A Case Study on Attribute Recognition of Heated Metal Mark Image Using Deep Convolutional Neural Networks


Abstract
:1. Introduction
- Deep convolutional neural networks models are adopted to recognize attribute of heated metal based on its marks image;
- The material benchmark dataset is completely new designed and generated;
- Extensive experimental evaluations and analyses are carried out.
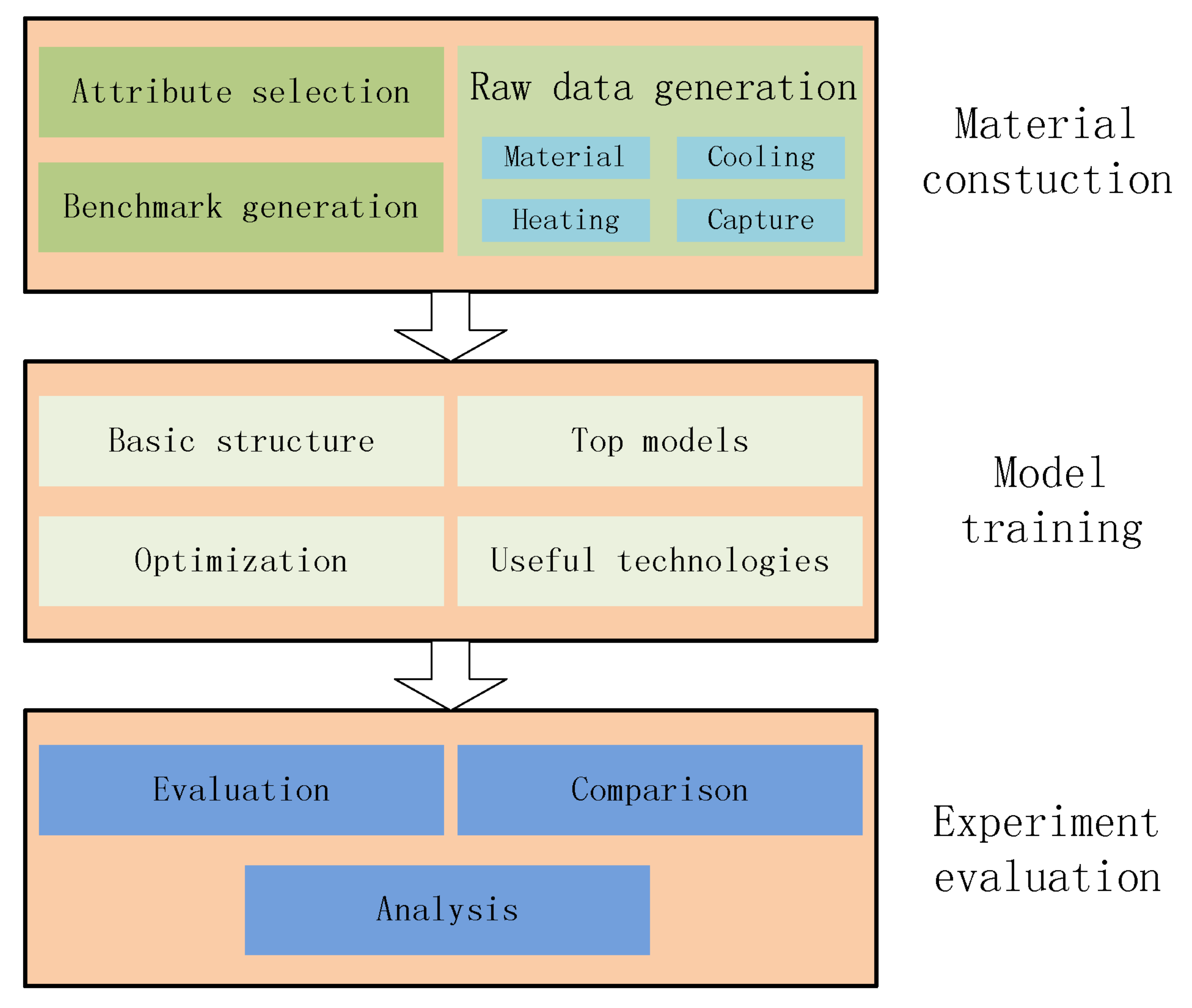
2. Materials Generation
2.1. Attribute Definition
- . This attribute indicates the type of heated metal in the fire scene;
- . This attribute indicates heating source and form;
- . This attribute indicates the temperature degree of the metal that being heated;
- . This attribute indicates the duration time of the metal that being heated;
- . This attribute indicates the method of the heated metal that being cooled;
- . This attribute indicates the humidity degree when the heated metal that being cooled;
- . This attribute indicates the duration time of the heated metal that being cooled.
2.2. Raw Image Generation
2.3. Benchmark Dataset Construction
3. Methodology
3.1. Basic Structures in CNNs
3.1.1. Convolutional Layer
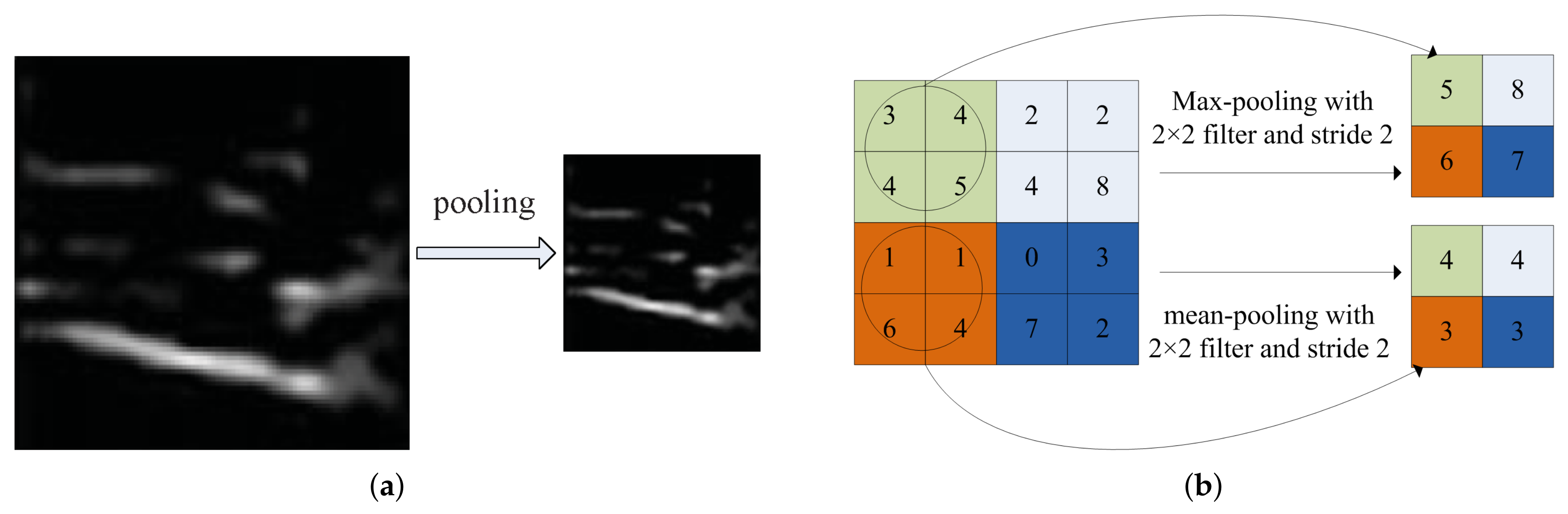
3.1.2. Pooling Layer
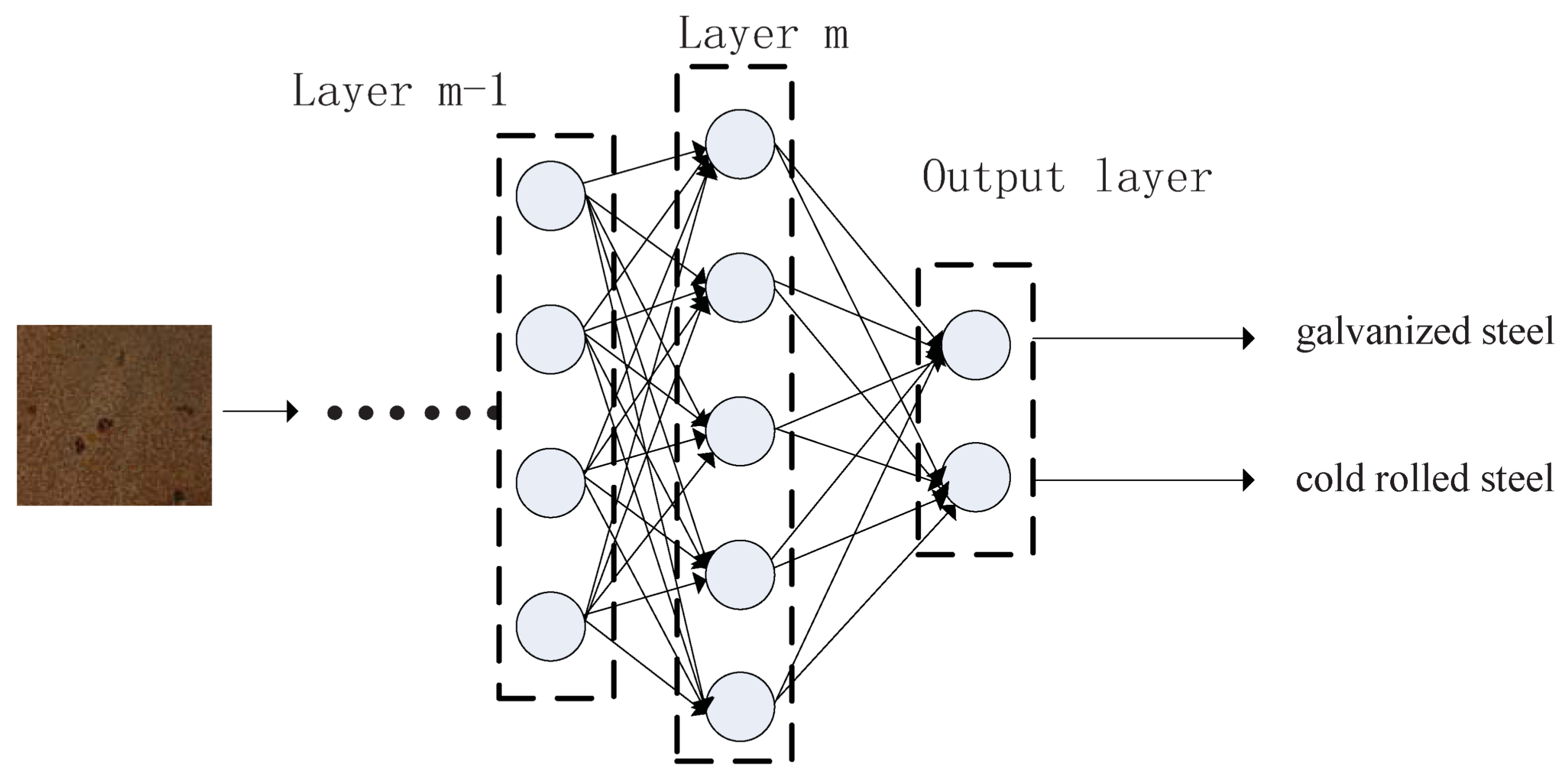
3.1.3. Fully Connected Layer
3.1.4. Loss Function and Model Training
3.2. Top CNNs Models
3.2.1. VGGNet
3.2.2. ResNet
3.2.3. Inception
3.2.4. Mobilenet
3.3. Useful Technique
3.3.1. Dropout
3.3.2. Data Augment
3.3.3. Pre-Trained Model
3.4. Pseudocode
| Algorithm 1 Pseudocode of the proposed method. |
| Input: , Initialized model parameter |
| Output: Optimized model parameter |
| 1: Loss L = 1, iteration number = N, counter i = 0, Loss threshold ; |
| 2: while () and ( do |
| 3: random select a batch of samples S from ; |
| 4: ; |
| 5: ; |
| 6: ; |
| 7: i++; |
| 8: end while |
| 9: = ; |
| 10: return ; |
4. Experimental Evaluations
4.1. Experiment Setup
4.2. Evaluation of Recognition Rate with Cross Validation
4.3. Evaluation of Recognition Efficiency
4.4. Evaluation of Optimization Method
4.5. Evaluation of Batch Size
4.6. Evaluation of Execution Times
5. Conclusion and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Inspection Methods for Trace and Physical Evidences from Fire Scene—Part 3: Ferrous Metal Work; GB/T 27905.3-2011; National Standard of People’s Republic of China: Shenzhen, China, 2011.
- Wu, Y.; Zhao, C.; Di, M.; Qi, Z. Application of metal oxidation theory in fire trace evidence identification. In Proceedings of the Building Electrical and Intelligent System, Shenyang, China, 11–13 November 2007; pp. 108–110. [Google Scholar]
- Wu, Y.; Zhao, C.; Di, M.; Qi, Z. Application of metal oxidation theory in fire investigation and fire safety. In Proceedings of the International Colloquium on Safety Science and Technology, Shenyang, China, 27–28 October 2008; pp. 538–540. [Google Scholar]
- Xu, Z.; Song, Y. Fuzzy identification of surface temperature for building members after fire. J. Dalian Univ. Technol. 2005, 45, 853–857. [Google Scholar]
- Li, D.; Yu, T. Analysis of surface discoloration of galvanizing sheet steel caused by unfavorable brazing heating. J. Phys. Test. Chem. Anal. Part A Phys. Test. 2007, 43, 176–178. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 1150–1157. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2006, 60, 91–110. [Google Scholar] [CrossRef]
- Navneet, D.; Bill, T. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Bay, H.; Tuytelaars, T.; van Gool, L. SURF: Speeded Up Robust Features. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- John, G.D. Uncertainty relation for resolution in space, spatial frequency, and orientation optimized by two-dimensional visual cortical filters. J. Opt. Soc. Am. A 1985, 2, 1160–1169. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Plaza, A.; Li, Y. Discriminative Low-Rank Gabor Filtering for Spectral-Spatial Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1381–1395. [Google Scholar] [CrossRef]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 32–39. [Google Scholar]
- Fei-Fei, L.; Fergus, R.; Torralba, A. Recognizing and Learning Object Categories. CVPR 2007 Short Course. Available online: http://people.csail.mit.edu/torralba/shortCourseRLOC/ (accessed on 18 March 2018).
- Grauman, K.; Darrell, T. The Pyramid Match Kernel: Discriminative Classification with Sets of Image Features. In Proceedings of the 10th IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; pp. 1458–1465. [Google Scholar]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the 23th IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Perronnin, F.; Dance, C. Fisher Kernels on Visual Vocabularies for Image Categorization. In Proceedings of the 20th IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 1381–1395. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV 5), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 1381–1395. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Proceedings of 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NE, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Faghih-Roohi, S.; Hajizadeh, S.; Núñez, A.; Babuska, R.; De Schutter, B. Deep convolutional neural networks for detection of rail surface defects. In Proceedings of the International Joint Conference on Neural Networks, Vancouver, BC, Canada, 24–29 July 22016; pp. 2584–2589. [Google Scholar]
- Li, S.; Liu, G.; Tang, X.; Lu, J.; Hu, J. An Ensemble Deep Convolutional Neural Network Model with Improved D-S Evidence Fusion for Bearing Fault Diagnosis. Sensors 2017, 17, 1729. [Google Scholar] [CrossRef] [PubMed]
- Psuj, G. Multi-Sensor Data Integration Using Deep Learning for Characterization of Defects in Steel Elements. Sensors 2018, 18, 292. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Chen, Y.; Zhang, D.; Xie, J.; Zhou, Y. Classification of surface defects on steel sheet using convolutional neural networks. Mater. Technol. 2017, 51, 123–131. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput.-Aided Civ. Infrastruct. Eng. 2018, 32, 361–378. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput.-Aided Civ. Infrastruct. Eng. 2017. [Google Scholar] [CrossRef]
- Xu, Y.; Bao, Y.; Chen, J.; Zuo, W.; Li, H. Surface fatigue crack identification in steel box girder of bridges by a deep fusion convolutional neural network based on consumer-grade camera images. Struct. Health Monit. 2018. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the 31th AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv, 2017; arXiv:1704.04861. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Tran, T.; Pham, T.; Carneiro, G.; Palmer, L.; Reid, I. A Bayesian Data Augmentation Approach for Learning Deep Models. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2794–2803. [Google Scholar]
- Ding, J.; Li, X.; Gudivada, V.N. Augmentation and evaluation of training data for deep learning. In Proceedings of the IEEE International Conference on Big Data, Boston, MA, USA, 11–14 December 2017; pp. 2603–2611. [Google Scholar]
- Simon, M.; Rodner, E.; Denzler, J. ImageNet pre-trained models with batch normalization. arXiv, 2016; arXiv:1612.01452. [Google Scholar]
- Senthilnath, J.; Kandukuri, M.; Dokania, A.; Ramesh, K.N. Application of UAV imaging platform for vegetation analysis based on spectral-spatial methods. Comput. Electron. Agric. 2017, 140, 8–24. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Color | Heating Temperature |
|---|---|
| dark purple | 300 C |
| sky blue | 350 C |
| brown | 450 C |
| dark red | 500 C |
| orange | 650 C |
| light yellow | 1000 C |
| white | 1200 C |
| Attribute Abbr. | Attribute Name | Types (Predefined Label Values) |
|---|---|---|
| Metal type | 2 types: (1) galvanized steel; (2) cold rolled steel | |
| Heating mode | 3 types: (1) vacuum; (2) muffle furnace; (3) gasoline burner | |
| Heating temperature | 4 degrees: (1) 400 C; (2) 600 C; (3) 800 C; (4) 1000 C | |
| Heating duration | 4 degrees: (1) 15 min; (2) 30 min; (3) 40 min; (4) 45 min | |
| Cooling mode | 2 types: (1) Natural cooling; (2) forced cooling | |
| Placing duration | 3 degrees: (1) 24 h; (2) 36 h; (3) 48 h | |
| Relative humidity | 2 degrees: (1) 65%; (2) 85% |
| Model | Pre-Trained | Data Augment | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| - | yes | no | 0.96 | 0.58 | 0.98 | 0.27 | 0.97 | 0.81 | 0.98 | 0.20 | 0.98 | 0.33 | 0.98 | 0.41 | 0.98 | 0.31 |
| yes | yes | 0.98 | 0.45 | 0.99 | 0.30 | 0.94 | 0.69 | 0.98 | 0.48 | 0.98 | 0.82 | 0.98 | 0.40 | 0.98 | 0.57 | |
| no | no | 0.98 | 0.72 | 0.92 | 0.82 | 0.99 | 0.80 | 0.95 | 0.49 | 0.99 | 0.85 | 0.98 | 0.62 | 0.91 | 0.83 | |
| no | yes | 0.96 | 0.92 | 0.98 | 0.90 | 0.98 | 0.83 | 0.97 | 0.85 | 0.99 | 0.92 | 0.97 | 0.78 | 0.95 | 0.91 | |
| - | yes | no | 0.96 | 0.60 | 0.98 | 0.25 | 0.99 | 0.81 | 0.97 | 0.47 | 0.99 | 0.80 | 0.96 | 0.47 | 0.92 | 0.31 |
| yes | yes | 0.99 | 0.72 | 0.97 | 0.40 | 0.99 | 0.81 | 0.99 | 0.53 | 0.99 | 0.87 | 0.99 | 0.54 | 0.99 | 0.34 | |
| no | no | 0.97 | 0.79 | 0.90 | 0.63 | 0.94 | 0.82 | 0.93 | 0.60 | 0.99 | 0.86 | 0.85 | 0.59 | 0.95 | 0.48 | |
| no | yes | 0.97 | 0.90 | 0.96 | 0.85 | 0.99 | 0.81 | 0.98 | 0.91 | 0.99 | 0.92 | 0.97 | 0.69 | 0.98 | 0.91 | |
| yes | no | 0.98 | 0.56 | 0.98 | 0.53 | 0.99 | 0.80 | 0.99 | 0.15 | 0.98 | 0.67 | 0.98 | 0.40 | 0.98 | 0.24 | |
| yes | yes | 0.98 | 0.45 | 0.98 | 0.43 | 0.99 | 0.79 | 0.97 | 0.26 | 0.99 | 0.67 | 0.98 | 0.39 | 0.98 | 0.39 | |
| no | no | 0.90 | 0.72 | 0.94 | 0.41 | 0.92 | 0.80 | 0.94 | 0.48 | 0.99 | 0.68 | 0.85 | 0.61 | 0.93 | 0.73 | |
| no | yes | 0.93 | 0.89 | 0.90 | 0.83 | 0.94 | 0.83 | 0.94 | 0.65 | 0.98 | 0.73 | 0.94 | 0.73 | 0.91 | 0.90 | |
| yes | no | 0.92 | 0.72 | 0.95 | 0.71 | 0.90 | 0.20 | 0.92 | 0.64 | 0.99 | 0.69 | 0.92 | 0.77 | 0.90 | 0.52 | |
| yes | yes | 0.96 | 0.68 | 0.97 | 0.65 | 0.98 | 0.21 | 0.96 | 0.49 | 0.99 | 0.74 | 0.96 | 0.60 | 0.94 | 0.55 | |
| no | no | 0.93 | 0.61 | 0.92 | 0.63 | 0.90 | 0.32 | 0.91 | 0.51 | 0.98 | 0.74 | 0.66 | 0.63 | 0.95 | 0.81 | |
| no | yes | 0.93 | 0.87 | 0.90 | 0.85 | 0.94 | 0.81 | 0.93 | 0.72 | 0.98 | 0.80 | 0.83 | 0.78 | 0.97 | 0.89 | |
| yes | no | 0.98 | 0.58 | 0.97 | 0.43 | 0.98 | 0.21 | 0.98 | 0.57 | 0.98 | 0.81 | 0.98 | 0.49 | 0.98 | 0.13 | |
| yes | yes | 0.97 | 0.73 | 0.98 | 0.55 | 0.99 | 0.38 | 0.98 | 0.66 | 0.98 | 0.79 | 0.97 | 0.61 | 0.99 | 0.34 | |
| no | no | 0.90 | 0.68 | 0.91 | 0.75 | 0.94 | 0.82 | 0.98 | 0.53 | 0.99 | 0.81 | 0.85 | 0.65 | 0.95 | 0.55 | |
| no | yes | 0.93 | 0.90 | 0.92 | 0.83 | 0.96 | 0.82 | 0.90 | 0.82 | 0.99 | 0.89 | 0.91 | 0.74 | 0.97 | 0.91 | |
| Attribute | Efficiency | - | - | |||
|---|---|---|---|---|---|---|
| 0.93 | 0.87 | 0.88 | 0.89 | 0.91 | ||
| 0.91 | 0.93 | 0.90 | 0.85 | 0.89 | ||
| 0.92 | 0.90 | 0.89 | 0.87 | 0.90 | ||
| 0.92 | 0.83 | 0.79 | 0.82 | 0.80 | ||
| 0.91 | 0.84 | 0.84 | 0.86 | 0.84 | ||
| 0.87 | 0.88 | 0.83 | 0.87 | 0.85 | ||
| 0.90 | 0.85 | 0.82 | 0.85 | 0.83 | ||
| 0.80 | 0.78 | 0.79 | 0.77 | 0.80 | ||
| 0.83 | 0.85 | 0.86 | 0.84 | 0.83 | ||
| 0.85 | 0.80 | 0.83 | 0.83 | 0.80 | ||
| 0.84 | 0.81 | 0.84 | 0.81 | 0.85 | ||
| 0.83 | 0.81 | 0.83 | 0.81 | 0.82 | ||
| 0.80 | 0.88 | 0.60 | 0.68 | 0.80 | ||
| 0.83 | 0.92 | 0.68 | 0.76 | 0.85 | ||
| 0.87 | 0.90 | 0.70 | 0.75 | 0.79 | ||
| 0.86 | 0.93 | 0.63 | 0.69 | 0.84 | ||
| 0.85 | 0.91 | 0.65 | 0.72 | 0.82 | ||
| 0.90 | 0.89 | 0.71 | 0.83 | 0.88 | ||
| 0.94 | 0.95 | 0.75 | 0.77 | 0.90 | ||
| 0.92 | 0.92 | 0.73 | 0.80 | 0.89 | ||
| 0.75 | 0.66 | 0.70 | 0.73 | 0.71 | ||
| 0.77 | 0.73 | 0.72 | 0.80 | 0.75 | ||
| 0.82 | 0.68 | 0.77 | 0.81 | 0.76 | ||
| 0.78 | 0.69 | 0.73 | 0.78 | 0.74 | ||
| 0.87 | 0.90 | 0.88 | 0.87 | 0.88 | ||
| 0.95 | 0.92 | 0.92 | 0.91 | 0.94 | ||
| 0.91 | 0.91 | 0.90 | 0.89 | 0.91 |
| Execution Time | Batch Size | - | - | |||
|---|---|---|---|---|---|---|
| Training time | 8 | 2.67 | 2.45 | 2.03 | 1.84 | 1.59 |
| 12 | 3.05 | 2.77 | 2.29 | 2.09 | 1.81 | |
| 16 | 3.33 | 3.08 | 2.54 | 2.31 | 2.04 | |
| 24 | 3.67 | 3.41 | 2.81 | 2.54 | 2.23 | |
| 32 | 4.33 | 4.05 | 3.34 | 3.02 | 2.65 | |
| Testing time | x | 0.11 | 0.083 | 0.062 | 0.045 | 0.031 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao , K.; Lu , D.; E , D.; Tan , Z. A Case Study on Attribute Recognition of Heated Metal Mark Image Using Deep Convolutional Neural Networks. Sensors 2018, 18, 1871. https://doi.org/10.3390/s18061871
Mao K, Lu D, E D, Tan Z. A Case Study on Attribute Recognition of Heated Metal Mark Image Using Deep Convolutional Neural Networks. Sensors. 2018; 18(6):1871. https://doi.org/10.3390/s18061871
Chicago/Turabian StyleMao , Keming, Duo Lu , Dazhi E , and Zhenhua Tan . 2018. "A Case Study on Attribute Recognition of Heated Metal Mark Image Using Deep Convolutional Neural Networks" Sensors 18, no. 6: 1871. https://doi.org/10.3390/s18061871
APA StyleMao , K., Lu , D., E , D., & Tan , Z. (2018). A Case Study on Attribute Recognition of Heated Metal Mark Image Using Deep Convolutional Neural Networks. Sensors, 18(6), 1871. https://doi.org/10.3390/s18061871