
Multiple Objects Fusion Tracker Using a Matching Network for Adaptively Represented Instance Pairs


Abstract
:1. Introduction
2. Related Work
3. Problem Definition and Pre-Requisites
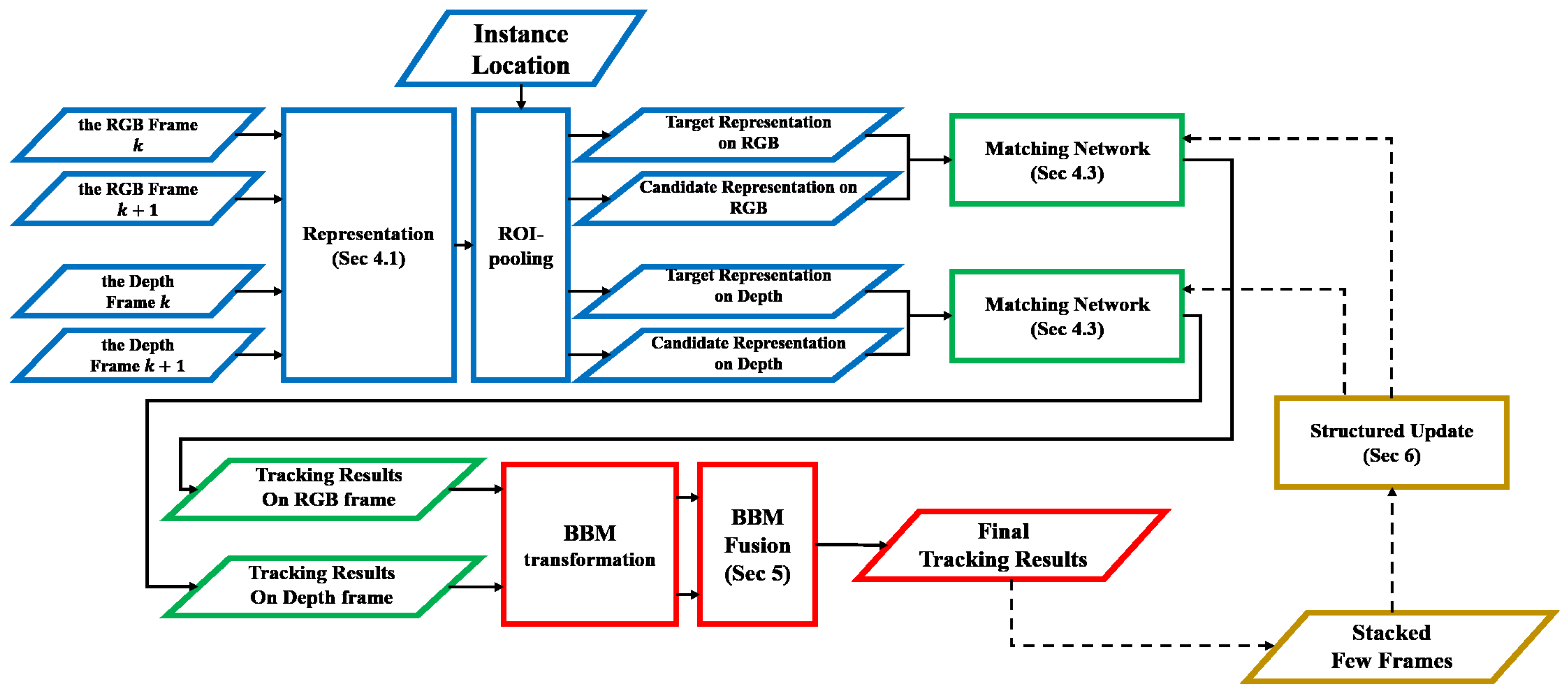
4. Matching Network
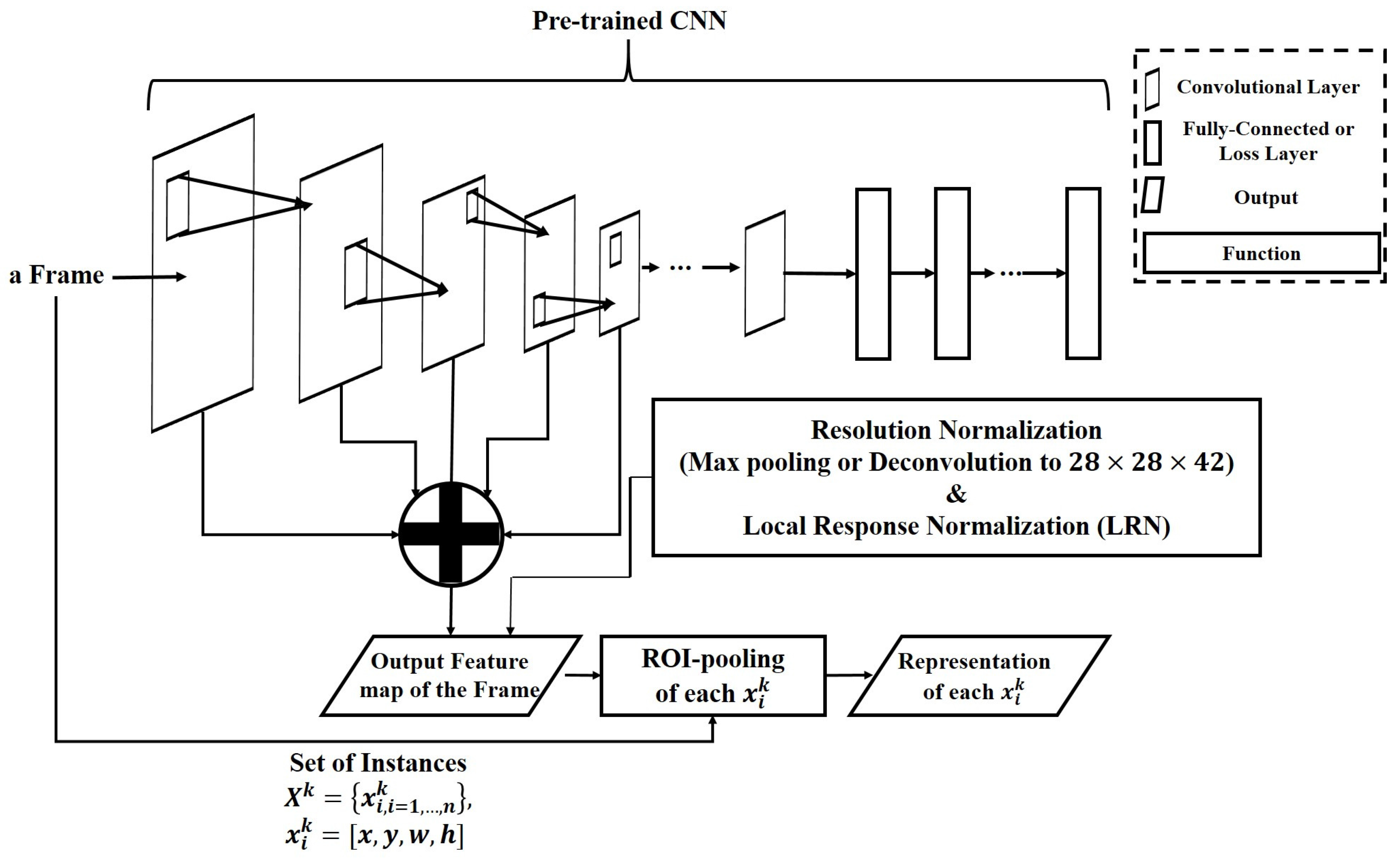
4.1. Target Representation
4.2. Representation of the Depth Frame
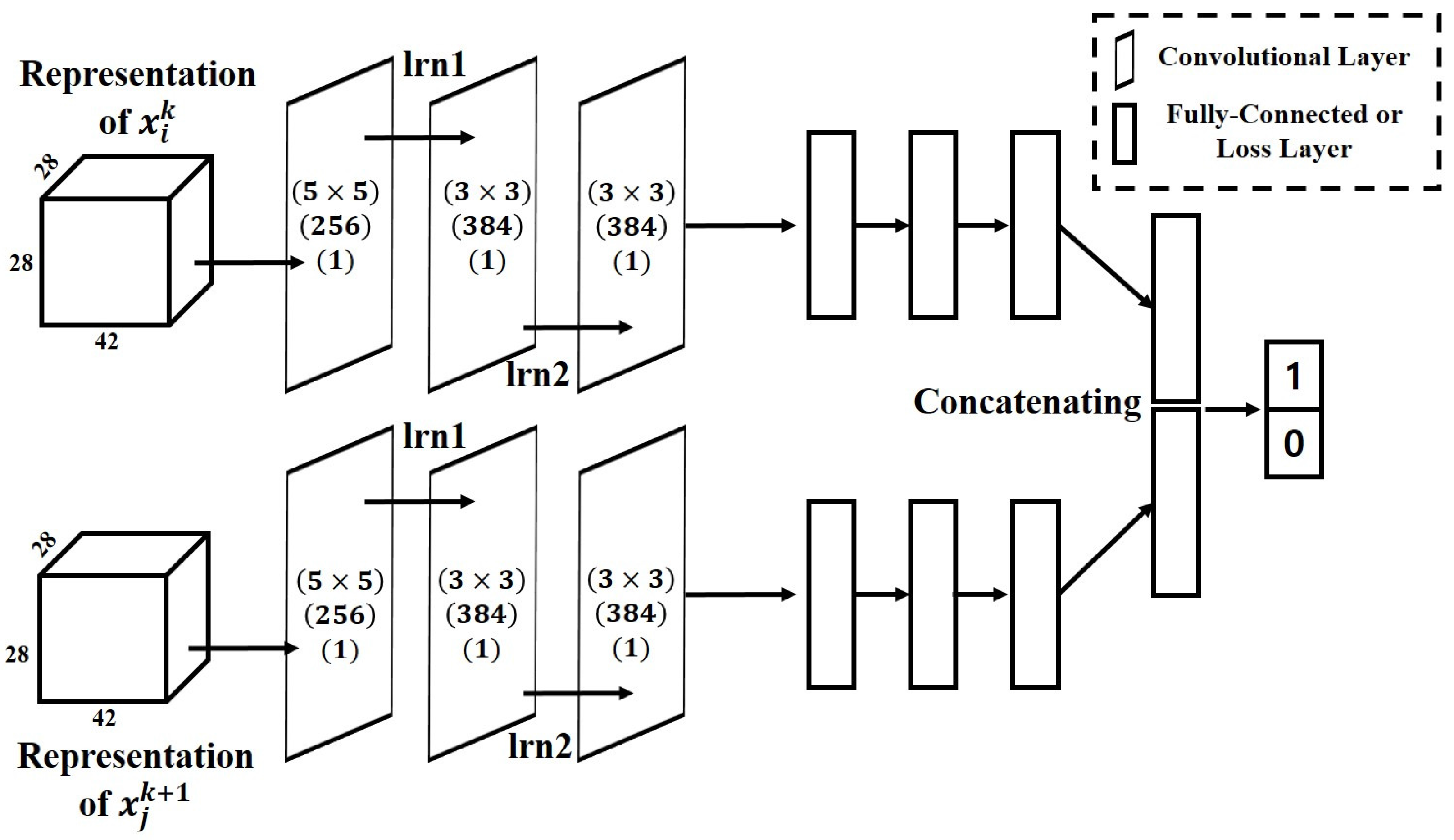
4.3. Architecture of the Matching Network
5. Fusion Tracker
5.1. Basic Belief Assignment
5.2. Fusion for Tracking Results
6. Structured Fine-Tuning of the Matching Network
6.1. Structured Target Appearance Models
6.2. Inference
6.3. Adaptive Model Update
7. Experimental Evaluation
7.1. Dataset and Evaluation Metric
7.2. Experimental Setup
7.3. Evaluation
8. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; Volume 2, pp. 674–679. [Google Scholar]
- Nguyen, H.T.; Smeulders, A.W. Robust tracking using foreground-background texture discrimination. Int. J. Comput. Vis. 2006, 69, 277–293. [Google Scholar] [CrossRef]
- Pan, J.; Hu, B. Robust occlusion handling in object tracking. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Yang, F.; Lu, H.; Yang, M.H. Robust superpixel tracking. IEEE Trans. Image Process. 2014, 23, 1639–1651. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Kundu, K.; Zhu, Y.; Berneshawi, A.G.; Ma, H.; Fidler, S.; Urtasun, R. 3D object proposals for accurate object class detection. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2015; pp. 424–432. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view RGB-d object dataset. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 1817–1824. [Google Scholar]
- Premebida, C.; Carreira, J.; Batista, J.; Nunes, U. Pedestrian detection combining RGB and dense lidar data. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 4112–4117. [Google Scholar]
- Spinello, L.; Arras, K.O. People detection in RGB-D data. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 3838–3843. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. arXiv 2016. [Google Scholar]
- Oh, S.I.; Kang, H.B. Fast Occupancy Grid Filtering Using Grid Cell Clusters From LIDAR and Stereo Vision Sensor Data. IEEE Sens. J. 2016, 16, 7258–7266. [Google Scholar] [CrossRef]
- Tao, R.; Gavves, E.; Smeulders, A.W. Siamese Instance Search for Tracking. arXiv 2016. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to Track at 100 FPS with Deep Regression Networks. arXiv 2016. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection. arXiv 2016. [Google Scholar]
- Gupta, S.; Hoffman, J.; Malik, J. 35-2: Invited Paper: RGB-D Image Understanding using Supervision Transfer. In SID Symposium Digest of Technical Papers; Wiley Online Library: Hoboken, NJ, USA, 2016; Volume 47, pp. 444–447. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. arXiv 2015. [Google Scholar]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online tracking by learning discriminative saliency map with convolutional neural network. arXiv 2015. [Google Scholar]
- Kuen, J.; Lim, K.M.; Lee, C.P. Self-taught learning of a deep invariant representation for visual tracking via temporal slowness principle. Pattern Recognit. 2015, 48, 2964–2982. [Google Scholar] [CrossRef]
- Li, H.; Li, Y.; Porikli, F. Deeptrack: Learning discriminative feature representations online for robust visual tracking. IEEE Trans. Image Process. 2016, 25, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Visual tracking with fully convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3119–3127. [Google Scholar]
- Xu, M.; Orwell, J.; Jones, G. Tracking football players with multiple cameras. In Proceedings of the 2004 International Conference on Image Processing, Singapore, 24–27 October 2004; Volume 5, pp. 2909–2912. [Google Scholar]
- Cheng, X.; Honda, M.; Ikoma, N.; Ikenaga, T. Anti-occlusion observation model and automatic recovery for multi-view ball tracking in sports analysis. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 1501–1505. [Google Scholar]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE international Symposium on Mixed and Augmented Reality (ISMAR), Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Cho, H.; Seo, Y.W.; Kumar, B.V.; Rajkumar, R.R. A multi-sensor fusion system for moving object detection and tracking in urban driving environments. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1836–1843. [Google Scholar]
- Allodi, M.; Broggi, A.; Giaquinto, D.; Patander, M.; Prioletti, A. Machine learning in tracking associations with stereo vision and lidar observations for an autonomous vehicle. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gotenburg, Sweden, 19–22 June 2016; pp. 648–653. [Google Scholar]
- Premebida, C.; Ludwig, O.; Nunes, U. LIDAR and vision-based pedestrian detection system. J. Field Robot. 2009, 26, 696–711. [Google Scholar] [CrossRef]
- Mertz, C.; Navarro-Serment, L.E.; MacLachlan, R.; Rybski, P.; Steinfeld, A.; Suppe, A.; Urmson, C.; Vandapel, N.; Hebert, M.; Thorpe, C.; et al. Moving object detection with laser scanners. J. Field Robot. 2013, 30, 17–43. [Google Scholar] [CrossRef]
- Aufrère, R.; Gowdy, J.; Mertz, C.; Thorpe, C.; Wang, C.C.; Yata, T. Perception for collision avoidance and autonomous driving. Mechatronics 2003, 13, 1149–1161. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Teutsch, M.; Muller, T.; Huber, M.; Beyerer, J. Low resolution person detection with a moving thermal infrared camera by hot spot classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 209–216. [Google Scholar]
- Kümmerle, J.; Hinzmann, T.; Vempati, A.S.; Siegwart, R. Real-Time Detection and Tracking of Multiple Humans from High Bird’s-Eye Views in the Visual and Infrared Spectrum. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2016; pp. 545–556. [Google Scholar]
- González, A.; Vázquez, D.; Lóopez, A.M.; Amores, J. On-Board Object Detection: Multicue, Multimodal, and Multiview Random Forest of Local Experts. IEEE Trans. Cybern. 2016. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Bach, J.; Macfarlane, J.; Ferrie, F.P. A new upsampling method for mobile LiDAR data. In Proceedings of the 2012 IEEE Workshop on Applications of Computer Vision (WACV), Breckenridge, CO, USA, 9–11 January 2012; pp. 17–24. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014. [Google Scholar]
- Yang, F.; Choi, W.; Lin, Y. Exploit all the layers: Fast and accurate cnn object detector with scale dependent pooling and cascaded rejection classifiers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 2129–2137. [Google Scholar]
- Wang, X.; Yang, M.; Zhu, S.; Lin, Y. Regionlets for generic object detection. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 17–24. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Smets, P. The combination of evidence in the transferable belief model. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 447–458. [Google Scholar] [CrossRef]
- Yager, R.; Fedrizzi, M.; Kacprzyk, J. Advances in the Dempster-Shafer Theory of Evidence; John Wiley & Sons: Hoboken, NJ, USA, 1994. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013. [Google Scholar] [CrossRef]
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. MOTChallenge 2015: Towards a benchmark for multi-target tracking. arXiv 2015. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The CLEAR MOT metrics. EURASIP J. Image Video Process. 2008, 2008, 1–10. [Google Scholar] [CrossRef]
- Li, Y.; Huang, C.; Nevatia, R. Learning to associate: Hybridboosted multi-target tracker for crowded scene. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2953–2960. [Google Scholar]
- Lee, S.; Lee, J.H.; Lim, J.; Suh, I.H. Robust stereo matching using adaptive random walk with restart algorithm. Image Vis. Comput. 2015, 37, 1–11. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016. [Google Scholar]
- Geiger, A.; Lauer, M.; Wojek, C.; Stiller, C.; Urtasun, R. 3D traffic scene understanding from movable platforms. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1012–1025. [Google Scholar] [CrossRef] [PubMed]
- Le, N.; Heili, A.; Odobez, J.M. Long-Term Time-Sensitive Costs for CRF-Based Tracking by Detection. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 43–51. [Google Scholar]
- Ban, Y.; Ba, S.; Alameda-Pineda, X.; Horaud, R. Tracking Multiple Persons Based on a Variational Bayesian Model. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 52–67. [Google Scholar]
- Sanchez-Matilla, R.; Poiesi, F.; Cavallaro, A. Online multi-target tracking with strong and weak detections. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 84–99. [Google Scholar]
- Fagot-Bouquet, L.; Audigier, R.; Dhome, Y.; Lerasle, F. Improving Multi-frame Data Association with Sparse Representations for Robust Near-online Multi-object Tracking. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 774–790. [Google Scholar]
- Kim, C.; Li, F.; Ciptadi, A.; Rehg, J.M. Multiple hypothesis tracking revisited. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4696–4704. [Google Scholar]
- Kieritz, H.; Becker, S.; Hübner, W.; Arens, M. Online multi-person tracking using Integral Channel Features. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 122–130. [Google Scholar]
- Tang, S.; Andres, B.; Andriluka, M.; Schiele, B. Subgraph decomposition for multi-target tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5033–5041. [Google Scholar]
- Choi, W. Near-online multi-target tracking with aggregated local flow descriptor. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3029–3037. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Ju, H.Y.; Lee, C.R.; Yang, M.H.; Yoon, K.J. Online multi-object tracking via structural constraint event aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 1392–1400. [Google Scholar]
- Milan, A.; Roth, S.; Schindler, K. Continuous Energy Minimization for Multitarget Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 58–72. [Google Scholar] [CrossRef] [PubMed]
- Andriyenko, A.; Schindler, K.; Roth, S. Discrete-Continuous Optimization for Multi-Target Tracking. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Lenz, P.; Geiger, A.; Urtasun, R. FollowMe: Efficient online min-cost flow tracking with bounded memory and computation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4364–4372. [Google Scholar]
- Geiger, A. Probabilistic Models for 3D Urban Scene Understanding from Movable Platforms; KIT Scientific Publishing: Karlsruhe, Germany, 2013; Volume 25. [Google Scholar]
- Pirsiavash, H.; Ramanan, D.; Fowlkes, C.C. Globally-optimal greedy algorithms for tracking a variable number of objects. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1201–1208. [Google Scholar]
- Lee, B.; Erdenee, E.; Jin, S.; Nam, M.Y.; Jung, Y.G.; Rhee, P.K. Multi-class Multi-object Tracking Using Changing Point Detection. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 68–83. [Google Scholar]
- Yoon, J.H.; Yang, M.H.; Lim, J.; Yoon, K.J. Bayesian multi-object tracking using motion context from multiple objects. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 33–40. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tracker | Matching Target | Representation | Representation Usage | Modality | Update |
|---|---|---|---|---|---|
| VGG-16 | Adaptively | RGB + Depth (PC) | w | ||
| Init. | VGG-16 | Adaptively | RGB + Depth (PC) | w | |
| AlexNet | Adaptively | RGB + Depth (PC) | w | ||
| VGG-16 | RGB + Depth (PC) | w | |||
| VGG-16 | RGB + Depth (PC) | w | |||
| VGG-16 | RGB + Depth (PC) | w | |||
| VGG-16 | RGB + Depth (PC) | w | |||
| VGG-16 | Adaptively | RGB | w | ||
| VGG-16 | Adaptively | Depth (PC) | w | ||
| VGG-16 | Adaptively | Depth (stereo) | w | ||
| VGG-16 | Adaptively | RGB + Depth (PC) | w/o |
| Tracker | MOTA↑ | MOTP↑ | MT↑ | ML↓ | IDS↓ |
|---|---|---|---|---|---|
| 66.38% | 78.95% | 30.89% | 21.79% | 7 | |
| 60.22% | 78.83% | 23.24% | 30.44% | 27 | |
| 62.42% | 69.25% | 24.58% | 31.57% | 20 | |
| 59.14% | 74.22% | 24.97% | 29.12% | 22 | |
| 59.46% | 73.39% | 26.14% | 27.41% | 29 | |
| 48.49% | 61.44% | 18.62% | 32.01% | 11 | |
| 64.21% | 77.61% | 27.55% | 24.88% | 29 | |
| 61.51% | 63.20% | 26.04% | 33.63% | 31 | |
| 60.55% | 68.24% | 26.88% | 34.58% | 30 | |
| 60.48% | 66.91% | 27.43% | 28.29% | 26 | |
| 63.47% | 77.79% | 28.81% | 23.33% | 14 |
| Tracker | MOTA↑ | MOTP↑ | MT↑ | ML↓ | IDS↓ |
|---|---|---|---|---|---|
| 61.51% | 63.20% | 26.04% | 33.63% | 31 | |
| 46.88% | 77.24% | 18.92% | 46.54% | 41 | |
| 60.11% | 61.09% | 22.23% | 33.98% | 33 | |
| 45.92% | 77.16% | 17.99% | 45.98% | 43 |
| Tracker | MOTA↑ | MOTP↑ | MT↑ | ML↓ |
|---|---|---|---|---|
| TBD [50] | 33.7% | 78.5% | 7.2% | 54.2% |
| LTTSC-CRF [51] | 37.6% | 75.9% | 9.6% | 55.2% |
| OVBT [52] | 38.4% | 75.4% | 7.5% | 47.3% |
| EAMTT-pub [53] | 38.8% | 75.1% | 7.9% | 49.1% |
| LINF1 [54] | 41.0% | 74.8% | 11.6% | 51.3% |
| MHT-DAM [55] | 42.9% | 76.6% | 13.6% | 46.9% |
| oICF [56] | 43.2% | 74.3% | 11.3% | 48.5% |
| JMC [57] | 46.3% | 75.7% | 15.5% | 39.7% |
| NOMT [58] | 46.4% | 76.6% | 18.3% | 41.4% |
| ours | 46.78% | 77.95% | 19.41% | 45.34% |
| Tracker | MOTA↑ | MOTP↑ | MT↑ | ML↓ |
|---|---|---|---|---|
| SCEA [60] | 51.30% | 78.84% | 26.22% | 26.22% |
| TBD [50] | 49.52% | 78.35% | 20.27% | 32.16% |
| NOMT [58] | 55.87% | 78.17% | 39.94% | 25.46% |
| CEM [61] | 44.31% | 77.11% | 19.51% | 31.40% |
| DCO [62] | 28.72% | 74.36% | 15.24% | 30.79% |
| mbodSSP [63] | 48.00% | 77.52% | 22.10% | 27.44% |
| HM [64] | 41.47% | 78.34% | 11.59% | 39.33% |
| DP-MCF [65] | 35.72% | 78.41% | 16.92% | 35.67% |
| MCMOT-CPD [66] | 72.11% | 82.13% | 52.13% | 11.43% |
| ours | 65.48% | 79.27% | 32.61% | 18.41% |
| Tracker | MOTA↑ | MOTP↑ | MT↑ | ML↓ |
|---|---|---|---|---|
| SCEA [60] | 26.02% | 68.45% | 9.62% | 47.08% |
| NOMT-HM [58] | 17.26% | 67.99% | 14.09% | 50.52% |
| NOMT [58] | 25.55% | 67.75% | 17.53% | 42.61% |
| CEM [61] | 18.18% | 68.48% | 8.93% | 51.89% |
| RMOT [67] | 25.47% | 68.06% | 13.06% | 47.42% |
| MCMOT-CPD [66] | 40.50% | 72.44% | 20.62% | 34.36% |
| ours | 44.87% | 70.55% | 24.60% | 37.92% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, S.-I.; Kang, H.-B. Multiple Objects Fusion Tracker Using a Matching Network for Adaptively Represented Instance Pairs. Sensors 2017, 17, 883. https://doi.org/10.3390/s17040883
Oh S-I, Kang H-B. Multiple Objects Fusion Tracker Using a Matching Network for Adaptively Represented Instance Pairs. Sensors. 2017; 17(4):883. https://doi.org/10.3390/s17040883
Chicago/Turabian StyleOh, Sang-Il, and Hang-Bong Kang. 2017. "Multiple Objects Fusion Tracker Using a Matching Network for Adaptively Represented Instance Pairs" Sensors 17, no. 4: 883. https://doi.org/10.3390/s17040883
APA StyleOh, S. -I., & Kang, H. -B. (2017). Multiple Objects Fusion Tracker Using a Matching Network for Adaptively Represented Instance Pairs. Sensors, 17(4), 883. https://doi.org/10.3390/s17040883