Relative Pose Based Redundancy Removal: Collaborative RGB-D Data Transmission in Mobile Visual Sensor Networks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Add detailed theoretical refinements, practical implementation and experimental performance evaluation of the cooperative relative pose estimation algorithm [24] (Section 3.2),
- Extend the theoretical development and practical implementation of the RPRR scheme for minimizing the transmission of redundant RGB-D data collected over multiple sensors with large pose differences (Section 3.3),
- Describe the lightweight crack and ghost artifacts removal algorithms as a solution to the undersampling problem (Section 3.5), and
- Include detailed experimental evaluation of wireless channel capacity utilization and energy consumption (Section 4.2).
2. Related Work
- Optimal camera selection,
- Collaborative compression and transmission, and
- Distributed source coding.
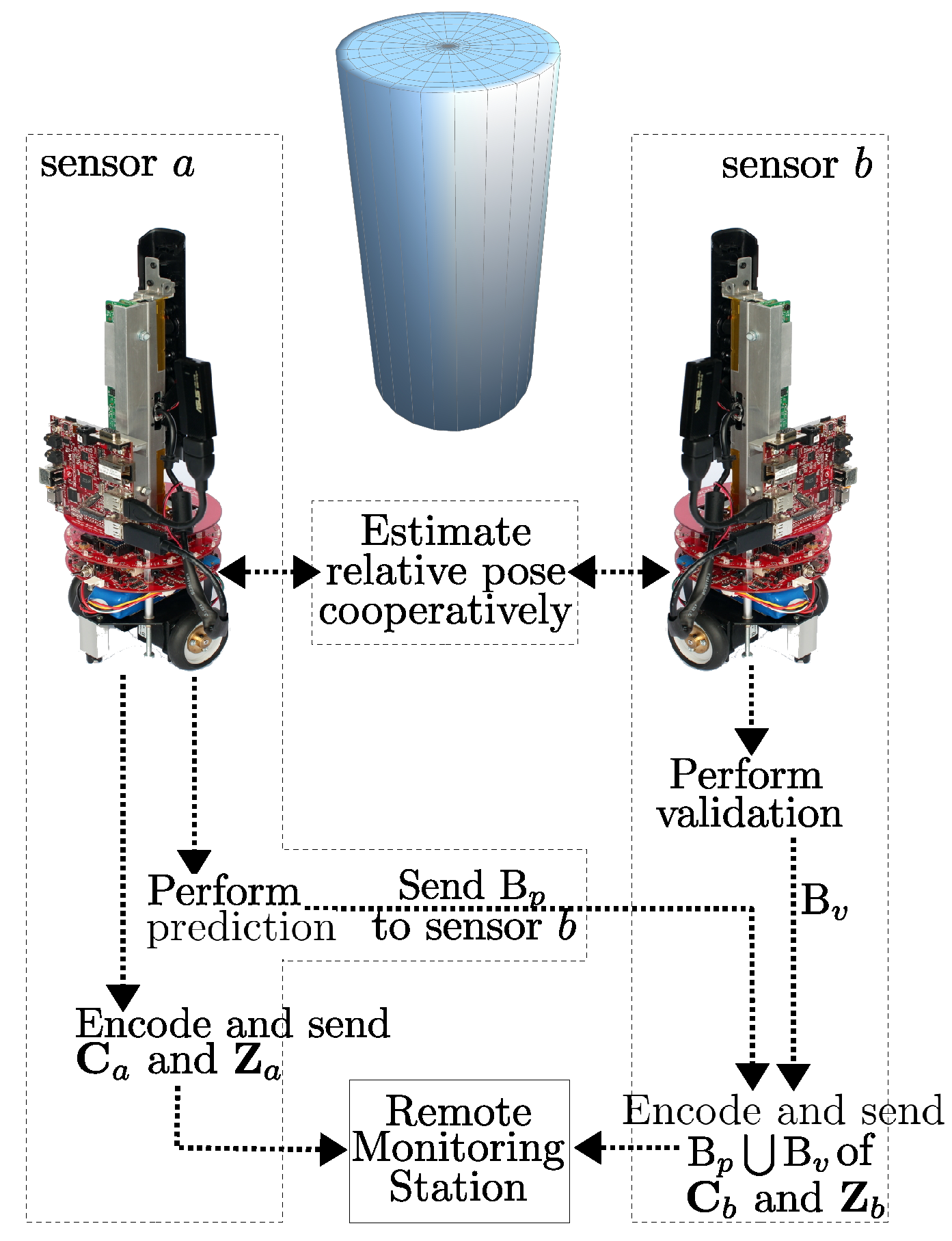
3. Relative Pose Based Redundancy Removal (RPRR) Framework
3.1. Overview
3.2. Relative Pose Estimation
- principal point coordinates , and
- focal length of the camera , ,
- the sum of squared distances from to , and
- the sum of squared distances from to .
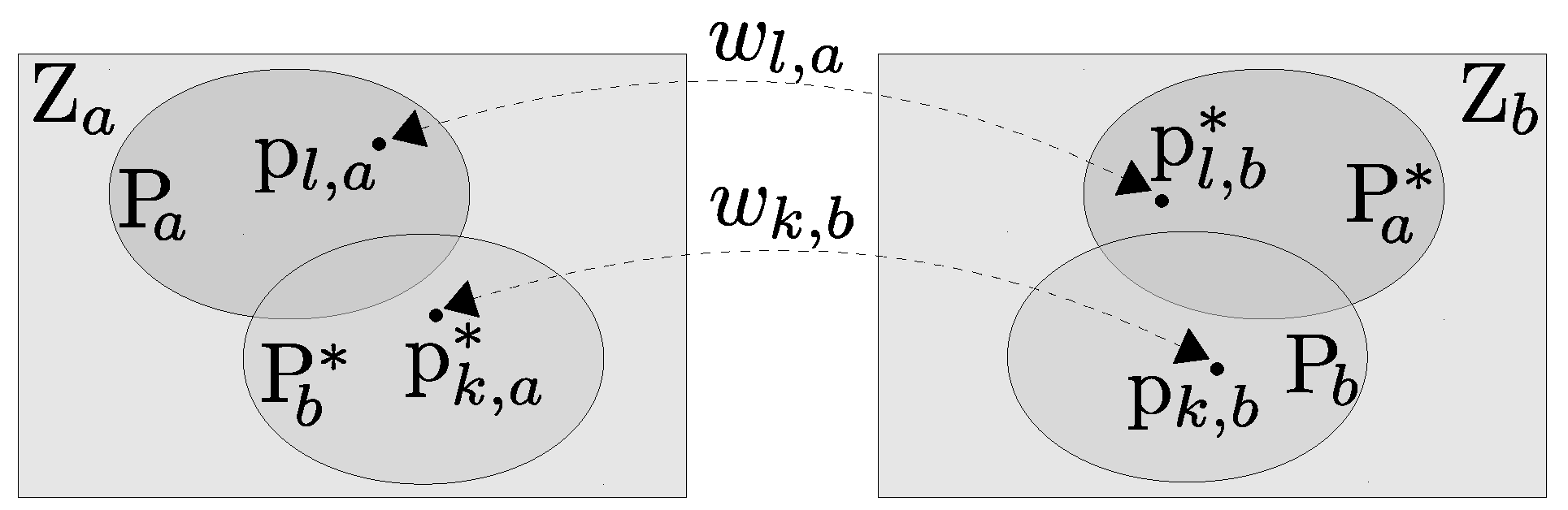
3.3. Identification of Redundant Regions in Images
3.3.1. Prediction
3.3.2. Validation
3.4. Image Coding
3.5. Post-Processing on the Decoder Side
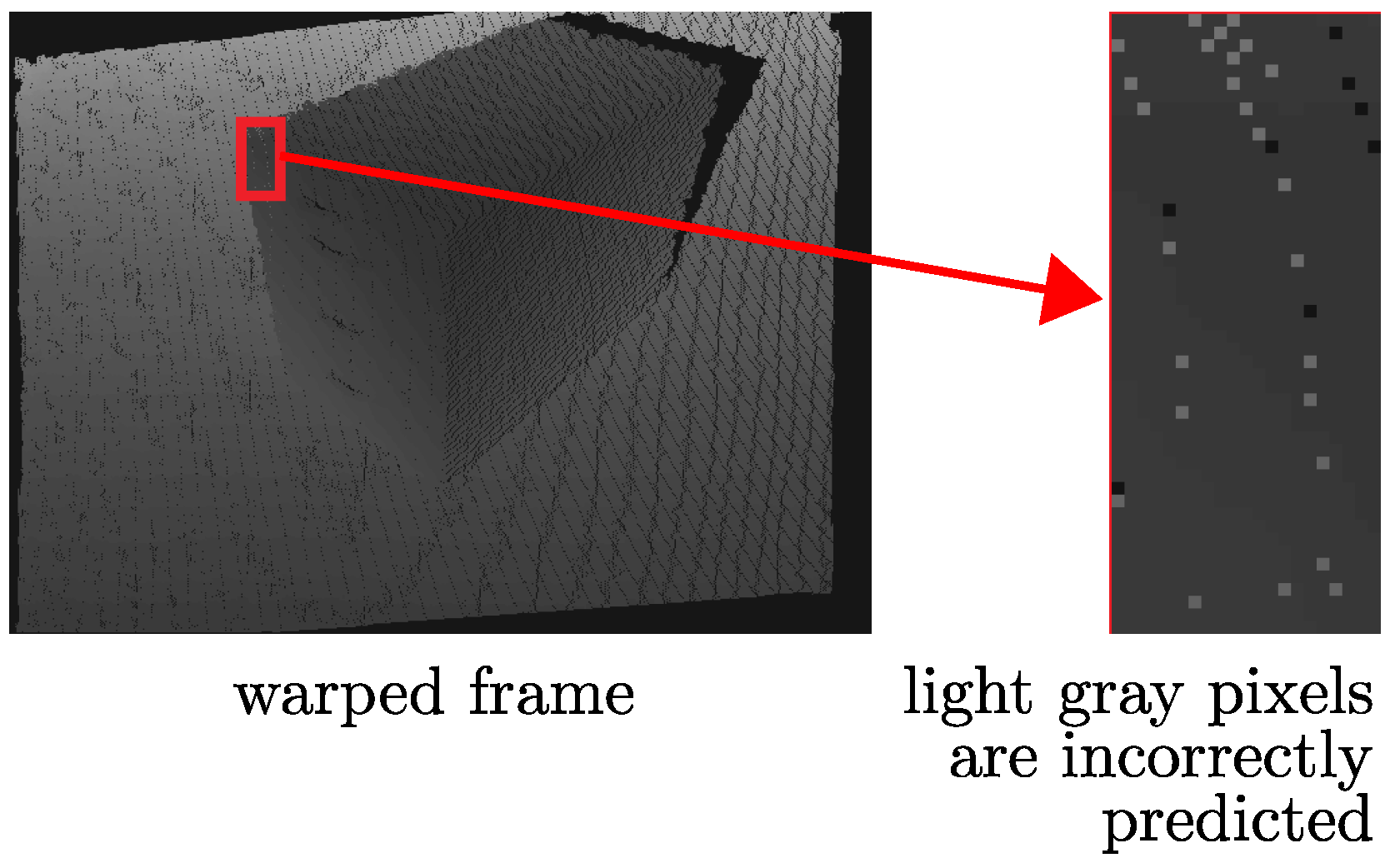
3.5.1. Removal of Crack Artifacts
- The cracks in the synthetic depth image are filled by a median filter, and then a bilateral filter is applied to smoothen the depth map while preserving the edges.
- The filtered depth image is warped back into the reference viewpoint to find the color of the synthetic view.
3.5.2. Removal of Ghost Artifacts
4. Experimental Results and Performance Evaluation
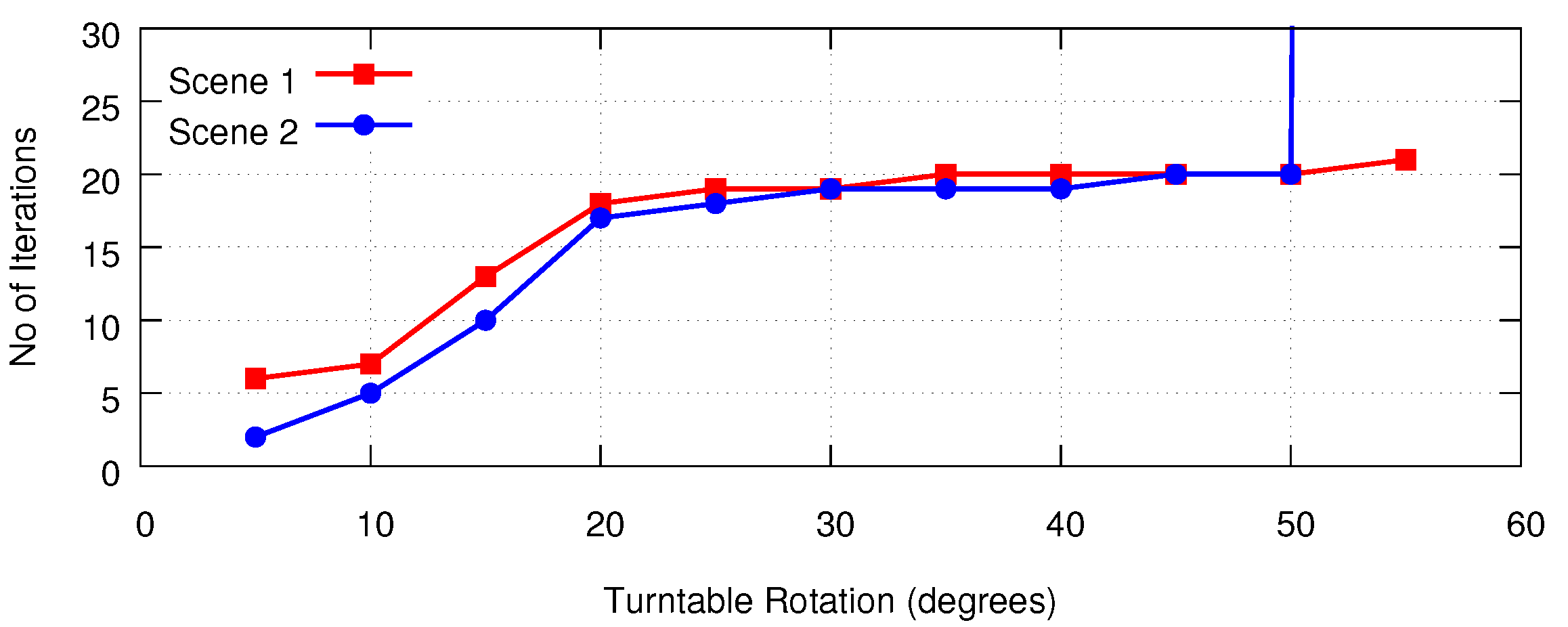
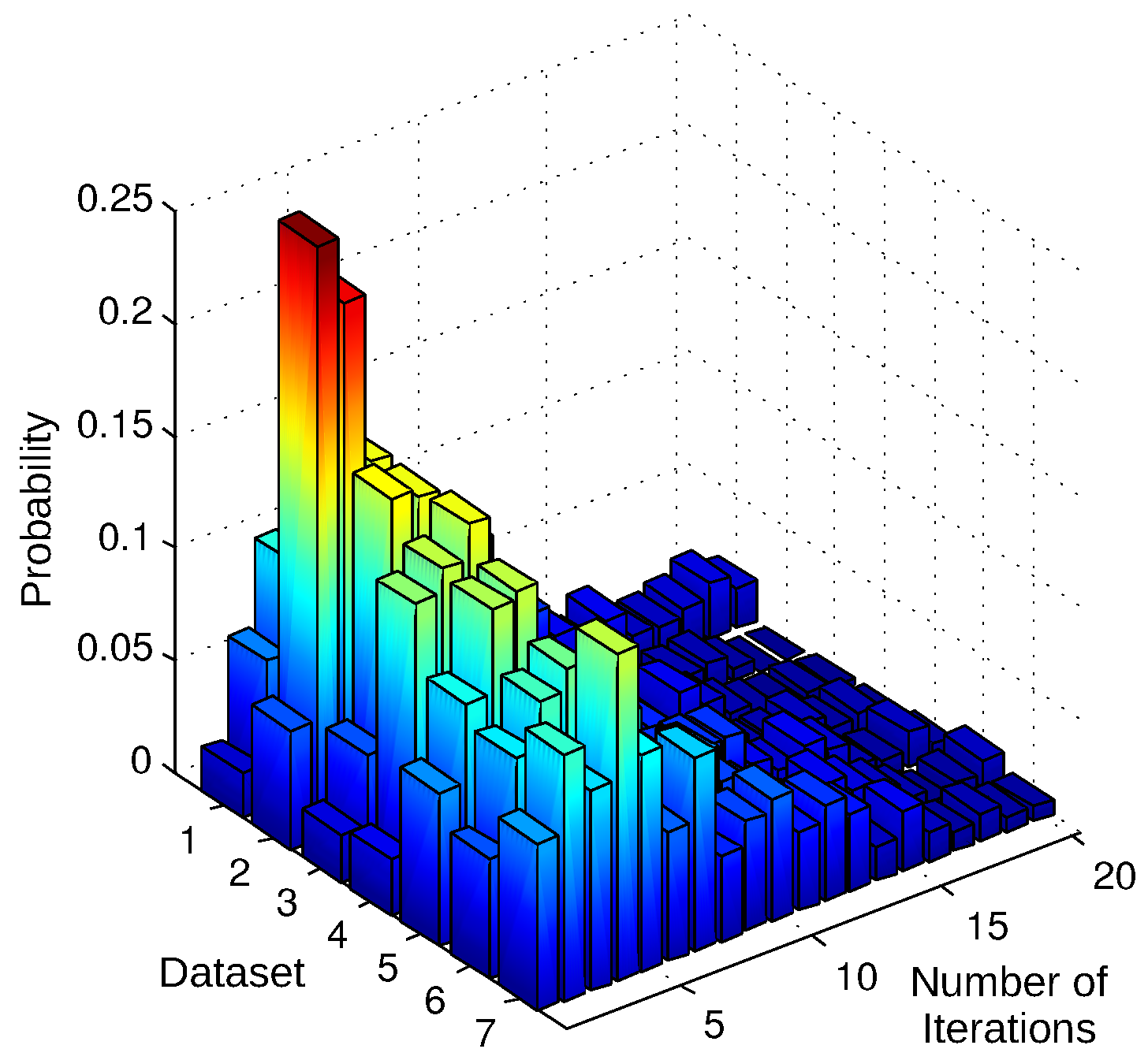
4.1. Performance Evaluation of the Relative Pose Estimation
- When the angular interval becomes greater than 15°, an increasing amount of occlusion occurs between two sensors’ views. Under such circumstances, ICP-BD outperforms other variants as it reports much lower translational and rotational RMS error.
- Standard ICP has the poorest performance across the experiments. ICP-IVD can provide similar accuracy in pose estimation before it diverges. However, as the scene becomes more occluded as the turntable is being rotated, ICP-IVD fails to converge sooner than ICP-BD.
4.2. Performance Evaluation of the RPRR Framework
4.2.1. Subjective Evaluation
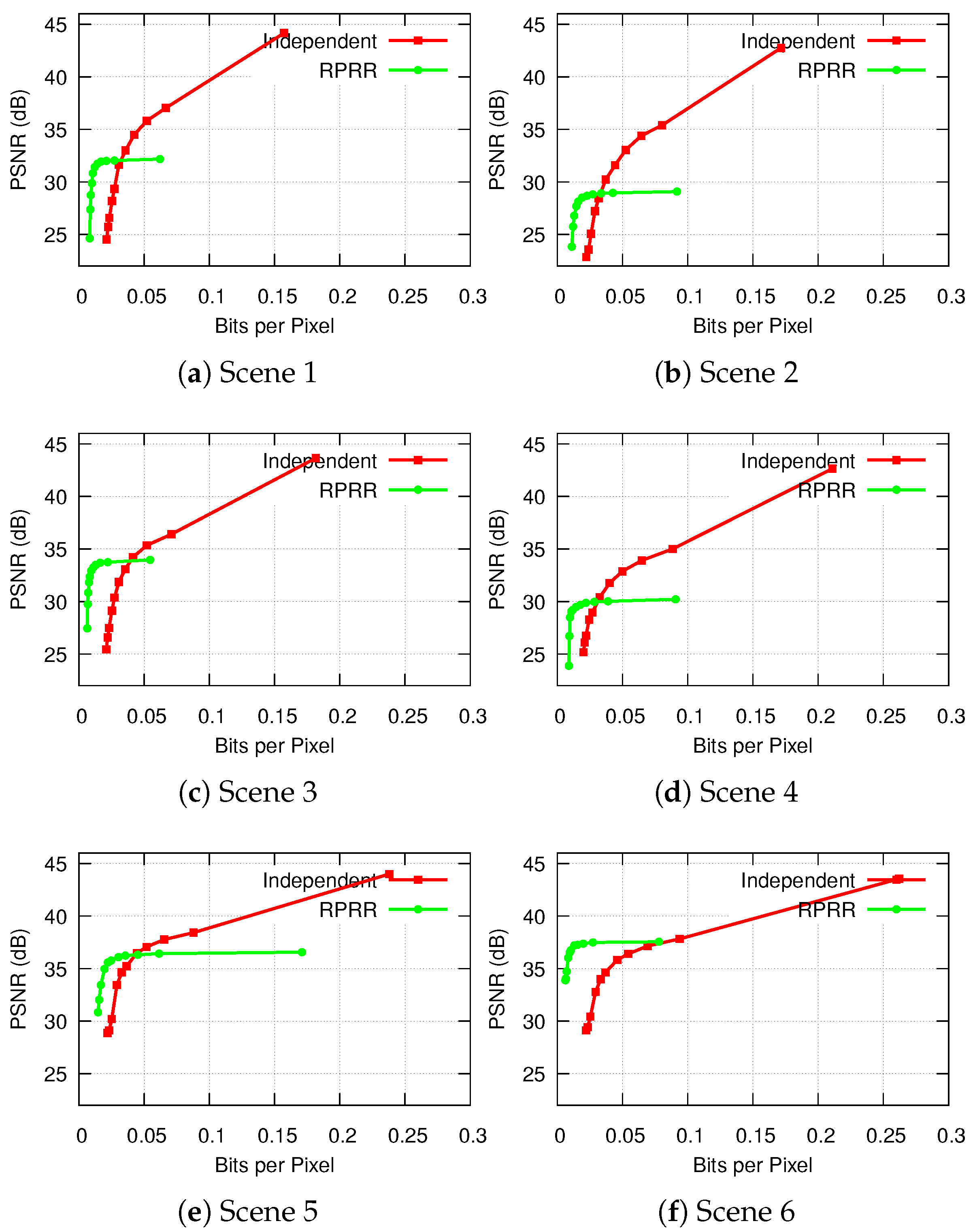
4.2.2. Objective Evaluation
4.2.3. Energy Consumption
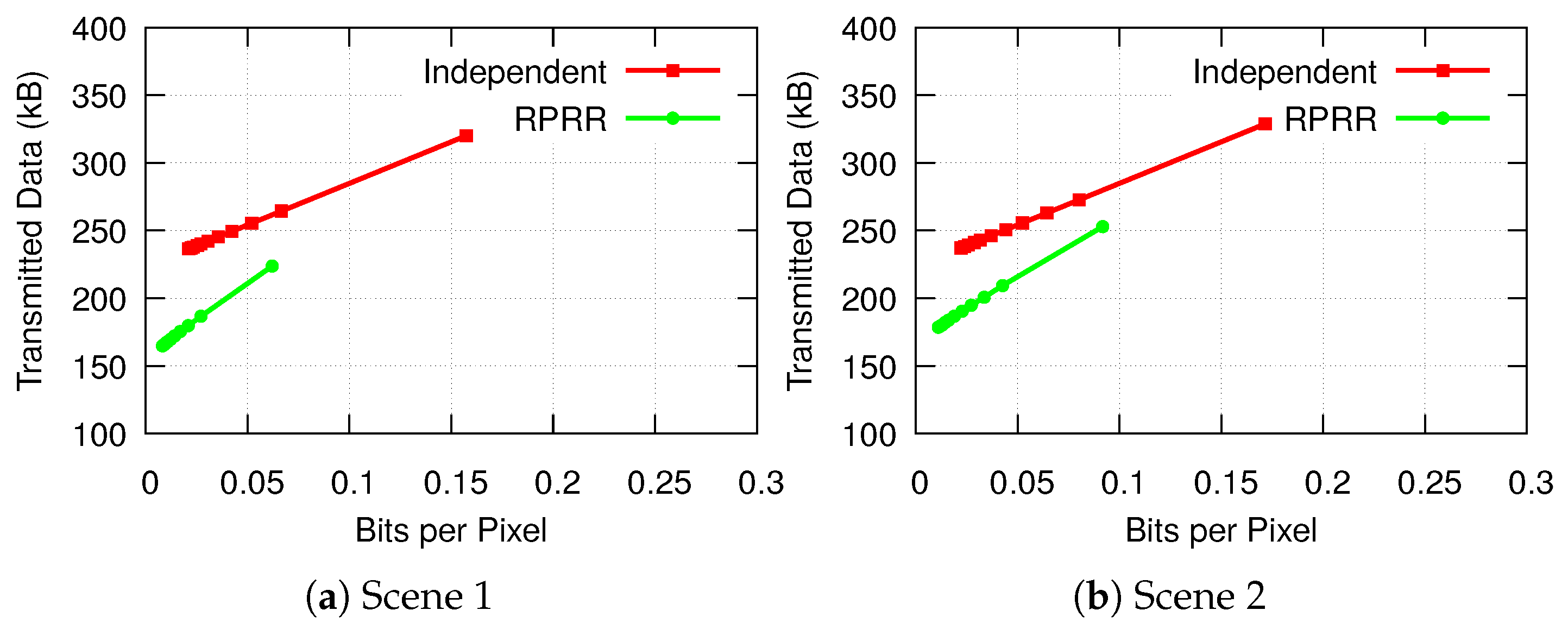
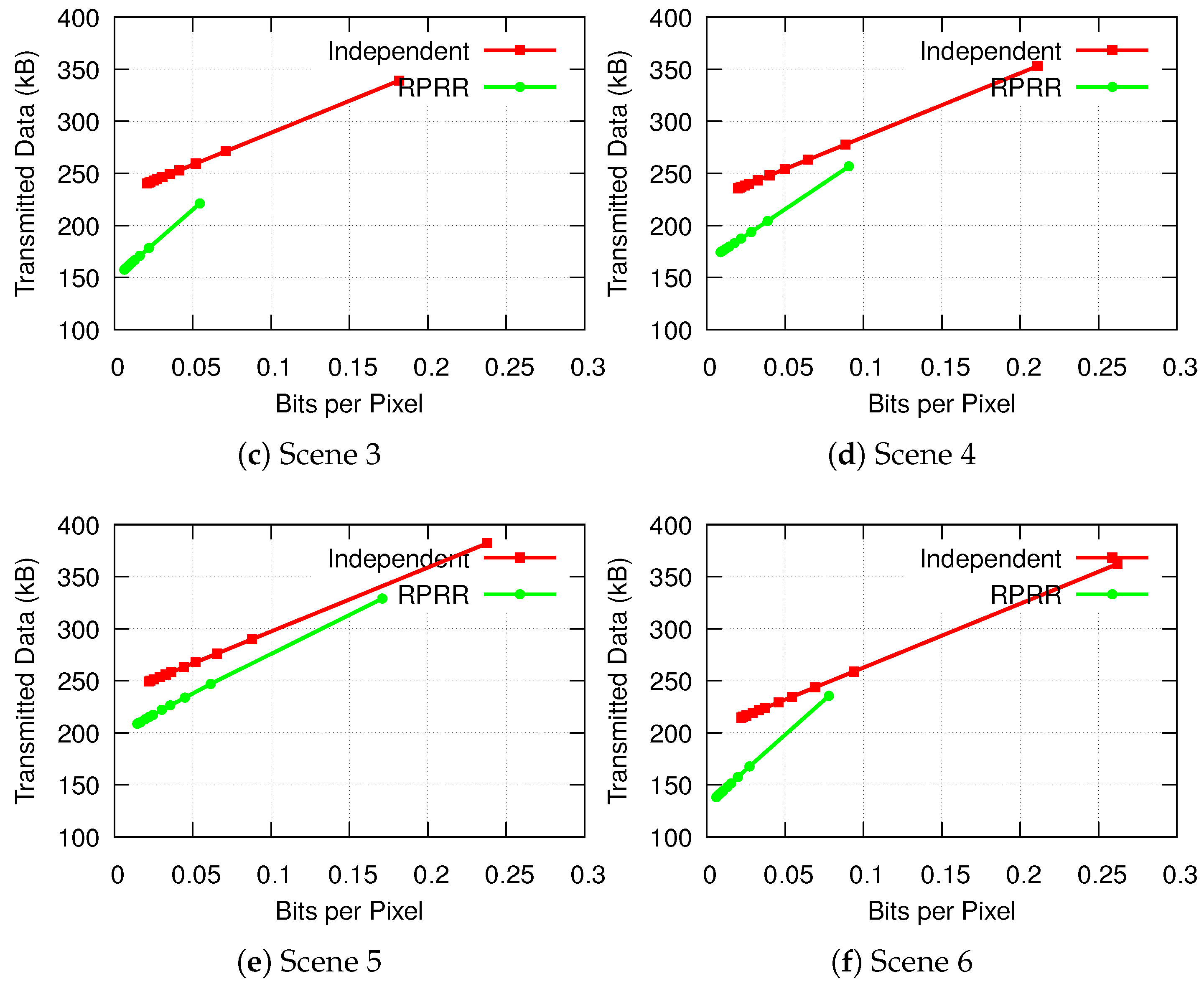
4.2.4. Transmitted Data Volume
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kinect RGB-D Sensor. Available online: https://developer.microsoft.com/en-us/windows/kinect (accessed on 24 July 2018).
- Xtion RGB-D Sensor. Available online: https://www.asus.com/fr/3D-Sensor/Xtion_PRO/ (accessed on 24 July 2018).
- RealSense RGB-D Sensor. Available online: https://www.intel.com/content/www/us/en/architecture-and-technology/realsense-overview.html (accessed on 24 July 2018).
- Mohanarajah, G.; Usenko, V.; Singh, M.; D’Andrea, R.; Waibel, M. Cloud-Based Collaborative 3D Mapping in Real-Time with Low-Cost Robots. IEEE Trans. Autom. Sci. Eng. 2015, 12, 423–431. [Google Scholar] [CrossRef]
- Beck, S.; Kunert, A.; Kulik, A.; Froehlich, B. Immersive Group-to-Group Telepresence. IEEE Trans. Vis. Comput. Graph. 2013, 19, 616–625. [Google Scholar] [CrossRef] [PubMed]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. RGB-D Mapping: Using Kinect-Style Depth Cameras for Dense 3D Modeling of Indoor Environments. Int. J. Robot. Res. 2012, 31, 647–663. [Google Scholar] [CrossRef]
- Lemkens, W.; Kaur, P.; Buys, K.; Slaets, P.; Tuytelaars, T.; Schutter, J.D. Multi RGB-D Camera Setup for Generating Large 3D Point Clouds. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1092–1099. [Google Scholar]
- Choi, W.; Pantofaru, C.; Savarese, S. Detecting and Tracking People Using an RGB-D Camera via Multiple Detector Fusion. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops, Barcelona, Spain, 6–13 November 2011; pp. 1076–1083. [Google Scholar]
- Liu, W.; Xia, T.; Wan, J.; Zhang, Y.; Li, J. RGB-D Based Multi-attribute People Search in Intelligent Visual Surveillance. In Advances in Multimedia Modeling; Springer: Berlin, Germany, 2012; Volume 7131, pp. 750–760. [Google Scholar]
- Almazan, E.; Jones, G. A Depth-Based Polar Coordinate System for People Segmentation and Tracking with Multiple RGB-D Sensors. In Proceedings of the IEEE ISMAR 2014 Workshop on Tracking Methods and Applications, Munich, Germany, 10–12 September 2014. [Google Scholar]
- Alexiadis, D.; Zarpalas, D.; Daras, P. Real-Time, Full 3D Reconstruction of Moving Foreground Objects from Multiple Consumer Depth Cameras. IEEE Trans. Multimed. 2013, 15, 339–358. [Google Scholar] [CrossRef]
- Tong, J.; Zhou, J.; Liu, L.; Pan, Z.; Yan, H. Scanning 3D Full Human Bodies Using Kinects. IEEE Trans. Vis. Comput. Graph. 2012, 18, 643–650. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, C.; Liu, Z.; Chan, S.C. Superpixel-Based Hand Gesture Recognition With Kinect Depth Camera. IEEE Trans. Multimed. 2015, 17, 29–39. [Google Scholar] [CrossRef]
- Duque Domingo, J.; Cerrada, C.; Valero, E.; Cerrada, J.A. An Improved Indoor Positioning System Using RGB-D Cameras and Wireless Networks for Use in Complex Environments. Sensors 2017, 17, 2391. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Liu, Q.; Gui, J.; Gu, D.; Hu, H. Indoor Relocalization in Challenging Environments With Dual-Stream Convolutional Neural Networks. IEEE Trans. Autom. Sci. Eng. 2018, 15, 651–662. [Google Scholar] [CrossRef]
- Aziz, A.A.; Şekercioğlu, Y.A.; Fitzpatrick, P.; Ivanovich, M. A Survey on Distributed Topology Control Techniques for Extending the Lifetime of Battery Powered Wireless Sensor Networks. IEEE Commun. Surv. Tutor. 2013, 15, 121–144. [Google Scholar] [CrossRef]
- Lu, J.; Cai, H.; Lou, J.G.; Li, J. An Epipolar Geometry-Based Fast Disparity Estimation Algorithm for Multiview Image and Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 737–750. [Google Scholar] [CrossRef] [Green Version]
- Merkle, P.; Smolic, A.; Muller, K.; Wiegand, T. Efficient Prediction Structures for Multiview Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 1461–1473. [Google Scholar] [CrossRef]
- Fehn, C. Depth-Image-Based Rendering (DIBR), Compression, and Transmission for a New Approach on 3D-TV. In Stereoscopic Displays and Virtual Reality Systems XI; International Society for Optics and Photonics: Bellingham, WA, USA, 2004; Volume 5291, pp. 93–104. [Google Scholar]
- Akansu, A.N.; Haddad, R.A. Multiresolution Signal Decomposition: Transforms, Subbands, and Wavelets; Academic Press, Inc.: Orlando, FL, USA, 1992. [Google Scholar]
- Wang, X.; Şekercioğlu, Y.A.; Drummond, T.; Natalizio, E.; Fantoni, I.; Fremont, V. Fast Depth Video Compression for Mobile RGB-D Sensors. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 673–686. [Google Scholar] [CrossRef]
- Mark, W.R. Post-Rendering 3D Image Warping: Visibility, Reconstruction and Performance for Depth-Image Warping. Ph.D. Thesis, University of North Carolina at Chapel Hill, Chapel Hill, NC, USA, 1999. [Google Scholar]
- Wang, X.; Şekercioğlu, Y.A.; Drummond, T.; Natalizio, E.; Fantoni, I.; Frémont, V. Collaborative Multi-Sensor Image Transmission and Data Fusion in Mobile Visual Sensor Networks Equipped with RGB-D Cameras. In Proceedings of the 2016 IEEE International Conference on Multisen Fusion and Integration for Intelligent Systems (MFI 2016), Baden-Baden, Germany, 19–21 September 2016. [Google Scholar]
- Wang, X.; Şekercioğlu, Y.A.; Drummond, T. A Real-Time Distributed Relative Pose Estimation Algorithm for RGB-D Camera Equipped Visual Sensor Networks. In Proceedings of the 7th ACM/IEEE International Conference on Distributed Smart Cameras (ICDSC 2013), Palm Springs, CA, USA, 29 October–1 November 2013. [Google Scholar]
- Chow, K.Y.; Lui, K.S.; Lam, E. Efficient Selective Image Transmission in Visual Sensor Networks. In Proceedings of the IEEE 65th Vehicular Technology Conference (VTC2007-Spring), Dublin, Ireland, 22–25 April 2007; pp. 1–5. [Google Scholar]
- Bai, Y.; Qi, H. Redundancy Removal Through Semantic Neighbor Selection in Visual Sensor Networks. In Proceedings of the Third ACM/IEEE International Conference on Distributed Smart Cameras (ICDSC 2009), Como, Italy, 30 August 30–2 September 2009; pp. 1–8. [Google Scholar]
- Bai, Y.; Qi, H. Feature-Based Image Comparison for Semantic Neighbor Selection in Resource-Constrained Visual Sensor Networks. J. Image Video Process. 2010, 2010, 469563. [Google Scholar] [CrossRef]
- Colonnese, S.; Cuomo, F.; Melodia, T. An Empirical Model of Multiview Video Coding Efficiency for Wireless Multimedia Sensor Networks. IEEE Trans. Multimed. 2013, 15, 1800–1814. [Google Scholar] [CrossRef] [Green Version]
- Dai, R.; Akyildiz, I. A Spatial Correlation Model for Visual Information in Wireless Multimedia Sensor Networks. IEEE Trans. Multimed. 2009, 11, 1148–1159. [Google Scholar] [CrossRef] [Green Version]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef] [Green Version]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In European Conference on Computer Vision; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 430–443. [Google Scholar]
- Lowry, S.; Sünderhauf, N.; Newman, P.; Leonard, J.J.; Cox, D.; Corke, P.; Milford, M.J. Visual Place Recognition: A Survey. IEEE Trans. Robot. 2016, 32, 1–19. [Google Scholar] [CrossRef]
- Chia, W.C.; Ang, L.M.; Seng, K.P. Multiview Image Compression for Wireless Multimedia Sensor Network Using Image Stitching and SPIHT Coding with EZW Tree Structure. In Proceedings of the International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC 2009), Hangzhou, China, 26–27 August 2009; Volume 2, pp. 298–301. [Google Scholar]
- Chia, W.C.; Chew, L.W.; Ang, L.M.; Seng, K.P. Low Memory Image Stitching and Compression for WMSN Using Strip-based Processing. Int. J. Sens. Netw. 2012, 11, 22–32. [Google Scholar] [CrossRef]
- Cen, N.; Guan, Z.; Melodia, T. Interview Motion Compensated Joint Decoding for Compressively Sampled Multiview Video Streams. IEEE Trans. Multimed. 2017, 19, 1117–1126. [Google Scholar] [CrossRef]
- Wu, M.; Chen, C.W. Collaborative Image Coding and Transmission over Wireless Sensor Networks. J. Adv. Signal Process. 2007, 2007, 223. [Google Scholar] [CrossRef]
- Shaheen, S.; Javed, M.Y.; Mufti, M.; Khalid, S.; Khanum, A.; Khan, S.A.; Akram, M.U. A Novel Compression Technique for Multi-Camera Nodes through Directional Correlation. Int. J. Distrib. Sens. Netw. 2015, 11, 539838. [Google Scholar] [CrossRef]
- Vetro, A.; Wiegand, T.; Sullivan, G. Overview of the Stereo and Multiview Video Coding Extensions of the H.264/MPEG-4 AVC Standard. Proc. IEEE 2011, 99, 626–642. [Google Scholar] [CrossRef] [Green Version]
- Redondi, A.E.; Baroffio, L.; Cesana, M.; Tagliasacchi, M. Multi-view Coding and Routing of Local Features in Visual Sensor Networks. In Proceedings of the the 35th Annual IEEE International Conference on Computer Communications (INFOCOM 2016), San Francisco, CA, USA, 10–15 April 2016. [Google Scholar]
- Ebrahim, M.; Chia, W.C. Multiview Image Block Compressive Sensing with Joint Multiphase Decoding for Visual Sensor Network. ACM Trans. Multimed. Comput. Commun. Appl. 2015, 12, 30. [Google Scholar] [CrossRef]
- Zhang, J.; Xiang, Q.; Yin, Y.; Chen, C.; Luo, X. Adaptive Compressed Sensing for Wireless Image Sensor Networks. Multimed. Tools Appl. 2017, 76, 4227–4242. [Google Scholar] [CrossRef]
- Deligiannis, N.; Verbist, F.; Iossifides, A.C.; Slowack, J.; de Walle, R.V.; Schelkens, R.; Muntenau, A. Wyner-Ziv Video Coding for Wireless Lightweight Multimedia Applications. J. Wirel. Commun. Netw. 2012, 2012, 1–20. [Google Scholar] [CrossRef]
- Yeo, C.; Ramchandran, K. Robust Distributed Multiview Video Compression for Wireless Camera Networks. IEEE Trans. Image Process. 2010, 19, 995–1008. [Google Scholar] [PubMed]
- Heng, S.; So-In, C.; Nguyen, T. Distributed Image Compression Architecture over Wireless Multimedia Sensor Networks. Wirel. Commun. Mob. Comput. 2017, 2017, 5471721. [Google Scholar] [CrossRef]
- Hanca, J.; Deligiannis, N.; Munteanu, A. Real-time Distributed Video Coding for 1K-Pixel Visual Sensor Networks. J. Electron. Imag. 2016, 25, 1–20. [Google Scholar] [CrossRef]
- Luong, H.V.; Deligiannis, N.; Forchhammer, S.; Kaup, A. Distributed Coding of Multiview Sparse Sources with Joint Recovery. In Proceedings of the 2016 Picture Coding Symposium (PCS), Nuremberg, Germany, 4–7 December 2016; pp. 1–5. [Google Scholar]
- Wang, X.; Şekercioğlu, Y.A.; Drummond, T. Multiview Image Compression and Transmission Techniques in Wireless Multimedia Sensor Networks: A Survey. In Proceedings of the 7th ACM/IEEE International Conference on Distributed Smart Cameras (ICDSC 2013), Palm Springs, CA, USA, 39 October–1 November 2013. [Google Scholar]
- Kadkhodamohammadi, A.; Gangi, A.; de Mathelin, M.; Padoy, N. A Multi-view RGB-D Approach for Human Pose Estimation in Operating Rooms. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar]
- Shen, J.; Su, P.C.; Cheung, S.; Zhao, J. Virtual Mirror Rendering With Stationary RGB-D Cameras and Stored 3D Background. IEEE Trans. Image Process. 2013, 22, 3433–3448. [Google Scholar] [CrossRef] [PubMed]
- Stamm, C. A New Progressive File Format for Lossy and Lossless Image Compression. In Proceedings of the International Conferences in Central Europe on Computer Graphics, Visualization and Computer Vision, Plzen, Czech Republic, 4–8 February 2002; pp. 30–33. [Google Scholar]
- San, X.; Cai, H.; Lou, J.G.; Li, J. Multiview Image Coding Based on Geometric Prediction. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 1536–1548. [Google Scholar]
- Ma, H.; Liu, Y. Correlation Based Video Processing in Video Sensor Networks. In Proceedings of the International Conference on Wireless Networks, Communications and Mobile Computing, Maui, HI, USA, 13–16 June 2005; Volume 2, pp. 987–992. [Google Scholar]
- Corke, P. Robotics, Vision and Control; Chapter 2—Representing Position and Orientation; Springer: Berlin, Germany, 2011. [Google Scholar]
- Benjemaa, R.; Schmitt, F. Fast Global Registration of 3D Sampled Surfaces Using a Multi-Z-Buffer Technique. Image Vis. Comput. 1999, 17, 113–123. [Google Scholar] [CrossRef]
- Lui, W.; Tang, T.; Drummond, T.; Li, W.H. Robust Egomotion Estimation Using ICP in Inverse Depth Coordinates. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA 2012), St. Paul, MN, USA, 14–18 May 2012; pp. 1671–1678. [Google Scholar]
- Drummond, T.; Cipolla, R. Real-Time Visual Tracking of Complex Structures. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 932–946. [Google Scholar] [CrossRef]
- Drummond, T. Lie Groups, Lie Algebras, Projective Geometry and Optimization for 3D Geometry, Engineering and Computer Vision. Available online: https://twd20g.blogspot.com/2014/02/updated-notes-on-lie-groups.html (accessed on 24 July 2018).
- Holland, P.W.; Welsch, R.E. Robust Regression Using Iteratively Reweighted Least-Squares. Commun. Stat. Theory Methods 1977, 6, 813–827. [Google Scholar] [CrossRef]
- Skodras, A.; Christopoulos, C.; Touradj, E. The JPEG 2000 Still Image Compression Standard. IEEE Signal Process. Mag. 2001, 18, 36–58. [Google Scholar] [CrossRef]
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H. 264/AVC Video Coding Standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef]
- libPGF Project. Available online: http://www.libpgf.org/ (accessed on 24 July 2018).
- Xi, M.; Xue, J.; Wang, L.; Li, D.; Zhang, M. A Novel Method of Multi-view Virtual Image Synthesis for Auto-stereoscopic Display. In Advanced Technology in Teaching; Springer: Berlin/Heidelberg, Germany, 2013; Volume 163, pp. 865–873. [Google Scholar]
- Fickel, G.P.; Jung, C.R.; Lee, B. Multiview Image and Video Interpolation Using Weighted Vector Median Filters. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 5387–5391. [Google Scholar]
- Mori, Y.; Fukushima, N.; Fujii, T.; Tanimoto, M. View Generation with 3D Warping Using Depth Information for FTV. Signal Process. Image Commun. 2009, 24, 65–72. [Google Scholar] [CrossRef]
- Do, L.; Zinger, S.; Morvan, Y.; de With, P. Quality Improving Techniques in DIBR for Free-Viewpoint Video. In Proceedings of the 2009 3DTV Conference: The True Vision—Capture, Transmission and Display of 3D Video, Potsdam, Germany, 4–6 May 2009; pp. 1–4. [Google Scholar]
- Besl, P.; McKay, N.D. A Method for Registration of 3D Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Technical University of Munich Computer Vision Group RGB-D SLAM Dataset and Benchmark. Available online: http://vision.in.tum.de/data/datasets/rgbd-dataset (accessed on 24 July 2018).
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the Evaluation of RGB-D SLAM Systems. In Proceedings of the International Conference on Intelligent Robot Systems (IROS 2012), Vilamoura, Algarve, 7–12 October 2012; pp. 573–580. [Google Scholar]
- D’Ademo, N.; Lui, W.L.D.; Li, W.H.; Şekercioğlu, Y.A.; Drummond, T. eBug: An Open Robotics Platform for Teaching and Research. In Proceedings of the Australasian Conference on Robotics and Automation (ACRA 2011), Melbourne, Australia, 7–9 December 2011. [Google Scholar]
- EyeBug—A Simple, Modular and Cheap Open-Source Robot. 2011. Available online: http://www.robaid.com/robotics/eyebug-a-simple-and-modular-cheap-open-source-robot.htm (accessed on 24 July 2018).
- Beagleboard-xM Single Board Computer. Available online: http://beagleboard.org/beagleboard-xm (accessed on 24 July 2018).
- OpenKinect Library. Available online: http://openkinect.org (accessed on 24 July 2018).
- OpenCV: Open Source Computer Vision Library. Available online: http://opencv.org (accessed on 25 July 2018).
- LibCVD—Computer Vision Library. Available online: http://www.edwardrosten.com/cvd/ (accessed on 25 July 2018).
- Colonnese, S.; Cuomo, F.; Melodia, T. Leveraging Multiview Video Coding in Clustered Multimedia Sensor Networks. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Anaheim, CA, USA, 3–7 December 2012; pp. 475–480. [Google Scholar]
- Gehrig, N.; Dragotti, P.L. Distributed Compression of Multi-View Images Using a Geometrical Coding Approach. In Proceedings of the IEEE International Conference on Image Processing (ICIP), San Antonio, TX, USA, 16–19 September 2007; Volume 6. [Google Scholar]
- Merkle, P.; Morvan, Y.; Smolic, A.; Farin, D.; Mueller, K.; de With, P.H.N.; Wiegand, T. The Effects of Multiview Depth Video Compression on Multiview Rendering. Signal Process. Image Commun. 2009, 24, 73–88. [Google Scholar] [CrossRef]
- Vijayanagar, K.; Loghman, M.; Kim, J. Refinement of Depth Maps Generated by Low-Cost Depth Sensors. In Proceedings of the 2012 International SoC Design Conference (ISOCC), Jeju Island, Korea, 4–7 November 2012; pp. 355–358. [Google Scholar]
- Vijayanagar, K.; Loghman, M.; Kim, J. Real-Time Refinement of Kinect Depth Maps using Multi-Resolution Anisotropic Diffusion. Mob. Netw. Appl. 2014, 19, 414–425. [Google Scholar] [CrossRef]















© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Şekercioğlu, Y.A.; Drummond, T.; Frémont, V.; Natalizio, E.; Fantoni, I. Relative Pose Based Redundancy Removal: Collaborative RGB-D Data Transmission in Mobile Visual Sensor Networks. Sensors 2018, 18, 2430. https://doi.org/10.3390/s18082430
Wang X, Şekercioğlu YA, Drummond T, Frémont V, Natalizio E, Fantoni I. Relative Pose Based Redundancy Removal: Collaborative RGB-D Data Transmission in Mobile Visual Sensor Networks. Sensors. 2018; 18(8):2430. https://doi.org/10.3390/s18082430
Chicago/Turabian StyleWang, Xiaoqin, Y. Ahmet Şekercioğlu, Tom Drummond, Vincent Frémont, Enrico Natalizio, and Isabelle Fantoni. 2018. "Relative Pose Based Redundancy Removal: Collaborative RGB-D Data Transmission in Mobile Visual Sensor Networks" Sensors 18, no. 8: 2430. https://doi.org/10.3390/s18082430
APA StyleWang, X., Şekercioğlu, Y. A., Drummond, T., Frémont, V., Natalizio, E., & Fantoni, I. (2018). Relative Pose Based Redundancy Removal: Collaborative RGB-D Data Transmission in Mobile Visual Sensor Networks. Sensors, 18(8), 2430. https://doi.org/10.3390/s18082430