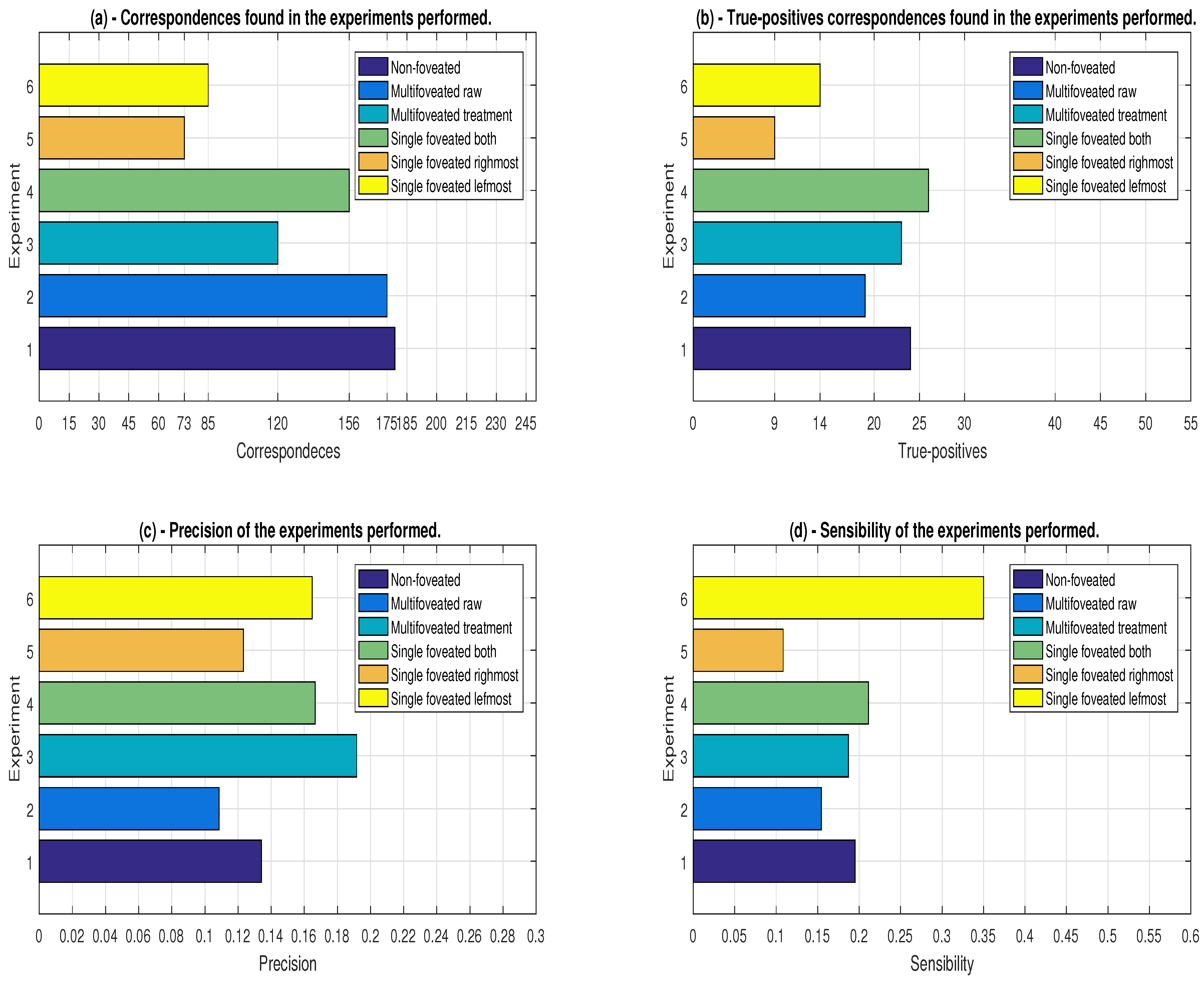
The idea is to apply several foveated structures on the PC, but with an additional step that remove the redundant points. In this scheme, it is possible to reduce the processing time while the densities around the several foveae are sufficient to guarantee the detection of the objects. In this scheme, the FS is a sectioned frame having different resolutions (multi-resolution), where the size of the level is inversely proportional to the quality of the resolution, so that each of these levels is successively encompassed by the other in such a way that all are disjoint.
4.2. Intersection Regions between Levels
The proposed multifoveated point cloud is composed by n structures with the same number of levels. However, adding several identical points in the PC is allowed by the storage data structure of the PC because it is basically a list of points and not pixels that have their values set on the display device with only one value at a time. To simplify this aspect of the PC, we name as the computational space (virtual) the representation of the 3D virtual region that has the peculiarity of allowing the existence of several identical points in the scene. Let the world coordinate system of this computational space. However, the amount of points is limited to the available memory of the operating system to which the file belongs. Nonetheless, the raster images are already limited by a standard format of the acquisition device or by the display device.
We are aided by set theory area to describe and determine the intersections between regions. Before performing this analysis, we define four specific sets:
,
,
and
R. The operating ranges (i.e., zones of possible modifications) of the FS levels in the 3D computational space are defined by
according to Equation (
1), where
and
. Term
v is one of the components of
. The action stretches
for each component of the parallelepiped relative to the level
i of a foveated structure
j is defined according to Equation (
1):
and
. The terms
and
are the displacement and size, respectively, as defined in the work of Beserra Gomes et al. [
7]. They are given in function of the level
k by
=
and
=
.
Each of the levels determines a subset of
defined by
according to Equation (2). Regions
are such that they obey Equation (
3) to
f constant, variation of
i levels and any foveated structure. They are composed of their respective intervals in the Cartesian axes, which are expressed by
(Equation (
1)) which defines the performance sections of each region, when observed the three axes
from the full volume of the related level.
The definition of 3D foveated structure is given by Equation (4), also for
f constant, being able to admit the values of
j.
We define
as the set formed by finite foveated structures, where each of them contains a finite number of levels, according to Equation (5).
In the MFPC model, for a given level
i of the FS
j, the density reduction factor
is constant for all space
with each having its estimated density [
7]. In the multifoveation context, when two or more sections of different indexes of levels intersect, there will be regions for which different reduction factors will be applied. In this case, these structures should always have the same number of levels. So our proposal is defined only in the case of multiple FS that have the same number of levels. The density question is important because it defines how the addition of the points in the structures will be evaluated.
A priori the homogeneity of some region of a FS means that the region does not have intersection with higher levels (a level i is higher than the level j case and lower case ) or has no intersection at all, that is, the entire region of has a density reduction equal to or less relative to that level, considering that the density of the region is already less than calculated it would not be possible to establish the density defined by the level (e.g., a region without points).
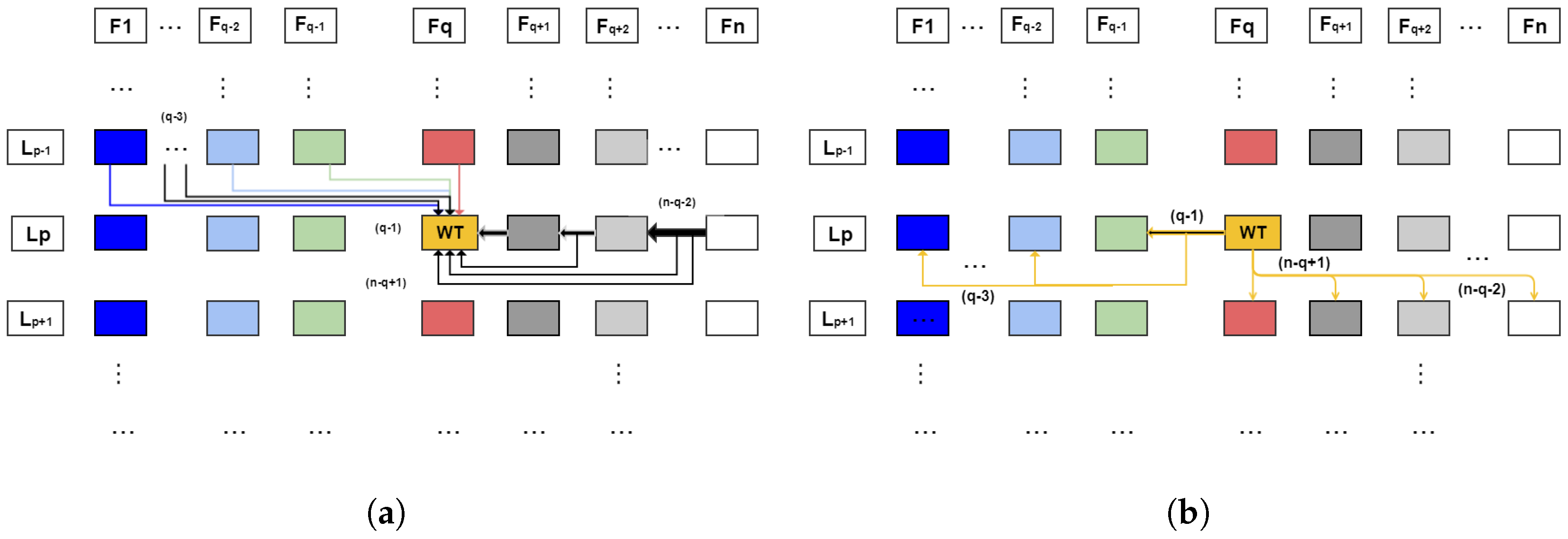
The redundancy validation operation diagram in the 3D multifoveated is shown in
Figure 2. It has its scheme divided into
n FS and
levels. The checks of a point of the non-zero PC that belong to any element of
are made by the directions of the arrows. Thus, it is verified whether a point
p belongs to the same level of previous structures or to a higher level of successor structures. If it is affirmative the point is not added to the level of the foveated structure observed
, otherwise it will be added. This diagram is the representation of how the redundancy treatment algorithm of this proposal works. For each point, the computational complexity in both the verification of the same predecessor levels and the successors at higher levels is
.
The operation of the redundancy treatment is given by the choice of a generic point
p non-zero of
(or region
R) in the PC. Given that we are observing a foveated structure
on one level
(box
) two searches are done. The first is made on the same level
as the predecessors of the structure (structures that were created earlier
), analyzing whether the observed point belonged to any of these previous levels. The second search is done on the
of successor FS (structures which will be created from
), given that the observed point belongs to some of these higher levels of successor FSs. If neither of these two tests is positive, then the
p (or region analyzed
R) will be added in
(the box analyzed), which is basically the function of adding points
made explicit in Equation (6).
From the development of Equation (6), a method has been implemented that allows the process of selection of points and
features to be sampled in each level of the FSs, removing the points and
features that generate ambiguity, deformations in the scene and, consequently, errors in the integrated tasks with our mechanism. Its operation is illustrated in
Figure 2; we can suggest a verification situation of a point that is in the second FS in level 1 (i.e., in
and
), so the checks would be performed: first, on the levels L2 of the second fovea on (i.e.,
green arrows); and, after that, the checks would be made in the levels
of the FSs previous to
, that is, only in the FS
, so which the point validation would be done from the cases of Equation (6). This whole procedure depends on the point to be checked and where it is embedded in the example, in FS
and level
.
For clarity, in
Figure 3a,b, we establish a level
in a foveated structure
called
shown in yellow. They are an observation of how the mechanism works given a separate observation. In
Figure 3a, the search process on
is shown where the validation is made by the predecessor levels
to the foveated structure
(i.e., current level and levels already searched). The search is performed at the same level of structure from
to
. In
Figure 3b, we have the search path made of
which are
backward and
forward, so the
searches are done at the same level as its
and for all previous structures being searched
backward observes if the point has already been inserted in previous levels. The search
forward is done to know if the point belongs to a level with greater magnitude of density than
, which is made in the
and posterior structures. The search is done only up to
levels, since the
covers up to the
.

 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}