IMLADS: Intelligent Maintenance and Lightweight Anomaly Detection System for Internet of Things


Abstract
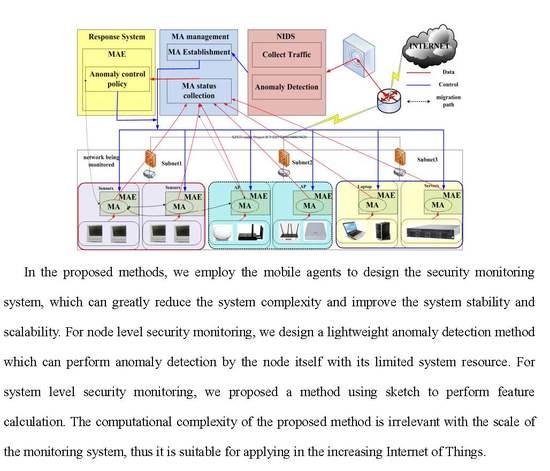
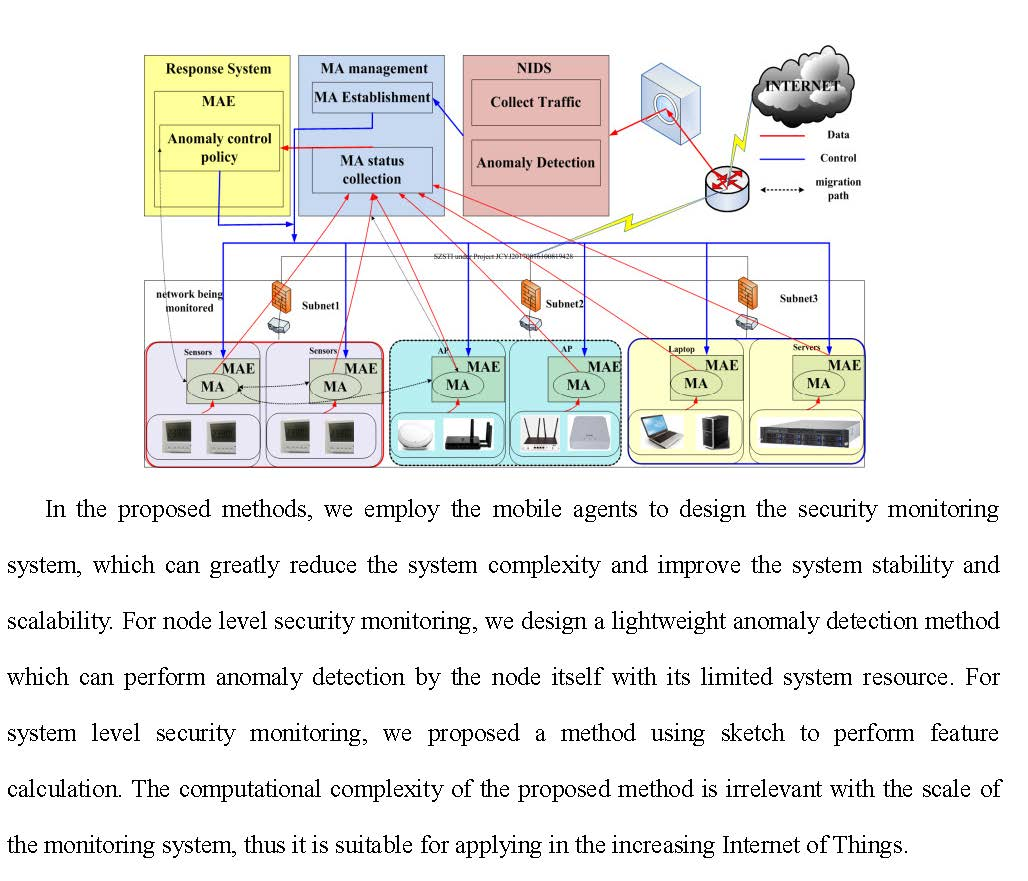
:
1. Introduction
- The mobile agent is cross-platform, it can transfer to any of the nodes that are installed on the mobile agent running platform. Most importantly, this new computing mechanism can not only reduce the number of data collection agents, but also greatly reduce the amount of data transferred from the terminal nodes to the control server.
- We design lightweight anomaly mining methods for the node level and system level security monitoring. The computational complexity of node level security monitoring method is reduced by combining several methods, and that of the system level is constant and irrelevant with the system scale.
2. Related Works
2.1. Anomaly Detection Methods
2.2. Abnormal Detection System
3. Simple Introduction to IMLADS
3.1. Introduction to Mobile Agent
- Autonomy: The most important characteristic of a mobile agent is that it can independently complete the pre-set tasks on behalf of the administrator without external interference.
- Mobility: The mobile agent is not only for a specific node, it can transfer to another node to perform a pre-set task. The mobility is handled by the mobile agent running platform and irrelevant with the node.
- Adaptability: The mobile agent can change its running state according to the changes of the end node’s environment.
- Cross-platform: A mobile agent has cross-platform characteristics. A mobile agent running platform provides middleware between agents and the node. A mobile agent can theoretically run on nodes with any operation system.
3.2. Introduction to IMLADS
3.3. Operation Procedure of the IMLADS.
3.4. Advantages of IMLADS
- Reduce network load. Mobile agents can package the administrator’s requests and dispatch them to the destination nodes, and then they perform the designed task using the local computing resource. There is no raw data transferred among the nodes. The mobile agent only reports the anomaly detection results to the control server. If there is no anomaly detected, the mobile agents do not report and transfer to another node selected from the migration path to perform the pre-set task. As the end nodes are working in normal status most of the time, there are only several alarm records transferred from the node to the control server, thus we can greatly reduce the amount of data transferred.
- Overcome network delay. Real-time or online anomaly detection is very important for network control and delay is unacceptable. The mobile agents transfer to the node directly to perform the tasks designed by the administrators, which is different than the traditional methods, where the node sends its data to the control server and waits for the analysis results. The mobile agent can greatly reduce network latency.
- Asynchronous and automatic execution. In a heterogeneous network, the nodes contact with each other through the network. But the network service is not stable enough, especially for the wireless nodes, which rely on expensive and fragile network connections. The mobile agents can overcome those shortcomings. They embed the code of a specific monitoring task and once the mobile agents are dispatched, they can operate asynchronously, automatically and independently.
- Heterogeneity. The mobility is handled by the mobile running platform and irrelevant with the operation systems. The designed system using mobile agents is suitable for performing security monitoring tasks in the heterogeneous IoT network.
- Robustness and fault-tolerance. Every running mobile agent can transfer to the other end node automatically and independently. If one of the mobile agents loses its efficiency, it will not affect other mobile agents. Thus, the system designed is more robust than that adopting static agents.
4. Feature Calculation and Analysis for Security Monitoring
4.1. Node Level Feature Selection and Collection
4.1.1. Node Level Selected Features
4.1.2. Collection Method Based on Regular Interval Waiting
- Step 1:
- Set waiting time interval Δt and the collection window deadline t0.
- Step 2:
- Obtain the current system time t1, IP address, MAC and other features (such as CPU, memory usage, disk read and write, packet flow, process and port).
- Step 3:
- Store the data obtained in Step 2 for further analysis.
- Step 4:
- If t1 > t0, then stop the collection process, otherwise increase the time interval Δt, then turn to Step 2. In this way, we can reduce the data collection frequency.
4.2. Node Level Anomaly Mining
4.2.1. Data Dimension Reduction Analysis
4.2.2. Abnormal Candidates Detection using the DBSCAN method
| Algorithm 1. DBSCAN Clustering Process |
| 1. Begin 2. Input: 3. U = {p1,p2,…pn}, MinPoints, 4. Output: 5. C1,C2,…Ck//clusters descended by number of elements 6. M = {m1,m2,…mn}//set of noises 7. k = 0, l = 0 8. for ( i = 1; i<= n; i ++) 9. if 10. k = k + 1 11. else 12. if 13. l = l+1 14. 15. end |
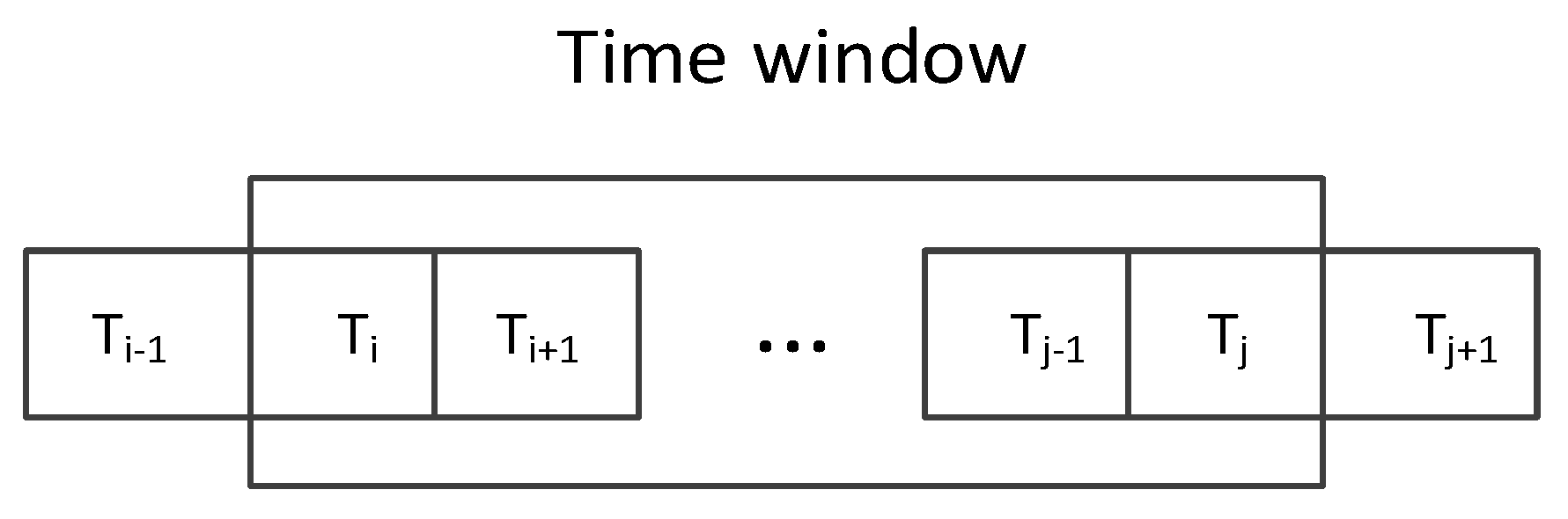
4.2.3. Detection Accuracy Improvement Based on Continuous Sliding Time Window
4.3. System-Level Feature Calculation and Anomaly Mining
4.3.1. System Level Features
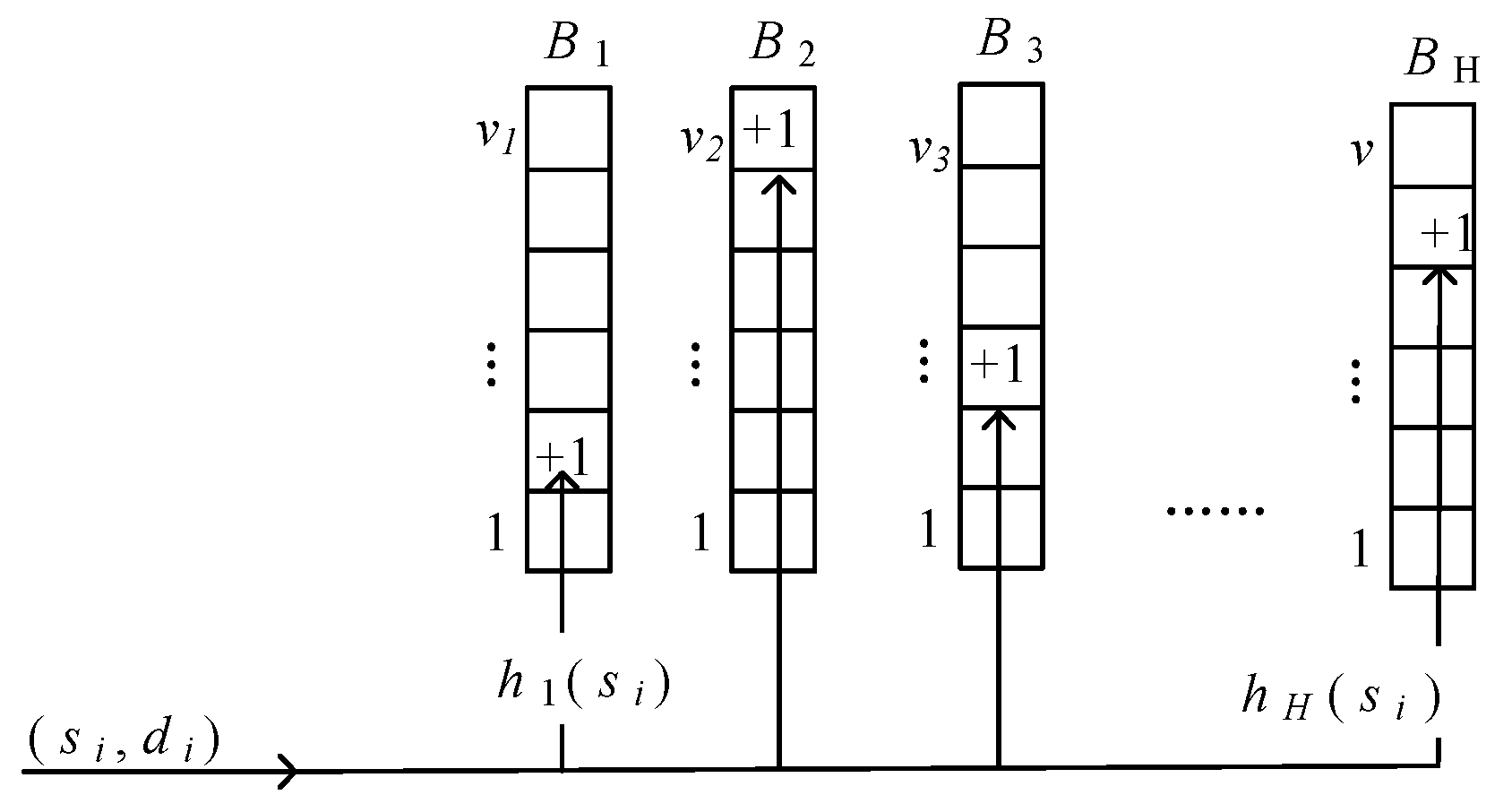
4.3.2. Method for Efficiency System Level Feature Calculation
4.3.3. Simple introduction to EWMA
5. Experiments and Performance Evaluations
5.1. Performance Evaluation for Node Level Abnormal Detection Method
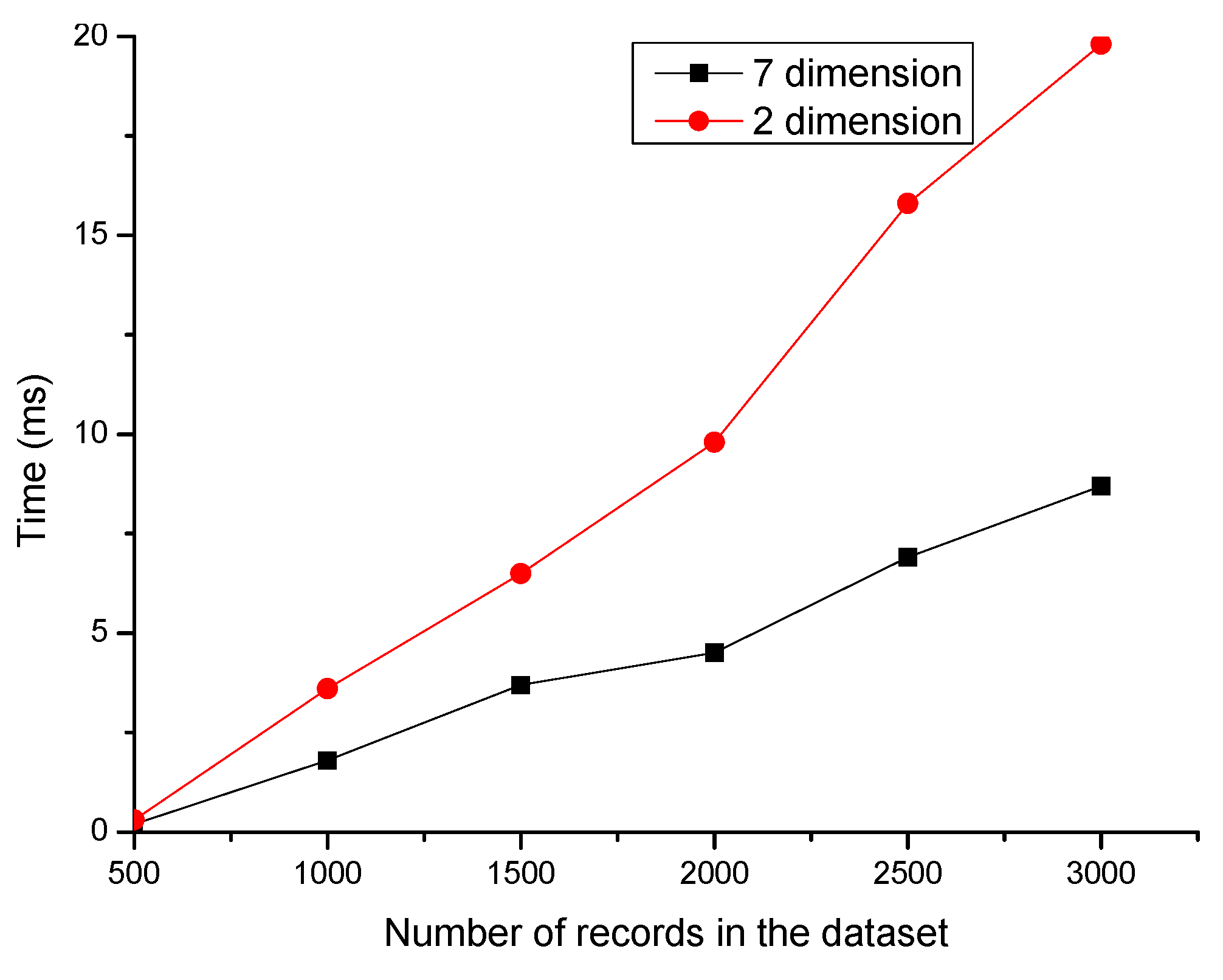
5.1.1. Dimension Reduction Efficiency Analysis
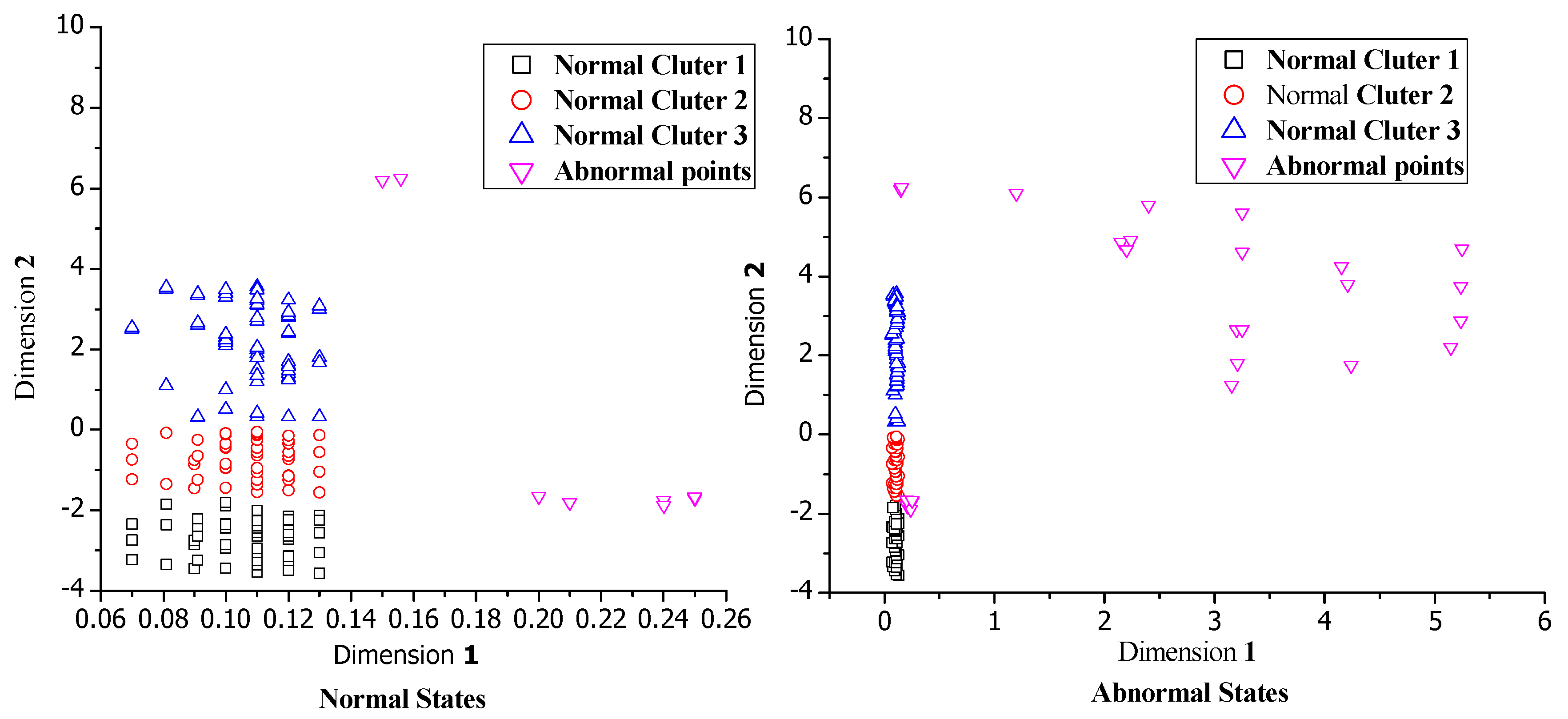
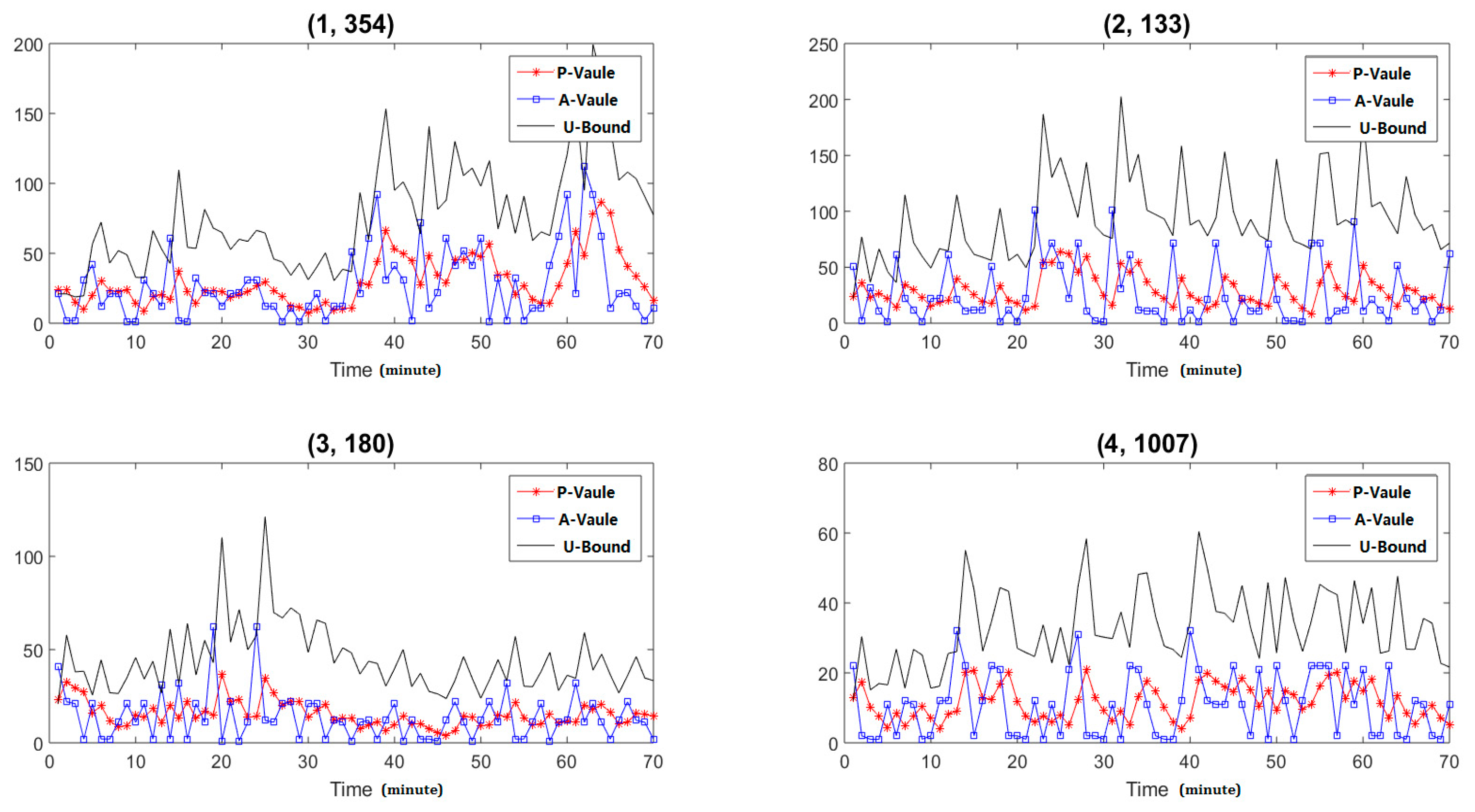
5.1.2. Abnormal Candidates Detection Use DBSCAN
5.2. Performance Evaluation for Network Level Abnormal Detection Method
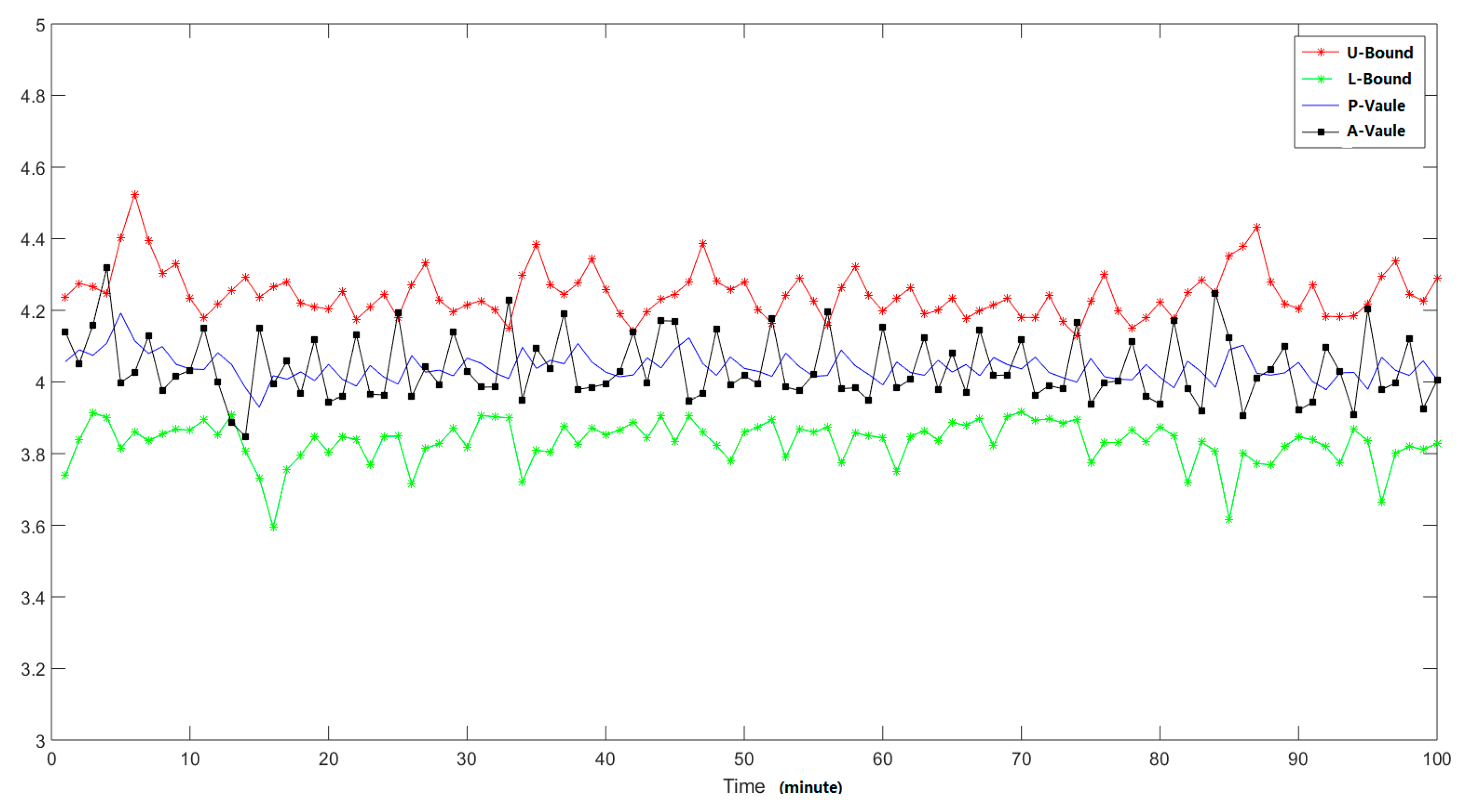
5.2.1. Performance Evaluation of EWMA Method
5.2.2. Method Sensitivity Analysis
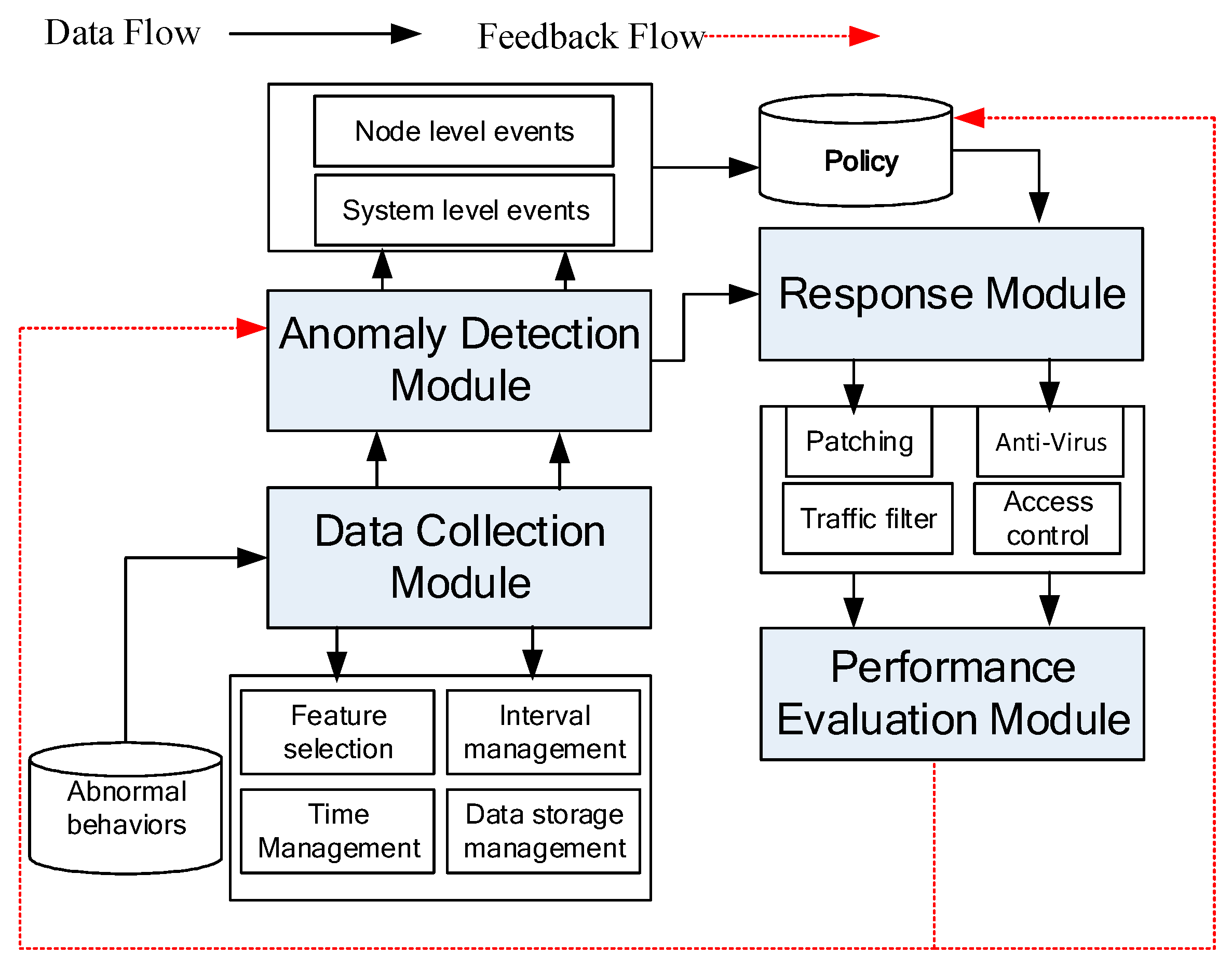
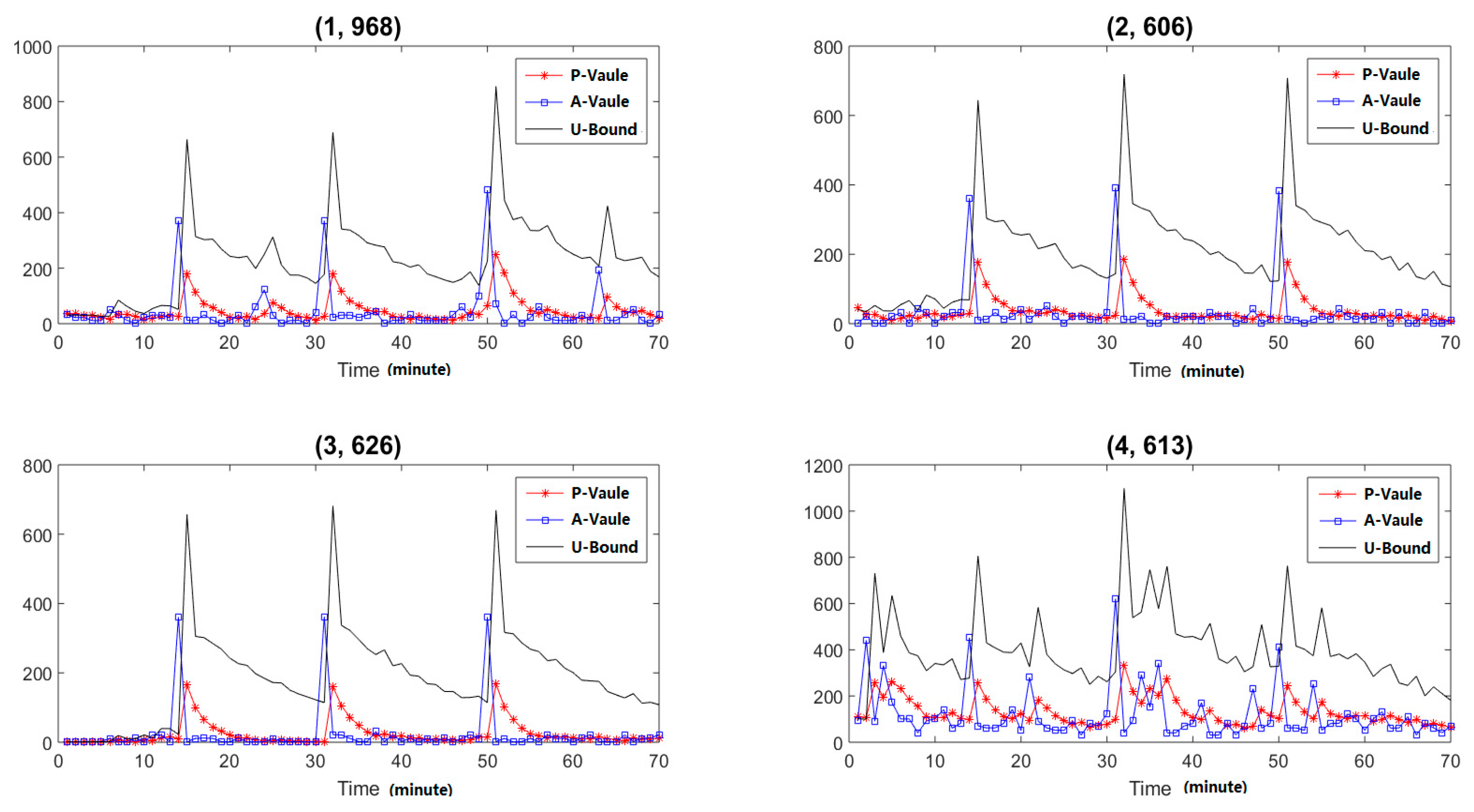
5.3. Response Policy Design
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, S.; Xu, L.D.; Zhao, S. The Internet of Things: A Survey; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2015. [Google Scholar]
- Mihailescu, P. MAE: A Mobile Agent Environment for Resource Limited Devices. Available online: https://www.monash.edu/library/researchers/repository (accessed on 1 October 2017).
- Zulkarnain, Z.A.; Hanapi, Z.M.; Subramaniam, S. A Spawn Mobile Agent Itinerary Planning Approach for Energy-Efficient Data Gathering in Wireless Sensor Networks. Sensors 2017, 17, 1280. [Google Scholar] [CrossRef]
- IBM Aglets Software Development Kit—Home Page. Available online: http://web.media.mit.edu/~stefanm/ibm/AgletsHomePage/index_new4.html (accessed on 1 October 2015).
- Obaidat, S.; Venkata, P.; Saritha, V. Advances in Key Stroke Dynamics-Based Security Schemes. In Biometric-Based Physical and Cybersecurity Systems; Springer: Cham, Switzerland, 2019; pp. 165–187. [Google Scholar]
- Cai, Z.; Shen, C.; Guan, X. Mitigating behavioral variability for mouse dynamics: A dimensionality-reduction-based approach. IEEE Trans. Hum. Mach. Syst. 2014, 44, 244–255. [Google Scholar] [CrossRef]
- Liu, Z.; Qin, T.; Guan, X.; Jiang, H.; Wang, C. An Integrated Method for Anomaly Detection from Massive System Logs. IEEE Access 2018, 6, 30602–30611. [Google Scholar] [CrossRef]
- Wang, Z.; Zhu, Y. A centralized HIDS framework for private cloud. In Proceedings of the 2017 18th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Kanazawa, Japan, 26–28 June 2017; pp. 115–120. [Google Scholar]
- Maske, S.A.; Parvat, T.J. Advanced anomaly intrusion detection technique for host based system using system call patterns. In Proceedings of the International Conference on Inventive Computation Technologies, Coimbatore, India, 26–27 August 2016. [Google Scholar]
- Anandapriya, M.; Lakshmanan, B. Anomaly based host intrusion detection system using semantic based system call patterns. In Proceedings of the 2015 IEEE 9th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 9–10 January 2015; pp. 1–4. [Google Scholar]
- Marteau, P.F. Sequence Covering for Efficient Host-Based Intrusion Detection. IEEE Trans. Inf. Forensics Secur. 2019, 14, 994–1006. [Google Scholar] [CrossRef]
- Gao, C.; Li, Z. Discovering host anomalies in multi-source information. In Proceedings of the International Conference on Multimedia Information Networking and Security (MINES’09), Wuhan, China, 18–20 November 2009; Volume 2, pp. 358–361. [Google Scholar]
- Lin, S.W.; Ying, K.C.; Lee, C.Y. An intelligent algorithm with feature selection and decision rules applied to anomaly intrusion detection. Appl. Soft Comput. 2012, 12, 3285–3290. [Google Scholar] [CrossRef]
- Anderson, J.P. Computer Security Threat Monitoring and Surveillance; Technical Report; James, P., Ed.; Anderson Company: Saint Paul, MN, USA, 1980. [Google Scholar]
- Li, S.; Tryfonas, T.; Li, H. The Internet of Things: A security point of view. Internet Res. 2016, 26, 337–359. [Google Scholar] [CrossRef]
- Elhadj, B.; Thomas, W.; Walaa, H. A Critical Review of Practices and Challenges in Intrusion Detection Systems for IoT: Towards Universal and Resilient Systems. IEEE Commun. Surv. Tutor. 2018, 20, 3496–3509. [Google Scholar]
- Zarpelão, B.B.; Miani, R.S.; Kawakani, C.T.; de Alvarenga, S.C. A survey of intrusion detection in Internet of Things. J. Netw. Comput. Appl. 2017, 84, 25–37. [Google Scholar] [CrossRef]
- Viegas, E.; Santin, A.O.; Franca, A. Towards an energy-efficient anomaly-based intrusion detection engine for embedded systems. IEEE Trans. Comput. 2017, 66, 163–177. [Google Scholar] [CrossRef]
- De França, A.L.; Jasinski, R.P.; Pedroni, V.A.; Santin, A.O. Moving network protection from software to hardware: An energy efficiency analysis. In Proceedings of the 2014 IEEE Computer Society Annual Symposium on VLSI, Tampa, FL, USA, 9–11 July 2014; pp. 456–461. [Google Scholar]
- Qiao, H.; Peng, J.; Feng, C.; Rozenblit, J.W. Behavior Analysis-Based Learning Framework for Host Level Intrusion Detection. In Proceedings of the IEEE International Conference & Workshops on the Engineering of Computer-Based Systems, Tucson, AZ, USA, 26–29 March 2007; IEEE Computer Society: Washington, DC, USA, 2007. [Google Scholar]
- Jolliffe, I. Principal Component Analysis; Springer: Berlin/Heidelberg, Germany, 1986; Volume 87, pp. 41–64. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Xu, X. A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the International Conference on Knowledge Discovery & Data Mining, Portland, OR, USA, 2–4 August 1996. [Google Scholar]
- Giorgi, G.; Narduzzi, C. Detection of anomalous behaviors in networks from traffic measurements. IEEE Trans. Instrum. Meas. 2008, 57, 2782–2791. [Google Scholar] [CrossRef]
- Garg, A.; Maheshwari, P. PHAD: Packet header anomaly detection. In Proceedings of the International Conference on Intelligent Systems & Control, Coimbatore, India, 7–8 January 2016. [Google Scholar]
- Schweller, R.; Li, Z.; Chen, Y. Reversible sketches: Enabling monitoring and analysis over high-speed data streams. IEEE/ACM Trans. Netw. 2007, 15, 1059–1072. [Google Scholar] [CrossRef]
- Cormode, G.; Muthukrishnan, S. An improved data stream summary: The count-min sketch and its applications. In Latin American Symposium on Theoretical Informatic; Springer: Berlin/Heidelberg, Germany, 2004; pp. 29–38. [Google Scholar]
- Huang, Q.; Lee, P. LD-Sketch: A distributed sketching design for accurate and scalable anomaly detection in network data streams. In Proceedings of the 2014 IEEE INFOCOM, Toronto, ON, Canada, 27 April–2 May 2014. [Google Scholar]
- Callegari, C.; Giordano, S.; Pagano, M. On the combined use of sketches and CUSUM for Anomaly Detection. In Proceedings of the 2015 International Conference on Computing and Network Communications, Trivandrum, India, 16–19 December 2015. [Google Scholar]
- Bakdi, A.; Kouadri, A.; Bensmail, A. Fault detection and diagnosis in a cement rotary kiln using PCA with EWMA-based adaptive threshold monitoring scheme. Control Eng. Pract. 2017, 66, 64–75. [Google Scholar] [CrossRef]
- XJTU, Botnet Detection System. Available online: http://botwarden.xjtu.edu.cn (accessed on 1 October 2016).
- Avast. Available online: https://www.avast.com/index. 2016.10 (accessed on 1 October 2016).
- Zou, C.C.; Gong, W.; Towsley, D. Worm propagation modeling and analysis under dynamic quarantine defense. In Proceedings of the 2003 ACM Workshop on Rapid Malcode, Washington, DC, USA, 27 October 2003; pp. 51–60. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Features | Simply Descriptions |
|---|---|---|
| 1 | CPU usage | CPU resources occupied by running programs |
| 2 | Memory usage | The memory occupied by processes |
| 3 | Disk read | The bytes disk read from memory |
| 4 | Disk write | The byte written into disk |
| 5 | Received packets | The data byte transferred from remote server to the local node |
| 6 | Sent packets | The data byte transferred from local node to the remote server |
| 7 | Process | The list of running processes in the current time window |
| 8 | Port | The list of open ports in the current time window |
| Eigenvalues | Contribution Rates | Cumulative Contribution Rates |
|---|---|---|
| 5.622 | 80.3% | 80.3% |
| 1.020 | 14.6% | 94.9% |
| 0.244 | 3.5% | 98.4% |
| 0.101 | 1.4% | 99.8% |
| 0.013 | 0.2% | 100% |
| 0.000 | 0.0 | 100% |
| Data Type | # of Clusters | # of ABNORMAL Points | Percentage of Difference |
|---|---|---|---|
| Original data | 2 | 11 | 0.0% |
| Three dimension | 2 | 11 | 0.0% |
| Two dimension | 2 | 11 | 0.0% |
| One dimension | 2 | 1 | 1% |
| Threshold | Detection Rate | False Positive Rate | False Negative Rate |
|---|---|---|---|
| 1 | 98.5% | 3.2% | 1.5% |
| 2 | 97.2% | 1.0% | 2.8% |
| 3 | 95.5% | 0.7% | 4.5% |
| 4 | 94.1% | 0.0% | 5.9% |
| 5 | 91.4% | 0.0% | 8.6% |
| 6 | 86.5% | 0.0% | 13.5% |
| 7 | 77.9% | 0.0% | 22.1% |
| 8 | 62.1% | 0.0% | 37.9% |
| 9 | 39.8% | 0.0% | 60.2% |
| 10 | 14.6% | 0.0% | 85.4% |
| Algorithm | Detection Rate |
|---|---|
| IMLADS | 95.5% |
| Avast | 0.0% |
| Algorithm | False Positive Rate | False Negative Rate |
|---|---|---|
| IMLADS | 4.5% | 0.7% |
| DBSCAN | 3.1% | 42.9% |
| No. | Sensitivity Level | Efficiency |
|---|---|---|
| 1 | 0.1% | 76.8% |
| 2 | 0.3% | 88.2% |
| 3 | 0.5% | 91.5% |
| 4 | 1.0% | 93.8% |
| 5 | 3.0% | 94.8% |
| 6 | 5.0% | 94.9% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, T.; Wang, B.; Chen, R.; Qin, Z.; Wang, L. IMLADS: Intelligent Maintenance and Lightweight Anomaly Detection System for Internet of Things. Sensors 2019, 19, 958. https://doi.org/10.3390/s19040958
Qin T, Wang B, Chen R, Qin Z, Wang L. IMLADS: Intelligent Maintenance and Lightweight Anomaly Detection System for Internet of Things. Sensors. 2019; 19(4):958. https://doi.org/10.3390/s19040958
Chicago/Turabian StyleQin, Tao, Bo Wang, Ruoya Chen, Zunying Qin, and Lei Wang. 2019. "IMLADS: Intelligent Maintenance and Lightweight Anomaly Detection System for Internet of Things" Sensors 19, no. 4: 958. https://doi.org/10.3390/s19040958
APA StyleQin, T., Wang, B., Chen, R., Qin, Z., & Wang, L. (2019). IMLADS: Intelligent Maintenance and Lightweight Anomaly Detection System for Internet of Things. Sensors, 19(4), 958. https://doi.org/10.3390/s19040958