Generative Adversarial Networks-Based Semi-Supervised Automatic Modulation Recognition for Cognitive Radio Networks


Abstract
:1. Introduction
- We provide a brief introduction to GANs, discuss their application in automatic modulation classification, and propose a suitable framework for this field.
- Based on the application characteristics of the cognitive radio field, a semi-supervised method is applied that makes full use of signal sampling. We compare our method based on GANs with the semi-supervised method used in traditional machine learning.
- We propose signal synchronization and normalization method based on the attention model. Using this module, the training stability of the whole framework is improved.
- The authenticity of the fake radio samples generated by the generator network is verified. A statistical analysis is applied to the original sampling and the learned model specifications. The learning ability of GANs’ on different modulation signals is verified.
2. Related Works
2.1. Deep Learning for AMR
- (1)
- For the first characteristic, most of the existing independent studies analyzed the supervised learning scenario. These studies explored the impacts of network structure and signal representation on classification results. They have achieved good results in this scenario. However, most of these efforts were conducted with ideal amounts of training data. They did not explore the use of AMR methods when missing labeled training data. These problems are more likely to occur when dealing with unknown tasks and signals, such as signal acquisition in non-cooperative situations. Additionally, Tang Bin et al. [17] applies GAN as an approach of data augmentation. But in essence, it is based on sufficient amount of labeled data.
- (2)
- Regarding the second characteristic, most of the existing methods are carried out by extracting features firstly and then performing classification. This approach is not fundamentally different from traditional expert-knowledge-based modulation recognition, except that the deep neural network is regarded as an enhanced classification tool. In the realization of cognitive radio, this limited the ability of systems to adapt to unknown and new tasks. We believe that this solution does not fully exploit the capabilities of deep neural networks for extracting features—it is simply a compromise to offset the complexity of training deep learning models. In contrast, our method uses the IQ signal as input and relies on appropriate network design to achieve better classification results. This is a major difference between our approach and the existing preprocessing methods.
2.2. Generative Adversarial Networks
2.3. Spatial Transformer Networks
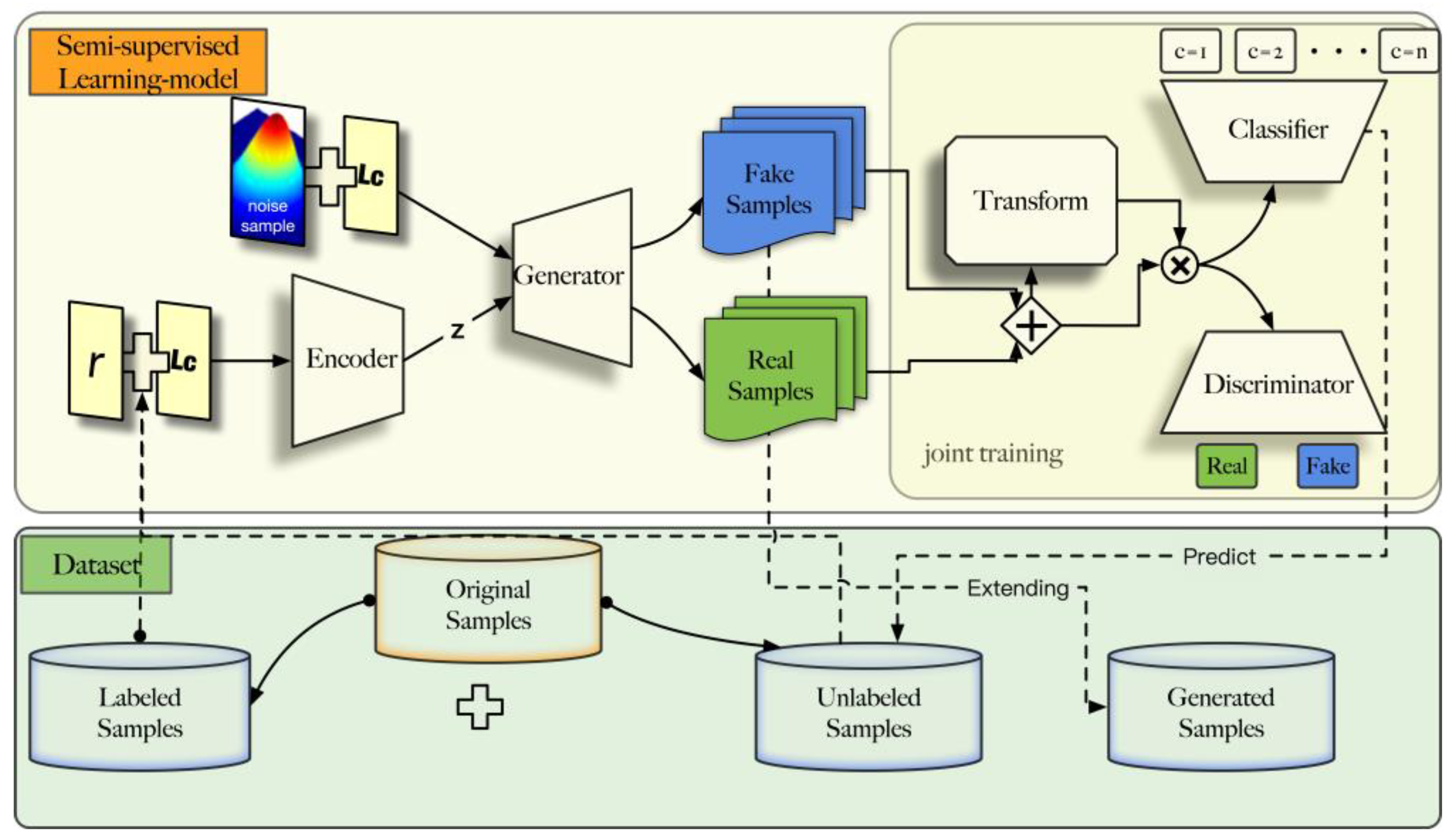
3. Generative Adversarial Network Design
3.1. Framework
- Due to the complexity of the modulation signals, mapping the high-dimensional parameter space to a low-dimensional classification space is prone to get trapped in non-convergence.
- The traditional GAN model is easy to mode collapse, sine the lack of generated samples’ diversity.
3.2. Signal Spatial Transformer Module
- Frequency Offset: Frequency offset is caused by differences in the local oscillator frequency between the receiver and the transmitter
- Phase offset: time drift is caused by the frequency offset of the local oscillator (LO).
- Timing drift: Timing drift is caused by different sampling rates.
- Noise: Noise introduced by components such as antennas, receivers, etc. is used to model this interference.
4. Evaluation Setup
4.1. Dataset Description
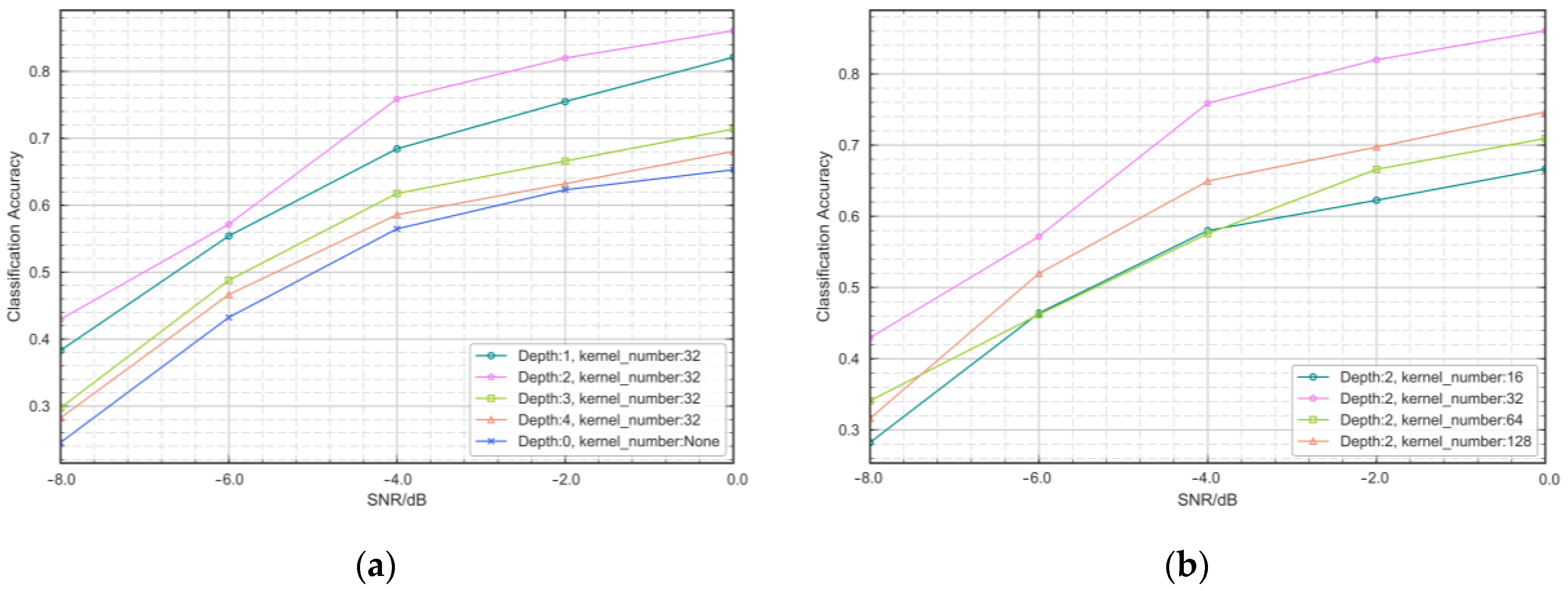
4.2. Network Structure
4.3. Implementation Details
| Algorithm 1. Semi-Supervised Learning through Asymmetric Training |
| Input: Original training data set S, number of total epoch iterations I, batch size N, C network parameters, , , , Output: Vectors of class probabilities h1 |
|
5. Numerical Results
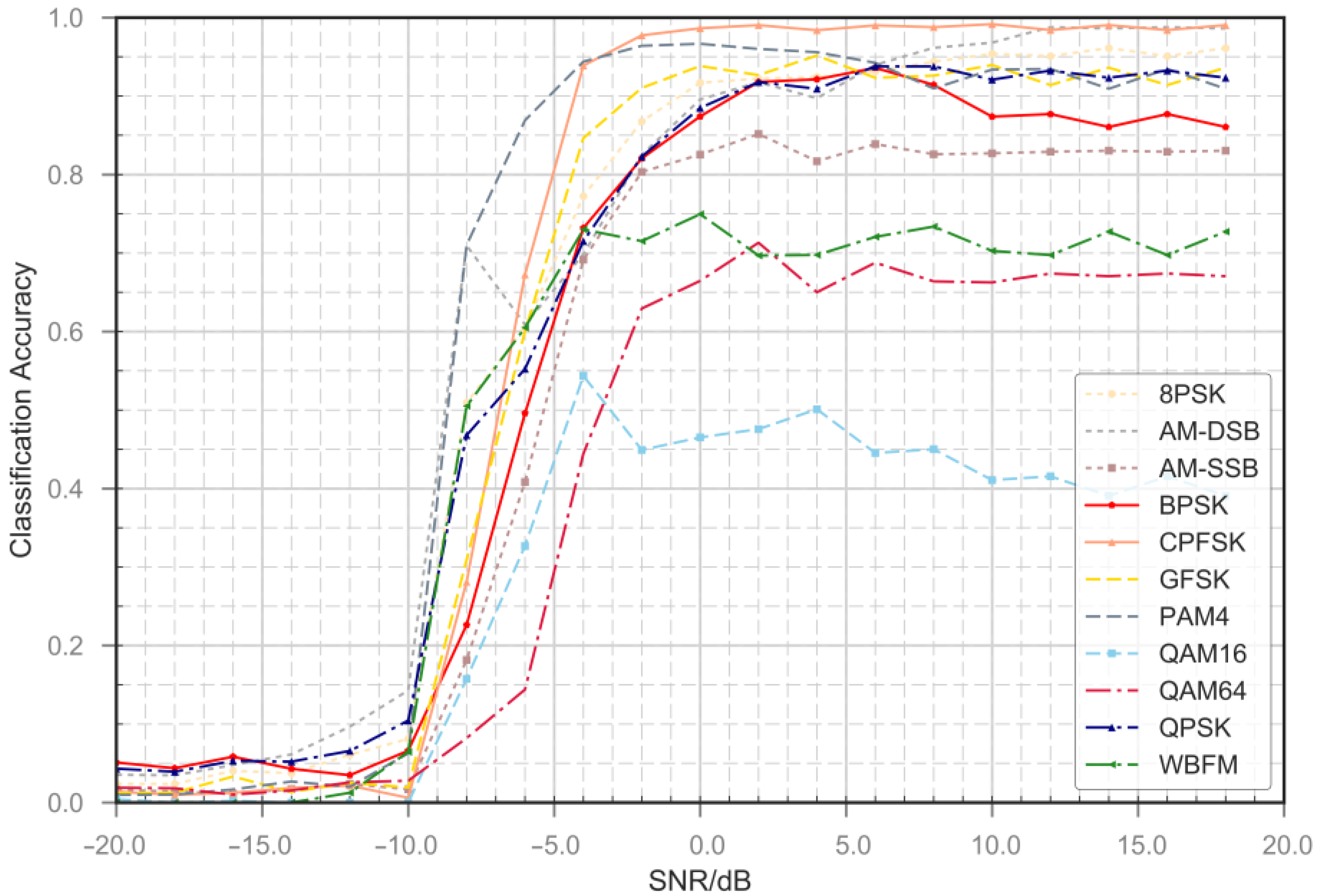
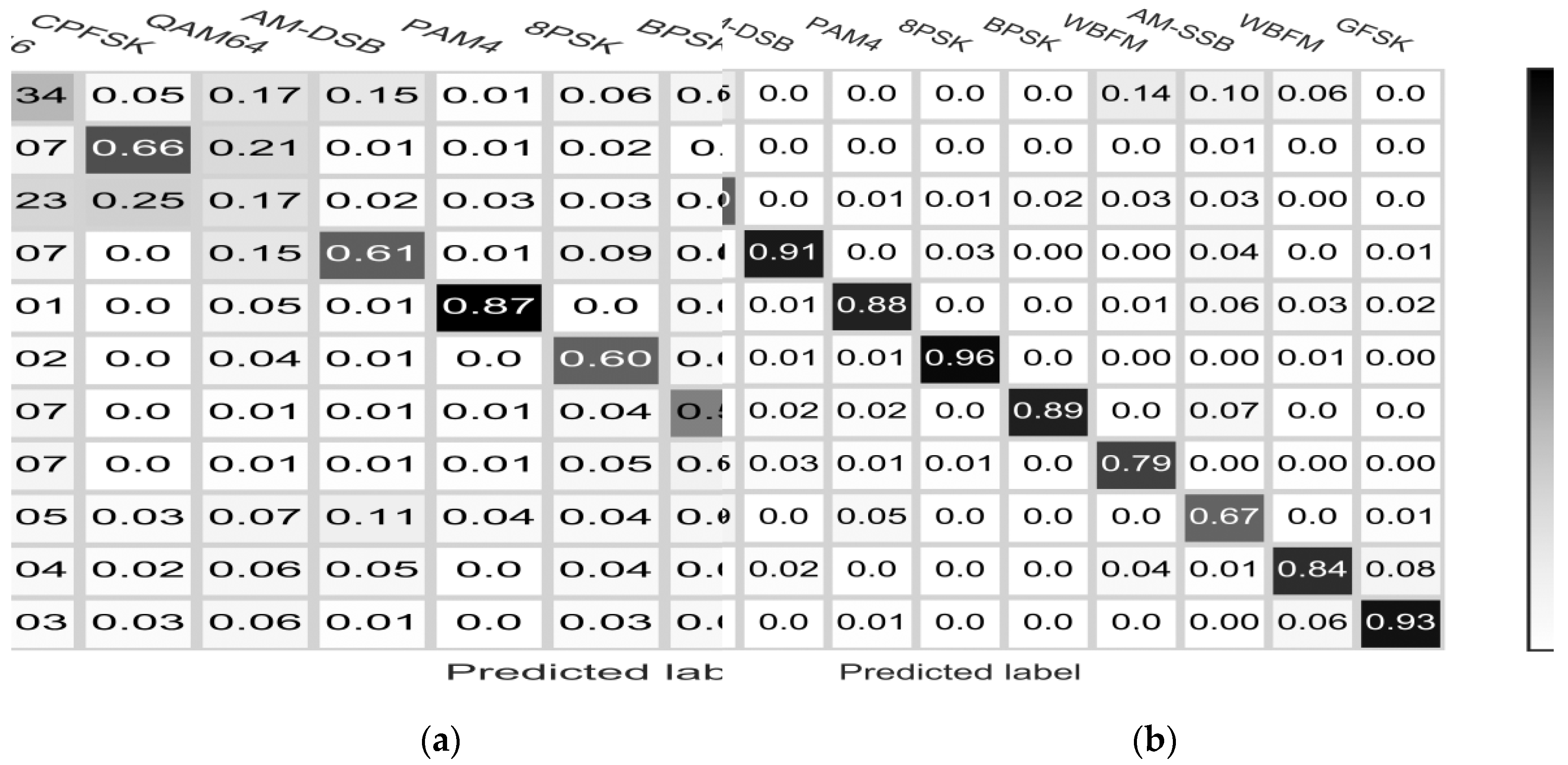
5.1. Classification Performance
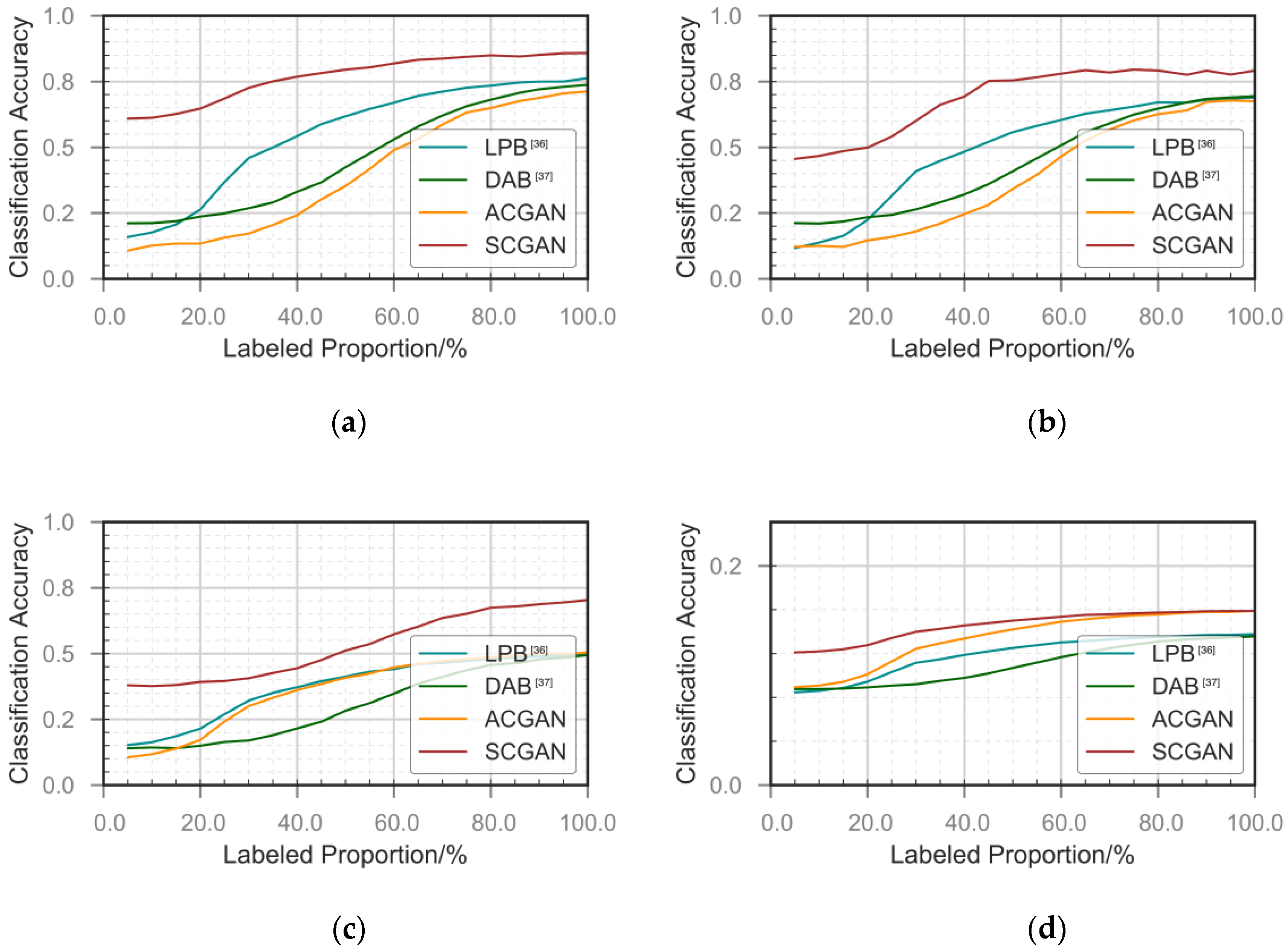
5.2. Semi-Supervised Learning
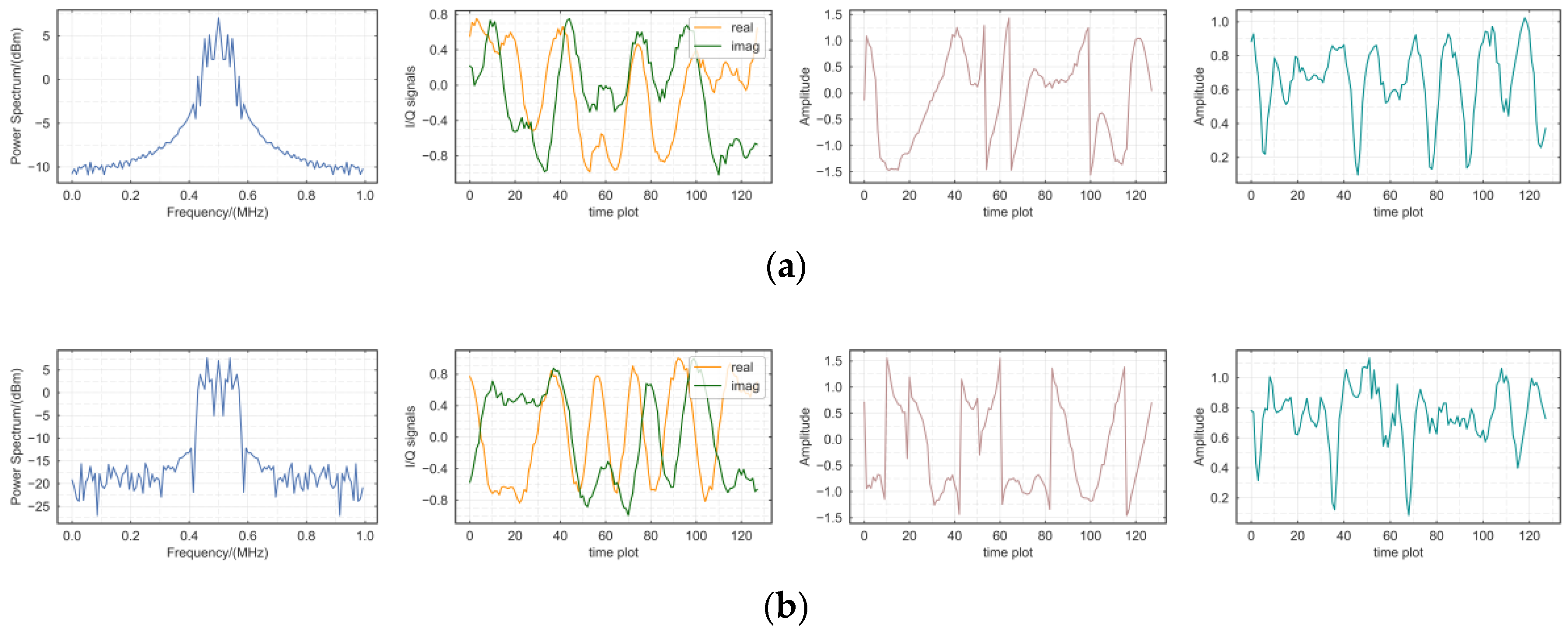
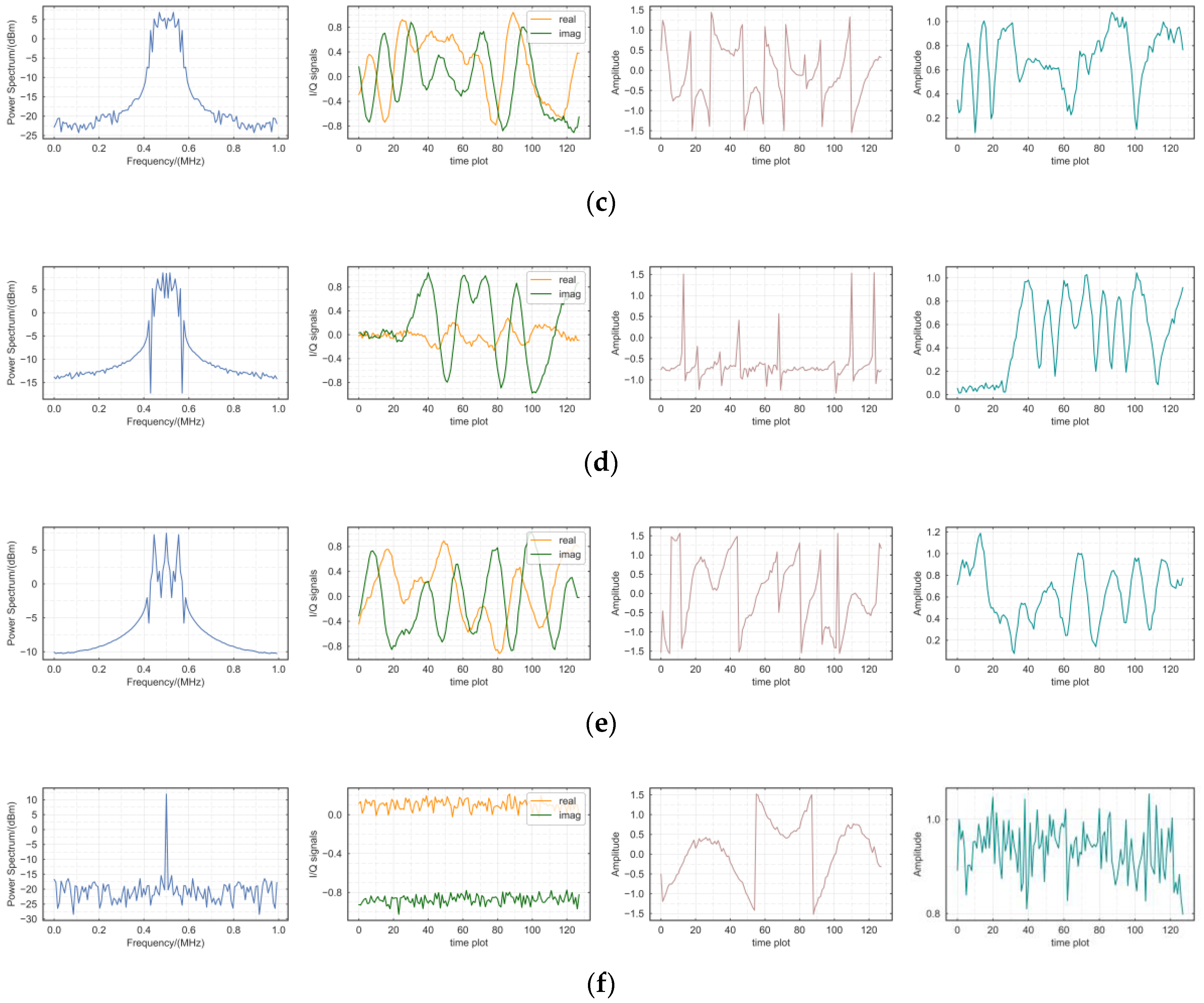
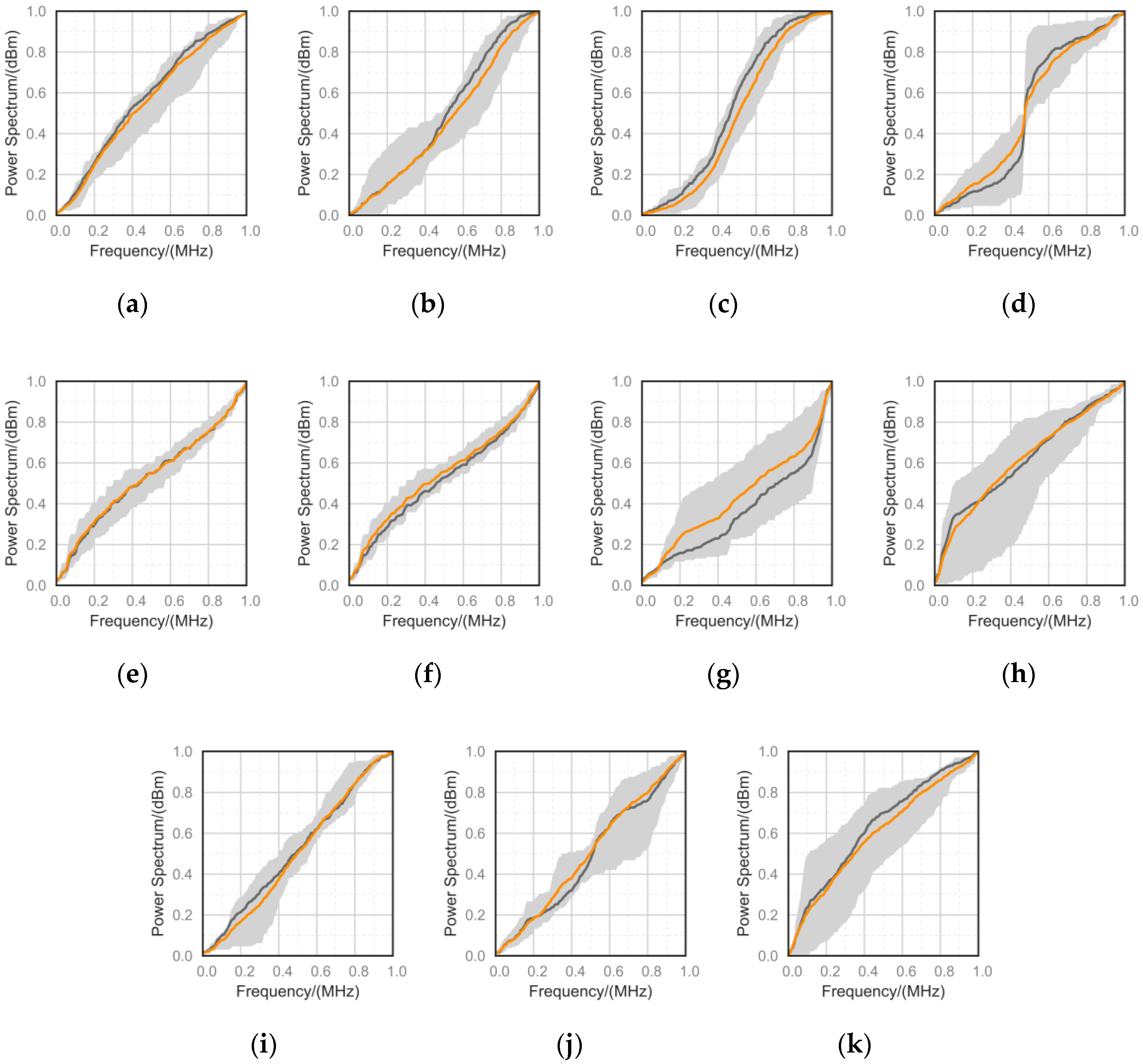
5.3. Numerical Distinction
6. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Haykin, S. Cognitive radio: Brain-empowered wireless communications. IEEE J. Sel. Areas Commun. 2005, 23, 201–220. [Google Scholar] [CrossRef]
- Mitola, J.; Maguire, G.Q. Cognitive radio: Making software radios more personal. IEEE Pers. Commun. 1999, 6, 13–18. [Google Scholar] [CrossRef]
- Axell, E.; Leus, G.; Larsson, E.G.; Poor, H.V. Spectrum Sensing for Cognitive Radio: State-of-the-Art and Recent Advances. IEEE Signal Process. Mag. 2012, 29, 101–116. [Google Scholar] [CrossRef]
- Fucai, Z.; Yihua, H.; Shiqi, H. Classification using wavelet packet decomposition and support vector machine for digital modulations. J. Syst. Eng. Electron. 2008, 19, 914–918. [Google Scholar] [CrossRef]
- Dobre, O.A.; Oner, M.; Rajan, S.; Inkol, R. Cyclostationarity-Based Robust Algorithms for QAM Signal Identification. IEEE Commun. Lett. 2012, 16, 12–15. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.C.; Saquib, M.; Yun, Z. Novel Automatic Modulation Classification Using Cumulant Features for Communications via Multipath Channels. IEEE Trans. Wirel. Commun. 2008, 7, 3098–3105. [Google Scholar]
- Shimaoka, S.; Stenetorp, P.; Inui, K.; Riedel, S. Neural Architectures for Fine-grained Entity Type Classification. arXiv, 2016; arXiv:1606.01341. [Google Scholar]
- Yu, D.; Deng, L. Automatic Speech Recognition: A Deep Learning Approach; Springer: Berlin, Germany, 2014. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 3, 2672–2680. [Google Scholar]
- Azzouz, E.E.; Nandi, A.K. Automatic Modulation Recognition of Communication Signals. IEEE Trans. Commun. 1996, 46, 431–436. [Google Scholar]
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional Radio Modulation Recognition Networks. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Aberdeen, UK, 2–5 September 2016; pp. 213–226. [Google Scholar]
- O’Shea, T.J.; Hoydis, J. An Introduction to Deep Learning for the Physical Layer. IEEE Trans. Cognit. Commum. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef] [Green Version]
- O’Shea, T.J.; Roy, T.; Clancy, T.C. Over-the-Air Deep Learning Based Radio Signal Classification. IEEE J. Sel. Top. Signal Process. 2018, 12, 168–179. [Google Scholar] [CrossRef] [Green Version]
- Khan, F.N.; Lu, C.; Lau, A.P.T. Joint modulation format/bit-rate classification and signal-to-noise ratio estimation in multipath fading channels using deep machine learning. Electron. Lett. 2016, 52, 1272–1274. [Google Scholar] [CrossRef]
- Li, R.; Li, L.; Yang, S.; Li, S. Robust Automated VHF Modulation Recognition Based on Deep Convolutional Neural Networks. IEEE Commun. Lett. 2018, 22, 946–949. [Google Scholar] [CrossRef]
- Tang, B.; Tu, Y.; Zhang, Z.; Lin, Y. Digital Signal Modulation Classification With Data Augmentation Using Generative Adversarial Nets in Cognitive Radio Networks. IEEE Access 2018, 6, 15713–15722. [Google Scholar] [CrossRef]
- Zhang, D.; Ding, W.; Zhang, B.; Xie, C.; Li, H.; Liu, C.; Han, J. Automatic Modulation Classification Based on Deep Learning for Unmanned Aerial Vehicles. Sensors 2018, 18, 924. [Google Scholar] [CrossRef] [PubMed]
- Graves, A. Long Short-Term Memory; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1735–1780. [Google Scholar]
- Hauser, S.C.; Headley, W.C.; Michaels, A.J. Signal detection effects on deep neural networks utilizing raw IQ for modulation classification. In Proceedings of the MILCOM 2017–2017 IEEE Military Communications Conference (MILCOM), Baltimore, MD, USA, 23–25 October 2017; pp. 121–127. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. In Proceedings of the Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Larsen, A.B.L.; Larochelle, H.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1558–1566. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. arXiv, 2016; arXiv:1506.02025. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. arXiv, 2016; arXiv:1606.03498. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv, 2017; arXiv:1701.07875. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis With Auxiliary Classifier GANs. arXiv, 2016; arXiv:1610.09585. [Google Scholar]
- O’Shea, T.J.; West, N. Radio Machine Learning Dataset Generation with GNU Radio. In Proceedings of the 6th GNU Radio Conference, Boulder, CO, USA, 6 September 2016. [Google Scholar]
- Chollet, F. Keras. Available online: https://github.com/fchollet/keras (accessed on 24 November 2015).
- Abadi, M.A.A. Tensorflow: Large-Scale Machine Learning on Heterogeneous Systems, Software. Available online: http://tensorflow.org/ (accessed on 4 June 2015).
- Goodfellow, I. NIPS 2016 Tutorial: Generative Adversarial Networks. arXiv, 2016; arXiv:1701.00160. [Google Scholar]
- Bergstra, J.S.; Yamins, D.; Cox, D.D. Hyperopt: A Python Library for Optimizing the Hyperparameters of Machine Learning Algorithms. Available online: http://hyperopt.github.io/ (accessed on 23 May 2015).
- Pelikan, M. Bayesian Optimization Algorithm. In Hierarchical Bayesian Optimization Algorithm; Springer: Berlin/Heidelberg, Germany, 2005; pp. 31–48. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Zhu, X. Semi-supervised learning using Gaussian fields and harmonic functions. In Proceedings of the 20th International conference on Machine learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 912–919. [Google Scholar]
- Zhou, Z.H. When Semi-supervised Learning Meets Ensemble Learning. In Proceedings of the International Workshop on Multiple Classifier Systems, Reykjavik, Iceland, 10–12 June 2009; pp. 529–538. [Google Scholar]
- Valle, R.; Cai, W.; Doshi, A. TequilaGAN: How to easily identify GAN samples. arXiv, 2018; arXiv:1807.04919. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Input Size | Parameters | Activation Function |
|---|---|---|---|
| Convolution layer | 2 × 128 | 1 × 3 filter kernel 32 feature maps | LeakyReLU |
| Pooling layer | 2 × 128 × 32 | 1 × 2 average | None |
| Convolution layer | 2 × 64 × 32 | 1 × 3 filter kernel 32 feature maps | LeakyReLU |
| Pooling layer | 2 × 32 × 32 | 1 × 2 average | None |
| Dense layer 1 | 2048 × 2 | 2 neurons | Softmax |
| Dense layer 2 | 2048 × 11 | 11 neurons | Softmax |
| Layer Type | Input Size | Parameters | Activation Function |
|---|---|---|---|
| LSTM layer | 2 × 128 | 10 kernel_size 10 filters | None |
| Flatten layer | 2 × 128 × 10 | None | None |
| Dense layer | 256 | 100 neurons | ReLU |
| Layer Type | Input Size | Parameters | Activation Function |
|---|---|---|---|
| Dense | 256 | 8192 neurons | LeakyReLU |
| TransConvolution layer | 2 × 128 × 32 | 1 × 3 filter kernel 256 feature maps | Tanh |
| TransConvolution layer | 256 × 128 × 32 | 1 × 3 filter kernel 80 feature maps | Tanh |
| TransConvolution layer | 80 × 128 × 32 | 1 × 3 filter kernel 1 feature maps | Tanh |
| Reshape layer | 1 × 128 × 32 | None | None |
| Hyperparamenters | Value |
|---|---|
| Loss Function | Binary Crossentropy (D), Categorical Crossentropy (C) |
| Optimizer | RMSPROP (C, D), ADAM (G) |
| Initializer | Lecun Normal [29] |
| Learning Rate | 0.0004 (C), 0.0001 (D, G) |
| Epochs | 500 |
| Mini Batch | 256 |
| Dropout Rate | 0.5 |
| SNR (dB) | SVM_5 | SVM_7 | NBC | ACGAN | VTCNN | CNN_SSTM | SCGAN |
|---|---|---|---|---|---|---|---|
| −10 | 0.14 | 0.14 | 0.21 | 0.18 | 0.20 | 0.17 | 0.21 |
| 0 | 0.58 | 0.54 | 0.47 | 0.66 | 0.68 | 0.70 | 0.86 |
| 10 | 0.61 | 0.59 | 0.46 | 0.70 | 0.72 | 0.71 | 0.85 |
| Framework | SNR | Labeled PRO 10% | Labeled PRO 50% | Labeled PRO 90% |
|---|---|---|---|---|
| LPB [36] | High | 0.14 | 0.56 | 0.68 |
| Medium | 0.17 | 0.61 | 0.75 | |
| Low | 0.10 | 0.15 | 0.17 | |
| DAB [37] | High | 0.21 | 0.40 | 0.69 |
| Medium | 0.21 | 0.42 | 0.73 | |
| Low | 0.11 | 0.12 | 0.17 | |
| ACGAN | High | 0.12 | 0.34 | 0.67 |
| Medium | 0.12 | 0.35 | 0.70 | |
| Low | 0.11 | 0.17 | 0.19 | |
| SCGAN | High | 0.46 | 0.75 | 0.77 |
| Medium | 0.61 | 0.80 | 0.85 | |
| Low | 0.15 | 0.18 | 0.20 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Li, O.; Liu, G.; Zhang, C. Generative Adversarial Networks-Based Semi-Supervised Automatic Modulation Recognition for Cognitive Radio Networks. Sensors 2018, 18, 3913. https://doi.org/10.3390/s18113913
Li M, Li O, Liu G, Zhang C. Generative Adversarial Networks-Based Semi-Supervised Automatic Modulation Recognition for Cognitive Radio Networks. Sensors. 2018; 18(11):3913. https://doi.org/10.3390/s18113913
Chicago/Turabian StyleLi, Mingxuan, Ou Li, Guangyi Liu, and Ce Zhang. 2018. "Generative Adversarial Networks-Based Semi-Supervised Automatic Modulation Recognition for Cognitive Radio Networks" Sensors 18, no. 11: 3913. https://doi.org/10.3390/s18113913
APA StyleLi, M., Li, O., Liu, G., & Zhang, C. (2018). Generative Adversarial Networks-Based Semi-Supervised Automatic Modulation Recognition for Cognitive Radio Networks. Sensors, 18(11), 3913. https://doi.org/10.3390/s18113913