Heterogeneous Data Fusion Method to Estimate Travel Time Distributions in Congested Road Networks



Abstract
:1. Introduction
2. Literature Review
3. Brief Introduction of the D-S Evidence Theory
4. Travel Time Distributions Estimated by Fusing Heterogeneous Data Sources
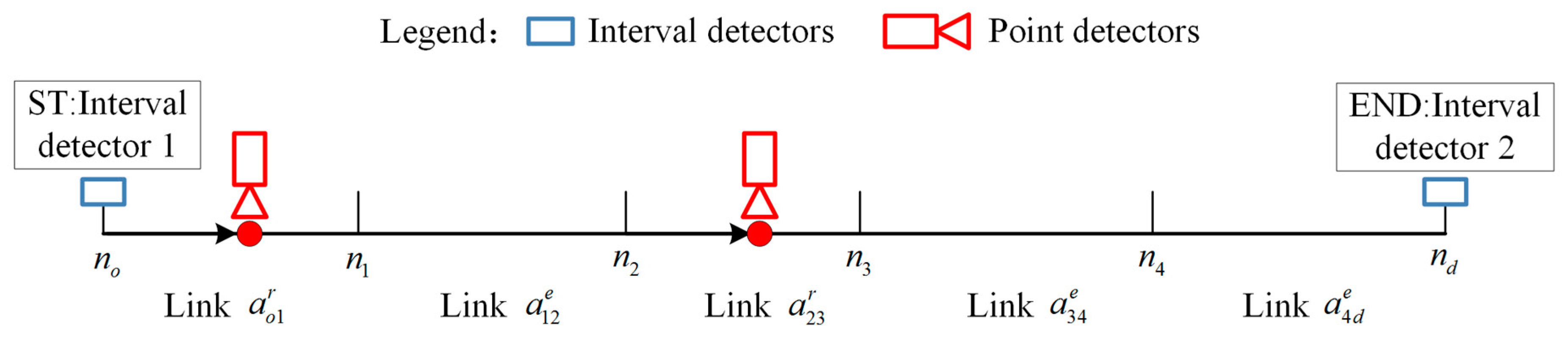
4.1. Problem Statement
4.2. Proposed Heterogeneous Data Fusion Method
4.2.1. Data Preprocessing Step
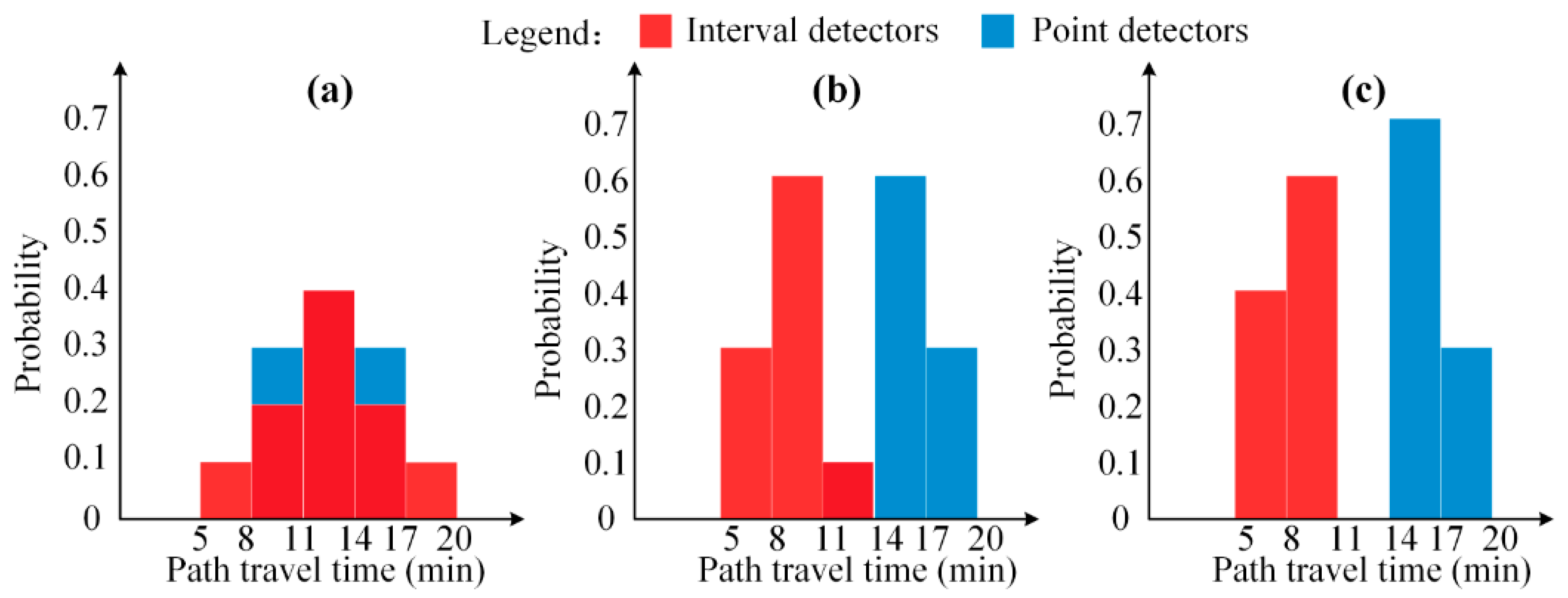
4.2.2. Distribution Fusion Step
4.2.3. Posterior Update Step
| Algorithm 1 |
| Step 1. Data preprocessing stage: |
| Estimate from interval detector data at current interval . |
| Estimate and for links with point detectors at current interval . Deduce and for links without point detectors using Equations (6) and (7). Estimate using Equations (9) and (10). |
| Step 2. Distribution fusion stage: |
| Estimate by fusing and based on Equations (11)–(21). |
| Step 3. Posterior update stage: |
| Update using Equations (22)–(24); and update using Equation (25). |
| Set , and . Go to Step 1 for next time interval. |
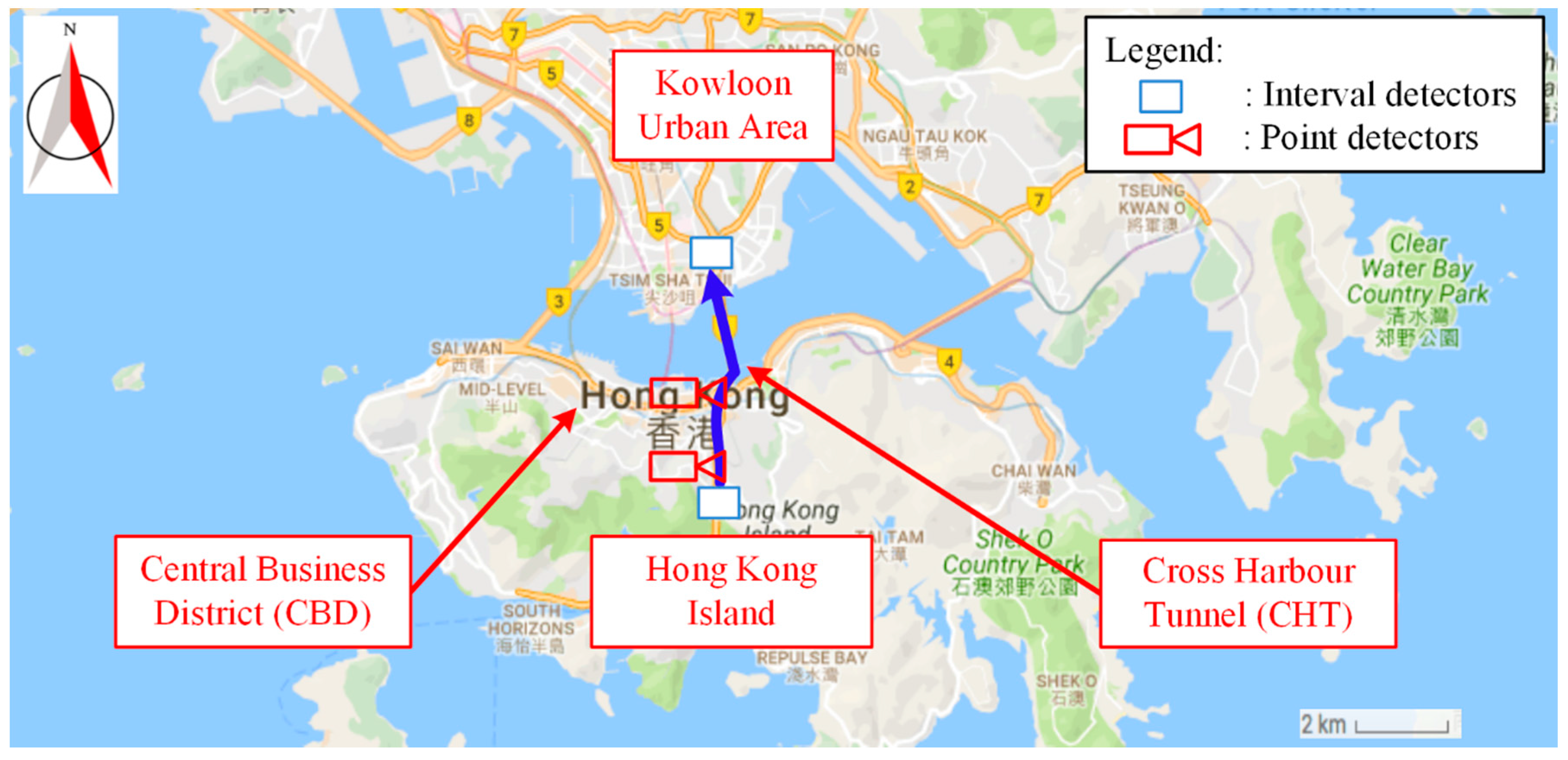
5. Numerical Experiments
5.1. Evaluation Metrics
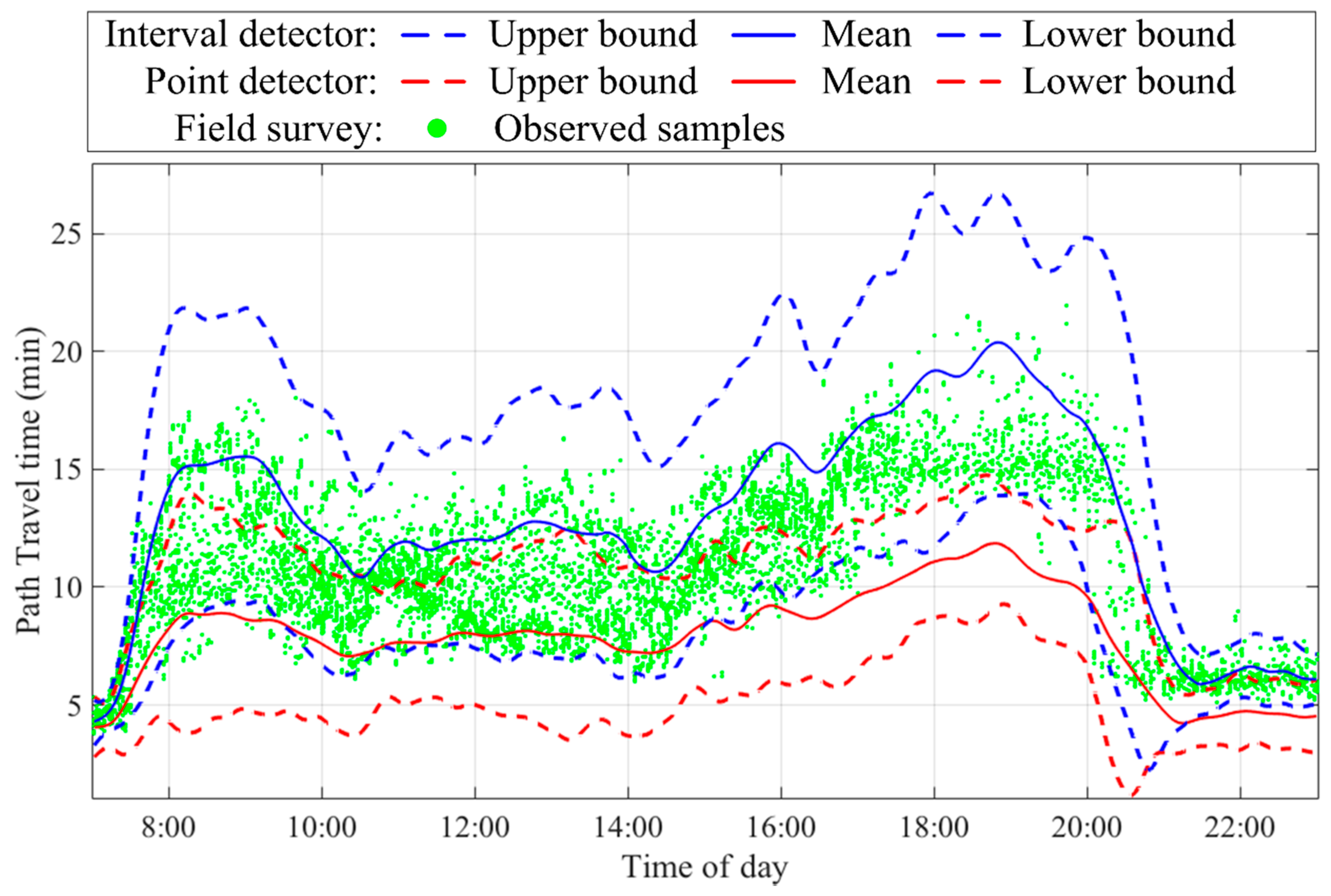
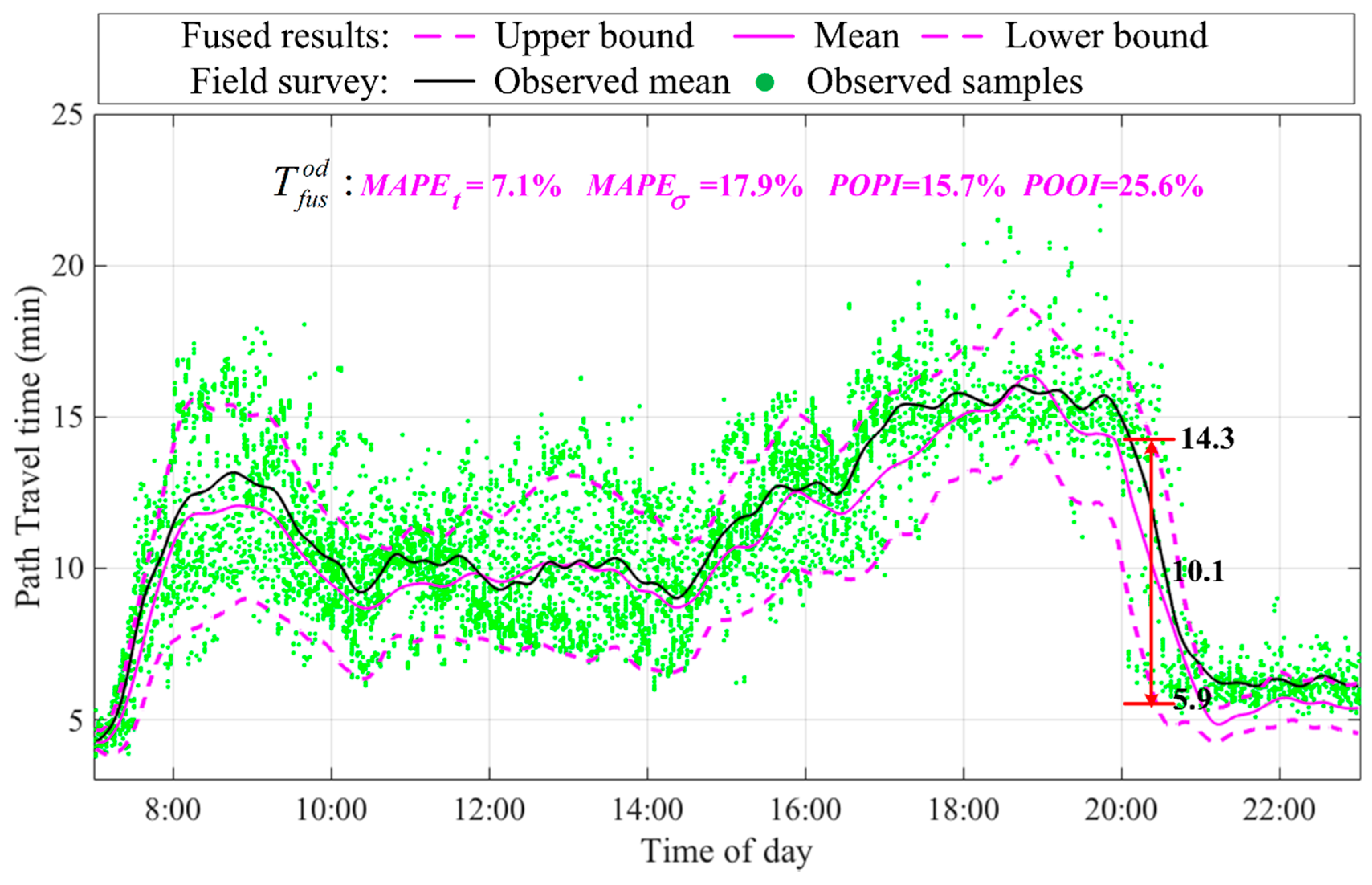
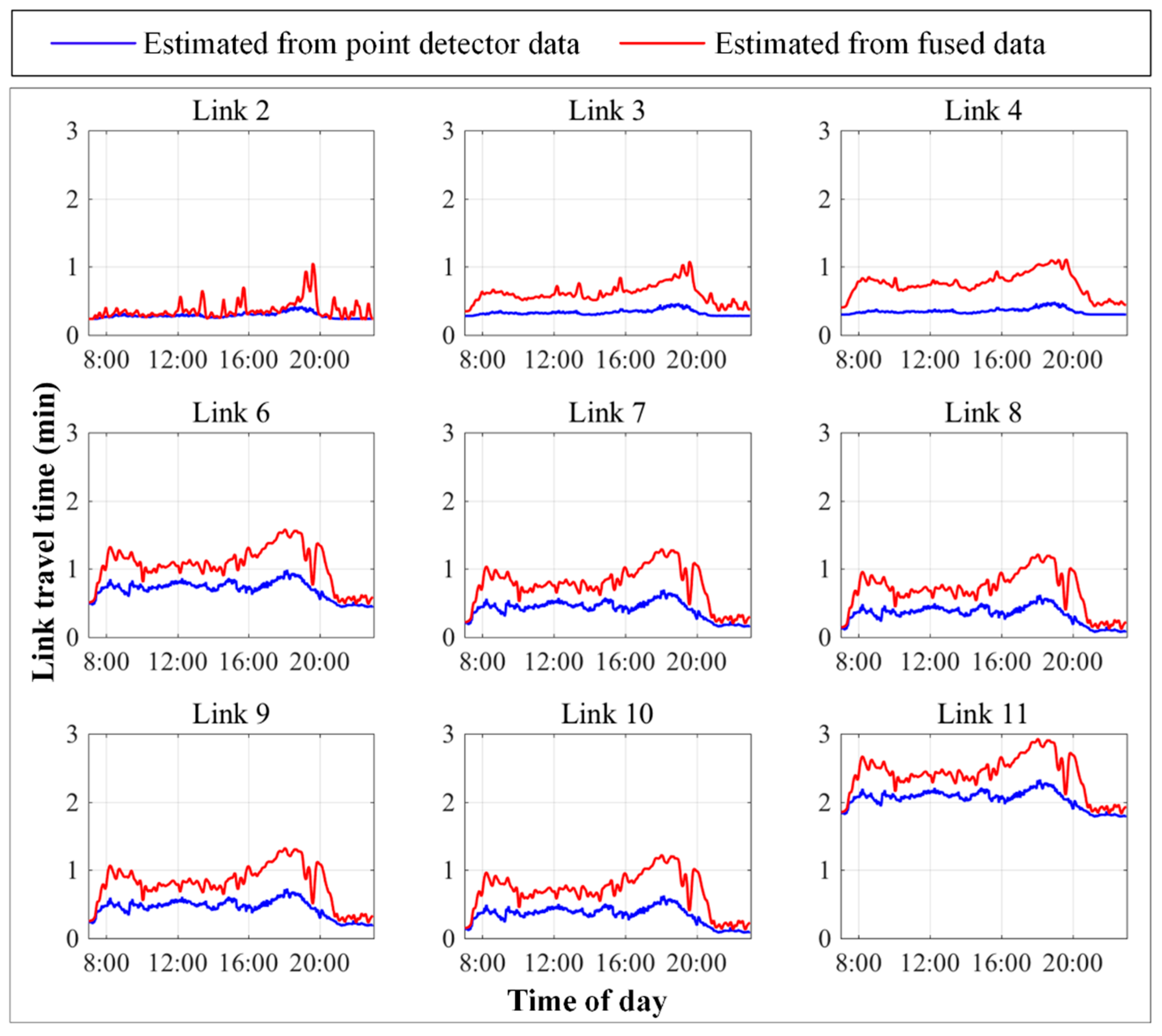
5.2. Experimental Results
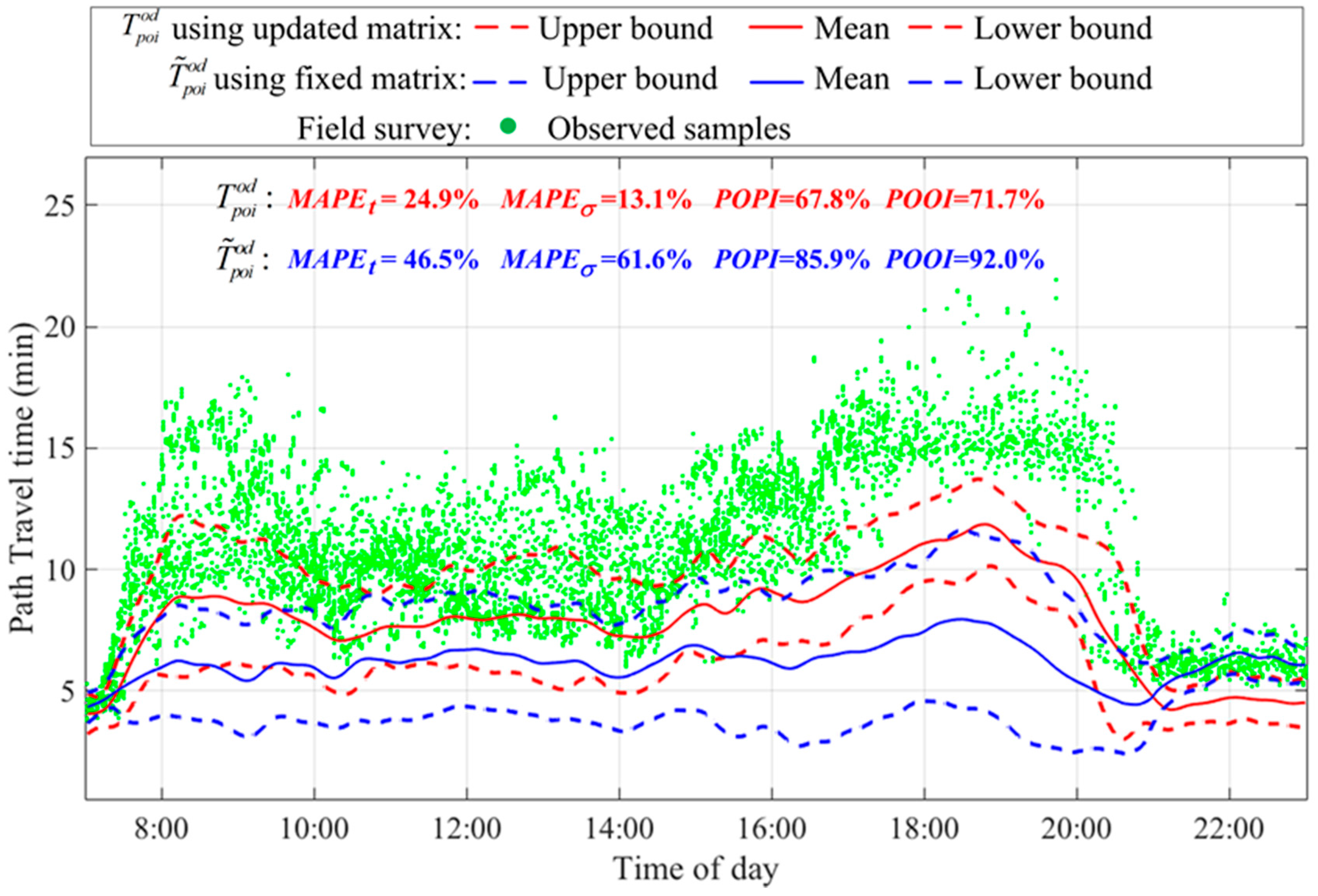
5.3. Comparison of Data Fusion and Single Data Source Results
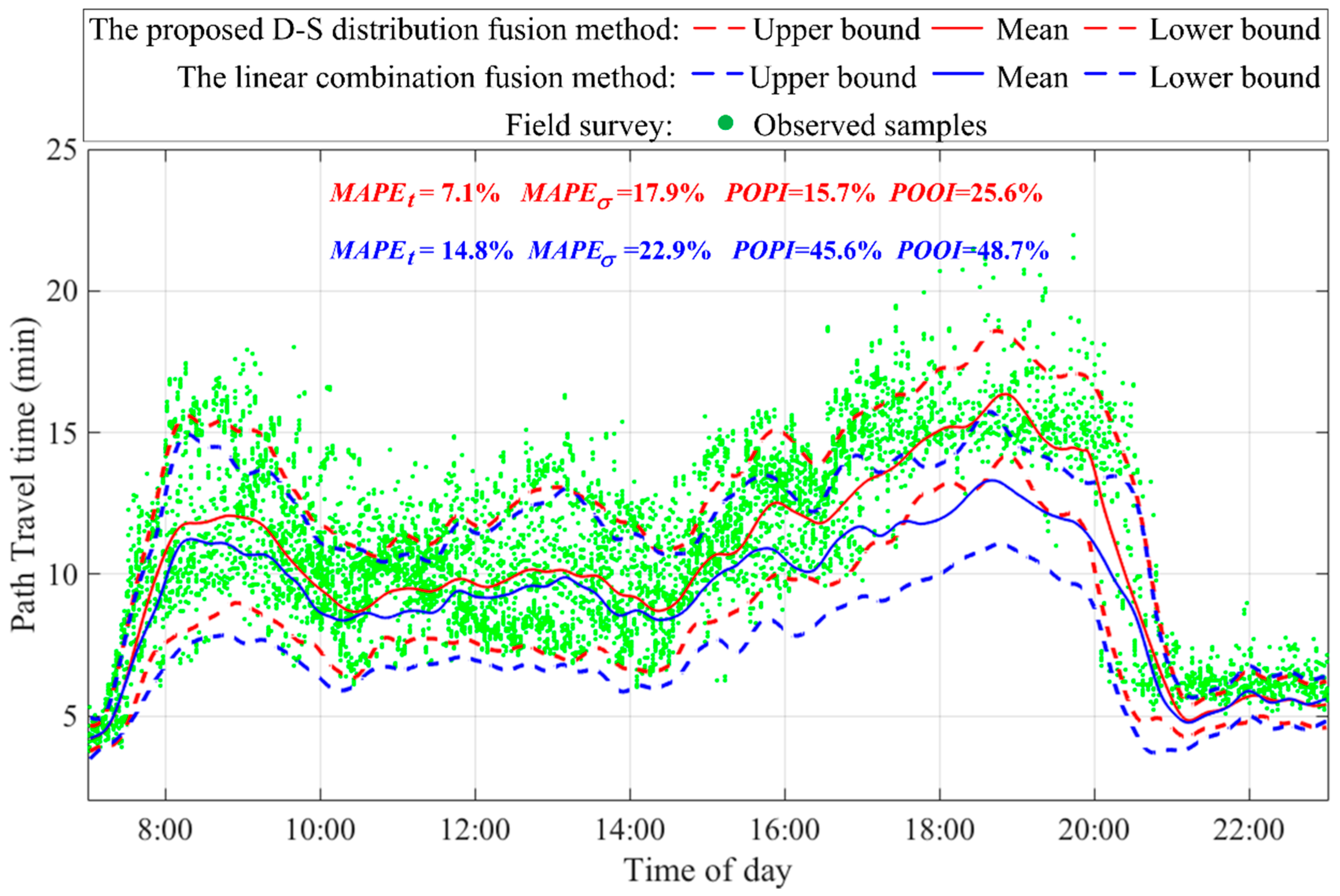
5.4. Comparison of Different Distribution Fusion Algorithms
6. Conclusions and Future Research
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chen, B.Y.; Lam, W.H.K.; Sumalee, A.; Li, Q.Q.; Shao, H.; Fang, Z.X. Finding reliable shortest paths in road networks under uncertainty. Netw. Spat. Econ. 2013, 13, 123–148. [Google Scholar] [CrossRef]
- Chen, B.Y.; Li, Q.Q.; Lam, W.H.K. Finding the k reliable shortest paths under travel time uncertainty. Transp. Res. B Methodol. 2016, 94, 189–203. [Google Scholar] [CrossRef]
- Yang, L.; Zhou, X. Optimizing on-time arrival probability and percentile travel time for elementary path finding in time-dependent transportation networks: Linear mixed integer programming reformulations. Transp. Res. B Methodol. 2017, 96, 68–91. [Google Scholar] [CrossRef]
- Zhong, R.; Sumalee, A.; Maruyama, T. Dynamic marginal cost, access control, and pollution charge: A comparison of bottleneck and whole link models. J. Adv. Transp. 2012, 46, 191–221. [Google Scholar] [CrossRef]
- Zhao, J.; Ma, W.; Liu, Y.; Han, K. Optimal operation of freeway weaving segment with combination of lane assignment and on-ramp signal control. Transp. A 2016, 12, 413–435. [Google Scholar] [CrossRef]
- Chen, B.Y.; Yuan, H.; Li, Q.Q.; Shaw, S.L.; Lam, W.H.K.; Chen, X. Spatiotemporal data model for network time geographic analysis in the era of big data. Int. J. Geogr. Inf. Sci. 2016, 30, 1041–1071. [Google Scholar] [CrossRef]
- Lim, S.; Lee, C. Data fusion algorithm improves travel time predictions. IET Intell. Transp. Syst. 2011, 5, 302–309. [Google Scholar] [CrossRef]
- Mori, U.; Mendiburu, A.; Alvarez, M.; Lozano, J.A. A review of travel time estimation and forecasting for Advanced Traveller Information Systems. Transp. A 2015, 11, 119–157. [Google Scholar] [CrossRef]
- Chen, B.Y.; Yuan, H.; Li, Q.Q.; Lam, W.H.K.; Shaw, S.L.; Yan, K. Map matching algorithm for large-scale low-frequency floating car data. Int. J. Geogr. Inf. Sci. 2014, 28, 22–38. [Google Scholar] [CrossRef]
- Du, L.; Peeta, S.; Kim, Y.H. An adaptive information fusion model to predict the short-term link travel time distribution in dynamic traffic networks. Transp. Res. B Methodol. 2012, 46, 235–252. [Google Scholar] [CrossRef]
- Bachmann, C.; Abdulhai, B.; Roorda, M.J.; Moshiri, B. A comparative assessment of multi-sensor data fusion techniques for freeway traffic speed estimation using microsimulation modeling. Transp. Res. C Emerg. Technol. 2013, 26, 33–48. [Google Scholar] [CrossRef]
- Bachmann, C.; Roorda, M.J.; Abdulhai, B.; Moshiri, B. Fusing a bluetooth traffic monitoring system with loop detector data for improved freeway traffic speed estimation. J. Intell. Transp. Syst. 2013, 17, 152–164. [Google Scholar] [CrossRef]
- Deng, W.; Lei, H.; Zhou, X. Traffic state estimation and uncertainty quantification based on heterogeneous data sources: A three detector approach. Transp. Res. B Methodol. 2013, 57, 132–157. [Google Scholar] [CrossRef]
- Tam, M.L.; Lam, W.H.K. Using automatic vehicle identification data for travel time estimation in Hong Kong. Transportmetrica 2008, 4, 179–194. [Google Scholar] [CrossRef]
- Zou, H.; Yue, Y.; Li, Q.; Yeh, A.G.O. An improved distance metric for the interpolation of link-based traffic data using kriging: A case study of a large-scale urban road network. Int. J. Geogr. Inf. Sci. 2012, 26, 667–689. [Google Scholar] [CrossRef]
- El Esawey, M.; Sayed, T. Travel time estimation in urban networks using limited probes data. Can. J. Civil. Eng. 2011, 38, 305–318. [Google Scholar] [CrossRef]
- Liu, H.X.; Ma, W. A virtual vehicle probe model for time-dependent travel time estimation on signalized arterials. Transp. Res. C Emerg. Technol. 2009, 17, 11–26. [Google Scholar] [CrossRef]
- Liu, H.X.; Ma, W.; Wu, X.; Hu, H. Real-time estimation of arterial travel time under congested conditions. Transportmetrica 2012, 8, 87–104. [Google Scholar] [CrossRef]
- Ndoye, M.; Totten, V.F.; Krogmeier, J.V.; Bullock, D.M. Sensing and signal processing for vehicle reidentification and travel time estimation. IEEE Trans. Intell. Transp. Syst. 2011, 12, 119–131. [Google Scholar] [CrossRef]
- Yu, B.; Lam, W.H.K.; Tam, M.L. Bus arrival time prediction at bus stop with multiple routes. Transp. Res. C Emerg. Technol. 2011, 19, 1157–1170. [Google Scholar] [CrossRef]
- Vlahogianni, E.I.; Golias, J.C.; Karlaftis, M.G. Short-term traffic forecasting: Overview of objectives and methods. Transp. Rev. 2004, 24, 533–557. [Google Scholar] [CrossRef]
- El Faouzi, N.E. Data fusion in road traffic engineering: An overview. In Proceedings of the SPIE—The International Society for Optical Engineering, Orlando, FL, USA, 14–15 April 2004. [Google Scholar]
- Choi, K.; Chung, Y. A data fusion algorithm for estimating link travel time. J. Intell. Transp. Syst. 2002, 7, 235–260. [Google Scholar] [CrossRef]
- El Faouzi, N.E. Bayesian and evidential approaches for traffic data fusion: Methodological issues and case study. In Proceedings of the Transportation Research Board 85th Annual Meeting (No. 06–1510), Washington, DC, USA, 22–26 January 2006. [Google Scholar]
- El Faouzi, N.E.; Klein, L.A.; De Mouzon, O. Improving travel time estimates from inductive loop and toll collection data with Dempster-Shafer data fusion. Transport. Res. Rec. 2009, 2129, 73–80. [Google Scholar] [CrossRef]
- Kong, Q.J.; Li, Z.; Chen, Y.; Liu, Y. An approach to urban traffic state estimation by fusing multisource information. IEEE Trans. Intell. Transp. Syst. 2009, 10, 499–511. [Google Scholar] [CrossRef]
- Kong, Q.J.; Chen, Y.; Liu, Y. A fusion-based system for road-network traffic state surveillance: A case study of Shanghai. IEEE Intell. Transp. Syst. 2009, 1, 37–42. [Google Scholar] [CrossRef]
- Nantes, A.; Dong, N.; Bhaskar, A.; Miska, M.; Chung, E. Real-time traffic state estimation in urban corridors from heterogeneous data. Transp. Res. C Emerg. Technol. 2015, 66, 99–118. [Google Scholar] [CrossRef]
- Shan, Z.; Xia, Y.; Hou, P.; He, J. Fusing Incomplete Multisensor Heterogeneous Data to Estimate Urban Traffic. IEEE Multimed. 2016, 23, 56–63. [Google Scholar] [CrossRef]
- Lederman, R.; Wynter, L. Real-time traffic estimation using data expansion. Transp. Res. B Methodol. 2011, 45, 1062–1079. [Google Scholar] [CrossRef]
- Haworth, J.; Cheng, T. Non-parametric regression for space-time forecasting under missing data. Comput. Environ. Urban. 2012, 36, 538–550. [Google Scholar] [CrossRef]
- Li, L.; Li, Y.B.; Li, Z.H. Efficient missing data imputing for traffic flow by considering temporal and spatial dependence. Transp. Res. C Emerg. Technol. 2013, 34, 108–120. [Google Scholar] [CrossRef]
- Chan, K.S.; Lam, W.H.K.; Tam, M.L. Real-time estimation of arterial travel times with spatial travel time covariance relationships. Transp. Res. Rec. 2009, 2121, 102–109. [Google Scholar] [CrossRef]
- Dion, F.; Rakha, H. Estimating dynamic roadway travel times using automatic vehicle identification data for low sampling rates. Transp. Res. B Methodol. 2006, 40, 745–766. [Google Scholar] [CrossRef]
- Jenelius, E.; Koutsopoulos, H.N. Travel time estimation for urban road networks using low frequency probe vehicle data. Transp. Res. B Methodol. 2013, 53, 64–81. [Google Scholar] [CrossRef]
- Rahmani, M.; Jenelius, E.; Koutsopoulos, H.N. Non-parametric estimation of route travel time distributions from low-frequency floating car data. Transp. Res. C Emerg. Technol. 2015, 58, 343–362. [Google Scholar] [CrossRef]
- Hans, E.; Chiabaut, N.; Leclercq, L. Applying variational theory to travel time estimation on urban arterials. Transp. Res. B Methodol. 2015, 78, 169–181. [Google Scholar] [CrossRef]
- Dempster, A.P. Upper and lower probabilities induced by multi-valued mapping. Ann. Math. Stat. 1967, 38, 325–339. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Beynon, M.; Cosker, D.; Marshall, D. An expert system for multi-criteria decision making using Dempster Shafer theory. Expert Syst. Appl. 2001, 20, 357–367. [Google Scholar] [CrossRef]
- Hegarat-Mascle, S.L.; Richard, D.; Ottle, C. Multi-scale data fusion using Dempster-Shafer evidence theory. Integr. Comput. Aided Eng. 2003, 10, 9–22. [Google Scholar]
- Gong, Y.; Wang, Y. Application Research on Bayesian Network and D-S Evidence Theory in Motor Fault Diagnosis. In Proceedings of the 6th International Conference on Intelligent Networks and Intelligent Systems (ICINIS), Shenyang, China, 1–3 November 2013. [Google Scholar]
- Khaleghi, B.; Khamis, A.; Karray, F.O.; Razavi, S.N. Multisensor data fusion: A review of the state-of-the-art. Inf. Fusion 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Deng, Y.; Chan, F.T.S. A new fuzzy dempster MCDM method and its application in supplier selection. Expert Syst. Appl. 2011, 38, 9854–9861. [Google Scholar] [CrossRef]
- Su, S.Y.; Deng, Y.; Mahadevan, S.; Bao, Q.L. An improved method for risk evaluation in failure modes and effects analysis of aircraft engine rotor blades. Eng. Fail. Anal. 2012, 26, 164–174. [Google Scholar] [CrossRef]
- Parikh, C.R.; Pont, M.J.; Jones, N.B. Application of Dempster–Shafer theory in condition monitoring applications: A case study. Pattern Recogn. Lett. 2001, 22, 777–785. [Google Scholar] [CrossRef]
- Dou, Z.; Xu, X.; Lin, Y.; Zhou, R. Application of D-S evidence fusion method in the fault detection of temperature sensor. Math. Probl. Eng. 2014, 2014, 1–6. [Google Scholar] [CrossRef]
- Fan, X.; Zuo, M.J. Fault diagnosis of machines based on D-S evidence theory. Part 1: D–S evidence theory and its improvement. Pattern Recogn. Lett. 2006, 27, 366–376. [Google Scholar] [CrossRef]
- Hu, Y.; Fan, X.; Zhao, H.; Hu, B. The Research of Target Identification Based on Neural Network and D-S Evidence Theory. In Proceedings of the International Asia Conference on Informatics in Control, Bangkok, Thailand, 1–2 February 2009. [Google Scholar]
- Dong, G.; Kuang, G. Target recognition via information aggregation through Dempster–Shafer’s evidence theory. IEEE Geosci. Remote Sens. 2015, 12, 1247–1251. [Google Scholar] [CrossRef]
- Li, Y.; Chen, J.; Ye, F.; Liu, D. The improvement of DS evidence theory and its application in IR/MMW target recognition. J. Sens. 2016, 2016, 1–15. [Google Scholar] [CrossRef]
- Dymova, L.; Sevastjanov, P. An Interpretation of Intuitionistic Fuzzy Sets in the Framework of the Dempster-Shafer Theory: Decision making aspect. Knowl. Based Syst. 2010, 23, 772–782. [Google Scholar] [CrossRef]
- Chen, N.; Sun, F.; Ding, L.; Wang, H. An adaptive PNN-DS approach to classification using multi-sensor information fusion. Neural Comput. Appl. 2009, 18, 455–467. [Google Scholar] [CrossRef]
- Yager, R.R. On the Dempster-Shafer framework and new combination rules. Inf. Sci. 1987, 41, 93–137. [Google Scholar] [CrossRef]
- Smets, P. The Combination of Evidence in the Transferable Belief Model. IEEE Trans. Pattern Anal. 1990, 12, 447–458. [Google Scholar] [CrossRef]
- Murphy, C.K. Combining belief functions when evidence conflicts. Decis. Support Syst. 2000, 29, 1–9. [Google Scholar] [CrossRef]
- Chen, B.Y.; Shi, C.; Zhang, J.; Lam, W.H.K.; Li, Q.Q.; Xiang, S. Most reliable path-finding algorithm for maximizing on-time arrival probability. Transp. B 2016, 5, 204–221. [Google Scholar] [CrossRef]
- Lomax, T.; Schrank, D.; Turner, S.; Margiotta, R. Selecting Travel Reliability Measures; Texas Transportation Institute Monograph: College Station, TX, USA, 2003. [Google Scholar]
- Hart, R.G. A Close approximation related to the error function. Math. Comput. 1966, 20, 600–602. [Google Scholar] [CrossRef]
- Khosravi, A.; Mazloumi, E.; Nahavandi, S.; Creighton, D.; Van Lint, J.W.C. A genetic algorithm-based method for improving quality of travel time prediction intervals. Transp. Res. C Emerg. Technol. 2011, 19, 1364–1376. [Google Scholar] [CrossRef]
- Khosravi, A.; Mazloumi, E.; Nahavandi, S.; Creighton, D.; Van Lint, J.W.C. Prediction intervals to account for uncertainties in travel time prediction. IEEE Trans. Intell. Transp. Syst. 2011, 12, 537–547. [Google Scholar] [CrossRef]
- Shi, C.; Chen, B.Y.; Li, Q. Estimation of Travel Time Distributions in Urban Road Networks Using Low-Frequency Floating Car Data. ISPRS Int. J. Geo-Inf. 2017, 6, 253. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Travel Time Ranges | Case 1 | Case 2 | Case 3 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 0 | 0 | 0.3 | 0 | 0 | 0.4 | 0 | - | |
| 0.2 | 0.3 | 0.2143 | 0.6 | 0 | 0 | 0.6 | 0 | - | |
| 0.4 | 0.4 | 0.5714 | 0.1 | 0.1 | 1 | 0 | 0 | - | |
| 0.2 | 0.3 | 0.2143 | 0 | 0.6 | 0 | 0 | 0.7 | - | |
| 0.1 | 0 | 0 | 0 | 0.3 | 0 | 0 | 0.3 | - | |
| Travel Time Ranges | Case 1 | Case 2 | Case 3 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0.075 | 0 | 0.0410 | 0.275 | 0 | 0.2415 | 0.375 | 0 | 0.3337 | |
| 0.2 | 0.275 | 0.2075 | 0.6 | 0 | 0.5270 | 0.575 | 0 | 0.5116 | |
| 0.4 | 0.4 | 0.4756 | 0.075 | 0.075 | 0.0874 | 0 | 0 | 0.0000 | |
| 0.2 | 0.275 | 0.2075 | 0 | 0.6 | 0.0687 | 0 | 0.675 | 0.0783 | |
| 0.075 | 0 | 0.0410 | 0 | 0.275 | 0.0315 | 0 | 0.275 | 0.0319 | |
| 0.05 | 0.05 | 0.0273 | 0.05 | 0.05 | 0.0439 | 0.05 | 0.05 | 0.0445 | |
| Data Source | Estimated Mean | Estimated STD | POPI | POOI | ||
|---|---|---|---|---|---|---|
| MAPE | RMSE (min) | MAPE | RMSE (min) | |||
| Point detectors | 46.5% | 2.32 | 61.6% | 0.75 | 85.9% | 92.0% |
| Interval detectors | 17.1% | 1.42 | 76.9% | 1.01 | 26.4% | 48.9% |
| Data fusion | 7.1% | 0.85 | 17.9% | 0.35 | 15.7% | 25.6% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, C.; Chen, B.Y.; Lam, W.H.K.; Li, Q. Heterogeneous Data Fusion Method to Estimate Travel Time Distributions in Congested Road Networks. Sensors 2017, 17, 2822. https://doi.org/10.3390/s17122822
Shi C, Chen BY, Lam WHK, Li Q. Heterogeneous Data Fusion Method to Estimate Travel Time Distributions in Congested Road Networks. Sensors. 2017; 17(12):2822. https://doi.org/10.3390/s17122822
Chicago/Turabian StyleShi, Chaoyang, Bi Yu Chen, William H. K. Lam, and Qingquan Li. 2017. "Heterogeneous Data Fusion Method to Estimate Travel Time Distributions in Congested Road Networks" Sensors 17, no. 12: 2822. https://doi.org/10.3390/s17122822
APA StyleShi, C., Chen, B. Y., Lam, W. H. K., & Li, Q. (2017). Heterogeneous Data Fusion Method to Estimate Travel Time Distributions in Congested Road Networks. Sensors, 17(12), 2822. https://doi.org/10.3390/s17122822