Classification of Incomplete Data Based on Evidence Theory and an Extreme Learning Machine in Wireless Sensor Networks


Abstract
:1. Introduction
- Data missing completely at random (MCAR): If a missing variable is independent of the value of itself and any other variable, then it can be denoted as MCAR.
- Data missing at random (MAR): If a missing value does not depend on the missing variable and it may be related to the known values of other variables, then the missing data can be denoted as MAR.
- Data not missing at random (NMAR): If a missing value depends on the missing variable itself, then the missing data is denoted as NMAR.
2. Preliminary Work
2.1. Basis of Belief Function Theory
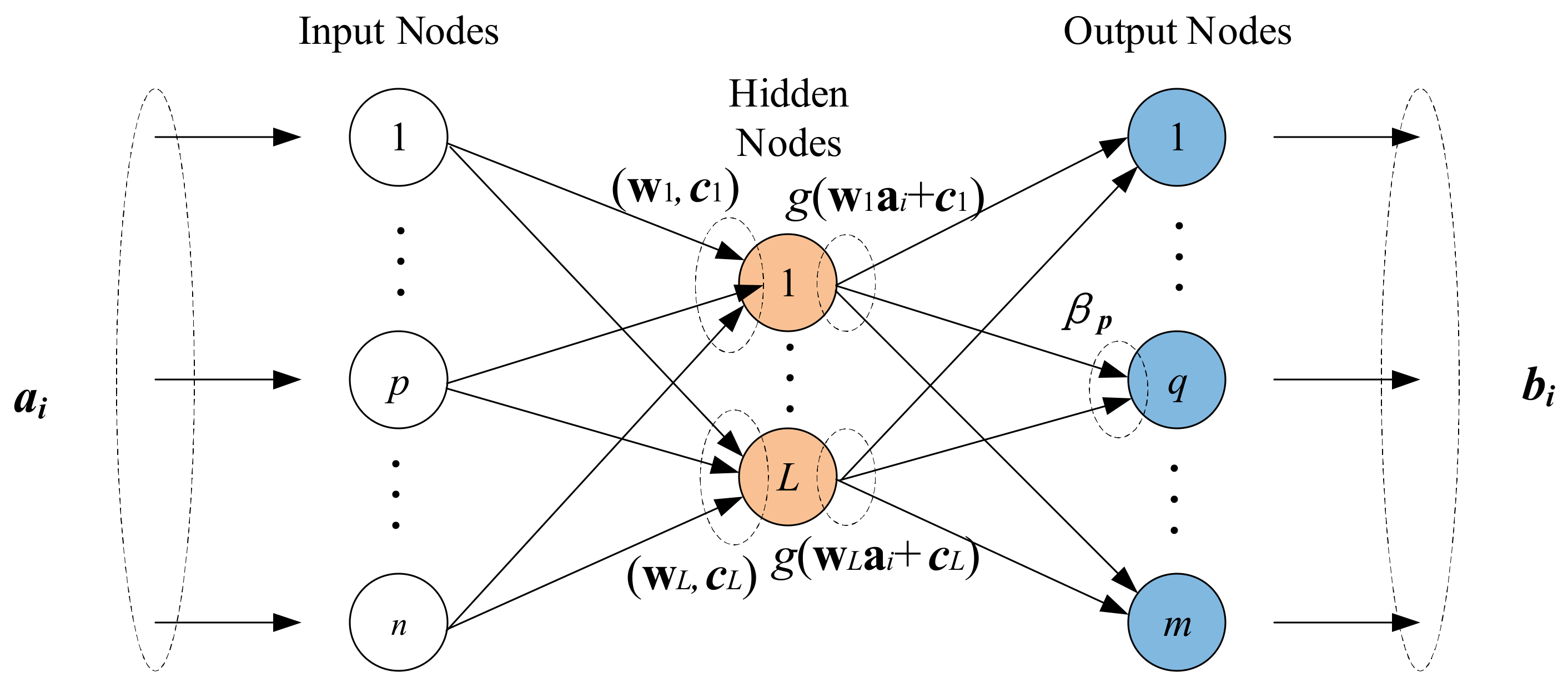
2.2. Overview of Extreme Learing Machine
3. Classification of Incomplete Data with ELMI and DST
3.1. Extreme Learning Machine Imputation
- Divide the training samples into c different training classes according to the class label of the samples;
- Determine the missing attributes of the monitoring object, ;
- Select the values of attributes of each training class as the output data, and select the rest of the attribute values of each training class as input data to compute c output weight vectors using Equation (10);
- Select the known attribute values of the monitoring object as input data, and calculate the output data to estimate the missing values according to Equation (6).
3.2. The Classification Method Based on Evidence Theory
3.2.1. The Classification Based on Interval Numbers and DST
- With an increase in this distance, the belief of belonging to class should have a monotone decrease.
- The sum of all BBAs should equal 1.
- The value of each BBA should be limited to the interval .
3.2.2. The Fusion of the Classification Results
| Algorithm 1. The combination of incomplete data. |
| Input: Training data: . |
| Test data: . |
| Parameters: : threshold for compound class. |
| for j = 1 to m |
| Calculate c versions of estimations of the missing attributes by ELMI. |
| Classify c edited attribute vectors with missing values by Equations (14) and (15). |
| Sub-combination of classification results in the same group using Equation (17). |
| Select compound classes by Equation (19). |
| Combination of the sub-combination results using Equations (20) and (21). |
| end |
4. Experimental Results
- The misclassification declared for the object corresponds to if it is classified into with .
- If and , it will be regarded as an imprecise classification.
- The error rate is denoted by , where is the number of misclassification errors, and is the number of test objects.
- The imprecise rate is denoted by , where is the number of objects classified into compound classes.
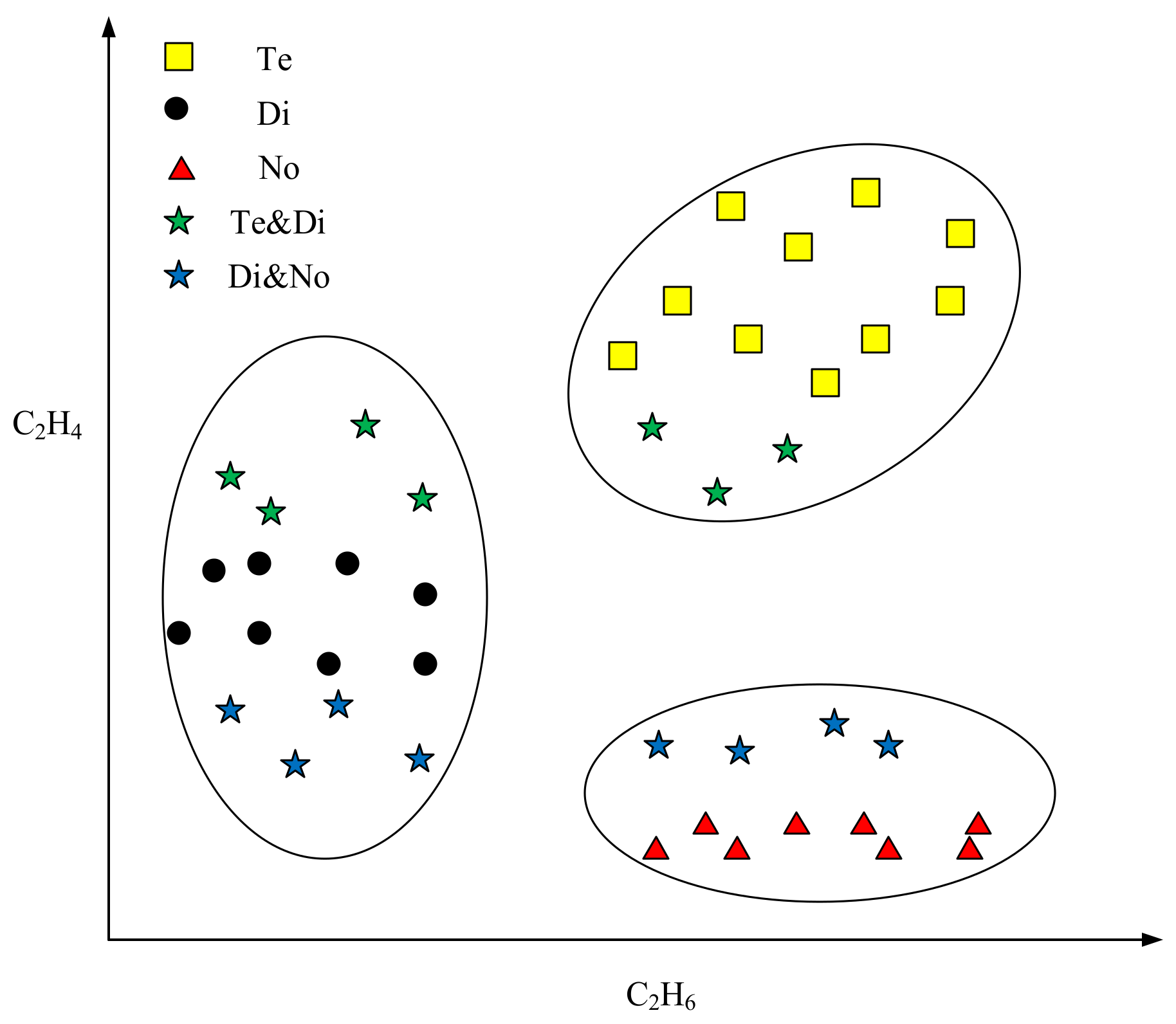
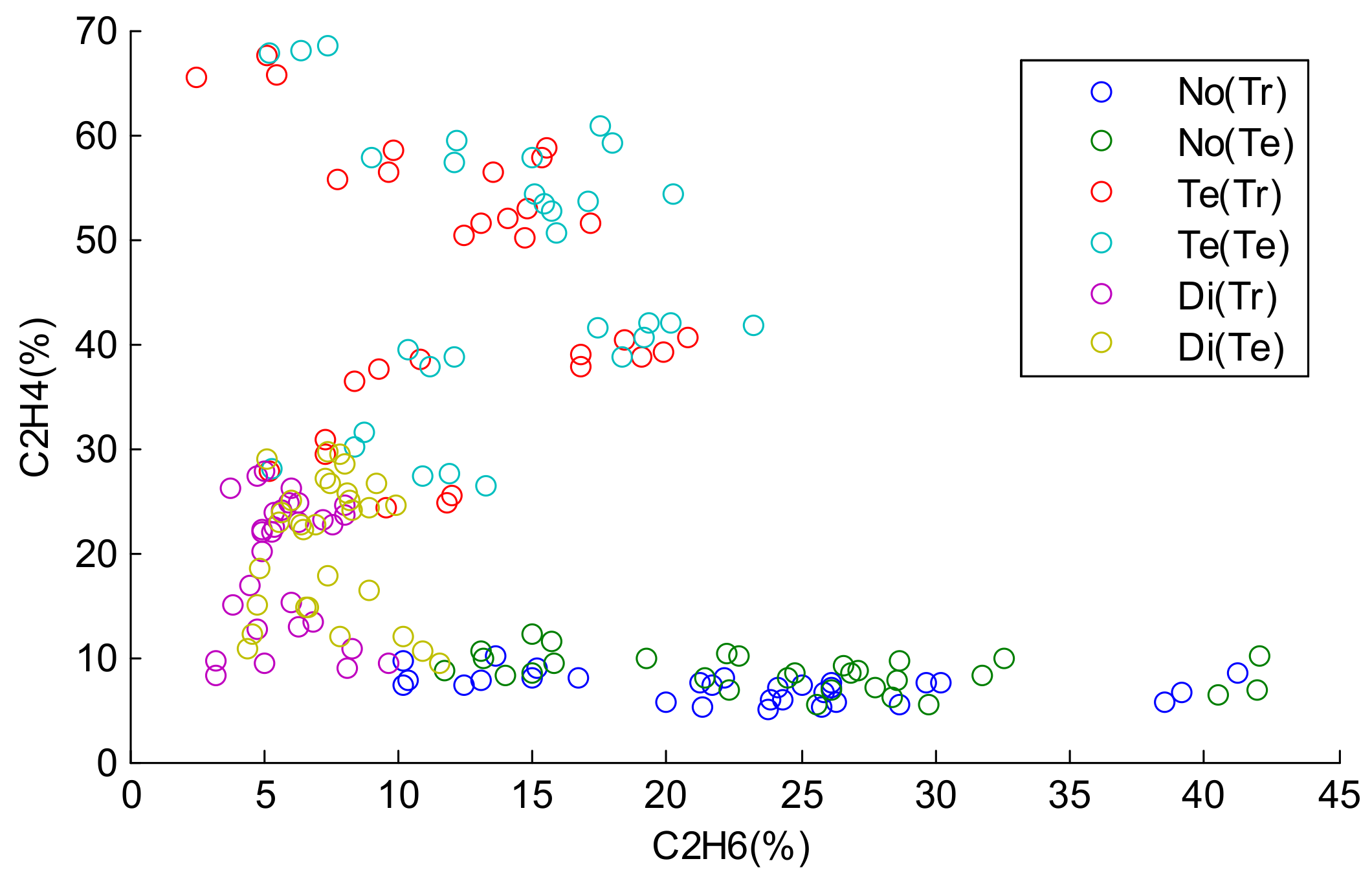
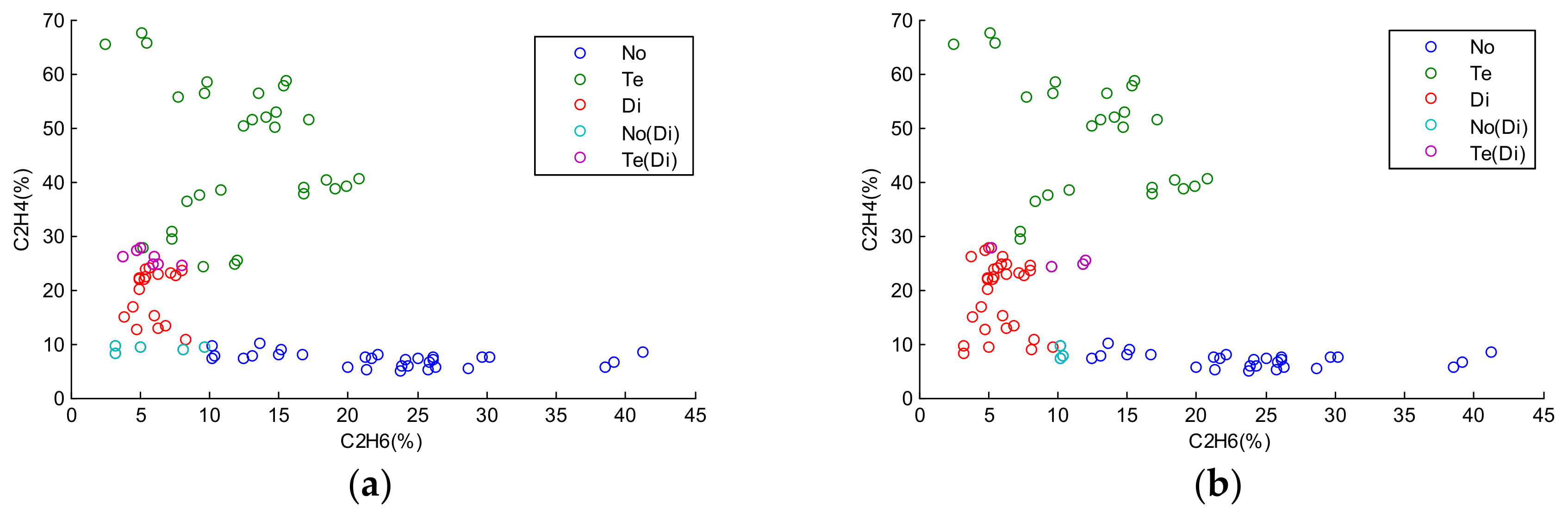
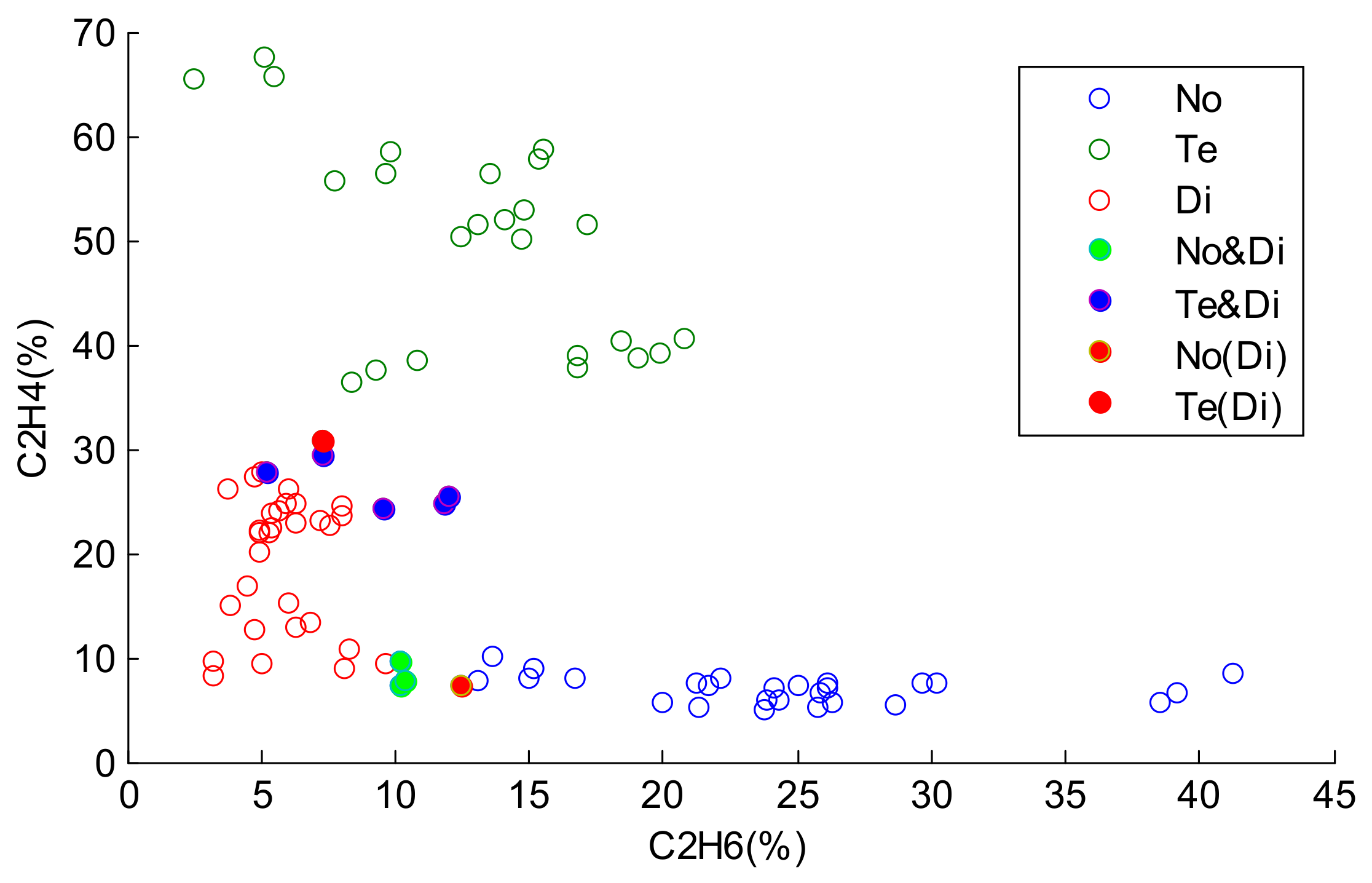
4.1. Experiment on Transformer Fault Diagnosis
4.2. Experiment on Machine Learning
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Khaleghi, B.; Khamis, A.; Karray, F.O.; Razavi, S.N. Multisensor data fusion: A review of the state-of-the-art. Inf. Fusion 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Z. Belief Function Based Decision Fusion for Decentralized Target Classification in Wireless Sensor Networks. Sensors 2015, 15, 20524–20540. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Liu, T.; Zhang, W. Novel Paradigm for Constructing Masses in Dempster-Shafer Evidence Theory for Wireless Sensor Network’s Multisource Data Fusion. Sensors 2014, 14, 7049–7065. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.J.; Lai, C.F.; Chao, H.C. A Green Data Transmission Mechanism for Wireless Multimedia Sensor Networks Using Information Fusion. IEEE Wirel. Commun. 2014, 21, 14–19. [Google Scholar] [CrossRef]
- Farash, M.S.; Turkanović, M.; Kumari, S.; Hölbl, M. An efficient user authentication and key agreement scheme for heterogeneous wireless sensor network tailored for the Internet of Things environment. Ad Hoc Netw. 2016, 36, 152–176. [Google Scholar] [CrossRef]
- Liu, Z.-G.; Pan, Q.; Dezert, J.; Martin, A. Adaptive imputation of missing values for incomplete pattern classification. Pattern Recognit. 2016, 52, 85–95. [Google Scholar] [CrossRef] [Green Version]
- Little, R.J.; Rubin, D.B. Statistical Analysis with Missing Data; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Yu, Q.; Miche, Y.; Eirola, E.; Van Heeswijk, M.; SéVerin, E.; Lendasse, A. Regularized extreme learning machine for regression with missing data. Neurocomputing 2013, 102, 45–51. [Google Scholar] [CrossRef]
- Liu, Z.-G.; Liu, Y.; Dezert, J.; Pan, Q. Classification of incomplete data based on belief functions and K-nearest neighbors. Knowl.-Based Syst. 2015, 89, 113–125. [Google Scholar] [CrossRef]
- Liu, Z.-G.; Pan, Q.; Mercier, G.; Dezert, J. A new incomplete pattern classification method based on evidential reasoning. IEEE Trans. Cybern. 2015, 45, 635–646. [Google Scholar] [CrossRef] [PubMed]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Statist. Soc. Ser. B (Methodol.) 1977, 1–38. [Google Scholar]
- Schafer, J.L. Analysis of Incomplete Multivariate Data; CRC Press: Boca Raton, FL, USA, 1997. [Google Scholar]
- Batista, G.E.; Monard, M.C. A Study of K-Nearest Neighbour as an Imputation Method. Available online: http://conteudo.icmc.usp.br/pessoas/gbatista/files/his2002.pdf (accessed on 30 March 2018).
- Rubin, D.B. Multiple Imputation for Nonresponse in Surveys; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 81. [Google Scholar]
- Azur, M.J.; Stuart, E.A.; Frangakis, C.; Leaf, P.J. Multiple imputation by chained equations: What is it and how does it work? Int. J. Methods Psychiatr. Res. 2011, 20, 40–49. [Google Scholar] [CrossRef] [PubMed]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42. [Google Scholar] [CrossRef]
- Li, D.; Deogun, J.; Spaulding, W.; Shuart, B. Towards Missing Data Imputation: A Study of Fuzzy k-Means Clustering Method. In Proceedings of the International Conference on Rough Sets and Current Trends in Computing, Uppsala, Sweden, 1–5 June 2004; pp. 573–579. [Google Scholar]
- Aydilek, I.B.; Arslan, A. A hybrid method for imputation of missing values using optimized fuzzy c-means with support vector regression and a genetic algorithm. Inf. Sci. 2013, 233, 25–35. [Google Scholar] [CrossRef]
- MartíNez-MartíNez, J.M.; Escandell-Montero, P.; Soria-Olivas, E.; MartíN-Guerrero, J.D.; Magdalena-Benedito, R.; GóMez-Sanchis, J. Regularized extreme learning machine for regression problems. Neurocomputing 2011, 74, 3716–3721. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Destercke, S.; Burger, T. Toward an Axiomatic Definition of Conflict between Belief Functions. IEEE Trans. Cybern. 2013, 43, 585–596. [Google Scholar] [CrossRef] [PubMed]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976; Volume 42. [Google Scholar]
- Smets, P. Analyzing the combination of conflicting belief functions. Inf. Fusion 2007, 8, 387–412. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, W.; Chao, H.-C.; Lai, C.-F. Toward Belief Function-Based Cooperative Sensing for Interference Resistant Industrial Wireless Sensor Networks. IEEE Trans. Ind. Inform. 2016, 12, 2115–2126. [Google Scholar] [CrossRef]
- Liu, Z.-G.; Pan, Q.; Dezert, J.; Mercier, G. Hybrid classification system for uncertain data. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 2783–2790. [Google Scholar] [CrossRef]
- Shen, B.; Liu, Y.; Fu, J.S. An integrated model for robust multisensor data fusion. Sensors 2014, 14, 19669–19686. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Zheng, J.; Yang, J.-B.; Xu, D.-L.; Chen, Y.-W. Data classification using evidence reasoning rule. Knowl.-Based Syst. 2017, 116, 144–151. [Google Scholar] [CrossRef]
- Denoeux, T. A k-nearest neighbor classification rule based on Dempster-Shafer theory. IEEE Trans. Syst. Man Cybern. 1995, 25, 804–813. [Google Scholar] [CrossRef]
- Denoeux, T. A neural network classifier based on Dempster-Shafer theory. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2000, 30, 131–150. [Google Scholar] [CrossRef]
- Liu, Z.-G.; Pan, Q.; Dezert, J.; Mercier, G. Credal classification rule for uncertain data based on belief functions. Pattern Recognit. 2014, 47, 2532–2541. [Google Scholar] [CrossRef]
- Han, D.Q.; Deng, Y.; Han, C.Z.; Hou, Z.Q. Weighted evidence combination based on distance of evidence and uncertainty measure. J. Infrared Millim. Waves 2011, 30, 396–400. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, T.; Chen, D.; Zhang, W. Novel algorithm for identifying and fusing conflicting data in wireless sensor networks. Sensors 2014, 14, 9562–9581. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.; Huang, G.-B.; Song, S.; You, K. Trends in extreme learning machines: A review. Neural Netw. 2015, 61, 32–48. [Google Scholar] [CrossRef] [PubMed]
- Deng, W.; Zheng, Q.; Chen, L. Regularized Extreme Learning Machine. In Proceedings of the IEEE Symposium on Computational Intelligence and Data Mining, Nashville, TN, USA, 30 March–2 April 2009; pp. 389–395. [Google Scholar]
- Tran, L.; Duckstein, L. Comparison of fuzzy numbers using a fuzzy distance measure. Fuzzy Sets Syst. 2002, 130, 331–341. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, K. Fast cross validation for regularized extreme learning machine. J. Syst. Eng. Electron. 2014, 25, 895–900. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Classes | Attributes | Instances |
|---|---|---|---|
| Breast | 2 | 9 | 699 |
| Iris | 3 | 4 | 150 |
| Seeds | 3 | 7 | 210 |
| Wine | 3 | 13 | 178 |
| Segment | 7 | 19 | 2310 |
| Satimage | 6 | 36 | 6435 |
| Data set | n | MI Re | KNNI Re | SVRI Re | ELMI {Re, Ri} |
|---|---|---|---|---|---|
| Breast | 3 | 4.79% | 4.86% | 4.71% | {4.52%, 3.18%} |
| 5 | 8.23% | 8.38% | 5.96% | {4.90%, 3.31%} | |
| 7 | 14.75% | 14.29% | 12.45% | {10.42%, 5.59%} | |
| Iris | 1 | 23.96% | 5.65% | 5.13% | {4.77%, 2.09%} |
| 2 | 43.67% | 13.72% | 8.07% | {8.12%, 6.52%} | |
| 3 | 65.49% | 21.06% | 12.89% | {12.92%, 9.23%} | |
| Seeds | 2 | 21.05% | 12.38% | 9.26% | {9.47%, 4.13%} |
| 4 | 28.39% | 13.62% | 10.83% | {9.65%, 4.86%} | |
| 6 | 40.93% | 27.34% | 18.37% | {17.02%, 12.53%} | |
| Wine | 3 | 31.26% | 27.18% | 26.51% | {26.17%, 1.64%} |
| 6 | 33.98% | 27.93% | 27.14% | {26.83%, 1.58%} | |
| 9 | 38.02% | 30.36% | 28.33% | {27.25%, 3.67%} | |
| Segment | 3 | 12.71% | 10.46% | 9.52% | {6.89%, 1.37%} |
| 7 | 15.83% | 12.38% | 10.07% | {7.16%, 3.25%} | |
| 11 | 20.23% | 17.35% | 12.06% | {10.35%, 3.76%} | |
| Satimag | 7 | 41.28% | 40.70% | 33.62% | {29.63%, 12.81%} |
| 9 | 44.75% | 42.36% | 36.59% | {30.87%, 18.24%} | |
| 19 | 52.96% | 51.22% | 47.67% | {36.92%, 22.75%} |
| Data Set | SVRI | ELMI | ||
|---|---|---|---|---|
| Training | Testing | Training | Testing | |
| Breast | 3.8371 s | 0.9353 s | 0.9761 s | 0.2572 s |
| Iris | 1.0639 s | 0.2108 s | 0.1924 s | 0.0497 s |
| Seeds | 2.4271 s | 0.5141 s | 0.4212 s | 0.1644 s |
| Wine | 2.1533 s | 0.5279 s | 0.3125 s | 0.1398 s |
| Segment | 753.2 s | 1.0422 s | 2.32 s | 0.5461 s |
| Satimag | 2157.3 s | 2.1823 s | 15.79 s | 0.5633 s |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Liu, Y.; Chao, H.-C.; Zhang, Z.; Zhang, Z. Classification of Incomplete Data Based on Evidence Theory and an Extreme Learning Machine in Wireless Sensor Networks. Sensors 2018, 18, 1046. https://doi.org/10.3390/s18041046
Zhang Y, Liu Y, Chao H-C, Zhang Z, Zhang Z. Classification of Incomplete Data Based on Evidence Theory and an Extreme Learning Machine in Wireless Sensor Networks. Sensors. 2018; 18(4):1046. https://doi.org/10.3390/s18041046
Chicago/Turabian StyleZhang, Yang, Yun Liu, Han-Chieh Chao, Zhenjiang Zhang, and Zhiyuan Zhang. 2018. "Classification of Incomplete Data Based on Evidence Theory and an Extreme Learning Machine in Wireless Sensor Networks" Sensors 18, no. 4: 1046. https://doi.org/10.3390/s18041046
APA StyleZhang, Y., Liu, Y., Chao, H. -C., Zhang, Z., & Zhang, Z. (2018). Classification of Incomplete Data Based on Evidence Theory and an Extreme Learning Machine in Wireless Sensor Networks. Sensors, 18(4), 1046. https://doi.org/10.3390/s18041046