Multiple Sound Sources Localization with Frame-by-Frame Component Removal of Statistically Dominant Source




Abstract
:1. Introduction
2. Problem Statement
2.1. Problem in the SSZ-Based Method
2.2. Exploring the Swss among Microphone Signals
3. Proposed Method
3.1. Review of DOA Estimation Based on the SSZ Detecting
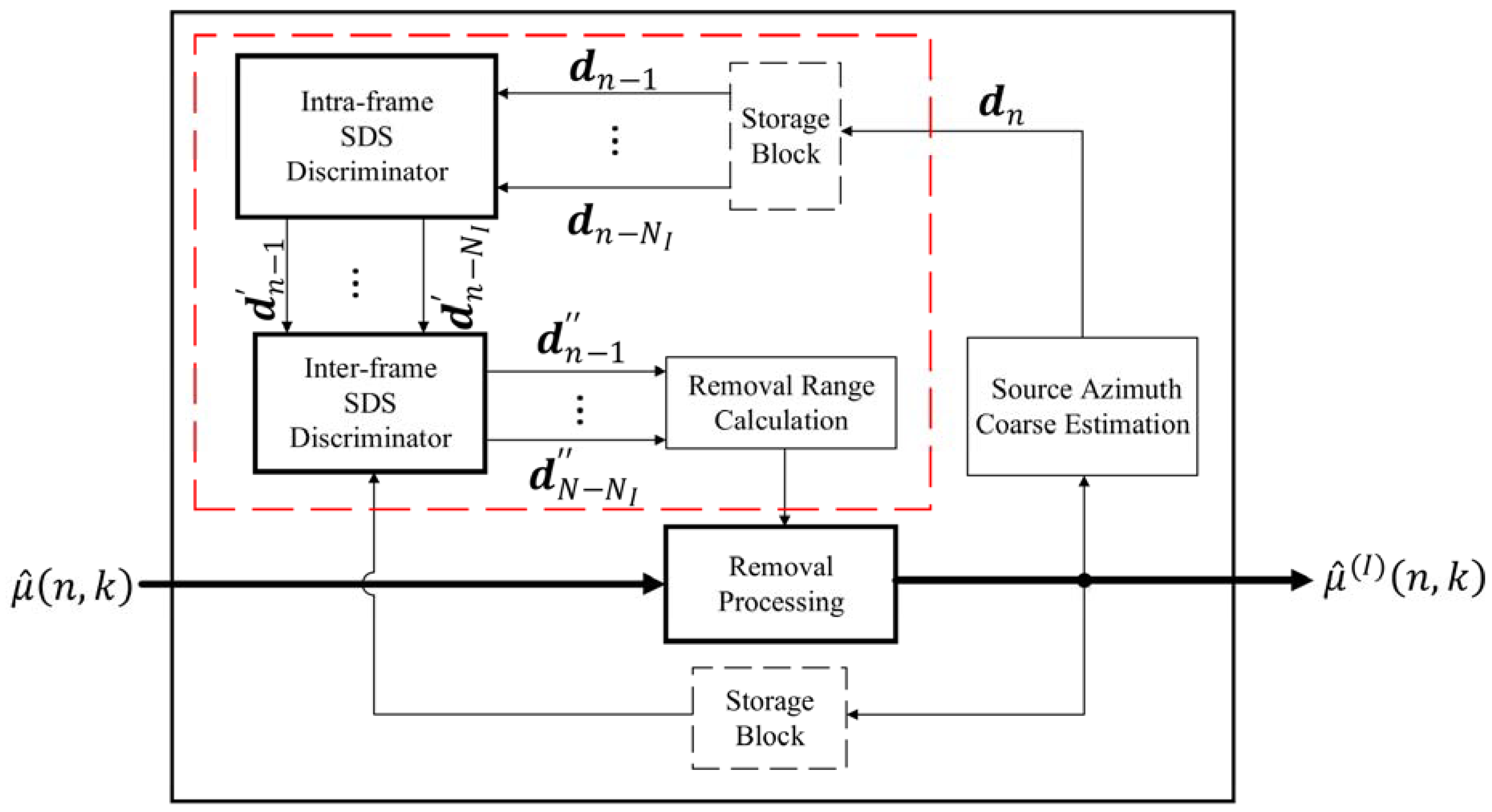
3.2. SDSCR Algorithm
| Algorithm 1: Intra-frame SDS Discrimination |
| Input: ►The number of look-back frames used to calculate the removal range Input: , where , Output: , where , 1. fori = 1 to do 2. Sort azimuth coarse estimates (the elements in ) in ascending order , where ,,…, [1,] are new index after sorting ► is the minimum element in ► is the maximum element in 3. for j = 1 to do ►look for the number of sound sources in 4. if , i.e., two estimated azimuths come from different source ► is the minimum difference threshold 5. then , else Set to be an illegal element: 6. end if 7. end for 8. 9. 10. if , i.e., all azimuths come from the different sound sources in 11. Delete the illegal elements in the vector and form a new index vector , 12. for k = 1 to do ►look for the intra-frame SDS 13. if , i.e., come from the same SDS ► is the minimum distance threshold 14. then , 15. else set to be an illegal element: 16. end if 17. end for 18. Delete the illegal elements in and form the vector where is the number of elements in (i.e., the number of estimated intra-frame SDS) 19. else, i.e., , all azimuths come from the same sound source in 20. Vector consists of the largest and smallest elements in 21. end if 22. end for 23. Output: |
| Algorithm 2: Inter-frame SDS Discrimination |
| Input: , where , Output: , where , ► is a set of estimated SDS azimuths in the (n − i)th frame ► is the number of SDSs in Count the number of DOA estimates of all history frames and record as 1. for i = 1 to do 2. for j = 1 to do Count the number of DOA estimates of all history frames locating in [ − , + ] and record as ► is the removal range threshold 3. if It means that there are enough DOA estimates belonging to azimuth corresponding sound source and the sound source is judged as SDS 4. then, 5. else 6. Set as an illegal element: 7. end if 8. end for 9. Delete the illegal elements in the set and form vector , 10. end for 11. Output: |
3.3. Post-Processing
4. Results and Discussion
4.1. The Evaluation of Localization Performance in Simulated Environments
4.1.1. DOA Estimation in Anechoic Room
4.1.2. DOA Estimation in Reverberant Room
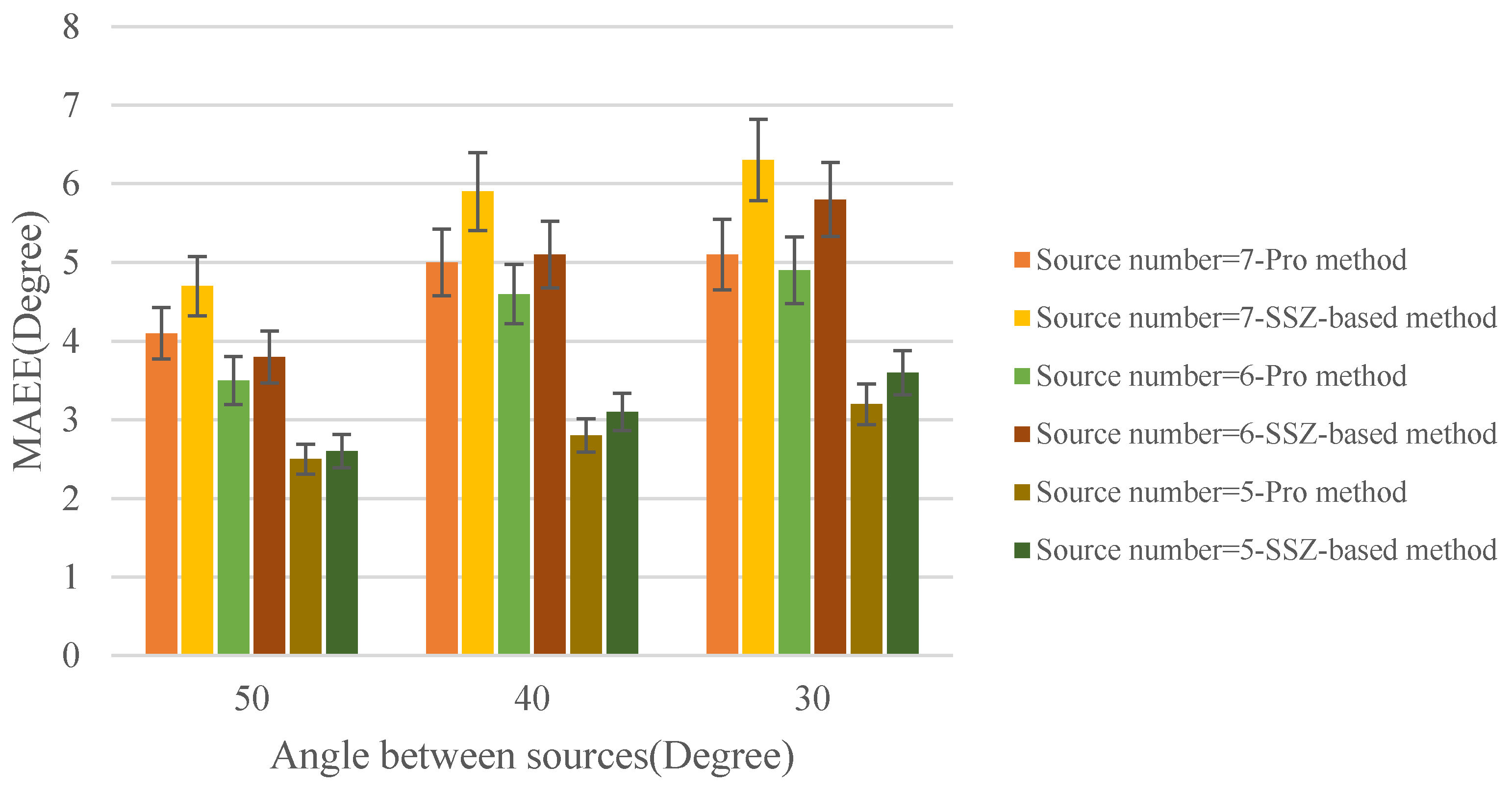
4.1.3. The Evaluation of Sources Counting
4.2. The Evaluation of Localization Performance in Real Environments
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Krim, H.; Viberg, M. Two decades of array signal processing research: The parametric approach. IEEE Signal Process. Mag. 1996, 13, 67–94. [Google Scholar] [CrossRef]
- Wang, H.; Chu, P. Voice source localization for automatic camera pointing system in videoconferencing. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997; Volume 1, pp. 187–190. [Google Scholar]
- Latif, T.; Whitmire, E.; Novak, T.; Bozkurt, A. Sound localization sensors for search and rescue biobots. IEEE Sens. J. 2016, 16, 3444–3453. [Google Scholar] [CrossRef]
- Van den Bogaert, T.; Carette, E.; Wouters, J. Sound source localization using hearing aids with microphones placed behind-the-ear, in-the-canal, and in-the-pinna. Int. J. Audiol. 2011, 50, 164–176. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Wang, W.; Gu, Y.I.; Lei, S.J. Underdetermined DOA Estimation of Quasi-Stationary Signals Using a Partly-Calibrated Array. Sensors 2017, 17, 702. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.R.; Tao, C.; Ben, W. An Improved DOA Estimation Approach Using Co-array Interpolation and Matrix Denoising. Sensors 2017, 17, 1140. [Google Scholar] [CrossRef] [PubMed]
- Li, W.X.; Zhang, Y.; Lin, J.Z.; Guo, R.; Chen, Z.P. Wideband Direction of Arrival Estimation in the Presence of Unknown Mutual Coupling. Sensors 2017, 17, 230. [Google Scholar] [CrossRef] [PubMed]
- Hacıhabiboglu, H.; Sena, E.D.; Cvetkovic, Z.; Johnston, J.; Smith, J.O., III. Perceptual spatial audio recording, simulation, and rendering: An overview of spatial-audio techniques based on psychoacoustics. IEEE Signal Process. Mag. 2017, 34, 36–54. [Google Scholar]
- Grosse, J.; Par, S.V.D. Perceptually Accurate Reproduction of Recorded Soundfields in Reverb Room using Spatially Loudspeakers. IEEE J. Sel. Topics Signal Process. 2015, 9, 867–880. [Google Scholar] [CrossRef]
- Galdo, G.D.; Taseska, M.; Thiergart, O.; Ahonen, J.; Pulkki, V. The diffuse sound field in energetic analysis. J. Acoust. Soc. Am. 2012, 131, 2141–2151. [Google Scholar] [CrossRef] [PubMed]
- Jia, M.; Yang, Z.; Bao, C.; Zheng, X.; Ritz, C. Encoding multiple audio objects using intra-object sparsity. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 1082–1095. [Google Scholar]
- Jia, M.; Zhang, J.; Bao, C.; Zheng, X. A Psychoacoustic-Based Multiple Audio Object Coding Approach via Intra-object Sparsity. Appl. Sci. 2017, 7, 1301. [Google Scholar] [CrossRef]
- Brandstein, M.S.; Silverman, H.F. A robust method for speech signal time-delay estimation in reverberant rooms. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997; Volume 1, pp. 375–378. [Google Scholar]
- Karbasi, A.; Sugiyama, A. A new DOA estimation method using a circular microphone array. In Proceedings of the European Signal Processing Conference, Poznan, Poland, 3–7 September 2007; pp. 778–782. [Google Scholar]
- Bechler, D.; Kroschel, K. Considering the second peak in the GCC function for multi-source TDOA estimation with a microphone array. In Proceedings of the International Workshop on Acoustic Echo and Noise Control, Kyoto, Japan, 8–11 September 2003; pp. 315–318. [Google Scholar]
- Nesta, F.; Omologo, M. Generalized state coherence transform for multidimensional TDOA estimation of multiple sources. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 246–260. [Google Scholar] [CrossRef]
- Argentieri, S.; Danes, P. Broadband variations of the MUSIC high-resolution method for sound source localization in robotics. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; Volume 11, pp. 2009–2014. [Google Scholar]
- Dmochowski, J.P.; Benesty, J.; Affes, S. Broadband MUSIC: Opportunities and challenges for multiple source localization. In Proceedings of the IEEE Workshop on Applications of Signals Processing to Audio and Acoustics, New York, NY, USA, 21–24 October 2007; pp. 18–21. [Google Scholar]
- Sun, H.; Teutsch, H.; Mabande, E.; Kellermann, W. Robust localization of multiple sources in reverberant environments using EB-ESPRIT with spherical microphone arrays. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Prague, Czech Republic, 22–27 May 2011; Volume 125, pp. 117–120. [Google Scholar]
- Nunes, L.O.; Martins, W.A.; Lima, M.V.; Biscainho, L.W.; Costa, M.V.; Goncalves, F.M.; Said, A.; Lee, B. A steered-response power algorithm employing hierarchical search for acoustic source localization using microphone arrays. IEEE Trans. Signal Process. 2014, 62, 5171–5183. [Google Scholar] [CrossRef]
- Epain, N.; Jin, C.T. Independent component analysis using spherical microphone arrays. Acta Acust. United Acust. 2012, 98, 91–102. [Google Scholar] [CrossRef]
- Noohi, T.; Epain, N.; Jin, C.T. Direction of arrival estimation for spherical microphone arrays by combination of independent component analysis and sparse recovery. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Vancouver, BC, Canada, 26–30 May 2013; Volume 32, pp. 346–349. [Google Scholar]
- Noohi, T.; Epain, N.; Jin, C.T. Super-resolution acoustic imaging using sparse recovery with spatial priming. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, South Brisbane, Australia, 19–24 April 2015; pp. 2414–2418. [Google Scholar]
- Swartling, M.; Sllberg, B.; Grbi, N. Source localization for multiple speech sources using low complexity non-parametric source separation and clustering. Signal Process. 2011, 91, 1781–1788. [Google Scholar] [CrossRef] [Green Version]
- Pavlidi, D.; Puigt, M.; Griffin, A.; Mouchtaris, A. Real-time multiple sound source localization using a circular microphone array based on single-source confidence measures. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Kyoto, Japan, 25–30 March 2012; Volume 32, pp. 2625–2628. [Google Scholar]
- Zheng, X.; Ritz, C.; Xi, J. Collaborative blind source separation using location informed spatial microphones. IEEE Signal Process. Lett. 2013, 20, 83–86. [Google Scholar] [CrossRef]
- Pavlidi, D.; Griffin, A.; Puigt, M.; Mouchtaris, A. Real-time multiple sound source localization and counting using a circular microphone array. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 2193–2206. [Google Scholar] [CrossRef]
- Jia, M.; Sun, J.; Bao, C. Real-time multiple sound source localization and counting using a soundfield microphone. J. Ambient Intell. Humaniz. Comput. 2017, 8, 829–844. [Google Scholar] [CrossRef]
- Campbell, D.R.; Palomki, K.J.; Brown, G.J. A matlab simulation of ‘‘shoebox’’ room acoustics for use in research and teaching. Comput. Inf. Syst. J. 2005, 9, 48–51. [Google Scholar]
- Jia, M.; Sun, J.; Bao, C.; Ritz, C. Speech Source Separation by Recovering Sparse and Non-Sparse Components from B-Format Microphone Recordings. Speech Commun. 2018, 96, 184–196. [Google Scholar] [CrossRef]
- Pulkki, V. Spatial sound reproduction with directional audio coding. J. Audio Eng. Soc. 2007, 55, 503–516. [Google Scholar]
- Gunel, B.; Hacihabiboglu, H.; Kondoz, A.M. Acoustic source separation of convolutive mixtures based on intensity vector statistics. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 748–756. [Google Scholar] [CrossRef]
- Chen, J.; Benesty, J.; Huang, Y. Robust time delay estimation exploiting redundancy among multiple microphones. IEEE Trans. Audio Speech Lang. Process. 2003, 11, 549–557. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y. Time-delay estimation via linear interpolation and cross correlation. IEEE Trans. Audio Speech Lang. Process. 2004, 12, 509–519. [Google Scholar] [CrossRef]
- Twirling 720 VR Audio Recorder. Available online: http://yun-en.twirlingvr.com/index.php/home/index/twirling720.html (accessed on 24 October 2018).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Reference | Comment |
|---|---|---|
| TDOA | [13,14,15] | Employing excessive microphones to improve the reliability |
| MUSIC, ESPRIT | [17,18,19] | Microphones number more than sources number |
| SRP | [20] | High computational complexity |
| ICA | [16,21,22,23] | Employing directional sparsity of sound sources |
| SCA | [24,25,26] | Employing W-DO property |
| CMA-based | [27] | Need excessive microphones for multi-sources localization |
| SSZ-based | [28] | Instability for multi-sources localization |
| Parameter | Notation | Value |
|---|---|---|
| Sampling frequency of speech source | fs | 16 kHz |
| Source distance | r | 1 m |
| STFT length | K | 2048 |
| T-F zone width | 64 | |
| Overlapping in frequency | 50% | |
| SSZ detection threshold | 0.1 | |
| Minimum difference threshold | 20° | |
| Minimum distance threshold | 1 | |
| Minimum quantity threshold | 0.1 | |
| Peak detection threshold | 0.2 | |
| Length of data | 1s |
| Simulated Room | Reverberation Time |
|---|---|
| Anechoic Room | 0 ms |
| Quiet Room | 40 ms |
| Room 1 | 250 ms |
| Room 2 | 450 ms |
| Room 3 | 600 ms |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, M.; Wu, Y.; Bao, C.; Wang, J. Multiple Sound Sources Localization with Frame-by-Frame Component Removal of Statistically Dominant Source. Sensors 2018, 18, 3613. https://doi.org/10.3390/s18113613
Jia M, Wu Y, Bao C, Wang J. Multiple Sound Sources Localization with Frame-by-Frame Component Removal of Statistically Dominant Source. Sensors. 2018; 18(11):3613. https://doi.org/10.3390/s18113613
Chicago/Turabian StyleJia, Maoshen, Yuxuan Wu, Changchun Bao, and Jing Wang. 2018. "Multiple Sound Sources Localization with Frame-by-Frame Component Removal of Statistically Dominant Source" Sensors 18, no. 11: 3613. https://doi.org/10.3390/s18113613
APA StyleJia, M., Wu, Y., Bao, C., & Wang, J. (2018). Multiple Sound Sources Localization with Frame-by-Frame Component Removal of Statistically Dominant Source. Sensors, 18(11), 3613. https://doi.org/10.3390/s18113613