Three-Dimensional Visualization System with Spatial Information for Navigation of Tele-Operated Robots


Abstract
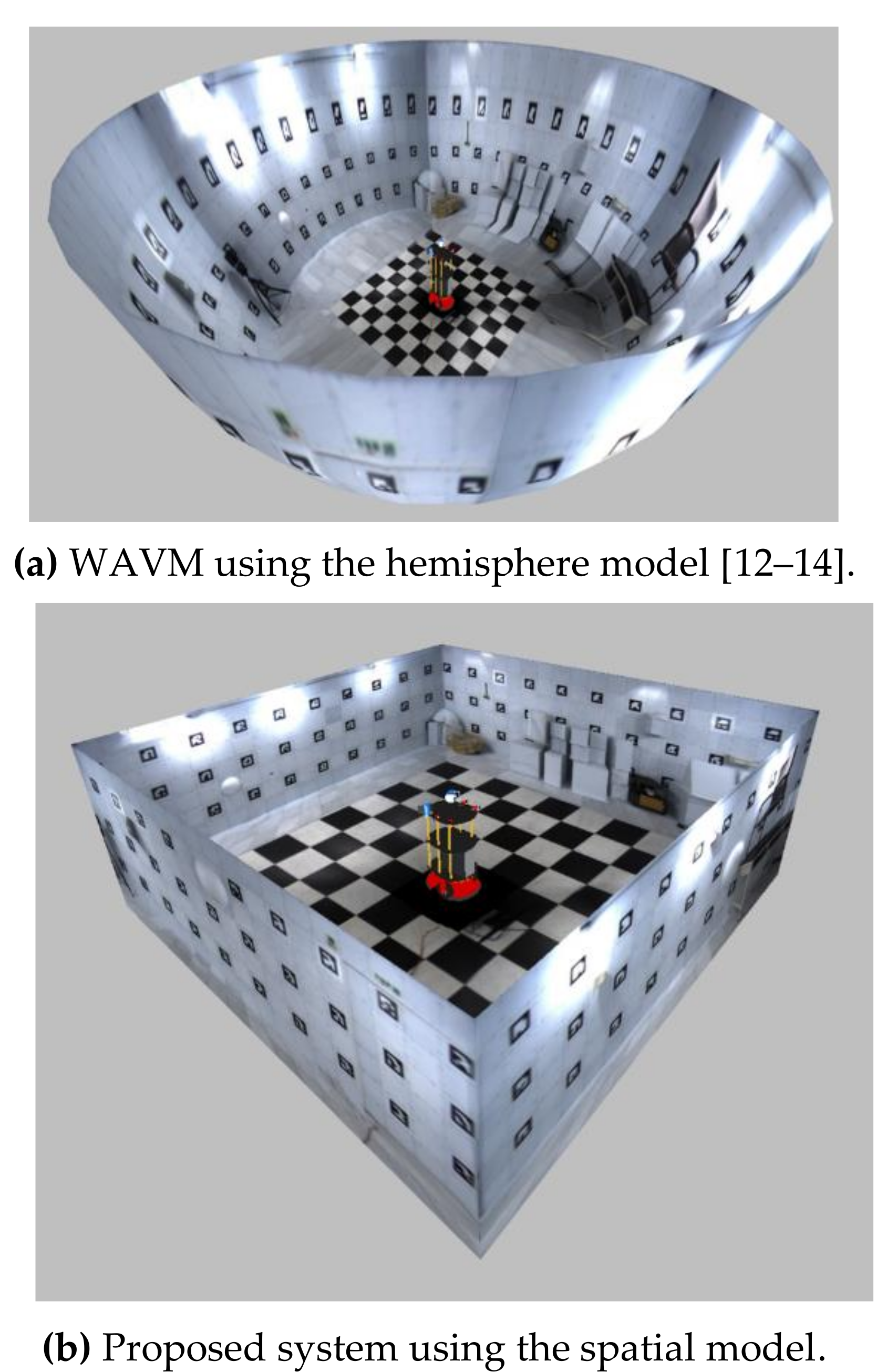
:1. Introduction
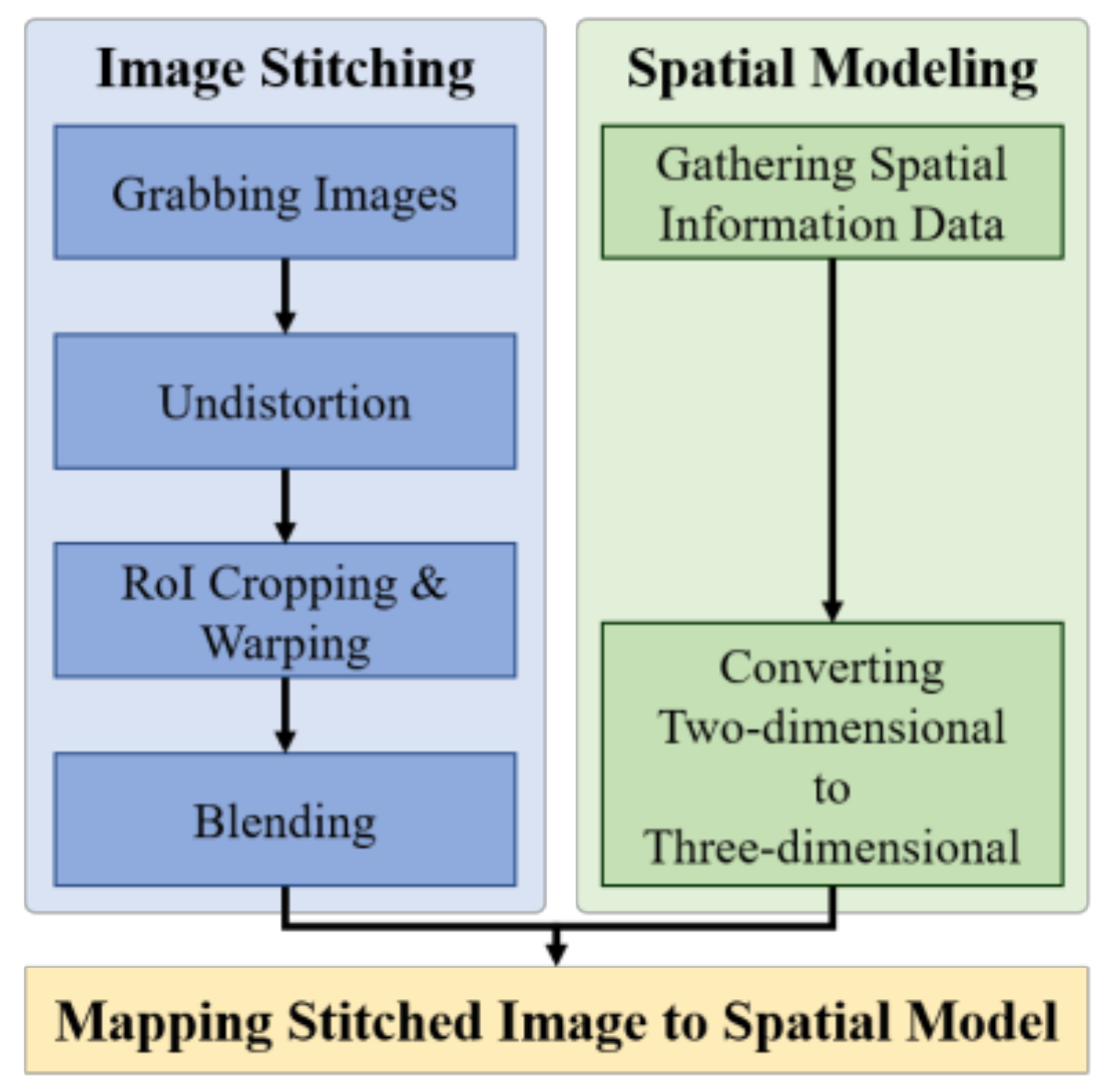
2. Proposed Method
2.1. Image Stitching
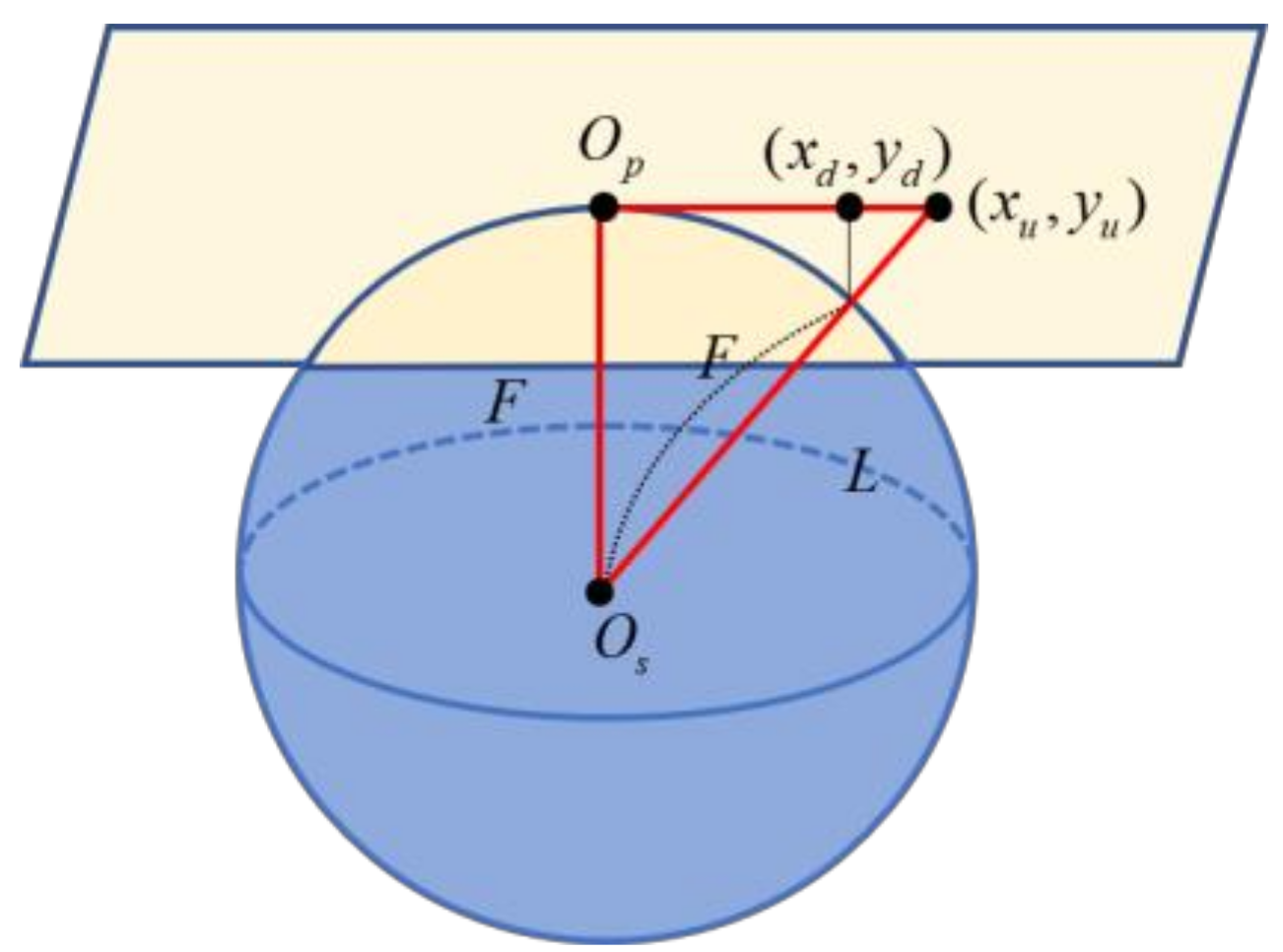
2.1.1. Undistortion
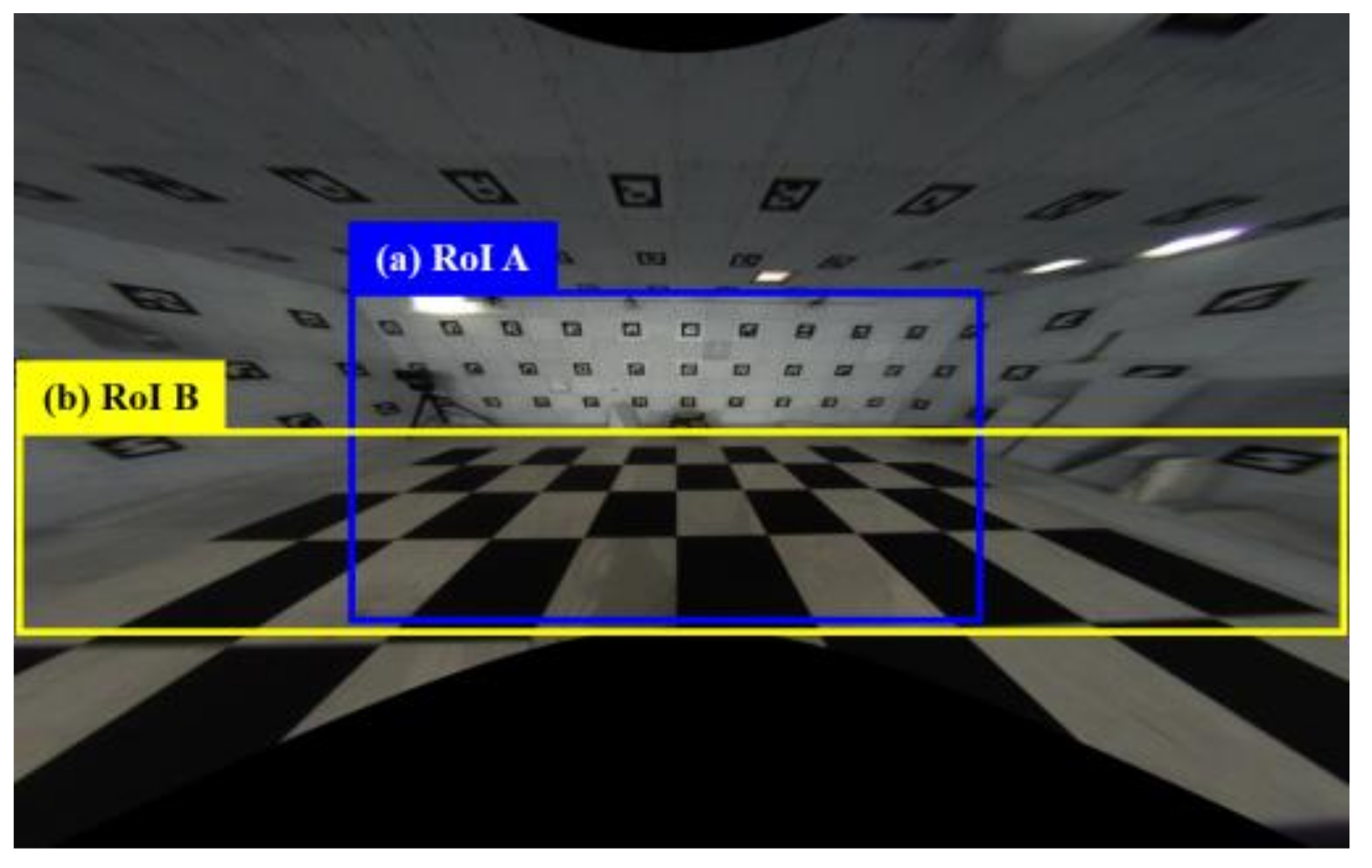
2.1.2. RoI Cropping and Warping
2.1.3. Blending
2.1.4. Acceleration for Image Stitching
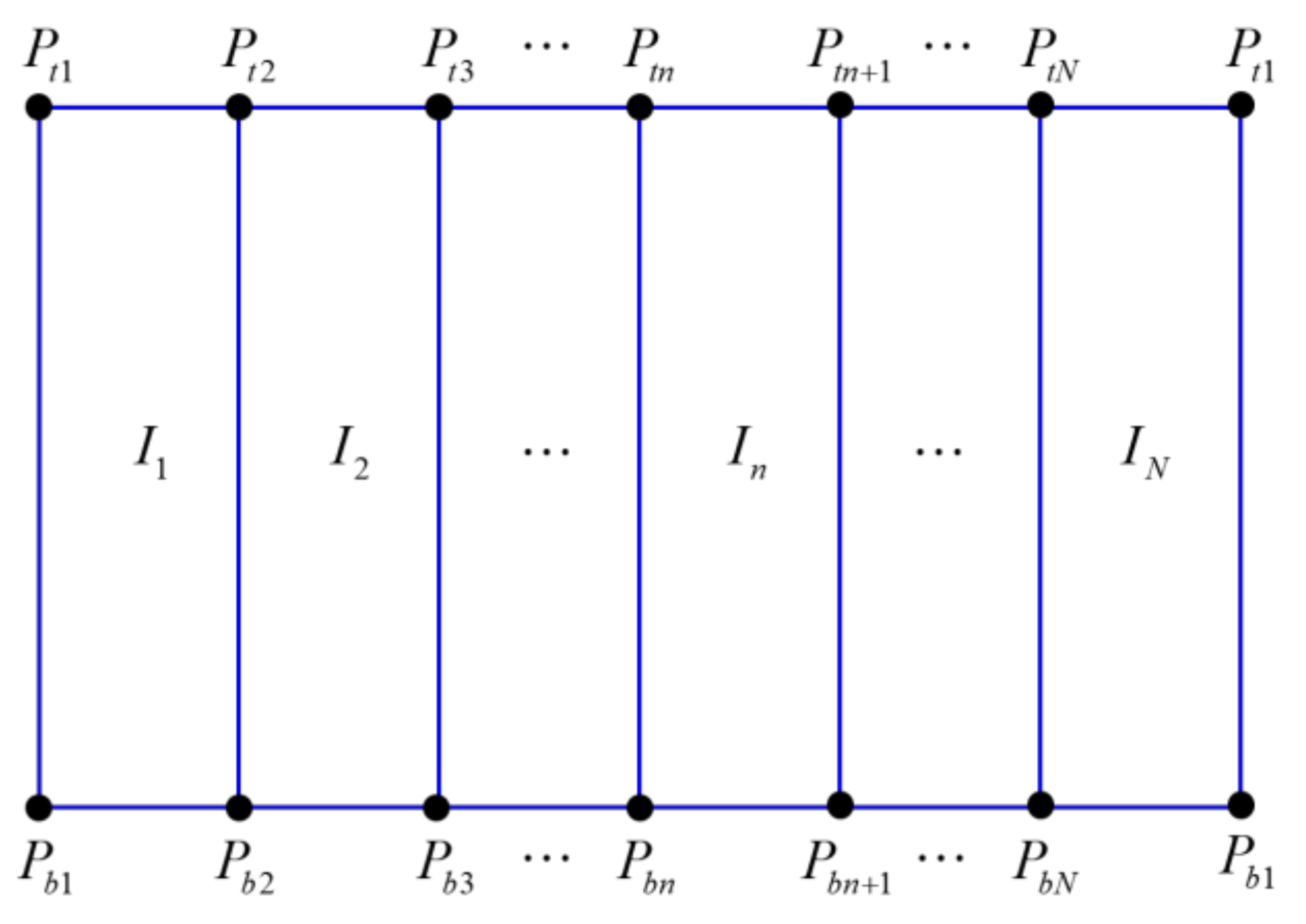
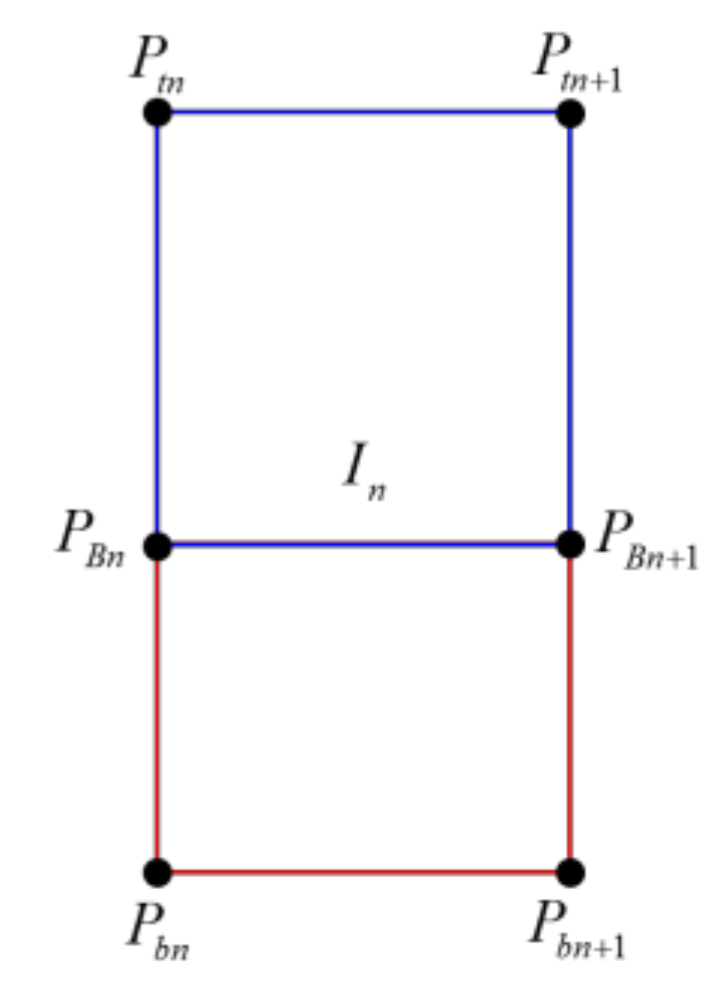
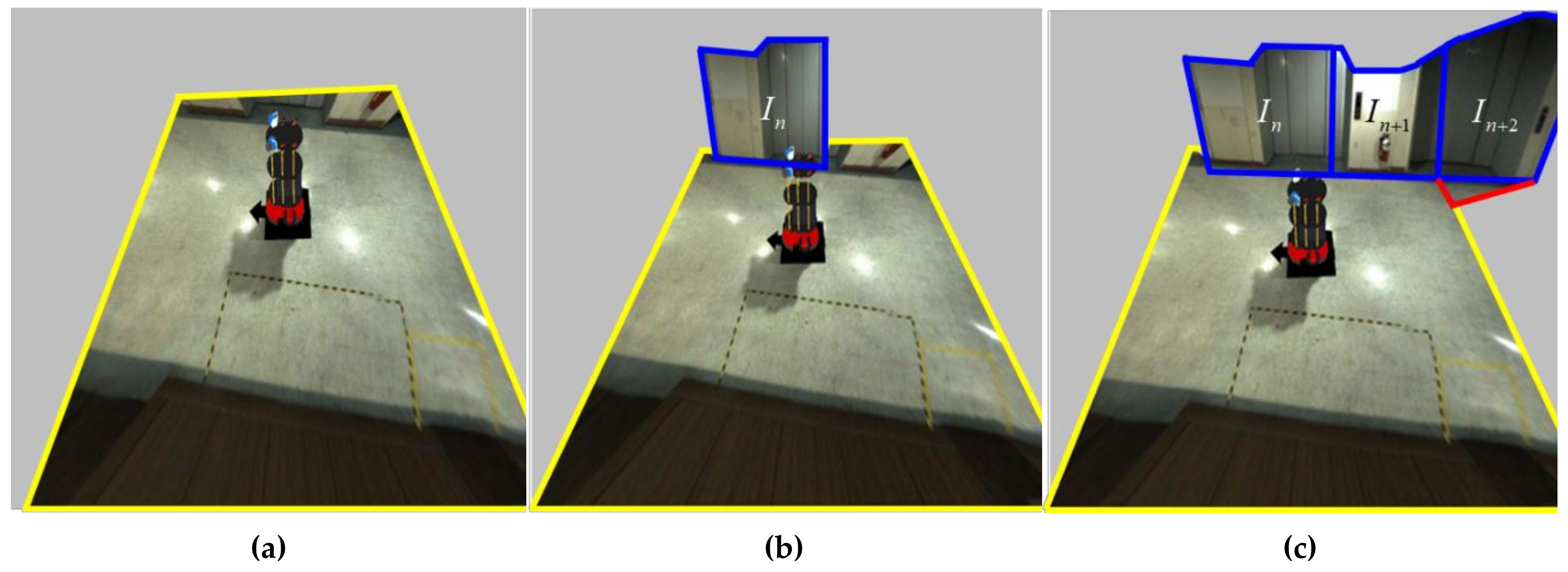
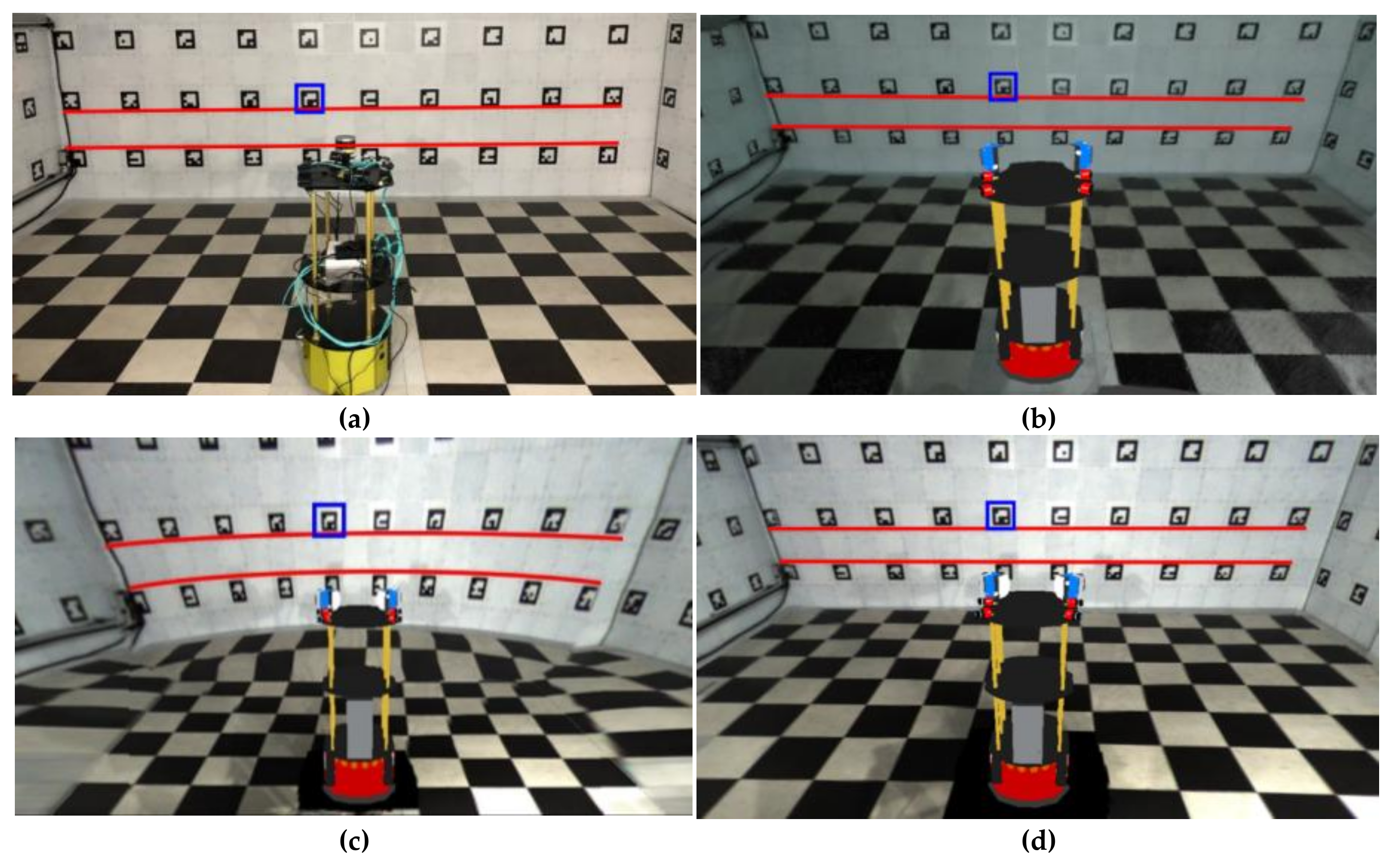
2.2. Spatial Modeling
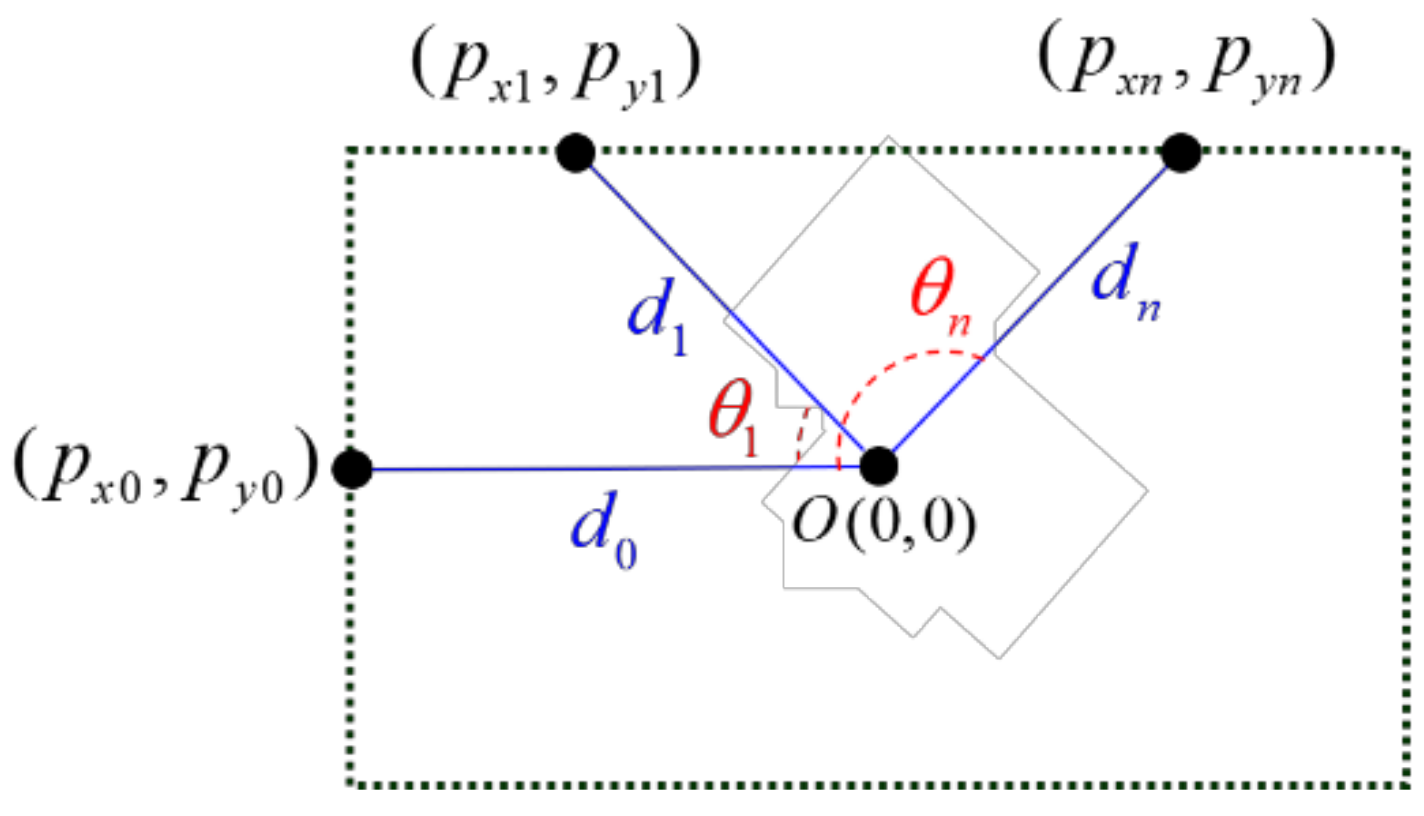
2.2.1. Gathering Spatial Information Data
2.2.2. Converting 2D Points to 3D Points
2.3. Mapping the Stitched Image to the Spatial Model
3. Experimental Results
3.1. Subjective Comparative Experiment
3.2. Objective Comparative Experiment
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lin, W.; Hu, J.; Xu, H.; Ye, C.; Ye, X.; Li, Z. Graph-based SLAM in indoor environment using corner feature from laser sensor. In Proceedings of the IEEE Youth Academic Annual Conference of Chinese Association of Automation, Hefei, China, 19–21 May 2017; pp. 1211–1216. [Google Scholar]
- Cheng, Y.; Bai, J.; Xiu, C. Improved RGB-D vision SLAM algorithm for mobile robot. In Proceedings of the Chinese Control and Decision Conference, Chongqing, China, 28–30 May 2017; pp. 5419–5423. [Google Scholar]
- Yuan, W.; Li, Z.; Su, C.-Y. RGB-D Sensor-based Visual SLAM for Localization and Navigation of Indoor Mobile Robot. In Proceedings of the IEEE International Conference on Advanced Robotics and Mechatronics, Macau, China, 18–20 August 2016; pp. 82–87. [Google Scholar]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Huang, S.; Zhao, L.; Ge, J.; He, S.; Zhang, C.; Wang, X. High Quality 3D Reconstruction of Indoor Environments using RGB-D Sensors. In Proceedings of the IEEE Conference on Industrial Electronics and Applications, Siem Reap, Cambodia, 18–20 June 2017. [Google Scholar]
- Choi, S.; Zhou, Q.-Y.; Koltun, V. Robust Reconstruction of Indoor Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chen, J.; Bautembach, D.; Izadi, S. Scalable real-time volumetric surface reconstruction. ACM Trans. Graph. 2013, 32, 113. [Google Scholar] [CrossRef]
- Lin, C.-C.; Wang, M.-S. Topview Transform Model for the Vehicle Parking Assistance System. In Proceedings of the 2010 International Computer Symposium, Tainan, Taiwan, 16–18 December 2010; pp. 306–311. [Google Scholar]
- Jia, M.; Sun, Y.; Wang, J. Obstacle Detection in Stereo Bird’s Eye View Images. In Proceedings of the 2014 Information Technology and Artificial Intelligence Conference, Chongqing, China, 20–21 December 2014; pp. 254–257. [Google Scholar]
- Awashima, Y.; Komatsu, R.; Fujii, H.; Tamura, Y.; Yamashita, A.; Asama, H. Visualization of Obstacles on Bird’s-eye View Using Depth Sensor for Remote Controlled Robot. In Proceedings of the 2017 International Workshop on Advanced Image Technology, Penang, Malaysia, 6–8 January 2017. [Google Scholar]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Shin, J.H.; Nam, D.H.; Kwon, G.J. Non-Metric Fish-Eye Lens Distortion Correction Using Ellipsoid Model; Human Computer Interaction Korea: Seoul, Korea, 2005; pp. 83–89. [Google Scholar]
- Sung, K.; Lee, J.; An, J.; Chang, E. Development of Image Synthesis Algorithm with Multi-Camera. In Proceedings of the IEEE Vehicular Technology Conference, Yokohama, Japan, 6–9 May 2012; pp. 1–5. [Google Scholar]
- Triggs, B.; Mclauchlan, P.F.; Hartley, R.I.; FitzGibbon, A.W. Bundle adjustment—A modern synthesis. In International Workshop on Vision Algorithms; Springer: Berlin/Heidelberg, Germany, 1999; pp. 298–375. [Google Scholar]
- Yebes, J.J.; Alcantarilla, P.F.; Bergasa, L.M.; Gonzalez, A.; Almazan, J. Surrounding View for Enhancing Safety on Vehicles. In Proceedings of the IEEE Intelligent Vehicles Symposium Workshops, Alcal de Henares, Madrid, Spain, 3–7 June 2012; pp. 92–95. [Google Scholar]
- Salomon, D. Transformations and Projections in Computer Graphics; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Labbe, M.; Michaud, F. Online Global Loop Closure Detection for Large-Scale Multi-Session Graph-Based SLAM. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 2661–2666. [Google Scholar]
- Labbe, M.; Michaud, F. Appearance-Based Loop Closure Detection for Online Large-Scale and Long-Term Operation. IEEE Trans. Robot. 2013, 29, 734–745. [Google Scholar] [CrossRef]
- Labbe, M.; Michaud, F. Memory management for real-time appearance-based loop closure detection. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and System, San Francisco, CA, USA, 25–30 September 2011; pp. 1271–1276. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.-H.; Jung, C.; Park, J. Three-Dimensional Visualization System with Spatial Information for Navigation of Tele-Operated Robots. Sensors 2019, 19, 746. https://doi.org/10.3390/s19030746
Kim S-H, Jung C, Park J. Three-Dimensional Visualization System with Spatial Information for Navigation of Tele-Operated Robots. Sensors. 2019; 19(3):746. https://doi.org/10.3390/s19030746
Chicago/Turabian StyleKim, Seung-Hun, Chansung Jung, and Jaeheung Park. 2019. "Three-Dimensional Visualization System with Spatial Information for Navigation of Tele-Operated Robots" Sensors 19, no. 3: 746. https://doi.org/10.3390/s19030746
APA StyleKim, S. -H., Jung, C., & Park, J. (2019). Three-Dimensional Visualization System with Spatial Information for Navigation of Tele-Operated Robots. Sensors, 19(3), 746. https://doi.org/10.3390/s19030746