The Lightweight Autonomous Vehicle Self-Diagnosis (LAVS) Using Machine Learning Based on Sensors and Multi-Protocol IoT Gateway

Abstract
:1. Introduction
2. Related Works
2.1. Gateway
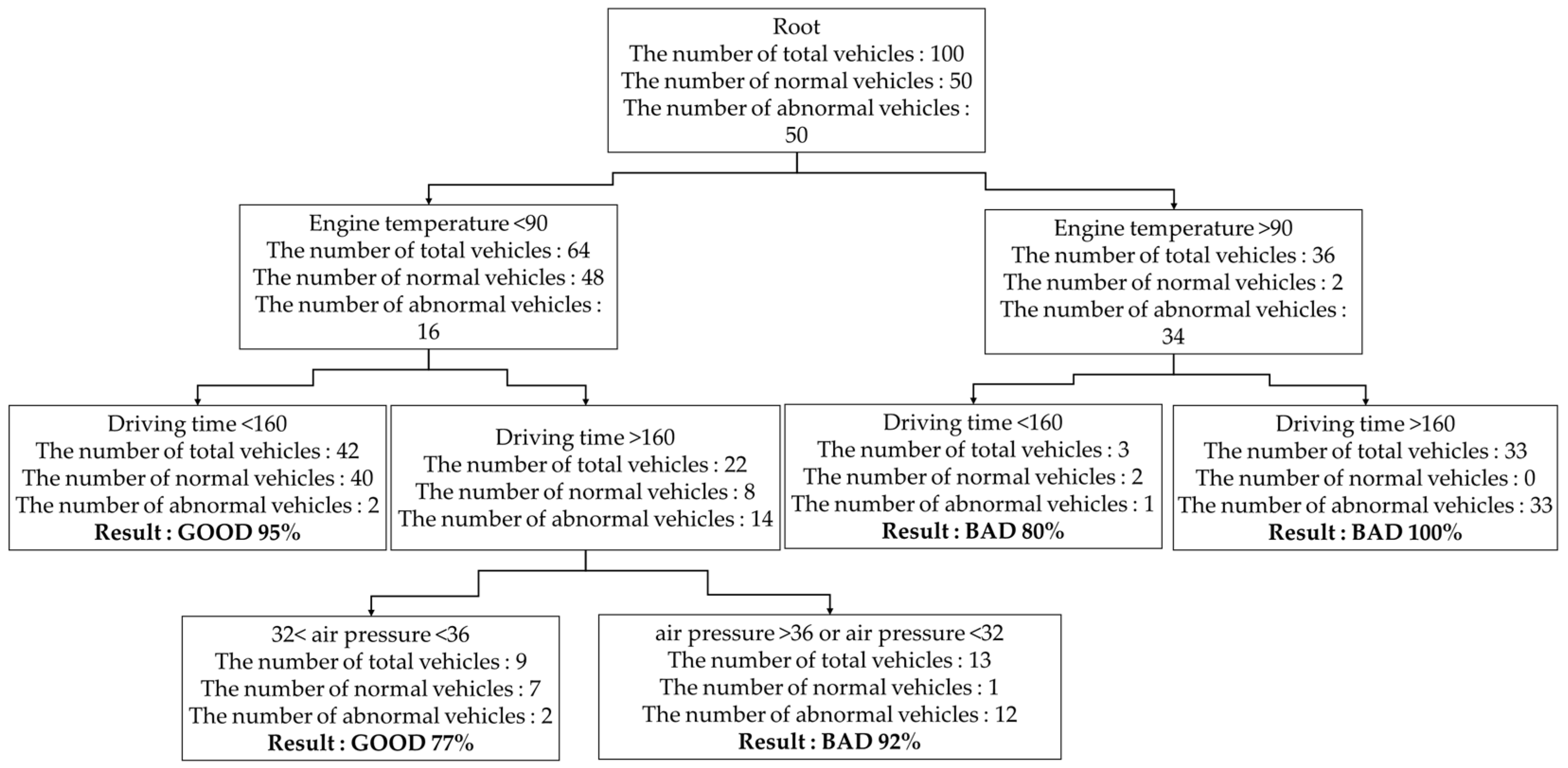
2.2. Random-Forest
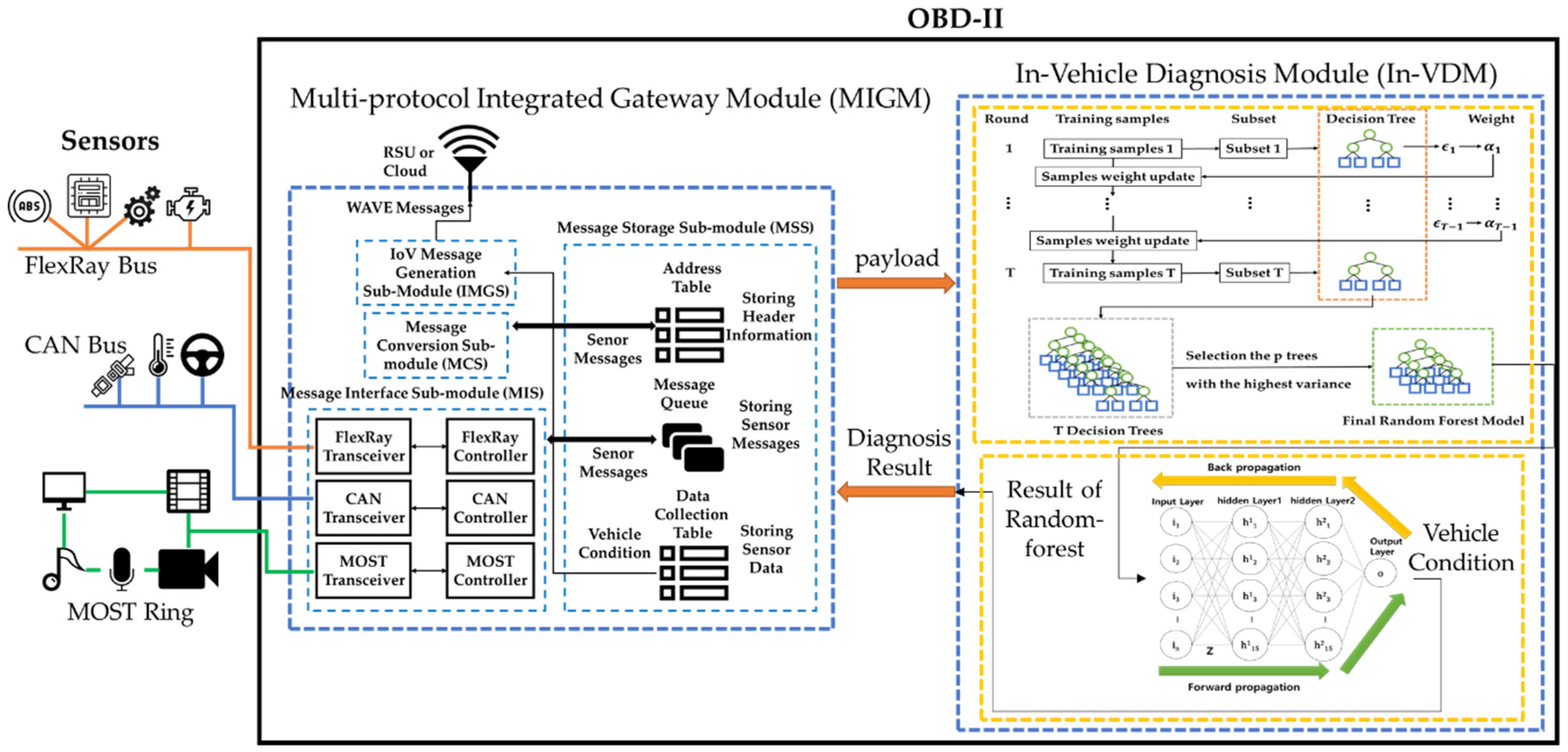
3. A Design of the Lightweight Autonomous Vehicle Self-Diagnosis (LAVS)
3.1. Overview
3.2. The Multi-Protocol Integrated Gateway Module (MIGM)
3.2.1. A Design of a Message Interface Sub-Module (MIS)
3.2.2. A Design of a Message Storage Sub-Module (MSS)
3.2.3. A Design of the Message Conversion Sub-Module (MCS)
3.2.4. A Design of a WAVE Message Generation Sub-Module (WMGS)
3.3. A Design of an In-Vehicle Diagnosis Module (In-VDM)
3.3.1. A Design of the Random-Forest Part-Diagnosis Sub-Module (RPS)
| Algorithm 1. The process generating a random-forest model. |
| Input: Training data X, Y, W X = set of payloads Y = set of results of training data W = set of weights initialize weight W : wi(1) = 1/N for(int j = 1; j <= T; j++) make subset St from Training data. ΔGmax = -∞ sample feature f from sensors randomly for(int k = 1; k <= K; k++) Sn = a current node split Sn into Sl or Sr by fk compute information gain ΔG: if(ΔG>ΔGmax) ΔGmax = ΔG end if end for if(ΔGmax = 0 or maximum depth) store the probability distribution P(c|l) in a leaf node. else generate a split node recursively. end if if(finish training of decision tree) estimate class label : = arg max Pt(c|l). compute an error rate of a decision tree : compute a weight of a decision tree : if( > 0 then) update a weight of training data else reject a decision tree end if end if end for |
3.3.2. A Design of a Neural Network Vehicle-Diagnosis Sub-Module (NNVS)
| Algorithm 2. The learning process of the NNVS |
| Input : Training data I, O I[] = result of RPS n = the number of input nodes y = training data initialize: weight Z [3][][] : for(int i = 0; i<n; i++){ for(int j = 0; j<15; j++){ Z [0][i][j] = sqrt(random(0,3)/n+15); } } for(int i = 0; i<15; i++){ for(int j = 0; j<15; j++){ Z[1][i][j] = sqrt(random(0,3)/30); } } for(int i = 0; i<15; i++){ Z[2][i][j] = sqrt(random(0,3)/16); } Emax = 0.03; E = 900; NET = 0; H[2][15] = 0; O = 0; while(E>Emax){ for(int i = 0; i<15; i++){ for(int j=0; j<n; j++){ NET = NET + I[j]*Z[0][j][i]; } H[0][i] = tanh(NET); NET = 0; } for(k = 1; k<3; k++){ for(int i = 0; i<15; i++){ for(int j = 0; j<15; j++){ NET = NET + H[k-1][j]*Z[k][j][i]; } H[k][i] = tanh(NET); NET = 0; } } for(int i = 0; i<15; i++){ NET = NET + H[2][i] * Z[3][i][0]; } O = tanh(NET); E = pow((o-y),2); Update_wights(Z, E); }end |
4. The Performance Analysis
4.1. The MIGM Performance Analysis
4.2. The In-VDM Performance Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Automated Vehicles for Safety. Available online: https://www.nhtsa.gov/technology-innovation/automated-vehicles-safety (accessed on 30 December 2018).
- Radier, B.; Salaun, M.; Guette, G.; Nait-Abdesselam, F. A vehicle gateway to manage IP multimedia subsystem autonomous mobility. Int. J. Auton. Adapt. Commun. Syst. 2010, 3, 159–177. [Google Scholar] [CrossRef]
- Xie, G.; Zeng, G.; Kurachi, R.; Takada, H.; Li, Z.; Li, R.; Li, K. WCRT Analysis of CAN Messages in Gateway-Integrated In-Vehicle Networks. IEEE Trans. Veh. Technol. 2017, 66, 9623–9637. [Google Scholar] [CrossRef]
- Kim, M.H.; Lee, S.; Lee, K.C. Performance Evaluation of Node-mapping-based Flexray-CAN Gateway for in-vehicle Networking System. Intell. Autom. Soft Comput. 2014, 21, 251–263. [Google Scholar] [CrossRef]
- Kim, J.H.; Seo, S.H.; Hai, N.T.; Cheon, B.M.; Lee, Y.S.; Jeon, J.W. Gateway Framework for In-Vehicle Networks Based on CAN, FlexRay, and Ethernet. IEEE Trans. Veh. Technol. 2015, 64, 4472–4486. [Google Scholar] [CrossRef]
- Benslimane, A.; Taleb, T.; Sivaraj, R. DynaMIGM Clustering-Based Adaptive Mobile Gateway Management in Integrated VANET—3G Heterogeneous Wireless Networks. IEEE J. Sel. Areas Commun. 2011, 29, 559–570. [Google Scholar] [CrossRef]
- Omar, H.A.; Zhuang, W.; Li, L. Gateway Placement and Packet Routing for Multihop In-Vehicle Internet Access. IEEE Trans. Emerg. Top. Comput. 2015, 3, 335–351. [Google Scholar] [CrossRef]
- Shafiee, K.; Leung, V.C.M. Connectivity-aware minimum-delay geographic routing with vehicle tracking in VANETs. Ad Hoc Netw. 2010, 9, 131–141. [Google Scholar] [CrossRef]
- Bruglieri, M.; Cappanera, P.; Nonato, M. The Gateway Location Problem: Assessing the impact of candidate site selection policies. Discret. Appl. Math. 2013, 165, 96–111. [Google Scholar] [CrossRef]
- Lee, Y.S.; Kim, J.H.; Jeon, J.W. FlexRay and Ethernet AVB Synchronization for High QoS Automotive Gateway. IEEE Trans. Veh. Technol. 2017, 66, 5737–5751. [Google Scholar] [CrossRef]
- Noura, A.; Kaouther, A.; Mohammed, A.; Azzedine, B. A reliable quality of service aware fault tolerant gateway discovery protocol for vehicular networks. Wirel. Commun. Mob. Comput. 2015, 15, 1485–1495. [Google Scholar]
- Daun, X.; Liu, Y.; Wang, X. SDN Enabled 5G-VANET: Adaptive Vehicle Clustering and Beamformed Transmission for Aggregated Traffic. IEEE Commun. Mag. 2015, 55, 120–127. [Google Scholar] [CrossRef]
- Ju, K.; Chen, L.; Wei, H.; Chen, K. An Efficient Gateway Discovery Algorithm with Delay Guarantee for VANET-3G Heterogeneous Networks. Wirel. Pers. Commun. 2014, 77, 2019–2036. [Google Scholar] [CrossRef]
- Jeong, Y.N.; Son, S.R.; Jeong, E.H.; Lee, B.K. An Integrated Self-Diagnosis System for an Autonomous Vehicle Based on an IoT Gateway and Deep Learning. Appl. Sci. 2018, 8, 1164. [Google Scholar] [CrossRef]
- Jeong, Y.N.; Son, S.R.; Jeong, E.H.; Lee, B.K. A Design of a Lightweight In-Vehicle Edge Gateway for the Self-Diagnosis of an Autonomous Vehicle. Appl. Sci. 2018, 8, 1594. [Google Scholar] [CrossRef]
- Mu, J.; Xu, L.; Duan, X.; Pu, H. Study on Customer Loyalty Prediction Based on RF Algorithm. JCP 2013, 8, 2134–2138. [Google Scholar] [CrossRef]
- Kalantarian, H.; Sarrafzadeh, M. Audio-based detection and evaluation of eating behavior using the smartwatch platform. Comput. Biol. Med. 2015, 65, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Huang, T.; Yu, Y.; Guo, G.; Li, K. A classification algorithm based on local cluster centers with a few labeled training examples. Knowl.-Based Syst. 2010, 23, 563–571. [Google Scholar] [CrossRef]
- Kalantarian, H.; Sarrafzadeh, M. Probabilistic time-series segmentation. Pervasive Mob. Comput. 2017, 41, 397–412. [Google Scholar] [CrossRef]
- Tahani, D.; Riyad, A. Diagnosis of Diabetes by Applying Data Mining Classification Techniques. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 329–332. [Google Scholar]
- AI-Jarrah, O.Y.; AI-Hammdi, Y.; Yoo, P.D.; Muhaidat, S.; AI-Qutayri, M. Semi-supervised multi-layered clustering model for intrusion detection. Digit. Commun. Netw. 2018, 4, 277–286. [Google Scholar] [CrossRef]
- Meeragandhi, G.; Appavoo, K.; Srivatsa, S.K. Effective Network Intrusion Detection using Classifiers Decision Trees and Decision rules. Int. J. Adv. Netw. Appl. 2010, 2, 686–692. [Google Scholar]
- Quiroz, J.C.; Mariun, N.; Mehrjou, M.R.; Izadi, M.; Misron, N.; Mohd Radzib, M.A. Fault detection of broken rotor bar in LS-PMSM using random forests. Measurement 2018, 116, 279–280. [Google Scholar] [CrossRef]
- V2X Communication Application Technology and Development Direction. Available online: http://www.krnet.or.kr/board/data/dprogram/1832/J2-2.pdf (accessed on 30 September 2018).
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. J. Mach. Learn. Res. 2010, 9, 249–256. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Attribute | Data (or Payload) |
|---|---|---|
| 2018.11.09 17:00:25:012 | Engine voltage | 12 V |
| 2018.11.09 17:00:25:054 | Tire Pressure | 30 psi |
| 2018.11.09 17:00:25:021 | Tire temp | 50 °C |
| 2018.11.09 17:00:25:008 | Front light | 9.254 lx |
| … | … | … |
| 2018.11.09 17:00:26:078 | Diagnosis result | 75% |
| Attribute | Value |
|---|---|
| The Number of Divided Messages | n |
| Current Message Number | 1 |
| Source Address | 1002 |
| Source Protocol Bus Number | 1 |
| Destination Address | 3315 |
| Destination Protocol Bus Number | 2 |
| Message Priority | 1 |
| The 1st message ID | 30 |
| …. | … |
| The nth message ID | 90 |
| Parts | Engine | Light | Steering | Transmission | … | Break |
|---|---|---|---|---|---|---|
| RPS result | –0.251 | 0.992 | 0.687 | –0.451 | … | 0.876 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, Y.; Son, S.; Lee, B. The Lightweight Autonomous Vehicle Self-Diagnosis (LAVS) Using Machine Learning Based on Sensors and Multi-Protocol IoT Gateway. Sensors 2019, 19, 2534. https://doi.org/10.3390/s19112534
Jeong Y, Son S, Lee B. The Lightweight Autonomous Vehicle Self-Diagnosis (LAVS) Using Machine Learning Based on Sensors and Multi-Protocol IoT Gateway. Sensors. 2019; 19(11):2534. https://doi.org/10.3390/s19112534
Chicago/Turabian StyleJeong, YiNa, SuRak Son, and ByungKwan Lee. 2019. "The Lightweight Autonomous Vehicle Self-Diagnosis (LAVS) Using Machine Learning Based on Sensors and Multi-Protocol IoT Gateway" Sensors 19, no. 11: 2534. https://doi.org/10.3390/s19112534
APA StyleJeong, Y., Son, S., & Lee, B. (2019). The Lightweight Autonomous Vehicle Self-Diagnosis (LAVS) Using Machine Learning Based on Sensors and Multi-Protocol IoT Gateway. Sensors, 19(11), 2534. https://doi.org/10.3390/s19112534