1. Introduction
Spectral mixture analysis (SMA) is an inverse process that decomposes the spectra of a mixed pixel into areal fractions based on the pure spectra of its component land covers (also termed as endmembers) [
1]. For successful SMA, the first step is the endmember selection, which involves the identification of types, numbers and corresponding spectra of endmembers [
2,
3]. Within this, some studies have been conducted for selecting the type and number of endmember classes, and several endmember class models have been proposed, such as vegetation-soil-shade (V-S-S) for estimating vegetation fraction in desert region [
4], vegetation-impervious surface-soil (V-I-S) [
5], vegetation-low albedo-high albedo (V-L-H) [
6], and vegetation-low albedo-high albedo-soil (V-L-H-S) [
7] for mapping urban biophysical composition. Although it is straightforward, only fixed endmember sets were adopted and applied for all pixels, which ignored the endmember class variability, and thereby making the estimation results less reliable. In order to address this issue, the first attempt was made by Roberts et al. [
8]. With the consideration of endmember class variation, the multiple endmember spectral mixture analysis (MESMA) has been proposed and widely used. In addition, Zhang et al. [
9] has proposed a prior-knowledge-based spectral mixture analysis, with which two different endmember class models, the V-L-H and V-L-H-S have been applied in high density areas and low density areas respectively. Zhang et al. [
10] proposed an object-based unmixing analysis. In particular, the software of eCognition Developer was employed first to separate the image into several objects, and the unmixing analysis was conducted with endmember classes identified from each object. Furthermore, Li et al. [
11] also developed a segmented and rule-based spectral mixture analysis for estimating imperviousness. Specifically, the study area was divided into segmented regions, and different endmember class sets were selected for unmixing analysis in each region. Recently, Li and Wu [
12] analyzed the endmember class variation with the help of spatial information, and satisfactory estimation results were achieved for large-scale impervious surfaces estimation.
In addition to the aforementioned endmember class selection, the endmember spectra extraction is the other important step for implementing SMA. Traditionally, the endmember spectra are extracted from the vertices of an n-dimensional scatter plot manually or automatically (e.g., N-FINDR [
13], Pixel Purity Index (PPI) [
14]). As a consequence, a fix set of endmember spectra was applied for the whole image for unmixing analysis. As in fact of the complexity of natural and urban landscapes, the endmember spectra variability may have not been fully considered, which in turn result in significant estimation error [
8,
15,
16]. Therefore, endmember spectra variability has been considered as a profound error source for SMA. Endmember spectra variability can be grouped into two categories: within-class and between-class variability. The within-class variability refers to the spectral variations of the same land use/cover, such as the tiles, concrete, asphalt of imperviousness. The between-class variability refers to the spectral confusion between various land uses/covers, such as the confusion of bare soil and impervious surfaces. In order to address the challenging issue, numerous models have been developed, including AutoSWIR [
15], derivative spectral unmixing (DSU) [
17], Normalized Spectral Mixture Analysis [
18], etc. In addition, spectral weighting techniques (weighted spectral mixture analysis, WSMA) [
19] and two-step weighting SMA [
20]), continuous wavelets techniques [
21], spectral modeling approaches [
22], iterative mixture analysis (MESMA) [
8], neighbourhood-specific endmember signature generation technique [
23] and geostatistical technique (Geostatistical temporal mixture analysis, GTMA [
24]) have also been proposed for addressing the endmember spectra variability issue.
While numerous approaches have been developed and widely used for addressing the endmember class and endmember spectra variability issue, some challenging problems still remain. Specifically, in most studies, endmember classes are still selected based on the n-dimensional feature spaces and finally a fixed set of endmember classes and averaged pure endmember spectra are applied in each pixel of the whole image. However, the physical meaning of endmember classes and local variation of endmember spectra has been totally neglected. In fact, on the one hand, the spatial distribution of endmember classes is majorly associated with global environmental and socio-economic driving forces such as elevation, slope, distance to water, distance to city, etc. For instance, urban areas tend to be distributed along the areas with gentle slope and convenient access to transportation networks, and vegetated areas are mainly located around lakes, river streams with gentle elevation. On the other hand, due to the spatial variations of natural and social environment, the endmember spectra tend to vary within a study area. For example, the spectra of impervious surfaces are varied spatially due to the heterogeneity of the materials (low albedo: asphalt, high albedo: glass and plastic), the spectra of vegetation might vary depending on the chlorophyll content and the shape, angle and density of the canopy elements. Therefore, instead of using one set of endmember classes and spectra, the spatially varied endmember classes and localized endmember spectra become essential for unmixing analysis. In addition, until now, most approaches only focussed on addressing either the issue of endmember class variability or endmember spectra variability; few studies have been conducted for both of them. In fact, the selection of endmember class is the foundation of endmember spectra extraction, and they are all serving as the key to successfully SMA. Therefore, both the issue of endmember class variability and endmember spectra variability needs to be seriously considered.
To address the aforementioned challenging problems, in this study, we proposed a geographic information-assisted temporal mixture analysis (GATMA). In particular, we utilized logistic regression analysis to analyze the relationship between land use/land covers and surrounding environmental and socio-economic forces (e.g., elevation, slope, and distance to the nearest city, town, river, lake, etc.) and derive the global spatial distribution probability of land use/land covers. Furthermore, a classification tree method was applied to identify the existence of endmember classes at each pixel in the whole study area. With the quantified per-pixel endmember classes, an ordinary kriging analysis was conducted to generate the ‘purest’ endmember spectra for each pixel. The proposed model can be detailed as three steps: (1) identifying the numbers and types of endmember classes for each pixel through logistic regression analysis and classification tree methods; (2) extracting spatially varied endmember spectra using ordinary kriging analysis; and (3) estimating land use/land cover fractions using temporal mixture analysis. The rest of the article is organized as follows. The study area and data are described in
Section 2; the proposed GATMA is introduced in
Section 3; estimation results of the proposed GATMA, accuracy assessment, and comparative analysis with the Phenology-based Temporal Mixture Analysis (PTMA) and Phenology-based Multiple Endmember Temporal Mixture Analysis (PMETMA) are listed in
Section 4; and finally, discussion, conclusions and future research directions are provided in
Section 5 and
Section 6.
2. Study Area and Data
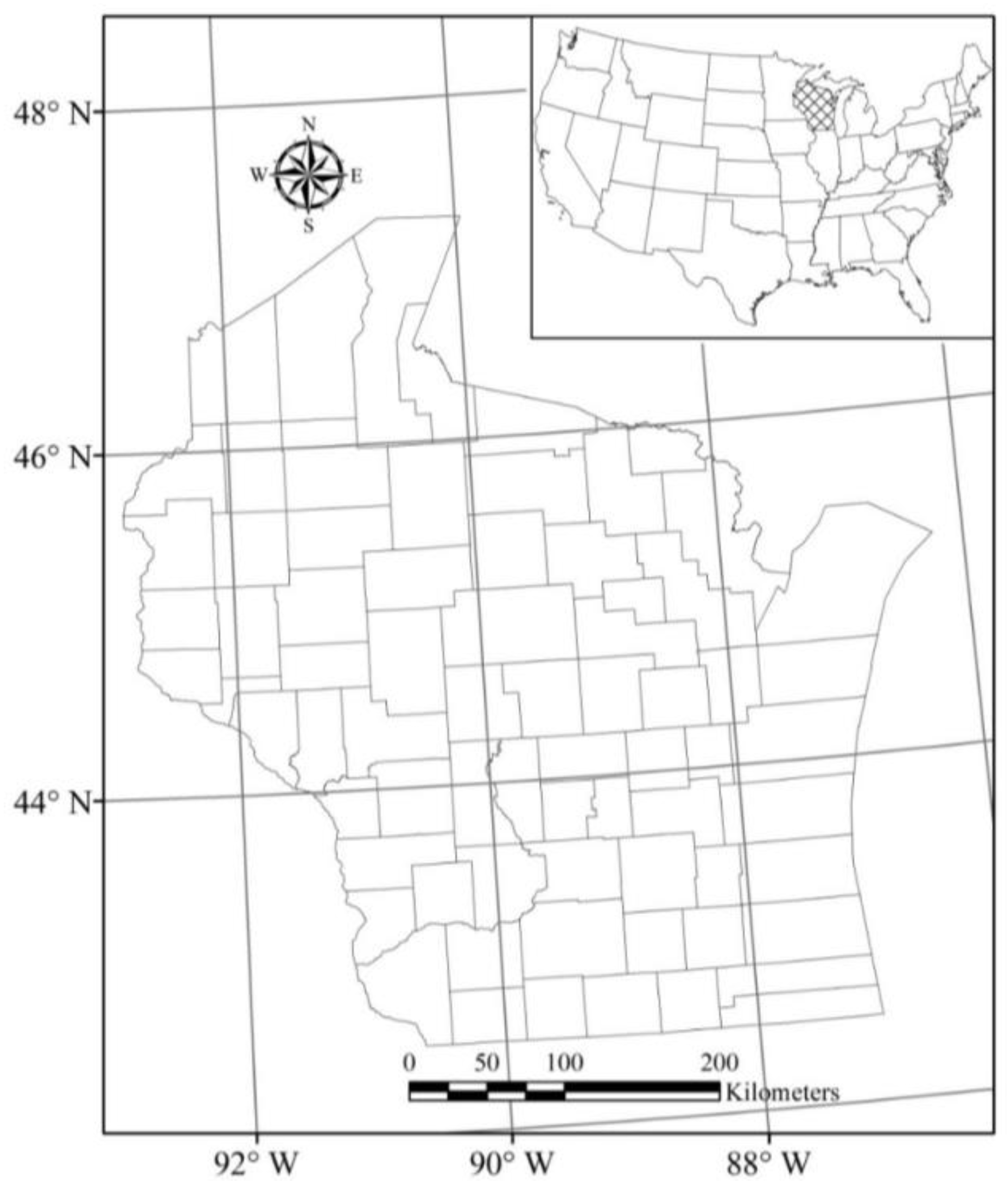
The selected study area, Wisconsin State, is located in the Midwest of the United States, and is composed of 72 counties with a geographic area of 169,639 km
2 (see
Figure 1). Wisconsin comprises a large number of natural landscapes, including deciduous and evergreen forest in the north, agriculture lands in the southwest, and pasture in the northwest. In contrast, most urbanized areas are located in the south-eastern Wisconsin, including the capital city, Madison and the state’s most populated area of Milwaukee. According to the data reported by United States Census Bureau on July 2013, the total population in Wisconsin was 5.74 million, increased about 16% in the past two decades, and approximately 68% of the population are living in urban areas and 35% of the population resides in the Southeastern Wisconsin. While the rapid population growth and urbanization brings some economic benefits, it also raises several environmental issues, including urban heat island effect, biodiversity reduction, etc. Therefore, accurate estimations of urban growth and impervious surface fractions have become essential in the study area.
In order to carry out the proposed GATMA for deriving the impervious surface fractions in the state of Wisconsin, the Moderate-resolution Imaging Spectroradiometer (MODIS) NDVI data in 2006 were collected and utilized in this study. In particular, the product of MOD13Q1 was collected every half month from the United States Geological Survey (USGS) website (
www.usgs.gov) with a positional accuracy of 0.5 pixels and spatial resolution of 250 m respectively. Moreover, due to large cloud cover and bad weather condition, one image in early November was removed and finally 22 MODIS NDVI images was obtained and applied for spectral unmixing. Furthermore, the National Land Cover Data (NLCD) 2006 was collected for identifying land use/land cover types and the NLCD 2006 Percent Developed Imperviousness data was obtained for evaluating the performances of the proposed GATMA (all collected from Multi-Resolution Land Characteristics Consortium (MRLC),
www.mrlc.gov/nlcd06_data.php). In addition, the city, village distribution data, and transportation data (e.g., road, railway) were collected from the American Geographical Society Library at the University of Wisconsin-Milwaukee. Moreover, the hydrological data (e.g., river, lake) and elevation data were obtained from the USGS website, and the slope data was generated using ArcGIS 10, a commercial GIS package.
3. Methodology
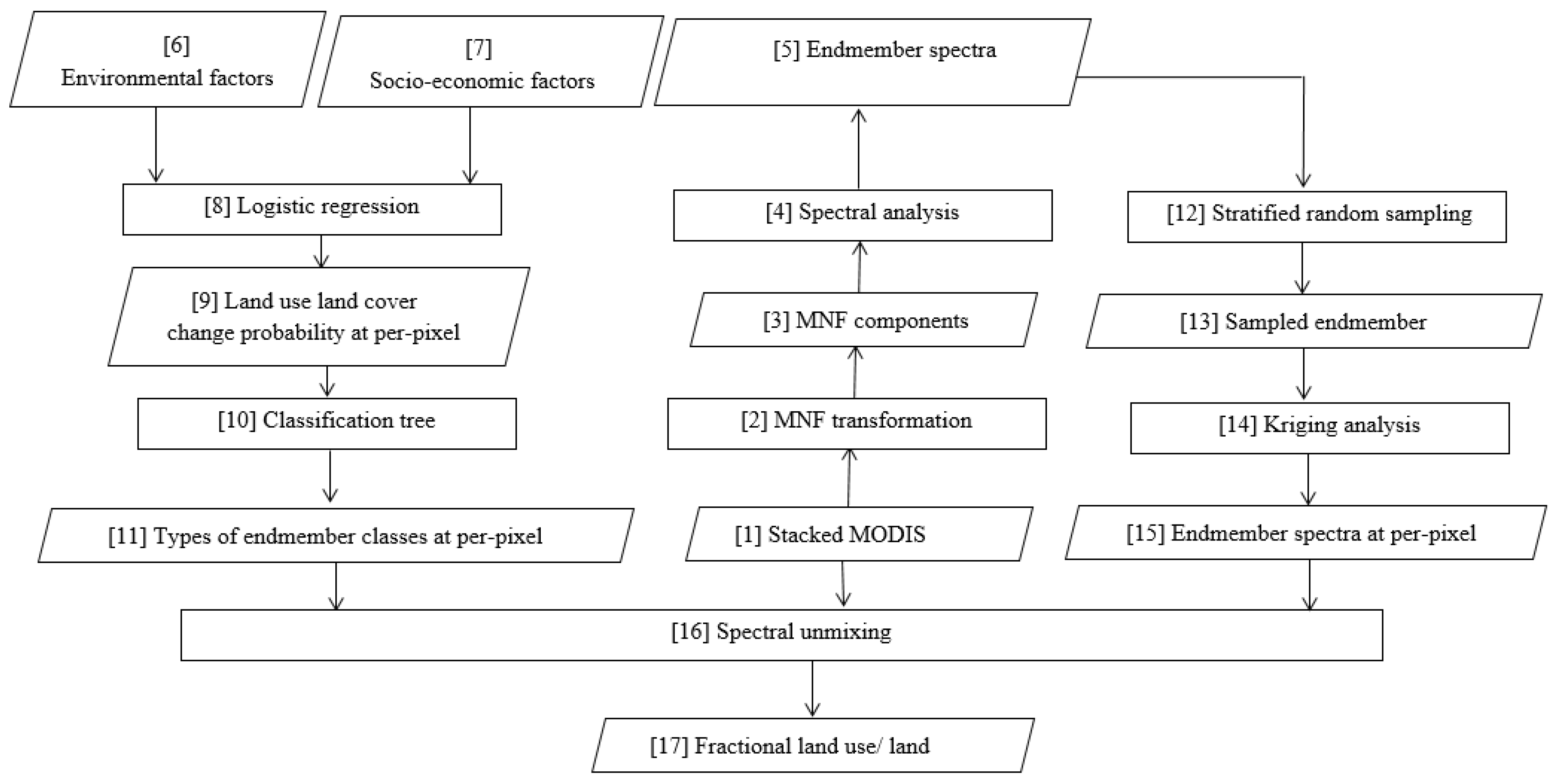
To carry out the proposed GATMA approach, three major steps were conducted, including the identification of the numbers and types of endmember classes, the extraction of spatially varied endmember spectra, and the estimation of fractional land use/land covers. Before conducting the proposed method, we identified potential endmembers and corresponding pure spectra using the minimum noise fraction (MNF) transformation (Step 2 in
Figure 2) based on the stacked temporal sequences of MODIS data (Step 1 in
Figure 2). In particular, ENVI—a commercial remote sensing program—was used for conducting MNF transformation. With the MNF transformation, approximately 90% of the variances were preserved in the first three components, and spectral correlations among spectral bands were effectively removed. Therefore, we generated several feature spaces using the first three MNF components (Step 3 in
Figure 2), and endmember pure spectra (Step 5 in
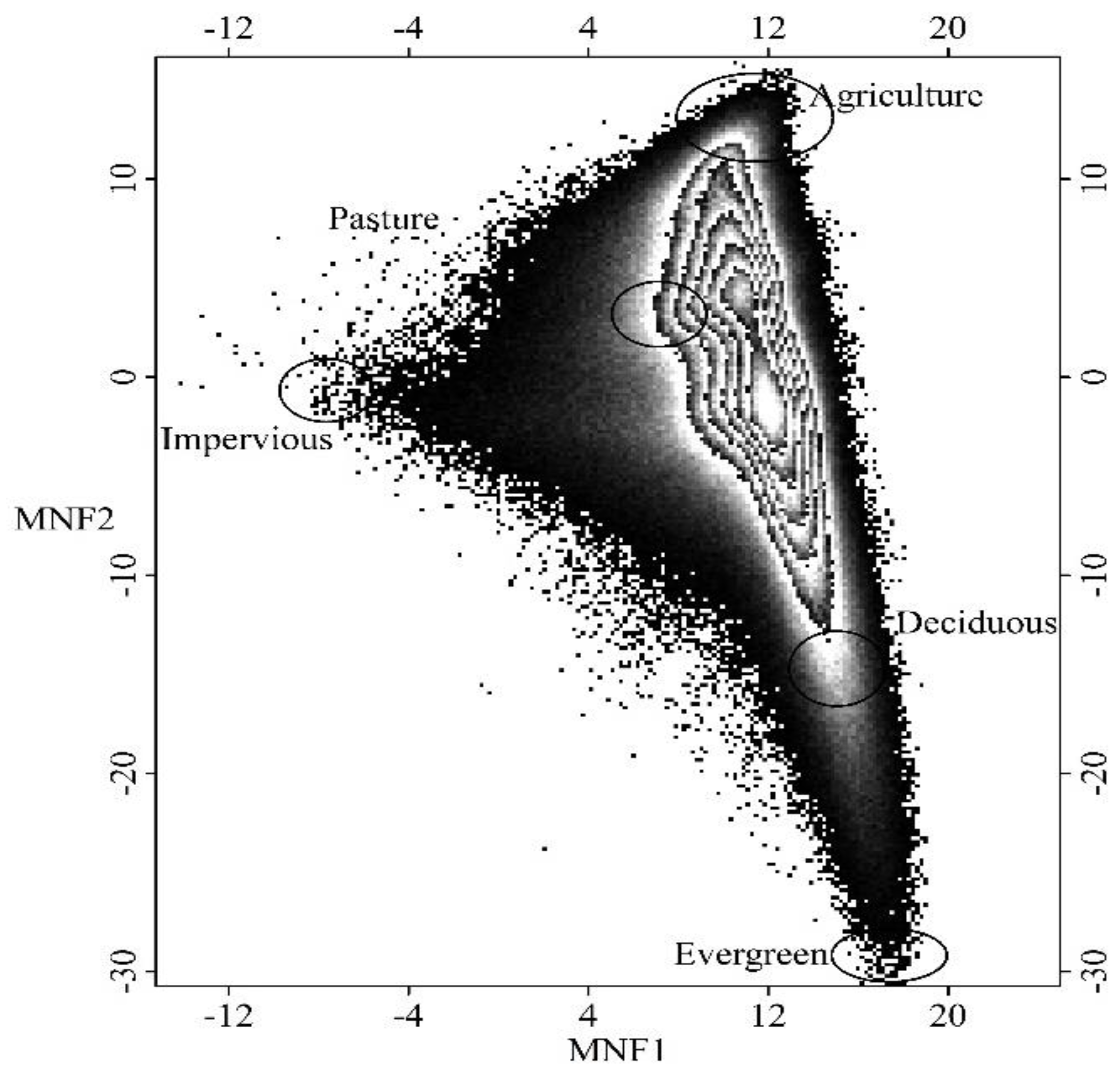
Figure 2) were extracted from the vertices of the feature space scatterplots (see
Figure 3) through spectral analysis (Step 4 in
Figure 2). Finally, five endmember classes (including agriculture, impervious surface, deciduous forest, evergreen forest, and pasture) and corresponding pure spectra were identified and extracted from the scatterplots of the first three MNF components and further verified with the observed data.
3.1. The Identification of Endmember Class Type and Number
In order to automatically identify the type and number of endmember classes for each pixel throughout the whole study area, the logistic regression analysis approach and classification tree method were applied. In particular, a logistic regression analysis (Step 8 in
Figure 2) was utilized to derive spatial distribution probability of endmember classes (Step 9 in
Figure 2) through analyzing the spatial relationship between land use/land covers and their surrounding environmental (Step 6 in
Figure 2) and socio-economic forces (Step 7 in
Figure 2), and the classification tree method (Step 10 in
Figure 2) was employed to identify the existence status (present or absent) (Step 11 in
Figure 2) of endmember classes for each individual pixel. In this study, five land use/land covers (agricultural land, built-up, deciduous forest, pasture, and evergreen forest) and eight driving forces (DEM, slope, the distance to the nearest road, railway, city, village, river, and lake) were considered in the logistic regression model, and the spatial distribution probability of endmember classes were derived by the following formula,
where
Pi,j is the distribution probability of endmember class
i at pixel
j;
Xn,i is the driving forces
j for endmember class
i, and
αn is the coefficient for the driving forces
n. In this study, 2000 samples of each endmember class were collected based on the NLCD 2006 data for constructing the logistic regression analysis model.
With the help of the derived spatial distribution probability of land use/land covers, the identification of numbers and types of endmember classes were implemented through classification tree method. Specifically, 1000 samples were selected (200 samples for each endmember class were randomly selected from the spatial distribution map of five endmember classes within the study area based on NLCD 2006 data) and input into the program of SEE5 to analyze the relationship between endmember class status (categorical variable) and the spatial distribution probability of endmember classes (independent variables) for each individual pixel. SEE5, also termed as C5.0, is a widely used commercial program developed by Quinlan (1996) for generated decision trees [
25] (
https:www.rulequest.com/see5-info.html). After implementing the classification tree method, we successfully generated rules to identify the numbers of endmember classes and the specific endmember class types in each pixel.
3.2. The Extraction of Spatial Varied Endmember Spectra
With the identified endmember classes at each pixel, the next step is to extract pure endmember spectra of each endmember class at the per-pixel level. We obtained pure represented endmember spectra (Step 5 in
Figure 2) from the vertices of the 2-D scatterplot through spectra analysis (Step 4 in
Figure 2). Then a stratified sampling scheme (Step 12 in
Figure 2) was applied to collect 200 endmember samples (Step 13 in
Figure 2) for agriculture, deciduous forest, evergreen forest, and pasture classes, and only 50 samples were collected for impervious surfaces due to the lack of pure pixels. Furthermore, a spatially varied endmember spectra extraction was conducted for quantifying per-pixel level ‘pure’ endmember spectra of each endmember class (90% of endmember samples were used for interpolation, 10% endmember samples were reserved for further evaluating interpolation accuracy). In this study, ‘pure’ endmember spectra (Step 15 in
Figure 2) were derived through applying the ordinary kriging analysis (Step 14 in
Figure 2). Ordinary kriging is a geo-statistical approach and commonly viewed as an interpolation technique, and has been widely applied in many fields. The implementation of ordinary kriging is based on the lease square optimization principle and can be conducted through implementing three major steps: (1) variogram estimation for spatial structure analysis; (2) model fitting; and (3) weight estimation and interpolation.
In order to analyze the spatial structure of all sample points, the experimental variogram can be calculated in the first step by the following formulation:
where,
is the variogram,
NDVIi,a (
xj) and
NDVIi,a (
xj +
d) are known ‘pure’ NDVI values of endmember
i in band
a at locations
xj and
xj +
d, respectively,
d is a lag to describe the distance and direction between location
xj and
xj +
d, and
n is the total number of sample point pairs separated by the vector
d.
With the knowledge of the spatial structure extracted from the experimental variogram calculation, a fitted theoretical model need to be selected. The theoretical variogram model is classified according to the function type, and for more discussions can be found in Curran and Atkinson (1998) [
26] and McBratney and Webster (1986) [
27].
Finally, the ‘pure’
NDVI value for endmember
i in band
a at pixel
k can be estimated by
where
NDVIi,a,k is the estimated ‘pure’
NDVI value of endmember
i in band
a at pixel
k,
NDVIi,a,j is the known ‘pure’
NDVI values of endmember
i in band
a at location
j, and
Wj are the weights that should be calculated.
In this study, the experimental variograms were conducted using GS + 7.0 (Geostatistics for the Environmental Sciences) to find the best fit theoretical model, and ArcGIS10 was used to implement ordinary kriging for interpolating localized endmember spectra.
3.3. Temporal Mixture Analysis
With the extracted pixel level adaptive endmember classes and corresponding spectral signature, a linear temporal mixture analysis (Step 16 in
Figure 2) was implemented for the estimation of land use/land cover fractions (Step 17 in
Figure 2). Temporal mixture analysis is an inverse model that a mixed
NDVI spectral signature is decomposed into areal abundances of its pure land cover components (also termed as endmember classes) through least squares optimization model. The temporal mixture analysis can be conducted with non-constrains and full-constrains, in this study, two constrains including the fractions of all endmember classes non-negative and sum to one were applied to make the unmixing results to be presented with physical meanings. The temporal mixture analysis and two constrains can be formulated as follows:
Subject to and
where
NDVIb is the mixed
NDVI spectral signature for band
b,
N is the total number of all identified endmember classes,
fi is the Abundances of endmember
i,
NDVIi,b,m is the ‘pure’
NDVI spectral signature of endmember
i in band
b at pixel
m, and
eb is the residual. In order to assess the model fitness, the
eb and
RMS were applied.
where
M is the number of bands in the remote sensing image.
3.4. Comparative Analysis and Accuracy Assessment
For comparative purposes, we have also implemented PTMA and PMETMA. With PTMA, only one endmember set (generated through averaging all pure endmembers) was employed to quantify the fraction of land use land covers for the whole study area through fully constrained TMA. For PMETMA, the issue of endmember class and spectra variability has been considered, it allows the variety of endmember set, and the best fit model are selected for unmixing analysis. For detailed information about PTMA and PMETMA, readers can refer to [
28].
In order to evaluate the performance of the proposed geographic information-assisted TMA approach, the NLCD 2006 Percent Developed Imperviousness data was collected and applied as the reference data, three widely applied measures including root mean square error (
RMSE, Equation (7)), systematic error (
SE, Equation (8)) and mean absolute error (
MAE, Equation (9)) were calculated to evaluate the estimation accuracy of the proposed TMA approach. The
SE and
MAE can be calculated as follows:
where
is the modelled impervious surface abundance from the proposed TMA approach for pixel
i,
Ai is the obtained NLCD 2006 impervious surfaces abundances for pixel
i, and
N is the total number of pixels.
6. Conclusions and Future Research Directions
In this study, we developed a geographic information-assisted temporal mixture analysis (GATMA) for modelling the impervious surface distribution in the state of Wisconsin. In particular, a logistic regression analysis was applied for examining the relationship between endmember classes and surrounding environmental and social-economic factors; furthermore, a classification tree method was utilized to quantify the spatially varied endmember class distributions for addressing the issue of endmember class variability. Moreover, an ordinary kriging analysis was employed to generate spatially varied endmember spectra for each endmember class to overcome the issue of endmember spectra spatial variability. Finally, the fully constrained linear temporal mixture analysis was conducted to generate the impervious surface distributions.
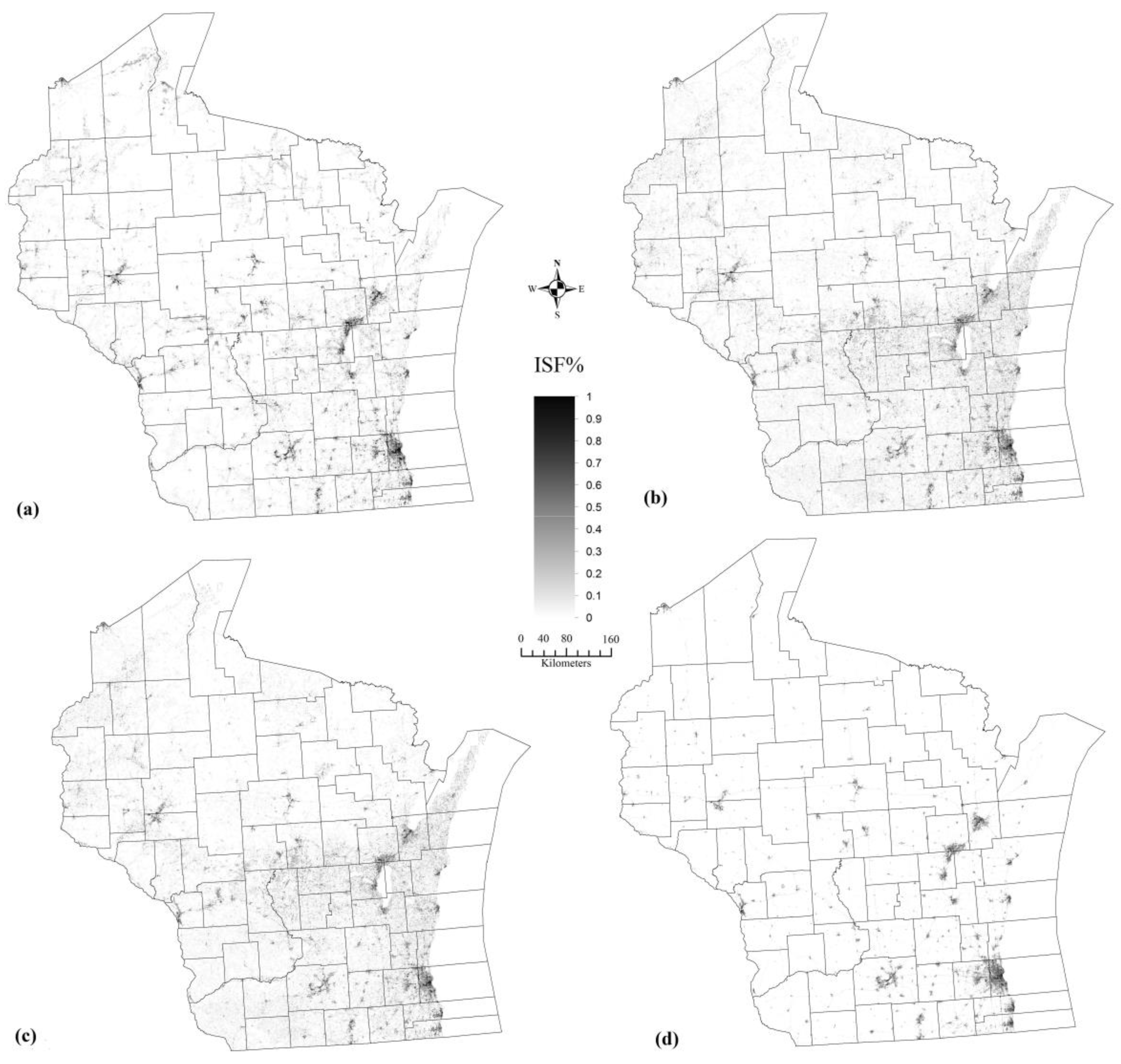
Analysis of results shows that the developed GATMA has achieved a promising accuracy for estimating the fraction of impervious surfaces with the RMSE of 6.81%, SE of 1.29% and MAE of 2.6% for the whole study area. Further analysis indicates that a satisfactory performance has also been achieved for both developed area and less developed area with slightly underestimation and slightly overestimation respectively. In order to further evaluate the proposed model performance, a comparison study has also been conducted between the developed GATMA and the PTMA, PMETMA. Comparative results suggest that the proposed GATMA achieved a promising performance. In particular, compared with the PTMA and PMETMA, the RMSE value for the whole study area decreased 6.33%% and 9.68%, the SE value decreased 60.31% and 39.44%, and the MAE decreased 35.48% and 22.62% respectively. Furthermore, for the developed area, while the RMSE value slightly increased 8.83% and 7.36%, the SE value significantly decreased 51.53% and 42.96%, and the MAE value decreased 9.55% and 9.62% respectively. For the less developed area, the RMSE value decreased 9.05% and 14.38%, the SE value decreased 58.89% and 39.22%, and the MAE value decreased 37.95% and 25.08% respectively. In summary, the proposed GATMA achieved a better performance than the PTMA and PMETMA as it has successfully addressed the endmember class and endmember spectra variability issue in unmixing analysis.
Although the proposed GATMA has achieved a promising accuracy for estimating impervious surfaces fractions, its ability in separating impervious surface from other land uses/land covers is still unclear, mainly due to the unavailability of other land use observation data at a large-scale. Therefore, one future research direction could be the collection of other land use reference data for further validation of the proposed GATMA approach. Furthermore, in this study, only MODIS NDVI data has been used, and it is necessary to evaluate the performance of the proposed GAMTA approach when applied to other dataset (e.g., hyperspectral image, Landsat TM, SPOT, etc.).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}