
A Layered Approach for Robust Spatial Virtual Human Pose Reconstruction Using a Still Image


Abstract
:1. Introduction
2. Related Work
3. Method
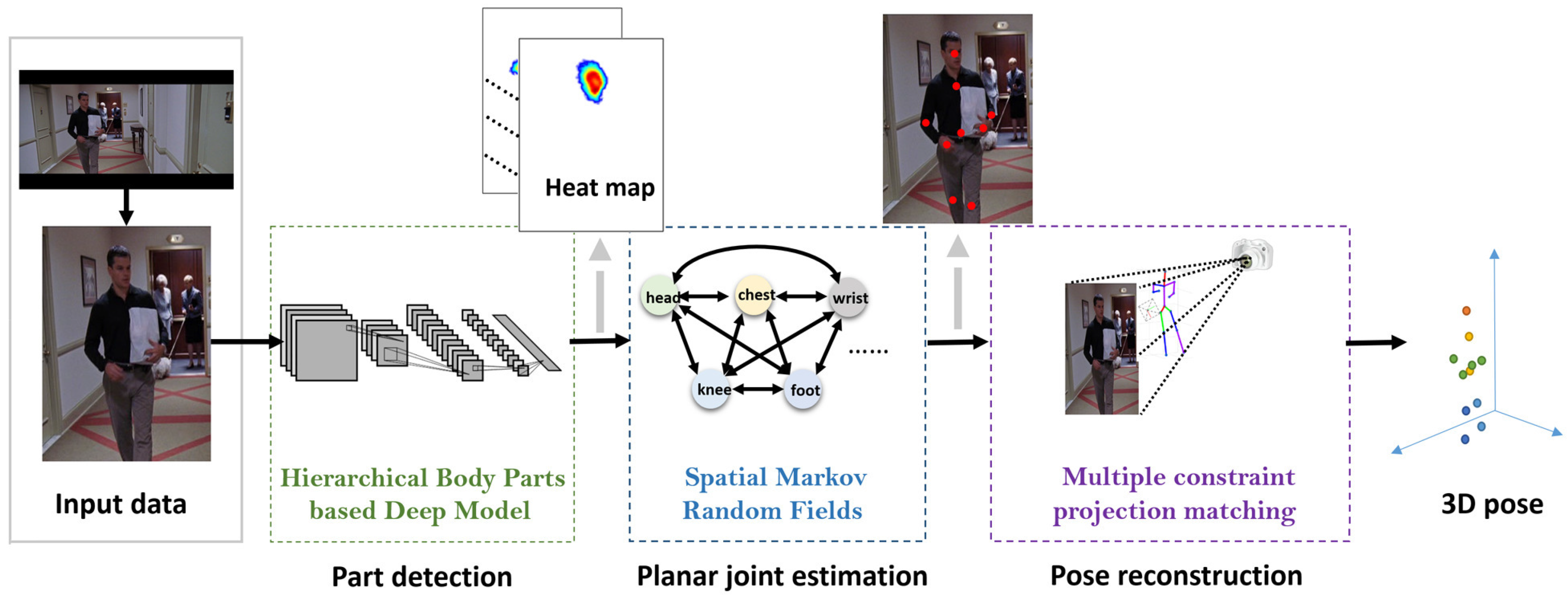
3.1. Overview
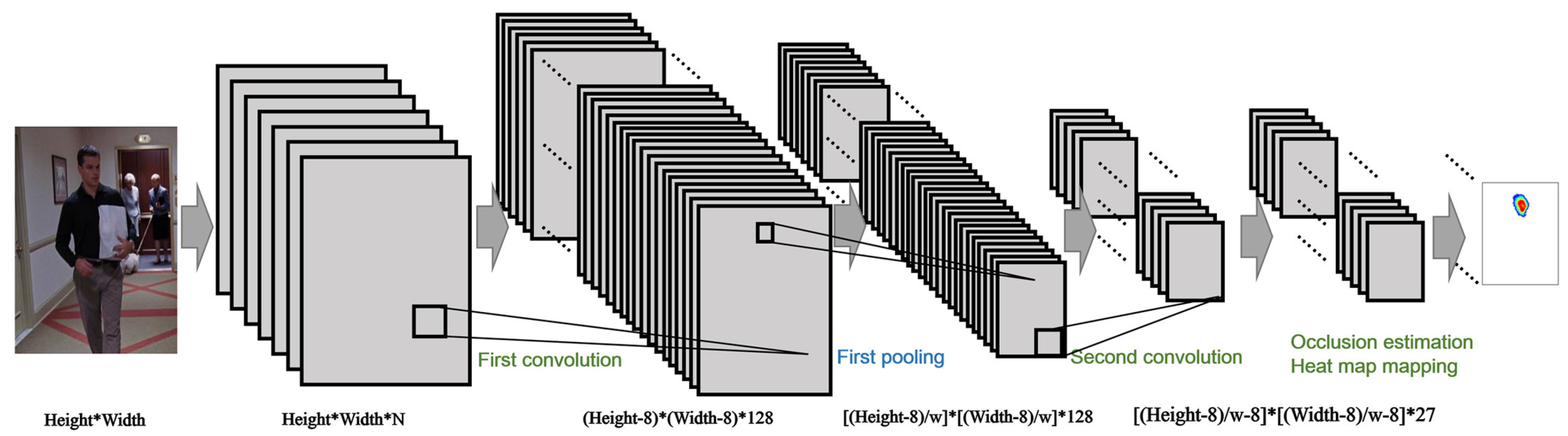
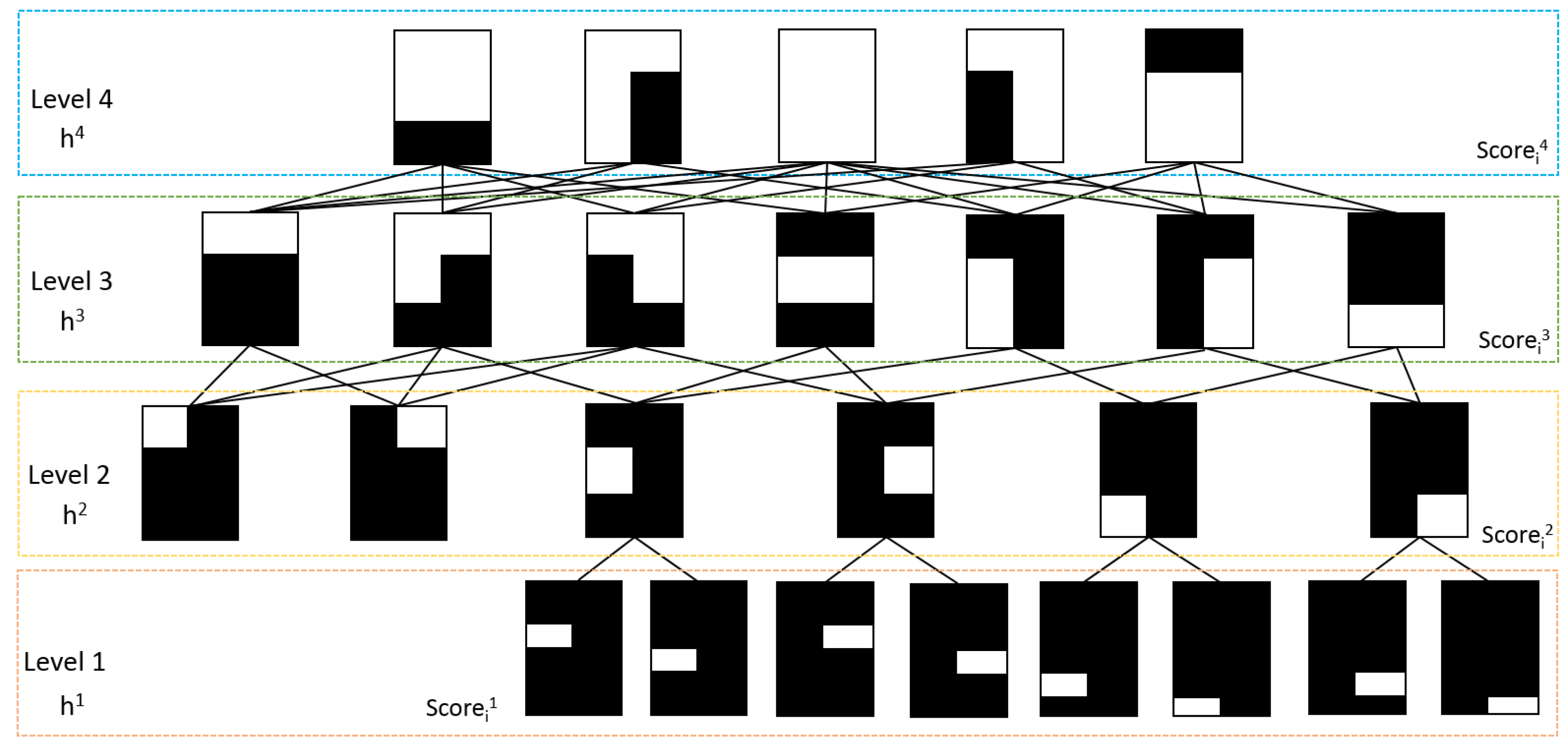
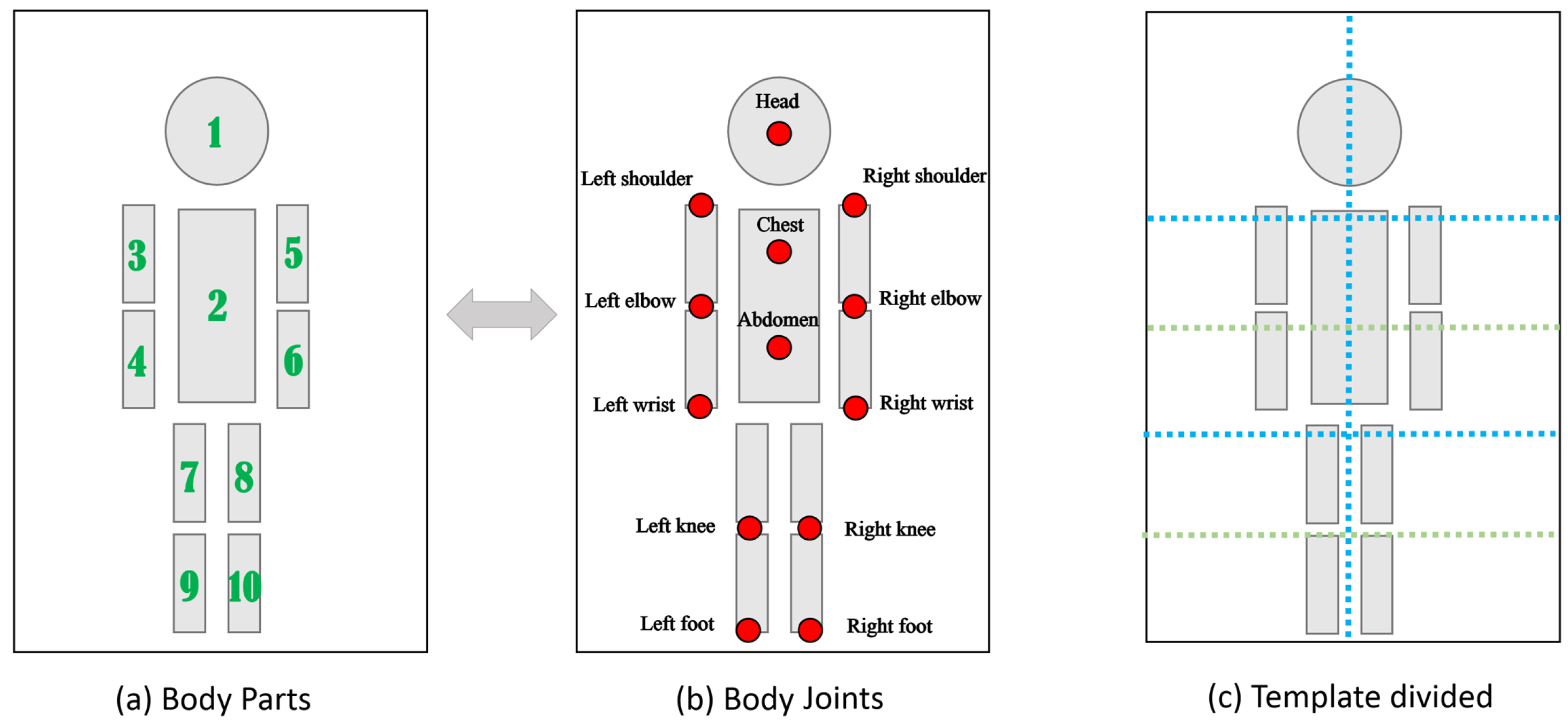
3.2. Low Level: Hierarchical Body Parts-Based Deep Model
3.3. High Level: Spatial Markov Random Fields
3.4. Spatial Level: Multiple Constraint Projection-Matching-Based Pose Reconstruction
4. Results and Discussion
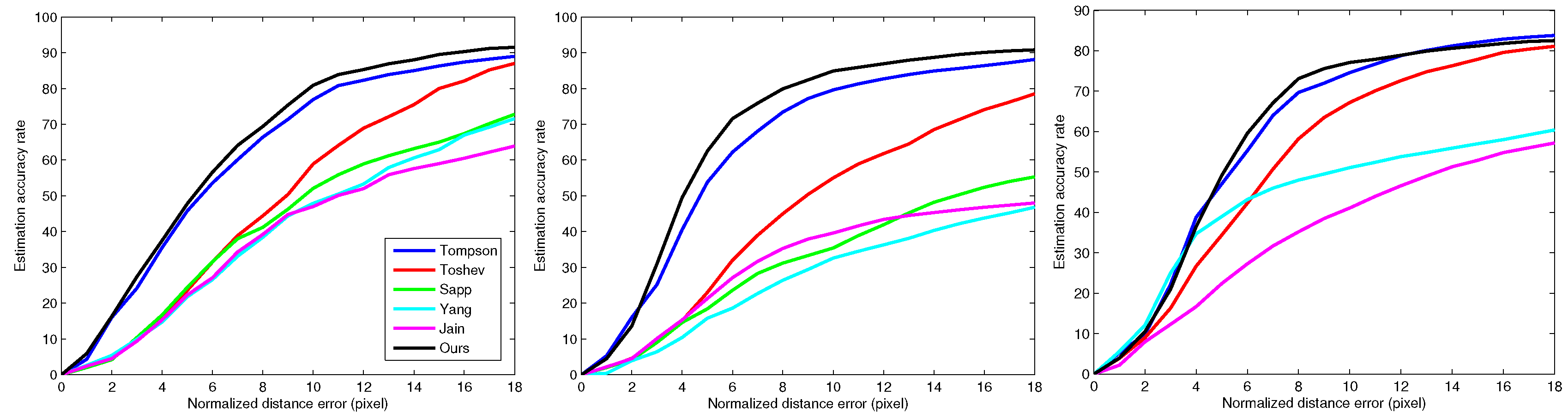
4.1. Results on Planar Body Detection and Estimation
4.2. Results on Three-Dimensional Pose Reconstruction
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ramanan, D.; Forsyth, D.A.; Zisserman, A. Tracking People by Learning their Appearance. IEEE Pattern Anal. Mach. Intell. 2007. [Google Scholar] [CrossRef]
- Sminchisescu, C.; Kanaujia, A.; Metaxas, D. Discriminative Density Propagation for Visual Tracking. IEEE Pattern Anal. Mach. Intell. 2007. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893.
- Johnson, S.; Everingham, M. Combining discriminative appearance and segmentation cues for articulated human pose estimation. In Proceedings of the 2nd IEEE international workshop on machine learning for vision-based motion analysis, Kyoto, Japan, 28–28 September 2009.
- Yang, Y.; Ramanan, D. Articulated pose estimation with flexible mixtures-of-parts. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1385–1392.
- Leonid, P.; Micha, A.; Peter, G.; Bernt, S. Strong appearance and expressive spatial models for human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013.
- Felzenszwalb, P.; Girshick, R.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Bourdev, L.D.; Malik, J. Poselets: Body part detectors trained using 3D human pose annotations. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 1365–1372.
- Rother, C.; Kolmogorov, V.; Blake, A. GrabCut: Interactive Foreground Extraction Using Iterated Graph Cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Agarwal, A.; Triggs, B. 3D human pose from silhouettes by relevance vector regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; pp. 882–888.
- Abhinav, G.; Trista, C.; Francine, C.; Don, K.; Davis, S. Context and observation driven latent variable model for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008.
- Perez-Sala, X.; Escalera, S.; Angulo, C.; Gonzalez, J. A Survey on Model Based Approaches for 2D and 3D Visual Human Pose Recovery. Sensors 2014, 14, 4189–4210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perez-Sala, X.; Escalera, S.; Angulo, C. Survey on spatio-temporal view invariant human pose recovery. In Proceedings of the 15th International Conference of the Catalan Association of Artificial Intelligence, Alicante, Spain, 24–26 October 2012; pp. 24–26.
- Sande, K.; Gevers, T.; Snoek, C. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1582–1596. [Google Scholar] [CrossRef] [PubMed]
- Barron, J.; Fleet, D.; Beauchemin, S. Performance of optical flow techniques. Int. J. Comput. Vis. 1994, 12, 43–77. [Google Scholar] [CrossRef]
- Simo-Serra, E.; Quattoni, A.; Torras, C.; Moreno-Noguer, F. A joint model for 2D and 3D pose estimation from a single image. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013.
- Dantone, M.; Gall, J.; Leistner, C.; van Gool, L. Human pose estimation using body parts dependent joint regressors. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013.
- Belagiannis, V.; Amin, S.; Andriluka, M.; Schiele, B.; Navab, N.; Ilic, S. 3D pictorial structures for multiple human pose estimation. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014.
- Toshev, A.; Szegedy, C. Deep pose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014.
- Chen, X.; Yuille, A. Articulated pose estimation by a graphical model with image dependent pairwise relations. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems, Stateline, NV, USA, 3–8 December 2012.
- Tompson, J.; Stein, M.; Lecun, Y.; Perlin, K. Real-time continuous pose recovery of human hands using convolutional networks. Acm Trans. Graph. 2014, 33, 1935–1946. [Google Scholar] [CrossRef]
- Dumitru, E.; Yoshua, B.; Aaron, C.; Pascal, V. Visualizing higher-layer features of a deep network. In Proceedings of the ICML, Montreal, QC, Canada, 14–18 June 2009.
- Jain, A.; Tompson, J.; Andriluka, M.; Taylor, G.W.; Bregler, C. Learning human pose estimation features with convolutional networks. In Proceedings of the Computer Vision and Pattern Recognition, Columbus OH, USA, 24–27 June 2014.
- Fan, J.; Wei, X.; Ying, W.; Yihong, G. Human tracking using convolutional neural networks. IEEE Trans. Neural Netw. 2010, 21, 1610–1623. [Google Scholar] [PubMed]
- Wang, K.; Wang, X.; Lin, L.; Wang, M.; Zuo, W. 3D human activity recognition with reconfigurable convolutional neural networks. In Proceedings of the ACM International Conference on Multimedia, Shanghai, China, 23–26 June 2015; pp. 97–106.
- Shuiwang, J.; Ming, Y.; Kai, Y. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar]
- Liu, K.; Skibbe, H.; Schmidt, T.; Blein, T.; Palme, K.; Brox, T.; Ronneberger, O. Rotation-invariant hog descriptors using Fourier analysis in polar and spherical coordinates. Int. J. Comput. Vis. 2014, 106, 342–364. [Google Scholar] [CrossRef]
- Giusti, A.; Ciresan, D.C.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Fast image scanning with deep max-pooling convolutional neural networks. 2013. 2004, arXiv:1302.1700. arXiv.org e-Print archive. Available online: http://arxiv.org/abs/1302.1700v1.
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; Lecun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. In Proceedings of the Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013.
- Ouyang, W.; Zeng, X.; Wang, X. Partial occlusion handling in pedestrian detection with a deep model. IEEE Trans. Circuits Syst. Video Technol. 2015. [Google Scholar] [CrossRef]
- Ouyang, W.; Wang, X. Joint deep learning for pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2056–2063.
- Mikolajczyk, K.; Leibe, B.; Schiele, B. Multiple object class detection with a generative model. In Proceedings of the Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006.
- Sigal, L.; Black, M.J. Humaneva: Synchronized video and motion capture dataset for evaluation of articulated human motion. Available online: http://humaneva.is.tue.mpg.de/ (accessed on 18 Devember 2015).
- Wang, C.; Wang, Y.; Lin, Z.; Yuille, A.L.; Gao, W. Robust estimation of 3D human poses from a single image. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2369–2376.
- Safonova, A.; Hodgins, J.K.; Pollard, N.S. Synthesizing physically realistic human motion in low-dimensional, behavior-specific spaces. ACM Trans. Graph. 2004, 23, 514–521. [Google Scholar] [CrossRef]
- He, Z.; Liang, X.; Wang, J.; Zhao, Q.; Guo, C. Flexible editing of human motion by three-way decomposition. Comput. Anim. Virtual Worlds 2014, 25, 57–68. [Google Scholar] [CrossRef]
- Guo, C.; Ruan, S.; Liang, X. Synthesis and editing of human motion with generative human motion model. In Proceedings of the International Conference on Virtual Reality and Visualization, Xiamen, China, 17–18 October 2015; pp. 1–4.
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: an evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Ramanan, D. Learning to parse images of articulated bodies. In Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, December 4–7 2006.
- Sapp, B.; Taskar, B. MODEC: Multimodal decomposable models for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013; pp. 3674–3681.
- CMU Human Motion Capture Database. Available online: http://mocap.cs.cmu.edu/search.html (accessed on 18 December 2015).
- Viola, P.; Jones, M. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Walk, S.; Majer, N.; Schindler, K.; Schiele, B. New features and insights for pedestrian detection. In Proceedings of the Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010.
- Ouyang, W.; Wang, X. A Discriminative deep model for pedestrian detection with occlusion handling. In Proceedings of the Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012.
- Ouyang, W.; Zeng, X.; Wang, X. Modeling mutual visibility relationship with a deep model in pedestrian detection. In Proceedings of the Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013.
- DollSar, P.; Tu, Z.; Perona, P.; Belongie, S. Integral channel features. In Proceedings of the British Machine Vision Conference, London, UK, 7–10 September 2009.
- DollSar, P.; Appel, R.; Belongie, S.; Perona, P. Fast feature pyramids for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014. [Google Scholar] [CrossRef]
- Tompson, J.; Jain, A.; Lecun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1799–1807.
- Daubney, B.; Xie, X. Tracking 3D human pose with large root node uncertainty. In Proceedings of the Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1321–1328.
- Simo-Serra, E.; Ramisa, A.; Aleny’a, G.; Torras, C.; Moreno-Noguer, F. Single image 3D human pose estimation from noisy observations. In Proceedings of the Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Occlusion Level | VJ | HOG | MFTr + CSS | MFTr + Mot | DBN-Mut | DBN-Isol | ChnFtrs | ACF | Our Methods |
|---|---|---|---|---|---|---|---|---|---|
| Overall | 99% | 90% | 81% | 78% | 82% | 84% | 81% | 81% | 80% |
| No occlusion | 96% | 72% | 58% | 51% | 58% | 62% | 60% | 60% | 57% |
| Partial occlusion | 98% | 92% | 83% | 78% | 81% | 81% | 77% | 79% | 76% |
| Heavy occlusion | 99% | 97% | 94% | 92% | 93% | 93% | 95% | 96% | 92% |
| Methods | Walk (S1) | Walk (S2) | Walk (S3) | Jog (S1) | Jog (S2) | Jog (S3) |
|---|---|---|---|---|---|---|
| SIRPF | 105.1 | 105.2 | 120.7 | – | – | – |
| Daubney [51] | 89.3 | 108.7 | 113.5 | – | – | – |
| Simo-Serra [52] | 99.6 | 108.3 | 127.4 | 109.2 | 93.1 | 115.8 |
| Wang [36] | 71.9 | 75.7 | 85.3 | 62.6 | 77.7 | 54.4 |
| Our framework | 68.8 | 69.9 | 82.6 | 59.1 | 70.4 | 50.8 |
| Condition | Walk (S1) | Walk (S2) | Walk (S3) | Jog (S1) | Jog (S2) | Jog (S3) |
|---|---|---|---|---|---|---|
| Random initial pose | 72.1 | 113.3 | 105.4 | 135.5 | 81.3 | 81.0 |
| Artificial specified initial pose | 70.4 | 69.2 | 82.6 | 58.7 | 69.1 | 52.4 |
| Constraints without human engineering | 90.1 | 93.3 | 102.4 | 75.5 | 89.3 | 76.1 |
| Constraints without occlusion | 70.6 | 70.1 | 83.0 | 60.1 | 75.6 | 53.2 |
| Our framework | 68.8 | 69.9 | 82.6 | 59.1 | 70.4 | 50.8 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, C.; Ruan, S.; Liang, X.; Zhao, Q. A Layered Approach for Robust Spatial Virtual Human Pose Reconstruction Using a Still Image. Sensors 2016, 16, 263. https://doi.org/10.3390/s16020263
Guo C, Ruan S, Liang X, Zhao Q. A Layered Approach for Robust Spatial Virtual Human Pose Reconstruction Using a Still Image. Sensors. 2016; 16(2):263. https://doi.org/10.3390/s16020263
Chicago/Turabian StyleGuo, Chengyu, Songsong Ruan, Xiaohui Liang, and Qinping Zhao. 2016. "A Layered Approach for Robust Spatial Virtual Human Pose Reconstruction Using a Still Image" Sensors 16, no. 2: 263. https://doi.org/10.3390/s16020263
APA StyleGuo, C., Ruan, S., Liang, X., & Zhao, Q. (2016). A Layered Approach for Robust Spatial Virtual Human Pose Reconstruction Using a Still Image. Sensors, 16(2), 263. https://doi.org/10.3390/s16020263