DISPAQ: Distributed Profitable-Area Query from Big Taxi Trip Data †


Abstract
:1. Introduction
- We proposed a distributed profitable-area query process system, called DISPAQ, for huge volumes of taxi trip data. The main goal of DISPAQ is to provide valuable profitable area information to users, which is one of main activities of data science.
- To quickly retrieve candidate profitable areas, DISPAQ organizes multiple factors about a profitable area into a spatial-temporal index called PQ-index. We define and extract multiple factors from the raw taxi trip dataset collected GPS sensors.
- DISPAQ executes an efficient Z-skyline algorithm to refine candidate profitable areas. The Z-skyline algorithm could reduce unnecessary dominance tests and avoid pairwise dominant tests. The Z-skyline approach is implemented as a distributed algorithm to manage big taxi trip data.
- We propose an optimized method for distributed Z-Skyline query processing by sending killer areas to each node, which maximizes the filtering of dominated areas.
- We conduct extensive experiments on a large scale two real datasets from New York City and Chicago to determine the efficiency and effectiveness of DISPAQ. We compared our Z-Skyline query processing method with two basic skyline methods (block-nested looping and divide-and-conquer) in a distributed approach. The experimental results show that our approach outperforms the existing methods.
2. Related Work
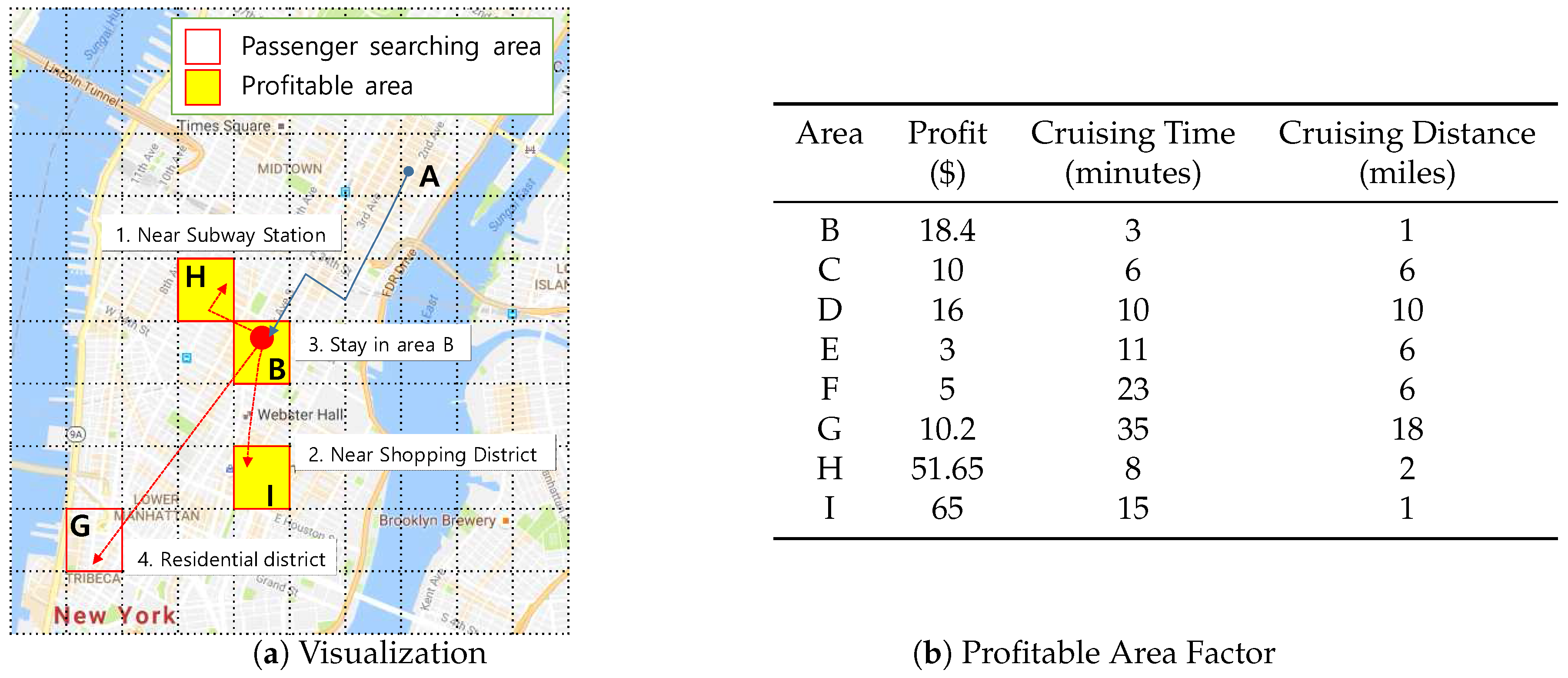
2.1. Taxi Passenger Searching Strategies
2.2. Taxi Information Data Structure
2.3. Distributed Skyline Query Processing
3. Preliminaries
3.1. Notations
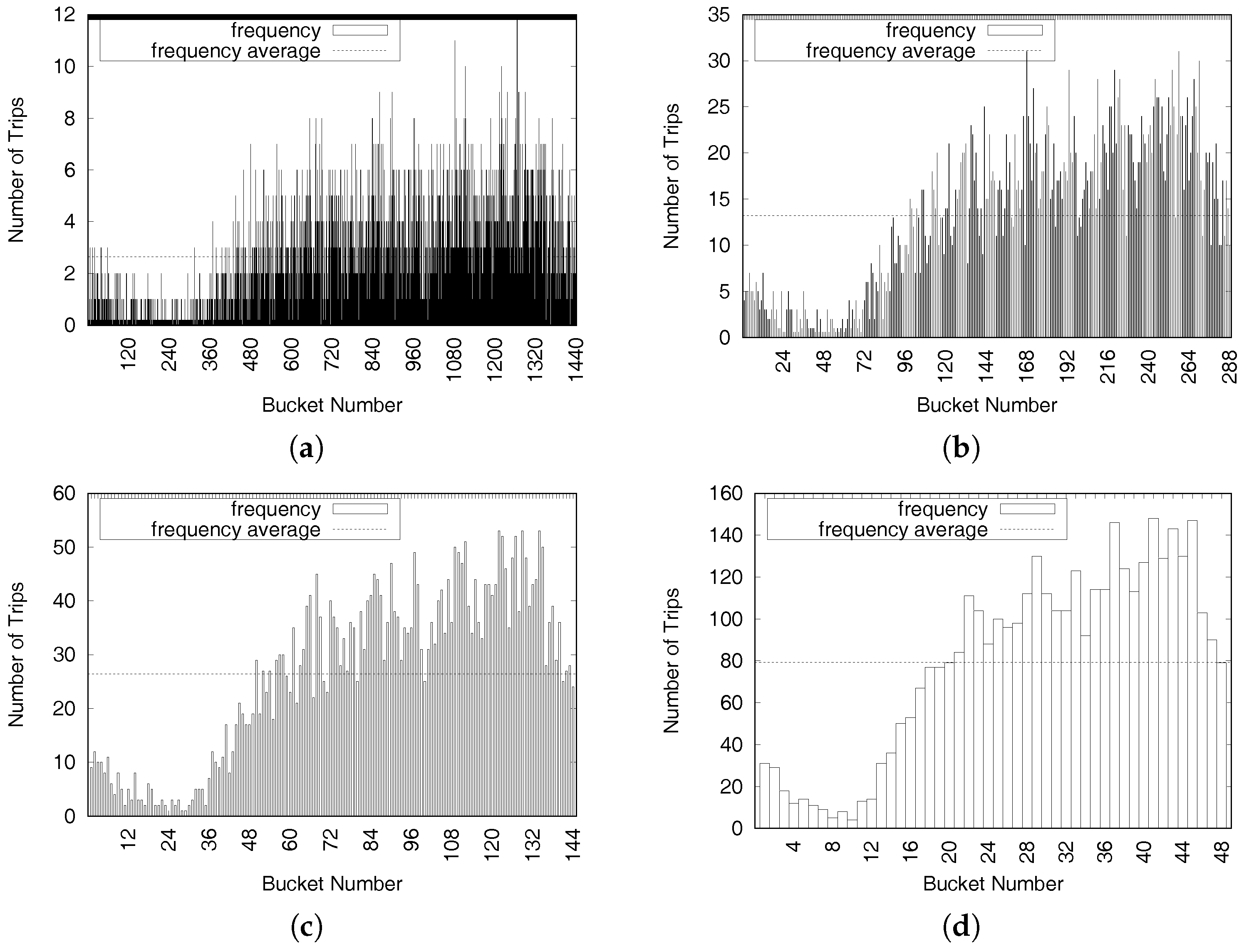
3.2. Taxi Trip Data
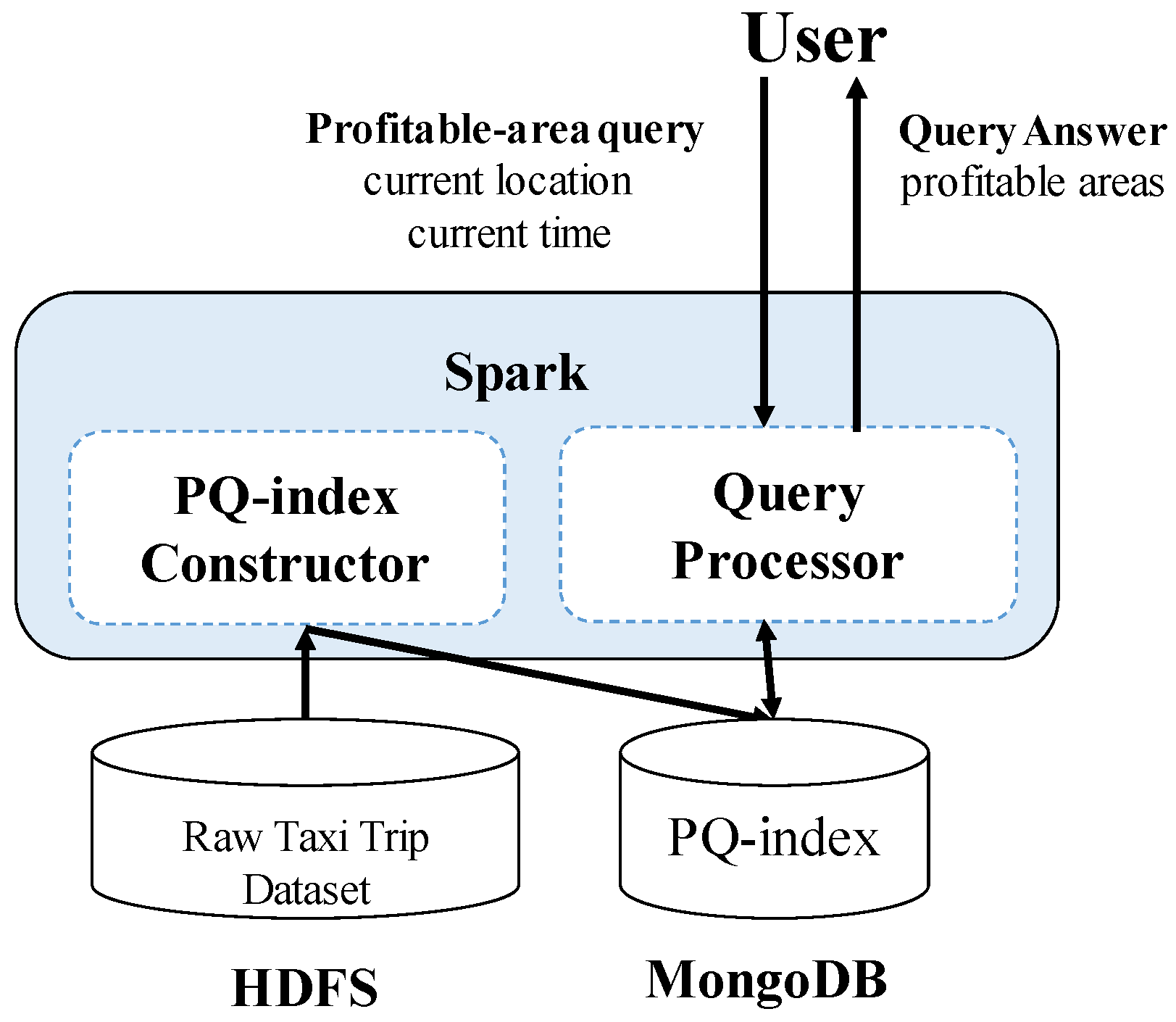
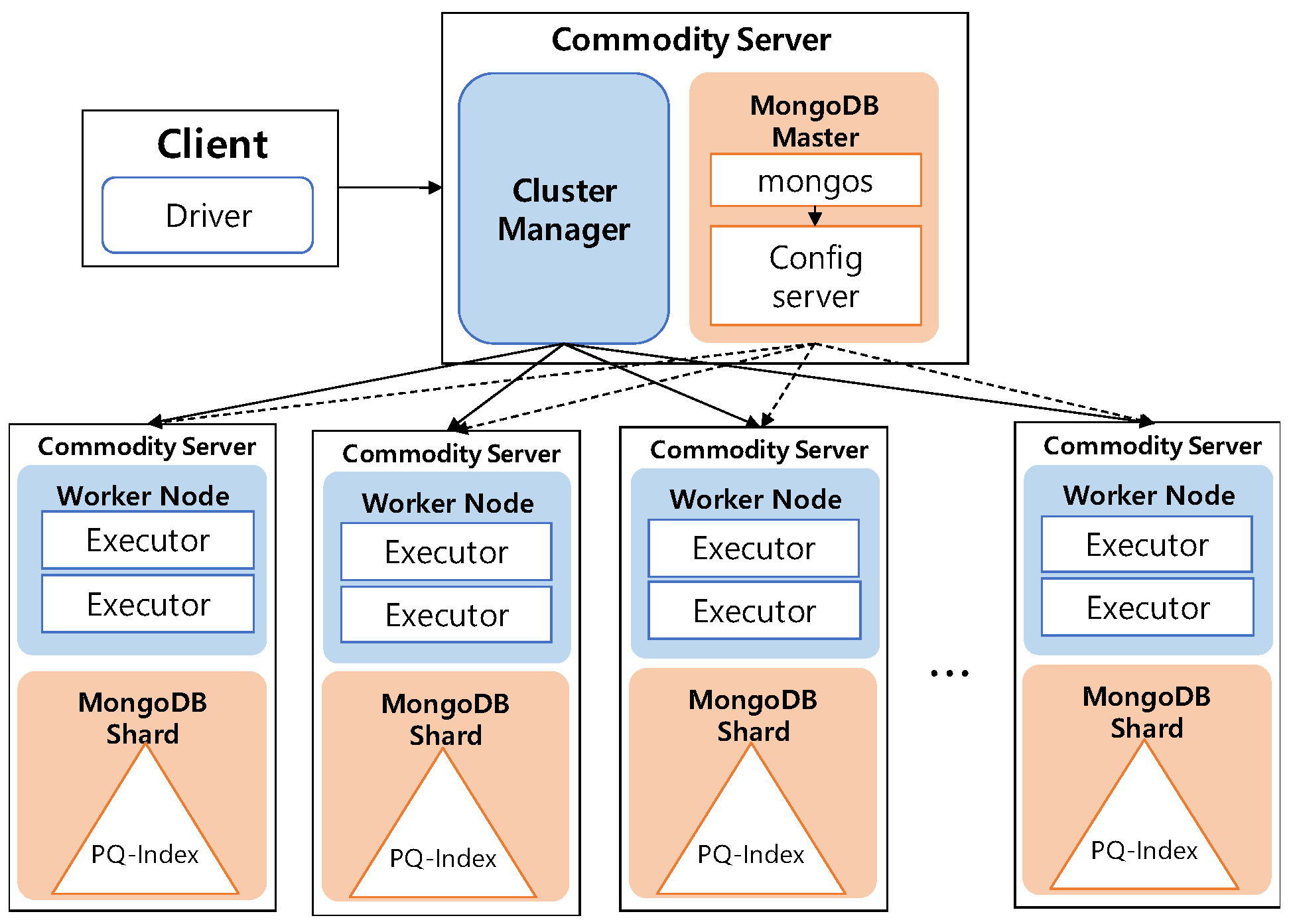
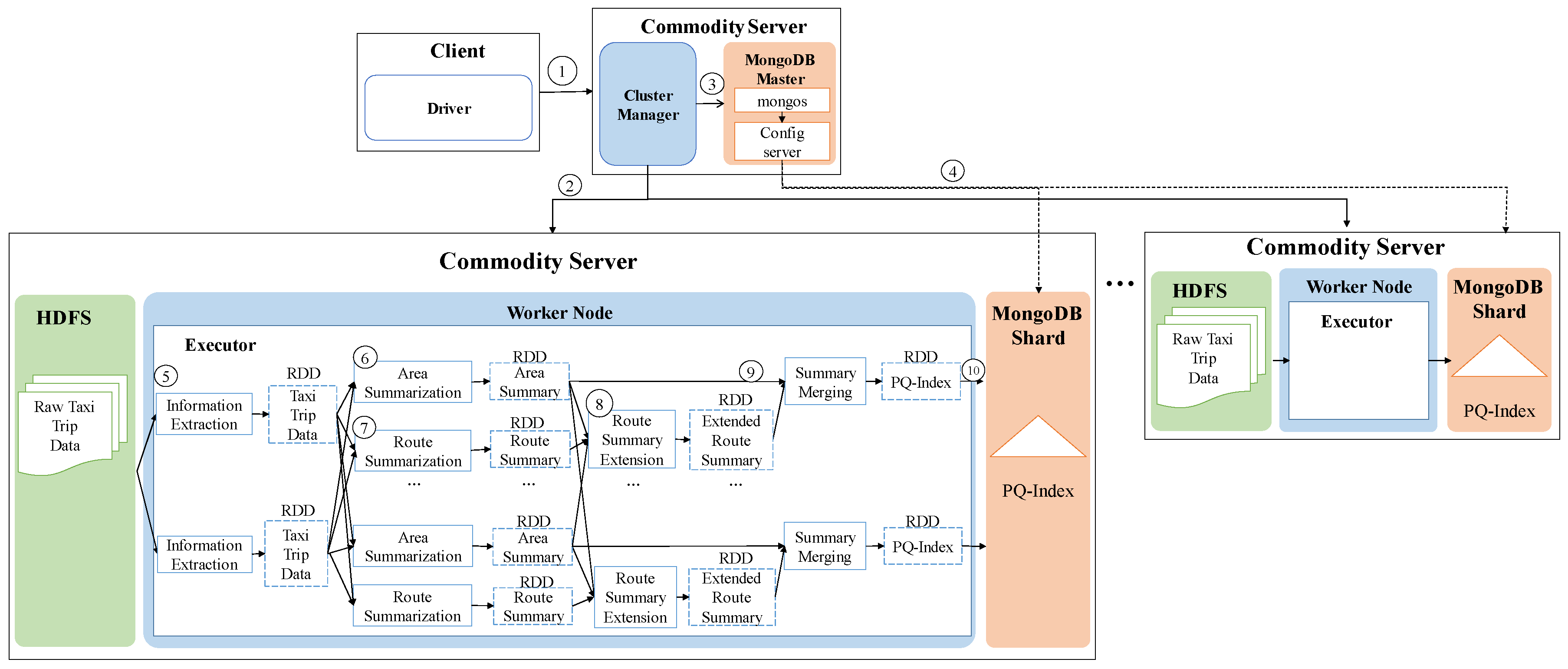
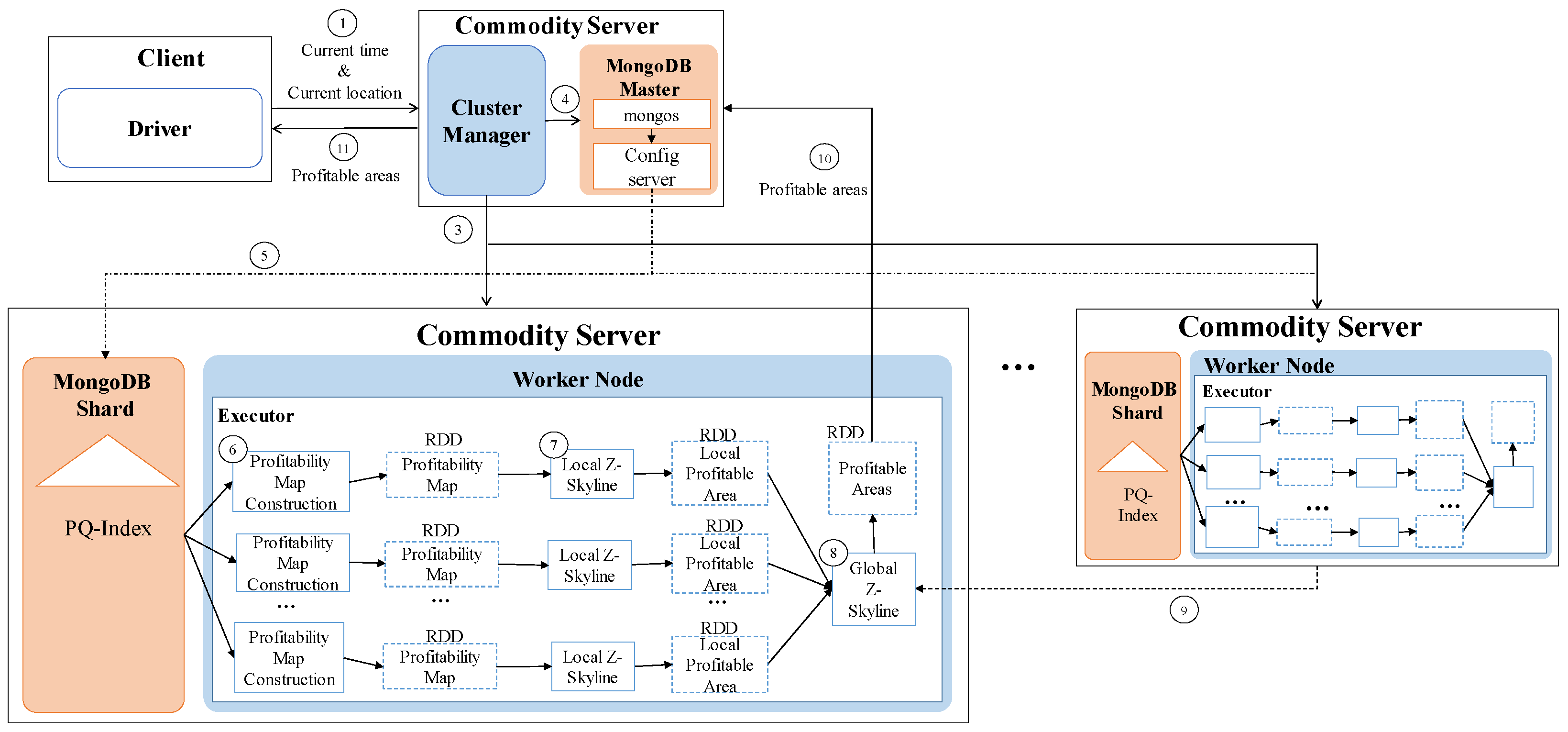
3.3. Architecture Overview
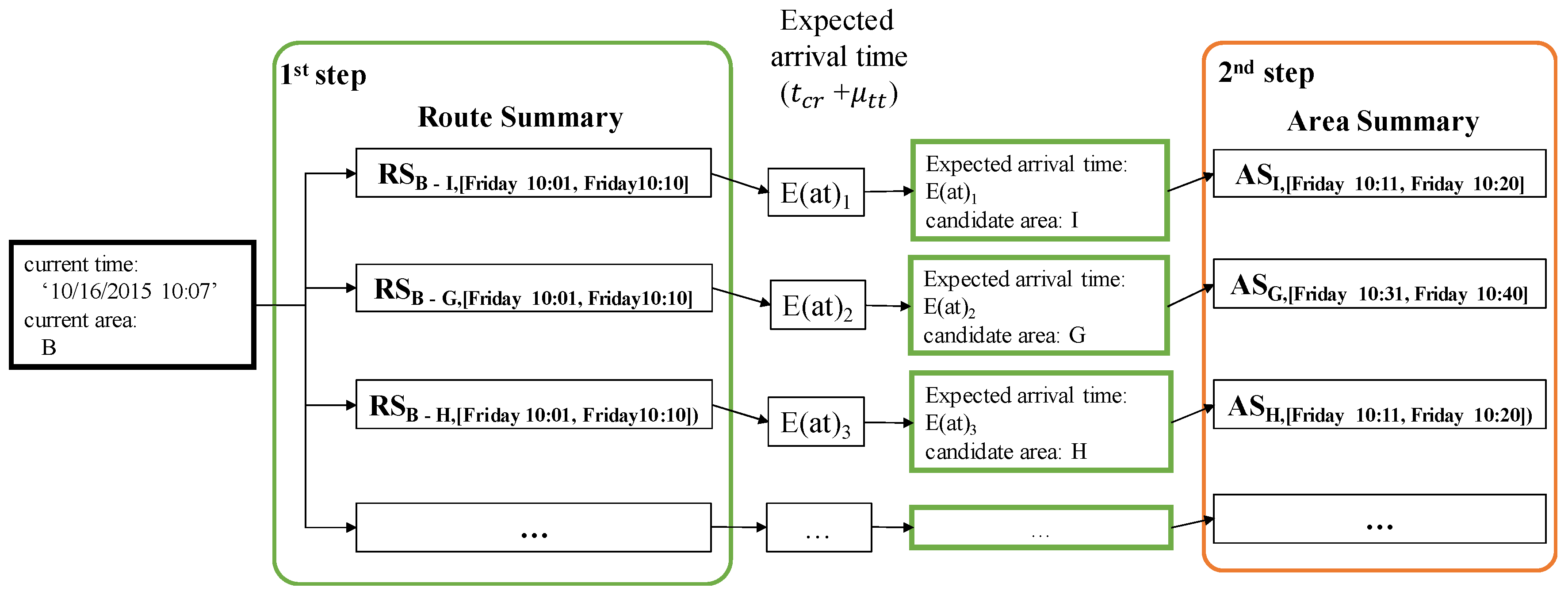
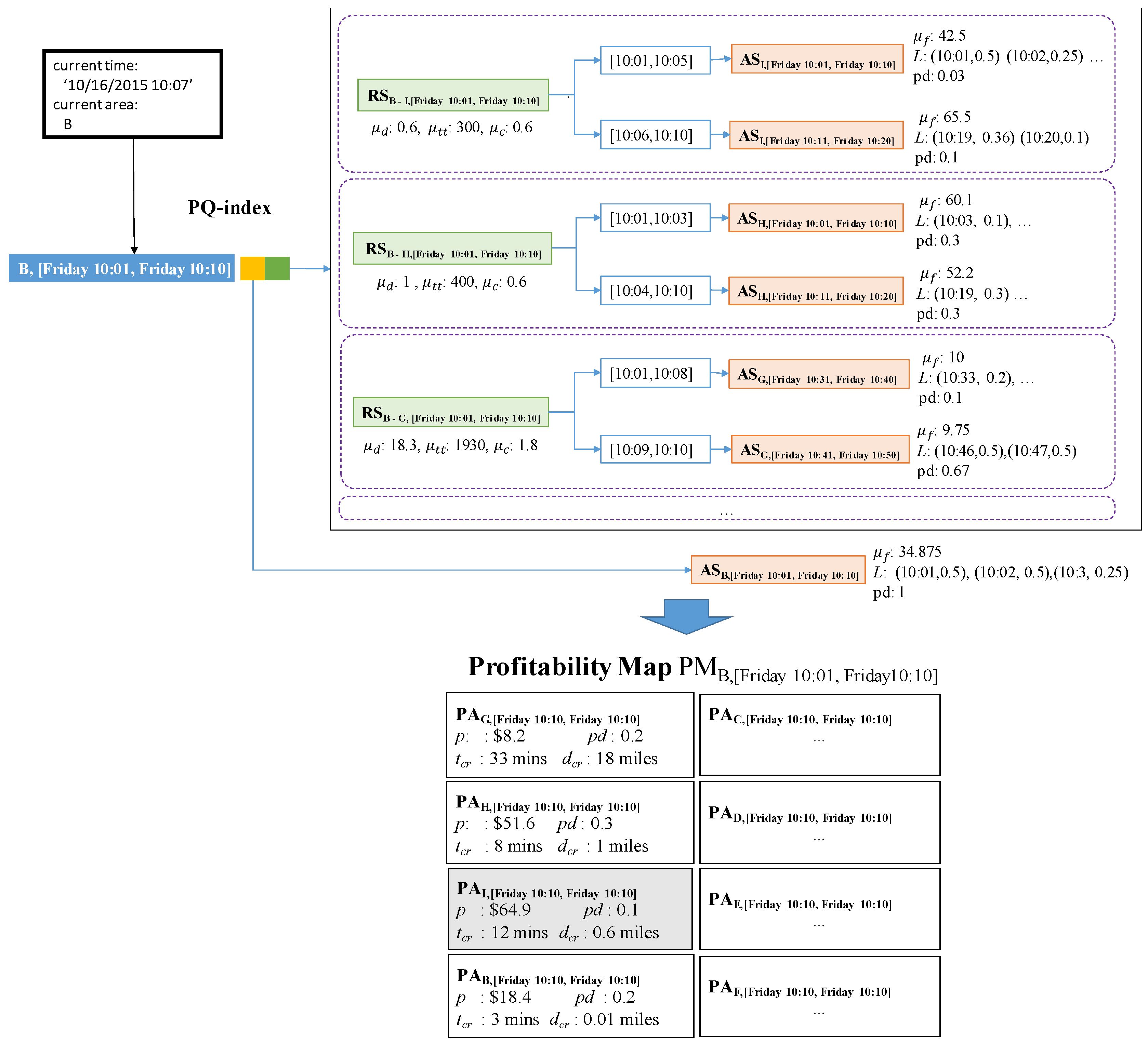
4. Constructing a Profitable Area Query Index
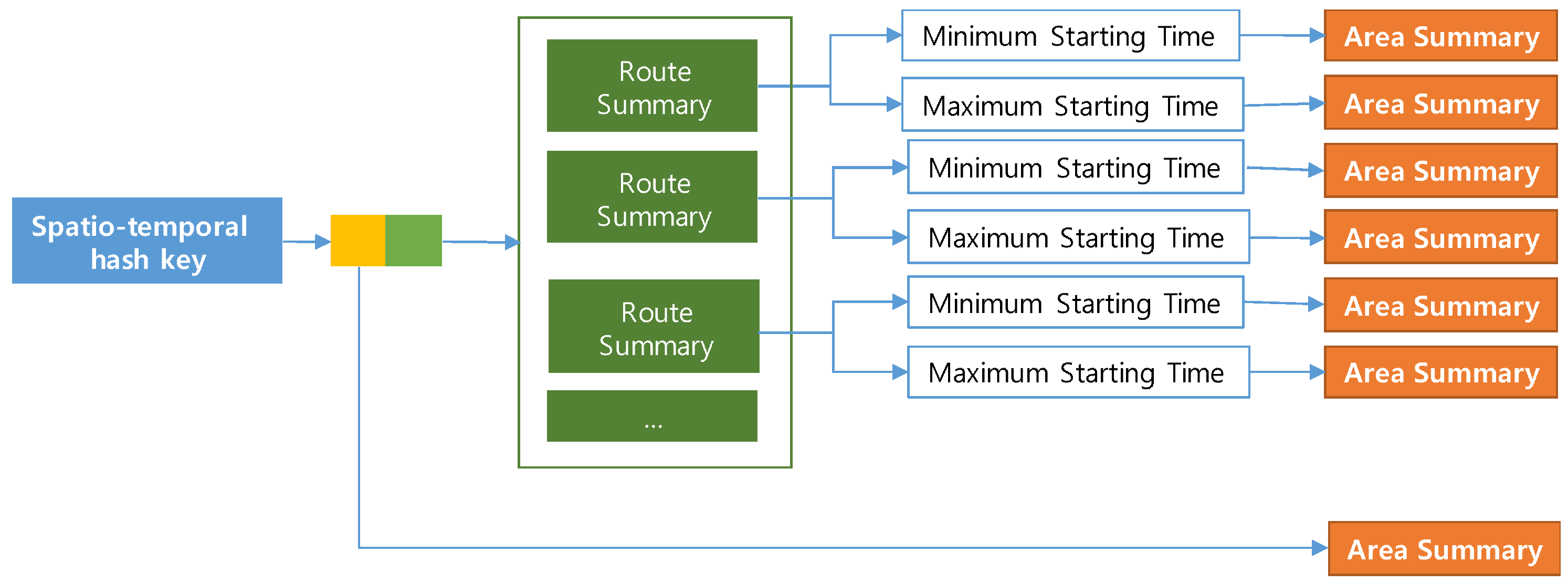
4.1. Components of the PQ-Index
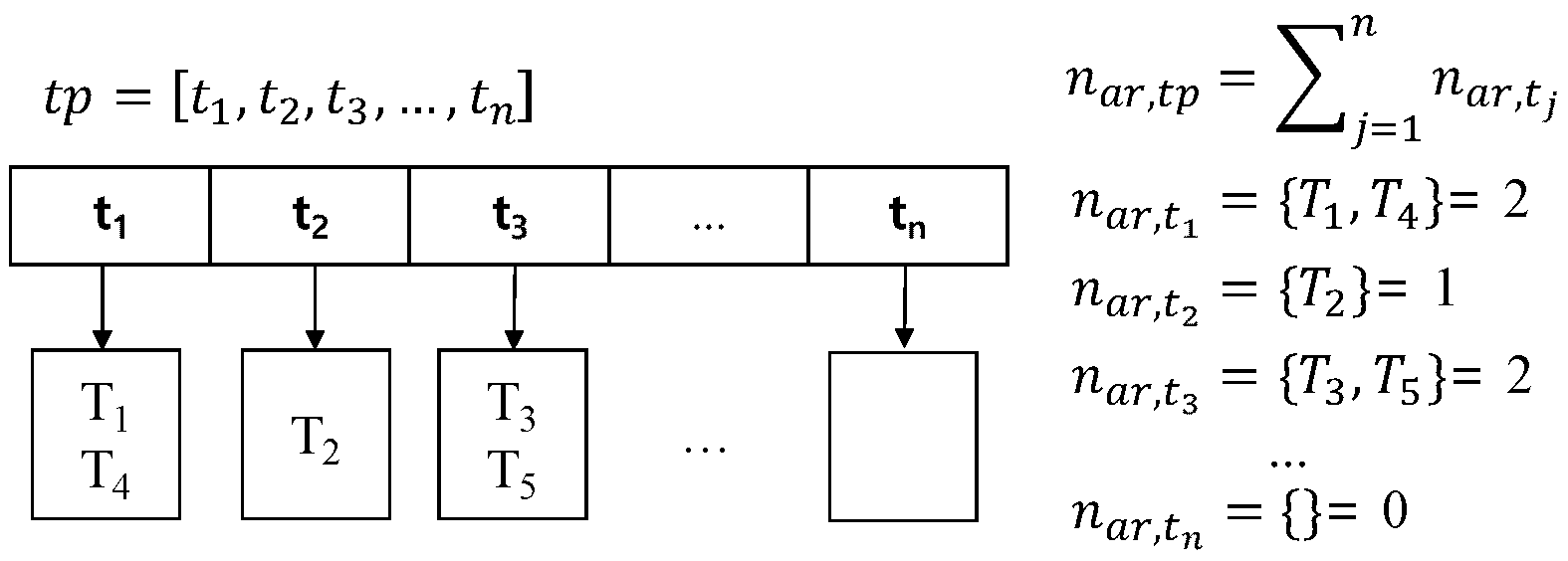
4.1.1. Spatio-Temporal Hash-Key Definition
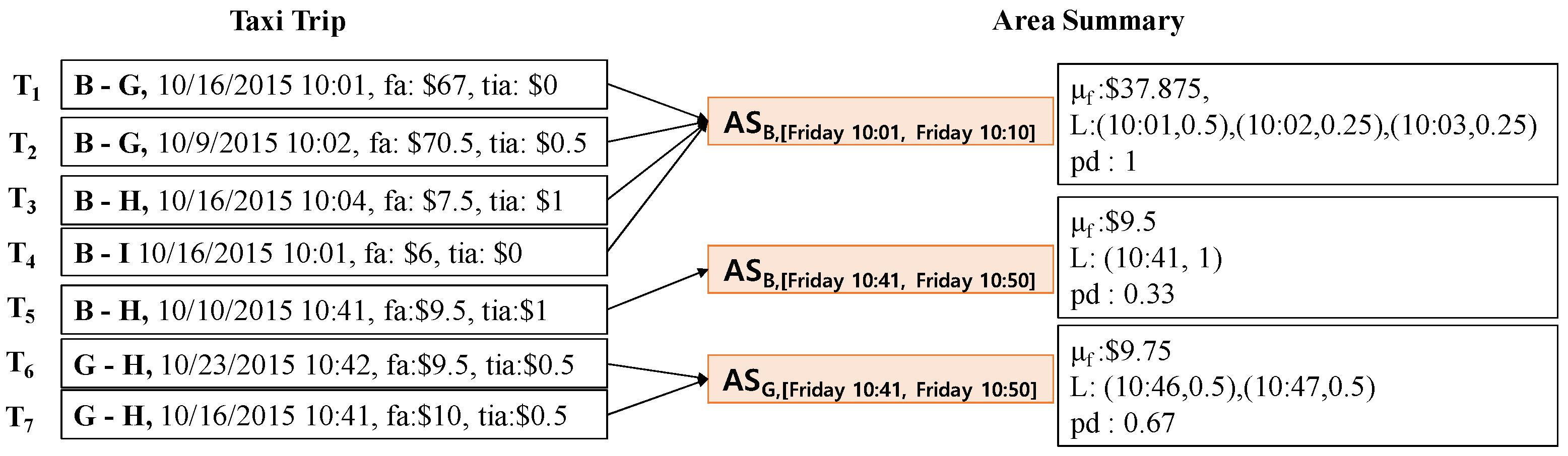
4.1.2. Area Summary
- = ((67 + 0) + (70.5 + 0.5) + (7.5 + 1) + (6 + 0))/4 = $37.875
- = {(10:01, ), (10:02, ), (10:03, )}= {(10:01, 0.5), (10:02, 0.25), (10:03, 0.25)}
- = 4/4 = 1
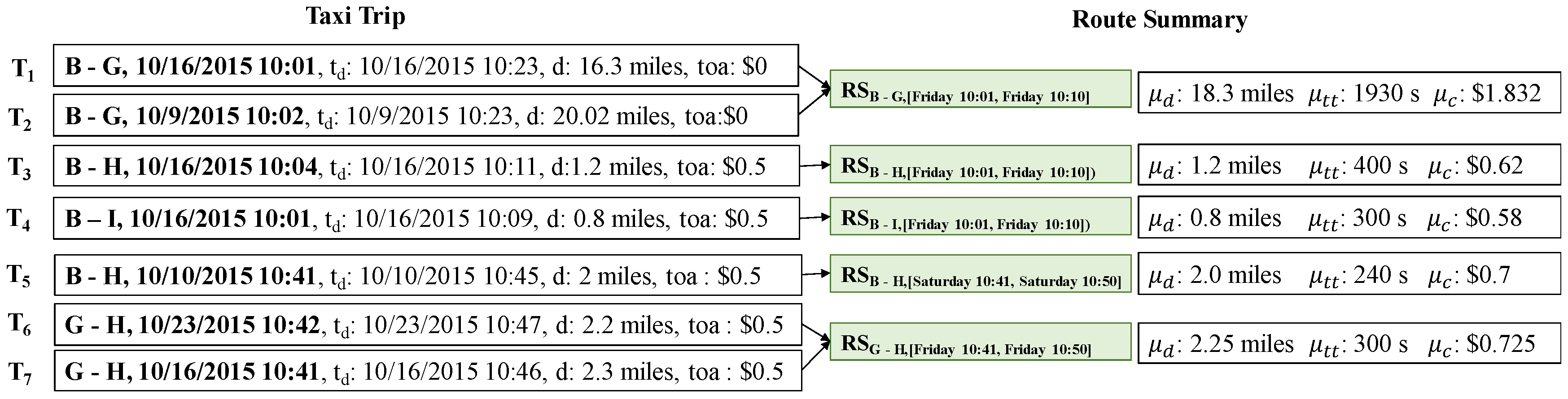
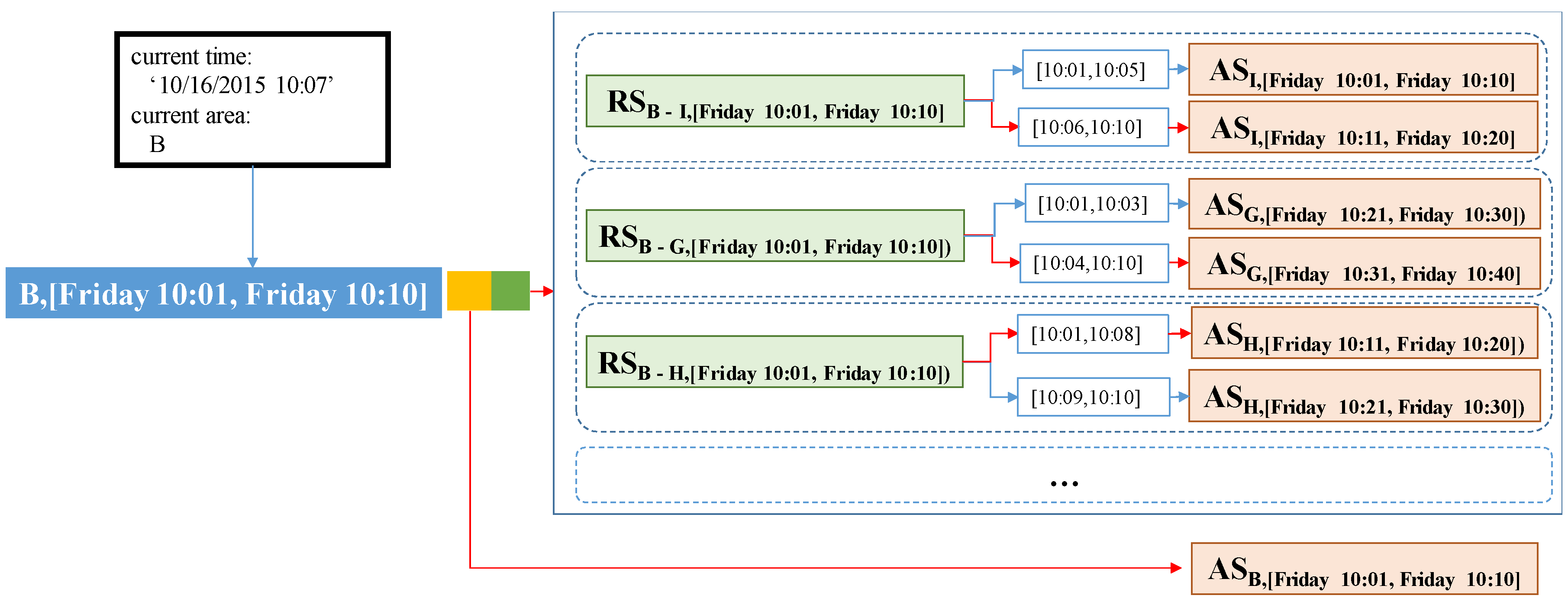
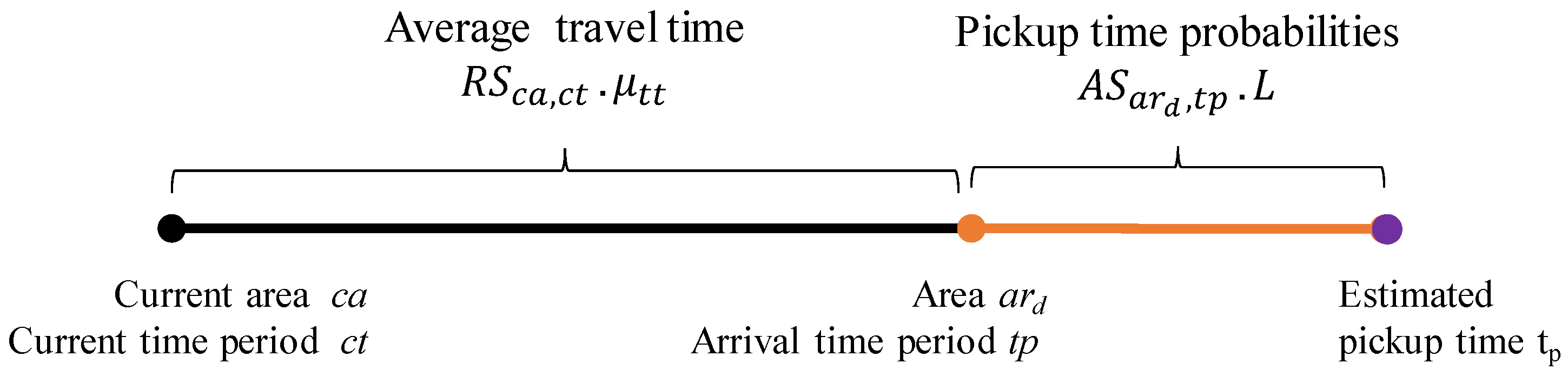
4.1.3. Route Summary Calculation
- = ((16.63 + 20.02)/2 = 18.325 miles
- = (2214 + 1654)/2 = 1934 s
- = ((0 + 1.663) + (0 + 2.002))/2 = $1.8325
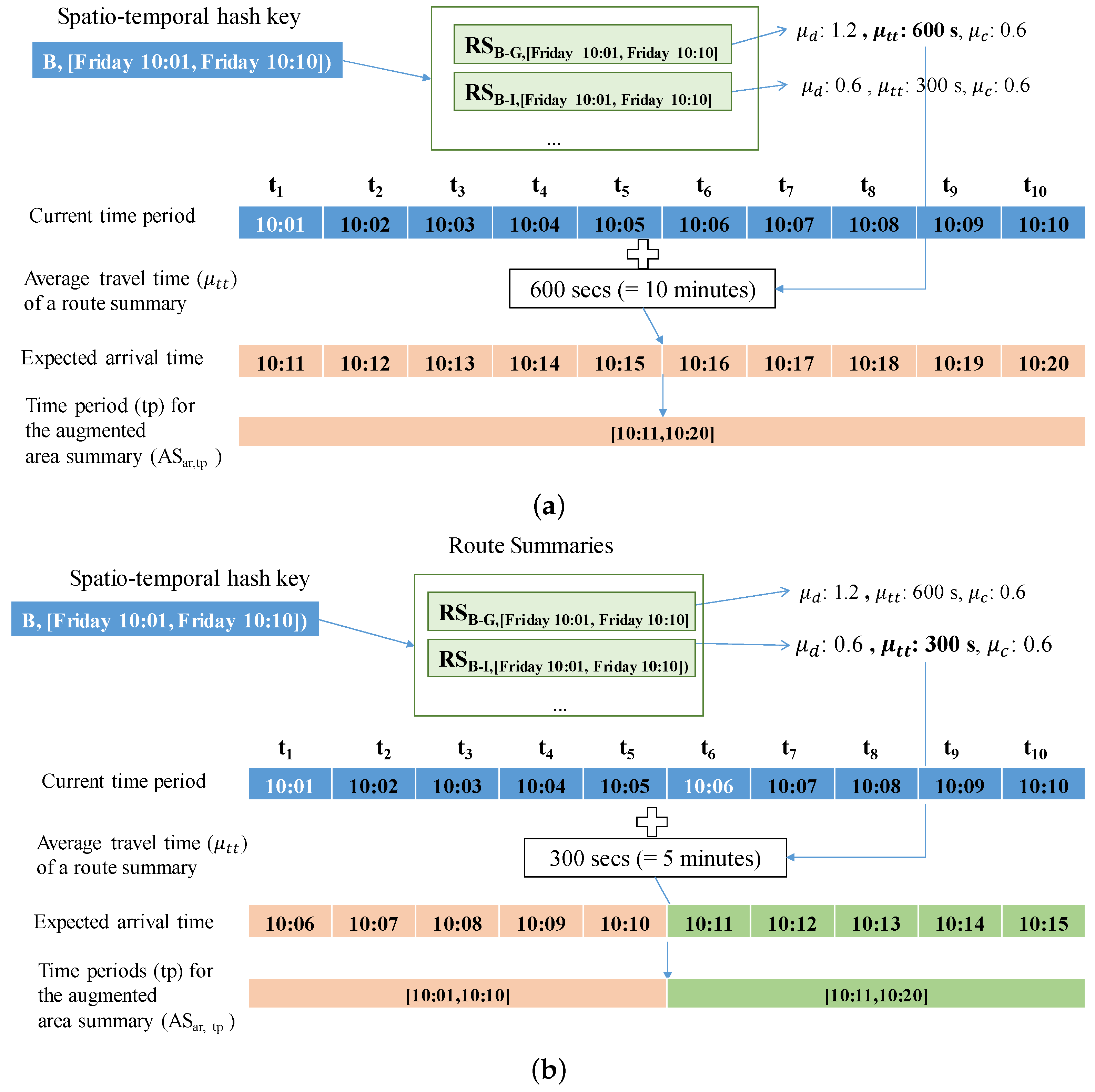
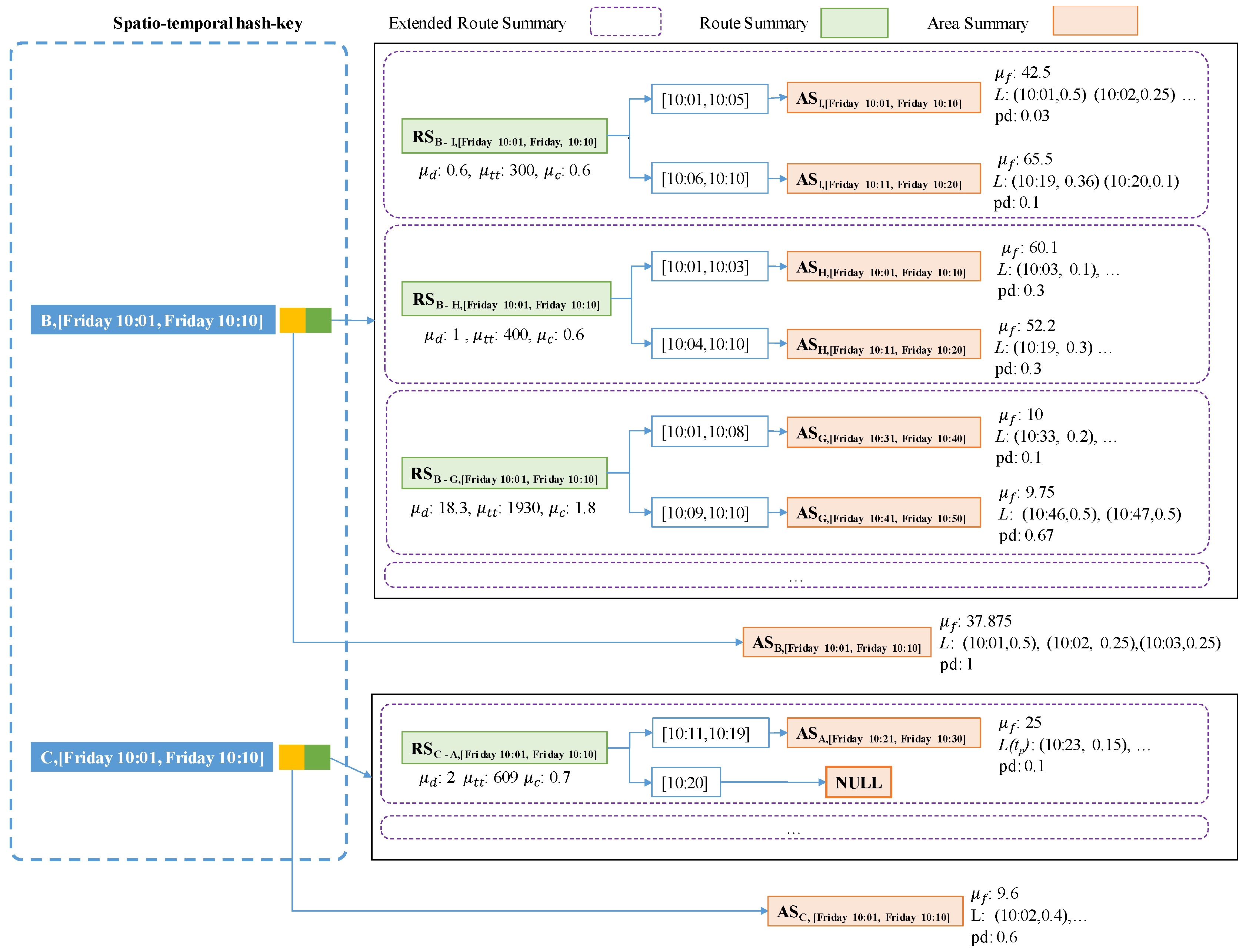
4.1.4. Extended Route Summary
4.1.5. Overall Design of a PQ-Index
4.2. Distributed PQ-Index Construction
| Algorithm 1: Distributed PQ-index Construction |
|
Input: Set of taxi trips T Output: PQ-index // information extraction 1: Taxi trip information ←(T); // grouping by area or route 2: Initialize as a tuple of (pair (,), a list of taxi trip information); 3: Initialize as a tuple of (pair (,), a list of taxi trip information); 4: ← (); 5: ← (); // construct basic summaries 6: Initialize for an area summary; 7: Initialize for a route summary; 8: ← (); // Algorithm 2 9: ← (); // Algorithm 3 // PQ-index construction 10: An extended route summary ← (); // Algorithm 4 11: ← (,); 12: return ; |
| Algorithm 2: Build an Area Summary |
|
Input: : a tuple (, L), where is a pair (area, time period) and L is a list of taxi information Output: : a pair (spatio-temporal hash-key , an area summary ) 1 Initialize as Area Summary; // calculate area summary value 2 ← ; 3 is calculated from each group of ; // Equation (2) 4 is computed from each group of ; // Equation (3) 5 is calculated from each group of ; // Equation (4) 6 ← pair(,); 7 return ; |
| Algorithm 3: Build a Route Summary |
|
Input: : a tuple (, L), where is the pair (route, time period) and L is a list of taxi information Output: : a tuple (a pair (ar, tp), area, first time period, second time period, a route summary) 1 Initialize as a route summary; // compute elements of a route summary 2 ← ; 3 is calculated from each group ; // Equation (5) 4 is computed from ; // Equation (6) 5 is calculated from ; // Equation (7) 6 a destination area ←; 7 an origin area ←; // compute two time intervals: and 8 ArrivalTimeMapping (, , ); // make an RSP with time invtervals for the extension 9 a spatio-temporal hashkey ← a pair of (, ); 10 ← a tuple of (, , , , ); 11 return ; |
| Algorithm 4: Build an Extended Route Summary |
|
Input: : tuple (key k, area , first time period , second time period , route summary ) Output: : pair (spatio-temporal hash-key , Extended Route Summary ) 1 Initialize as Extended Route Summary; // Assign a route summary 2 ← ; 3 ← ; 4 ← ; // augmenting a route summary with area summries 5 ← GetAreaSummary , ; 6 ← GetAreaSummary , ; // combine a spatio-temporal hashkey with an extended route summary 7 ← a pair of (, ); 8 return ; |
4.3. Complexity Analysis of PQ-Index Construction
5. Processing Profitable-Area Query
5.1. Profitable-Area Query
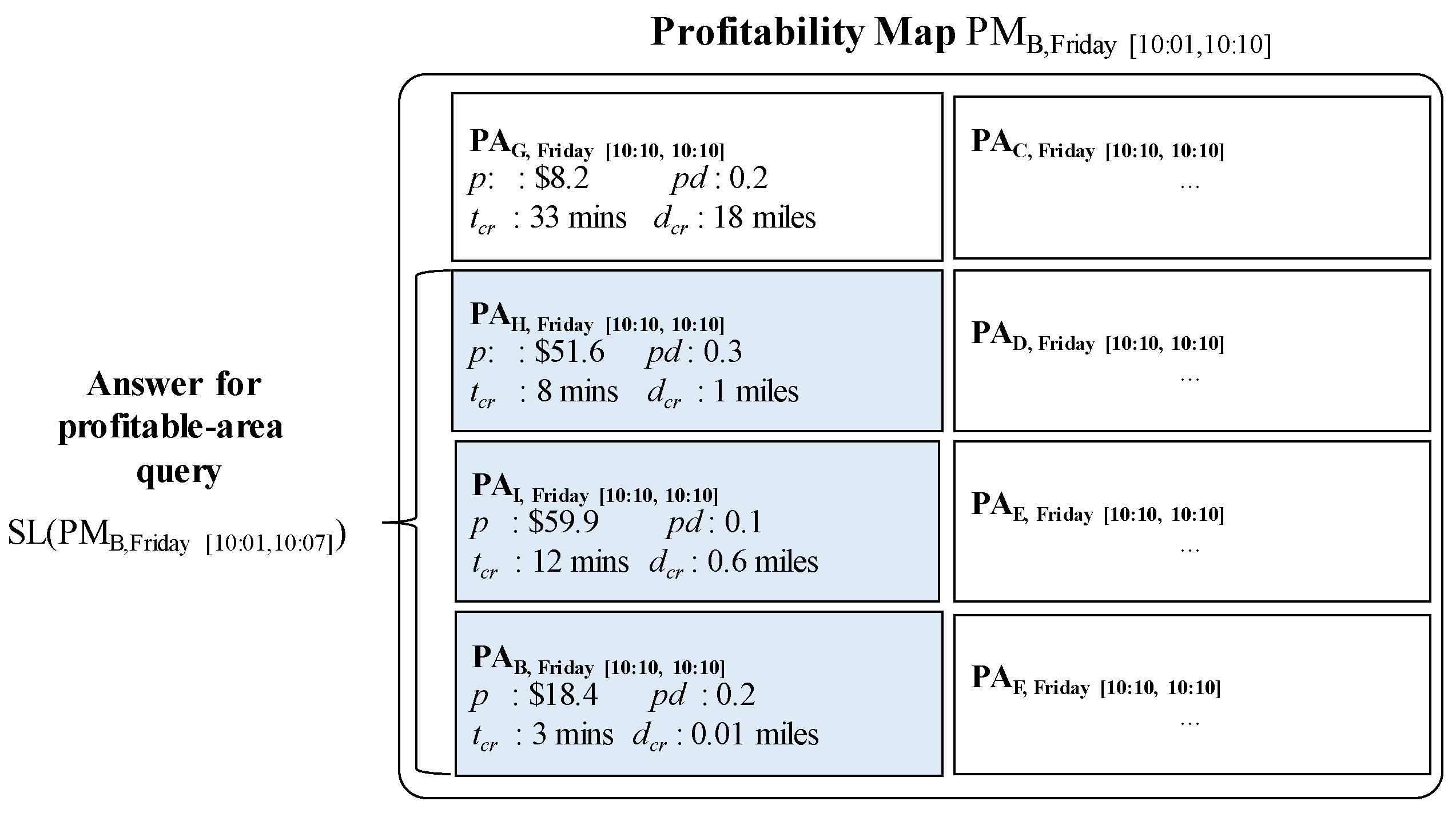
5.2. Retrieving Candidate Profitable Areas into a Profitability Map
5.3. Refining Candidate Profitable Areas
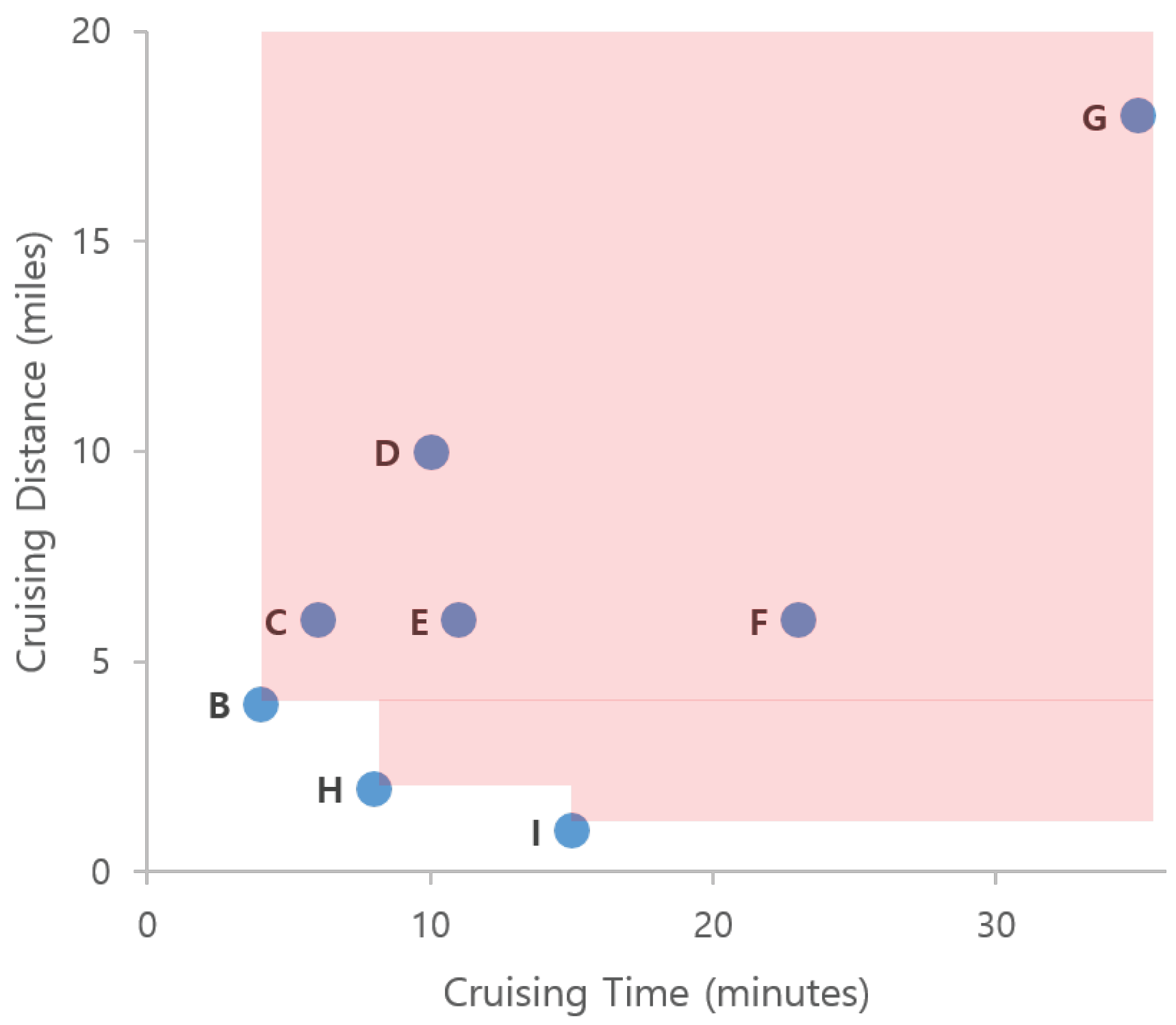
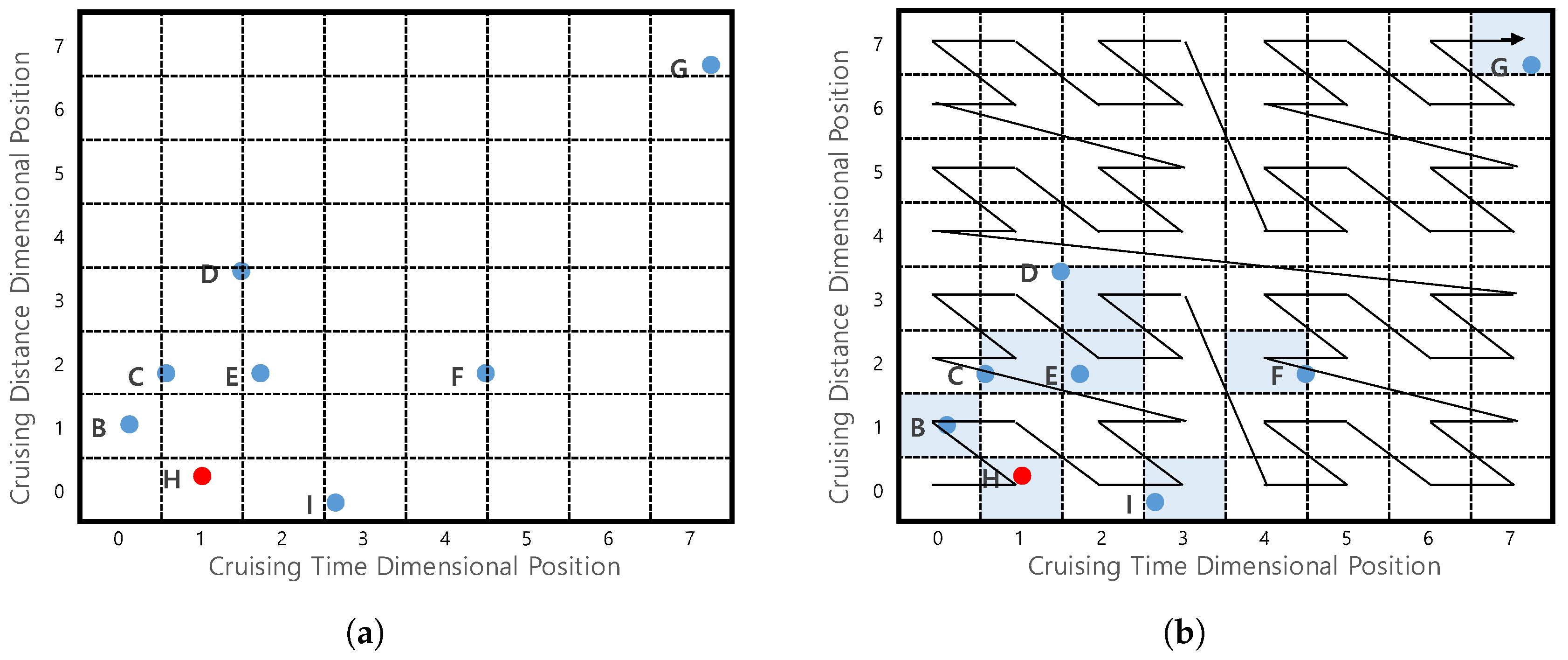
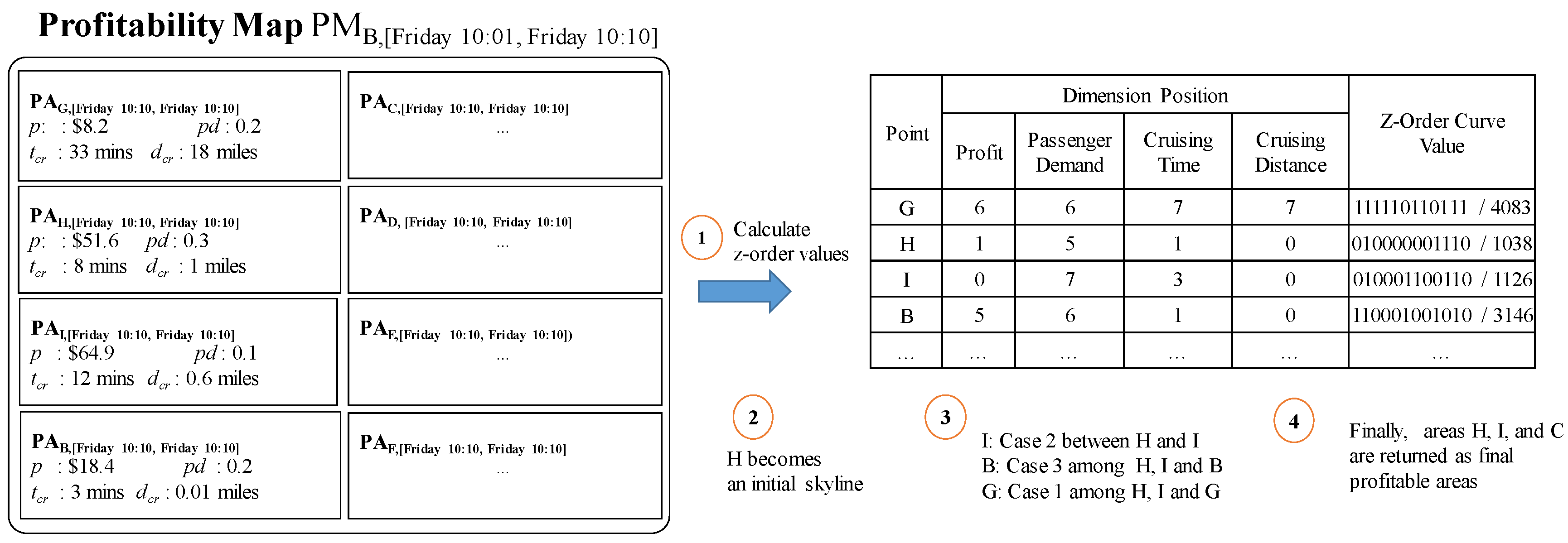
5.3.1. Z-Order Values to Profitable Areas
- (1)
- All profitable areas in region are dominated by region .
- (2)
- Some profitable areas in may be dominated by others in .
- (3)
- All profitable areas in region are not dominated by region .
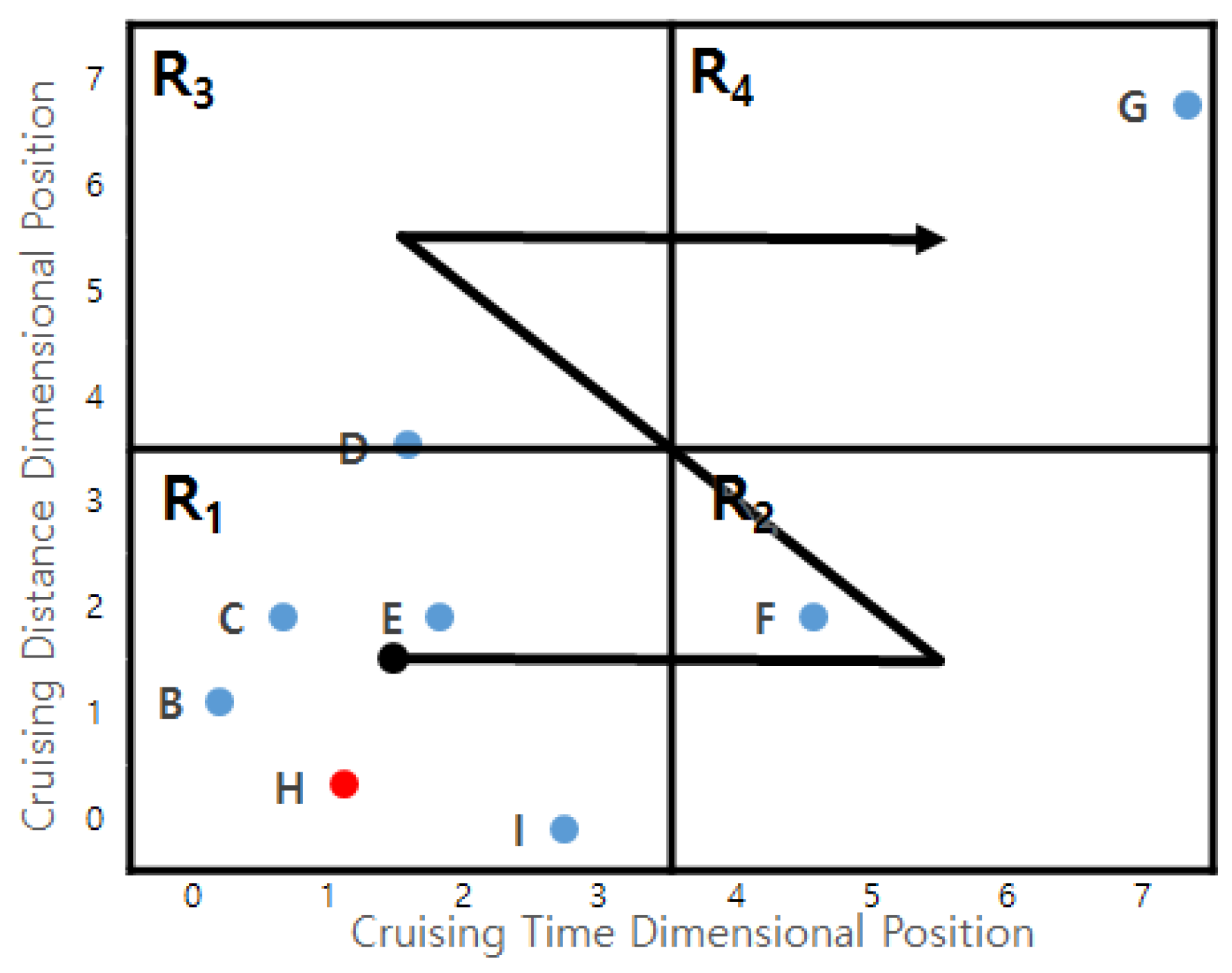
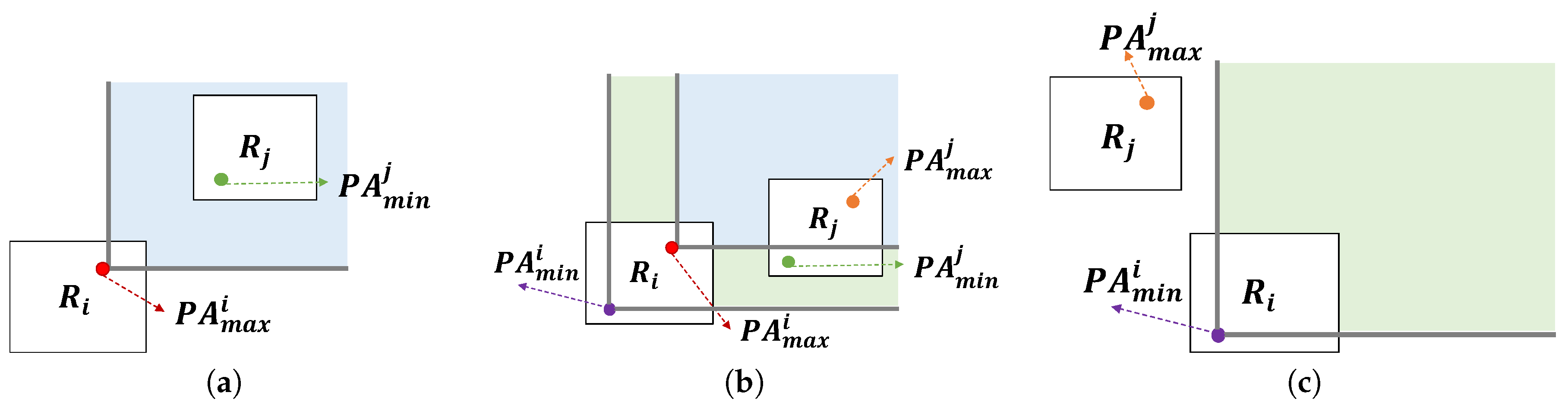
- Case 1: This happens when dominates . Figure 20a depicts this case. Since the other profitable areas in dominate , they have smaller Z-order values. also dominates the others in since it has the smallest Z-order value in . Thus, any pairs of two profitable areas and satisfy the condition that dominates . In other words, dominates .
- Case 2: This happens when does not dominate and dominates . In this case, profitable area in is dominated by profitable area in . Thus, the case holds.
- Case 3: This happens when does not dominate as shown in Figure 20c. We will prove this case by contradiction. Assume profitable area dominates profitable area . Then the z-oder value of is smaller than that of . Since we choose profitable area in , the Z-order value of is larger than that of . The Z-order value of is smaller than that of . If we combine the above statements, we could conclude that Z-order value of is smaller than that of . In other words, dominates . This contradicts the case.
5.3.2. Profitable-Area Query by Z-Skyline Method
- When is empty: profitable areas of region r will added to by invoking the dominance test. Thus, contains non-dominated areas.
- When is not empty: Candidate profitable areas of region r should be handled based on the three cases in Lemma 1, which guarantees that only non-dominated areas will be added to . Thus, also contains a set of non-dominated areas in the case.
| Algorithm 5: Z-skyline for Refining Profitable Areas |
 |
5.4. Distributed Profitable-Area Query Processing
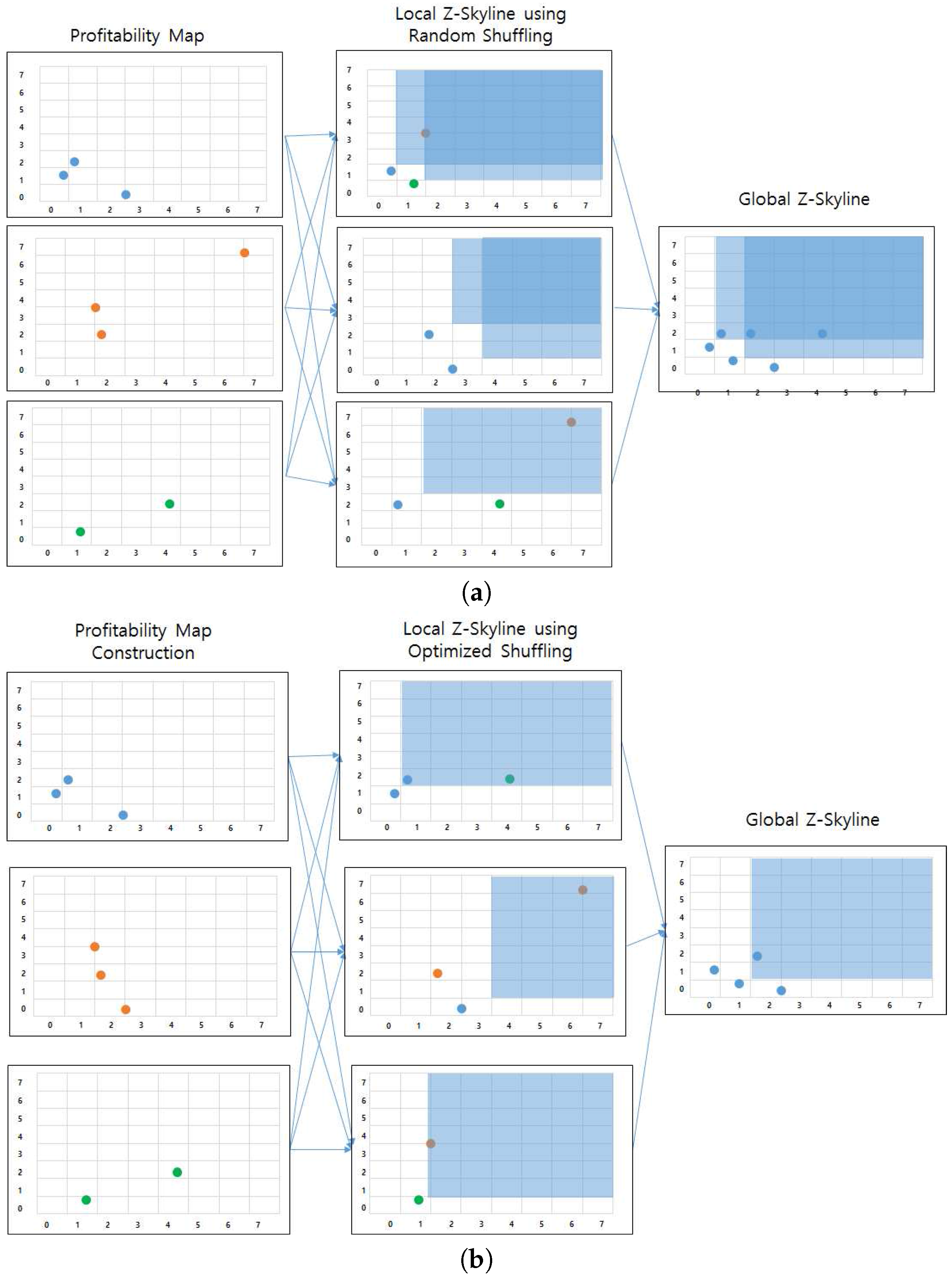
5.4.1. A Distributed Z-Skyline Approach
5.4.2. Optimizing a Distributed Z-Skyline Approach
5.5. Complexity Analysis of Distributed Profitable-Area Query Processing
6. Experimental Evaluation
6.1. Experimental Setup
Dataset
Queries
6.2. Experimental Results
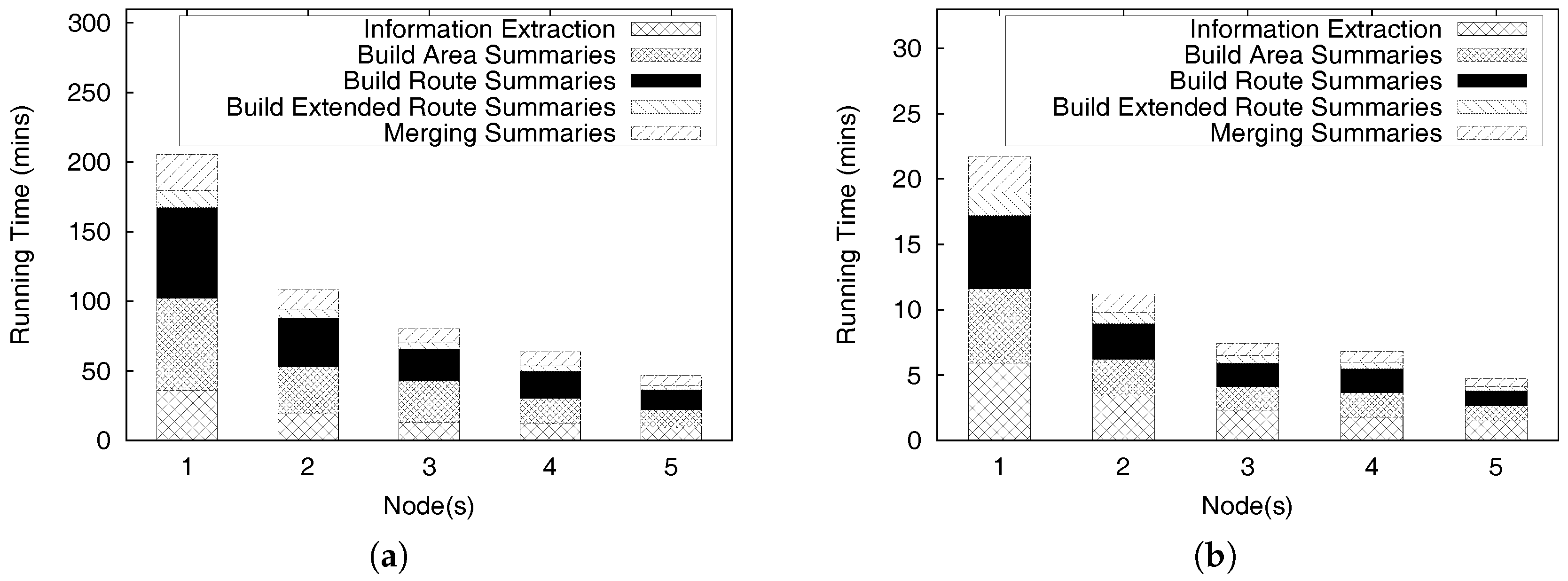
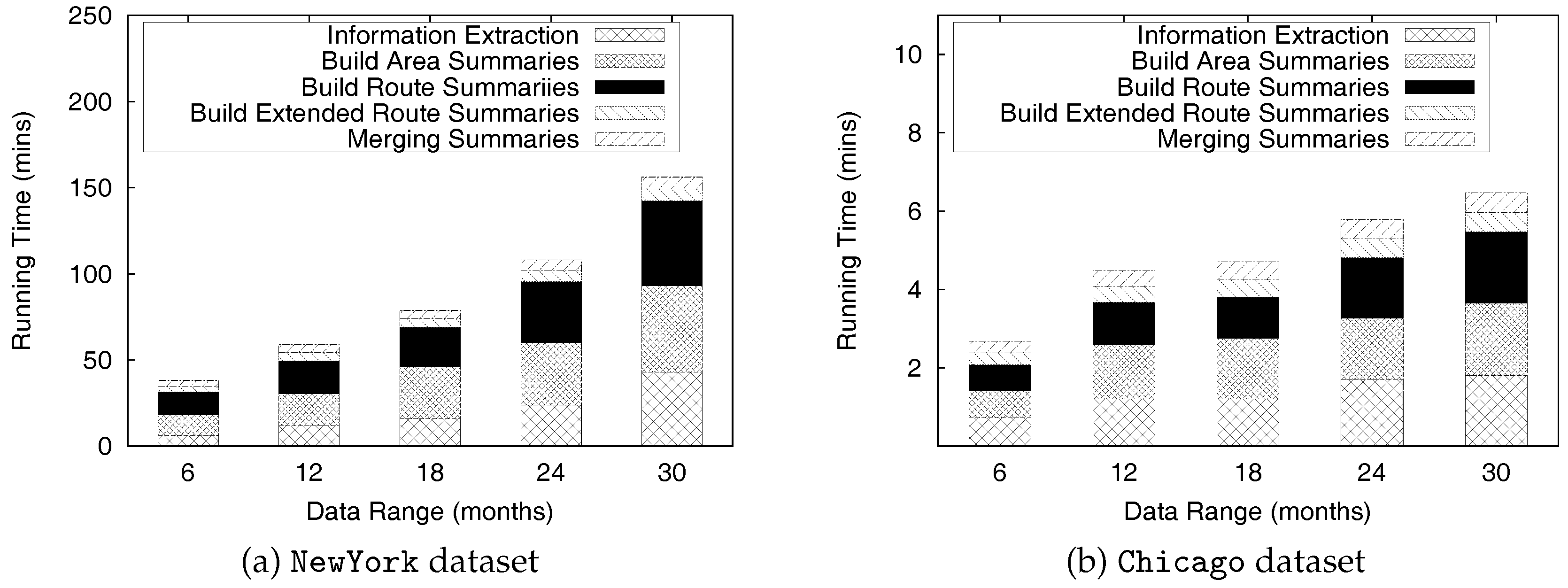
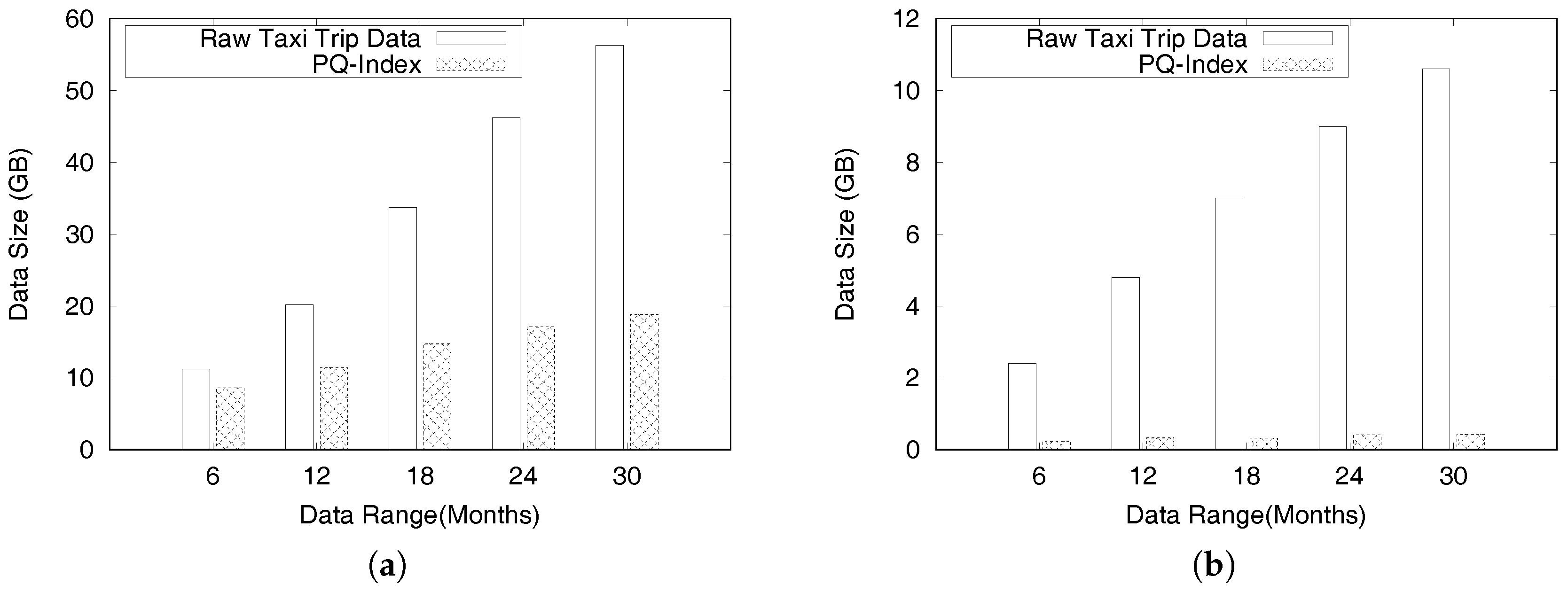
6.2.1. PQ-Index Construction
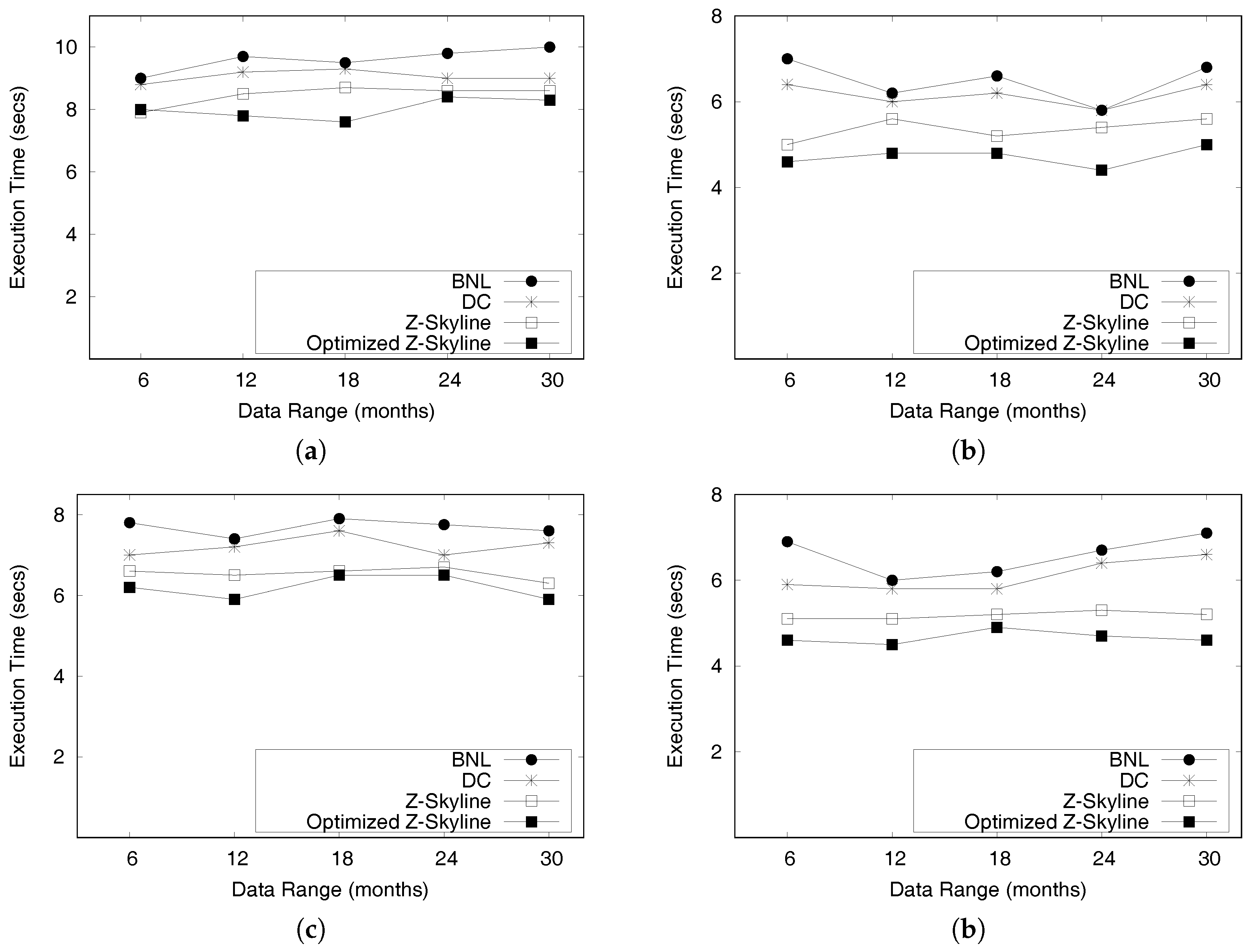
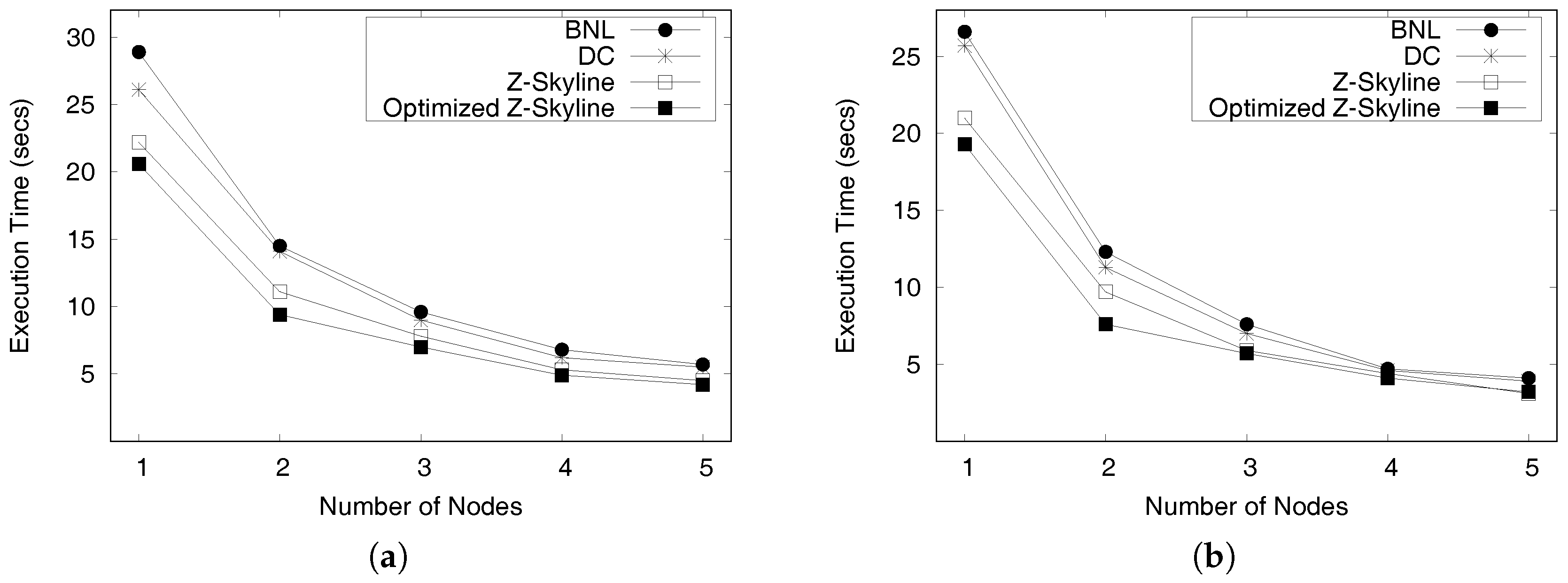
6.3. Distributed Query Processing
6.3.1. Query Performance
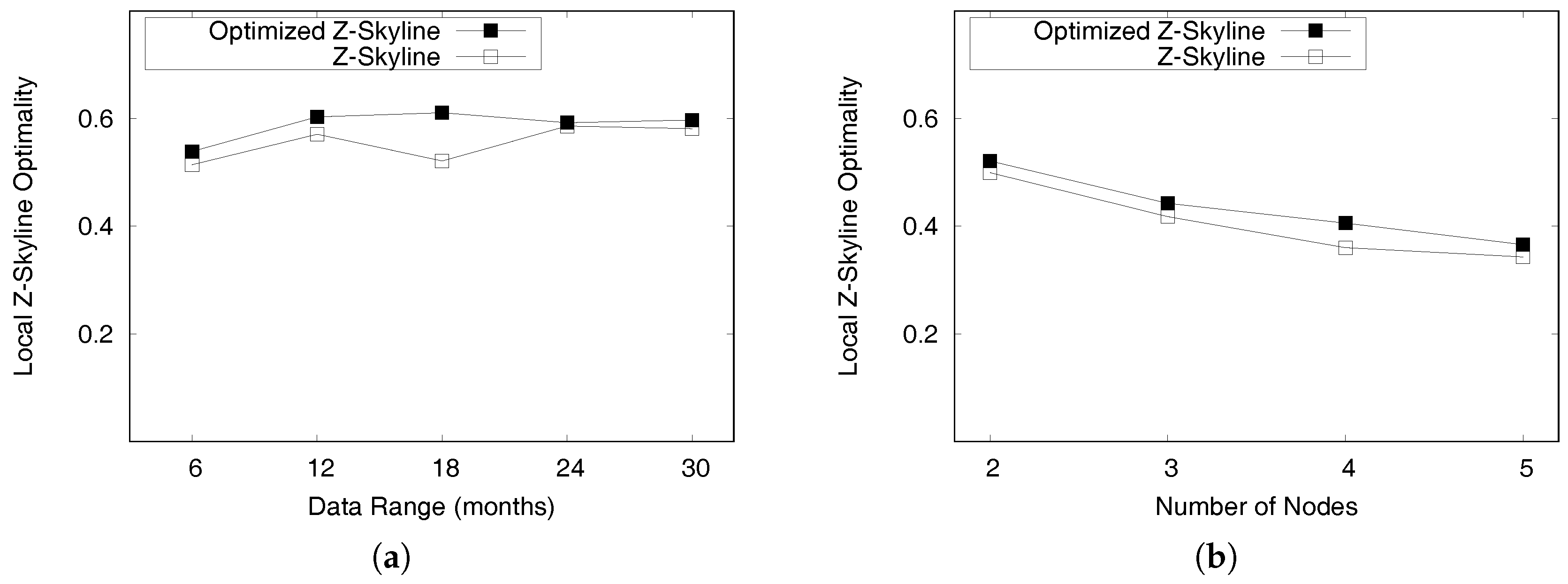
6.3.2. Local Z-Skyline Optimization
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Vehicle Safety Technology Report. 2016. Available online: http://www.nyc.gov/html/tlc/downloads/pdf/second_vehicle_safety_technology_report.pdf (accessed on 19 September 2017).
- Bischoff, J.; Michal Maciejewski, A.A.S. Analysis of Berlin’s taxi services by exploring GPS traces. In Proceedings of the 2015 International Conference on Models and Technologies for Intelligent Transportation Systems, Budapest, Hungary, 3–5 June 2015; pp. 209–215. [Google Scholar]
- VIA and Japan Unveil Smart IoT Mobility System. 2016. Available online: http://www.viatech.com/en/2016/03/via-and-japan-taxi-unveil-smart-iot-mobility-system/ (accessed on 19 September 2017).
- Lee, J.; Park, G.L.; Kim, H.; Yang, Y.K.; Kim, P.; Kim, S.W. A telematics service system based on the Linux cluster. In Proceedings of the International Conference on Computational Science, Beijing, China, 27–30 May 2007; Springer: Berlin, Germany, 2007; pp. 660–667. [Google Scholar]
- Chou, S.; Li, W.; Sridharan, R. Democratizing Data Science. In Proceedings of the KDD 2014 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014. [Google Scholar]
- Zhang, D.; Sun, L.; Li, B.; Chen, C.; Pan, G.; Li, S.; Wu, Z. Understanding taxi service strategies from taxi GPS traces. IEEE Trans. Intell. Transp. Syst. 2015, 16, 123–135. [Google Scholar] [CrossRef]
- Shao, D.; Wu, W.; Xiang, S.; Lu, Y. Estimating taxi demand-supply level using taxi trajectory data stream. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop, Seoul, Korea, 13–17 April 2015; pp. 407–413. [Google Scholar]
- Zhan, X.; Qian, X.; Ukkusuri, S.V. A graph-based approach to measuring the efficiency of an urban taxi service system. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2479–2489. [Google Scholar] [CrossRef]
- Powell, J.W.; Huang, Y.; Bastani, F.; Ji, M. Towards reducing taxicab cruising time using spatio-temporal profitability maps. In Proceedings of the International Symposium on Spatial and Temporal Databases, Minneapolis, MN, USA, 24–26 August 2011; Springer: Berlin, Germany; pp. 242–260. [Google Scholar]
- Li, X.; Pan, G.; Wu, Z.; Qi, G.; Li, S.; Zhang, D.; Zhang, W.; Wang, Z. Prediction of urban human mobility using large-scale taxi traces and its applications. Front. Comput. Sci. 2012, 6, 111–121. [Google Scholar]
- Yuan, N.J.; Zheng, Y.; Zhang, L.; Xie, X. T-finder: A recommender system for finding passengers and vacant taxis. IEEE Trans. Knowl. Data Eng. 2013, 25, 2390–2403. [Google Scholar] [CrossRef]
- Liu, L.; Andris, C.; Ratti, C. Uncovering cabdrivers’ behavior patterns from their digital traces. Comput. Environ. Urban Syst. 2010, 34, 541–548. [Google Scholar] [CrossRef]
- Lee, J.; Shin, I.; Park, G.L. Analysis of the passenger pick-up pattern for taxi location recommendation. In Proceedings of the 2008 4th International Conference on Networked Computing and Advanced Information Management, Gyeongju, Korea, 2–4 September 2008; pp. 199–204. [Google Scholar]
- Chang, H.W.; Tai, Y.C.; Hsu, J.Y.J. Context-aware taxi demand hotspots prediction. Int. J. Bus. Intell. Data Min. 2009, 5, 3–18. [Google Scholar] [CrossRef]
- Matias, L.M.; Gama, J.; Ferreira, M.; Moreira, J.M.; Damas, L. On predicting the taxi-passenger demand: A real-time approach. In Proceedings of the Portuguese Conference on Artificial Intelligence, Azores, Portugal, 9–12 September 2013; Springer: Berlin, Germany; pp. 54–65. [Google Scholar]
- Shen, Y.; Zhao, L.; Fan, J. Analysis and visualization for hot spot based route recommendation using short-dated taxi GPS traces. Information 2015, 6, 134–151. [Google Scholar] [CrossRef]
- Zhang, D.; He, T.; Lin, S.; Munir, S.; Stankovic, J.A. Taxi-passenger-demand modeling based on big data from a roving sensor network. IEEE Trans. Big Data 2017, 3, 362–374. [Google Scholar] [CrossRef]
- Wan, X.; Kang, J.; Gao, M.; Zhao, J. Taxi Origin-destination areas of interest discovering based on functional region division. In Proceedings of the 2013 Third International Conference on Innovative Computing Technology, London, UK, 29–31 August 2013; pp. 365–370. [Google Scholar]
- Liu, Y.; Liu, J.; Wang, J.; Liao, Z.; Tang, M. Recommending a personalized sequence of pick-up points. In Proceedings of the 10th Asia-Pacific Services Computing Conference on Advances in Services Computing, Zhangjiajie, China, 16–18 November 2016; Springer: Berlin, Germany; pp. 278–291. [Google Scholar]
- Hwang, R.H.; Hsueh, Y.L.; Chen, Y.T. An effective taxi recommender system based on a spatio-temporal factor analysis model. Inf. Sci. 2015, 314, 28–40. [Google Scholar] [CrossRef]
- Börzsönyi, S.; Kossmann, D.; Stocker, K. The skyline operator. In Proceedings of the 17th International Conference on Data Engineering, Lisbon, Portugal, 11–15 October 2001; pp. 421–430. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauley, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation, San Jose, CA, USA, 25–27 April 2012; p. 2. [Google Scholar]
- Apache Foundation. Apache Spark. 2016. Available online: http://spark.apache.org/docs/latest/index.html (accessed on 19 September 2017).
- MongoDB Inc. MongoDB Manual. 2014. Available online: https://docs.mongodb.com/manual/ (accessed on 19 September 2017).
- Lee, K.C.; Lee, W.C.; Zheng, B.; Li, H.; Tian, Y. Z-SKY: An efficient skyline query processing framework based on Z-order. VLDB J. 2010, 19, 333–362. [Google Scholar] [CrossRef]
- Putri, F.K.; Kwon, J. A distributed system for fining high profit areas over big taxi trip data with MognoDB and Spark. In Proceedings of the 2017 IEEE International Congress on Big Data, Honolulu, HI, USA, 25–30 June 2017; pp. 533–536. [Google Scholar]
- Castro, P.S.; Zhang, D.; Chen, C.; Li, S.; Pan, G. From taxi GPS traces to social and community dynamics: A survey. ACM Comput. Surv. 2013, 46, 17:1–17:34. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, J.; Liu, Y.; Hu, Z.; Yi, L. Recommending Pick-up Points for Taxi-drivers based on Spatio-temporal Clustering. In Proceedings of the 2012 Second International Conference on Cloud and Green Computing, Xiangtan, China, 1–3 November 2012; pp. 67–72. [Google Scholar]
- Moreira-Matias, L.; Fernandes, R.; Gama, J.; Ferreira, M.; Mendes-Moreira, J.; Damas, L. An online recommendation system for the taxi stand choice problem (Poster). In Proceedings of the 2012 IEEE Vehicular Networking Conference, Seoul, Korea, 14–16 November 2012. [Google Scholar]
- Moreira-Matias, L.; Gama, J.; Ferreira, M.; Mendes-Moreira, J.; Damas, L. Predicting taxi-passenger demand using streaming data. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1393–1402. [Google Scholar] [CrossRef]
- Dong, H.; Zhang, X.; Dong, Y.; Chen, C.; Rao, F. Recommend a profitable cruising route for taxi drivers. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems, ITSC 2014, Qingdao, China, 8–11 October 2014; pp. 2003–2008. [Google Scholar]
- Qian, S.; Cao, J.; Mouël, F.L.; Sahel, I.; Li, M. SCRAM: A sharing considered route assignment mechanism for fair taxi route recommendations. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 955–964. [Google Scholar]
- Moreira-Matias, L.; Mendes-Moreira, J.; Ferreira, M.; Gama, J.; Damas, L. An online learning framework for predicting the taxi stand’s profitability. In Proceedings of the 2014 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 2009–2014. [Google Scholar]
- Huang, Z.; Zhao, Z.; Shi, E.; Yu, C.; Shan, G.; Li, T.; Cheng, J.; Sun, J.; Xiang, Y. PRACE: A Taxi Recommender for Finding Passengers with Deep Learning Approaches. In Proceedings of the 13th International Conference on Intelligent Computing Methodologies—ICIC 2017, Liverpool, UK, 7–10 August 2017; Part III. pp. 759–770. [Google Scholar]
- Wang, D.; Cao, W.; Li, J.; Ye, J. DeepSD: Supply-Demand Prediction for Online Car-Hailing Services Using Deep Neural Networks. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 243–254. [Google Scholar]
- Verma, T.; Varakantham, P.; Kraus, S.; Lau, H.C. Augmenting Decisions of Taxi Drivers through Reinforcement Learning for Improving Revenues. In Proceedings of the International Conference on Automated Planning and Scheduling, Pittsburgh, PA, USA, 18–23 June 2017; Volume 27, pp. 409–417. [Google Scholar]
- Wang, W.; Zhang, M.; Chen, G.; Jagadish, H.V.; Ooi, B.C.; Tan, K. Database Meets Deep Learning: Challenges and Opportunities. SIGMOD Rec. 2016, 45, 17–22. [Google Scholar] [CrossRef]
- Ferreira, N.; Poco, J.; Vo, H.T.; Freire, J.; Silva, C.T. Visual exploration of big spatio-temporal urban data: A study of new york city taxi trips. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2149–2158. [Google Scholar] [CrossRef] [PubMed]
- Balan, R.K.; Nguyen, K.X.; Jiang, L. Real-time trip information service for a large taxi fleet. In Proceedings of the 9th International Conference on Mobile Systems, Applications and Services, Bethesda, MD, USA, 28 June–1 July 2011; pp. 99–112. [Google Scholar]
- Cudre-Mauroux, P.; Wu, E.; Madden, S. Trajstore: An adaptive storage system for very large trajectory data sets. In Proceedings of the 26th IEEE International Conference on Data Engineering, Long Beach, CA, USA, 1–6 March 2010; pp. 109–120. [Google Scholar]
- Xu, M.; Wang, D.; Li, J. DESTPRE: A data-driven approach to destination prediction for taxi rides. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 729–739. [Google Scholar]
- Lee, K.; Ganti, R.K.; Srivatsa, M.; Liu, L. Efficient spatial query processing for big data. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; pp. 469–472. [Google Scholar]
- Ma, S.; Zheng, Y.; Wolfson, O. T-share: A large-scale dynamic taxi ridesharing service. In Proceedings of the 29th International Conference on Data Engineering, Brisbane, Australia, 8 April 2013; pp. 410–421. [Google Scholar]
- Huang, Y.; Bastani, F.; Jin, R.; Wang, X.S. Large scale real-time ridesharing with service guarantee on road networks. Proc. VLDB Endow. 2014, 7, 2017–2028. [Google Scholar] [CrossRef]
- Doraiswamy, H.; Vo, H.T.; Silva, C.T.; Freire, J. A GPU-based index to support interactive spatio-temporal queries over historical data. In Proceedings of the 206 IEEE 32nd International Conference on Data Engineering (ICDE) 2016, Helsinki, Finland, 16–20 May 2016; pp. 1086–1097. [Google Scholar]
- Lins, L.D.; Klosowski, J.T.; Scheidegger, C.E. Nanocubes for real-time exploration of spatiotemporal datasets. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2456–2465. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Zhou, J.; Liu, Y.; Xu, Z.; Zhao, X. Taxi-RS: Taxi-hunting recommendation system based on taxi GPS data. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1716–1727. [Google Scholar] [CrossRef]
- Imawan, A.; Indikawati, F.I.; Kwon, J.; Rao, P. Querying and extracting timeline information from road traffic sensor data. Sensors 2016, 16, 1340. [Google Scholar] [CrossRef] [PubMed]
- Moreira-Matias, L.; Gama, J.; Ferreira, M.; Mendes-Moreira, J.; Damas, L. Time-evolving O-D matrix estimation using high-speed GPS data streams. Expert Syst. Appl. 2016, 44, 275–288. [Google Scholar] [CrossRef]
- Damaiyanti, T.I.; Imawan, A.; Indikawati, F.I.; Choi, Y.H.; Kwon, J. A similarity query system for road traffic data based on a NoSQL document store. J. Syst. Softw. 2017, 127, 28–51. [Google Scholar] [CrossRef]
- Ahmed, K.; Nafi, N.S.; Gregory, M.A. Enhanced distributed dynamic skyline query for wireless sensor networks. J. Sens. Actuator Netw. 2016, 5, 2. [Google Scholar] [CrossRef]
- Afrati, F.N.; Koutris, P.; Suciu, D.; Ullman, J.D. Parallel skyline queries. Theory Comput. Syst. 2015, 57, 1008–1037. [Google Scholar] [CrossRef]
- Zhou, X.; Li, K.; Zhou, Y.; Li, K. Adaptive processing for distributed skyline queries over uncertain data. IEEE Trans. Knowl. Data Eng. 2016, 28, 371–384. [Google Scholar] [CrossRef]
- Zhang, B.; Zhou, S.; Guan, J. Adapting skyline computation to the mapreduce framework: Algorithms and experiments. In Proceedings of the International Conference on Database Systems for Advanced Applications, Tsukuba, Japan, 1–4 April 2010; Springer: Berlin, Germany; pp. 403–414. [Google Scholar]
- Chen, L.; Hwang, K.; Wu, J. MapReduce skyline query processing with a new angular partitioning approach. In Proceedings of the 2012 IEEE 26th International Parallel and Distributed Processing Symposium Workshops & PhD Forum, Shanghai, China, 21–25 May 2012; pp. 2262–2270. [Google Scholar]
- Mullesgaard, K.; Pedersen, J.L.; Lu, H.; Zhou, Y. Efficient skyline computation in MapReduce. In Proceedings of the 17th International Conference on Extending Database Technology, Athens, Greece, 24–28 March 2014; pp. 37–48. [Google Scholar]
- Park, Y.; Min, J.K.; Shim, K. Parallel computation of skyline and reverse skyline queries using mapreduce. Proc. VLDB Endow. 2013, 6, 2002–2013. [Google Scholar] [CrossRef]
- Koh, J.L.; Chen, C.C.; Chan, C.Y.; Chen, A.L. MapReduce skyline query processing with partitioning and distributed dominance tests. Inf. Sci. 2017, 375, 114–137. [Google Scholar] [CrossRef]
- Fox, A.; Eichelberger, C.; Hughes, J.; Lyon, S. Spatio-temporal indexing in non-relational distributed databases. In Proceedings of the 2013 IEEE International Conference on Big Data, Santa Clara, CA, USA, 27 June–2 July 2013; pp. 291–299. [Google Scholar]
- Islam, M.S.; Liu, C. Know your customer: Computing k-most promising products for targeted marketing. VLDB J. 2016, 25, 545–570. [Google Scholar] [CrossRef]
- Furia, C.A.; Meyer, B.; Velder, S. Loop invariants: Analysis, classification, and examples. Comput. Surv. 2014, 46, 34. [Google Scholar] [CrossRef]
- TLC Trip Record Data. 2016. Available online: http://www.nyc.gov/html/tlc/html/about/trip_record_data.shtml (accessed on 19 September 2017).
- City of Chicago. Chicago Taxi Data Released. 2016. Available online: http://digital.cityofchicago.org/index.php/chicago-taxi-data-released/ (accessed on 19 September 2017).
- TLC Factbook. 2016. Available online: http://www.nyc.gov/html/tlc/downloads/pdf/2016_tlc_factbook.pdf (accessed on 19 September 2017).






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| T | a set of taxi trips |
| area which has a group of locations | |
| route containing a pair (origin area , destination area ) | |
| time period denoted as [start time, end time] | |
| a profitable area computed from the input area and time period | |
| a set of profitable areas computed from the input area and time period | |
| ith element contained in , in other words, a profitable area | |
| the skyline of which contains only dominant profitable areas, | |
| in other words, this is the answer for a profitable-area query | |
| p | profit |
| passenger demand | |
| cruising time | |
| cruising distance | |
| area summary computed from the input area and time period | |
| the average fare | |
| L | a list of pickup probabilities |
| route summary computed from the input route and time period | |
| average distance | |
| average travel time | |
| average expense | |
| extended route summary computed from the input route and time period | |
| region which has a set of profitable areas used in the skyline processing |
| No. | Pickup | Drop-Off | Pickup Location | Drop-Off Location | Trip | Fare | Tip | Tolls | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Date/Time | Date/Time | Longitude | Latitude | Longitude | Latitude | Distance | Amount | Amount | Amount | |
| 1 | 10/16/2015 | 10/16/2015 | −73.98278 | 40.75492 | −74.18142 | 40.68773 | 16.63 | 67 | 0 | 0 |
| 10:01 | 10:23 | |||||||||
| 2 | 10/09/2015 | 10/09/2015 | −73.98956 | 40.75796 | −74.18147 | 40.68773 | 20.02 | 70.5 | 0.5 | 0 |
| 10:02 | 10:23 | |||||||||
| 3 | 10/16/2015 | 10/16/2015 | −73.9902 | 40.75703 | −73.99946 | 40.745 | 1.2 | 7.5 | 0 | 0.5 |
| 10:04 | 10:11 | |||||||||
| 4 | 10/16/2015 | 10/16/2015 | −73.98652 | 40.75424 | −73.99525 | 40.74455 | 0.8 | 6 | 0 | 0.5 |
| 10:01 | 10:09 | |||||||||
| 5 | 10/10/2015 | 10/10/2015 | −73.96738 | 40.80349 | −73.95052 | 40.78425 | 2 | 9.5 | 1 | 0.5 |
| 10:41 | 10:45 | |||||||||
| 6 | 10/23/2015 | 10/23/2015 | −73.96693 | 40.80349 | −73.95477 | 40.78422 | 2.2 | 9.5 | 0.5 | 0.5 |
| 10:42 | 10:47 | |||||||||
| 7 | 10/16/2015 | 10/16/2015 | −73.96551 | 40.80593 | −73.95576 | 40.78287 | 2.31 | 10 | 0.5 | 0.5 |
| 10:41 | 10:46 | |||||||||
| 8 | 10/16/2015 | 10/16/2015 | −73.96752 | 40.80129 | −73.96394 | 40.80769 | 0.51 | 4 | 1 | 0.5 |
| 10:22 | 10:26 | |||||||||
| 9 | 10/16/2015 | 10/16/2015 | −73.96781 | 40.80042 | −73.96479 | 40.80662 | 0.5 | 4 | 0 | 0.5 |
| 10:25 | 10:30 | |||||||||
| 10 | 10/16/2015 | 10/16/2015 | −73.96803 | 40.80112 | −73.95999 | 40.80827 | 0.9 | 5.5 | 0.5 | 0.5 |
| 10:21 | 10:26 | |||||||||
| Months | Information Extraction (GB) | Build Area Summaries (GB) | Build Route Summaries (GB) | Build Extended Route Summaries (GB) | Merging Summaries (GB) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Input | SW | SR | SW | SR | SW | SR | SW | SR | Output | |
| 6 | 11.2 | 5.3 | 5.3 | 0.04 | 5.3 | 2 | 2 | 3.9 | 3.9 | 8.6 |
| 12 | 20.2 | 9.4 | 9.4 | 0.8 | 9.4 | 2.6 | 2.7 | 5.4 | 5.4 | 11.4 |
| 18 | 33.7 | 14.7 | 14.7 | 0.05 | 14.7 | 3.4 | 3.5 | 7.8 | 7.8 | 14.7 |
| 24 | 46.2 | 19.7 | 19.7 | 0.06 | 19.7 | 4.0 | 4.1 | 9.3 | 9.3 | 17.1 |
| 30 | 56.3 | 24.1 | 24.1 | 0.06 | 24.1 | 4.5 | 4.6 | 10.4 | 10.4 | 18.8 |
| Months | Information Extraction (GB) | Build Area Summaries (GB) | Build Route Summaries (GB) | Build Extended Route Summaries (GB) | Merging Summaries (GB) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Input | SW | SR | SW | SR | SW | SR | SW | SR | Output | |
| 6 | 2.4 | 0.24 | 0.24 | 0.0025 | 0.24 | 0.14 | 0.14 | 0.15 | 0.15 | 0.23 |
| 12 | 4.8 | 0.47 | 0.47 | 0.0022 | 0.47 | 0.19 | 0.19 | 0.22 | 0.22 | 0.31 |
| 18 | 7 | 0.69 | 0.69 | 0.0023 | 0.69 | 0.27 | 0.27 | 0.30 | 0.30 | 0.37 |
| 24 | 9 | 0.88 | 0.88 | 0.0024 | 0.88 | 0.33 | 0.34 | 0.39 | 0.39 | 0.39 |
| 30 | 10.6 | 1 | 1 | 0.0025 | 1 | 0.35 | 0.35 | 0.40 | 0.40 | 0.40 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Putri, F.K.; Song, G.; Kwon, J.; Rao, P. DISPAQ: Distributed Profitable-Area Query from Big Taxi Trip Data. Sensors 2017, 17, 2201. https://doi.org/10.3390/s17102201
Putri FK, Song G, Kwon J, Rao P. DISPAQ: Distributed Profitable-Area Query from Big Taxi Trip Data. Sensors. 2017; 17(10):2201. https://doi.org/10.3390/s17102201
Chicago/Turabian StylePutri, Fadhilah Kurnia, Giltae Song, Joonho Kwon, and Praveen Rao. 2017. "DISPAQ: Distributed Profitable-Area Query from Big Taxi Trip Data" Sensors 17, no. 10: 2201. https://doi.org/10.3390/s17102201
APA StylePutri, F. K., Song, G., Kwon, J., & Rao, P. (2017). DISPAQ: Distributed Profitable-Area Query from Big Taxi Trip Data. Sensors, 17(10), 2201. https://doi.org/10.3390/s17102201