High-Fidelity Depth Upsampling Using the Self-Learning Framework †


Abstract
:1. Introduction
- We propose an RGB image-guided high-quality depth upsampling method robust against specific depth outliers introduced by a depth sensor, e.g., outlier points, flipping points, and dis-occlusion. We design the systematic method consisting of depth outlier handling, RGB image-guided depth upsampling, confidence map estimation, and the self-learning framework to predict high-fidelity depth regions.
- We train our proposed depth map rejection in a self-learning way, which does not require human-annotated supervision labels, but collects training data autonomously.
- Through extensive experiments, we qualitatively and quantitatively validate the effectiveness of our proposed depth upsampling framework. We also demonstrate that our method performs favorably even on the stereo matching scenario.
Related Work
- Visual sensor system: By virtue of the robustness of the LiDAR sensors, many robotic systems mainly rely on LiDARs along with cameras. For instance, mobility platforms including autonomous vehicles typically use a combined system constituted by the stereo camera and LiDAR sensors [14], and field robots mainly use rotating axial LiDAR and multiple cameras, e.g., Tartan Rescue [15], Atlas [16], and DRC-HUBO+ [17]. On the other hand, instead of expensive LiDARs, robots for indoor activities deploy 3D-ToF or active pattern cameras. These sensors are rarely chosen for outdoor robots because they are often vulnerable to the changes of the environmental lighting condition, e.g., direct sunlight often overwhelms the spectrum range of the light patterns of the active imaging sensors [18]. Thus, improving the LiDAR system by our upsampling method can broaden overall successful application regimes of subsequent algorithms that use the estimated depth information as input.
- Guided depth upsampling: Given a pair of a depth and a high-resolution color image, depth upsampling approaches estimate a high-resolution dense depth map that follows crisp edge information of the color image. Joint bilateral upsampling (JBU) [9] applies a spatially-varying filter to the sparse samples while considering local color affinity and radial distance. Chan et al. [19] accelerated the JBU using a GPU and introduced a depth noise-aware kernel. Dolson et al. [20] presented a flexible high-dimensional filtering method for increased spatial and temporal depth resolution. Park et al. [21] used a least-squares cost function that combines several weighting factors with a non-local structure. Ferstl et al. [10] designed a smoothness term as a second-order total generalized variation and propagated sparse seed points using an anisotropic diffusion tensor obtained from a high-resolution image. In terms of degenerated depth measurements occurred due to dis-occlusion or a distant element of a scene (e.g., sky), all these approaches propagate erroneous observations to a large area if the size of depth hole regions exceeds the algorithmic limit that can be dealt with, e.g., the kernel size limit for the filtering approaches. In our work, we explicitly deal with such erroneous propagation by the initial outlier filtering step and the self-learning-based post-filtering step. This enables us to obtain high-fidelity depth upsampling results.
- Depth outliers’ handling: In practice, sparse seed points used for depth upsampling could often contain outliers. Most typical types of outliers that require separate handling would be flipping points and depth dis-occlusion that occur due to unreliable projection with parallax. Furthermore, there are outlier points, which indicate floating points with intermediate depth values between foreground and background depths occurring around object boundaries. To overcome these issues, Kang et al. [22] detected the flipping points based on the distribution of depth values within a color image segment. Park et al. [21] measured depth variation of the local regions for detecting depth discontinuity and proposed a heuristic approach that identifies flipped depth orders after depth projection. However, their work evaluated the performance of their algorithm on exactly-aligned depth-color image pairs. To a broader extent, ToF depth camera and stereo color camera fusion [23,24] was also introduced. Gandhi et al. [24] investigated specific local regions that had mixed foreground and background depth samples. Georgios et al. [23] grew seeds using a smoothness term that was conditionally defined by an occlusion label obtained from depth discontinuity analysis.
2. Materials and Methods
2.1. Early Outlier Rejection
- Outlier points’ rejection: LiDAR sensors could potentially cause depth measurement failure when measuring a light emitted from the sensor that is not adequately reflected due to degenerated surface conditions, such as the extreme edge case of the angle between the light ray and surface normal (edge of an object or a cracked object surface), specific materials with high reflectivity, and so on. These outlier points yield incoherent depth measurements with other close-by correct depth points, i.e., appear as a fractional floating point. Thus, we may eliminate most of these isolated outlier points with a simple 1D or 2D filter. In this paper, we use a simple 1D filter as follows:where Pf is a set of outlier points, is the Euclidean distance between two points, and is the point in the scan-line. Tf is a predefined threshold. This filter is applied along every horizontal scan line-by-line. The scan-line stands for a trace of a ray of the LiDAR sensor, the direction of which is congruent with the direction of the rotating axis of the mirror in the LiDAR. In this work, we assume that the horizontal direction of the image is roughly similar to the scan-line direction of the LiDAR, i.e., horizontal scan-line. After that, we use morphological operations in the image to remove isolated sparse points. In some cases, desirable depth points near the object boundaries could be also removed in this process, but we show that it is easily recoverable during the subsequent depth upsampling process.
- Flipping points’ rejection: Most depth upsampling methods assume that a sparse depth and high-resolution color image pair is well aligned, and they do not seriously treat the effect of flipping points, which causes a severe problem in depth upsampling. In this paper, we detect the flipping points by the geometric difference between two sensors and remove them in order to be free from the bad influence of the flipping points.
2.2. Depth Map Upsampling and Confidence Map Estimation
2.2.1. Depth Map Upsampling
2.2.2. Confidence Map Estimation
2.2.3. Parameter Selection
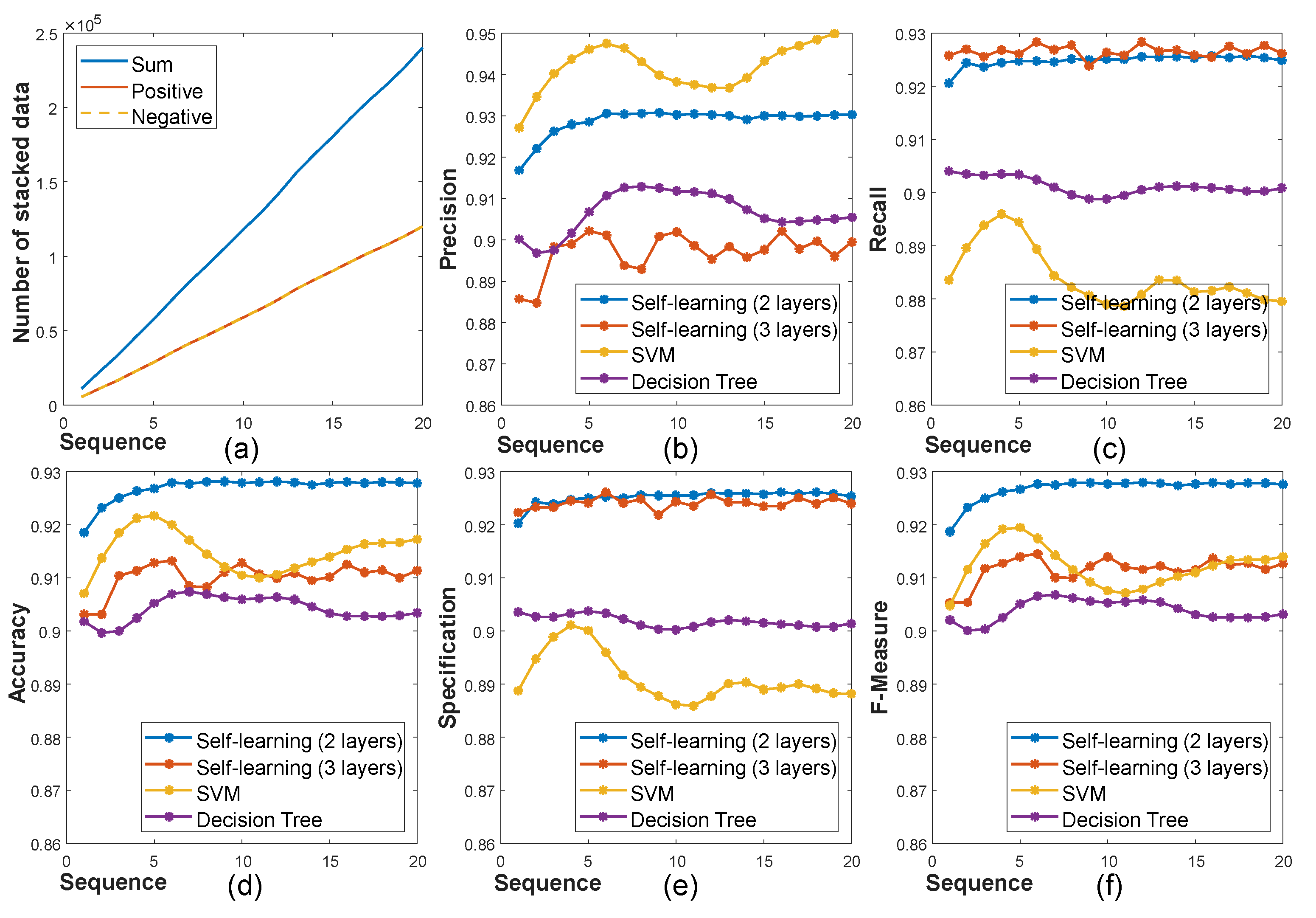
2.3. Self-Learning Framework to Predict High-Fidelity Depth
2.3.1. Training Data
2.3.2. Input Features
2.3.3. Classifier with the Online Self-Learning Framework
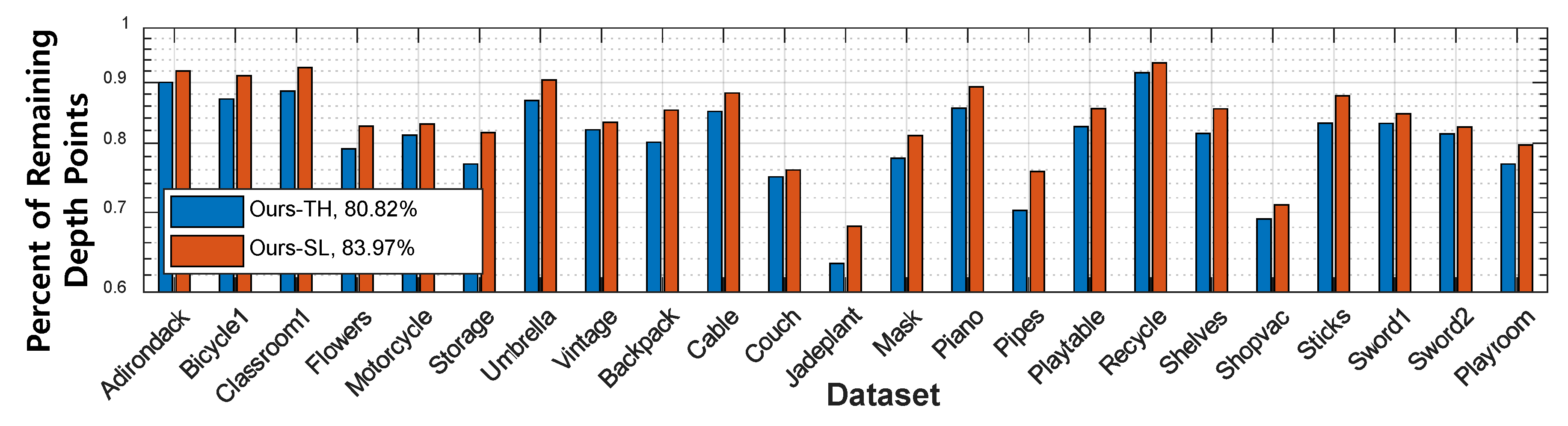
3. Results and Discussion
3.1. Quantitative Evaluation: Middlebury
3.2. Quantitative Evaluation: KITTI
4. Conclusions
- Possible applications: According to Qi, C.R. et al. [46], the performance of 3D object detection is highly related to the density of depth. Because our proposed method provides structure-aware dense depth with confidence information, we may expect to improve the performance when applied to 3D object detection.Our method will be also helpful for 6D object pose estimation, which is essential to robot-world interaction such as grasping an object. The recent Amazon Picking Challenge [47] showed that a dense depth map and object pose estimation are key components in practical applications. In our previous work [12], we already showed the effectiveness of the high-fidelity depth map on robot-world interaction tasks.
- Discussion and limitations: Filter-based upsampling approaches including our proposed method require some density of measurement points within a local kernel window size to have reliable depth estimation. Thus, depending on the sparsity and the gap among nearest neighbors of seed points, we may need to tune the kernel region-related parameter accordingly. Under our sensor configuration, we have shown that our parameter setup is fairly generalizable across many different scenes, but we do not provide other parameter setups for other configurations with different LiDAR models, which may require a different proximity parameter. It would be useful to learn adaptive parameter prediction according to the scene and hardware configuration, which we leave as a future direction.Another issue is the computational cost for practical real-world applications. The computation time highly depends on the image resolution and the number of upsampling iterations. In this work, the overall processing time of the proposed method spends about one second to process a 640 × 480 resolution image with five iterations. Some applications that do not require real-time capabilities such as the DARPA Robotics Challenge, https://en.wikipedia.org/wiki/DARPA_Robotics_Challenge, and exploration robots, can utilize our proposed method without significant changes. However, in the case of time-critical applications such as autonomous driving, they may require strict real-time performance. Because most computation is conducted through the greedy convolutional filter operation, it can be parallelized by leveraging modern GPUs.
Author Contributions
Funding
Conflicts of Interest
References
- Endres, F.; Hess, J.; Engelhard, N.; Sturm, J.; Cremers, D.; Burgard, W. An evaluation of the RGB-D SLAM system. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), St. Paul, MN, USA, 14–18 May 2012. [Google Scholar]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Yoon, K.J.; Kweon, I.S. Adaptive support-weight approach for correspondence search. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 650–656. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lange, R.; Seitz, P. Solid-state time-of-flight range camera. IEEE J. Quantum Electron. 2001, 37, 390–397. [Google Scholar] [CrossRef]
- Smisek, J.; Jancosek, M.; Pajdla, T. 3D with Kinect. In Consumer Depth Cameras for Computer Vision; Springer: London, UK, 2013; pp. 3–25. [Google Scholar]
- Shim, I.; Oh, T.H.; Lee, J.Y.; Choi, J.; Choia, D.G.; Kweon, I.S. Gradient-based Camera Exposure Control for Outdoor Mobile Platforms. IEEE Trans. Circuits Syst. Video Technol. 2018, 1. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Science & Business Media: New York, NY, USA, 2010. [Google Scholar]
- Ryde, J.; Hillier, N. Performance of laser and radar ranging devices in adverse environmental conditions. J. Field Robot. 2009, 26, 712–727. [Google Scholar] [CrossRef]
- Kopf, J.; Cohen, M.F.; Lischinski, D.; Uyttendaele, M. Joint bilateral upsampling. ACM Trans. Gr. 2007, 26, 96. [Google Scholar] [CrossRef] [Green Version]
- Ferstl, D.; Reinbacher, C.; Ranftl, R.; Rüther, M.; Bischof, H. Image guided depth upsampling using anisotropic total generalized variation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Shin, S.; Im, S.; Shim, I.; Jeon, H.G.; Kweon, I.S. Geometry Guided Three-Dimensional Propagation for Depth From Small Motion. IEEE Signal Process. Lett. 2017, 24, 1857–1861. [Google Scholar] [CrossRef]
- Shim, I.; Shin, S.; Bok, Y.; Joo, K.; Choi, D.G.; Lee, J.Y.; Park, J.; Oh, J.H.; Kweon, I.S. Vision system and depth processing for DRC-HUBO+. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016. [Google Scholar]
- Strecha, C.; Fransens, R.; Van Gool, L. Combined depth and outlier estimation in multi-view stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Thrun, S.; Montemerlo, M.; Dahlkamp, H.; Stavens, D.; Aron, A.; Diebel, J.; Fong, P.; Gale, J.; Halpenny, M.; Hoffmann, G.; et al. Stanley: The robot that won the DARPA Grand Challenge. J. Field Robot. 2006, 23, 661–692. [Google Scholar] [CrossRef]
- Stentz, A.; Herman, H.; Kelly, A.; Meyhofer, E.; Haynes, G.C.; Stager, D.; Zajac, B.; Bagnell, J.A.; Brindza, J.; Dellin, C.; et al. CHIMP, the CMU highly intelligent mobile platform. J. Field Robot. 2015, 32, 209–228. [Google Scholar] [CrossRef]
- Johnson, M.; Shrewsbury, B.; Bertrand, S.; Wu, T.; Duran, D.; Floyd, M.; Abeles, P.; Stephen, D.; Mertins, N.; Lesman, A.; et al. Team IHMC’s Lessons Learned from the DARPA Robotics Challenge Trials. J. Field Robot. 2015, 32, 192–208. [Google Scholar] [CrossRef]
- Lim, J.; Lee, I.; Shim, I.; Jung, H.; Joe, H.M.; Bae, H.; Sim, O.; Oh, J.; Jung, T.; Shin, S.; et al. Robot System of DRC-HUBO+ and Control Strategy of Team KAIST in DARPA Robotics Challenge Finals. J. Field Robot. 2017, 34, 802–829. [Google Scholar] [CrossRef]
- O’Toole, M.; Achar, S.; Narasimhan, S.G.; Kutulakos, K.N. Homogeneous codes for energy-efficient illumination and imaging. ACM Trans. Gr. 2015, 34, 35. [Google Scholar] [CrossRef]
- Chan, D.; Buisman, H.; Theobalt, C.; Thrun, S. A noise-aware filter for real-time depth upsampling. In Proceedings of the ECCV Workshop on Multi-camera and Multi-modal Sensor Fusion Algorithms and Applications, Marseille, France, 18 October 2008. [Google Scholar]
- Dolson, J.; Baek, J.; Plagemann, C.; Thrun, S. Upsampling range data in dynamic environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Park, J.; Kim, H.; Tai, Y.W.; Brown, M.S.; Kweon, I.S. High-Quality Depth Map Upsampling and Completion for RGB-D Cameras. IEEE Trans. Image Process. 2014, 23, 5559–5572. [Google Scholar] [CrossRef] [PubMed]
- Kang, Y.S.; Ho, Y.S. Efficient up-sampling method of low-resolution depth map captured by time-of-flight depth sensor. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, Kaohsiung, Taiwan, 29 October–1 November 2013. [Google Scholar]
- Georgios, D.; Evangelidis, M.H.; Horaud, R. Fusion of Range and Stereo Data for High-Resolution Scene-Modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2178–2192. [Google Scholar]
- Vineet Gandhi, J.C.; Horaud, R. High-Resolution Depth Maps Based on TOF-Stereo Fusion. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), St. Paul, MN, USA, 14–18 May 2012. [Google Scholar]
- Zhang, Q.; Pless, R. Extrinsic calibration of a camera and laser range finder (improves camera calibration). In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004. [Google Scholar]
- Lee, D.T.; Schachter, B.J. Two algorithms for constructing a Delaunay triangulation. Int. J. Comput. Inf. Sci. 1980, 9, 219–242. [Google Scholar] [CrossRef]
- Zhang, Q.; Shen, X.; Xu, L.; Jia, J. Rolling Guidance Filter. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Rosenberg, C.; Hebert, M.; Schneiderman, H. Semi-supervised self-training of object detection models. In Proceedings of the IEEE International Workshop on Application of Computer Vision (WACV), Breckenridge, CO, USA, 5–7 January 2005. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Manzagol, P.A.; Vincent, P.; Bengio, S. Why does unsupervised pre-training help deep learning? J. Mach. Learn. Res. 2010, 11, 625–660. [Google Scholar]
- Chapelle, O.; Scholkopf, B.; Zien, A. Semi-Supervised Learning; MIT Press: Cambridge, MA, USA, 2006; ISBN 978-0-26-203358-9. [Google Scholar]
- Kalal, Z.; Matas, J.; Mikolajczyk, K. Pn learning: Bootstrapping binary classifiers by structural constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Schlkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond (Adaptive Computation and Machine Learning); MIT Press: Cambridge, MA, USA, 2001; ISBN 978-0-26-219475-4. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.; Olshen, R. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984; ISBN 978-0-41-204841-8. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy Layer-Wise Training of Deep Networks. Available online: http://papers.nips.cc/paper/3048-greedy-layer-wise-training-of-deep-networks.pdf (accessed on 17 December 2018).
- Bengio, Y. Learning Deep Architectures for AI; Now Publishers Inc.: Hanover, MA, USA, 2009; ISBN 978-1-60-198294-0. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Park, J.; Kim, H.; Tai, Y.W.; Brown, M.S.; Kweon, I. High quality depth map upsampling for 3D-TOF cameras. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Scharstein, D.; Hirschmüller, H.; Kitajima, Y.; Krathwohl, G.; Nešić, N.; Wang, X.; Westling, P. High-resolution stereo datasets with subpixel-accurate ground truth. In Proceedings of the German Conference on Pattern Recognition, Münster, Germany, 2–5 September 2014. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Baker, S.; Scharstein, D.; Lewis, J.; Roth, S.; Black, M.J.; Szeliski, R. A database and evaluation methodology for optical flow. Int. J. Comput. Vis. 2011, 92, 1–31. [Google Scholar] [CrossRef]
- Shin, S.; Shim, I.; Jung, J.; Bok, Y.; Oh, J.H.; Kweon, I.S. Object proposal using 3D point cloud for DRC-HUBO+. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016. [Google Scholar]
- Zbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zeng, A.; Song, S.; Yu, K.T.; Donlon, E.; Hogan, F.R.; Bauza, M.; Ma, D.; Taylor, O.; Liu, M.; Romo, E.; et al. Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error Metric A80 | TGV | Non-Local | Bilat-Eral | Ours-Conf | Ours-TH | Ours-SL | Error Metric A95 | TGV | Non-Local | Bilat-Eral | Ours-Conf | Ours-TH | Ours-SL |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Adirondack | 19.6 | 9.7 | 4.7 | 4.0 | 3.3 | 3.7 | Adirondack | 152.3 | 285.9 | 160.5 | 8.4 | 7.0 | 7.4 |
| Bicycle1 | 14.5 | 9.1 | 4.4 | 3.6 | 4.5 | 3.3 | Bicycle1 | 86.8 | 183.7 | 116.0 | 8.0 | 6.4 | 6.5 |
| Classroom1 | 40.2 | 6.3 | 4.4 | 3.6 | 3.2 | 3.4 | Classroom1 | 364.3 | 99.0 | 21.0 | 9.0 | 6.3 | 7.7 |
| Flowers | 64.5 | 125.5 | 7.5 | 3.7 | 3.3 | 3.3 | Flowers | 1028.0 | 682.2 | 575.6 | 7.6 | 5.7 | 6.1 |
| Motorcycle | 32.0 | 29.7 | 7.5 | 5.7 | 5.0 | 5.0 | Motorcycle | 388.9 | 471.8 | 379.0 | 15.5 | 9.9 | 10.6 |
| Storage | 44.9 | 86.1 | 4.9 | 3.9 | 3.6 | 3.6 | Storage | 723.2 | 1084.8 | 448.4 | 10.4 | 7.9 | 9.0 |
| Umbrella | 32.9 | 8.2 | 4.6 | 3.6 | 3.5 | 3.5 | Umbrella | 259.5 | 229.4 | 89.8 | 7.4 | 6.4 | 6.8 |
| Vintage | 40.3 | 8.9 | 4.3 | 4.6 | 4.4 | 4.3 | Vintage | 403.8 | 84.5 | 17.1 | 8.1 | 7.5 | 7.9 |
| Backpack | 16.7 | 7.6 | 4.5 | 3.9 | 3.5 | 3.5 | Backpack | 112.7 | 126.9 | 54.3 | 9.5 | 6.0 | 6.1 |
| Cable | 14.8 | 6.6 | 4.3 | 4.1 | 4.0 | 4.0 | Cable | 69.5 | 83.2 | 57.2 | 6.9 | 6.3 | 6.3 |
| Couch | 119.2 | 40.3 | 6.9 | 5.2 | 4.2 | 4.5 | Couch | 820.6 | 502.6 | 435.2 | 15.0 | 8.6 | 10.2 |
| Jadeplant | 96.5 | 91.8 | 62.3 | 6.3 | 4.6 | 4.9 | Jadeplant | 540.0 | 334.0 | 336.4 | 96.4 | 8.9 | 10.5 |
| Mask | 34.6 | 14.8 | 4.7 | 4.4 | 4.0 | 4.0 | Mask | 294.4 | 251.6 | 103.8 | 9.5 | 7.0 | 7.2 |
| Piano | 18.8 | 8.6 | 4.7 | 4.6 | 4.2 | 4.1 | Piano | 98.7 | 94.7 | 38.3 | 10.3 | 8.4 | 8.3 |
| Pipe | 156.0 | 238.3 | 40.0 | 8.7 | 6.7 | 6.9 | Pipe | 1268.8 | 1347.2 | 1194.7 | 38.2 | 12.6 | 13.5 |
| Playtable | 32.1 | 24.1 | 5.8 | 5.5 | 4.6 | 4.9 | Playtable | 340.7 | 264.8 | 142.5 | 12.7 | 9.1 | 9.8 |
| Recycle | 22.6 | 15.9 | 5.8 | 3.6 | 3.4 | 3.4 | Recycle | 225.2 | 171.1 | 153.1 | 7.4 | 6.8 | 6.9 |
| Shelves | 14.6 | 6.6 | 4.1 | 3.5 | 3.4 | 3.3 | Shelves | 75.7 | 101.1 | 41.1 | 7.6 | 6.7 | 6.8 |
| Shopvac | 16.9 | 8.8 | 4.5 | 3.8 | 3.3 | 3.6 | Shopvac | 97.2 | 99.9 | 40.3 | 9.7 | 6.6 | 7.6 |
| Sticks | 39.6 | 6.8 | 4.1 | 4.8 | 3.5 | 4.4 | Sticks | 120.3 | 45.8 | 10.3 | 10.0 | 7.1 | 7.3 |
| Sword1 | 13.3 | 6.3 | 4.4 | 4.2 | 4.2 | 3.7 | Sword1 | 56.7 | 26.7 | 18.9 | 11.8 | 6.8 | 7.3 |
| Sword2 | 22.4 | 9.4 | 4.9 | 4.0 | 3.6 | 3.8 | Sword2 | 181.1 | 151.1 | 106.5 | 8.3 | 7.1 | 6.2 |
| Playroom | 21.2 | 8.7 | 4.6 | 5.4 | 3.7 | 4.6 | Playroom | 170.1 | 146.0 | 124.5 | 13.8 | 6.0 | 9.3 |
| Dataset | 0002 | 0038 | 0091 | 0093 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Error Metric | D1-all | A92 | A95 | pts(%) | D1-all | A86 | A90 | pts(%) | D1-all | A87 | A90 | pts(%) | D1-all | A84 | A90 | pts(%) |
| MC-CNN [45] | 8.8% | 2.27 | 4.02 | 100% | 13.9% | 1.36 | 2.09 | 100% | 12.6% | 1.56 | 2.24 | 100% | 16.3% | 0.85 | 1.90 | 100% |
| Ours-TH [12] | 1.4% | 0.22 | 0.32 | 49.3% | 3.8% | 0.28 | 0.47 | 48.4% | 3.4% | 0.22 | 0.35 | 49.7% | 2.5% | 0.20 | 0.32 | 50.3% |
| Ours-SL | 4.4% | 0.29 | 0.52 | 61.5% | 9.7% | 0.44 | 1.10 | 63.0% | 9.3% | 0.34 | 1.03 | 64.2% | 8.6% | 0.26 | 0.56 | 62.7% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shim, I.; Oh, T.-H.; Kweon, I.S. High-Fidelity Depth Upsampling Using the Self-Learning Framework. Sensors 2019, 19, 81. https://doi.org/10.3390/s19010081
Shim I, Oh T-H, Kweon IS. High-Fidelity Depth Upsampling Using the Self-Learning Framework. Sensors. 2019; 19(1):81. https://doi.org/10.3390/s19010081
Chicago/Turabian StyleShim, Inwook, Tae-Hyun Oh, and In So Kweon. 2019. "High-Fidelity Depth Upsampling Using the Self-Learning Framework" Sensors 19, no. 1: 81. https://doi.org/10.3390/s19010081
APA StyleShim, I., Oh, T. -H., & Kweon, I. S. (2019). High-Fidelity Depth Upsampling Using the Self-Learning Framework. Sensors, 19(1), 81. https://doi.org/10.3390/s19010081