PPSDT: A Novel Privacy-Preserving Single Decision Tree Algorithm for Clinical Decision-Support Systems Using IoT Devices



Abstract
:1. Introduction
- We propose a model for a Privacy-Preserving Clinical Decision-Support System (PPCDSS) which allows hospitals to privately generate the classification model of the clinical decision-support system and to diagnose new symptoms without sharing their datasets.
- To ensure patients’ privacy, we propose a novel Privacy-Preserving Single Decision Tree (PPSDT) algorithm to generate decision tree models from distributed datasets without disclosing their actual content using homomorphic encryption.
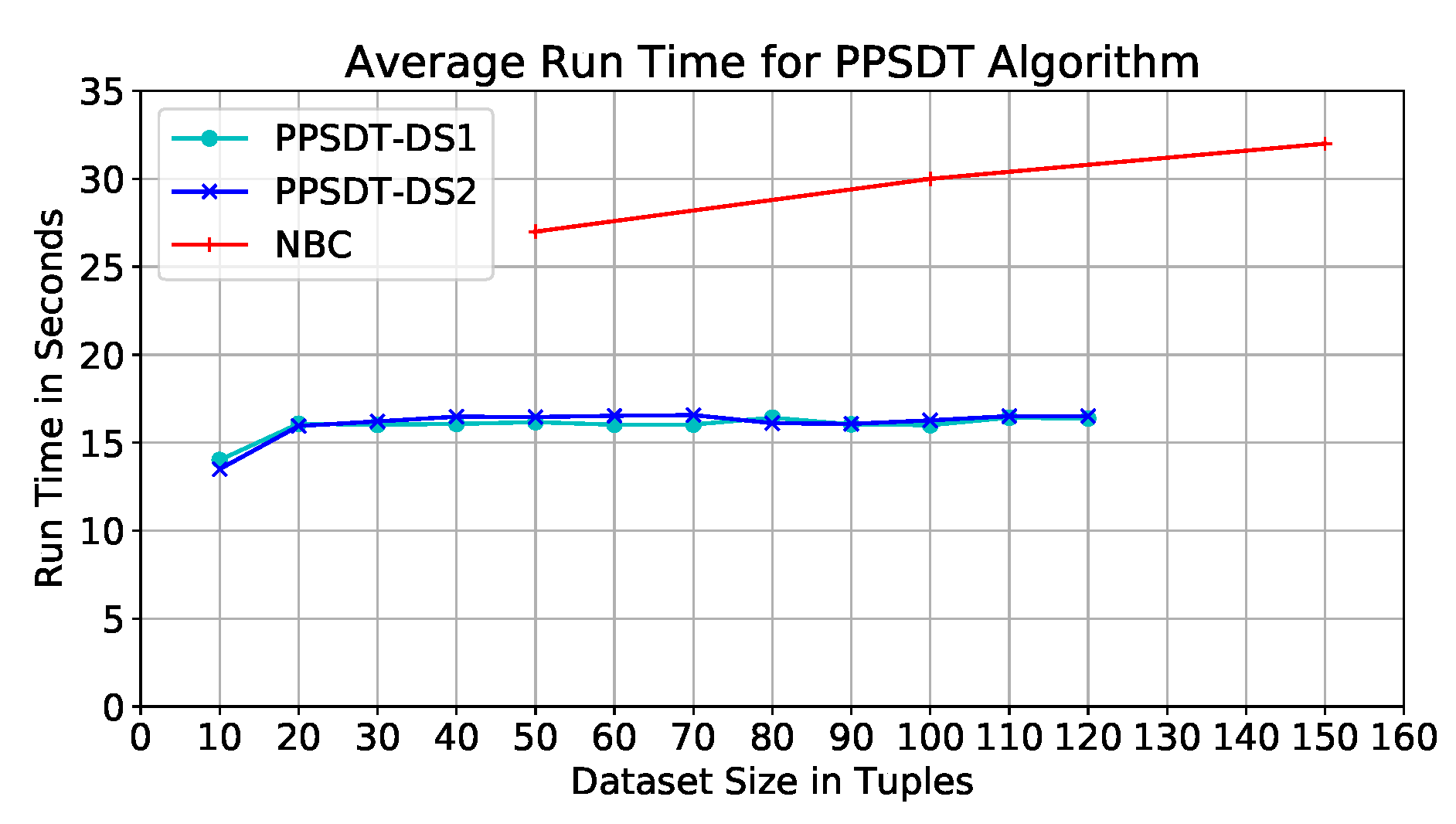
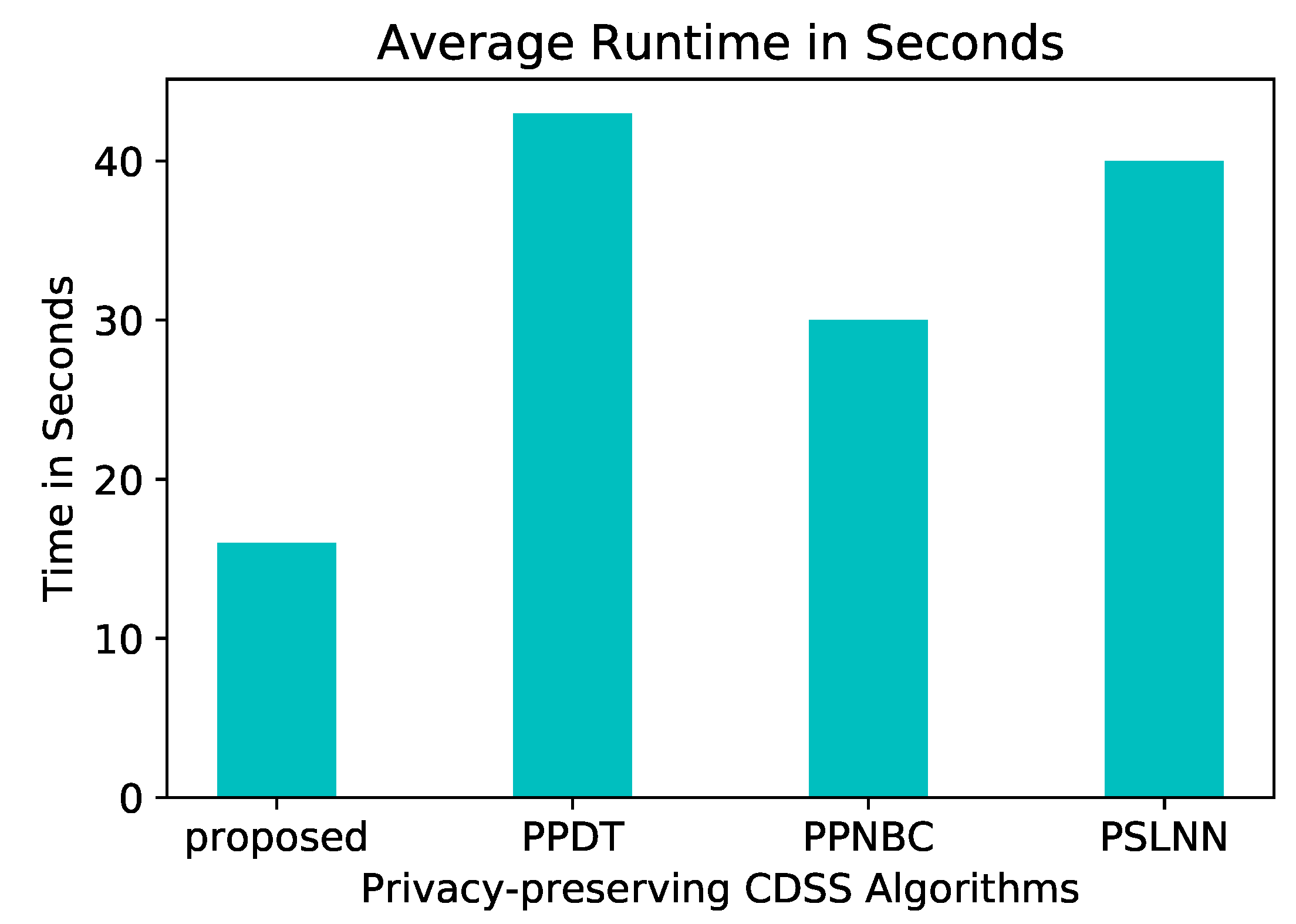
- With the help of our method, the results show that our model has improved the classification model generation time by 46.67% compared to the current work in Ref. [9].
2. Related Work
3. Problem Formulations
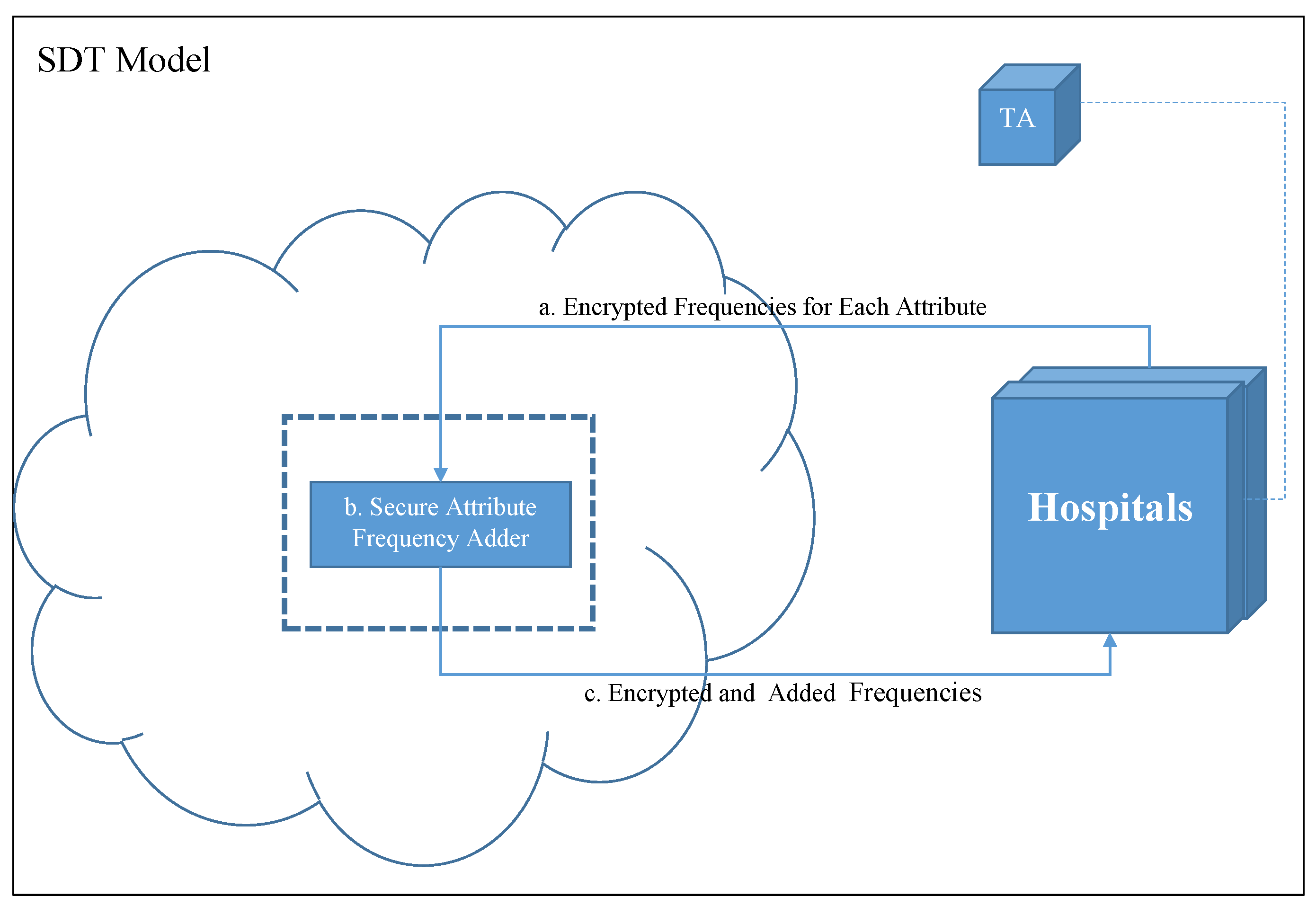
3.1. System Model
- Trusted Authority (TA): key distribution and management during setup is handled by the TA.
- Hospitals: provide the system with the needed proportion of the historical medical data (HMD).
- Cloud: Securely sums the frequency of attribute values, , and returns them back to the hospitals.
3.2. Attacker Model
3.3. Privacy Requirements
- Privacy of the hospitals’ datasets: each hospital records patients’ medical history and diagnosis in their databases forming a dataset that could be used as a training corpora for the PPSDT algorithm. However, due to the sensitive nature of such records, hospitals will refrain from sharing them, normally. Therefore, their privacy must be assured and preserved in the design of our model.
- Privacy of the frequency of attribute values (): when each hospital count the required for calculating the entropy (E) and information gain (IG), they are aware that such data could reveal sensitive information, and normally will not share them willingly unless privacy measures are taken. Therefore, in the design of our model we must satisfy the privacy requirements for keeping them private.
- Privacy of the nonce: due to the fact that in homomorphic encryption the parties use the same public and private key pair, participating hospitals would be considered as semi-honest-but-curious users [34]. Such users are expected to follow the rules, but however, they might be curious to know more. Using the same key pair, would allow any hospital to decrypt another hospital’s data; therefore, each hospital will generate a random nonce to hide the actual values of their data to thwart the threat of having a curious hospital decrypting them. Consequently, the nonce will be encrypted using the cloud’s RSA public key and attached to the sent data.
- Privacy of the patients’ diagnosed symptoms: after diagnosing a patient, a physician would use the CDSS to retrieve the possible diagnosis using patient’s symptoms. However, if no privacy guarantees were offered, then no patient will accept his symptoms to be fed into the system. Therefore, patients’ symptoms must be kept private.
4. Notations and Preliminaries
4.1. Notation
4.2. Preliminaries
4.2.1. Paillier Cryptosystem
- Key Generation:
- Set security parameter k
- Set two large prime numbers p, q
- Calculate
- Calculate
- Choose a generator
- Calculate
- Set the public key
- Set the private key
- Encryption: given message , and choosing randomly evaluate the following:
- Decryption: given ciphertext , calculate:
- Addition Property: given two ciphertexts, and , which are encrypted with the same key:
4.2.2. Decision Tree Algorithm C4.5
5. The Proposed PPSDT Algorithm
5.1. Design Rationale
5.2. Construction
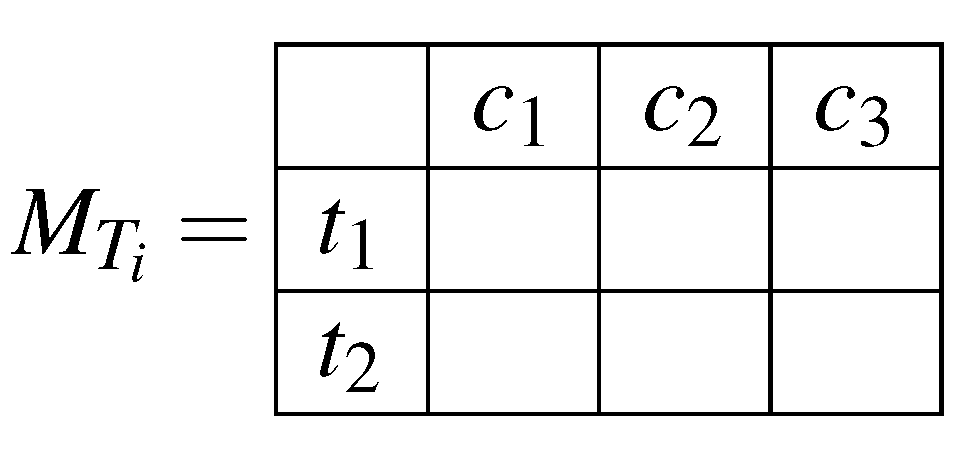
- The cloud will prompt the hospitals to prepare the for each attribute . Where is the frequency of each attribute value per class.
- The hospitals will prepare the ’s and store them in a matrix (). The size of the matrix will be ; where k is the number of possible values for a given attribute, and l is the number of possible decision classes. Each cell ; where and ; will hold the frequency of class b with attribute value a over one hospital’s dataset. This way, we can retrieve the important values for calculating the entropy and information gain from summing different cells together. For instance, the summation of one row will yield the frequency of an attribute value over the dataset, and the summation of all matrix’ cells will yield the dataset size. In Figure 2 we illustrate an example matrix for an attribute of two possible values (), and three different classes ().
- Each hospital will randomly generate a nonce, z, and add it to each cell in the above matrix.
- The nonce will be encrypted using the cloud’s RSA public key.
- The hospitals will homomorphically encrypt all matrix cells’ values using the public key before sending them to the cloud. The encryption is performed cell by cell because the input of the homomorphic encryption must be an integer or float.
- The encrypted matrix and nonce are sent to the cloud.
- The cloud will decrypt the nonce using its own RSA private key.
- The cloud will subtract the nonce value, z, from each cell value.
- The cloud will homomorphically sum the cells of corresponding matrices then return the results back to the hospitals.
- Each hospital will homomorphically decrypt the cells of all matrices using the private key.
- Using the values of the matrix, each hospital will calculate the Entropy and Information Gain (IG), and then pick the attribute of maximum IG as the next node of the tree.
- The cloud is informed by their selection, then the process will repeat for remaining partitions.
5.3. Algorithm Design
| Algorithm 1: Build SDT |
 |
| Algorithm 2:Countingand Encrypting the matrix |
 |
| Algorithm 3:Splitting Dataset |
 |
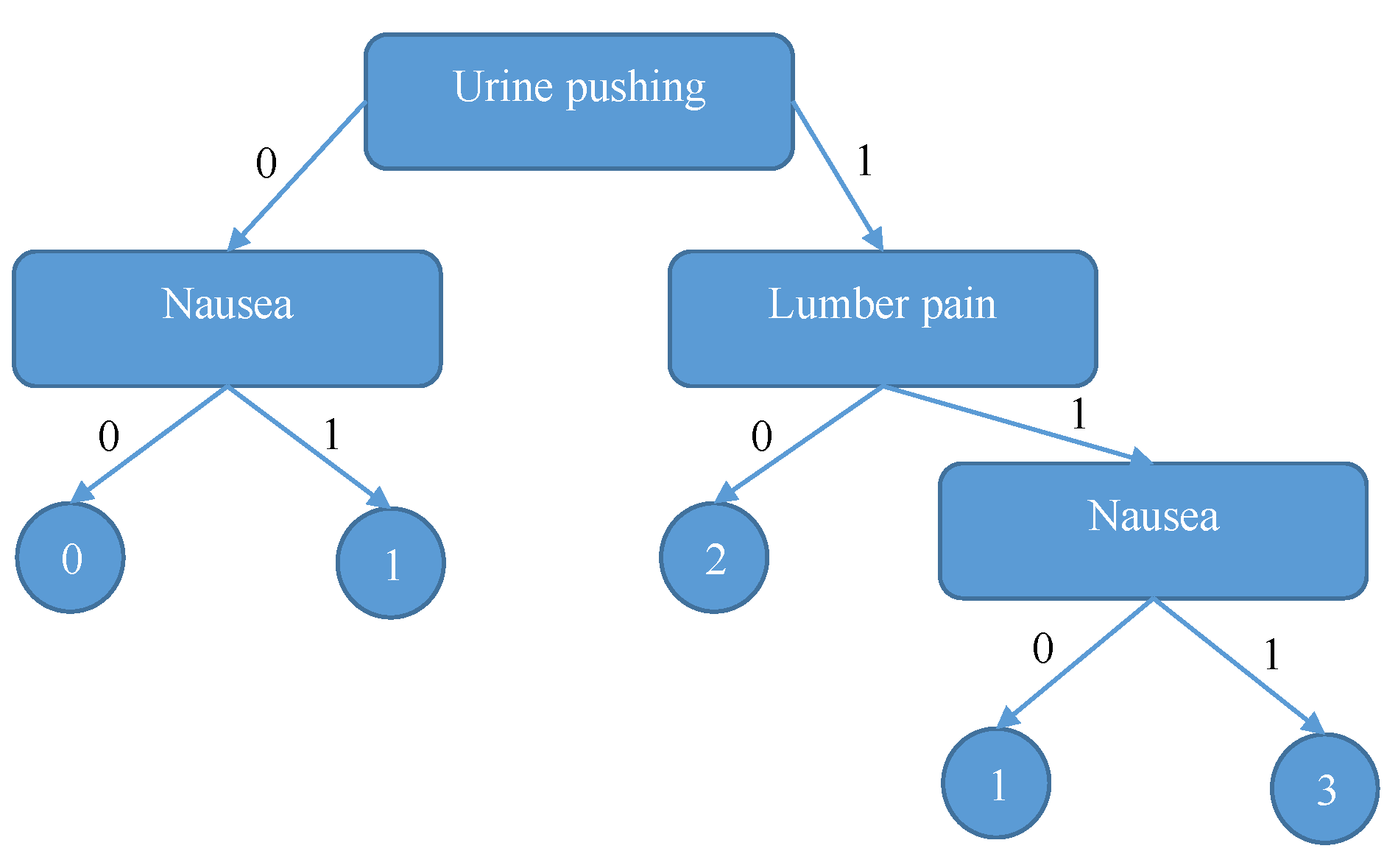
5.4. Descriptive Scheme
6. Privacy Analysis
6.1. Privacy of Hospitals’ Datasets
6.2. Privacy of Counted Frequencies ()
6.3. Privacy of the Nonce
6.4. Privacy of the Diagnosed Symptoms
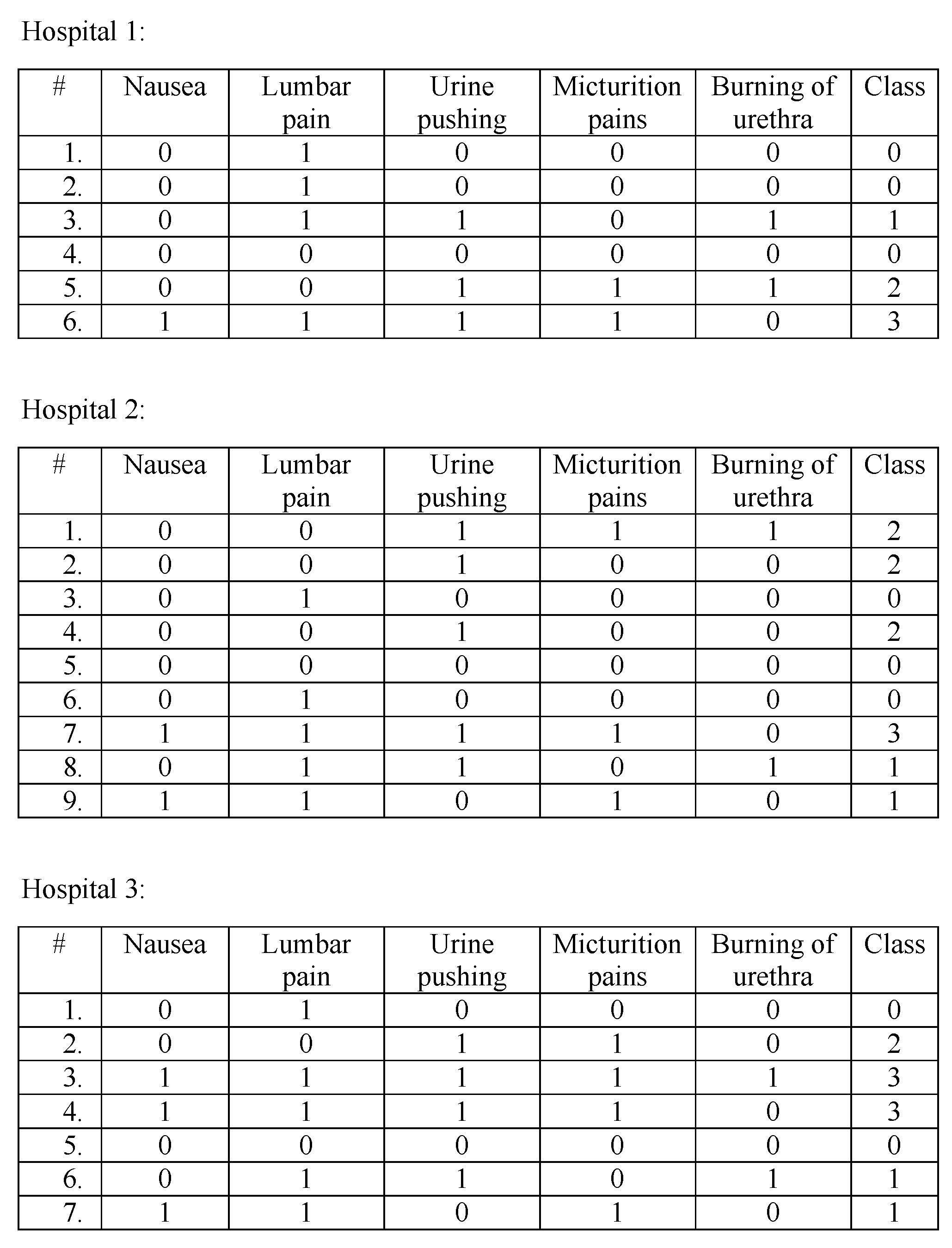
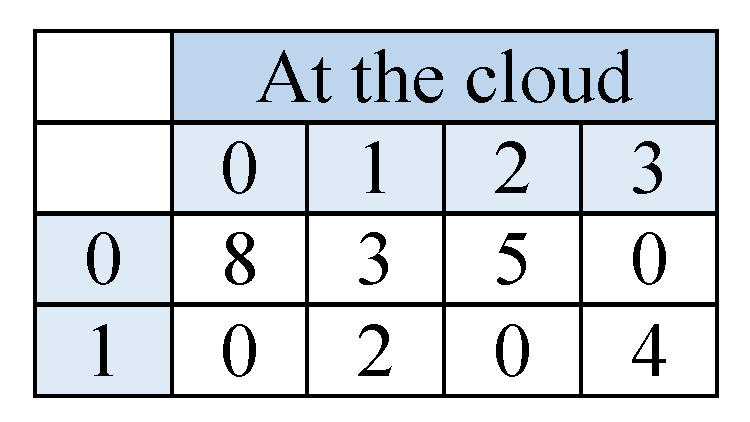
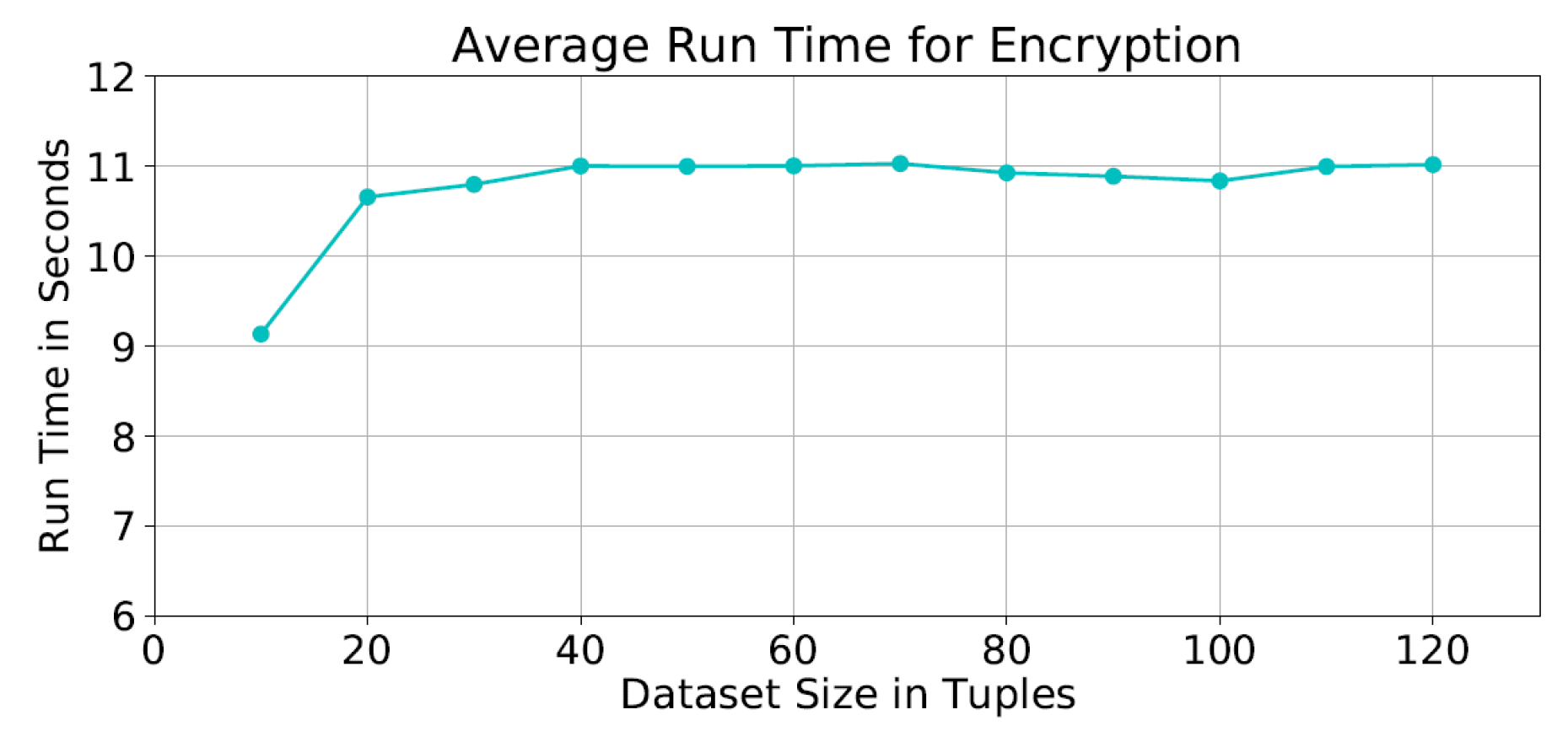
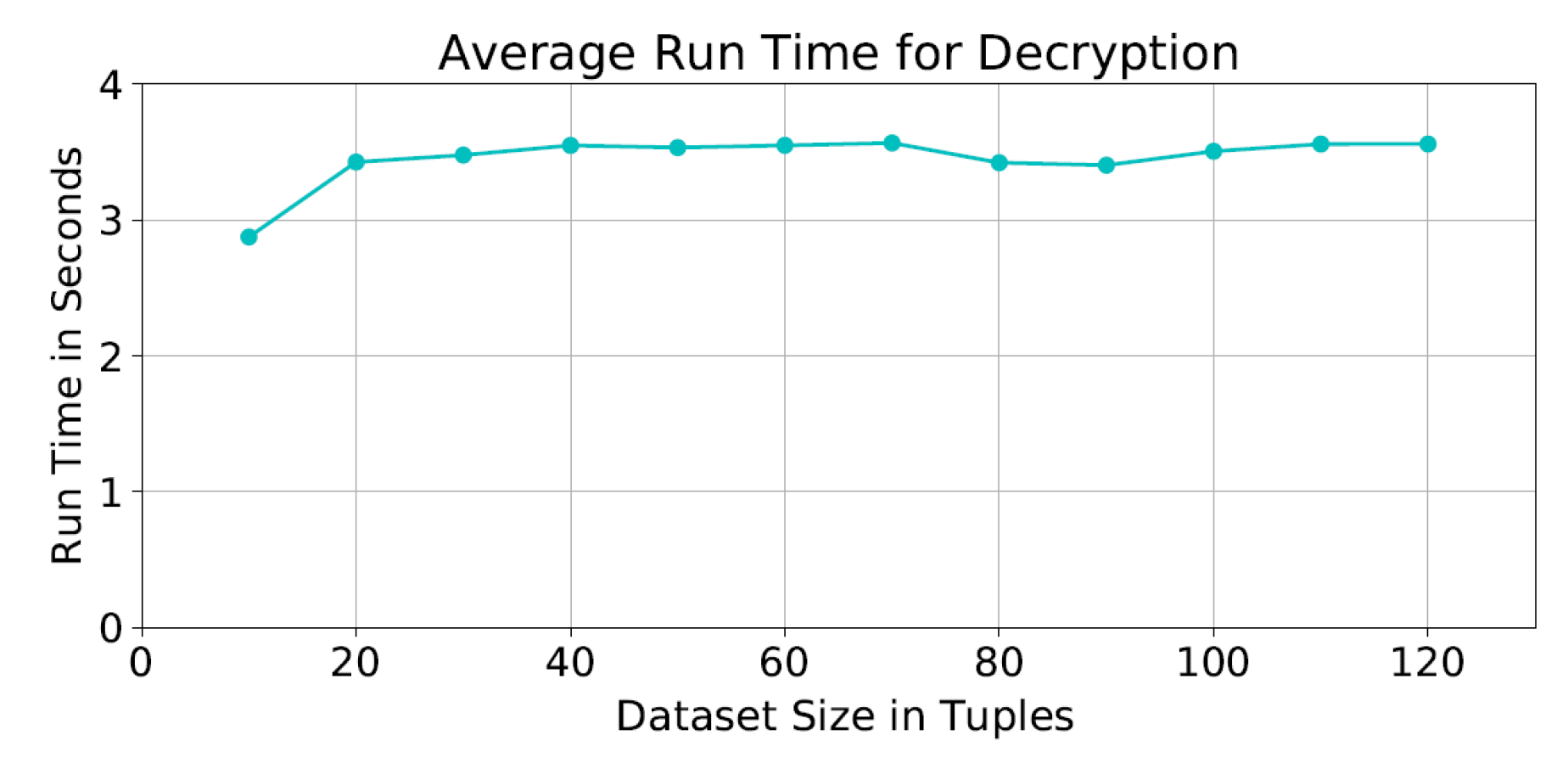
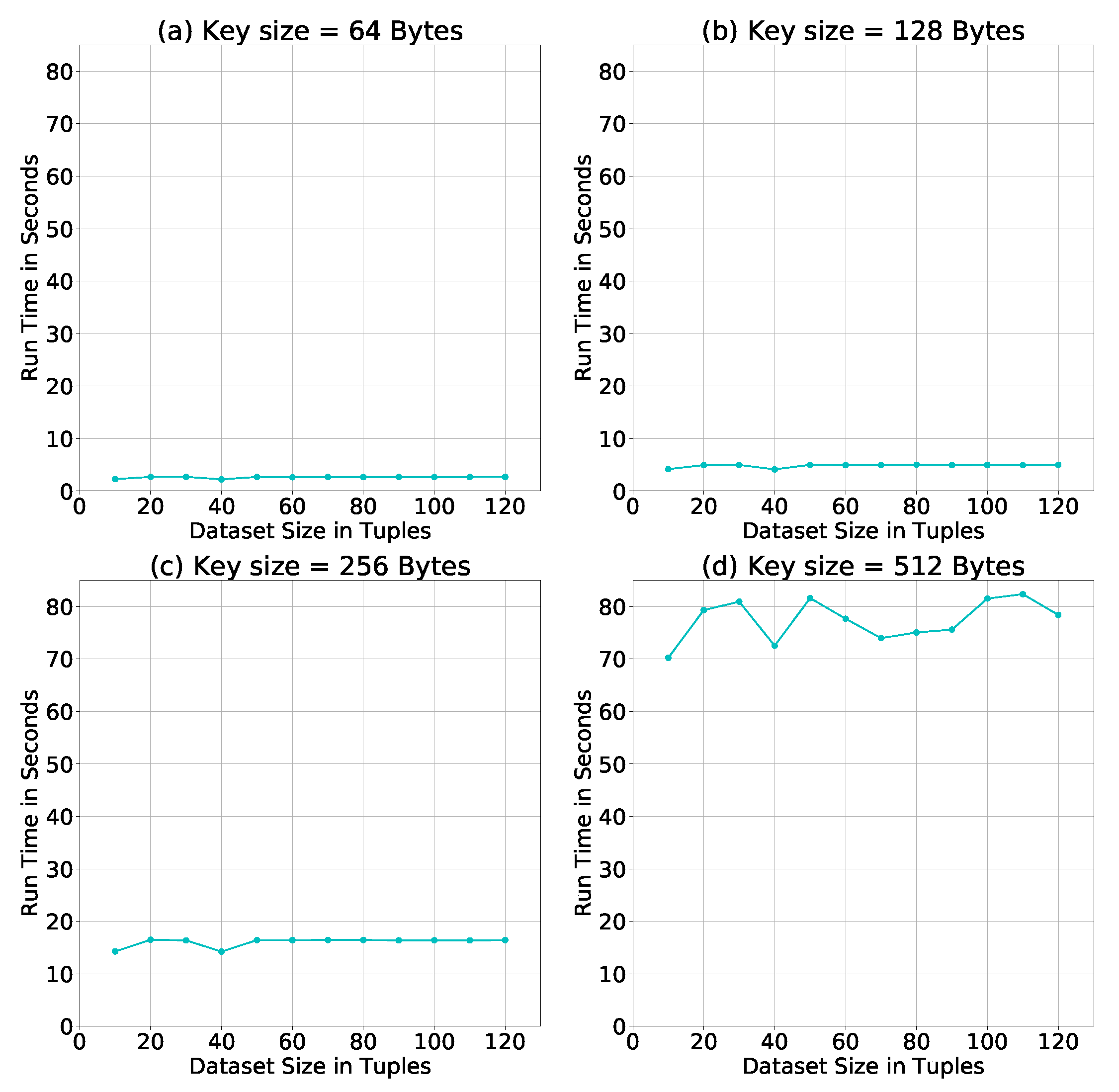
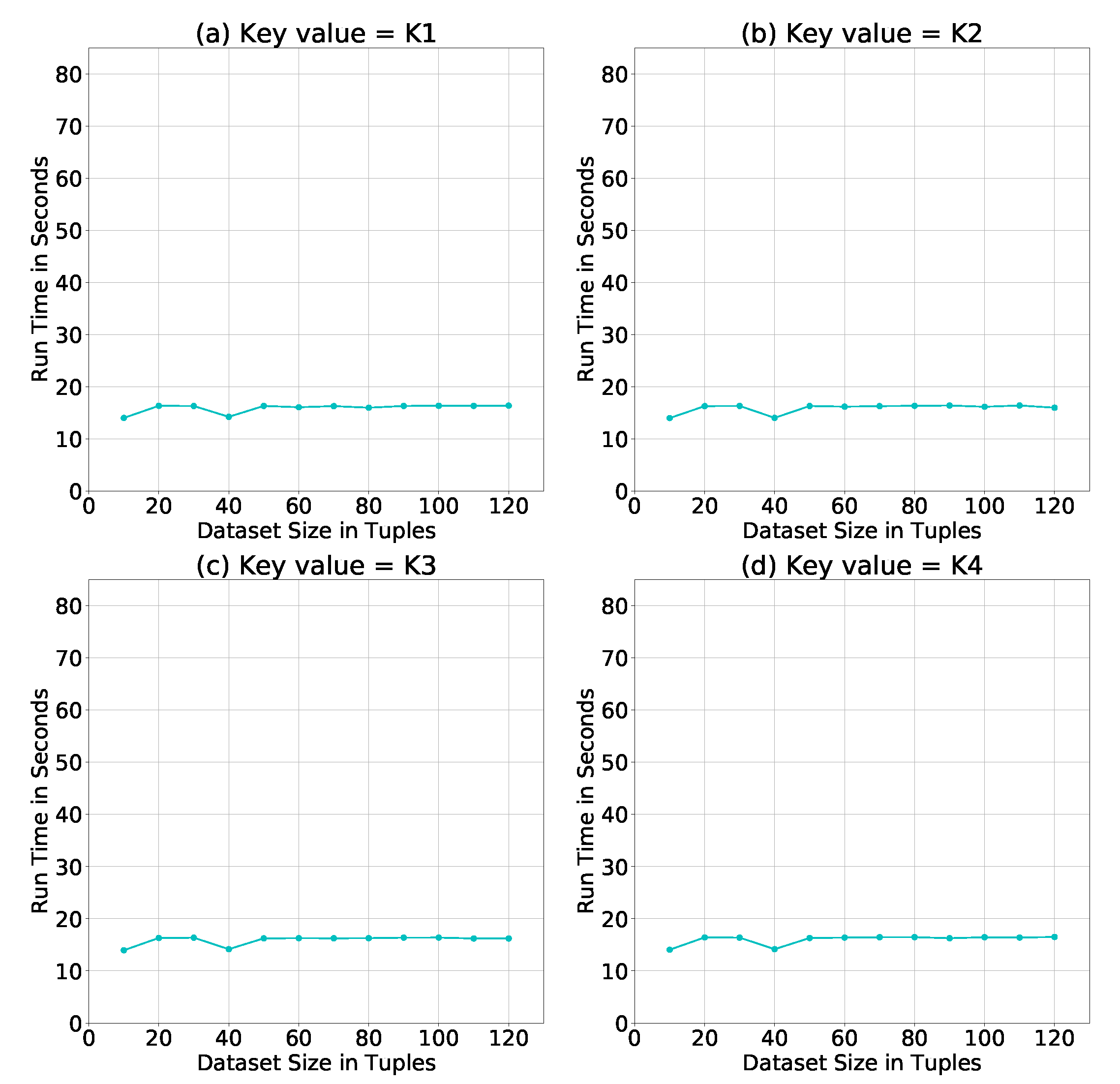
7. Performance Evaluation
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CDSS | Clinical Decision-Support System |
| HMD | Historical Medical Data |
| IoT | Internet of Things |
| PHI | Patient Health Information |
| PHR | Patient Health Record |
| PPCDSS | Privacy-Preserving CDSS |
| PPDM | Privacy-Preserving Data Mining |
| PPRF | Privacy-Preserving SDT |
| SDT | Single Decision Tree |
| TA | Trusted Authority |
References
- Habte, T.T.; Saleh, H.; Mohammad, B.; Ismail, M. IoT for Healthcare. In Ultra Low Power ECG Processing System for IoT Devices; Springer: Berlin, Germany, 2019; pp. 7–12. [Google Scholar]
- Ledley, R.S.; Lusted, L.B. Reasoning foundations of medical diagnosis; symbolic logic, probability, and value theory aid our understanding of how physicians reason. Science (New York) 1959, 130, 9–21. [Google Scholar] [CrossRef]
- Musen, M.A.; Middleton, B.; Greenes, R.A. Clinical Decision-Support Systems. In Biomedical Informatics; Shortliffe, E.H., Cimino, J.J., Eds.; Springer: London, UK, 2014; pp. 643–674. [Google Scholar]
- Berner, E.S. Clinical Decision Support Systems: State of the Art. Available online: https://healthit.ahrq.gov/sites/default/files/docs/page/09-0069-EF_1.pdf (accessed on 2 January 2019).
- Kaplan, B. Evaluating informatics applications—Some alternative approaches: Theory, social interactionism, and call for methodological pluralism. Int. J. Med. Inform. 2001, 64, 39–56. [Google Scholar] [CrossRef]
- Berner, E.S.; La Lande, T.J. Overview of clinical decision support systems. In Clinical Decision Support Systems; Springer: Berlin, Germany, 2007; pp. 3–22. [Google Scholar]
- Ma, T.; Zhang, Y.; Cao, J.; Shen, J.; Tang, M.; Tian, Y.; Al-Dhelaan, A.; Al-Rodhaan, M. KDVEM: A k-degree anonymity with vertex and edge modification algorithm. Computing 2015, 97, 1165–1184. [Google Scholar] [CrossRef]
- Rong, H.; Ma, T.; Tang, M.; Cao, J. A novel subgraph K+-isomorphism method in social network based on graph similarity detection. Soft Comput. 2018, 22, 2583–2601. [Google Scholar] [CrossRef]
- Liu, X.; Lu, R.; Ma, J.; Chen, L.; Qin, B. Privacy-preserving patient-centric clinical decision support system on naive Bayesian classification. IEEE J. Biomed. Health Inform. 2016, 20, 655–668. [Google Scholar] [CrossRef]
- Lu, R.; Lin, X.; Shen, X. SPOC: A secure and privacy-preserving opportunistic computing framework for mobile-healthcare emergency. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 614–624. [Google Scholar] [CrossRef]
- Liang, X.; Lu, R.; Chen, L.; Lin, X.; Shen, X. PEC: A privacy-preserving emergency call scheme for mobile healthcare social networks. J. Commun. Netw. 2011, 13, 102–112. [Google Scholar] [CrossRef] [Green Version]
- Alabdulkarim, A.; Al-Rodhaan, M.; Tian, Y. Privacy-Preserving Healthcare System for Clinical Decision-Support and Emergency Call Systems. Commun. Netw. 2017, 9, 249–274. [Google Scholar] [CrossRef]
- Zhang, P.; Tong, Y.; Tang, S.; Yang, D. Privacy preserving naïve bayes classification. In Advanced Data Mining and Applications; Springer: Berlin, Germany, 2005; pp. 744–752. [Google Scholar]
- Abdar, M.; Kalhori, S.R.N.; Sutikno, T.; Subroto, I.M.I.; Arji, G. Comparing Performance of Data Mining Algorithms in Prediction Heart Diseases. Int. J. Electr. Comput. Eng. 2015, 5, 1569–1576. [Google Scholar]
- Chaurasia, V.; Pal, S. Data Mining Approach to Detect Heart Dieses. Int. J. Adv. Comput. Sci. Inf. Technol. 2013, 2, 56–66. [Google Scholar]
- Rahman, R.M.; Afroz, F. Comparison of various classification techniques using different data mining tools for diabetes diagnosis. J. Softw. Eng. Appl. 2013, 6, 85–97. [Google Scholar] [CrossRef]
- Krishnaiah, V.; Narsimha, D.G.; Chandra, D.N.S. Diagnosis of lung cancer prediction system using data mining classification techniques. Int. J. Comput. Sci. Inf. Technol. 2013, 4, 39–45. [Google Scholar]
- Alizadehsani, R.; Habibi, J.; Hosseini, M.J.; Mashayekhi, H.; Boghrati, R.; Ghandeharioun, A.; Bahadorian, B.; Sani, Z.A. A data mining approach for diagnosis of coronary artery disease. Comput. Methods Programs Biomed. 2013, 111, 52–61. [Google Scholar] [CrossRef]
- Zhan, J. Using homomorphic encryption for privacy-preserving collaborative decision tree classification. In Proceedings of the IEEE Symposium onComputational Intelligence and Data Mining (CIDM 2007), Honolulu, HI, USA, 1 March–5 April 2007. [Google Scholar]
- Warner, H.R. A Mathematical Approach to Medical Diagnosis: Application to Congenital Heart Disease. JAMA 1961, 177, 177–183. [Google Scholar] [CrossRef] [PubMed]
- Schurink, C.; Lucas, P.; Hoepelman, I.; Bonten, M. Computer-assisted decision support for the diagnosis and treatment of infectious diseases in intensive care units. Lancet Infect. Dis. 2005, 5, 305–312. [Google Scholar] [CrossRef]
- Liu, X.; Deng, R.; Choo, K.K.R.; Yang, Y. Privacy-Preserving Outsourced Clinical Decision Support System in the Cloud. IEEE Trans. Serv. Comput. 2017. [Google Scholar] [CrossRef]
- Liu, X.; Deng, R.; Choo, K.K.R.; Yang, Y.; Pang, H. Privacy-Preserving Outsourced Calculation Toolkit in the Cloud. IEEE Trans. Dependable Secure Comput. 2018. [Google Scholar] [CrossRef]
- Du, W.; Zhan, Z. Building decision tree classifier on private data. In Proceedings of the IEEE International Conference on Privacy, Security and Data Mining—Volume 14; Australian Computer Society, Inc.: Darlinghurst, Australia, 2002; pp. 1–8. [Google Scholar]
- Bost, R.; Popa, R.A.; Tu, S.; Goldwasser, S. Machine Learning Classification over Encrypted Data; NDSS: New York, NY, USA, 2015. [Google Scholar]
- Lindell, Y.; Pinkas, B. Privacy preserving data mining. In Advances in Cryptology—CRYPTO 2000; Springer: Berlin, Germany, 2000; pp. 36–54. [Google Scholar]
- Lindell, Y.; Pinkas, B. Privacy preserving data mining. J. Cryptol. 2002, 15, 177–206. [Google Scholar] [CrossRef]
- Emekçi, F.; Sahin, O.D.; Agrawal, D.; El Abbadi, A. Privacy preserving decision tree learning over multiple parties. Data Knowl. Eng. 2007, 63, 348–361. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Deng, R.H.; Yang, Y.; Tran, H.N.; Zhong, S. Hybrid privacy-preserving clinical decision support system in fog–cloud computing. Future Gener. Comput. Syst. 2018, 78, 825–837. [Google Scholar] [CrossRef]
- Zhang, C.; Zhu, L.; Xu, C.; Lu, R. PPDP: An efficient and privacy-preserving disease prediction scheme in cloud-based e-Healthcare system. Future Gener. Comput. Syst. 2018, 79, 16–25. [Google Scholar] [CrossRef]
- Gao, C.; Cheng, Q.; He, P.; Susilo, W.; Li, J. Privacy-preserving Naive Bayes classifiers secure against the substitution-then-comparison attack. Inf. Sci. 2018, 444, 72–88. [Google Scholar] [CrossRef]
- Guo, W.; Shao, J.; Lu, R.; Liu, Y.; Ghorbani, A.A. A Privacy-Preserving Online Medical Prediagnosis Scheme for Cloud Environment. IEEE Access 2018, 6, 48946–48957. [Google Scholar] [CrossRef]
- Zhu, D.; Zhu, H.; Liu, X.; Li, H.; Wang, F.; Li, H. Achieve Efficient and Privacy-Preserving Medical Primary Diagnosis Based on kNN. In Proceedings of the 2018 27th International Conference on Computer Communication and Networks (ICCCN), Hangzhou, China, 30 July–2 August 2018. [Google Scholar]
- Xing, H.; Chen, C.; Yang, B.; Guan, X. SymMatch: Secure and privacy-preserving symptom matching for mobile healthcare social networks. In Proceedings of the International Conference on Wireless Communications & Signal Processing (WCSP), Hangzhou, China, 24–26 October 2013. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Elsevier: New York, NY, USA, 2014. [Google Scholar]
- Dheeru, D.; Karra Taniskidou, E. UCI Machine Learning Repository: Acute Inflammations Data Set. 2003. Available online: https://archive.ics.uci.edu/ml/datasets/Acute+Inflammations (accessed on 2 January 2019).
- Samanthula, B.K.; Elmehdwi, Y.; Jiang, W. K-nearest neighbor classification over semantically secure encrypted relational data. IEEE Trans. Knowl. Data Eng. 2015, 27, 1261–1273. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| T | Set of attributes |
| Single attribute | |
| Possible values for attribute | |
| Possible classes | |
| 2-dimensional matrix for storing ’s different . Rows represent , and columns represent | |
| z | A unique randomly generated nonce for each hospital |
| Frequency of attribute value | |
| Paillier encryption function | |
| Paillier decryption function | |
| L | Paillier function |
| Least Common Multiplicative | |
| Security variables | |
| A multiplicative group of integers of modulo n | |
| ’s cell value at row a and column b | |
| D | Dataset |
| Size of dataset D | |
| The sum of the cell values of all columns of all matrices | |
| The sum of row j’s cell values |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alabdulkarim, A.; Al-Rodhaan, M.; Ma, T.; Tian, Y. PPSDT: A Novel Privacy-Preserving Single Decision Tree Algorithm for Clinical Decision-Support Systems Using IoT Devices. Sensors 2019, 19, 142. https://doi.org/10.3390/s19010142
Alabdulkarim A, Al-Rodhaan M, Ma T, Tian Y. PPSDT: A Novel Privacy-Preserving Single Decision Tree Algorithm for Clinical Decision-Support Systems Using IoT Devices. Sensors. 2019; 19(1):142. https://doi.org/10.3390/s19010142
Chicago/Turabian StyleAlabdulkarim, Alia, Mznah Al-Rodhaan, Tinghuai Ma, and Yuan Tian. 2019. "PPSDT: A Novel Privacy-Preserving Single Decision Tree Algorithm for Clinical Decision-Support Systems Using IoT Devices" Sensors 19, no. 1: 142. https://doi.org/10.3390/s19010142
APA StyleAlabdulkarim, A., Al-Rodhaan, M., Ma, T., & Tian, Y. (2019). PPSDT: A Novel Privacy-Preserving Single Decision Tree Algorithm for Clinical Decision-Support Systems Using IoT Devices. Sensors, 19(1), 142. https://doi.org/10.3390/s19010142