TrackCC: A Practical Wireless Indoor Localization System Based on Less-Expensive Chips



Abstract
:1. Introduction
- (1)
- Based on a commercial low-cost low-power system-on-chip, nRF24LE1, the proposed system can achieve decimeter-level accuracy for indoor localization and outperform a classical power level based ILS, LANDMARC, and a recently proposed ILS, SAIL. In addition, in the aspect of hardware cost, for a medium or large localization area, unlike SpotFi [3] that needed to deploy multiple access points (APs) with continuous power supplies, and LANDMARC, including its variants VIRE [12] and SAIL[11], which needed to deploy very expensive RFID readers to receive the signal of tags with relatively long distances, the proposed system just needs to deploy the corresponding number of cheap wireless nodes according to actual site area.
- (2)
- This paper introduces the Markov theory to remove the fluctuation in power levels, which has not been addressed in the literature.
- (3)
- We propose a priority-based pattern matching technique to find the most similar power level vector with fingerprint based localization methods. We found a noteworthy phenomenon that, even if two power level vectors are similar in Euclidean distance, their corresponding nodes may still be located at two far-away points in the constructed radio map. Thus, the conventional sequence matching algorithm, such as k-Nearest-Neighbor (kNN), is unsuitable to our case.
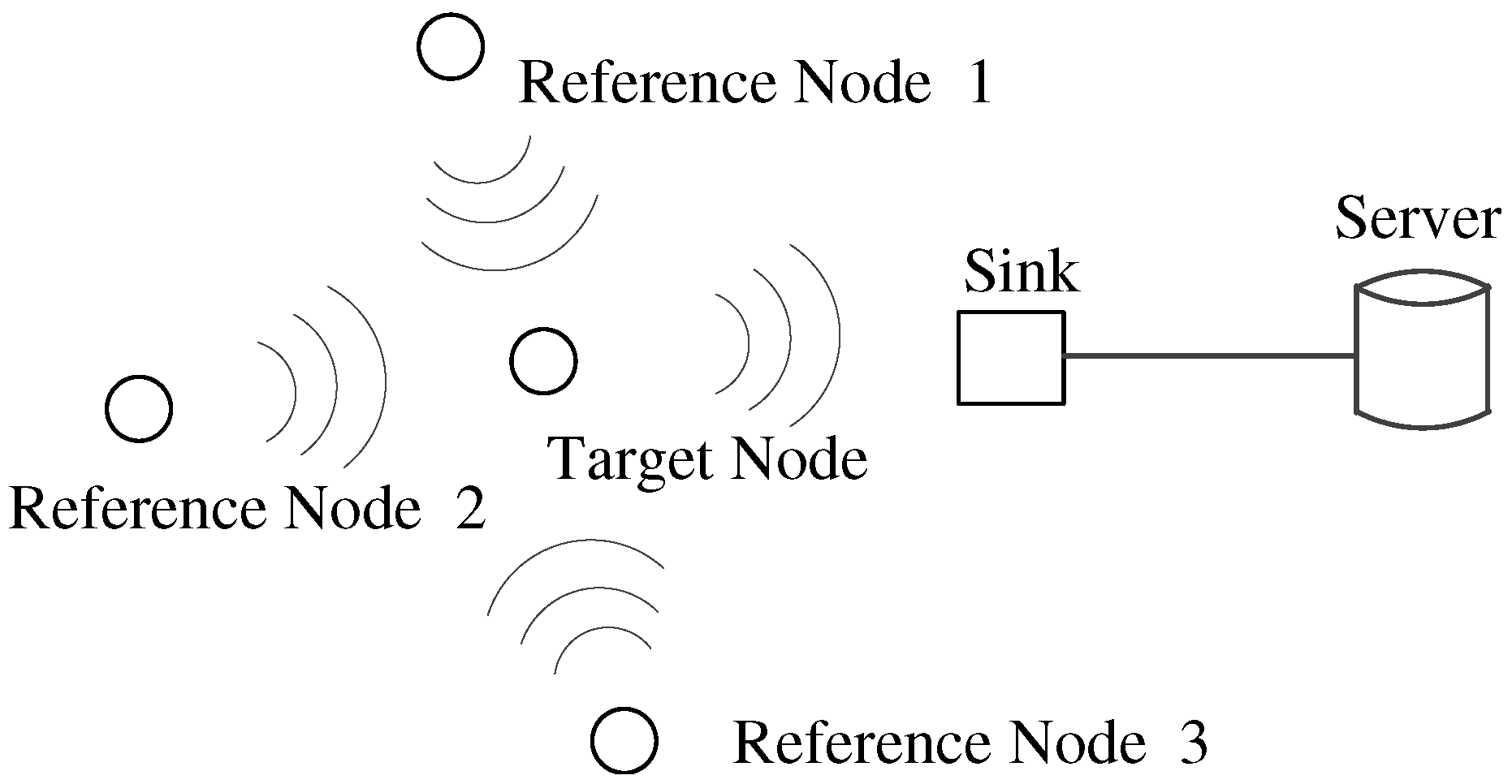
2. System Framework
3. Background and Problem
4. Offline Stage
4.1. Deployment
- (1)
- for any reference node, if the target moves more than d in its VLA, even in the case of open space, the value of received power level will be changed; and
- (2)
- there may be -sized square grids, where nodes’ movement will not result in changes in VReMipl value.
4.2. Remove Fluctuation
| Algorithm 1: The construction of fingerprint for grid |
 |
5. Online Stage
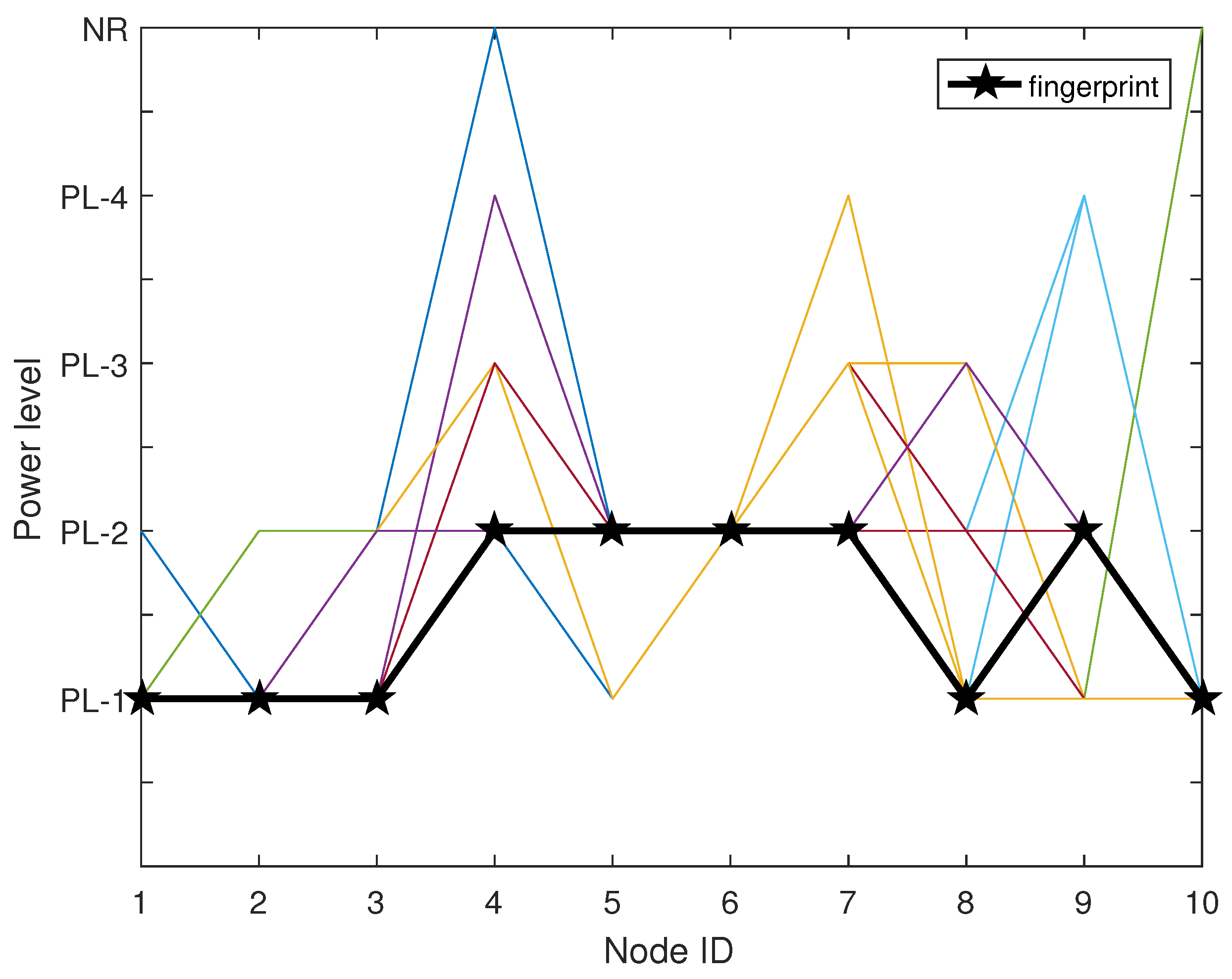
5.1. Similarity Calculation
5.2. Priority-Base Pattern Matching
- (1)
- In accordance with their existing order in list , a candidate is selected as a benchmark, denoted with .
- (2)
- TrackCC records two power levels from the same reference node in the target vector and the benchmark, denoted as and , respectively.
- (3)
- The priority to is changed based on a priority conversion rule from transition to . The details of the priority conversion rule will be provided later. Then, return to step 2 until two vectors have been traversed.
- (4)
- Return to step 1, pick another candidate as a new benchmark and go to step 2, until all candidates have been traversed.
| Algorithm 2: The priority-based 1NN pattern matching algorithm |
 |
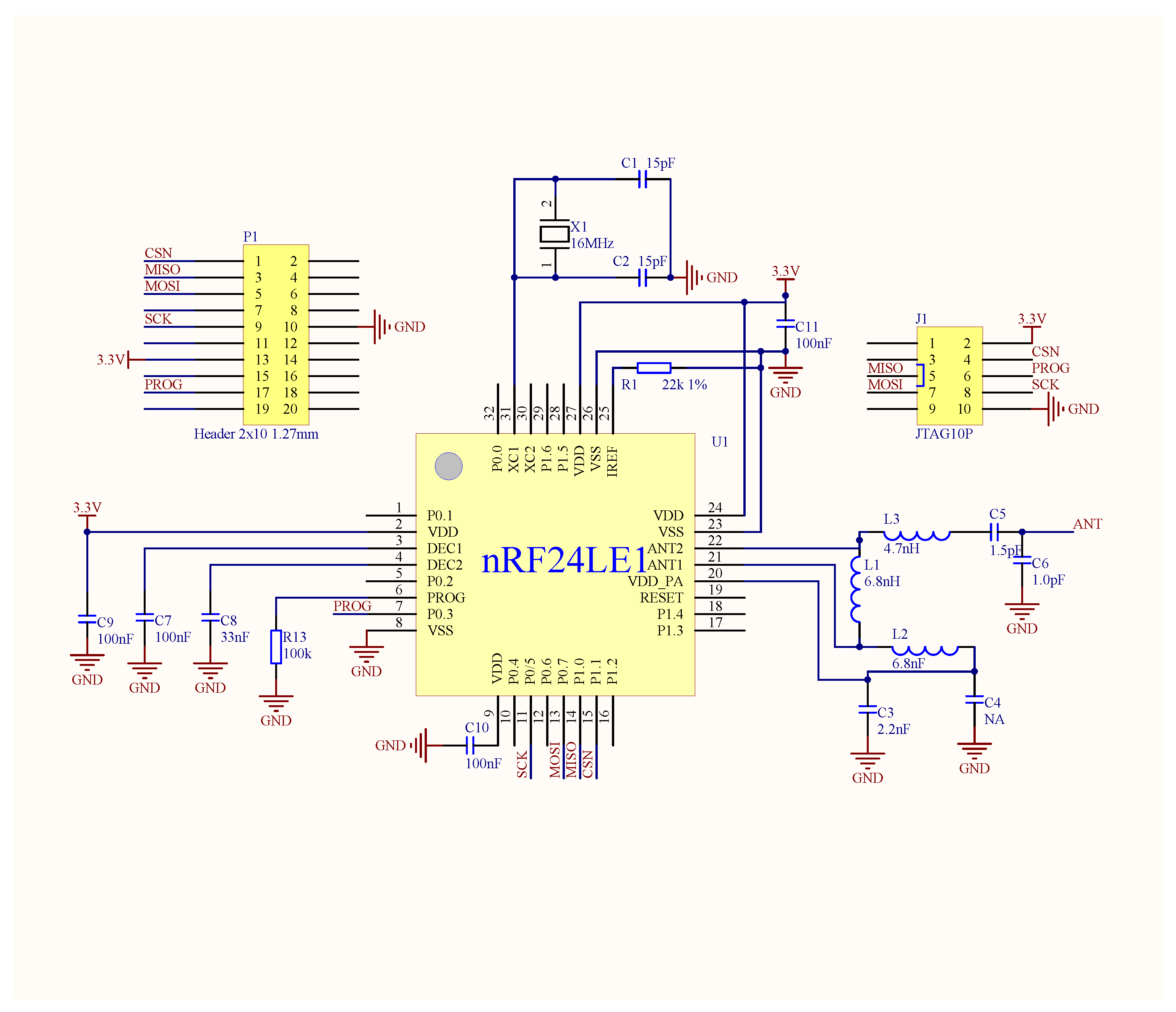
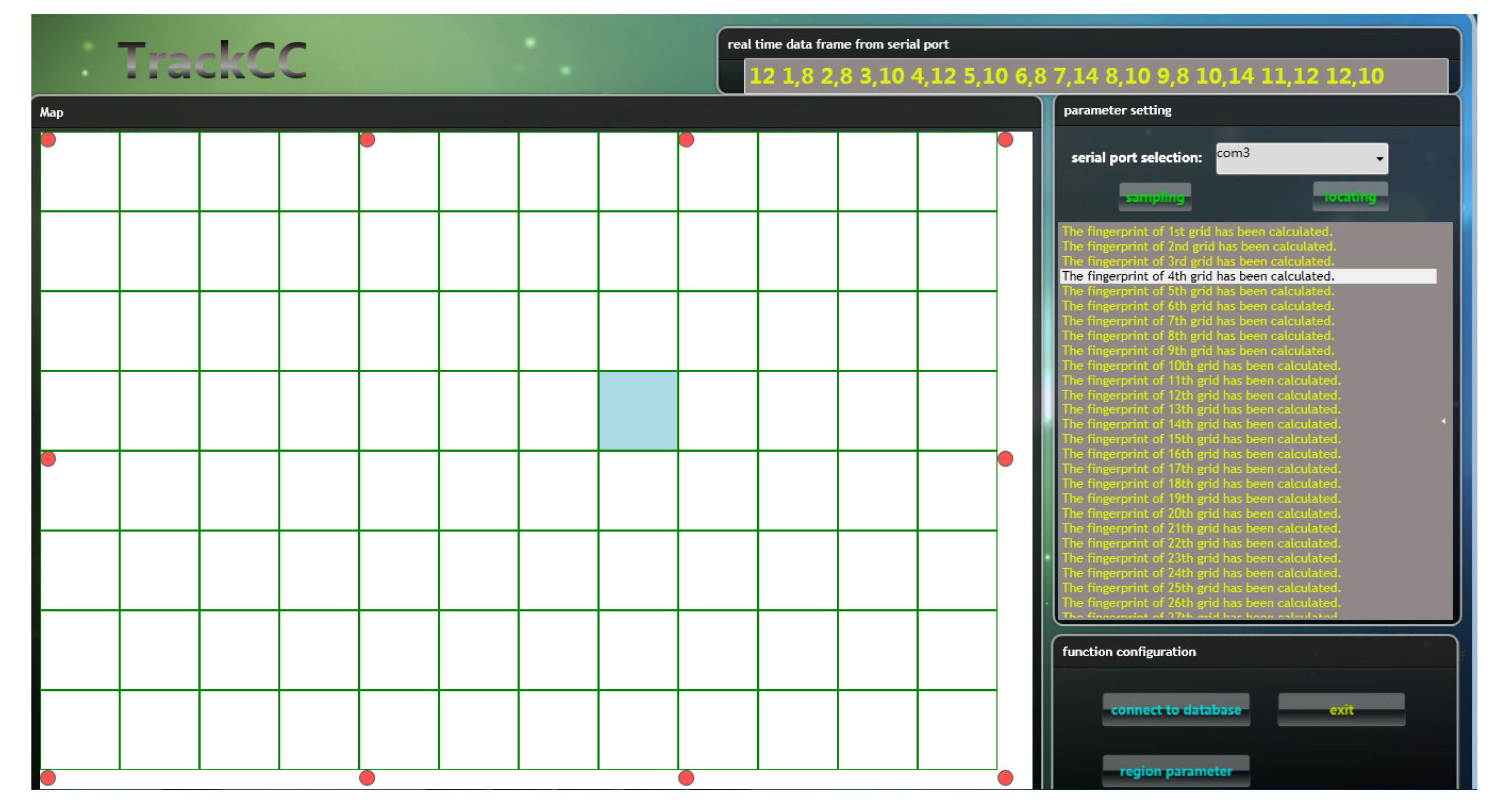
6. System Implementation and Experimental Results
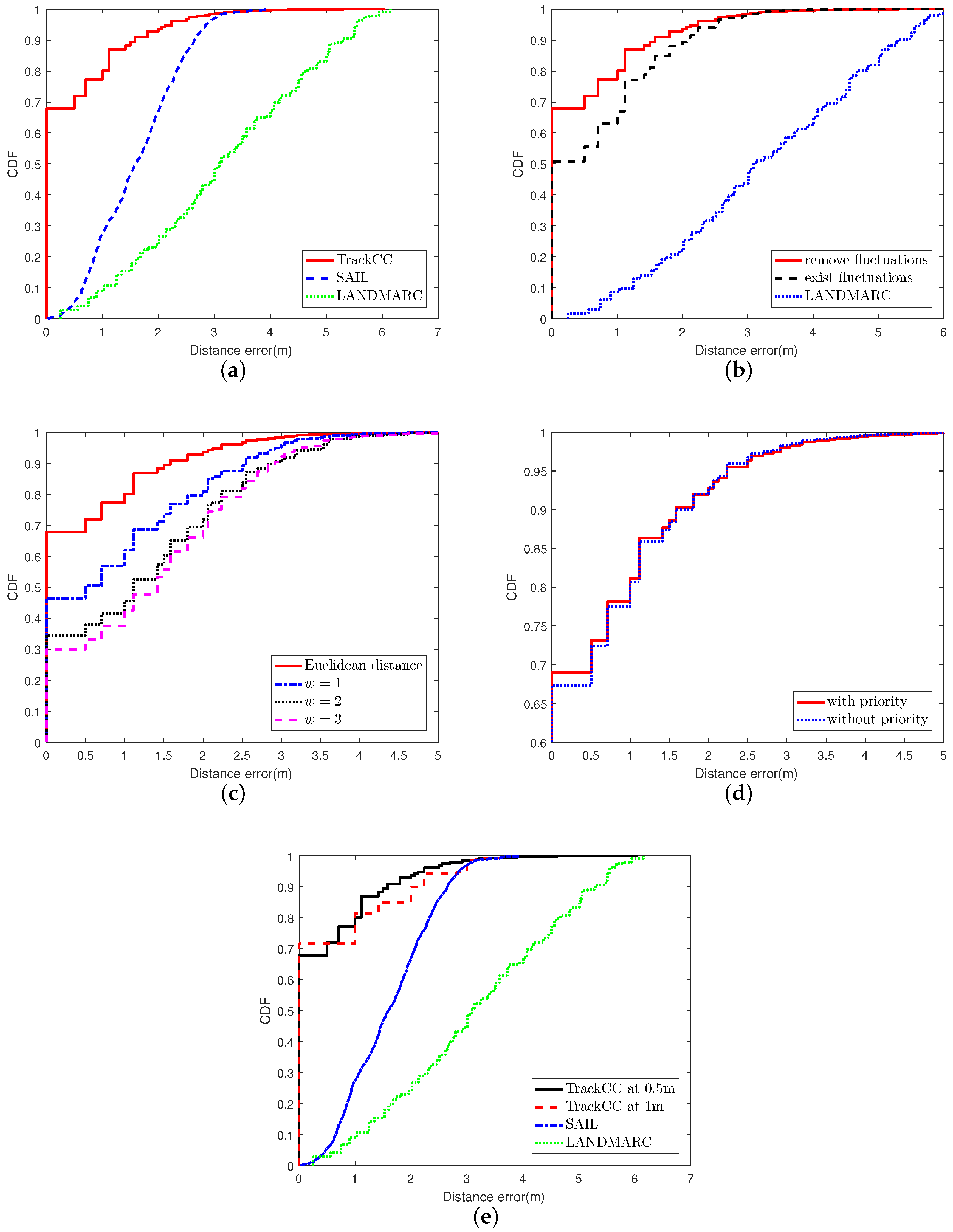
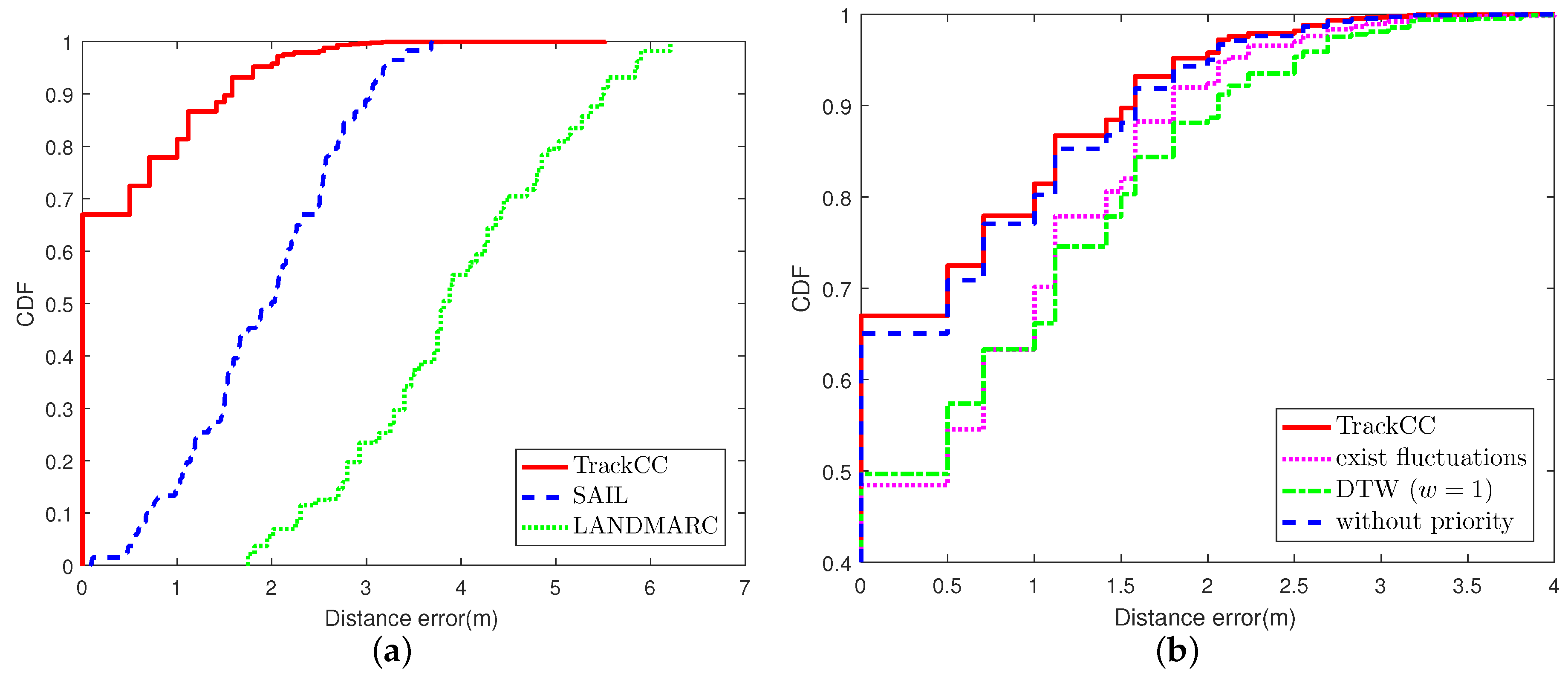
6.1. The Performance in the LOS Scenario
6.2. The Effect of Fluctuation Removal
6.3. Euclidean Distance and DTW
6.4. The Performance of Priority Conversion Rule
6.5. The Localization Effect for Different Sizes of Grids
6.6. The Performance in the NLOS Scenario
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
- (1)
- When , we have . Since , we have , and the radius of and are . It is easy to get that and are two circumscribed circles. Define that the overlapping area of and , denoted with , equals . For of radius centered at B, even in the case , it also contains and . Since and , we can derive . Similar with the above derivation, reference tag B’s ILA can also be covered by A’s VLA. In the case of , the theorem holds as long as there exist at least two tags in a row in the target region.
- (2)
- When , from , it is easy to derive that . Since the radius of and are , and , and overlap, i.e., . For the two circles and with meters away from their centers, because the radius of and are and , respectively, we can obtain that is contained in , i.e., . Furthermore, . It is equivalent to (. Thus, . Similar to the above derivation, we have . Since the minimum value of is , according to the geometry theory, when belongs to the interval , it is not hard to derive that , and . It means that . Thus, Finally, we get that A’s ILA is covered by the union set of the VLAs of both tags B and C, which are two consecutive tags located on the right side of A as shown in Figure A1. Likewise, the claim holds true for the case on the left side. In the case of , it can be summarized that the theorem holds as long as there exist at least two continuous adjacent tags either on the left side or the right side.
References
- Yang, L.; Chen, Y.; Li, X.; Xiao, C.; Li, M.; Liu, Y. Tagoram: Real-Time Tracking of Mobile RFID Tags to High Precision Using COTS Devices. In Proceedings of the IEEE MOBICOM, Maui, HI, USA, 7–11 September 2014. [Google Scholar]
- Chen, Z.; Zhu, Q.; Soh, Y.C. Smartphone Inertial Sensor-Based Indoor Localization and Tracking with iBeacon Corrections. IEEE Trans. Ind. Inform. 2016, 12, 1540–1549. [Google Scholar] [CrossRef]
- Kotaru, M.; Joshi, K.; Bharadia, D.; Katti, S. SpotFi: Decimeter level localization using wifi. ACM SIGCOMM Comput. Commun. Rev. 2015, 45, 269–282. [Google Scholar] [CrossRef]
- Tung, Y.C.; Shin, K.G. EchoTag: Accurate infrastructure-free indoor location tagging with smartphones. In Proceedings of the 21st Annual International Conference on Mobile Computing and Networking ACM, Paris, France, 7–11 September 2015; pp. 525–536. [Google Scholar]
- Wang, Y.; Song, L. An algorithmic and systematic approach for improving robustness of ToA-based localization. In Proceedings of the 2013 IEEE 10 th International Conference on Embedded and Ubiquitous Computing (HPCC-EUC), Zhangjiajie, China, 13–15 November 2013; pp. 2066–2073. [Google Scholar]
- Pak, J.M.; Ahn, C.K.; Shmaliy, Y.S.; Lim, M.T. Improving reliability of particle filter-based localization in wireless sensor networks via hybrid particle/FIR filtering. IEEE Trans. Ind. Inform. 2015, 11, 1089–1098. [Google Scholar] [CrossRef]
- Xiong, J.; Sundaresan, K.; Jamieson, K. ToneTrack: Leveraging frequency-agile radios for time-based indoor wireless localization. In Proceedings of the 21st Annual International Conference on Mobile Computing and Networking ACM, Paris, France, 7–11 September 2015; pp. 537–549. [Google Scholar]
- Xiong, J.; Jamieson, K. ArrayTrack: A Fine-Grained Indoor Location System. In Proceedings of the NSDI 2013, Lombard, IL, USA, 2–5 April 2013; pp. 71–84. [Google Scholar]
- Huang, C.H.; Lee, L.H.; Ho, C.C.; Wu, L.L.; Lai, Z.H. Real-time RFID indoor positioning system based on Kalman-filter drift removal and Heron-bilateration location estimation. IEEE Trans. Instrum. Meas. 2015, 64, 728–739. [Google Scholar] [CrossRef]
- Ni, L.M.; Liu, Y.; Lau, Y.C.; Patil, A.P. LANDMARC: Indoor location sensing using active RFID. Wirel. Netw. 2004, 10, 701–710. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, K.; Ma, Y.; Gao, Z.; Zang, Y.; Teng, J. Similarity Analysis-Based Indoor Localization Algorithm With Backscatter Information of Passive UHF RFID Tags. IEEE Sens. J. 2017, 17, 185–193. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, Y.; Ni, L.M. VIRE: Active RFID-based localization using virtual reference elimination. In Proceedings of the IEEE International Conference on Parallel Processing (ICPP 2007), Xi’an, China, 10–14 September 2007; p. 56. [Google Scholar]
- Nordic Semiconductor. nRF24L01+ Single Chip 2.4 GHz Transceiver Product Specification v1.0. September 2008. Available online: http://www.nordicsemi.com/eng/Products/2.4GHz-RF/ nRF24L01P (accessed on 23 February 2017).
- Yang, Z.; Zhou, Z.; Liu, Y. From RSSI to CSI: Indoor localization via channel response. ACM Comput. Surv. (CSUR) 2013, 46, 25. [Google Scholar] [CrossRef]
- Xing, Z.; Pei, J.; Keogh, E. A brief survey on sequence classification. ACM SIGKDD Explor. Newsl. 2010, 12, 40–48. [Google Scholar] [CrossRef]
- Zhang, J.; Firooz, M.H.; Patwari, N.; Kasera, S.K. Advancing wireless link signatures for location distinction. In Proceedings of the 14th ACM International Conference on Mobile Computing and Networking ACM, San Francisco, CA, USA, 14–19 September 2008; pp. 26–37. [Google Scholar]
- Ross, S.M. Introduction to Probability Models; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Keogh, E.; Kasetty, S. On the need for time series data mining benchmarks: A survey and empirical demonstration. Data Min. knowl. Discov. 2003, 7, 349–371. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
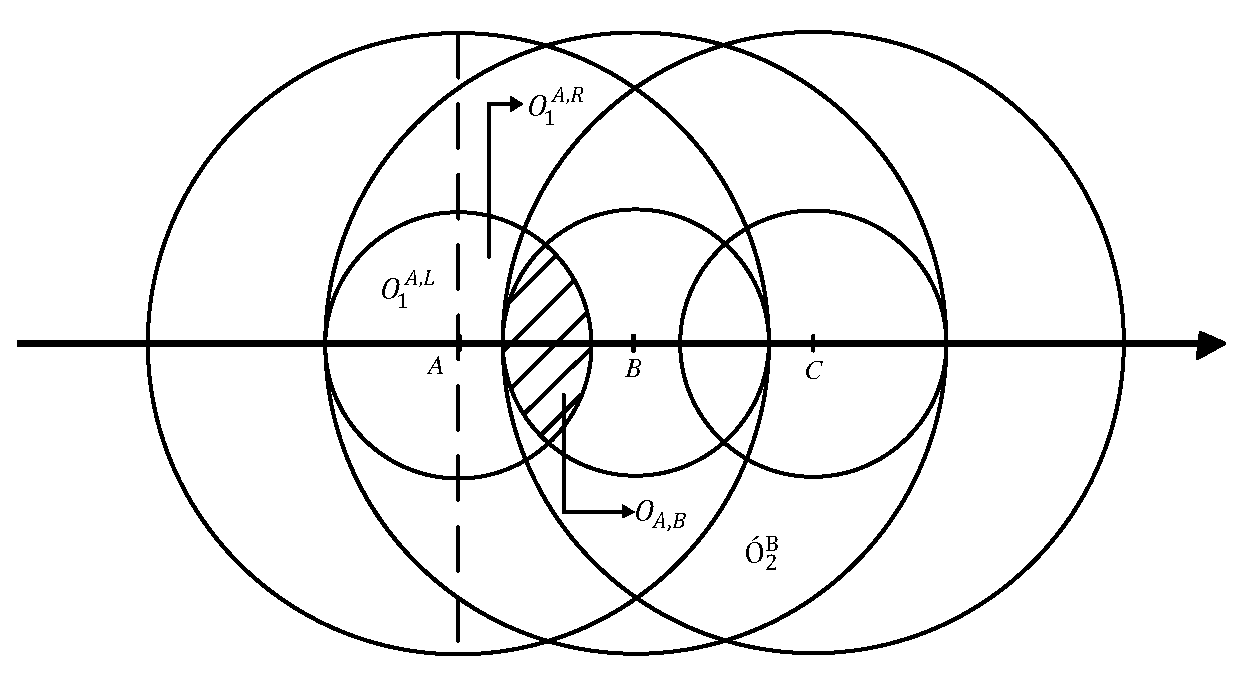{kind=link}
| Benchmark Candidate | ||||||||
|---|---|---|---|---|---|---|---|---|
| PL-1 | PL-2 | PL-3 | PL-4 | … | PL- | NR | ||
| Target | PL-1 | 0 | +2 | +3 | +4 | … | +l | +(l+1) |
| PL-2 | -1 | 0 | -2 | +1 | … | +(l-3) | +(l-2) | |
| PL-3 | +1 | -1 | 0 | -2 | … | +(l-4) | +(l-3) | |
| PL-4 | +2 | +1 | -1 | 0 | … | +(l-5) | +(l-4) | |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋱ | ⋮ | ⋮ | |
| PL-l | +(l-2) | +(l-3) | +(l-4) | +(l-5) | … | 0 | −2 | |
| NR | +(l-1) | +(l-2) | +(l-3) | +(l-4) | … | −1 | 0 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Zheng, Y.; Cai, J.; Yi, Y. TrackCC: A Practical Wireless Indoor Localization System Based on Less-Expensive Chips. Sensors 2017, 17, 1391. https://doi.org/10.3390/s17061391
Li X, Zheng Y, Cai J, Yi Y. TrackCC: A Practical Wireless Indoor Localization System Based on Less-Expensive Chips. Sensors. 2017; 17(6):1391. https://doi.org/10.3390/s17061391
Chicago/Turabian StyleLi, Xiaolong, Yan Zheng, Jun Cai, and Yunfei Yi. 2017. "TrackCC: A Practical Wireless Indoor Localization System Based on Less-Expensive Chips" Sensors 17, no. 6: 1391. https://doi.org/10.3390/s17061391
APA StyleLi, X., Zheng, Y., Cai, J., & Yi, Y. (2017). TrackCC: A Practical Wireless Indoor Localization System Based on Less-Expensive Chips. Sensors, 17(6), 1391. https://doi.org/10.3390/s17061391