Semi-Supervised Generative Adversarial Nets with Multiple Generators for SAR Image Recognition





Abstract
:1. Introduction
2. Related Work
2.1. Generative Adversarial Networks
2.2. Improved GANs Models
3. Materials and Methods
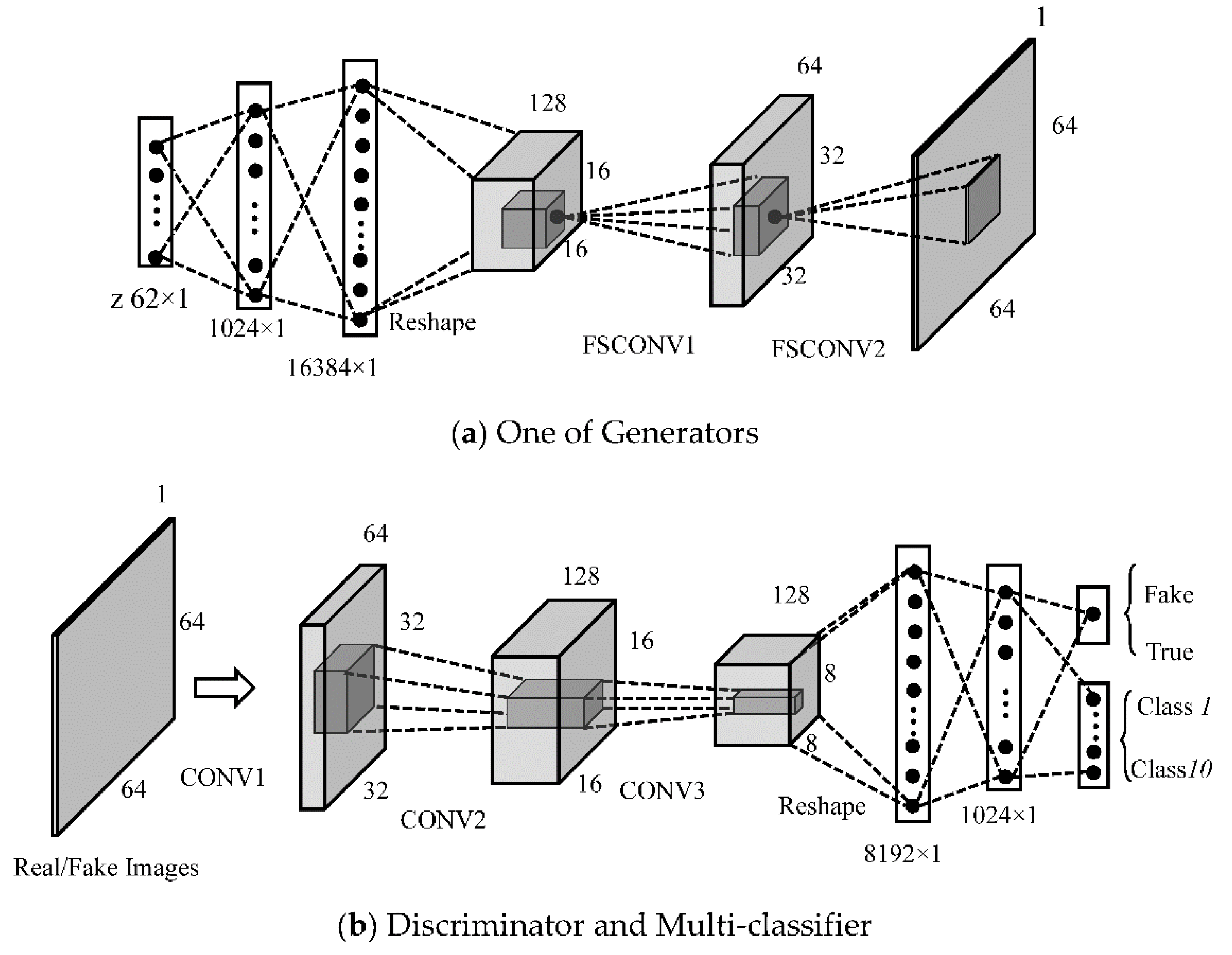
3.1. The MCGAN for SAR Images
3.2. Architectureof Semi-Supervised Recognition forSAR Images
4. Results
4.1. Description of the Data Sets
4.2. Experimental Results
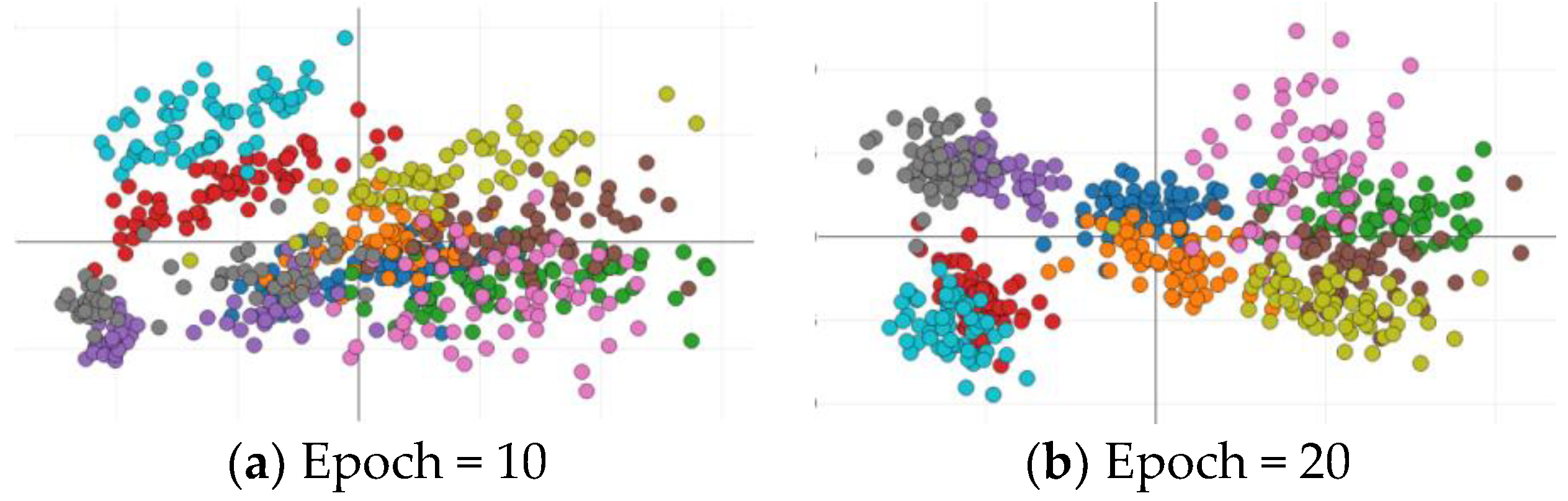
4.2.1. Training of MCGAN with 600 Labeled Images
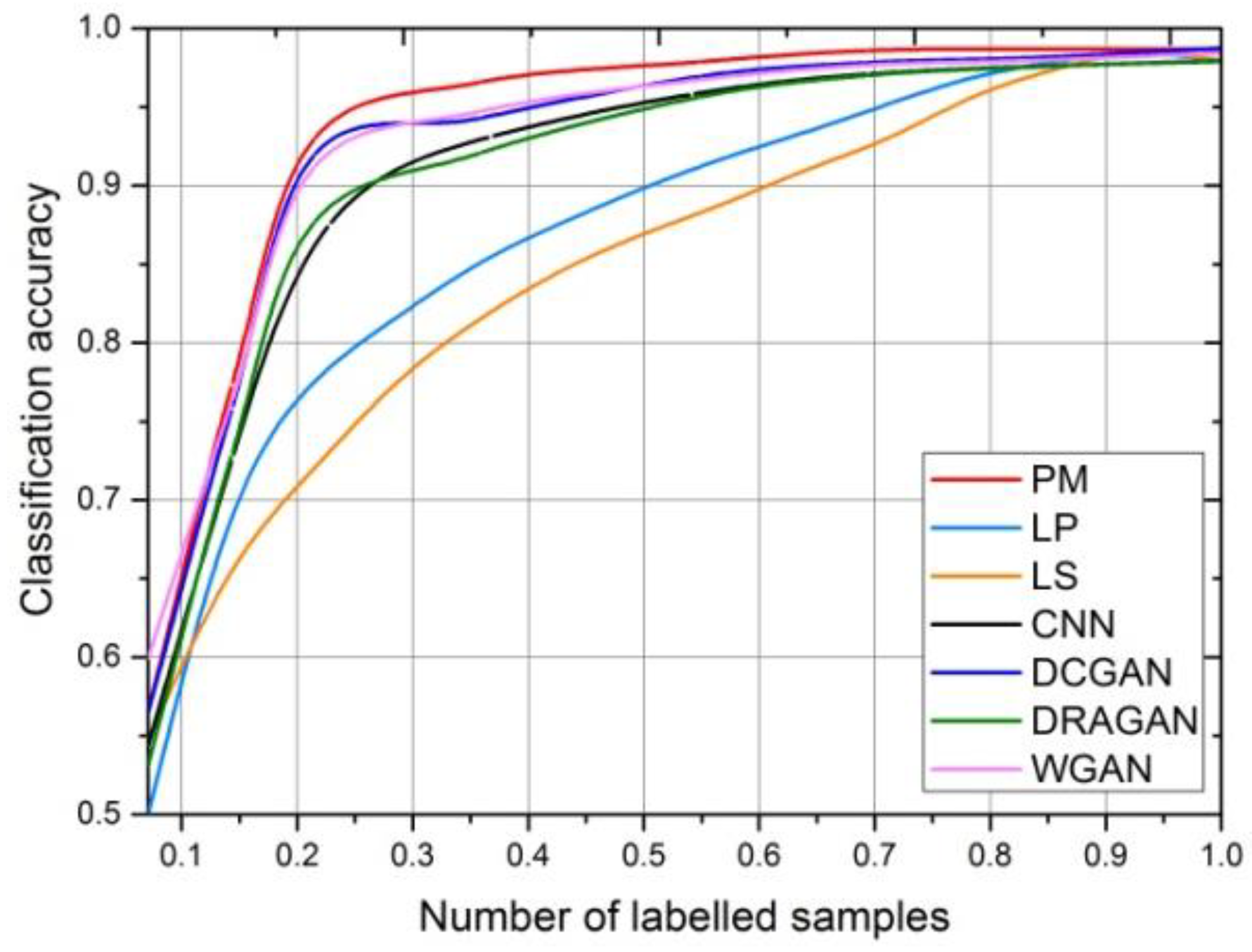
4.2.2. Recognition Results Trained with 600 Labeled Images
4.2.3. Recognition Results Trained by Different Numbers of Labeled Images
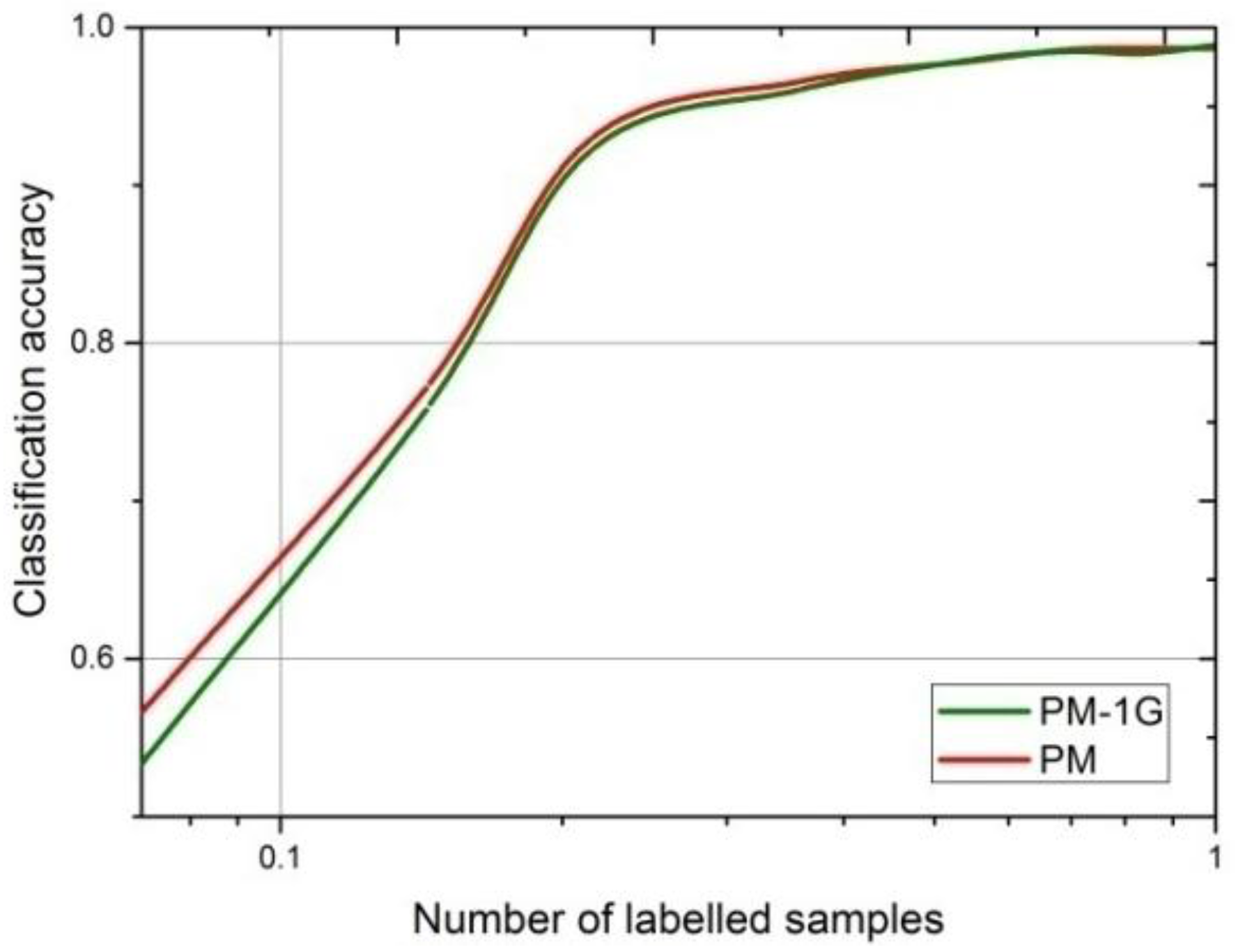
4.2.4. Choosing the Number of the Generators of MCGAN
4.2.5. Running Time
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mason, D.C.; Davenport, I.J.; Neal, J.C.; Schumann, G.J.; Bates, P.D. Near real-time flood detection in urban and rural areas using high-resolution synthetic aperture radar images. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3041–3052. [Google Scholar] [CrossRef]
- Covello, F.; Battazza, F.; Coletta, A.; Lopinto, E.; Fiorentino, C.; Pietranera, L.; Valentini, G.; Zoffoli, S. COSMO-SkyMed an existing opportunity for observing the Earth. J. Geodyn. 2010, 49, 171–180. [Google Scholar] [CrossRef] [Green Version]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Mika, S.; Ratsch, G.; Weston, J.; Scholkopf, B.; Mullers, K.R. Fisher discriminant analysis with kernels. In Proceedings of the InNeural Networks for Signal Processing IX: 1999 IEEE Signal Processing Society Workshop, Madison, WI, USA, 25 August 1999; pp. 41–48. [Google Scholar] [Green Version]
- Zhang, F.; Hu, C.; Yin, Q.; Li, W.; Li, H.C.; Hong, W. Multi-Aspect-Aware Bidirectional LSTM Networks for Synthetic Aperture Radar Target Recognition. IEEE Access 2017, 5, 26880–26891. [Google Scholar] [CrossRef]
- Wang, G.; Tan, S.; Guan, C.; Wang, N.; Liu, Z. Multiple model particle flter track-before-detect for range ambiguous radar. Chin. J. Aeronaut. 2013, 26, 1477–1487. [Google Scholar] [CrossRef]
- Tian, Q.; Arbel, T.; Clark, J.J. Deep lda-pruned nets for efficient facial gender classification. In Proceedings of the 2017 IEEE Conference on InComputer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 512–521. [Google Scholar]
- Yu, S.; Cheng, Y.; Su, S.; Cai, G.; Li, S. Stratified pooling based deep convolutional neural networks for human action recognition. Multimed. Tools Appl. 2017, 76, 13367–13382. [Google Scholar] [CrossRef]
- Wagner, S. Combination of convolutional feature extraction and support vector machines for radar ATR. In Proceedings of the 17th International Conference on Information Fusion (FUSION), Salamanca, Spain, 7–10 July 2014; pp. 1–6. [Google Scholar]
- Wagner, S. Morphological component analysis in SAR images to improve the generalization of ATR systems. In Proceedings of the 2015 3rd International Workshop on Compressed Sensing Theory and its Applications to Radar, Sonar and Remote Sensing (CoSeRa), Pisa, Italy, 17–19 June 2015; pp. 46–50. [Google Scholar]
- Ding, J.; Chen, B.; Liu, H.; Huang, M. Convolutional neural network with data augmentation for SAR target recognition. IEEE Geosci. Remote Sens. Lett. 2016, 13, 364–368. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Le, Q.V. Building high-level features using large scale unsupervised learning. In Proceedings of the 2013 IEEE International Conference on In Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 8595–8598. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Wang, H. SAR target recognition based on deep learning. In Proceedings of the 2014 International Conference on Data Science and Advanced Analytics (DSAA), Shanghai, China, 30 October–1 November 2014; pp. 541–547. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Yeh, R.; Chen, C.; Lim, T.Y.; Hasegawa-Johnson, M.; Do, M.N. Semantic image inpainting with perceptual and contextual losses. arXiv, 2016; arXiv:1607.07539. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. arXiv, 2017; arXiv:1609.04802. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Springenberg, J.T. Unsupervised and semi-supervised learning with categorical generative adversarial networks. arXiv, 2015; arXiv:1511.06390. [Google Scholar]
- Guo, J.; Lei, B.; Ding, C.; Zhang, Y. Synthetic aperture radar image synthesis by using generative adversarial nets. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1111–1115. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv, 2015; arXiv:1511.06434. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv, 2017; arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of Wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Kodali, N.; Abernethy, J.; Hays, J.; Kira, Z. On convergence and stability of GANs. arXiv, 2017; arXiv:1705.07215. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv, 2014; arXiv:1411.1784. [Google Scholar]
- Denton, E.L.; Chintala, S.; Fergus, R. Deep generative image models using a laplacian pyramid of adversarial networks. In Proceedings of the Advances in Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 1486–1494. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Smolley, S.P. Least squares generative adversarial networks. In Proceedings of the 2017 IEEE International Conference onComputer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2813–2821. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards principled methods for training generative adversarial networks. arXiv, 2017; arXiv:1701.04862. [Google Scholar]
- Hoang, Q.; Nguyen, T.D.; Le, T.; Phung, D. MGAN: Training generative adversarial nets with multiple generators. In Proceedings of the ICLR 2018 Conference, Vancouver, BC, Canada, 30 April 2018–3 May 2018. [Google Scholar]
- Zhu, X.; Ghahramani, Z. Learning from Labeled and Unlabeled Data with Label Propagation; School of Computer Science, Carnegie Mellon University: Pittsburgh, PA, USA, 2002. [Google Scholar]
- Zhou, D.; Bousquet, O.; Lal, T.N.; Weston, J.; Schölkopf, B. Learning with local and global consistency. In Proceedings of the Advances in Neural Information Processing Systems 2004, Vancouver, BC, Canada, December 2004; pp. 321–328. [Google Scholar]
- Gao, F.; Huang, T.; Wang, J.; Sun, J.; Hussain, A.; Yang, E. Dual-branch deep convolution neural network for polarimetric SAR image classification. Appl. Sci. 2017, 7, 447. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step1: Training the GANs for SAR images | |
 | |
| Step2: Training the Recognition Network for SAR images | |
| for Number of training iterations do | |
| |
| End for | |
| Type | Train Data | Test Data |
|---|---|---|
| 2S1 | 299 | 274 |
| ZSU234 | 299 | 274 |
| BRDM-2 | 298 | 274 |
| BTR60 | 256 | 195 |
| BTR70 | 233 | 196 |
| BMP2 | 233 | 195 |
| D7 | 299 | 274 |
| ZIL131 | 299 | 274 |
| T62 | 299 | 273 |
| T72 | 232 | 196 |
| Total | 2747 | 2425 |
| Method | 64 × 64 | 128 × 128 | ||
|---|---|---|---|---|
| AC | Std | AC | Std | |
| PM | 92.89% | 0.473% | 90.19% | 0.355% |
| PM-1G | 92.15% | 0.379% | 89.10% | 0.733% |
| DCGAN | 91.87% | 0.639% | 87.16% | 0.594% |
| CNN | 89.58% | 0.527% | 89.16% | 0.771% |
| DRAGAN | 87.58% | 0.504% | 84.25% | 0.407% |
| WGAN-GP | 91.11% | 0.557% | 89.59% | 0.666% |
| Method | Kappa Coefficient (κ) | |
| 64 × 64 | 128 × 128 | |
| PM | 0.922 | 0.919 |
| PM-1G | 0.920 | 0.899 |
| DCGAN | 0.916 | 0.877 |
| CNN | 0.888 | 0.897 |
| DRAGAN | 0.869 | 0.845 |
| WGAN-GP | 0.907 | 0.906 |
| Number of Generators | AC | Std | Training Time (s/epoch) |
|---|---|---|---|
| 1 | 75.76% | 0.66% | 5.1 |
| 2 | 75.63% | 0.47% | 8.3 |
| 3 | 76.08% | 0.62% | 12.1 |
| 4 | 75.93% | 0.50% | 15.6 |
| 5 | 77.13% | 0.55% | 17.9 |
| 6 | 76.89% | 0.28% | 21.4 |
| 7 | 77.00% | 0.42% | 24.3 |
| 8 | 76.52% | 0.74% | 27.1 |
| Method | Training GANs(s/epoch) | Training Recognition Nets(s/epoch) |
|---|---|---|
| PM | 17.9 | 0.28 |
| PM-1G | 5.1 | 0.26 |
| DCGAN | 5.1 | 0.26 |
| CNN | - | 0.26 |
| DRAGAN | 7.7 | 0.28 |
| WGAN-GP | 5.51 | 0.26 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, F.; Ma, F.; Wang, J.; Sun, J.; Yang, E.; Zhou, H. Semi-Supervised Generative Adversarial Nets with Multiple Generators for SAR Image Recognition. Sensors 2018, 18, 2706. https://doi.org/10.3390/s18082706
Gao F, Ma F, Wang J, Sun J, Yang E, Zhou H. Semi-Supervised Generative Adversarial Nets with Multiple Generators for SAR Image Recognition. Sensors. 2018; 18(8):2706. https://doi.org/10.3390/s18082706
Chicago/Turabian StyleGao, Fei, Fei Ma, Jun Wang, Jinping Sun, Erfu Yang, and Huiyu Zhou. 2018. "Semi-Supervised Generative Adversarial Nets with Multiple Generators for SAR Image Recognition" Sensors 18, no. 8: 2706. https://doi.org/10.3390/s18082706
APA StyleGao, F., Ma, F., Wang, J., Sun, J., Yang, E., & Zhou, H. (2018). Semi-Supervised Generative Adversarial Nets with Multiple Generators for SAR Image Recognition. Sensors, 18(8), 2706. https://doi.org/10.3390/s18082706