1. Introduction
Autonomous vehicles require a robust and efficient localization system capable of fusing all available information from different sensors and data sources, such as metric maps or GIS databases. Metric maps can be automatically built by means of Simultaneous Localization and Mapping (SLAM) methods onboard the vehicle or retrieved from an external entity in charge of the critical task of map building. At present, some companies already have plans to prepare and serve such map databases suitable for autonomous vehicle navigation, e.g., Mapper.AI or Mitsubishi’s Mobile Mapping System (MMS). However, at present, most research groups build their own maps by means of SLAM methods or, alternatively, using precise real-time kinematic (RTK)-grade global navigation satellite system (GNSS) solutions. For benchmarking purposes, researchers have access to multiple public datasets including several sensor types in urban environments [
1,
2,
3].
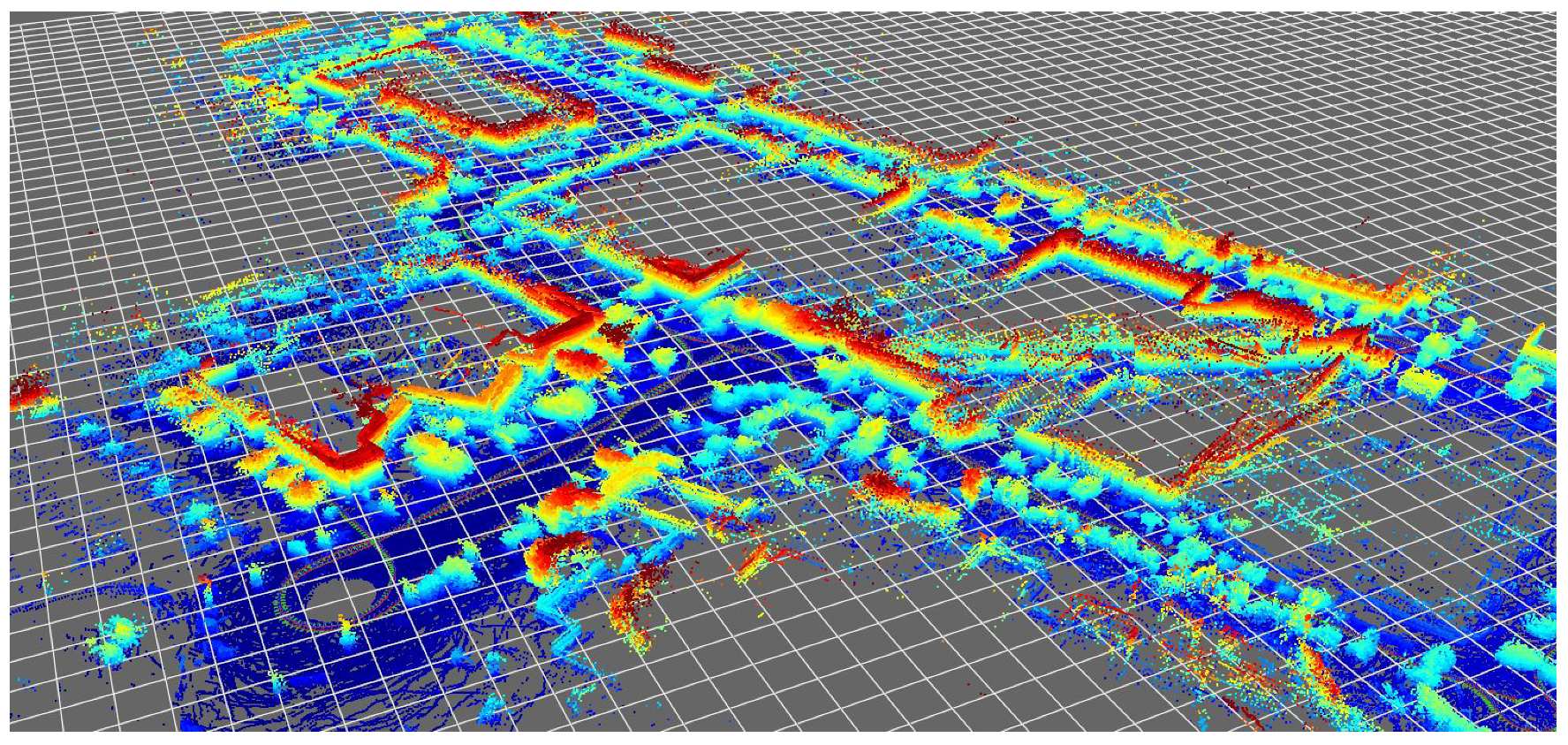
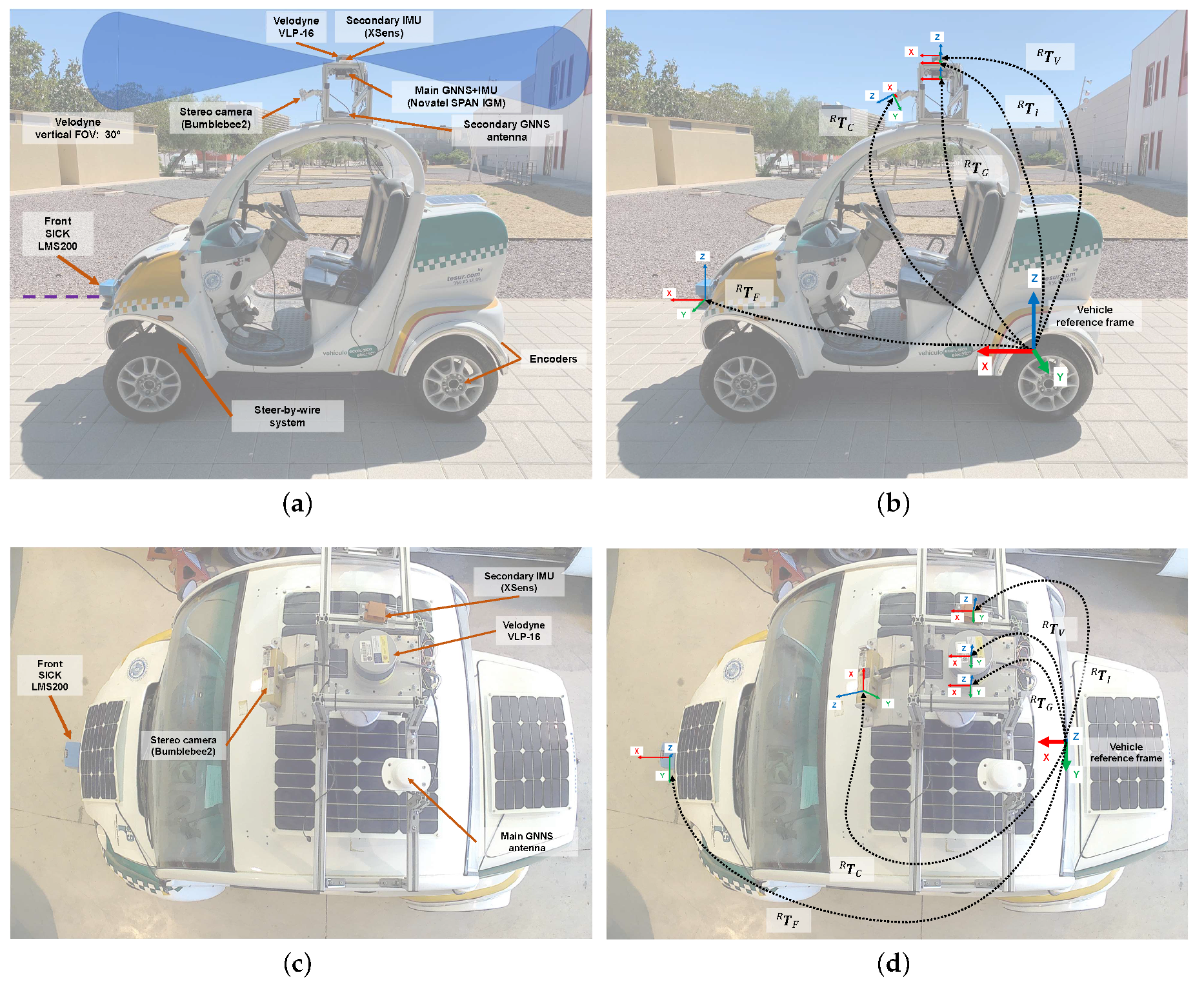
In the present work, we address the suitability of particle filter (PF) algorithms to localize a vehicle, equipped with a 3D LiDAR (Velodyne VLP-16, Velodyne Lidar, San Jose, CA, USA),within a previously-built reference metric map. An accurate navigation solution from Novatel (SPAN IGN INS, Novatel, Calgary, AB, Canada) is used for RTK-grade centimeter localization, whose purpose is twofold: (i) to help build the reference global map of the environment without the need to apply any particular SLAM algorithm (see
Figure 1), and (ii) to provide a ground-truth positioning to which the output of the PF-based localization can be compared in a quantitative way.
The main contribution of this work is twofold: (a) providing a systematic and quantitative evaluation of the trade-off between how many raw points from a 3D-LiDAR must be actually used in a PF, and the attainable localization quality; and (b) benchmarking the particle density that is required to bootstrap localization, i.e., the “global relocalization” problem. For the sake of reproducibility, the datasets used in this work have been released online (refer to
Appendix A).
The rest of this paper is structured as follows.
Section 2 provides an overview of related works in the literature, as well as some basic mathematical background on the employed PF algorithms. Then,
Section 3 proposes an observation model for Velodyne scans, applicable to raw point clouds. Next,
Section 4 provides mathematical grounds of how a decimation in the input raw LiDAR scan can be understood as an approximation to the underlying likelihood function, and it is experimentally verified with numerical simulations. The experimental setup is discussed in
Section 5. Next, the results of the benchmarks are presented in
Section 6 and we end with some brief conclusions in
Section 7.
3. Map and Sensor Model
A component required by both benchmarked algorithms is the pointwise evaluation of the sensor likelihood function , hence we need to propose one for Velodyne scans () when the robot is at pose along a trajectory given a prebuilt map m.
Regarding the metric map
m, we will assume that it is represented as a 3D point cloud. We employed a Novatel’s inertial RTK-grade GNSS solution to build the maps for benchmarking and also to obtain the ground-truth vehicle path to evaluate the PF output. This solution provides us with accurate WGS84 geodetic coordinates, as well as heading, pitch and roll attitude angles. Using an arbitrary nearby geodetic coordinate as a reference point, coordinates are then converted to a local ENU (East-North-Up) Cartesian frame of reference. Time interpolation of
is used to estimate the ground-truth path of the Velodyne scanner and the orientation of each laser LED as they rotate to scan the environment; this is known as de-skewing [
9] and becomes increasingly important as vehicle dynamics become faster. From each such interpolated pose, we compute the local Euclidean coordinates of the point corresponding to each laser-measured range, then project it from the interpolated sensor pose in global coordinates. Repeating this for each measured range over the entire data set leads to the generation of the global point cloud of the campus employed as ground-truth map in this work.
Once a global map is built for reference, we evaluate the likelihood function as depicted in Algorithm 1. First, it is worth mentioning the need to work with log-likelihood values when working with a particle filter to extend the valid range of likelihood values that can be represented within machine precision. The inputs of the observation likelihood (line 1) are the robot pose , a decimation parameter, the list of all N points in local coordinates with respect to the scanner, the reference map as a point cloud, a scaling value that determines how sharp the likelihood function is, and a smoothing parameter that prevent underflowing. Put in words, from a decimated list of points, each point is first projected to the map coordinate frame (line 6), and the nearest neighbor is searched for within all map points using a K-Dimensional tree (KD-tree) (line 7). Next, the distance between each such local point and its candidate match in the global map is clipped to a maximum and the squared distances accumulated into . Finally, the log likelihood is simply , which implies that we are assuming a truncated (via ) Gaussian error model as a likelihood function. Obviously, the decimation parameter linearly scales the computational cost of the method: larger decimation values provide faster computation speed at the price of discarding potentially valuable information. A quantitative experimental determination of an optimal value for this decimation is presented later on.
| Algorithm 1 Observation likelihood. |
| Input: , decim, , , , |
Output: loglik
- 1:
begin - 2:
loglik ← 0 - 3:
← 0 - 4:
foreach i in 1:decim:N - 5:
- 6:
← map.kdtree.query() - 7:
← - 8:
end - 9:
loglik ← - 10:
return loglik - 11:
end
|
It is noteworthy that the proposed likelihood model in Algorithm 1 can be shown to be equivalent to a particular kind of robustified least-square kernel function in the framework of M-estimation [
27]. In particular, our cost function is equivalent to the so-called truncated least squares [
28,
29], or trimmed-mean M-estimator [
30,
31].
With
the vehicle pose to be estimated, a least-squares formulation to find the optimal pose
that minimizes the total square error between
N observed points and their closest correspondences in the map reads:
However, this naive application of least-squares suffers from a lack of robustness against outliers: it is well known that a single outlier ruins a least-squares estimator [
30]. Therefore, robust M-estimators are preferred, where Equation (
3) is replaced by:
with some robust kernel function
. Regular least-squares correspond to the choice
, while other popular robust cost functions are the Huber loss function [
27] or the truncated least-squares function:
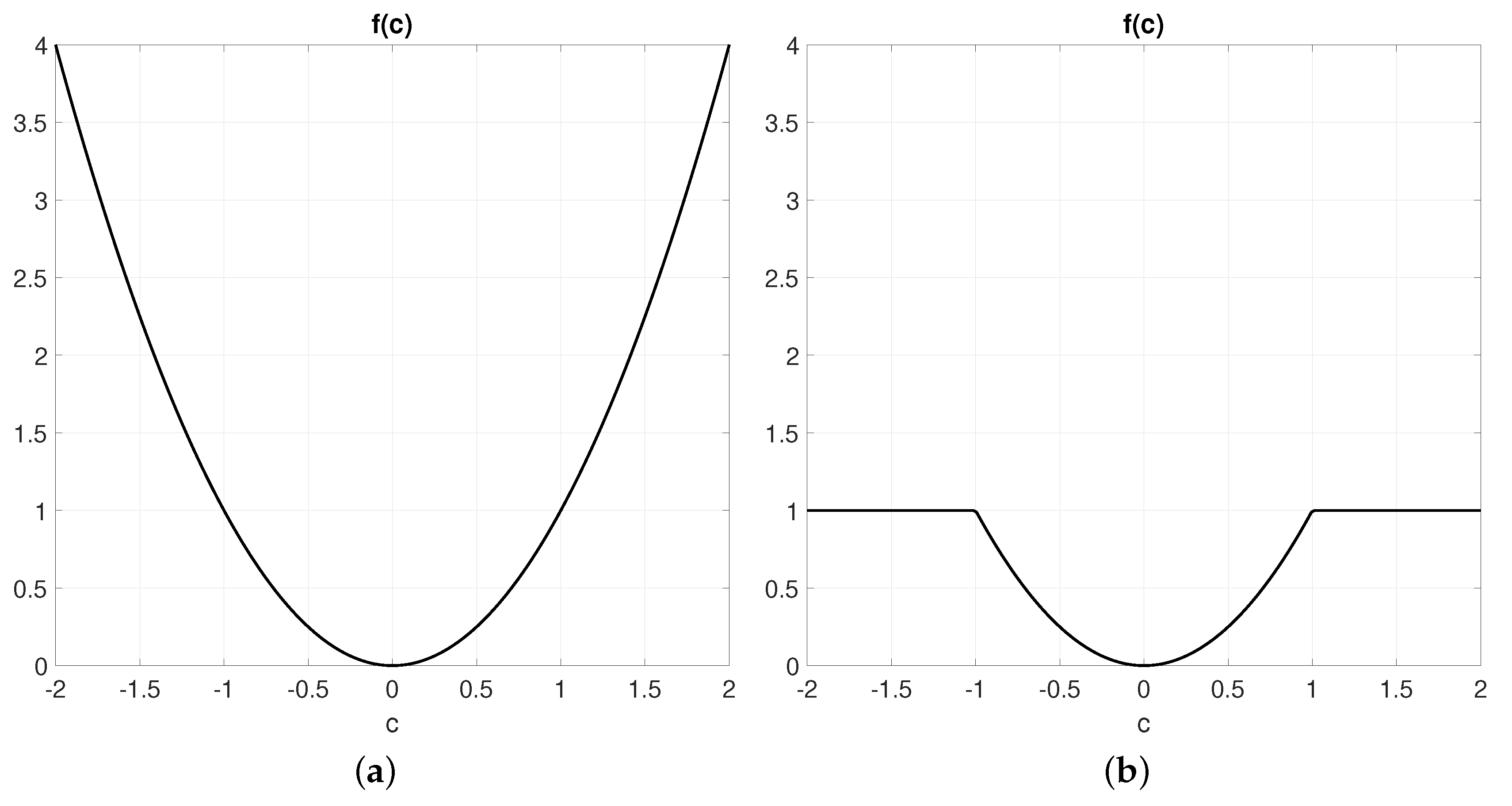
which is illustrated in
Figure 2. The parameter
establishes a threshold for what should be considered an outlier. The insight behind M-estimators is that, by reducing the error assigned to outliers in comparison to a pure least-squares formulation, the optimizer will tend to ignore them and “focus” on minimizing the error of inliers instead that is of those observed points that actually do correspond to map points.
Furthermore, this robust least-squares formulation can be shown to be exactly equivalent to an maximum a posteriori (MAP) probabilistic estimator if observations are assumed to be corrupted with additive Gaussian noise. To prove this, we start from the formulation of a MAP estimator:
where, for simplicity of notation, we used
and
to refer to the set of
N observed points and the vehicle pose for an arbitrary time step of interest, and we took logarithms (a monotonic function that does not change the found optimal value) for convenience in further derivations. Assuming the following generative model for observations:
where
means the local coordinates of point
p as seen from the frame of reference
,
is the multivariate Gaussian distribution with mean
and variance
, and
is the standard deviation of the assumed additive Gaussian error in measured points. Then, replacing Equation (
8) into Equation (
7), using the known exponential formula for the Gaussian distribution, we find:
Identifying the last line above with Equation (
3), it is clear that the MAP statistical estimator is identical to a least squares problem with error terms
. By using a truncated Gaussian in Equation (
8), i.e., by modeling outliers as having a uniform probability density, one can also show that the corresponding MAP estimator becomes the robust least-squares problem in Equation (
5).
Therefore, the proposed observation likelihood function in Algorithm 1 enables an estimator to find the most likely pose of a vehicle while being robust to outlier observations, for example, from dynamic obstacles.
4. Justification of Decimation as an Approximation to the Likelihood Function
A key feature of the proposed likelihood model in Algorithm 1, and which is being benchmarked in this work, is the decimation ratio, that is, how many points from each observed scan are actually considered, with the rest being plainly ignored.
The intuition behind this simple approach is that information in point clouds is highly redundant, such that, by using only a fraction of the points, one could save a significant computational cost while still achieving good vehicle localization. From the statistical point of view, justifying the decimation is only possible if the resulting likelihood functions (which in turn are probability density functions, p.d.f.) are still similar. From Equations (
11)–(
18) above, solving the decimated problem is finding optimal pose
to the approximated p.d.f. with decimation ratio
D:
Numerically, the decimated and the original p.d.f. are clearly not identical, but this is not an issue for we are mostly interested in the location of the global optimum and the shape of the cost function in its neighborhood. The sum of convex functions is convex. In our case, we have truncated square cost functions (recall
Figure 2b), but the overall p.d.f. will still be convex near the true vehicle pose. Note that, since associations between observed and map points are determined based solely on pairwise nearness, in practice, the observation likelihood is not convex when evaluated far from the real vehicle pose. However, this fact can be exploited by the particular kind of estimator used in this work (particle filters) to obtain multi-modal pose estimations, where localization hypotheses are spread among several candidate “spots”—for example, during global relocalization, as will be shown experimentally.
As a motivational example, we propose measuring the similarity between the decimated
and the original p.d.f.
using the Kullback–Leibler divergence (KLD) [
32] using the following experimental procedure. Given a portion of the reference point cloud map, and a scan observation from a Velodyne VLP-16, we have numerically evaluated both the original and the decimated likelihood function in the neighborhood of the known ground-truth solution for the vehicle pose. In particular, we evaluated the functions in a 6D grid (since SE(3) poses have six degrees of freedom) within an area of
for translation in
,
for yaw (azimuth), and
for pitch and roll, with spatial and angular resolutions of
and 5
, respectively. For such discretized model of likelihood functions, we applied the discrete version of KLD that is:
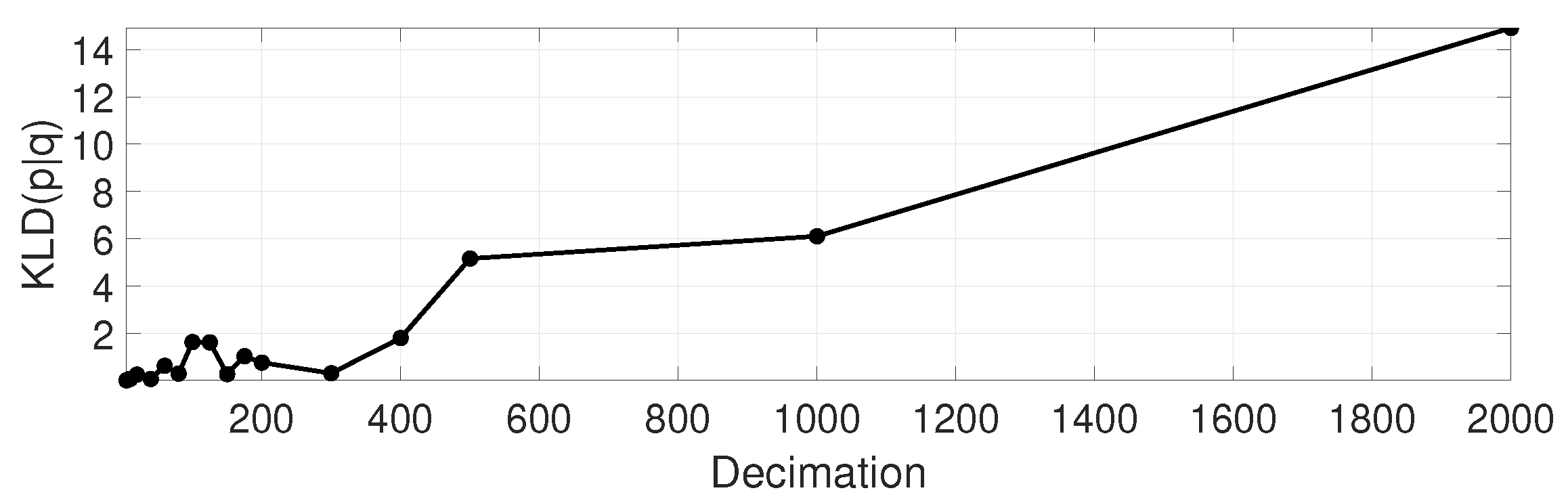
which has been summed for the
grid cells around the ground truth pose, for a set of decimation ratio values. The result KLD is shown in
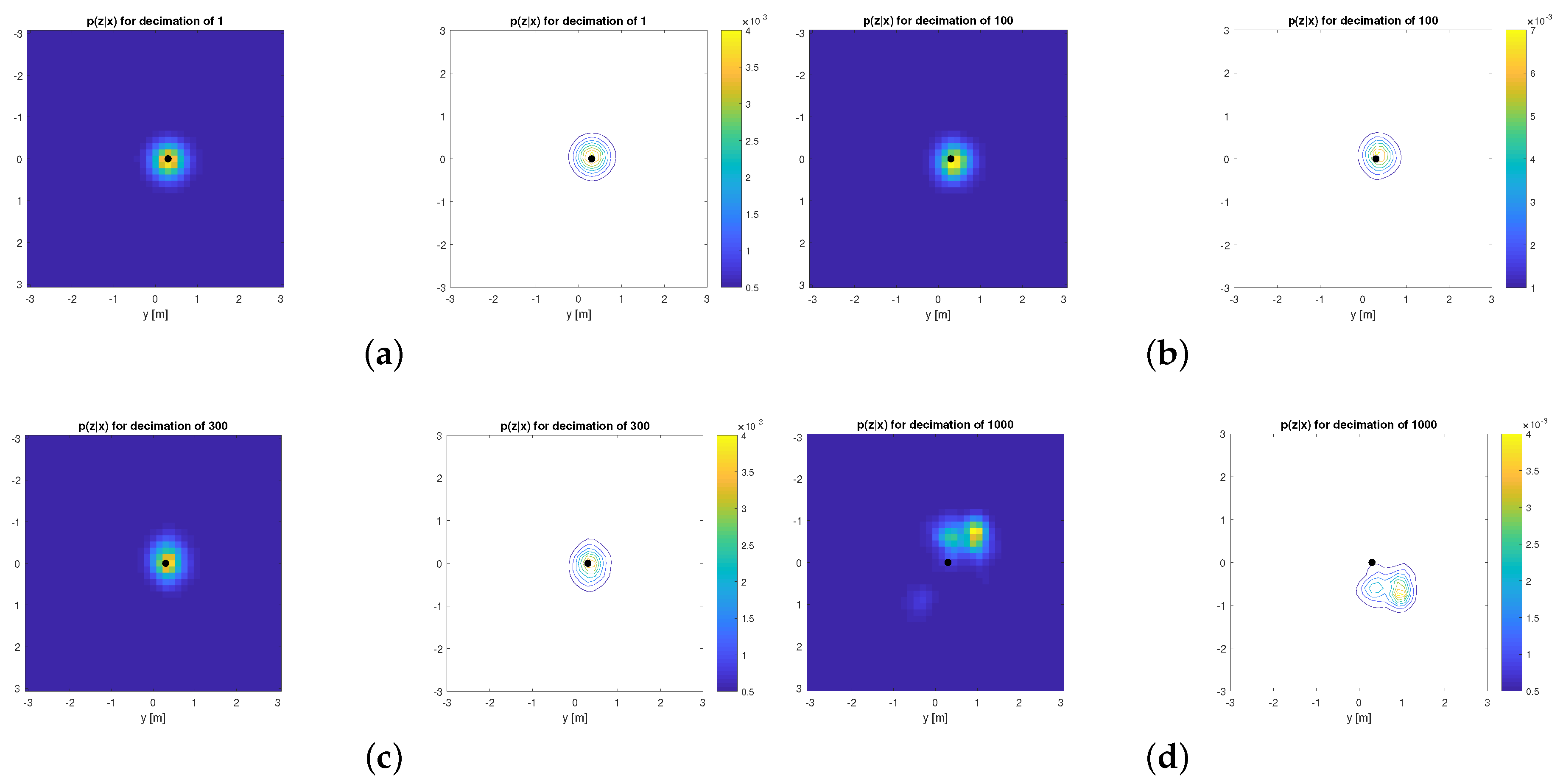
Figure 3, and some example planar slices of the corresponding likelihood functions are illustrated in
Figure 4. Decimated versions are clearly quite similar to the original one up to decimation ratios of roughly ∼500, which closely coincides with statistical localization errors presented later on in
Section 6.
6. Results and Discussion
Next, we discuss the results for each individual experiment and benchmark. All experiments ran within a single-thread on an Intel i5-4590 CPU, (Intel Corporation, Santa Clara, CA, USA) @ 3.30 GHz. Due to the stochastic nature of PF algorithms, statistical results are presented for all benchmarks, which have been evaluated a number of times feeding the pseudorandom number generators with different seeds.
6.1. Mapping
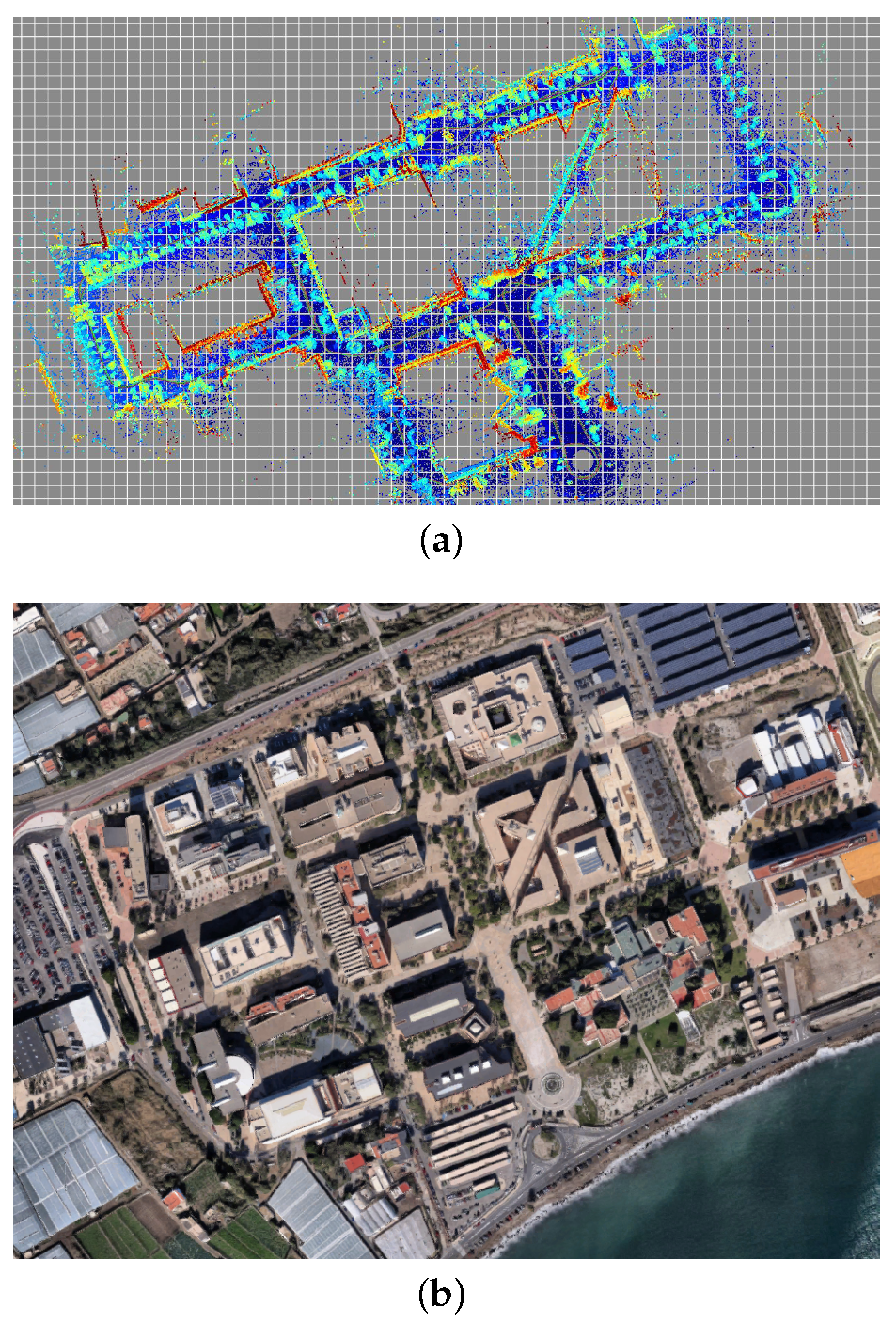
We acquired a dataset in the UAL campus (see
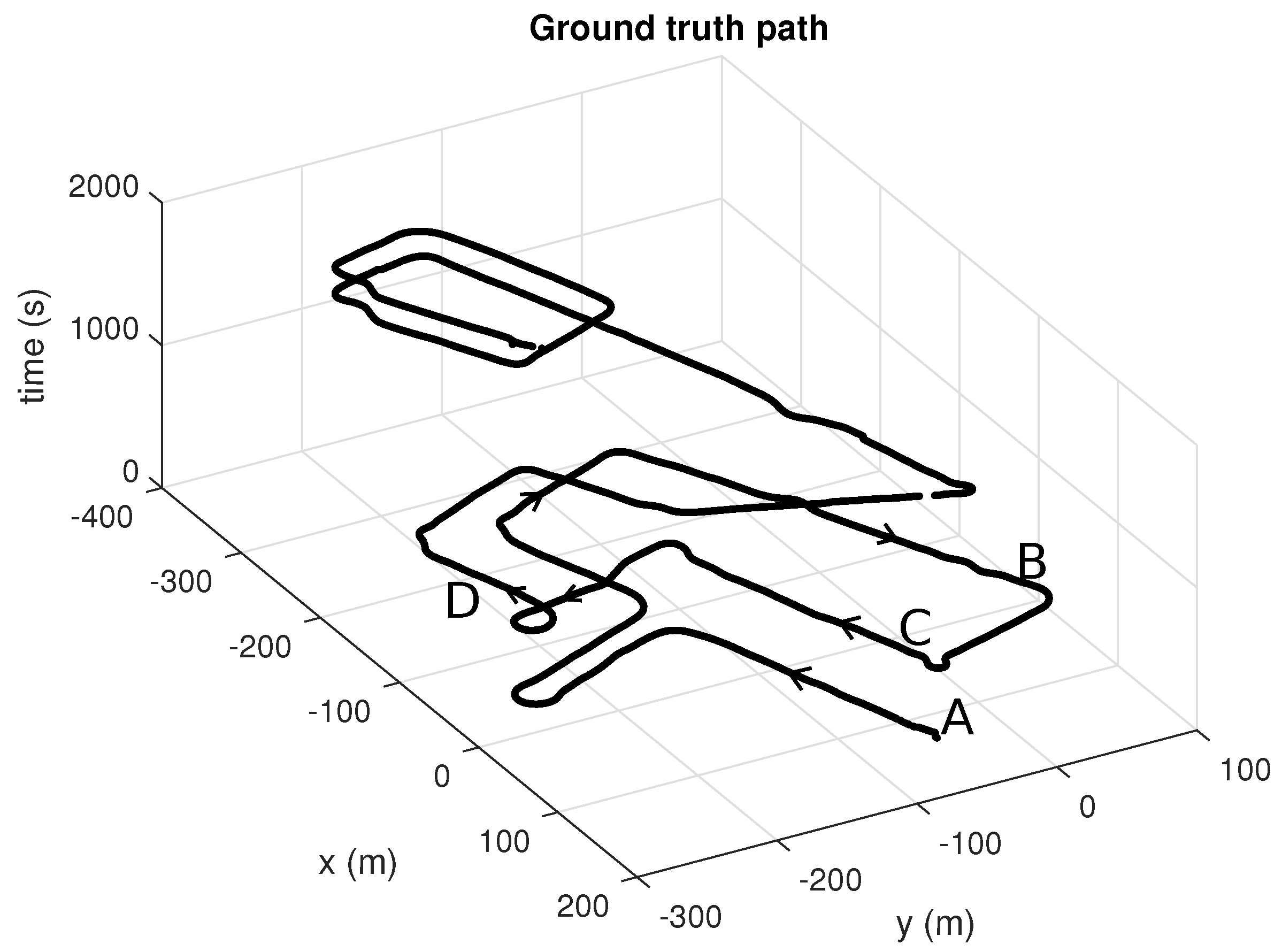
Figure 6) with the purpose of serving to build a reference metric map and also to benchmark PF-based localization algorithms. As described in former sections, we used centimeter-accurate GPS positioning and Novatel SPAN INS attitude estimation for orientation angles. Poses were recorded at 20 Hz along the path shown in
Figure 6b. Since time has been represented in the vertical axis, it is easy to see how the vehicle was driven through the same areas several times during the dataset. In particular, we manually selected a first fragment of this dataset to generate a metric map (segment A–B in
Figure 6b), then a second non-overlapping fragment (segment C–D) to test the localization algorithms as discussed in the following. The global map obtained for the entire dataset is depicted in
Figure 6a, whereas the corresponding ground-truth path can be seen in
Figure 7.
6.2. Relocalization, Part 1: Aided by Poor-Signal GPS
Global localization, the “awakening problem” or “relocalization” are all names of specific instances of the localization problem: those in which uncertainty is orders of magnitude larger than during regular operation. Depending on the case and available sensors, uncertainty may span a few square meters within one room, or an entire city-scale area. Since our work addresses localization in outdoor environments, we will assume that a consumer-grade, low-cost GPS device is available during the initialization of the localization system. To benchmark such a situation, we initialize the PF with different number of particles (ranging from 20 to 4000) spread over an area of
that includesthe actual vehicle pose. No clue is given for orientation (despite the fact that it might be easy to obtain from low-cost magnetic sensors) and no GPS measurements are used in subsequent steps of the PF, whose only inputs are Velodyne scans and odometry readings. The size of this area has been chosen to cover a typical worst-case GPS positioning data with poor precision, that is, with a large dilution of precision (DOP). Such a situation is typically found in areas where direct sight of satellites is blocked by obstacles (e.g., trees, buildings). Refer to [
34] for an experimental measurement of such GPS positioning errors.
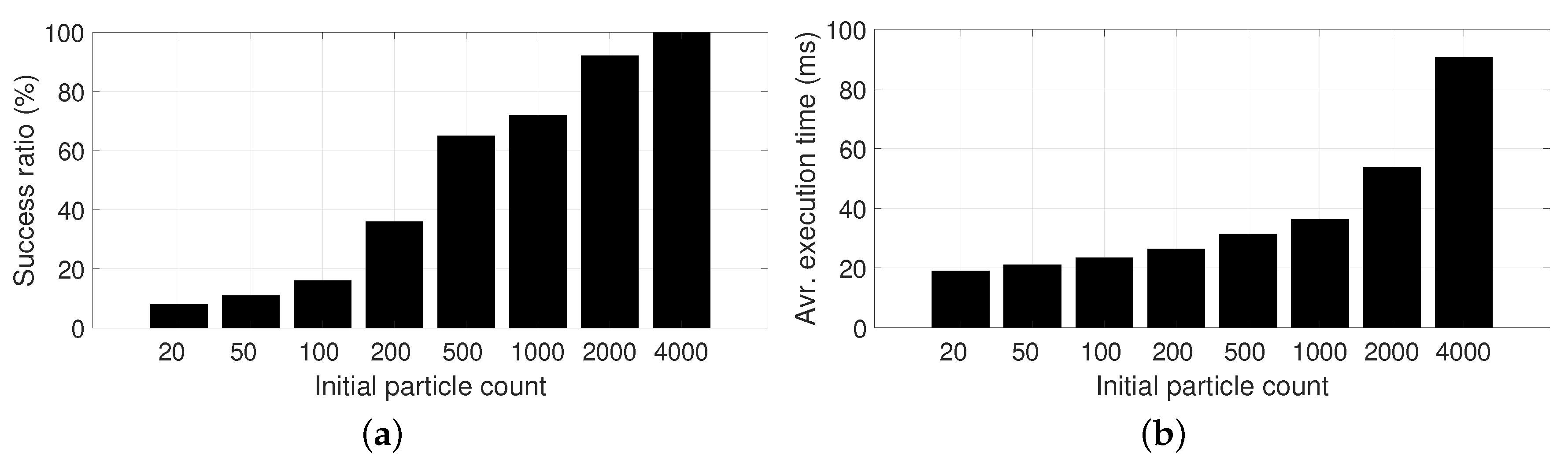
Notice that the particle density is small even for the largest case (N = 4000, density is particles/m), but the choice of the optimal-sampling PF algorithm makes it possible to successfully converge to the correct vehicle pose within a few timesteps.
We investigated what is the minimum particle density required to ensure a high probability of converging to the correct pose, since oversizing might lead to excessive delays while the system waits for convergence. Relocalization success was assessed by running a PF during 100 timesteps and checking whether (i) the average particle pose is close to the actual (known) ground truth solution (closer than two meters), and (ii) the determinant of the covariance fitting all particles is below a threshold (
). Together, these conditions are a robust indicator of whether convergence was successful. The experiment was run 100 times for each initial population size
N, using a point cloud decimation of 100, and automatic sample size was in effect in the second and subsequent time steps. The success ratio results can be seen in
Figure 8a, and demonstrate that the optimal-sampling PF requires, in our dataset, a minimum of 4000 particles (4.4 particles/m
) to ensure convergence. Obviously, the computational cost grows with
N as
Figure 8b shows, hence the interest in finding the minimum feasible population size. Note that the computational cost is not linear with
N due to the complex evolution of the actual population size during subsequent timesteps. Normalized statistics regarding number of initial particles per area are also provided in
Table 1, where it becomes clear that an initial density of ∼2 particles/m
seems to be the minimum required to ensure convergence for the proposed model of observation likelihood.
6.3. Relocalization, Part 2: LiDAR Only
Next, we analyze the performance of the particle filter algorithm to localize, from scratch, our vehicle without any previous hint about its approximate pose within the map of the entire campus.
For that, we draw N random particles following a uniform distribution (in x, y, and also in the vehicle azimuth ) as the initial distribution, with different values of N, and after 100 time steps, we detect whether the filter has converged to a single spot, and whether the average estimated pose is actually close to the ground truth pose. The experiment has been repeated 150 times for each initial particle count N. The area where particles are initialized has a size of . Notice that the dynamic sample size algorithm ensures that computational cost quickly decreases as the filter converges, hence the higher computational cost associated with a larger number of particles only affects the first iterations (typically, less than 10 iterations).
The summary of results can be found in
Table 2, and are consistent with the relationship between initial particle densities and convergence success ratio in
Table 1. A video for a representative run of this test is available online for the convenience of the reader (Video available in:
https://www.youtube.com/watch?v=LJ5OV-KMQLA).
6.4. Choice of PF Algorithm
In this benchmark, we analyzed the pose tracking accuracy (positioning error with respect to ground-truth) and efficiency (average computational cost per timestep) of a PF using the standard proposal distribution in contrast to another using the optimal proposal. Please refer to [
13] for details on how this algorithm achieves a better random sampling of the target probability distribution, by simultaneously taking into account both the odometry model and the observation likelihood
in Algorithm 1.
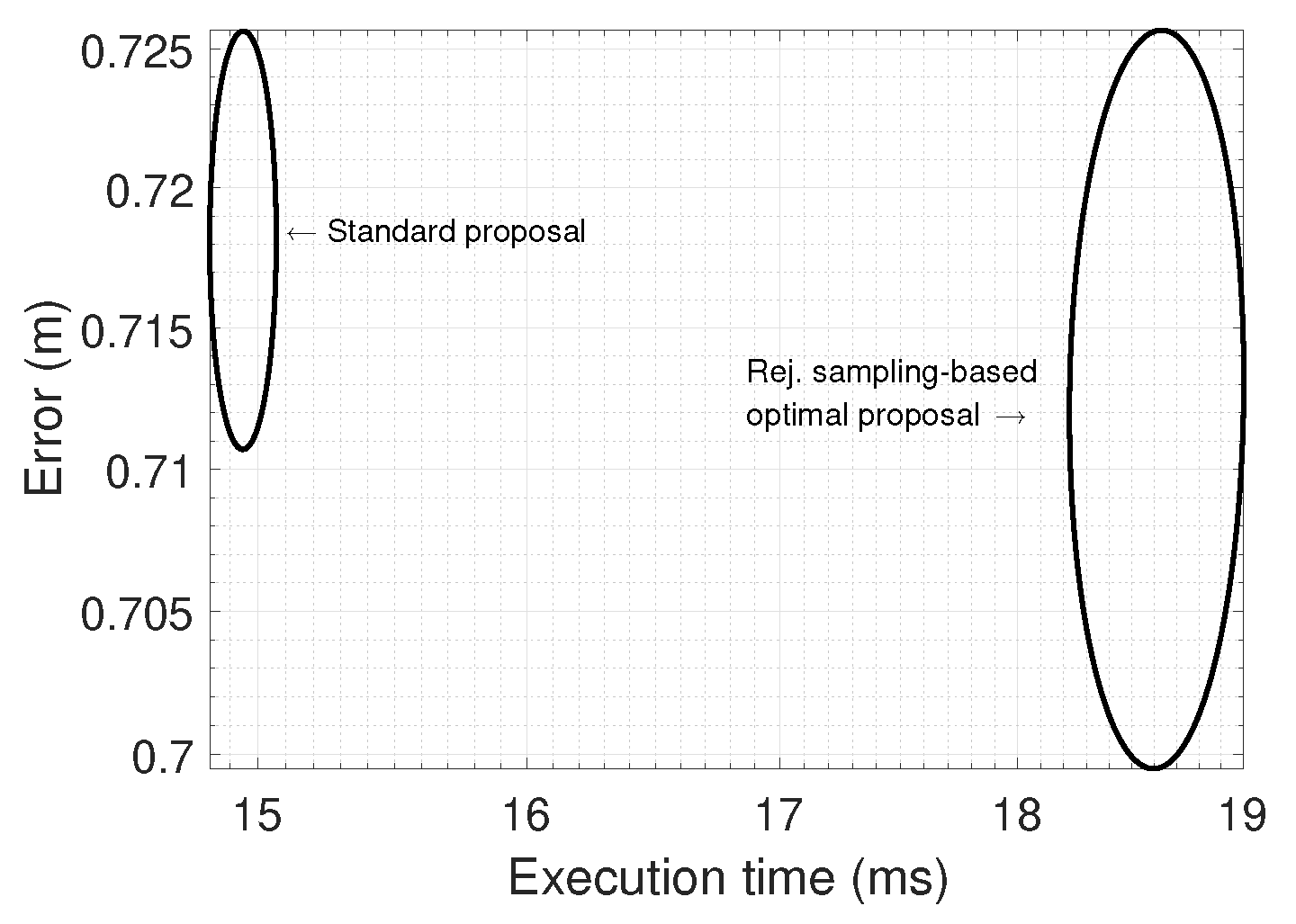
Experiments were run 25 times and average errors and execution times were collected for each algorithm, then data fitted as a 2D Gaussian as represented in
Figure 9. The minimum population size of the standard PF was set to 200, while it was 10 for the optimal PF. However, their “effective” number of particles are equivalent since each particle in the optimal algorithm was set to employ 20 terations in the internal sampling-based stage. The optimal PF achieves a slightly better accuracy with a relatively higher computational cost, which still falls below 20 ms per iteration. Therefore, the conclusion is that the optimal algorithm is recommended, but with a small practical gain, a finding in accordance with previous works that revealed that the advantages of the optimal PF become more patent when applied to SLAM, while only representing a substantial improvement for localization when the sensor likelihood model is sharper [
13].
6.5. Tracking Performance
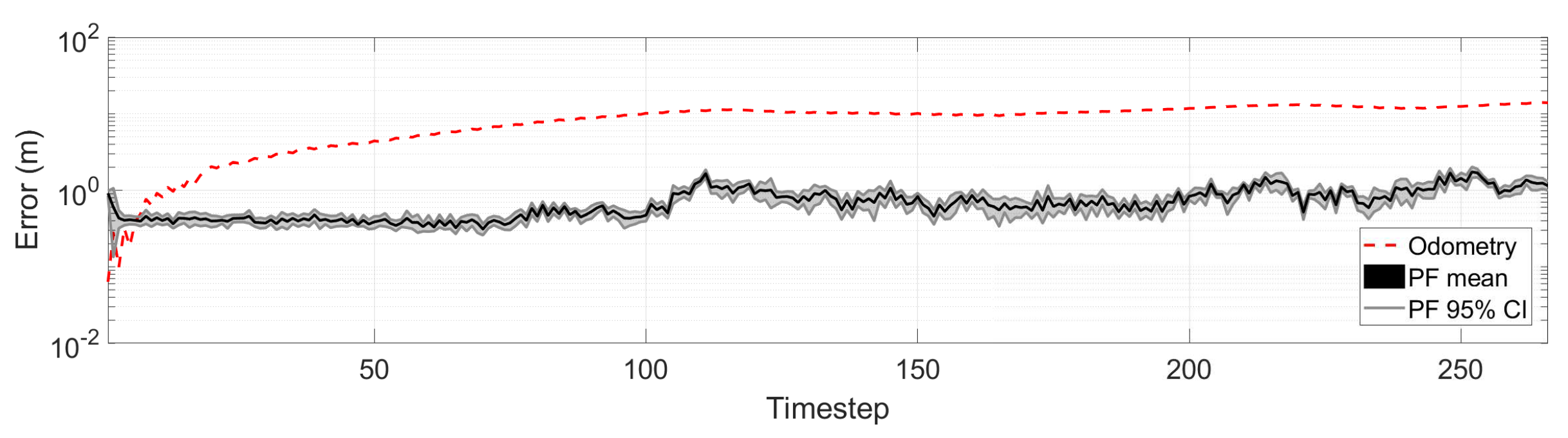
To demonstrate the suitability of the proposed observation model, we run 10 instances of a pose tracking PF using the standard proposal distribution, point cloud decimation of 100, and a dynamic number of samples with a minimum of 100. We evaluated the mean and 95% confidence intervals for the localization error over the vehicle path, and compared it to the error that would accumulate from odometry alone in
Figure 10. As can be seen, the PF keeps track of the actual vehicle pose with a error median of 0.6 m (refer to
Table 3).
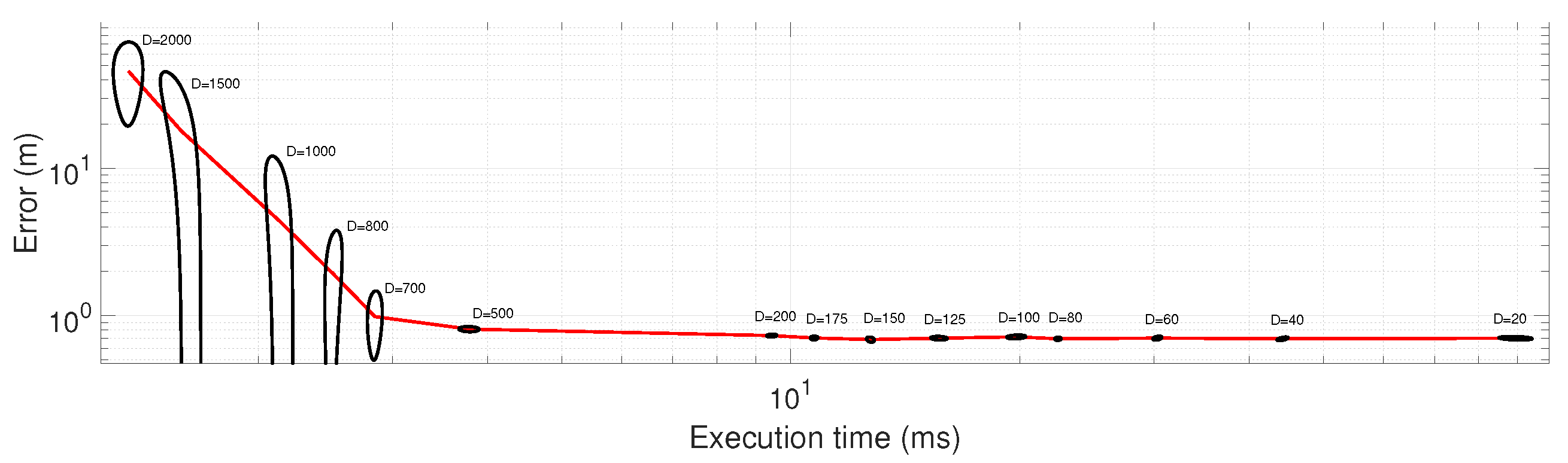
6.6. Decimating Likelihood Evaluations
Finally, we addressed the issue of how much information can be discarded from each incoming scan while preventing the growth of positioning error. Decimation is the single most crucial parameter regarding the computational cost of pose tracking with PF, hence the importance of quantitatively evaluating its range of optimal values. The results, depicted in
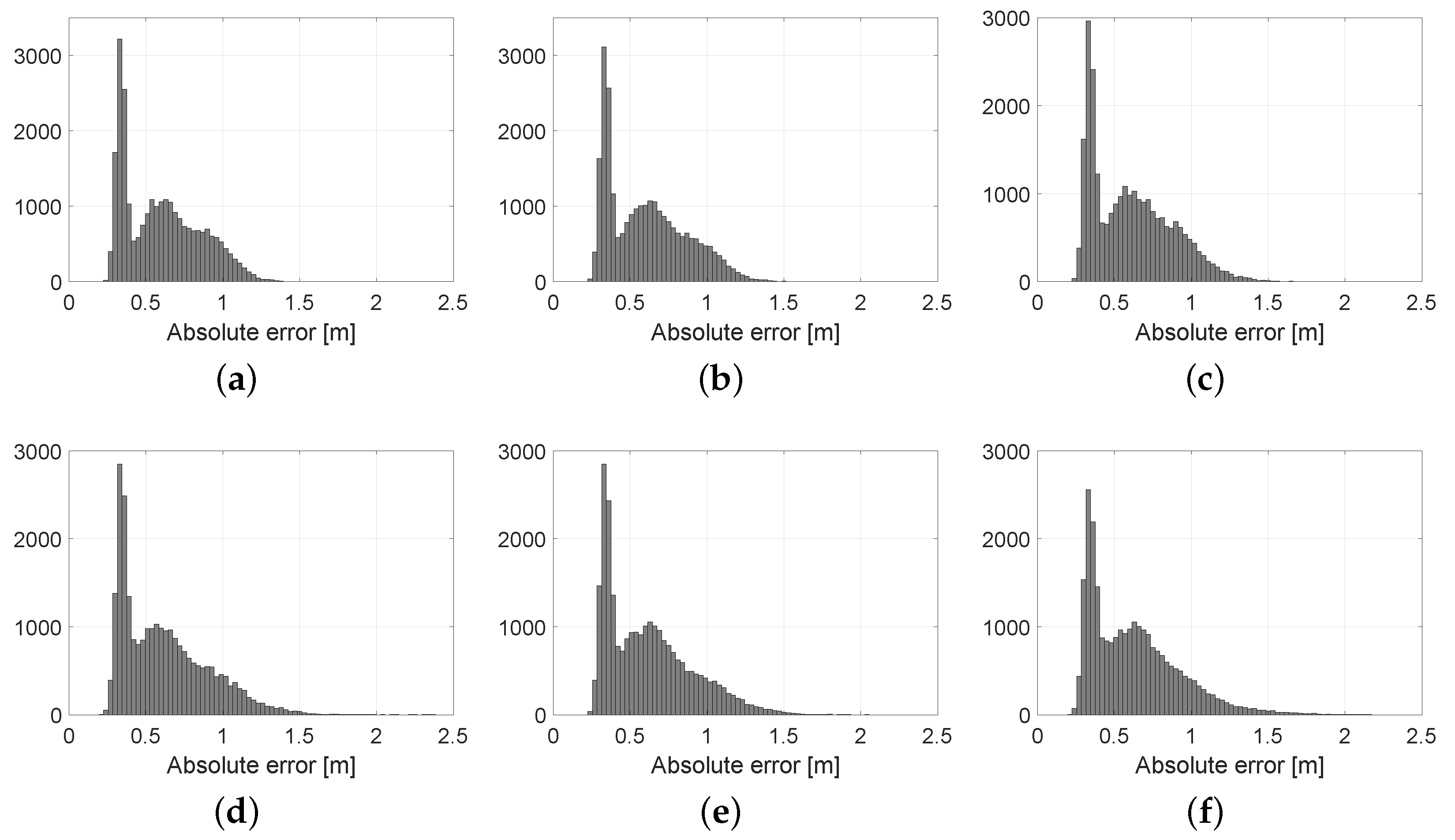
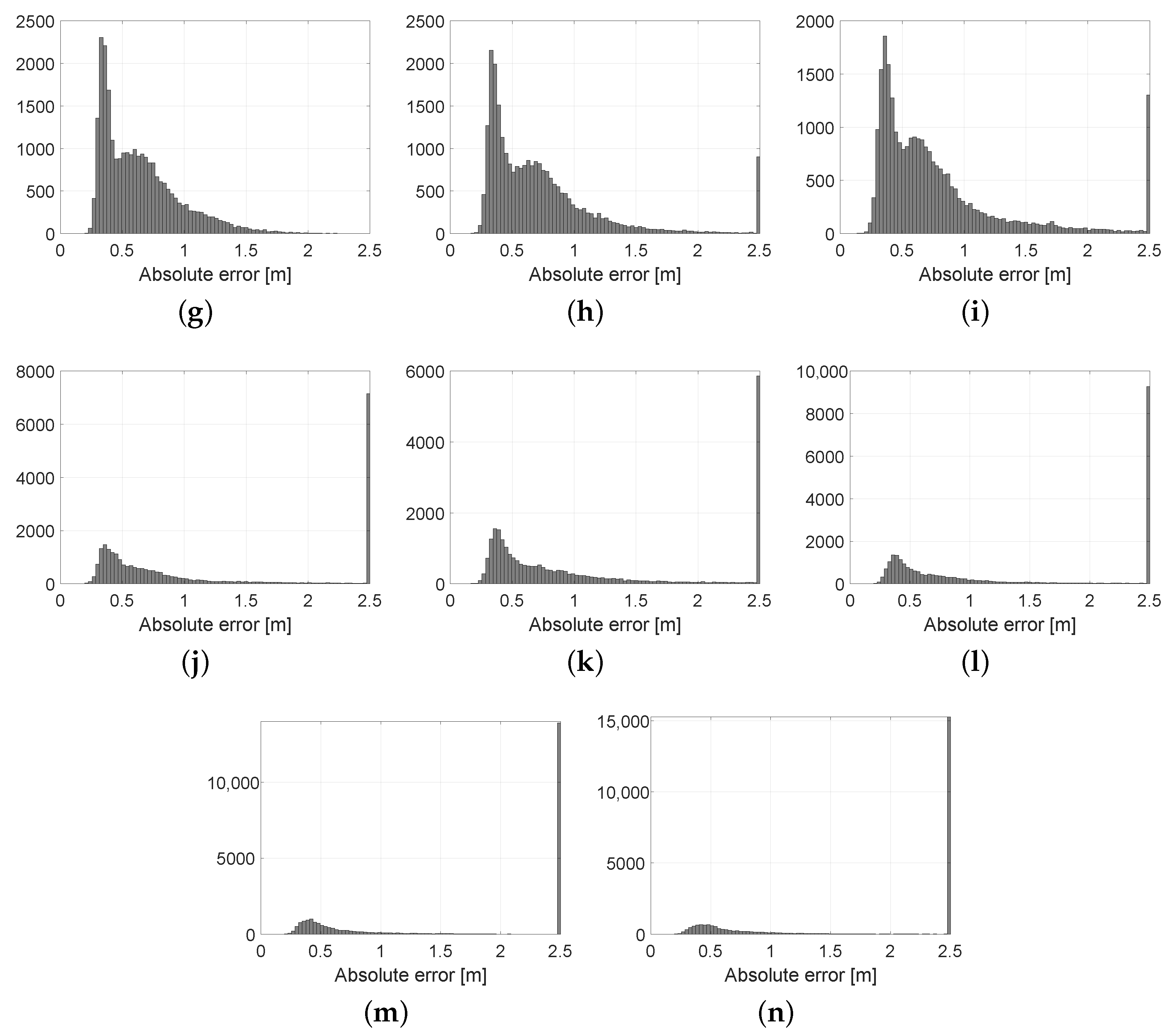
Figure 11, clearly show that decimation values in the range 100 to 200 should be the minimum choice since error is virtually unaffected. In other words, Velodyne scans apparently have so much redundant information that we can keep only 0.5% of them and still remain well-localized. Statistical results of these experiments, and the corresponding error histograms, are shown in
Table 3 and
Figure 12, respectively. As can be seen from the results, the average error is relatively stable for decimation values of up to 500, and quickly grows afterwards.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













