IoT Service Clustering for Dynamic Service Matchmaking



Abstract
:1. Introduction
1.1. Background
1.2. Motivation
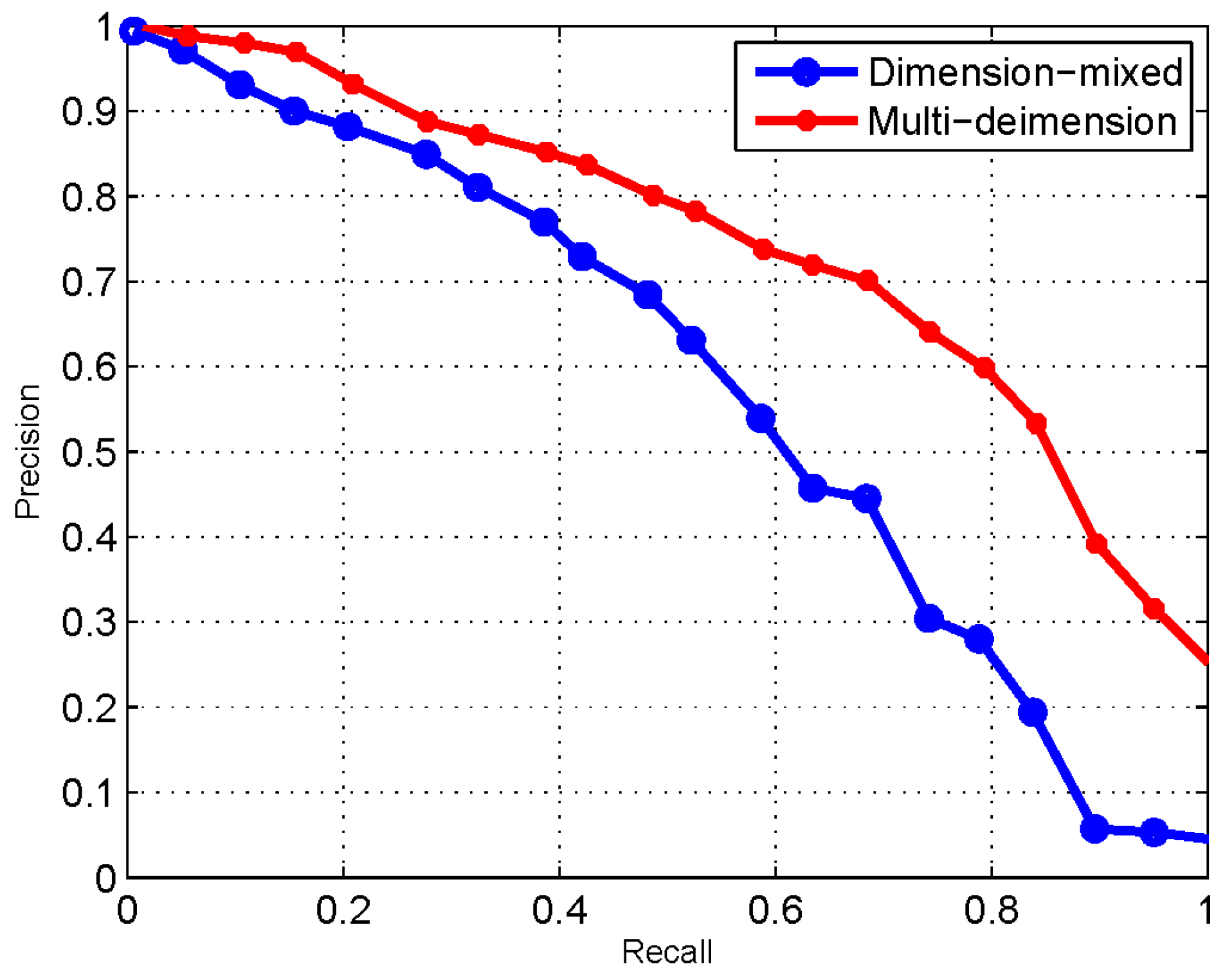
- This paper proposes the MDM algorithm for measuring the similarity between IoT services based on multidimensional service model. The accuracy and efficiency of MDM outperform the dimension-mixed approaches.
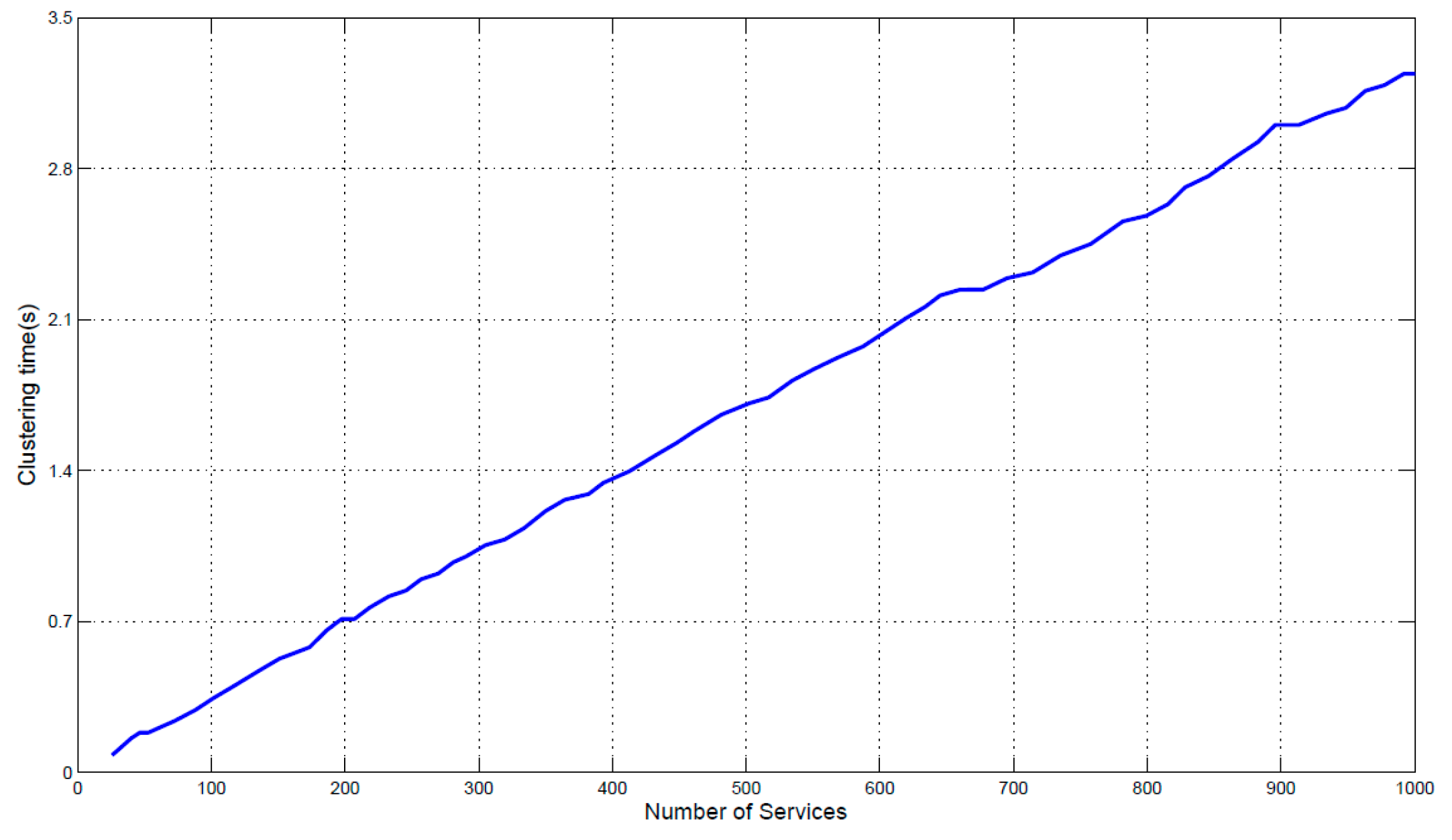
- MDM algorithm employs a density-peaks-based clustering approach to gather similar services together according to the actual distribution of services. It avoids the complicated process of estimating or optimizing parameters.
- To evaluate the applicability of proposed approaches, we use a combined data set including real and synthetic data. The experiment results indicate that the performance of proposed approaches are applicable to real-life scenarios.
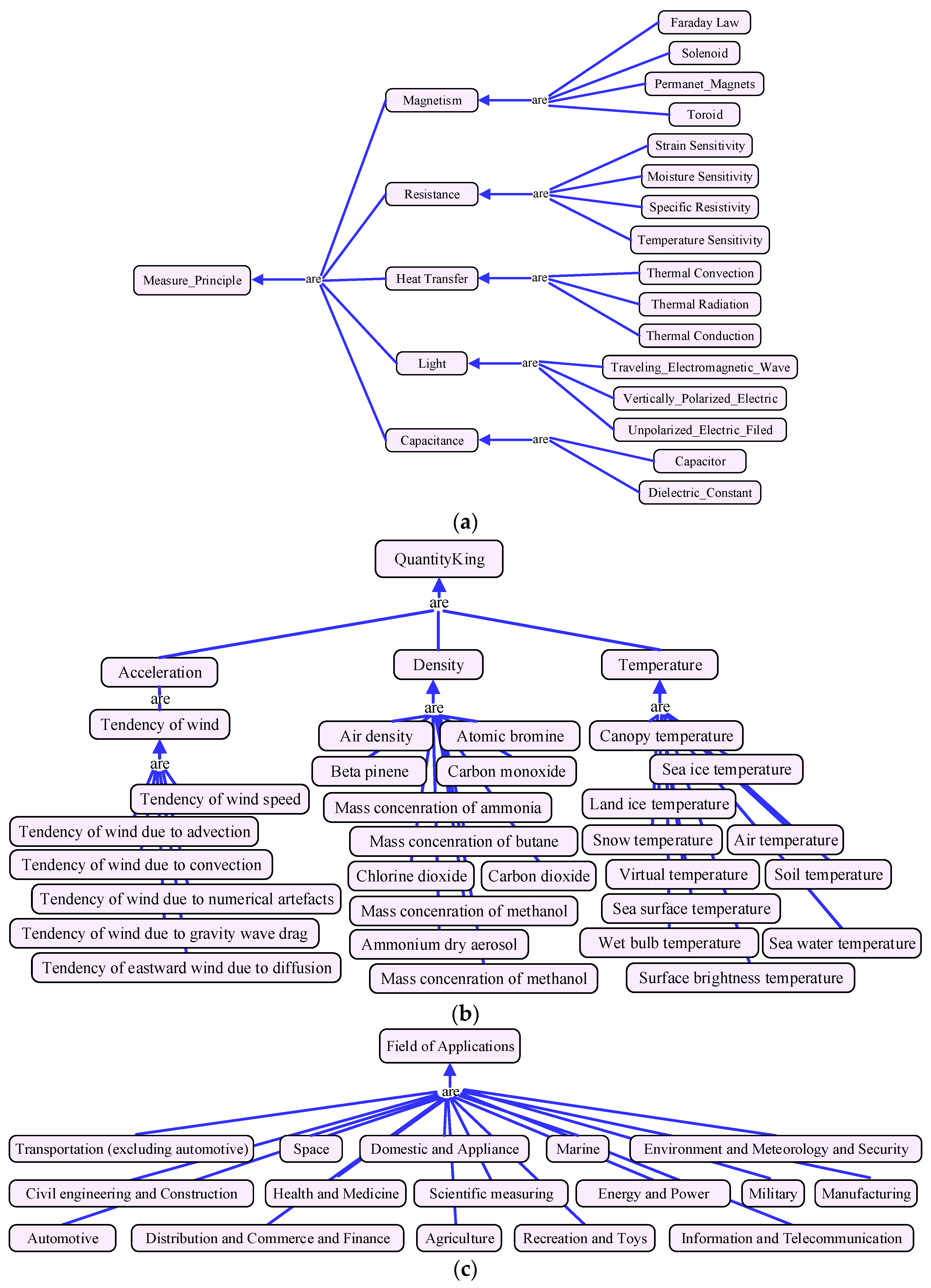
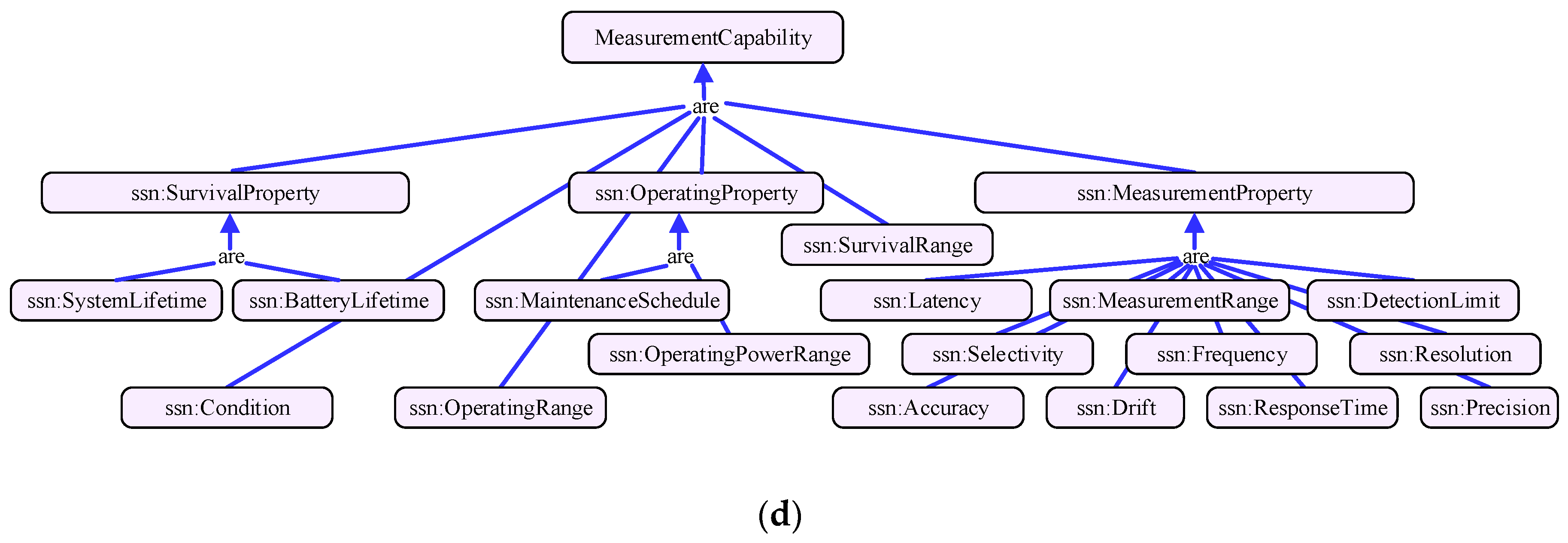
2. Preliminaries: Multidimensional Service Model and Model Vectorization
3. MDM Similarity Measurement
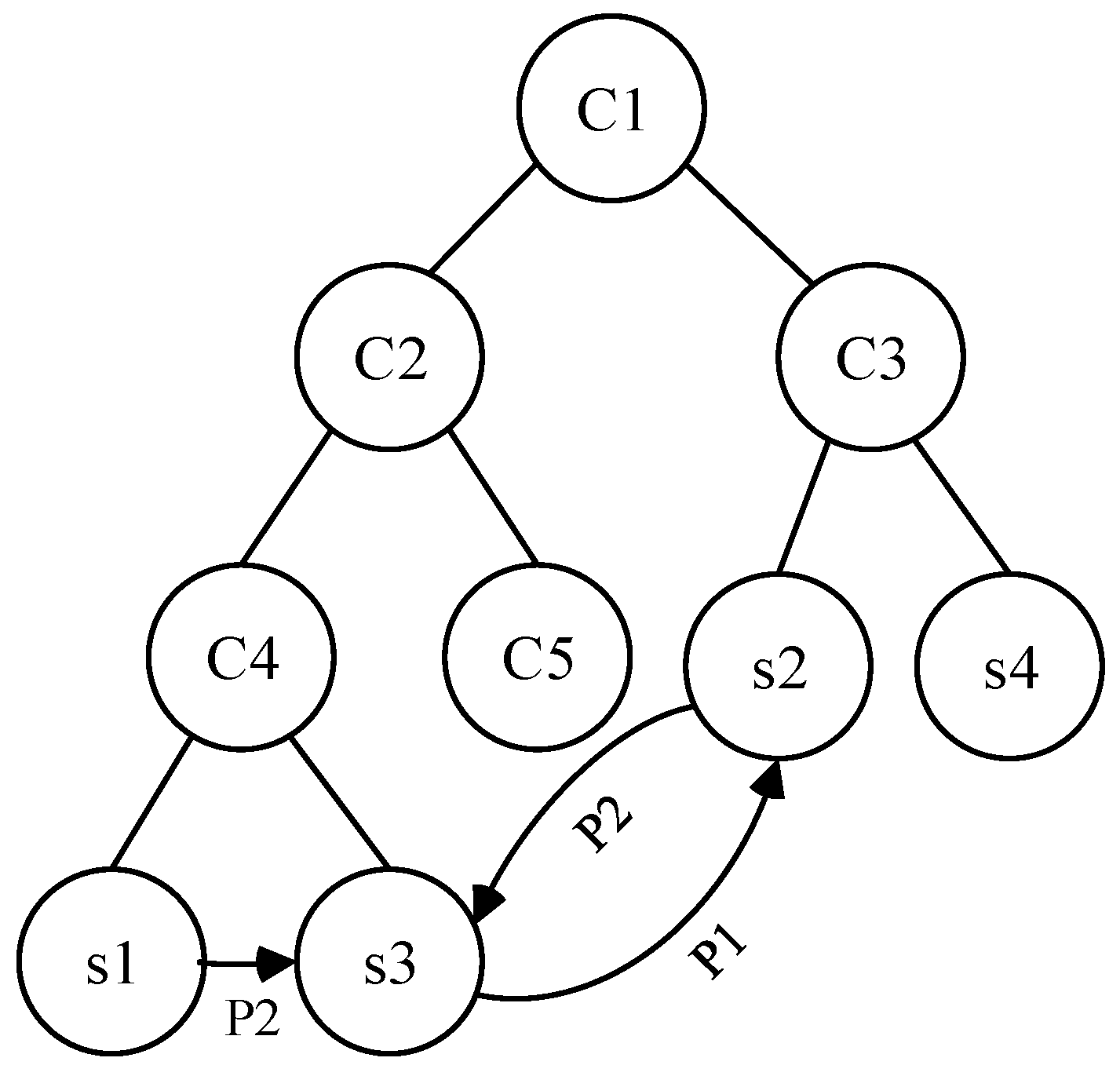
3.1. Structure Similarity
3.2. Service Description Similarity
3.3. Multidimensional Aggregation
4. IoT Service Clustering
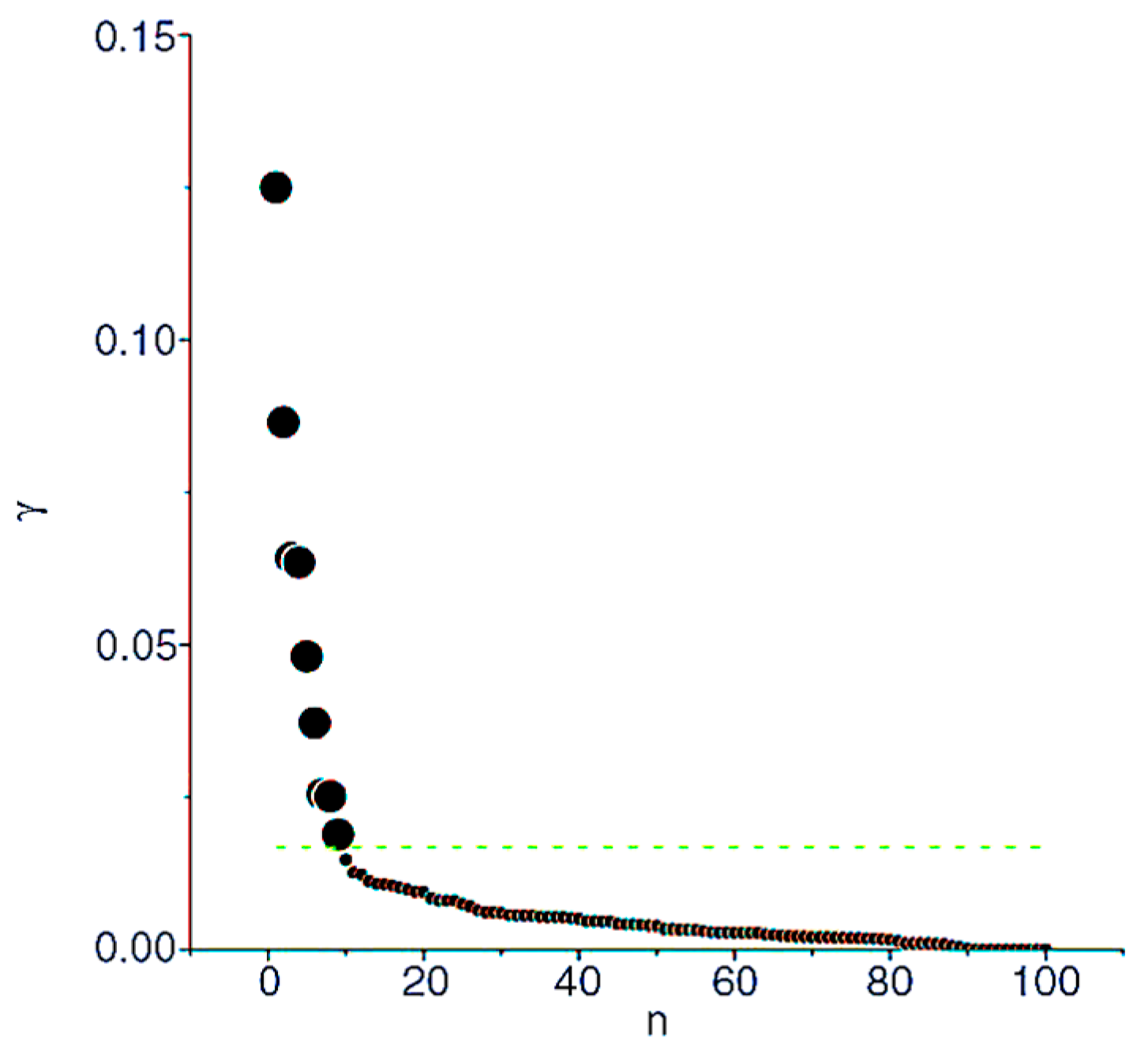
4.1. Local Density and Distance Calculating
| Algorithm 1. Calculating Clustering Distance | |
| Input: | : the matrix of distances between services; |
| : local density of each service; | |
| Output: | : the clustering distance of each service; |
| : the index of service that has larger density and closest to ; | |
| Sort in descending order by density 1: 2: ←descending order index of density; Distance assignment of 3: ← 0; 4: for i:=1 to N do 5: ←; 6: for j:=1 to i−1 do 7: if then 8: 9: ; 10: end if 11: end for 12: end for 13: | |
4.2. Cluster Center Selecting
4.3. Cluster Assignment
| Algorithm 2. Cluster Assignment | |
| Input: | : the descending order of index according to density ; |
| : the index of cluster center of cluster j; | |
| : total number of clusters (centers); | |
| : the index of service which has larger density than and closest to ; | |
| Output: | : the cluster of each service belongs to, i.e., belongs to ; |
| 1: ; //initialization of 2: for j:=1 to do 3: =j; //cluster centers 4: end for Non-center services assignment 5: for i:=1 to N do //descending order of index 6: if then 7: ; 8: end if 9: end for | |
| Algorithm 3. Determining Cluster Core and Cluster Halo | |
| Input: | : the matrix of distances between services; |
| : cut-off distance; | |
| : the cluster of each service belongs; | |
| Output: | : the signal of core or halo that service belongs to; |
| Initialization 1: ← 0; 2: ← 0; 3: for i:=1 to N−1 do 4: for j:=I + 1 to N do 5: if and then 6: ; 7: if then 8: ; 9: end if 10: if then 11: ; 12: end if 13: end if 14: end for 15: end for 16: for i:=1 to N 17: if then 18: ; //belongs to halo part of cluster 19: end if 20: end for | |
5. Experimental Evaluation
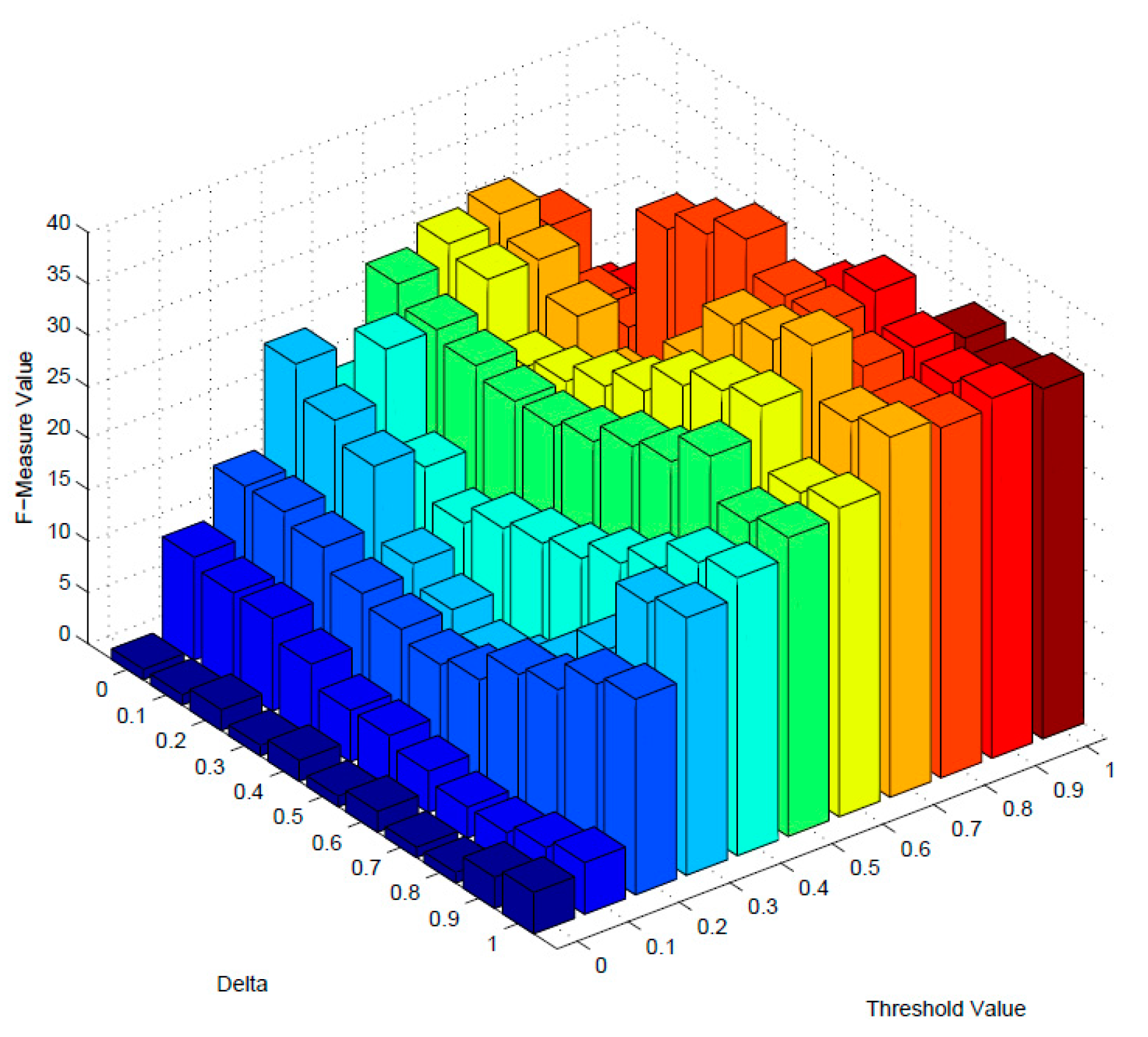
5.1. Performance of Similarity Measurement
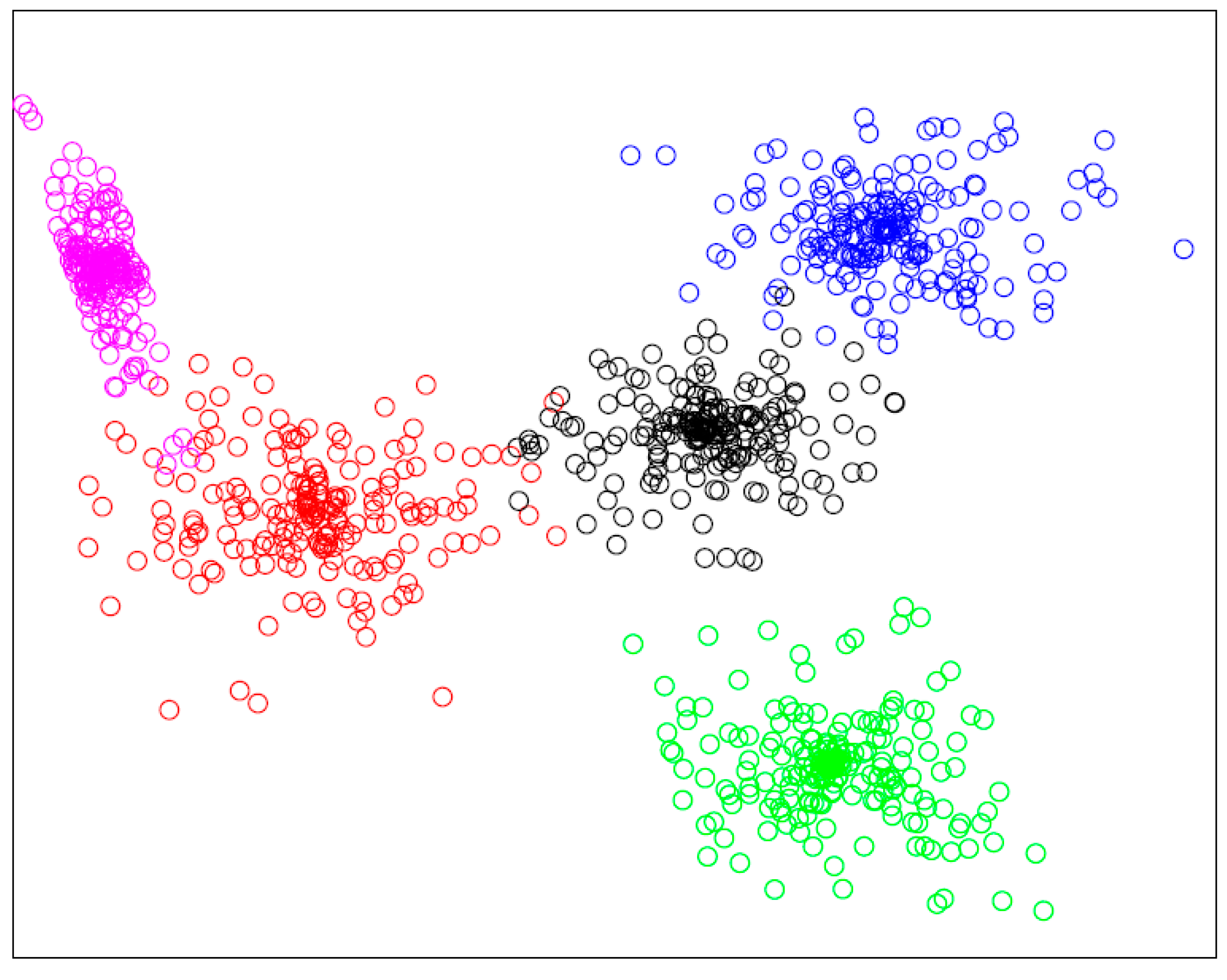
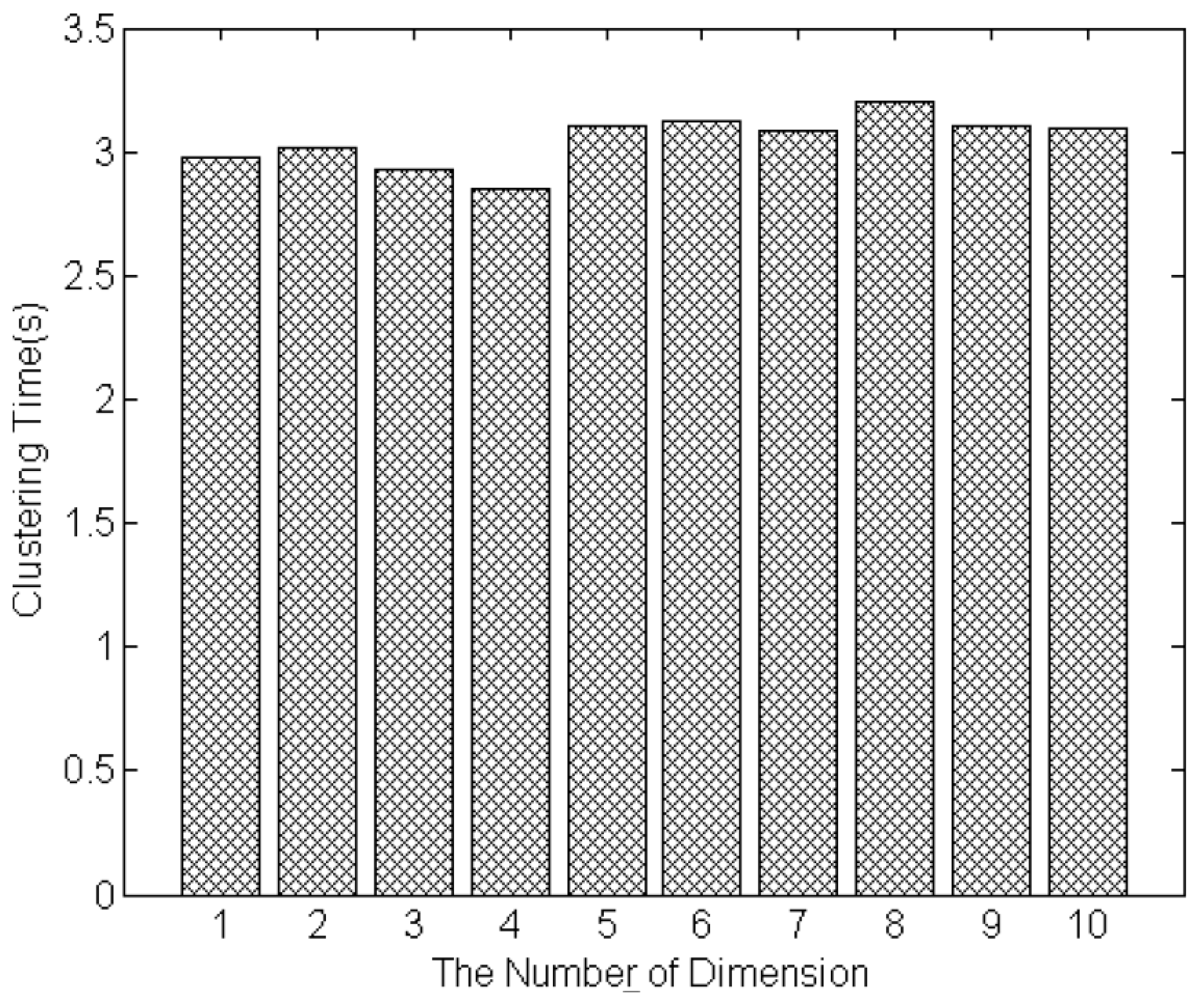
5.2. Performance of Service Clustering
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Papazoglou, M.P.; Heuvel, W.-J. Service oriented architectures: Approaches, technologies and research issues. VLDB J. Int. J. Very Larg. Data Bases 2007, 16, 389–415. [Google Scholar] [CrossRef]
- Du, Y.; Li, X.; Xiong, P. A petri net approach to mediation-aided composition of web services. IEEE Trans. Autom. Sci. Eng. 2012, 9, 429–435. [Google Scholar] [CrossRef]
- Kyusakov, R.; Eliasson, J.; Delsing, J.; van Deventer, J.; G ustafsson, J. Integration of wireless sensor and actuator nodes with IT infrastructure using service-oriented architecture. IEEE Trans. Ind. Inform. 2013, 9, 43–51. [Google Scholar] [CrossRef]
- Soldatos, J.; Kefalakis, N.; Hauswirth, M.; Serrano, M.; Calbimonte, J.-P.; Riahi, M.; Aberer, K.; Jayaraman, P.P.; Zaslavsky, A.; Žarko, I.P. Openiot: Open source internet-of-things in the cloud. In Interoperability and Open-Source Solutions for the Internet of Things; Springer: Berlin, Germany, 2015; pp. 13–25. [Google Scholar]
- Butun, I.; Morgera, S.D.; Sankar, R. A survey of intrusion detection systems in wireless sensor networks. IEEE Commun. Surv. Tutor. 2014, 16, 266–282. [Google Scholar] [CrossRef]
- Sinha, N.; Pujitha, K.E.; Alex, J.S.R. Xively based sensing and monitoring system for IoT. In Proceedings of the 2015 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 8–10 January 2015; pp. 1–6. [Google Scholar]
- Dong, X.; Halevy, A.; Madhavan, J.; Nemes, E.; Zhang, J. Similarity search for web services. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, ON, Canada, 31 August–3 September 2004; pp. 372–383. [Google Scholar]
- Plebani, P.; Pernici, B. URBE: Web service retrieval based on similarity evaluation. IEEE Trans. Knowl. Data Eng. 2009, 21, 1629–1642. [Google Scholar] [CrossRef]
- Liu, X.; Huang, G.; Mei, H. Discovering homogeneous web service community in the user-centric web environment. IEEE Trans. Serv. Comput. 2009, 2, 167–181. [Google Scholar] [CrossRef]
- Cheng, B.; Zhu, D.; Zhao, S.; Chen, J. Situation-aware IoT service coordination using the event-driven SOA paradigm. IEEE Trans. Netw. Serv. Manag. 2016, 13, 349–361. [Google Scholar] [CrossRef]
- Zhang, L.-J.; Cheng, S.; Chang, C.K.; Zhou, Q. A pattern-recognition-based algorithm and case study for clustering and selecting business services. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2012, 42, 102–114. [Google Scholar] [CrossRef]
- Yachir, A.; Amirat, Y.; Chibani, A.; Badache, N. Event-aware framework for dynamic services discovery and selection in the context of ambient intelligence and Internet of Things. IEEE Trans. Autom. Sci. Eng. 2016, 13, 85–102. [Google Scholar] [CrossRef]
- Zhou, Z.; Sellami, M.; Gaaloul, W.; Barhamgi, M.; Defude, B. Data providing services clustering and management for facilitating service discovery and replacement. IEEE Trans. Autom. Sci. Eng. 2013, 10, 1131–1146. [Google Scholar] [CrossRef]
- Pilioura, T.; Tsalgatidou, A. Unified publication and discovery of semantic web services. ACM Trans. Web 2009, 3, 11. [Google Scholar] [CrossRef]
- Resnik, P. Semantic similarity in a taxonomy: An information-based measure and its application to problems of ambiguity in natural language. J. Artif. Intell. Res. 1999, 11, 95–130. [Google Scholar]
- Sánchez, D.; Batet, M.; Isern, D. Ontology-based information content computation. Knowl. Based Syst. 2011, 24, 297–303. [Google Scholar] [CrossRef]
- Sussna, M. Word sense disambiguation for free-text indexing using a massive semantic network. In Proceedings of the 2nd International Conference on Information and Knowledge Management, Washington, DC, USA, 3–5 November 1993; pp. 67–74. [Google Scholar]
- Pedersen, T.; Patwardhan, S.; Michelizzi, J. WordNet:: Similarity: Measuring the relatedness of concepts. In Proceedings of the HLT-NAACL 2004, Boston, MA, USA, 2–7 May 2004; pp. 38–41. [Google Scholar]
- Klusch, M.; Fries, B.; Sycara, K. OWLS-MX: A hybrid Semantic Web service matchmaker for OWL-S services. Web Semant. Sci. Serv. Agents World Wide Web 2009, 7, 121–133. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [PubMed]
- Compton, M.; Neuhaus, H.; Taylor, K.; Tran, K.-N. Reasoning about sensors and compositions. In Proceedings of the 2nd International Conference on Semantic Sensor Networks, Washington, DC, USA, 26 October 2009; pp. 33–48. [Google Scholar]
- Goodwin, J.C.; Russomanno, D.J.; Qualls, J. Survey of Semantic Extensions to UDDI: Implications for Sensor Services. In Proceedings of the International Conference on Sematic Web and Web Services, Las Vegas, NV, USA, 28 January 2007; pp. 16–22. [Google Scholar]
- Perera, C.; Zaslavsky, A.; Christen, P.; Georgakopoulos, D. Sensing as a service model for smart cities supported by internet of things. Trans. Emerg. Telecommun. Technol. 2014, 25, 81–93. [Google Scholar] [CrossRef]
- Rodríguez-García, M.Á.; Valencia-García, R.; García-Sánchez, F.; Samper-Zapater, J.J. Ontology-based annotation and retrieval of services in the cloud. Knowl. Based Syst. 2014, 56, 15–25. [Google Scholar] [CrossRef]
- Feng, G.; Chen, H.; Liu, M. An ontology service model for flexible service customization. In Proceedings of the 2014 11th International Conference on Service Systems and Service Management (ICSSSM), Beijing, China, 25–27 June 2014; pp. 1–4. [Google Scholar]
- Jin, X.; Chun, S.; Jung, J.; Lee, K.-H. IoT service selection based on physical service model and absolute dominance relationship. In Proceedings of the 2014 IEEE 7th International Conference on Service-Oriented Computing and Applications (SOCA), Matsue, Japan, 17–19 November 2014; pp. 65–72. [Google Scholar]
- Kim, J.; Chung, K.-Y. Ontology-based healthcare context information model to implement ubiquitous environment. Multimed. Tools Appl. 2014, 71, 873–888. [Google Scholar] [CrossRef]
- Klusch, M.; Kapahnke, P.; Schulte, S.; Lecue, F.; Bernstein, A. Semantic web service search: A brief survey. KI-Künstliche Intell. 2016, 30, 139–147. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, Y.; Yu, L.; Cheng, B.; Ji, Y.; Chen, J. A multidimensional resource model for dynamic resource matching in internet of things. Concurr. Comput. Pract. Exp. 2015, 27, 1819–1843. [Google Scholar] [CrossRef]
- Fraden, J. Handbook of Modern Sensors: Physics, Designs, and Applications; Springer Science & Business Media: Berlin, Germany, 2004. [Google Scholar]
- Calbimonte, J.-P.; Yan, Z.; Jeung, H.; Corcho, O.; Aberer, K. Deriving semantic sensor metadata from raw measurements. In Proceedings of the 5th International Conference on Semantic Sensor Networks at ISWC, at ISWC, Boston, MA, USA, 12 November 2012; pp. 33–48. [Google Scholar]
- Compton, M.; Barnaghi, P.; Bermudez, L.; GarcíA-Castro, R.; Corcho, O.; Cox, S.; Graybeal, J.; Hauswirth, M.; Henson, C.; Herzog, A. The SSN ontology of the W3C semantic sensor network incubator group. Web Semant. Sci. Serv. Agents World Wide Web 2012, 17, 25–32. [Google Scholar] [CrossRef] [Green Version]
- Dong, H.; Hussain, F.K.; Chang, E. A context-aware semantic similarity model for ontology environments. Concurr. Comput. Pract. Exp. 2011, 23, 505–524. [Google Scholar] [CrossRef]
- Li, Y.; Bandar, Z.A.; McLean, D. An approach for measuring semantic similarity between words using multiple information sources. IEEE Trans. Knowl. Data Eng. 2003, 15, 871–882. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Ikemura, S.; Fujiyoshi, H. Real-Time Human Detection Using Relational Depth Similarity Features. In Proceedings of the 10th Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; pp. 25–38. [Google Scholar]
- Rodríguez, M.A.; Egenhofer, M.J. Determining semantic similarity among entity classes from different ontologies. IEEE Trans. Knowl. Data Eng. 2003, 15, 442–456. [Google Scholar] [CrossRef]
- Ahsaee, M.G.; Naghibzadeh, M.; Naeini, S.E.Y. Semantic similarity assessment of words using weighted WordNet. Int. J. Mach. Learn. Cybern. 2014, 5, 479–490. [Google Scholar] [CrossRef]
- Varelas, G.; Voutsakis, E.; Raftopoulou, P.; Petrakis, E.G.; Milios, E.E. Semantic similarity methods in wordNet and their application to information retrieval on the web. In Proceedings of the 7th Annual ACM International Workshop on Web Information and Data Management, Bremen, Germany, 4 November 2005; pp. 10–16. [Google Scholar]
- Bulskov, H.; Knappe, R.; Andreasen, T. On Measuring Similarity for Conceptual Querying; Springer: Beilin, Germany, 2002; pp. 100–111. [Google Scholar]
- Stoer, J.; Bulirsch, R. Introduction to Numerical Analysis; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Number of Services | Number after Expansion | |
|---|---|---|---|
| Outdoor | ABM | 105 | 200 |
| LSM | 100 | 200 | |
| CCMWS | 93 | 200 | |
| DHCIS | 76 | 200 | |
| Indoor | IntelLab | 54 | 100 |
| MavHome | 82 | 100 | |
| Total | 510 | 1000 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, S.; Yu, L.; Cheng, B.; Chen, J. IoT Service Clustering for Dynamic Service Matchmaking. Sensors 2017, 17, 1727. https://doi.org/10.3390/s17081727
Zhao S, Yu L, Cheng B, Chen J. IoT Service Clustering for Dynamic Service Matchmaking. Sensors. 2017; 17(8):1727. https://doi.org/10.3390/s17081727
Chicago/Turabian StyleZhao, Shuai, Le Yu, Bo Cheng, and Junliang Chen. 2017. "IoT Service Clustering for Dynamic Service Matchmaking" Sensors 17, no. 8: 1727. https://doi.org/10.3390/s17081727
APA StyleZhao, S., Yu, L., Cheng, B., & Chen, J. (2017). IoT Service Clustering for Dynamic Service Matchmaking. Sensors, 17(8), 1727. https://doi.org/10.3390/s17081727