An Improved Method of Measuring Wavefront Aberration Based on Image with Machine Learning in Free Space Optical Communication


 ,
,
Abstract
:1. Introduction
2. Method
2.1. Imaging System
2.2. Structure of the CNNs
2.2.1. Batch Normalization Layer Filter
2.2.2. Attention Layer
3. Simulation
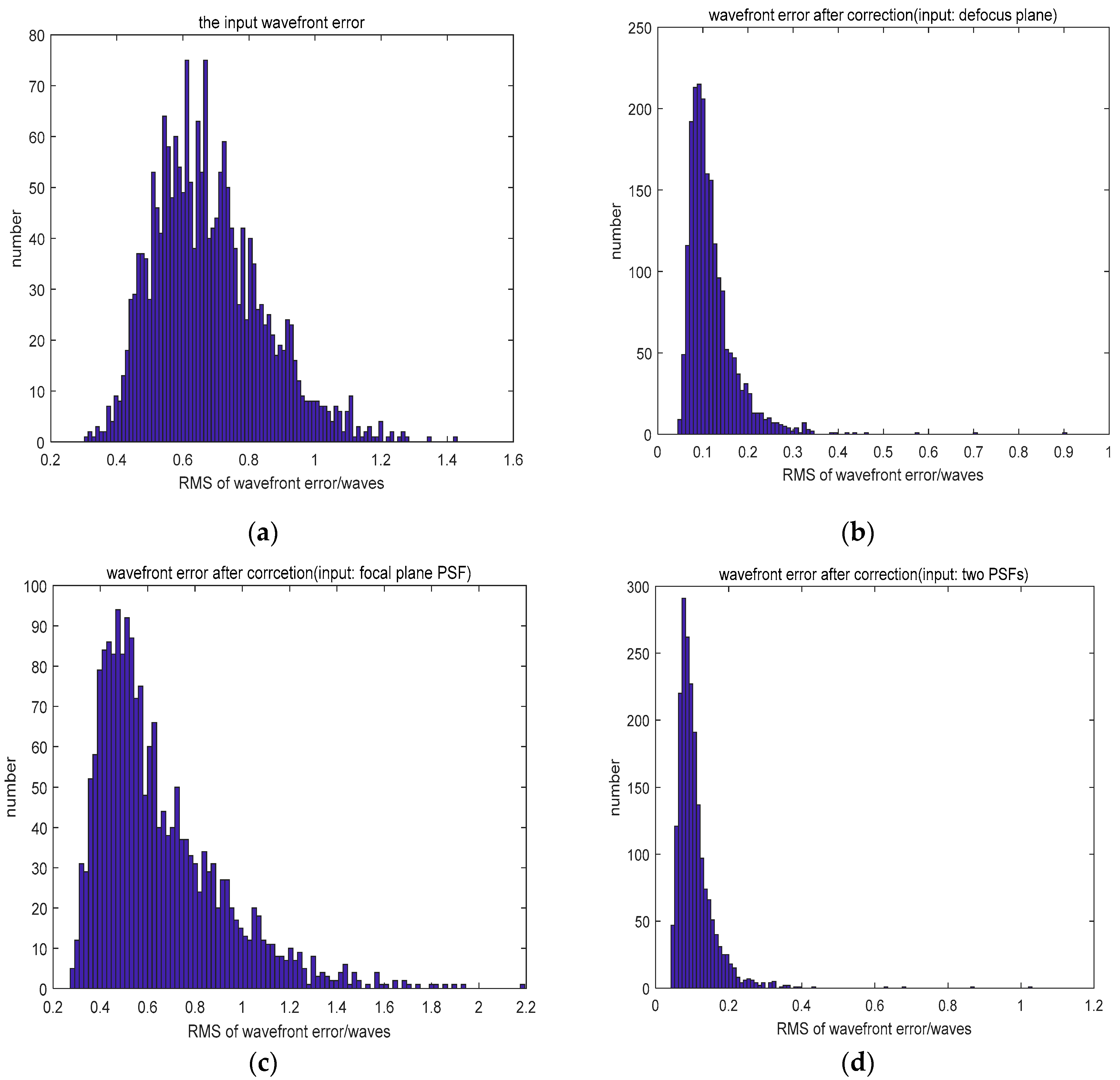
3.1. Feasibility Verification
3.2. Simulations with Different Sample Sizes
3.3. Generalization Ability
4. Experiment
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Platt, B.C.; Shack, R. History and principles of Shack-Hartmann wavefront sensing. J. Refract. Surg. 1995, 17, 573–577. [Google Scholar] [CrossRef]
- Vargas, J.; González-Fernandez, L.; Quiroga, J.A.; Belenguer, T. Calibration of a Shack-Hartmann wavefront sensor as an orthographic camera. Opt. Lett. 2010, 35, 1762–1764. [Google Scholar] [CrossRef] [PubMed]
- Gonsalves, R.A. Phase retrieval and diversity in adaptive optics. Opt. Eng. 1982, 21, 829–832. [Google Scholar] [CrossRef]
- Nugent, K.A. The measurement of phase through the propagation of intensity: An introduction. Contemp. Phys. 2011, 52, 55–69. [Google Scholar] [CrossRef]
- Misell, D.L. An examination of an iterative method for the solution of the phase problem in optics and electronoptics: I. Test calculations. J. Phys. D Appl. Phys. 1973, 6, 2200–2216. [Google Scholar] [CrossRef]
- Fienup, J.R. Phase-retrieval algorithms for a complicated optical system. Appl. Opt. 1993, 32, 1737–1746. [Google Scholar] [CrossRef] [PubMed]
- Allen, L.J.; Oxley, M.P. Phase retrieval from series of images obtained by defocus variation. Opt. Commun. 2001, 199, 65–75. [Google Scholar] [CrossRef]
- Sandler, D.G.; Barrett, T.K.; Palmer, D.A.; Fugate, R.Q.; Wild, W.J. Use of a neural network to control an adaptive optics system for an astronomical telescope. Nature 1991, 351, 300–302. [Google Scholar] [CrossRef]
- Angel, J.R.P.; Wizinowich, P.; Lloyd-Hart, M.; Sandler, D. Adaptive optics for array telescopes using neural-network techniques. Nature 1990, 348, 221–224. [Google Scholar] [CrossRef]
- Barrett, T.K.; Sandler, D.G. Artificial neural network for the determination of Hubble Space Telescope aberration from stellar images. Appl. Opt. 1993, 32, 1720–1727. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kumar, A.; Paramesran, R.; Lim, C.L.; Dass, S.C. Tchebichef moment based restoration of Gaussian blurred images. Appl. Opt. 2016, 55, 9006–9016. [Google Scholar] [CrossRef] [PubMed]
- Ju, G.; Qi, X.; Ma, H.; Yan, C. Feature-based phase retrieval wavefront sensing approach using machine learning. Opt. Express 2018, 26, 31767–31783. [Google Scholar] [CrossRef] [PubMed]
- Mukundan, R. Some computational aspects of discrete orthonormal moments. IEEE Trans. Image Process. 2004, 13, 1055–1059. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556v6. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition CVPR, Las Vegas, VN, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Paine, S.W.; Fienup, J.R. Machine learning for improved image-based wavefront sensing. Opt. Lett. 2018, 43, 1235–1238. [Google Scholar] [CrossRef] [PubMed]
- Yohei, N.; Matias, V.; Ryoichi, H.; Katsuhisa, K.; Mamoru, S.; Jun, T.; Esteban, V. Deep learning wavefront sensing. Opt. Express 2019, 27, 240–251. [Google Scholar]
- Roddier, N.A. Atmospheric wavefront simulation using Zernike polynomials. Opt. Eng. 1990, 29, 1174–1180. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980v9. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167v3. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W. SCA-CNN: Spatial and Channel-Wise Attention in Convolutional Networks for Image Captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Training Set | Network | MRMS of WFE (Testing Set) | Computation Time |
|---|---|---|---|---|
| 1 | defocused PSF | Alexnet | 0.2183λ | 6.5–7.5 ms |
| 2 | defocused PSF | VGG | 0.1490λ | 11–12 ms |
| 3 | defocused PSF | Inception V3 | 0.1187λ | 24–28 ms |
| 4 | defocused PSF | CNN1 | 0.2371λ | 5–6 ms |
| 5 | defocused PSF | CNN2 | 0.1344λ | 6–7 ms |
| 6 | defocused PSF | CNN3 | 0.1263λ | 6–7 ms |
| 7 | focal PSF | CNN3 | 0.6510λ | 6–7 ms |
| 8 | two PSFs | CNN3 | 0.1248λ | 7–8.5 ms |
| Number | Training Set | Network | MRMS of WFE (Testing Set) |
|---|---|---|---|
| 1 | 5000 PSFs | CNN3 | 0.2255λ |
| 2 | 10,000 PSFs | CNN3 | 0.1597λ |
| 3 | 15,000 PSFs | CNN3 | 0.1360λ |
| 4 | 20,000 PSFs | CNN3 | 0.1263λ |
| Networks | MRMS of WFE (D/r0 = 6) | MRMS of WFE (D/r0 = 10) | MRMS of WFE (D/r0 = 15) | MRMS of WFE (D/r0 = 20) |
|---|---|---|---|---|
| Input | 0.2463λ | 0.3780λ | 0.5272λ | 0.6789λ |
| Alexnet | 0.1145λ | 0.1220λ | 0.1732λ | 0.2183λ |
| VGG | 0.0884λ | 0.0981λ | 0.1122λ | 0.1490λ |
| Inception V3 | 0.1360λ | 0.0965λ | 0.0922λ | 0.1187λ |
| CNN1 | 0.1286λ | 0.1273λ | 0.1681λ | 0.2371λ |
| CNN2 | 0.0754λ | 0.0709λ | 0.0962λ | 0.1344λ |
| CNN3 | 0.0705λ | 0.0629λ | 0.0833λ | 0.1263λ |
| No. | Network | MRMS of WFE (Testing Set) | Computation Time |
|---|---|---|---|
| 1 | Alexnet | 0.0625λ | 6.5–7.5 ms |
| 2 | VGG | 0.0578λ | 11–12 ms |
| 3 | Inception V3 | 0.0782λ | 24–28 ms |
| 4 | CNN3 | 0.0521λ | 6–7 ms |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; He, D.; Wang, Q.; Guo, H.; Li, Q.; Xie, Z.; Huang, Y. An Improved Method of Measuring Wavefront Aberration Based on Image with Machine Learning in Free Space Optical Communication. Sensors 2019, 19, 3665. https://doi.org/10.3390/s19173665
Xu Y, He D, Wang Q, Guo H, Li Q, Xie Z, Huang Y. An Improved Method of Measuring Wavefront Aberration Based on Image with Machine Learning in Free Space Optical Communication. Sensors. 2019; 19(17):3665. https://doi.org/10.3390/s19173665
Chicago/Turabian StyleXu, Yangjie, Dong He, Qiang Wang, Hongyang Guo, Qing Li, Zongliang Xie, and Yongmei Huang. 2019. "An Improved Method of Measuring Wavefront Aberration Based on Image with Machine Learning in Free Space Optical Communication" Sensors 19, no. 17: 3665. https://doi.org/10.3390/s19173665
APA StyleXu, Y., He, D., Wang, Q., Guo, H., Li, Q., Xie, Z., & Huang, Y. (2019). An Improved Method of Measuring Wavefront Aberration Based on Image with Machine Learning in Free Space Optical Communication. Sensors, 19(17), 3665. https://doi.org/10.3390/s19173665