Object Recognition, Segmentation, and Classification of Mobile Laser Scanning Point Clouds: A State of the Art Review



Abstract
:1. Introduction
- We discuss the impact of scene types (forest, railway, tunnel, and urban/street) on development of MLS data processing methods.
- Object recognition approaches are reviewed with technical details summarized from different perspectives.
- Point cloud classification is also covered and summarized from multiple aspects including segmentation, feature extraction, classification techniques, and achievable classes.
- We summarize available benchmark datasets for evaluating an object recognition or point cloud classification approach.
- General limitations and challenges of the existing approaches for object recognition and point cloud classification are discussed extensively.
2. Overview of MLS Data Processing Workflow
3. Feature Extraction and Segmentation
4. Scene Type
4.1. Forest
4.2. Railway
4.3. Tunnel
4.4. Street
5. Object Recognition
5.1. Ground Objects
5.1.1. Ground Extraction
5.1.2. Road Boundary
5.1.3. Road Markings
5.1.4. Manholes
5.1.5. Pavement
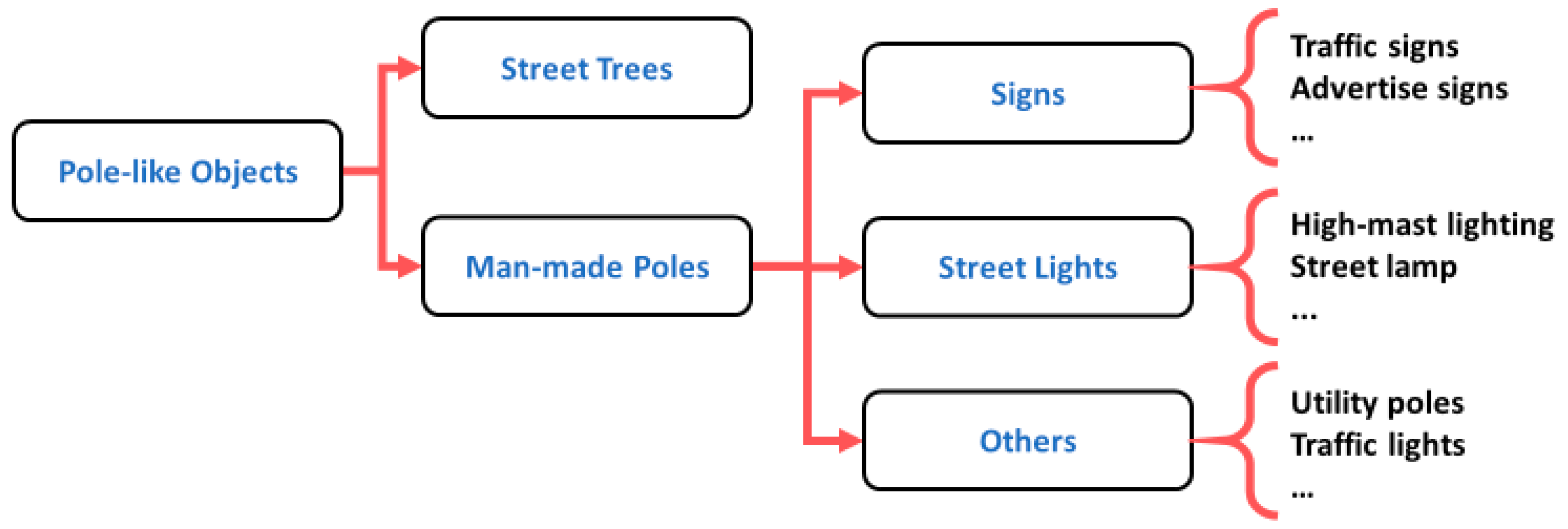
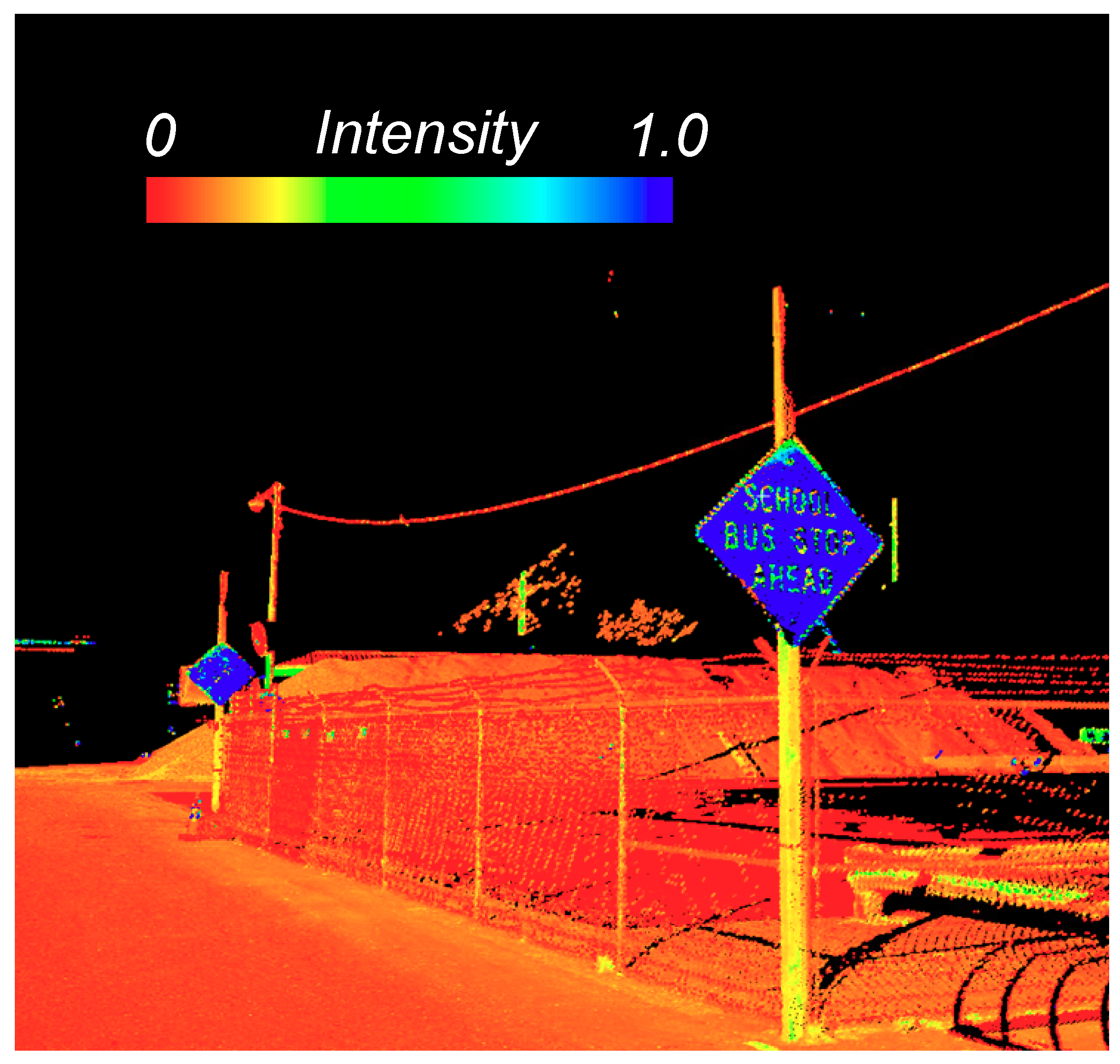
5.2. Pole-Like Objects
5.2.1. Preprocessing
5.2.2. Pole-Like Object Detection
5.2.3. Pole-Like Object Classification
5.3. Other Objects
5.3.1. Buildings
5.3.2. Vehicles
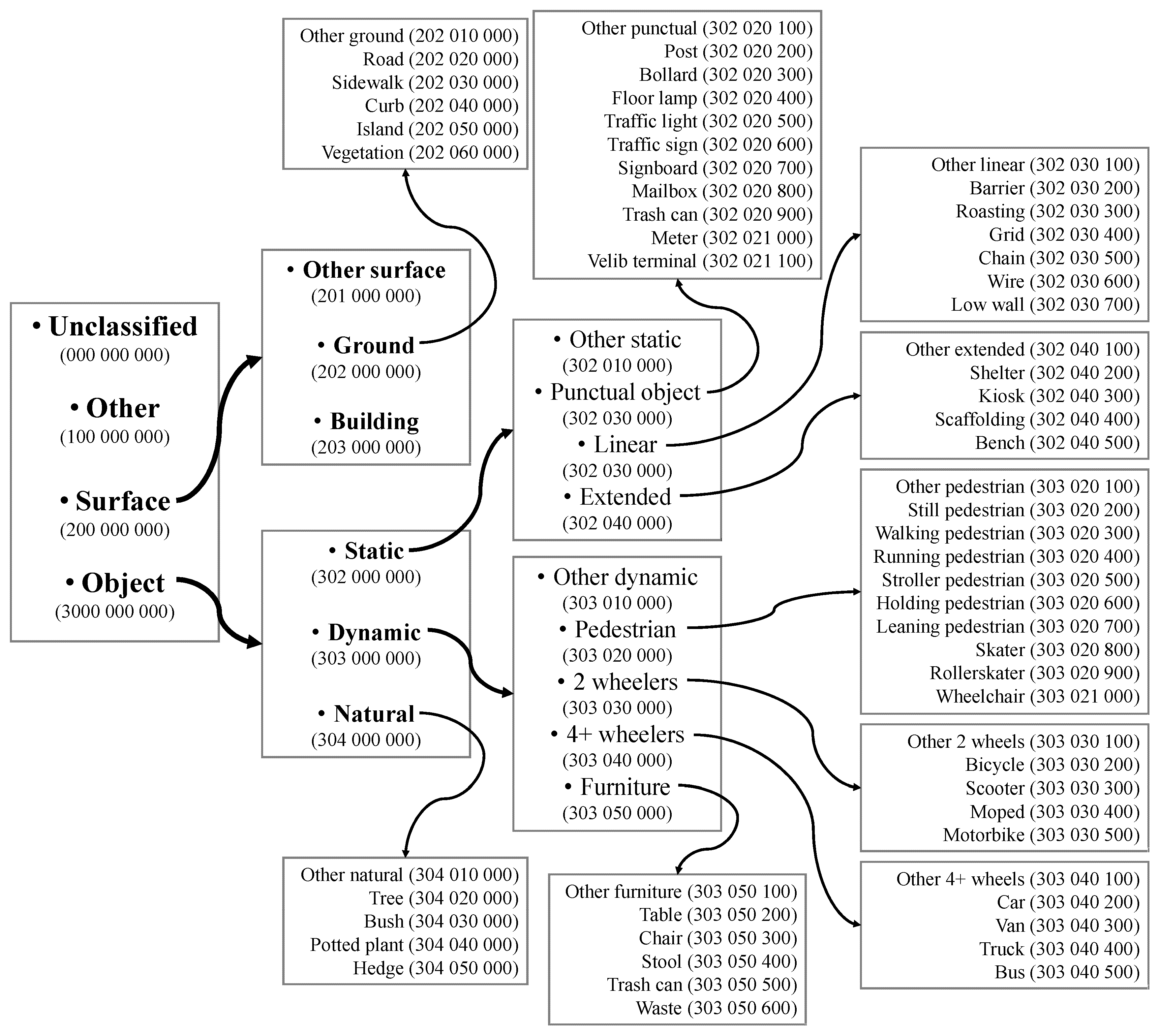
6. Classification
6.1. Feature Extraction
6.2. Point-Wise Classification
6.3. Segment-Wise Classification
6.4. Object-Wise Classification
6.5. Deep Learning
7. Benchmark Datasets
8. Discussion
9. Conclusions and Future Outlook
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Nolan, J.; Eckels, R.; Evers, M.; Singh, R.; Olsen, M. Multi-Pass Approach for Mobile Terrestrial Laser Scanning. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2, 105–112. [Google Scholar] [CrossRef]
- Nolan, J.; Eckels, R.; Olsen, M.J.; Yen, K.S.; Lasky, T.A.; Ravani, B. Analysis of the Multipass Approach for Collection and Processing of Mobile Laser Scan Data. J. Surv. Eng. 2017, 143, 04017004. [Google Scholar] [CrossRef]
- Kashani, A.; Olsen, M.; Parrish, C.; Wilson, N. A review of LiDAR radiometric processing: From ad hoc intensity correction to rigorous radiometric calibration. Sensors 2015, 15, 28099–28128. [Google Scholar] [CrossRef] [PubMed]
- Olsen, M.J.; Raugust, J.D.; Roe, G.V. Use of Advanced Geospatial Data, Tools, Technologies, and Information in Department of Transportation Projects; TRB NCHRP Synthesis 446; Transportation Research Board: Washington, DC, USA, 2013. [Google Scholar]
- Olsen, M.J.; Roe, G.V.; Glennie, C.; Persi, F.; Reedy, M.; Hurwitz, D.; Williams, K.; Tuss, H.; Squellati, A.; Knodler, M. Guidelines for the Use of Mobile LIDAR in Transportation Applications; TRB NCHRP Final Report; Transportation Research Board: Washington, DC, USA, 2013. [Google Scholar]
- Oliveira, A.; Oliveira, J.F.; Pereira, J.M.; De Araújo, B.R.; Boavida, J. 3D modelling of laser scanned and photogrammetric data for digital documentation: The Mosteiro da Batalha case study. J. Real-Time Image Process. 2014, 9, 673–688. [Google Scholar] [CrossRef]
- Puente, I.; González-Jorge, H.; Martínez-Sánchez, J.; Arias, P. Review of mobile mapping and surveying technologies. Measurement 2013, 46, 2127–2145. [Google Scholar] [CrossRef]
- Williams, K.; Olsen, M.; Roe, G.; Glennie, C. Synthesis of transportation applications of mobile LiDAR. Remote Sens. 2013, 5, 4652–4692. [Google Scholar] [CrossRef]
- Che, E.; Olsen, M.J. Multi-scan segmentation of terrestrial laser scanning data based on normal variation analysis. ISPRS J. Photogramm. Remote Sens. 2018, 143, 233–248. [Google Scholar] [CrossRef]
- Guan, H.; Li, J.; Cao, S.; Yu, Y. Use of mobile LiDAR in road information inventory: A review. Int. J. Image Data Fusion 2016, 7, 219–242. [Google Scholar] [CrossRef]
- Gargoum, S.; El-Basyouny, K. Automated extraction of road features using LiDAR data: A review of LiDAR applications in transportation. In Proceedings of the 2017 4th International Conference on Transportation Information and Safety (ICTIS), Banff, AB, Canada, 8–10 August 2017; pp. 563–574. [Google Scholar]
- Wang, R.; Peethambaran, J.; Chen, D. LiDAR Point Clouds to 3-D Urban Models: A Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 606–627. [Google Scholar] [CrossRef]
- Ma, L.; Li, Y.; Li, J.; Wang, C.; Wang, R.; Chapman, M. Mobile laser scanned point-clouds for road object detection and extraction: A review. Remote Sens. 2018, 10, 1531. [Google Scholar] [CrossRef]
- Hough, P.V. Method and Means for Recognizing Complex Patterns. U.S. Patent 3,069,654, 18 December 1962. [Google Scholar]
- Ballard, D.H. Generalizing the Hough transform to detect arbitrary shapes. Pattern Recognit. 1981, 13, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Vosselman, G.; Gorte, B.G.; Sithole, G.; Rabbani, T. Recognising structure in laser scanner point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 46, 33–38. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient RANSAC for point-cloud shape detection. Comput. Graph. Forum. 2007, 26, 214–226. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal component analysis. In International Encyclopedia of Statistical Science; Springer: Berlin, Germany, 2011; pp. 1094–1096. [Google Scholar]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation (ICRA), Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Rabbani, T.; Van Den Heuvel, F.; Vosselmann, G. Segmentation of point clouds using smoothness constraint. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2006, 36, 248–253. [Google Scholar]
- Golovinskiy, A.; Funkhouser, T. Min-cut based segmentation of point clouds. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops (ICCV Workshops), Kyoto, Japan, 27 September–4 October 2009; pp. 39–46. [Google Scholar]
- Papon, J.; Abramov, A.; Schoeler, M.; Worgotter, F. Voxel cloud connectivity segmentation-supervoxels for point clouds. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2027–2034. [Google Scholar]
- Yang, B.; Dong, Z.; Zhao, G.; Dai, W. Hierarchical extraction of urban objects from mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2015, 99, 45–57. [Google Scholar] [CrossRef]
- Che, E.; Olsen, M.J. An Efficient Framework for Mobile Lidar Trajectory Reconstruction and Mo-norvana Segmentation. IEEE Trans. Geosci. Remote Sens. 2018. under review. [Google Scholar]
- Meng, X.; Currit, N.; Zhao, K. Ground filtering algorithms for airborne LiDAR data: A review of critical issues. Remote Sens. 2010, 2, 833–860. [Google Scholar] [CrossRef]
- Van Leeuwen, M.; Hilker, T.; Coops, N.C.; Frazer, G.; Wulder, M.A.; Newnham, G.J.; Culvenor, D.S. Assessment of standing wood and fiber quality using ground and airborne laser scanning: A review. For. Ecol. Manag. 2011, 261, 1467–1478. [Google Scholar] [CrossRef]
- Liang, X.; Kankare, V.; Hyyppä, J.; Wang, Y.; Kukko, A.; Haggrén, H.; Yu, X.; Kaartinen, H.; Jaakkola, A.; Guan, F. Terrestrial laser scanning in forest inventories. ISPRS J. Photogramm. Remote Sens. 2016, 115, 63–77. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Guo, Q.; Jakubowski, M.K.; Kelly, M. A new method for segmenting individual trees from the lidar point cloud. Photogramm. Eng. Remote Sens. 2012, 78, 75–84. [Google Scholar] [CrossRef]
- Liang, X.; Hyyppä, J. Automatic stem mapping by merging several terrestrial laser scans at the feature and decision levels. Sensors 2013, 13, 1614–1634. [Google Scholar] [CrossRef] [PubMed]
- Tao, S.; Wu, F.; Guo, Q.; Wang, Y.; Li, W.; Xue, B.; Hu, X.; Li, P.; Tian, D.; Li, C. Segmenting tree crowns from terrestrial and mobile LiDAR data by exploring ecological theories. ISPRS J. Photogramm. Remote Sens. 2015, 110, 66–76. [Google Scholar] [CrossRef] [Green Version]
- Herrero-Huerta, M.; Lindenbergh, R.; Rodríguez-Gonzálvez, P. Automatic tree parameter extraction by a Mobile LiDAR System in an urban context. PLoS ONE 2018, 13, e0196004. [Google Scholar] [CrossRef] [PubMed]
- Mikrut, S.; Kohut, P.; Pyka, K.; Tokarczyk, R.; Barszcz, T.; Uhl, T. Mobile laser scanning systems for measuring the clearance gauge of railways: State of play, testing and outlook. Sensors 2016, 16, 683. [Google Scholar] [CrossRef] [PubMed]
- Blug, A.; Baulig, C.; Wolfelschneider, H.; Hofler, H. Fast fiber coupled clearance profile scanner using real time 3D data processing with automatic rail detection. In Proceedings of the 2004 IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 658–663. [Google Scholar]
- Yang, B.; Fang, L. Automated extraction of 3-D railway tracks from mobile laser scanning point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens 2014, 7, 4750–4761. [Google Scholar] [CrossRef]
- Elberink, S.O.; Khoshelham, K. Automatic extraction of railroad centerlines from mobile laser scanning data. Remote Sens. 2015, 7, 5565–5583. [Google Scholar] [CrossRef]
- Hackel, T.; Stein, D.; Maindorfer, I.; Lauer, M.; Reiterer, A. Track detection in 3D laser scanning data of railway infrastructure. In Proceedings of the 2015 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Pisa, Italy, 11–14 May 2015; pp. 693–698. [Google Scholar]
- Stein, D. Mobile Laser Scanning Based Determination of Railway Network Topology and Branching Direction on Turnouts; KIT Scientific Publishing: Karlsruhe, Germany, 2018; Volume 38. [Google Scholar]
- Arastounia, M. Automated recognition of railroad infrastructure in rural areas from LiDAR data. Remote Sens. 2015, 7, 14916–14938. [Google Scholar] [CrossRef]
- Pastucha, E. Catenary system detection, localization and classification using mobile scanning data. Remote Sens. 2016, 8, 801. [Google Scholar] [CrossRef]
- Yang, B.; Fang, L.; Li, J. Semi-automated extraction and delineation of 3D roads of street scene from mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2013, 79, 80–93. [Google Scholar] [CrossRef]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Roca-Pardiñas, J.; Argüelles-Fraga, R.; de Asís López, F.; Ordóñez, C. Analysis of the influence of range and angle of incidence of terrestrial laser scanning measurements on tunnel inspection. Tunn. Undergr. Space Technol. 2014, 43, 133–139. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, W.; Huang, L.; Vimarlund, V.; Wang, Z. Applications of terrestrial laser scanning for tunnels: A review. J. Traffic Transp. Eng. (Engl. Ed.) 2014, 1, 325–337. [Google Scholar] [CrossRef]
- Pejić, M. Design and optimisation of laser scanning for tunnels geometry inspection. Tunn. Undergr. Space Technol. 2013, 37, 199–206. [Google Scholar] [CrossRef]
- Arastounia, M. Automated as-built model generation of subway tunnels from mobile LiDAR data. Sensors 2016, 16, 1486. [Google Scholar] [CrossRef]
- Puente, I.; Akinci, B.; González-Jorge, H.; Díaz-Vilariño, L.; Arias, P. A semi-automated method for extracting vertical clearance and cross sections in tunnels using mobile LiDAR data. Tunn. Undergr. Space Technol. 2016, 59, 48–54. [Google Scholar] [CrossRef]
- Puente, I.; González-Jorge, H.; Martínez-Sánchez, J.; Arias, P. Automatic detection of road tunnel luminaires using a mobile LiDAR system. Measurement 2014, 47, 569–575. [Google Scholar] [CrossRef]
- Yoon, J.-S.; Sagong, M.; Lee, J.; Lee, K.-S. Feature extraction of a concrete tunnel liner from 3D laser scanning data. Ndt E Int. 2009, 42, 97–105. [Google Scholar] [CrossRef]
- Lin, X.; Zhang, J. Segmentation-based ground points detection from mobile laser scanning point cloud. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 99. [Google Scholar] [CrossRef]
- Serna, A.; Marcotegui, B. Detection, segmentation and classification of 3D urban objects using mathematical morphology and supervised learning. ISPRS J. Photogramm. Remote Sens. 2014, 93, 243–255. [Google Scholar] [CrossRef] [Green Version]
- Che, E.; Olsen, M.J. Fast ground filtering for TLS data via Scanline Density Analysis. ISPRS J. Photogramm. Remote Sens. 2017, 129, 226–240. [Google Scholar] [CrossRef]
- Hernández, J.; Marcotegui, B. Point cloud segmentation towards urban ground modeling. In Proceedings of the 2009 Joint Urban Remote Sensing Event, Shanghai, China, 20–22 May 2009; pp. 1–5. [Google Scholar]
- Hernández, J.; Marcotegui, B. Filtering of artifacts and pavement segmentation from mobile lidar data. In Proceedings of the 2009 ISPRS Workshop on Laser Scanning, Paris, France, 1–2 September 2009. [Google Scholar]
- Serna, A.; Marcotegui, B. Urban accessibility diagnosis from mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2013, 84, 23–32. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Wei, Z.; Li, Q.; Li, J. Automated extraction of street-scene objects from mobile lidar point clouds. Int. J. Remote Sens. 2012, 33, 5839–5861. [Google Scholar] [CrossRef]
- Husain, A.; Vaishya, R. A time efficient algorithm for ground point filtering from mobile LiDAR data. In Proceedings of the 2016 International Conference on Control, Computing, Communication and Materials (ICCCCM), Allahabad, India, 21–22 October 2016; pp. 1–5. [Google Scholar]
- Yadav, M.; Singh, A.K.; Lohani, B. Extraction of road surface from mobile LiDAR data of complex road environment. Int. J. Remote Sens. 2017, 38, 4655–4682. [Google Scholar] [CrossRef]
- Axelsson, P. DEM generation from laser scanner data using adaptive TIN models. Int. Arch. Photogramm. Remote Sens. 2000, 33, 110–117. [Google Scholar]
- Ibrahim, S.; Lichti, D. Curb-based street floor extraction from mobile terrestrial LiDAR point cloud. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 39, B5. [Google Scholar] [CrossRef]
- Teo, T.-A.; Yu, H.-L. Empirical radiometric normalization of road points from terrestrial mobile LiDAR system. Remote Sens. 2015, 7, 6336–6357. [Google Scholar] [CrossRef]
- Wu, B.; Yu, B.; Huang, C.; Wu, Q.; Wu, J. Automated extraction of ground surface along urban roads from mobile laser scanning point clouds. Remote Sens. Lett. 2016, 7, 170–179. [Google Scholar] [CrossRef]
- Kumar, P.; McElhinney, C.P.; Lewis, P.; McCarthy, T. An automated algorithm for extracting road edges from terrestrial mobile LiDAR data. ISPRS J. Photogramm. Remote Sens. 2013, 85, 44–55. [Google Scholar] [CrossRef] [Green Version]
- Miraliakbari, A.; Hahn, M.; Sok, S. Automatic extraction of road surface and curbstone edges from mobile laser scanning data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 119. [Google Scholar] [CrossRef]
- Xu, S.; Wang, R.; Zheng, H. Road Curb Extraction From Mobile LiDAR Point Clouds. IEEE Trans. Geosci. Remote Sens. 2017, 55, 996–1009. [Google Scholar] [CrossRef] [Green Version]
- Zai, D.; Li, J.; Guo, Y.; Cheng, M.; Lin, Y.; Luo, H.; Wang, C. 3-D road boundary extraction from mobile laser scanning data via supervoxels and graph cuts. IEEE Trans. Intell. Transp. Syst. 2018, 19, 802–813. [Google Scholar] [CrossRef]
- Miyazaki, R.; Yamamoto, M.; Hanamoto, E.; Izumi, H.; Harada, K. A line-based approach for precise extraction of road and curb region from mobile mapping data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 2, 243–250. [Google Scholar] [CrossRef]
- Cabo, C.; Kukko, A.; García-Cortés, S.; Kaartinen, H.; Hyyppä, J.; Ordoñez, C. An algorithm for automatic road asphalt edge delineation from mobile laser scanner data using the line clouds concept. Remote Sens. 2016, 8, 740. [Google Scholar] [CrossRef]
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartogr. Int. J. Geogr. Inf. Geovisualization 1973, 10, 112–122. [Google Scholar] [CrossRef]
- El-Halawany, S.; Moussa, A.; Lichti, D.D.; El-Sheimy, N. Detection of road curb from mobile terrestrial laser scanner point cloud. In Proceedings of the 2011 ISPRS Workshop on Laser Scanning, Calgary, AB, Canada, 29–31 August 2011. [Google Scholar]
- Rodríguez-Cuenca, B.; Garcia-Cortes, S.; Ordóñez, C.; Alonso, M.C. An approach to detect and delineate street curbs from MLS 3D point cloud data. Autom. Constr. 2015, 51, 103–112. [Google Scholar] [CrossRef]
- Rodríguez-Cuenca, B.; García-Cortés, S.; Ordóñez, C.; Alonso, M.C. Morphological operations to extract urban curbs in 3D MLS point clouds. ISPRS Int. J. Geo-Inf. 2016, 5, 93. [Google Scholar]
- Zhong, L.; Liu, P.; Wang, L.; Wei, Z.; Guan, H.; Yu, Y. A Combination of Stop-and-Go and Electro-Tricycle Laser Scanning Systems for Rural Cadastral Surveys. ISPRS Int. J. Geo-Inf. 2016, 5, 160. [Google Scholar] [CrossRef]
- Guo, J.; Tsai, M.-J.; Han, J.-Y. Automatic reconstruction of road surface features by using terrestrial mobile lidar. Autom. Constr. 2015, 58, 165–175. [Google Scholar] [CrossRef]
- Yan, L.; Liu, H.; Tan, J.; Li, Z.; Xie, H.; Chen, C. Scan line based road marking extraction from mobile LiDAR point clouds. Sensors 2016, 16, 903. [Google Scholar] [CrossRef] [PubMed]
- Guan, H.; Li, J.; Yu, Y.; Wang, C.; Chapman, M.; Yang, B. Using mobile laser scanning data for automated extraction of road markings. ISPRS J. Photogramm. Remote Sens. 2014, 87, 93–107. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Guan, H.; Jia, F.; Wang, C. Learning hierarchical features for automated extraction of road markings from 3-D mobile LiDAR point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 709–726. [Google Scholar] [CrossRef]
- Yang, B.; Liu, Y.; Dong, Z.; Liang, F.; Li, B.; Peng, X. 3D local feature BKD to extract road information from mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 130, 329–343. [Google Scholar] [CrossRef]
- Yang, B.; Dong, Z.; Liu, Y.; Liang, F.; Wang, Y. Computing multiple aggregation levels and contextual features for road facilities recognition using mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2017, 126, 180–194. [Google Scholar] [CrossRef]
- Cheng, M.; Zhang, H.; Wang, C.; Li, J. Extraction and classification of road markings using mobile laser scanning point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1182–1196. [Google Scholar] [CrossRef]
- Yang, M.; Wan, Y.; Liu, X.; Xu, J.; Wei, Z.; Chen, M.; Sheng, P. Laser data based automatic recognition and maintenance of road markings from MLS system. Opt. Laser Technol. 2018, 107, 192–203. [Google Scholar] [CrossRef]
- Kumar, P.; McElhinney, C.P.; Lewis, P.; McCarthy, T. Automated road markings extraction from mobile laser scanning data. Int. J. Appl. Earth Obs. Geoinf. 2014, 32, 125–137. [Google Scholar] [CrossRef] [Green Version]
- Guan, H.; Li, J.; Yu, Y.; Chapman, M.; Wang, C. Automated road information extraction from mobile laser scanning data. IEEE Trans. Intell. Transp. Syst. 2015, 16, 194–205. [Google Scholar] [CrossRef]
- Riveiro, B.; González-Jorge, H.; Martínez-Sánchez, J.; Díaz-Vilariño, L.; Arias, P. Automatic detection of zebra crossings from mobile LiDAR data. Opt. Laser Technol. 2015, 70, 63–70. [Google Scholar] [CrossRef]
- Soilán, M.; Riveiro, B.; Martínez-Sánchez, J.; Arias, P. Segmentation and classification of road markings using MLS data. ISPRS J. Photogramm. Remote Sens. 2017, 123, 94–103. [Google Scholar] [CrossRef]
- Jung, J.; Che, E.; Olsen, M.J.; Parrish, C. Efficient and robust lane marking extraction from mobile lidar point clouds. ISPRS J. Photogramm. Remote Sens. 2019, 147, 1–18. [Google Scholar] [CrossRef]
- Yang, B.; Fang, L.; Li, Q.; Li, J. Automated extraction of road markings from mobile LiDAR point clouds. Photogramm. Eng. Remote Sens. 2012, 78, 331–338. [Google Scholar] [CrossRef]
- Li, J.; Mei, X.; Prokhorov, D.; Tao, D. Deep neural network for structural prediction and lane detection in traffic scene. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 690–703. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Gelernter, J.; Wang, X.; Chen, W.; Gao, J.; Zhang, Y.; Li, X. Lane marking detection via deep convolutional neural network. Neurocomputing 2018, 280, 46–55. [Google Scholar] [CrossRef] [PubMed]
- Wen, C.; Sun, X.; Li, J.; Wang, C.; Guo, Y.; Habib, A. A deep learning framework for road marking extraction, classification and completion from mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2019, 147, 178–192. [Google Scholar] [CrossRef]
- FHWA. Manual on Uniform Traffic Control Devices for Streets and Highways; US Department of Transportation: Washington, DC, USA, 2009.
- Guan, H.; Yu, Y.; Li, J.; Liu, P.; Zhao, H.; Wang, C. Automated extraction of manhole covers using mobile LiDAR data. Remote Sens. Lett. 2014, 5, 1042–1050. [Google Scholar] [CrossRef]
- Yu, Y.; Guan, H.; Ji, Z. Automated detection of urban road manhole covers using mobile laser scanning data. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3258–3269. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. ManCybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Guan, H.; Wang, C.; Yu, J. Automated detection of road manhole and sewer well covers from mobile LiDAR point clouds. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1549–1553. [Google Scholar]
- Díaz-Vilariño, L.; González-Jorge, H.; Bueno, M.; Arias, P.; Puente, I. Automatic classification of urban pavements using mobile LiDAR data and roughness descriptors. Constr. Build. Mater. 2016, 102, 208–215. [Google Scholar] [CrossRef]
- Li, D.; Elberink, S.O. Optimizing detection of road furniture (pole-like objects) in mobile laser scanner data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 1, 163–168. [Google Scholar] [CrossRef]
- Li, L.; Li, Y.; Li, D. A method based on an adaptive radius cylinder model for detecting pole-like objects in mobile laser scanning data. Remote Sens. Lett. 2016, 7, 249–258. [Google Scholar] [CrossRef]
- Teo, T.-A.; Chiu, C.-M. Pole-like road object detection from mobile lidar system using a coarse-to-fine approach. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4805–4818. [Google Scholar] [CrossRef]
- Li, F.; Oude Elberink, S.; Vosselman, G. Pole-Like Road Furniture Detection and Decomposition in Mobile Laser Scanning Data Based on Spatial Relations. Remote Sens. 2018, 10, 531. [Google Scholar]
- Rodríguez-Cuenca, B.; García-Cortés, S.; Ordóñez, C.; Alonso, M.C. Automatic detection and classification of pole-like objects in urban point cloud data using an anomaly detection algorithm. Remote Sens. 2015, 7, 12680–12703. [Google Scholar] [CrossRef]
- Yan, W.Y.; Morsy, S.; Shaker, A.; Tulloch, M. Automatic extraction of highway light poles and towers from mobile LiDAR data. Opt. Laser Technol. 2016, 77, 162–168. [Google Scholar] [CrossRef]
- Guan, H.; Yu, Y.; Li, J.; Liu, P. Pole-like road object detection in mobile LiDAR data via supervoxel and bag-of-contextual-visual-words representation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 520–524. [Google Scholar] [CrossRef]
- Ordóñez, C.; Cabo, C.; Sanz-Ablanedo, E. Automatic Detection and Classification of Pole-Like Objects for Urban Cartography Using Mobile Laser Scanning Data. Sensors 2017, 17, 1465. [Google Scholar] [CrossRef]
- Yadav, M.; Lohani, B.; Singh, A.K.; Husain, A. Identification of pole-like structures from mobile lidar data of complex road environment. Int. J. Remote Sens. 2016, 37, 4748–4777. [Google Scholar] [CrossRef]
- Yan, L.; Li, Z.; Liu, H.; Tan, J.; Zhao, S.; Chen, C. Detection and classification of pole-like road objects from mobile LiDAR data in motorway environment. Opt. Laser Technol. 2017, 97, 272–283. [Google Scholar] [CrossRef]
- Lehtomäki, M.; Jaakkola, A.; Hyyppä, J.; Kukko, A.; Kaartinen, H. Detection of vertical pole-like objects in a road environment using vehicle-based laser scanning data. Remote Sens. 2010, 2, 641–664. [Google Scholar] [CrossRef]
- Cabo, C.; Ordoñez, C.; García-Cortés, S.; Martínez, J. An algorithm for automatic detection of pole-like street furniture objects from Mobile Laser Scanner point clouds. ISPRS J. Photogramm. Remote Sens. 2014, 87, 47–56. [Google Scholar] [CrossRef]
- Wang, J.; Lindenbergh, R.; Menenti, M. SigVox—A 3D feature matching algorithm for automatic street object recognition in mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 128, 111–129. [Google Scholar] [CrossRef]
- El-Halawany, S.I.; Lichti, D.D. Detection of road poles from mobile terrestrial laser scanner point cloud. In Proceedings of the 2011 International Workshop on Multi-Platform/Multi-Sensor Remote Sensing and Mapping (M2RSM), Xiamen, China, 10–12 January 2011; pp. 1–6. [Google Scholar]
- Yokoyama, H.; Date, H.; Kanai, S.; Takeda, H. Detection and classification of pole-like objects from mobile laser scanning data of urban environments. Int. J. Cad/Cam 2013, 13, 31–40. [Google Scholar]
- Fukano, K.; Masuda, H. Detection and Classification of Pole-Like Objects from Mobile Mapping Data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2, 57–64. [Google Scholar] [CrossRef]
- Li, F.; Lehtomäki, M.; Oude Elberink, S.; Vosselman, G.; Puttonen, E.; Kukko, A.; Hyyppä, J. Pole-Like Road Furniture Detection in Sparse and Unevenly Distributed Mobile Laser Scanning Data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 185–192. [Google Scholar] [CrossRef]
- Li, F.; Elberink, S.O.; Vosselman, G. Semantic labelling of road furniture in mobile laser scanning data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42. [Google Scholar] [CrossRef]
- Rutzinger, M.; Pratihast, A.K.; Oude Elberink, S.; Vosselman, G. Detection and modelling of 3D trees from mobile laser scanning data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2010, 38, 520–525. [Google Scholar]
- Zhong, L.; Cheng, L.; Xu, H.; Wu, Y.; Chen, Y.; Li, M. Segmentation of individual trees from TLS and MLS Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 774–787. [Google Scholar] [CrossRef]
- Huang, P.; Chen, Y.; Li, J.; Yu, Y.; Wang, C.; Nie, H. Extraction of street trees from mobile laser scanning point clouds based on subdivided dimensional features. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 557–560. [Google Scholar]
- Weinmann, M.; Weinmann, M.; Mallet, C.; Brédif, M. A classification-segmentation framework for the detection of individual trees in dense MMS point cloud data acquired in urban areas. Remote Sens. 2017, 9, 277. [Google Scholar] [CrossRef]
- Guan, H.; Yu, Y.; Ji, Z.; Li, J.; Zhang, Q. Deep learning-based tree classification using mobile LiDAR data. Remote Sens. Lett. 2015, 6, 864–873. [Google Scholar] [CrossRef]
- Wu, B.; Yu, B.; Yue, W.; Shu, S.; Tan, W.; Hu, C.; Huang, Y.; Wu, J.; Liu, H. A voxel-based method for automated identification and morphological parameters estimation of individual street trees from mobile laser scanning data. Remote Sens. 2013, 5, 584–611. [Google Scholar] [CrossRef]
- Li, L.; Li, D.; Zhu, H.; Li, Y. A dual growing method for the automatic extraction of individual trees from mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2016, 120, 37–52. [Google Scholar] [CrossRef]
- Wu, S.; Wen, C.; Luo, H.; Chen, Y.; Wang, C.; Li, J. Using mobile LiDAR point clouds for traffic sign detection and sign visibility estimation. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 565–568. [Google Scholar]
- Sairam, N.; Nagarajan, S.; Ornitz, S. Development of mobile mapping system for 3D road asset inventory. Sensors 2016, 16, 367. [Google Scholar] [CrossRef] [PubMed]
- Huang, P.; Cheng, M.; Chen, Y.; Luo, H.; Wang, C.; Li, J. Traffic sign occlusion detection using mobile laser scanning point clouds. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2364–2376. [Google Scholar] [CrossRef]
- Ai, C.; Tsai, Y.J. An automated sign retroreflectivity condition evaluation methodology using mobile LIDAR and computer vision. Transp. Res. Part C Emerg. Technol. 2016, 63, 96–113. [Google Scholar] [CrossRef]
- Li, Y.; Fan, J.; Huang, Y.; Chen, Z. Lidar-Incorporated Traffic Sign Detection from Video Log Images of Mobile Mapping System. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 661–668. [Google Scholar] [CrossRef]
- Vu, A.; Yang, Q.; Farrell, J.A.; Barth, M. Traffic sign detection, state estimation, and identification using onboard sensors. In Proceedings of the 2013 16th International IEEE Conference on Intelligent Transportation Systems-(ITSC), The Hague, The Netherlands, 6–9 October 2013; pp. 875–880. [Google Scholar]
- Yang, B.; Dong, Z. A shape-based segmentation method for mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2013, 81, 19–30. [Google Scholar] [CrossRef]
- Riveiro, B.; Díaz-Vilariño, L.; Conde-Carnero, B.; Soilán, M.; Arias, P. Automatic segmentation and shape-based classification of retro-reflective traffic signs from mobile LiDAR data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 295–303. [Google Scholar] [CrossRef]
- Soilán, M.; Riveiro, B.; Martínez-Sánchez, J.; Arias, P. Traffic sign detection in MLS acquired point clouds for geometric and image-based semantic inventory. ISPRS J. Photogramm. Remote Sens. 2016, 114, 92–101. [Google Scholar] [CrossRef]
- Zhou, L.; Deng, Z. LIDAR and vision-based real-time traffic sign detection and recognition algorithm for intelligent vehicle. In Proceedings of the 2014 IEEE 17th International Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 578–583. [Google Scholar]
- Wen, C.; Li, J.; Luo, H.; Yu, Y.; Cai, Z.; Wang, H.; Wang, C. Spatial-related traffic sign inspection for inventory purposes using mobile laser scanning data. IEEE Trans. Intell. Transp. Syst. 2016, 17, 27–37. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Wen, C.; Guan, H.; Luo, H.; Wang, C. Bag-of-visual-phrases and hierarchical deep models for traffic sign detection and recognition in mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2016, 113, 106–123. [Google Scholar] [CrossRef]
- Guan, H.; Yan, W.; Yu, Y.; Zhong, L.; Li, D. Robust Traffic-Sign Detection and Classification Using Mobile LiDAR Data With Digital Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1715–1724. [Google Scholar] [CrossRef]
- Møgelmose, A.; Trivedi, M.M.; Moeslund, T.B. Vision-Based Traffic Sign Detection and Analysis for Intelligent Driver Assistance Systems: Perspectives and Survey. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1484–1497. [Google Scholar] [CrossRef] [Green Version]
- Pu, S.; Rutzinger, M.; Vosselman, G.; Elberink, S.O. Recognizing basic structures from mobile laser scanning data for road inventory studies. ISPRS J. Photogramm. Remote Sens. 2011, 66, S28–S39. [Google Scholar] [CrossRef]
- Luo, H.; Wang, C.; Wen, C.; Cai, Z.; Chen, Z.; Wang, H.; Yu, Y.; Li, J. Patch-based semantic labeling of road scene using colorized mobile LiDAR point clouds. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1286–1297. [Google Scholar] [CrossRef]
- Wu, F.; Wen, C.; Guo, Y.; Wang, J.; Yu, Y.; Wang, C.; Li, J. Rapid localization and extraction of street light poles in mobile LiDAR point clouds: A supervoxel-based approach. IEEE Trans. Intell. Transp. Syst. 2017, 18, 292–305. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, H.; Li, Y.; Wu, Z.; Mao, J.; Liu, Y. Streetlamp extraction and identification from mobile LiDAR point cloud scenes. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1468–1471. [Google Scholar]
- Zai, D.; Chen, Y.; Li, J.; Yu, Y.; Wang, C.; Nie, H. Inventory of 3D street lighting poles using mobile laser scanning point clouds. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 573–576. [Google Scholar]
- Bhattacharyya, A. On a measure of divergence between two multinomial populations. Sankhyā Indian J. Stat. 1946, 7, 401–406. [Google Scholar]
- Zheng, H.; Wang, R.; Xu, S. Recognizing street lighting poles from mobile lidar data. IEEE Trans. Geosci. Remote Sens. 2017, 55, 407–420. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Guan, H.; Wang, C.; Yu, J. Semiautomated extraction of street light poles from mobile LiDAR point-clouds. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1374–1386. [Google Scholar] [CrossRef]
- Manandhar, D.; Shibasaki, R. Auto-extraction of urban features from vehicle-borne laser data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2002, 34, 650–655. [Google Scholar]
- Rutzinger, M.; Höfle, B.; Oude Elberink, S.; Vosselman, G. Feasibility of facade footprint extraction from mobile laser scanning data. Photogramm. Fernerkund. Geoinf. 2011, 2011, 97–107. [Google Scholar] [CrossRef]
- Jochem, A.; Höfle, B.; Rutzinger, M. Extraction of vertical walls from mobile laser scanning data for solar potential assessment. Remote Sens. 2011, 3, 650–667. [Google Scholar] [CrossRef]
- Wang, R.; Bach, J.; Ferrie, F.P. Window detection from mobile LiDAR data. In Proceedings of the 2011 IEEE Workshop on Applications of Computer Vision (WACV), Kona, HI, USA, 5–7 January 2011; pp. 58–65. [Google Scholar]
- Yang, B.; Wei, Z.; Li, Q.; Li, J. Semiautomated building facade footprint extraction from mobile LiDAR point clouds. IEEE Geosci. Remote Sens. Lett. 2013, 10, 766–770. [Google Scholar] [CrossRef]
- Cabo, C.; Cortés, S.G.; Ordoñez, C. Mobile Laser Scanner data for automatic surface detection based on line arrangement. Autom. Constr. 2015, 58, 28–37. [Google Scholar] [CrossRef]
- Xia, S.; Wang, R. Extraction of residential building instances in suburban areas from mobile LiDAR data. ISPRS J. Photogramm. Remote Sens. 2018, 144, 453–468. [Google Scholar] [CrossRef]
- Arachchige, N.H.; Perera, S.N.; Maas, H.-G. Automatic processing of mobile laser scanner point clouds for building facade detection. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, XXXIX-B5, 187–192. [Google Scholar] [CrossRef]
- Arachchige, N.H.; Perera, S. Automatic modelling of building façade objects via primitive shapes. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 40, 115. [Google Scholar] [CrossRef]
- Lin, Y.; Hyyppä, J.; Kaartinen, H.; Kukko, A. Performance analysis of mobile laser scanning systems in target representation. Remote Sens. 2013, 5, 3140–3155. [Google Scholar] [CrossRef]
- Xiao, W.; Vallet, B.; Schindler, K.; Paparoditis, N. Street-side vehicle detection, classification and change detection using mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2016, 114, 166–178. [Google Scholar] [CrossRef]
- Bremer, M.; Wichmann, V.; Rutzinger, M. Eigenvalue and graph-based object extraction from mobile laser scanning point clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 5, W2. [Google Scholar] [CrossRef]
- Munoz, D.; Vandapel, N.; Hebert, M. Directional associative markov network for 3-d point cloud classification. In Proceedings of the 2008 4th International Symposium on 3D Data Processing, Visualization and Transmission, Atlanta, GA, USA, 18–20 June 2008; pp. 65–72. [Google Scholar]
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast Semantic Segmentation of 3d Point Clouds with Strongly Varying Density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 177–184. [Google Scholar] [CrossRef]
- Landrieu, L.; Raguet, H.; Vallet, B.; Mallet, C.; Weinmann, M. A structured regularization framework for spatially smoothing semantic labelings of 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 132, 102–118. [Google Scholar] [CrossRef]
- Luo, H.; Wang, C.; Wen, C.; Chen, Z.; Zai, D.; Yu, Y.; Li, J. Semantic Labeling of Mobile LiDAR Point Clouds via Active Learning and Higher Order MRF. IEEE Trans. Geosci. Remote Sens. 2018. [Google Scholar] [CrossRef]
- Sun, Z.; Xu, Y.; Hoegner, L.; Stilla, U. Classification of Mls Point Clouds in Urban Scenes Using Detrended Geometric Features from Supervoxel-Based Local Contexts. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 271–278. [Google Scholar] [CrossRef]
- Golovinskiy, A.; Kim, V.G.; Funkhouser, T. Shape-based recognition of 3D point clouds in urban environments. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2154–2161. [Google Scholar]
- Aijazi, A.K.; Checchin, P.; Trassoudaine, L. Segmentation based classification of 3D urban point clouds: A super-voxel based approach with evaluation. Remote Sens. 2013, 5, 1624–1650. [Google Scholar] [CrossRef]
- Lehtomäki, M.; Jaakkola, A.; Hyyppä, J.; Lampinen, J.; Kaartinen, H.; Kukko, A.; Puttonen, E.; Hyyppä, H. Object classification and recognition from mobile laser scanning point clouds in a road environment. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1226–1239. [Google Scholar] [CrossRef]
- Babahajiani, P.; Fan, L.; Kämäräinen, J.-K.; Gabbouj, M. Urban 3D segmentation and modelling from street view images and LiDAR point clouds. Mach. Vis. Appl. 2017, 28, 679–694. [Google Scholar] [CrossRef] [Green Version]
- Xiang, B.; Yao, J.; Lu, X.; Li, L.; Xie, R.; Li, J. Segmentation-based classification for 3D point clouds in the road environment. Int. J. Remote Sens. 2018, 1–31. [Google Scholar] [CrossRef]
- Fan, H.; Yao, W.; Tang, L. Identifying man-made objects along urban road corridors from mobile LiDAR data. IEEE Geosci. Remote Sens. Lett. 2014, 11, 950–954. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 2012 Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv, 2017; arXiv:1704.06857. [Google Scholar]
- Zhuang, Y.; He, G.; Hu, H.; Wu, Z. A novel outdoor scene-understanding framework for unmanned ground vehicles with 3D laser scanners. Trans. Inst. Meas. Control 2015, 37, 435–445. [Google Scholar] [CrossRef]
- Lawin, F.J.; Danelljan, M.; Tosteberg, P.; Bhat, G.; Khan, F.S.; Felsberg, M. Deep projective 3D semantic segmentation. In Proceedings of the 2017 International Conference on Computer Analysis of Images and Patterns, Ystad, Sweden, 22–24 August 2017; pp. 95–107. [Google Scholar]
- Qiu, Z.; Zhuang, Y.; Yan, F.; Hu, H.; Wang, W. RGB-DI Images and Full Convolution Neural Network-Based Outdoor Scene Understanding for Mobile Robots. IEEE Trans. Instrum. Meas. 2018. [Google Scholar] [CrossRef]
- Huang, J.; You, S. Point cloud labeling using 3d convolutional neural network. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2670–2675. [Google Scholar]
- Wang, L.; Huang, Y.; Shan, J.; He, L. MSNet: Multi-Scale Convolutional Network for Point Cloud Classification. Remote Sens. 2018, 10, 612. [Google Scholar] [CrossRef]
- Roynard, X.; Deschaud, J.-E.; Goulette, F. Classification of Point Cloud Scenes with Multiscale Voxel Deep Network. arXiv, 2018; arXiv:1804.03583. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Munoz, D.; Bagnell, J.A.; Vandapel, N.; Hebert, M. Contextual classification with functional max-margin markov networks. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 975–982. [Google Scholar]
- Serna, A.; Marcotegui, B.; Goulette, F.; Deschaud, J.-E. Paris-rue-Madame database: A 3D mobile laser scanner dataset for benchmarking urban detection, segmentation and classification methods. In Proceedings of the 2014 4th International Conference on Pattern Recognition, Applications and Methods (ICPRAM), Angers, France, 6–8 March 2014. [Google Scholar]
- Vallet, B.; Brédif, M.; Serna, A.; Marcotegui, B.; Paparoditis, N. TerraMobilita/iQmulus urban point cloud analysis benchmark. Comput. Graph. 2015, 49, 126–133. [Google Scholar] [CrossRef] [Green Version]
- Roynard, X.; Deschaud, J.-E.; Goulette, F. Paris-Lille-3D: A large and high-quality ground-truth urban point cloud dataset for automatic segmentation and classification. Int. J. Robot. Res. 2017, 0278364918767506. [Google Scholar] [CrossRef]
- Samberg, A. An implementation of the ASPRS LAS standard. In Proceedings of the 2007 ISPRS Workshop on Laser Scanning and SilviLaser, Espoo, Finland, 12–14 September 2007; pp. 363–372. [Google Scholar]
- ASPRS. LAS Specification (Version 1.4–R13). Available online: https://www.asprs.org/a/society/committees/standards/LAS_1_4_r13.pdf (accessed on 2 February 2019).
- OpenLSEF. OpenLSEF Topography & Assets. Available online: https://beta.openlsef.org/topography-assets/ (accessed on 22 November 2018).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Measurement of Interest | Description of Approach | Assumptions/Limitations |
|---|---|---|---|
| Blug, et al. [35] | Rail tracks for clearance measurements for intelligent systems | Scanline profiles in polar coordinates. Evaluates angle of the outer rail edge, distance from the scanner to the rails, distance between the two rails, and height differences between rail foot and rail head. |
|
| Yang and Fang [36] | Railway tracks and beds | Slope within consecutive profiles (Yang et al. 2013), height and slope between head and foot of the rail, and intensity contrast between the ballast and rails. |
|
| Elberink and Khoshelham [37] | Rail track centerlines | Local geometric properties (height and parallelism) followed by modeling for fine extraction. Smoothed by a Fourier series interpolation |
|
| Hackel, et al. [38] | Rail tracks and turnouts | SVM with Shape matching. Identifies occluding edges (e.g., depth discontinuities) followed by height evaluation. Shape matching using ICP with a simple, piecewise linear element model. Fine-tuned by evaluating longitudinal consistency between sections and rail normal. |
|
| Stein [39] | Rail tracks and turnouts | 2D (profile) scanner with intensity information. Search near ground, identify areas with significant changes in distance, template matching. |
|
| Arastounia [40] | Cables (catenary, contact, return current), rail track, mast, cantilever | Data driven approach using k-d tree, the distribution of heights, followed by PCA. |
|
| Pastucha [41] | Catenary systems | Geometric based approach, which searches within a distance of the trajectory and evaluates point densities above the tracks. Utilizes RANSAC to classify the points. Projects coordinates to the ground, and improves the classification with a modified DBSCAN algorithm. |
|
| Study | Measurement(s) of Interest | Description of Approach | Assumptions/Limitations |
|---|---|---|---|
| Arastounia [47] | Side wall, ceiling, floor | Extracts cross section along main tunnel axis, fit ellipse, refine and evaluate. | -Only provides measurements at cross sections -Assumes an elliptical tunnel |
| Puente, et al. [48] | Vertical clearance/cross sections, asphalt, pavement markings. | Generate cross sections and use extracted lane markings to identify lanes for clearance evaluation. | -Only provides measurements at cross sections |
| Puente, et al. [49] | Road Luminares | Height filter and adjusted RGB color histogram. Apply motion blur correction. | Reliable RGB information is challenging in terms of calibration, image quality, etc. particularly in dark tunnels. |
| Yoon, et al. [50] | Automated inspection and damage detection (e.g., cracks) | Combination of geometric and radiometric data to identify anomalies. | -Assumes a planar tunnel. |
| Study | Methods | Characteristics | ||||
|---|---|---|---|---|---|---|
| Rasterization | 3D-Based | Scanline | Point Density | Elevation Variance | Elevation Jump | |
| Yang, et al. [57] | ✓ | - | - | - | ✓ | - |
| Hernández and Marcotegui [54,55], Serna and Marcotegui [52,56] | ✓ | - | - | - | - | ✓ |
| Wu, et al. [63] | ✓ | - | ✓ | - | ✓ | - |
| Ibrahim and Lichti [61] | - | ✓ | - | ✓ | - | - |
| Husain and Vaishya [58], Yadav, et al. [59] | - | ✓ | - | - | ✓ | - |
| Lin and Zhang [51] | - | ✓ | - | - | - | ✓ |
| Teo and Yu [62] | - | - | ✓ | - | - | ✓ |
| Study | Methods | Characteristics | |||
|---|---|---|---|---|---|
| Rasterization | 3D-Based | Scanline | Intensity | Geometry | |
| Serna and Marcotegui [56] | ✓ | - | - | - | ✓ |
| Kumar, et al. [64] | ✓ | - | - | ✓ | ✓ |
| Rodríguez-Cuenca, et al. [72] | ✓ | ✓ | - | - | |
| El-Halawany, et al. [71], Rodríguez-Cuenca, et al. [73] | ✓ | ✓ | - | - | ✓ |
| Ibrahim and Lichti [61], Miraliakbari, et al. [65], Xu, et al. [66], Zai, et al. [67] | - | ✓ | - | - | ✓ |
| Yadav, et al. [59] | - | ✓ | - | ✓ | ✓ |
| Miyazaki, et al. [68], Cabo, et al. [69] | - | - | ✓ | - | ✓ |
| Study | Methods | Characteristics | Classification | |||
|---|---|---|---|---|---|---|
| Rasterization | 3D-Based | Scanline | Intensity | Geometry | ||
| Guan, et al. [77], Kumar, et al. [83] | ✓ | - | - | ✓ | - | - |
| Guan, et al. [84], Riveiro, et al. [85], Jung, et al. [87], Yang et al. [88] | ✓ | - | - | ✓ | ✓ | - |
| Guo, et al. [75], Cheng, et al. [81], Soilán, et al. [86], Wen et al. [87] | ✓ | - | - | ✓ | ✓ | ✓ |
| Yang, et al. [79] | - | ✓ | - | ✓ | ✓ | - |
| Yu, et al. [78] | - | ✓ | - | ✓ | ✓ | ✓ |
| Yan, et al. [76] | - | - | ✓ | ✓ | ✓ | - |
| Yang, et al. [82] | - | - | ✓ | ✓ | ✓ | ✓ |
| References | Position | Verticality | Continuity | Shape | Size |
|---|---|---|---|---|---|
| El-Halawany and Lichti [111] | - | - | ✓ | ✓ | ✓ |
| Fukano and Masuda [113], Wang, et al. [110] | - | - | ✓ | ✓ | - |
| Yokoyama, et al. [112] | - | ✓ | ✓ | ✓ | ✓ |
| Ordóñez, et al. [105], Cabo, et al. [109] | - | ✓ | ✓ | - | ✓ |
| Lehtomäki, et al. [108], Yadav, et al. [106], Guan, et al. [104], Yan, et al. [107], Li, et al. [114] | - | ✓ | ✓ | ✓ | ✓ |
| Li and Elberink [98] | ✓ | - | ✓ | - | ✓ |
| Teo and Chiu [100], Li, et al. [115] | ✓ | - | ✓ | ✓ | ✓ |
| Rodríguez-Cuenca et al. [102], Li, et al. [99] | ✓ | ✓ | ✓ | - | ✓ |
| Li, et al. [101] | ✓ | ✓ | ✓ | ✓ | ✓ |
| Study | Characteristics for Traffic Sign Detection and Recognition | Machine Learning | |||||
|---|---|---|---|---|---|---|---|
| Color | Intensity | Planarity | Size | Shape | Others | ||
| Yang and Dong [129] | - | - | √ | √ | √ | - | SVM |
| Riveiro, et al. [130] | - | √ | √ | - | √ | - | - |
| Soilán, et al. [131] | √ | √ | √ | - | √ | - | SVM |
| Zhou and Deng [132] | √ | √ | √ | √ | - | Position | SVM |
| Li, et al. [127] | - | - | √ | - | √ | Height | - |
| Pu, et al. [137] | √ | √ | √ | √ | √ | Position | - |
| Wen, et al. [133] | √ | √ | - | - | - | - | SVM |
| Vu, et al. [128] | - | √ | - | - | - | Position, orientation | - |
| Wu, et al. [123] | √ | √ | √ | - | - | Position | - |
| Yang, et al. [25] | - | - | √ | √ | - | Height | - |
| Sairam, et al. [124] | - | √ | - | √ | - | Height | - |
| Yang, et al. [80] | - | - | √ | √ | - | Position | SVM |
| Yu, et al. [134] | √ | √ | √ | √ | √ | - | DBM |
| Guan, et al. [135] | √ | √ | √ | √ | √ | Height, position | DBM |
| Huang, et al. [125] | - | √ | √ | - | - | Orientation, height | - |
| Fukano and Masuda [113] | - | - | √ | - | - | Orientation | Random Forest |
| Ai and Tsai [126] | √ | - | √ | - | - | - | - |
| Study | Segmentation | Features | Classification | Class | |
|---|---|---|---|---|---|
| Point-wise Classification | Bremer, et al. [156] | - | Geometric | Rule-based | 7 (Ground, ground inventory, wall, wall inventory, roof, artificial poles, trees) |
| Munoz, et al. [157] | - | Geometric Contexual | Associate Markov Network | 5 (Wire, pole/trunk, façade, ground, vegetation); 6 (Façade, ground, cars, motorcycles, traffic signs, pedestrians) | |
| Weinmann, et al. [20] | - | Geometric | 10 classifiers tested | ||
| Hackel, et al. [158] | - | Geometri Contexual | Random Forest | ||
| Landrieu, et al. [159] | - | Geometric Contexual | Random Forest | ||
| Segment-wise Classification | Luo, et al. [138] | Voxel | Geometric Colormetric Contextual | Graph matching | 7 (Road, grass, palm tree, cycas, brushwood, light pole, vehicle) |
| Luo, et al. [160] | Supervoxel | Geometric Colormetric Contextual | Conditional Random Field matching | ||
| Sun, et al. [161] | Supervoxel | Geometric Radiometric Contextual | Random Forest | 8 (man-made terrain, natural terrain, high vegetation, low vegetation, building, Hard scape, Scanning artefacts, vehicle) | |
| Object-wise Classification | Golovinskiy, et al. [162] | 3 approaches tested | Geometric Contextual | 4 classifiers tested | 10 (short post, car, lamp post, sign, light standard, traffic light, newspaper box, tall post, fire hydrant, trash can) |
| Pu, et al. [137] | Connected component | Geometric Colormetric Contextual | Rule-based | 3 (Poles, tree, ground) | |
| Aijazi, et al. [163] | Supervoxel | Geometric Radiometric Colormetric | Rule-based | 5 (building, road, pole, car, tree) | |
| Serna and Marcotegui [52] | Connected component | Geometric Colormetric Contextual | SVM | 6 (Car, lamppost, light, post, sign, tree) | |
| Yang, et al. [25] | Supervoxel | Geometric Colormetric Contextual | Rule-based | 7 (Building, utility poles, traffic signs, trees, street lamps, enclosures, cars) | |
| Lehtomäki, et al. [164] | Connected component | Geometric | SVM | 6 (tree, lamp post, traffic pole, car, pedestrian, hoarding) | |
| Babahajiani, et al. [165] | Supervoxel | Geometric Radiometric | Template matching | 4 (Building, road, traffic sign, car) | |
| Yang, et al. [80] | Region growing | Geometric Contextual | SVM | 11 (Ground, Road, Road marking, building, utility pole, traffic sign, tree, street lamp, guardrail, car, powerline) | |
| Xiang, et al. [166] | Graph-cut | Geometric Contextual | SVM | 9 (ground, building, fence, utility pole, tree, electrical wire, street light, curb, car) |
| Dataset/Reference | Sensor | Format | Primary Fields | # Points | # Classes | Example Classes |
|---|---|---|---|---|---|---|
| Oakland [178] | Unknown | ASCII | X, Y, Z Class | 1.6M | 5 | Vegetation, wire, utility pole, ground, façade. |
| Paris-rue-Madame [179] | Velodyne HDL32 | PLY (binary) | X, Y, Z Intensity Object ID Class | 20.0M | 17 | Façade, ground, cars, light poles, pedestrians, motorcycles, traffic signs, trashcan, wall light, balcony plant, parking meter, wall sign… |
| iQmulus [180] | Riegl LMS-Q120i | PLY (binary) | X, Y, Z Intensity GPS time Scan origin # echoes Object ID Class | 12.0M | 22 | Road, sidewalk, curb, building, post, street light, traffic sign, mailbox, trashcan, pedestrian, motorcycle, bicycle, tree, potted plant… |
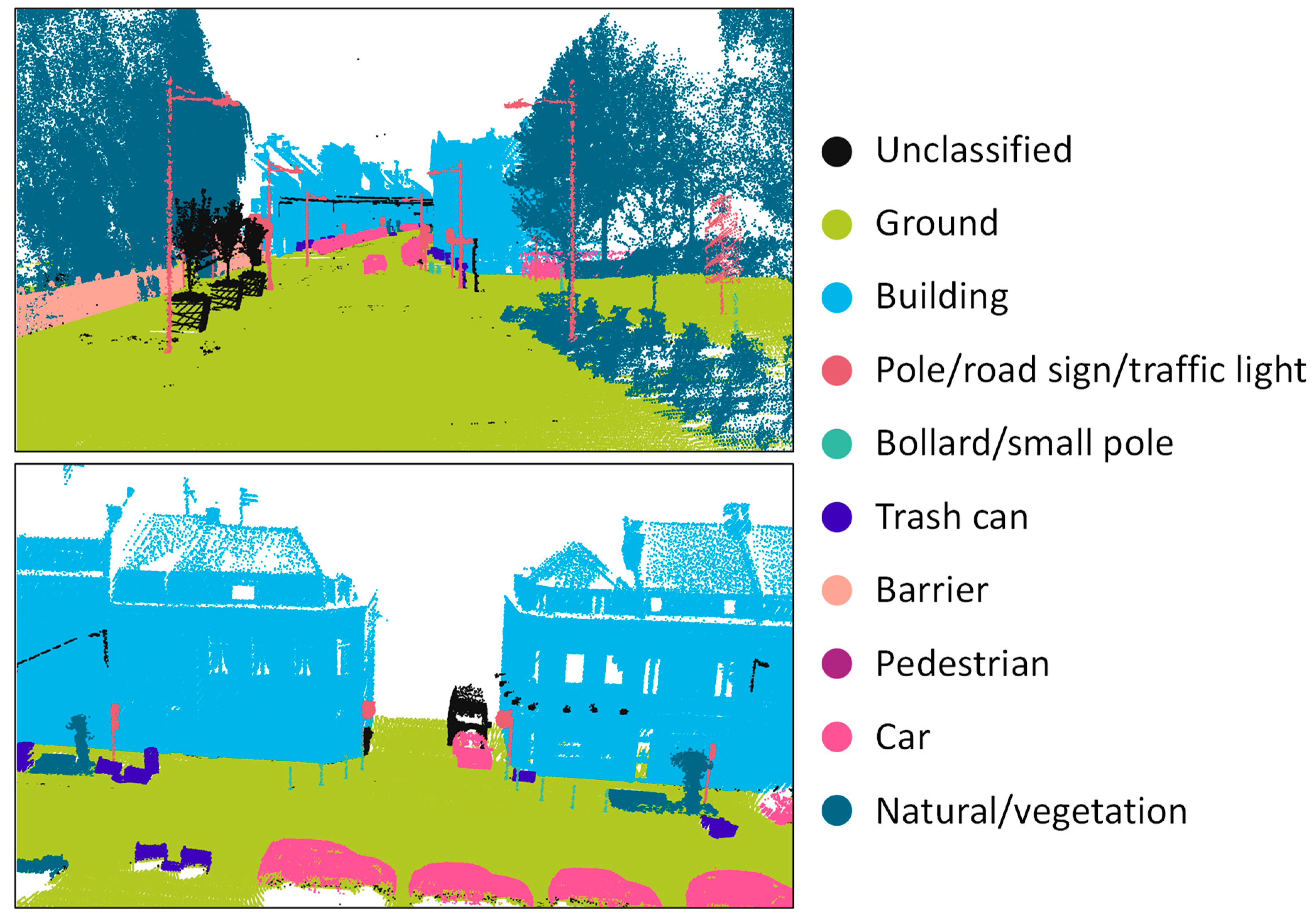
| Paris-Lille-3D [181] | Velodyne HDL32 | PLY (binary) | X, Y, Z Intensity Class | 143.1M | 50 | Ground, building, pole, small pole, trash can, barrier, pedestrian, car, vegetation… |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Che, E.; Jung, J.; Olsen, M.J. Object Recognition, Segmentation, and Classification of Mobile Laser Scanning Point Clouds: A State of the Art Review. Sensors 2019, 19, 810. https://doi.org/10.3390/s19040810
Che E, Jung J, Olsen MJ. Object Recognition, Segmentation, and Classification of Mobile Laser Scanning Point Clouds: A State of the Art Review. Sensors. 2019; 19(4):810. https://doi.org/10.3390/s19040810
Chicago/Turabian StyleChe, Erzhuo, Jaehoon Jung, and Michael J. Olsen. 2019. "Object Recognition, Segmentation, and Classification of Mobile Laser Scanning Point Clouds: A State of the Art Review" Sensors 19, no. 4: 810. https://doi.org/10.3390/s19040810
APA StyleChe, E., Jung, J., & Olsen, M. J. (2019). Object Recognition, Segmentation, and Classification of Mobile Laser Scanning Point Clouds: A State of the Art Review. Sensors, 19(4), 810. https://doi.org/10.3390/s19040810