The Optimally Designed Variational Autoencoder Networks for Clustering and Recovery of Incomplete Multimedia Data


Abstract
:1. Introduction
2. Preliminaries
2.1. Variational Autoencoder
2.2. Fuzzy C-Means Algorithm (FCM)
3. Problem Formulation and Proposed Method
- Learning the features of incomplete data: feature extraction and analysis are the basic steps of clustering. In general, many feature extraction methods, such as machine learning and deep learning, have been successfully applied to image, text, and audio feature learning. However, the current algorithm focuses on feature learning and extraction of high quality data. In other words, they can not effectively extract the features of lossy data. Therefore, feature learning of incomplete data is the primary problem of heterogeneous data clustering.
- Clustering in feature space: an important feature of large-scale multimedia data is its diversity, which means that large-scale data sources are diverse, including structured, unstructured data and semi-structured data from a large number of sources. In particular, a large number of objects in large data sets are multi-model. For example, web pages usually contain both images and text. Each mode of multimodal object has its own characteristics, which leads to the complexity of data. Therefore, the feature representation of multimedia data is significant in cluster tasks.
- Filling missing values to reconstruct data: in wireless multimedia sensor networks, reliable data transmission is critical to provide the ideal quality of network-based services. However, multimedia data transmission may not be successful due to different reasons such as sensory errors, connection errors, or external attacks. These problems can result in incomplete data and degrade the performance of WMSNS applications. After feature extraction and cluster analysis, it is very important to recover missing data from the sensor network.
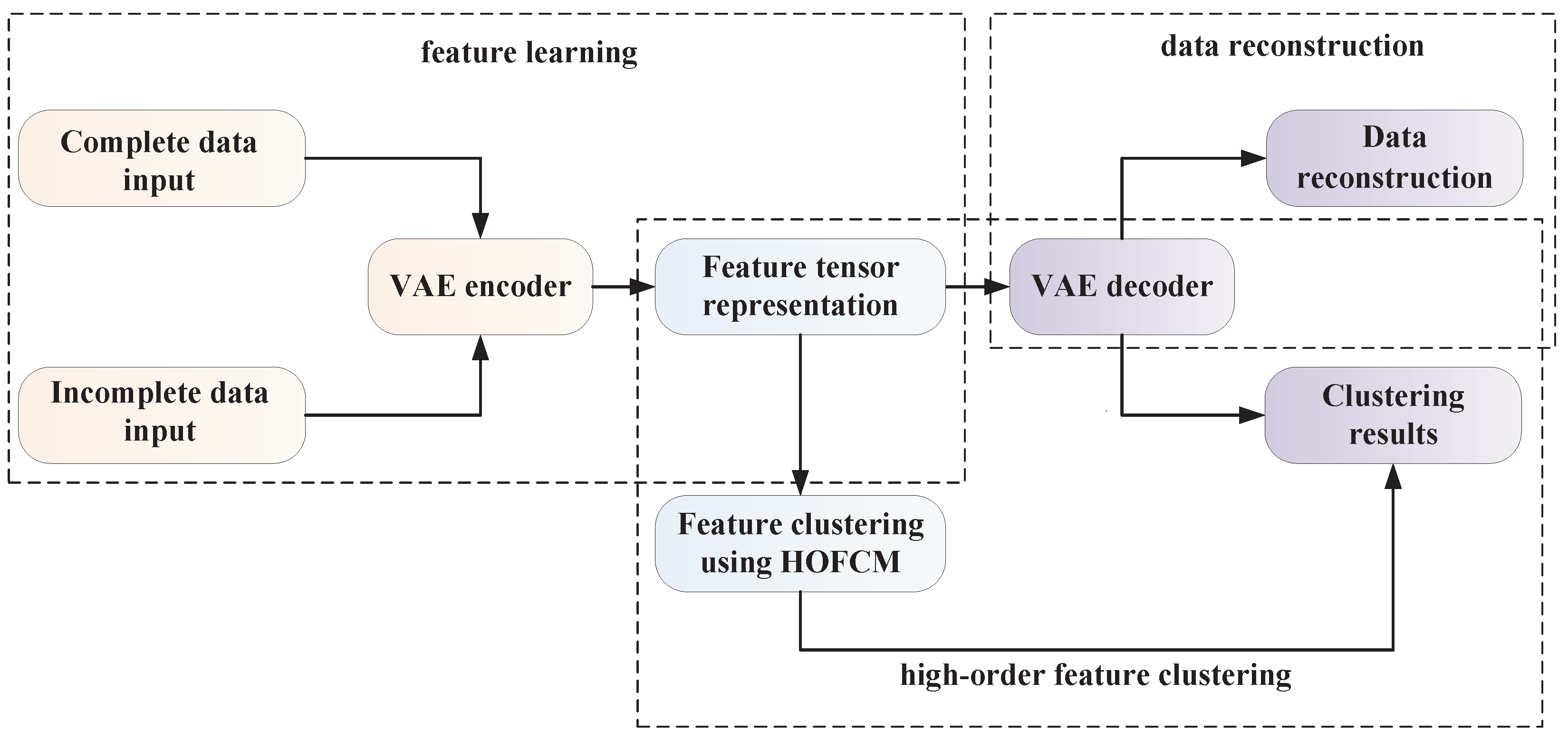
3.1. Description of the Proposed Method
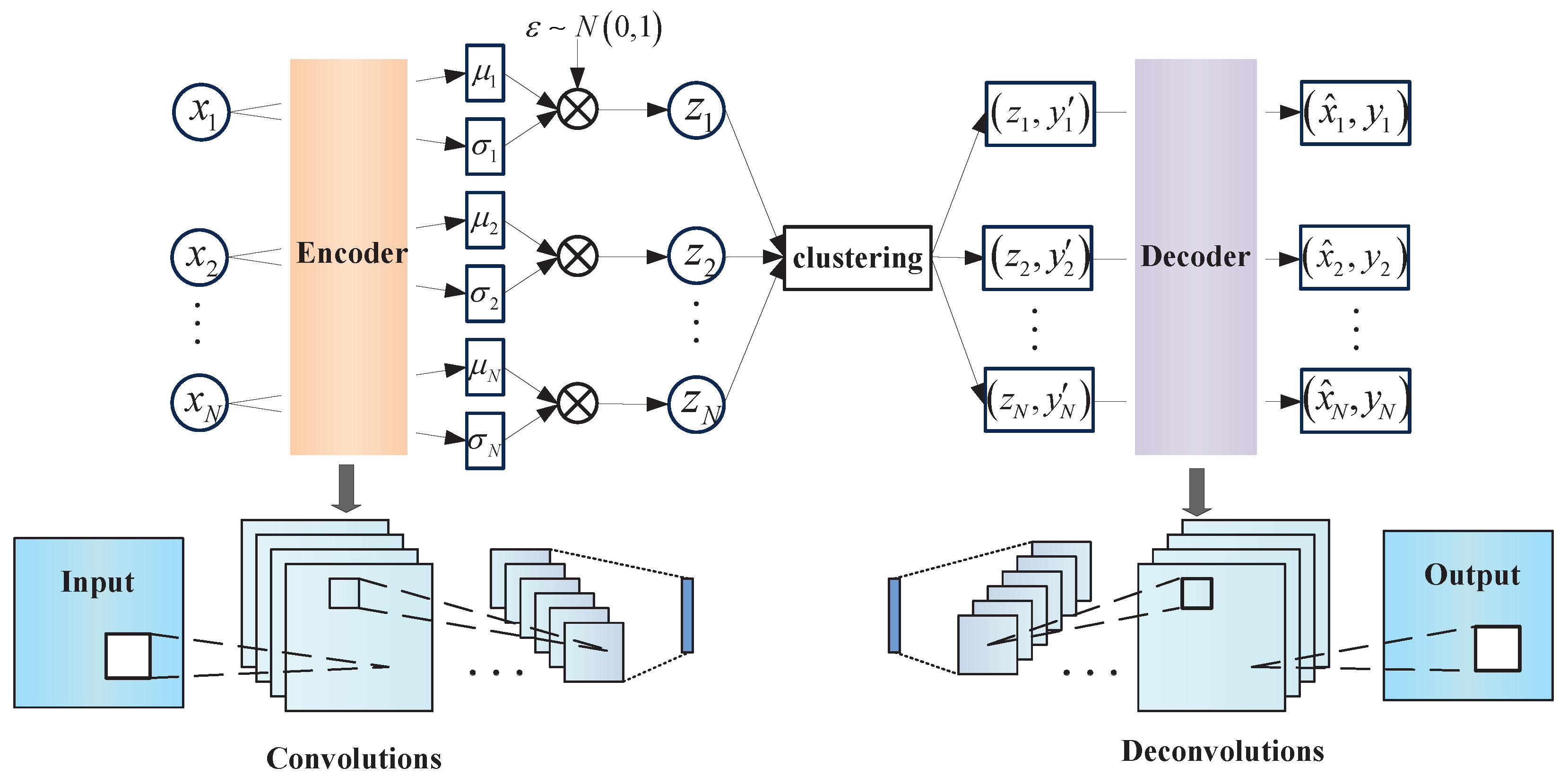
3.2. Feature Learning Network Architecture
- Sampling to x from the original data, coding feature z can then be obtained by . Then, the coding feature is classified by classifier to obtain the classification.
- Select a category y from distribution , select a random hidden variable z from distribution , and then decode the original sample through generator .
| Algorithm 1 Variational Autoencoder Optimization. |
| Input: Training set , corresponding labels , loss weight . Output: VAE parameters ,.
|
3.3. Variational Autoencoder Based High-Order Fuzzy C-Means Algorithm
| Algorithm 2 The VAE-HOFCM algorithm. |
| Input: Output: and .
|
4. Experiments
- MNIST: The MNIST dataset consists of 70,000 hand-written digits of 28-by-28 pixel size. The digits are centered and and the size is standardized.
- STL-10: A dataset consists of 96-by-96 color images. It contains 13,000 labeled images and 100,000 unlabeled images.
- NUS-WIDE: The NUS-WIDE dataset consists of 269,648 images and can be downloaded from Flickr.com, a famous photo-sharing website.
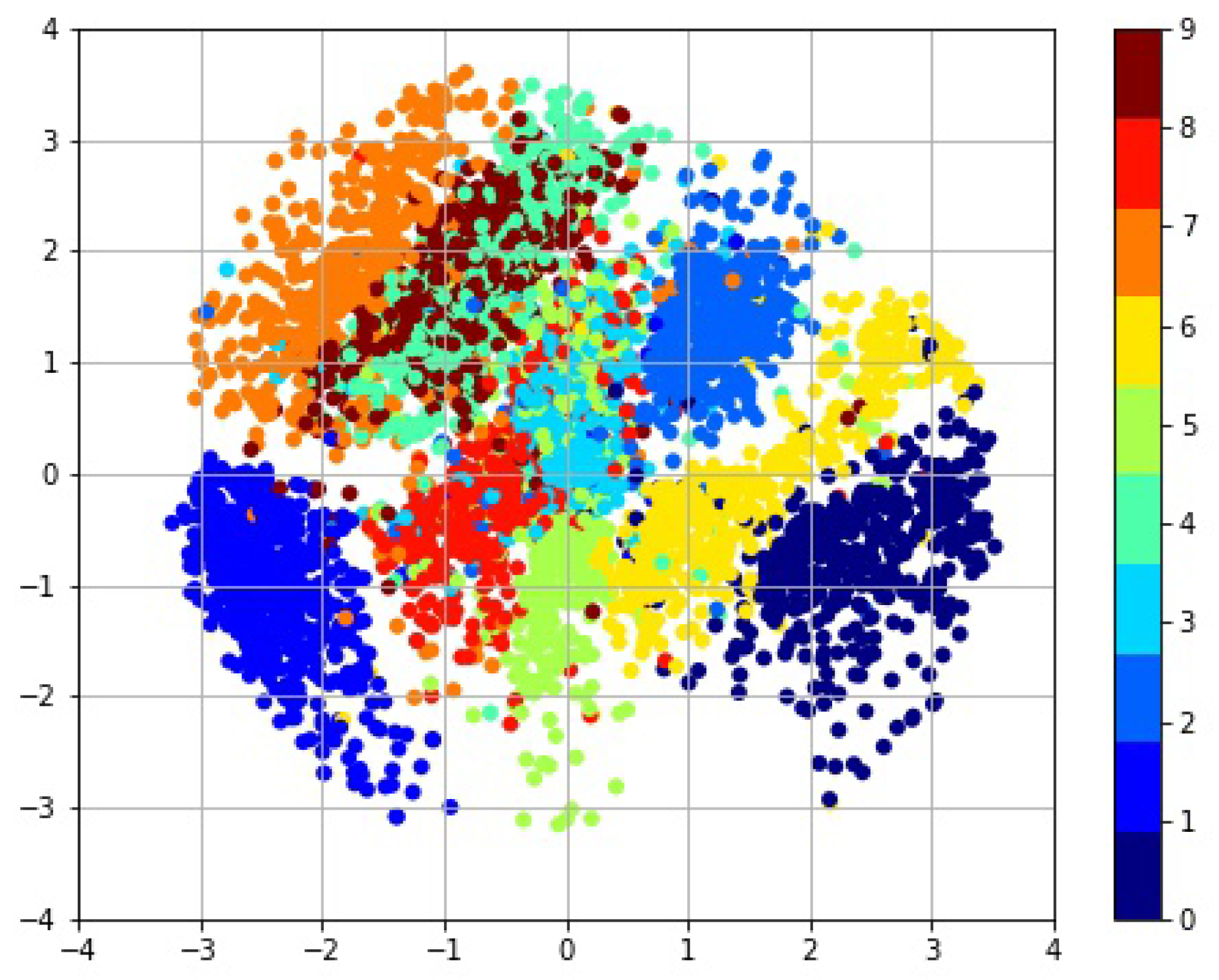
4.1. Experimental Results on Complete Datasets
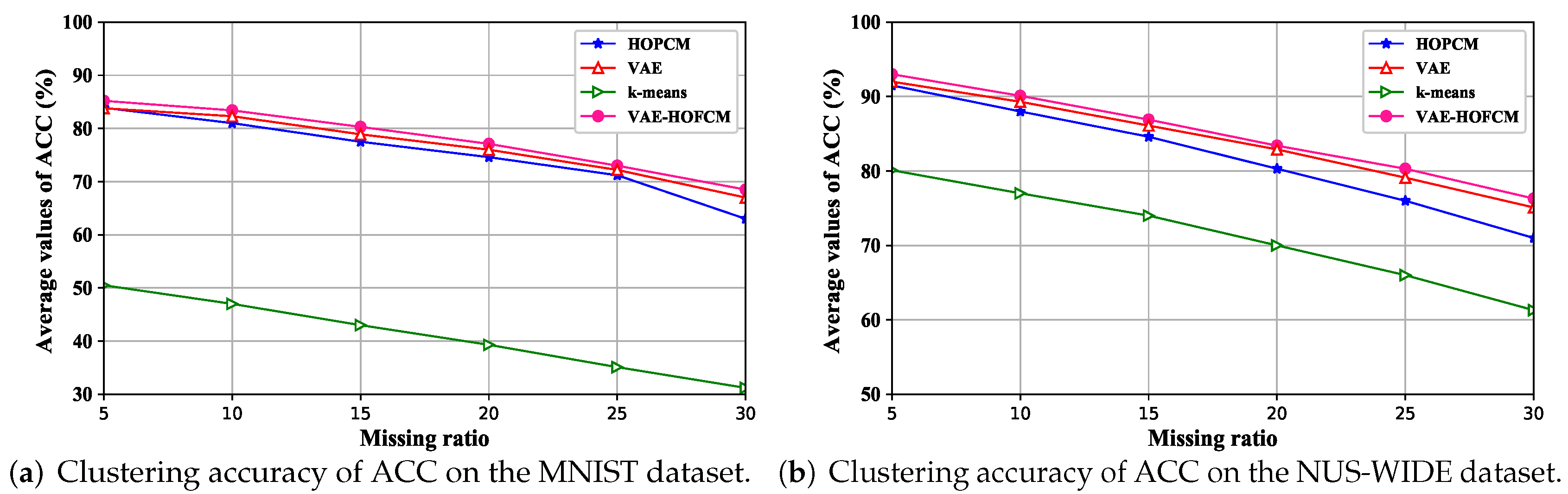
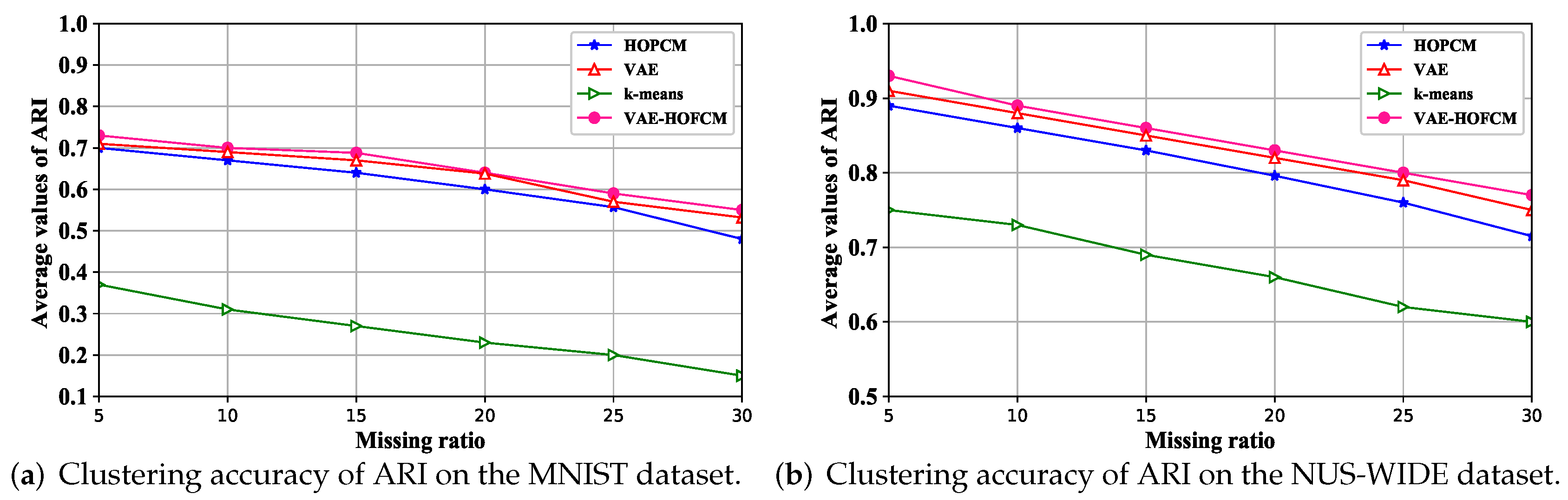
4.2. Experimental Results on Incomplete Data Sets
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, Z.J.; Lai, C.F.; Chao, H.C. A green data transmission mechanism for wireless multimedia sensor networks using information fusion. IEEE Wirel. Commun. 2014, 21, 14–19. [Google Scholar] [CrossRef]
- Wu, Y.; Guan, Y.; He, S.; Xin, M. An Industrial-Based Framework for Distributed Control of Heterogeneous Network Systems. IEEE Trans. Cybern. Syst. 2018, 99, 1–9. [Google Scholar] [CrossRef]
- Wu, X.; Wang, H.; Liu, C.; Jia, Y. Cross-View Action Recognition Over Heterogeneous Feature Spaces. IEEE Trans. Image Process. 2015, 24, 4096–4108. [Google Scholar] [PubMed]
- Shan, Z.; Xia, Y.; Hou, P.; He, J. Fusing Incomplete Multisensor Heterogeneous Data to Estimate Urban Traffic. IEEE MultiMed. 2016, 23, 56–63. [Google Scholar] [CrossRef]
- Zhang, Z.; Zou, Y.; Gan, C. Textual sentiment analysis via three different attention convolutional neural networks and cross-modality consistent regression. Neurocomputing 2018, 275, 1407–1415. [Google Scholar] [CrossRef]
- Mantri, D.S.; Prasad, N.R.; Prasad, R. Mobility and Heterogeneity Aware Cluster-Based Data Aggregation for Wireless Sensor Network. Wirel. Pers. Commun. 2016, 86, 975–993. [Google Scholar] [CrossRef]
- Akbar, A.; Khan, A.; Carrez, F.; Moessner, K. Predictive Analytics for Complex IoT Data Streams. IEEE Internet Things J. 2017, 4, 1571–1582. [Google Scholar] [CrossRef]
- Yim, H.J.; Seo, D.; Jung, H.; Back, M.K.; Kim, I.; Lee, K.C. Description and classification for facilitating interoperability of heterogeneous data/events/services in the Internet of Things. Neurocomputing 2017, 256, 13–22. [Google Scholar] [CrossRef]
- Qiu, T.; Chen, N.; Li, K.; Atiquzzaman, M.; Zhao, W. How Can Heterogeneous Internet of Things Build Our Future: A Survey. IEEE Commun. Surv. Tutor. 2018, 20, 2011–2027. [Google Scholar] [CrossRef]
- Yang, J.; Han, Y.; Wang, Y.; Jiang, B.; Lv, Z.; Song, H. Optimization of real-time traffic network assignment based on IoT data using DBN and clustering model in smart city. Future Gener. Comput. Syst. 2017. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, L.T.; Chen, Z.; Xia, F. A High-Order Possibilistic C-Means Algorithm for Clustering Incomplete Multimedia Data. IEEE Syst. J. 2017, 11, 2160–2169. [Google Scholar] [CrossRef]
- Han, Y.; Wang, Z.; Li, D.; Guo, Q.; Liu, G. Low-Complexity Iterative Detection Algorithm for Massive Data Communication in IIoT. IEEE Access 2018, 6, 11166–11172. [Google Scholar] [CrossRef]
- Fekade, B.; Maksymyuk, T.; Kyryk, M.; Jo, M. Probabilistic Recovery of Incomplete Sensed Data in IoT. IEEE Internet Things J. 2018, 5, 2282–2292. [Google Scholar] [CrossRef]
- Mendes, L.D.P.; Rodrigues, J.J.P.C.; Lloret, J.; Sendra, S. Cross-Layer Dynamic Admission Control for Cloud-Based Multimedia Sensor Networks. IEEE Syst. J. 2014, 8, 235–246. [Google Scholar] [CrossRef] [Green Version]
- Zhao, L.; Chen, Z.; Yang, Z.; Hu, Y.; Obaidat, M.S. Local Similarity Imputation Based on Fast Clustering for Incomplete Data in Cyber-Physical Systems. IEEE Syst. J. 2018, 12, 1610–1620. [Google Scholar] [CrossRef]
- Zhang, Z.; Zeng, T.; Yu, X.; Sun, S. Social-aware D2D Pairing for Cooperative Video Transmission Using Matching Theory. Mob. Netw. Appl. 2018, 23, 639–649. [Google Scholar] [CrossRef]
- Li, T.; Zhang, L.; Lu, W.; Hou, H.; Liu, X.; Pedrycz, W.; Zhong, C. Interval kernel Fuzzy C-Means clustering of incomplete data. Neurocomputing 2017, 237, 316–331. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, Z.; Xing, X.; Gao, Y.; Xie, D.; Wong, H.S. Generalized Pair-Counting Similarity Measures for Clustering and Cluster Ensembles. IEEE Access 2017, 5, 16904–16918. [Google Scholar] [CrossRef]
- Hoecker, M.; Polsterer, K.L.; Kugler, S.D.; Heuveline, V. Clustering of Complex Data-Sets Using Fractal Similarity Measures and Uncertainties. In Proceedings of the 2015 IEEE 18th International Conference on Computational Science and Engineering, Porto, Portugal, 21–23 October 2015; pp. 82–91. [Google Scholar]
- Zhou, L.; Wu, D.; Zheng, B.; Guizani, M. Joint physical-application layer security for wireless multimedia delivery. IEEE Commun. Mag. 2014, 52, 66–72. [Google Scholar] [CrossRef]
- Li, F.; Qiao, H.; Zhang, B. Discriminatively boosted image clustering with fully convolutional auto-encoders. Pattern Recognit. 2018, 83, 161–173. [Google Scholar] [CrossRef] [Green Version]
- Gebru, I.D.; Alameda-Pineda, X.; Forbes, F.; Horaud, R. EM Algorithms for Weighted-Data Clustering with Application to Audio-Visual Scene Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2402–2415. [Google Scholar] [CrossRef] [Green Version]
- Abualigah, L.M.; Khader, A.T.; Al-Betar, M.A. Unsupervised feature selection technique based on genetic algorithm for improving the Text Clustering. In Proceedings of the 2016 7th International Conference on Computer Science and Information Technology (CSIT), Amman, Jordan, 13–14 July 2016; pp. 1–6. [Google Scholar]
- Saadaoui, F.; Bertrand, P.R.; Boudet, G.; Rouffiac, K.; Dutheil, F.; Chamoux, A. A Dimensionally Reduced Clustering Methodology for Heterogeneous Occupational Medicine Data Mining. IEEE Trans. Nanobiosci. 2015, 14, 707–715. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Q. Research on heterogeneous data integration model of group enterprise based on cluster computing. Clust. Comput. 2016, 19, 1275–1282. [Google Scholar] [CrossRef]
- Ramachandran, N.; Perumal, V. Delay-aware heterogeneous cluster-based data acquisition in Internet of Things. Comput. Electr. Eng. 2018, 65, 44–58. [Google Scholar] [CrossRef]
- Meng, L.; Tan, A.H.; Xu, D. Semi-Supervised Heterogeneous Fusion for Multimedia Data Co-Clustering. IEEE Trans. Knowl. Data Eng. 2014, 26, 2293–2306. [Google Scholar] [CrossRef]
- Li, P.; Chen, Z.; Yang, L.T.; Zhao, L.; Zhang, Q. A privacy-preserving high-order neuro-fuzzy C-means algorithm with cloud computing. Neurocomputing 2017, 256, 82–89. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, L.T.; Chen, Z.; Li, P. High-order possibilistic c-means algorithms based on tensor decompositions for big data in IoT. Inf. Fusion 2018, 39, 72–80. [Google Scholar] [CrossRef]
- Mohammadi, M.; Al-Fuqaha, A.; Sorour, S.; Guizani, M. Deep Learning for IoT Big Data and Streaming Analytics: A Survey. IEEE Commun. Surv. Tutor. 2018, 20, 2923–2960. [Google Scholar] [CrossRef]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised Deep Embedding for Clustering Analysis. arXiv, 2015; arXiv:1511.06335. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv, 2013; arXiv:1312.6114. [Google Scholar]
- Li, X.; Chen, Z.; Poon, L.K.M.; Zhang, N.L. Learning Latent Superstructures in Variational Autoencoders for Deep Multidimensional Clustering. arXiv, 2018; arXiv:1803.05206. [Google Scholar]
- Hou, X.; Shen, L.; Sun, K.; Qiu, G. Deep Feature Consistent Variational Autoencoder. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1133–1141. [Google Scholar]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J. Conditional Variational Autoencoder for Prediction and Feature Recovery Applied to Intrusion Detection in IoT. Sensors 2017, 17, 1967. [Google Scholar] [CrossRef] [PubMed]
- Celikyilmaz, A.; Trksen, I.B. Modeling Uncertainty with Fuzzy Logic: With Recent Theory and Applications; Springer Publishing Company: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Dovžan, D.; Škrjanc, I. Recursive fuzzy C-means clustering for recursive fuzzy identification of time-varying processes. ISA Trans. 2011, 50, 159–169. [Google Scholar] [CrossRef] [PubMed]
- Jérôme, M.; Rui, A.; Francisco, S. Adaptive fuzzy identification and predictive control for industrial processes. Expert Syst. Appl. 2013, 40, 6964–6975. [Google Scholar]
- Rastegar, S.; Araujo, R.; Mendes, J. Online Identification of Takagi-Sugeno Fuzzy Models Based on Self-Adaptive Hierarchical Particle Swarm Optimization Algorithm. Appl. Math. Model. 2017, 45, 606–620. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm/Dataset | MNIST | STL-10 | NUS-WIDE |
|---|---|---|---|
| k-means | 53.49% | 28.40% | 81.51% |
| HOPCM | 80.34% | 33.12% | 92.75% |
| VAE | 84.20% | 35.48% | 93.32% |
| DEC | 84.31% | 35.90% | 93.75% |
| VAE-HOFCM | 85.54% | 36.44% | 95.14% |
| Algorithm/Dataset | MNIST | STL-10 | NUS-WIDE |
|---|---|---|---|
| k-means | 0.41 | - | 0.74 |
| HOPCM | 0.69 | - | 0.89 |
| VAE | 0.75 | - | 0.90 |
| DEC | 0.76 | - | 0.90 |
| VAE-HOFCM | 0.78 | - | 0.92 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, X.; Li, H.; Zhang, Z.; Gan, C. The Optimally Designed Variational Autoencoder Networks for Clustering and Recovery of Incomplete Multimedia Data. Sensors 2019, 19, 809. https://doi.org/10.3390/s19040809
Yu X, Li H, Zhang Z, Gan C. The Optimally Designed Variational Autoencoder Networks for Clustering and Recovery of Incomplete Multimedia Data. Sensors. 2019; 19(4):809. https://doi.org/10.3390/s19040809
Chicago/Turabian StyleYu, Xiulan, Hongyu Li, Zufan Zhang, and Chenquan Gan. 2019. "The Optimally Designed Variational Autoencoder Networks for Clustering and Recovery of Incomplete Multimedia Data" Sensors 19, no. 4: 809. https://doi.org/10.3390/s19040809
APA StyleYu, X., Li, H., Zhang, Z., & Gan, C. (2019). The Optimally Designed Variational Autoencoder Networks for Clustering and Recovery of Incomplete Multimedia Data. Sensors, 19(4), 809. https://doi.org/10.3390/s19040809