Superpixel-Based Feature for Aerial Image Scene Recognition


Abstract
:
1. Introduction
1.1. Background
1.2. Related Work
1.3. Contribution of This Paper
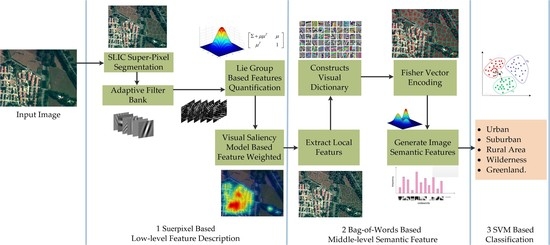
2. Methodology
2.1. Aerial Image Semantic Hierarchical Structure
2.2. Superpixel-Based Feature Description
2.2.1. SLIC Superpixel Segmentation
2.2.2. Adaptive Filter Bank Construction
2.2.3. Lie Group-Based Feature Quantification
2.2.4. Visual Saliency Model-Based Feature Weighting
2.3. Scene Recognition of Aerial Images
3. Result and Discussion
3.1. Experimental Data
3.2. Experimental Results Analysis
3.2.1. Influence of Filter Template Size on Feature Expression
3.2.2. Influence of Saliency Model on Scene Recognition
3.2.3. Comparison of Feature Performances
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Teng, H.; Rossel, R.A.V.; Shi, Z.; Behrens, T.; Chappell, A.; Bui, E. Assimilating satellite imagery and visible-near infrared spectroscopy to model and map soil loss by water erosion in australia. Environ. Model. Softw. 2016, 77, 156–167. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, B.; Su, H.; Li, W.; Wang, L. Land-use scene classification using multi-scale completed local binary patterns. Signal Image Video Process. 2016, 10, 745–752. [Google Scholar] [CrossRef]
- Tong, X.; Liu, X.; Chen, P.; Liu, S.; Luan, K.; Li, L.; Liu, S.; Liu, X.; Xie, H.; Jin, Y. Integration of UAV-based photogrammetry and terrestrial laser scanning for the three-dimensional mapping and monitoring of open-pit mine areas. Remote Sens. 2015, 7, 6635–6662. [Google Scholar] [CrossRef]
- Peña, J.M.; Torressánchez, J.; Serranopérez, A.; de Castro, A.I.; Lópezgranados, F. Quantifying efficacy and limits of unmanned aerial vehicle (UAV) technology for weed seedling detection as affected by sensor resolution. Sensors 2015, 15, 5609–5626. [Google Scholar] [CrossRef] [PubMed]
- Chrétien, L.P.; Théau, J.; Ménard, P. Visible and thermal infrared remote sensing for the detection of white-tailed deer using an unmanned aerial system. Wildl. Soc. Bull. 2016, 40, 181–191. [Google Scholar] [CrossRef]
- Getzin, S.; Nuske, R.S.; Wiegand, K. Using unmanned aerial vehicles (UAV) to quantify spatial gap patterns in forests. Remote Sens. 2014, 6, 6988–7004. [Google Scholar] [CrossRef]
- Kakooei, M.; Baleghi, Y. Fusion of satellite, aircraft, and UAV data for automatic disaster damage assessment. Int. J. Remote Sens. 2017, 38, 1–24. [Google Scholar] [CrossRef]
- Moranduzzo, T.; Melgani, F.; Bazi, Y.; Alajlan, N. A fast object detector based on high-order gradients and gaussian process regression for UAV images. Int. J. Remote Sens. 2015, 36, 2713–2733. [Google Scholar]
- Huang, Y.; Cao, X.; Zhang, B.; Zheng, J.; Kong, X. Batch loss regularization in deep learning method for aerial scene classification. In Proceedings of the Integrated Communications, Navigation and Surveillance Conference, Herndon, VA, USA, 18–20 April 2017. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999. [Google Scholar]
- Lowe, D.G.; Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Csurka, G.; Dance, C.R.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. Workshop Stat. Learn. Comput. Vis. ECCV 2004, 44, 1–22. [Google Scholar]
- Willamowski, J.; Arregui, D.; Csurka, G.; Dance, C.R.; Fan, L. Categorizing nine visual classes using local appearance descriptors. ICPR Workshop Learn. Adaptable Vis. Syst. 2004, 17, 21. [Google Scholar]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607. [Google Scholar] [CrossRef] [PubMed]
- Felzenszwalb, P.; Mcallester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Gao, X.; Hua, G.; Niu, Z.; Tian, Q. Context aware topic model for scene recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2743–2750. [Google Scholar]
- Zang, M.; Wen, D.; Wang, K.; Liu, T.; Song, W. A novel topic feature for image scene classification. Neurocomputing 2015, 148, 467–476. [Google Scholar] [CrossRef]
- Grauman, K.; Darrell, T. The pyramid match kernel: Discriminative classification with sets of image features. In Proceedings of the Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; Volume 1452, pp. 1458–1465. [Google Scholar]
- Kim, J.; Liu, C.; Sha, F.; Grauman, K. Deformable spatial pyramid matching for fast dense correspondences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; Volume 9, pp. 2307–2314. [Google Scholar]
- Harris, C. A combined corner and edge detector. Alvey Vis. Conf. 1988, 15, 147–151. [Google Scholar]
- Rosten, E.; Porter, R.; Drummond, T. Faster and better: A machine learning approach to corner detection. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 105–119. [Google Scholar] [CrossRef] [PubMed]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Content-Based Image Retrieval: A Report to the JISC Technology Application Program. Available online: http://www.leeds.ac.uk/educol/documents/00001240.htm (accessed on 24 October 2017).
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. Slic superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Jiao, L.; Hou, B.; Wang, S.; Zhao, J.; Chen, P. Locality-constraint discriminant feature learning for high-resolution SAR image classification. Neurocomputing 2016, 207, 772–784. [Google Scholar] [CrossRef]
- Liang, Z.; Li, Y.; Shi, P. A note on two-dimensional linear discriminant analysis. Pattern Recognit. Lett. 2008, 29, 2122–2128. [Google Scholar] [CrossRef]
- Liyu, G. Research on Lie Group Based Image Generalized Gaussian Feature Structure Analysis; Huazhong University of Science & Technology: Wuhan, China, 2012. [Google Scholar]
- Wei, J.; Jianfang, L.; Bingru, Y. Semi-supervised discriminant analysis on Riemannian manifold framework. J. Comput. Aided Des. Comput. Graph. 2014, 26, 1099–1108. [Google Scholar]
- Wang, Q.; Li, P.; Zhang, L.; Zuo, W. Towards effective codebookless model for image classification. Pattern Recognit. 2016, 59, 63–71. [Google Scholar] [CrossRef]
- Li, P.; Wang, Q.; Hui, Z.; Lei, Z. Local log-Euclidean multivariate Gaussian descriptor and its application to image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 803–817. [Google Scholar] [CrossRef] [PubMed]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. In Proceedings of the European Conference on Computer Vision, Cambridge, UK, 14–18 April 1996. [Google Scholar]
- Itti, L.; Koch, C. Computational modelling of visual attention. Nat. Rev. Neurosci. 2001, 2, 194–203. [Google Scholar] [CrossRef] [PubMed]
- Erdem, E.; Erdem, A. Visual saliency estimation by nonlinearly integrating features using region covariances. J. Vis. 2013, 13, 11. [Google Scholar] [CrossRef] [PubMed]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Murray, N.; Vanrell, M.; Otazu, X.; Parraga, C.A. Low-level spatiochromatic grouping for saliency estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2810–2816. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Template Size | 3 × 3 | 5 × 5 | 7 × 7 | 9 × 9 |
| Recognition Accuracy | 88.3% | 88% | 88.3% | 88.9% |
| Saliency Model | Null | Itti | Erdem | Achanta | SIM |
|---|---|---|---|---|---|
| Recognition Accuracy | 88.9% | 92.1% | 94.2% | 85.4% | 95.1% |
| Local Feature Type | Recognition Accuracy | Time Consumption |
|---|---|---|
| Dense SIFT | 78.3% | 16.86 s |
| Dense HOG | 79.1% | 15.23 s |
| Dense LBP | 82.6% | 15.96 s |
| Dense Gabor | 72.8% | 45.75 s |
| Harris Interest Points | 73.5% | 0.73 s |
| FAST Interest Points | 78.2% | 0.53 s |
| Proposed Feature | 95.1% | 21.57 s |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Shi, Y.; Zhang, B.; Wang, Y. Superpixel-Based Feature for Aerial Image Scene Recognition. Sensors 2018, 18, 156. https://doi.org/10.3390/s18010156
Li H, Shi Y, Zhang B, Wang Y. Superpixel-Based Feature for Aerial Image Scene Recognition. Sensors. 2018; 18(1):156. https://doi.org/10.3390/s18010156
Chicago/Turabian StyleLi, Hongguang, Yang Shi, Baochang Zhang, and Yufeng Wang. 2018. "Superpixel-Based Feature for Aerial Image Scene Recognition" Sensors 18, no. 1: 156. https://doi.org/10.3390/s18010156
APA StyleLi, H., Shi, Y., Zhang, B., & Wang, Y. (2018). Superpixel-Based Feature for Aerial Image Scene Recognition. Sensors, 18(1), 156. https://doi.org/10.3390/s18010156