1. Introduction
The videos captured by hand-hold cameras often suffer from inevitable blur because of camera shake. As it is easy to generate global motion blur when using a tracking shot, and this type of blur widely exists in the field of mobile video surveillance, how to deblur the uniform motion blurred videos is a problem worth studying. In general, a video frame with camera shake can be modeled by a motion blur kernel, which can describes the motion blur of each video frame captured by camera in the assumption that the motion blur of each video frame is shift-invariant. Mathematically, the relationship between an observed blurry video frame and the latent sharp frame can be modeled according as follows:
where
B,
k,
L and
N denote the observed blurry video frame, the blur kernel, the latent sharp frame and additive noise, respectively, and
is convolution operator. The objective of video motion deblurring is to obtain
L from
B, and the problem can be converted into a blind deconvolution operation while the blur kernel is unknown.
A straightforward idea for this problem is to apply existing single or multiple image deblurring methods to each blurry frame [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15]. For now, there are many mature single image deblurring methods [
1,
2,
3,
4,
5,
6,
7,
8]. Xiong et al. [
1] deblurred sparsity-constrained blind image by alternating direction optimization methods. Fergus et al. [
2] showed that it is possible to deblur real-world images under a sparse blur kernel prior and a mixture-of-Gaussian prior on the image gradients, but it takes a relatively long time to estimate a blur kernel for the estimation process performed in a coarse-to-fine fashion. Shan et al. [
3] formulated the image deblurring problem as a Maximum a Posteriori (MAP) problem and solved it by an iterative method. A hallmark of this method is that it constrains the spatial distribution of noise by high-order models to estimate highly accurate blur kernel and latent image. Cho and Lee [
4] proposed a deblurring method by introducing fast Fourier transforms (FFTs) for latent sharp frame restoration model deconvolution and using image derivatives to accelerate the blur kernel estimation, but their deblurring results are relatively sensitive to the parameters. Xu and Jia [
5] proposed a texture-removal method to guide edge selection and detect large-scale structures. However, the method may fail when there are strong and complex textures in images. Krishnan et al. [
6] used a L1/L2 regularization scheme to overcome the shortcomings of existing priors in an MAP setting, but it suppressed image details in the early stage during optimization. Zhang et al. [
7] proposed a nonlocal blur kernel regression (NL-KR) model that exploits both the nonlocal self-similarity and local structural regularity properties in natural images, but this method is computationally expensive. Focusing on the various types of blur caused by camera shake, Kim and Lee [
8] proposed an efficient dynamic scene deblurring method that does not require accurate motion segmentation with the aid of total variation (TV)-L1 based model. However, this method is not good at global motion blur.
Considering that more information will be conducive to the deblurring process, some other methods make the deblurring problem more tractable by leveraging additional input and joint multiple blurry images [
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20] in video recovery using block match multi-frame motion estimation based on single pixel cameras [
9]. Tan et al. compared a blurry patch directly against the sharp candidates in spatial domain, in which the nearest neighbor matches could be recovered [
10]. However, the blurry regions and the sharp regions in a frame are difficult to divide accurately in airspace. The difference of these methods is that while [
11] leveraged the information in two or multiple motion blurred images, [
12,
13,
14] employed a blurred and noisy image pair. Blurry frame could also be indicated by the inter-frame multiple images accumulation [
15,
16,
17,
18]. Tai et al. proposed a projective motion blur model with a sequence of transformation matrices [
15]. Blurry images were formulated as an integration of some clear intermediate images after an optical-based transform [
16]. Cho et al. proposed an approximate blur model to estimate blur function of video frames [
17]. Zhang and Yao proposed a removing video blur approach that could handle non-uniform blur with non-rigid inter-frame motions [
18]. However, the inter-frame multiple images accumulation model needs long program run times, because it must calculate a lot of inter-frame multiple images for estimating a blurred frame. Besides, Zhang et al. [
19] described a unified multi-image deconvolution method for restoring a latent image from a given set of blurry and/or noisy observations. These multi-image deblurring methods require multiple degenerate observations of the same scene, which restricts their application in general videos. Cai et al. [
20] developed a robust numerical method for restoring a sharp image from multiple motion blurred images. This method could be extended to the applicability of motion deblurring on videos, because it does not require a prior parametric model on the motion blur kernel or an accurate image alignment among frames. Nonetheless, it assumes that the input multiple images share a uniform blur kernel.
Because the temporal information of video is ignored and only the spatial prior information of an image is utilized, the performance of both single and multiple image methods is unsatisfactory while applying them to restore videos. The phenomena of artifacts, noise and inconsistencies often can be seen in the restored videos. In order to solve these problems, several video deblurring methods are explored in recent years. Takeda et al. [
21] and Chan et al. [
22] treated a video as a space-time volume. These methods give good spatiotemporal consistent results, however they are time-consuming as the size of space-time volume is large, and it assumes the exposure time is known in [
21] and the blur kernel is identical for all frames in [
22]. Qiao et al. presented a PatchMatch-based search strategy to search for a sharp superpixel to replace a blurry region [
23], but each sharp superpixel was selected from a frame, so when a region in all the adjacent frames is not sharp enough, the method cannot restore the blurred region. Building upon the observation that the same objective may appear sharp on some frames whereas blurry on others, Cho et al. [
17] proposed a patch-based synthesis method which ensures that the deblurred frames are both spatially and temporally coherent, because it can take full advantage of inter-frame information, but this method may fail when the camera motion is constantly large or has no sharp patches available. Besides, for solving complex motion blur, many optical flow depended methods was proposed. Wulff and Black [
24] addressed the deblurring problem with a layered model and focused on estimating the parameters for both foreground and background motions with optical flow. Kim and Lee [
25] proposed a method for tackling the problem by simultaneously estimating the optical flow and latent sharp frame. These methods both have strong requirements of processing time and memory consumption. To accelerate the processing, inspiring by the Fourier deblurring fusion introduced in [
26,
27], Delbracio and Sapiro [
28] proposed an efficient deblurring method by locally fusing the consistent information of nearby frames in the Fourier domain. It makes the computation of optical flow more robust by subsampling and computing at a coarser scale. However, the method cannot effective deblurring videos with no sharp frames.
Other methods take into account the temporal coherence between video frames in the blur kernel estimation or the latent sharp frame restoration [
29,
30,
31,
32,
33]. Lee et al. [
29,
30] utilized the high-resolution information of adjacent unblurred frames to reconstruct blurry frames. This method can accelerate the precise estimation of the blur kernel, but meanwhile it assumes that the video is sparsely blurred. Chan and Nguyen [
31] introduced a L2-norm regularization function along the temporal direction to avoid flickering artifacts for LCD motion blur problem. Gong et al. [
32] proposed a temporal cubic rhombic mask technique for deconvolution to enhance the temporal consistency. However, it cannot lead to sharp result because the frames used in the temporal mask term are the blurry frames adjacent to current frame, which denotes that the restoration will be close to the blurry frame. Zhang et al. [
33] proposed a video deblurring approach by estimating a bundle of kernels and applying the residual deconvolution. This method has spatiotemporal consistent, but the processing time is long for estimating a bundle of kernels and iterating the residual deconvolution.
In order to solve the above-mentioned problems, we proposed a removing camera shake method for restoring the blurred videos with no sharp frames. In the proposed method, except for the spatial information, we also make full use of the temporal information for both blur kernel estimation and latent sharp frame restoration considering that the temporal information between neighboring frames can accelerate the precise estimation of blur kernel, suppress the ringing artifacts and maintain the temporal consistency of restoration. We derive a motion-compensated frame by performing motion estimation and compensation on two adjacent frames. The derived motion-compensated frame has sharp edges and little noise because it is a predictor of current sharp frame. Therefore, we apply it to a regularization model after processed for efficiently getting an accurate blur kernel. Our improved blur kernel estimation method can improve more effective restored quality than the method proposed by Lee et al. [
29] in avoiding the pixel error of the motion-compensated frame and handling the blur video without sharp frame. Finally, in order to suppress the ringing artifacts and guarantee the temporal consistency in the latent sharp frame restoration step, we propose a spatiotemporal constraint term for restoring the video frames with the estimated blur kernel. The proposed spatiotemporal constraint term constrains the inter-frame information between the current sharp frame and the motion-compensated frame by the temporal regularization function rather than the temporal mask term in [
32]. The proposed spatiotemporal constraint energy function is solved by extend FTVd.
The contributions of this paper can be summarized as follows:
- (1)
We propose a blur kernel estimation strategy by applying the derived motion-compensated frame to an improved regularization model for enhancing the quality of the estimated blur kernel and reducing the processing time.
- (2)
We propose a spatiotemporal constraint algorithm that introduces a temporal regularization term for obtaining latent sharp frame.
- (3)
We extend the computationally efficient FTVd for solving the minimization problem of the proposed spatiotemporal constraint energy function.
The rest of this paper is organized as follows:
Section 2 describes the proposed method in detail. The experimental results are illustrated in
Section 3.
Section 4 is the conclusions.
2. Proposed Method
According to model (1), the
t-th observed blurry frame
B(
x,
y,
t) could be related to the latent sharp frame
L(
x,
y,
t) as:
where (
x,
y) and
t are the coordinate in space and time, respectively. Given a blurry video, as illustrated in
Figure 1, our aim is to obtain the latent sharp frame
L from the blurry frame
B. Here, we focus on the uniform blur caused by camera motion, so the blur kernel is assumed to be shift-invariant. However, the blur kernel may be different from each other along the time direction, i.e., the blur kernel is spatially-invariant, meanwhile, may be temporally variant.
2.1. The Outline of the Proposed Video Deblurring Method
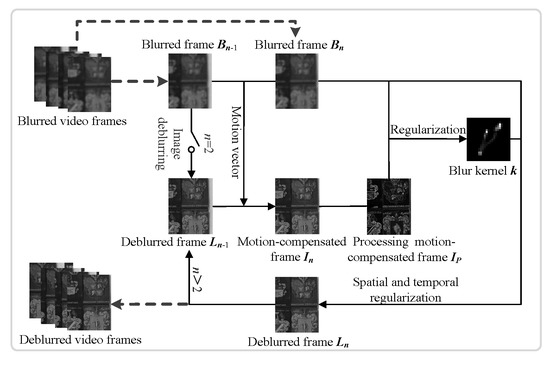
A detailed description of the proposed video deblurring method is given in this section. Because there may be no sharp frame in the video, we employ a frame grouping strategy for deblurring the video. The first frame of each group is restored by a single image deblurring method, and the remaining frames of the group can be deblurred by the proposed video deblurring method with the first restored frame. For deblurring the
n-th blurry frame in a video, our method consists of three steps and the outline of the proposed method is shown in
Figure 2.
As shown in
Figure 2, in the first step, we estimate the motion vector between the two adjacent blurry frames
Bn−1 and
Bn, and derive the motion-compensated frame
In by performing motion compensation on the previous restored frame
Ln−1. In the second step, we estimate the accurate blur kernel by the regularization algorithm with the current blurry frame
Bn and the preprocessed motion-compensated frame
IP. In the third step, we obtain the deblurred frame
Ln by using the spatiotemporal constraint algorithm with the blur kernel
k from the second step and the motion-compensated frame
In from the first step. The deblurred frame
Ln in the third step will be used as one of input for estimating the motion compensation and the motion-compensated frame in the next loop.
The pseudocode of the proposed video deblurring method is summarized as follows (Algorithm 1):
| Algorithm 1: Overview of the proposed video deblurring method. |
Input: The blurry video.
Divide the video into M groups that have N frames in a group. Set the group ordinal of the video m = 1 and the frame ordinal of this group n = 2.
Repeat
Repeat- (1)
Obtain the first deblurred frame L1 of this group by utilizing an image deblurring method. - (2)
Perform motion estimation algorithm to get the motion vector between the blurry frames Bn−1 and Bn, and using it to derive the motion-compensated frame In from the previous deblurred frame Ln−1. - (3)
Obtain the preprocessing motion-compensated frame IP by preprocessing In, and then estimate the blur kernel k with IP and Bn by the regularization method. - (4)
Estimate the deblurred frame Ln by the spatiotemporal constraint algorithm with k and In. - (5)
n ← n + 1.
Until n > N
m ← m + 1
Until m > M
Output: The deblurred video. |
2.2. The Proposed Blur Kernel Estimation Strategy
We first estimate the motion-compensated frame by the motion vector of the blurry frame and the previous frame for obtaining the blur kernel. We still take the n-th blurry frame Bn, for example. Because the accuracy of the motion-compensated frame In affects the overall performance of our method, an accurate motion vector between the current and the previous blurry frames is needed. In this paper, for generating a sufficient correct motion-compensated frame In, according to whether the blur kernel is temporally invariant, we introduce two different matching methods that are block matching method and feature extraction method respectively.
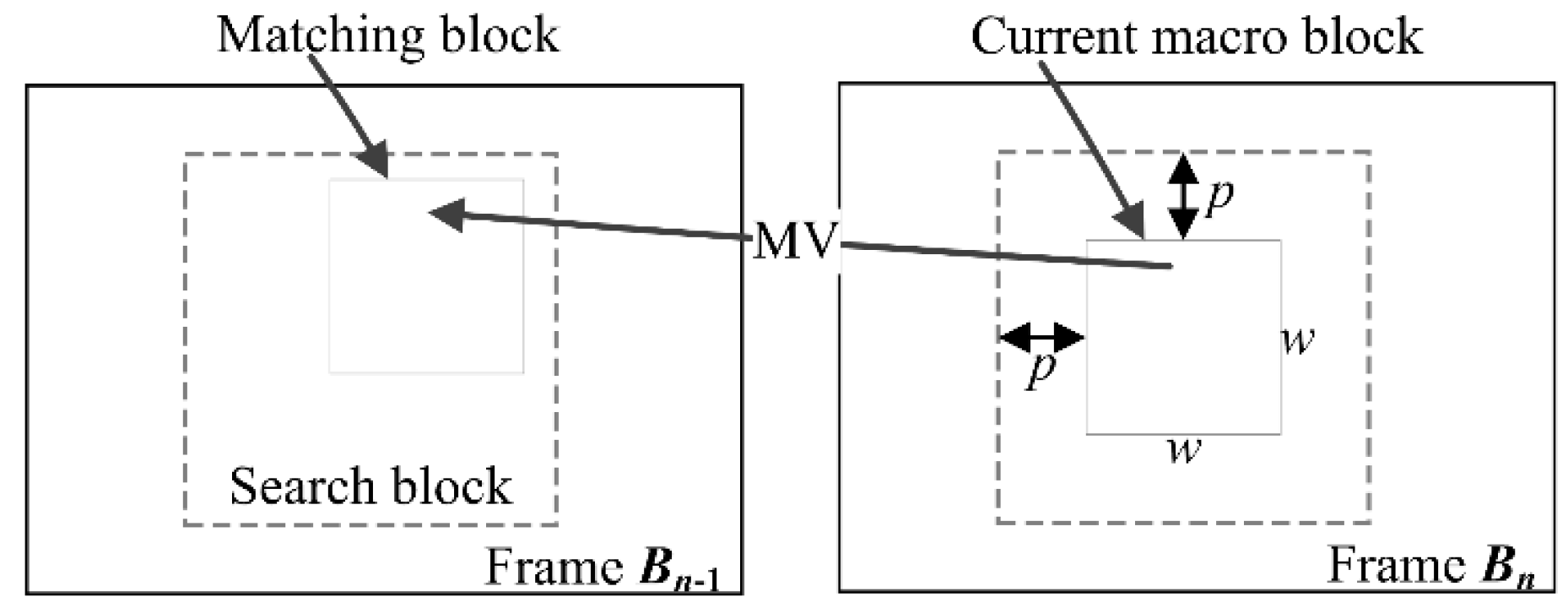
The block matching method divides the current blurry frame into a matrix of macro block and then searches the corresponding block with the same content in the previous blurry frame. The macro block size is
w ×
w and the searched area is constrained up to
p pixels on all four sides of the corresponding macro block in the previous frame as shown in
Figure 3. When the blur kernel is temporally invariant, all frames have exactly the same blur. As a result, an identical macro block can be found in the previous frame except the edge regions, and then a sufficiently accurate motion vector is derived. Because the exhaustive search block matching method [
34] could find the best possible match amongst block matching methods, we introduce it for estimating the motion vector and set the parameters
w = 16 and
p = 7 as a default.
As for temporally variant blur kernels, video frames are deblurred with the blur kernels that have different sizes and directions. Consequently, we introduce a feature extraction method to track the feature points across the adjacent blurry frames due to it is robust to image blur and noise. As the Oriented Fast and Rotated BRIEF (ORB) method [
35] is much faster than the other extraction methods and shows good performance on blurry images [
36], we employ the method to estimate the motion vector. Firstly, we match the feature points between the adjacent frames. Then, we calculate the mean motion vector of all feature points when the scene is static for that all the pixels have a same motion vector. When there are moving objects in the scene, the frames are divided into a matrix of macro blocks, and the motion vector of each block is dependent on the feature points in the current block and its neighborhood blocks.
After obtaining the motion vector between the adjacent blurry frames Bn−1 and Bn, the motion-compensated frame In, i.e., the initial estimation of the current sharp frame can be derived by performing motion compensation on the previous deblurred frame Ln−1, which is estimated in the previous loop. It should be noted that the first deblurred frame L1 of each group can be achieved by an image deblurring method.
We estimate the blur kernel by edge information after obtained the motion-compensated frame. Cho and Lee [
4] estimate the blur kernel by solving the energy function similar to:
where
is the data term, and
is L2-norm.
B is the current blurry frame, namely,
Bn,
I is the latent sharp frame, and
α is a weight for the regularization term
.
In energy function (3), the blurry frame is used to estimate the blur kernel, the latent sharp frame I has to be obtained firstly through the prior information of the current frame. Considering that it takes a great deal of time if a coarse-to-fine scheme or an alternating iterative optimization scheme is employed, Cho and Lee used a simple de-convolution method to estimate the latent sharp frame I and formulated the optimization function using image derivatives rather than pixel values to accelerate the blur kernel estimation. However, the method needs to estimate the latent sharp frame without the inter-frame information of the video, and the estimated one is of enough sharp edges.
In order to take full advantages of the temporal information and accelerate the precise estimation of the blur kernel, we propose a blur kernel estimation strategy based on [
4] which applying the motion-compensated frame
In to the data term of (3) for
In is pretty close to the current latent sharp frame. However, there may exist error of
In, and as illustrated in [
4], sharp edges and noise suppression in smooth regions will enable accurate kernel estimation. For obtaining salient edges, removing noise, and avoiding the influence of the errors, we preprocess
In by anisotropic diffusion and shock filter to get a preprocessing motion-compensated frame
IP.
The anisotropic diffusion equation is as follows:
where
div and
are the divergence operator and the gradient operator respectively.
denotes the coefficient of diffusion and can be obtained by using:
where
g is the gradient threshold and is set to 0.05 as a default.
The evolution equation of a shock filter is formulated as follows:
where
It is an image at time
t,
and
are the Laplacian and gradient operators, respectively,
dt is the time step for a single evolution and is set to 0.1 in the experiments.
The anisotropic diffusion is firstly applied to the motion-compensated frame In and then the shock filter is used to obtain the preprocessing motion-compensated frame IP. Due to the fact the above processing steps can sharpen edges and discard small details, the motion estimation errors have little effect on the blur kernel estimation. So, an accurate blur kernel can be estimated by energy function (3), where we use the preprocessing motion-compensated frame IP as I in the data term. The parameter α is set to 1 in our experiments. Besides the proposed blur kernel estimation strategy without iterative can improve greatly the running speed.
For solving energy function (3), we perform the fast Fourier transform (FFT) on all variables and then set the derivative of
k to 0 for solving the minimization problem. Hence, the equation of
k is derived as follows:
where
and
denote the forward and inverse FFT, respectively, and
is the complex conjugate of
,
is an element-wise multiplication operator.
2.3. The Proposed Spatiotemporal Constraint Algorithm
We propose a kind of new spatiotemporal constraint algorithm for obtaining latent sharp frame. The proposed model is improved from energy function (8) that initially is proven in [
31]:
where
is L1-norm, and
Di is the spatial directional gradient operators at 0°, 45°, 90° and 135°,
L,
L0, and
M represent the current sharp frame, the previous deblurred frame, and the motion compensation, respectively,
ML0 is equivalent to the motion-compensated frame
In,
λ and
β are two regularization parameters.
The first part of energy function (8) is a data term, where the image pixel values are calculated. However, in the data term, the noise for all pixels cannot capture at all the spatial randomness of noise, and that would lead to deconvolution ringing artifacts. For reducing the ringing artifacts of image deconvolution, we introduce the likelihood term proposed by Shan et al. [
3] as shown in the first term of energy function (9). In the latter two terms of energy function (8), the spatial regularization function employs L1-norm to suppress noises and preserve edges, and the temporal regularization function employs L2-norm to maintain the smoothness along time axis. These regularization functions are capable of reducing the spatiotemporal noise, as well as keeping the temporal coherence of the deblurred video. However, it is inevitable that a few errors exist during motion estimation and compensation. Since the temporal regularization term makes the estimated current sharp frame close to the motion-compensated frame for each image pixel, the errors of motion estimation and compensation give rise to a deviation in the estimated current sharp frame. We propose a temporal regularization constraint term with L2-norm on the differential operators that able to avoid introducing pixel errors.
For illustrating the effectiveness of the temporal regularization function, the proposed deconvolution algorithm is compared with the spatial regularization algorithm and the L2-norm temporal regularization based deconvolution algorithm as shown in
Figure 4. The comparison results show that the smoothness of the restored result in
Figure 4c by the spatial regularization algorithm without temporal regularization term is poor, and the restored result in
Figure 4d by the L2-norm temporal regularization based deconvolution algorithm contains some noise. As shown in
Figure 4e, the result restored by our algorithm has sharper edges than the above algorithms.
The proposed energy function is as follows:
where
stands for the partial derivative operators and
is a series of weights for each partial derivative, which is determined as Shan et al. [
3],
λS and
λT are the spatial and temporal regularization constraint parameters respectively. When
λT is too small, the deblurred frames are not smoothness enough. When
λT is too large, the accumulated error in time axis can be amplified, especially for large loop numbers. Therefore,
λT is calculated according to the ordinal of the frame in a group.
represents the first difference operator and
is the motion-compensated frame, i.e.,
.
Then, we extend FTVd for solving the minimization problem of energy function (9) effectively. Main idea of FTVd is to employ the splitting technique and translate the problem to a pair of easy subproblems. To this end, an intermediate variable
u is introduced to transform energy function (9) into an equivalent minimizing problem as follows:
where
γ is a penalty parameter, which controls the weight of the penalty term
.
Next, we solve problem (10) by minimizing the following subproblems:
u-Subproblem: With
L fixed, we update
u by minimizing:
Using the shrinkage formula to solve this problem,
ux and
uy are given as follows:
L-subproblem: By fixing
u, (10) can be simplified to:
The blur kernel
k is a block-circulant matrix. Hence, (14) has the following solution according to Plancherel’s theorem:
where
and
.
Algorithm 2 is the pseudocode of the proposed spatiotemporal constraint algorithm.
| Algorithm 2: The proposed spatiotemporal constraint algorithm. |
Input: the blurry frame Bn (2), the motion-compensated frame In, the blur kernel k and the parameters λS and λT. Initialize the deblurred frame L = Bn.
While not converge do- (1)
Save the previous iterate: Lp = L. - (2)
With L fixed, solve the u-subproblem using (12) and (13). - (3)
With u fixed, solve the L-subproblem using (15).
If then
Break
End if
End while
Output: the deblurred frame L. |



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}