An Industrial Micro-Defect Diagnosis System via Intelligent Segmentation Region


Abstract
:1. Introduction
2. Methodology of the System Implement
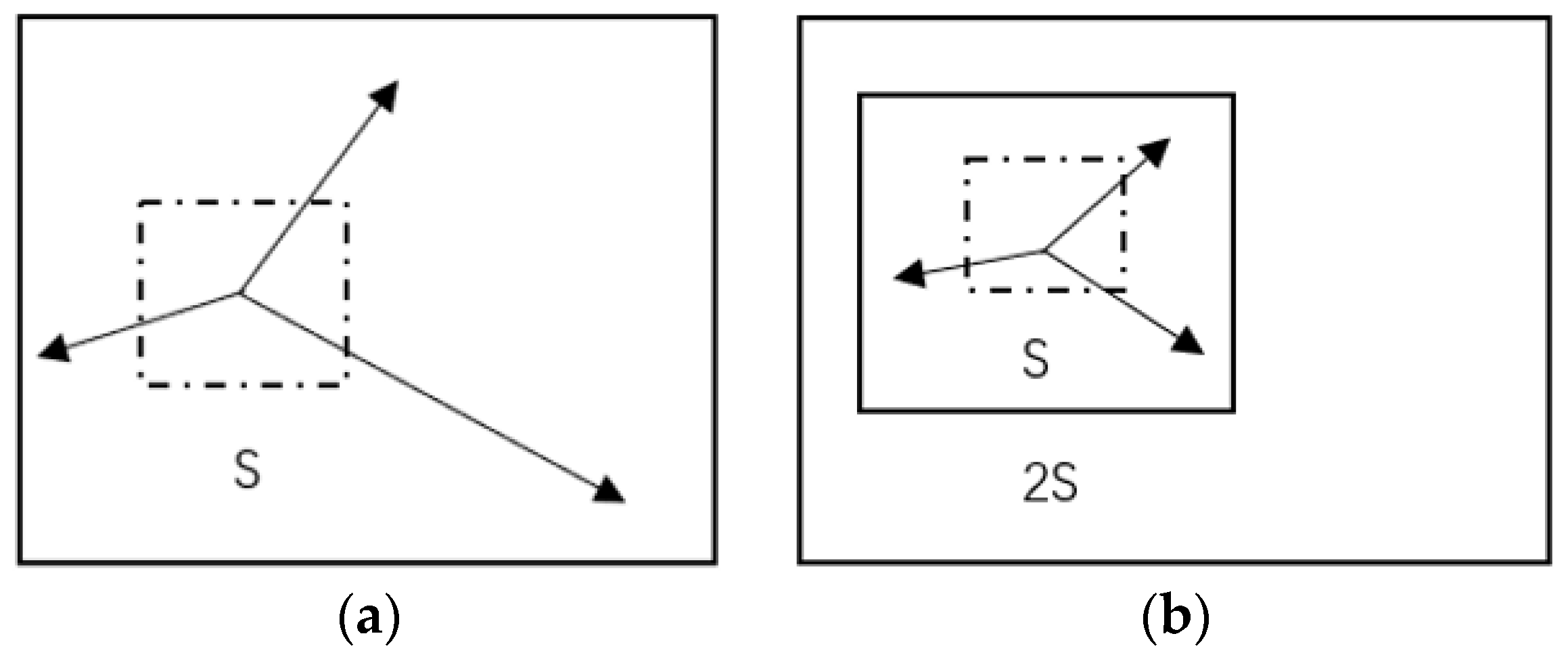
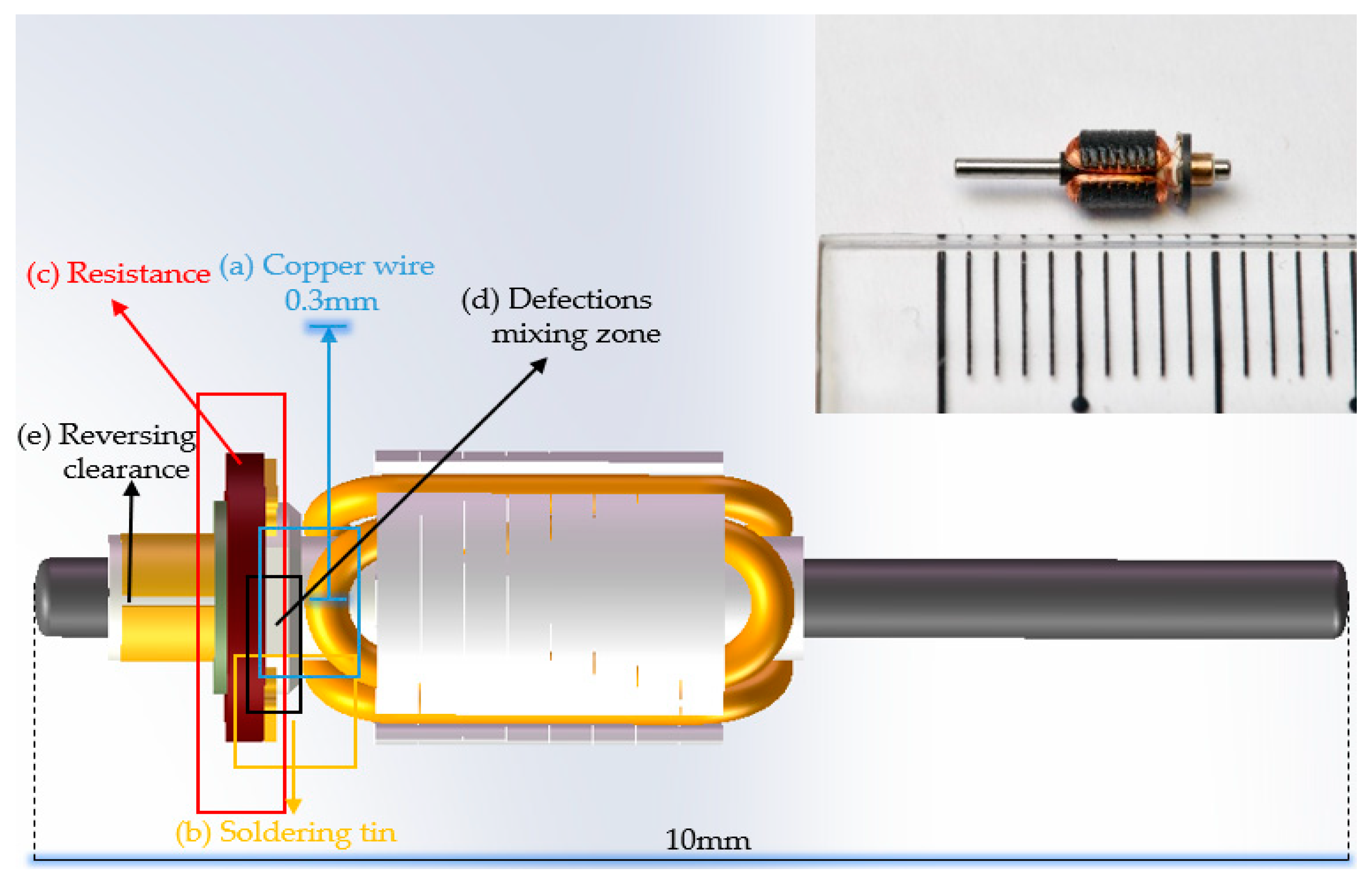
2.1. Mask Augment through SLIC
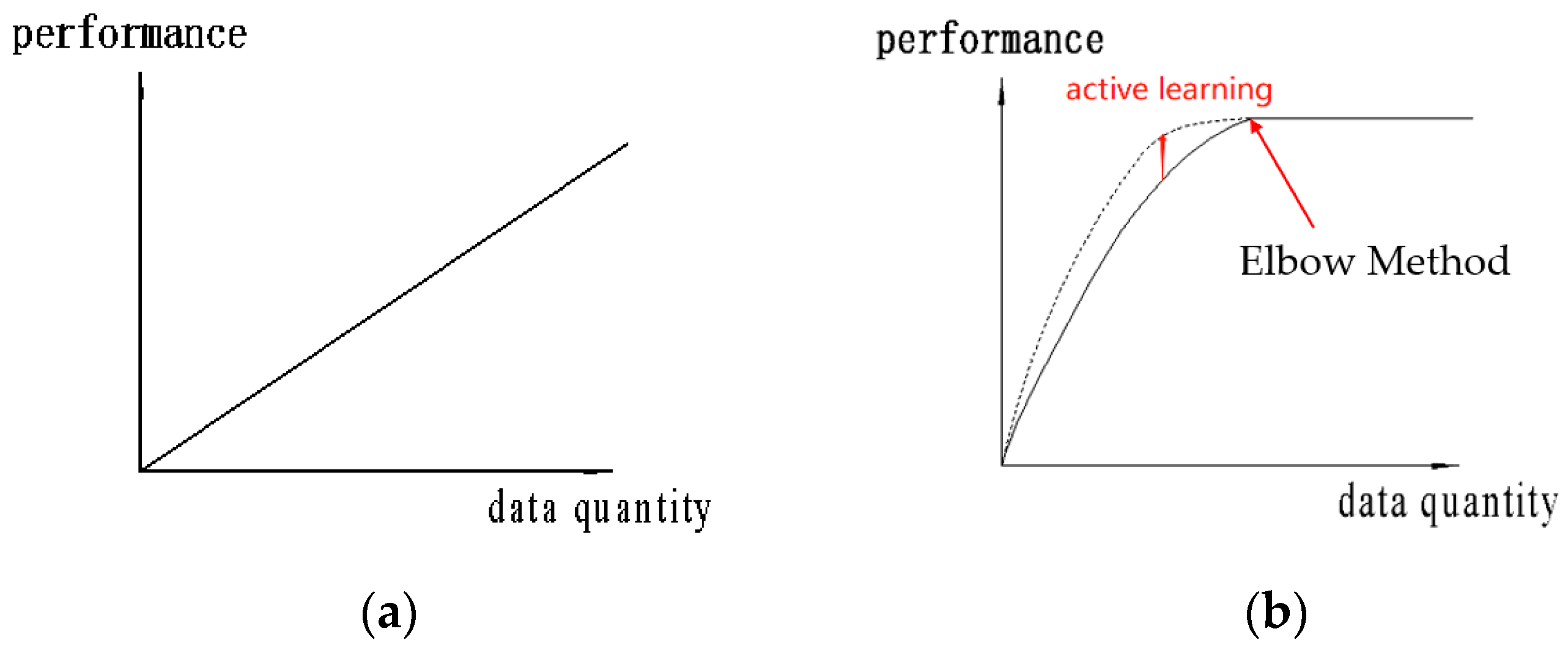
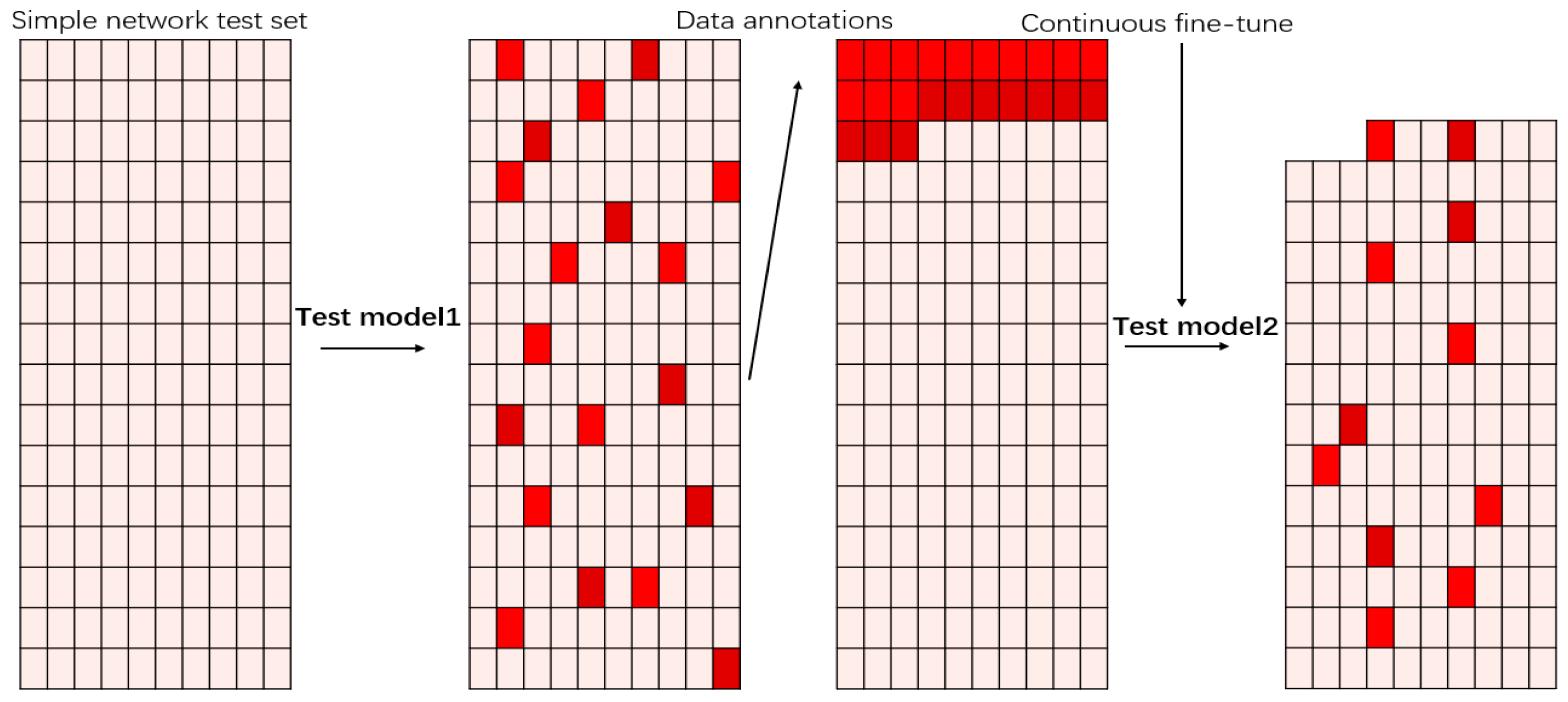
2.2. Data Processing Process of the System
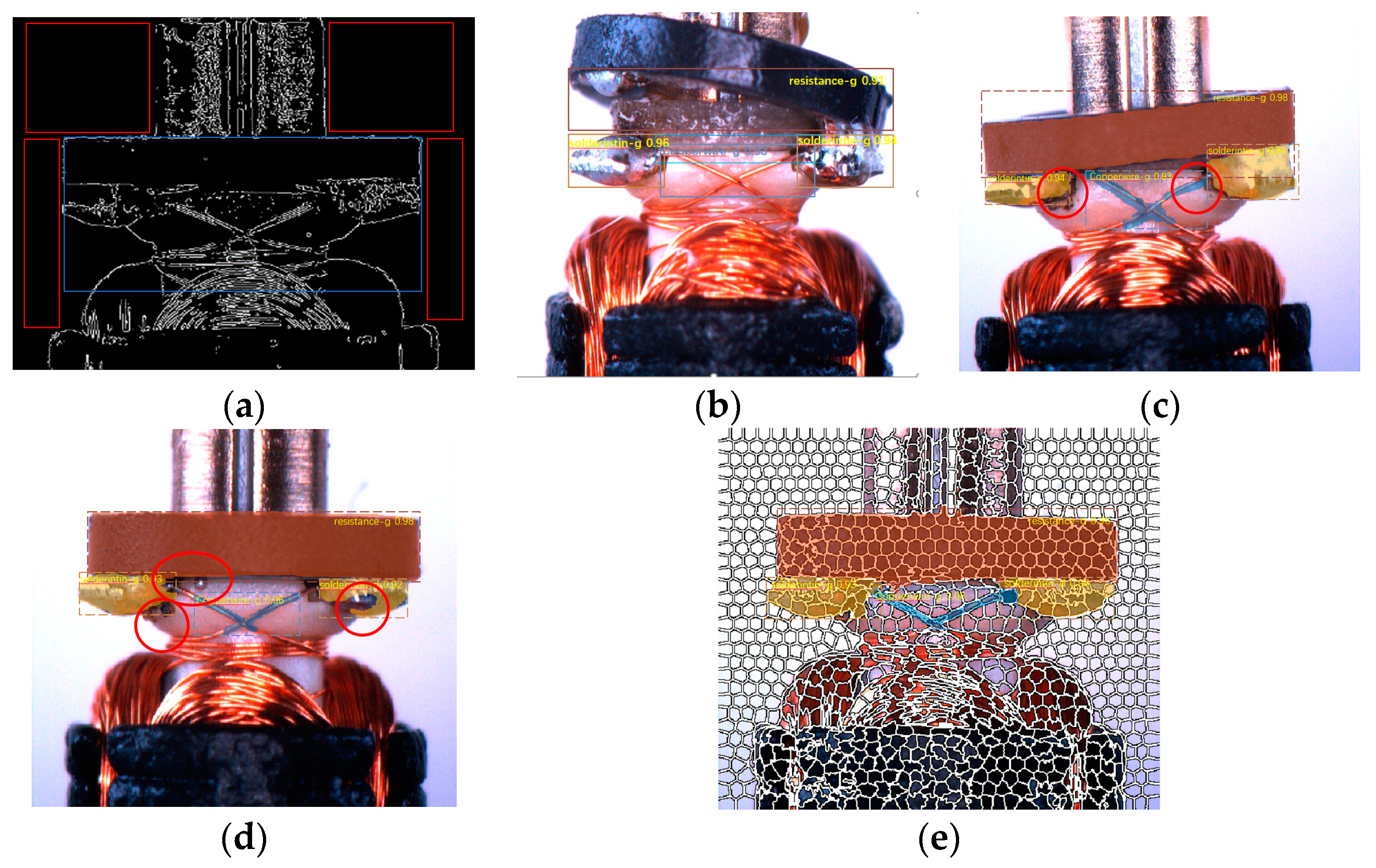
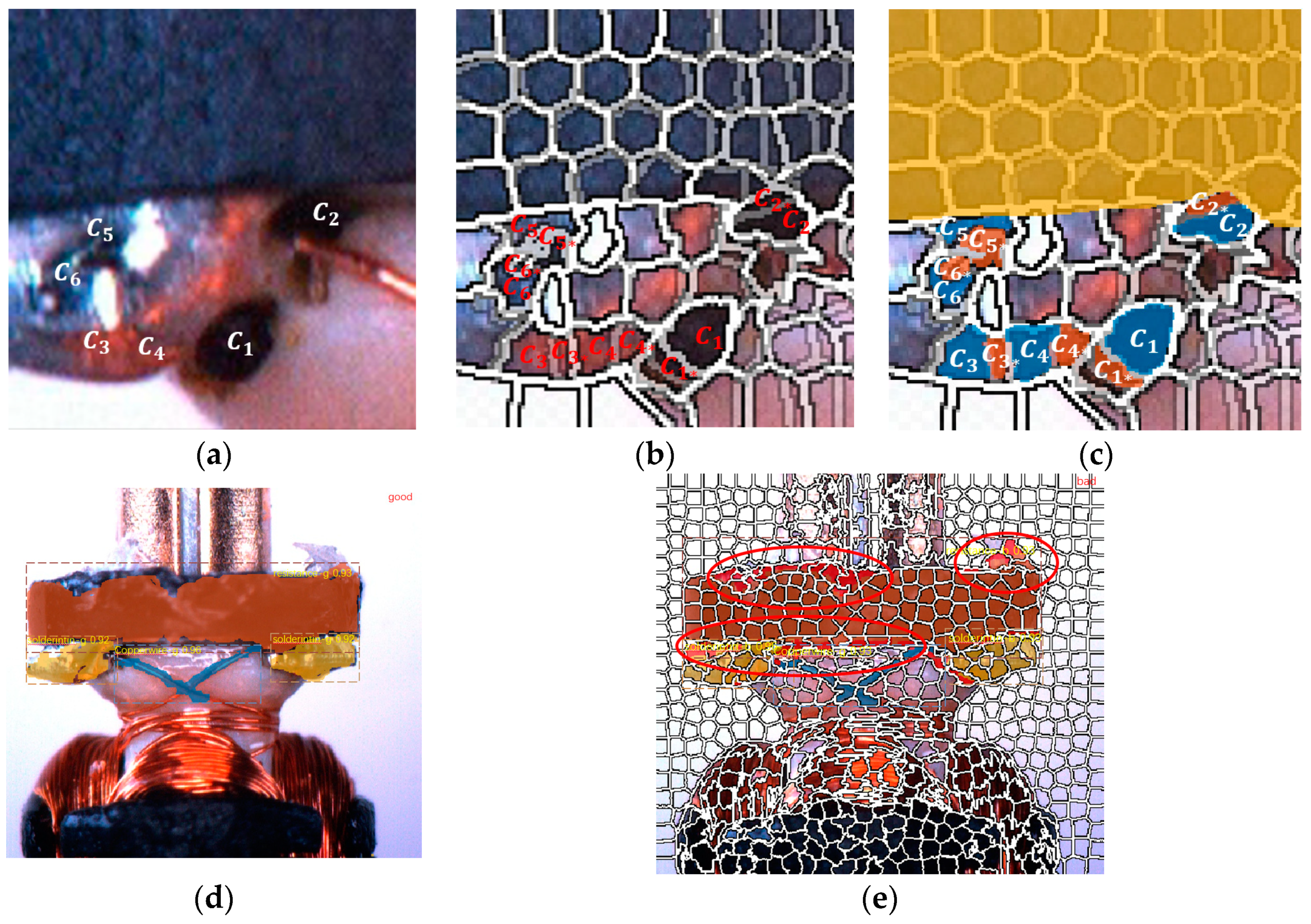
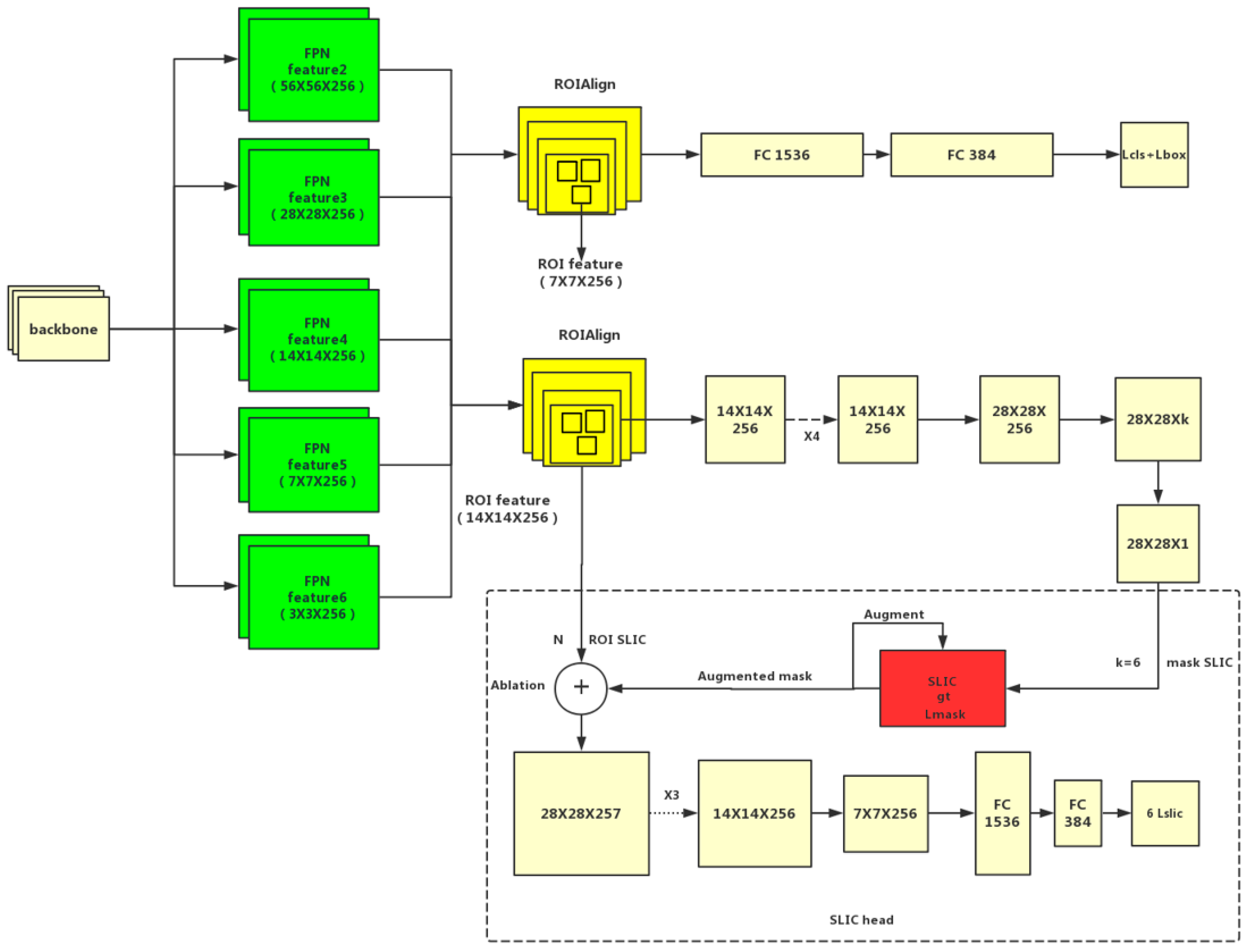
3. Implementation Details of SLIC Head
4. System Apparatus and Related Work
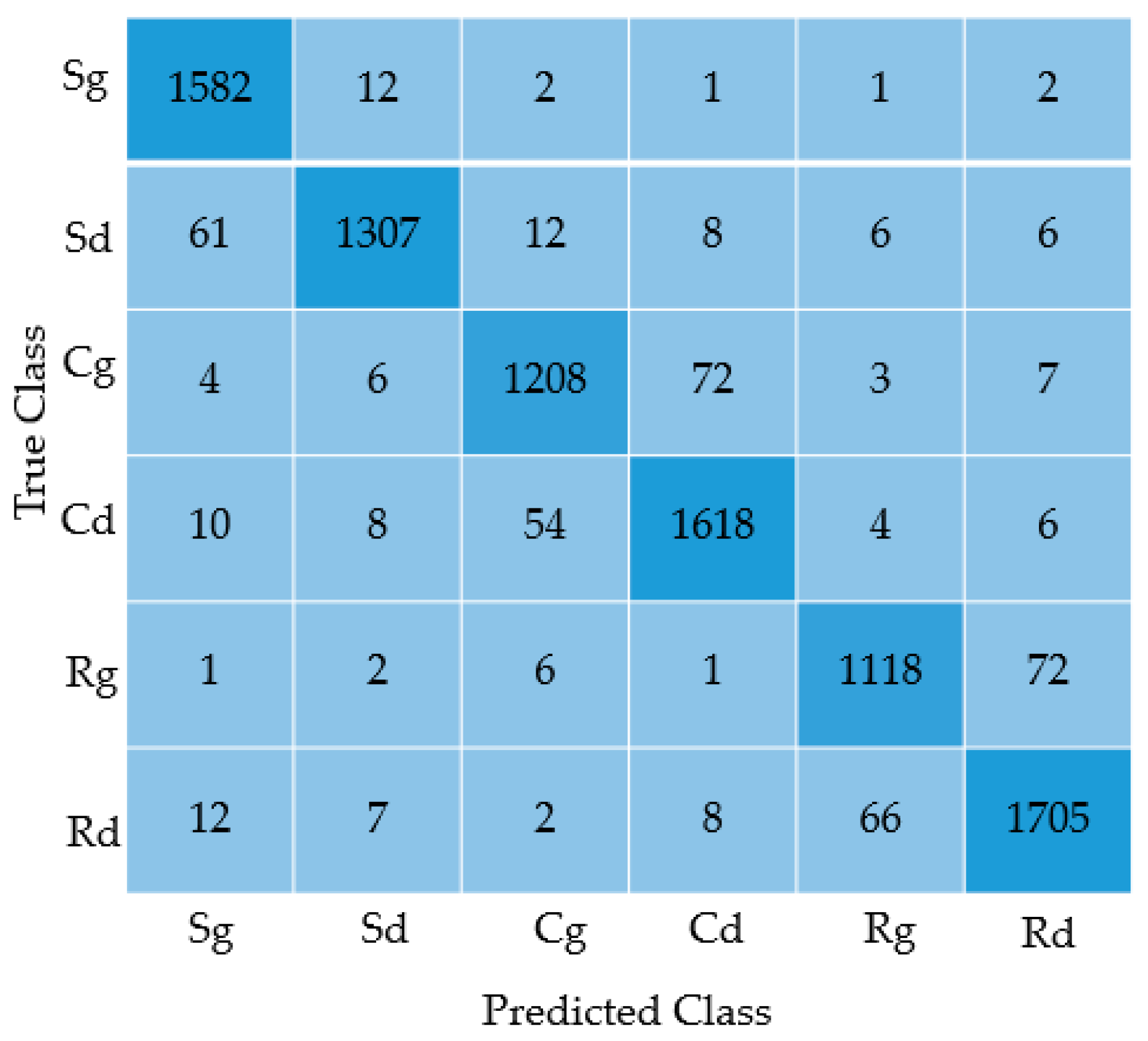
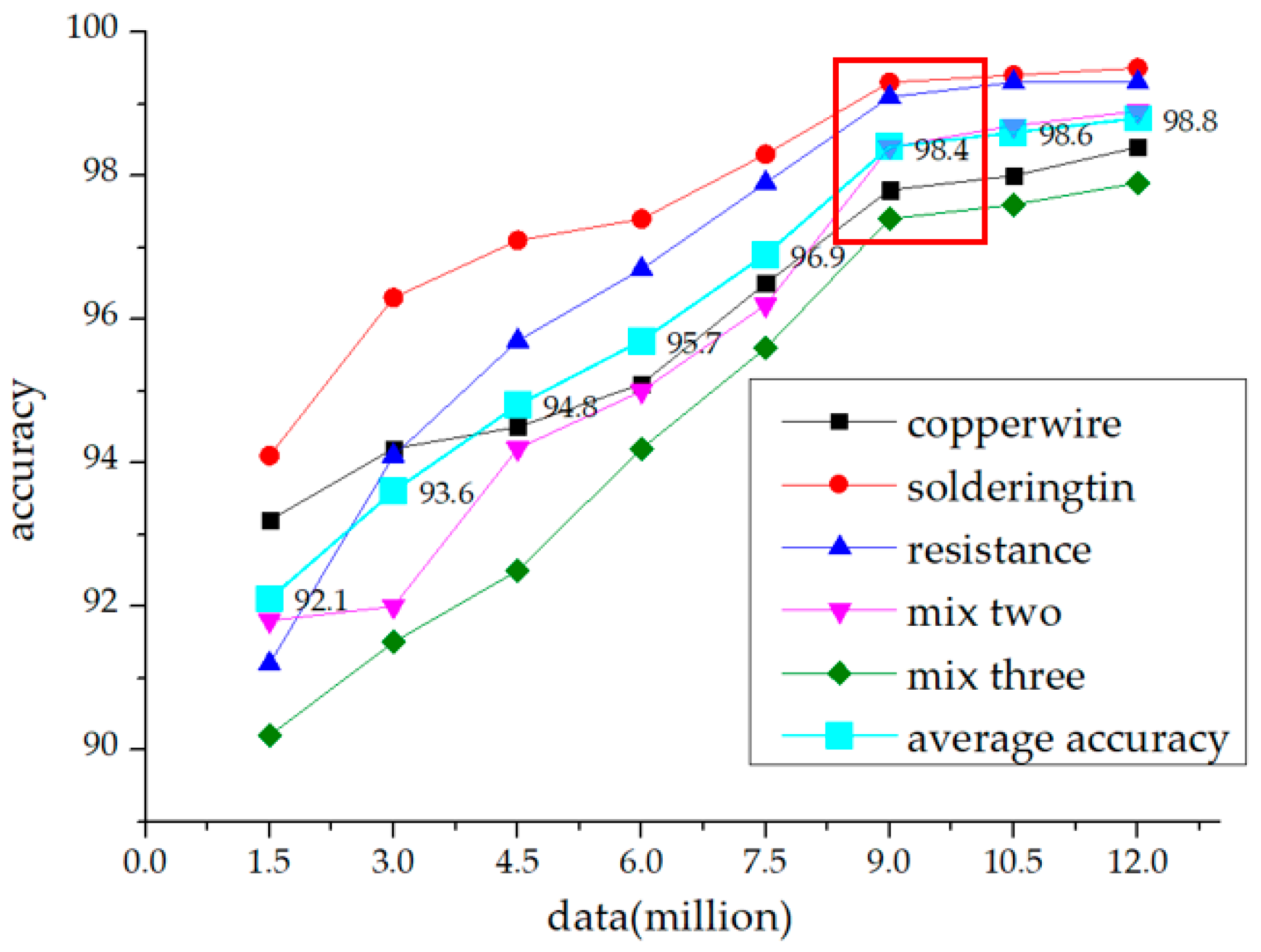
5. Results
6. Conclusions
- An armature defect detection system for eccentric rotor motors was built. The replaceable fixture in the system was made of POM, which made the system more universal. In the field of non-standard workpiece vision detection, a better application will be achieved.
- The method of mask augmentation based on the superpixel element decomposition contour was proposed to improve the accuracy of selecting the mixed region with high gradient. The mask confidence is also adjusted for this class of workpiece.
- We build a dataset processing system that improved the system robustness with the increase of the detection numbers.
7. Patents
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Liu, Y.; Wang, F. The Research on VR-Based of Technology Generating Equipment and Interaction Equipment. Adv. Intell. Syst. 2017, 481, 207–215. [Google Scholar]
- Huang, T.L.; Liao, S.L. A model of acceptance of augmented-reality interactive technology: The moderating role of cognitive innovativeness. Electron. Commer. Res. 2015, 15, 269–295. [Google Scholar] [CrossRef]
- Nee, A.Y.C.; Ong, S.K.; Chryssolouris, G.; Mourtzis, D. Augmented reality applications in design and manufacturing. CIRP Ann-Manuf. Technol. 2012, 61, 657–679. [Google Scholar] [CrossRef]
- Benjamin, S.; Okamura, A.M. Three-Dimensional Skin Deformation as Force Substitution: Wearable Device Design and Performance During Haptic Exploration of Virtual Environments. IEEE Trans. Haptics 2017, 10, 418–430. [Google Scholar]
- Velazquez, R.; Pissaloux, E.; Rodrigo, P.; Carrasco, M.; Giannoccaro, N.I.; Lay-Ekuakille, A. An Outdoor Navigation System for Blind Pedestrians Using GPS and Tactile-Foot Feedback. Appl. Sci. 2018, 8, 578. [Google Scholar] [CrossRef]
- Lim, J.M.; Lee, J.U.; Kyung, K.U.; Ryou, J.C. An Audio-Haptic Feedbacks for enhancing User Experience in Mobile Devices. In Proceedings of the 2013 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–14 January 2013. [Google Scholar]
- Che, Y.H.; Culbertson, H.; Tang, C.W.; Aich, S.; Okamura, A.M. Facilitating Human-Mobile Robot Communication via Haptic Feedback and Gesture Teleoperation. ACM Trans. Hum-Robot Interact. 2018, 7. [Google Scholar] [CrossRef]
- Dharma, A.A.G.; Tomimatsu, K. A Heuristic Model of Vibrotactile Haptic Feedbacks Elicitation Based on Empirical Review. In Proceedings of the 16th International Conference, HCI International 2014, Human-Computer Interaction. Advanced Interaction Modalities and Techniques, Heraklion, Crete, Greece, 22–27 June 2014; pp. 624–632. [Google Scholar]
- Glowacz, A.; Glowacz, W.; Glowacz, Z. Recognition of Armature Current of Dc Generator Depending on Rotor Speed Using Fft, Msaf-1 And Lda. Eksploat. Niezawodn. 2015, 17, 64–69. [Google Scholar] [CrossRef]
- Du, Y.B.; Cao, P.; Yang, Y.Y.; Wang, F.Y.; Liu, R.Z.; Wu, F.; Zhang, P.; Chai, H.; Jiang, J.; Zhang, Y.; et al. Defect detection method for complex surface based on human visual characteristics and feature extracting. In Proceedings of the 10th International Symposium on Precision Engineering Measurements and Instrumentation, Kunming, China, 8–10 August 2018. [Google Scholar]
- Li, Y.A.; Li, Y.F.; Wang, Q.L.; Xu, D.; Tan, M. Measurement and Defect Detection of the Weld Bead Based on Online Vision Inspection. IEEE Trans. Instrum. Meas. 2010, 59, 1841–1849. [Google Scholar]
- Shen, H.; Li, S.X.; Gu, D.Y.; Chang, H.X. Bearing defect inspection based on machine vision. Measurement 2012, 45, 719–733. [Google Scholar] [CrossRef]
- Kaya, Y.; Kayci, L. Application of artificial neural network for automatic detection of butterfly species using color and texture features. Vis. Comput. 2014, 30, 71–79. [Google Scholar] [CrossRef]
- Rokni, K.; Ahmad, A.; Solaimani, K.; Hazini, S. A new approach for surface water change detection: Integration of pixel level image fusion and image classification techniques. Int. J. Appl. Earth Obs. 2015, 34, 226–234. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2014, arXiv:1311.2524v5. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 346–361. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Las Vegas, NV, USA, 27–30 June 2017; pp. 936–944. [Google Scholar]
- Sirinukunwattana, K.; Raza, S.E.A.; Tsang, Y.W.; Snead, D.R.J.; Cree, I.A.; Rajpoot, N.M. Locality Sensitive Deep Learning for Detection and Classification of Nuclei in Routine Colon Cancer Histology Images. IEEE Trans. Med. Imaging 2016, 35, 1196–1206. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Couteaux, V.; Si-Mohamed, S.; Nempont, O.; Lefevre, T.; Popoff, A.; Pizaine, G.; Villain, N.; Bloch, I.; Cotten, A.; Boussel, L. Automatic knee meniscus tear detection and orientation classification with Mask-RCNN. Diagn. Interv. Imaging 2019, 100, 235–242. [Google Scholar] [CrossRef] [PubMed]
- Tang, Z.; Liu, K.K.; Xiao, J.B.; Yang, L.; Xiao, Z. A parallel k-means clustering algorithm based on redundance elimination and extreme points optimization employing MapReduce. Concurr. Comput-Pract. Exp. 2017, 29, e4109. [Google Scholar] [CrossRef]
- Han, C.Y. Improved SLIC imagine segmentation algorithm based on K-means. Cluster Comput. 2017, 20, 1017–1023. [Google Scholar] [CrossRef]
- Xie, X.L.; Xie, G.; Xu, X.Y. High precision image segmentation algorithm using SLIC and neighborhood rough set. Multimed. Tools Appl. 2018, 77, 31525–31543. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 234, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Connick, M.J.; Beckman, E.; Vanlandewijck, Y.; Malone, L.A.; Blomqvist, S.; Tweedy, S.M. Cluster analysis of novel isometric strength measures produces a valid and evidence-based classification structure for wheelchair track racing. Br. J. Sport Med. 2018, 52, 1123–1129. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Shrivastava, N.; Tyagi, V. A Review of ROI Image Retrieval Techniques. In Proceedings of the 3rd International Conference on Frontiers of Intelligent Computing: Theory and Applications (FICTA), Odisha, India, 14–15 November 2014; Volume 2, pp. 509–520. [Google Scholar]
- Feng, L.T.; Po, L.M.; Xu, X.Y.; Li, Y.M.; Cheung, C.H.; Cheung, K.W.; Yuan, F. Dynamic Roi Based on K-Means for Remote Photoplethysmography. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 1310–1314. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.F.; Shi, J.P.; Jia, J.Y. Path Aggregation Network for Instance Segmentation. In Proceedings of the CVPR IEEE, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Perona, P.; Malik, J. Scale-Space and Edge Detection Using Anisotropic Diffusion. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 629–639. [Google Scholar] [CrossRef]
- Fang, L.Y.; Li, S.T.; Kang, X.D.; Benediktsson, J.A. Spectral-Spatial Classification of Hyperspectral Images with a Superpixel-Based Discriminative Sparse Model. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4186–4201. [Google Scholar] [CrossRef]
- Kim, J.; Han, D.; Tai, Y.W.; Kim, J. Salient Region Detection via High-Dimensional Color Transform and Local Spatial Support. IEEE Trans. Image Process. 2016, 25, 9–23. [Google Scholar] [CrossRef] [PubMed]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar]
- Jin, K.H.; McCann, M.T.; Froustey, E.; Unser, M. Deep Convolutional Neural Network for Inverse Problems in Imaging. IEEE Trans. Image Process. 2017, 26, 4509–4522. [Google Scholar] [CrossRef] [PubMed]
- Syakur, M.A.; Khotimah, B.K.; Rochman, E.M.S.; Satoto, B.D. Integration K-Means Clustering Method and Elbow Method for Identification of The Best Customer Profile Cluster. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Istanbul, Turkey, 8 August 2018. [Google Scholar]
- Zhou, Z.W.; Shin, J.; Zhang, L.; Gurudu, S.; Gotway, M.; Liang, J.M. Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Las Vegas, NV, USA, 27–30 June 2017; pp. 4761–4772. [Google Scholar]
- Huang, Z.; Huang, L. Mask Scoring R-CNN. arXiv 2019, arXiv:1903.00241. [Google Scholar]
- Zhu, W.; Zeng, N. Sensitivity, specificity, accuracy, associated confidence interval and ROC analysis with practical SAS implementations. In Proceedings of the NESUG 2010 Proceedings: Health Care and Life Sciences, Baltimore, MD, USA, 14–17 November 2010; Volume 19, pp. 1–9. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) | |
| Size of Cell | Accuracy (%) |
| 300 | 91.7 |
| 350 | 93.1 |
| 400 | 93.6 |
| 450 | 92.5 |
| 500 | 92.6 |
| (b) | |
| Overlap Area (%) | Accuracy (%) |
| 20 | 92.7 |
| 30 | 93.6 |
| 40 | 91.6 |
| 50 | 88.5 |
| Defect Type | SLIC Head + Mask R-CNN | SLIC Head +Mask R-CNN Expansion 30,000 Data | Statistical Features | Faster R-CNN | Mask R-CNN |
|---|---|---|---|---|---|
| Accuracy (%) | |||||
| Copper wire | 94.2 | 95.1 | 75.6 | 90.2 | 94.1 |
| Soldering tin | 96.3 | 97.4 | 82 | 92.3 | 92.4 |
| Resistance | 94.1 | 96.7 | 85.1 | 93.1 | 91.4 |
| Mix two | 92 | 95 | 68.5 | 88.5 | 92 |
| Mix three | 91.5 | 94.2 | 61.5 | 90.2 | 91 |
| Average accuracy (%) | 93.6 | 95.7 | 74.5 | 90.9 | 92.2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, X.; Jie, W.; Feng, T. An Industrial Micro-Defect Diagnosis System via Intelligent Segmentation Region. Sensors 2019, 19, 2636. https://doi.org/10.3390/s19112636
Fang X, Jie W, Feng T. An Industrial Micro-Defect Diagnosis System via Intelligent Segmentation Region. Sensors. 2019; 19(11):2636. https://doi.org/10.3390/s19112636
Chicago/Turabian StyleFang, Xia, Wang Jie, and Tao Feng. 2019. "An Industrial Micro-Defect Diagnosis System via Intelligent Segmentation Region" Sensors 19, no. 11: 2636. https://doi.org/10.3390/s19112636
APA StyleFang, X., Jie, W., & Feng, T. (2019). An Industrial Micro-Defect Diagnosis System via Intelligent Segmentation Region. Sensors, 19(11), 2636. https://doi.org/10.3390/s19112636