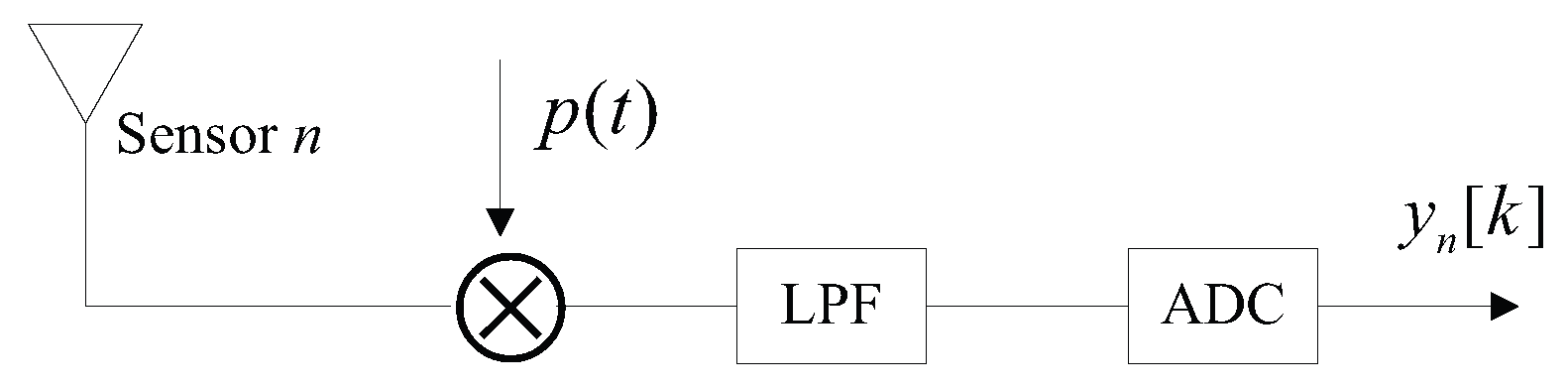
4.1. Carrier Frequency Recovery
By invoking (
11), the temporal covariance matrix can be written as
Because we assume that the baseband transmissions are uncorrelated with each other,
is a diagonal matrix. Then, by vectorizing the covariance matrix
, we can get
where
is a
vector including the diagonal elements of
. Note that the above equations hold only when all transmissions are uncorrelated with each other. Here, we denote
as the manifold matrix of difference coarray. Obviously, the
-th element of
is given by
where
is the
-th element of
and
is the
-th element of
.
. So we can easily get that the aperture of the difference coarray extends from
to
. But this difference coarray is not filled, there are some holes in it. By referring to [
11], we know that it has a contiguous set of elements from
to
, which acts like a filled virtual uniform linear array (ULA). To make it more clear, we first define the weight function at each element position of the virtual ULA.
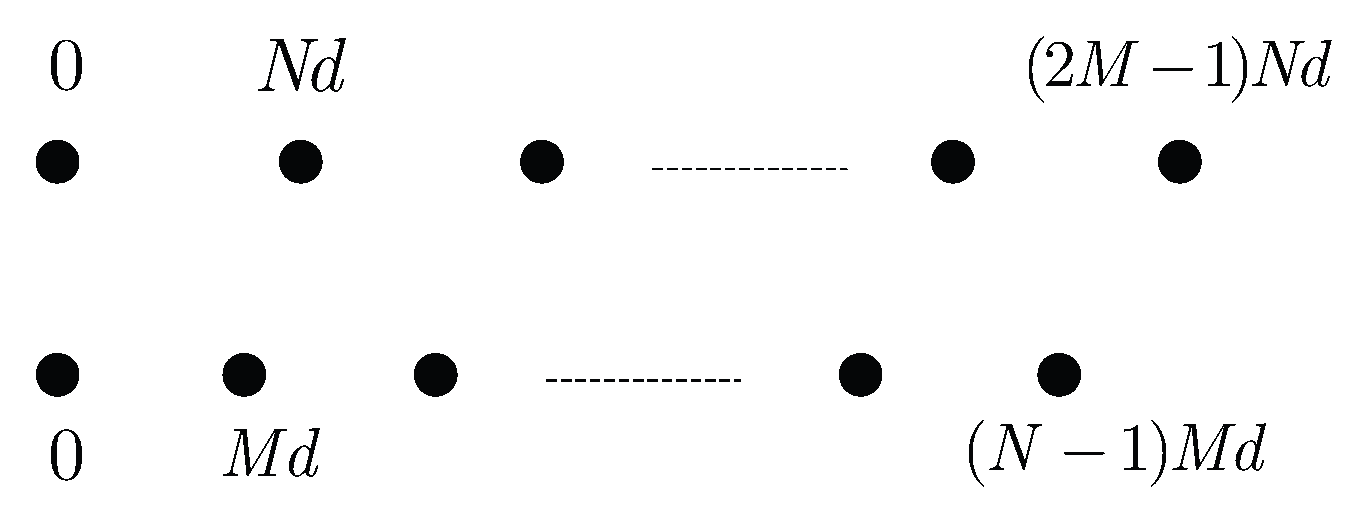
Definition 1. (The weight function, ). Consider a co-prime array with its co-prime parameters M and N. Let be the element position set of physical array and be the element position set of virtual ULA. The weight function is the number of pairs which have a difference , defined as
For example, if we choose , then and . The weight function satisfies , etc.
Based on (
13), we denote
as the row of
, which is produced by the
n-th row of
and the
m-th row of
via Khatri-Rao product. So by choosing the continuous lags from
to
and taking the weight function into account, we can get a virtual ULA model
where the
i-th (
) element of
is
and
, namely the array manifold of the virtual ULA, has the structure
where
. Based on (
17), we have the following sufficient condition for unique solution to
. Obviously,
is equivalent to
K coherent sources with only one snapshot.
Theorem 1. Consider a co-prime array consisting of sensor elements which can be transformed into a virtual filled ULA in (17). Ifthen (17) has a unique solution of . Proof. Because
is equivalent to
K coherent sources, we have
. And the virtual array acts as a filled ULA with inter-element spacing
d satisfies
and the number of virtual elements is
. So we refer the reader to [
10] which deals with the physical ULA case. With these substitutions, the result follows from Theorem 1 in [
10]. ☐
Next, we define
Because
we need to implement a spatial smoothing step to enhance the rank of the covariance matrix. As analyzed above, the virtual ULA has the element position from
to
. Now, we divide this virtual array into
overlapping subarrays, each with
elements. The
i-th subarray has sensors located at
which corresponds to the
-th to
-th rows of
. So we have
where
is a
matrix consisting of the
-th to
-th rows of
which has the structure
Obviously, from the above structure, we can get
where
is a diagonal matrix with its diagonal elements as
. So, we rewrite (
23) as
Then, we can get the spatially smoothed matrix
where
The spatially smoothed matrix can be used to estimate carrier frequencies by the following theorem.
Theorem 2. Consider the spatially smoothed matrix in (27) and define a diagonal matrix with its diagonal elements as the covariances of K targets. Then, we have Proof. The proof follows the same lines as Theorem 1 in [
12], only substituting the values of
and
in our paper. ☐
By decomposing using the singular value decomposition, we have
The columns of the matrix
are the left singular vectors of
, where
contains the vectors corresponding to the first
K singular values,
is a
diagonal matrix with the
K first singular values of
, and
contains the right singular vector of
. Based on (
29) and (
30), we know that there exists an invertible
matrix
such that
Consider the first rows of , we have
Similarly, we can have the last
rows of
where
is the virtual sub-array consisting of element positions
and
is the virtual sub-array consisting of elements positions
. So, we can get the relationship between
and
as
where
is a diagonal matrix which is defined in (
26). So we rewrite (
32) as
Here, we use the least squares recovery
Then, we have
where
is the
i-th diagonal element of
.
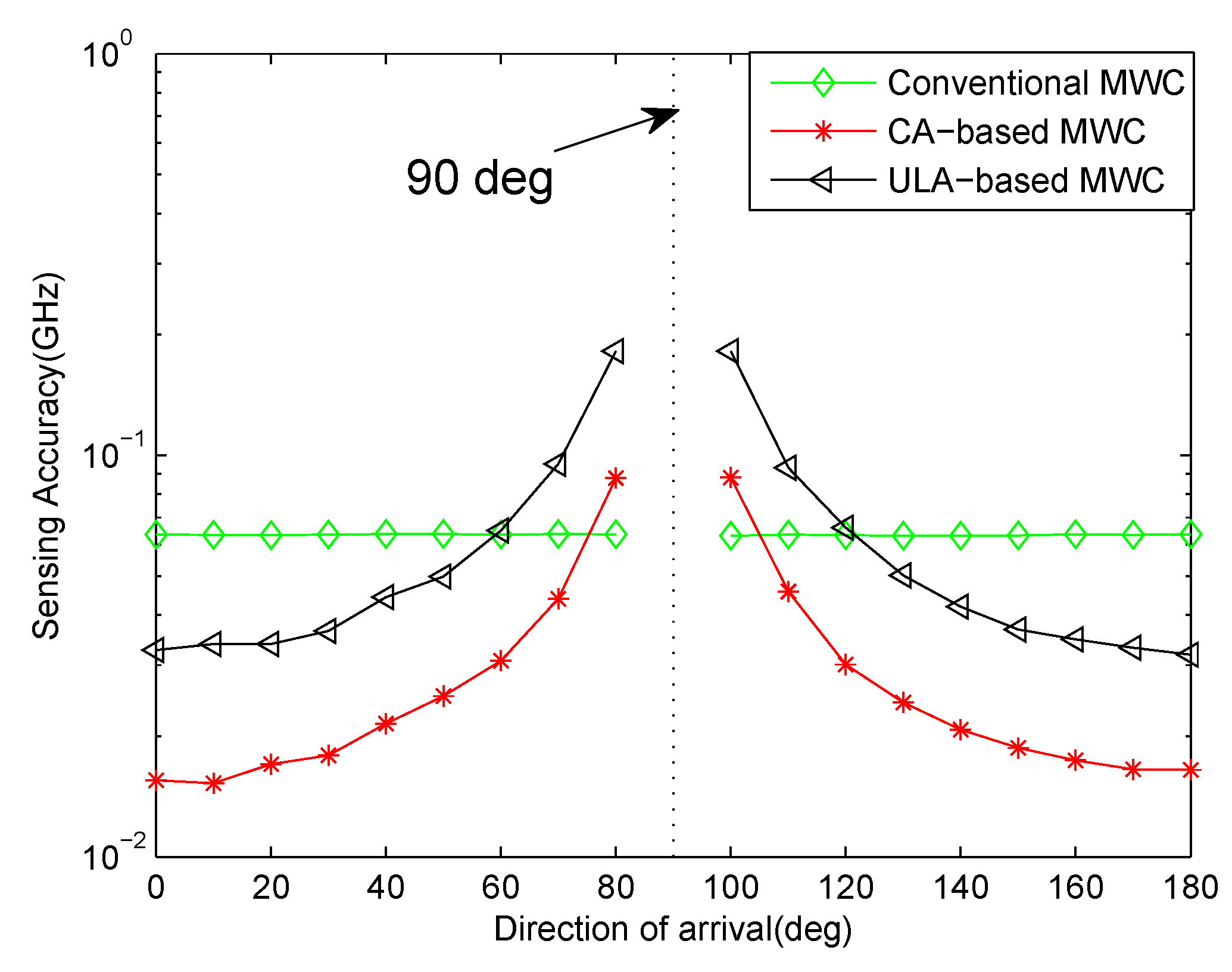
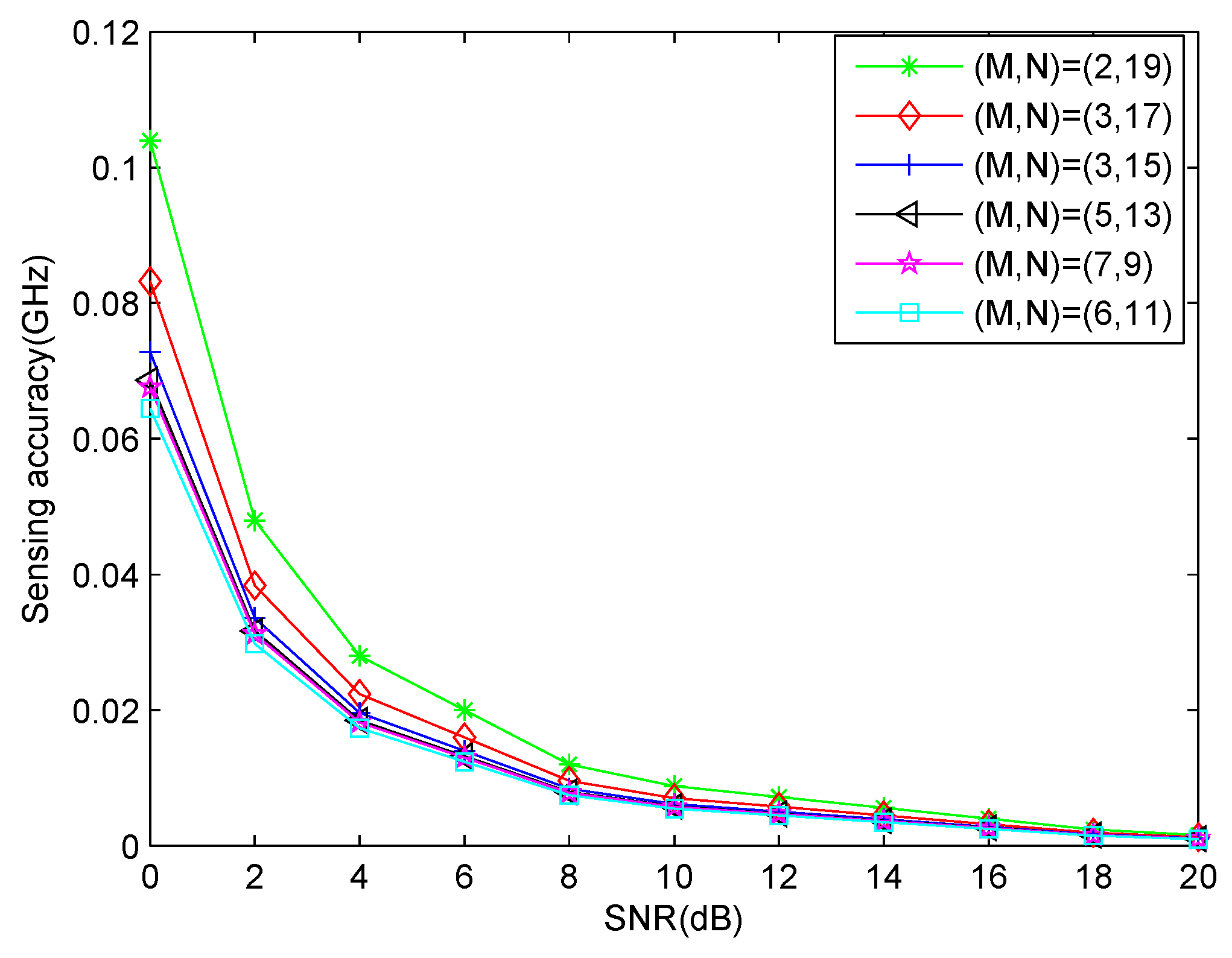
Remark 1. It can be seen from (37) that θ can not be equal to . And the performance of carrier frequency estimation is affected by θ. Because is the denominator term in (37), a small will amplify the error which is caused by the calculation of Ψ.
Assuming , the closer to or the impinging direction θ is, the smaller the estimation error is. Conversely, the closer to , the larger the error is. In practice, if we know that θ is approaching , we can add an adjustable known time delay line after each sensor which is equivalent to rotating the array with a known angle. If we denote the man-made time delay as , then the denominator term in (37) is modified as . In the following discussion, we consider the case that θ is close to or for simplicity. 4.2. Signal Power Spectrum Recovery
Once the carrier frequencies are recovered, the steering matrix defined in (
17) can be constructed. So in this subsection, we will first consider the power spectrum recovery of
. After that, we will investigate how to recover the power spectrum of
from
.
By invoking (
9), we consider the signal model in the frequency domain. Define the autocorrelation matrix of
as
. Similarly, define
and
for
. Then, we have
Due to the assumption that all transmissions are uncorrelated with each other, so
and
are both diagonal matrixes. Then, similar to the processing steps in (
13) and (
17), by vectorization, removing the redundancies and choosing the continuous lags, we can get the virtual array model in the frequency domain
where
is a
vector which contains the diagonal elements of
. Similarly, we denote
as a
vector which contains the diagonal elements of
. From (
17),
is a Vandermonde matrix, it has full column rank if and only if
. Referring to Theorem 1, if the sufficient condition (
19) is satisfied,
will have full column rank. Then we can obtain the power spectrum of
by inverting the steering matrix,
As analyzed in the third section, is a cyclic and shifted version of .
Consider the
i-th transmission
. It holds that
where
is known as
Then we have the relationship between the power spectrum of
and
,
where
is the
i-th element of the
vector
and
is the the
i-th element of the
vector
. After a change of variables,
Observing (
43) and (
44), the equality in (
44) holds if and only if
.
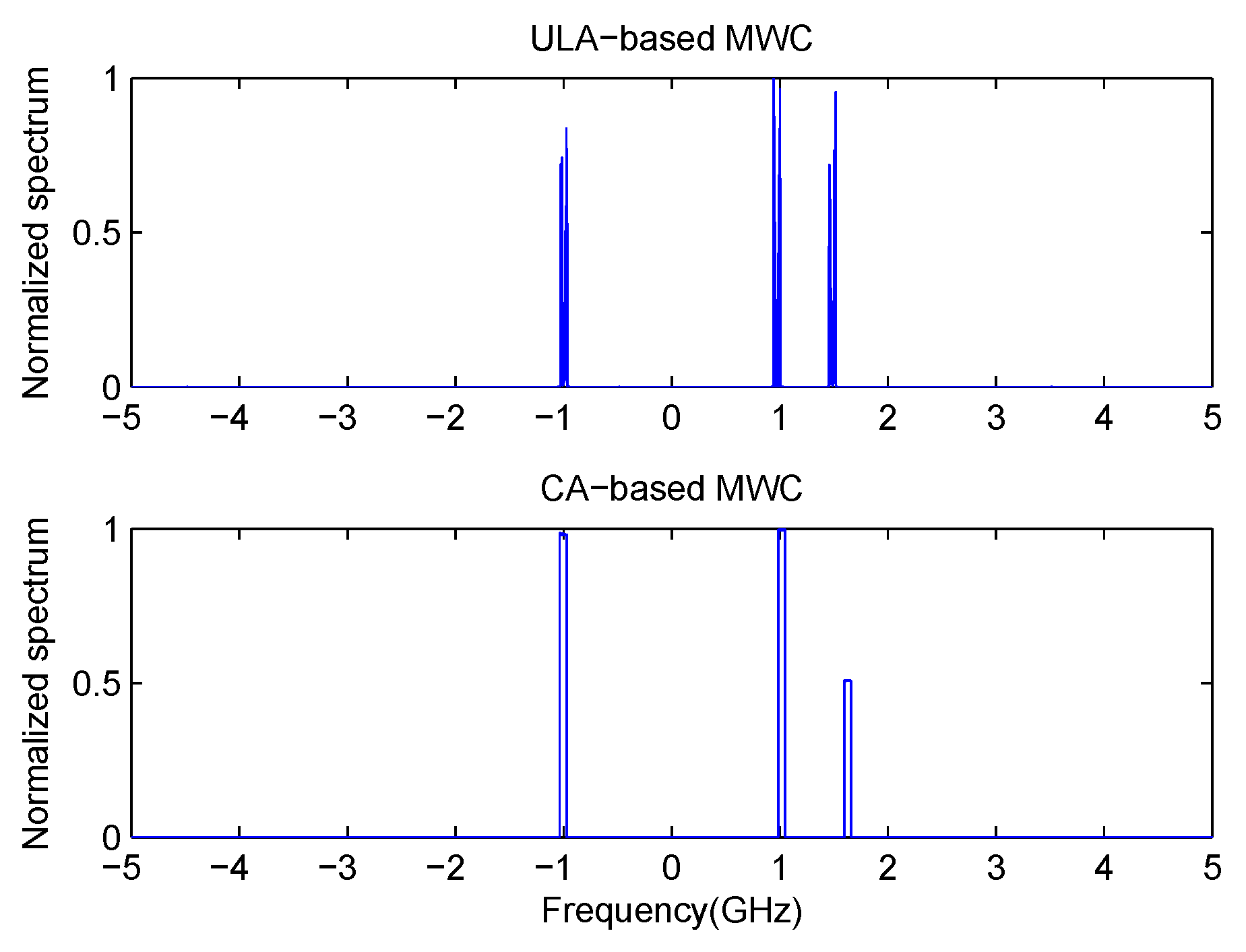
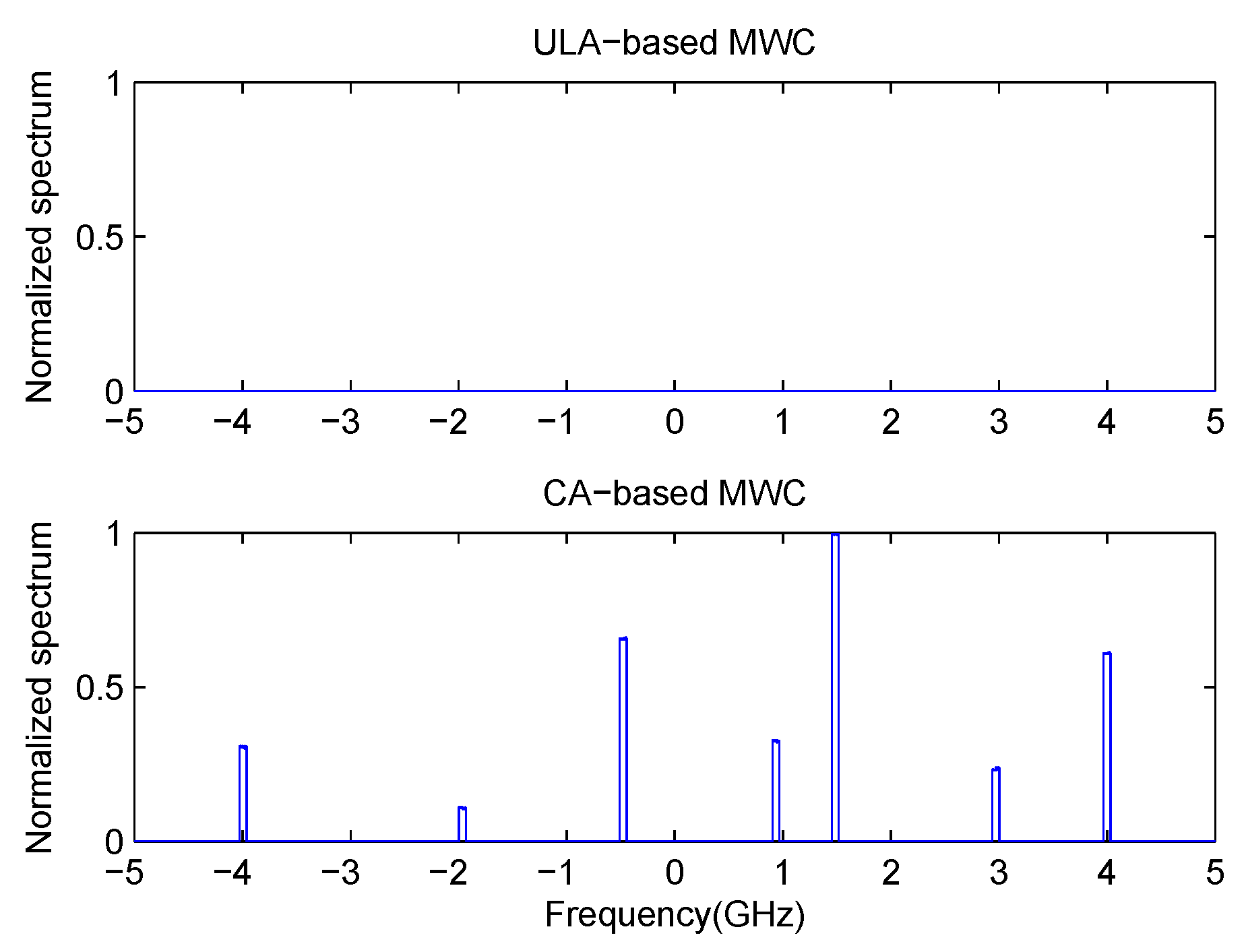
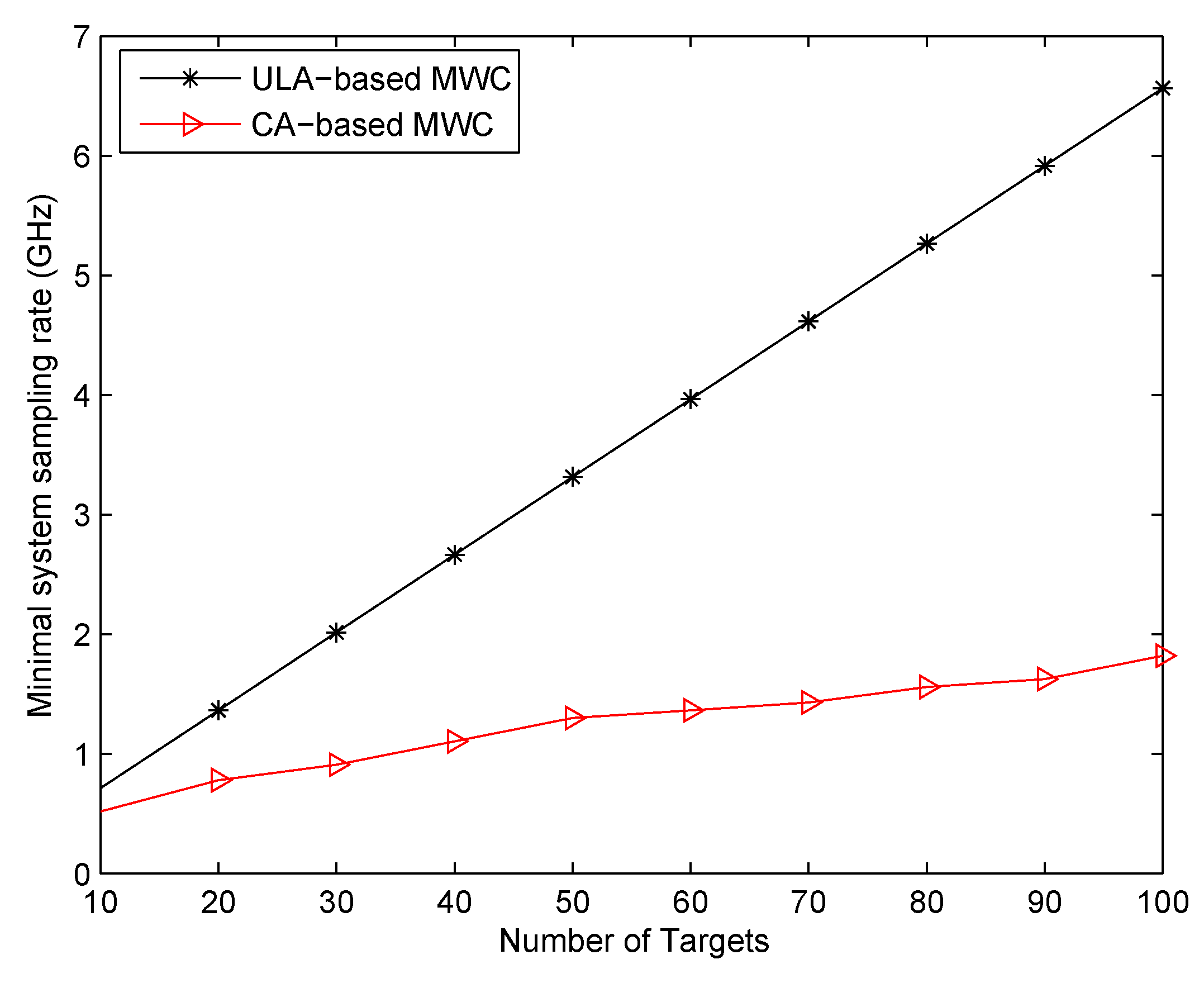
4.3. Comparison with Previous MWC Systems
By referring to conventional MWC [
7] and ULA-based MWC [
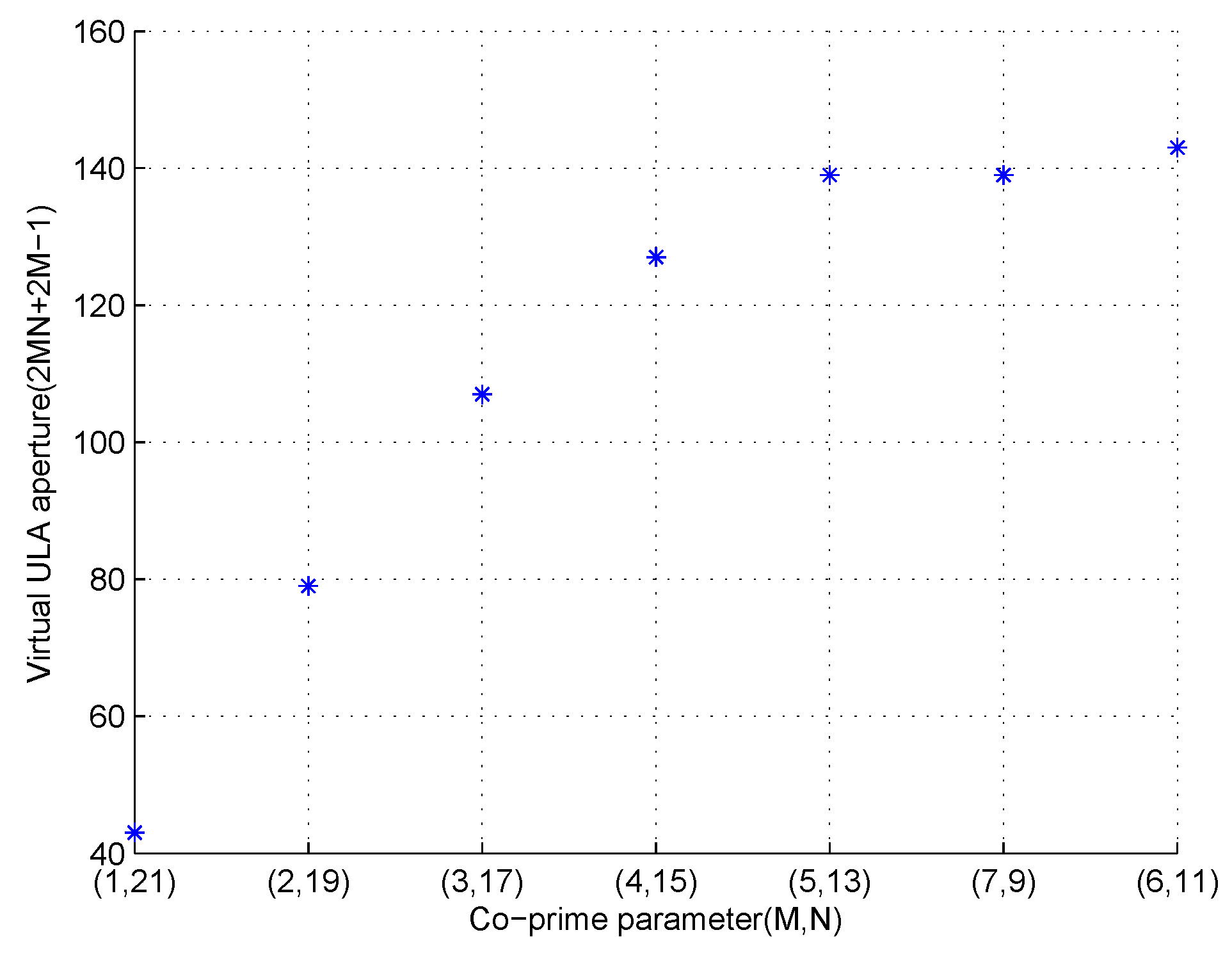
10], we can have the following conclusions. Firstly, we compare our proposed CA-based MWC with ULA-based MWC and conventional MWC. Our method processes the signal in the co-array domain, while the latter two methods process signal in physical sensor (channel) domain. That means, if we fix the number of physical sensors or channels as
, then our proposed CA-based method can produce a virtual ULA which has
elements. It is much larger than that of ULA-based MWC and conventional MWC which can increase the system’s robustness to noise. Another difference is that our method can directly recover the power spectrum of impinging signal, while the latter methods must first recover the signal itself after which the power spectrum is calculated. Here, we need to point out a disadvantage as shown in (
13) that the impinging signal for our method must be uncorrelated with each other. Secondly, we compare CA-based MWC, ULA-based MWC with conventional MWC. In our proposed CA-based MWC and ULA-based MWC, carrier frequencies are first estimated, then the baseband transmissions are estimated. For conventional MWC, there’s no need to estimate carrier frequencies, all RF signals are estimated directly. In addition, each channel of CA-based MWC and ULA-based MWC is corrupted by independent noise, while each channel of conventional MWC is corrupted by the same noise. Lastly, we compare our method with ULA-based MWC. Besides a difference about the number of sensors, another difference is that our proposed system is a sparse array system while ULA-based MWC is a filled array system. As we all know, the closer the sensors are, the more correlated their samples are, which can affect the performance. The differences among these three methods are shown clearly in
Table 1 where × denotes “Not exist”.













{kind=link}
{kind=link}
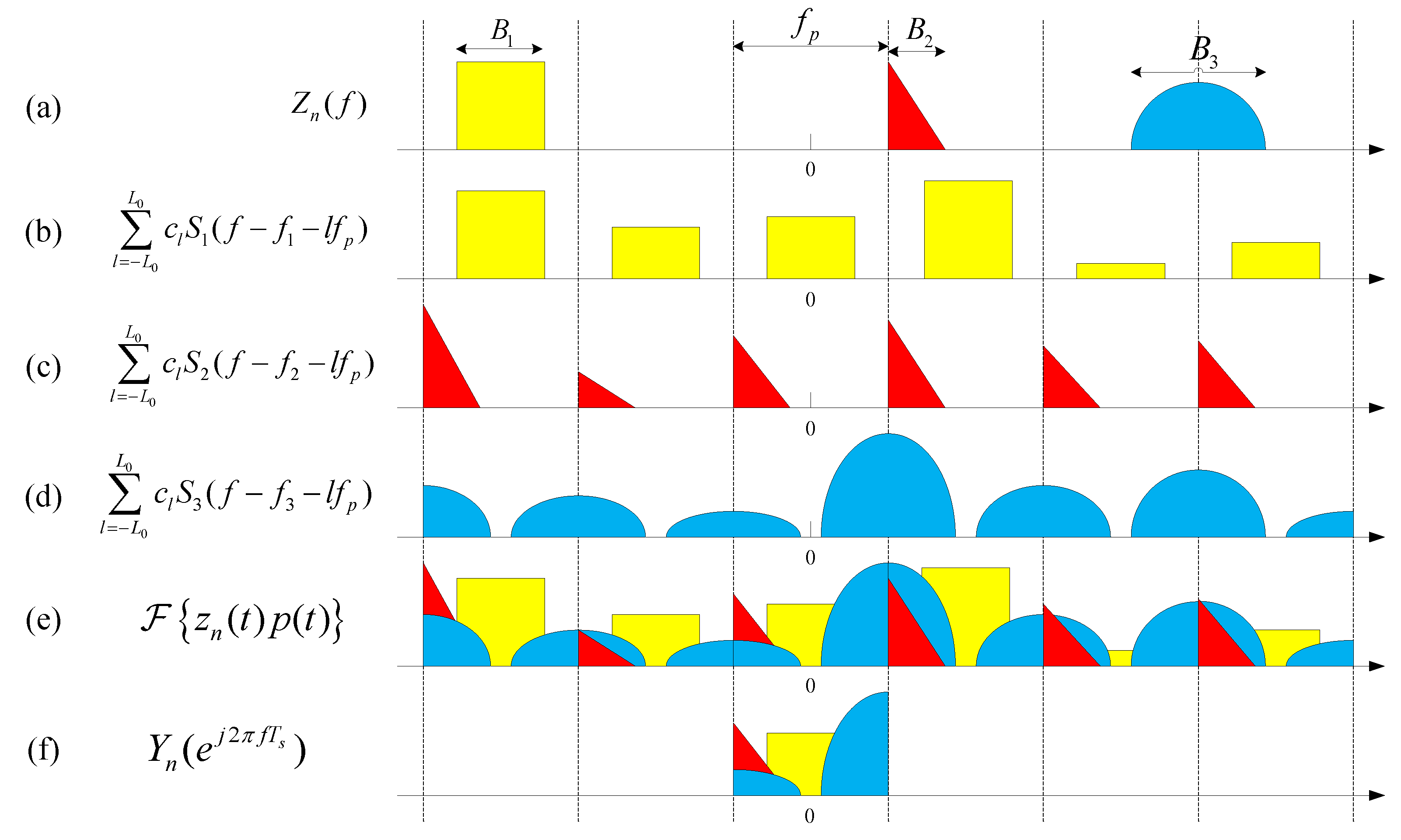{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}