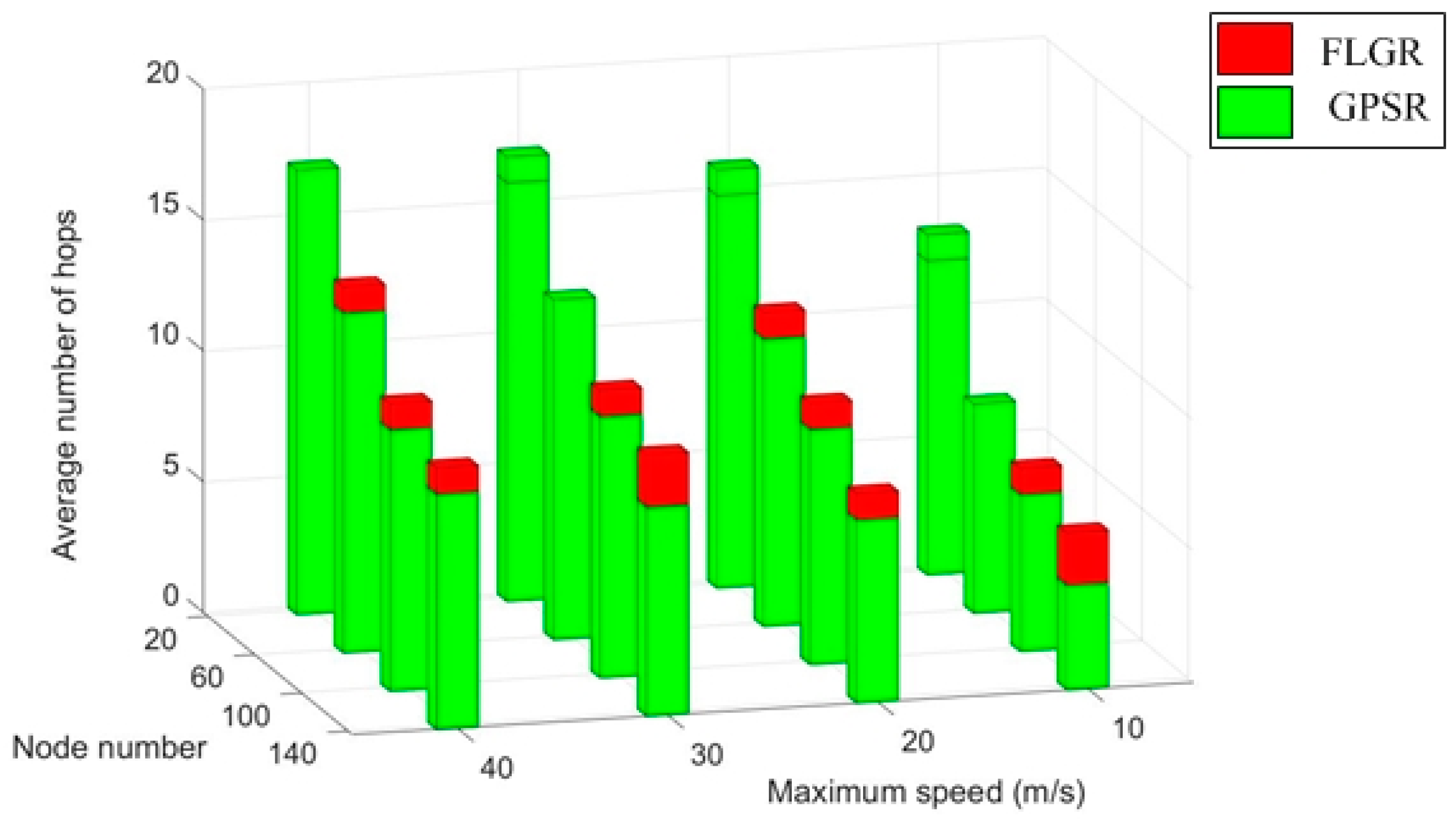
The traditional data forwarding mode is not suitable in the situation without the accuracy location information of the destination node. In FLGR protocol, the nodes to be selected can first be confirmed, based on the fuzzy location region of the destination node. Then, we can select the better forwarding node based on the fuzzification, fuzzy reasoning, and defuzzification of node parameters. In addition, the scheme to avoid the routing void problem is also proposed. In this way, the FLGR protocol can effectively reduce routing overhead and improve the success rate of data transmission.
3.1. Network Model and Assumptions
Consider a wireless sensor network with N nodes, which move randomly in the region with an area of S. In this paper, denotes the maximum speed of a node, and denotes the transmission radius of a node. Each node is equipped with a GPS receiver, which can obtain its location information. Each node periodically broadcasts a “Hello” message, which contains the location information of themselves and their neighbor nodes. Each node knows its own neighbor nodes through an exchanging beacon.
In this study, the following assumptions are made for the network model: (1) A two-dimensional space is considered, and denotes the location information of node , while the coordinates of node can be denoted by . (2) We assume that the geographical locations of any two nodes do not overlap, that is, if , then . (3) When a network is established, each node stores the initial location information of all the network nodes locally. (4) There is no error in data transmission within the range of transmission. A single data packet can be transmitted completely, without considering the transmission link interruption. (5) Each node in the network maintains time synchronization.
For ease of description, a detailed list of acronyms and notations adopted in this section is presented in
Table 1.
3.2. Message Format and Local Storage Structure
The Hello message is the basis of the FLGR protocol. Based on Hello messages, the neighbor nodes can be found, and their location information can be obtained. The format of the Hello message is presented in
Table 2.
As given in
Table 2, each Hello message has a unique sequence number, Num_seq, which can be used to indicate the freshness of the information carried by the Hello message. The ID of the Hello message denotes the unique identity label of the sending node. The neighbor node IDs and locations are also included in the Hello message, which can be used to obtain the parameter of CN. The node location can be represented by 16 Bytes. The x and y axis can be represented by 64 bits, respectively, with 1 bit to the sign of the number, 16 bits to the exponent, and 47 bits to the fractional part. Through the periodic broadcasting of the Hello message, the information table of neighbor nodes can be established.
To update the neighbor node table in a timely manner, the periodicity of the Hello message changes according to the node’s maximum speed. In
Section 4.2, the periodicity of the Hello message is given in different scenarios.
When the Hello message reaches a node, the neighbor node table will be updated. The neighbor node will be deleted in neighbor node table when its information is not included during two Hello message intervals. Once the information of a new node occurs in the Hello message, it will be added to the neighbor node table.
In addition, other than the transmission data, the data message also contains information on the destination node and all previous forwarding nodes. The format of the data message is given as follows:
As given in
Table 3, Num_seq indicates the freshness of the information carried by the data message. Node IDs_pre denotes the IDs of all previous forwarding nodes. Nodes locations_pre denotes the locations of all previous forwarding nodes. Num_pre denotes the number of all previous forwarding nodes. In practical application, the maximum value of Num_pre should be set. This changes according to different scenarios. If the reserve space is full, the latter forwarding node information is discarded.
With the transmission of data messages in the network, each node can update its local network location table frequently. The local network location table is presented as follows:
As shown in
Table 4, each node stores the local network location table, including node ID, node location, and update time. The update time indicates when the last update of the node location occurs. If a node has a message to be sent, the fuzzy region of the destination node can be obtained by the interval between the update time of the destination node in the local network location table and the current moment (as shown in Formula (1)).
3.3. FLGR Forwarding Mode
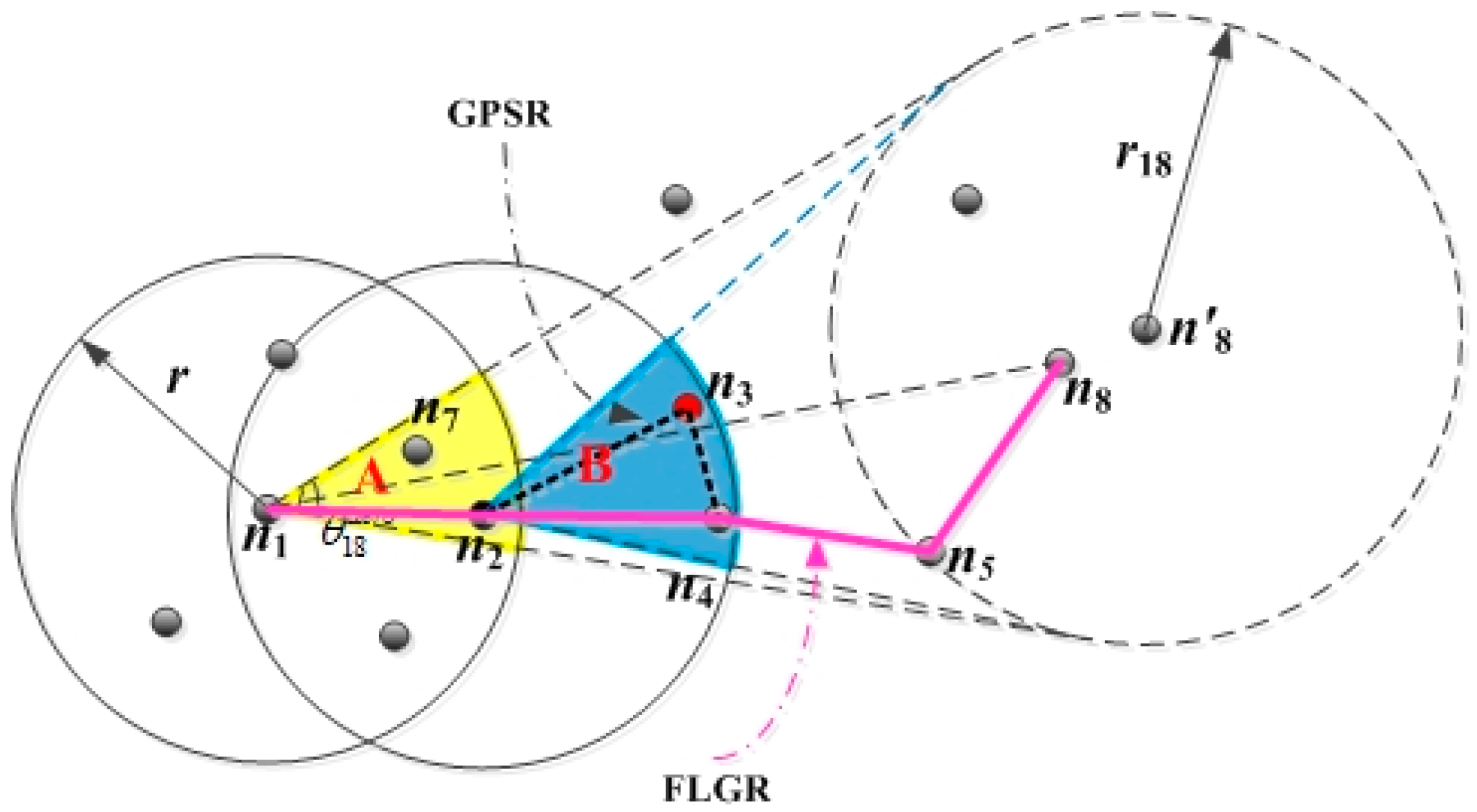
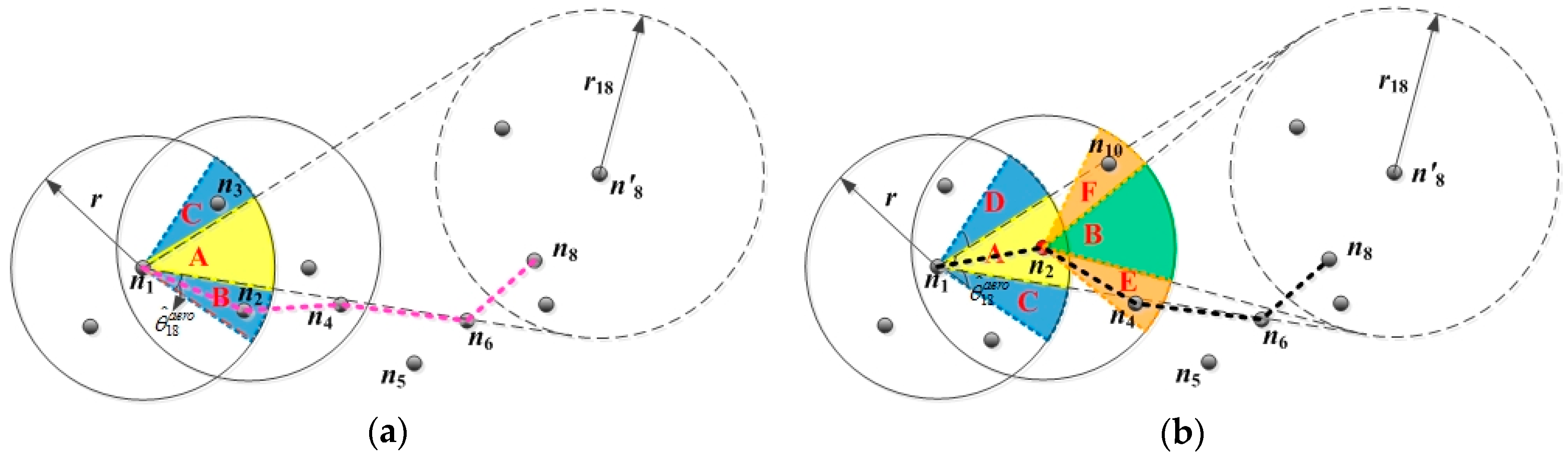
Owing to the inaccurate location of the destination node, the greedy forwarding mode does not fit into the FLGR protocol. The next forwarding node can be selected by the node parameters of CN. Taking an example in which EN sent a data message to the destination node , the FLGR forwarding mode is shown as follows.
As shown in
Figure 1, the location of node
is the current accuracy location, and the location of node
is the fuzzy location by looking up the local network location table of EN
. When EN
has a data message to be sent to the destination node
, the previous location and update time of node
can be obtained through the local network location table of EN
. Next, the fuzzy location region of node
can be obtained, according to the time interval
from the previous update time to the current moment. The fuzzy location region can be denoted by radius
, which can be calculated as follows:
According to the fuzzy location region of destination node
, we can get the CNR A of the EN
. The CNR A is denoted by angle
, which can be calculated as follows:
To select the better forwarding node in the CNR of EN , a comprehensive assessment of node and should first be obtained.
3.4. Selection Criteria and Parameters for Assessment
To obtain a comprehensive assessment of the nodes in CNR, the selection criteria and parameters for assessment should be confirmed first.
Fewer hops and a higher packet delivery rate are the goals of the FLGR forwarding mode. In addition, the scheme used to avoid the routing void problem should also be considered. Based on this, this paper gives the selection criteria of the next forwarding node:
The CN has a larger probability of being selected if it is farther away from EN. That is, a larger distance between the EN and CN indicates that the probability that the CN is close to the destination node is larger.
The CN that has more nodes in its CNR has a larger probability of being selected to be the next forwarding node. If there are more nodes to be selected in the CNR, the probability of selecting the optimal forwarding node is larger in the next data forwarding node. In this way, the node that has no CN in its CNR will be discarded, and thus, the routing void problem can be solved.
The CN has an advantage in being selected to be the next forwarding node if its CNs distribute more evenly along the communication boundary.
According to the above selection criteria, the void node can be avoided effectively. As shown in
Figure 1, in the GPSR protocol, according to the greedy forwarding mode and peripheral forwarding mode, the nodes
are selected as forwarding nodes. The nodes
are selected as forwarding nodes according to the selection criteria of the FLGR protocol. In this way, the void node
can be discarded, and the number of hops reduces. Hence, the routing void problem can be effectively avoided by using the selection criteria above.
According to the selection criteria of the FLGR protocol, the corresponding parameters of CN can be obtained: the distance to EN, relative density of the nodes in CNR, and distribution degree of the nodes in CNR.
Distance to EN is the distance between CN and EN, which is denoted by
in this paper. The value range of
is
. Taking no account of link interruption, the larger
is, the more likely CN is to approach the destination node. In this paper, the set
denotes the set of nodes in CNR of EN. For node
, the distance between node
and EN
can be calculated as follows:
Relative density of the nodes in CNR is the ratio of the density of nodes in CNR of CN to the density of the entire network, which is denoted by . In this paper, the set denotes the set of nodes in the CNR of CN. If , then . In this way, invalid routing can be effectively avoided.
In FLGR protocol, a larger value of
indicates that there are more nodes in CNR. The probability of selecting the optimal forwarding node is larger with more nodes to be selected. Taking the example of CN
, when EN
has a data message to be sent to the destination node
, there are
neighbor nodes in the CNR of CN
. Then,
can be expressed as follows:
In Equation (4),
denotes the density of nodes in the CNR of CN
.
denotes the density of the entire network. The value range of
is
. An increase in the value of
, indicates that the density of the nodes in CNR increases, and the number of nodes is relatively bigger. However, the case of
is a small probability event according to statistics in the simulation in
Section 4. Therefore, the situation
is considered in this paper.
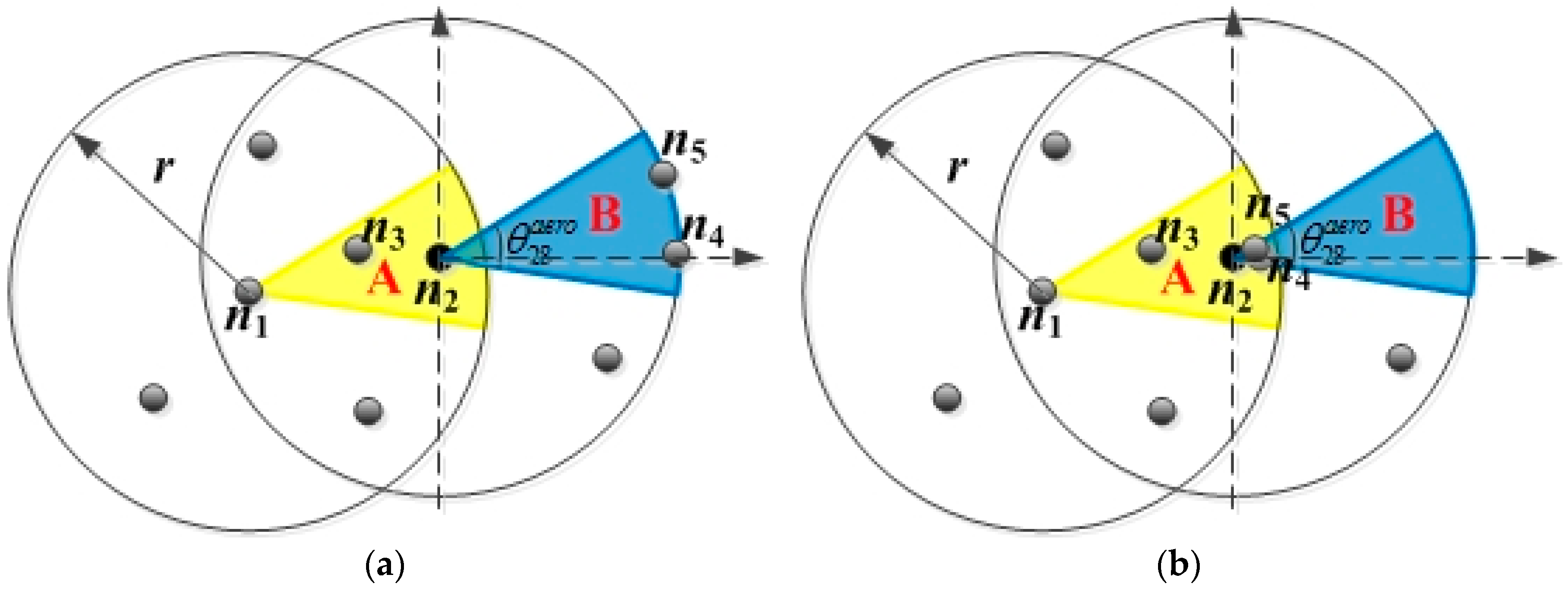
The distribution degree of the nodes in CNR represents the distribution of nodes in the CNR of CN, and it is denoted by in this paper. In the FLGR protocol, if the nodes in CNR are evenly distributed along the communication boundary, the distribution of the nodes in CNR is optimal. The probability that the CN is selected as the next forwarding node is the highest. However, if the nodes in CNR are centrally distributed near the CN, the distribution of the nodes in CNR is the worst. Taking the CN of EN , for example, node and are in the CNR of CN , and the optimal distribution and worst distribution are shown as follows.
As shown in
Figure 2a, there are two nodes (
and
) in the CNR B of CN
, and they are uniformly distributed along the communication boundary. In this situation, the parameter
of CN
is the largest. By contrast, the distribution of nodes
and
in
Figure 2b is the worst, and the parameter
of CN
is smallest.
Thus, taking the CN
for example, if
, and there are
nodes in its CNR, the optimal locations of the
nodes, denoted by
, can be obtained as follows:
As shown in Equation (5), taking the node as the origin of coordinates, the angle represents the angle of the th optimal distribution node relative to the CN .
In this paper, the distribution function is defined as
, and the parameter
of CN
can be obtained as follows:
In Equation (7), are the positions of modes in CNR. According to the distribution function, the value range of parameter is .
3.5. Selection Process Based on Fuzzy Logic
Owing to the uncertainty and no boundary of node parameters, it is very difficult to find the optimal weight coefficient for the decision algorithm based on utility function [
19] and multiple-attribute decision-making [
20]. The decision algorithm based on machine learning and game theory [
21] has a higher complexity and longer time delay. Therefore, the decision algorithm based on fuzzy logic is chosen in this paper, owing to its higher accuracy and lower complexity. In addition, the decision algorithm based on fuzzy logic can express the expression of the human beings accurately. The decision algorithm based on fuzzy logic involves fuzzification, fuzzy reasoning and defuzzification.
3.5.1. Fuzzification of Node Parameters
Fuzzification mainly refers to the fuzzification of attribute parameters through the subordinating degree function, to obtain the fuzzy set corresponding to the attribute. In general, the commonly used subordinating degree functions include the triangular subordinating degree function, trapezoidal subordinating degree function, sigmoid subordinating degree function and Gaussian subordinating degree function. As Gaussian subordinating degree function can satisfactorily show the gradual change characteristics of intermediate transitional nature and meet the human thinking mode well, it is selected in the fuzzification stage. The Gaussian subordinating degree function is denoted by in this paper.
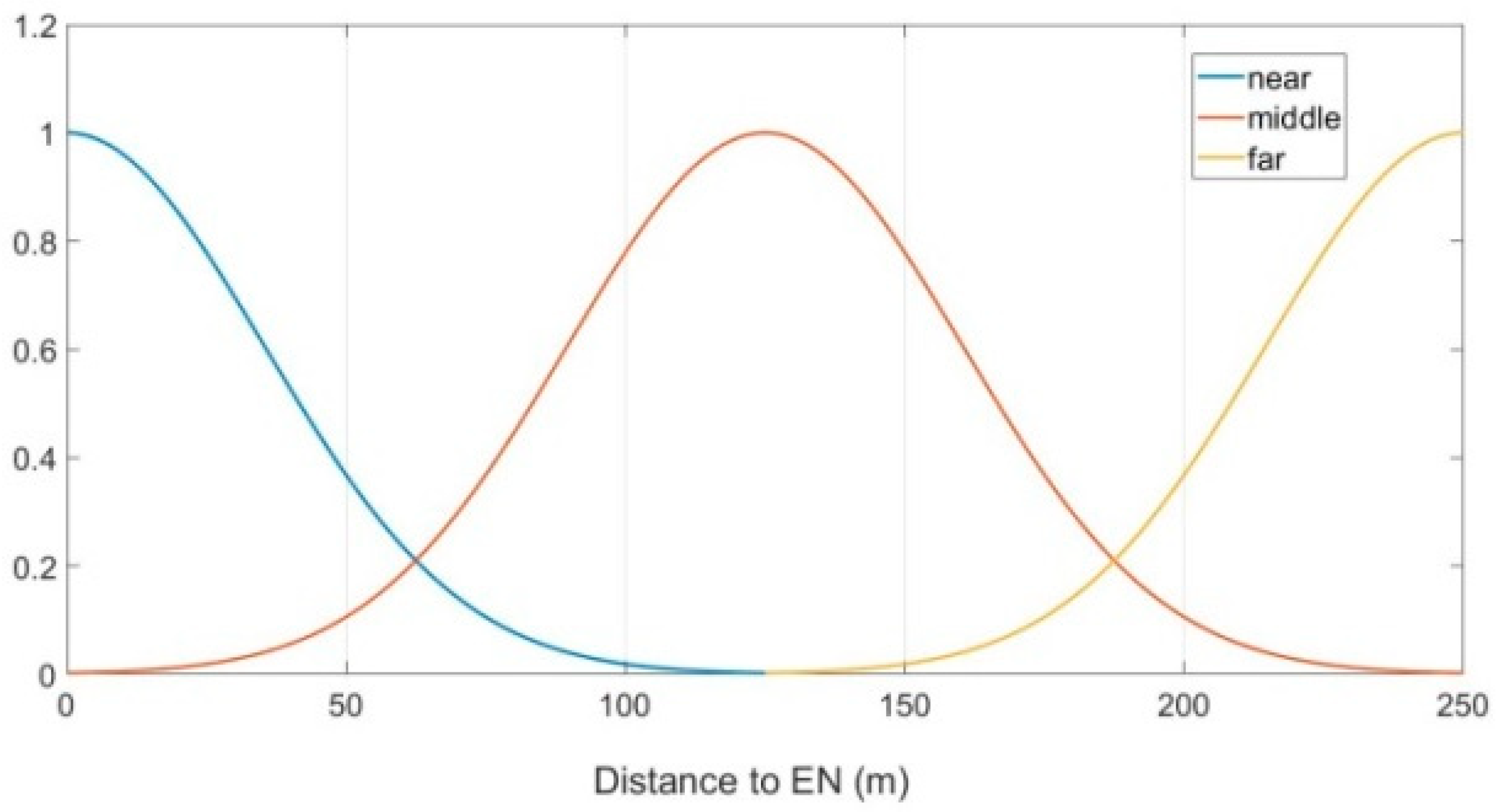
In the FLGR protocol, parameter
represents the distance between the CN and the EN, which can be divided into three fuzzy sets, namely, “near, middle and far”. In this paper, the subordinating degree function of parameter
is as follows:
Taking a communication radius of 250 m for example,
Figure 3 shows the subordinating degree function of parameter
.
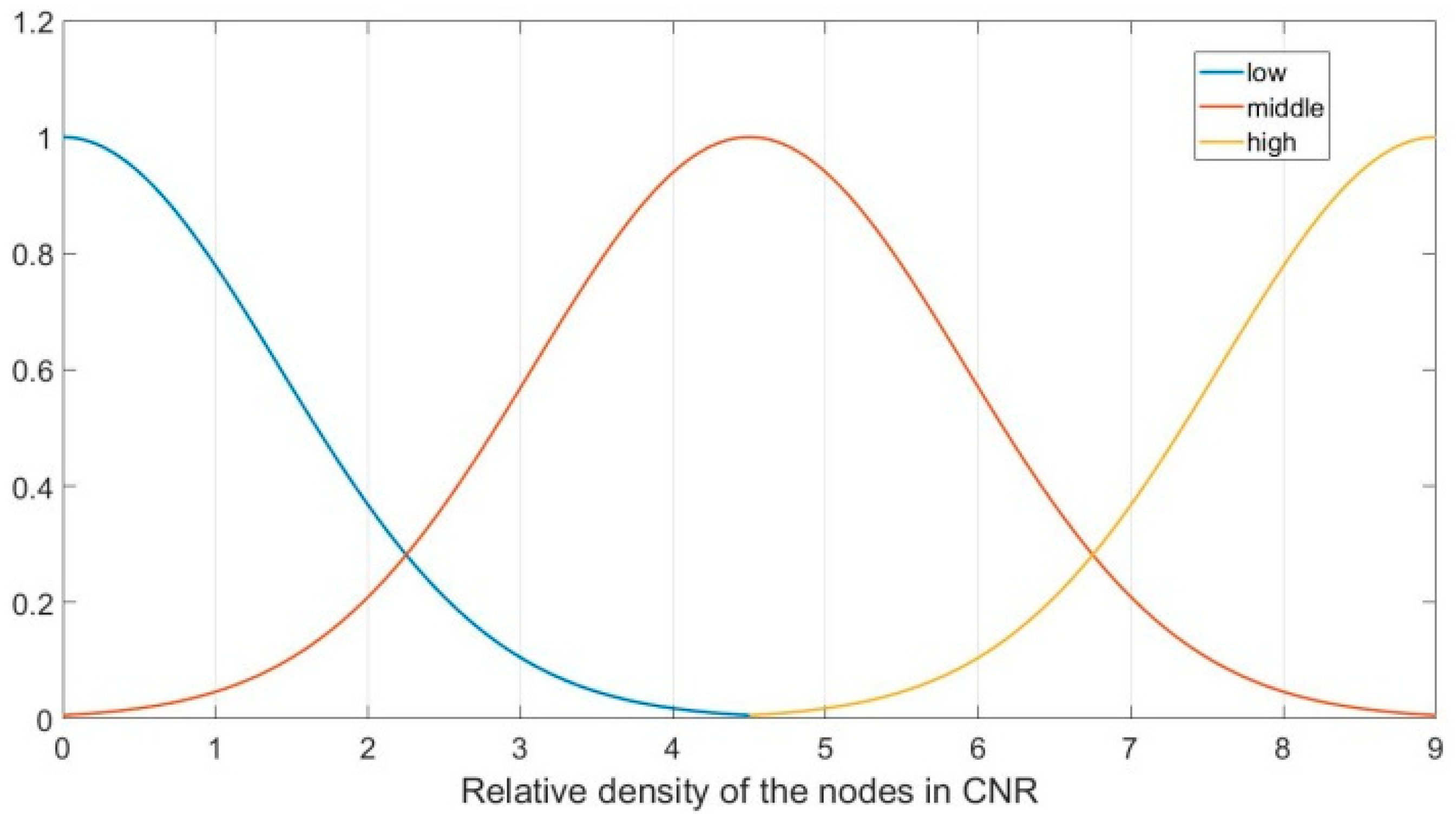
In the FLGR protocol, parameter
represents the intensive degree of the nodes in CNR, which can be divided into three fuzzy sets, namely, “low, middle and high”. In this paper, the subordinating degree function of parameter
is as follows:
Figure 4 shows the subordinating degree function of parameter
.
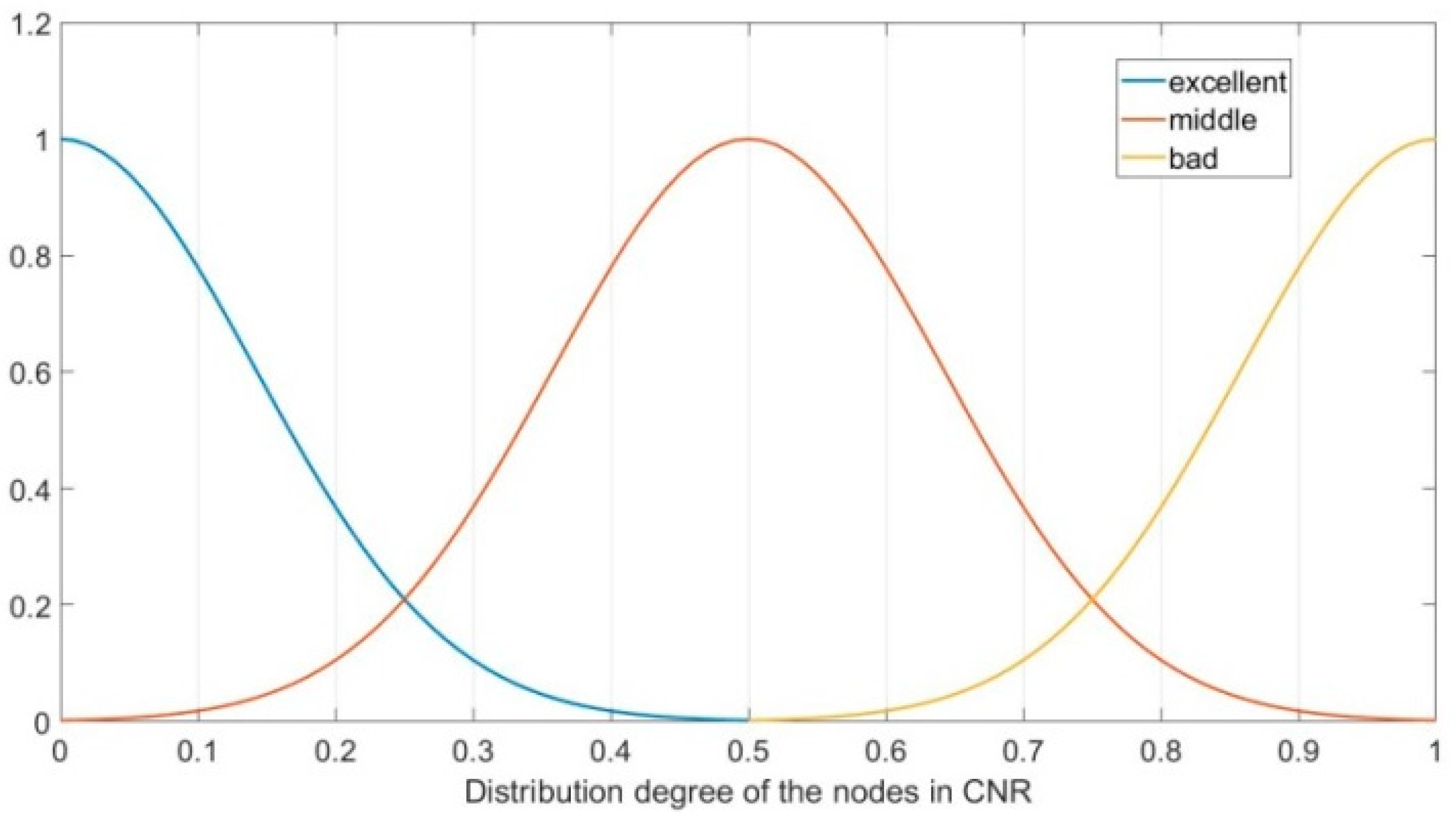
The parameter
represents the distribution situation of the nodes in the CNR of CN, which can be divided into three fuzzy sets, namely, “bad, middle, and excellent”. In this paper, the subordinating degree function of parameter
is as follows:
Figure 5 shows the subordinating degree function of parameter
.
3.5.2. Fuzzy Reasoning Rules and Fuzzy Reasoning Rule Base
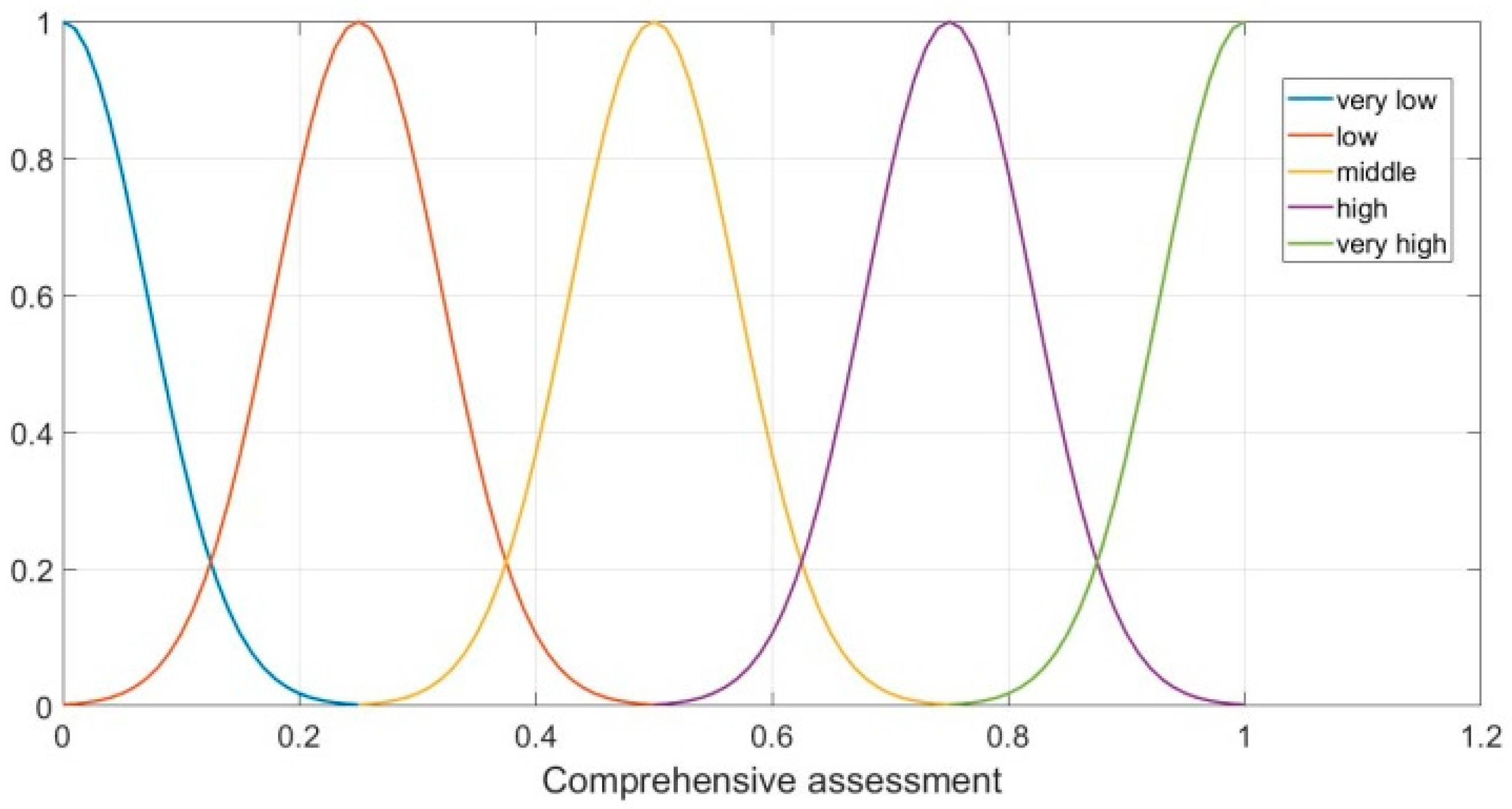
In the fuzzy logic system, node parameter
,
and
are the input variables, and we can get the comprehensive assessment of CN as the output variable, which can be denoted by
. In this paper, five fuzzy sets (very low, low, middle, high, and very high) represent that the comprehensive assessment is very low, low, middle, high, very high, respectively. Therefore, there are a total of
fuzzy reasoning rules in the fuzzy reasoning rule base. A part of fuzzy reasoning rule base is presented as follows (The whole table is presented in
Appendix A):
As given in
Table 5, taking the node with the ID of 2 for example, its parameter
belongs to the middle fuzzy set, parameter
belongs to the middle fuzzy set, and parameter
belongs to the middle fuzzy set, as a result, the output parameter
belongs to the middle fuzzy set through the fuzzy logic system.
3.5.3. Defuzzification
Through the two stages in fuzzy logic system above, the comprehensive assessments of all CNs can be obtained. However, when selecting the next forwarding node from the CNs, it is generally necessary to sort and compare the comprehensive assessments of all CNs. Hence, the comprehensive assessment of CN should be expressed by numerical values. Therefore, the defuzzification process should be conducted next.
Defuzzification transforms the fuzzy set into certain determined values, to conduct the subsequent mathematical calculation. The subordinating degree function of parameter
is as follows:
Figure 6 shows the subordinating degree function of parameter
:
In the defuzzification stage, the graded mean integration representation method (GMIRM) [
22] is adopted. The graded mean integration evaluation
of fuzzy number
is as follows:
In Equation (21), denotes the standard deviation of the left half of normal function, denotes the standard deviation of the right half of normal function, and is the mean value of normal function.
In FLGR, when the fuzzy number
belongs to the very low set, the graded mean integration evaluation
can be further simplified as follows:
When the fuzzy number
belongs to the very high set, the graded mean integration evaluation
can be further simplified as follows:
When the fuzzy number
belonged to the low, medium and high set,
, and the graded mean integration evaluation
can be further simplified as follows:
Through the defuzzification by GMIRM, the comparison table between the fuzzy sets and their corresponding values can be obtained as presented in
Table 6:



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











