
A Framework for Bus Trajectory Extraction and Missing Data Recovery for Data Sampled from the Internet

Abstract
:1. Introduction
- A novel framework of urban bus trajectory extraction is developed, which provides a generalized preprocessing of the raw data sampled from the real-time bus arrival information querying website offered by the Suzhou Transportation Bureau. The trajectory extraction framework consists of three sub-procedures: data clustering to aggregate trajectory fragments, data cleaning to eliminate noisy data in the trajectories and data connecting to merge the fragments into complete one-route trajectories. The proposed framework enables researchers from different regions to sample the urban bus traveling data from the Internet and to extract the trajectories with noise removal, thus providing a new method for urban computing via the traffic data of buses.
- The fuzzy membership function matrix is first introduced to deal with the problems of contextual anomalies detection, which is applied for noisy data removal in the trajectories. Furthermore, the MF matrix is extended to solve the problem of trajectory fragments connecting with erroneous data tolerance. The proposed MF matrix can be evaluated by the given empirical parameters and can be refined by the sampled data, which is easy to implement and is robust in the trajectory cleaning capability.
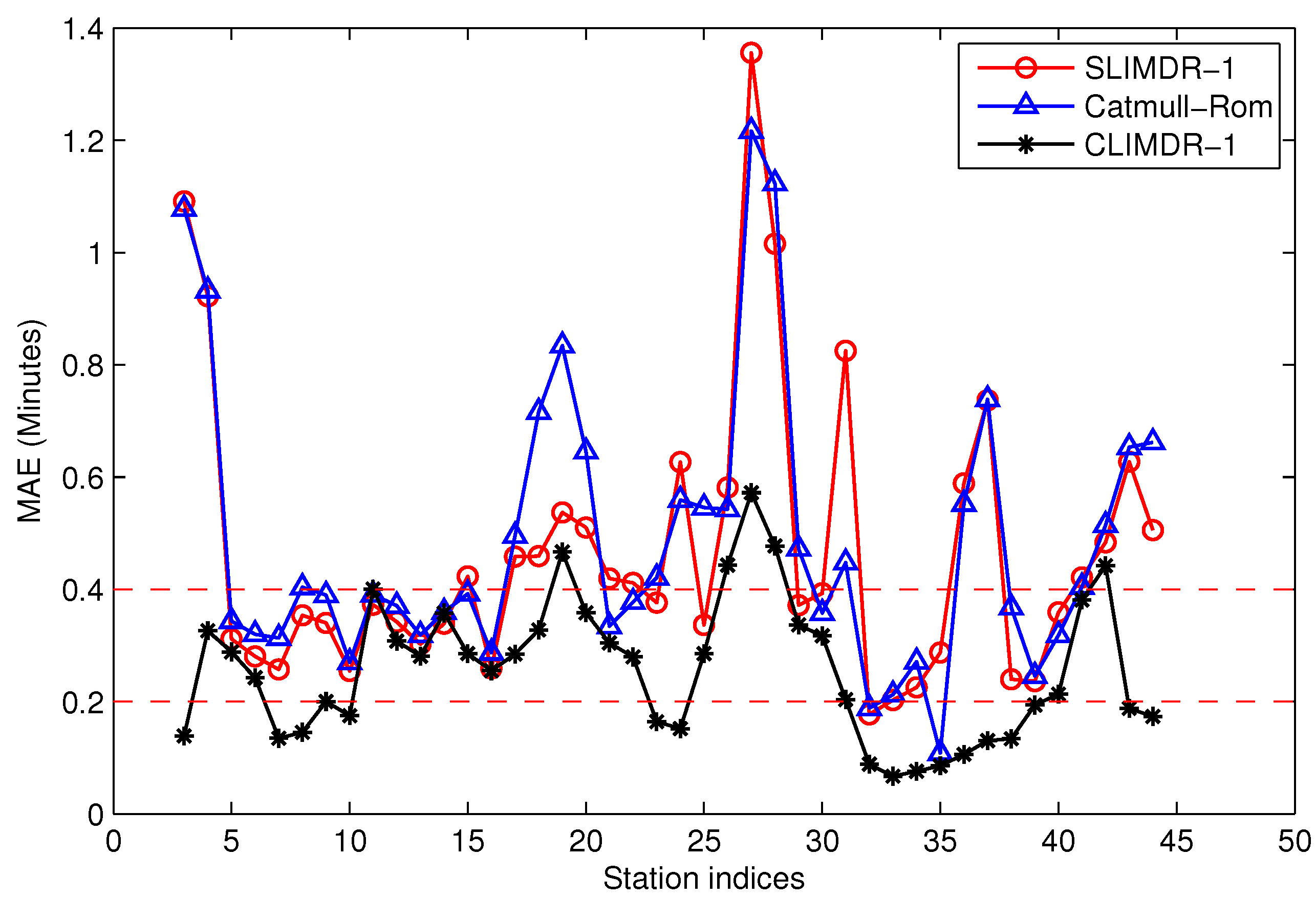
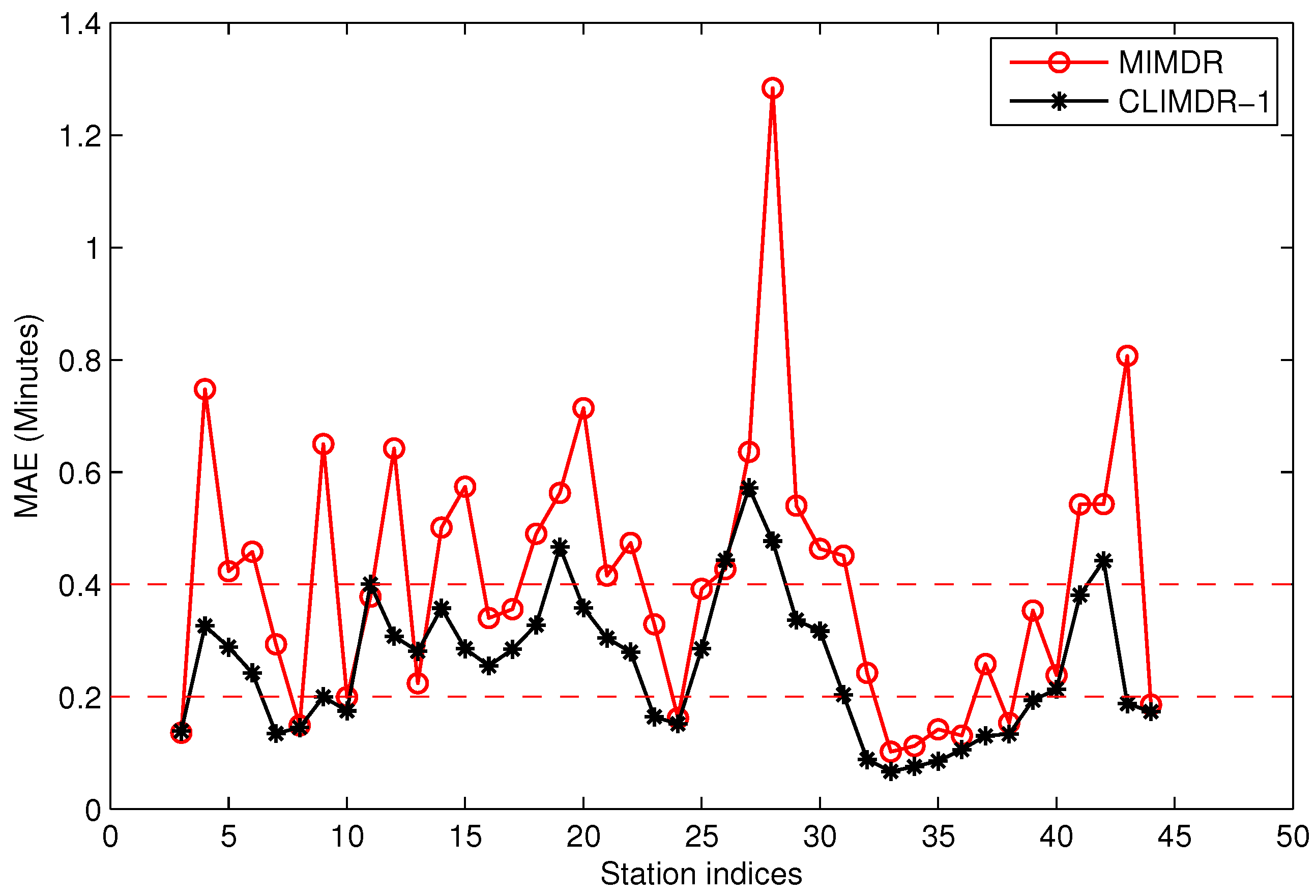
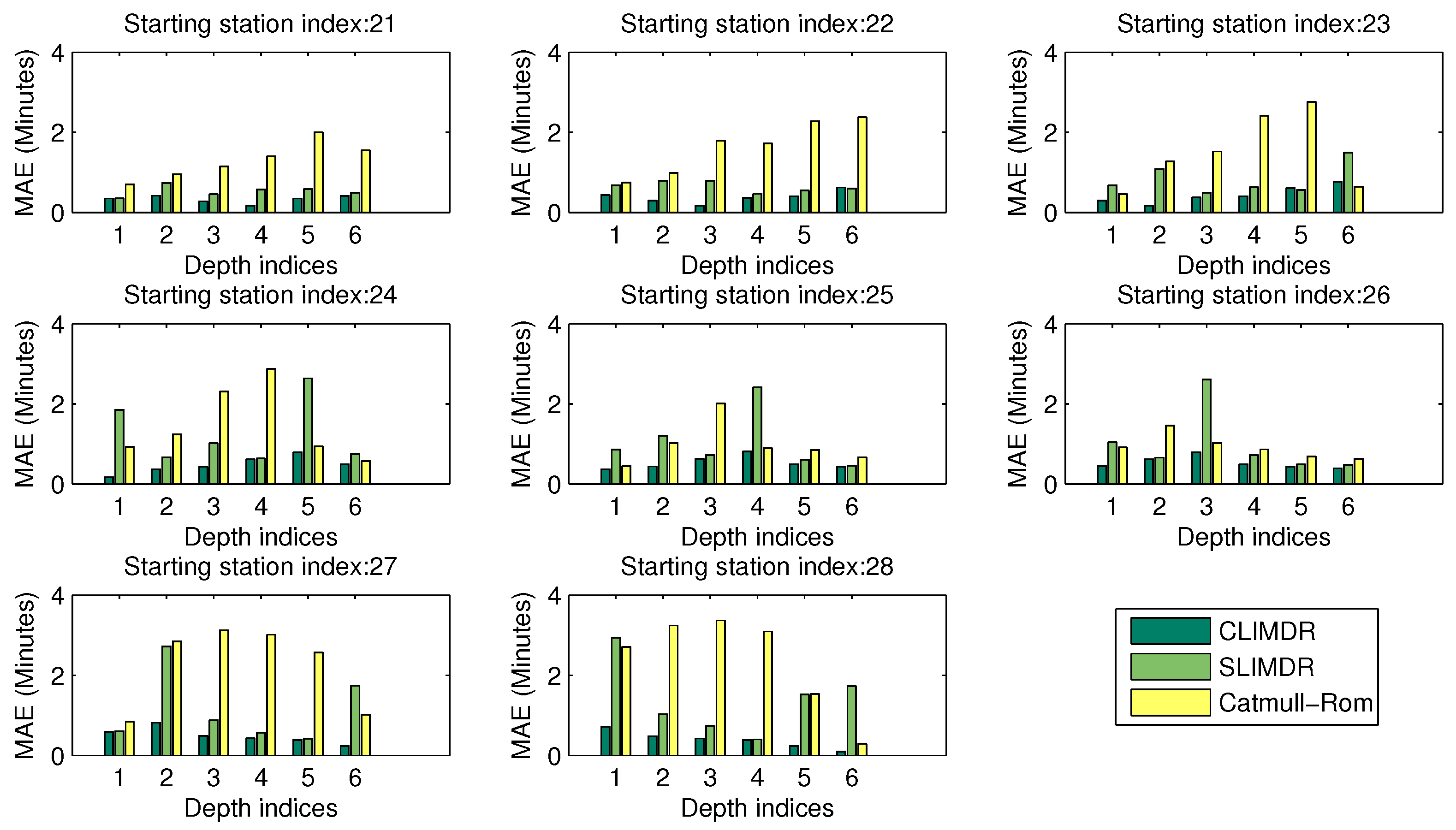
- An efficient scheme that takes into consideration historical data, as well as contextual arrival information is presented for the missing data recovery of the traveling data. Numerous experiments demonstrate that the proposed method outperforms other traditional interpolating methods, such as straight linear interpolation and Catmull-Rom curves.
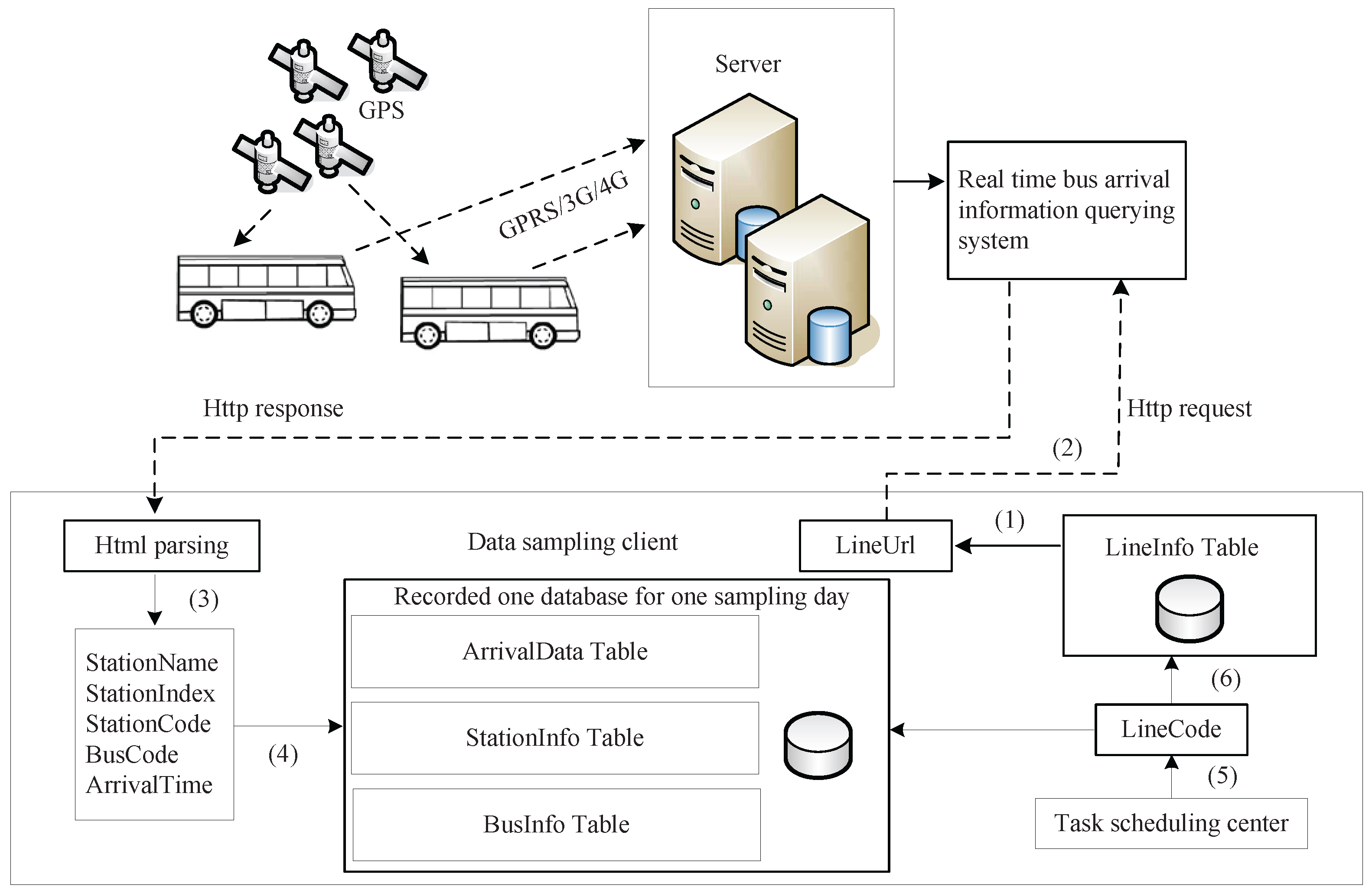
2. The Bus Arrival Data Acquisition Project
- Query the LineUrl by LineCode in the “LineInfo” table by the task scheduling center.
- Query the bus arrival information by http request with the URL bundled to LineCode.
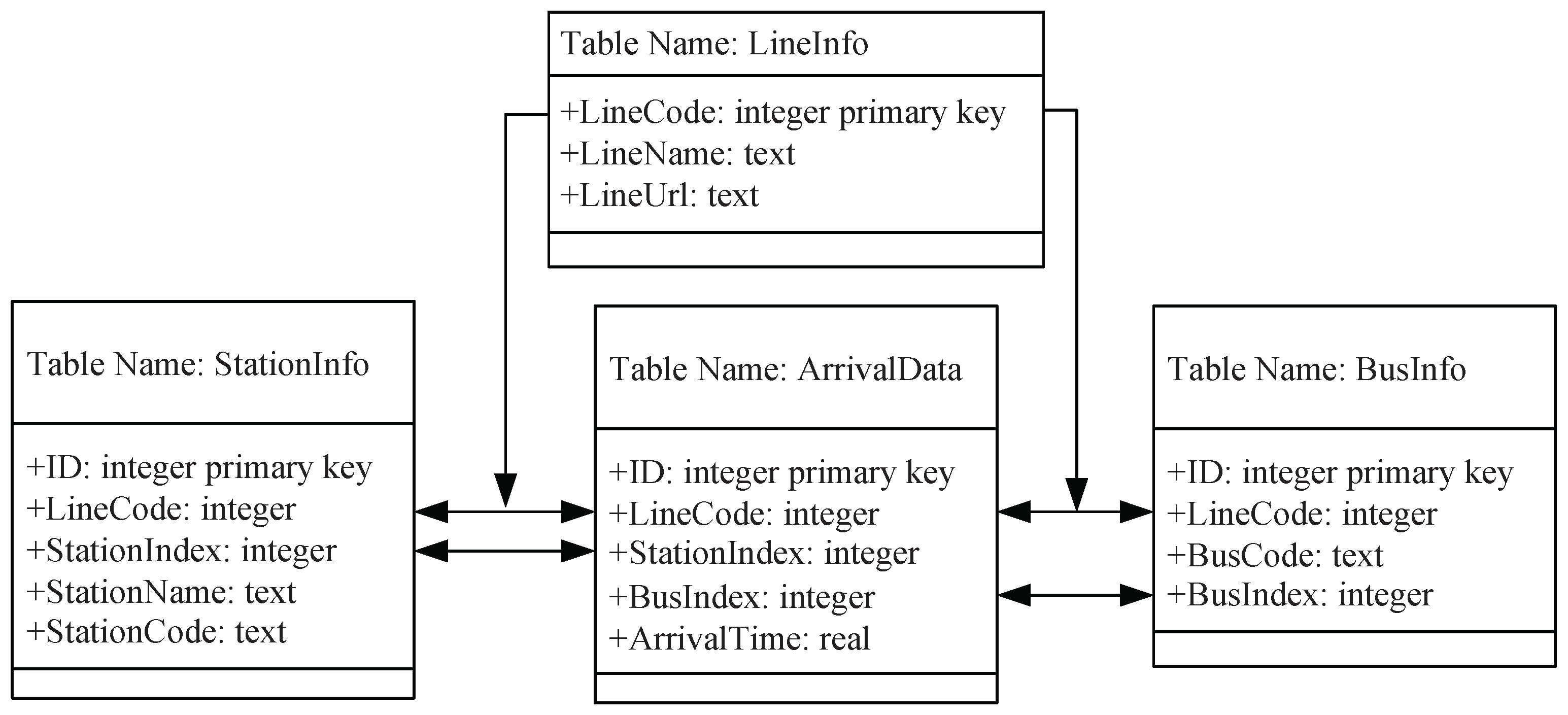
- Parse the HTML from the remote server and extract the arrival data StationName, StationIndex (processed by program), StationCode, BusCode and ArrivalTime (parsed from text to float number by program) from the web page, as shown in Figure 1.
- Write the arrival data to the corresponding three tables.
- Sleep until the next sampling time occurs, and then, update the LineCode to the next line by the task scheduling center.
- Go back to Step 1 and perform the sampling until the task finishing time hits.
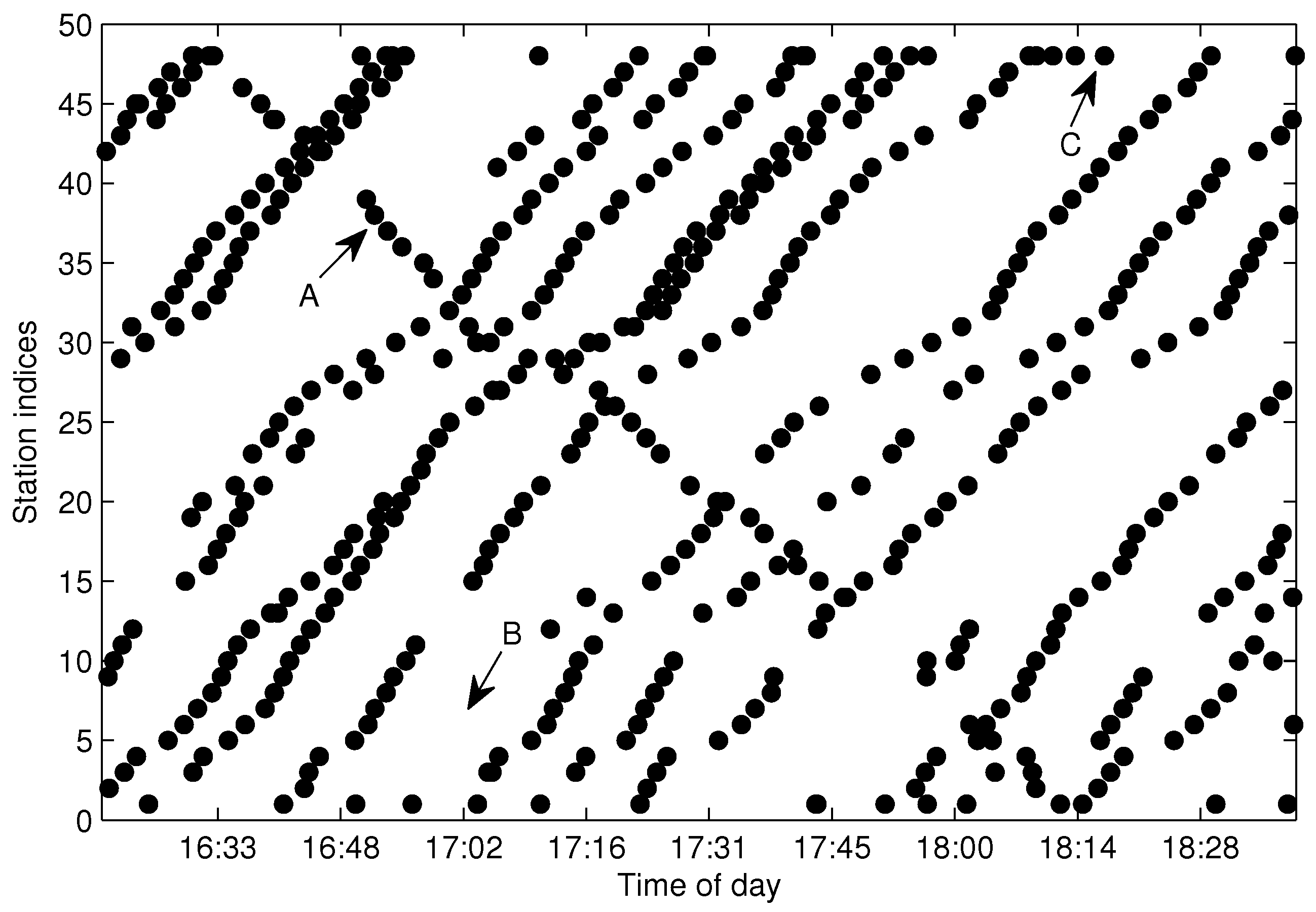
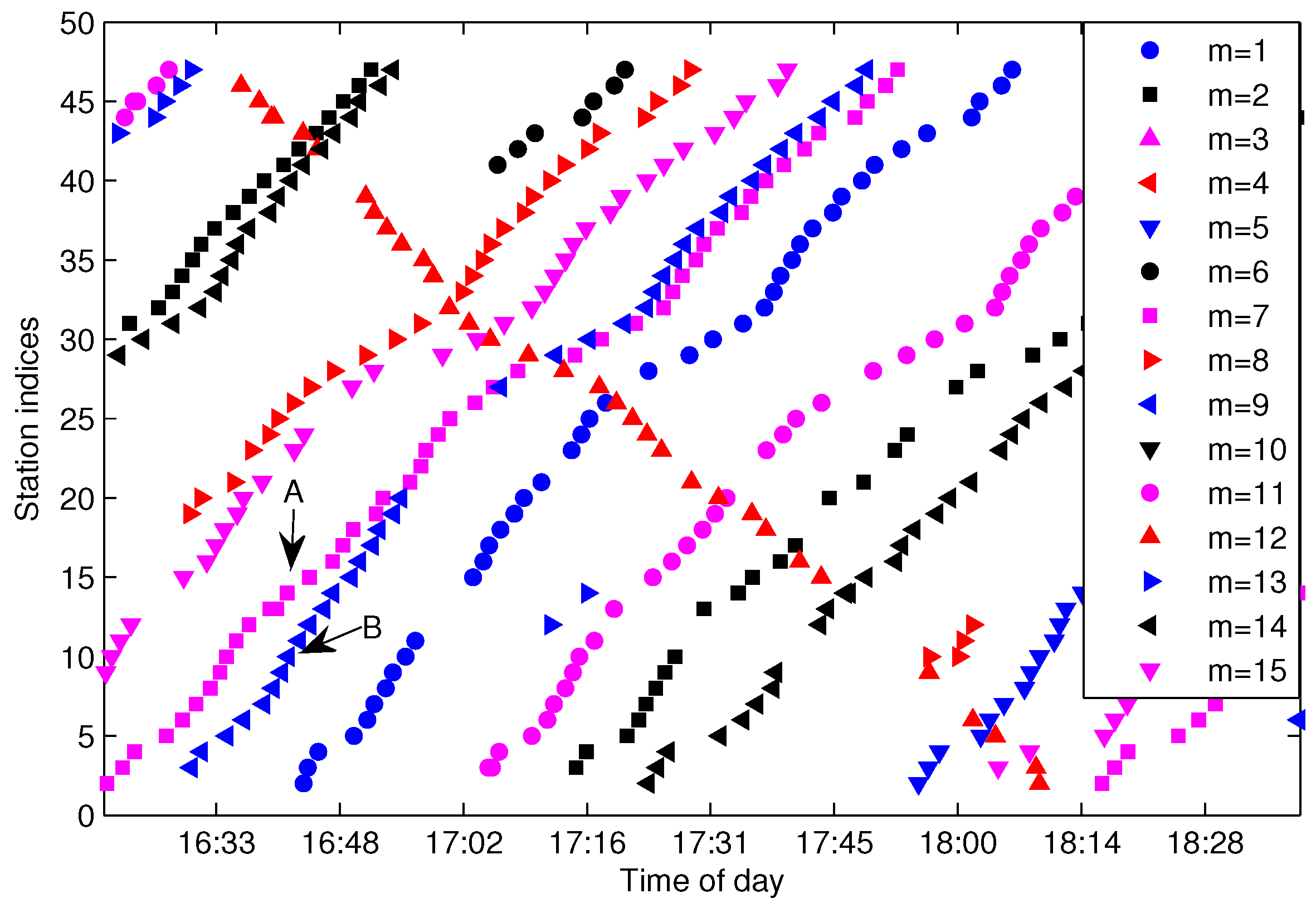
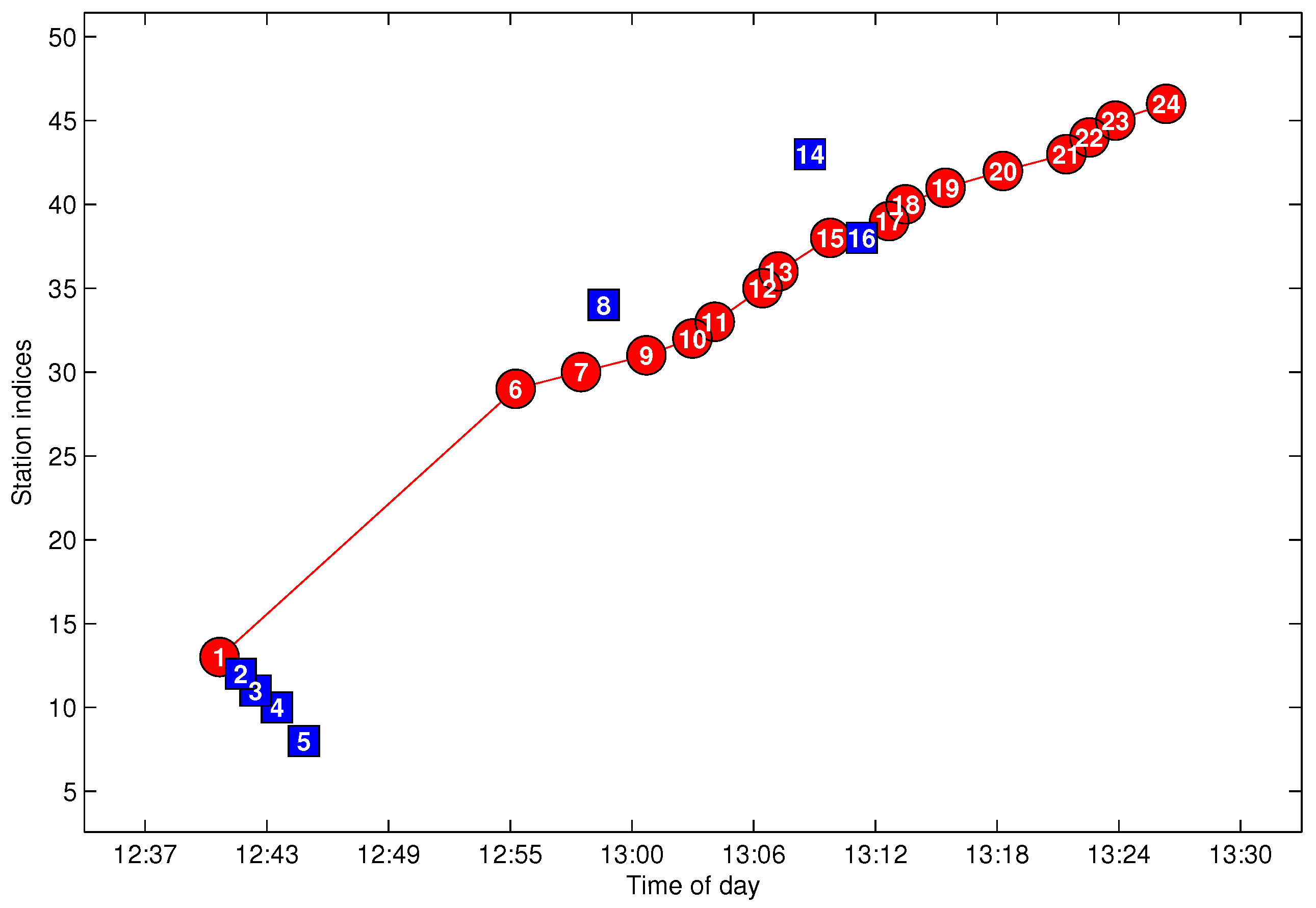
3. Problem Statements
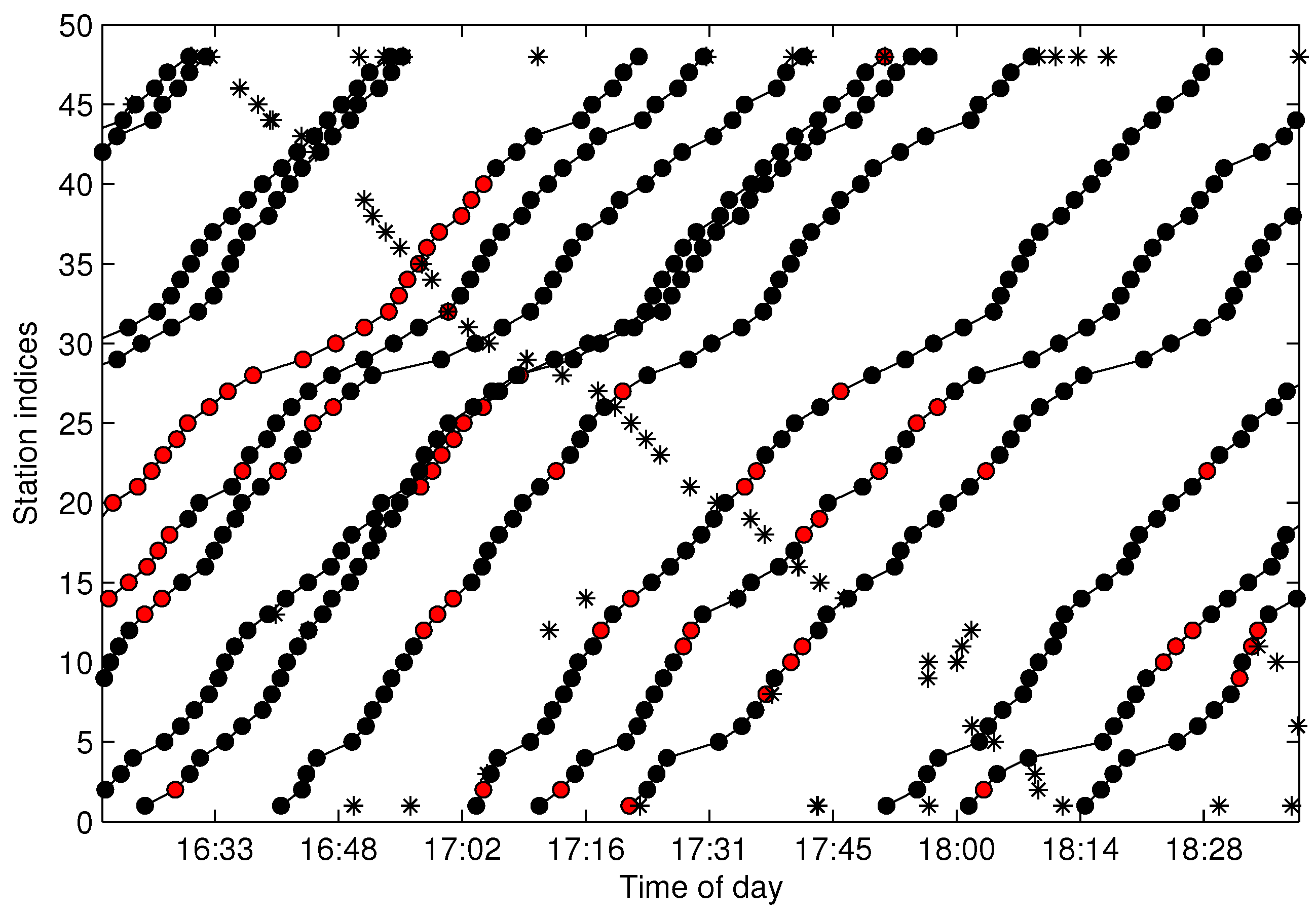
4. Trajectories Extraction and Missing Data Recovery
4.1. Fuzzy C-Means Clustering
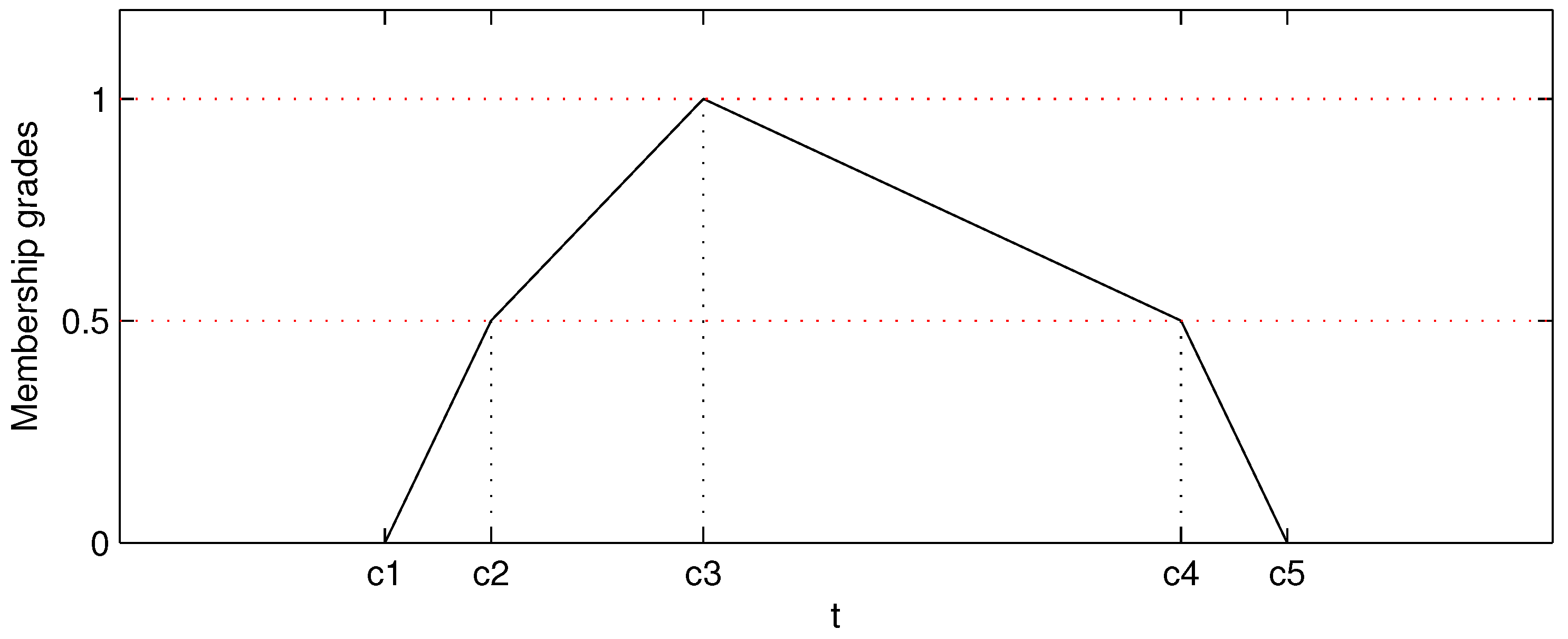
4.2. Feature Construction for FCM
4.3. Parameters Selection for FCM
4.4. The FCM Clustering Algorithm
| Algorithm 1 F-FCM clustering algorithm. |
| Input: ; |
| Output: (the partition matrix), (the prototypes set), (the objective function); |
Process:
|
| Algorithm 2 FCM clustering algorithm. |
| Input: , N (the number of data in , i.e., ); |
| Output: U (the partition matrix), (the aggregated clusters); |
Process:
|
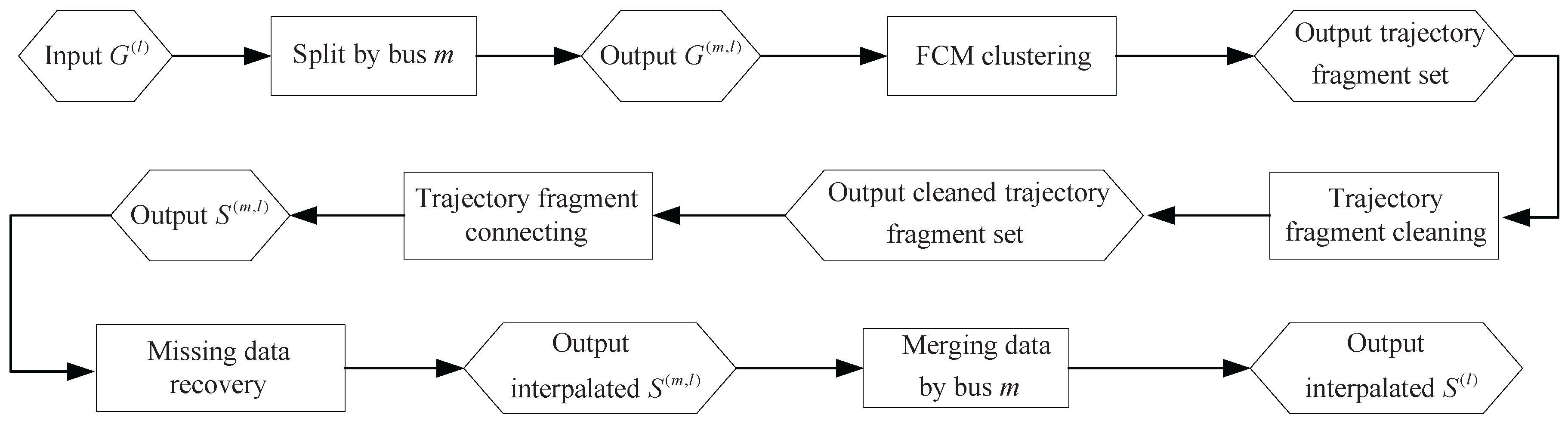
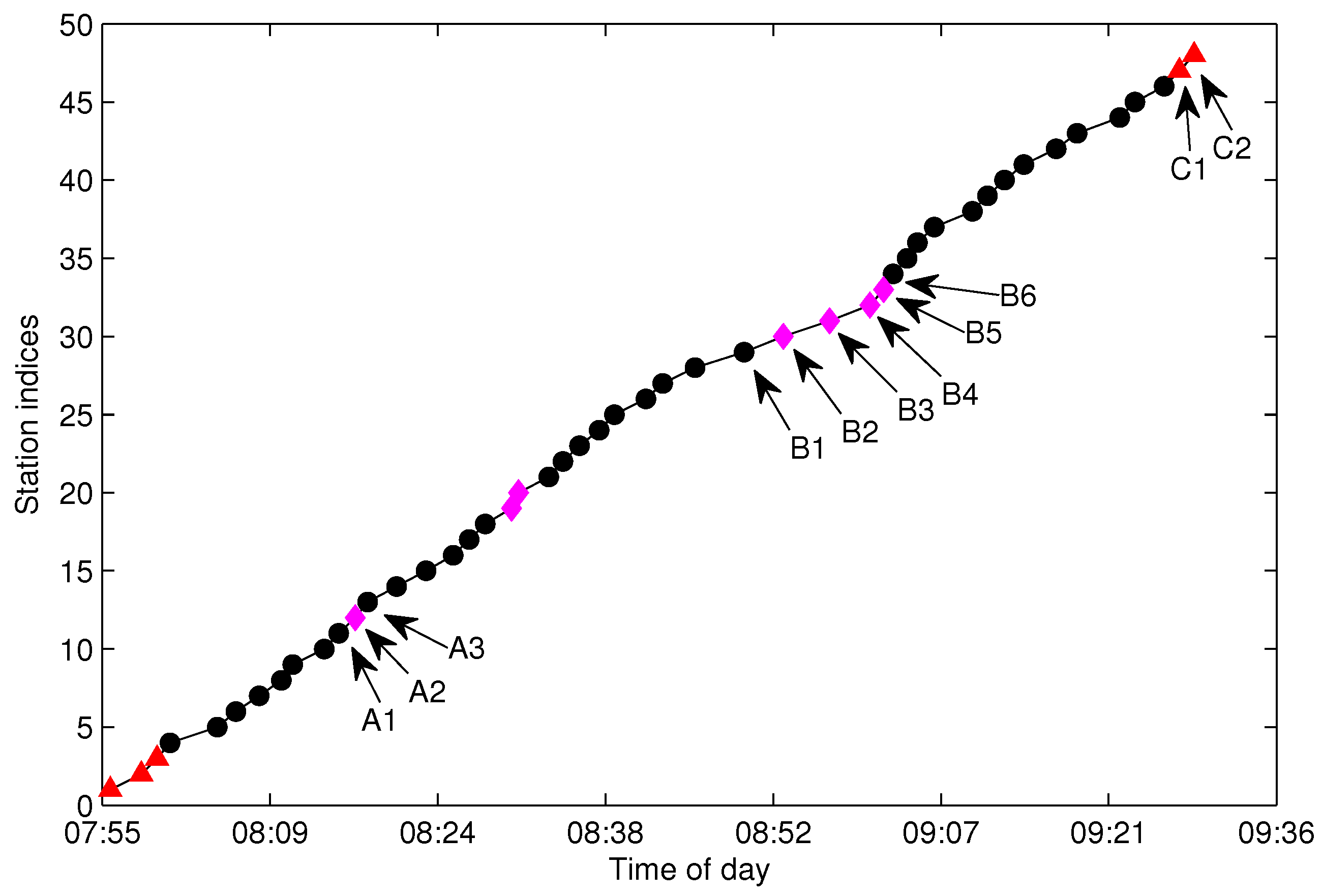
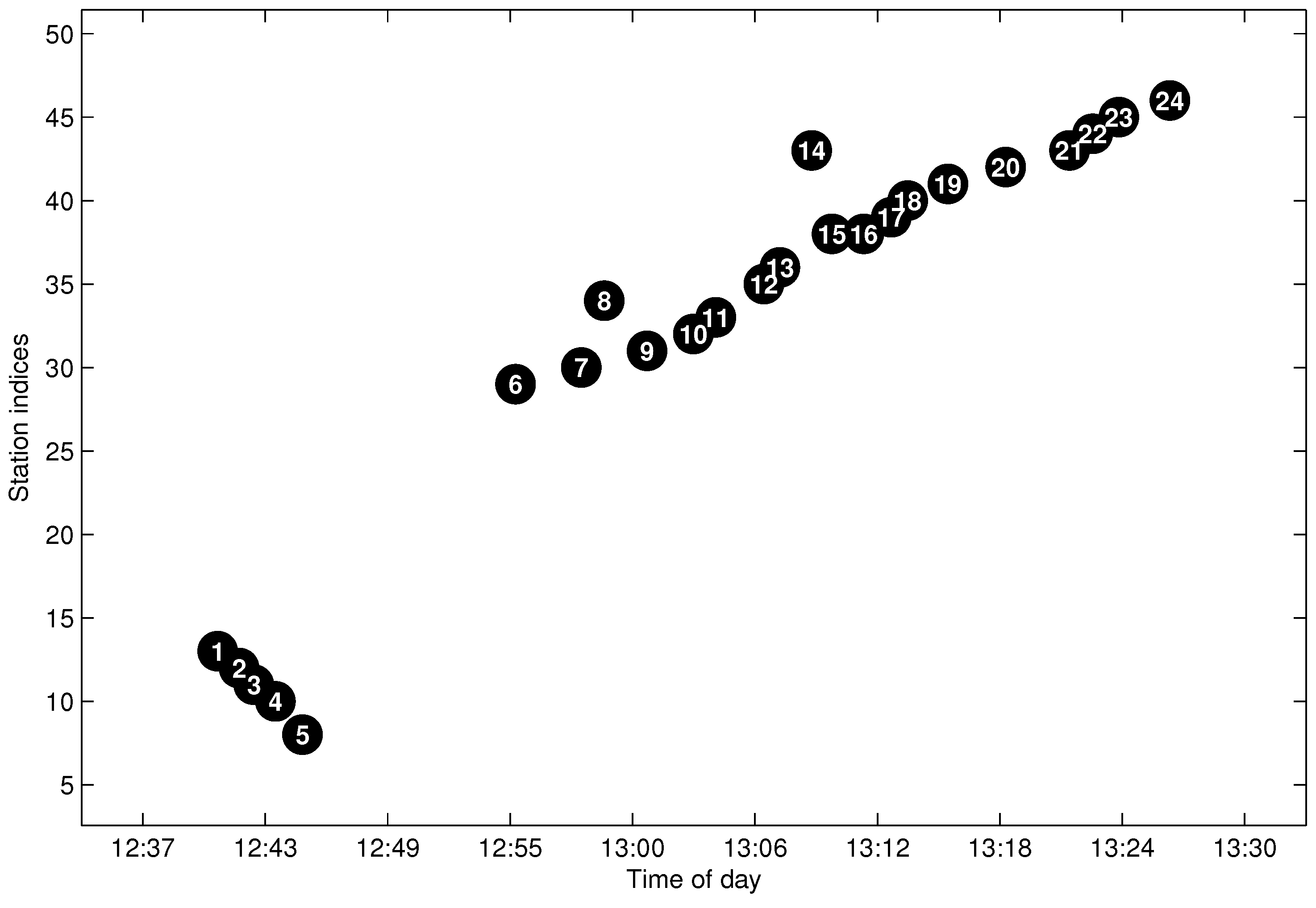
4.5. Trajectory Fragment Cleaning
| Algorithm 3 Trajectory fragment cleaning algorithm. |
| Input: , , ; |
| Output: , , ; |
Process:
|
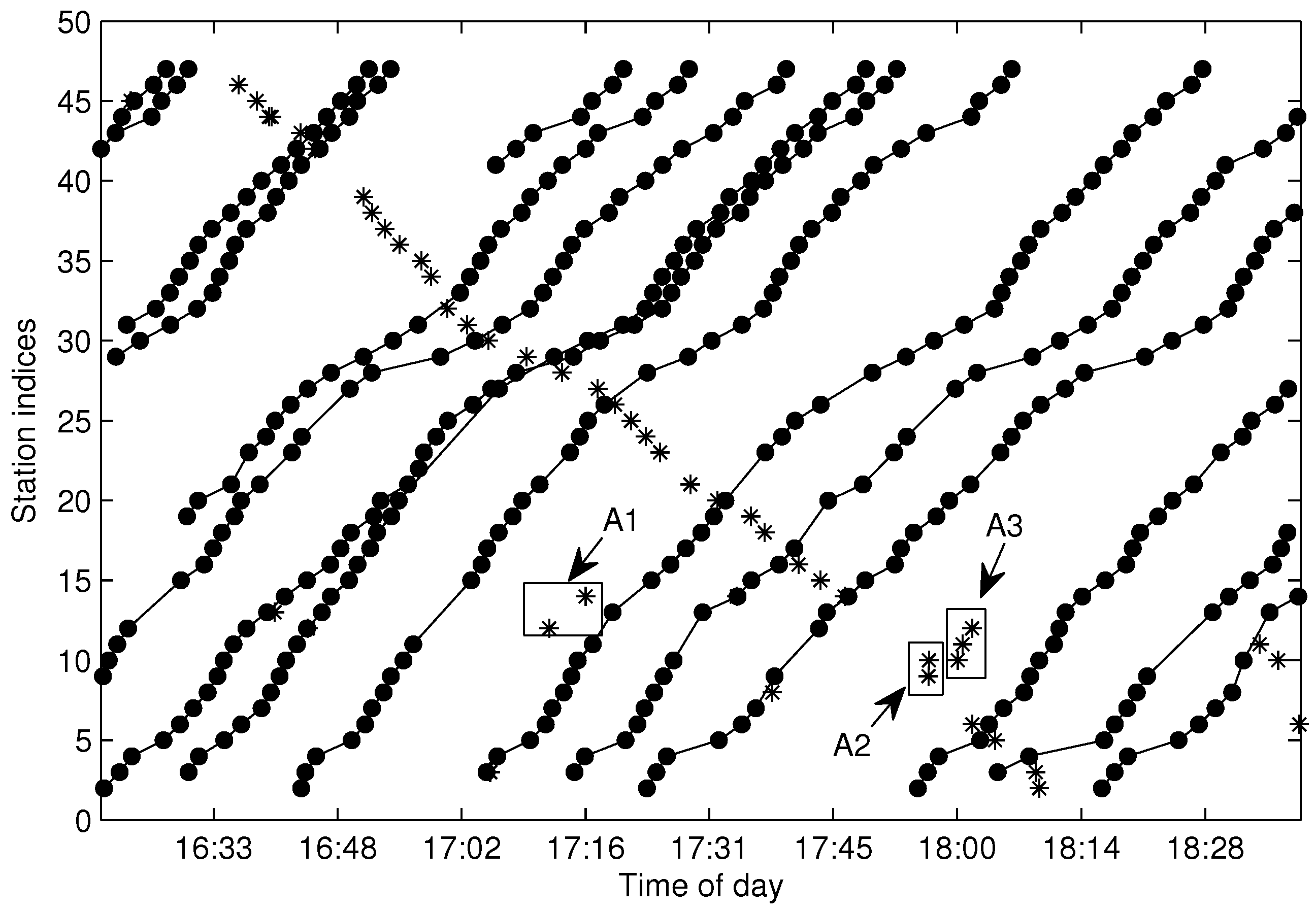
4.6. Trajectory Fragments Connecting
| Algorithm 4 Trajectory fragments connecting. |
| Input: , , ; |
| Output: ; |
Process:
|
4.7. Missing Data Recovery
- set , where the first symbol “:” means selecting all rows of , and the second parameter set “” means selecting the corresponding columns of with the station index of ;
- delete the rows of when any elements in the row equal zero (missing data).
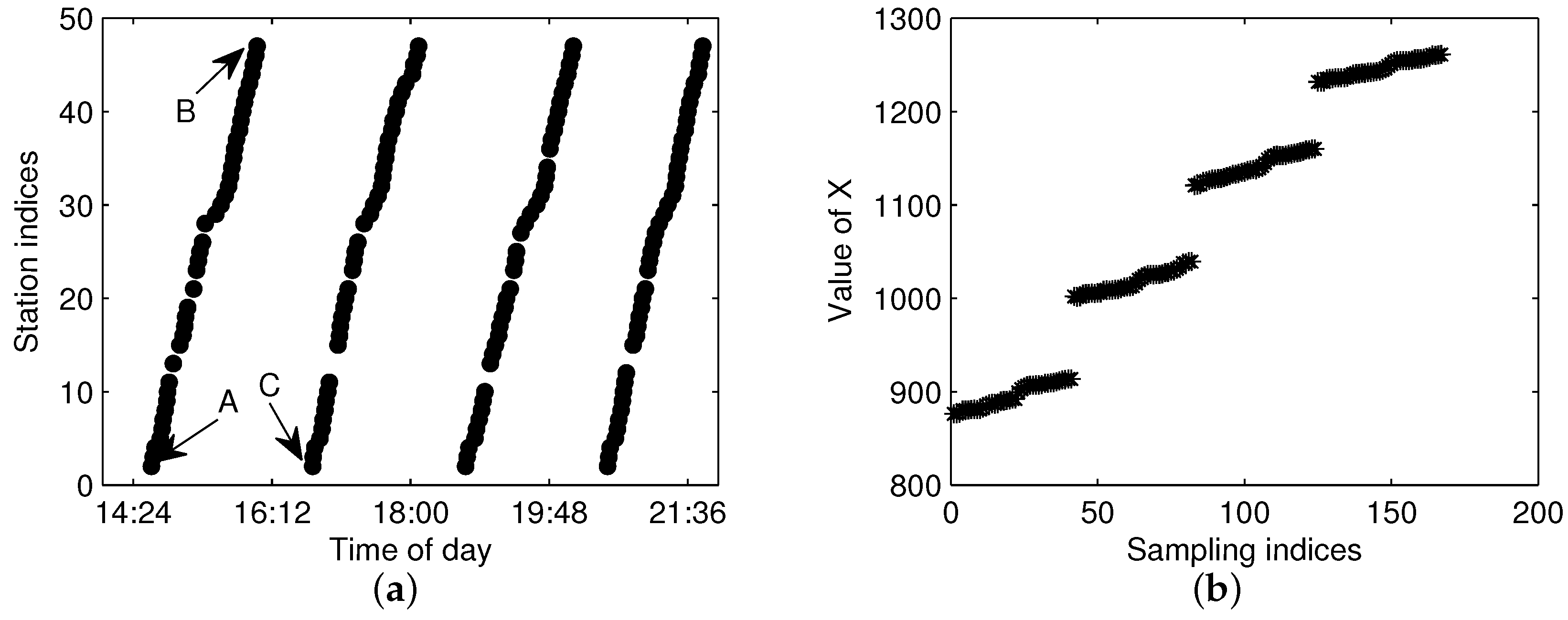
5. Results and Discussion
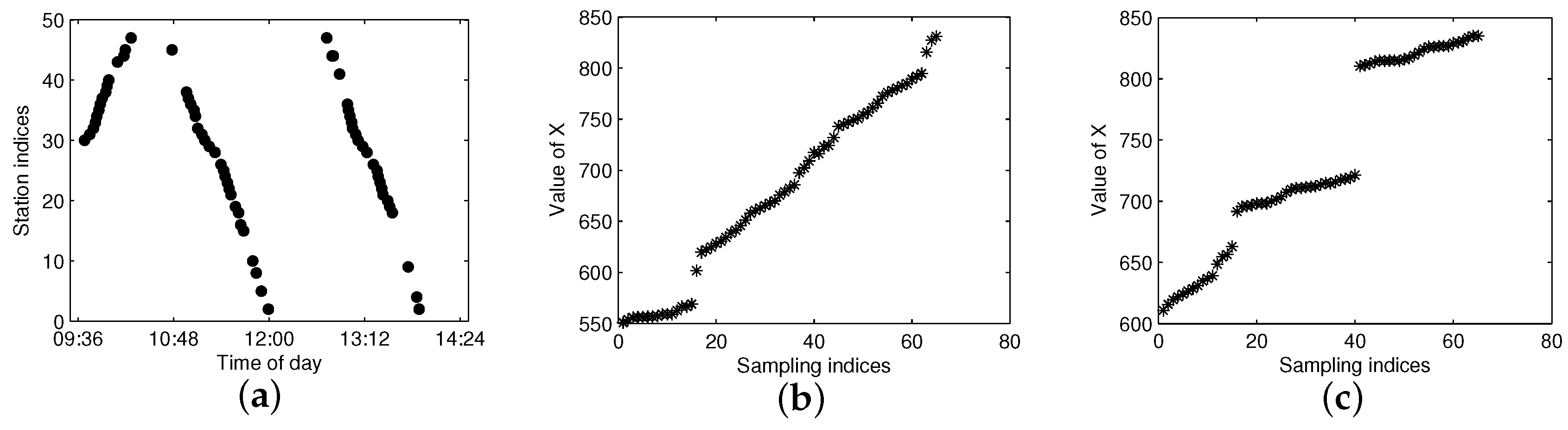
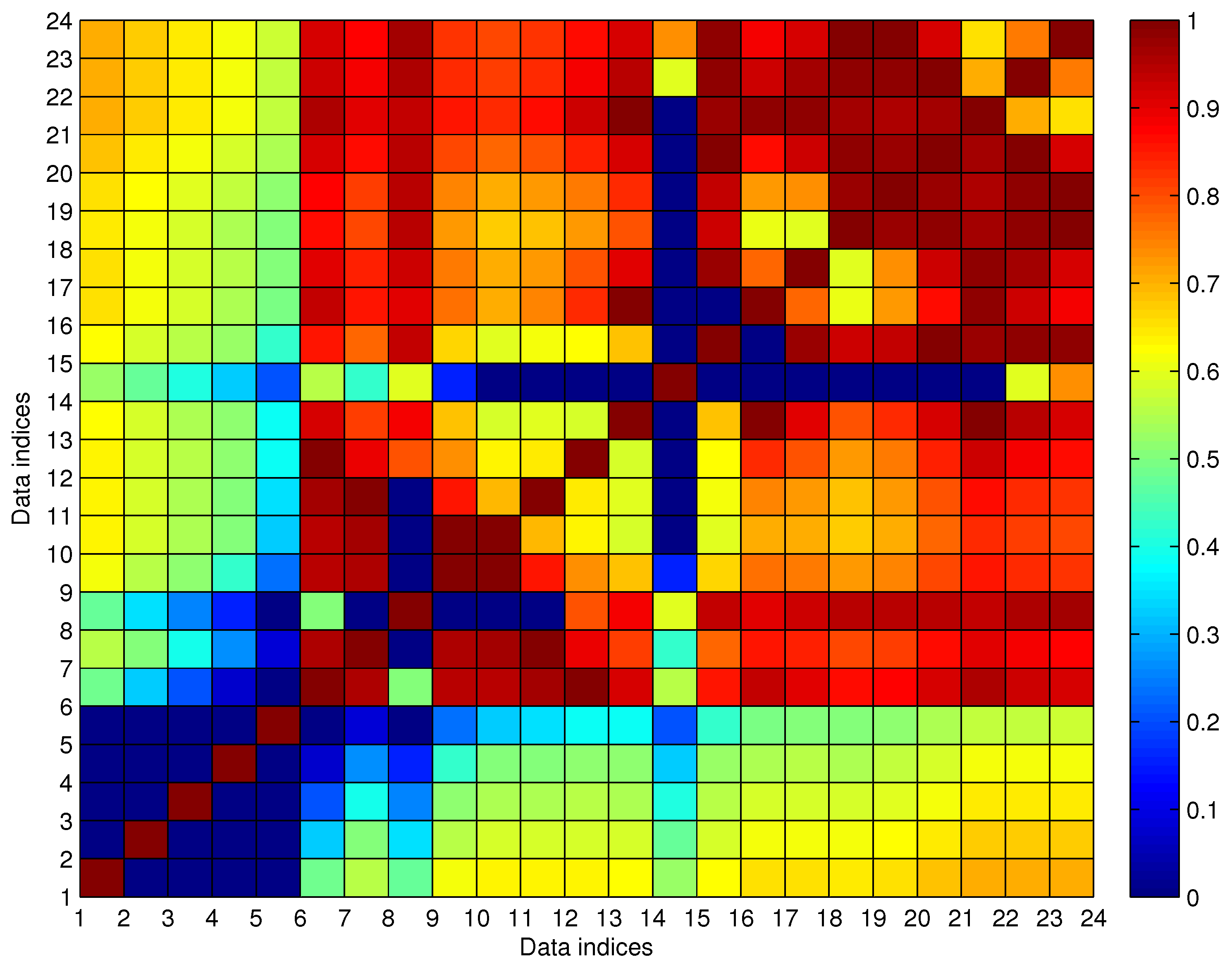
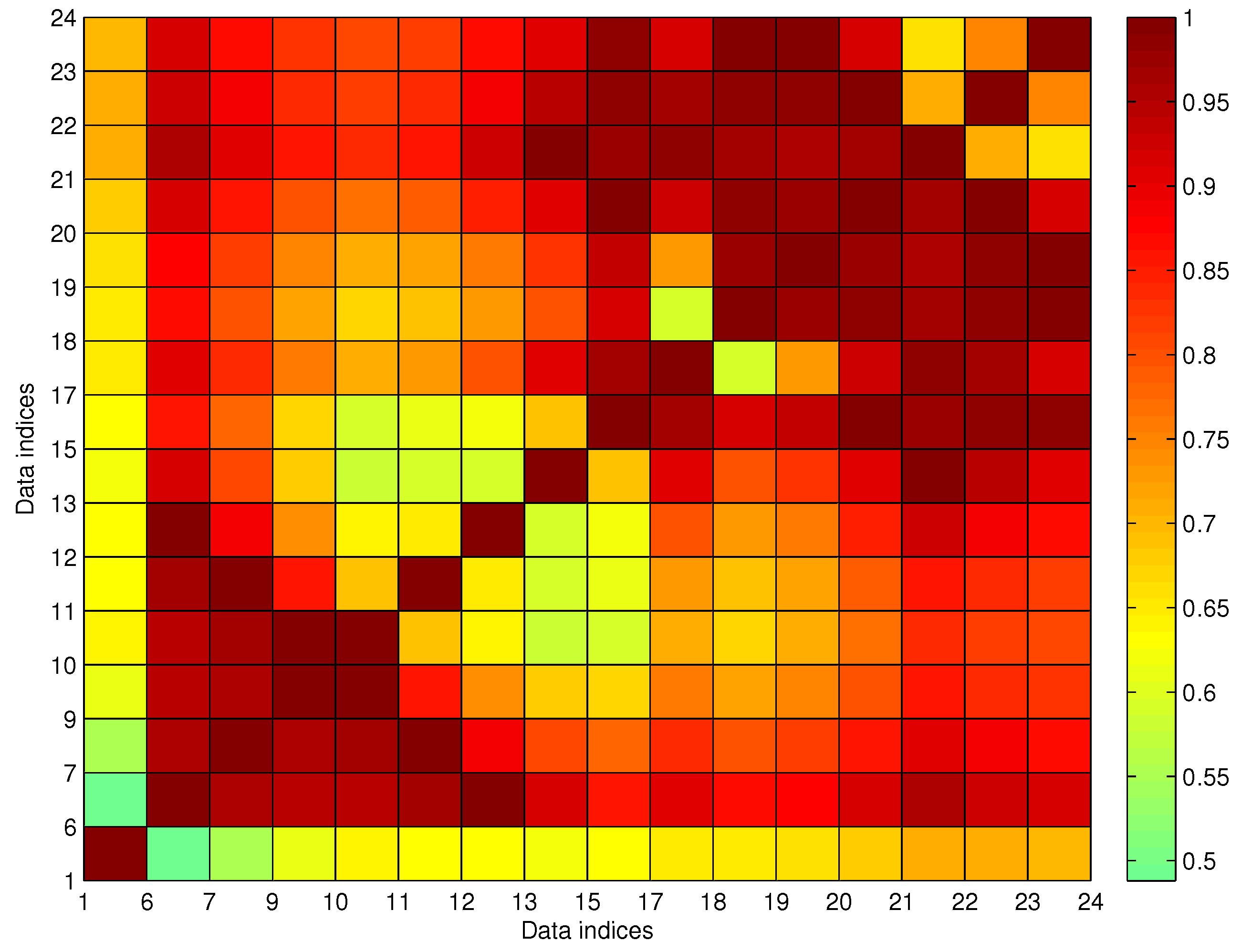
5.1. Comparing Trajectory Clustering between F-FCM and B-FCM
5.2. Discussing the Setting of Cluster Number for FCM
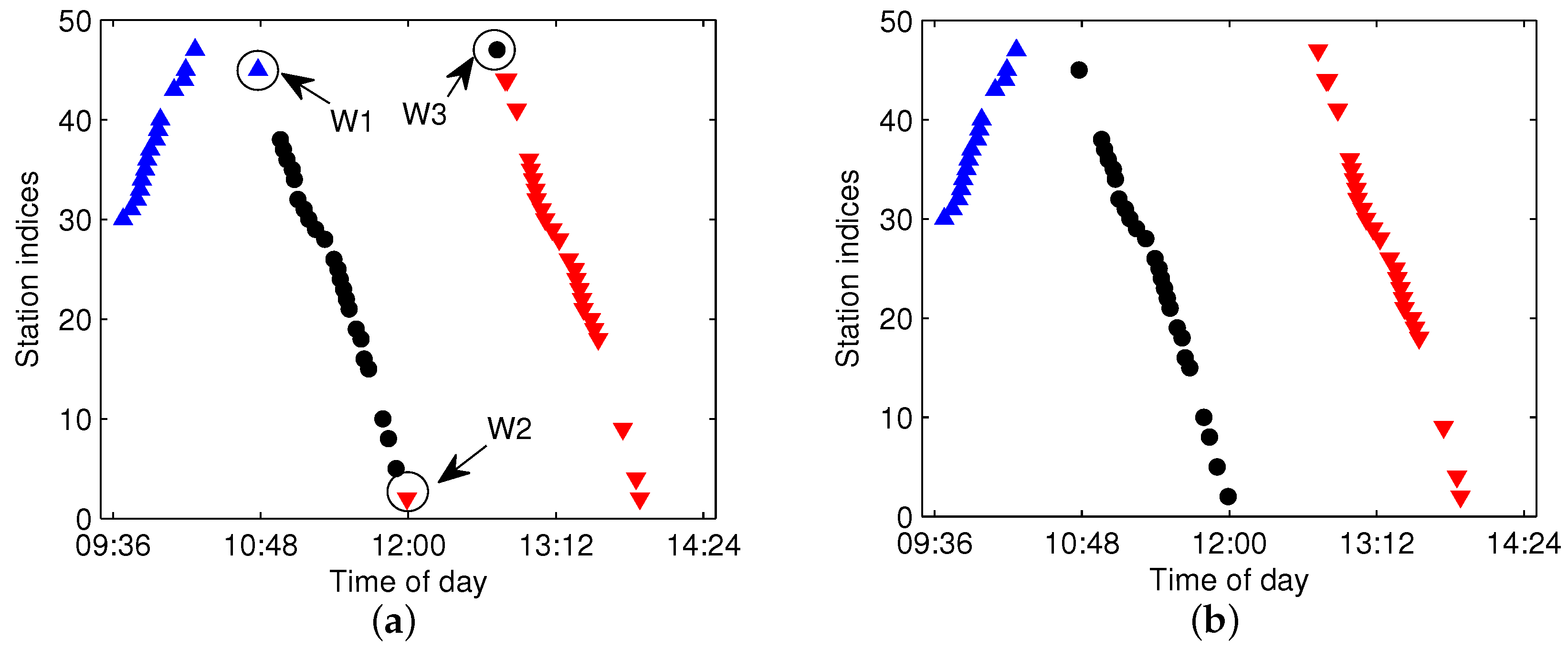
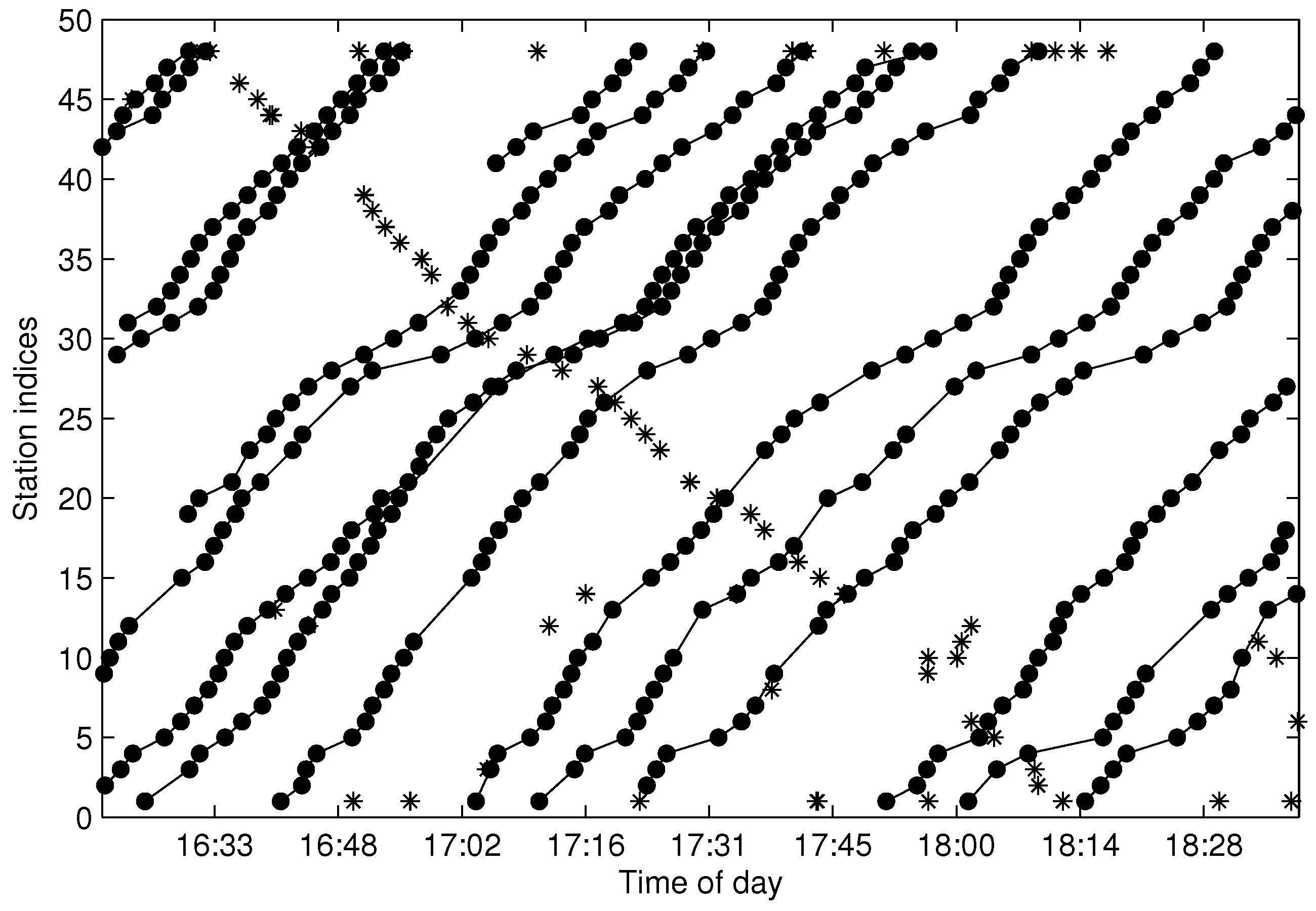
5.3. Testing of the Trajectory Fragment Cleaning Algorithm
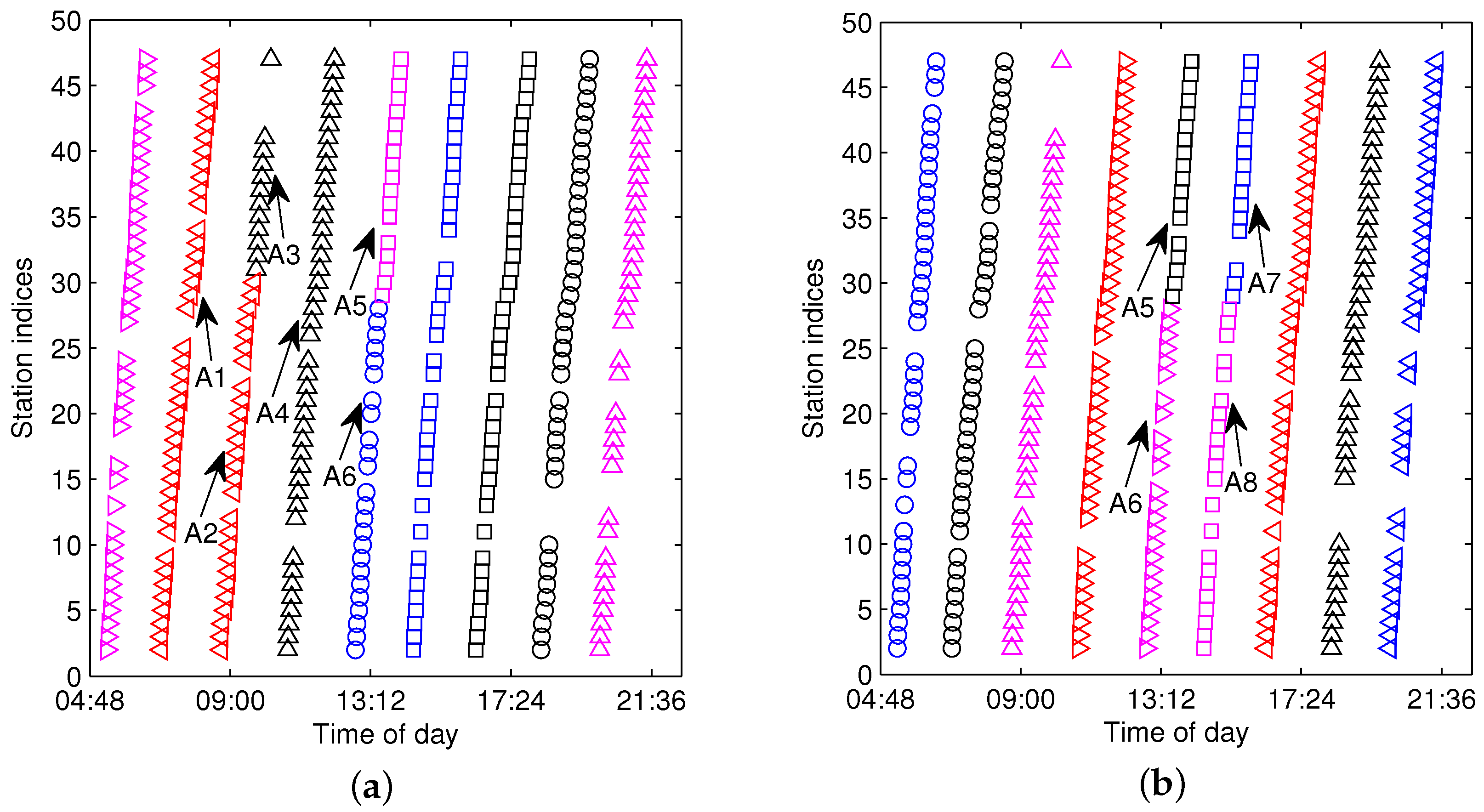
5.4. Testing of the Trajectory Fragments Connecting Algorithm
5.5. Performance of the Missing Data Recovery Methods
6. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
References
- Zheng, Y. Trajectory Data Mining: An Overview. ACM Trans. Intell. Syst. Technol. 2015, 6, 1–45. [Google Scholar] [CrossRef]
- Zhang, F.; Yuan, N.J.; Wilkie, D.; Zheng, Y.; Xie, X. Sensing the Pulse of Urban Refueling Behavior: A Perspective from Taxi Mobility. ACM Trans. Intell. Syst. Technol. 2015, 6, 1–24. [Google Scholar] [CrossRef]
- Ma, S.; Zheng, Y.; Wolfson, O. Real-Time City-Scale Taxi Ridesharing. IEEE Trans. Knowl. Data Eng. 2015, 27, 1782–1795. [Google Scholar] [CrossRef]
- Yuan, N.J.; Zheng, Y.; Xie, X.; Wang, Y.; Zheng, K.; Xiong, H. Discovering Urban Functional Zones Using Latent Activity Trajectories. IEEE Trans. Knowl. Data Eng. 2015, 27, 712–725. [Google Scholar] [CrossRef]
- Zhang, D.; Sun, L.; Li, B.; Chen, C.; Pan, G.; Li, S.; Wu, Z. Understanding Taxi Service Strategies From Taxi GPS Traces. IEEE Trans. Intell. Transp. Syst. 2015, 16, 123–135. [Google Scholar] [CrossRef]
- Castro, P.S.; Zhang, D.; Chen, C.; Li, S.; Pan, G. From Taxi GPS Traces to Social and Community Dynamics: A Survey. ACM Comput. Surv. 2013, 46, 1–34. [Google Scholar] [CrossRef]
- Pan, G.; Qi, G.D.; Zhang, W.S.; Li, S.J.; Wu, Z.H.; Yang, L.T. Trace Analysis and Mining for Smart Cities: Issues, Methods, and Applications. IEEE Commun. Mag. 2013, 51, 120–126. [Google Scholar] [CrossRef]
- Pan, G.; Qi, G.; Wu, Z.; Zhang, D.; Li, S. Land-Use Classification Using Taxi GPS Traces. IEEE Trans. Intell. Transp. Syst. 2013, 14, 113–123. [Google Scholar] [CrossRef]
- Li, X.; Pan, G.; Wu, Z.; Qi, G.; Li, S.; Zhang, D.; Zhang, W.; Wang, Z. Prediction of urban human mobility using large-scale taxi traces and its applications. Front. Comput. Sci. China 2012, 6, 111–121. [Google Scholar]
- Liu, X.; Biagioni, J.; Eriksson, J.; Wang, Y.; Forman, G.; Zhu, Y. Mining Large-scale, Sparse GPS Traces for Map Inference: Comparison of Approaches. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’12), Beijing, China, 12–16 August 2012; ACM: New York, NY, USA, 2012; pp. 669–677. [Google Scholar]
- Bejan, A.; Gibbens, R.; Evans, D.; Beresford, A.; Bacon, J.; Friday, A. Statistical modelling and analysis of sparse bus probe data in urban areas. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Funchal, Portugal, 19–22 September 2010; pp. 1256–1263.
- Bejan, A.; Gibbens, R. Evaluation of Velocity Fields via Sparse Bus Probe Data in Urban Areas. In Proceedings of the 14th Internation IEEE Conference on Intelligent Transportation Systems, Washington, DC, USA, 5–7 October 2011; pp. 746–753.
- Do Amaral, B.G.; Nasser, R.; Casanova, M.A.; Lopes, H. BusesinRio: Buses as mobile traffic sensors: Managing the bus GPS data in the city of Rio de Janeiro. In Proceedings of the 17th IEEE International Conference on Mobile Data Management, Porto, Portugal, 13–16 June 2016; pp. 369–372.
- Suzhou Transportation Bureau. The Official Website of Bus Arrival Information Quering System for Suzhou. [EB/OL]. 2017. Available online: http://www.szjt.gov.cn/apts/APTSLine.aspx (accessed on 18 January 2017). [Google Scholar]
- Dai, D.; Mu, D. An Algorithm for Bus Trajectory Extraction Based on Incomplete Data Source. Chin. J. Electron. 2012, 21, 599–603. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Yamanishi, K.; Takeuchi, J.I.; Williams, G.; Milne, P. On-Line Unsupervised Outlier Detection Using Finite Mixtures with Discounting Learning Algorithms. Data Min. Knowl. Discov. 2004, 8, 275–300. [Google Scholar] [CrossRef]
- Markou, M.; Singh, S. A Neural Network-Based Novelty Detector for Image Sequence Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1664–1677. [Google Scholar] [CrossRef] [PubMed]
- Ghoting, A.; Parthasarathy, S.; Otey, M.E. Fast mining of distance-based outliers in high-dimensional datasets. Data Min. Knowl. Discov. 2008, 16, 349–364. [Google Scholar] [CrossRef]
- Piciarelli, C.; Micheloni, C.; Foresti, G.L. Trajectory-Based Anomalous Event Detection. IEEE Trans. Circ. Syst. Video Technol. 2008, 18, 1544–1554. [Google Scholar] [CrossRef]
- Fanaee-T, H.; Gama, J. Tensor-based anomaly detection: An interdisciplinary survey. Knowl. Based Syst. 2016, 98, 130–147. [Google Scholar] [CrossRef]
- Hayes, M.A.; Capretz, M.A. Contextual anomaly detection framework for big sensor data. J. Big Data 2015, 2, 1–22. [Google Scholar] [CrossRef]
- Long, J.A. Kinematic interpolation of movement data. Int. J. Geogr. Inf. Sci. 2016, 30, 854–868. [Google Scholar] [CrossRef]
- Winkel, R. On a generalization of Bernstein polynomials and Bezier curves based on umbral calculus (II): De Casteljau algorithm. Comput. Aided Geom. Des. 2015, 39, 1–16. [Google Scholar] [CrossRef]
- Yuksel, C.; Schaefer, S.; Keyser, J. Parameterization and applications of Catmull-Rom curves. Comput. Aided Des. 2011, 43, 747–755. [Google Scholar] [CrossRef]
- Lei, P.R. A framework for anomaly detection in maritime trajectory behavior. Knowl. Inf. Syst. 2016, 47, 189–214. [Google Scholar] [CrossRef]
- Ando, S.; Thanomphongphan, T.; Seki, Y.; Suzuki, E. Ensemble anomaly detection from multi-resolution trajectory features. Data Min. Knowl. Discov. 2015, 29, 39–83. [Google Scholar] [CrossRef]
- Bezdek, J. Pattern Recognition with Fuzzy Objective Function Algorithms; Plenum Press: New York, NY, USA, 1981. [Google Scholar]
- Ang, K.K.; Quek, C. Supervised pseudo self-evolving cerebellar algorithm for generating fuzzy membership functions. Expert Syst. Appl. 2012, 39, 2279–2287. [Google Scholar] [CrossRef]
- Zenebe, A.; Norcio, A.F. Representation, similarity measures and aggregation methods using fuzzy sets for content-based recommender systems. Fuzzy Sets Syst. 2009, 160, 76–94. [Google Scholar] [CrossRef]
- Bartholdi, J.J., III; Eisenstein, D.D. A self-coordinating bus route to resist bus bunching. Transp. Res. Part B Methodol. 2012, 46, 481–491. [Google Scholar] [CrossRef]
- Li, Y.; Xu, W.; He, S. Expected value model for optimizing the multiple bus headways. Appl. Math. Comput. 2013, 219, 5849–5861. [Google Scholar] [CrossRef]
- Chen, X.; Yu, L.; Zhang, Y.; Guo, J. Analyzing urban bus service reliability at the stop, route, and network levels. Transp. Res. Part A Policy Pract. 2009, 43, 722–734. [Google Scholar] [CrossRef]
- Lin, J.; Wang, P.; Barnum, D.T. A quality control framework for bus schedule reliability. Transp. Res. Part E Logist. Transp. Rev. 2008, 44, 1086–1098. [Google Scholar] [CrossRef]
- He, S.X. An anti-bunching strategy to improve bus schedule and headway reliability by making use of the available accurate information. Comput. Ind. Eng. 2015, 85, 17–32. [Google Scholar] [CrossRef]
- Mendes-Moreira, J.; Moreira-Matias, L.; Gama, J.; Freire de Sousa, J. Validating the coverage of bus schedules: A Machine Learning approach. Inf. Sci. 2015, 293, 299–313. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | LineCode | StationIndex | BusIndex | ArrivalTime |
|---|---|---|---|---|
| 1 | 158 | 3 | 1 | 584.2000 |
| 2 | 158 | 7 | 2 | 583.0167 |
| 3 | 158 | 12 | 3 | 584.8333 |
| Label | Station Index | Arrival Time | Label | Station Index | Arrival Time |
|---|---|---|---|---|---|
| P1 | 13 | 761.0 | P13 | 36 | 788.0 |
| P2 | 12 | 762.1 | P14 | 43 | 789.5 |
| P3 | 11 | 762.8 | P15 | 38 | 790.5 |
| P4 | 10 | 763.8 | P16 | 38 | 792.0 |
| P5 | 8 | 765.1 | P17 | 39 | 793.3 |
| P6 | 29 | 775.3 | P18 | 40 | 794.1 |
| P7 | 30 | 778.5 | P19 | 41 | 796.0 |
| P8 | 34 | 779.6 | P20 | 42 | 798.8 |
| P9 | 31 | 781.6 | P21 | 43 | 801.8 |
| P10 | 32 | 783.8 | P22 | 44 | 803.0 |
| P11 | 33 | 784.9 | P23 | 45 | 804.2 |
| P12 | 35 | 787.2 | P24 | 46 | 806.7 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tong, C.; Chen, H.; Xuan, Q.; Yang, X. A Framework for Bus Trajectory Extraction and Missing Data Recovery for Data Sampled from the Internet. Sensors 2017, 17, 342. https://doi.org/10.3390/s17020342
Tong C, Chen H, Xuan Q, Yang X. A Framework for Bus Trajectory Extraction and Missing Data Recovery for Data Sampled from the Internet. Sensors. 2017; 17(2):342. https://doi.org/10.3390/s17020342
Chicago/Turabian StyleTong, Changfei, Huiling Chen, Qi Xuan, and Xuhua Yang. 2017. "A Framework for Bus Trajectory Extraction and Missing Data Recovery for Data Sampled from the Internet" Sensors 17, no. 2: 342. https://doi.org/10.3390/s17020342
APA StyleTong, C., Chen, H., Xuan, Q., & Yang, X. (2017). A Framework for Bus Trajectory Extraction and Missing Data Recovery for Data Sampled from the Internet. Sensors, 17(2), 342. https://doi.org/10.3390/s17020342