3D Pose Detection of Closely Interactive Humans Using Multi-View Cameras

Abstract
:1. Introduction
2. Related Work
2.1. Human 2D Pose Detection
2.2. 3D Pose and Shape Recovery
3. Method
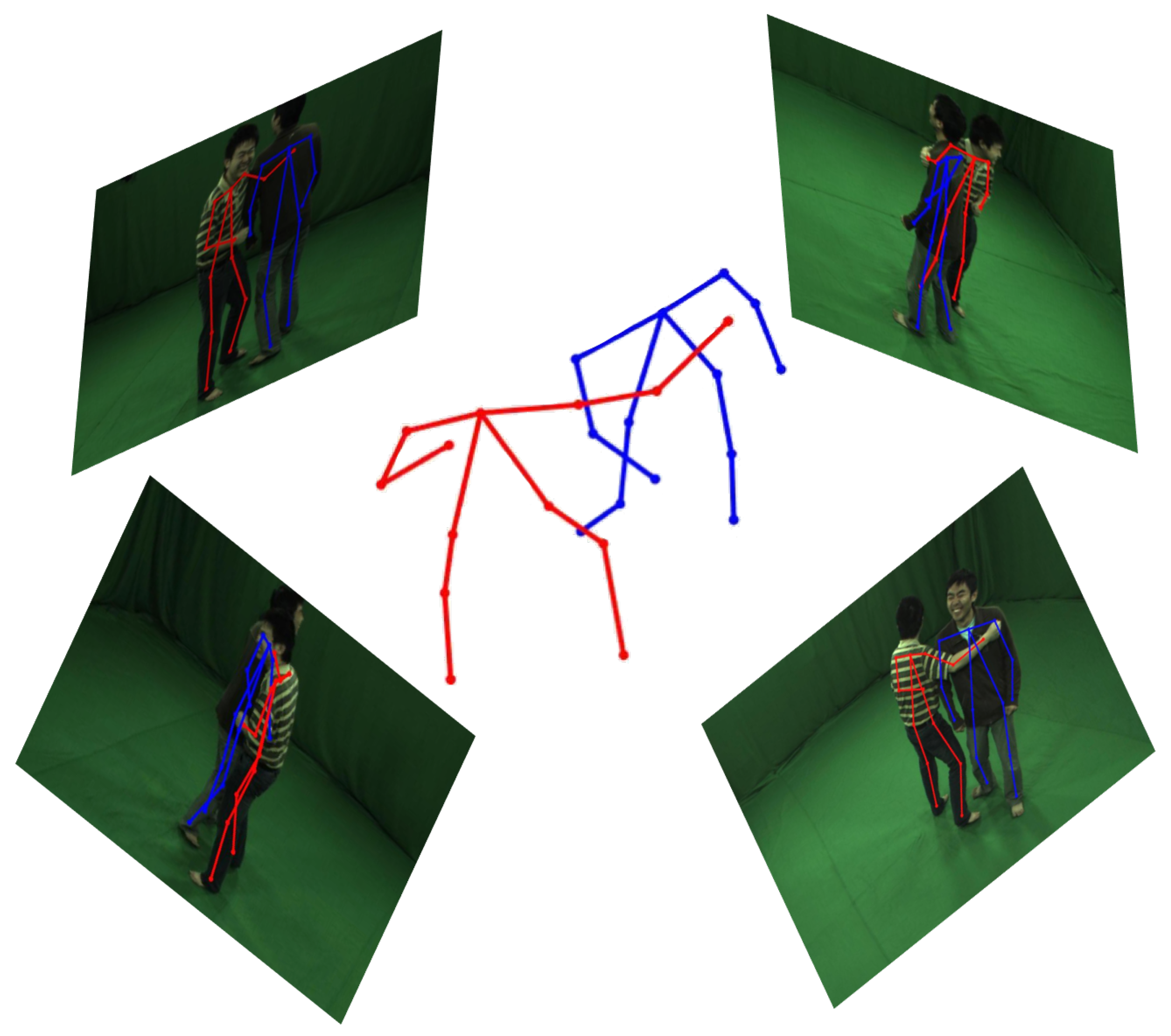
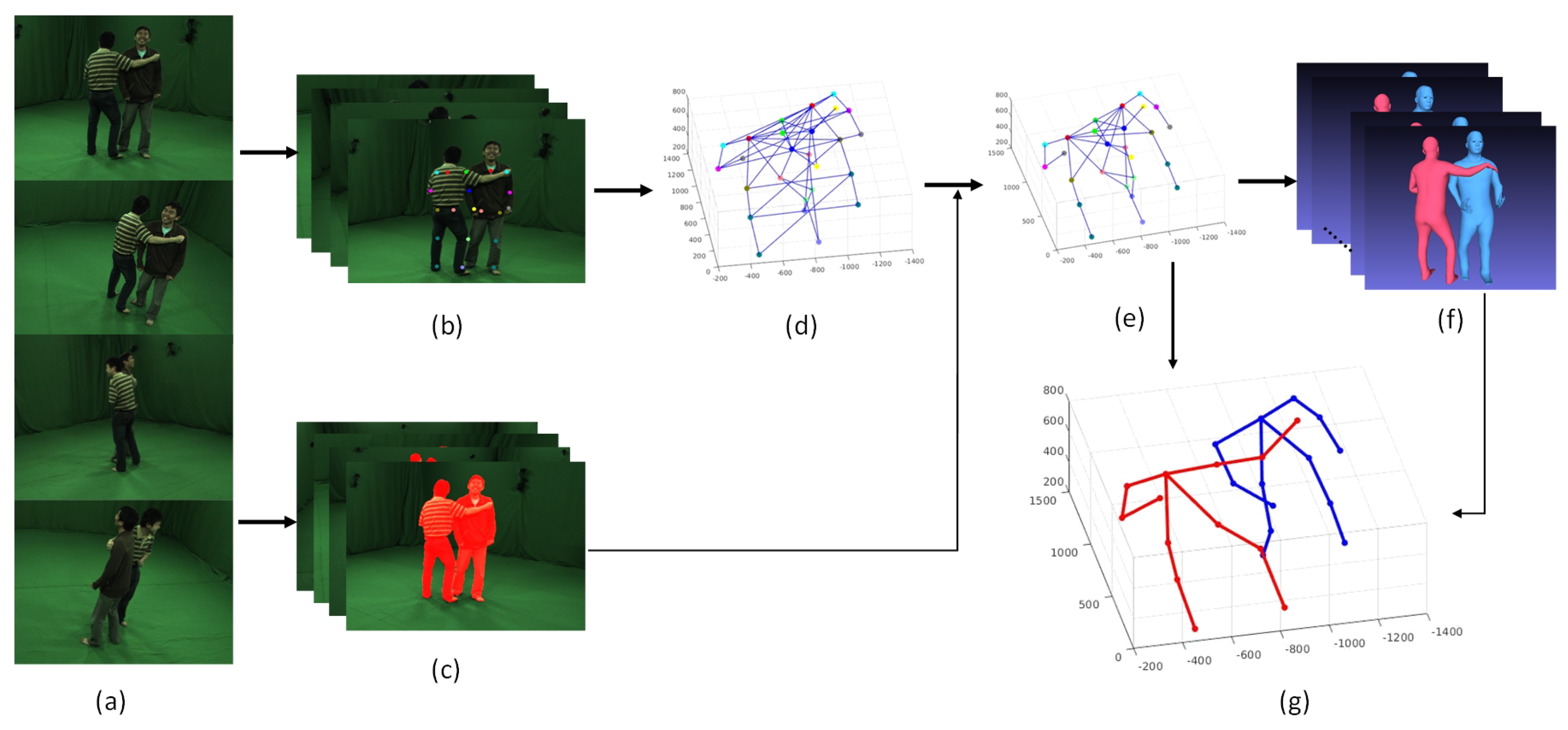
3.1. Overview
3.2. 3D Joints Triangulation
3.3. Joints Pre-Assembling
Symmetric Joints Grouping
Skeleton Reprojection Term U
Symmetry Limb Length Constrain L
3.4. Joints Post-Assembling
Shape Interpenetration Constrain O
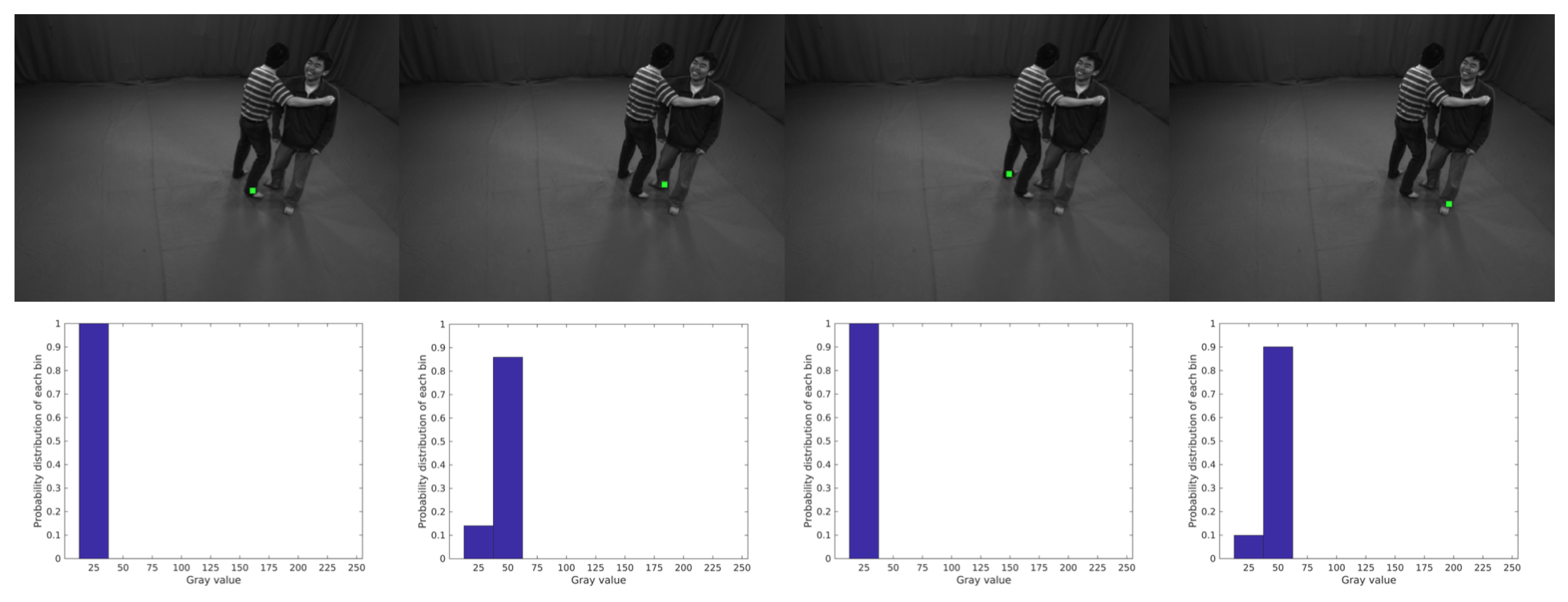
Symmetry Parts Gray Similarity Term R
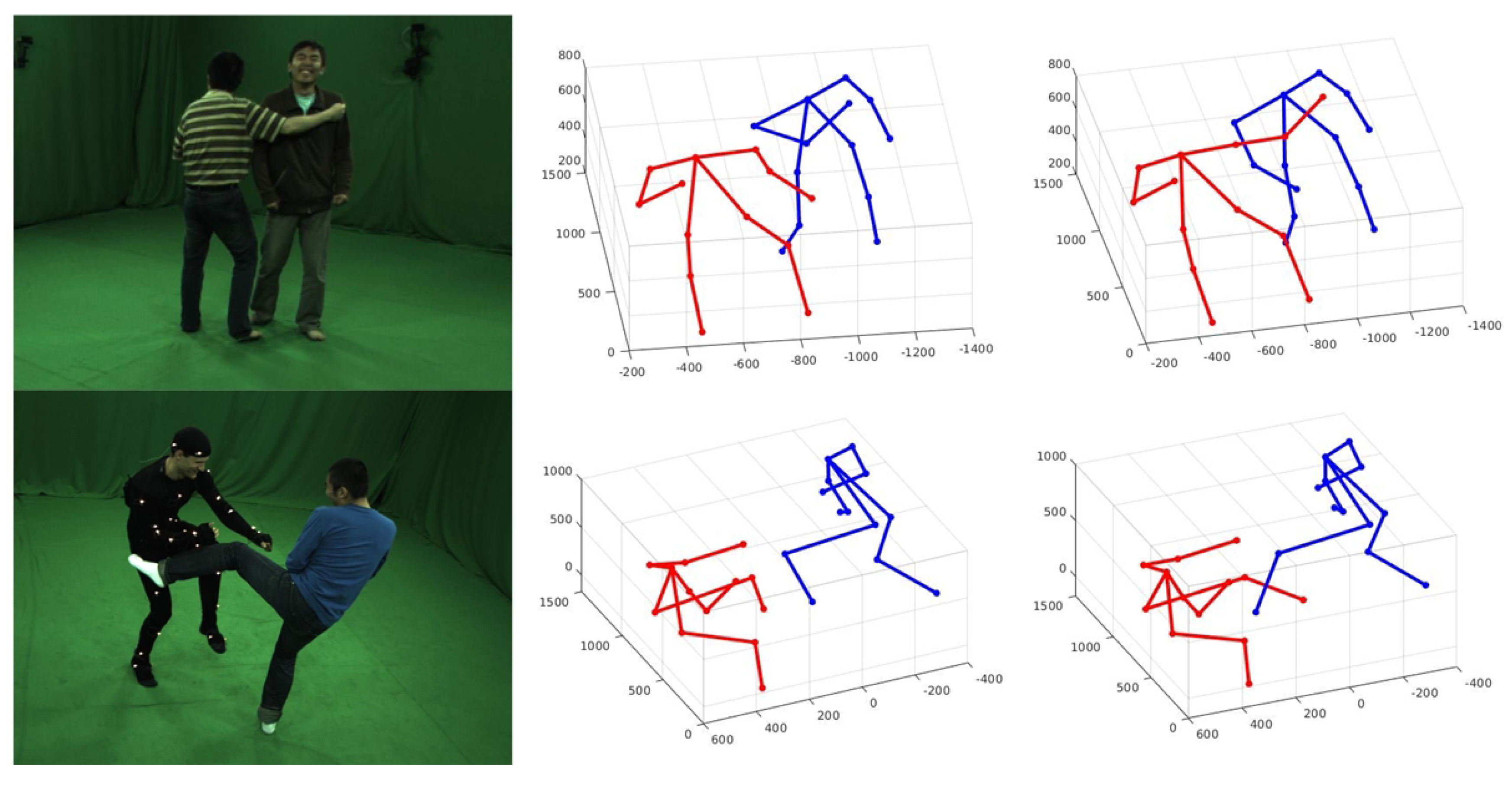
4. Results
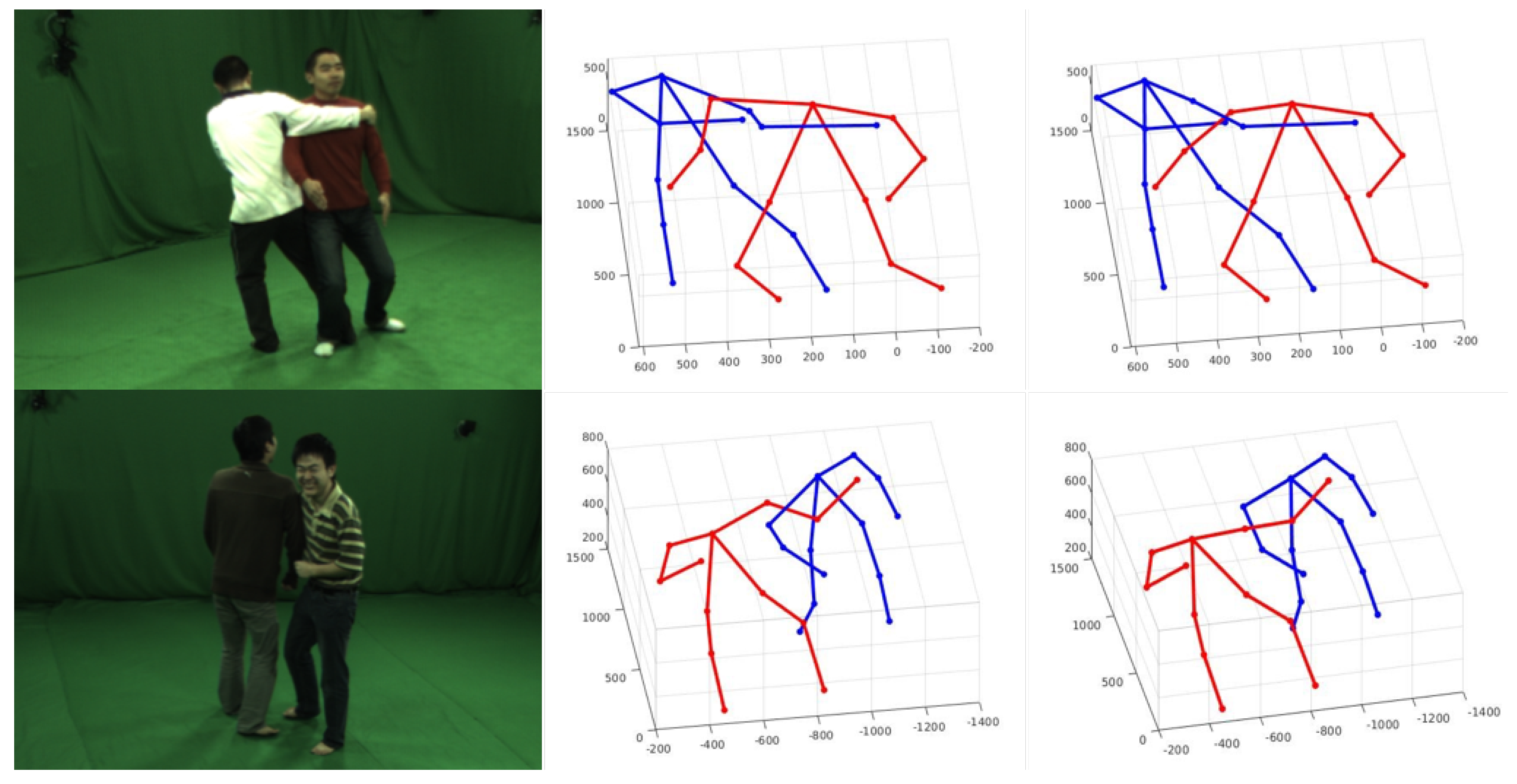
4.1. Datasets and 3D Pose Detection Results
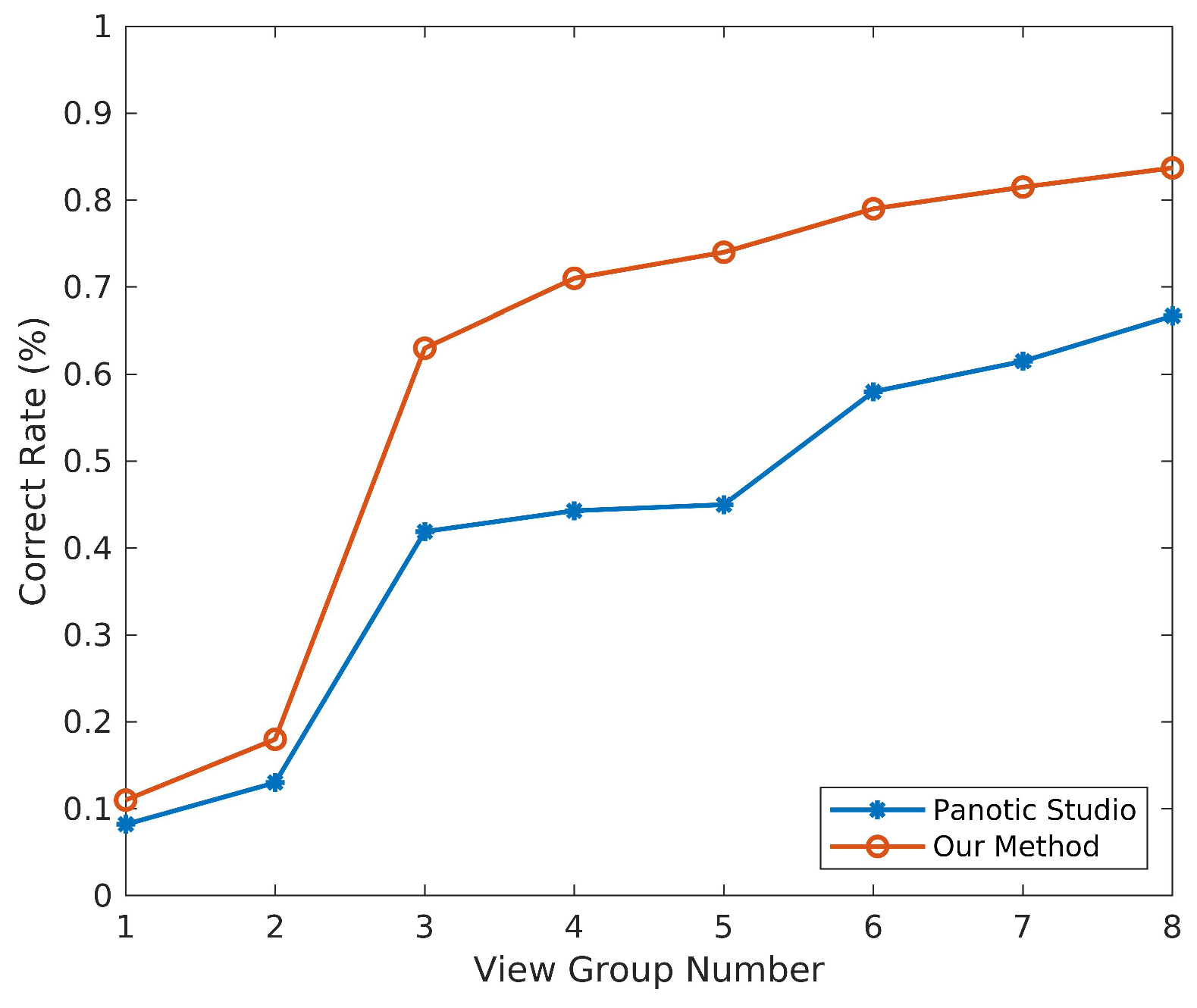
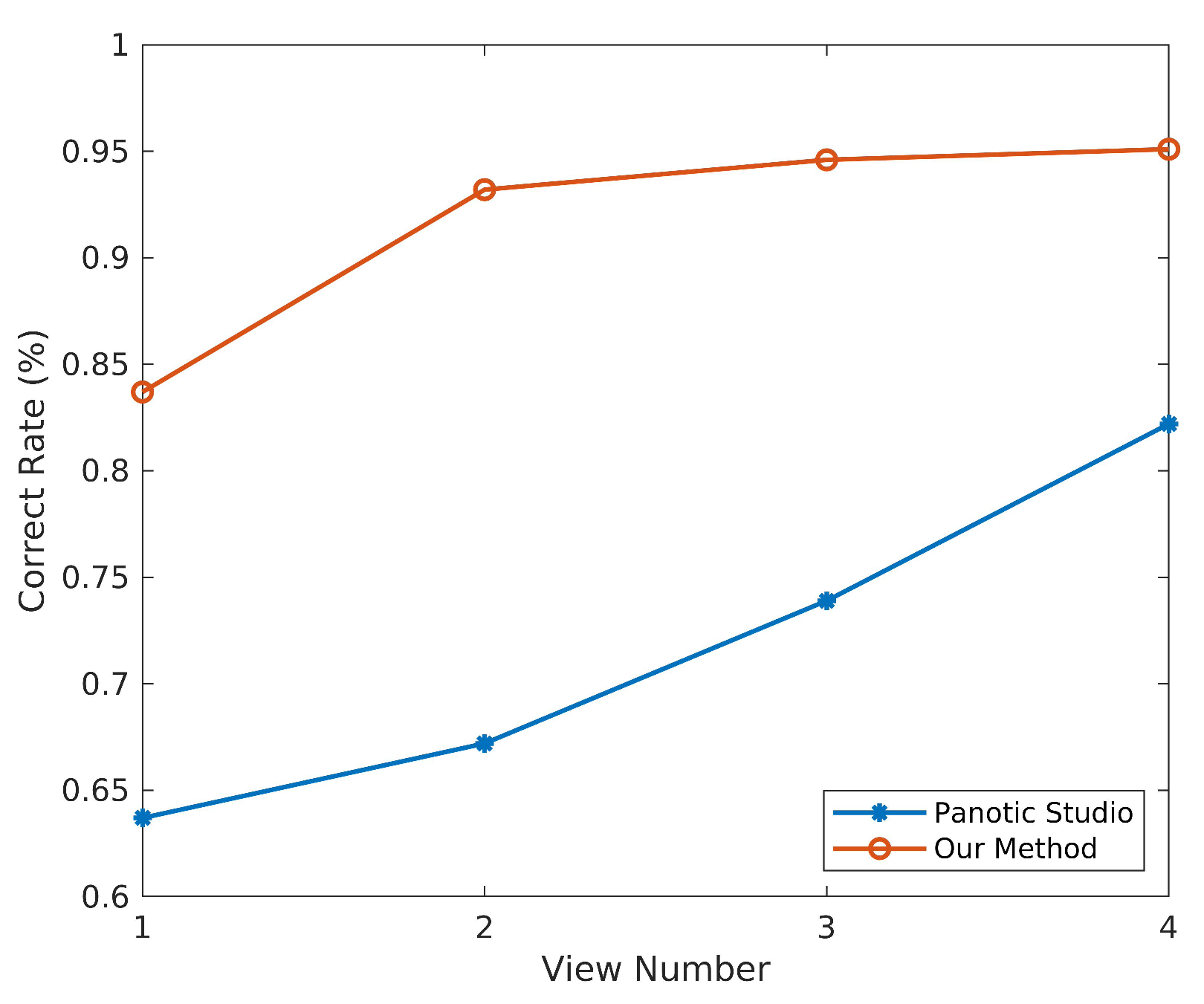
4.2. Comparison
View Selection Analysis
4.3. Method Efficiency
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Tompson, J.J.; Jain, A.; LeCun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 1799–1807. [Google Scholar]
- Qiang, B.; Zhang, S.; Zhan, Y.; Xie, W.; Zhao, T. Improved Convolutional Pose Machines for Human Pose Estimation Using Image Sensor Data. Sensors 2019, 19, 718. [Google Scholar] [CrossRef]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A simple yet effective baseline for 3d human pose estimation. In Proceedings of the 2017 International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Volume 1, p. 5. [Google Scholar]
- Wang, C.; Wang, Y.; Lin, Z.; Yuille, A.L.; Gao, W. Robust estimation of 3d human poses from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2361–2368. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Fang, H.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 2. [Google Scholar]
- Liu, Y.; Stoll, C.; Gall, J.; Seidel, H.P.; Theobalt, C. Markerless motion capture of interacting characters using multi-view image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2011), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1249–1256. [Google Scholar]
- Alp Güler, R.; Neverova, N.; Kokkinos, I. Densepose: Dense human pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7297–7306. [Google Scholar]
- Joo, H.; Liu, H.; Tan, L.; Gui, L.; Nabbe, B.; Matthews, I.; Kanade, T.; Nobuhara, S.; Sheikh, Y. Panoptic studio: A massively multiview system for social motion capture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3334–3342. [Google Scholar]
- Li, K.; Jiao, N.; Liu, Y.; Wang, Y.; Yang, J. Shape and Pose Estimation for Closely Interacting Persons Using Multi-view Images. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2018; Volume 37, pp. 361–371. [Google Scholar]
- Li, X.; Li, H.; Joo, H.; Liu, Y.; Sheikh, Y. Structure from Recurrent Motion: From Rigidity to Recurrency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 28–22 June 2018; pp. 3032–3040. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4724–4732. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Pishchulin, L.; Insafutdinov, E.; Tang, S.; Andres, B.; Andriluka, M.; Gehler, P.V.; Schiele, B. Deepcut: Joint subset partition and labeling for multi person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4929–4937. [Google Scholar]
- Insafutdinov, E.; Pishchulin, L.; Andres, B.; Andriluka, M.; Schiele, B. Deepercut: A deeper, stronger, and faster multi-person pose estimation model. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 34–50. [Google Scholar]
- Iqbal, U.; Gall, J. Multi-person pose estimation with local joint-to-person associations. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 627–642. [Google Scholar]
- Newell, A.; Huang, Z.; Deng, J. Associative embedding: End-to-end learning for joint detection and grouping. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 2277–2287. [Google Scholar]
- Zhou, X.; Huang, Q.; Sun, X.; Xue, X.; Wei, Y. Towards 3d human pose estimation in the wild: A weakly-supervised approach. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Moreno-Noguer, F. 3d human pose estimation from a single image via distance matrix regression. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1561–1570. [Google Scholar]
- Mehta, D.; Sridhar, S.; Sotnychenko, O.; Rhodin, H.; Shafiei, M.; Seidel, H.P.; Xu, W.; Casas, D.; Theobalt, C. Vnect: Real-time 3d human pose estimation with a single rgb camera. ACM Trans. Graph. (TOG) 2017, 36, 44. [Google Scholar] [CrossRef]
- Tome, D.; Russell, C.; Agapito, L. Lifting from the deep: Convolutional 3d pose estimation from a single image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2500–2509. [Google Scholar]
- Rhodin, H.; Spörri, J.; Katircioglu, I.; Constantin, V.; Meyer, F.; Müller, E.; Salzmann, M.; Fua, P. Learning Monocular 3D Human Pose Estimation from Multi-view Images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Bogo, F.; Kanazawa, A.; Lassner, C.; Gehler, P.; Romero, J.; Black, M.J. Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 561–578. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. (TOG) 2015, 34, 248. [Google Scholar] [CrossRef]
- Kanazawa, A.; Black, M.J.; Jacobs, D.W.; Malik, J. End-to-end recovery of human shape and pose. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Rogez, G.; Weinzaepfel, P.; Schmid, C. Lcr-net: Localization-classification-regression for human pose. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Rogez, G.; Weinzaepfel, P.; Schmid, C. Lcr-net++: Multi-person 2d and 3d pose detection in natural images. IEEE Trans. Pattern Anal. Mach. Intell. 2019, in press. [Google Scholar] [CrossRef] [PubMed]
- Mehta, D.; Sotnychenko, O.; Mueller, F.; Xu, W.; Sridhar, S.; Pons-Moll, G.; Theobalt, C. Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 120–130. [Google Scholar]
- Yin, K.; Huang, H.; Ho, E.S.; Wang, H.; Komura, T.; Cohen-Or, D.; Zhang, R. A Sampling Approach to Generating Closely Interacting 3D Pose-pairs from 2D Annotations. IEEE Trans. Vis. Comput. Graph. 2018. [Google Scholar] [CrossRef] [PubMed]
- Belagiannis, V.; Amin, S.; Andriluka, M.; Schiele, B.; Navab, N.; Ilic, S. 3D pictorial structures for multiple human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1669–1676. [Google Scholar]
- Dong, J.; Jiang, W.; Huang, Q.; Bao, H.; Zhou, X. Fast and Robust Multi-Person 3D Pose Estimation from Multiple Views. arXiv 2019, arXiv:1901.04111. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Thiery, J.M.; Guy, É.; Boubekeur, T. Sphere-meshes: Shape approximation using spherical quadric error metrics. ACM Trans. Graph. (TOG) 2013, 32, 178. [Google Scholar] [CrossRef]
- Ericson, C. Real-Time Collision Detection; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Katz, S.; Tal, A.; Basri, R. Direct visibility of point sets. ACM Trans. Graph. (TOG) 2007, 26, 24. [Google Scholar] [CrossRef]
- Huang, C.; Gao, F.; Pan, J.; Yang, Z.; Qiu, W.; Chen, P.; Yang, X.; Shen, S.; Cheng, K.T.T. Act: An autonomous drone cinematography system for action scenes. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7039–7046. [Google Scholar]
- Nägeli, T.; Oberholzer, S.; Plüss, S.; Alonso-Mora, J.; Hilliges, O. Flycon: Real-Time Environment-Independent Multi-View Human Pose Estimation with Aerial Vehicles; SIGGRAPH Asia 2018 Technical Papers; ACM: New York, NY, USA, 2018; p. 182. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group Number | Camera Number | Group Number | Camera Number |
|---|---|---|---|
| 1 | cam8, cam11, cam12 | 2 | cam3, cam10, cam12 |
| 3 | cam1, cam4, cam7 | 4 | cam5, cam6, cam9 |
| 5 | cam1, cam2, cam3 | 6 | cam4, cam9, cam10 |
| 7 | cam1, cam6, cam8 | 8 | cam5, cam7, cam10 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Fan, Z.; Liu, Y.; Li, Y.; Dai, Q. 3D Pose Detection of Closely Interactive Humans Using Multi-View Cameras. Sensors 2019, 19, 2831. https://doi.org/10.3390/s19122831
Li X, Fan Z, Liu Y, Li Y, Dai Q. 3D Pose Detection of Closely Interactive Humans Using Multi-View Cameras. Sensors. 2019; 19(12):2831. https://doi.org/10.3390/s19122831
Chicago/Turabian StyleLi, Xiu, Zhen Fan, Yebin Liu, Yipeng Li, and Qionghai Dai. 2019. "3D Pose Detection of Closely Interactive Humans Using Multi-View Cameras" Sensors 19, no. 12: 2831. https://doi.org/10.3390/s19122831
APA StyleLi, X., Fan, Z., Liu, Y., Li, Y., & Dai, Q. (2019). 3D Pose Detection of Closely Interactive Humans Using Multi-View Cameras. Sensors, 19(12), 2831. https://doi.org/10.3390/s19122831