1. Introduction
Wireless sensor networks (WSNs) are widely used in observing, agriculture, home, and defence environments that are dynamic. Emerging information technology and application requirements have shifted the paradigm of a static network scenario to dynamic environments of WSNs. The mobility of nodes (anchor and unknown) in the network makes it difficult to estimate the location of an unknown node. The accuracy of the location of nodes in such networks is of great importance and depends on location estimation and verification [
1,
2]. The major drawback of WSNs is the lifetime of the network, as the nodes have limited resources to power up. Compared to unknown nodes, anchor nodes are more privileged, with better power and computational resources. However, unknown nodes drain their resources faster to perform heavy computational tasks. Therefore, the network becomes partially unavailable until the exhausted nodes are replaced. However, the replacement process is not always feasible in the dynamic configuration settings of the applications. Moreover, WSNs use a virtual backbone to prolong the network lifetime [
3,
4,
5]. Therefore, the localization process has to be efficient in the terms of minimizing resource utilization. Such efficient utilization of resources is achieved by optimization [
6,
7,
8] and load balancing [
9] on the virtual backbones.
In this paper, we introduce an approach by constructing a connected dominating set (CDS) based virtual backbone only with anchor nodes optimized in terms of load balance using a vector-based swarm optimization (VBSO) mechanism [
10]. This optimized CDS is then used for location estimation in WSNs. The purpose of including CDS in the proposed algorithm is to use the anchor nodes properly and to increase the overall network lifetime. The remaining paper is organized as follows.
Section 2 reviews the related work in this field. The network model for the algorithm is explained in
Section 3. The proposed algorithm is shown in
Section 4. The detailed process of the applied optimization is explained in
Section 5, and the localization details are discussed in
Section 6. The results are explained in
Section 7. Finally, conclusions are drawn in
Section 8.
2. Related Work
Researchers have recently considered various algorithms to improve the lifetime of nodes without compromising their location estimation accuracy. Localization techniques are broadly categorized into (i) direct and (ii) indirect approaches. The former is based on manual configuration and GPS-based techniques and the latter on range-based and range-free techniques [
1]. Location identification of nodes with range-based approaches uses different methods, such as time difference of arrival (TDoA), angle of arrival (AoA), time of arrival (ToA), and a received signal strength indicator (RSSI). On the other hand, range-free approaches use region inclusion, hop count, and neighbor location identification methods that avoid a direct relationship between point-to-point distances and are, therefore, more economic. Some hybrid approaches, including RSS–AoA and RSS–ToA, have been discussed in References [
11,
12,
13,
14]. These hybrid approaches provide generality by applying data fusion and are also used for global synchronization with high accuracy but lag behind in computational cost, special hardware requirements, and energy consumption. Another hybrid localization algorithm is shown in Reference [
15] that uses message passing and approximation of posterior distribution of targets. It also uses Bayesian distribution [
16,
17]. These techniques either use range or angle as their measurement parameter and geometrical interpretations (such as triangulation or trilateration) are calculated accordingly. This seems easier to apply in the absence of noise. Moreover, the problem with such a geometric-based calculation is the existence of a larger intersection area of hyperbolas rather than a point. Therefore, to improve the efficiency of the localization techniques in the presence of noise, the two measurements—range and angle—are integrated as hybrid approaches. The generic approaches of range-free methods were recently further modified for their economic value and are discussed hereafter. Energy-efficient load- balanced clustering (EELBC) is one of the range-free approaches for localization [
18]. This algorithm uses a minimum heap of cluster heads (CHs) or gateway nodes and the nodes are assumed to be aware of the position through GPS. Additionally, network setup is performed in two phases, bootstrapping and clustering. In the clustering phase, the sink executes the clustering algorithm depending on the minimum heap algorithm. The extra cost of GPS makes this algorithm less attractive.
Another variant of the load-balanced cluster-based algorithm creates clusters based on distances and the distribution density of the nodes [
19]. Here, node distribution follows Poisson’s process and has fixed locations and, hence, mobility is not considered. This algorithm lacks load balancing factors. In another range-free approach, three NP-hard problems: the min–max degree maximal independent set (MDMIS), the load-balanced virtual backbone (LBVB), and the min–max valid-degree nonbackbone node allocation (MVBA) were considered [
20]. An additional approximation algorithm was also proposed in the method which uses the linear relaxing and random rounding techniques. Genetic-based approaches have been discussed in References [
21,
22,
23,
24]. One variant of the genetic algorithm using a simplex method is shown in Reference [
25]. This simplex method is used to optimize the error minimization problem in widely used DV-hop for searching a local optima. The use of the multiobjective genetic algorithm to create a load-balanced virtual backbone is shown in Reference [
26]. The mobility of the network increases the iterations of the algorithm to get a local optimum solution, making the overall approach disadvantageous. The identification of balanced nodes in wireless sensor networks for data aggregation has also been shown with a probabilistic network model for a data aggregation tree [
27]. Moreover, an algorithm for the identification of a load-balanced maximal dominator node Set (LBMDS) and connector nodes for LBMDS have been developed. An expected allocation probability algorithm (EAP) to solve parent node assignment (PNA) has been proposed. A novel distributed tracking process of the sensor nodes has been introduced [
28]. In this approach, a local node using a fuzzy system provides a partial solution, with a centralized algorithm that merges all the partial solutions. The centralized algorithm is based on the calculation of the centroid of the partial solutions. The deviation of the partial solutions increases the complexity of the algorithm, which is an identified concern in this approach.
The solution for swarm configuration-based localization uses the min–max method and swarm optimization [
29]. Swarm uses a sequential Monte Carlo localization method to consider mobility and does not require additional hardware. As it can work with seed movement, the mobility factor lowers the cost of implementation without compromising accuracy. We have considered this approach as a candidate, as well for comparison. An ant colony-based optimization approach is described in the literature [
30]. A distributed method for parametric regression in a clustered WSN using particle swarm optimization was also introduced recently with multiobjective optimization (MO) [
31]. Moreover, the same as the vector-evaluated particle swarm optimization method, it considers the MO problem in two phases; the algorithm obtains a set of candidate network regressors and computes the final model using a weighted averaging rule. However, this parametric regression is not suitable for real time-based scenarios with the mobility effect. A novel optimized localization method using glowworm swarm optimization (GSOL) has been introduced to overcome this drawback [
32]. The fitness function of this optimization process follows the deviation or error calculation with the Euclidean distance aspect. After the multi-iterations, all the mobile nodes within the network concentrates around one or multiple nodes providing local optimal location create the global optimal location. We have considered this algorithm also as another candidate for comparison due to its claimed efficiency. Some other techniques for the optimization and load balancing the virtual backbone include: Neural networks [
33], the machine learning approach [
34], and the differential evolution approach [
35].
The aforementioned short survey on the range-free optimization algorithms in WSNs has some drawbacks: (i) The algorithms are not load-balanced and, therefore, partial exhaustion of the network exists; (ii) the redundancy of the clustering nodes makes the process complex; (iii) heavy functioning load on some nodes lowers the network lifetime; and (iv) validation for the overall mobile (unknown and anchor: Both are mobile) environment is not ensured. The present work aims to provide a solution for the abovementioned deficiencies by developing an approach of localization using a VBSO-based CDS construction.
3. Network Scenario
The present research work considers that the n unknown nodes are located within a plane of area with true locations defined by and estimated locations are defined by , . We have also considered m anchor nodes with known locations defined by .
The transmission area is considered to be a circle. The centre of the circle consists of the corresponding node itself. The number of unknown nodes connected to an anchor node is variable at different time intervals and, therefore, we have calculated that the expected number of connectivity for each anchor node in the network can be given as:
The network of n unknown nodes and m anchor nodes along with their connectivity is considered as a graph . ⊆, where is the original sensor network scenario and consists only of the optimized backbone anchor nodes considered as optimized CDS and its links to the unknown nodes , the set of unknown nodes, such that and . All the unknown nodes in the set U are the one-hop neighbors of any anchor node present in the CDS such that , the set of anchor nodes , and , where D is the dominating set.
The proposed network model is mobile in nature for both the anchor nodes and unknown nodes. Relative mobility is required to be calculated to check the mobility direction and the relative distances. The relative mobility between an unknown node
with respect to anchor node
at a given time
t is given by:
where
=
and
is the power received by the receiving antenna and is calculated by the Friis space model [
36].
k is constant here.
is used to calculate the distance and closeness between two nodes.
is positive if node
u is moving away from
a and negative if
u is coming closer to
a. This relative mobility effects the CDS generation and further the related vectors. This relative mobility is used to generate the updated distance matrices for location estimation.
4. Vector-Based Swarm Optimized CDS
Our proposed algorithm considers the following assumptions:
The anchor nodes are preinstalled with their own location, also known to the base station (BS).
The base station can control all the anchor and unknown nodes. Multiple base stations are allowed, depending on the range of communication.
Unknown nodes and anchor nodes have random mobility.
According to the privilege concern, BS is the most privileged in terms of storage and resource. Anchor nodes are more privileged, compared to unknown nodes. Therefore, the maximum computing tasks are controlled by BS; anchor nodes and unknown nodes are kept only with a minimum message exchange process. One BS broadcasts the aggregated information to other BS.
The proposed method starts with broadcasting by anchor nodes which have more privileges than the resource constrained unknown nodes. The anchor nodes broadcast the neighbor discovery packet (NDP) as per the following format.
where
is the source address of the anchor node,
is set to 1 to bound the packet with a limited transmission of one-hop nodes, Seq is the sequence number of the NDP to avoid void routing and stale of packets, and
is the status of the acceptance of the NDP by an unknown node set at 0. It may happen that in this process of broadcast, another anchor node receives the NDP, in which case, the receiving anchor node will simply discard the NDP. Once this NDP is received by the unknown nodes who are in the one-hop neighborhood of the sender, the unknown nodes reply with a reply neighbor set (RPNS) by decrementing the leash value by 1 and changing the acceptance status to 1. The RPNS is composed of the following components.
Upon receiving the RPNS, the anchor nodes enlist the
as its one-hop neighbor in a neighbor set list (NSL) and send it to the base station (BS) with cryptographic services so that the list cannot be manipulated by any third party attack or compromised insider node.
After receiving all the NSLs from the anchor nodes, BS calculates the maximum degree anchor node and enlists the anchor node in an empty dominating set D. This operation iterates until at least three anchor nodes are in the dominating set and all the unknown nodes are a one-hop neighbor of at least one of the anchor nodes in the set of anchor nodes A. The process outputs a connected dominating set (CDS), but the problem is the anchor nodes are unbalanced in terms of number connections with unknown nodes. To solve this problem, swarm optimization is performed on the CDS. BS creates binary vector for each of the anchor nodes present in the CDS and vector-based swarm optimization is applied for the best solution to achieve an optimized CDS for the backbone. All these n-bit binary vectors (as number of unknown nodes is n) create the initial population of swarm. Fitness value is calculated on each of these vectors and direct and indirect cooperation is calculated. After mutation on the initial population of vectors, boundary values are checked and selection starts again for the next iteration. If the convergence condition is met successfully, we get the output of the best-fit solution for our purpose. Once we get the optimized dominating set, trilateration is performed to get the location of unknown nodes. The algorithm is summarized in Algorithm 1.
| Algorithm 1 Proposed Localization Algorithm |
- 1:
procedure Anchor nodes and unknown nodes - 2:
Initialize and and dominating set - 3:
for Broadcast by anchor node do - 4:
Send - 5:
end for - 6:
for On receiving, node computes do - 7:
Leash_C = Leash_C - 1; - 8:
Accept_S = 1; - 9:
Send - 10:
end for - 11:
if then - 12:
Create - 13:
- 14:
else - 15:
exit - 16:
end if - 17:
BS performs: - 18:
while True do - 19:
if then - 20:
Break while loop; - 21:
else - 22:
Calculate the maximum degree anchor nodes - 23:
- 24:
end if - 25:
end while - 26:
- 27:
for k = 1 to m’ do - 28:
BS creates binary vector - 29:
Apply algorithm - 30:
Apply Trilateration - 31:
end for - 32:
end procedure
|
5. Optimization Process with VBSO
To optimize the obtained CDS, we have applied vector-based swarm optimization (VBSO) on the obtained CDS. The solution for optimizing the CDS exhibits the features of the maximization problem. To solve this problem, we considered the connections of anchor nodes in the CDS with their corresponding one-hop neighboring unknown nodes as n-dimensional vector . The proposed method provides a global maximization solution, which is formulated as a pair , where is a bounded set on and is n dimensional real valued function. The domain of function f is considered the search space. We have to find a point so that is a global maximum on . Thus, each element x of is considered a candidate solution in the defined search space with being optimal such that . The optimization process for CDS with VBSO algorithm has been summarized in Algorithm 2.
5.1. Initialization of Vectors
Each unknown node in the network is allocated to one of the anchor nodes in the CDS. Each anchor node and its connections with one-hop neighboring unknown nodes is represented by an n-dimensional binary vector , where is the number of anchor nodes in CDS and .
Let us consider the scenario shown in
Figure 1. The scenario consists of five anchor nodes and twelve unknown nodes. The blue circles represent anchor nodes, green circle nodes represent unknown nodes, blue solid lines represent a CDS and green solid lines represent the connection between an anchor node of CDS and unknown node in the network. As per our algorithm, we require at least three anchor nodes in the CDS to calculate a location with the trilateration process. Therefore, anchor nodes 1, 2, and 3 create the required CDS for the purpose for which the vector representation (V1, V2, and V3) is shown in
Figure 2. These vectors are considered parent vectors for the VBSO algorithm. The vector representation for each anchor node is formulated as:
5.2. Calculate the Fitness Vector
The formulation of the fitness function is a critical and important task in the optimization process, as it helps for fast convergence with the optimum solution. To formulate the fitness function, we have used two parameters, which are also considered in our previous work [
37].
Dominating set value for the connected dominating set D given as: , where is the degree of each dominator anchor node in the set D and is the mean of all the degrees of the dominator in the set D. The calculation of allocation scheme value: | considers that there are disjointed sets for anchor nodes present in the set D, such that and so that . here represents the neighborhood. is the valid degree of an anchor node , i.e., the number of unknown nodes already allocated to the anchor node .
The objective of the problem defined in this paper is to identify an optimized CDS with minimum
and
values. Therefore, the fitness function can be given as:
The linear combination of the two metrics and is made to adjust the bias factors and , according to the network environment. The above equation emphasizes that to maximize the fitness function for achieving optimum value, the denominator needs to be minimized and the numerator needs to be maximized so that the overall fitness function will be maximized accordingly. The experimented value of = 2, as it is analogous for an electro static field.
5.3. Reproduction in VBSO
The reproduction method in the VBSO algorithm primarily depends on creating cooperation vectors. Multiple vectors in the search space are combined with vector operations to achieve the cooperation vector.
The direct cooperation vector and differential cooperation vectors are used to create a cooperation vector. The direct cooperation vector at the kth iteration is given by:
where
,
,
belongs to the initial population vectors,
is the best vector in the neighborhood, and
is the random vector and
+
+
+
+
=1. These values are called cooperative weighting coefficients (CWC).
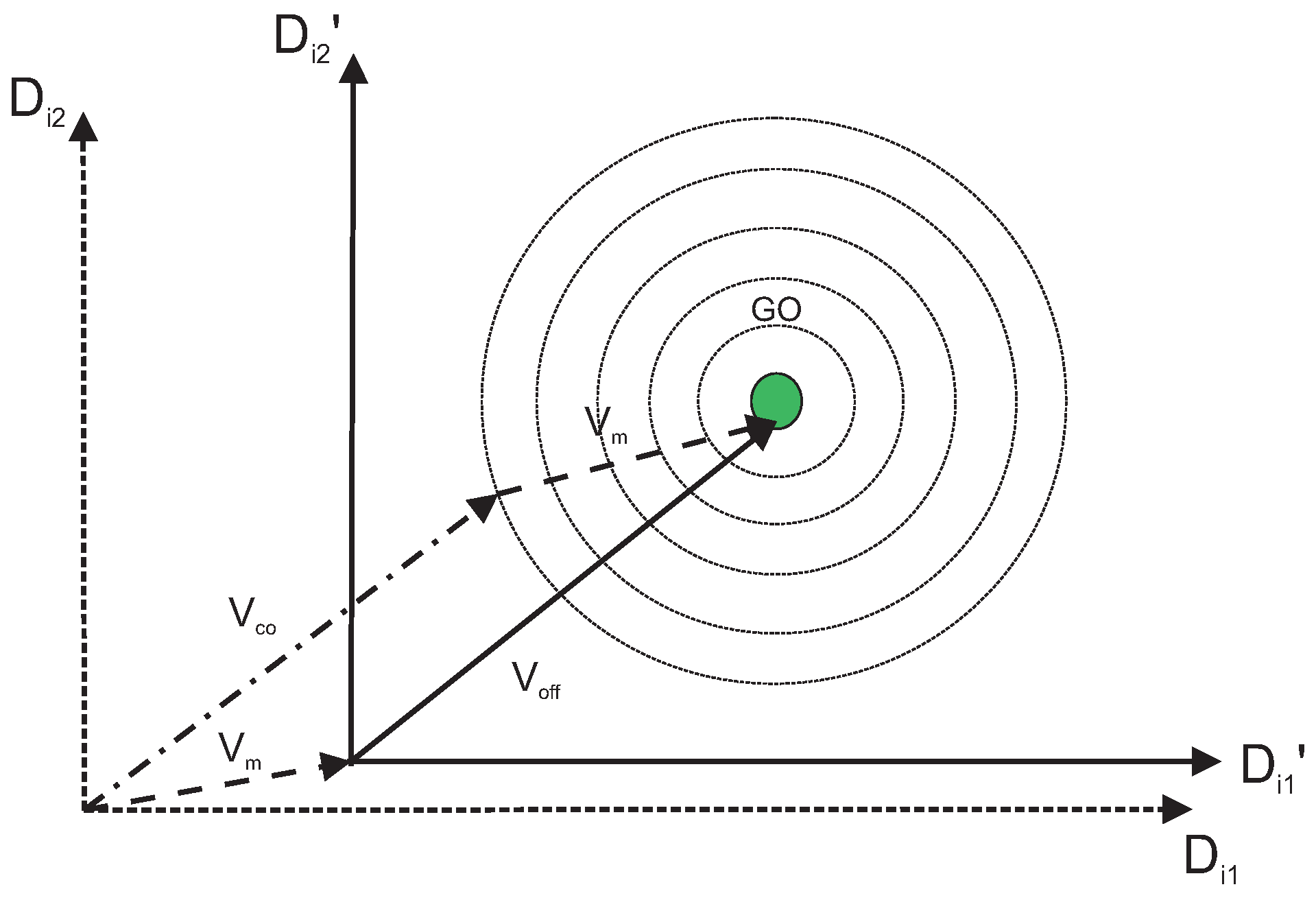
Figure 3 represents a direct cooperation vector with
and
which actually outputs the global optimum (GO). Following the same line,
Figure 4 represents another direct cooperation vector with
,
,
m and
.
For the scenario of more than three initial population vectors, the selection of three among them is another crucial part which depends on higher fitness values and with a higher probability of selection. The probability is therefore given as:
The differential cooperation vector signifies the search around direct cooperation vector. It helps the algorithm to pass local optimums and converge to global one, as shown in
Figure 5. Direct cooperation vectors provide a local solution, whereas the differential cooperation vector uses these direct vectors to get the global optimal solution, which is as good or better than all the other feasible solutions. To obtain the unknown global optimum, we have followed
k iterations, in which if two simultaneous iterations have output the same values of local optima, we have considered it the global optimum. The differential cooperation vector (
) of the population is calculated by considering proper portions of differential vectors of a current solution, for example
, given as:
Figure 6 shows the generation of the cooperation vector obtained from direct and differential cooperation vectors, which can be given as:
5.4. Mutation
To increase the diversity of the population, mutation is applied to the initial population vectors. A number of mutation operators have been suggested in Reference [
38,
39,
40]. Applying direct and differential cooperation implicitly provide mutation in the process. In addition, a second mutation is also applied to transfer the search space origin to a point far enough from the current origin. A random mutation probability
is selected. A random number r is generated and then compared with
. The second mutation is applied if
and
is in
. In the mutation process, the random bits in a vector
are flipped to get the mutation vector
. The candidate offspring vector
is obtained by the following equation, and also shown in
Figure 7:
5.5. Boundary Check
After the mutation, new offspring vectors are checked for the boundary condition so that all the offsprings must belong to the search space. An invalid offspring can lead to ab uncoordinated and invalidated search and the convergence will become a delay. Different methods are shown in References [
41,
42]. We have used the boundary check with a fitness function. If the fitness function of a vector in the current iteration is smaller than the fitness function of the best vector in the previous iteration, then replace the current unfit vector with its parent vector. The formulation of this process is given as:
For example, considering the scenario of
Figure 2, the fitness value of the best solution is 5.89 (considering
and
(analogy to electro static field). After reproduction and mutation, we have got the offspring vector as in
Figure 8.
The candidate offspring has a fitness value of 0.278, which is less than the previous best solution of 5.89. Therefore, we need to replace this candidate with one of the parents of the previous iteration by calculating the hamming distance. This vector has a hamming distance of 3, 6, and 9 from the initial parent vectors , , and , respectively. Thus, this candidate offspring will be replaced by vector that corresponds to . This process of retaining the parent of best solution helps to converge faster to the global optimum.
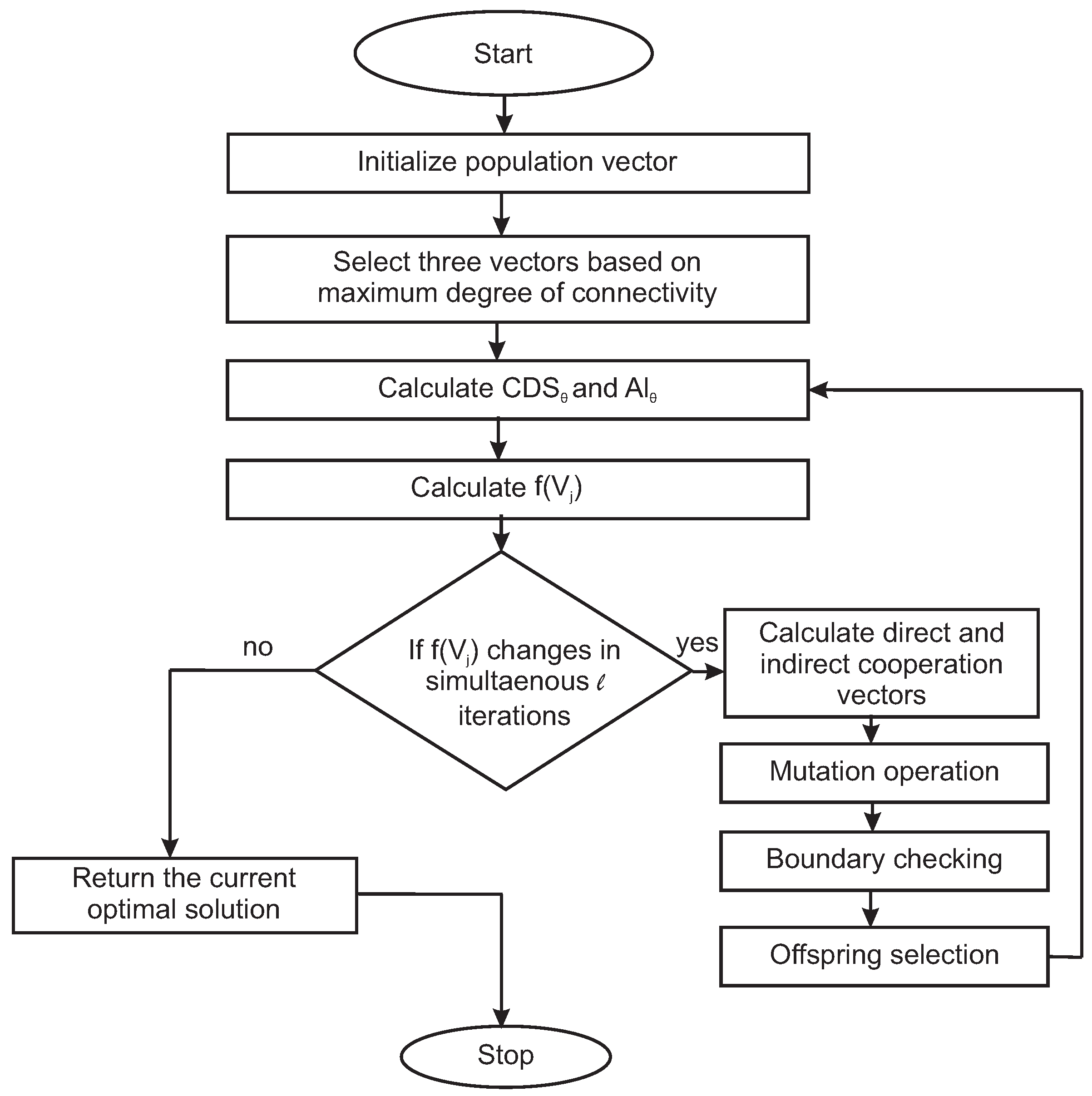
5.6. Selection of Offsprings
The identification of the next iteration vectors requires a selection process for suitable offspring vectors. Various methods of selection have been discussed in References [
38,
43,
44]. In our proposed approach, all the valid candidate offsprings are directly transferred to the next iteration. The overall process of the vector-based optimization approach used in our purpose has been summarized in Algorithm 2. The convergence process of the optimization method is depicted in the form of a flowchart in
Figure 9.
| Algorithm 2 VBSO Algorithm on CDS |
- 1:
procedure vector - 2:
while does not change successive l iterations do - 3:
Calculate - 4:
Calculate expected allocated neighbour values as: - 5:
Calculate the allocation value given as: - 6:
Calculate - 7:
if does not change in simultaneously l iterations then - 8:
goto Step 15 - 9:
else - 10:
Calculate direct and indirect cooperation vectors - 11:
Apply mutation - 12:
Check boundary condition - 13:
Selection of offsprings for next iteration - 14:
goto 6 - 15:
return the current optimal solution - 16:
end if - 17:
end while - 18:
end procedure
|
6. Localization of Unknown Nodes
Once the optimized CDS is achieved, we can apply any trilateration method to estimate the location of an unknown node
. The estimated distance
from an unknown node
to each dominator anchor node in optimized CDS is given by the respective Euclidean distances between them, as shown below.
where
is the estimated location of an unknown node of
.
The calculated distance with relative mobility becomes:
The above equation for
can be transformed into the
form, where:
Equation
is solvable by the standards of the least-square [
45] solution to provide the value of
x given by:
The problems identified in the existing algorithms as stated in the section of related work have been addressed by our proposed solution and summarized in
Table 1.
7. Result and Analysis
The proposed algorithm has been simulated in NS-2 with the following parameters enlisted in the
Table 2.
The performance of the algorithm has been analyzed in the terms of localization error and network lifetime and number of iterations used to provide the global optimum solution. The location estimation error is defined as a squared error of the estimation and is given by:
where
is the estimated distance and
is the true distance between unknown node
and anchor node
. The average error is given as:
The statistical values of localization errors for our different simulation environment are shown in
Table 3. Results are shown for the variable number of anchor nodes ranging from 10 to 40, with unknown nodes ranging from 100 to 200. The table also represents the number of anchor nodes used in the VBSO-optimized CDS, by which the given number of unknown nodes has been localized. The result signifies the fact that only 50% to 57% of all the anchor nodes are used. This means that the unused anchor nodes can save their energy for future tasks, which actually elongates the network lifetime.
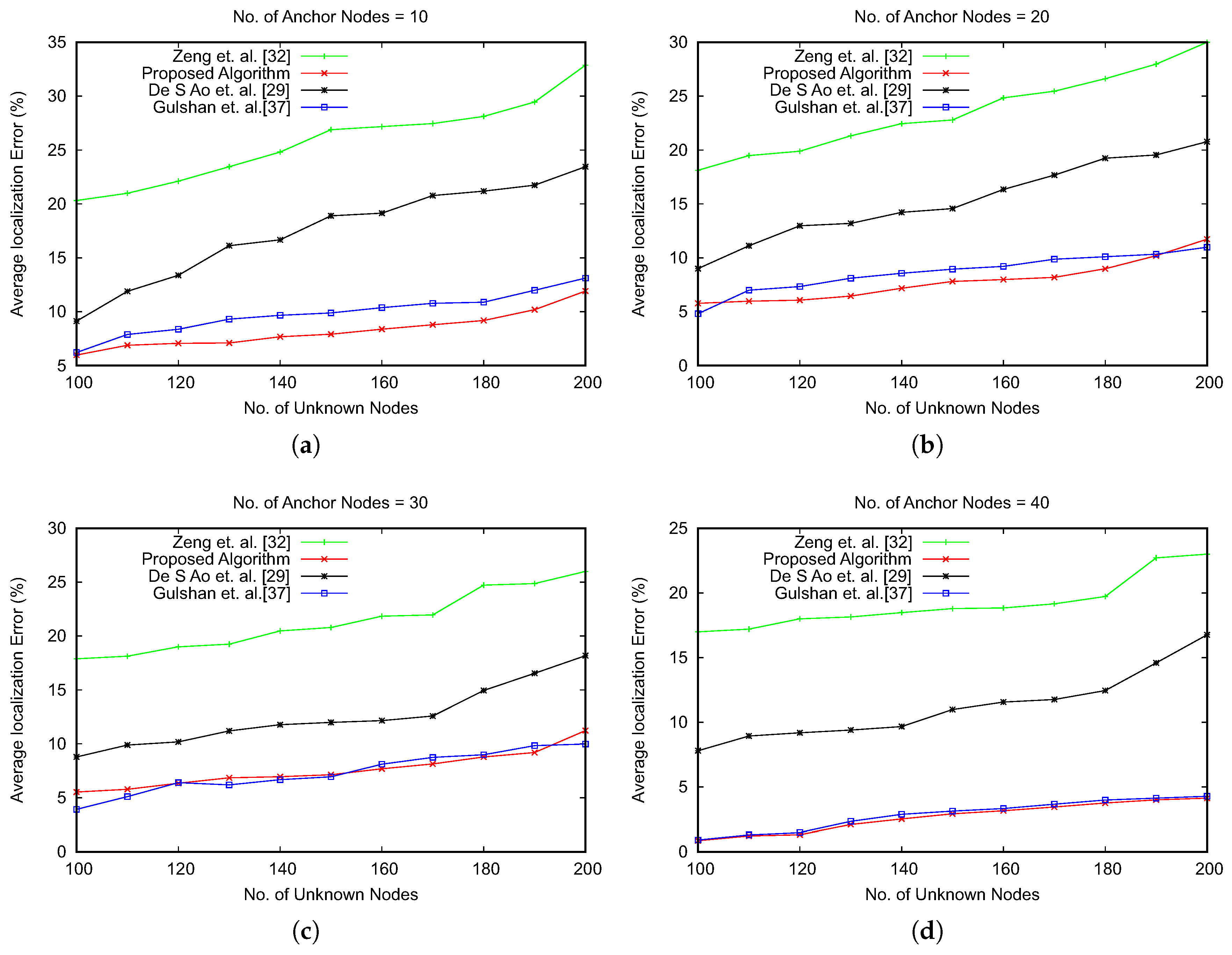
The results of the average localization error have also been compared with three recent optimization-based approaches, as shown in References [
29,
32,
37]. The comparison results are shown in
Figure 10. The results emphasize that our proposed approach reduces the average error for localization of unknown nodes. We have observed that with the increasing number of anchor nodes, the proposed algorithm and the work in Reference [
37] have a marginal difference of average localization error. However, the advantage of the proposed algorithm lies with the number of iterations for obtaining the global optimum, as shown in
Figure 11. The optimization algorithms consider the number of iterations in searching the global optima as an important performance metric. We have compared the number of iterations executed by varying the number of anchor nodes and unknown nodes.
Figure 11 shows the results of comparison, which signify that our proposed algorithm is faster in providing the global optimum value with a lower number of iterations of the optimization process.
The objective of the proposed algorithm is to elongate the network lifetime. Therefore, we have also evaluated the performance of the proposed algorithm in terms of residual energy. The proposed algorithm uses a linear energy model. The overall residual energy of the proposed optimized CDS depends on the constituents, i.e., the dominator anchor nodes. We have considered a timeline, say
t1 to
t2, for this energy consumption measurement. Residual energy in time
t is defined by omitting consumed energy in
from the initial battery power in
. Thus, the energy consumption is determined in
. Therefore, the residual energy equation is given as:
With the minimum usage of message exchange between anchor nodes and unknown nodes and the handing over the optimization and localization tasks on BS, our proposed approach significantly improves the residual energy of the overall network scenario.
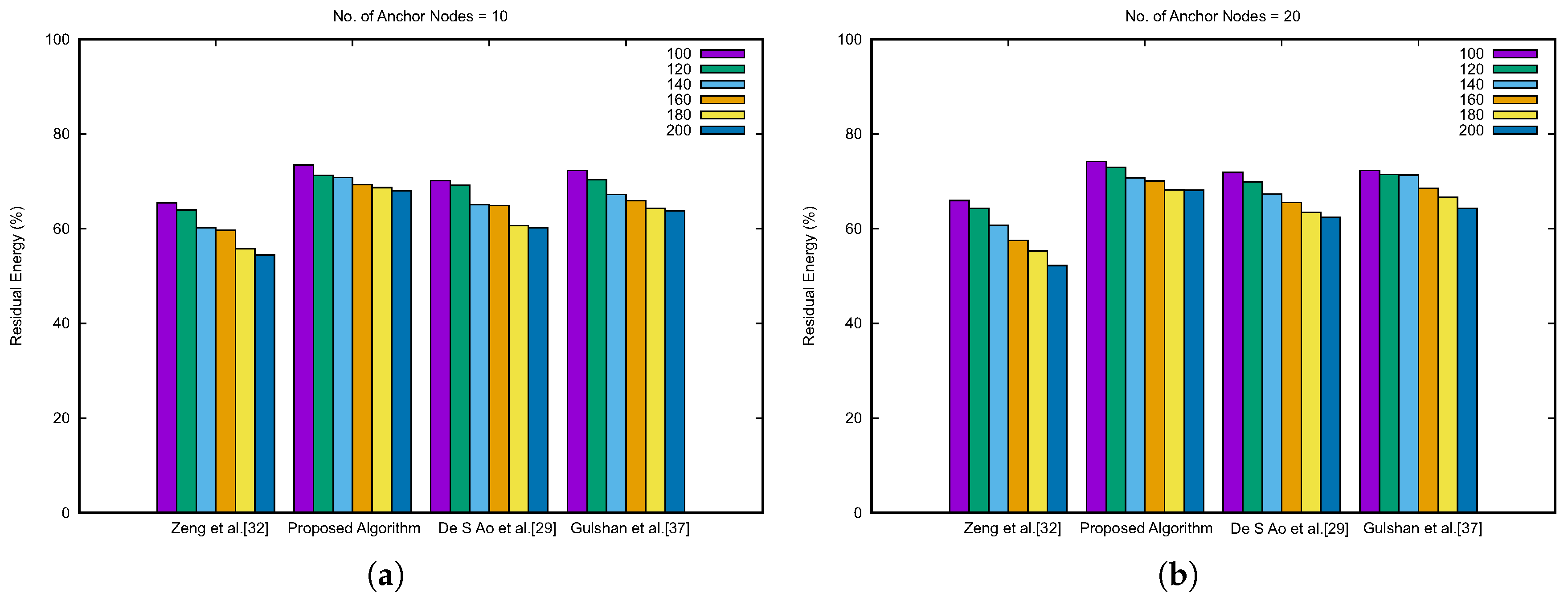
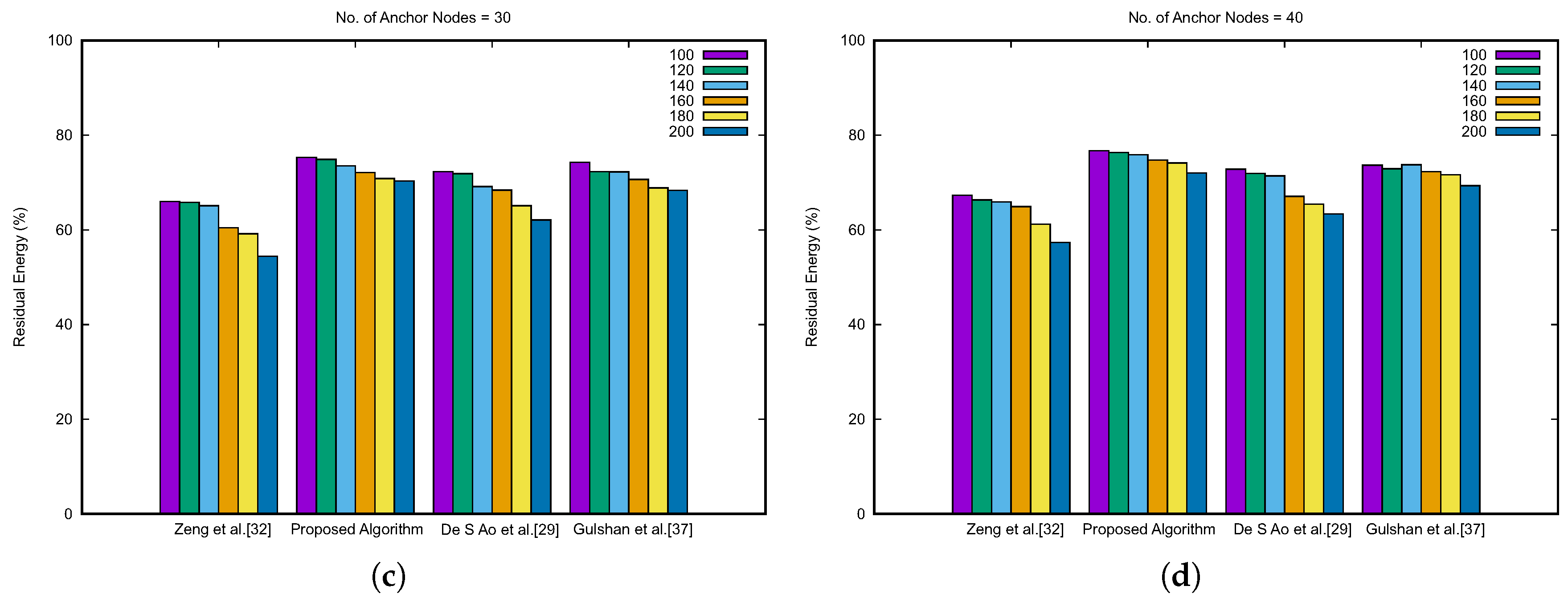
Figure 12 describes the result for the network lifetime comparison. The data are represented by varying the anchor nodes from 10 to 40. The data are plotted for a number of unknown nodes vs. the percentage of residual energy. In all the circumstances as shown in
Figure 12, the percentage of residual energy for our proposed algorithm is higher than the other algorithms in comparison. Moreover, it shows an effective point for our proposed algorithm: With the increasing number of anchor nodes, the energy residual amount also increases. This signifies that the load is balanced and distributed, for which overall residual energy increases. Furthermore, we have analyzed the complexity of algorithms, which are compared in
Table 4, where
m is the number of anchor nodes used for localization and
n is the number of unknown nodes.
8. Conclusions
In the present study, a novel algorithm is proposed to optimize anchor nodes in CDS. In this case, the algorithm used random mobility for both the anchor as well as unknown nodes and BS was considered to perform the major tasks, such as optimization of CDS, localization with optimized CDS, etc. The vector-based swarm method used for optimization process converges to the global optima rather than the local optima. By keeping anchor nodes and unknown nodes to a minimum working level, traffic overload in the network and message-processing functions are substantially reduced. The localization process is executed with a transformation matrix of nonlinear equations and applying the standard least-square method. The simulated results were compared with recent algorithms. The accuracy and network lifetime are approximately 30% and 67%, respectively, better than the other compared approaches. This algorithm can be used in a dynamic environment, as it converges to the global optimum solution with a lower number of iterations. Additionally, the method is scalable and works with different network sizes, which makes it adaptable to various applications.

 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}