1. Introduction
Intelligent sound recognition (ISR) is a technology for identifying sound events that exist in the real environment. This method is mainly based on analyzing human auditory awareness characteristics and embedding such percept ability in machines or robots. Environmental sound classification (ESC), also known as sound event recognition, serves as a fundamental and essential step of ISR. The main goal of ESC is to precisely classify the class of a detected sound, such as children playing, car horn and gunshot. With the popular applications of ISR in audio surveillance systems [
1] and healthcare [
2], the ESC problem has received increasing attention in recent years. Depending on the different properties of various sound sources, sound signals can be roughly classified into human voice, music sound, and environmental sound. Recent developments have brought great improvements in automatic speech recognition (ASR) [
3] and music information recognition (MIR) [
4]. However, on account of considerably non-stationary characteristics of environmental sounds, this kind of signals cannot be described as speech or music only. We can imagine that the system developed for ASR and MIR will be inefficient when applying to ESC tasks. Therefore, it is essential to develop an efficient ISR system for environment sound recognition.
Environment sound taxonomy generally consists of two basic components: acoustic features and classifiers. In order to extract acoustic features, sound signals are first separated into frames with a cosine window function (Hamming or Hanning window). Then, features are extracted from each frame and this set of features is used as one instance of training or testing [
5]. The classification result of one sound is the summation of probabilities predicted for each segment. Features derived from Mel filters: Mel Frequency Cepstral Coefficients (MFCC) and Log-Mel Spectrogram (LM) are two widely used features in ESC [
6,
7] with acceptable performance, although they are originally developed for ASR. Moreover, a considerable number of research works indicate that combined features performed better than only use one feature set in ESC tasks. While adding more conventional features cannot improve the performance. Hence, a suitable feature aggregate scheme is an essential part of sound taxonomy.
Support-vector machines (SVM), Gaussian mixture model (GMM) extreme learning machine (ELM) are widely used classifiers in sound related classification tasks in the past decades [
8,
9,
10,
11] and other categorization problems as well. However, these conventional classifiers are designed to model small variations which result in the lack of time and frequency invariance. In recent years, deep neural network-based models have been proven to be more efficient than traditional classifiers in solving complex categorize problems. The convolutional neural network (CNN) is one of the most commonly used architectures of deep learning models, which could address the former limitations by learning filters that are shifted in both time and frequency [
12]. The CNN is designed to process data that come in the form of multiple arrays: 1D for various kinds of sound signals, such as speech and music, and 2D for image or audio spectrograms [
13]. Ref. [
14] first use the CNN in image recognition and outperform all the traditional methods in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). CNN has been successfully used for ASR [
15] and MIR [
4], and this deep architecture is also shown to be extremely powerful in ESC tasks. In 2018 Detection and Classification of Acoustic Scenes and Events challenge (DCASE), 55 of the 97 submissions being based on a CNN architecture [
16]. Although great improvement has been achieved by using CNN in ESC problems, however, there is still a long way to go when compared with CNN based image classification algorithms. Therefore, some researchers consider to merge two CNN or fuse CNN with other deep learning models to elevate the performance.
Despite the fact that CNN can solve the limitations of conventional classifiers, the longer temporal context information still cannot be captured by this method. Hence, several works propose to use merged neural networks to address the above-mentioned shortcomings through integrating information from the earlier steps [
17,
18,
19,
20]. In these methods, one or more CNNs are used to extract the spatial information with different acoustic features firstly. Then, the outputs are merged by concatenation and feed to recurrent neural network (RNN) layers or another CNN layers for temporal information extraction. Inspired by sensor fusion framework, several research works apply decision-level fusion in ESC tasks. The main idea of decision level fusion method is to fuse the softmax values acquired from different neural networks through mean calculation, or uncertainty reasoning algorithms such as Dempster—Shafer evidence theory (DS theory) and Bayesian Theory [
20,
21]. The experiment results indicate that merged neural networks with decision level fusion outperform single deep architectures in taxonomic tasks [
20,
21,
22,
23].
The main obstacles of current algorithms for ESC tasks are as follows: 1) the most widely used acoustic features applied to ESC tasks were originally designed for ASR and MIR, such as log-mel spectrogram and MFCC. Since the environment sounds are mostly non-stationary signals without meaningful patterns or sub-structures, use a single feature may lead to the failure of capturing important information about environmental audio events. 2) In recent years, with the advancement of deep learning models, the CNN becomes a primary choice in environment sounds recognition and outperform the conventional classifiers like SVM or GMM [
7,
24]. Even though some research works attempt to use deeper neural networks [
25,
26] or stacked deep architectures [
17,
18,
19,
20] to improve the taxonomic accuracy, however, the performance is still unsatisfactory. Hence, there is need to develop appropriate auditory features and novel neural network models to achieve high categorization accuracy for ESC tasks.
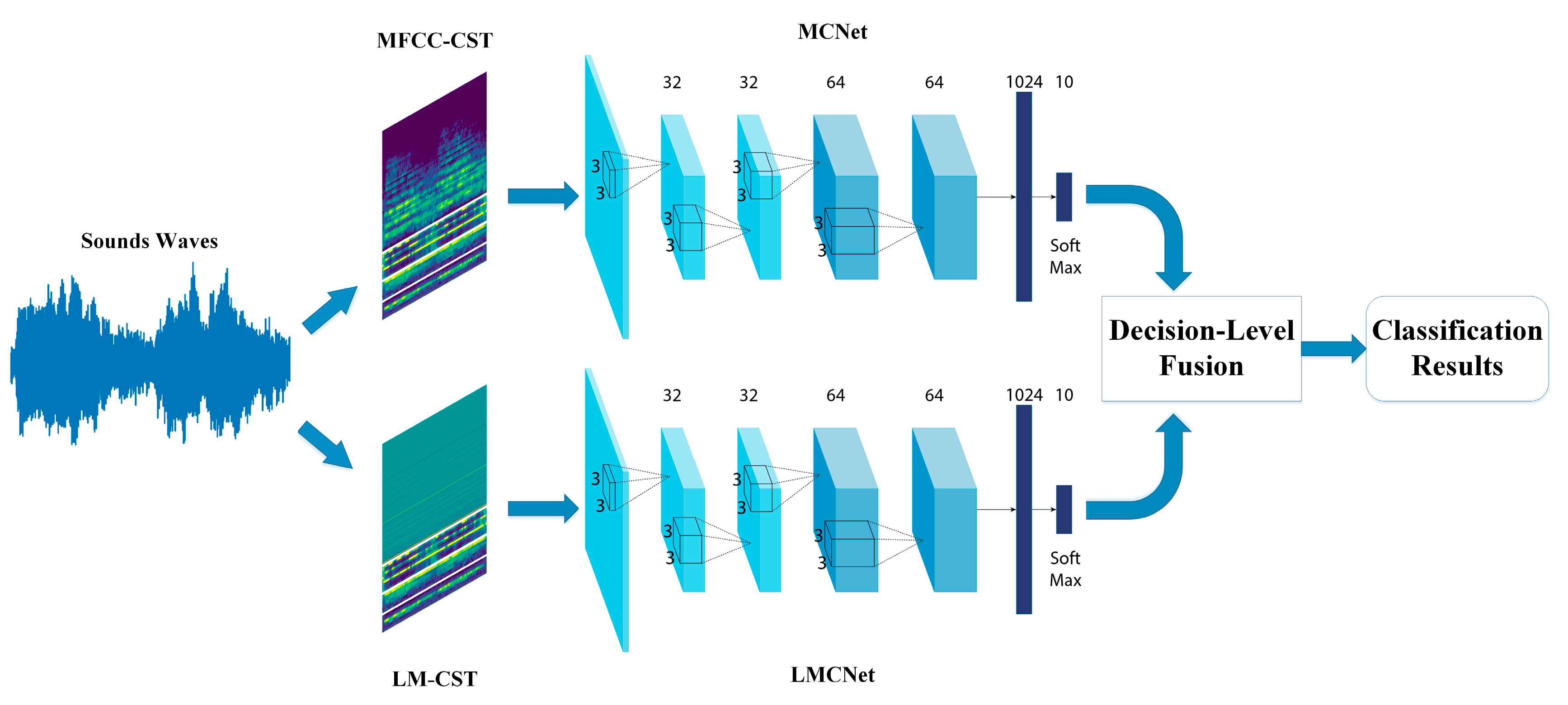
In order to address these two deficiencies, we propose a novel four-layer stacked CNN architecture based on two combined auditory features and DS theory-based information fusion method, called TSCNN. The proposed system consists of three components: feature extraction and combination, CNN training and DS theory-based decision-level fusion. We extract five auditory features: log-mel spectrogram (LM), MFCC, chroma, spectral contrast and tonnetz (in order to facilitate the description in the rest of papers, we call the last features as CST). Then, LM and CST (LMC) are combined as one feature sets, MFCC and CST (MC) are aggregated as another for training two CNNs, respectively. At last, the outputs derived from the softmax layer of these two CNNs are fused by DS theory to exploit both combined features. The experimental results indicate that the taxonomic accuracy of the proposed architecture can surpass both LCNet (CNN use LMC feature) and MCNet (CNN use MC feature), and is also outperforming the existing models on Urbansound8K [
27] dataset. To our best knowledge, this is the first time that the classification accuracy of CNN-based ISR system is higher than 97% in ESC tasks.
The remaining structure of this paper is organized as follows.
Section 2 introduces the related works on environment sound recognition.
Section 3 describes the feature extraction and the architecture of the proposed model. The experiment results and detailed analysis are shown in
Section 4. In
Section 5, the conclusion of our work is presented.
2. Related Works
With the growing number of evidence that the CNN-based models outperform conventional methods in various categorization tasks, they have been applied in sound recognition tasks in recent years. Ref. [
28] first evaluated the performance of using CNN in ESC tasks. In this work, an ESC system consists of 2-layer CNN with max-pooling and 2 fully connected layers is proposed. Log-mel spectrograms are extracted as an auditory feature to train the neural network. The experiment results indicate that the classification accuracy of this model is 5.6% higher than traditional methods. Ref. [
12] propose to use CNN with smoothed and de-noised spectrogram image feature in sound recognition tasks. Ref. [
29] presents a CNN model using mel-spectrograms as features. The performance of three neural network layers as classifiers are investigated, which is a fully connected layer, convolutional layer and convolutional layer without max-pooling. The results indicate that using a convolutional layer as a classifier outperforms the model applying a fully connected layer as the classifier. Ref. [
24] presents a six-layer CNN model for acoustic event recognition. In this work, the log-mel spectrograms with their first order derivation and second order derivation are extracted for each recording without segmentation. Then, multiple instance learning is applied and the softmax layer is replaced by an aggregation layer to aggregate the outputs of each network. The data augmentation is applied to prevent over–fitting and improve the robustness of the model. CNN has a strong ability to extract features directly from raw inputs, which has been verified in various image recognition problems. Based on this, Ref. [
30] proposes to use CNN to extract features from raw waveform and use SVM or extreme learning machines as classifiers in ESC tasks. The results denote that this architecture outperforms the CNN trained by MFCC. However, the accuracy is only 70.74%. Ref. [
26] and uses raw waveforms to train CNNs as well. In this work, the problem of how many layers are the most suitable for CNNs has been studied. With considerable experiments, it is pointed out that deeper layers do not give better performance. Meanwhile, the results also indicate that using waveforms just achieve an approximative performance of models using log-mel features.
Traditional CNN models have several drawbacks for auditory tasks. For example, pooling layers are generally applied in CNN models for feature dimensional reduction, however, these processes can lead to information loss and hinder the performance of neural networks. Therefore, a considerable number of works attempt to use improved CNNs for ESC tasks. Dilated convolution layers are exploited for ESC [
31,
32] to avoid the above-discussed obstacles. Several research works exploit CNN models which were originally developed for image recognition tasks, and achieve outstanding performance in ESC as well [
25]; the environment sound classification accuracy of AlexNet and GoogLeNet [
33] are evaluated on UrbanSound8K, ESC-10 and ESC-50 [
34] datasets. Spectrograms (Spec), MFCC and Cross Recurrence Plot (CRP) feature sets are extracted and concatenated as three-channel image feature to train both models. The experiment results indicate that the image recognition models could also obtain good taxonomic accuracy for sound recognition problems. The authors in Ref. [
35] use an end-to-end ESC system using a convolutional neural network. In this model, raw waveforms are used as inputs and two convolution layers are applied to extract features. Then, three max-pooling layers are performed for feature dimensional reduction followed by two fully connected layers as the classifier. A VGGNet [
36] based ESC system is presented by Ref. [
6], where the convolution filters are set to 1-D for learning frequency patterns and temporal patterns, respectively. Ref. [
37] proposes a CNN based model called WaveNet, which uses multi-scale features to make a CNN that learns comprehensive information of environment sounds. First, features are extracted from one recording through the first convolution layer using three types of filter size. The second convolution layer uses corresponding pooling stride to equal the dimension of these features and then, the three features are concatenated to form the multi-scale features. This feature is further combined with a log-mel spectrogram and perform better than other systems on an ESC-50 dataset. The DS-CNN model presented by Ref. [
20] also uses a raw waveform and log-mel spectrogram as inputs to train CNN based ESC system. The difference between WaveNet and DS-CNN is: the WaveNet combined two kinds of features together while in DS-CNN, two different CNN use raw waveform and log-mel spectrogram as inputs, respectively, and the outputs are fused by DS theory.
From these works, we can notice that most ESC models use raw waveform directly or single auditory features to train neural networks. However, after a comprehensive investigation of a considerable number of sound recognition works, Ref. [
5] pointed out that aggregate features will give better performance than single features in ESC problems. Meanwhile, from the classification accuracy derived from these recently published works, we can also find out that the CNN-based ESC or ISR systems still has great potentials for making further progress. Hence, we hope to find efficient aggregated features and appropriate CNN architecture to elevate the performance for environment sound categorization.
4. Experiment and Analysis
The UrbanSound8K dataset includes 8732 labeled urban sounds (the length is less than or equal to 4 s) collected from the real-world, totaling 9.7 h. The dataset is separated into 10 audio event classes: air conditioner (ac), car horn (ch), children playing (cp), dog bark (db), drilling (dr), engine idling (ei), gunshot (gs), jackhammer (jh), siren (si) and street music (sm).
The same feature extraction method presented by Ref. [
28] is used in this work. All sound clips are converted to the single channel wave files with the frequency of 22,050 Hz. Then, divided into 41 frames with an overlap of 50% (each frame is about 23 ms). We use the pre-setting channels of Librosa to extract the Chroma, Spectral Contrast and Tonnetz features. For the MFCC extraction, the value of first twenty channels with their first and second order derivatives are used, resulting in 60-dimensional feature vectors. The channels of Log-Mel Spectrogram are set to 60, in order to make the dimension to be equal to the MFCC. Then, all the spectrograms are represented as a matrix with a size of
. The feature size of chroma, tonnetz and spectral contrast is
,
and
, separately. Therefore, the size of LMC and MC are all
.
Figure 4 shows the graphical representation of how does the feature learned by the proposed fourfour-layer CNN.
It can be seen from
Figure 4 that the feature maps derived from first and second convolutional layers have the same size as the input feature. After
max pooling processing, the size of input feature maps for third convolutional layer is
. Since the max pooling is not performed after convolutional layer 3, so that the size of input features for 4th convolutional layer is
as well. Then, features with size of
are derived from the last hidden layer and feed to the fully-connected layer which has 1024 hidden units. The output is a
tensor according to the number of classed of UrbanSound8K dataset is 10.
For each experiment, the ten-fold cross-validation is performed to evaluate the proposed ISR model on UrbanSound8K dataset. The combined features and four-layer CNN architecture are two main contributions of this work. Hence, we first analyze the efficiency of the CNN model trained with combined features. Meanwhile, the influence of the different number of convolution layers (six and eight) on CNN-based ESC system is also investigated. The additional convolution layers in the CNNs for comparison use the same receptive fields of
and stride step of
, batch-normalization is performed on each layer with ReLU as activation function. Dropout with a rate of 0.5 is exploited for the sixth and eighth convolution layer in the two additional CNN models, respectively.
Table 1 presents the number of parameters and the memory cost of CNN with different number of convolutional layers.
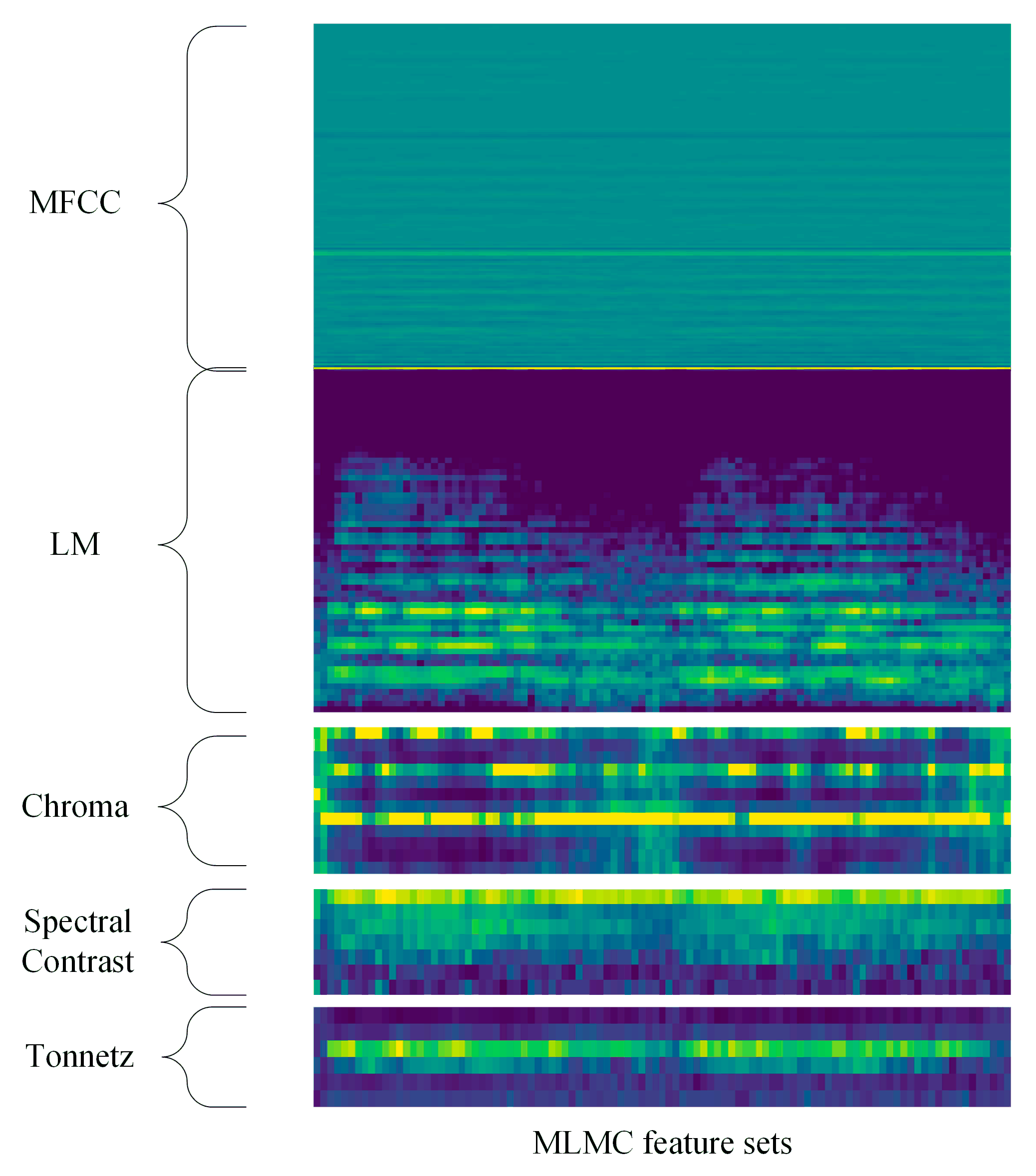
Furthermore, the classification performance of feature level fusion method is also presented. We combined LM, MFCC and CST together to form a new feature set called MLMC, to make a further investigation of the influence of various feature combination strategies in ESC tasks. The feature size of MLMC is
. The spectrogram of MLMC is shown in
Figure 5. The experiment results are shown in Tables 2, 4 and 5. The class-wise classification accuracy and the average accuracy of ten-fold cross-validation of three combined features and the proposed TSCNN-DS model on UrbanSound8K dataset is presented in each table.
The
Table 2 describes the experimental results of each method with four-layer CNN models. We can find that the feature combination of LMC and MC performs well in the four-layer CNN based ISR system. Taxonomic accuracy of five and six classes are higher than 95% using LMC and MC, respectively. While the feature aggregated of all feature sets not only reduces the performance but also makes it slightly worse. The LMCNet and MCNet achieves 95.2% and 95.3%, which is 22.5% and 22.6% higher than the model presented in Ref. [
28], respectively. The feature combination of MLMC has the worst performance among the four models, however, it is still 21.9% higher than the 72.7% of Piczak’s model. It can be seen that for both methods, the classification accuracy of all categories is higher than 90% except for gunshot of LMC and MLMC. The proposed TSCNN-DS model reaches 97.2% which is 24.5% higher than Piczak’s work, and it significantly improved the classification accuracy of gunshots (95.4%).
Moreover, in order to further illustrate whether the proposed TSCNN-DS model outperform LMCNet, MCNet and four-layer CNN using MLMC feature sets, we show the standard deviation and time cost in
Table 3. The classification accuracy obtained by TSCNN-DS is 2% and 1.9% higher than LMCNet and MCNet. It is also shown in
Table 3 that the standard deviation of TSCNN-DS is much less than three other methods, which further demonstrate that the fusion model outperforms three other single models. The mean time cost for LMCNet, MCNet, MLMC and TSCNN-DS is 0.023 s, 0.024 s, 0.028 s and 0.077 s, separately. The test is down in Python under Microsoft Windows 10 x64 OS on a computer with Intel Core i7-8700 CPU, two GTX 1080 GPU (the memory of each GPU is 8 GB) and 32 GB RAM. Although the time cost of proposed model is almost three times longer than single neural networks, the computational cost of TSCNN-DS is still well acceptable for ESC tasks in real time.
It can be seen in
Table 4 that, the six-layer CNN based models performs slightly worse than the methods use four-layer CNN. The LMCNet, MCNet, MLMC-CNN and TSCNN is 2.2%, 6.0%, 1.9% and 2.3% worse when compared with the four-layer CNN-based models. The categorization accuracy of gunshot for both methods is less than 90% and it is less than 80% for LMC and MC feature sets. Classification accuracy of dog barking with MCNet failed to reach 90%, and taxonomic accuracy on children playing of MCNet dramatically reduced to 69.4%. The MLMC feature cannot improve the classification performance as well, where the accuracy of children playing and gunshot failed to reach 90%. The same situation also appeared in the TSCNN model. Nevertheless, the proposed TSCNN model still achieves the best classification result (94.9%).
From
Table 5 we can find that the performance of all methods is unsatisfactory with the eight-layer CNN. Most of the categories and all methods obtain a taxonomic result that less than 90%. This indicates that using deeper layers may not give a better result for deep architectures, while appropriate layers and suitable parameter settings are the most important components of deep learning models.
In general, we can find out that the proposed LMC and MC features present to be efficiency with the proposed ISR system, which clarifies the advantage of the proposed feature combination strategies in ESC tasks. The TSCNN-DS model outperforming other models for both CNN architectures with different convolution layers. Then, the four-layer CNN achieves the best taxonomic accuracy when compared with six-layer and eight-layer CNN models for both methods. Meanwhile, the classification accuracy of both methods with the proposed four-layer CNN are higher than existing models. These results demonstrate the efficiency of the proposed four-layer CNN and DS theory fusion method based TSCNN-DS model.
In order to make a comprehensively comparison, we also investigate the two-stream CNN with the layer stack method. This model combined the outputs of the second convolution layer of both CNN and the concatenate feature maps are than used as inputs for the next convolution layers. We test this stacked CNN with 4, 6 and 8 layers as well. The parameter settings of each convolution layers and fully connected layers are equal to the 4-, 6- and 8-layer CNN described above. The classification accuracy of these stacked CNNs on UrbanSound8K dataset are shown in
Table 6.
It is clearly that the stacked four-layer CNN models achieve the highest (86.4%) classification accuracy among the three models. Which is 6.6% and 6.3% higher than stacked six- and eight-layer CNN respectively. This result further proves that the proper number of layers and parameters is the key to the deep learning model based ISR system, where the advantage of the proposed four-layer CNN is further proved as well.
At last, we compare our TSCNN-DS model with several existing CNN based ISR models as presented by Refs. [
6,
20,
25,
28,
32,
35]. The results are shown in
Table 7. The LMCNet uses LMC feature sets and achieves an accuracy of 95.2%, which is 22.5% higher than the Ref. [
28] model that uses LM features. Meanwhile, it is 11.5% higher than the Ref. [
32] model and uses LM and Gammatone Spectrogram combined feature. Furthermore, the performance of LMCNet is slightly higher (3%) than the model presented by Ref. [
20], which also applies DS theory as a sfusion method to fuse two CNN models. The classification accuracy of MCNet is 95.3%, which is much higher than the 72.7% of the model proposed by Ref. [
28]. Moreover, the proposed MCNet is also significantly higher than the Ref. [
28] model and is 2.3% higher than the Ref. [
25] model with MFCC based aggregated featurs. Finally, the proposed DS theory-based TSCNN-DS model obtains the highest taxonomic accuracy (97.2%) among all the ESC models. The performance of our algorithm is much higher than the Ref. [
28] model and is 5% higher than the Ref. [
20] model which uses the same fusion strategy. To our best knowledge, this is the first time that the categorization accuracy has reached over 95% on the UrbanSound8K dataset and is the highest accuracy compared with existing models.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}