Network Distance-Based Simulated Annealing and Fuzzy Clustering for Sensor Placement Ensuring Observability and Minimal Relative Degree




Abstract
:1. Introduction
2. Sensor Placement to Ensure Observability and Minimal Relative Order
2.1. Problem Formulation
2.2. Placing Sensors to Ensure Observability
2.3. Simulated Annealing and Fuzzy Clustering-based Output Configuration Design
| Algorithm 1 Pseudo code of the modified CLASA algorithm (mCLASA). |
|
| Algorithm 2 Pseudo code of the Geodesic Distance-based Fuzzy c-Medoid Clustering with Simulated Annealing algorithm (GDFCMSA). |
|
3. Results
3.1. Description of the Case Studies
3.2. Effect of the Additional Nodes and the Robustness of the Optimization Algorithms
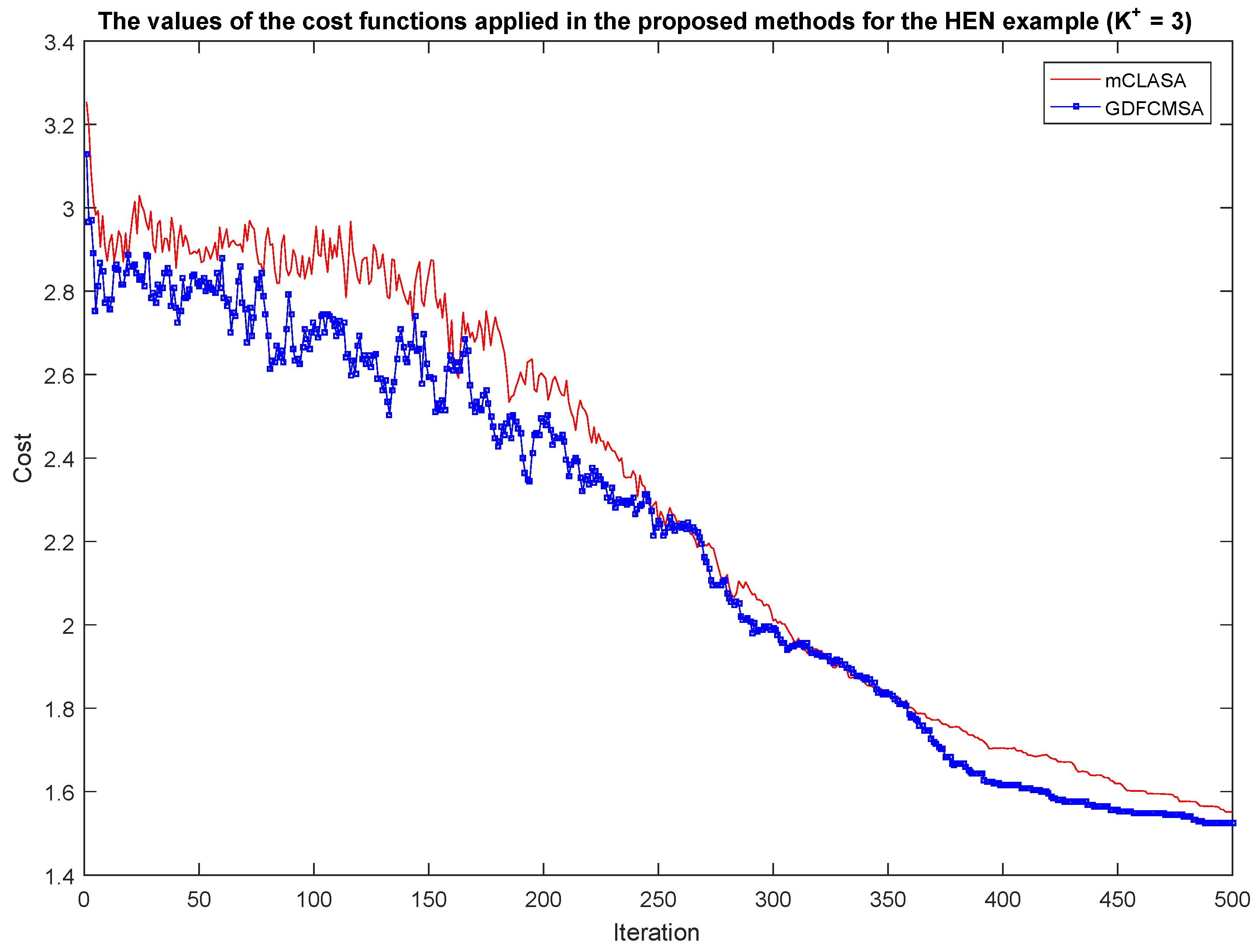
3.3. Convergence Analysis
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CLASA: | Clustering Large Applications based on Simulated Annealing |
| GDFCM: | Geodesic Distance-based Fuzzy c-Medoid Clustering method |
| GDFCMSA: | Geodesic Distance-based Fuzzy c-Medoid Clustering with Simulated Annealing method |
| HEN: | Heat Exchanger Network |
| mCLASA: | modified Clustering Large Applications based on Simulated Annealing |
| MIMO: | Multiple-input and multiple-output |
| SA: | Simulated Annealing |
Nomenclature
| vector of state variables | |
| vector of inputs | |
| vector of disturbances | |
| vector of outputs | |
| state-transition matrix | |
| input matrix | |
| disturbance matrix | |
| output matrix | |
| observability matrix | |
| N | number of state variables |
| M | number of inputs |
| K | number of outputs |
| number of additional sensor nodes | |
| jth column of matrix | |
| jth row of matrix | |
| relative degree of and | |
| relative degree of | |
| r | relative order of the system |
| network representation of the system | |
| V | set of vertices of the network representation of the system |
| E | connections between the state variables |
| undirected representation of G | |
| S | set of sensor nodes |
| set of fixed sensor nodes | |
| set of candidate sensor nodes | |
| weighting parameter of cost function | |
| edges of a maximum matching | |
| matched nodes | |
| unmatched nodes | |
| difference between cost functions in SA | |
| maximum and minimum temperature in SA | |
| maximum and minimum fuzzy exponent in SA | |
| temperature in iteration i | |
| fuzzy exponent in iteration i | |
| reduction rate of temperature | |
| reduction rate of the fuzzy exponent | |
| number of iterations of SA | |
| set of the state variables of the cluster of sensor node | |
| fuzzy membership function |
References
- Chmielewski, D.J.; Palmer, T.; Manousiouthakis, V. On the theory of optimal sensor placement. AIChE J. 2002, 48, 1001–1012. [Google Scholar] [CrossRef]
- Papadimitriou, C.; Lombaert, G. The effect of prediction error correlation on optimal sensor placement in structural dynamics. Mech. Syst. Signal Process. 2012, 28, 105–127. [Google Scholar] [CrossRef]
- Yuen, K.V.; Kuok, S.C. Efficient Bayesian sensor placement algorithm for structural identification: A general approach for multi-type sensory systems. Earthq. Eng. Struct. Dyn. 2015, 44, 757–774. [Google Scholar] [CrossRef]
- Papadopoulou, M.; Raphael, B.; Smith, I.F.; Sekhar, C. Hierarchical sensor placement using joint entropy and the effect of modeling error. Entropy 2014, 16, 5078–5101. [Google Scholar] [CrossRef]
- Rosich, A.; Sarrate, R.; Puig, V.; Escobet, T. Efficient optimal sensor placement for model-based FDI using an incremental algorithm. In Proceedings of the 46th IEEE Conference on Decision and Control, New Orleans, LA, USA, 12–14 December 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 2590–2595. [Google Scholar]
- Düştegör, D.; Frisk, E.; Cocquempot, V.; Krysander, M.; Staroswiecki, M. Structural analysis of fault isolability in the DAMADICS benchmark. Control Eng. Pract. 2006, 14, 597–608. [Google Scholar] [CrossRef]
- Berger-Wolf, T.Y.; Hart, W.E.; Saia, J. Discrete sensor placement problems in distribution networks. Math. Comput. Model. 2005, 42, 1385–1396. [Google Scholar] [CrossRef]
- Isidori, A. Nonlinear Control Systems; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Boukhobza, T.; Hamelin, F. State and input observability recovering by additional sensor implementation: A graph-theoretic approach. Automatica 2009, 45, 1737–1742. [Google Scholar] [CrossRef]
- Yan, G.; Tsekenis, G.; Barzel, B.; Slotine, J.J.; Liu, Y.Y.; Barabási, A.L. Spectrum of controlling and observing complex networks. Nat. Phys. 2015, 11, 779–786. [Google Scholar] [CrossRef] [Green Version]
- Ruths, J.; Ruths, D. Control profiles of complex networks. Science 2014, 343, 1373–1376. [Google Scholar] [CrossRef] [PubMed]
- Pósfai, M.; Liu, Y.Y.; Slotine, J.J.; Barabási, A.L. Effect of correlations on network controllability. Sci. Rep. 2013, 3, 1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leitold, D.; Vathy-Fogarassy, Á.; Süle, Z.; Manchin, R.; Abonyi, J. Measuring sustainability—Network science based analysis of water resources models. In Proceedings of the 7th EDSI Conference, Helsinki, Finland, 24–27 May 2016; p. 189. [Google Scholar]
- Leitold, D.; Vathy-Fogarassy, Á.; Abonyi, J. Controllability and observability in complex networks—The effect of connection types. Sci. Rep. 2017, 7, 151. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Lv, T.; Yang, X.; Zhang, B. Structural controllability of complex networks based on preferential matching. PLoS ONE 2014, 9, e112039. [Google Scholar] [CrossRef] [PubMed]
- Kang, L.; Liu, Y. Design of Control Structure for Integrated Process Networks Based on Graph-Theoretic Analysis. Chem. Eng. Trans. 2017, 61, 1711–1716. [Google Scholar]
- Liu, Y.Y.; Slotine, J.J.; Barabási, A.L. Controllability of complex networks. Nature 2011, 473, 167–173. [Google Scholar] [CrossRef] [PubMed]
- Müller, F.J.; Schuppert, A. Few inputs can reprogram biological networks. Nature 2011, 478, E4–E5. [Google Scholar] [CrossRef] [PubMed]
- Varga, E.; Hangos, K.; Szigeti, F. Controllability and observability of heat exchanger networks in the time-varying parameter case. Control Eng. Pract. 1995, 3, 1409–1419. [Google Scholar] [CrossRef]
- Liu, X.; Mo, Y.; Pequito, S.; Sinopoli, B.; Kar, S.; Aguiar, A.P. Minimum robust sensor placement for large scale linear time-invariant systems: A structured systems approach. IFAC Proc. Vol. 2013, 46, 417–424. [Google Scholar] [CrossRef]
- Sharon, L.P.; Rex, K.K. Optimization Strategies for Sensor and Actuator Placement; Technical Report; NASA Langley Research Center: Hampton, VA, USA, 1999.
- Bagajewicz, M.J. Design and retrofit of sensor networks in process plants. AIChE J. 1997, 43, 2300–2306. [Google Scholar] [CrossRef]
- Watson, J.P.; Hart, W.E.; Berry, J.W. Scalable high-performance heuristics for sensor placement in water distribution networks. In Impacts of Global Climate Change; American Society of Civil Engineers: Reston, VA, USA, 2005; pp. 1–12. [Google Scholar]
- Liu, Y.Y.; Slotine, J.J.; Barabási, A.L. Observability of complex systems. Proc. Natl. Acad. Sci. USA 2013, 110, 2460–2465. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carballido, J.A.; Ponzoni, I.; Brignole, N.B. CGD-GA: A graph-based genetic algorithm for sensor network design. Inf. Sci. 2007, 177, 5091–5102. [Google Scholar] [CrossRef]
- Aguirre-Salas, L.; Begovich, O.; Ramirez-trevino, A. Sensor assignment for observability in interpreted petri nets. IFAC Proc. Vol. 2004, 37, 441–446. [Google Scholar] [CrossRef]
- Chiu, P.; Lin, F.Y. A simulated annealing algorithm to support the sensor placement for target location. In Proceedings of the 2004 Canadian Conference on Electrical and Computer Engineering, Niagara Falls, ON, USA, 2–5 May 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 2, pp. 867–870. [Google Scholar]
- Martin, O.C.; Otto, S.W. Combining simulated annealing with local search heuristics. Ann. Oper. Res. 1993, 63, 57–75. [Google Scholar] [CrossRef]
- Torres-Jimenez, J.; Izquierdo-Marquez, I.; Garcia-Robledo, A.; Gonzalez-Gomez, A.; Bernal, J.; Kacker, R.N. A dual representation simulated annealing algorithm for the bandwidth minimization problem on graphs. Inf. Sci. 2015, 303, 33–49. [Google Scholar] [CrossRef]
- Worden, K.; Burrows, A. Optimal sensor placement for fault detection. Eng. Struct. 2001, 23, 885–901. [Google Scholar] [CrossRef]
- Qin, B.Y.; Lin, X.K. Optimal sensor placement based on particle swarm optimization. Adv. Mater. Res. Trans. Technol. Publ. 2011, 271, 1108–1113. [Google Scholar] [CrossRef]
- Blanloeuil, P.; Nurhazli, N.A.; Veidt, M. Particle swarm optimization for optimal sensor placement in ultrasonic SHM systems. In Nondestructive Characterization and Monitoring of Advanced Materials, Aerospace, and Civil Infrastructure 2016; International Society for Optics and Photonics: Bellingham, WA, USA, 2016; Volume 9804, p. 98040E. [Google Scholar]
- Zhang, X.; Li, J.; Xing, J.; Wang, P.; Yang, Q.; Wang, R.; He, C. Optimal sensor placement for latticed shell structure based on an improved particle swarm optimization algorithm. Math. Probl. Eng. 2014, 2014. [Google Scholar] [CrossRef]
- Samora, I.; Franca, M.J.; Schleiss, A.J.; Ramos, H.M. Simulated annealing in optimization of energy production in a water supply network. Water Res. Manag. 2016, 30, 1533–1547. [Google Scholar] [CrossRef]
- Mamano, N.; Hayes, W. SANA: Simulated Annealing Network Alignment Applied to Biological Networks. arXiv, 2016; arXiv:1607.02642. [Google Scholar]
- Zhang, X.X.; Li, H.X.; Qi, C.K. Spatially constrained fuzzy-clustering-based sensor placement for spatiotemporal fuzzy-control system. IEEE Trans. Fuzzy Syst. 2010, 18, 946–957. [Google Scholar] [CrossRef]
- Chu, S.C.; Roddick, J.F.; Pan, J.S. A Comparative Study and Extension to K-Medoids Algorithms; Contemporary Development Company: Hongkong, China, 2001; pp. 1–10. [Google Scholar]
- Sastry, S.S.; Isidori, A. Adaptive control of linearizable systems. IEEE Trans. Autom. Control 1989, 34, 1123–1131. [Google Scholar] [CrossRef]
- Kalman, R.E. Mathematical description of linear dynamical systems. J. Soc. Ind. Appl. Math. Ser. A Control 1963, 1, 152–192. [Google Scholar] [CrossRef]
- Király, A.; Vathy-Fogarassy, Á.; Abonyi, J. Geodesic distance based fuzzy c-medoid clustering–searching for central points in graphs and high dimensional data. Fuzzy Sets Syst. 2016, 286, 157–172. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization, and Machine Learning; Addison-Wesley: Boston, MA, USA, 1989. [Google Scholar]
- Westphalen, D.L.; Young, B.R.; Svrcek, W.Y. A controllability index for heat exchanger networks. Ind. Eng. Chem. Res. 2003, 42, 4659–4667. [Google Scholar] [CrossRef]
- Chahlaoui, Y.; Van Dooren, P. A Collection of Benchmark Examples for Model Reduction of Linear Time Invariant Dynamical Systems; The University of Manchester: Manchester, UK, 2002; pp. 1–26. [Google Scholar]
- Odabasioglu, A.; Celik, M.; Pileggi, L.T. PRIMA: Passive reduced-order interconnect macromodeling algorithm. In Proceedings of the 1997 IEEE/ACM International Conference on Computer-Aided Design, Santa Clara, CA, USA, 9–13 November 1997; pp. 58–65. [Google Scholar]
- Heeb, H.; Ruehli, A.E.; Bracken, J.E.; Rohrer, R.A. Three dimensional circuit oriented electromagnetic modeling for VLSI interconnects. In Proceedings of the IEEE 1992 International Conference on Computer Design: VLSI in Computers and Processors, ICCD’92, Cambridge, MA, USA, 11–14 October 1992; pp. 218–221. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Description | ||||
|---|---|---|---|---|---|
| HEN | A simple heat exchanger network. | 22 | 56 | 3 | |
| MNA_1 | Modified Nodal Analysis of a multiport, voltage sources. | 578 | 1694 | 3 | |
| MNA_4 | Modified Nodal Analysis of a multiport, voltage sources. | 980 | 2872 | 2 | |
| peec | Partial element equivalent circuit (PEEC) model. | 480 | 1346 | 1 |
| HEN | MNA_1 | MNA_4 | peec | |||||
|---|---|---|---|---|---|---|---|---|
| mCLASA | GDFCMSA | mCLASA | GDFCMSA | mCLASA | GDFCMSA | mCLASA | GDFCMSA | |
| 1 | 0.0158 s | 0.0164 s | 0.1311 s | 0.1396 s | 0.1795 s | 0.1892 s | 0.0704 s | 0.0715 s |
| 2 | 0.0173 s | 0.0183 s | 0.1752 s | 0.1689 s | 0.2240 s | 0.2306 s | 0.0945 s | 0.0955 s |
| 3 | 0.0205 s | 0.0227 s | 0.2230 s | 0.2120 s | 0.2676 s | 0.2922 s | 0.1176 s | 0.1179 s |
| 5 | 0.0233 s | 0.0280 s | 0.2638 s | 0.2999 s | 0.3724 s | 0.3749 s | 0.1602 s | 0.1614 s |
| 10 | 0.0310 s | 0.0315 s | 0.3965 s | 0.4106 s | 0.6353 s | 0.7106 s | 0.2829 s | 0.2850 s |
| 15 | 0.0427 s | 0.0428 s | 0.5984 s | 0.6721 s | 0.9049 s | 0.9176 s | 0.4631 s | 0.4237 s |
| 25 | n.a. | n.a. | 0.8052 s | 0.8170 s | 1.5417 s | 1.4754 s | 0.6385 s | 0.6862 s |
| 35 | n.a. | n.a. | 1.3258 s | 1.3404 s | 2.1008 s | 2.0255 s | 0.9229 s | 1.0077 s |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leitold, D.; Vathy-Fogarassy, A.; Abonyi, J. Network Distance-Based Simulated Annealing and Fuzzy Clustering for Sensor Placement Ensuring Observability and Minimal Relative Degree. Sensors 2018, 18, 3096. https://doi.org/10.3390/s18093096
Leitold D, Vathy-Fogarassy A, Abonyi J. Network Distance-Based Simulated Annealing and Fuzzy Clustering for Sensor Placement Ensuring Observability and Minimal Relative Degree. Sensors. 2018; 18(9):3096. https://doi.org/10.3390/s18093096
Chicago/Turabian StyleLeitold, Daniel, Agnes Vathy-Fogarassy, and Janos Abonyi. 2018. "Network Distance-Based Simulated Annealing and Fuzzy Clustering for Sensor Placement Ensuring Observability and Minimal Relative Degree" Sensors 18, no. 9: 3096. https://doi.org/10.3390/s18093096
APA StyleLeitold, D., Vathy-Fogarassy, A., & Abonyi, J. (2018). Network Distance-Based Simulated Annealing and Fuzzy Clustering for Sensor Placement Ensuring Observability and Minimal Relative Degree. Sensors, 18(9), 3096. https://doi.org/10.3390/s18093096