1. Introduction
Sensors deployed in cyber-physical systems (CPS) for monitoring and control purposes are prone to anomalies (e.g., reliability failures and cyber-attacks). To detect anomalies and prevent their harmful effects, anomaly detection systems (ADS) are utilized. However, ADS suffer from false positives (i.e., false alarms) and false negatives (i.e., missed detections), which may result in high performance degradation in CPS applications. In particular, false positives result in recovery that is not required, and false negatives result in failing to perform recovery when it is indeed required. Such detection errors can cause incorrect measurements being transmitted to a controller, and thus result in obtaining non-optimal or even destabilizing control decisions, which may compromise the performance of the system. For example, detection errors may result in disastrous events, such as reactor explosion in process control systems, water contamination in water distribution networks, and extremely heavy traffic congestion in intelligent transportation systems [
1,
2].
To address the challenges caused by detection errors, it is necessary to take into account the CPS application when designing anomaly detectors, and to quantify the losses in the application caused by potential detection errors. To minimize the losses, it is desirable to reduce the detection errors as much as possible. However, there exists a trade-off between them (i.e., decreasing the rate of false alarms may increase the rate of missed faults, and vice versa), which can be changed through a detection threshold. Therefore, the performance loss caused by detection errors can be minimized by selecting the right detection threshold.
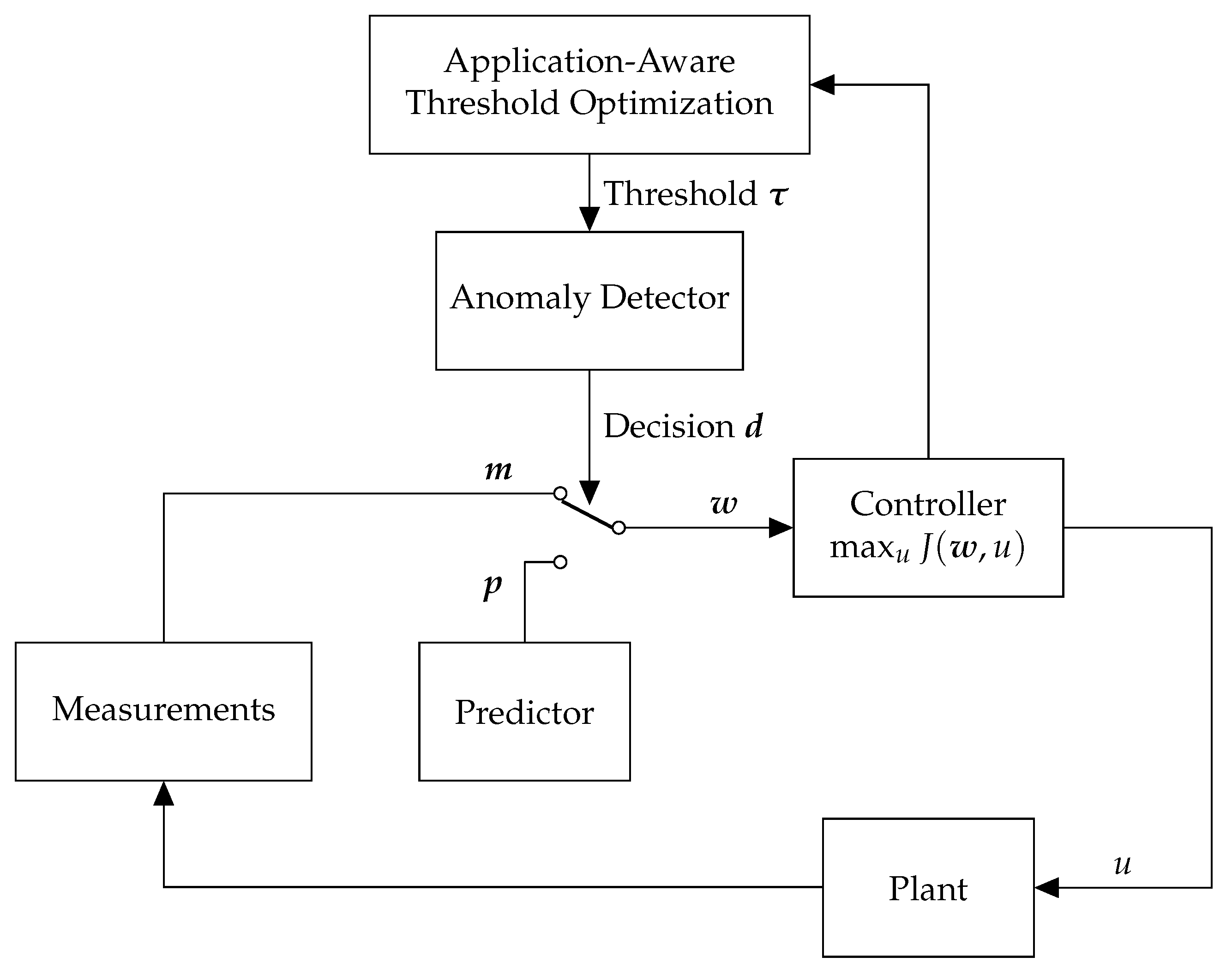
Our goal is to perform these steps using a novel approach, which takes an existing anomaly detector and configures it considering the behavior of the controller. We call our framework Application-Aware Anomaly Detection (AAAD). This framework takes into account the interactions between the controller and the application, and so it can compute how each detection decision may affect the underlying application. Knowing this, the detector attempts to make detection decisions that will result in the least performance loss in the underlying application if the detection decision is not accurate due to false positive and false negative errors.
Previous works have proposed different anomaly detection methods for CPS [
1]. In addition, there is a wide body of literature on machine learning-based anomaly detection [
3]. The problem of finding optimal thresholds for intrusion detectors is studied in [
4]. The paper shows that computing optimal attacks and defenses is computationally expensive, and proposes heuristic algorithms for computing near-optimal strategies. Further, the work in [
5] studies the problem of finding optimal thresholds for anomaly-based detectors implemented in dynamical systems in the face of strategic attacks. The paper provides algorithms to compute optimal thresholds that minimize losses considering best-response attacks. However, there is little work that takes into account the tight interaction between the detector and the controller of a CPS, which as we show in this work if taken into account, can result in improved performance and robustness.
Contributions
In this paper, we propose an application-aware anomaly detection framework for minimizing the impact of detection errors in CPS. The contributions of AAAD are as follows:
We devise an effective detector for identifying anomalies in sensor measurements using machine learning regression and an approach to recover from anomalies in order to maintain operation when detection alerts are triggered.
We formulate the AAAD problem, in which a detector is optimally configured such that the performance loss in the presence of detection errors is minimized. In particular, the thresholds are selected so that the performance of the system in the presence of detection errors is as close as possible to the performance that could have been achieved if there were no detection errors.
We show that the AAAD problem is computationally challenging, and then we present an efficient algorithm to find near-optimal solutions.
We analyze two special cases of the application-aware detection problem: (a) single detector and (b) detectors with equal thresholds. We present optimal solutions for both special cases which can provide insights into the novelty of the approach.
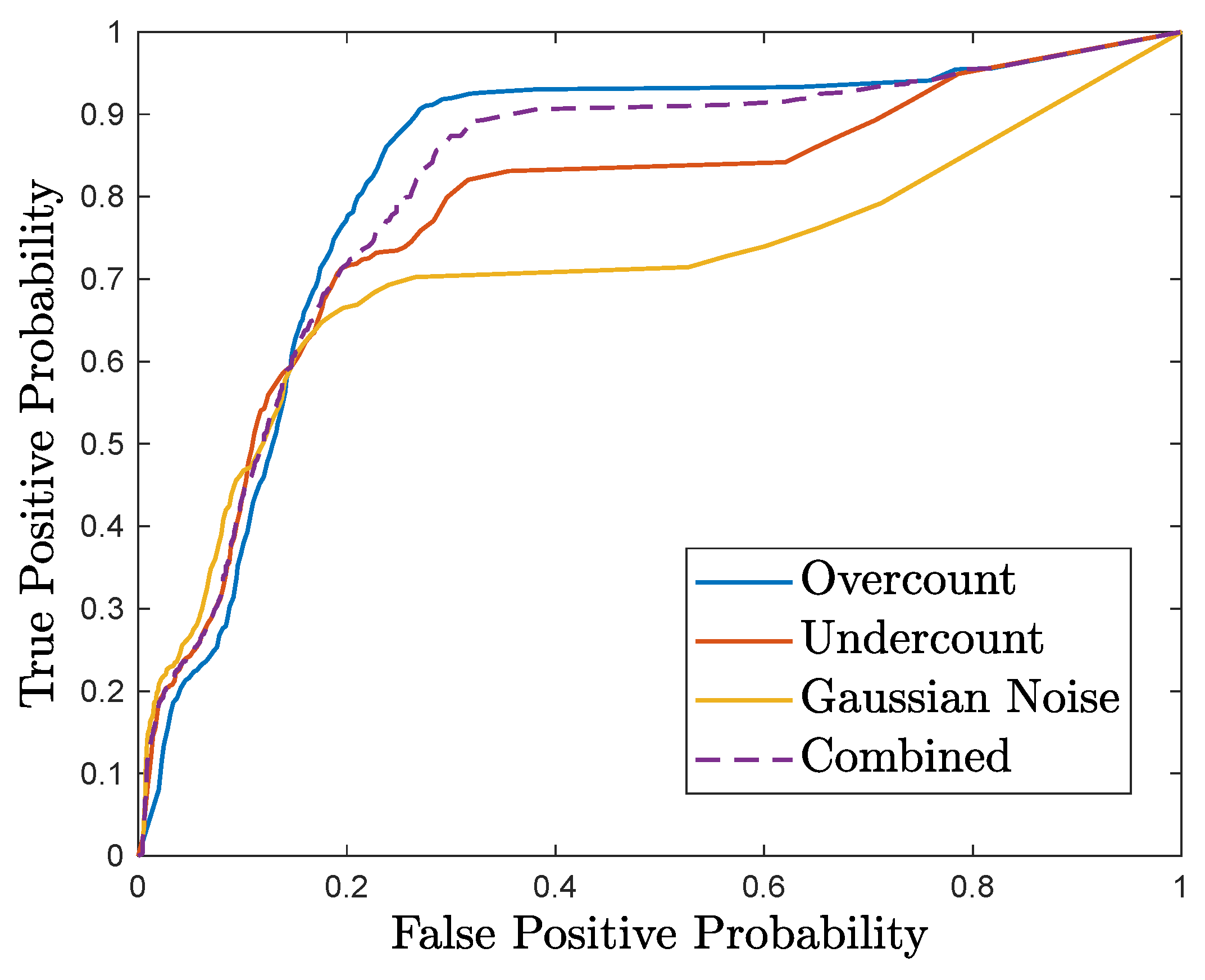
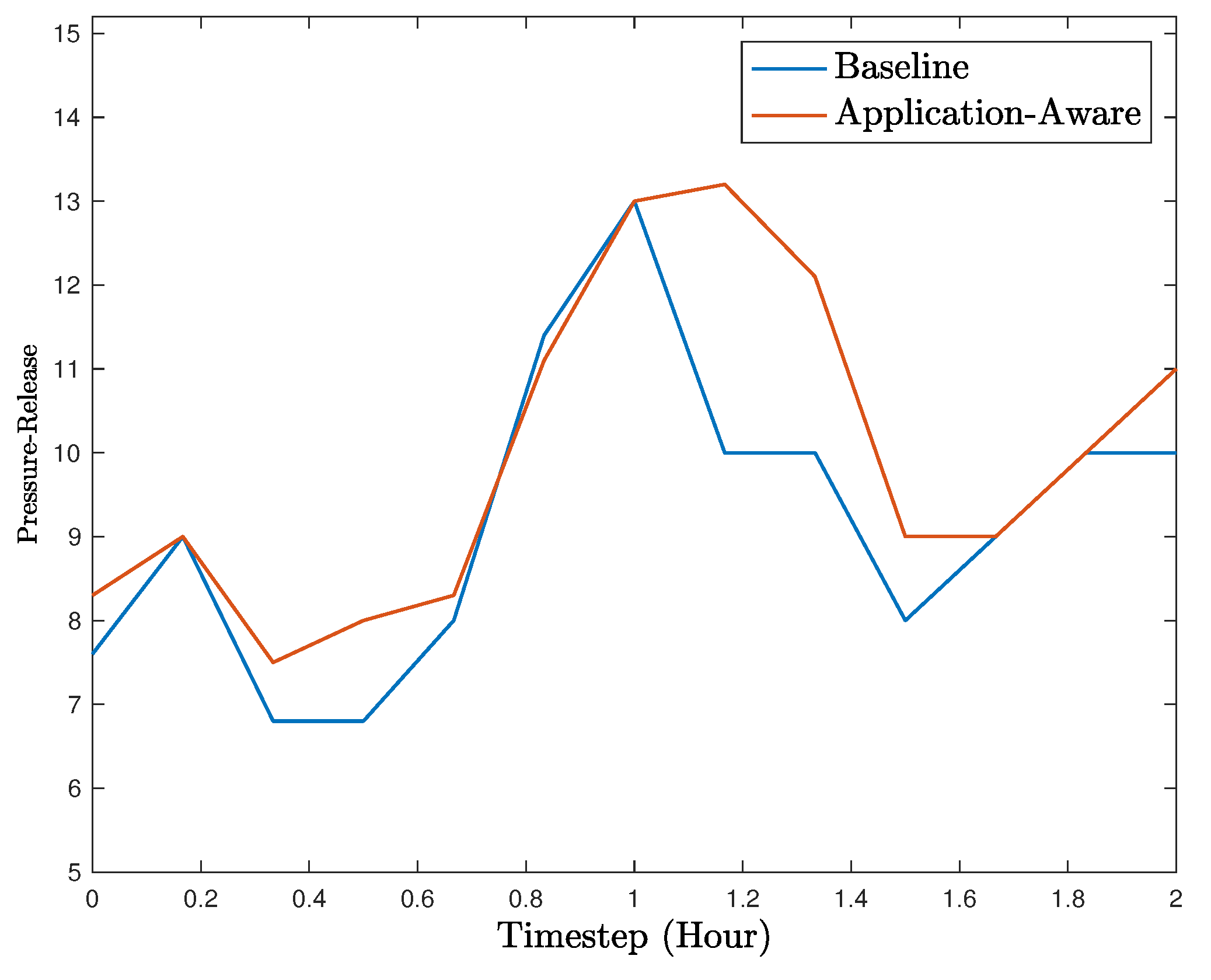
We evaluate AAAD using simulation experiments on a case study of real-time control of traffic signals. The evaluation results demonstrate the benefits of the approach compared with standard anomaly detection techniques.
We believe that the proposed approach can be useful in any system where there are a significant number of sensors with high variations in sensor values, which may cause many false-positive and false-negative errors. A real-world example of such a CPS application would be real-time control of traffic signals since in large cities, there are thousands of sensors that could become anomalous. Throughout the paper, we will use traffic sensors as a running example to illustrate the application of our framework, but we present the model and results using a general, domain-agnostic formulation. Alternative examples of possible application domains include sensors in water-distribution networks [
6].
Related Work
Anomaly detection in cyber-physical systems presents an important and challenging problem [
7,
8]. As a result, a variety of approaches have been proposed in prior work on anomaly detection. In contrast to our approach, these prior results focused on the design of detectors rather than the optimal configuration of an existing detector.
Several detectors have been built on machine learning and, in particular, neural networks. Goh et al. present an unsupervised approach for anomaly detection in cyber-physical systems based on recurrent neural networks and the cumulative sum method [
9]. Kosek presents a contextual anomaly detection method for smart grids based on neural networks [
10]. Krishnamurthy et al. use an alternative model, Bayesian networks [
11]. They present an approach for learning causal relations and temporal correlations in cyber and physical variables from unlabeled data using Bayesian networks. These networks can then be used to detect anomalies and isolate their root causes.
Jones et al. propose a formal-methods-based approach for anomaly detection in cyber-physical systems [
12]. They introduce a model-free, unsupervised learning procedure that constructs a signal temporal logic (STL) formula from system output data collected during normal operations. Then, anomalies can be detected by flagging system trajectories that do not satisfy the learned formula. In a follow-up work, Kong et al. describe a formal-methods-based approach for supervised anomaly learning [
13]. Chibani et al. investigate the problem of designing fault-detection filters for fuzzy systems, considering faults and unknown disturbances in discrete-time polynomial fuzzy systems [
14,
15]. A diagnostic observer-based system for fault detection of fuzzy systems which optimizes the worst case robustness and fault sensitivity is presented in [
16].
Anomaly detection has also been considered in the context of security intrusions, that is, to detect cyber-physical attack against a CPS [
17]. For example, Urbina et al. study physics-based detection of stealthy attacks against industrial control systems [
1]. They review prior work on attack detection and argue that many of these use detection schemes that do not limit the impact of stealthy attacks. They then propose a new metric for measuring impact and demonstrate that attacks may be detected with a proper configuration. In contrast, Kleinmann and Wool consider detection of attacks against industrial control systems based on cyber anomalies [
18].
Besides anomaly detection, other approaches have also been considered for detecting faults or attacks in traffic networks. Lu et al. review prior work on the problem of anomaly detection of traffic sensors [
19]. Based on the level of data used, they divide detection methods into three levels: macroscopic (highly-aggregated data), mesoscopic (synchronized data for a section of freeways), and microscopic. They also review data-correction methods and provide practical guidelines for anomaly detection in traffic applications. Zygouras et al. present three methods—based on Pearson’s correlation, cross-correlation, and multivariate ARIMA—to detect faulty traffic measurements [
20]. They discuss the performance of all three methods and demonstrate that they are complementary to each other. Further, they employ crowd-sourcing to resolve whether irregular measurements are due to faulty sensors or unusual traffic. Finally, Robinson presents a test, based on the relationship between flows at adjacent sensors, to detect faulty loop detectors [
21].
Nonetheless, to the best of our knowledge, none of these papers consider the performance of the controller in the design and configuration of anomaly detectors, and they do not perform any application-aware optimization to improve detection performance.
Paper Outline
The rest of this paper is organized as follows. In
Section 2, we introduce the system model. In
Section 3, we discuss the regression-based anomaly detection. In
Section 4, we present the application-aware detection problem for detection error-tolerant selection of thresholds in anomaly detectors. In
Section 5, we analyze the application-aware detection problem and present an algorithm to obtain near-optimal solutions. In
Section 6, we study two special variations of the application-aware detection problem, that is, single detector and detectors with equal threshold. In
Section 7, we evaluate our approach numerically using a case study of real-time control of traffic signals. Finally, we offer concluding remarks in
Section 8.
2. Model
In this section, we present the system model and informally introduce the problem of application aware anomaly detection. We also present a running example of real-time control of traffic signals that is used throughout the paper to demonstrate our approach.
2.1. Notation
Vectors are denoted by bold symbols. Vector
at timestep
k is described by
. We omit the timestep symbol when all symbols have same timestep
k. However, timestep symbol is used when there are different timesteps present or when it eases understanding. Given vector
and set of indices
I, vector
is defined as a vector with same size as
that has the same size as
for indices in
I, and is zero otherwise. For a list of symbols used in this section, see
Table 1.
2.2. System Model
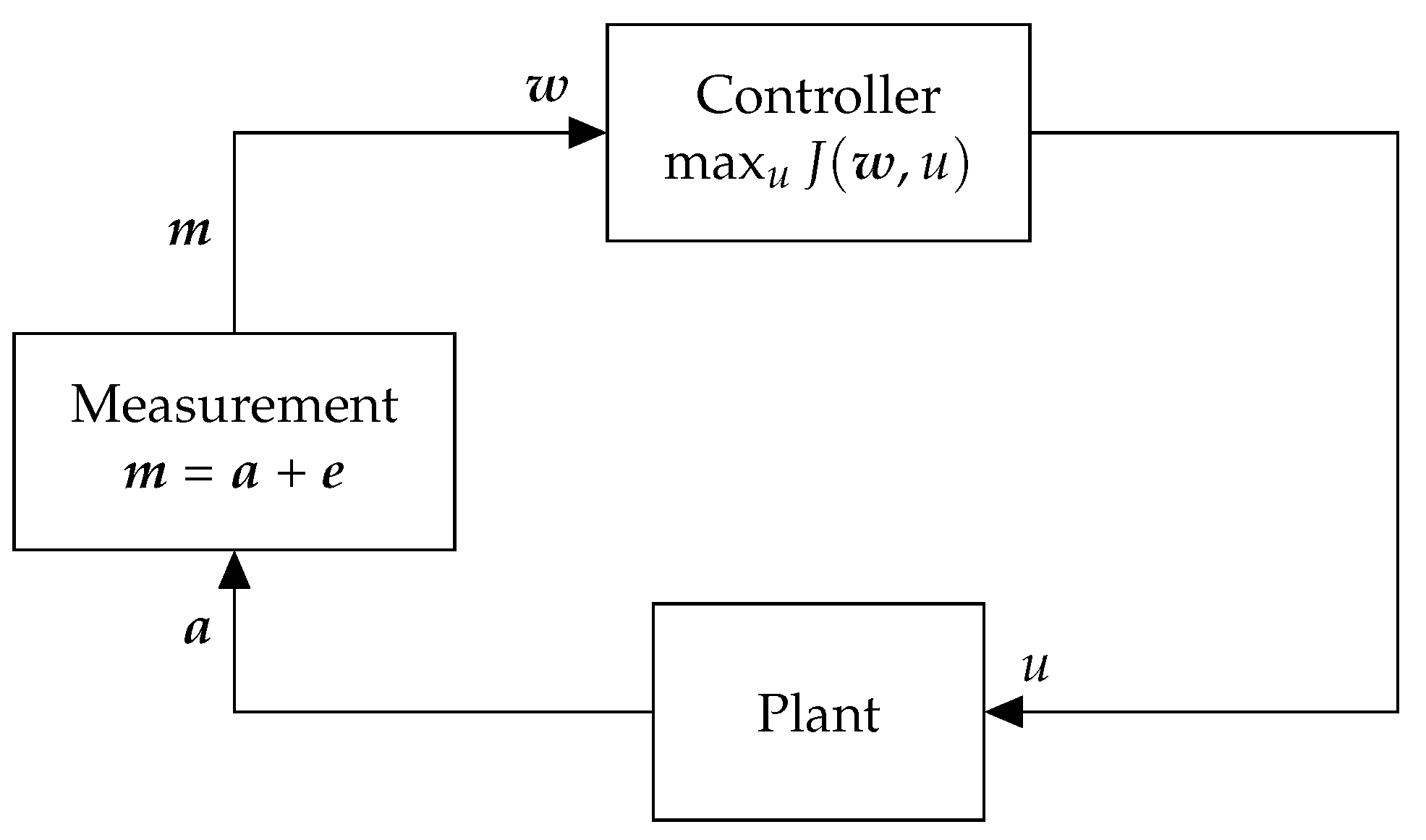
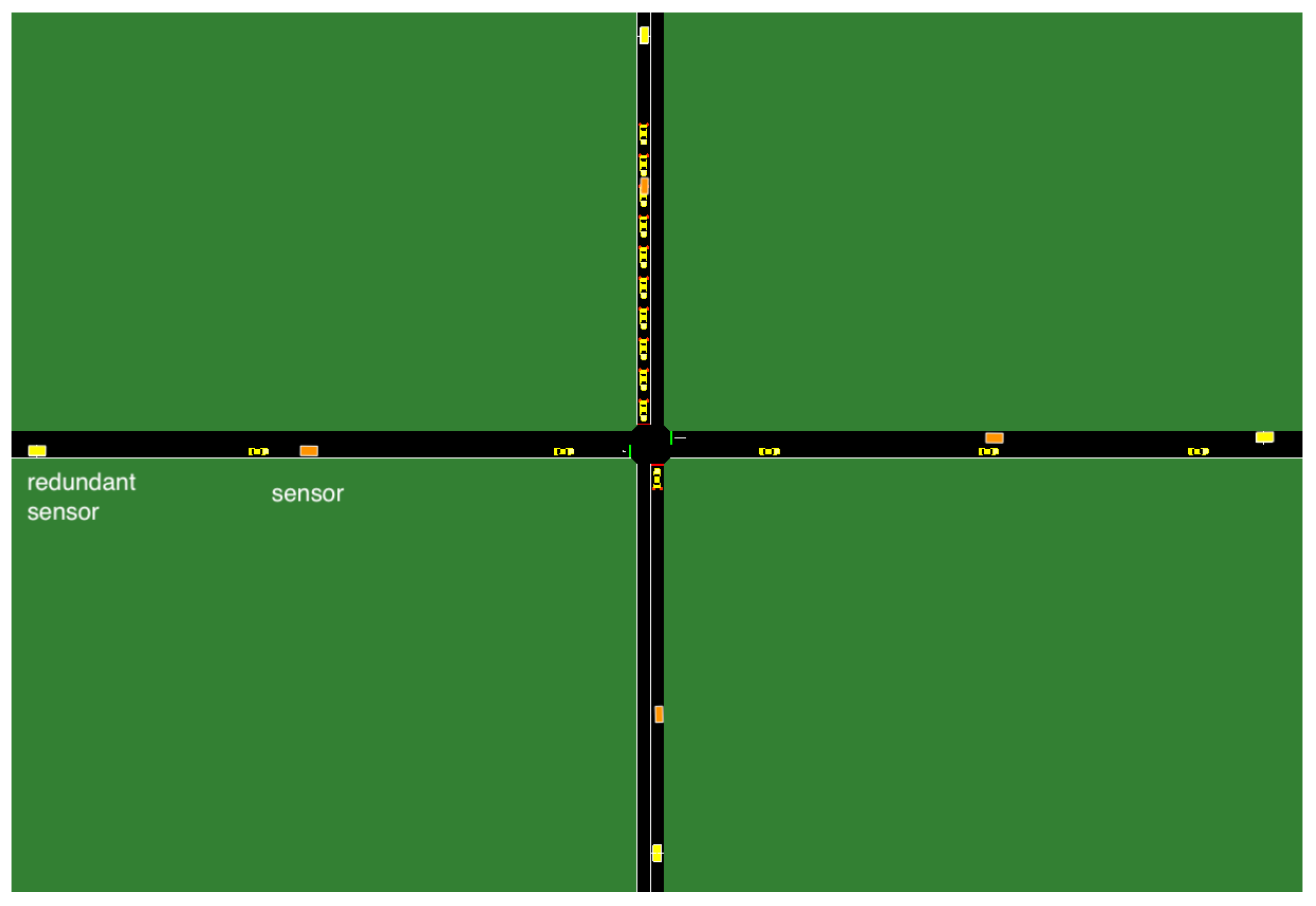
Consider a CPS, for example, an intelligent transportation system or a process control system, consisting of a plant and a controller as shown in
Figure 1. At each timestep, given measurements
containing information about the system, a controller computes a control input
u that maximizes a utility function
. In other words, the controller determines the optimal control input
defined as
where the optimal utility is denoted by
.
Anomalous Sensors
Sensors may be anomalous due to hardware failures or sensor attacks. If sensor is anomalous, there is a discrepancy between the actual and observed measured values. In other words, if is the actual value and is the observed measurement at a timestep, for an anomalous sensor we have , where is the error value at that timestep.
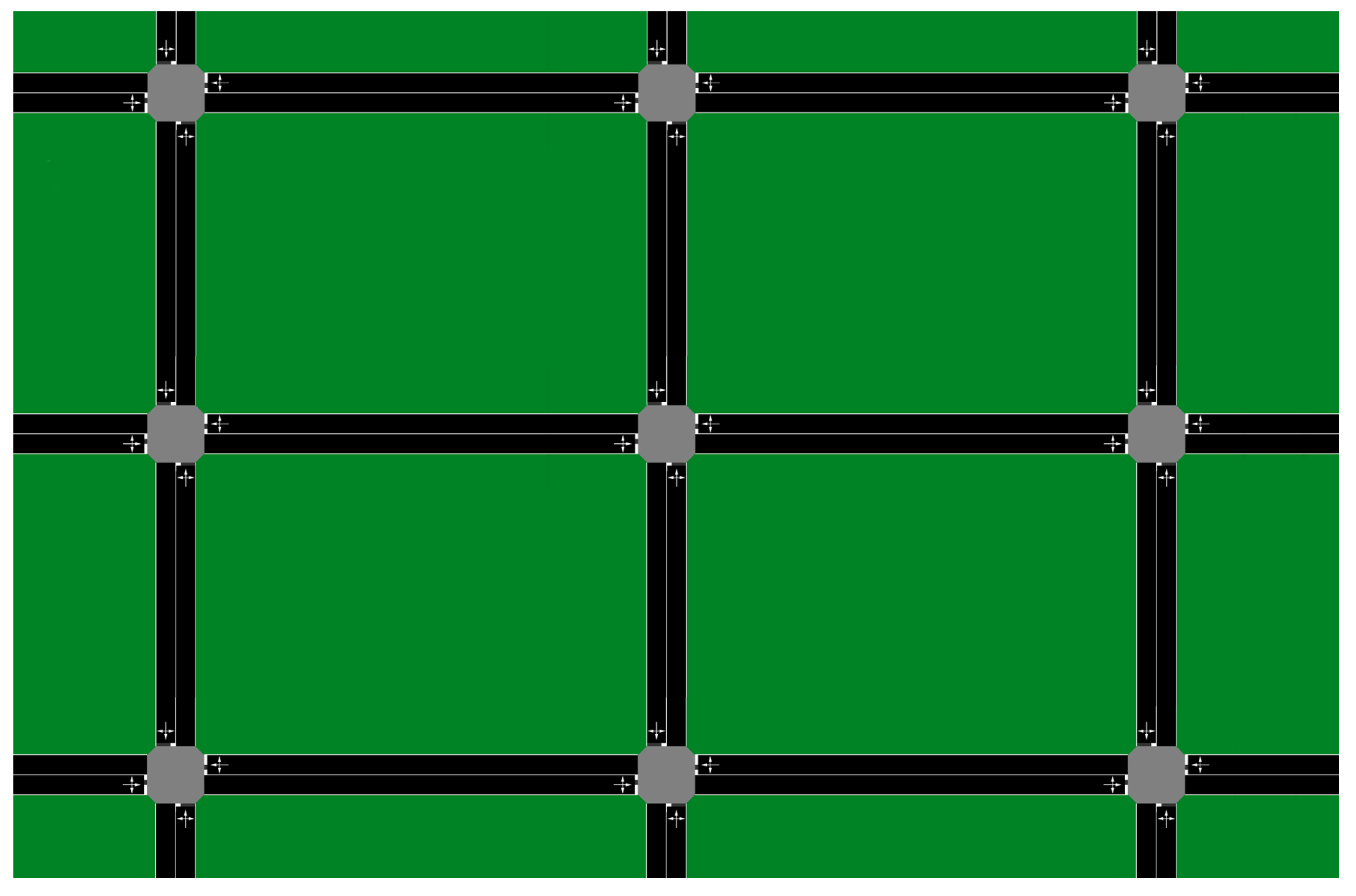
2.3. Example: Real-Time Traffic Signal Control
We present real-time control of traffic signals as a running example that is used throughout the paper to demonstrate the applicability of our approach. In the following, we describe the widely-popular max-pressure controller for optimal control of traffic signals [
22]. In the original max-pressure algorithm presented in [
22], the traffic state is represented using exogenous demands that are then routed through the network using routing ratios. In this work, instead of using exogenous demands that are then transformed to internal demands through using routing ratios, we assume that the internal demands are directly provided. Please note that this does not affect the max-pressure algorithm as the algorithm effectively uses internal demands in its computations.
Max-Pressure Controller
Consider a network of intersections
I with road links
L. Movement from a link
to a link
is denoted by a pair
. Further, let each movement
have a queue associated with it, and at each timestep, let
represent the length of this queue. The length of the queue shows how many vehicles intend to travel from
i to
j. For each movement
, the pressure is defined as
which is simply the number of cars in the queue minus the total number of cars in the downstream queues.
Each intersection
n has a traffic signal with a set of admissible stages
. Each stage
is a set of simultaneous movements that are permitted by the traffic signal. If
permits a movement
, then
, otherwise
. Let
be the saturation flow of movement
. Given a stage
, pressure-release (i.e., utility) for intersection
n is defined as
Traffic sensors can be used to measure for all and they are prone to failures.
Algorithm 1 presents the max-pressure (MP) controller in detail. At each intersection
n, the MP controller selects the stage
that results in the maximum pressure-release. In other words, the MP controller computes
Please note that at each intersection, the MP control selects a stage that depends only on the queues adjacent to the intersection. It is shown that the MP controller maximizes network throughput [
22].
| Algorithm 1 Max-Pressure Controller [22]. |
- 1:
for alldo - 2:
for all do - 3:
- 4:
end for - 5:
- 6:
end for - 7:
return
|
The overall utility for traffic network can be calculated by adding individual utilities for the intersections. That is,
where
. Please note that using this representation, the MP optimization problem becomes the same as (
1).
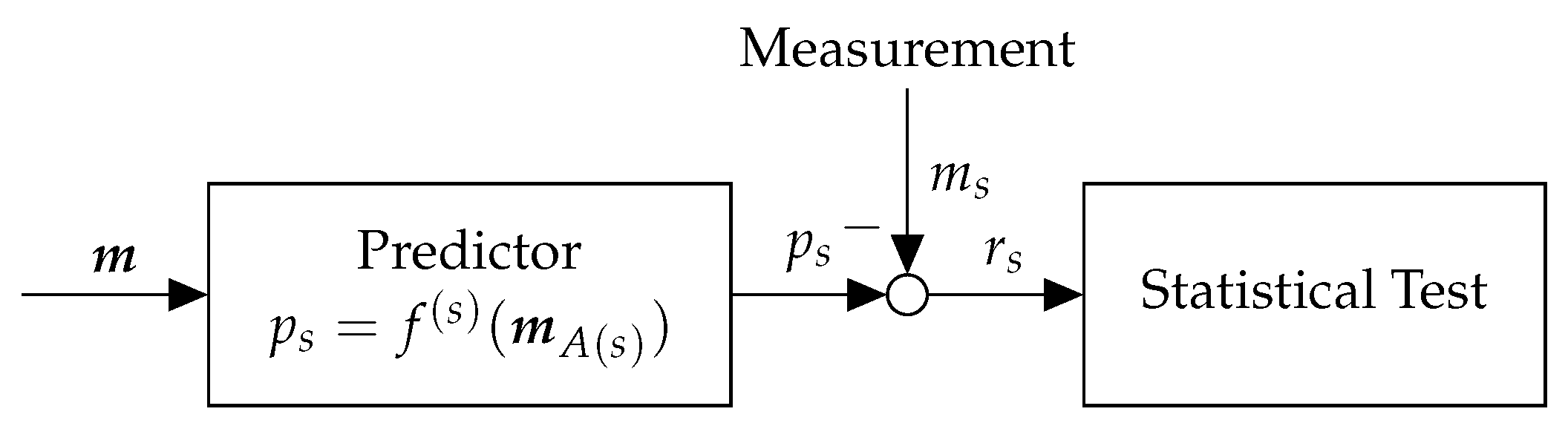
2.4. Anomaly Detection, Recovery, and Resilience
Next, we discuss anomalies caused by sensor faults and their detection, and we informally introduce the problem of optimal detector configuration, which we will formalize in
Section 4.4. In contrast to the previous subsection, where we introduced our running example, the discussion here will again be domain agnostic.
Anomalies may cause damage to the system and significantly degrade the performance of the CPS application (as measured by the utility function ). Consequently, we must employ an anomaly detector to detect faults in sensor measurements. In our running example, anomalies can affect the traffic measurements, and therefore, degrade the utility of the traffic signal control. Suppose that we have an anomaly detection method. Upon detection, the system must recover from anomalies and continue operation. To this end, we must employ a recovery method in order to continue operation in the presence of detection alerts. In the traffic signal control example, operation must continue even in the presence of anomalous traffic measurements.
Now, suppose that we have a recovery approach that computes a recovered vector of measurements in the presence of detection alerts. In anomaly detectors, there are detection errors, that is, false positives (i.e., false alarms) and false negatives (i.e., missed faults). If there were no detection errors, the recovered vector of measurements would be close to the actual values (of course assuming that the recovery approach works well). However, in the presence of detection errors, false positives result in recovery that is not required, and false negatives result in failing to perform recovery when it is indeed needed.
To illustrate the effect of detection errors on the application, let denote the recovered measurement vector, which will result in the utility . However, if there were no detection error, we could have obtained the optimal utility . Hence, we face the problem of optimally configuring an anomaly detector through the selection of detection thresholds so that the actual obtained utility in the presence of detection errors (i.e., ) is as close as possible to the utility that would have been obtained if there were no detection errors (i.e., ). In the traffic signal control example, the utility is quantified by the pressure release for an intersections that can be used as a proxy for maximizing network throughput.
5. Analysis
In this section, we solve the problems (
10) and (
12). First, we analyze the problem of worst-case detection error loss (
9), and we prove that solving this problem is computationally challenging. We then present Algorithm 2 which is an efficient algorithm to obtain approximately optimal solutions. Second, we present Algorithm 3 to solve the application-aware detection problem (
10) and obtain near-optimal thresholds. Finally, we propose Algorithm 4 to solve the problem of application-aware detection in a time period. The algorithm implements a variation of simulated annealing algorithm and finds near-optimal detection thresholds.
5.1. Algorithm for Worst-Case Detection Error Loss Problem
We begin our analysis by studying the computational complexity of finding worst-case loss due to detection errors (
9). To this end, we formulate the problem of finding a worst-case loss as a decision problem.
Definition 4 (Worst-Case Detection Error Problem (Decision Version)). Given a set of sensors S, detection thresholds τ, residuals , and desired loss , determine whether there exists a detection error scenario that incurs the detection error loss of at least .
The following theorem establishes the computational complexity of finding a worst-case detection error.
Theorem 1. Worst-Case Detection Error Problem (WCDE) is NP-Hard.
Proof. We prove the above theorem using a reduction from a well-known NP-hard problem, the Maximum Independent Set Problem.
Definition 5 (Maximum Independent Set Problem (Decision Version)). Given an undirected graph and a threshold cardinality k, determine whether there exists an independent set of nodes (i.e., a set of nodes such that there is no edge between any two nodes in the set) of cardinality k.
Given an instance of the Maximum Independent Set Problem (MIS), that is, a graph and a threshold cardinality k, we construct an instance of the WCDE as follows:
Let the set of sensors be .
Let and for every sensor .
For every sensor , let where , so that and .
Let for every sensor .
Let the dimension of the control signal be . For each element i of u, let .
Let the utility function be if the non-zero elements in form a non-empty independent set, and otherwise.
Finally, let the threshold loss be .
Clearly, the above reduction can be performed in polynomial time. Hence, it remains to show that the constructed instance of WCDE has a solution if and only if the given instance of MIS does.
MIS then WCDE. First, suppose that MIS has a solution, that is, there exists an independent set
I of
k nodes. We claim that the set
and
is a solution to WCDE. We have
Since for any given sets of detection error, we obtain .
Not MIS then Not WCDE. Second, suppose that MIS has no solution, that is, every set of at least k nodes is non-independent. Then, we have that for every ; otherwise, there would exist a set of at least k nodes in I that are independent of each other, which would contradict our supposition. Then, since , we conclude . □
| Algorithm 2 Algorithm for Computing Worst-Case Loss. |
- 1:
functionWorst_Loss() - 2:
for all do - 3:
() ? : - 4:
end for - 5:
, - 6:
, - 7:
- 8:
while do - 9:
- 10:
- 11:
if then - 12:
- 13:
- 14:
- 15:
else - 16:
- 17:
- 18:
- 19:
end if - 20:
if then - 21:
- 22:
else - 23:
return - 24:
end if - 25:
end while - 26:
return - 27:
end function
|
We present Algorithm 2 which uses a greedy approach to obtain the worst-case loss due to detection errors. The algorithm starts considering a scenario of perfect detection, that is, , , and . In each iteration, the algorithm moves an element from either or to respectively or that maximally increases the utility loss. If no such element exists, the algorithm terminates with the best solution found so far.
The runtime of Algorithm 2 depends on the function J, which depends on the considered application. If there is an oracle that computes and in constant time, the runtime of Algorithm 2 is linear with respect to . That is, the runtime of Algorithm 2 is .
5.2. Algorithm for Application Aware Anomaly Detection Problem
To solve the AAAD problem, we first prove the following lemma. The lemma shows that the problem is equal to the problem of selecting a set of normal sensors N and a set of anomalous sensors A, which has a much smaller search space than the original problem.
Lemma 1. For sensor s with residual , the optimal threshold with respect to (10) satisfies . Proof. We need to prove that for sensor
s with residual
, the optimal threshold with respect to (
10) is in the set
. First, let us recall that the optimal threshold is
where
.
Suppose there exists a set of optimal thresholds such that some of its elements are not in the set mentioned above. Let s be one such sensor, that is, . First, let . Clearly, . Then, we write if , and so cannot be the optimal threshold if s is in the set of true positives. Also, if , and so cannot be the optimal threshold if s is in the set of false positives either. Second, let . Again, we have . Then, we write if . Also, if . This means that cannot be the optimal threshold if s is in the set of true negatives or false negatives either. This contradicts our supposition, and thus, can never be correct. This concludes our proof. □
| Algorithm 3 Algorithm for Design of Application-Aware Detector. |
- 1:
functionApplication_Aware() - 2:
, - 3:
- 4:
while do - 5:
- 6:
if then - 7:
- 8:
- 9:
- 10:
else - 11:
return - 12:
end if - 13:
end while - 14:
return - 15:
end function
|
Following the above lemma, we present Algorithm 3 to obtain application-aware detection thresholds. The algorithm begins by initializing all sensors as normal, that is, and . In each iteration, the algorithm moves a sensor from N to A, which maximally decreases the worst-case loss. To compute the worst-case loss, Algorithm 2 is used.
Similar to the previous algorithm, the running time depends on the function J and the considered application. If there is an oracle that returns and in constant time, the runtime of Algorithm 3 is .
5.3. Algorithm for Application-Aware Anomaly Detection in a Time Period
We present Algorithm 4 which solves the problem of application-aware detection in a time period T (2). The algorithm is based on a variation of simulated annealing algorithm, and finds near-optimal thresholds . The idea is to start with an arbitrary solution and improving it iteratively. In each iteration, we generate a new candidate solution in the neighborhood of . If the candidate solution is better in minimizing the loss, then the current solution is replaced with the new one. However, if increases the loss, the new solution replaces the current solution with only a small probability. This probability depends on the difference between the two solutions in terms of loss as well as a temperature parameter which is a decreasing function of the number of iterations. These random replacements decreases the likelihood of getting stuck in a local minimum.
| Algorithm 4 Algorithm for Design of the Application-Aware in a Time Period. |
- 1:
Input:, - 2:
Initialize:, , - 3:
- 4:
whiledo - 5:
- 6:
- 7:
- 8:
if then - 9:
, - 10:
end if - 11:
- 12:
- 13:
end while - 14:
return
|
In Algorithm 4, defines the neighborhood of in the nth iteration, from which is randomly sampled. More specifically, means that each in is replaced by . Here, for each , is randomly picked from the uniform distribution over for some . Moreover, since is nonnegative, we replace it with 0 if .










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}