A Study of Deep CNN-Based Classification of Open and Closed Eyes Using a Visible Light Camera Sensor

Abstract
:1. Introduction
- -
- This is the first research to adopt a CNN for the classification of open and closed eye images using only a general-purpose visible light camera. By adopting a deep residual CNN, we can enhance classification performance when compared to conventional CNN structures.
- -
- Because the optimal filter coefficients and weights for the classifier are learned during the deep residual CNN learning process, the proposed method does not require optimal threshold setting and manual filter selection for feature extraction.
- -
- Without using a separate CNN classifier for each database (DB), and by using all DBs in a variety of environments (different images capture distances, image resolutions, image blurring, and lighting changes) for CNN learning, we implement a CNN-based classifier for open and closed eyes that can withstand different types of changes in the environment.
- -
- By comparing the performance of the proposed method with fuzzy system-based methods, HOG-SVM based methods, and various CNN models, we demonstrate its superiority to these other models. Additionally, the self-collected database and various CNN models including the proposed deep residual CNN model trained on our experimental databases have been made public so that other researchers can compare and evaluate the performance the proposed method.
2. Proposed Method
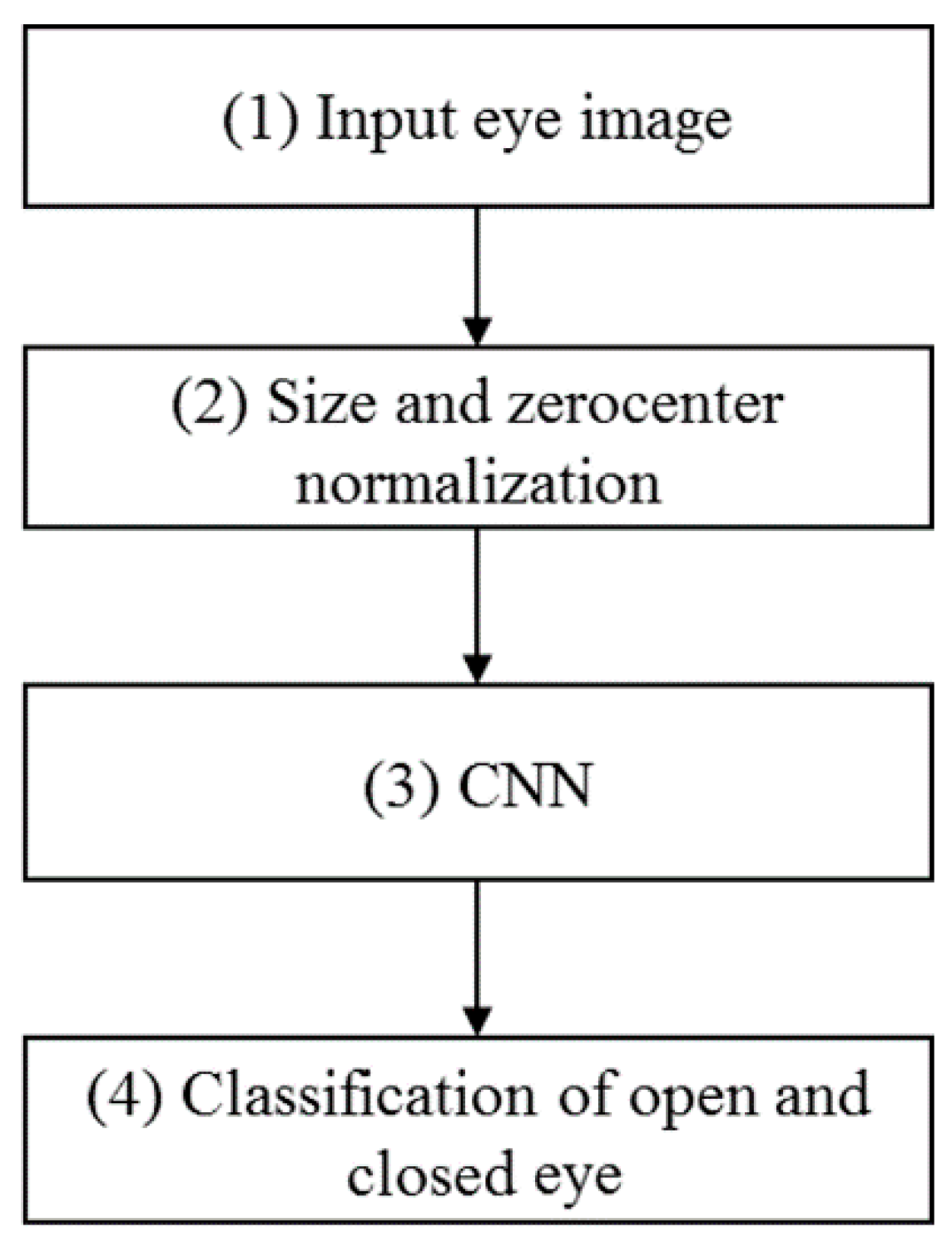
2.1. An Overview of the Proposed Approach
2.2. The Structure of the Deep Residual CNN
2.2.1. Feature Extraction via Convolutional Layers
2.2.2. Classification Using One FC Layer
2.3. CNN Training
3. Experimental Results
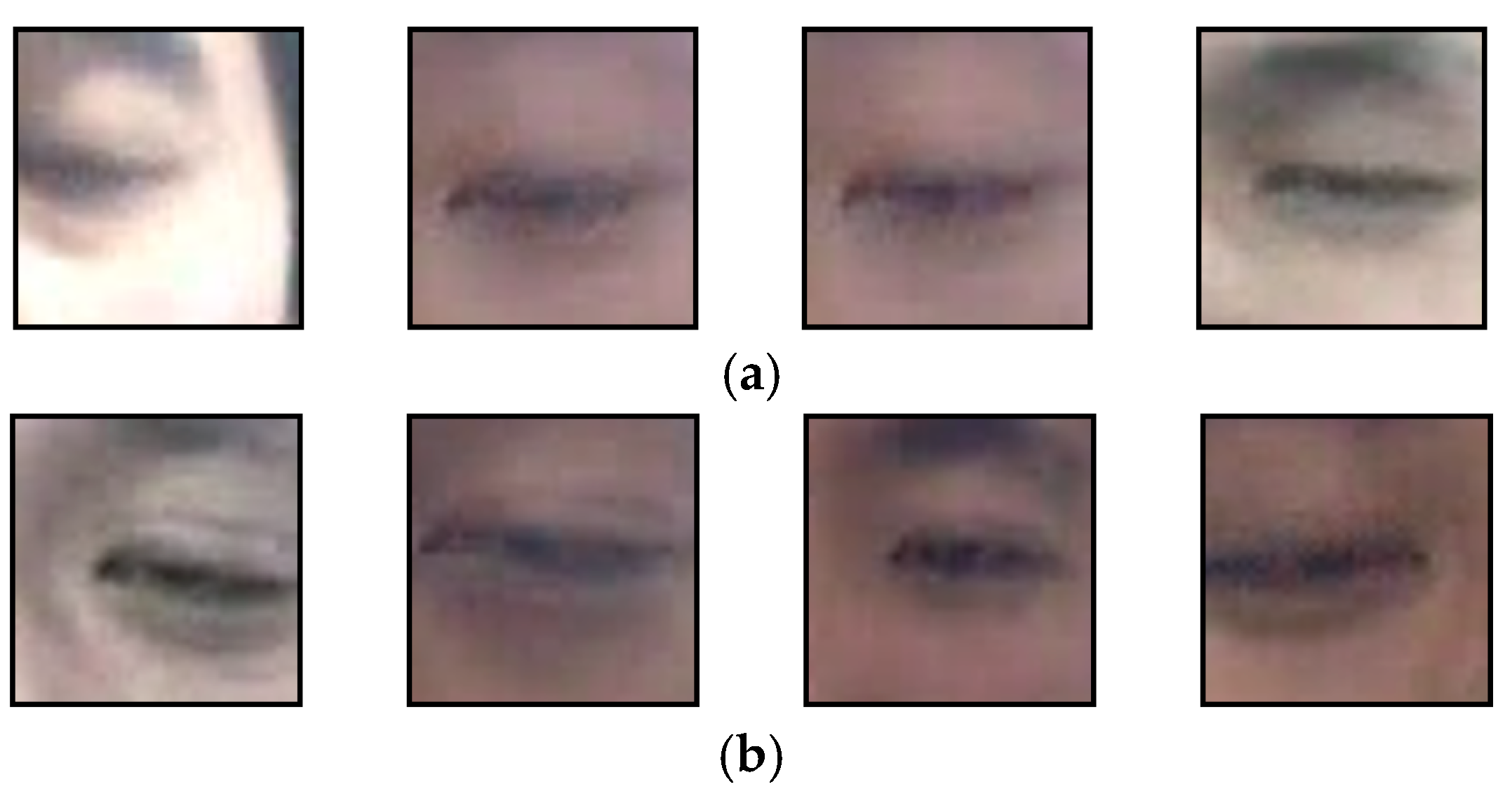
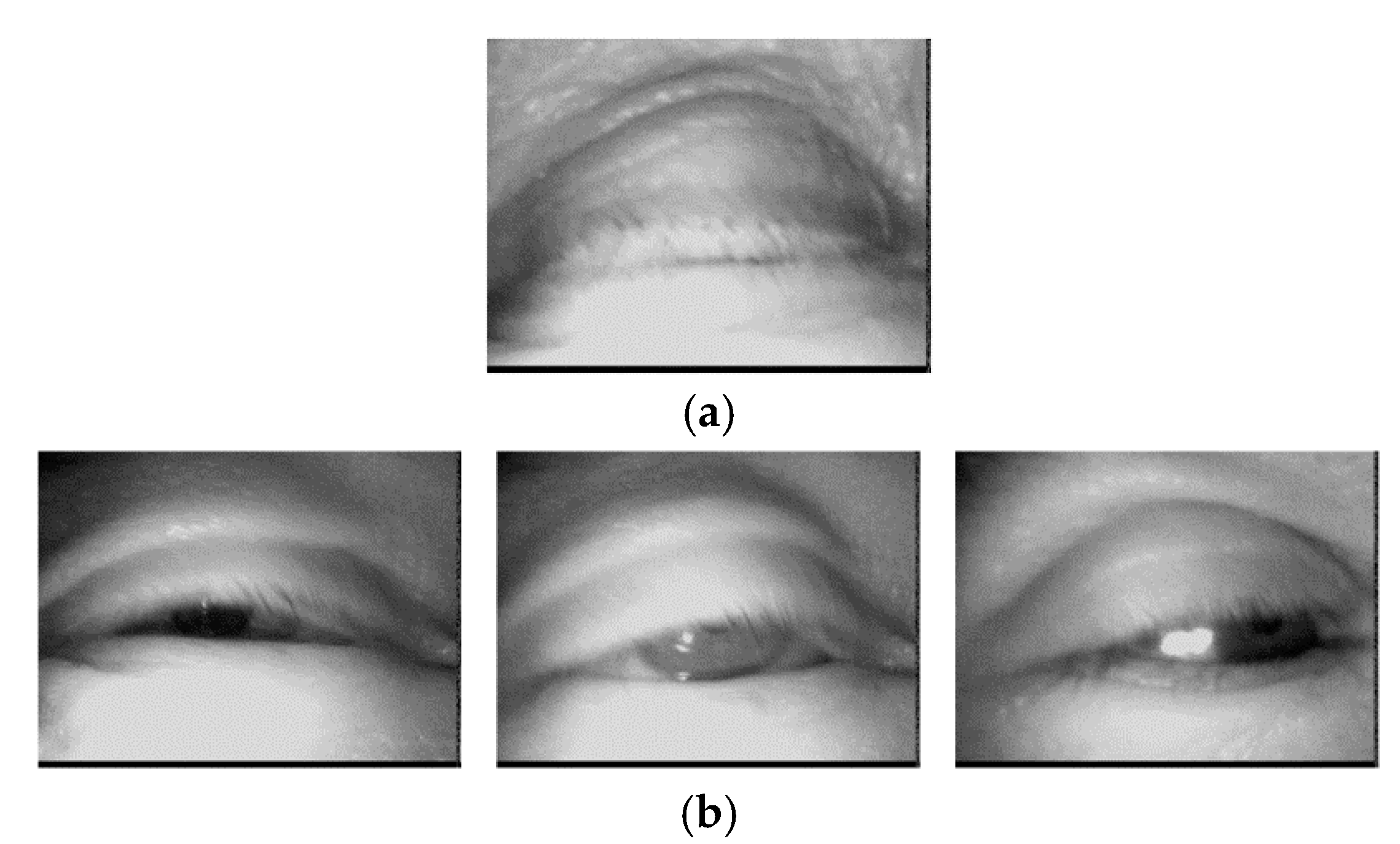
3.1. Experimental Environment and Data Augmentation
3.2. Training of the Proposed Deep Residual CNN
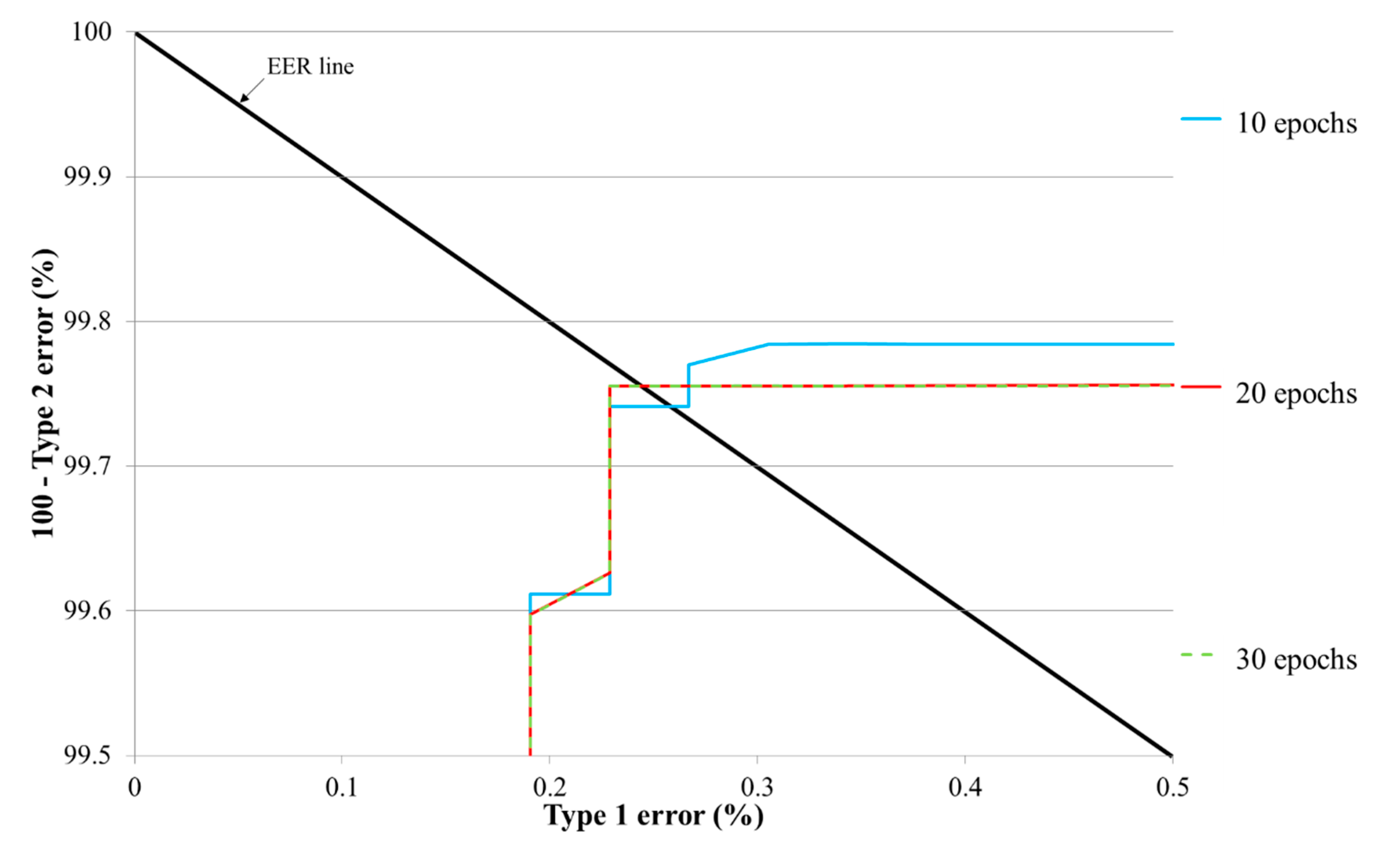
3.3. Testing Accuracies of the Proposed CNN Structure Based on Number of Training Epochs
3.4. Comparative Experimental Results and Analyses with the Proposed Method and Others
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gwon, S.Y.; Cho, C.W.; Lee, H.C.; Lee, W.O.; Park, K.R. Gaze tracking system for user wearing glasses. Sensors 2014, 14, 2110–2134. [Google Scholar] [CrossRef] [PubMed]
- Bang, J.W.; Lee, E.C.; Park, K.R. New computer interface combining gaze tracking and brainwave measurements. IEEE Trans. Consum. Electron. 2011, 57, 1646–1651. [Google Scholar] [CrossRef]
- Soltani, S.; Mahnam, A. A practical efficient human computer interface based on saccadic eye movements for people with disabilities. Comput. Biol. Med. 2016, 70, 163–173. [Google Scholar] [CrossRef] [PubMed]
- Kotani, M.; Kiyoshi, A.; Murai, T.; Nakako, T.; Matsumoto, K.; Matsumoto, A.; Ikejiri, M.; Ogi, Y.; Ikeda, K. The dopamine D1 receptor agonist SKF-82958 effectively increases eye blinking count in common marmosets. Behav. Brain Res. 2016, 300, 25–30. [Google Scholar] [CrossRef] [PubMed]
- Appel, T.; Santini, T.; Kasneci, E. Brightness- and motion-based blink detection for head-mounted eye trackers. In Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct, Heidelberg, Germany, 12–16 September 2016; pp. 1726–1735. [Google Scholar]
- Hsieh, C.-S.; Tai, C.-C. An improved and portable eye-blink duration detection system to warn of driver fatigue. Instrum. Sci. Technol. 2013, 41, 429–444. [Google Scholar] [CrossRef]
- Bulling, A.; Ward, J.A.; Gellersen, H.; Tröster, G. Eye movement analysis for activity recognition using electrooculography. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 741–753. [Google Scholar] [CrossRef] [PubMed]
- Chittaro, L.; Sioni, R. Exploring eye-blink startle response as a physiological measure for affective computing. In Proceedings of the Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 227–232. [Google Scholar]
- Champaty, B.; Pal, K.; Dash, A. Functional electrical stimulation using voluntary eyeblink for foot drop correction. In Proceedings of the International Conference on Microelectronics, Communication and Renewable Energy, Kerala, India, 4–6 June 2013; pp. 1–4. [Google Scholar]
- Chang, W.-D.; Lim, J.-H.; Im, C.-H. An unsupervised eye blink artifact detection method for real-time electroencephalogram processing. Physiol. Meas. 2016, 37, 401–417. [Google Scholar] [CrossRef] [PubMed]
- Lalonde, M.; Byrns, D.; Gagnon, L.; Teasdale, N.; Laurendeau, D. Real-time eye blink detection with GPU-based SIFT tracking. In Proceedings of the Fourth Canadian Conference on Computer and Robot Vision, Montreal, QC, Canada, 28–30 May 2007; pp. 481–487. [Google Scholar]
- Mohanakrishnan, J.; Nakashima, S.; Odagiri, J.; Yu, S. A novel blink detection system for user monitoring. In Proceedings of the 1st IEEE Workshop on User-Centered Computer Vision, Tampa, FL, USA, 15–17 January 2013; pp. 37–42. [Google Scholar]
- Lee, W.O.; Lee, E.C.; Park, K.R. Blink detection robust to various facial poses. J. Neurosci. Methods 2010, 193, 356–372. [Google Scholar] [CrossRef] [PubMed]
- Colombo, C.; Comanducci, D.; Bimbo, A.D. Robust tracking and remapping of eye appearance with passive computer vision. ACM Trans. Multimed. Comput. Commun. Appl. 2007, 3, 20:1–20:20. [Google Scholar] [CrossRef]
- Choi, J.-S.; Bang, J.W.; Heo, H.; Park, K.R. Evaluation of fear using nonintrusive measurement of multimodal sensors. Sensors 2015, 15, 17507–17533. [Google Scholar] [CrossRef] [PubMed]
- Królak, A.; Strumiłło, P. Eye-blink detection system for human–computer interaction. Univ. Access. Inf. Soc. 2012, 11, 409–419. [Google Scholar]
- Kim, K.W.; Lee, W.O.; Kim, Y.G.; Hong, H.G.; Lee, E.C.; Park, K.R. Segmentation method of eye region based on fuzzy logic system for classifying open and closed eyes. Opt. Eng. 2015, 54, 033103. [Google Scholar] [CrossRef]
- Fuhl, W.; Santini, T.; Geisler, D.; Kübler, T.; Rosenstiel, W.; Kasneci, E. Eyes wide open? Eyelid location and eye aperture estimation for pervasive eye tracking in real-world scenarios. In Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct, Heidelberg, Germany, 12–16 September 2016; pp. 1656–1665. [Google Scholar]
- Fuhl, W.; Santini, T. Fast and robust eyelid outline and aperture detection in real-world scenarios. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Santa Rosa, CA, USA, 24–31 March 2017; pp. 1089–1097. [Google Scholar]
- Fuhl, W.; Tonsen, M.; Bulling, A.; Kasneci, E. Pupil detection for head-mounted eye tracking in the wild: An evaluation of the state of the art. Mach. Vis. Appl. 2016, 27, 1275–1288. [Google Scholar] [CrossRef]
- Fuhl, W.; Santini, T.C.; Kübler, T.; Kasneci, E. ElSe: Ellipse selection for robust pupil detection in real-world environments. In Proceedings of the 9th Biennial ACM Symposium on Eye Tracking Research & Applications, Charleston, SC, USA, 14–17 March 2016; pp. 123–130. [Google Scholar]
- Jo, J.; Lee, S.J.; Jung, H.G.; Park, K.R.; Kim, J. Vision-based method for detecting driver drowsiness and distraction in driver monitoring system. Opt. Eng. 2011, 50, 127202. [Google Scholar] [CrossRef]
- Bacivarov, I.; Ionita, M.; Corcoran, P. Statistical models of appearance for eye tracking and eye-blink detection and measurement. IEEE Trans. Consum. Electron. 2008, 54, 1312–1320. [Google Scholar] [CrossRef]
- Trutoiu, L.C.; Carter, E.J.; Matthews, I.; Hodgins, J.K. Modeling and animating eye blinks. ACM Trans. Appl. Percept. 2011, 8, 17:1–17:17. [Google Scholar] [CrossRef]
- Missimer, E.; Betke, M. Blink and wink detection for mouse pointer control. In Proceedings of the 3rd International Conference on Pervasive Technologies Related to Assistive Environments, Samos, Greece, 23–25 June 2010; pp. 1–8. [Google Scholar]
- Miluzzo, E.; Wang, T.; Campbell, A.T. EyePhone: Activating mobile phones with your eyes. In Proceedings of the Second ACM SIGCOMM Workshop on Networking, Systems, and Applications on Mobile Handhelds, New Delhi, India, 30 August 2010; pp. 15–20. [Google Scholar]
- Wu, J.; Trivedi, M.M. An eye localization, tracking and blink pattern recognition system: Algorithm and evaluation. ACM Trans. Multimed. Comput. Commun. Appl. 2010, 6, 8:1–8:23. [Google Scholar] [CrossRef]
- Lenskiy, A.A.; Lee, J.-S. Driver’s eye blinking detection using novel color and texture segmentation algorithms. Int. J. Control Autom. Syst. 2012, 10, 317–327. [Google Scholar] [CrossRef]
- Hoang, L.; Thanh, D.; Feng, L. Eye blink detection for smart glasses. In Proceedings of the IEEE International Symposium on Multimedia, Anaheim, CA, USA, 9–11 December 2013; pp. 305–308. [Google Scholar]
- Histogram of Oriented Gradient. Available online: https://www.mathworks.com/help/vision/ref/extracthogfeatures.html (accessed on 17 May 2017).
- Pauly, L.; Sankar, D. Detection of drowsiness based on HOG features and SVM classifiers. In Proceedings of the IEEE International Conference on Research in Computational Intelligence and Communication Networks, Kolkata, India, 20–22 November 2015; pp. 181–186. [Google Scholar]
- Wang, M.; Guo, L.; Chen, W.-Y. Blink detection using Adaboost and contour circle for fatigue recognition. Comput. Electr. Eng. 2017, 58, 502–512. [Google Scholar] [CrossRef]
- Multilayer Perceptron. Available online: http://deeplearning.net/tutorial/mlp.html (accessed on 17 May 2017).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Support Vector Machine. Available online: https://en.wikipedia.org/wiki/Support_vector_machine (accessed on 17 May 2017).
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 1–12. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Reconition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Reconition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Compute Image Mean. Available online: http://caffe.berkeleyvision.org/gathered/examples/imagenet.html (accessed on 17 May 2017).
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Heaton, J. Artificial Intelligence for Humans, Volume 3: Deep Learning and Neural Networks; Heaton Research, Inc.: St. Louis, MO, USA, 2015. [Google Scholar]
- Softmax Function. Available online: https://en.wikipedia.org/wiki/Softmax_function (accessed on 17 May 2017).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Fully-Connected, Locally-Connected and Shared Weights Layer in Neural Networks Easy Explained. Available online: https://pennlio.wordpress.com/2014/04/11/fully-connected-locally-connected-and-shared-weights-layer-in-neural-networks/ (accessed on 17 May 2017).
- Softmax Regression. Available online: http://ufldl.stanford.edu/wiki/index.php/Softmax_Regression (accessed on 17 May 2017).
- Stochastic Gradient Descent. Available online: https://en.wikipedia.org/wiki/Stochastic_gradient_descent (accessed on 17 May 2017).
- TrainingOptions. Available online: http://kr.mathworks.com/help/nnet/ref/trainingoptions.html (accessed on 17 May 2017).
- Dongguk Open and Closed Eyes Database (DOCE-DB1) & CNN Model. Available online: http://dm.dgu.edu/link.html (accessed on 17 May 2017).
- Webcam C600. Available online: http://www.logitech.com/en-us/support/5869 (accessed on 17 May 2017).
- Pan, G.; Sun, L.; Wu, Z.; Lao, S. Eyeblink-based anti-spoofing in face recognition from a generic webcamera. In Proceedings of the 11th IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–8. [Google Scholar]
- Geforce GTX 1070. Available online: https://www.nvidia.com/en-us/geforce/products/10series/geforce-gtx-1070/ (accessed on 17 May 2017).
- CUDA. Available online: https://en.wikipedia.org/wiki/CUDA (accessed on 17 May 2017).
- Caffe. Available online: http://caffe.berkeleyvision.org (accessed on 17 February 2017).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Advantages | Drawbacks | |
|---|---|---|---|---|
| Non-image-based | EOG [6,7], EMG [8,9] | Fast data acquisition speed. | - Inconvenient because sensors have to be attached to a user. - Low accuracy if noise from the movements of a user are included. Thus, there are limitations on user behavior. | |
| Image-based | Video-based | Uses optical flow, SIFT, difference images [11], and eyelid and facial movements [12]. Calculates the difference in the number of black pixels in the eye areas in consecutive frames [13]. | High accuracy because it uses information from several images in a videos. | Long processing time due to working with several images. |
| Single image-based (non-training-based) | Iris detection-based [14], sub-block-based template matching and ellipse-fitting-based method [15], template-matching-based method [16], fuzzy-system-based method [17], approximation of the lower and upper eyelids based on a likelihood map [18], and oriented edges [19]. | Classifying open/closed eyes from a single image without any additional training process. | Low classification accuracy if vague features are extracted because the information about open/closed eyes is extracted from a single image. Therefore, there are restrictions on the environment in terms of obtaining optimal images for feature extraction. | |
| Single image-based (training-based) | SVM-based [22], HOG-SVM based [31], AAM-based [23], user dependent eye template-based matching [25,26], tensor PCA-based [27], neural network and probability density functions-based [28], PCA-based [29], and trained Adaboost with CC-based [32]. | - Shorter processing time than that of video-based methods. - Relatively high accuracy in classifying open/closed eyes compared to single-image-based (non-training-based) methods. | - Difficult to extract accurate features with the AAM method in cases with complex backgrounds or far away faces, leading to low resolution in the image. - Difficult to find an optimal feature extraction method and feature dimension for extracting the features used as the input for a classifier. | |
| CNN-based (proposed method) | - The filters and classifiers for optimal feature extraction can be automatically obtained from the training data without pre- or post-processing. - Condition-change-enduring classification performance due to a large-capacity DB learning under different conditions (image capture distance, image resolution, image blurring, and lighting changes). | - Requires a learning process from a large-capacity DB. | ||
| Layer Name | Size of Feature Map | Number of Filters | Size of Filters | Number of Strides | Amount of Padding | Number of Iterations | |
|---|---|---|---|---|---|---|---|
| Image input layer | 224 (height) × 224 (width) × 3 (channel) | ||||||
| Conv1 | 112 × 112 × 64 | 64 | 7 × 7 × 3 | 2 | 3* | 1 | |
| Max pool | 56 × 56 × 64 | 1 | 3 × 3 | 2 | 0 | 1 | |
| Conv2 | Conv2-1 | 56 × 56 × 64 | 64 | 1 × 1 × 64 | 1 | 0 | 3 |
| Conv2-2 | 56 × 56 × 64 | 64 | 3 × 3 × 64 | 1 | 1* | ||
| Conv2-3 | 56 × 56 × 256 | 256 | 1 × 1 × 64 | 1 | 0 | ||
| Conv2-4 (Shortcut) | 56 × 56 × 256 | 256 | 1 × 1 × 64 | 1 | 0 | ||
| Conv3 | Conv3-1 | 28 × 28 × 128 | 128 | 1 × 1 × 256 | 2/1** | 0 | 4 |
| Conv3-2 (Bottleneck) | 28 × 28 × 128 | 128 | 3 × 3 × 128 | 1 | 1* | ||
| Conv3-3 | 28 × 28 × 512 | 512 | 1 × 1 × 128 | 1 | 0 | ||
| Conv3-4 (Shortcut) | 28 × 28 × 512 | 512 | 1 × 1 × 256 | 2 | 0 | ||
| Conv4 | Conv4-1 | 14 × 14 × 256 | 256 | 1 × 1 × 512 | 2/1** | 0 | 6 |
| Conv4-2 (Bottleneck) | 14 × 14 × 256 | 256 | 3 × 3 × 256 | 1 | 1* | ||
| Conv4-3 | 14 × 14 × 1024 | 1024 | 1 × 1 × 256 | 1 | 0 | ||
| Conv4-4 (Shortcut) | 14 × 14 × 1024 | 1024 | 1 × 1 × 512 | 2 | 0 | ||
| Conv5 | Conv5-1 | 7 × 7 × 512 | 512 | 1 × 1 × 1024 | 2/1** | 0 | 3 |
| Conv5-2 (Bottleneck) | 7 × 7 × 512 | 512 | 3 × 3 × 512 | 1 | 1* | ||
| Conv5-3 | 7 × 7 × 2048 | 2048 | 1 × 1 × 512 | 1 | 0 | ||
| Conv5-4 (Shortcut) | 7 × 7 × 2048 | 2048 | 1 × 1 × 1024 | 2 | 0 | ||
| AVG pool | 1 × 1 × 2048 | 1 | 7 × 7 | 1 | 0 | 1 | |
| FC layer | 2 | 1 | |||||
| Softmax | 2 | 1 | |||||
| Kinds of Image | Original Database | Augmented Database | ||||
|---|---|---|---|---|---|---|
| DB1 | DB2 | Combined DB | Augmented DB1 | Augmented DB2 | Combined Augmented DB | |
| Open eye images | 2062 | 4891 | 6953 | 103,100 | 244,550 | 347,650 |
| Closed eye images | 4763 | 485 | 5248 | 238,150 | 24,250 | 262,400 |
| Total | 6825 | 5376 | 12,201 | 341,250 | 268,800 | 610,050 |
| Kinds of Image | 1st-Fold Cross Validation | 2nd-Fold Cross Validation | ||
|---|---|---|---|---|
| Training (Augmented Database) | Testing (Original Database) | Training (Augmented Database) | Testing (Original Database) | |
| Open eye images | 173,850 | 3476 | 173,800 | 3477 |
| Closed eye images | 131,150 | 2625 | 131,250 | 2623 |
| Total | 305,000 | 6101 | 305,050 | 6100 |
| # of Epochs | Type 1 Error | Type 2 Error | EER |
|---|---|---|---|
| 10 | 0.26687 | 0.25888 | 0.26288 |
| 20 | 0.22875 | 0.2445 | 0.23663 |
| 30 | 0.22875 | 0.2445 | 0.23663 |
| Method | # of Epochs | Type 1 Error | Type 2 Error | EER |
|---|---|---|---|---|
| Fuzzy system-based method [17] | N/A | 5.55 | 5.58 | 5.565 |
| HOG-SVM [31] | N/A | 1.29623 | 1.29416 | 1.2952 |
| AlexNet [34] | 10 | 0.91498 | 0.90617 | 0.91058 |
| 20 | 0.91498 | 0.93494 | 0.92496 | |
| 30 | 0.91498 | 0.93494 | 0.92496 | |
| GoogLeNet [38] | 10 | 0.64811 | 0.64718 | 0.64765 |
| 20 | 0.68624 | 0.66157 | 0.67391 | |
| 30 | 0.68624 | 0.66157 | 0.67391 | |
| VGG face fine-tuning [36] | 10 | 0.60999 | 0.61832 | 0.61416 |
| 20 | 0.60999 | 0.60405 | 0.60702 | |
| 30 | 0.60999 | 0.60405 | 0.60702 | |
| Proposed method | 10 | 0.26687 | 0.25888 | 0.26288 |
| 20 | 0.22875 | 0.2445 | 0.23663 | |
| 30 | 0.22875 | 0.2445 | 0.23663 |
| Methods | EER |
|---|---|
| Fuzzy system-based method [17] | 5.565 |
| HOG-SVM [31] | 1.2952 |
| AlexNet [34] | 0.91058 |
| GoogLeNet [38] | 0.64765 |
| VGG face fine-tuning [36] | 0.60702 |
| Proposed method | 0.23663 |
| Method | Average Processing Time |
|---|---|
| Proposed method | 35.41 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, K.W.; Hong, H.G.; Nam, G.P.; Park, K.R. A Study of Deep CNN-Based Classification of Open and Closed Eyes Using a Visible Light Camera Sensor. Sensors 2017, 17, 1534. https://doi.org/10.3390/s17071534
Kim KW, Hong HG, Nam GP, Park KR. A Study of Deep CNN-Based Classification of Open and Closed Eyes Using a Visible Light Camera Sensor. Sensors. 2017; 17(7):1534. https://doi.org/10.3390/s17071534
Chicago/Turabian StyleKim, Ki Wan, Hyung Gil Hong, Gi Pyo Nam, and Kang Ryoung Park. 2017. "A Study of Deep CNN-Based Classification of Open and Closed Eyes Using a Visible Light Camera Sensor" Sensors 17, no. 7: 1534. https://doi.org/10.3390/s17071534
APA StyleKim, K. W., Hong, H. G., Nam, G. P., & Park, K. R. (2017). A Study of Deep CNN-Based Classification of Open and Closed Eyes Using a Visible Light Camera Sensor. Sensors, 17(7), 1534. https://doi.org/10.3390/s17071534