1. Introduction
Multiple object tracking on a moving platform is an active research topic in computer vision, with applications such as automotive driver assistance systems, robot navigation and traffic safety. To date, much progress has been made in this field. Tracking-by-detection is one of the more extensively investigated methods. It formulates the problem as associating detection results with each other across video sequences to get the trajectories and identities of the targets. Traditional tracking-by-detection methods are heavily dependent on detection results, because there are many factors, such as inaccurate detections, similarity between objects, frequent occlusion, etc., which lead to tracklets or tracking drift, making multi-object tracking (MOT) still a very challenging task.
To solve the problem, many approaches have been presented during past decades. Some trackers explore different tracking algorithms to connect the detected targets’ positions and form trajectories. The tracking algorithms generally use associations or build an affinity model to connect the detected target, even predicting the positions of targets in the next frame. All existing tracking-by-detection approaches can be loosely categorized into batch mode [
1,
2,
3,
4,
5,
6,
7] or online mode [
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22], depending on the frames used by the tracker.
Batch mode-based methods utilize the detection of entire sequences for global association to establish a robust target trajectory, so as to compensate against occlusion and false detections. The global association is realized by a sliding window or hierarchical association, and often formulated as a graph optimization problem. It models the tracking problem as a network flow and solves it either with k-shortest paths in dynamic programing with non-maximum suppression (DP NMS) [
1], as a Generalized Maximum Multi-Clique problem which is solved with Binary Integer Programing in reference [
2], in a conditional random field (as in SegTrack) [
3], with Long-term time-sensitive costs for CRF(LTTSC-CRF) [
4], or with discrete-continuous energy minimization [
5], to name a few. These algorithms can correct previous data association errors and recover observations from an occluded state by using a future frame for association. Deep learning has also been applied to tracking for robust link detections; however, its application to the problem at hand remains rather sparse. One example is the jump Markov chain (JMC) method in [
6], which uses deep matching to improve affinity measurement, Siamese-convolutional neural network (CNN) uses a CNN in a Siamese configuration to estimate the likelihood that two pedestrian detections belong to the same tracked entity [
7]. However, these kinds of methods usually need detections for the entire sequence as input, only then generating globally optimized tracks by iterative associations. It is difficult to apply batch methods to real-time applications due to the expensive computation and special input required.
On the other hand, online mode-based methods [
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22] take real-time applications into consideration. Such methods use information up to the current frame, and link the detections frame by frame to build trajectories. This method solves the association problem by Bayesian filter or local data association, such as the Markov chain Monte Carlo (MCMC) filter [
8,
9], Kalman filter [
10,
11], or probability hypothesis density (PHD) filter [
12,
13]. The tracking problem is formulated as a Bayesian framework given past and current measurements to find the maximum-a-posteriori (MAP) solution. However, online methods are prone to producing fragmented tracklets and drifting with occlusion and detection errors, as it is more difficult to cope with inaccurate detections (such as false positives and false negatives) compared with the batch methods [
14]. Many online methods have been proposed to solve the track fragments and tracking drift problems due to inaccurate detections. Some attention shifted towards building robust pairwise similarity costs, mostly based on strong appearance cues. For example, the discriminative deep appearance learning in reference [
14], integral channel feature appearance models in online integral channel features (oICF) [
15], and temporal dynamic appearance models in Temporal dynamic appearance modeling (TDAM) [
16] are proposed to improve detection affinity, while utilizing markov decision process neural network (MDPNN16) [
17], which leverages Recurrent Neural Networks, in order to encode appearance, motion, and interactions. Comparatively, single object tracking (SOT) is another field of active research [
18], where correlation filters (CFs) may be the mainstream in this field. Many enhanced methods, such as output constraint transfer for kernelized correlation filter (OCT_KCF) [
19] and latent constrained correlation filter (LCCF) [
20] are proposed to further improve the performance on model drifting or other aspects. In reference [
21], hierarchical convolutional features are used for the adaptive correlation filters to address the appearance variation, another correlation filter is designed for scale estimation and target re-detection in case of tracking failure, the latter is necessary for long-term tracking tasks. Though CF-based methods show impressive performance, but most of the designed trackers are limited to single object tracking currently. How to extend CF to MOT is still an open issue. Further attention has been given to motion models of the tracked objects, which can be exploited to predict the target position. Relative motion network (RMN) [
22], for instance, constructs a relative motion network that accounts for the relative movement among objects to predict the objects’ positions when detection fails and to handle unexpected camera motion for robust tracking.
In the scenarios we address in this paper, the monocular camera is moving and there are moving targets in the scene. This brings great challenges to the problem. Reconstructing the scene structure while estimating the camera’s motion simultaneously is the well-studied structure-from-motion (SFM) problem, wherein the scene is stationary in the computer vision community. But when the camera is moving, the motions of tracked objects will couple with the camera’s motion. To tackle this problem, we need to estimate the camera’s motion along with other stationary features, so we need to separate the extracted stationary features from the dynamic ones, which allows us to estimate the camera’s motion robustly and compensate for target motion.
Additionally, we focus on the online method to address the fragmented trajectories and drifting caused by inaccurate detection. The relative-motion context of targets in 3D space is proposed for target association, which describes the 3D movement relationships among the tracked targets. Relatively speaking, the relative motion in two-dimensional (2D) imaging loses its depth information and can’t describe the relative positions of targets as accurately as in 3D space. Furthermore, in the case of camera motion, we incorporate a relative-motion model into a sequential Bayesian framework to track multiple objects and estimate the ego-motion. Because the number of targets changes dynamically, we use a sample method with reversible jump Markov chain Monte Carlo (RJMCMC), which unifies all modules under the Bayesian framework.
The main contributions of our work include: (1) A 3D relative-motion model is proposed to improve the track fragments due to occlusion or unreliable detections, which is more intuitive and reasonable for motion prediction; (2) Based on the 3D relative-motion model, an unified Bayesian framework is presented, which combines the MOT problem with camera motion estimation, and formulates it as finding a MAP solution of joint probability; (3) Validation of the proposed method with standard dataset and real data collected in the campus.
Figure 1 shows some outperforming results of the proposed method. In this figure, the tracked objects are marked with different colors. It shows that the proposed method can track targets even in a crowded scene.
The paper is organized as follows. The related works are reviewed in
Section 2.
Section 3 describes the unified Bayesian model and key parts of the proposed method. The proposal distributions for the models are introduced in
Section 4. Experimental results are presented in
Section 5 and followed by conclusions in
Section 6.
3. The Proposed Method
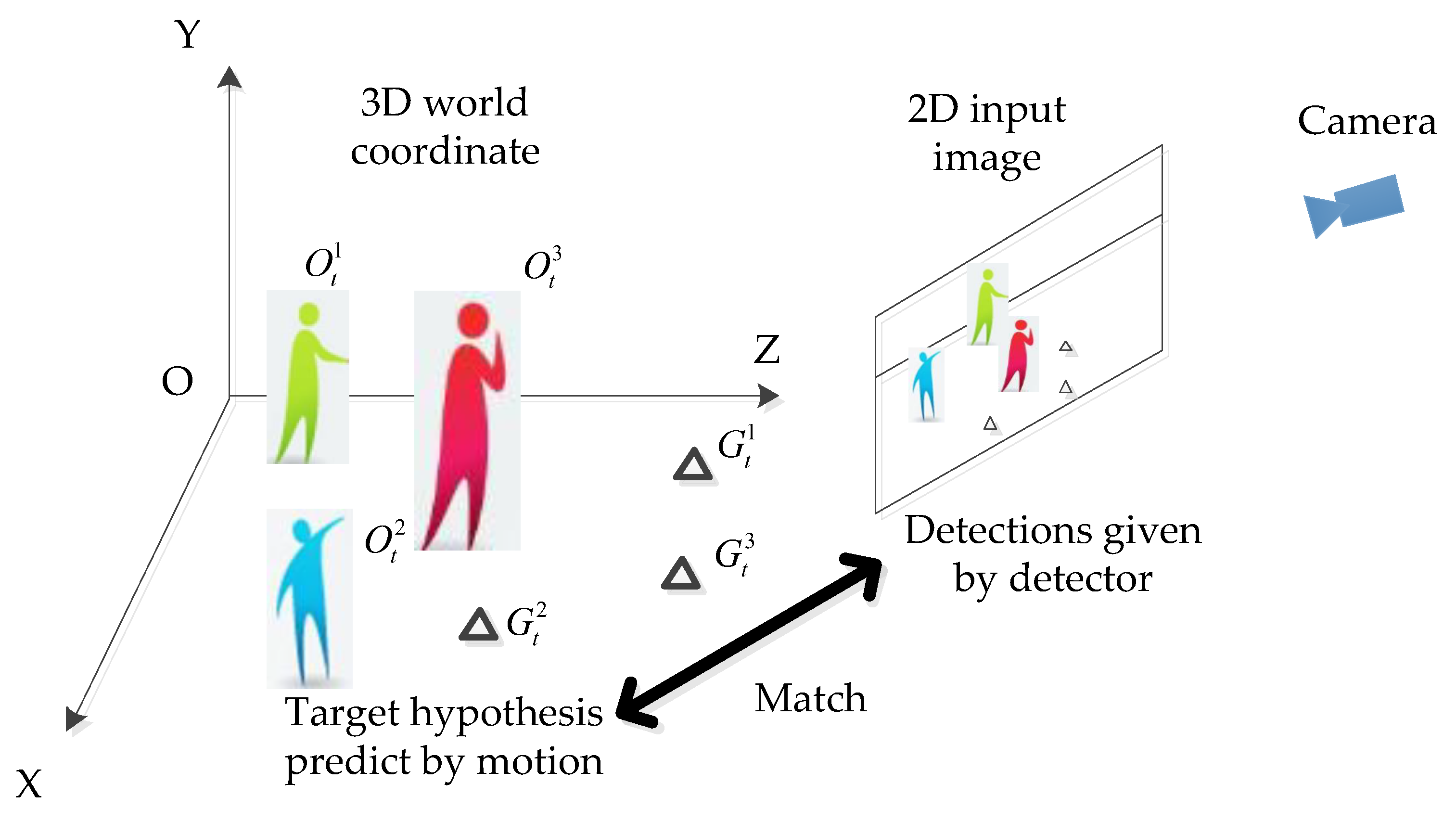
To address multi-target tracking issues with a moving camera, a Bayes posterior estimation-based MOT method was proposed under the framework of tracking by detection. The data processing flow of the proposed method is shown in
Figure 2. The Bayes posterior estimation-based method uses observation cues to generate a proposal, then uses the observation likelihood and relative-motion models to estimate a proposal to generate the trajectory. The observation cues are provided by different detectors, and then the observation likelihood between observation cues and the target’s hypothesized position is computed. The target hypotheses are predicted by a relative-motion model in 3D space. A 3D relative-motion model describes the relative movement between targets three-dimensionally, which is more accurate and intuitive than the 2D motion network in a single image plane. We exploited the camera model to establish the relationship between the targets in 3D space and in the 2D image plane to compute a target’s motion model observational likelihood. Because the camera is moving, we estimated the camera’s motion by estimating stationary geometric features, then projecting targets’ hypothesized positions into the image plane at each step.
This method fuses multiple detection clues to adapt to changes in target appearance and exploration of a complex environment, and utilizes the relative-motion model in 3D space to resolve track fragments and tracking drift due to mis-detection and occlusion. Our method could also adapt to the complex motion of a target and reduce the dependence of the tracking algorithm on the detection results. RJMCMC particle filtering was exploited to solve the posterior estimation problem. It can add or remove targets randomly via the reversible jump move operation, and adapts to random changes in the number of targets.
3.1. The Unified Bayesian Framework
The tracking task and camera motion estimation are unified with a Bayesian framework and formulated as finding the maximum a posteriori (MAP) solution of the joint probability. There are three types of parameters that need to be estimated: the camera parameter , a set of targets’ states , and the geometric features’ states . All these parameters are expressed as random variables and the relationships among them are expressed by the joint posterior probability. The approximate posterior distribution can be obtained with the RJMCMC method. The basic process is discussed as follows.
Given an image sequence
at time (0, 1, 2, ...
t), and the configurations of all the parameters at time
t are written by
, the goal is to find the best match configuration. The MAP problem
is factored into several parts as follows:
The first term indicated by A in Equation (1) defines the observation likelihood, which models the similarity between configuration and the sensory input at time t. This part measures how well the observations support the hypothesis for the current configuration. The second term indicated by B in Equation (1) is related to the motion model, which predicts the current state from the previous state under the Markov assumption conditions, and is composed of motion model, shape change, and interaction between objects. The third term indicated by C is the prior, which is actually the posterior probability from the previous time step.
3.2. Camera Model and Camera Motion Estimation
(1) Camera Model
We adopted a camera model similar to reference [
36], and set up the relationship of targets in 3D space and a 2D image, given the image’s horizon location and the camera’s height beforehand. The parameters of the camera
include: focal length
f, horizon line
, image center
, yaw angle
, camera height
, velocity
, and 3D location
. The projection function
, which expressed the relationship between camera parameters
and object location
O was defined as:
where
is the position of target in the present camera coordinates, and
refers to the location and height of the corresponding bounding box in the image plane, respectively. The projection function is also suitable for geometric features, such as the projected location for targets’ feet.
(2) Camera Motion Estimation
The camera motion was estimated first in the proposed framework, which is used for obtaining the current camera state, and removing the influence of camera motion to calculate the target motion between two frames. This estimation is composed of two parts, the camera motion priori and geometric feature based motion estimation.
Camera motion priori. A dynamic model with a constant velocity was employed to model camera motion, which was based on a reasonable assumption that the motion of a camera is smooth over a short time. In terms of robustness, an error item is included to account for uncertainty in the simplified camera model. This constant perturbation model was applied to the parameters, such as camera height, horizon, velocity, and yaw angle, etc.:
. The location updating process can be written as:
The intrinsic camera parameters, such as focal length, skewness, optical center, etc., are assumed to be known and provided by default.
Geometric feature-based motion estimation. Feature tracking was the fundamental of motion estimation in this work. To balance the efficiency and the performance, Speed-Up Robust Features (SURF) detector [
37] was used for feature descriptor, and the Kanade-Lucas-Tomasi Feature Tracker (KLT) tracker [
38] was employed for the feature tracking of adjacent frames. Because the camera is moving, the extracted geometric features consist of static features from the background and dynamic ones from the moving targets, but only the static features will be used for the camera motion estimation. Therefore, removing the dynamic features from all extracted features is very important for the camera motion estimation. Based on the results of KLT tracker, some constraints were used for selecting the static features first.
Generally, we assumed that the valid static features are all below the horizon line [
39] because the platform with camera was moving on a flat ground, and not on the target. To avoid the concentration of the selected features, the distances among the features should be larger than a threshold. Usually, we can select out many points for the next step, but only about 40 feature points are used for the efficiency. Among these left points, there may exist a few of mismatched feature points which will affect the motion estimation. Then the validity of the left features will be further verified by the motion prior and observation likelihood as follows.
The motion priori of the geometric feature. The motion priori encodes smooth transition between features of adjacent frames, and describes whether geometric features’ positions are consistent with their previous locations. Correspondently, it also describes the possibility of static or moving states. Let
be the validity prior to describe the features as static or not static, and
be the consistency prior. Then, we can get:
Two binomial probabilities are included, consisting of the probability of staying in the scene
and the probability of entering the scene
, to model the prior validity respectively. Basically, these variables can represent the probability that a valid geometric feature will likely remain valid in the next frame. Then the validity prior can be written as:
As the features are defined as static 3D world points, an indicator function is exploited to model a single feature’s priori of consistency
:
Geometric feature observation likelihood. The likelihood calculation process is completed by two steps: projecting the feature in 3D space to the image plane, and then detecting the feature using a detector. The point of interest in the image plane corresponding to a geometric feature
is represented as
, the likelihood is modeled as a normal Gauss distribution centered on the projection of feature
, and we introduce a uniform background model for invalid features, such as occluded or non-stationary features. Equation (9) defines the function for measuring geometric feature likelihood.
By the combination of Gauss distribution and uniform background model, which can exclude the outliers with the maximum possibility, the robustness of the estimated camera motion can be improved.
Through the validity prior and consistency prior, the invalid and inconsistency features were removed. Only the valid static feature points were considered for the camera motion estimation.
3.3. 3D Relative Motion Model Based MOT
After the camera state and motion have been estimated, the estimated camera motion can be applied to the motion compensation for the MOT with the moving camera. With the unified Bayesian framework expressed in Equation (1), the observation likelihood and motion prior for the MOT problem then needs to be calculated. The proposed 3D relative motion model was applied for the motion prior estimation, which can make the motion model more robust and flexible. The observation likelihood model measured target hypotheses generated by motion priori that matched the input data (detection) best.
(1) The observation likelihood model
The observation likelihood model provides a measurement for evaluating which configuration Xt matches the input data It best. Configuration Xt is provided by a set of hypotheses generated by prior motion, representing the true state of targets and geometric features in 3D coordinates. The input data It is given by the detectors in the way of bounding box. Hence, the evaluation should transform the two variables into one coordinate.
As shown in
Figure 3, given a hypothesis for the target
, we can evaluate the following two steps: (1) using the camera model to project each hypothesized target into the image, the projecting function is expressed as
, and then (2) evaluating the observation likelihood given the detection cues. These two steps can be described in Equations (10) and (11). Here the likelihood between hypothesis targets and detection cues was calculated by the Hungarian algorithm as in reference [
40]. The detection cues were provided by the deformable part model (DPM) detector [
41] and the mean-Shift tracker [
42].
After re-projecting the target’s hypothesized position back to the image, we obtained the observation likelihood measurements both for the validity of the target and the accuracy of the location. The accuracy of targets is modeled via the observation likelihood
. Two detectors are employed as observation cues for various appearances. For simplicity, instead of using the likelihood
, log likelihood
is adopted for each detector
j with weight
as:
It is difficult to describe the possibility of a target actually existing or not. Here, the ratio of the likelihoods
is adopted for the validity measurement. It can allow the target states variable
to have different dimensions. However, as the likelihood of an empty set is ambiguous, the ratio is modeled with a soft max
g(◦) of the hypothesis likelihood, because it is robust against sporadic noise:
(2) 3D Relative Motion Model and Motion Priori
The term for motion priori
in Equation (1) is the evolution of the configuration between time steps which is consist of three parts: (1) camera’s prior motion; (2) target’s prior motion; or (3) geometric feature’s prior motion. It can be expressed as follows:
The camera motion prior and geometric feature motion prior are discussed in the section of camera motion estimation. Here we focused on the proposed 3D relative motion model and the target motion prior.
To describe the relative-motion model among objects in 3D space, both the spatial and velocity information are considered. Let
is the state of object
i at time
t, where (
,
,
) and (
,
,
) denote the 3D position and velocity respectively. Then the relative-motion model between two objects
i and
j is defined based on the position and velocity difference as:
Then, the relative-motion model for N objects
is then defined as:
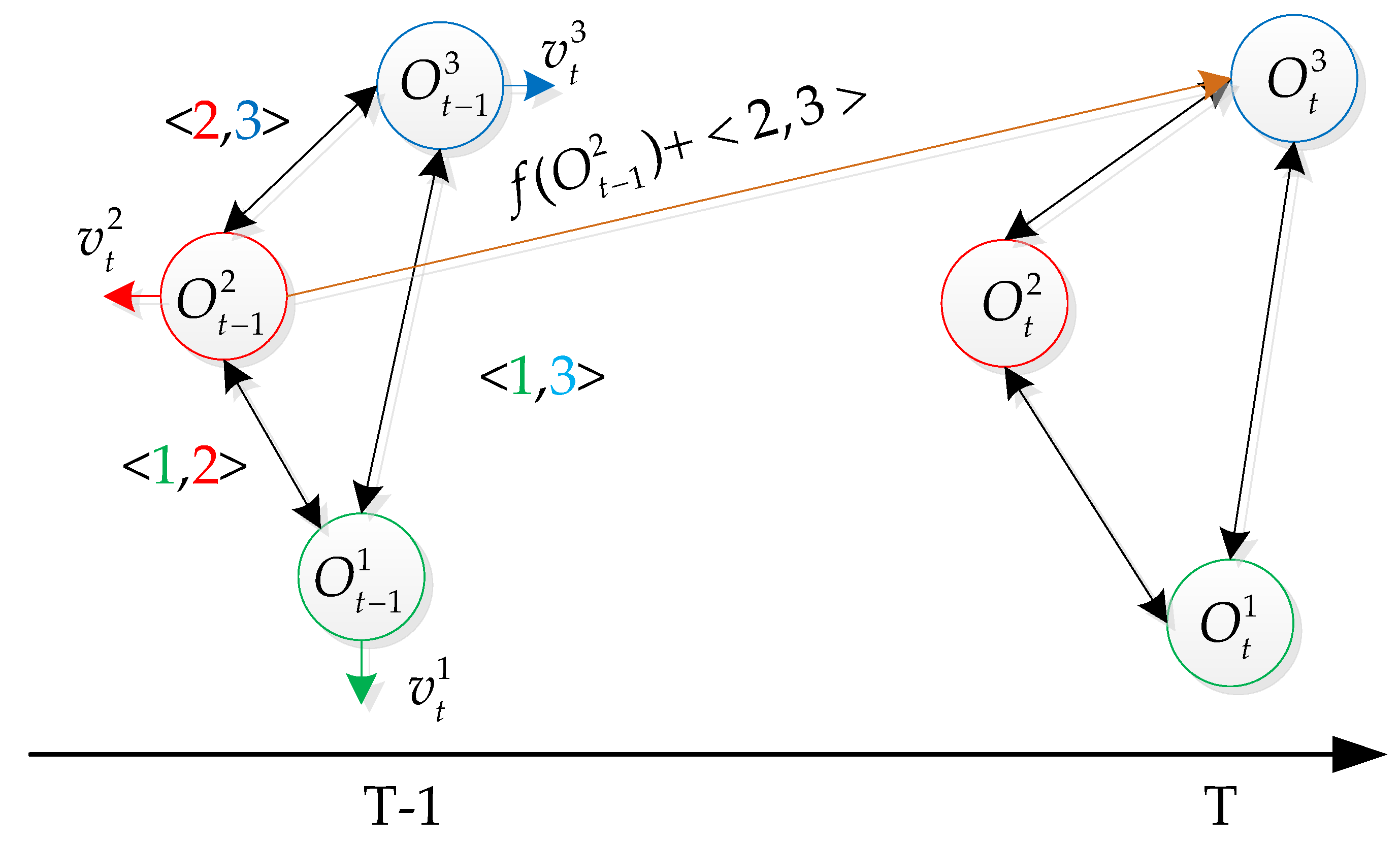
The 3D relative-motion model actually represents a set of linked edges between objects. As illustrated in
Figure 4, the states of different targets are represented as circles of different colors, the relative motion model
represents two different targets (
i,
j), and is denoted as black lines. While the relative motion model
encodes the self-motion model of target
i, which is always included in case that there exists only one target. Usually, there are more than one relative motion for a target
i. We chose the closest target
j to target
i that had detection assigned for predicting target
. The relative motion model
can be used to predict the mis-detected target
j according to the state of target
j at previous time.
For both relative-motion models and the previous targets’ states, the motion transition is expressed by:
where
is the transition matrix based on a constant velocity of motion model. The computation of object at y coordinate has no practical use and
w is the assumed white Gaussian noise.
According to the relative-motion model, the state of target
i can be solved by using the previous state of target
j and the relative-motion model between them, which is more accurate and adaptable than targeting predicted directly by linear motion model. When target
i is missed in the detection stage, its location can be predicted through target
j according to the motion model, which effectively reduces the false tracking caused by missed detection. The target’s prior motion is written as:
Three motion priori were used to account for the smooth transition of camera, targets, and geometric features through time. The target’s and geometric features’ prior motions also allowed them to appear, interact, and disappear, which made the model more robust and flexible.
4. Implementation
The unified Bayesian model for multiple object tracking and camera estimation, has been presented in last section. The solution of this model can be obtained typically by the maximum-a-posteriori method. Because the number of targets and features are variable in the tracking process, RJ-MCMC particle filtering was employed to find the MAP solution of the posterior distribution. The advantages of the RJ-MCMC method made it particularly suitable for adding and removing targets via random jump proposal moves in different dimensions.
As illustrated in Equation (1), the goal of tracking is defined as finding the states that maximize the posterior configuration
. To obtain the posterior, RJ-MCMC samples, the posteriors from 1 to t to obtain a number of samples to approximate the posterior
, where
n is the number of samples and
is the
sample. If the set of samples at previous time
t − 1 is provided, then the posterior distribution can be expressed as:
4.1. Proposal Distribution
As discussed in the previous section, the configuration variables defined in this paper are composed of three parts . We needed to sample from those three components, but they would converge very slowly to steady-state distribution if we sampled from the whole configuration, due to their high dimensionality. To solve the problem, we sampled only one variable at a time. For example, we chose only one type of parameter to perturb to generate a new sample. Usually, the RJMCMC method follows the Metropolis-Hasting rule to generate samples, and then accepts or rejects samples to construct the Markov chain .
Let
be the proposal distribution; we used probability
to perturb the target proposal
, probability
to perturb the geometric feature proposal
, and probability
to perturb the camera proposal
. Then, the proposal distribution can be written as:
For example, with the probability , the target proposal was randomly chosen; upon perturbation, the new configuration will be . Only a single target’s state has been changed in , and the other terms will remain unchanged.
The three proposal distributions in Equation (20) are presented as follows.
(1) Target proposal distribution
Five jump moves for the target-state transition were defined: Stay, Leave, Add, Delete, and Update. Stay/Leave was defined as targets staying or leaving from the tracking scene with variable dimensionality, and Add/Delete was defined as new entering targets or false alarms in the tracking scene. Those two couple moves were designed to be reversible counterparts to each other; this guaranteed that the Markov Chain satisfied the detailed balance condition. The update move was defined for targets’ position updates. Overall, those five jump moves covered all conditions of target movement. During exploration, one of the five moves was randomly chosen with probabilities of
,
,
,
,
, respectively. In
Table 1, the proposal distribution for each jump move and corresponding targets that suit for this jump move are listed.
will be set to 1 when there is no corresponding detection, or it will be set to , otherwise.
(2) Proposal Distribution of Geometric Feature
Because the geometric features state
is also a high dimensional vector with variable dimensionality same as the target state, we used the RJ-MCMC method to sample from the geometric features to generate proposal distribution. However, only three jump moves (Stay, Leave, and Update) were necessary to update the geometric feature states, and with the same strategy as the target proposal distribution, one of the moves was randomly chosen with a probability of p
s, p
l and p
u, respectively, to generate a proposal. Because of the validity of features needs to compare the previous features, we did not need the Add and Delete moves to add new features. All of the newly detected features were automatically added to the feature set in the current frame, and the validity of features in the subsequent frames was checked by comparing the observed and predicted positions with Stay and Leave moves.
Table 2 lists each jump move’s proposal and the corresponding geometric features that suit this jump move.
(3) Camera State Proposal Distribution
Because the state dimensionality of the camera was kept constant, its state proposal distribution
can be expressed by a simple normal distribution as:
4.2. Acceptance Ratio
In the traditional MH algorithm [
43], for the acceptance ratio, only the ratio of the likelihood of the proposed configuration to the likelihood of the previous configuration was considered. We extended it to a product of three terms as follows:
On the right hand side of Formula (22), the first term refers to the ratio of image likelihoods between the proposed configuration and the previous configuration, the second term describes the ratio of approximated predictions and the last term stands for the ratio of proposal distributions. By adding the ratio of prediction and proposal distribution, the results can be improved.
5. Experiments and Discussion
To evaluate the performance of the proposed tracking method, two kinds of dataset were used: the dataset collected by us in the campus, and some benchmark dataset with a moving camera, such as ETH-Bahnhof, ETH-Linthescher, ETH-Sunnyday [
44], MOT16-05, and MOT16-11 [
45]. For all experiments, we assumed that an initial camera configuration was provided, which included the focal length and height of the camera. Because the camera was not calibrated for the dataset collected by ourself, the camera configuration parameters were initialized with rough values. For the ETH dataset and MOT16s, the calibrated parameters were provided and used as the default value in the experiments. For the video sequences collected by ourselves, only the camera height and focal length needed to be roughly set. Accurate camera calibration was not necessary for the proposed method. The focal length can be set according to the datasheet of the camera, and the camera height is set to the value estimated by the eye in the experiments. The proposed methods would be applied in any flat environment.
Many evaluation metrics for quantitative evaluation of MOT have been proposed in the past. In this paper, we followed the evaluation metrics suggested in the MOT2D benchmark challenge [
44,
45].
These metrics could evaluate a method from different aspects, and their definitions are listed as follows:
The tracking accuracy can be evaluated by multiple object tracking accuracy (MOTA). It is widely used because of its expressiveness, as it includes three sources of errors, which are defined as:
where
t is the frame index, FP denotes false positives, which means the output is a false alarm, FN is false negatives; a target that is missed by any hypothesis is a false negative. GT is the number of ground truth objects. IDSW is the number of target identification (ID) switches. The MOTA score can give a good indication of the overall performance.
The tracking precision is evaluated by multiple object tracking precision (MOTP). It is the average dissimilarity between all true positives and their corresponding ground truth targets. It is computed as:
where
denotes the number of matches in frame
t and
is the bounding box overlap of target
i related to the ground truth. MOTP measures the localization precision, and describes the average overlap between all correctly matched hypotheses and their respective objects ranges between 50% and 100%.
The tracking quality for each ground truth trajectory can be classified into mostly tracked (MT), partially tracked (PT), or mostly lost (ML). A target is mostly tracked, which defines as it is successfully tracked for at least 80% of its life span. If a target track is only recovered for less than 20% of its total length, then it is mostly lost (ML). All other tracks are defined as partially tracked. Usually, they are expressed as a ratio to the total number of ground truth trajectories.
Recall is defined as the ratio of correctly matched detections to the total detections in ground truth.
Precision is defined as the ratio of the correctly matched detections to total detections in the tracking result.
FAR is defined as the ratio of the false alarms per frame.
Currently, most of the MOT methods use a static camera; only few of them are moving-camera-based. Among them, continuous energy minimization (CEM) [
30] and RJMCMC [
27] are two typical methods with a moving camera; both the RMN method [
22] and structural constraint event aggregation (SCEA) method [
26] make use of the 2D motion context for the MOT. The CEM method belongs to a kind of batch-optimization method, and all of the historical data are used for the offline tracking optimization, which makes the data association robust, and the problem of target ID switch is improved. On the other hand, the RJMCMC method is an online optimization mode; the proposed method in this paper also employs the RJMCMC framework to find the maximum-a-posterior (MAP) solution. Thus, we made a thorough comparison among five methods: CEM, RJMCMC, RMN, SCEA and the proposed method. Because the proposed method was based on RJ-MCMC, we took it as the baseline method.
Table 2 shows the comparison results for the benchmark dataset, ETH-Bahnhof, ETH-Sunnyday, MOT16-05, and MOT16-11. The proposed method outperformed the other four methods in precision, FAR, MOTA, and FP with the ETH-Bahnhof dataset, especially in MOTA and precision, though the CEM method was globally optimized. This is because the proposed algorithm can pass the 3D motion model to track the target in the detection process, which can improve the tracking accuracy. Because only the previous frame information was considered for online purposes in the proposed method, there were more target identity switch errors than in the CEM method, but fewer than in the RJMCMC method. At the same time, it can be seen that the overall performances in the proposed method were better than in the RJMCMC method. It confirms that by exploiting the 3D relative motion model, the tracking performance was improved greatly.
For the experiment results with the ETH-Sunnyday, MOT16-05, and MOT16-11 dataset, the proposed method in MT, FN, and Recall was better than the CEM and RJMCMC algorithms. Because FN represents the number of missed target tracks, the results showed that the proposed method can greatly reduce missed detection by making use of the relative-motion model. Compared with the motion context methods (SCEA_ver1 and RMOT), the indexes of recall and MOTP for both methods were outperformed compared to the proposed method, because they exploited the motion context of all targets and we only exploited the nearest target’s motion context for calculation. There were some indexes of the proposed method that were higher than those two methods, and showed in bold in
Table 3. But we also found that the proposed method might fail to predict target if the target is miss-detected for several frames. The feature work will aim at robust tracking methods account for unreliable detection.
Because the particle filter was exploited to solve the posterior estimation problem both in the proposed and RJ-MCMC method, we conducted some qualitative comparison experiments between the proposed and the RJMCMC method with the ETH-Linthescher sequence, and the same detection method was used.
Figure 5a–c shows the tracking results of the 32th, 34th and 54th frame, respectively, in the ETH-Linthescher sequence. When occlusion occurred, the target ID switch happened in the RJMCMC method, but for the proposed method, targets ID did not switch, as shown in (e). Similarly, the target ID switched in the 54th frame in the RJMCMC method, but our method could keep the correct target ID. It shows that the proposed method prevented the tracking drift when occlusion occurred, because it benefitted from the proposed relative motion model.
Generally, a weakness of tracking by detection is that the tracking result is heavily dependent on the reliability of the detection module. If the detection module fails to detect the target, then the target may not be tracked, and this leads to the generation of track fragments or tracking drift. To alleviate this issue, the proposed method exploits the relative-motion model in 3D space to describe the motion constraints among targets, which can improve the performance. Some demonstrative experiments were conducted with ETH-Sunnyday, ETH-Bahnhof, and the datasets we collected.
As shown in
Figure 6, both the RJMCMC method and the proposed method failed to detect the old woman, this led to the fragments showed in
Figure 6a because the RJMCMC method could not track the woman. However, the proposed method could work successfully, and avoid generating the tracking fragments when mis-detection occurred.
Beside the experiments on these standard datasets, we also conducted some experiments with the video data collected in our campus. As shown in
Figure 7, it was challenging for the tracking because of the illumination change, scale variation of the target, and the appearance differences. Because there was no ground truth data available, only some qualitative results could be provided. In this figure, given the same detection result, the tracking result of the proposed algorithm outperformed the RJMCMC method.
Figure 7a shows the detection results, which include a wrong detection result (indicated by the largest bounding box). Both the proposed and RJMCMC method could remove it in the tracking process. However, as shown in
Figure 7b, the RJMCMC method fail to track the woman with an umbrella. The proposed method worked well in this case.
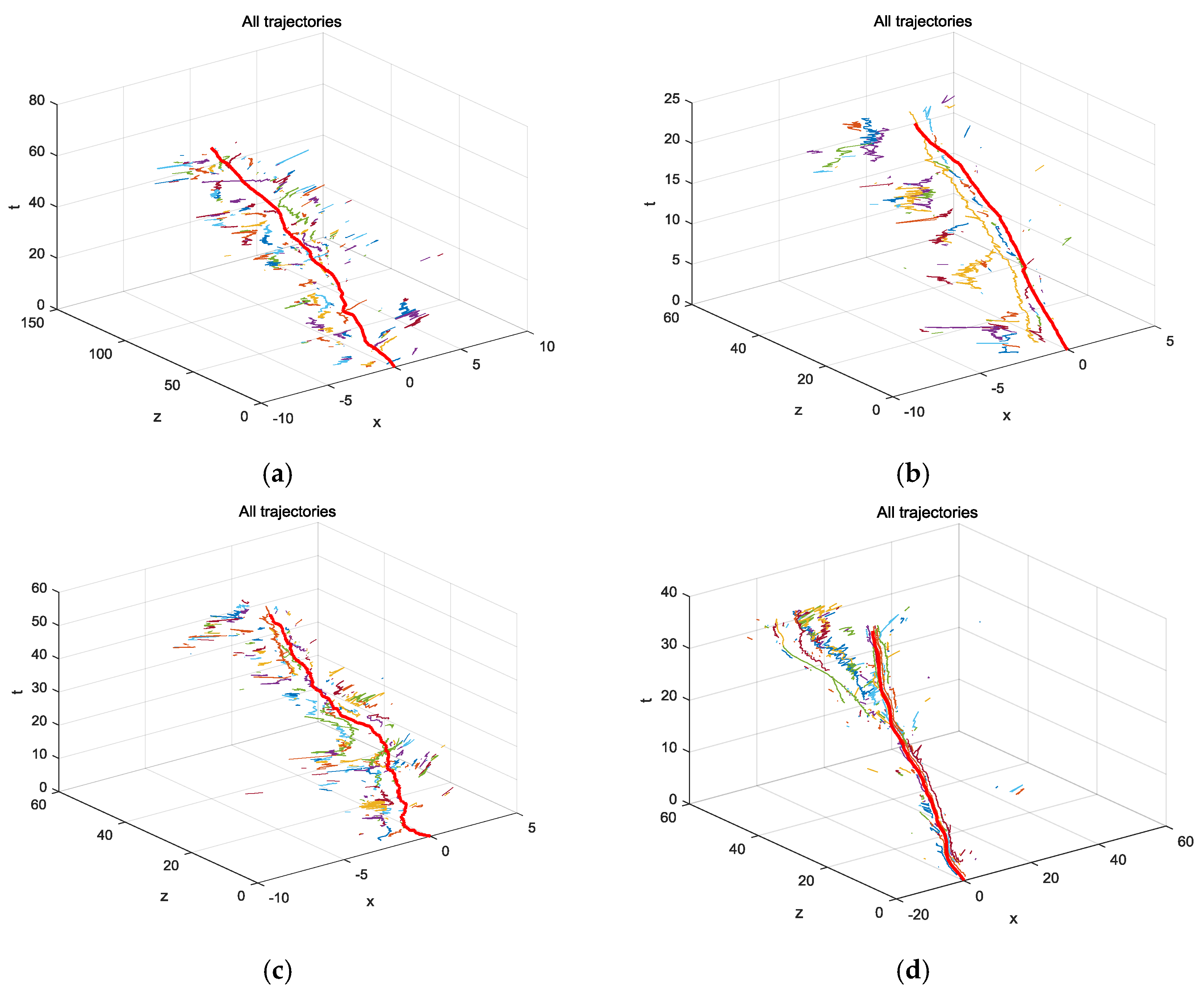
Figure 8 shows the results of the camera and target trajectories in terms of time with four video sequences, ETH-Bahnhof, ETH-Sunnyday, MOT16-05, MOT16-11. In these figures, the plane (
x,
z) was defined according to the camera coordinate in the very first frame of each sequence. It can be seen that although no ground truth is available for the camera motion, the camera motion estimated here qualitatively matched what we saw in the video.
All the experiments are run on an Intel core i5 personal computer (PC) with 8 GB memory, and Visual Studio 2012 and Opencv2.4.9 were used, the sample particles were set to 5000. Currently, the average computation time of detection and tracking was approximately 0.17 s without any code optimization. Most of the time was spent by the detector, about 91% in total. It is mainly because the DPM detector is time-consuming.
The experiments also showed that, because the proposed method is based on the principle of tracking-by-detection, it could not track the target mis-detected when it first appeared. As showed in
Figure 7a,c, the person in the purple T-shirt was not detected at first, then he could not be tracked consequently. A more powerful detector may improve this case.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}