Research on RSS Data Optimization and DFL Localization for Non-Empty Environments


Abstract
:1. Introduction
- (1)
- With studies of correlations and pseudo-correlations of time-series data, a TDDC distributed wavelet filtering algorithm is proposed, which can better refine the detailed coefficient in the wavelet coefficients, and obtain more accurate characteristics of the interference to achieve the adaptive filtering threshold. It can also preserve the normal fluctuations, as much as possible. Compared with other common filtering methods in this field, the filtering algorithm provides more excellent RSS data for the DFL process and improves the localization accuracy rate.
- (2)
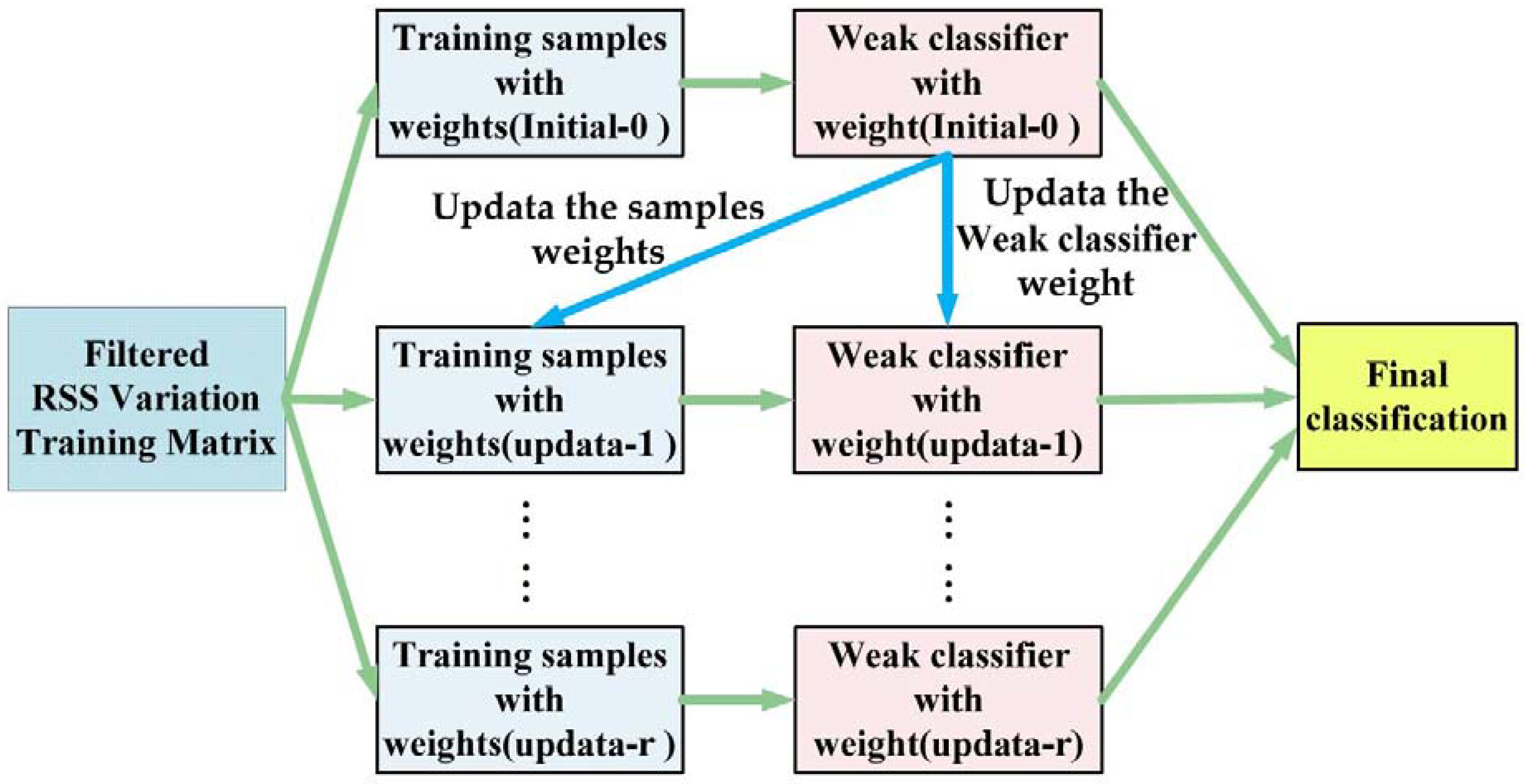
- GDTE can improve the unsatisfactory localization results of single machine learning models, which do not have enough generalization ability and adaptability. The GDTE localization model chooses the more helpful sample attributes for localization and pay more attention to the samples that are more difficult to classify. These characteristics enable the model to deal with the complex relationship between the RSS and the target location. At the same time, weights are updated for RSS samples and weak classifiers (decision trees in this paper). Then, multiple classification results with different weights are generated and the final result is judged by voting. This mechanism can make the model have stronger generalization ability.
- (3)
- We conducted experiments with the hardware test bed in different drawing room environments and evaluated the proposed schemes extensively.
2. Related Work
3. System Architecture and Motivation
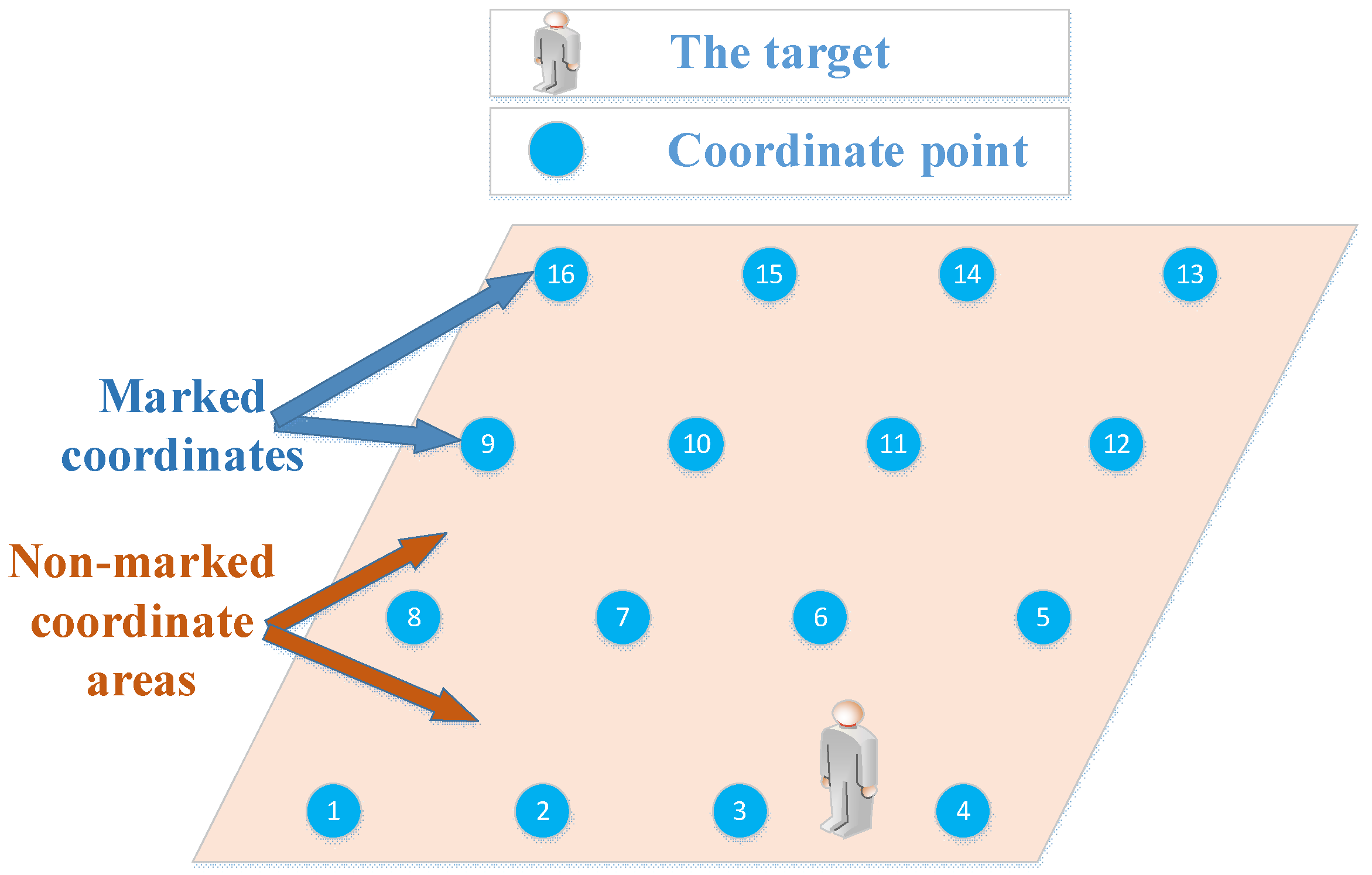
3.1. System Architecture
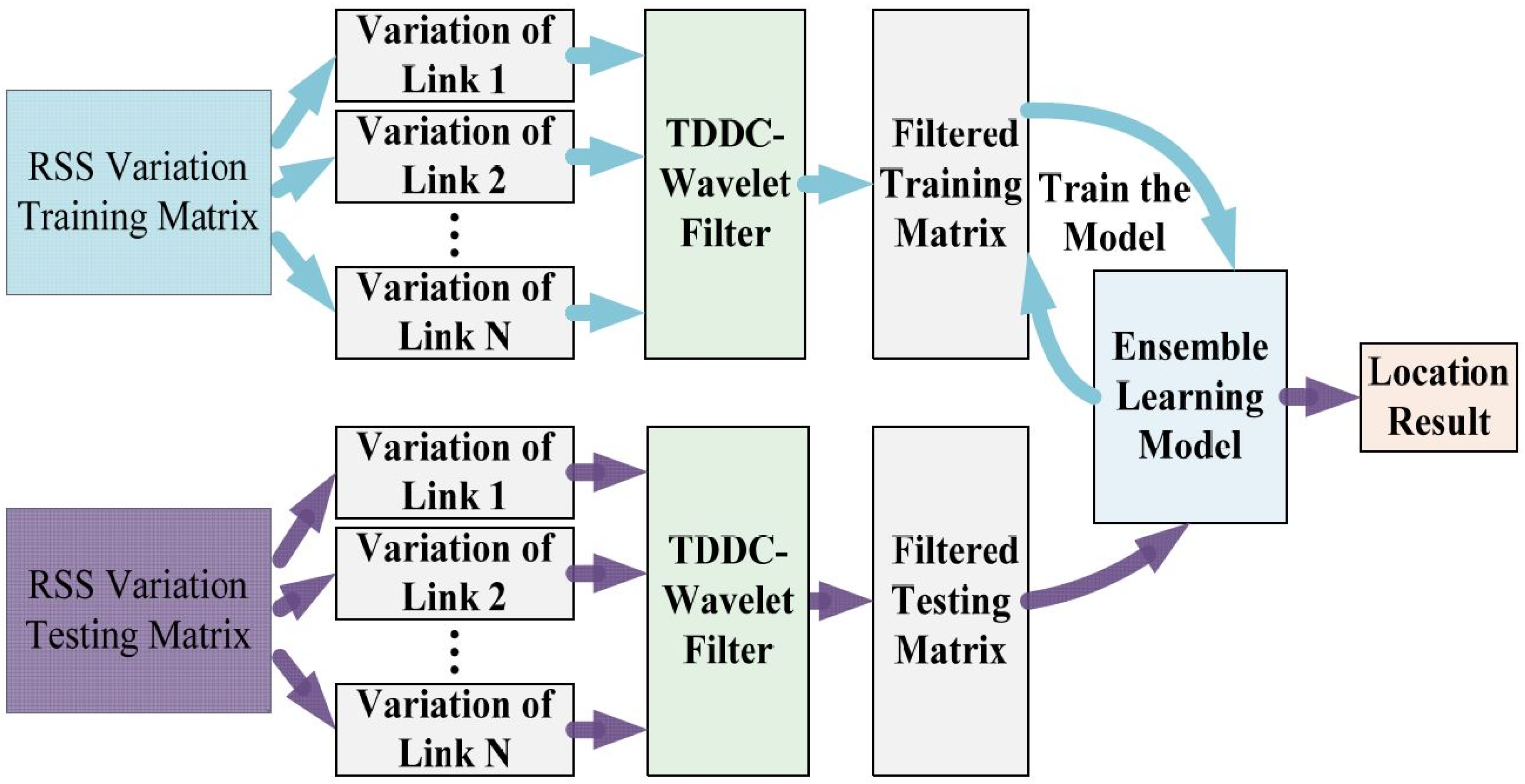
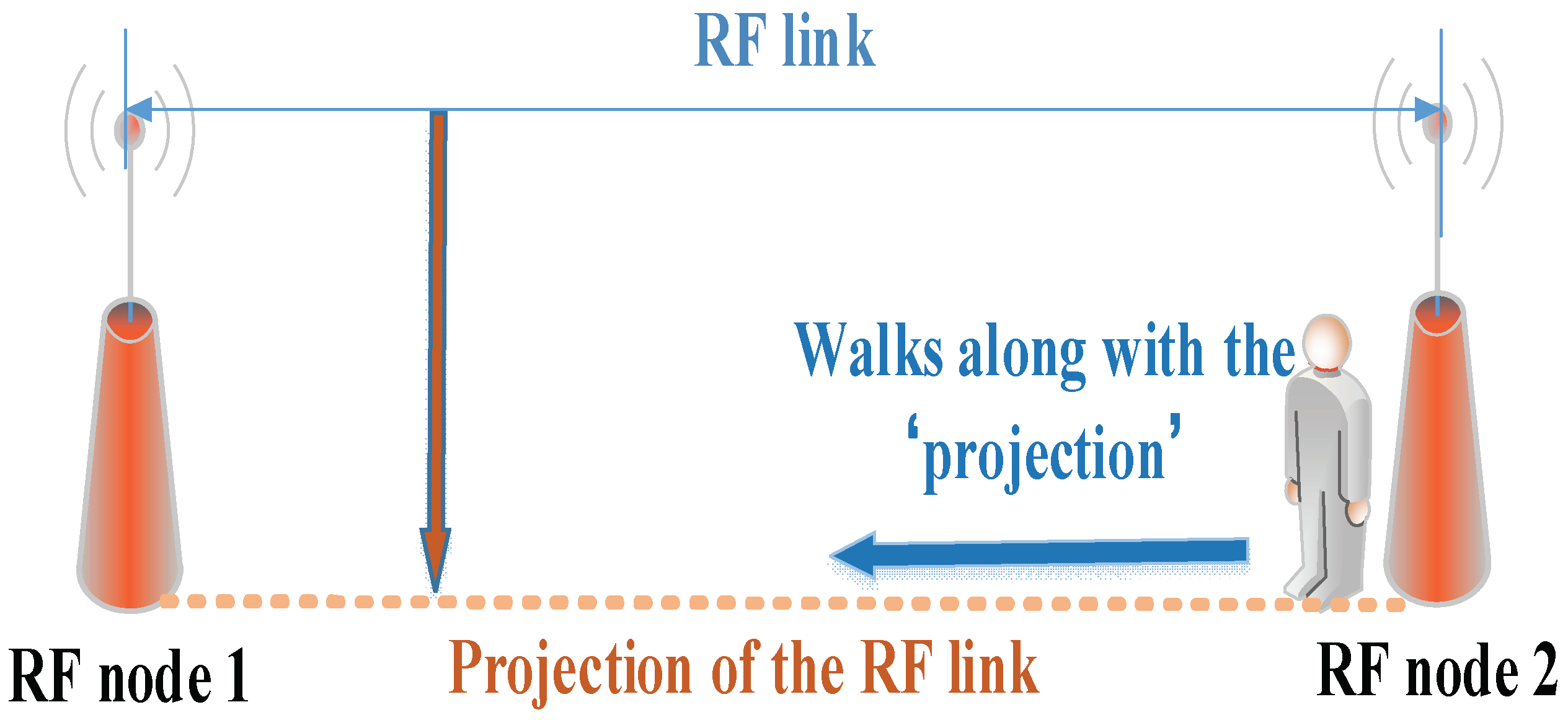
3.2. Main Idea of TDDC Distributed Wavelet Filtering
4. Two-Dimensional Double Correlation Distributed Wavelet Filtering and Adaboost.M2 Ensemble Learning Model Based on the Gini Decision Tree
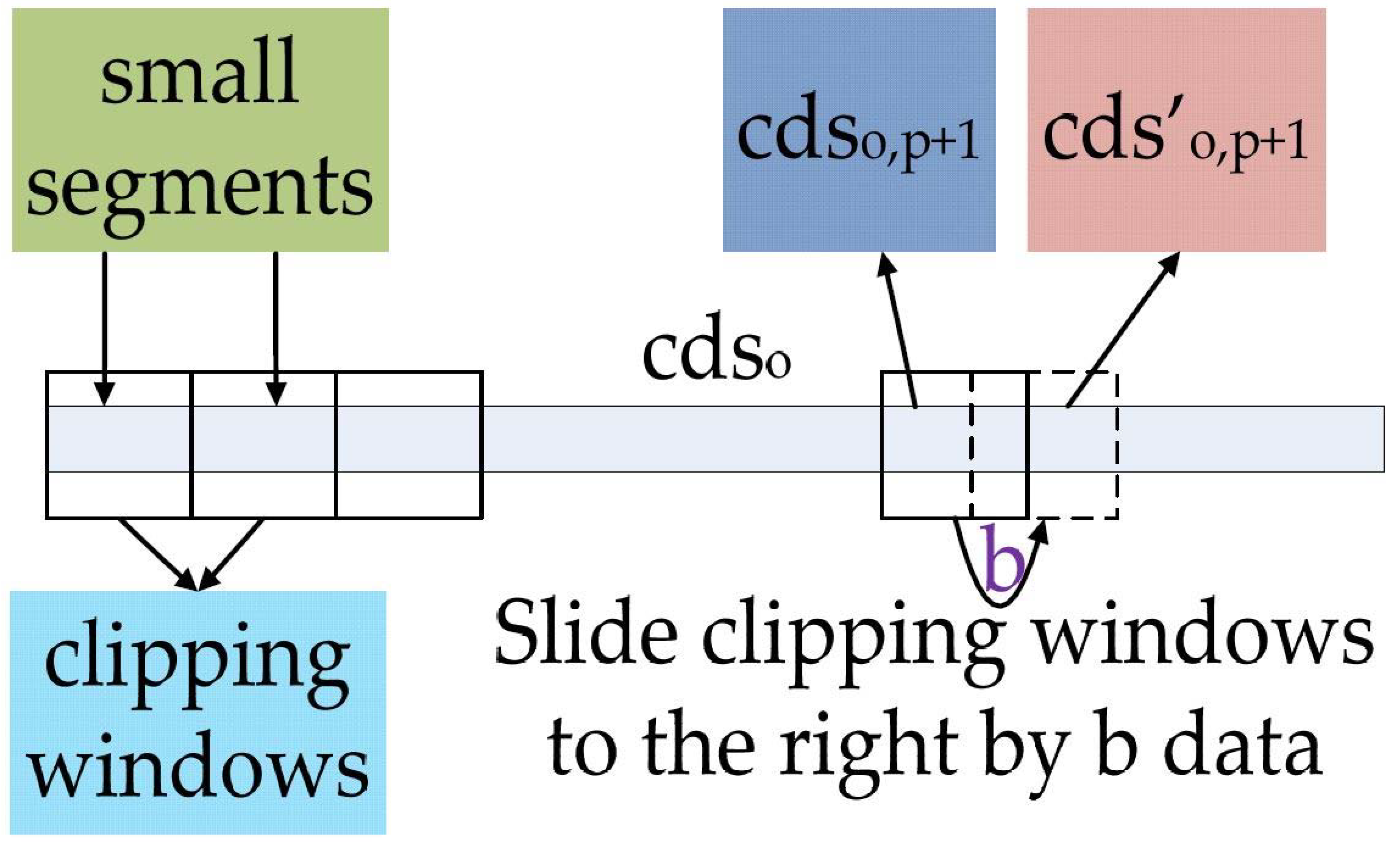
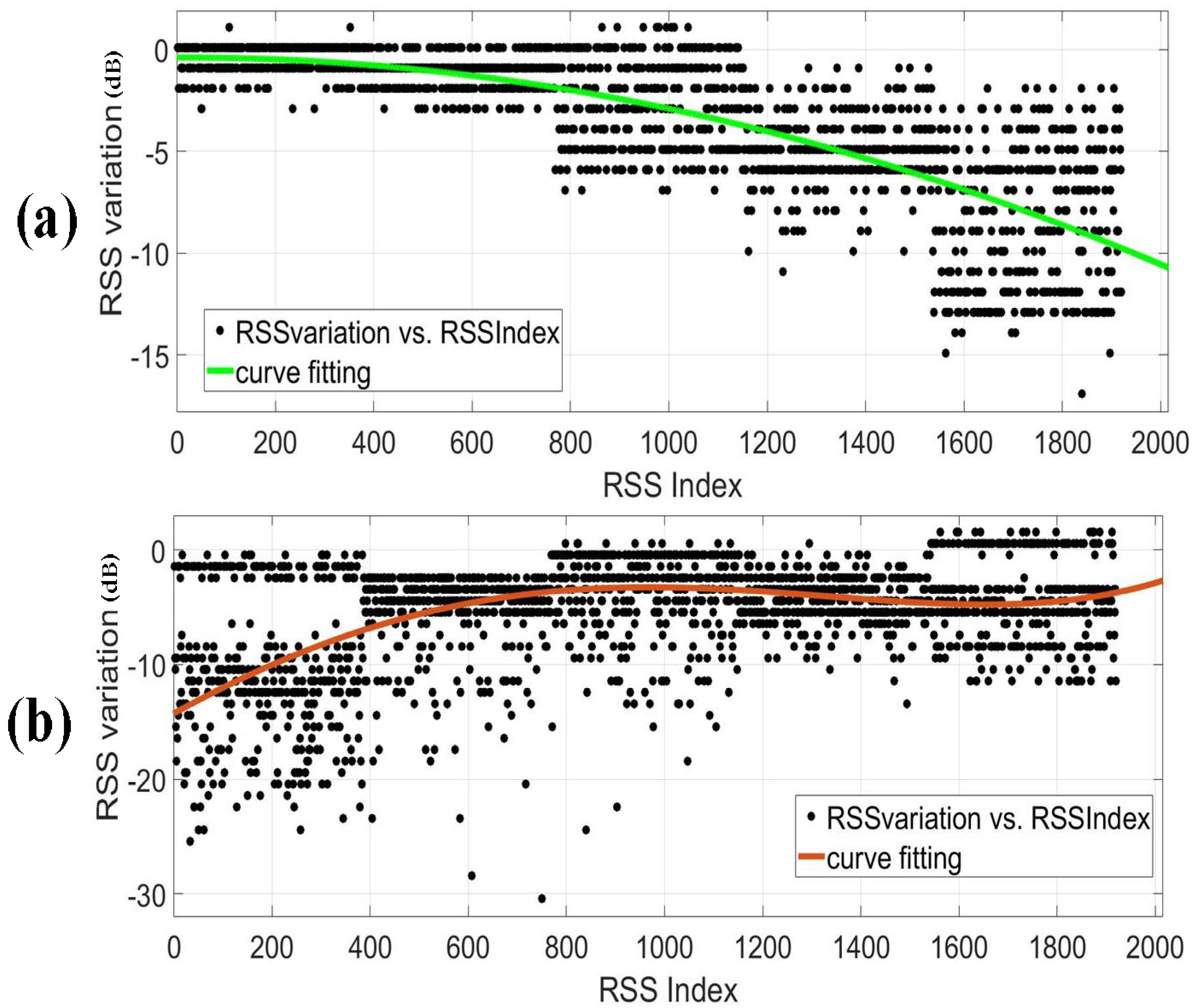
4.1. TDDC Distributed Wavelet Filtering
4.2. GDTE Localization Model
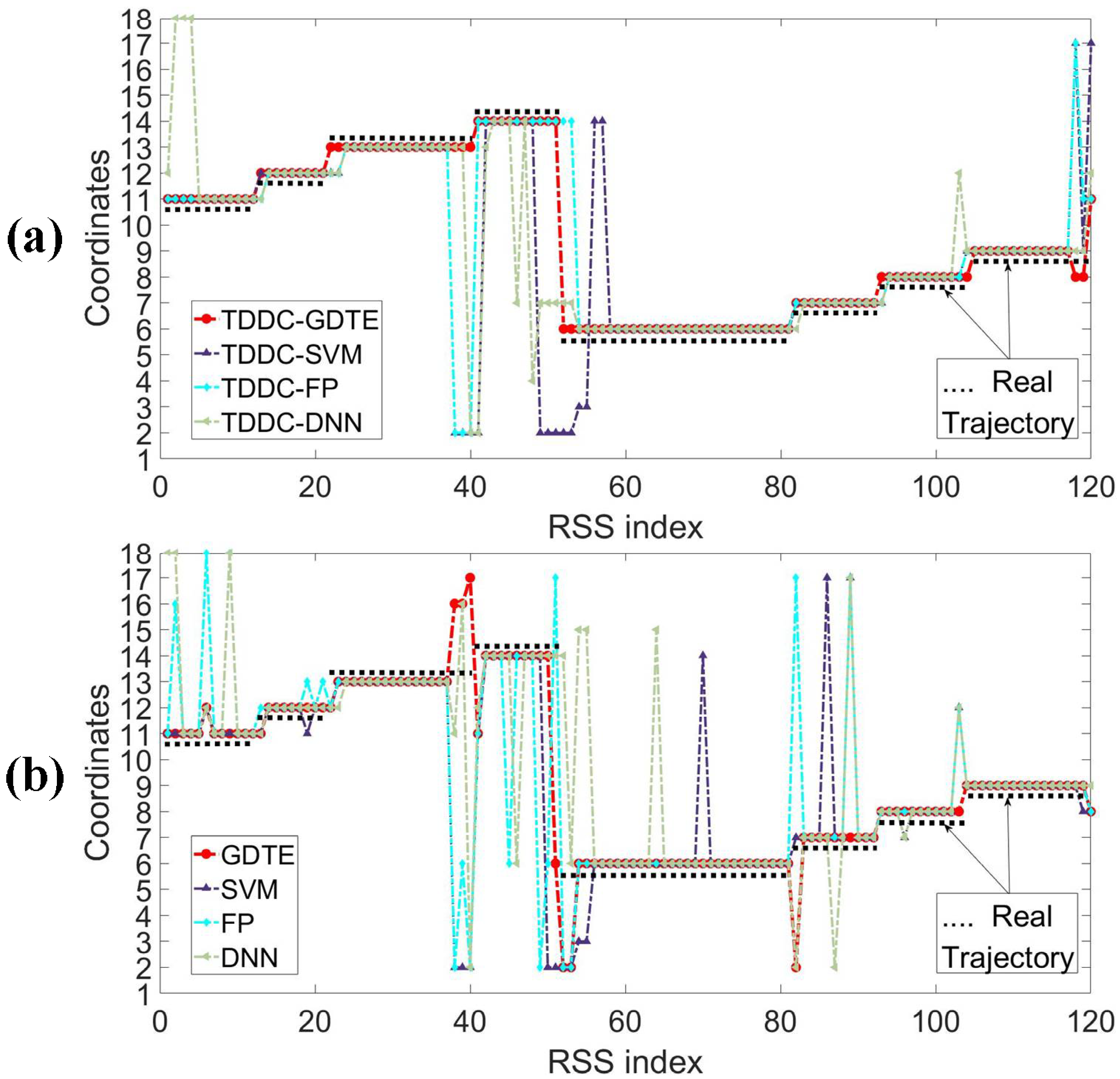
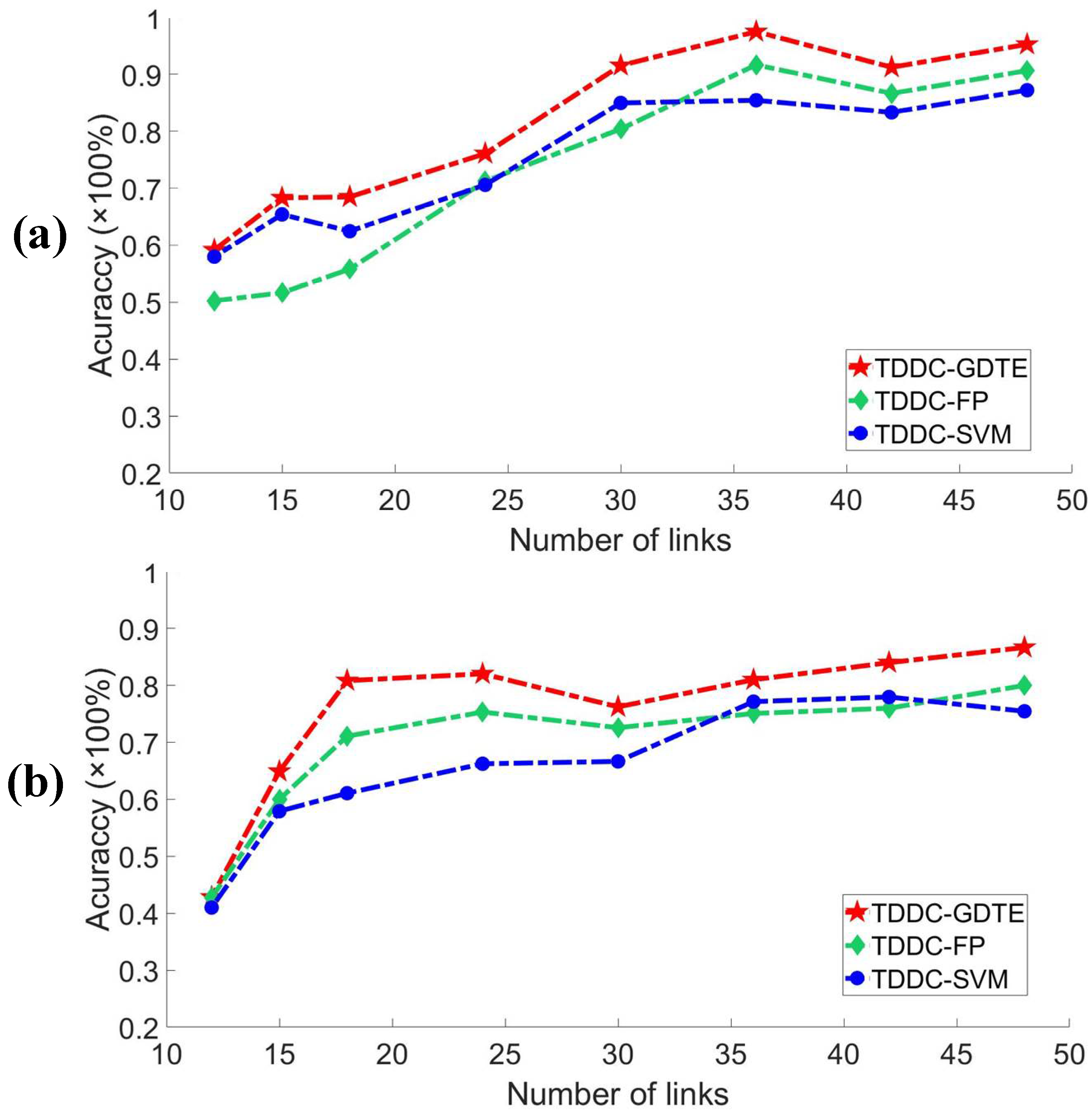
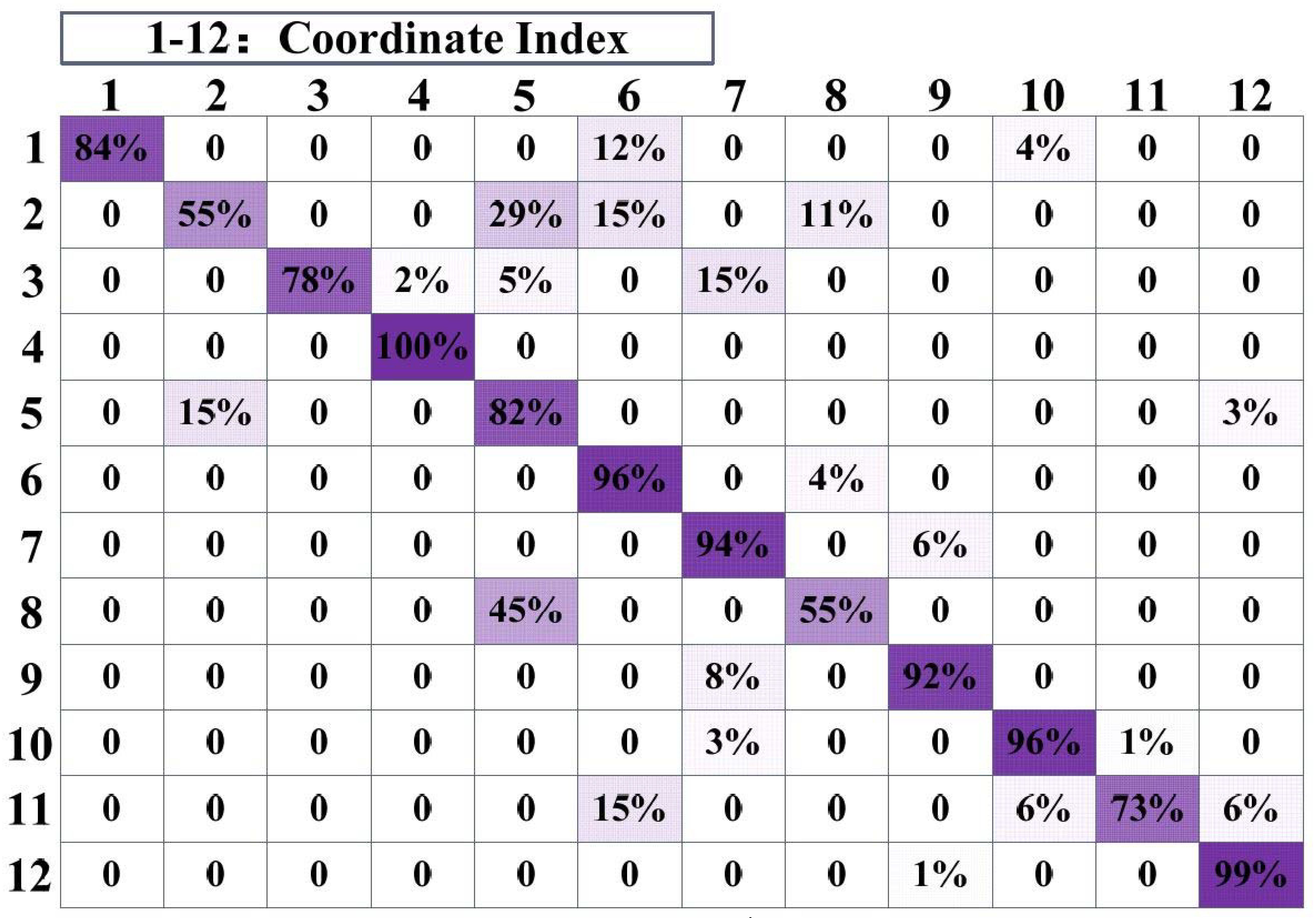
5. Experimental Evaluation
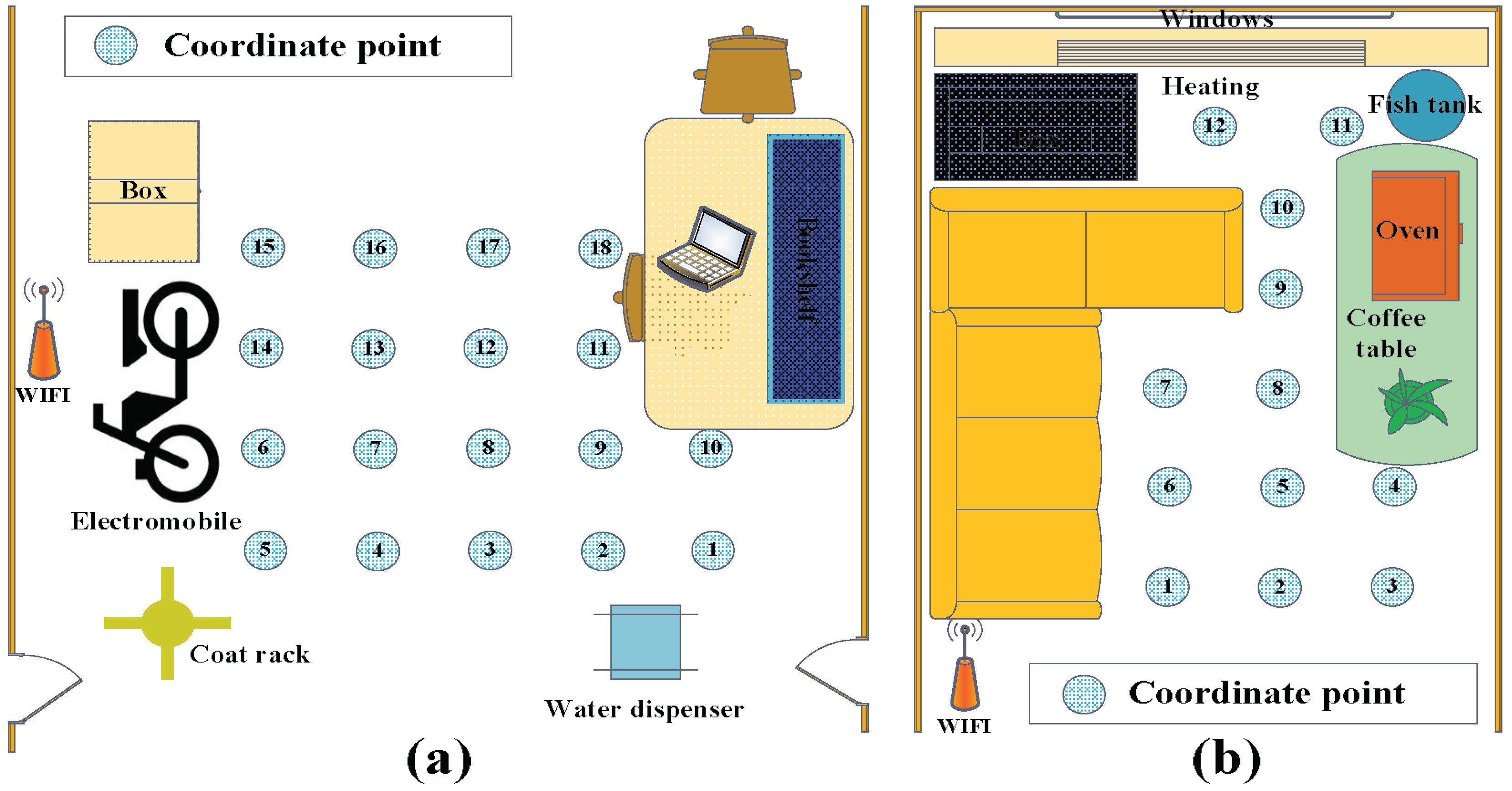
5.1. Description of the Experiment
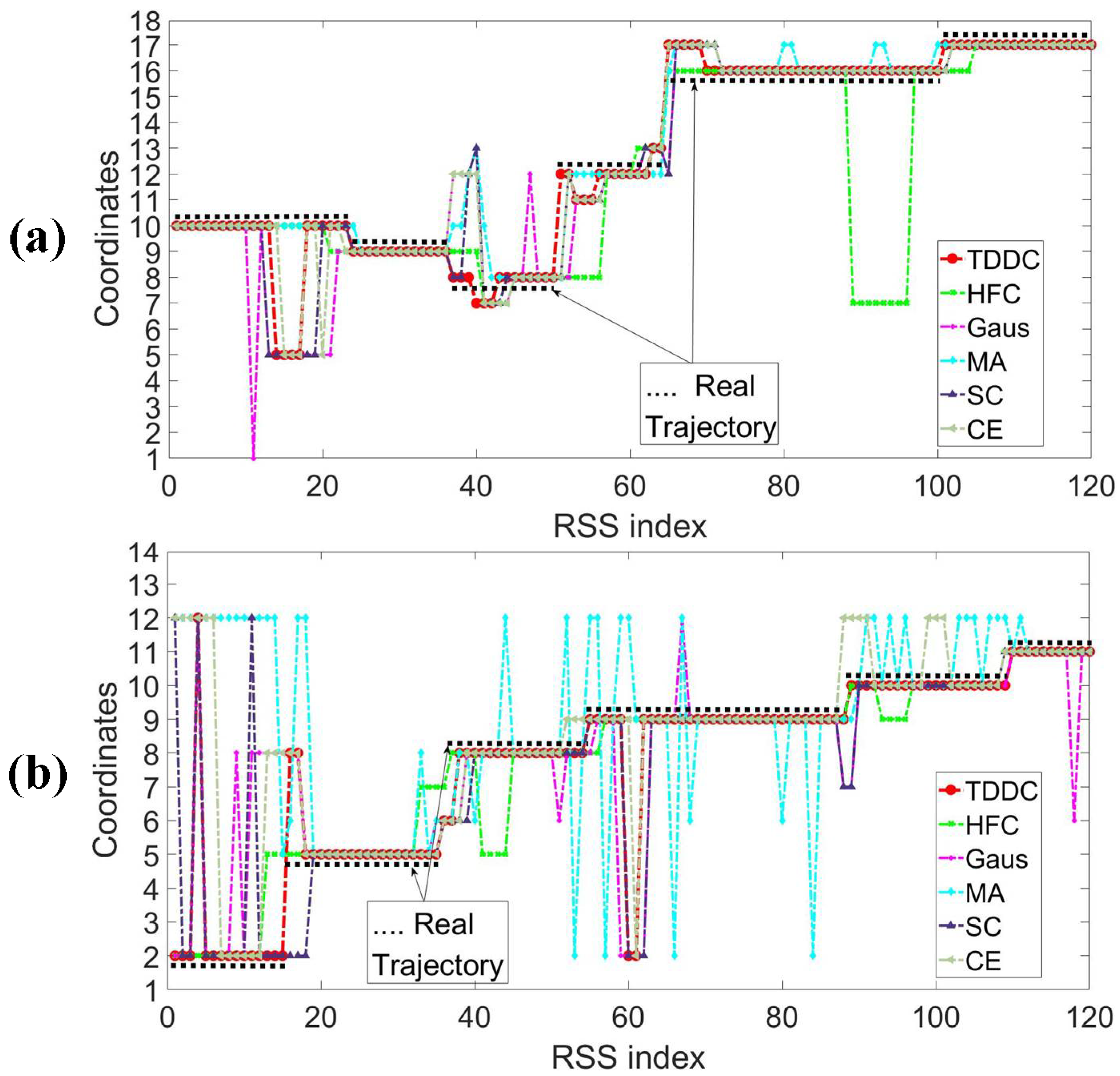
5.2. Performance Comparison
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Patwari, N.; Wilson, J. RF sensor networks for device-free localization and tracking. Proc. IEEE 2010, 98, 1961–1973. [Google Scholar] [CrossRef]
- Kaltiokallio, O.; Bocca, M.; Patwari, N. Long-Term Device-Free Localization for Residential Monitoring. In Proceedings of the 37th Annual IEEE Conference on Local Computer Networks—Workshops, Clearwater, FL, USA, 22–25 October 2012; pp. 991–998. [Google Scholar]
- Wang, J.; Zhang, X.; Gao, Q.; Yue, H.; Wang, H.Y. Device-free Wireless Localization and Activity Recognition: A Deep Learning Approach. IEEE Trans. Veh. Technol. 2017, 66, 6258–6267. [Google Scholar] [CrossRef]
- Granger, C.W.; Newbold, P. Spurious regressions in econometrics. J. Econom. 1974, 2, 111–120. [Google Scholar] [CrossRef] [Green Version]
- Phillips, P.C. New tools for understanding spurious regressions. Econometrica 1998, 6, 1299–1325. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Experiments with a New Boosting Algorithm. In Proceedings of the ICML’96 Proceeding of the 13th International Conference on Machine Learning, Bari, Italy, 3–6 July 1996; pp. 1–9. [Google Scholar]
- Eeti, L.N.; Buddhiraju, K.M. Comparison of AdaBoost.M2 and perspective based model ensemble in multispectral image classification. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Seifeldin, M.; Saeed, A.; Kosba, A.; El-keyi, A.; Youssef, M. Nuzzer: A large-scale device-free passive localization system for wireless environments. IEEE Trans. Mob. Comput. 2013, 12, 1321–1334. [Google Scholar] [CrossRef]
- Zhang, D.; Liu, Y.; Ni, L.M. Link-centric probabilistic coverage model for transceiver-free object detection in wireless networks. In Proceedings of the 30th IEEE International Conference on Distributed Computing Systems, Genova, Italy, 21–25 June 2010; pp. 21–25. [Google Scholar]
- Zhang, D.; Liu, Y.; Ni, L.M. RASS: A real-time, accurate and scalable system for tracking transceiver-free objects. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 996–1008. [Google Scholar] [CrossRef]
- Wilson, J.; Patwari, N. Radio Tomographic Imaging with Wireless Networks. IEEE Trans. Mob. Comput. 2010, 9, 621–632. [Google Scholar] [CrossRef] [Green Version]
- Wilson, J.; Patwari, N. See through walls: Motion tracking using variance-based radio tomography networks. IEEE Trans. Mob. Comput. 2011, 10, 612–621. [Google Scholar] [CrossRef]
- Zhao, Y.; Patwari, N.; Phillips, J.M. Radio Tomographic Imaging and Tracking of Stationary and Moving People via Kernel Distance. In Proceedings of the 12th Information Processing in Sensor Networks (IPSN), Philadelphia, PA, USA, 8–11 April 2013; pp. 229–240. [Google Scholar]
- Zhao, Y.; Patwari, N. Robust Estimators for Variance-Based Device-Free Localization and Tracking. IEEE Trans. Mob. Comput. 2015, 14, 2116–2129. [Google Scholar] [CrossRef]
- Banerjee, A.; Maheshwari, M.; Patwari, N.; Kasera, S.K. Detecting Receiver Attacks in VRTI-based Device Free Localization. In Proceedings of the 2012 IEEE International Symposium on a World of Wireless, Mobile and Multimedia, San Francisco, CA, USA, 22–28 June 2012; pp. 1–6. [Google Scholar]
- Kaltiokallio, O.; Bocca, M.; Patwari, N. A Fade Level-Based Spatial Model for Radio Tomographic Imaging. IEEE Trans. Mob. Comput. 2014, 13, 1159–1172. [Google Scholar]
- Lei, Q.; Zhang, H.J.; Sun, H.; Tang, L.L. A New Elliptical for Device-Free Localization. Sensors 2016, 16, 577. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.N.; Ke, W.; Lu, J.; Shao, J.H. Comments on “A New Elliptical Model for Device-Free Localization”. Sensors 2018, 18, 715. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Ma, J.; Chen, Q.H.; Ni, L.M. An RF-Based System for Tracking Transceiver-Free Objects. In Proceedings of the 15th IEEE PerCom, White Plains, NY, USA, 19–23 March 2007; pp. 135–144. [Google Scholar]
- Zhang, D.; Lu, K.Z.; Mao, R.; Feng, Y.H.; Liu, Y.H.; Ming, Z.; Ni, L.M. Fine-Grained Localization for Multiple Transceiver-Free Objects by using RF-Based Technologies. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 1464–1475. [Google Scholar] [CrossRef]
- Xiao, W.D.; Song, B.; Yu, X.T.; Chen, P.Y. Nonliner Optimization based Device-Free Localization with Outlier Link Rejection. Sensors 2015, 15, 8072–8087. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Huang, K.D.; Jiang, N.Y.; Guo, X.M.; Li, Y.F.; Wang, G.L. An Exponential-Rayleigh Model for RSS-Based Device-Free Localization and Tracking. IEEE Trans. Mob. Comput. 2015, 14, 484–494. [Google Scholar] [CrossRef]
- Wang, Z.H.; Liu, H.; Xu, S.X.; Bu, X.Y.; An, J.P. Bayesian Device-Free Localization and Tracking in a Binary RF Sensor Network. Sensors 2017, 17, 969. [Google Scholar]
- Li, Y.P.; Chen, X.; Coates, M.; Yang, B. Sequential Monte Carlo radio-frequency tomographic tracking. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 3976–3979. [Google Scholar]
- Chen, X.; Edelstein, A.; Li, Y.; Coates, M.; Rabbat, M.; Men, A. Sequential Monte Carlo for simultaneous passive device-free tracking and sensor localization using received signal strength measurements. In Proceedings of the 10th International Conference on Information Processing in Sensor Networks (IPSN), Chicago, IL, USA, 12–14 April 2011; pp. 342–353. [Google Scholar]
- Hong, J.H.; Ohtsuki, T. Signal Eigenvector-Based Device-Free Passive Localization Using Array Sensor. IEEE Trans. Veh. Technol. 2015, 64, 1354–1363. [Google Scholar] [CrossRef]
- Wang, Z.H.; Liu, H.; Xu, S.X.; Bu, X.Y.; An, J.P. A Diffraction Measurement Model and Particle Filter Tracking Method for RSS-Based DFL. IEEE J. Sel. Areas Commun. 2015, 33, 2391–2403. [Google Scholar] [CrossRef]
- Song, B.; Wang, H.L.; Xiao, W.D.; Huang, S.D.; Shi, L. Gaussian process model enabled particle filter for device-free localization. In Proceedings of the 20th International Conference on Information Fusion, Xi’an, China, 10–13 August 2017. [Google Scholar]
- Savazzi, S.; Nicoli, M.; Carminati, F.; Riva, M. A Bayesian Approach to Device-Free Localization: Modeling and Experimental Assessment. IEEE J. Sel. Top. Signal Process. 2014, 8, 16–29. [Google Scholar] [CrossRef]
- Wang, J.; Gao, Q.H.; Pan, M.; Zhang, X.; Yu, Y.; Wang, H.Y. Toward Accurate Device-Free Wireless Localization with a Saddle Surface Model. IEEE Trans. Veh. Technol. 2016, 65, 6665–6677. [Google Scholar] [CrossRef]
- Wang, J.; Gao, Q.H.; Cheng, P.; Yu, Y.; Wang, H.Y. Lightweight Robust Device-Free Localization in Wireless Networks. IEEE Trans. Ind. Electron. 2014, 61, 5681–5689. [Google Scholar] [CrossRef]
- Ruan, W.; Sheng, Q.Z.; Yao, L.; Li, X.; Falkner, N.J.; Yang, L. Device-free human localization and tracking with UHF passive RFID tags: A data-driven approach. J. Netw. Comput. Appl. 2018, 104, 78–96. [Google Scholar] [CrossRef]
- Youssef, M.; Mah, M.; Agrawala, A. Challenges: Device-free passive localization for wireless environments. In Proceedings of the 13th ACM International Conference on Mobile Computing and Networking, Montreal, QC, Canada, 9–14 September 2007; pp. 222–229. [Google Scholar]
- Aly, H.; Youssef, M. New Insight into WiFi-based Device-Free Localization. In Proceedings of the 2013 ACM Conference on Pervasive and Ubiquitous Computing (UbiComp’13), New York, NY, USA, 8–12 September 2013; pp. 541–548. [Google Scholar]
- Chiang, Y.Y.; Hsu, W.H.; Yeh, S.C.; Li, Y.C.; Wu, J.S. Fuzzy Support Vector Machines for Device-free Localization. In Proceedings of the IEEE International and Measurement Technology Conference (I2MTC), Graz, Austria, 13–16 May 2012; pp. 1–4. [Google Scholar]
- Wagner, B.; Timmermann, D.; Ruscher, G.; Kirste, T. Device-free user localization utilizing artificial neural networks and passive RFID. In Proceedings of the Ubiquitous Positioning, Indoor Navigation, and Location Based Service, Helsinki, Finland, 3–4 Steptember 2012; pp. 3–4. [Google Scholar]
- Zhang, J.; Xiao, W.; Zhang, S.; Huang, S. Device-Free Localization via an Extreme Learning Machine with Parameterized Geometrical Feature Extraction. Sensors 2017, 17, 879. [Google Scholar] [CrossRef] [PubMed]
- Ke, W.; Wang, T.T.; Shao, J.H. CS-based device-free localization in the presence of model errors. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 20–25. [Google Scholar]
- Vance, P.J.; Prasad, G.; Harkin, J.; Curran, K. A wireless approach to device-free localization (DFL) for indoor environments. In Proceedings of the IET Seminar on Assisted Living, London, UK, 6 April 2011; p. 6. [Google Scholar]
- Li, W.; Liu, X.; Duan, Y.B.; Liu, J.C. High-Resolution Threshold De-Noising Method Based on Wavelet Entropy and Correlation. J. Data Acquis. Process. 2013, 28, 371–375. [Google Scholar]
- Texas Instruments. CC253x System on Chip Solution for 2.4 GHz IEEE 802.15.4 and ZigBee®Applications. April 2009. Available online: http://www.ti.com/product/CC2530 (accessed on 1 February 2011).
- Donoho, D.L. De-noising by soft-thresholding. IEEE Trans. Inf. Theory 1995, 41, 613–627. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L.; Johnstone, I.M. Ideal spatial adaptation by wavelet shrinkage. Biometrika 1994, 81, 425–455. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Q.H.; Qiu, J.; Liu, G.J. Application of Hidden Semi-Markov Models Based on Wavelet Correlation Feature Scale Entropy in Equipment Degradation State Recognition. In Proceedings of the 7th World Congress on Intelligent Control and Automation, Chongqing, China, 25–27 June 2008; pp. 269–273. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Filter Accuracy Scenario | TDDC | SC | CE | HFC | Gaus | MA |
|---|---|---|---|---|---|---|
| Drawing room 1 | 95.28% | 91.50% | 93.89% | 80.50% | 89.50% | 86.40% |
| Drawing room 2 | 87.67% | 81.71% | 83.23% | 67.82% | 80.74% | 63.17% |
| Filter Accuracy Scenario | GDTE | DNN | FP | SVM |
|---|---|---|---|---|
| Drawing room 1 | 90.67% | 80.80% | 80.77% | 82.77% |
| Drawing room 2 | 82.49% | 72.77% | 74.55% | 75.91% |
| Filter Accuracy Scenario | TDDC-GDTE | TDDC-DNN | TDDC-FP | TDDC-SVM |
|---|---|---|---|---|
| Drawing room 1 | 95.28% | 84.61% | 90.66% | 87.22% |
| Drawing room 2 | 87.67% | 77.11% | 81.00% | 77.46% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, W.; Shen, R.; Wang, K.; Gong, G.; Xiao, Y.; Lu, H. Research on RSS Data Optimization and DFL Localization for Non-Empty Environments. Sensors 2018, 18, 4419. https://doi.org/10.3390/s18124419
Mao W, Shen R, Wang K, Gong G, Xiao Y, Lu H. Research on RSS Data Optimization and DFL Localization for Non-Empty Environments. Sensors. 2018; 18(12):4419. https://doi.org/10.3390/s18124419
Chicago/Turabian StyleMao, Wenyu, Rongxuan Shen, Ke Wang, Guoliang Gong, Yi Xiao, and Huaxiang Lu. 2018. "Research on RSS Data Optimization and DFL Localization for Non-Empty Environments" Sensors 18, no. 12: 4419. https://doi.org/10.3390/s18124419
APA StyleMao, W., Shen, R., Wang, K., Gong, G., Xiao, Y., & Lu, H. (2018). Research on RSS Data Optimization and DFL Localization for Non-Empty Environments. Sensors, 18(12), 4419. https://doi.org/10.3390/s18124419