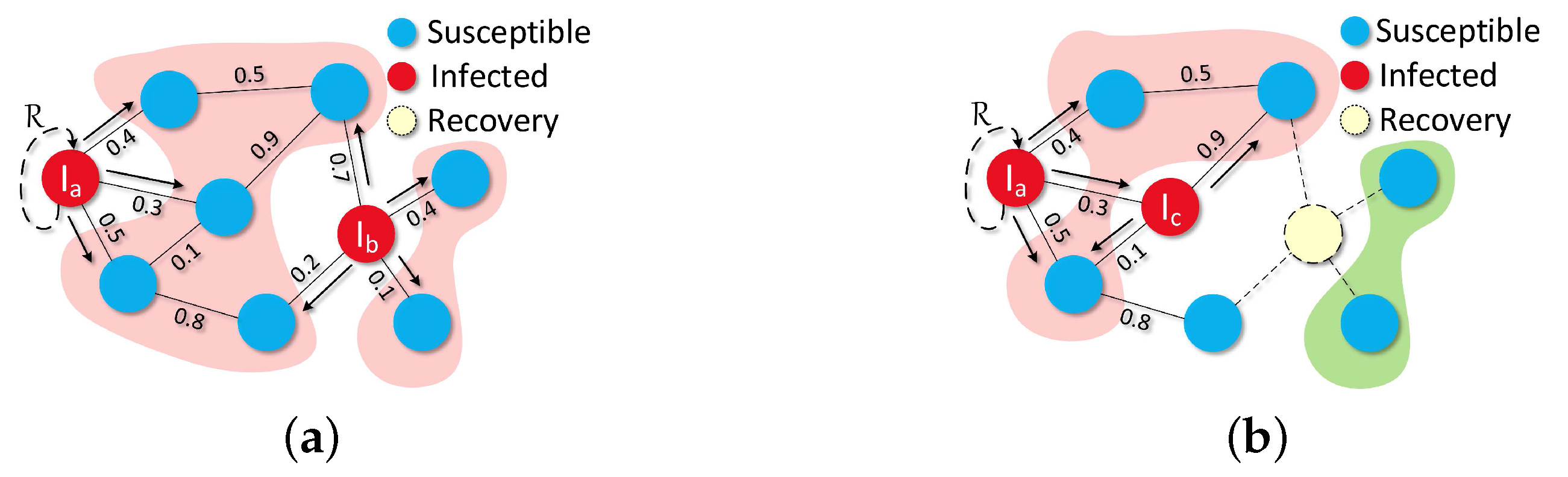
Lemma 1. Given a DT with infected root node, we should not just treat the nodes in MDL as optimal candidates for Equation (2) since sometimes we can own a bigger from other layers of DT by waiting some transmission time slots.
Proof. For now, we are using
Figure 5 as an example to prove our view and we assume the number of vaccines is one to ease of calculation. (1) We can simply vaccinate the node
A in
Figure 5a; (2) In
Figure 5b, by using Algorithm 1, we can calculate out
which means we can expectedly save 0.19 healthy node. At the same time,
which is bigger than
. Then, we decide to put vaccine on
B for a bigger
so that we can save more nodes; (3) As shown in
Figure 5c, if we are using the strategy of SVP, then we will save 0.271 max. Whereas, we are pondering whether we can get a bigger
by adding the
time division into our strategy. That is, we wait for one time slot and do nothing with the MDL (
, as shown in
Figure 5c), then
and
. At that time, if some nodes get infected at
, then we can surely obtain a bigger
in
as for the benefit of each node in
is much bigger than in
. Otherwise, no one gets infected which means that we do not even use vaccines, but this is a small probability event. ☐
4.3. Prove the Advantages of DVP over SVP
After
is converted to DT, obviously, we can get
so long as without taking
time dimension into consideration, where
,
,
is the children set of node
i. However, as lemma 1 shows, once we aware that
will not always bigger than
, where
, then the
time dimension becomes an indispensable factor of VP problem. Namely, we need to take
time dimension into our strategy to determine whether we should put vaccines at
or
, where
,
,
θ represent the current moment. So, we need to cautiously compare the expected benefit of
at
and
, until
or
. At the same time, if we can own some bigger
β at
, then we can wait to
to obtain a bigger
. For better understanding, we need to look back to
Figure 5c. At
, we can have 0.271 of benefit max, as we only put vaccines on
. Whereas, at
, as have already known that node
B is infected, then we can get a bigger
as 1.71.
Lemma 2. The benefit of each node is time-sensitive. Namely, in each propagation round, the structure of will be changed by infected nodes and these changes directly impact the benefits.
Proof. As for the transmission model we based on, the infected nodes set will keep developing until no one is infected in . Once one node gets recovered, it will be removed from the network and the will not be changed either. Sometimes these changes will bring a bigger value of the benefit of as compared to previous time slot, and sometimes they bring a smaller one. Meanwhile, means that immunizing i can save more healthy nodes than immunizing j on average. Thus, as , the value of must be changed by adjusting the placement time of vaccine, sometimes bigger and sometimes smaller. ☐
Theorem 2. The strategy of obtaining the maximum value of is related to every time slot , rather than just about as previous works assumed. Moreover, the strategy of DVP will get more benefit than SVP does, as Proof. Shortly, combining the idea of lemmas 1 and 2, we know that the strategy of DVP can save more healthy nodes. Specially, the vaccines set of DVP is selected from multi time slots, only when the benefit of some candidates in is bigger than in can these candidates of wait to . Besides, the worst case of DVP is that there is no node has bigger benefit as compared with SVP. At that time, DVP and SVP will have the same . Thus, is valid. ☐
4.4. Immunization Time Comparing
As mentioned previously, the core of our approach not only selecting out the right nodes to put vaccines on it but also choosing the right time to put it on . To do so, we need to find out that if there have , where and . Then, we put those nodes that has bigger β at and keep others idling until . The computation is a cyclic operation till the , then we will get the as announced at Equation (3).
The details of
Find the most valuable set of vaccines is shown in Algorithm 2. After knowing the
then we calculate out the
, and accurately predict the
then we calculate out the
, in addition, both sets of vaccines are sorted by
β. Then we can let these node wait to
to obtain a higher
.
| Algorithm 2 Find the most valuable set of vaccines. |
| Input: , k, , infected set and , most-k-benefit vaccines set and |
| Output: Vaccines set |
- 1:
- 2:
while and do - 3:
for to k do - 4:
- 5:
if then - 6:
Updating the by - 7:
- 8:
else - 9:
Updating the by - 10:
end if - 11:
end for - 12:
- 13:
- 14:
- 15:
end while
|
As shown in Algorithm 2, it is easy to see that to get the at a different time is also a major component of DVP strategy. So, we need to focus on the method of calculating those , where . At the beginning, we proposed an accurate method, which will not incur any meaningless waiting. Then, in consideration of the performance of the algorithm, we proposed a flexible version.
Firstly, we want to know every possible status of MDL, which status can help us to analyze the benefits from waiting one time slot. For better understanding, we make an example of this calculation. We assume there are two neighbors of the infected root node of DT, A and B. So, there are four possible statuses of A and B, like , , , , where A is the event that one node get infected and is not.
After analyzing the possibility of each status and their benefit, we can have the expected benefit from waiting one time slot. Now, in Algorithm 3, and are corresponding benefit sets to and . The idea of Algorithm 3 is something like ‘binary decision tree’ as shown in line (5–7), by using these tools so that we can know the possibility of each event. Thus, we can use Algorithm 3 to analyze the expected benefit, and then, we can make a decision that put the nodes which have a bigger benefit at at , and others wait to next time slot.
It is easy to verify that Algorithm 3 can calculate out
and
but with a higher computation complexity(
). For that reason, we need to propose a fast algorithm to make it more available for a larger network. Using Monte Carlo simulation method to get the vaccines set is a well-studied method [
35]. In contrast to [
35], we need not find all the vaccine sets but just simulate the propagation procedure in one time slot, which has so much less complexity than [
35] dose. So we adopt the idea of Monte Carlo simulation method and use it to calculate out the possible benefit of
. At the same time, we both have
and
, and these are all we need.
Finally, we can get the complete DWPV Algorithm 4. In Algorithm 4, we first find
and get its corresponding benefit
, then we use the
Monte Carlo Process to get a simulated result of
to check out that if we obtain some nodes with a higher benefit than
. After that, we put those vaccines with higher benefit on
in this round and others wait to next time slot. We will keep this process going until
. There is another thing that should be noticed: when we decide to put one vaccine down, there must be some neighbors of that position that have been infected or we let these vaccines wait. This little trick can bring some benefit in case some unexpected things to happen, such as we put one vaccine on the
but its neighbors are hardly infected as
is always changing.
| Algorithm 3 Analyzing the benefit of each time slot. |
| Input: A dominator tree with infected root node, one vaccine, , and |
| Output: Expected benefit with one vaccine in layer 1 and layer 2 |
- 1:
{Probability of transmit to layer 1 according to } - 2:
for to do - 3:
Initialize with 1 with 0{The set of all kinds of sort in the situation of layer 1 and The maximum benefit will owned when one node is selected} - 4:
end for - 5:
for to do - 6:
Get all the immunization benefit from layer 1, namely, we get - 7:
end for - 8:
for to do - 9:
Get all the nodes infection possibility in layer 2, which are conveyed from layer 1 - 10:
end for - 11:
for to do - 12:
Get all the immunization benefit from layer 2, namely, we get - 13:
end for - 14:
return
|
| Algorithm 4 DWPV Algorithm. |
| Input: , and k |
| Output: |
- 1:
- 2:
while NULL and do - 3:
- 4:
HeapSort(k, using Cal-Benefit() to calculate out every node’s benefit of ) - 5:
Using Monte Carlo Process to get - 6:
HeapSort(k, using Cal-Benefit() to calculate out every node’s benefit of ) - 7:
for to do - 8:
- 9:
if and neighborInfected(i) then - 10:
Removing node i from - 11:
- 12:
end if - 13:
end for - 14:
- 15:
IC-Process(, ) - 16:
end while - 17:
IC-Process()
|
4.5. IC Model to SIR Model
In the beginning of our paper, we introduced two classical propagation models which could represent the process of virus transmission. In all of our paper, we illustrate our method on IC model. However, the SIR model is also important to the virus controlling problem, and it will be our future work to make our method adapted to this model. Now, we will show how to exchange from IC model to SIR model. It is obvious that SIR has a very complicated process that we can not easily describe, so we want to follow the analyzing process of IC model and find a right place and time to put vaccines on
. The difference between those two models is on
. In IC model, we treat
is 1, which means each infected node just has one chance to infect its neighbors. In SIR model,
, which means before the node is recovered, every infected node has a multi-chance to infect its neighbors. Here, we convert this multi-try infecting action into one-chance through calculating the entire possibility. Specially, the probability of being infected by one node is
P and after
n times trying (
) could be illustrate like
. Once being infected, it will be added to the infected set. The relation between the infected node and its neighbors can be represented as
then we just need to use
to replace
, and it will make SIR model described as IC model.
6. Related Work
The problem of node immunization has been studied for a quite long time, most of the existing works try to allocate their vaccines before they know the initially infected nodes. Wang et al. [
4,
5] and Tong et al. [
6,
7] started their works on an arbitrary graph, while Madar et al. [
41] studied this problem on complex networks, like power law graphs. Cohen et al. [
42] and A. L. Buchsbaum et al. [
43] analyzed the
acquaintance immunization method that the vaccinated nodes have the most number of degrees in their network, for the SIS model and the SIR model. Hayashi et al. [
3] described the propagation process by using SHIR (Susceptible, Hidden, Infectious, Recovered) model. Besides, Kimura et al. [
44] introduce a novel solution to minimize the spread of contamination by blocking links rather than immunize nodes. However, none of above works based on the more realistic scenario that taking the initially infected nodes into the immunization strategy.
Some more practical works have been proposed by Zhang et al. [
25] and its extending work [
26], in which immunization decisions are based on the known initially infected nodes. They formalize the vaccines placement problem as Data-Aware Vaccination problem and convert the original graph into a dominator tree to distribute all vaccines on the neighbors of the root immediately. However, they miss a major concept in these algorithms that the benefit of putting the vaccine on one node is the dynamic change. Hence, using these strategies would sacrifice a great number of healthy nodes which could have been saved by a multi-step distribution.
While DWPV employs an dynamic-like vaccines placement strategy, it significantly differs from all past approaches [
29,
45,
46] in how it defines the
dynamic. Past schemes assume the network itself is changing, and their strategies are focusing on these changes. If these changes of the network are slight, they still choose to put all vaccines on the network at once. DWPV uses a simulation-based method to estimate how the limited vaccines should be distributed over the propagation process, and the vaccines are placed in batches on the appropriate nodes and at the appropriate time. Compared with previous well studied simulation-based methods [
35], DWPV differentiates itself in the scope of simulation. DWPV simulates the transmission process just around the limited scope of these candidate nodes, and we need no more simulation once all vaccines have been placed, which reduces the computation complicity to a great extent and makes our algorithm more scalable than [
35].
Finally, even if the strategy has been made by DWPV, we will put the vaccines on the network until a neighbor of the designated node has been infected, which gives our algorithm a further protection of the stochastic propagation model as compared with [
25,
26].


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}