FPGA Modeling and Optimization of a SIMON Lightweight Block Cipher


Abstract
:1. Introduction
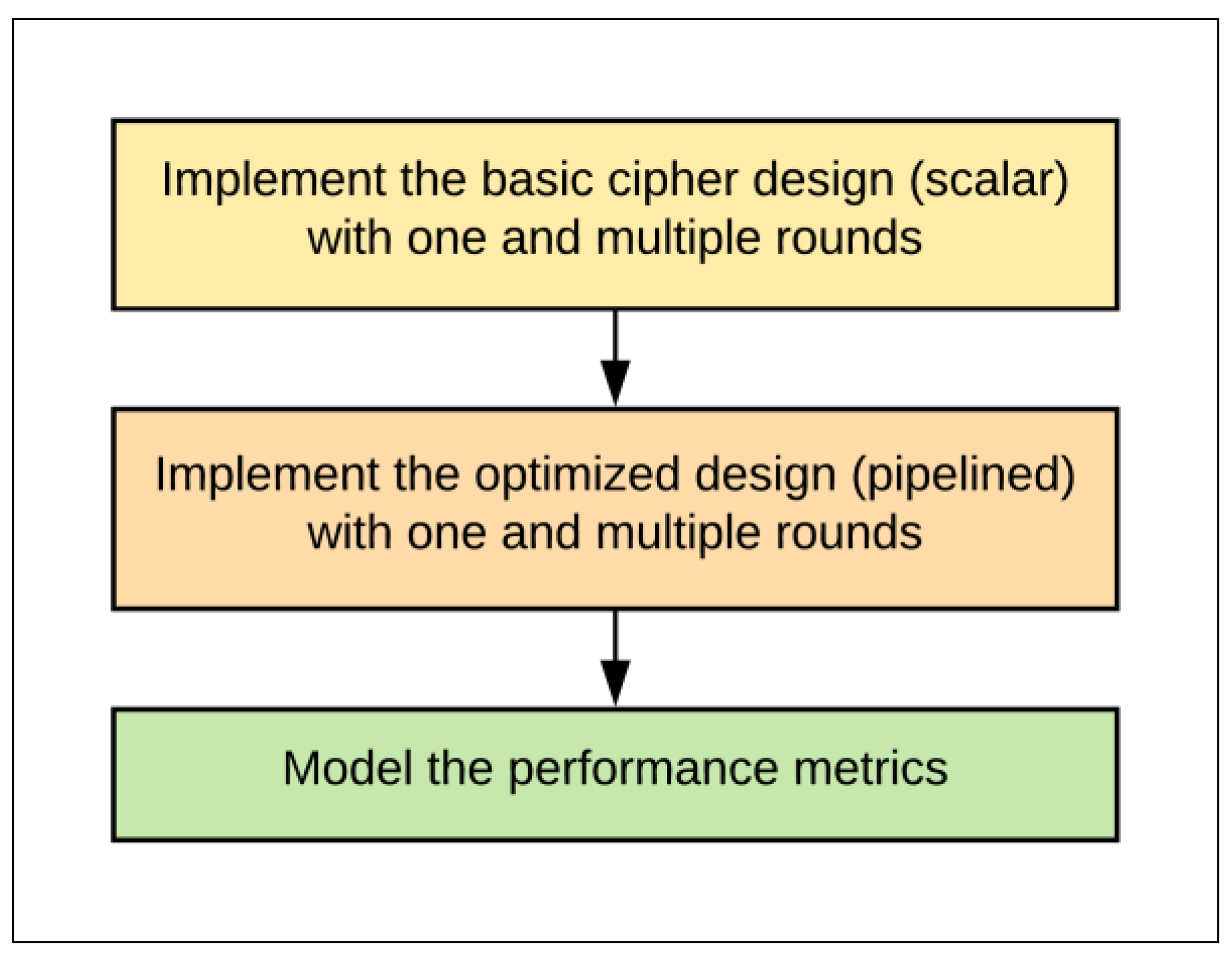
- Implement a basic SIMON design (scalar/non-pipelined) with one and multiple rounds. Scalar implementations are more appropriate for intermittent (non-continuous) data.
- Implement and examine pipelined design (pipelined) with one and multiple rounds. Pipelined designs are better suited to encrypt a continuous stream of data.
- Derive accurate performance models for throughput, area, power, and energy metrics based on the implementation results.
- Determine the best implementation for each performance metric with a particular area and energy (with slightly higher emphasis on energy), i.e., the most critical metrics in LRDs.
2. Related Work
3. Methods
- Implement the basic one-round SIMON scalar design to optimize the basic design.
- Implement scalar designs with multiple hardware rounds, e.g., 2, 4, 8, 16, or 32.
- Implement pipelined designs with one and multiple rounds.
- Measure and model the performance metrics (area, speed, power, and energy) for each step.
- Discuss recommendations for the optimum design.
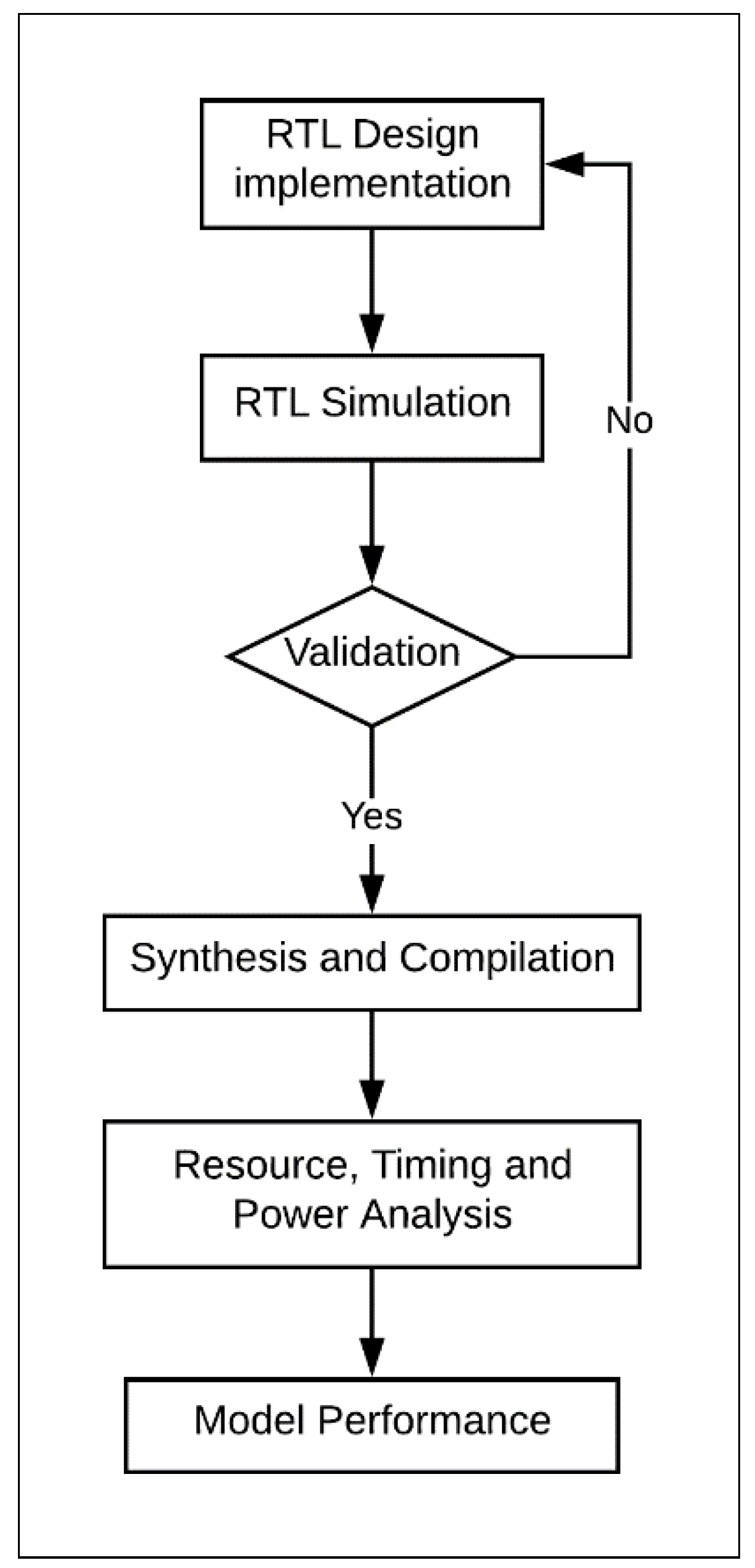
- The cipher was designed and implemented at the register transfer level (RTL) using VerilogTM, a hardware description language. The Verilog implementation was verified by dynamic simulations using ModelSimTM. ModelSim provides wave-files, which capture the node activity used to compute the power dissipation of the design.
- The design was synthesized and compiled using the Altera FPGA software package Quartus-II. The choice of FPGA family should not impact the results of the research. Mohd et al. examined several implementations of steganography algorithms in Altera and Xilinx FPGAs [32]. The study concluded that Altera and Xilinx provide similar trending results.
- For Quartus-II synthesis, timing constraints were used during the compiling process.
- The design underwent the following analyses using Quartus-II:
- -
- Timing analysis reported the maximum frequency of the design. The designs were compiled with clock constraints of 50 MHz.
- -
- Resource utilization analysis showed the number of logic elements (LEs) and the type (i.e., combinational, register logic, or both) used in the FPGA design [13]. LE is the smallest unit of logic in the Altera architecture; it is compact and facilitates efficient logic utilization. Each LE includes a four-input look-up table (LUT) and a programmable register. The LUT is a function generator that can implement any function of four variables [33].
- -
- Power analysis computed the average power of the design. The computed power is the dynamic core power that consists of combinational, register, and clock. The power required by node activities was extracted from the value change dump (VCD) files generated by ModelSim simulations. This approach to computing power was used in other works, such as References [4,13].
- Performance models for area, power, and energy were derived based on implementation results.
3.1. SIMON Algorithm
- Block size (2n): 32;
- Key size (mn): 64;
- Word size (n): 16;
- Key words (m): 4;
- Constant sequence (zj): z0;
- Cipher rounds (T): 32.
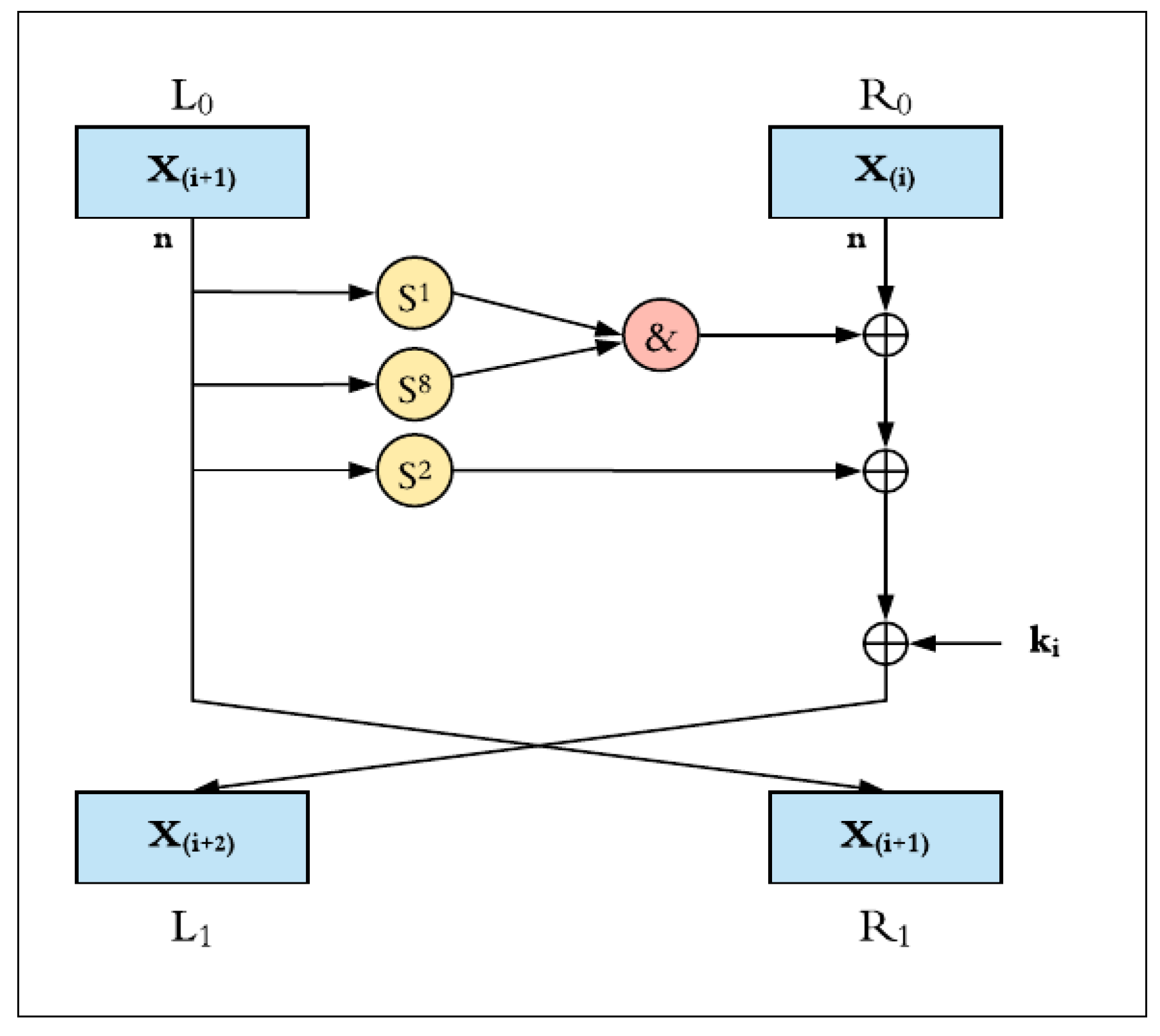
3.1.1. Round Function
- Bitwise XOR, ⊕;
- Bitwise AND, &;
- Left circular shift, Sj, by j bits.
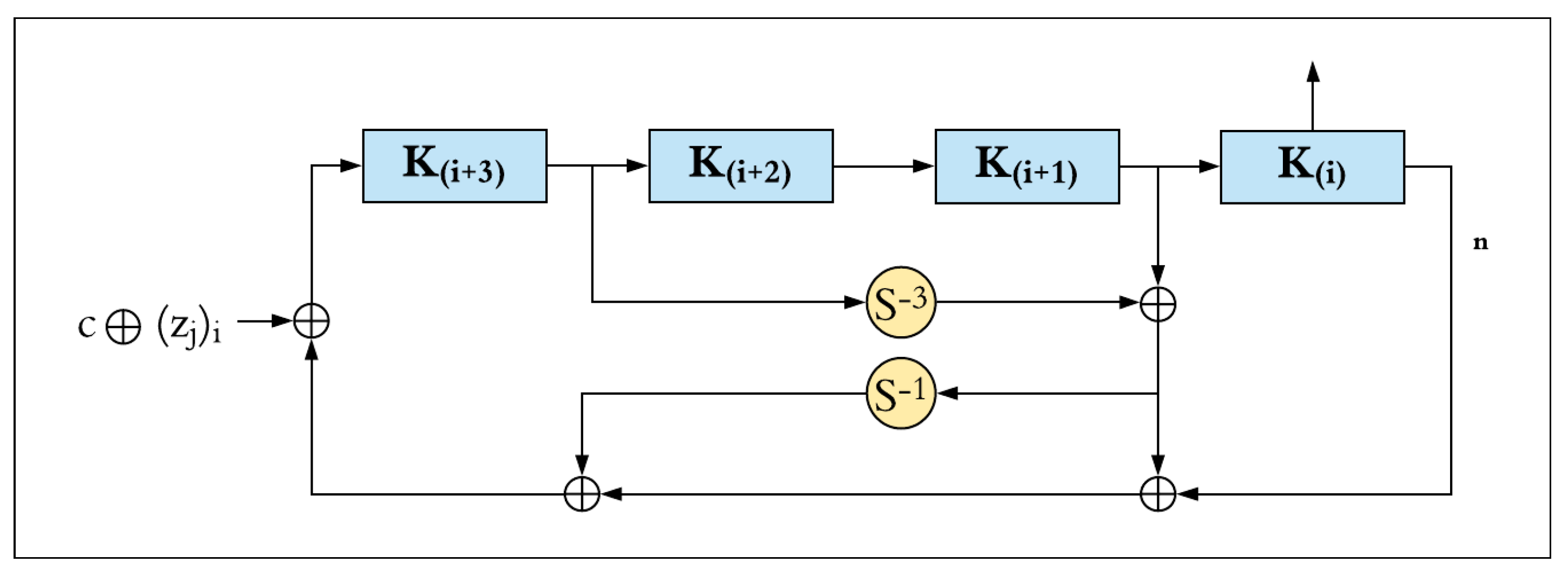
3.1.2. Key Schedule
- Bitwise XOR, ⊕;
- Right circular shift, S−j, by j bits.
3.2. Scalar Design
3.2.1. Basic Scalar Design for One Round (Iterative)
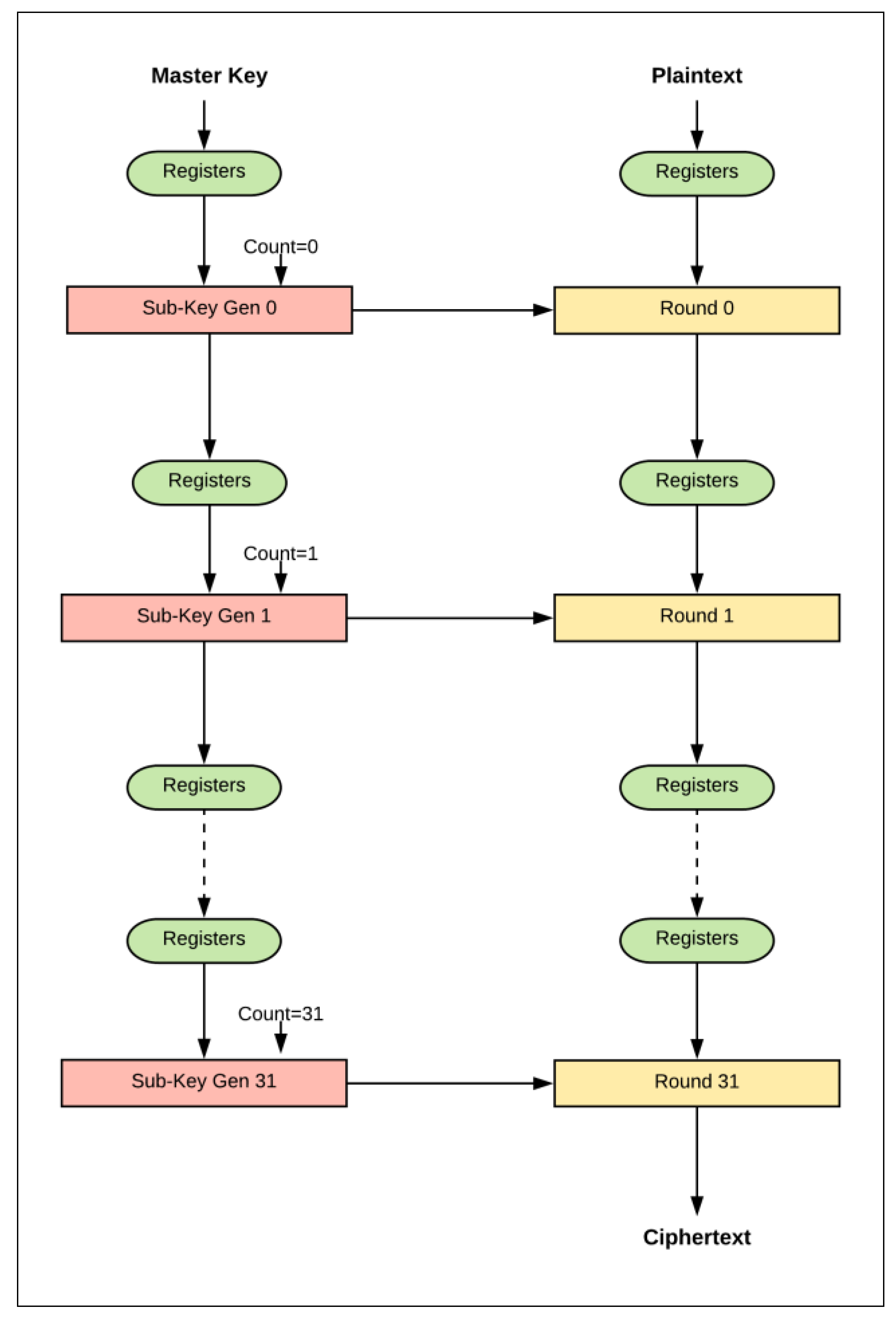
- Only one block cipher is encrypted at a time.
- The number of clock cycles required to encrypt a single block cipher is equal to the number of cipher rounds (i.e., T) plus the number of cycles to load plaintext and output ciphertext (i.e., Cidle).
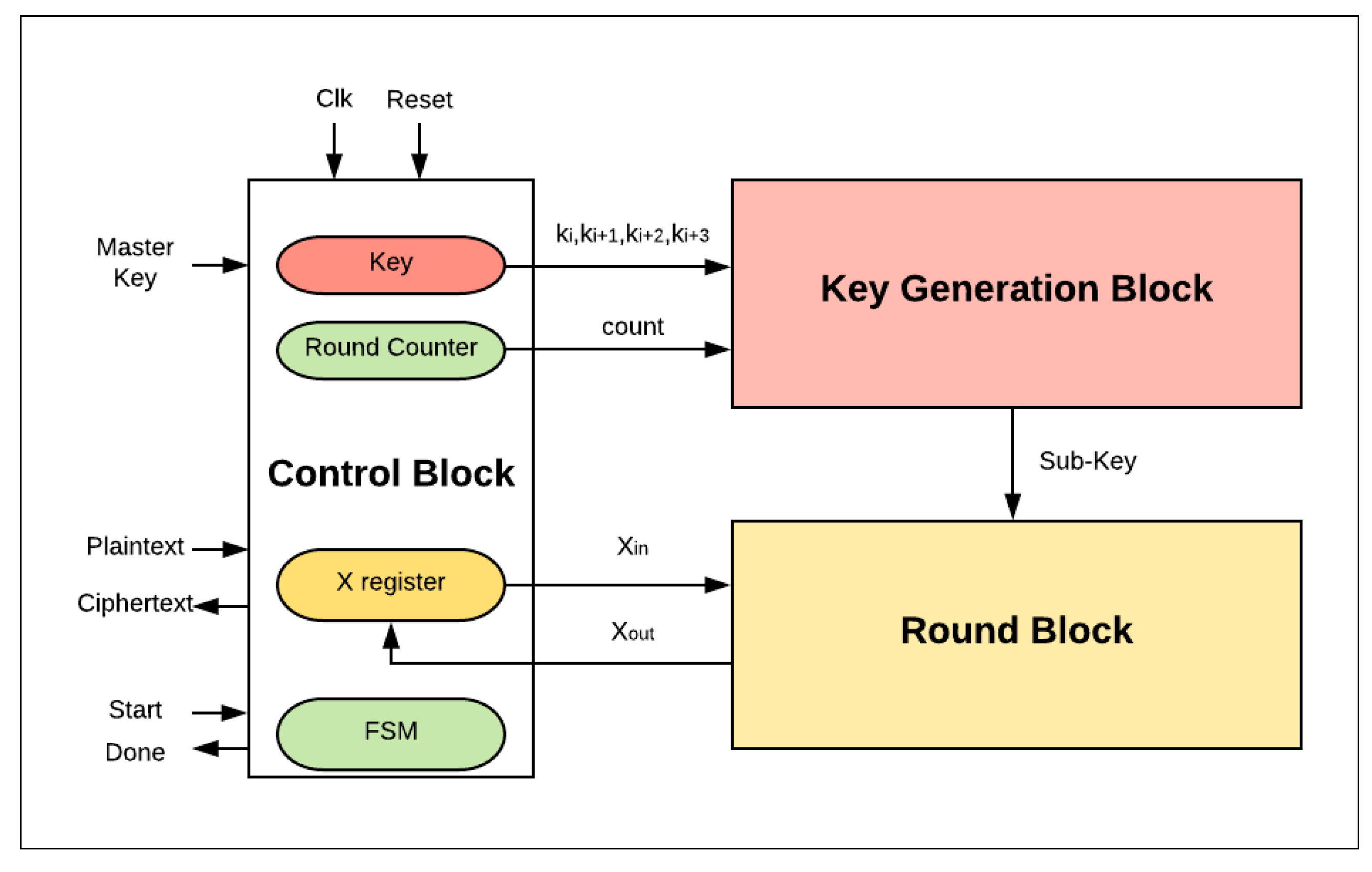
- The control logic block is responsible for managing the external and internal activities of the system. It controls three main registers: key, round counter, and X register. Additionally, it organizes the sequence order of these activities’ functionalities through a finite-state machine (FSM). The encryption process begins with the assertion of a start signal. The plaintext is then loaded into the X register and the round counter is initialized to zero. The value of Key (master key) is also stored in specific sub-key registers in order to perform the key generation process. In the following cycles, the control block assigns sub-key and round counter values to the key generation block and Xin to the round logic block. Once the counter reaches its maximum value (the number of corresponding rounds has finished), the done signal is asserted by the control block to state that the encryption process is complete.
- The key generation block generates the sub-key required for the current round.
- The round block performs one hardware round operation and updates the X register. In the last clock cycle, the ciphertext value is saved in the X register.
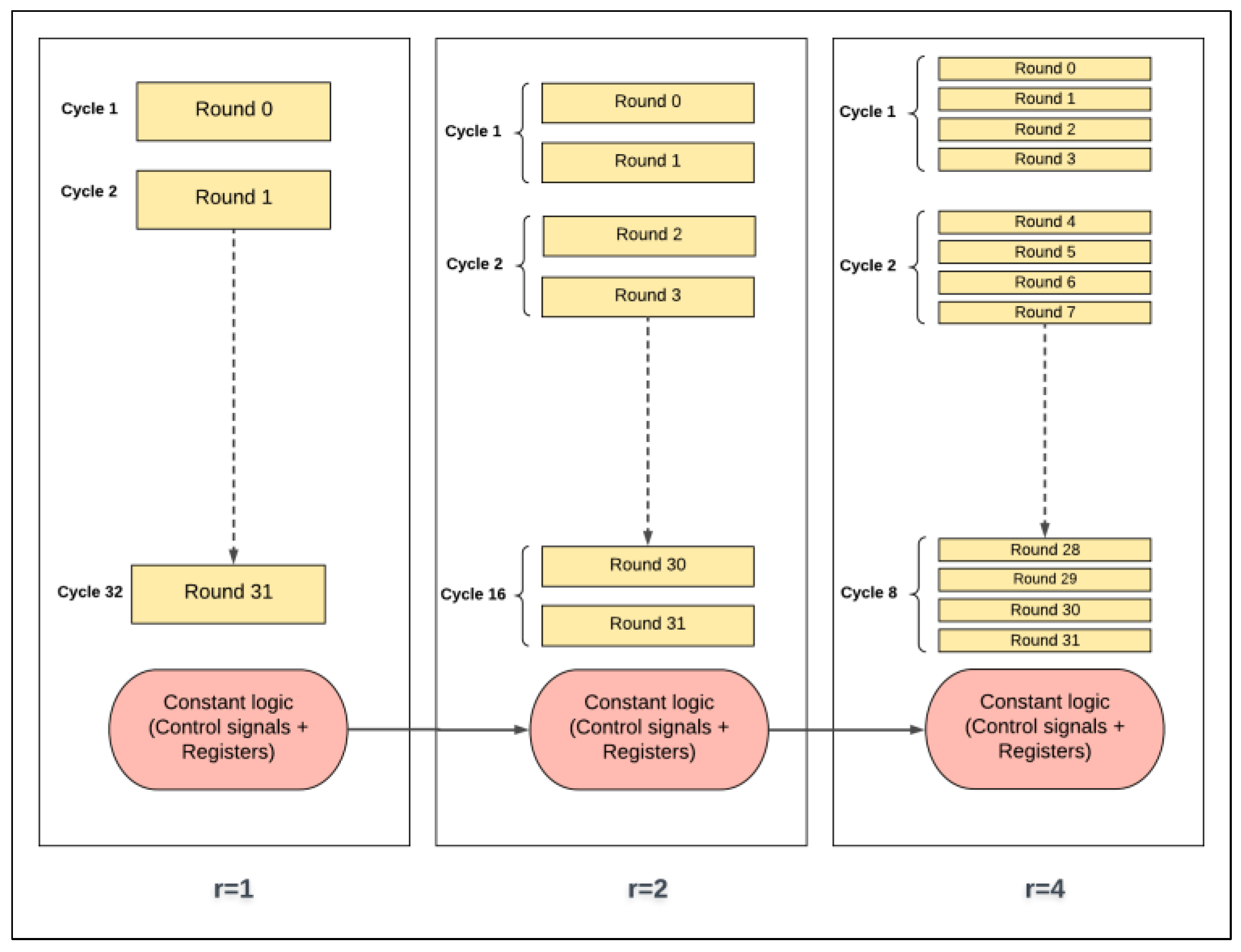
3.2.2. Scalar Design with Multiple Rounds (Loop Unrolling)
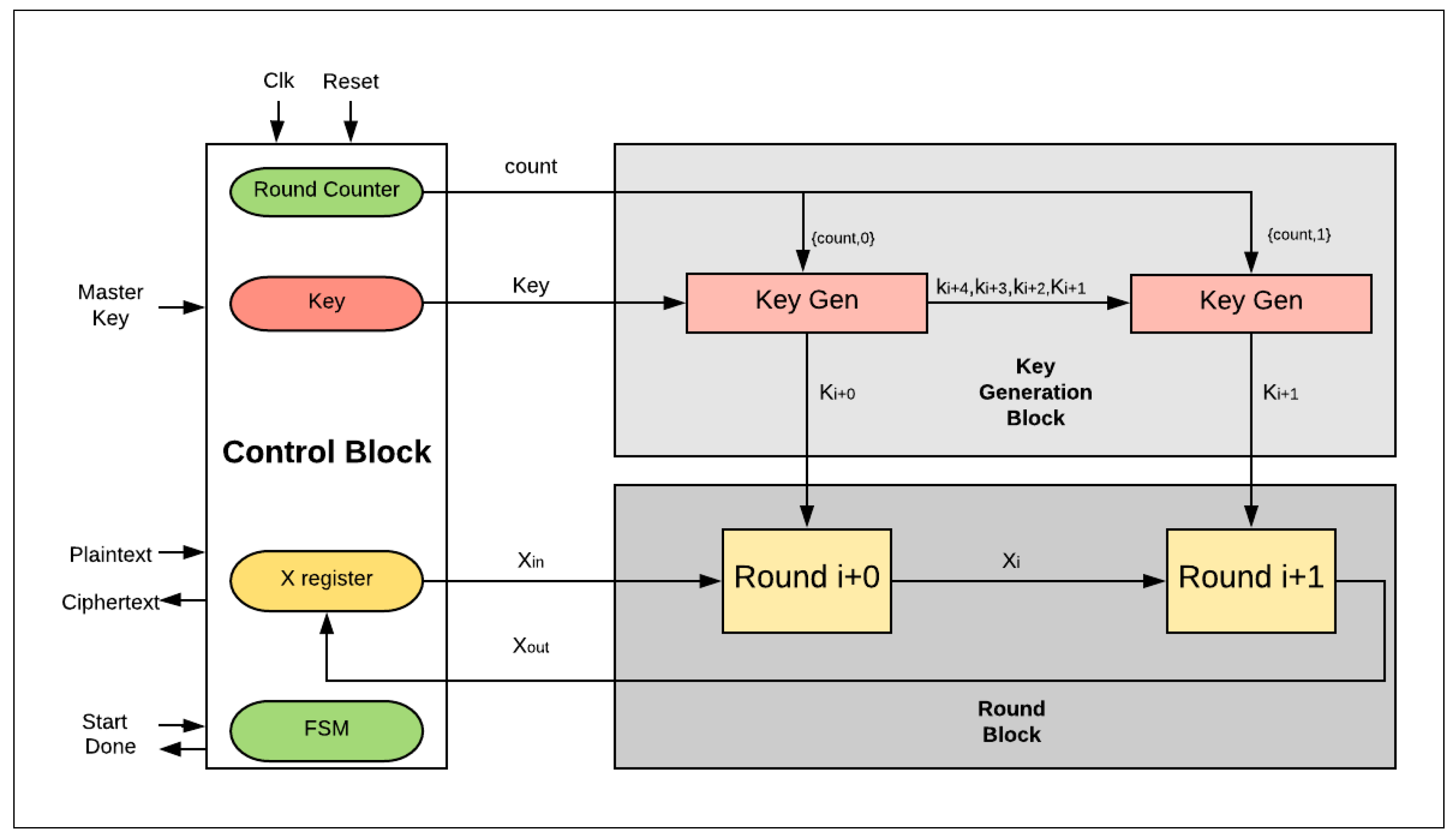
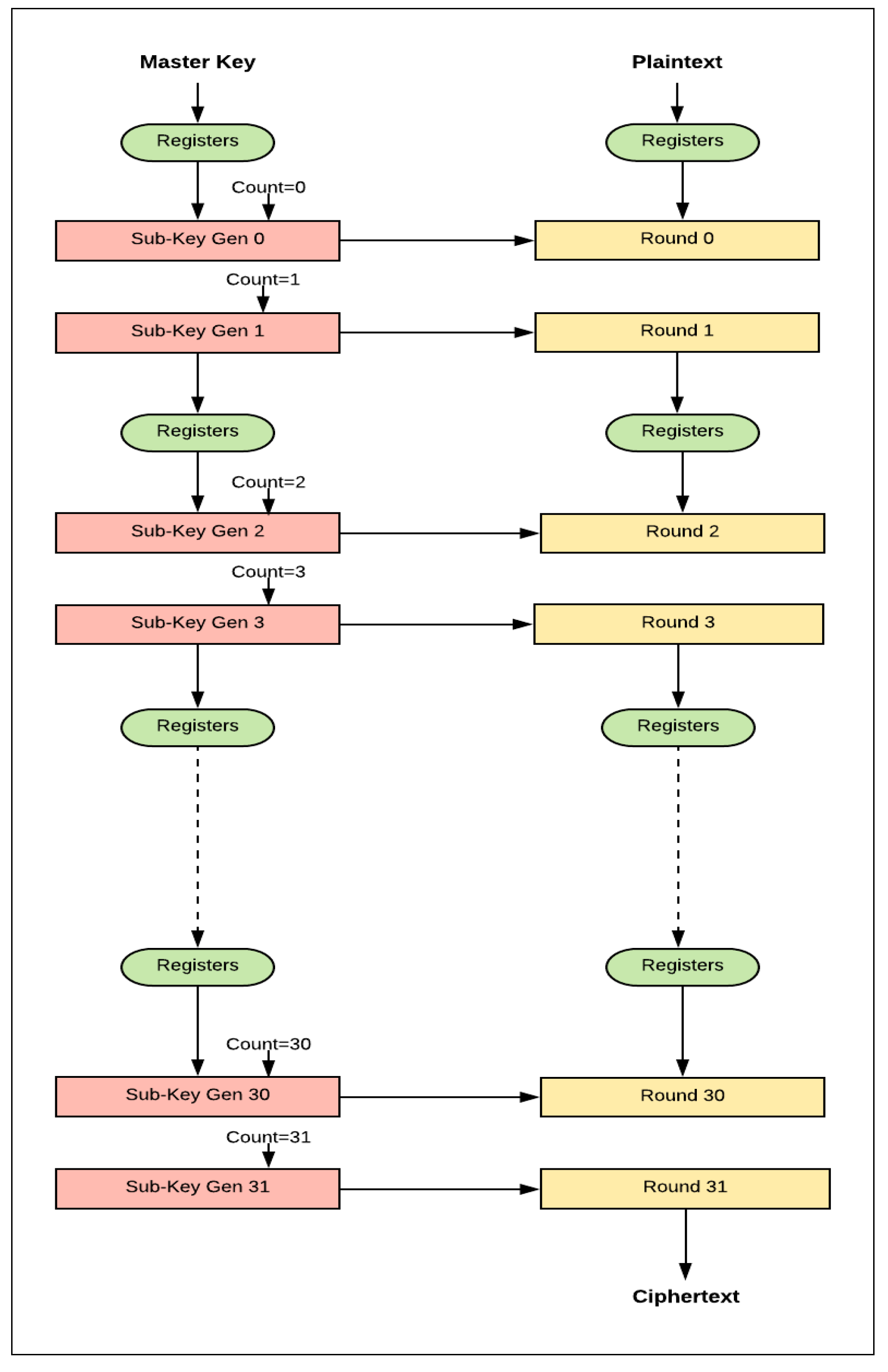
- There are two hardware rounds in the two-round design, Roundi+0 and Roundi+1, which are executed simultaneously.
- There is a smaller counter in the two-round design: a 4-bit counter is required; in general, 2j-round design requires a (5-j)-bit counter.
- Dataflow for each round starts from the X-register to Roundi+0, and then to Roundi+1, returning to the X-register.
- Two sub-keys are generated each iteration instead of one sub-key, as in the basic design: sub-Ki+0 and sub-Ki+1 are required to feed Roundi+0 and Roundi+1.
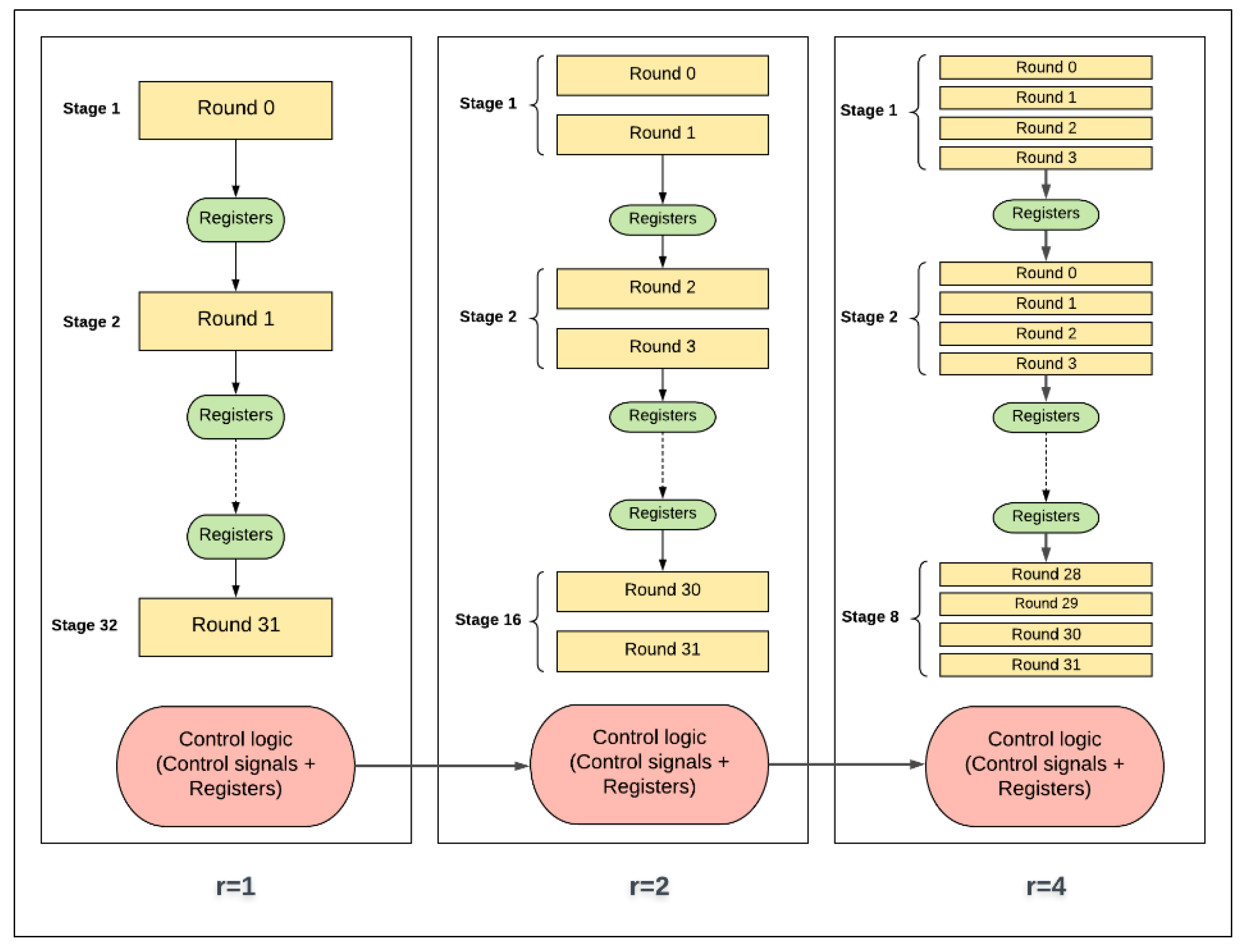
3.3. Pipelined Design
4. Results
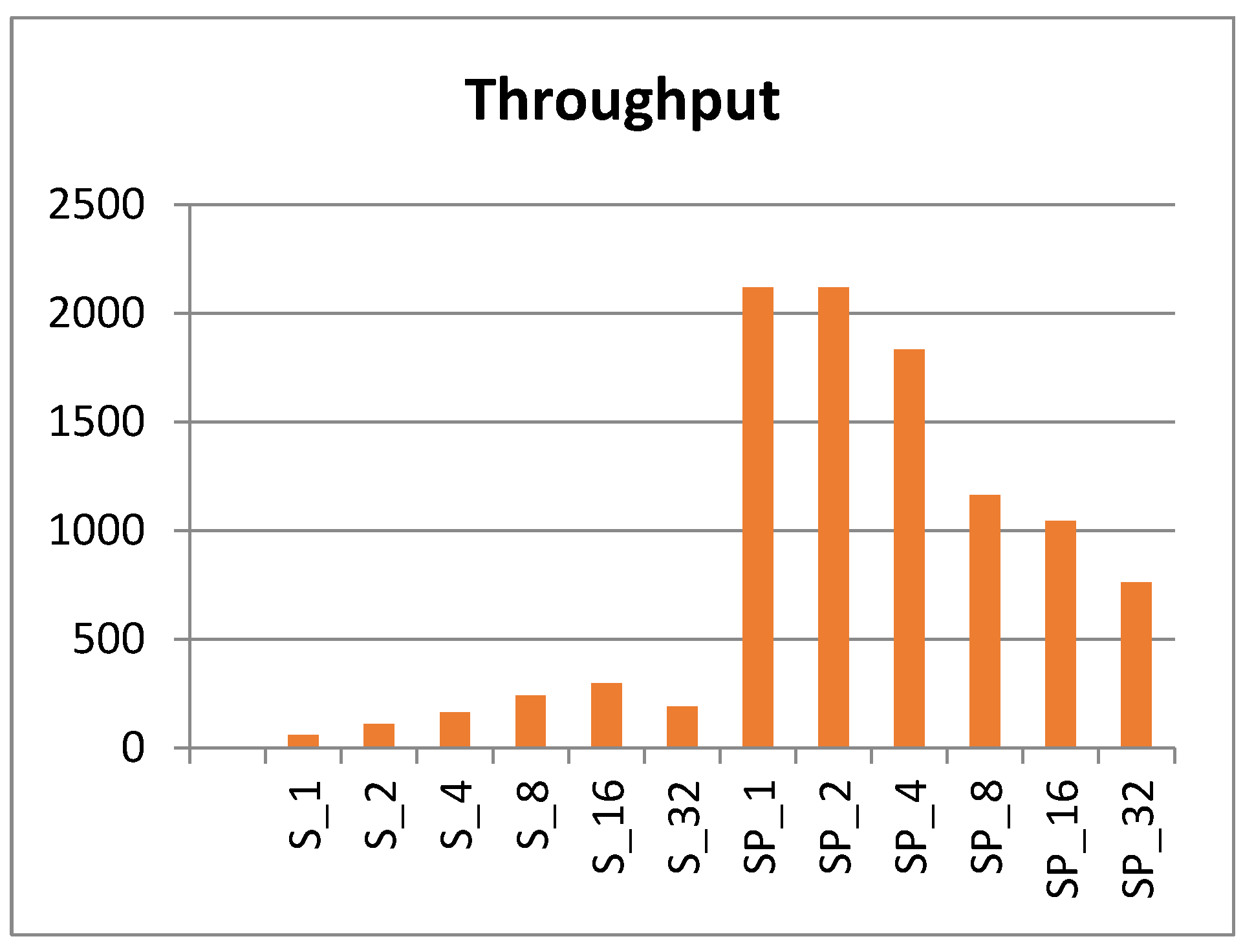
- Sr represents FPGA scalar implementation with r hardware rounds, where r = {1, 2, 4, 8, 16, 32}.
- SPr represents FPGA pipelined implementation with r hardware rounds per stage. The number of pipeline stages is equal to (32/r). As an example, SP4 has four implemented rounds per stage and has eight stages.
4.1. Scalar Implementation Results
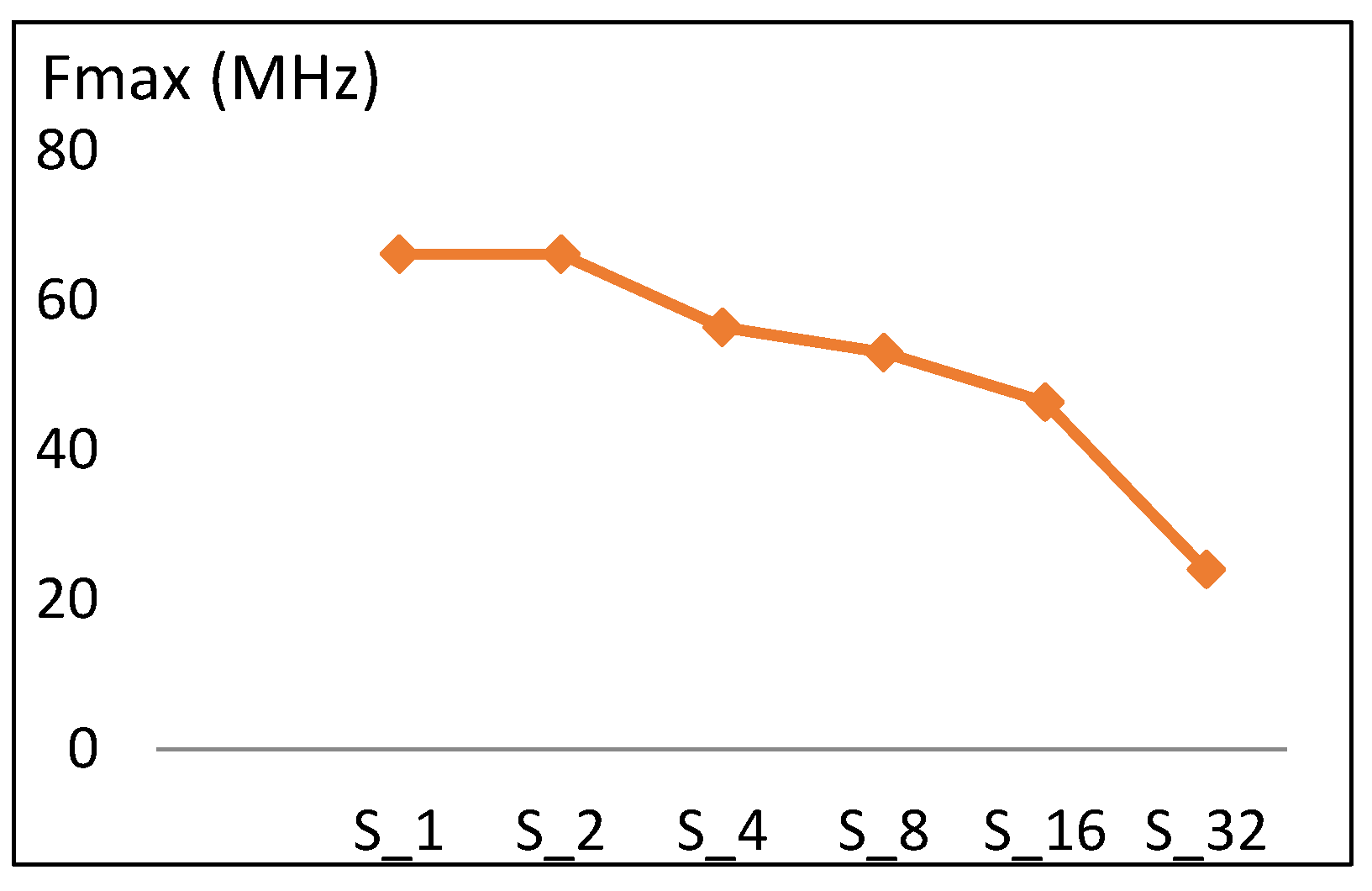
4.1.1. Frequency
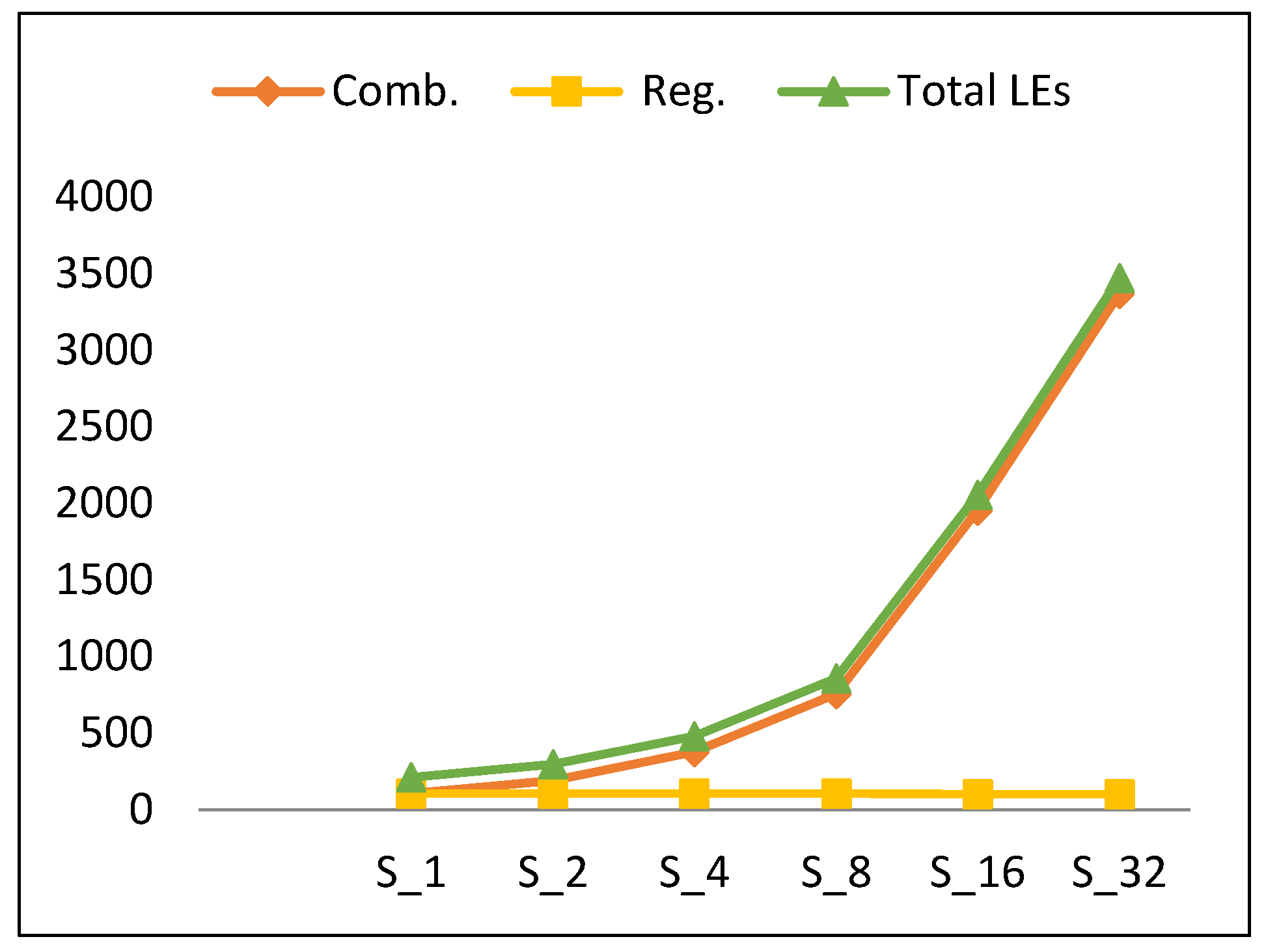
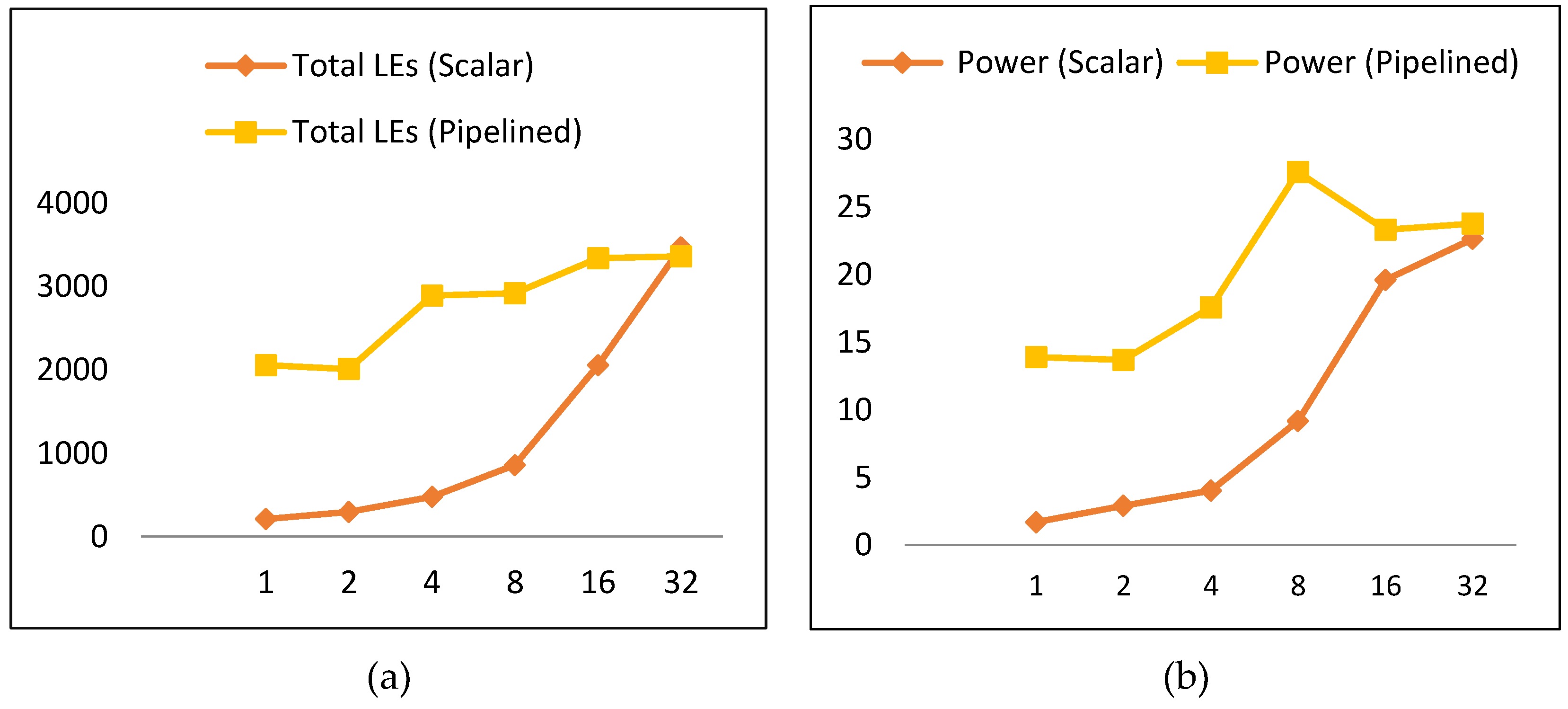
4.1.2. Resource utilization
= 2.02 LE (Sk (Comb)) + LE (S1 (Register)),
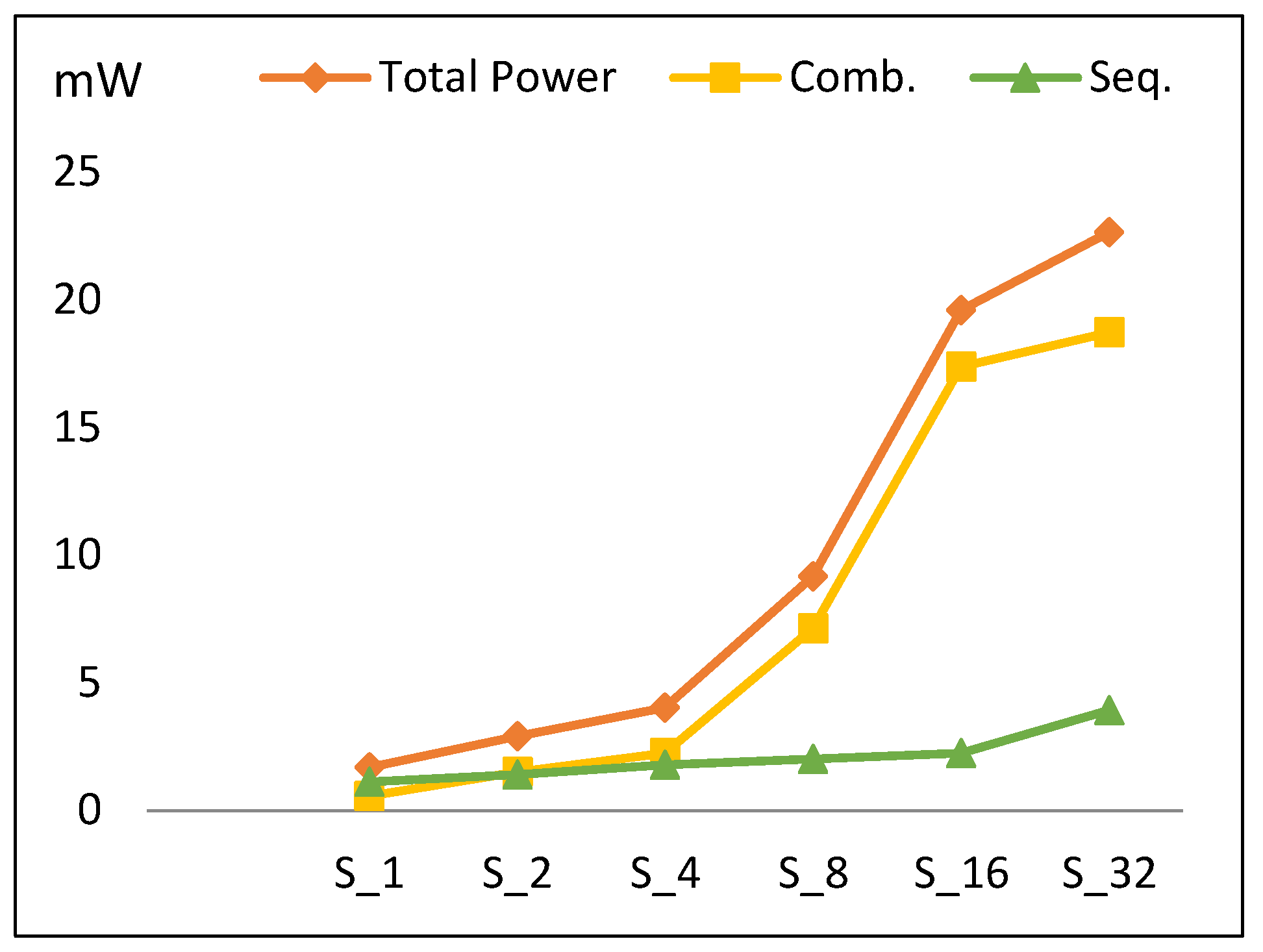
4.1.3. Power
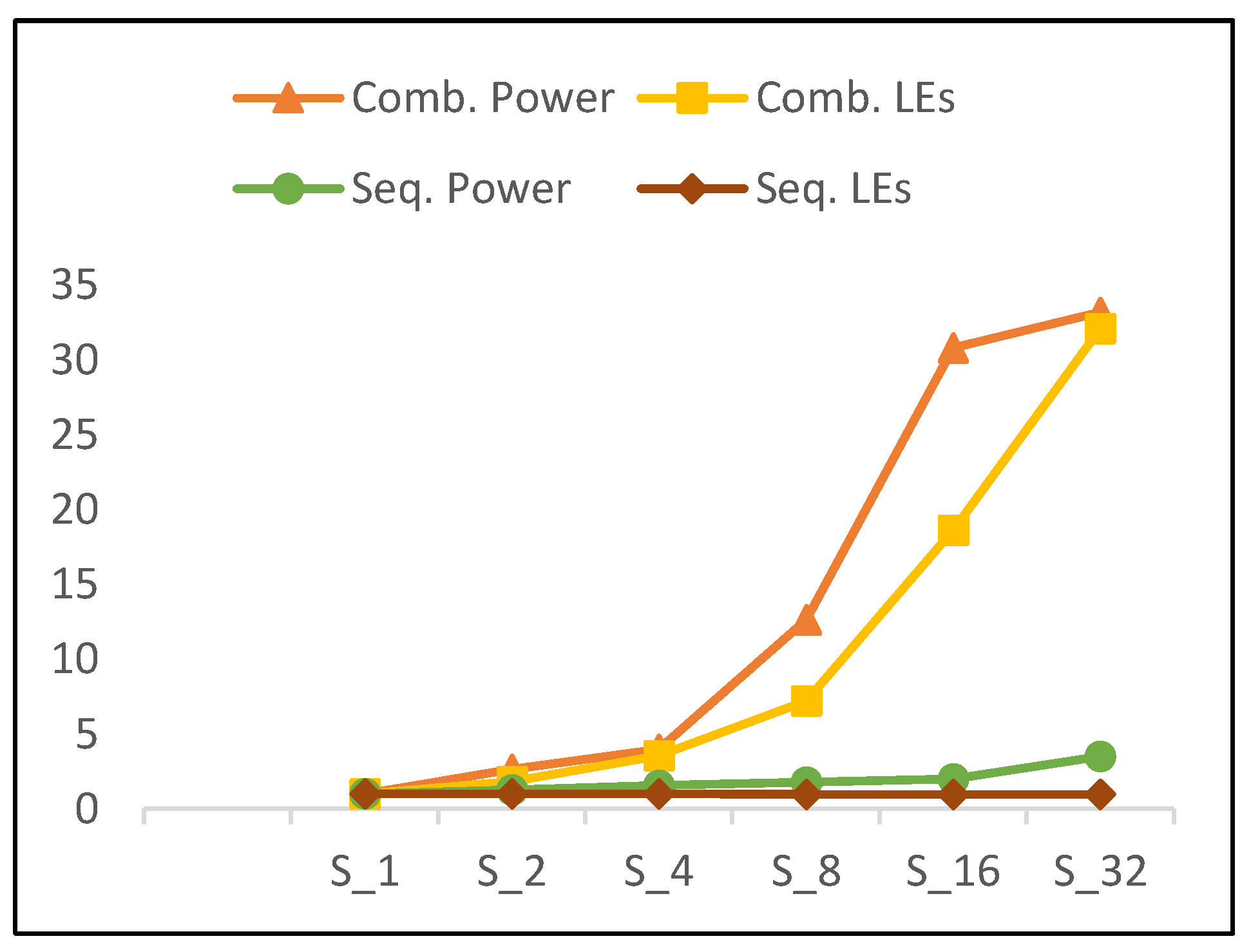
- Combinational power (which estimates the combinational logic power) increases by 105% when the number of rounds is doubled. The increase in the combinational power is due to an increase in implemented logic, as well as an increase in glitch power [35].
- Sequential power (which estimates the sequential logic, i.e., register, control block) increases by an average of 30%.
- The main reason for the total power increasing is the combinational power.
- The power trend shows a slight increase for S32 power when compared to the overall increasing average for other scalar designs. This is due to the reduction in combinational power growth at this point, as S32 is optimized by the synthesis tool to reduce wiring, thereby reducing routing power.
= 2.05 P (Sk (Comb)) + 1.30 P (Sk (Seq)),
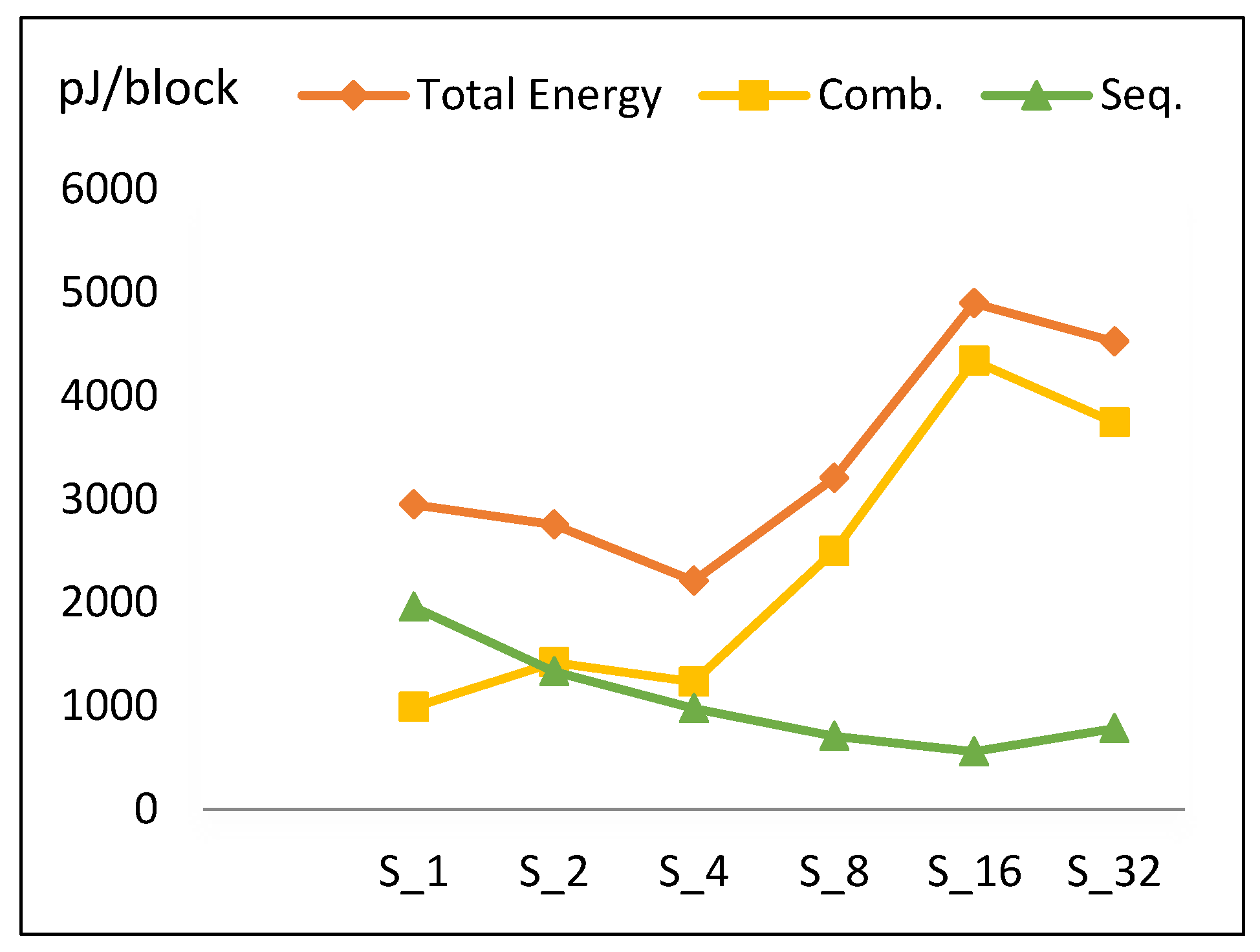
4.1.4. Energy
= (R + Cidle) × Tcycle
= (T/r + 2) × Tcycle.
- Increasing the number of implemented rounds increases combinational power and (to a lesser extent) sequential power, as shown in Figure 11.
- Increasing the number of implemented rounds, r, decreases the time to process one block (Tblock).
- Combinational energy in general increases 42% when the number of implemented rounds doubles. Routing power in S16 is not optimized, as compared to S32 and S8.
- Sequential energy slightly decays as the number of implemented rounds is doubled.
- Since energy is estimated by multiplying power with time to encrypt the block, and power and time exhibit different behavior with respect to r, the energy trend has a V-like curve, as seen in Figure 12.
- The highest energy consumption value at S16 is due to the high combinational energy from the high routing power/energy with additional glitch power/energy [36]. The drop of energy at S32 is due to the drop in combinational energy, as the tools optimize better for larger logic.
= 1.42 E (Sk (Comb)) + 0.73 E (Sk (Seq)),
4.2. Pipelined Implementation Results
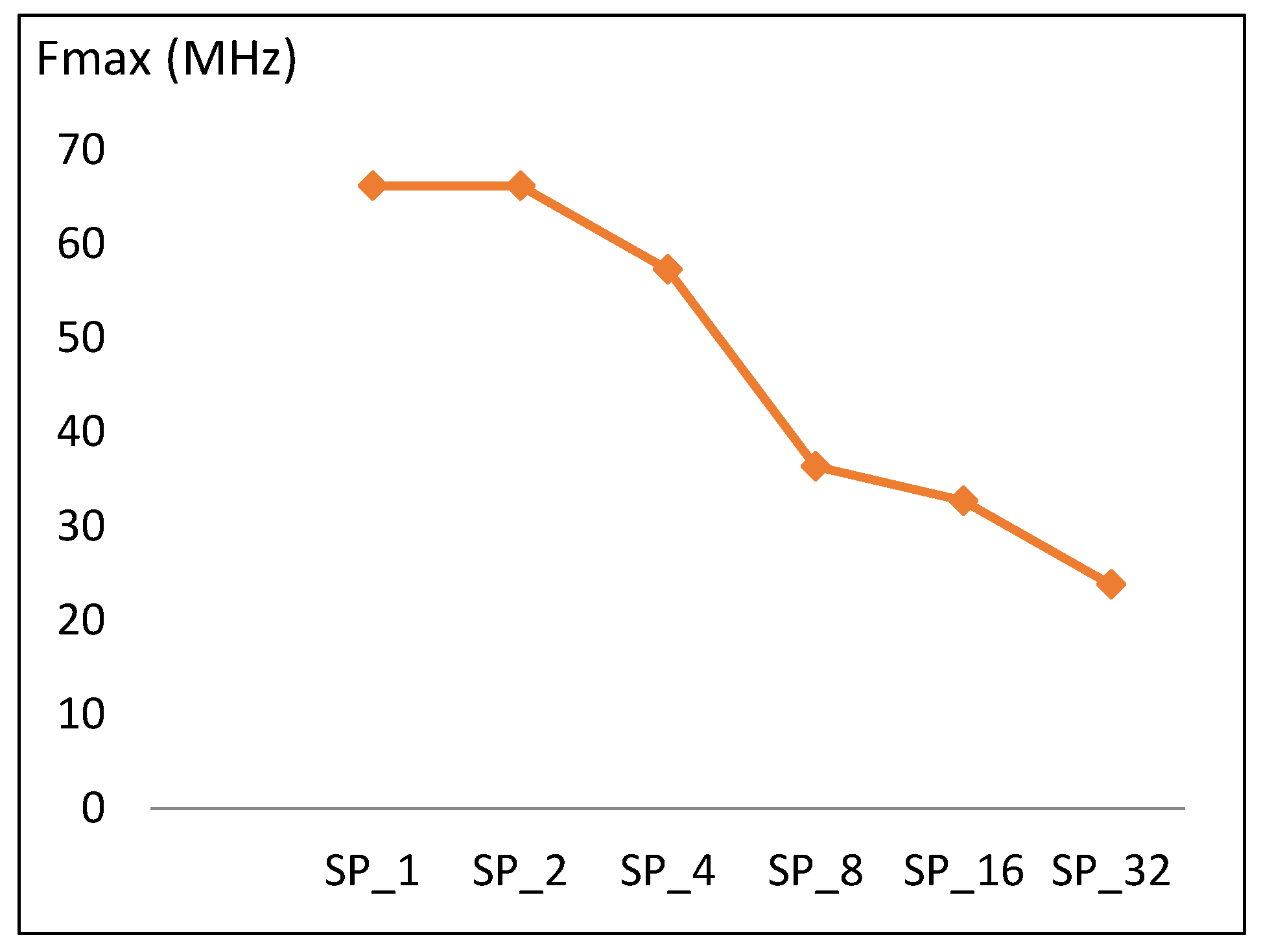
4.2.1. Frequency
4.2.2. Resource Utilization
= 1.4 LE (SPk (Comb)) + 0.58 LE (SPk (Register)),
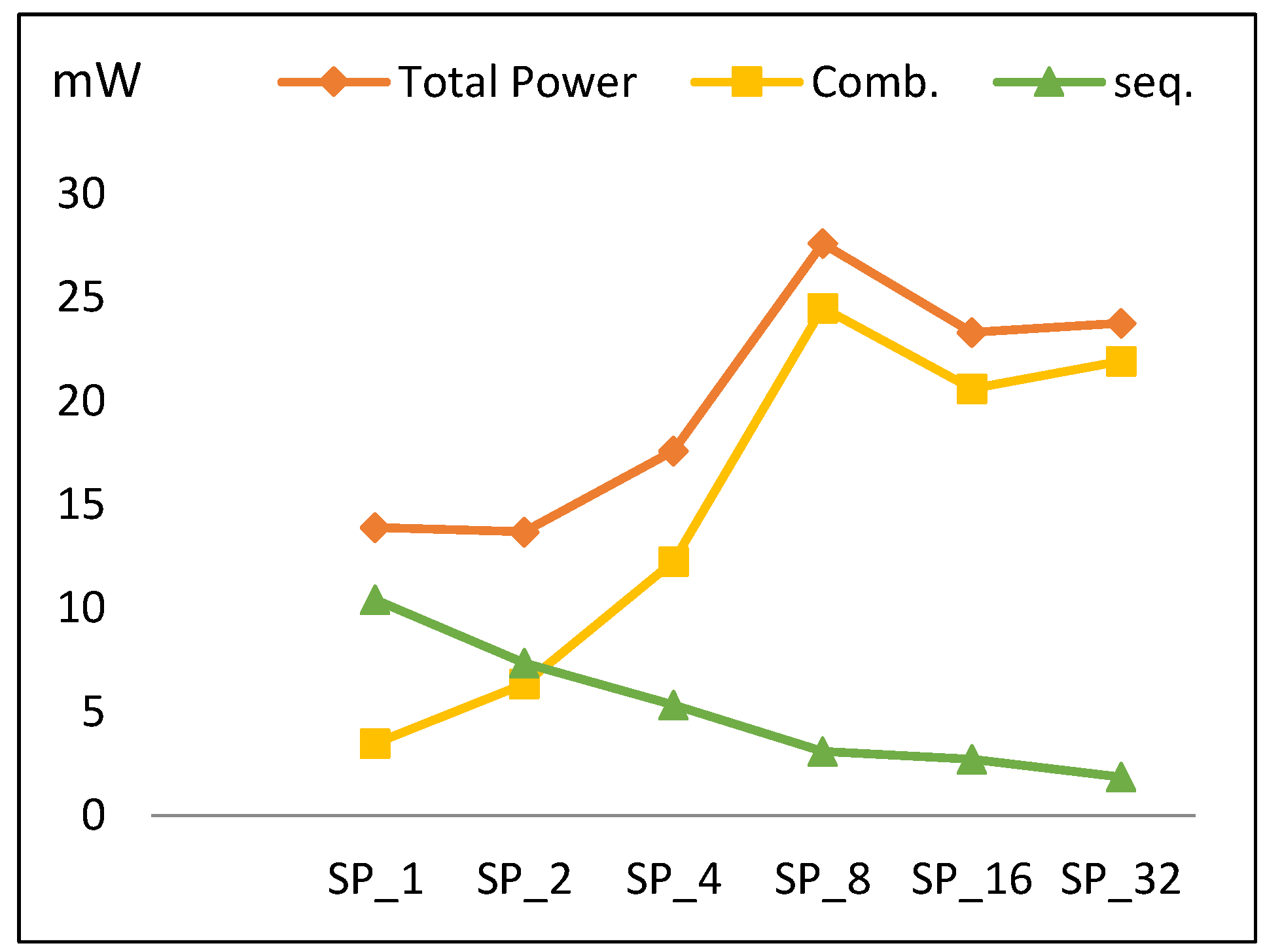
4.2.3. Power
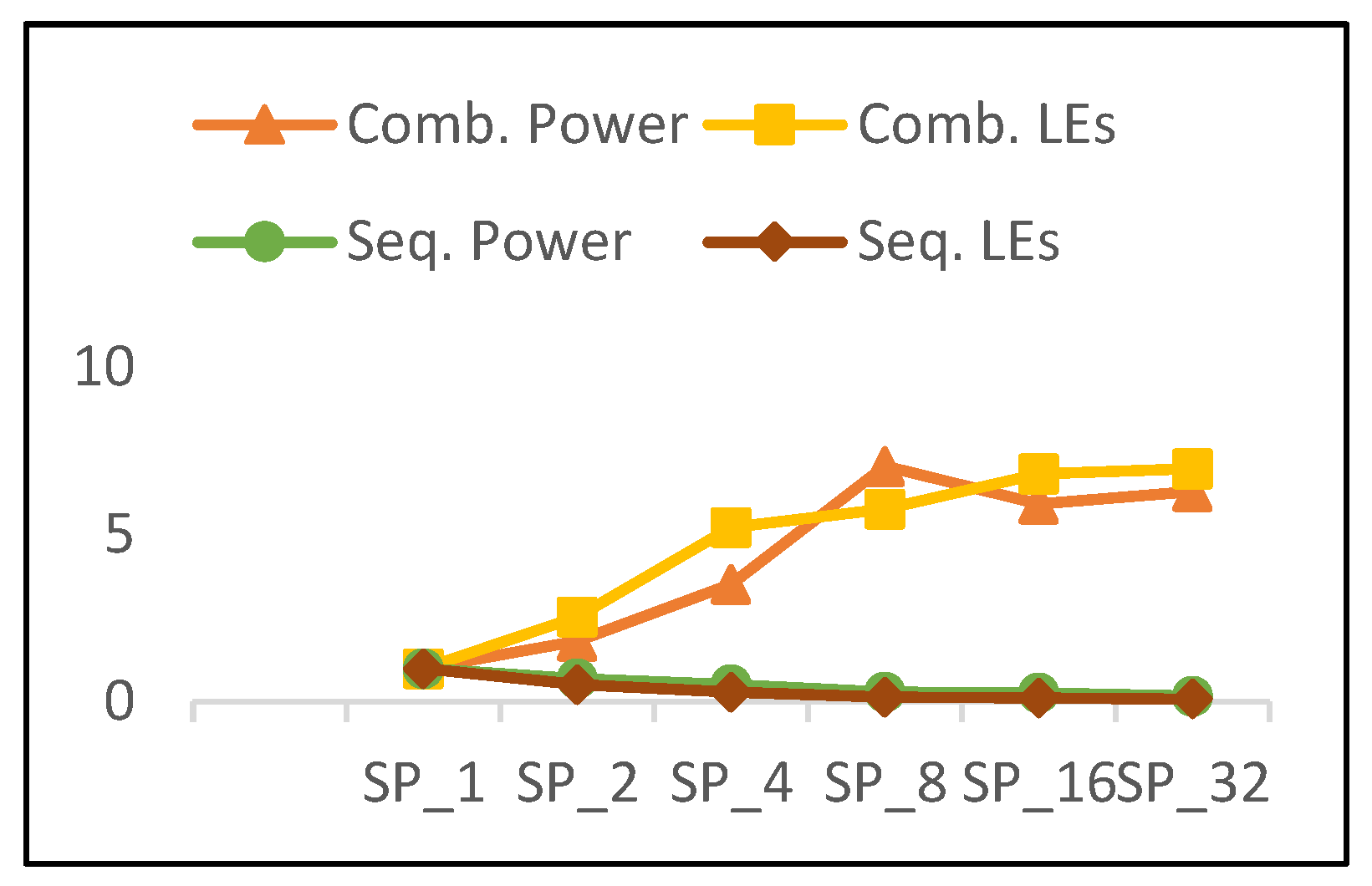
- As the number of rounds is doubled, combinational power grows by an average of 35%.
- As the number of rounds is doubled, sequential power decays by an average of 20% and the number of register LEs decreases.
4.2.4. Energy
- The energy curve looks the same as the power curve with minimum energy at SP2. Energy increases gradually until reaching SP8, decays at SP16, and then increases to SP32.
- To better understand this trend, Figure 16 plots the energy components throughout pipelined implementations, which are combinational and sequential. Combinational energy increases by an average of 50%, while sequential decreases by an average of 15%. The growth in combinational energy is due to the glitch and interconnect power, while the decay in sequential energy is because of the decreasing number of flip-flops as the number of rounds per stage is doubled. The decay of combinational energy at SP16 is due to how the synthesis tool routes the connections and optimizes the design, as stated in Section 4.2.3.
= 1.5 E (SPk (Comb)) + 0.85 E (SPk (Seq)),
5. Discussion
5.1. Speed and Throughput
5.2. Power and LEs
- 102% growth in combinational LEs and 105% growth in combinational power.
- No change in sequential LEs and a 30% increase in sequential power.
- 40% growth in combinational LEs and 35% growth in combinational power.
- 42% decay in sequential LEs and 20% decay in sequential power.
- Interconnect power and glitch power [36].
- The way the synthesis tool routes the connections and optimizes the designs.
5.3. Energy
- The control logic, which includes the control signals (e.g., clock, done, start signals, etc.) and registers (e.g., flip-flops, round counter), is executed 50% less as r is doubled. As the number of rounds is increased, the number of hardware iterations decreases. Hence, control logic energy decreases. Generally, clock and registers contribute less to energy with a higher number of rounds, which leads to energy savings. This is one source of the decreasing trend.
- Theoretically, the round logic should not be affected, because, as the number of rounds implemented in the hardware is doubled, cycles are halved. Yet, the following factors should also be taken into consideration when the number of hardware rounds, r, is doubled:
- -
- The synthesis tool can find more opportunity to optimize larger logic, as there is a better chance to reduce the logic. Thus, doubling the number of hardware rounds typically results in an area less than the summation of the two rounds. This is another source for the decreasing trend [37].
- -
- The logic becomes more complex with a larger number of rounds, due to many interconnections and levels. Thus, glitch and interconnect power and energy tend to increase [36].
- The control logic is executed less as r is doubled. As the number of rounds per stage increases, the number of stages and the round counter decreases. Hence, control logic is simplified when doubling the number of rounds, and, as a result, power/energy decreases. This is one source of the decreasing trend in the pipelined implementation.
- The round logic is affected by two main factors as follows:
- -
- The synthesis tool tends to optimize larger logic better, as opportunities for sharing and minimizing logic cones increases. Therefore, as the number of rounds per stage is increased, power and energy decrease. This is another source for the decreasing trend.
- -
- Stage complexity increases as number of rounds per stage is doubled. As the level of complexity increases, interconnection, routing, and glitch power and energy increase. This is one source for the increase in the energy trend.
- The registers (i.e., flip flops) inserted between pipeline stages reduce by a factor of two when the number of rounds per stage is doubled, and the number of stages is halved. Thus, power and energy decrease. This is another source of the decreasing trend.
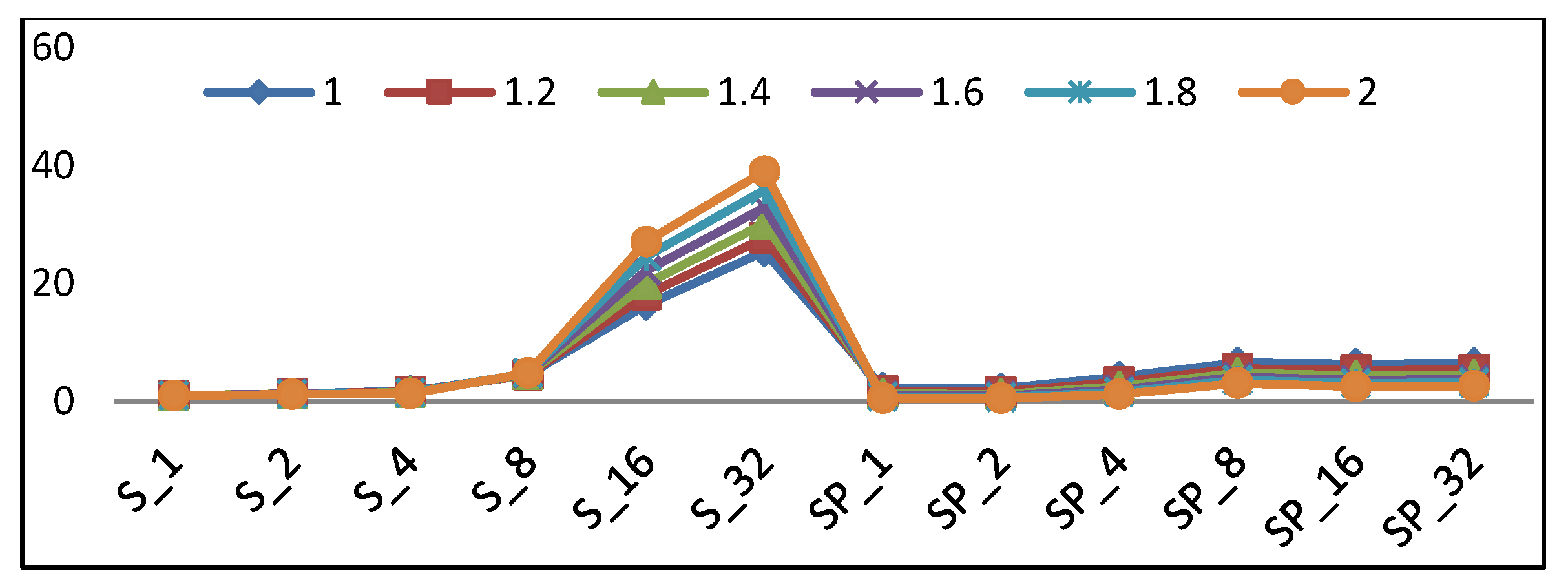
5.4. The Optimum Design
- With a higher emphasis on energy (µ > 1.5), the optimum implementation is SP2 followed by SP1.
- With a lower emphasis on energy (1 < µ < 1.5), the optimum implementation is S1 followed by S2.
- For scalar implementations, the optimum design is S1 followed by S2 and S4.
- In pipelined implementations, the optimum design is SP2 followed by SP1.
- Pipelined implementation performs better with a higher emphasis on energy and, as a result, is the best choice for low-resource/constrained devices.
- SP2 is best for the low-energy requirement, and S1 is the best for the low-resource requirement.
- The best implementations are SP2, SP1, S1, S2, and S4.
5.5. Implementations and Security
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mohd, B.J.; Hayajneh, T.; Vasilakos, A.V. A survey on lightweight block ciphers for low-resource devices: Comparative study and open issues. J. Netw. Comput. Appl. 2015, 58, 73–93. [Google Scholar] [CrossRef]
- Law, Y.W.; Doumen, J.; Hartel, P. Survey and benchmark of block ciphers for wireless sensor networks. ACM Trans. Sens. Netw. 2006, 2, 65–93. [Google Scholar] [CrossRef] [Green Version]
- Symmetric, vs Asymmetric Ciphers. Available online: http://windowsitpro.com/security/symmetric-vs-asymmetric-ciphers (accessed on 12 July 2018).
- Mohd, B.J.; Hayajneh, T.; Yousef, K.M.A.; Khalaf, Z.A.; Bhuiyan, M.Z.A. Hardware design and modeling of lightweight block ciphers for secure communications. Future Gener. Comput. Syst. 2017, 83, 510–521. [Google Scholar] [CrossRef]
- Katz, J.; Menezes, A.J.; Van Oorschot, P.C.; Vanstone, S.A. Handbook of Applied Cryptography, 1st ed.; CRC Press: Boca Raton, FL, USA, 1996. [Google Scholar]
- An Introduction to Stream Ciphers and Block Ciphers. Available online: http://www.jscape.com/blog/stream-cipher-vs-block-cipher (accessed on 10 August 2018).
- Bernstein, D.J. The Salsa20 family of stream ciphers. In New Stream Cipher Designs; Springer: Berlin/Heidelberg, Germany, 2008; Volume 4986, pp. 84–97. [Google Scholar]
- Hell, M.; Johansson, T.; Meier, W. Grain: A stream cipher for constrained environments. Int. J. Wirel. Mob. Comput. 2007, 2, 86–93. [Google Scholar] [CrossRef]
- De Canniere, C. Trivium: A stream cipher construction inspired by block cipher design principles. In International Conference on Information Security; Springer: Berlin/Heidelberg, Germany, 2006; pp. 171–186. [Google Scholar]
- Fan, X.; Mandal, K.; Gong, G. Wg-8: A lightweight stream cipher for resource-constrained smart devices. In International Conference on Heterogeneous Networking for Quality, Reliability, Security and Robustness; Springer: Berlin/Heidelberg, Germany, 2013; Volume 115, pp. 617–632. [Google Scholar]
- Cazorla, M.; Marquet, K.; Minier, M. Survey and benchmark of lightweight block ciphers for wireless sensor networks. In Proceedings of the 2013 International Conference on Security and Cryptography (SECRYPT), Reykjavik, Iceland, 29–31 July 2013; pp. 1–6. [Google Scholar]
- Wollinger, T.; Guajardo, J.; Paar, C. Security on FPGAs: State-of-the-art implementations and attacks. ACM Trans. Embed. Comput. Syst. 2004, 3, 534–574. [Google Scholar] [CrossRef]
- Mohd, B.J.; Hayajneh, T.; Khalaf, Z.A.; Ahmad Yousef, K.M. Modeling and optimization of the lightweight HIGHT block cipher design with FPGA implementation. Secur. Commun. Netw. 2016, 9, 2200–2216. [Google Scholar] [CrossRef]
- Beaulieu, R.; Treatman-Clark, S.; Shors, D.; Weeks, B.; Smith, J.; Wingers, L. The SIMON and SPECK families of lightweight block ciphers. Available online: https://eprint.iacr.org/2013/404 (accessed on 22 April 2018).
- Aysu, A.; Gulcan, E.; Schaumont, P. SIMON Says, Break Area Records of Block Ciphers on FPGAs. IEEE Embed. Syst. Lett. 2014, 6, 37–40. [Google Scholar] [CrossRef]
- Beaulieu, R.; Shors, D.; Smith, J.; Treatman-Clark, S.; Weeks, B.; Wingers, L. The SIMON and SPECK block ciphers on AVR 8-bit microcontrollers. In International Workshop on Lightweight Cryptography for Security and Privacy; Springer: Cham, Switzerland, 2015; pp. 3–20. [Google Scholar]
- Hosseinzadeh, J.; Bafghi, A.G. Software Implementation and Evaluation of Lightweight Symmetric Block Ciphers of the Energy Perspectives and Memory. Int. J. Eng. Educ. 2017, 9, 1–6. [Google Scholar]
- Beaulieu, R.; Shors, D.; Smith, J.; Treatman-Clark, S.; Weeks, B.; Wingers, L. Implementation and Performance of the Simon and Speck Lightweight Block Ciphers on ASICs. Unpublished work.
- Beaulieu, R.; Shors, D.; Smith, J.; Treatman-Clark, S.; Weeks, B.; Wingers, L. SIMON and SPECK: Block Ciphers for the Internet of Things. Available online: https://eprint.iacr.org/2015/585 (accessed on 10 March 2018).
- Wetzels, J.; Bokslag, W. Simple SIMON: FPGA implementations of the SIMON 64/128 Block Cipher. Cryptogr. Eng. Kerckhoffs Inst. 2015, 1, 1–20. [Google Scholar]
- Feizi, S.; Ahmadi, A.; Nemati, A. A hardware implementation of SIMON cryptography algorithm. In Proceedings of the 2014 4th International eConference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 29–30 October 2014; pp. 245–250. [Google Scholar]
- Gulcan, E.; Aysu, A.; Schaumont, P. A flexible and compact hardware architecture for the SIMON block cipher. In International Workshop on Lightweight Cryptography for Security and Privacy; Springer: Cham, Switzerland, 2014; Volume 8898, pp. 34–50. [Google Scholar]
- Wan, T.; Salman, H. Ultra Low Power SIMON Core for Lightweight Encryption. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Yang, G.; Zhu, B.; Suder, V.; Aagaard, M.D.; Gong, G. The simeck family of lightweight block ciphers. In International Workshop on Cryptographic Hardware and Embedded Systems; Springer: Berlin/Heidelberg, Germany, 2015; pp. 307–329. [Google Scholar]
- Ryabko, B.; Soskov, A. Application of the distinguishing attack to lightweight block ciphers. In Proceedings of the 2017 International Multi-Conference on Engineering, Computer and Information Sciences (SIBIRCON), Novosibirsk, Russia, 18–22 September 2017; pp. 338–341. [Google Scholar]
- Kölbl, S.; Roy, A. A brief comparison of Simon and Simeck. In International Workshop on Lightweight Cryptography for Security and Privacy; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Zhang, X.; Heys, H.M.; Li, C. Fpga implementation and energy cost analysis of two light-weight involutional block ciphers targeted to wireless sensor networks. Mob. Netw. Appl. 2013, 18, 222–234. [Google Scholar] [CrossRef]
- Abed, S.; Mohd, B.J.; Al-bayati, Z.; Alouneh, S. Low power Wallace multiplier design based on wide counters. Int. J. Circuit Theory Appl. 2012, 40, 1175–1185. [Google Scholar] [CrossRef]
- Hayajneh, T.; Ullah, S.; Mohd, B.; Balagani, K. An Enhanced WLAN Security System with FPGA Implementation for Multimedia Applications. IEEE Syst. J. 2015, 11, 2536–2545. [Google Scholar] [CrossRef]
- Mohd, B.J.; Hayajneh, T.; Abed, S.; Itradat, A. Analysis and modeling of FPGA implementations of spatial steganography methods. J. Circuits Syst. Comput. 2014, 23, 1450018. [Google Scholar] [CrossRef]
- Mohd, B.J.; Hayajneh, T. Wavelet-transform steganography: Algorithm and hardware implementation. Int. J. Electron. Secur. Digit. Forensics 2013, 5, 241–256. [Google Scholar] [CrossRef]
- Mohd, B.J.; Hayajneh, T.; Khalaf, Z.A.; Vasilakos, A.V. A comparative study of steganography designs based on multiple FPGA platforms. Int. J. Electron. Secur. Digit. Forensics 2016, 8, 164–190. [Google Scholar] [CrossRef]
- Altera Cyclone II Device Handbook. Available online: http://www.altera.com/products/devices/ cyclone2/cy2-index.jsp (accessed on 12 August 2018).
- Menezes, A.J.; van Oorschot, P.C.; Vanstone, S.A. Handbook of Applied Cryptography, 5th ed.; CRC Press: Boca Raton, FL, USA, 2001; p. 251. [Google Scholar]
- Mohd, B.; Hayajneh, T.; Shakir, M.; Qaraqe, K.; Vasilakos, A. Energy model for light-weight block ciphers for WBAN applications. In Proceedings of the 2014 EAI 4th International Conference on Wireless Mobile Communication and Healthcare (Mobihealth), Athens, Greece, 3–5 November 2014; pp. 1–4. [Google Scholar]
- Kolay, S.; Mukhopadhyay, D. Khudra: A new lightweight block cipher for FPGAs. In International Conference on Security, Privacy, and Applied Cryptography Engineering; Chakraborty, R.S., Matyas, V., Schaumont, P., Eds.; Springer: Cham, Switzerland, 2014; pp. 126–145. [Google Scholar]
- Mohd, B.J.; Hayajneh, T. Lightweight Block Ciphers for IoT: Energy Optimization and Survivability Techniques. IEEE Access 2018, 6, 35966–35978. [Google Scholar] [CrossRef]
- Bhasin, S.; Graba, T.; Danger, J.L.; Najm, Z. A look into SIMON from a side-channel perspective. In Proceedings of the 2014 IEEE International Symposium on Hardware-Oriented Security and Trust (HOST), Arlington, VA, USA, 6–7 May 2014; pp. 56–59. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
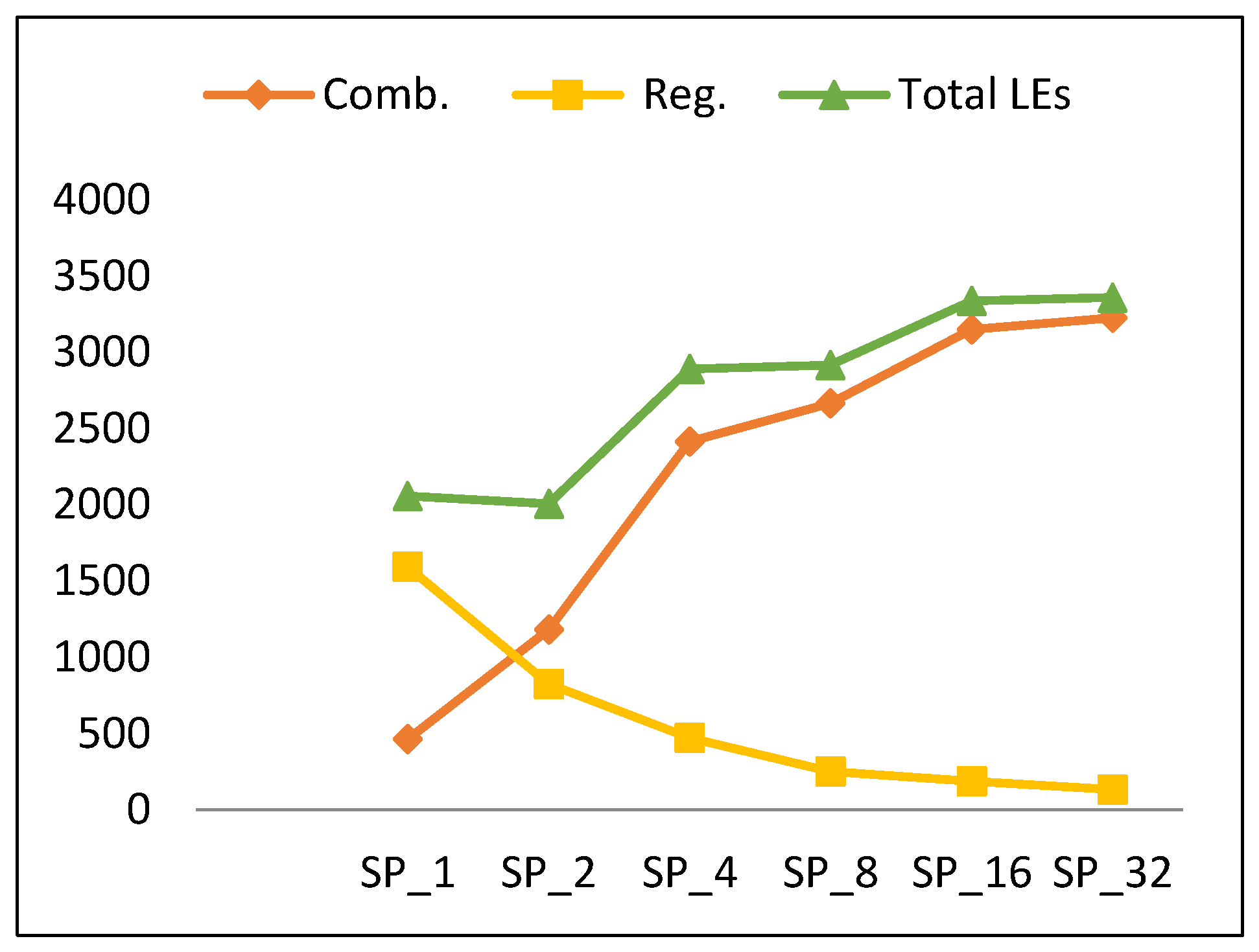{kind=link}
{kind=link}
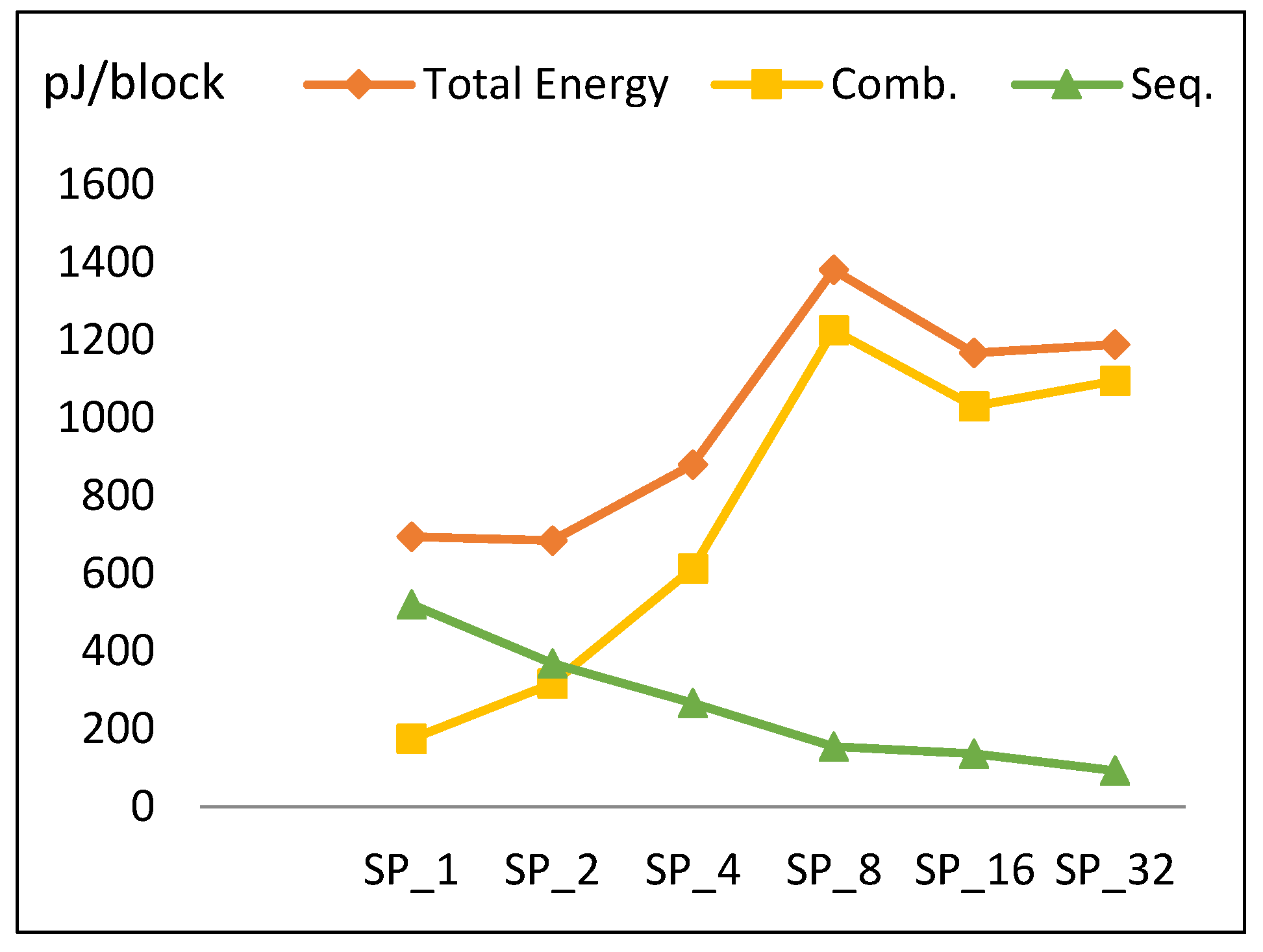{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
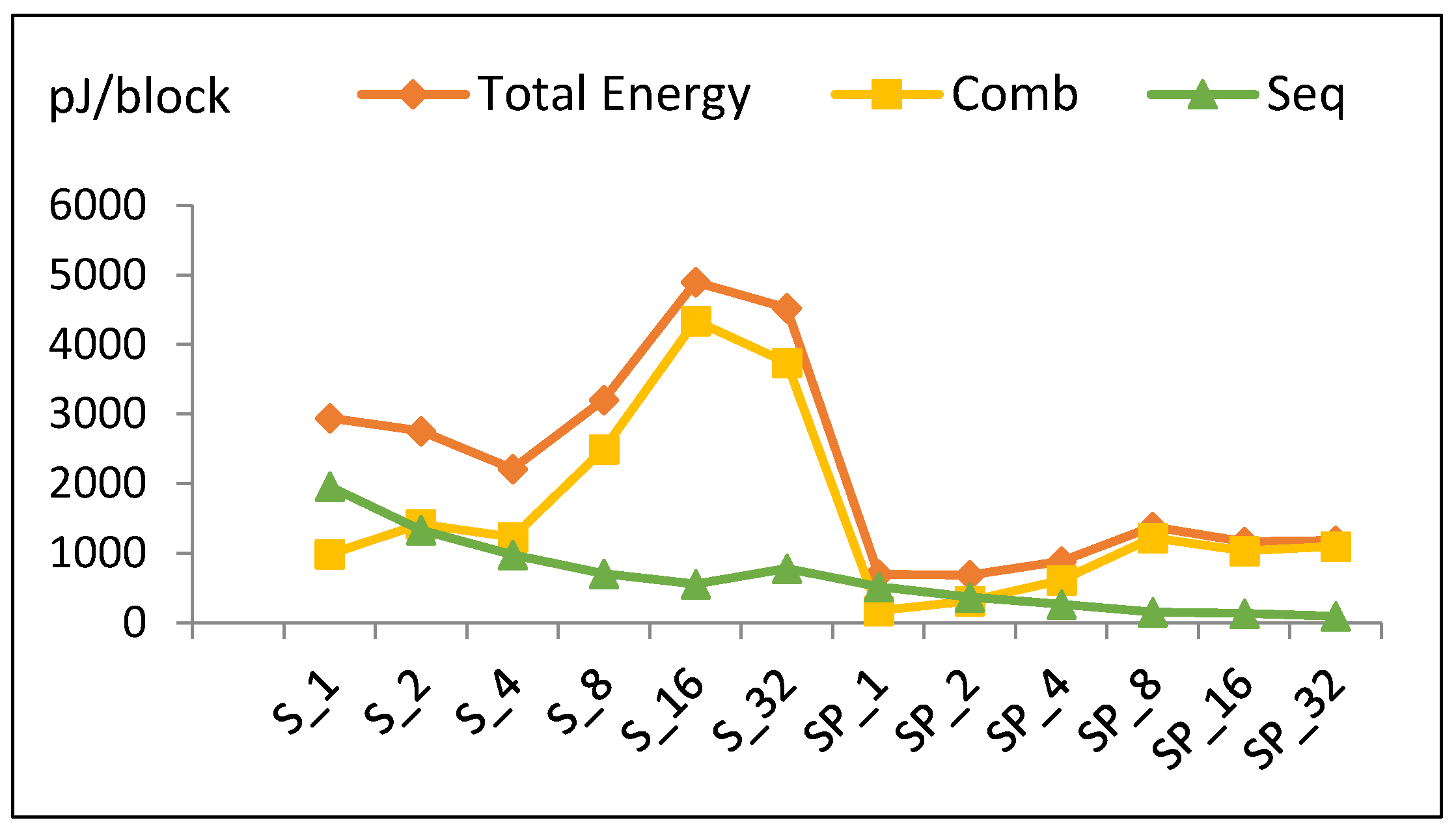{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Security Configuration | Block Size (2n) | Key Size (mn) | Word Size (n) | Key Words (m) | Constant Sequence (zj) | Rounds (T) |
|---|---|---|---|---|---|---|
| 1 | 32 | 64 | 16 | 4 | z0 | 32 |
| 2 | 48 | 72 | 24 | 3 | z0 | 36 |
| 3 | 48 | 96 | 24 | 4 | z1 | 36 |
| 4 | 64 | 96 | 32 | 3 | z2 | 42 |
| 5 | 64 | 128 | 32 | 4 | z3 | 44 |
| 6 | 96 | 96 | 48 | 2 | z2 | 52 |
| 7 | 96 | 144 | 48 | 3 | z3 | 54 |
| 8 | 128 | 128 | 64 | 2 | z2 | 68 |
| 9 | 128 | 192 | 64 | 3 | z3 | 69 |
| 10 | 128 | 256 | 64 | 4 | z4 | 72 |
| Notation | Description |
|---|---|
| ⊕ | Bitwise XOR |
| & | Bitwise AND |
| Sj | Left circular shift, Sj, by j bits |
| S−j | Right circular shift, S−j, by j bits |
| n | Word size |
| 2n | Block size |
| m | Key words |
| mn | Key size |
| i | Round counter, where 0 ≤ i ≤ T − 1 |
| zj | Constant sequence, where j = 0, 1, 2, 3, 4 |
| T | Number of cipher rounds |
| F | Round function |
| k | Round key (sub-key) |
| c | Constant |
| Notation | Description |
|---|---|
| r | Number of rounds implemented in hardware |
| R | Number of iterations/rounds to encrypt one block |
| Tcycle | Cycle time (i.e., clock period) |
| Tblock | Time to encrypt one block |
| Cidle | Setup cycles to load input plaintext and output ciphertext |
| CB | Number of cycles to encrypt one block |
| Notation | Description |
|---|---|
| f | Frequency of the design |
| LE | Resource utilization of the design |
| P | Power consumption of the design |
| E | Energy of the design |
| Scalar Implementation | Fmax (MHz) | LEs | Power (mW) | Energy (pJ/block) |
|---|---|---|---|---|
| S1 | 66. 2 | 210 | 1.68 | 2947 |
| S2 | 66.19 | 294 | 2.9 | 2755 |
| S4 | 56.42 | 479 | 4.02 | 2211 |
| S8 | 53.11 | 858 | 9.16 | 3204.6 |
| S16 | 46.41 | 2056 | 19.6 | 4900 |
| S32 | 24.02 | 3469 | 22.64 | 4528 |
| Scalar Implementation | LEs | LUT-4 | LUT-3 | LUT-2 or less | LUT RegOnly |
|---|---|---|---|---|---|
| S1 | 210 | 50 | 108 | 52 | 0 |
| S2 | 294 | 121 | 103 | 68 | 2 |
| S4 | 479 | 228 | 95 | 121 | 35 |
| S8 | 858 | 554 | 191 | 98 | 15 |
| S16 | 2056 | 1466 | 434 | 140 | 16 |
| S32 | 3469 | 2410 | 718 | 324 | 17 |
| Pipelined Implementation | Fmax (MHz) | LEs | Power (mW) | Energy (pJ/block) |
|---|---|---|---|---|
| SP1 | 66.2 | 2057 | 13.88 | 694.2 |
| SP2 | 66.2 | 2008 | 13.69 | 684.4 |
| SP4 | 57.32 | 2891 | 17.58 | 879 |
| SP8 | 36.39 | 2918 | 27.60 | 1379.8 |
| SP16 | 32.68 | 3338 | 23.32 | 1166 |
| SP32 | 23.79 | 3361 | 23.76 | 1187.8 |
| Pipelined Implementation | LEs | LUT-4 | LUT-3 | LUT-2 or less | LUT RegOnly |
|---|---|---|---|---|---|
| SP1 | 2057 | 1400 | 83 | 477 | 97 |
| SP2 | 2008 | 1379 | 263 | 349 | 17 |
| SP4 | 2891 | 2001 | 461 | 347 | 82 |
| SP8 | 2918 | 2031 | 562 | 277 | 48 |
| SP16 | 3338 | 2264 | 766 | 282 | 26 |
| SP32 | 3361 | 2422 | 591 | 325 | 23 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abed, S.; Jaffal, R.; Mohd, B.J.; Alshayeji, M. FPGA Modeling and Optimization of a SIMON Lightweight Block Cipher. Sensors 2019, 19, 913. https://doi.org/10.3390/s19040913
Abed S, Jaffal R, Mohd BJ, Alshayeji M. FPGA Modeling and Optimization of a SIMON Lightweight Block Cipher. Sensors. 2019; 19(4):913. https://doi.org/10.3390/s19040913
Chicago/Turabian StyleAbed, Sa’ed, Reem Jaffal, Bassam Jamil Mohd, and Mohammad Alshayeji. 2019. "FPGA Modeling and Optimization of a SIMON Lightweight Block Cipher" Sensors 19, no. 4: 913. https://doi.org/10.3390/s19040913
APA StyleAbed, S., Jaffal, R., Mohd, B. J., & Alshayeji, M. (2019). FPGA Modeling and Optimization of a SIMON Lightweight Block Cipher. Sensors, 19(4), 913. https://doi.org/10.3390/s19040913