Toward a Trust Evaluation Mechanism in the Social Internet of Things



Abstract
:1. Introduction
2. Augmentation of Trust Concept in the SIoT
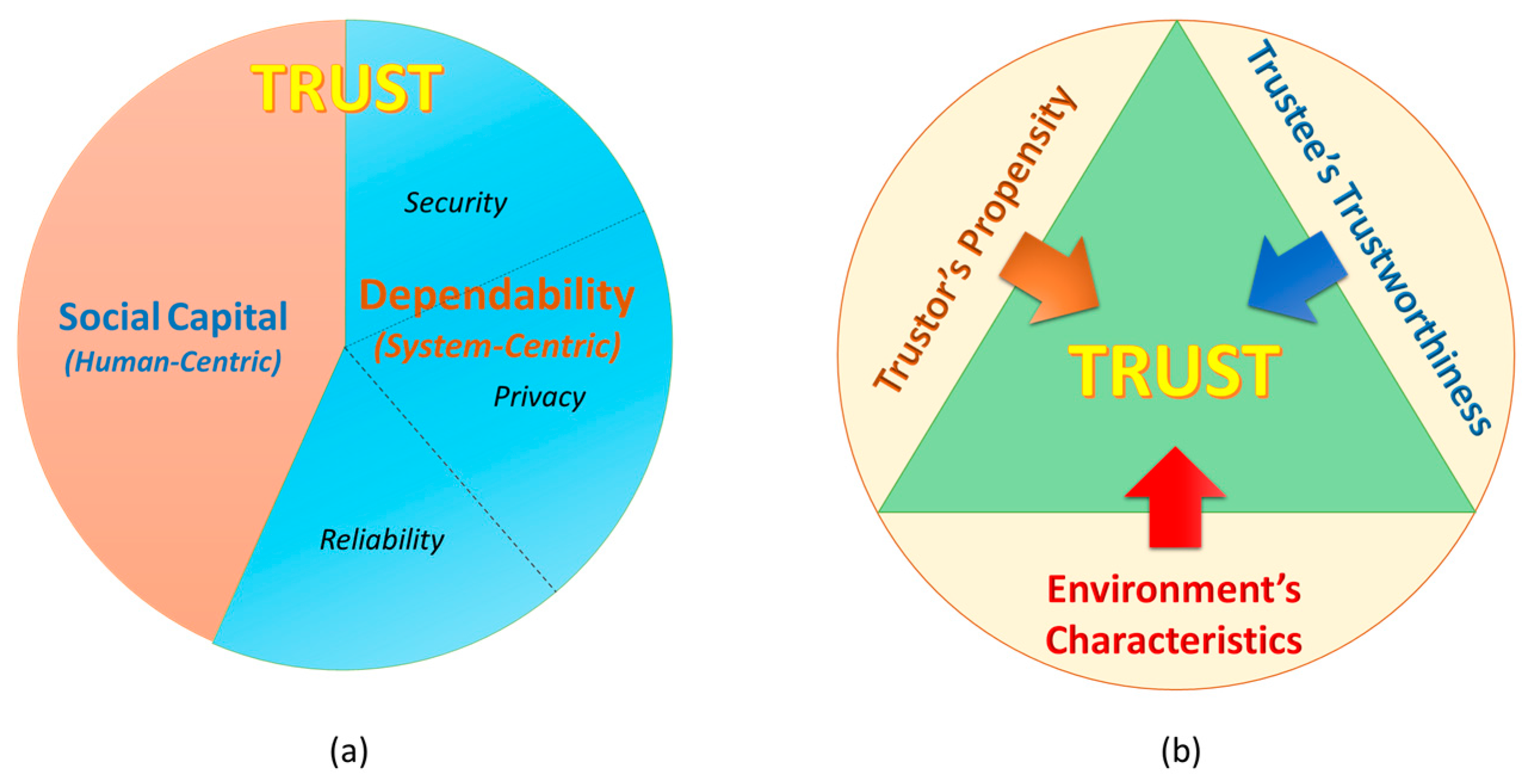
2.1. Trust Concept Clarification
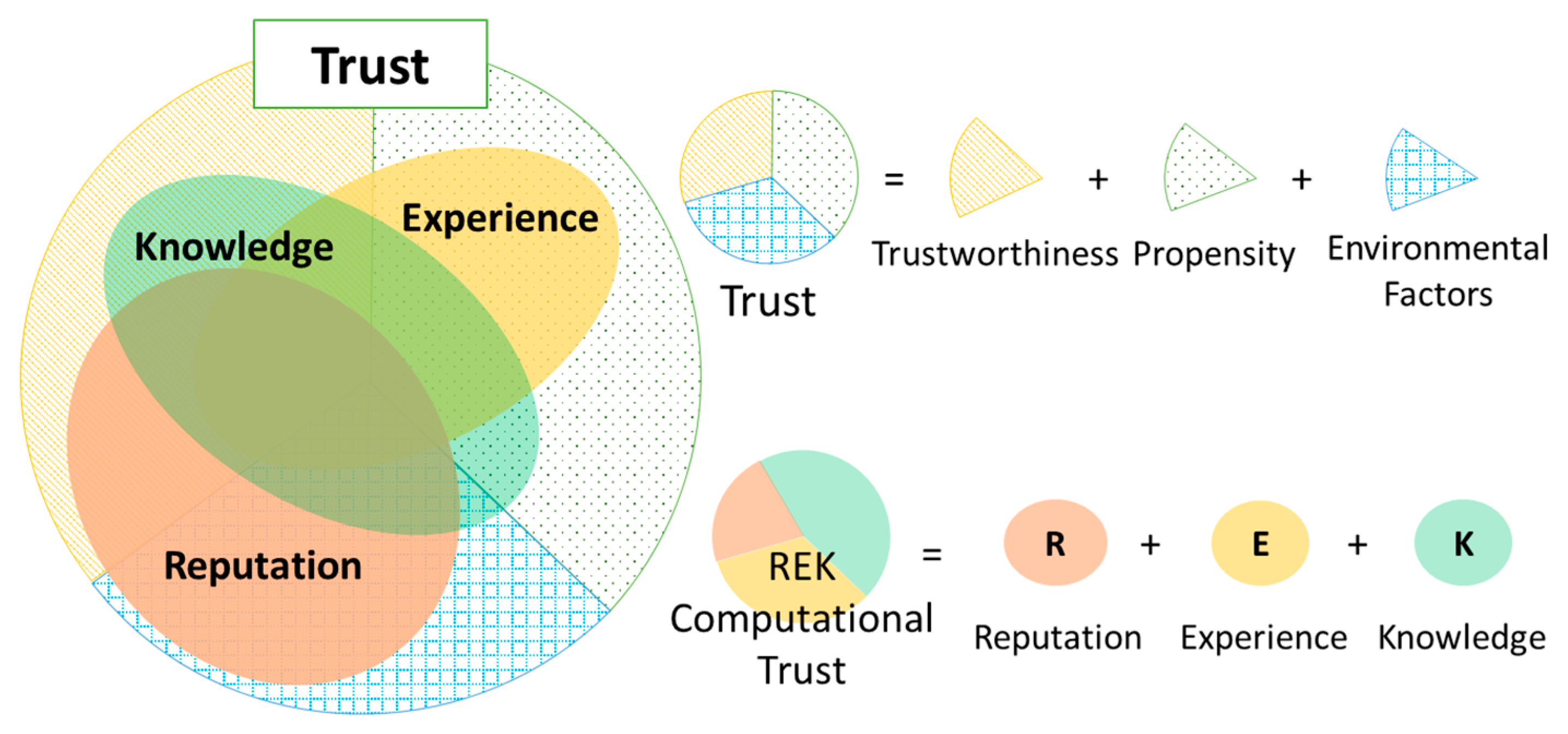
2.2. Definition of Trust in SIoT
2.3. Trust Characteristics
- Trust is subjective: With the same trustee and trust context, trust might be different from trustors. In other word, trust is dependent on trustor’s perspective. For example, Alice (highly) trusts Bob but Charlie does not (for fulfilling a trust goal).
- Trust is asymmetric: Trust is a non-mutual reciprocal in nature although in some special cases, trust may be symmetric. For example, if Alice (highly) trusts Bob (in fulfilling a trust goal) it does not mean that Bob will (highly) trust Alice (in fulfilling such trust goal).
- Trust is context-dependent: With the same trustor and trustee, trust might be different depending on context including: (i) task goal, (ii) period of time, and (iii) environment. For instance, (i) Alice (highly) trusts Bob to provide a cloud storage service but not for a real-time streaming service; (ii) Alice (highly) trusted Bob to provide a cloud storage service two years ago but not for now; and (iii) Alice (highly) trusts Bob to provide a cloud storage service in the United Kingdom but not in the United States.
- Trust is not necessarily transitive but propagative: If Alice (highly) trusts Bob, and Bob (highly) trusts Charlie then it is not necessarily true that Alice will (highly) trust Charlie. However there are some evidences from the trust relationship between Bob and Charlie that Alice can rely on in order to judge the trust in Charlie.
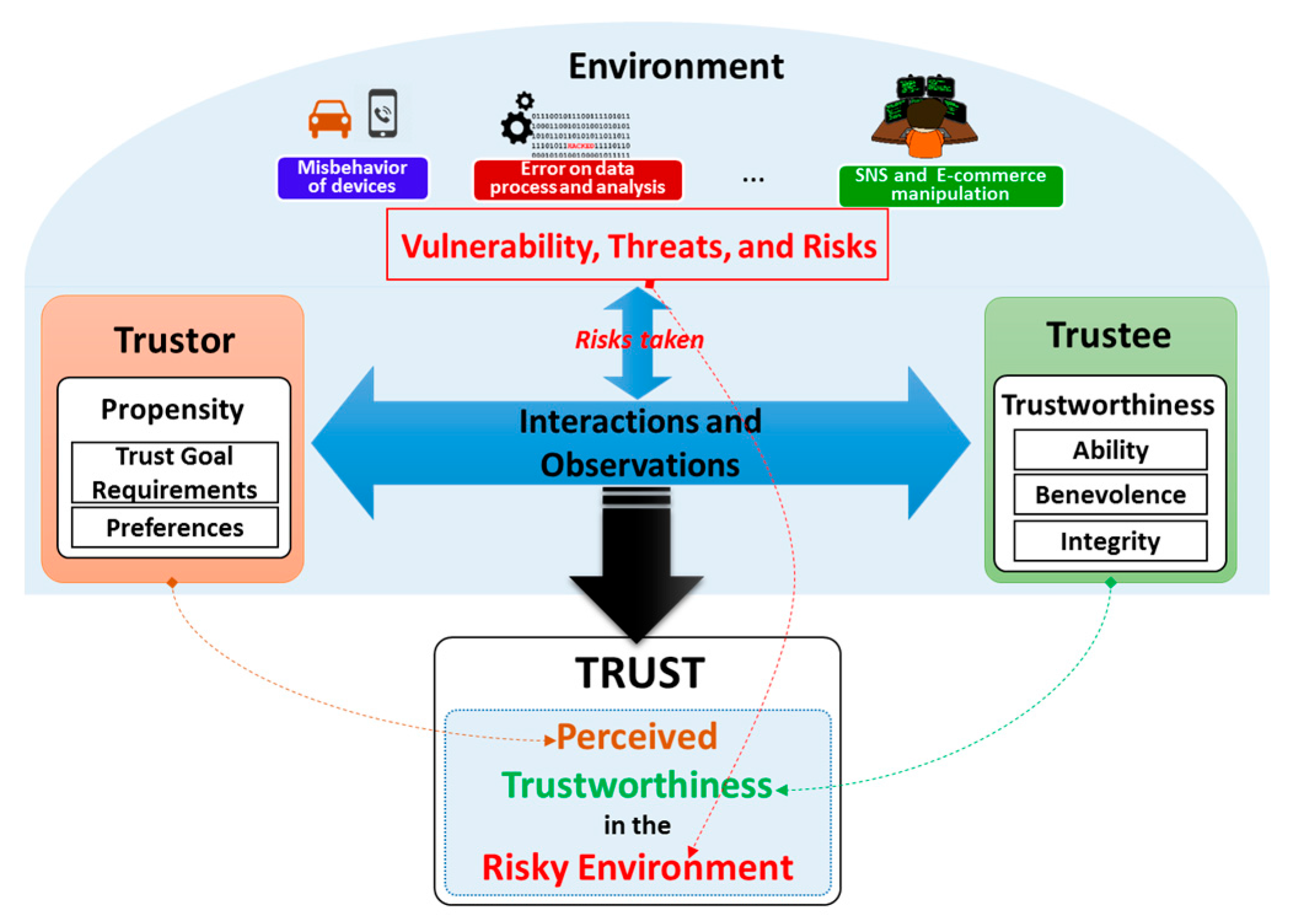
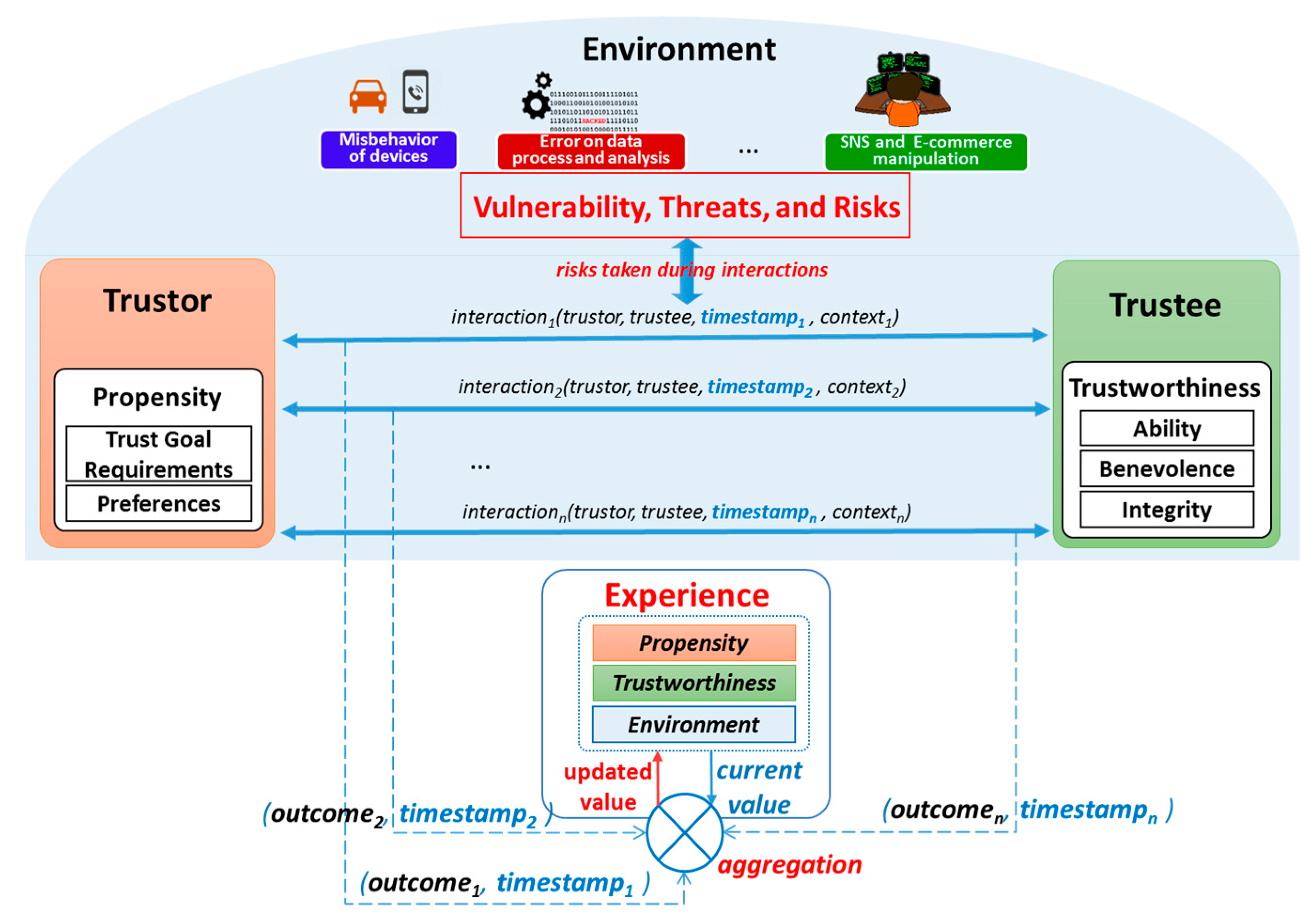
2.4. Conceptual Trust Model in SIoT Environment
2.5. Trustworthiness and Trustworthiness Attributes
- Ability: is a dimension of trustworthiness showing the capability of a trustee to accomplish a trust goal. An entity may be high benevolent and integrity for fulfilling a trust goal but the results may not be satisfactory if it is not capable. This term incorporates some other terms that have been used as TAs in many trust-related literature such as competence, expertness, and credibility.
- Benevolence: is a dimension of trustworthiness showing to what extent a trustee is willing to do good things or not harm the trustor. Benevolence ensures that the trustee will have good intentions toward the trustor. This term incorporates some TAs such as credibility, relevance, and assurance as TAs.
- Integrity: is a dimension of trustworthiness showing the trustee adheres to a set of principles that helps the trustor believe that the trustee is not harmful and not betray what it has committed to do. These principles can come from various sources such as fairness, or morality. This term incorporates some TAs such as honesty, completeness, and consistency.
3. Trust Evaluation Model: Background and Provisions
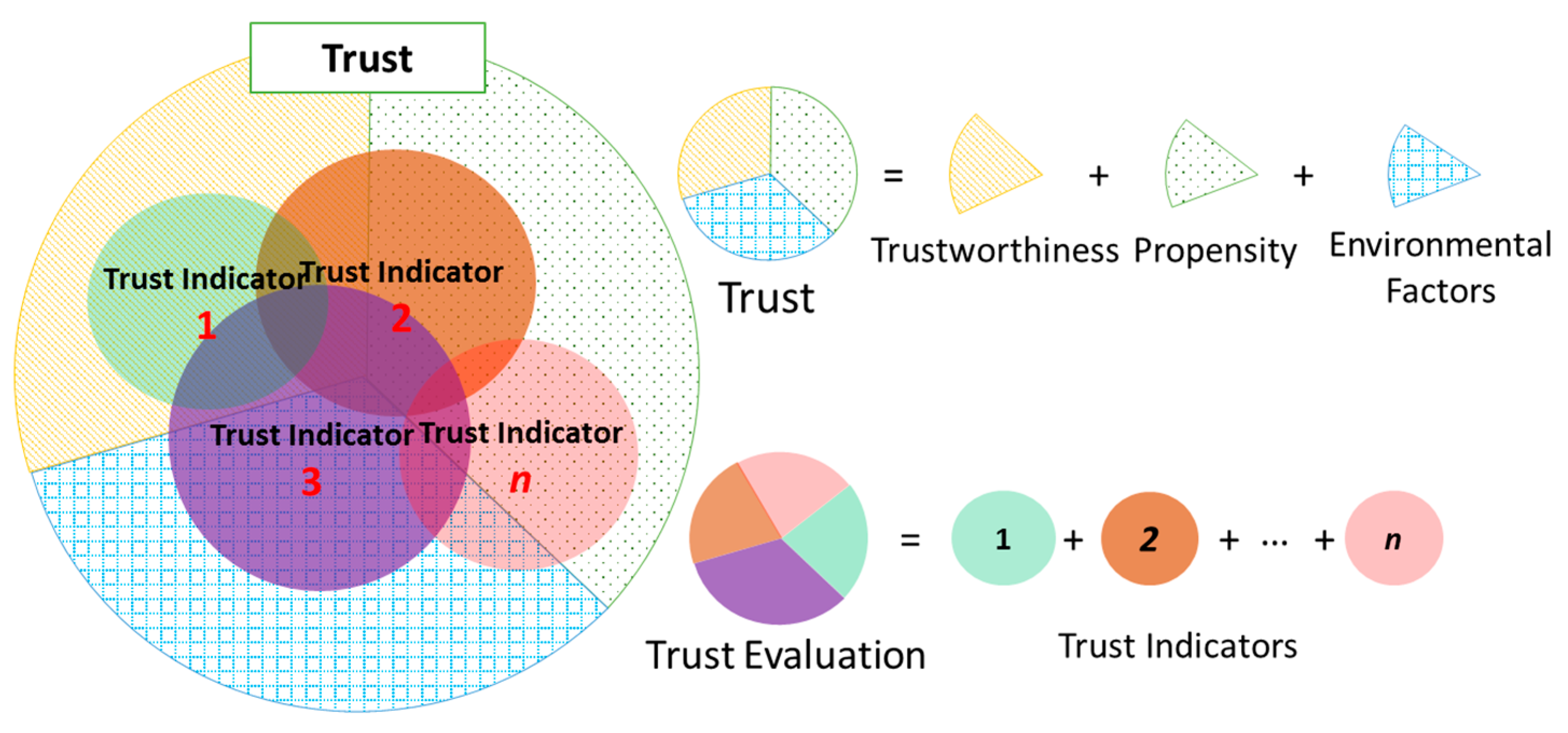
3.1. Brief Understanding on How to Evaluate Trust
3.2. Related Work on Trust Evaluation
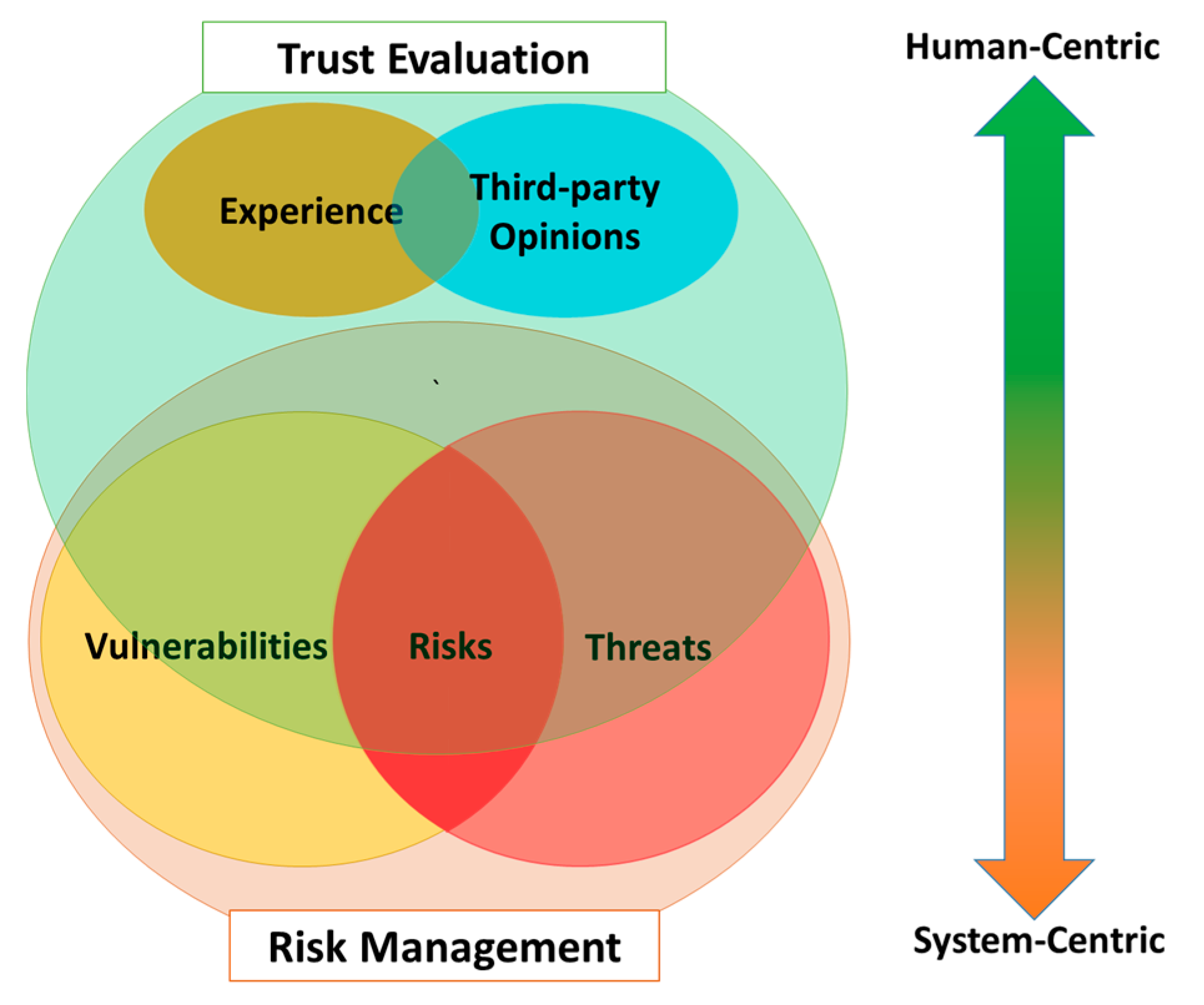
3.3. Trust Evaluation Versus Risk Management
4. REK Trust Evaluation Model in the SIoT
4.1. REK Trust Evaluation Model
4.2. Knowledge TI Evaluation Model
4.2.1. A General Set of TAs for Knowledge TI
- Availability: Probability of an entity in operation in a given period of time.
- Confidentiality: Preserving the authorized restriction on access and disclosure on data, information or system.
- Integrity: Ability to guard against improper modifications and destruction.
- Safety: A property to guarantee that an entity will not fail in a manner that would cause a great amount damage in a period of time.
- Reliability: Probability that a component correctly performs a required job in a specified period of time under stated conditions.
- Serviceability: Property indicating how easy and simply a system can be repaired or maintained.
- Cooperativeness: this property indicates the level of cooperativeness between a trustor and a trustee based on the following hypothesis: “the more cooperative between the two entities in a social network, the more trustworthy they are”. Cooperativeness can be calculated by considering the common features between the two entities such as mutual friends and same locations.
- Community-Interest: Due to the integration of social networks in SIoT, concept of community (of SIoT entities) is also introduced that refers to a group of entities sharing same characteristics (e.g., physical areas, a same goal, and same required tasks). This property indicates the level of community relationship between two entities based on the following hypothesis: “the more similar among communities that entities belong to, the more trustworthy they get”.
- Honesty: a property indicates the level of honesty of an entity based on observation toward an entity that whether it conducts some suspicious interactions or it breaks social etiquette using a set of anomaly detection rules.
- Similarity: a property indicates the level of similarity between two entities (in terms of their features) using similarity measurement mechanisms between two profiles of entities [40]. This TA is taken into account because of the following hypothesis: “a trustor tends to trust a trustee if they are similar”.
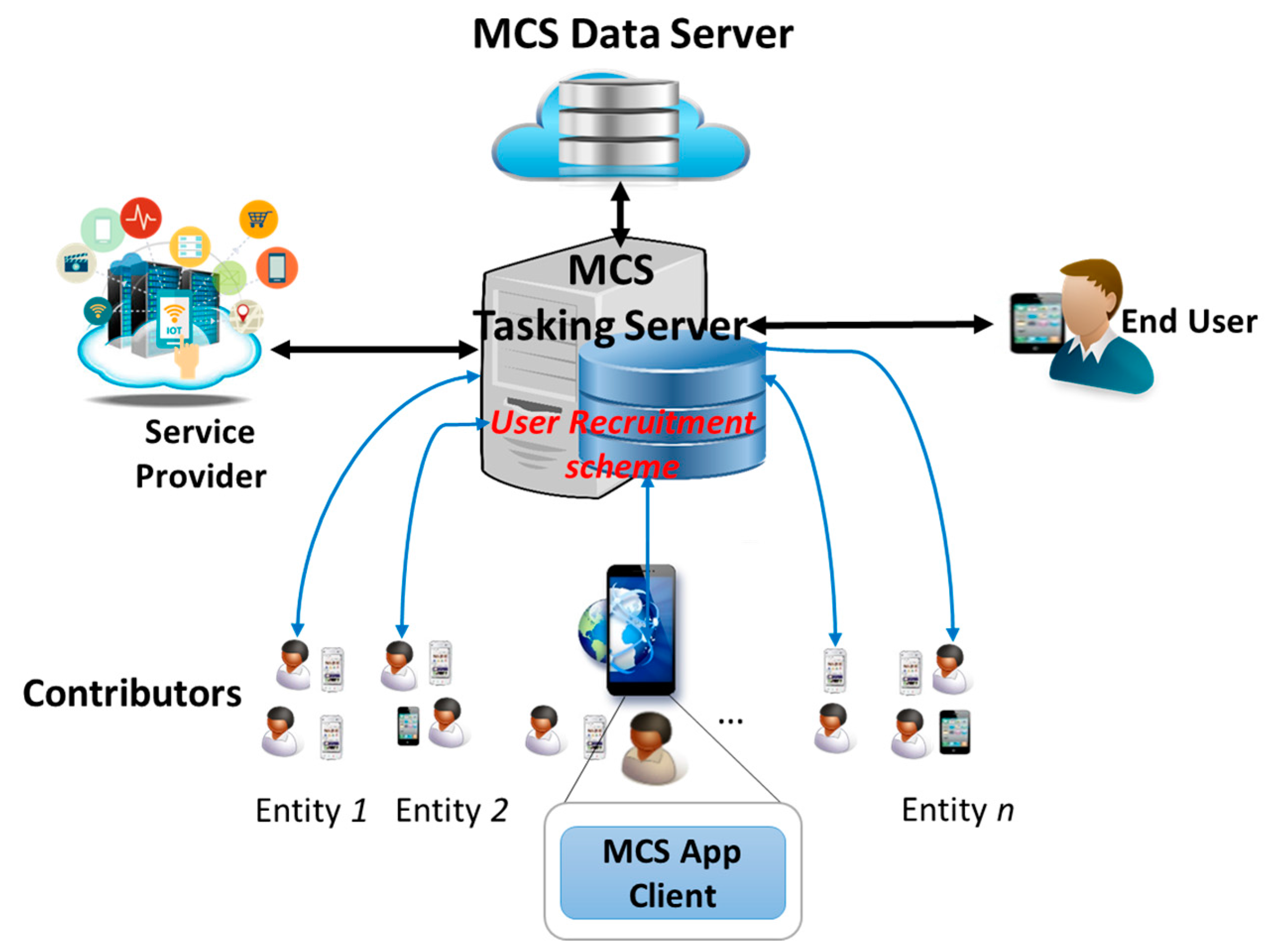
4.2.2. User Recruitment in Mobile Crowd-Sensing Use-Case
- Spatial Distance: This TA shows the distance between a contributor and the crossroad X. The contributors should be close enough to the crossroad X so that it is able to report traffic situation correctly to the MCS server. The distance can be calculated based on the GPS coordinates of the smartphone and the crossroad X using the “haversine” formula presented in [49]. This TA belongs to the Ability dimension and should not exceed the distance boundary (as a threshold).
- Availability: Availability is a TA indicating the activeness of a user in getting connected to social activities. It shows how much a user uses his smart device for social applications and is ready to fulfil an assign task which is essential to consider for user recruitment. The Availability can be calculated based on both time spending on social network application and amount of data consumed [44,45]. This TA belongs to the Ability dimension.
- Transmission Capability: It is required to be reliable, fast, and secure when fulfilling important tasks in traffic incident reports; thus this indicator is essential for reflecting the capability of a smart device to transmit data in real-time or nearly real-time as well as in a secure and privacy manner without compromise. Therefore, this indicator includes several TAs in Ability dimension mentioned in Section 4.2.1 such as Reliability, Confidentiality and Integrity. For simplicity, we specify the level of the Transmission Capability based on some information: signal strength, signal-to-interference-plus-noise-ratio (SIRN), and the communication technology in use (WiFi, LTE, 3G, WiMax, and Bluetooth). For example, Transmission Capability is high when the user is using 4G LTE for data transmission with high signal strength (4G LTE Signal ≥ −50 dBm) and high LTE SIRN (LTE SIRN ≥ 12.5) whereas it is low when 3G is used with low 3G SIRN (3G SIRN ≤ −5).
- Cooperativeness: This TA represents the degree of a user cooperates with crowd-sensing tasks, thus, high cooperativeness indicates more opportunities that the user is willing to accomplish an assigned sensing task, and vice versa. This TA belongs to the Benevolence dimension. Cooperativeness can be simply calculated by using Equation (1):where indicates how frequently the user i has involved in the crowd-sensing campaign. It is calculated based on Equation (2)The numbers of tasks requested is the number of times the MCS Tasking server has requested the user to participate in a sensing task; and the number of tasks involved is the number of times the user has accepted to involve in sensing tasks that the MCS has requested. The number of tasks canceled is the number of times the user cancels a sensing task when it has already accepted to involve in the sensing task. The number of requested, involved, and canceled sensing tasks of the user i is kept track and managed by the MCS Tasking Server.
- Honesty: This TA represents the degree of keeping promise once a sensing task is already assigned to a user. High honesty means that the user is not going to cancel a task once it is assigned due to any cause whatsoever. This TA belongs to the Integrity dimension and it is simply measured by the Equation (3).
4.3. Experience TI Evaluation Model
- Experience Increase (in case of a cooperative interaction occurs):The Experience Increase trend is modelled using a linear difference equation as following:where indicates Experience TI at the time t; and indicates the increase value of Experience TI. α is a parameter indicating the maximum increase value of the experience. is a parameter indicating the maximum value of Experience TI (obviously ). Usually it is more convenient for Experience TI to use the same scale with trust (i.e., the range of [0,1]), thus, is 1. Consequently, the Equations (4) and (5) can be rewritten as:As shown in the Equation (6), the increase value is relatively large when the current value is small; but the increase value is reaching to 0 when the current value is high (approaching to 1).
- Experience Decrease (in case of an uncooperative interaction occurs):The mathematical model for the Experience Decrease is as following:where is specified as in Equation (2); and is as a damping factor controlling the rate of the decrease. The parameter can be fixed or dynamic depending on situations, but it should be always greater than 1 because the experience relationship is hard to gain but easy to lose. is a parameter indicating the minimum value of the experience (i.e., 0), which guarantees that the experience value cannot go lower than that.
- Experience Decay (in case of no interaction):Experience TI decreases if there is no interaction during a period of time. However the rate of the decrease may vary according to the level of current status of the relationship (i.e., the current experience value). If the current status is high (meaning that there is a strong tie between two entities) then the decrease is not much; but if current status is low (i.e., a weak tie between the two) then the decrease is much. Hence, experience is assumed to require periodic maintenance but strong ties tend to persist longer even without reinforcing cooperative interactions. Decay is assumed to be inversely proportional to the current experience value; thus, experience with a high value will exhibit less decay than experience with a low value. Then, the mathematical model for the Experience Decay is proposed as following:The is a parameter indicating the minimal decay value of Experience which guarantees that even strong ties still get decreased if experience is not maintained. is a parameter indicating the rate of decay which can be fixed or dynamic depending on particular situations.
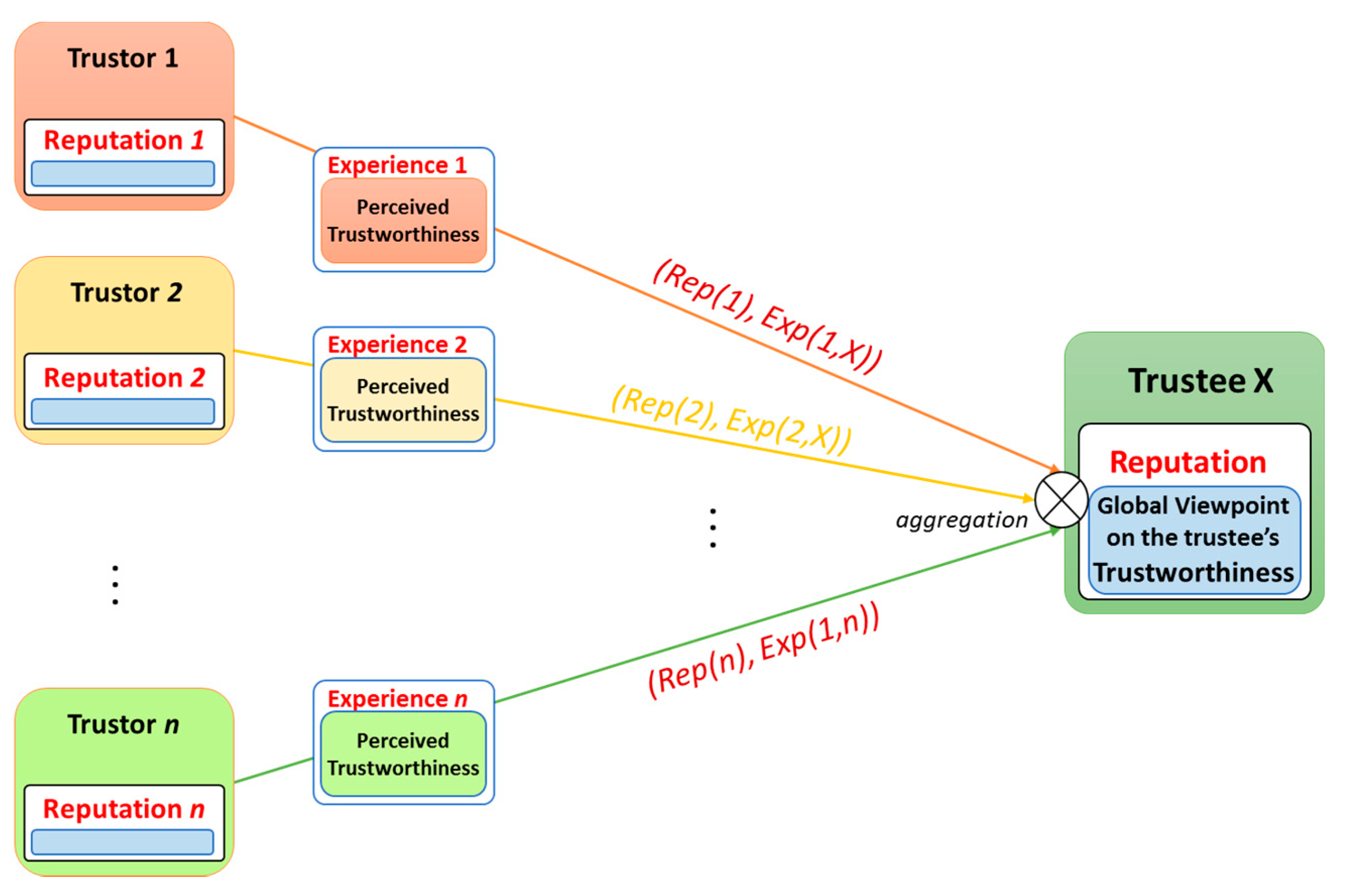
4.4. Reputation TI Evaluation Model
- -
- N is total number of entities in the networks for calculating Reputation
- -
- is called positive reputation of the entity i which considers only positive recommendations.
- -
- = is the total values of all positive recommendations that the entity i is currently sharing.
- -
- is called negative reputation of the entity i which considers only negative recommendations.
- -
- = is the total values of all complements of the negative recommendations that the entity i is currently sharing.
- -
- is the reputation of the entity i that we are interested.
- -
- is a parameter indicating the minimal value of reputation (i.e., 0). This guarantee the reputation value will not go below the.
- -
- -
- d is the damping factor. Various studies on PageRank-related literature have tested different damping factors for ranking webpages on the Internet, and they have come up with an appropriate value around 0.85. The research on the damping factor for the Reputation TI model is left as our future work.
4.5. Aggregation Mechanism for REK Trust Evaluation Model
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Xiong, G.; Zhu, F.; Liu, X.; Dong, X.; Huang, W.; Chen, S.; Zhao, K. Cyber-physical-social system in intelligent transportation. IEEE/CAA J. Autom. Sin. 2015, 2, 320–333. [Google Scholar]
- Sheth, A.; Anantharam, P.; Henson, C. Physical-cyber-social computing: An early 21st century approach. IEEE Intell. Syst. 2013, 28, 78–82. [Google Scholar] [CrossRef]
- Atzori, L.; Iera, A.; Morabito, G. Siot: Giving a social structure to the internet of things. IEEE Commun. Lett. 2011, 15, 1193–1195. [Google Scholar] [CrossRef]
- Atzori, L.; Iera, A.; Morabito, G.; Nitti, M. The social internet of things (siot)—When social networks meet the internet of things: Concept, architecture and network characterization. Comput. Netw. 2012, 56, 3594–3608. [Google Scholar] [CrossRef]
- Sicari, S.; Rizzardi, A.; Grieco, L.A.; Coen-Porisini, A. Security, privacy and trust in internet of things: The road ahead. Comput. Netw. 2015, 76, 146–164. [Google Scholar] [CrossRef]
- Mahalle, P.N.; Thakre, P.A.; Prasad, N.R.; Prasad, R. A fuzzy approach to trust based access control in internet of things. In Proceedings of the 2013 3rd International Conference on Wireless Communications, Vehicular Technology, Information Theory and Aerospace & Electronic Systems (VITAE), Atlantic City, NJ, USA, 24–27 June 2013. [Google Scholar]
- Josang, A.; Ismail, R.; Boyd, C. A survey of trust and reputation systems for online service provision. Decis. Support Syst. 2007, 43, 618–644. [Google Scholar] [CrossRef]
- Brin, S.; Page, L. Reprint of: The anatomy of a large-scale hypertextual web search engine. Comput. Netw. 2012, 56, 3825–3833. [Google Scholar] [CrossRef]
- Yan, Z.; Zhang, P.; Vasilakos, A.V. A survey on trust management for internet of things. J. Netw. Comput. Appl. 2014, 42, 120–134. [Google Scholar] [CrossRef]
- Guo, B.; Wang, Z.; Yu, Z.; Wang, Y.; Yen, N.Y.; Huang, R.; Zhou, X. Mobile crowd sensing and computing: The review of an emerging human-powered sensing paradigm. ACM Comput. Surv. (CSUR) 2015, 48. [Google Scholar] [CrossRef]
- Rousseau, D.M.; Sitkin, S.B.; Burt, R.S.; Camerer, C. Not so different after all: A cross-discipline view of trust. Acad. Manag. Rev. 1998, 3, 393–404. [Google Scholar] [CrossRef]
- Alcalde, B.; Dubois, E.; Mauw, S.; Mayer, N.; Radomirović, S. Towards a decision model based on trust and security risk management. In Proceedings of the Seventh Australasian Conference on Information Security, Wellington, New Zealand, 1 January 2009; Australian Computer Society, Inc.: Darlinghurst, Australia, 2009; pp. 61–70. [Google Scholar]
- Thompson, K. Reflections on trusting trust. Commun. ACM 1984, 27, 761–763. [Google Scholar] [CrossRef]
- Truong, N.B.; Cao, Q.H.; Um, T.W.; Lee, G.M. Leverage a trust service platform for data usage control in smart city. In Proceedings of the 2016 IEEE Global Communications Conference (Globecom), Washington, DC, USA, 4–8 December 2016. [Google Scholar]
- Grandison, T.; Sloman, M. A survey of trust in internet applications. IEEE Commun. Surv. Tutor. 2000, 3, 2–16. [Google Scholar] [CrossRef]
- Lewis, J.D.; Weigert, A. Trust as a social reality. Soc. Forces 1985, 63, 967–985. [Google Scholar] [CrossRef]
- Schoorman, F.D.; Mayer, R.C.; Davis, J.H. An integrative model of organizational trust: Past, present, and future. Acad. Manag. Rev. 2007, 32, 344–354. [Google Scholar] [CrossRef]
- Chang, E.; Hussain, F.K.; Dillon, T.S. Fuzzy nature of trust and dynamic trust modeling in service oriented environments. In Proceedings of the 2005 Workshop on Secure Web Services, Fairfax, VA, USA, 11 November 2005. [Google Scholar]
- Mayer, R.C.; Davis, J.H.; Schoorman, F.D. An integrative model of organizational trust. Acad. Manag. Rev. 1995, 20, 709–734. [Google Scholar]
- Yan, Z.; Ding, W.; Niemi, V.; Vasilakos, A.V. Two schemes of privacy-preserving trust evaluation. Future Gener. Comput. Syst. 2016, 62, 175–189. [Google Scholar] [CrossRef]
- Atif, Y. Building trust in e-commerce. IEEE Int. Comput. 2002, 6, 18–24. [Google Scholar] [CrossRef]
- Li, X.; Liu, L. A reputation-based trust model for peer-to-peer e-commerce communities. In Proceedings of the 2003 IEEE International Conference on E-Commerce (CEC), Newport Beach, CA, USA, 24–27 June 2003; pp. 275–284. [Google Scholar]
- Bao, F.; Chen, I. Trust management for internet of things and its application to service composition. In Proceedings of the 2012 IEEE International Symposium on a World of Wireless, Mobile and Multimedia Networks (WoWMoM), San Francisco, CA, USA, 25–28 June 2012. [Google Scholar]
- Yu, Y.; Li, K.; Zhou, W.; Li, P. Trust mechanisms in wireless sensor networks: Attack analysis and countermeasures. J. Netw. Comput. Appl. 2012, 35, 867–880. [Google Scholar] [CrossRef]
- Govindan, K.; Mohapatra, P. Trust computations and trust dynamics in mobile adhoc networks: A survey. IEEE Commun. Surv. Tutor. 2012, 14, 279–298. [Google Scholar] [CrossRef]
- Cho, J.H.; Swami, A.; Chen, R. A survey on trust management for mobile ad hoc networks. IEEE Commun. Surv. Tutor. 2011, 13, 562–583. [Google Scholar] [CrossRef]
- Li, J.; Li, R.; Kato, J. Future trust management framework for mobile ad hoc networks. IEEE Commun. Mag. 2008, 46. [Google Scholar] [CrossRef]
- Kraounakis, S.; Demetropoulos, I.N.; Michalas, A.; Obaidat, M.S.; Sarigiannidis, P.G.; Louta, M.D. A robust reputation-based computational model for trust establishment in pervasive systems. IEEE Syst. J. 2015, 878–891. [Google Scholar] [CrossRef]
- Wang, J.P.; Bin, S.; Yu, Y.; Niu, X.X. Distributed trust management mechanism for the internet of things. Appl. Mech. Mater. 2013, 347–350, 2463–2467. [Google Scholar] [CrossRef]
- Palaghias, N.; Loumis, N.; Georgoulas, S.; Moessner, K. Quantifying trust relationships based on real-world social interactions. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016. [Google Scholar]
- Can, A.B.; Bhargava, B. Sort: A self-organizing trust model for peer-to-peer systems. IEEE Trans. Dependable Secur. Comput. 2013, 10, 14–27. [Google Scholar] [CrossRef]
- Sherchan, W.S.; Nepal, S.; Paris, C. A survey of trust in social networks. ACM Comput. Surv. (CSUR) 2013, 45. [Google Scholar] [CrossRef]
- Bao, F.; Chen, I. Dynamic trust management for internet of things applications. In Proceedings of the 2012 International Workshop on Self-Aware Internet of Things (Self-IoT), San Jose, CA, USA, 17 September 2012. [Google Scholar]
- Nitti, M.; Girau, R.; Atzori, L.; Iera, A.; Morabito, G. A subjective model for trustworthiness evaluation in the social internet of things. In Proceedings of the 2012 IEEE International Symposium on Personal Indoor and Mobile Radio Communications (PIMRC), Sydney, Australia, 9–12 September 2012. [Google Scholar]
- Velloso, P.B.; Laufer, R.P.; Cunha, D.O.; Duarte, O.; Pujolle, G. Trust management in mobile ad hoc networks using a scalable maturity-based model. IEEE Trans. Netw. Serv. Manag. 2010, 7, 172–185. [Google Scholar] [CrossRef]
- Radack, S.M. Managing Information Security Risk: Organization, Mission, and Information System View; USA Department of Commerce: Gaithersburg, MD, USA, 2011. [Google Scholar]
- Kumar, R.; Khan, S.A.; Khan, R.A. Revisiting software security: Durability perspective. Int. J. Hybrid Inf. Technol. (SERSC) 2015, 8, 311–322. [Google Scholar] [CrossRef]
- Al-Kuwaiti, M.; Kyriakopoulos, N.; Hussein, S. A comparative analysis of network dependability, fault-tolerance, reliability, security, and survivability. IEEE Commun. Surv. Tutor. 2009, 11, 106–124. [Google Scholar] [CrossRef]
- NIST. Cyber-Physical Systems (CPS) Framework Release 1.0; USA Department of Commerce: Gaithersburg, MD, USA, 2016.
- Santini, S.; Jain, R. Similarity measures. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 9, 871–883. [Google Scholar] [CrossRef]
- Chen, I.; Bao, F.; Guo, J. Trust-based service management for social internet of things systems. IEEE Trans. Dependable Secur. Comput. 2015, 13, 684–696. [Google Scholar] [CrossRef]
- Ganti, R.K.; Ye, F.; Lei, H. Mobile crowdsensing: Current state and future challenges. IEEE Commun. Mag. 2011, 49. [Google Scholar] [CrossRef]
- Guo, B.; Yu, Z.; Zhou, X.; Zhang, D. From participatory sensing to mobile crowd sensing. In Proceedings of the 2014 IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), Budapest, Hungary, 24–28 March 2014; pp. 593–598. [Google Scholar]
- Anjomshoa, F.; Catalfamo, M.; Hecker, D.; Helgeland, N.; Rasch, A. Sociability assessment and identification of smartphone users via behaviormetric software. In Proceedings of the 2016 IEEE Symposium on Computers and Communications (ISCC), Messina, Italy, 27–30 June 2016. [Google Scholar]
- Fiandrino, C.; Kantarci, B.; Anjomshoa, F.; Kliazovich, D.; Bouvry, P.; Matthews, J. Sociability-driven user recruitment in mobile crowdsensing internet of things platforms. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016. [Google Scholar]
- An, J.; Gui, X.; Wang, Z.; Yang, J.; He, X. A crowdsourcing assignment model based on mobile crowd sensing in the internet of things. IEEE Int. Things J. 2015, 2, 358–369. [Google Scholar] [CrossRef]
- Bhoraskar, R.; Vankadhara, N.; Raman, B.; Kulkarni, P. Wolverine: Traffic and road condition estimation using smartphone sensors. In Proceedings of the 2012 International Conference on Communication Systems and Networks (COMSNETS), Bangalore, India, 3–7 January 2012. [Google Scholar]
- Mohan, P.; Padmanabhan, V.N.; Ramjee, R. Nericell: Rich monitoring of road and traffic conditions using mobile smartphones. In Proceedings of the ACM Conference on Embedded Network Sensor Systems, Raleigh, NC, USA, 5–7 November 2008; ACM: New York, NY, USA, 2008; pp. 323–336. [Google Scholar]
- Movable Type, Ltd. Calculate Distance, Bearing and More between Latitude/Longitude Points; Movable Type Ltd.: Cambridge, UK, 2016. [Google Scholar]
- Baumeister, R.F.; Leary, M.R. The need to belong: Desire for interpersonal attachments as a fundamental human motivation. Psychol. Bull. 1995, 117, 497–529. [Google Scholar] [CrossRef] [PubMed]
- Oswald, D.L.; Clark, E.M.; Kelly, C.M. Friendship maintenance: An analysis of individual and dyad behaviors. J. Soc. Clin. Psychol. 2004, 3, 413–441. [Google Scholar] [CrossRef]
- Kamvar, S.; Schlosser, M. The eigentrust algorithm for reputation management in p2p networks. In Proceedings of the 12th International Conference on World Wide Web, Budapest, Hungary, 20–24 May 2003; pp. 640–651. [Google Scholar]
- Josang, A.; Golbeck, J. Challenges for robust trust and reputation systems. In Proceedings of the International Workshop on Security and Trust Management (STM), SaintMalo, France, 24–25 September 2003. [Google Scholar]
- Dellarocas, C. Reputation mechanism design in online trading environments with pure moral hazard. Inf. Syst. Res. 2005, 16, 209–230. [Google Scholar] [CrossRef]
- Jayasinghe, U.; Truong, N.B.; Um, T.W.; Lee, G.M. Rpr: A trust computation model for social internet of things. In Proceedings of the 2016 International IEEE Conferences on Ubiquitous Intelligence & Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld), Toulouse, France, 18–21 July 2016. [Google Scholar]
- Tyagi, N.; Simple, S. Weighted page rank algorithm based on number of visits of links of web page. Int. J. Soft Comput. Eng. (IJSCE) 2012, 2, 2231–2307. [Google Scholar]
- Ding, Y. Topic-based pagerank on author cocitation networks. J. Assoc. Inf. Sci. Technol. 2011, 62, 449–466. [Google Scholar] [CrossRef]
- Backstrom, L.; Jure, L. Supervised random walks: Predicting and recommending links in social networks. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; ACM: New York, NY, USA, 2011; pp. 635–644. [Google Scholar]
- Kotsiantis, S.B.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. In Proceedings of the 2007 Conference on Emerging Artificial Intelligence Applications in Computer Engineering: Real Word AI Systems with Applications in eHealth, HCI, Information Retrieval and Pervasive Technologies, Amsterdam, The Netherlands, 2007; IOS Press: Amsterdam, The Netherlands, 2007; pp. 3–24. [Google Scholar]
- Chandrashekar, G.; Ferat, S. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Ren, Y.; Boukerche, A. Modeling and managing the trust for wireless and mobile ad hoc networks. In Proceedings of the 2008 IEEE International Conference on Communication (ICC’08), Beijing, China, 19–23 May 2008; pp. 2129–2133. [Google Scholar]
- Shaikh, R.A.; Jameel, H.; Lee, S.; Song, Y.J.; Rajput, S. Trust management problem in distributed wireless sensor networks. In Proceedings of the 2006 IEEE International Conference on Embedded and Real-Time Computing Systems and Applications, Sydney, Australia, 16–18 August 2006; pp. 411–414. [Google Scholar]
- Bao, F.; Chen, R.; Guo, J. Scalable, adaptive and survivable trust management for community of interest based internet of things systems. In Proceedings of the 2013 IEEE Eleventh International Symposium on Autonomous Decentralized Systems (ISADS), Mexico City, Mexico, 6–8 March 2013. [Google Scholar]
- Buchegger, S.; Jean-Yves, L.B. A Robust Reputation System for Peer-to-Peer and Mobile Ad-Hoc Networks; P2P Econ: Berkeley, CA, USA, 2004. [Google Scholar]
- Jayasinghe, U.; Lee, H.W.; Lee, G.M. A computational model to evaluate honesty in social internet of things. In Proceedings of the 32nd ACM Symposium on Applied Computing, Marrakesh, Morocco, 3–7 April 2017. [Google Scholar]
- Russell, S.J.; Norvig, P. Knowledge and reasoning. In Artificial Intelligence: A Modern Approach; Prentice Hall: Upper Saddle River, NJ, USA, 2014; pp. 149–297. [Google Scholar]
- Truong, N.B.; Won, T.U.; Lee, G.M. A reputation and knowledge based trust service platform for trustworthy social internet of things. In Proceedings of the 19th International Conference on Innovations in Clouds, Internet and Networks (ICIN), Paris, France, 1–3 March 2016. [Google Scholar]
- Baader, F.; Calvanese, D.; McGuinness, D.; Nardi, D.; Patel-Schneider, P.F. The Description Logic Handbook: Theory, Implementation and Applications; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ability TAs | Benevolence TAs | Integrity TAs |
|---|---|---|
| Competence, ability, capability, expertness, credibility, predictability, timeliness, robustness, safety, stability, scalability, reliability, dependability | Good intention, goodness, certainty, cooperation, cooperativeness, loyalty, openness, caring, receptivity, assurance | Honesty, morality, completeness, consistency, accuracy, certainty, availability, responsiveness, faith, discreetness, fairness, promise fulfilment, persistence, responsibility, tactfulness, sincerity, value congeniality, accessibility |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Truong, N.B.; Lee, H.; Askwith, B.; Lee, G.M. Toward a Trust Evaluation Mechanism in the Social Internet of Things. Sensors 2017, 17, 1346. https://doi.org/10.3390/s17061346
Truong NB, Lee H, Askwith B, Lee GM. Toward a Trust Evaluation Mechanism in the Social Internet of Things. Sensors. 2017; 17(6):1346. https://doi.org/10.3390/s17061346
Chicago/Turabian StyleTruong, Nguyen Binh, Hyunwoo Lee, Bob Askwith, and Gyu Myoung Lee. 2017. "Toward a Trust Evaluation Mechanism in the Social Internet of Things" Sensors 17, no. 6: 1346. https://doi.org/10.3390/s17061346
APA StyleTruong, N. B., Lee, H., Askwith, B., & Lee, G. M. (2017). Toward a Trust Evaluation Mechanism in the Social Internet of Things. Sensors, 17(6), 1346. https://doi.org/10.3390/s17061346