Sensor Distribution Optimization for Structural Impact Monitoring Based on NSGA-II and Wavelet Decomposition



Abstract
:1. Introduction
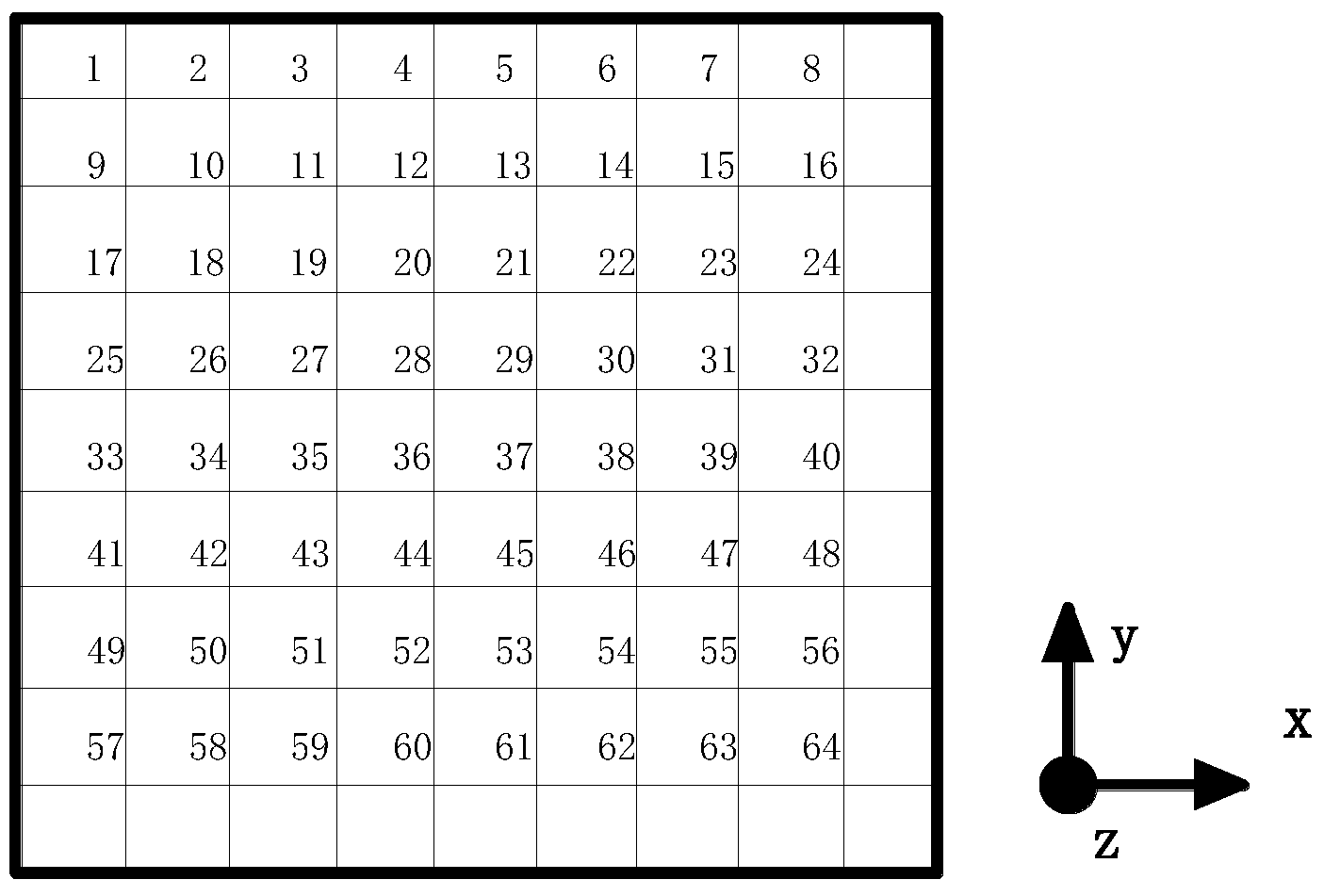
2. Description of Problem
- (1)
- Minimizing the number of sensors
- (2)
- Maximizing the sensor network’s optimization performance index based on impact categories
3. Problem Formulation
3.1. Objective Function I
3.2. Objective Function II
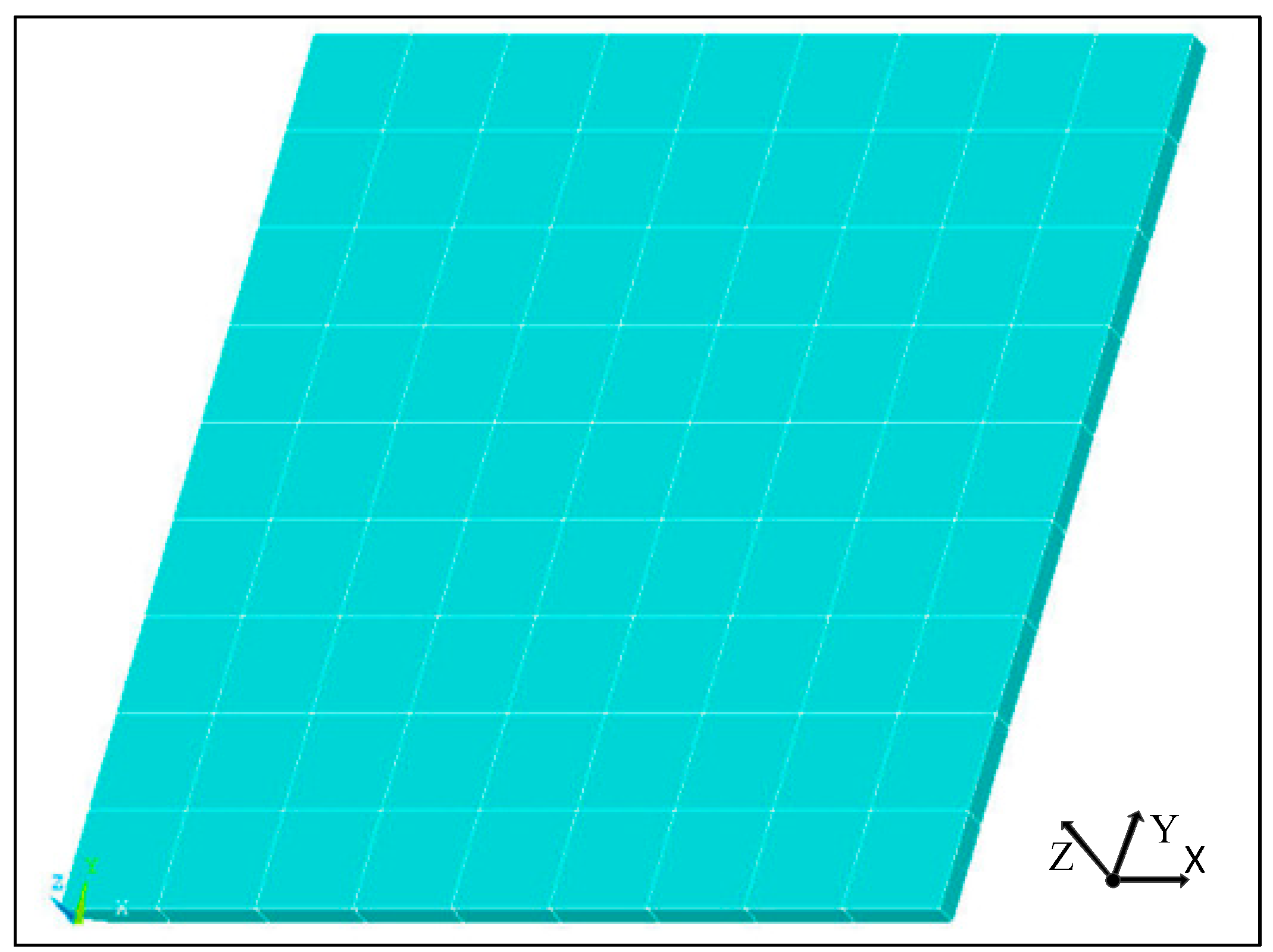
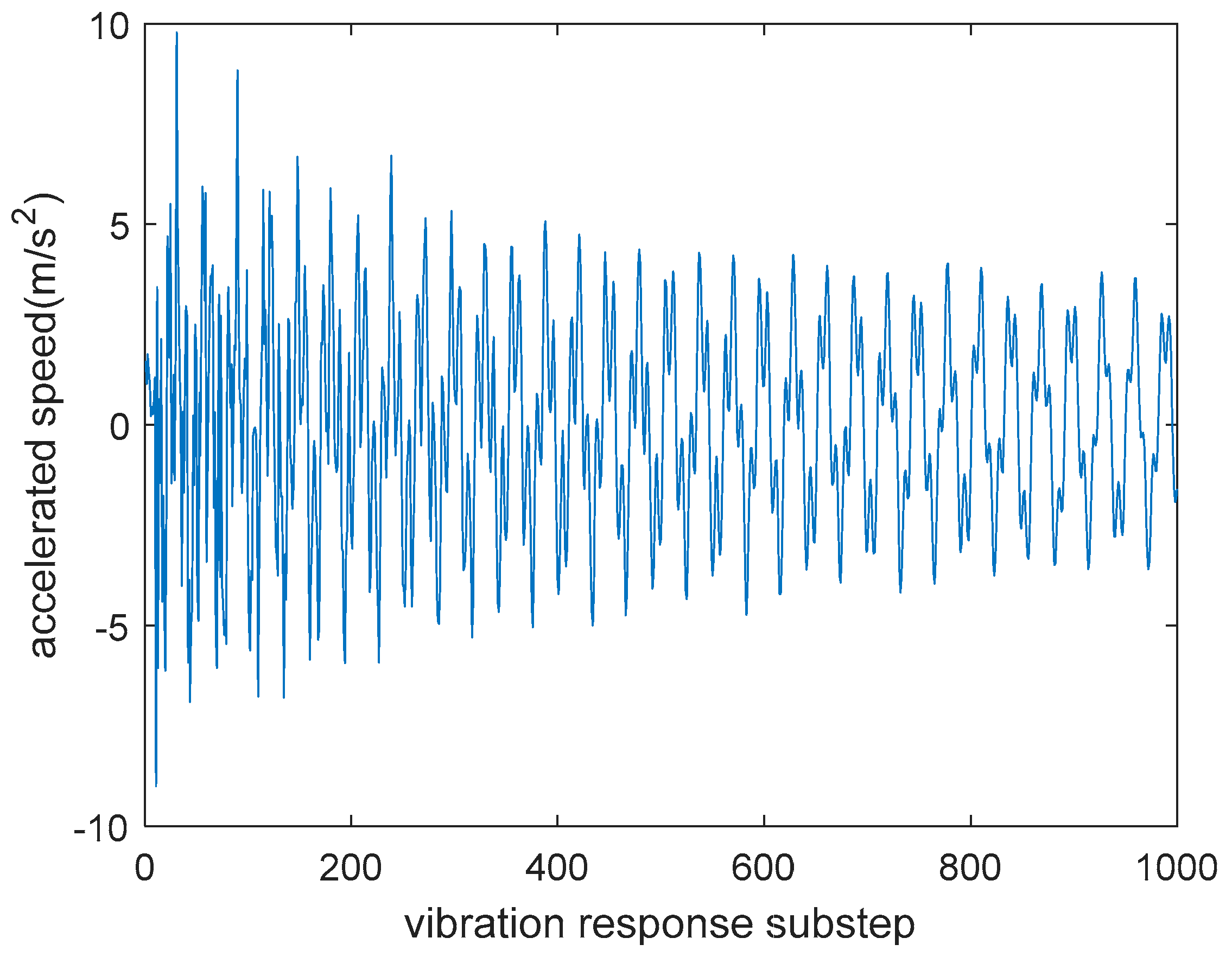
3.2.1. Numerical Simulation
3.2.2. Energy Analysis of Wavelet Band
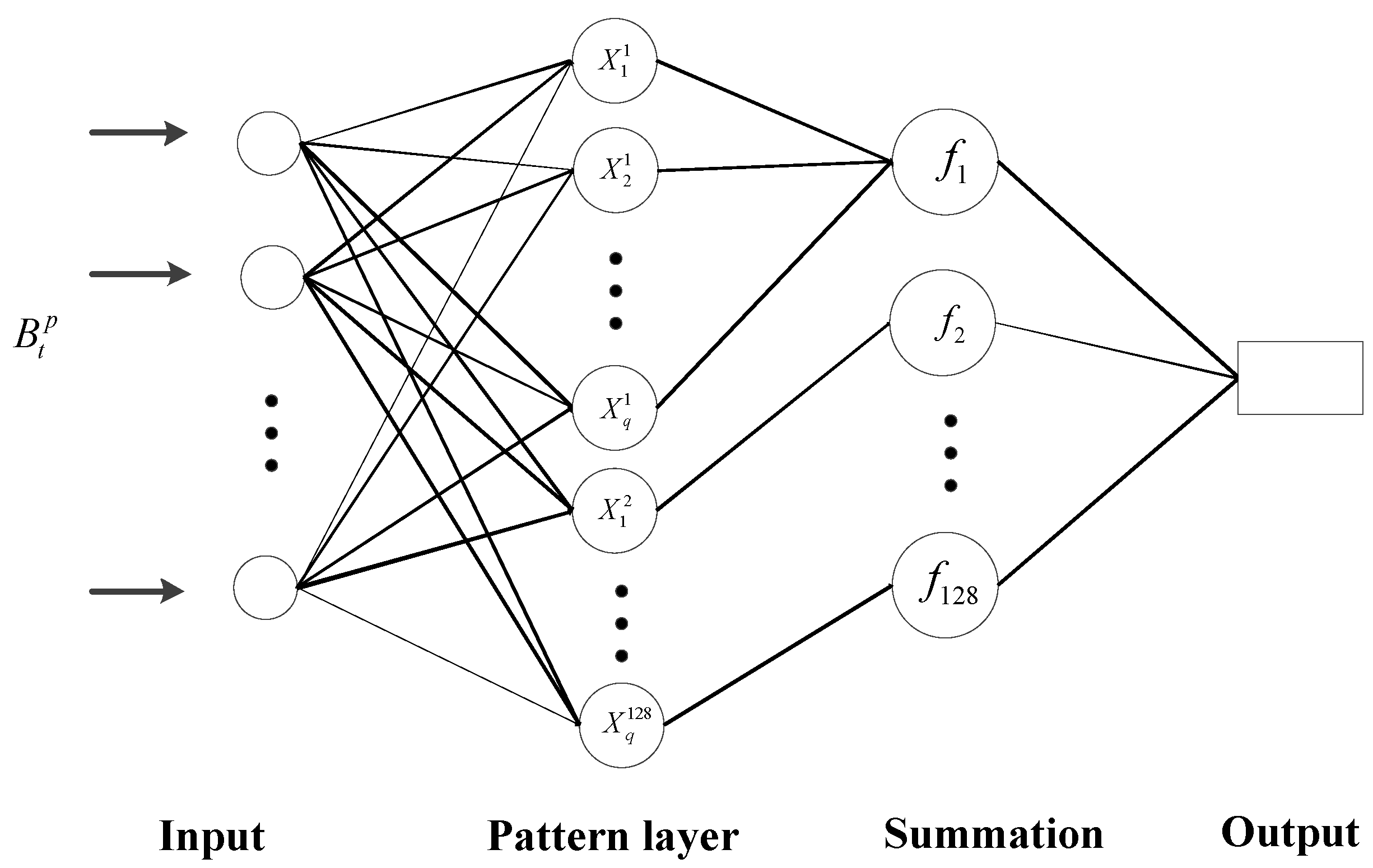
3.2.3. Sensor Location Optimization Performance Index
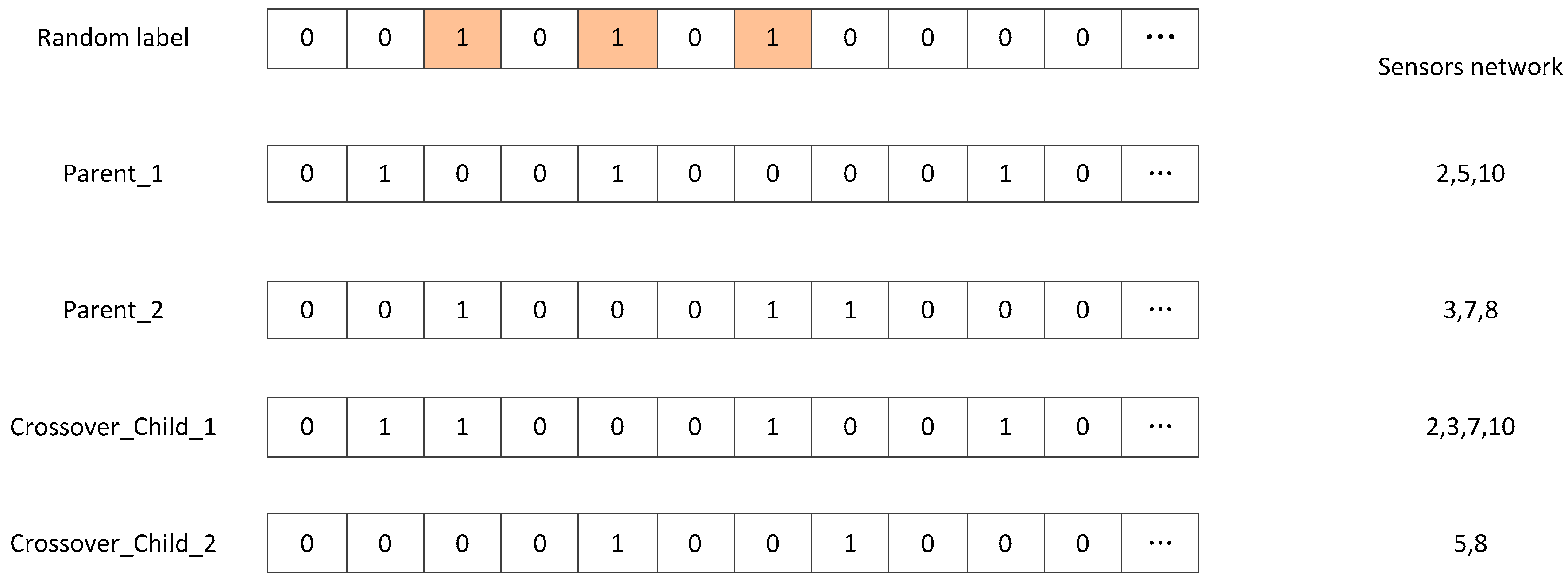
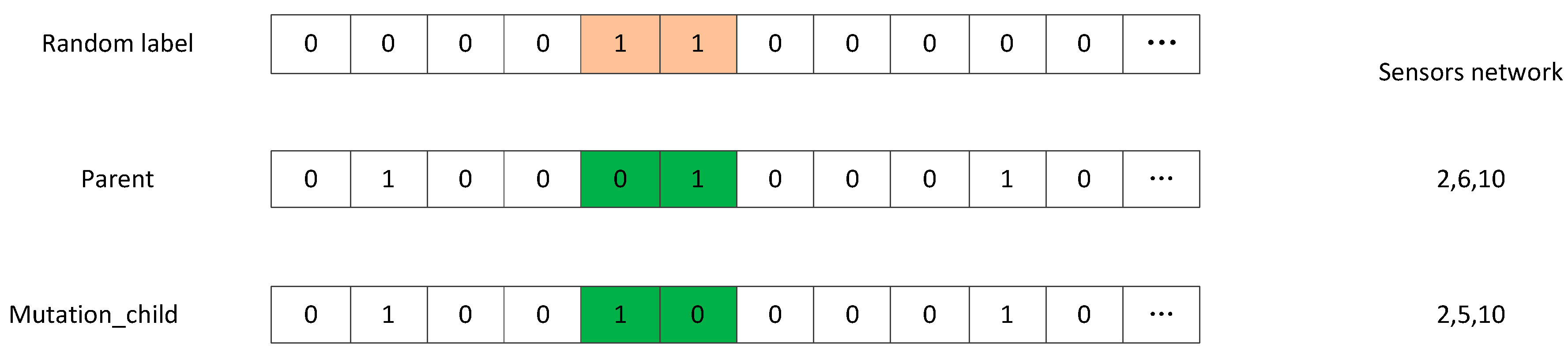
4. Sensor Network Optimization Algorithm
5. Results and Discussion
6. Method Evaluation
6.1. Experimental Setup
6.2. Localization Methodology
6.3. Experimental Results and Discussion
7. Conclusions
- (a)
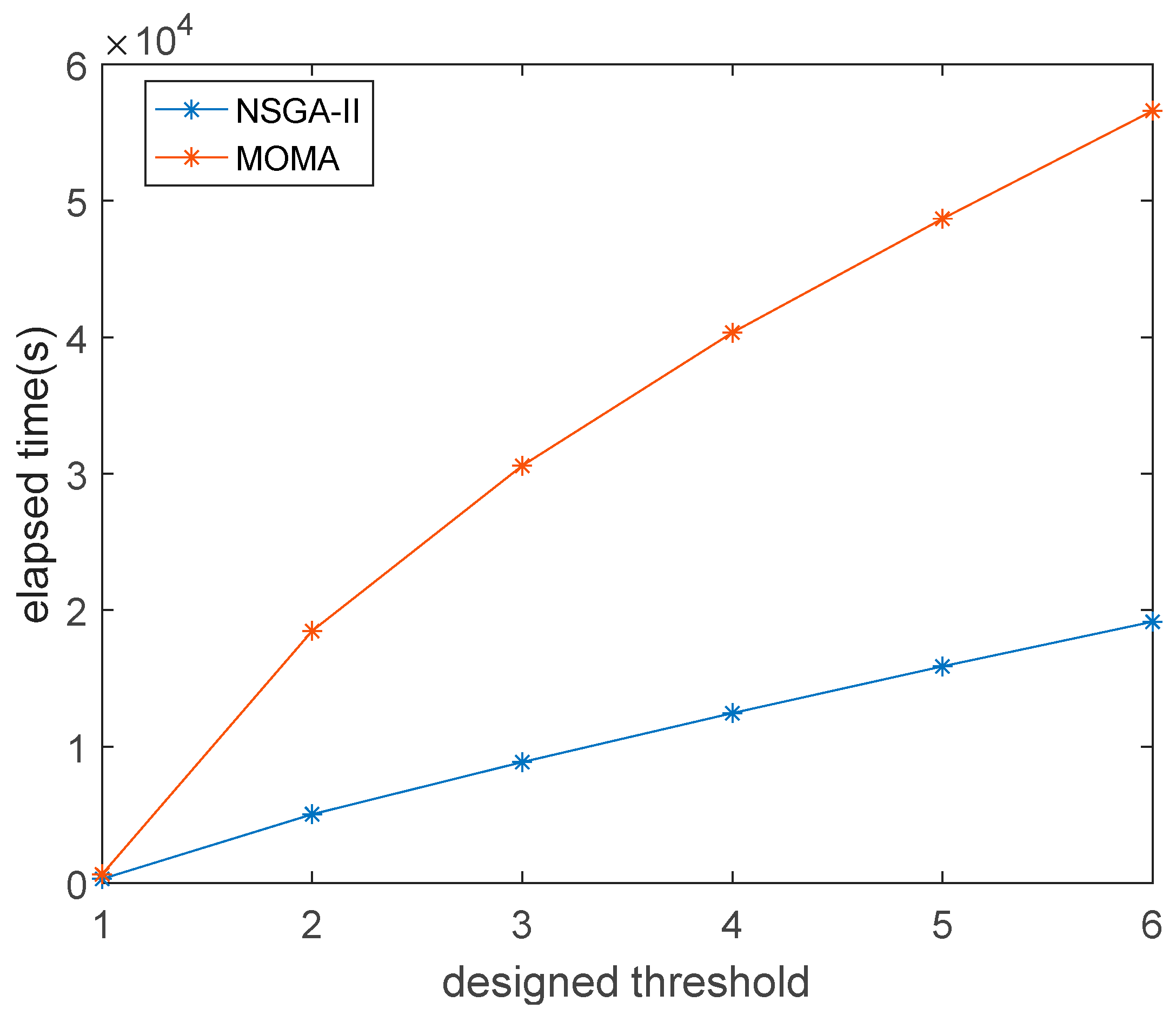
- Comparing NSGA-II and MOMA, the two algorithms can get the same result. However, NSGA-II is better than the MOMA in terms of iteration time, and the gap will become more pronounced with increasing numbers of sensors;
- (b)
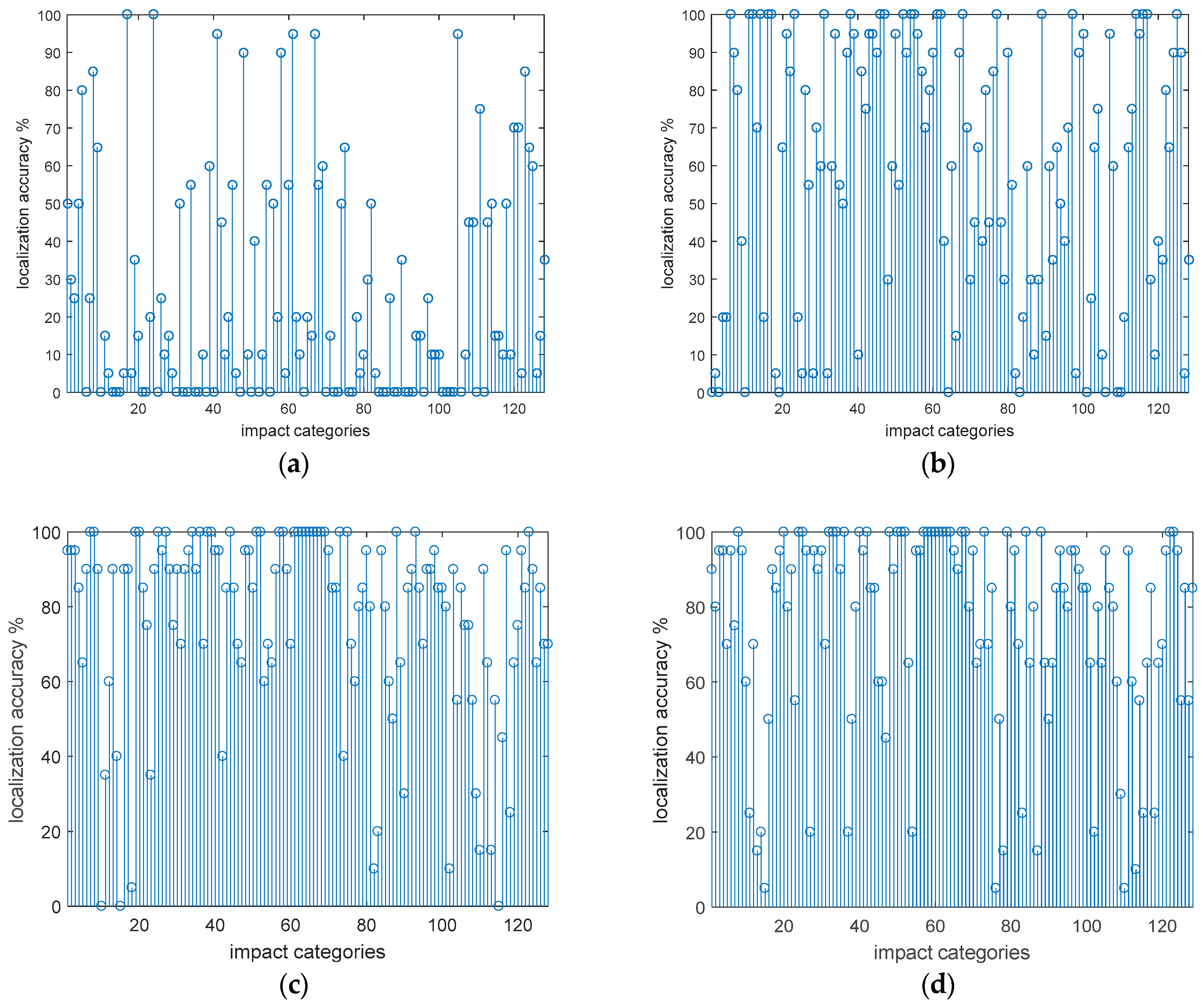
- When the number of sensors in the sensor network is 2, 3, and 4, the average recognition accuracy is 25.27%, 59.14% and 76.95%, respectively. The results show that as the number of sensors increases, higher recognition accuracy is obtained;
- (c)
- When there are four sensors, the identification accuracy of the first non-inferior sensor network is 76.95%, and the recognition accuracy of the second non-inferior sensor network is 75.55%. Results show that when the number of sensors is constant, the accuracy of impact recognition will be correlated with the sensor network optimization performance index. The experiment shows that the optimized sensors network can achieve the best impact recognition accuracy;
- (d)
- When there are two sensors in the experiment, the average of full-load impact and half-load impact are 23.67% and 26.88%, respectively; with three sensors, the average of full-load impact and half-load impact are 52.97% and 65.31%, respectively; and with four sensors in the experiment, the average of full-load impact and half-load impact are 72.19% and 81.72%, respectively. The results show that the accuracy of the half-load is slightly higher than full-load under the same conditions;
- (e)
- The calculation time of the experimental results shows that when the number of sensors increases, the recognition accuracy increases. However, computing time also increases. Therefore, in real application, it is necessary to select the appropriate number of sensors according to the real-time requirements.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhou, G.D.; Yi, T.H.; Li, H.N. Sensor Placement Optimization in Structural Health Monitoring Using Cluster-in-Cluster Firefly Algorithm. Adv. Struct. Eng. 2014, 17, 1103–1115. [Google Scholar] [CrossRef]
- Mallardo, V.; Aliabadi, M.H. Optimal Sensor Placement for Structural, Damage and Impact Identification: A Review. Sdhm Struct. Durab. Health Monit. 2013, 9, 287–323. [Google Scholar]
- Hajializadeh, D.; Obrien, E.J.; Oconnor, A. Virtual Structural Health Monitoring and Remaining Life Prediction of steel bridges. Can. J. Civil Eng. 2017, 44, 264–273. [Google Scholar] [CrossRef]
- Yu, S.; Ou, J. Structural Health Monitoring and Model Updating of Aizhai Suspension Bridge. J. Aerosp. Eng. 2017, 30, B4016009. [Google Scholar] [CrossRef]
- Kuang, K.; Maalej, M.; Quek, S.T. An Application of a Plastic Optical Fiber Sensor and Genetic Algorithm for Structural Health Monitoring. J. Intell. Mater. Syst. Struct. 2006, 17, 361–379. [Google Scholar] [CrossRef]
- Buczak, A.L.; Wang, H.; Darabi, H.; Jafari, M.A. Genetic algorithm convergence study for sensor network optimization. Inf. Sci. Inform. Comput. Sci. Int. J. 2001, 13, 267–282. [Google Scholar] [CrossRef]
- Tong, K.H.; Yassin, A.Y.M.; Bakhary, N.; Kueh, A.B.H. Optimal sensor placement for mode shapes using improved simulated annealing. Smart Struct. Syst. 2014, 13, 389–406. [Google Scholar] [CrossRef]
- Yi, T.H.; Li, H.N.; Gu, M.; Zhang, X.D. Sensor Placement Optimization in Structural Health Monitoring Using Niching Monkey Algorithm. Int. J. Struct. Stabil. Dyn. 2014, 14, 1440012. [Google Scholar] [CrossRef]
- Ho, J.H.; Shih, H.C.; Liao, B.Y.; Chu, S.C. A ladder diffusion algorithm using ant colony optimization for wireless sensor networks. Inf. Sci. Int. J. 2012, 192, 204–212. [Google Scholar] [CrossRef]
- Kim, H.; Chang, S.; Kim, J. Consensus Achievement of Decentralized Sensors Using Adapted Particle Swarm Optimization Algorithm. Int. J. Distrib. Sens. Netw. 2014, 2014, 1–13. [Google Scholar] [CrossRef]
- Li, P.; Liu, Y.; Zou, T.; Huang, J. Optimal design of microvascular networks based on non-dominated sorting genetic algorithm II and fluid simulation. Adv. Mech. Eng. 2017, 9, 1687814017708175. [Google Scholar] [CrossRef]
- Céspedes-Mota, A.; Castañón, G.; Martínez-Herrera, A.F. Optimization of the Distribution and Localization of Wireless Sensor Networks Based on Differential Evolution Approach. Math. Probl. Eng. 2016, 2016, 1–12. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T.A.M.T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Wang, Y.; Hu, J.; Zhou, J. Sensors distribution optimization for impact localization using NSGA-II. Sens. Rev. 2015, 35, 409–418. [Google Scholar] [CrossRef]
- Sajid, M.; Ghosh, D. Logarithm of short-time Fourier transform for extending the seismic bandwidth. Geophys. Prospect. 2014, 62, 1100–1110. [Google Scholar] [CrossRef]
- Wang, F.; Ma, X.; Zou, Y.; Zhang, Z. Local power feature extraction method of frequency bands based on wavelet packet decomposition. Trans. Chin. Soc. Agric. Mach. 2004, 3, 167–170. [Google Scholar]
- Bianchi, D.; Mayrhofer, E.; Gröschl, M.; Betz, G.; Vernes, A. Wavelet packet transform for detection of single events in acoustic emission signals. Mech. Syst. Sig. Process. 2015, 64, 441–451. [Google Scholar] [CrossRef]
- Suma, M.N.; Narasimhan, S.V.; Kanmani, B. Interspersed discrete harmonic wavelet packet transform based OFDM—IHWT OFDM. Int. J. Wavelets Multiresolut. Inf. Process. 2014, 12, 1450034. [Google Scholar] [CrossRef]
- Yu, Z.; Xia, H.; Goicolea, J.M.; Xia, C. Bridge Damage Identification from Moving Load Induced Deflection Based on Wavelet Transform and Lipschitz Exponent. Int. J. Struct. Stab. Dyn. 2016, 16, 1550003. [Google Scholar] [CrossRef] [Green Version]
- Mallardo, V.; Aliabadi, M.H.; Khodaei, Z.S. Optimal sensor positioning for impact localization in smart composite panels. J. Intell. Mater. Syst. Struct. 2013, 24, 559–573. [Google Scholar] [CrossRef]
- Li, C.F.; Liu, L.; Lei, Y.M.; Yin, J.Y.; Zhao, J.J.; Sun, X.K. Clustering for HSI hyperspectral image with weighted PCA and ICA. J. Intell. Fuzzy Syst. 2017, 32, 3729–3737. [Google Scholar] [CrossRef]
- Draper, B.A.; Baek, K.; Bartlett, M.S.; Beveridge, J.R. Recognizing faces with PCA and ICA. Comput. Vis. Image Underst. 2003, 91, 115–137. [Google Scholar] [CrossRef]
- Zhou, S.; Mao, M.; Jianhui, S.U. Prediction of Wind Power Based on Principal Component Analysis and Artificial Neural Network. Power Syst. Technol. 2011, 35, 128–132. [Google Scholar]
- Zhao, R.; Tang, W. Monkey algorithm for global numerical optimization. J. Uncertain Syst. 2008, 2, 165–176. [Google Scholar]
- Ting-Hua, Y.I.; Zhang, X.D.; Hong-Nan, L.I. Immune monkey algorithm for optimal sensor placement. Chin. J. Comput. Mech. 2014, 30, 174–179. [Google Scholar]
- Sun, Q.; Wu, C.; Li, Y.L. A new probabilistic neural network model based on backpropagation algorithm. J. Intell. Fuzzy Syst. 2017, 32, 215–227. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Equipment | Parameter |
|---|---|
| thickness and area | 15 mm × 500 mm × 500 mm |
| elastic modulus | Ez = 7.2 GPa, Ex = Ey = 6.9 GPa |
| Poisson ratio | Vxz = Vyz = 0.29, Vxy = 0.28 |
| shear elasticity | Gxz = Gyz = 7.6 GPa, Gxy = 4.4GPa |
| density | 2100 Kg/m3 |
| Parameter | Numeric |
|---|---|
| initial population size | min(n × 64,200) |
| crossover probability | 0.5 |
| mutation probability | 0.16 |
| off-springs population size after mutation operation and crossover operation | min(n × 64 × 1.5300) |
| termination condition | min(n × 64,200) (selection according to crowding distance) |
| Designed Threshold | Solution No. | Sensor No. (NSGA-II) | Sensor No. (MOMA) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6 | 6 | 4 | 5 | 35 | 36 | 37 | 38 | 4 | 5 | 35 | 36 | 37 | 38 |
| 5 | 18 | 27 | 28 | 30 | 55 | 18 | 27 | 28 | 30 | 55 | |||
| 4 | 27 | 30 | 50 | 55 | 27 | 30 | 50 | 55 | |||||
| 3 | 11 | 25 | 29 | 11 | 25 | 29 | |||||||
| 2 | 28 | 30 | 28 | 30 | |||||||||
| 1 | 25 | 25 | |||||||||||
| 3 | 3 | 11 | 25 | 29 | 11 | 25 | 29 | ||||||
| 2 | 28 | 30 | 28 | 30 | |||||||||
| 1 | 25 | 25 | |||||||||||
| 1 | 1 | 25 | 25 | ||||||||||
| Equipment | Model Number | Parameter |
|---|---|---|
| acceleration sensors | CA-YD-188T | with a range of −10 g to 10 g, sensitivity is 500 mV/g, frequency response is 0.6~5000 |
| conditioning circuit | YE3826A | 12 channels, with a gain of 10, the electric current output is 4 mA |
| I/O junction box | NI SCB-68A | 16 channel analog input channel, custom cable connector kits and mounting accessories |
| data acquisition module | NI PCI-6251 | 16 analog inputs at 16 bits, 1.25 MS/s (1 MS/s scanning), Up to 4 analog outputs at 16 bits, 2.8 MS/s (2 μs full-scale settling), Analog and digital triggering, Two 32-bit, 80 MHz counter/timers |
| Sensors Network | Average Accuracy | Half-Load Impact Average Accuracy | Full-Load Impact Average Accuracy | Computation Time |
|---|---|---|---|---|
| (28, 30) | 25.27% | 26.88% | 23.67% | 6.01 ms |
| (11, 25, 29) | 59.14% | 65.31% | 52.97% | 8.36 ms |
| (27, 30, 50, 55) | 76.95% | 81.72% | 72.19% | 11.33 ms |
| (10, 15, 35, 38) | 75.55% | 80.23% | 70.86% | 11.33 ms |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Huang, L.; Peng, J. Sensor Distribution Optimization for Structural Impact Monitoring Based on NSGA-II and Wavelet Decomposition. Sensors 2018, 18, 4264. https://doi.org/10.3390/s18124264
Li P, Huang L, Peng J. Sensor Distribution Optimization for Structural Impact Monitoring Based on NSGA-II and Wavelet Decomposition. Sensors. 2018; 18(12):4264. https://doi.org/10.3390/s18124264
Chicago/Turabian StyleLi, Peng, Liuwei Huang, and Jiachao Peng. 2018. "Sensor Distribution Optimization for Structural Impact Monitoring Based on NSGA-II and Wavelet Decomposition" Sensors 18, no. 12: 4264. https://doi.org/10.3390/s18124264
APA StyleLi, P., Huang, L., & Peng, J. (2018). Sensor Distribution Optimization for Structural Impact Monitoring Based on NSGA-II and Wavelet Decomposition. Sensors, 18(12), 4264. https://doi.org/10.3390/s18124264