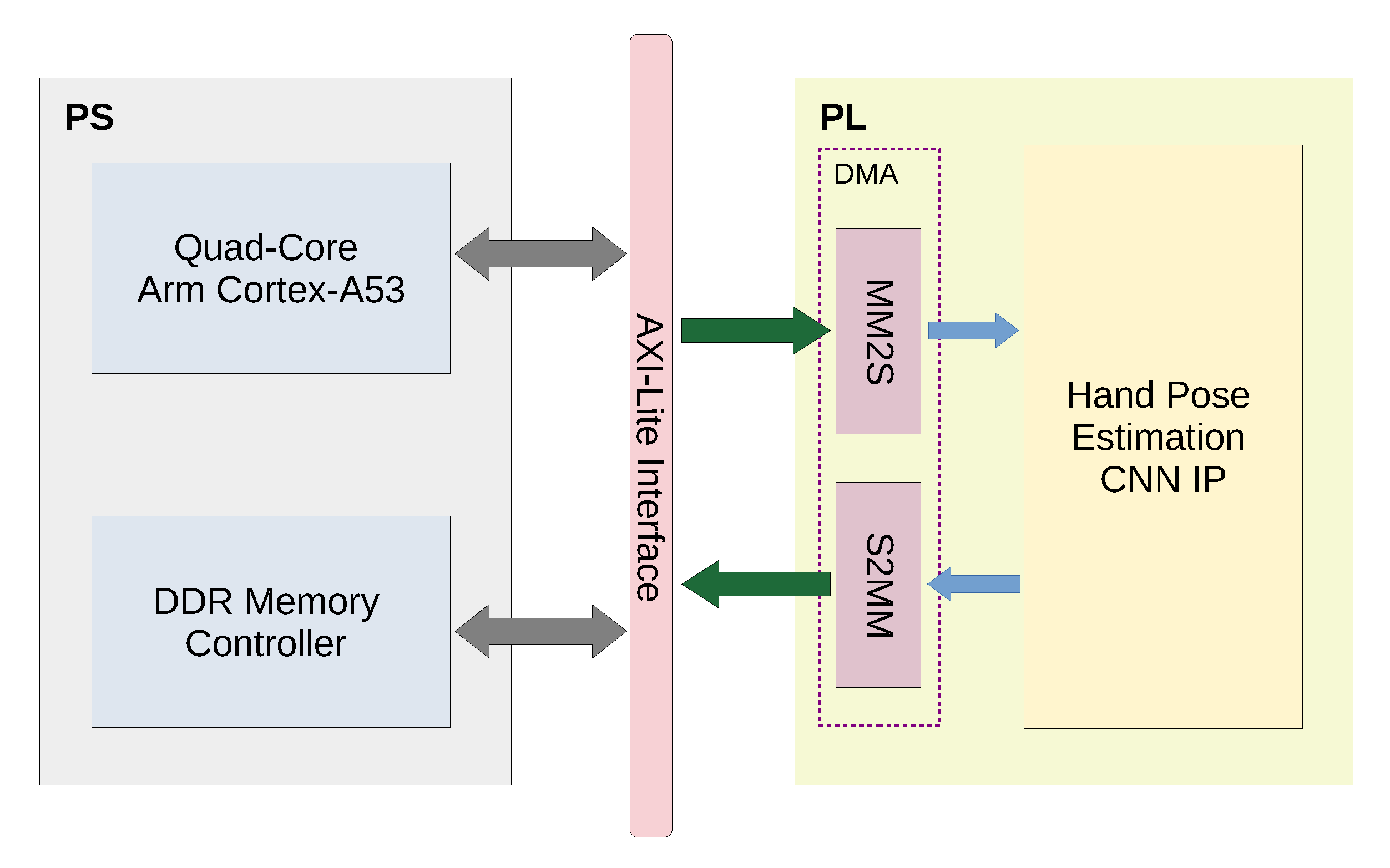
In the streaming architecture, each layer of the CNN is mapped to a separate hardware block and the blocks are connected to each other via stream channels to form a pipeline (as shown in
Figure 3). Furthermore, the implementation of each layer can be optimized independently and the data can be streamed between layers on the fly. Particularly, a partial result of a layer can be directly streamed to the next layer without having to wait until the complete calculation is done [
14]. As a result, this architecture facilitates the parallelism between layer blocks through pipelining.
5.1.1. Convolutional and Pooling Layer Architecture
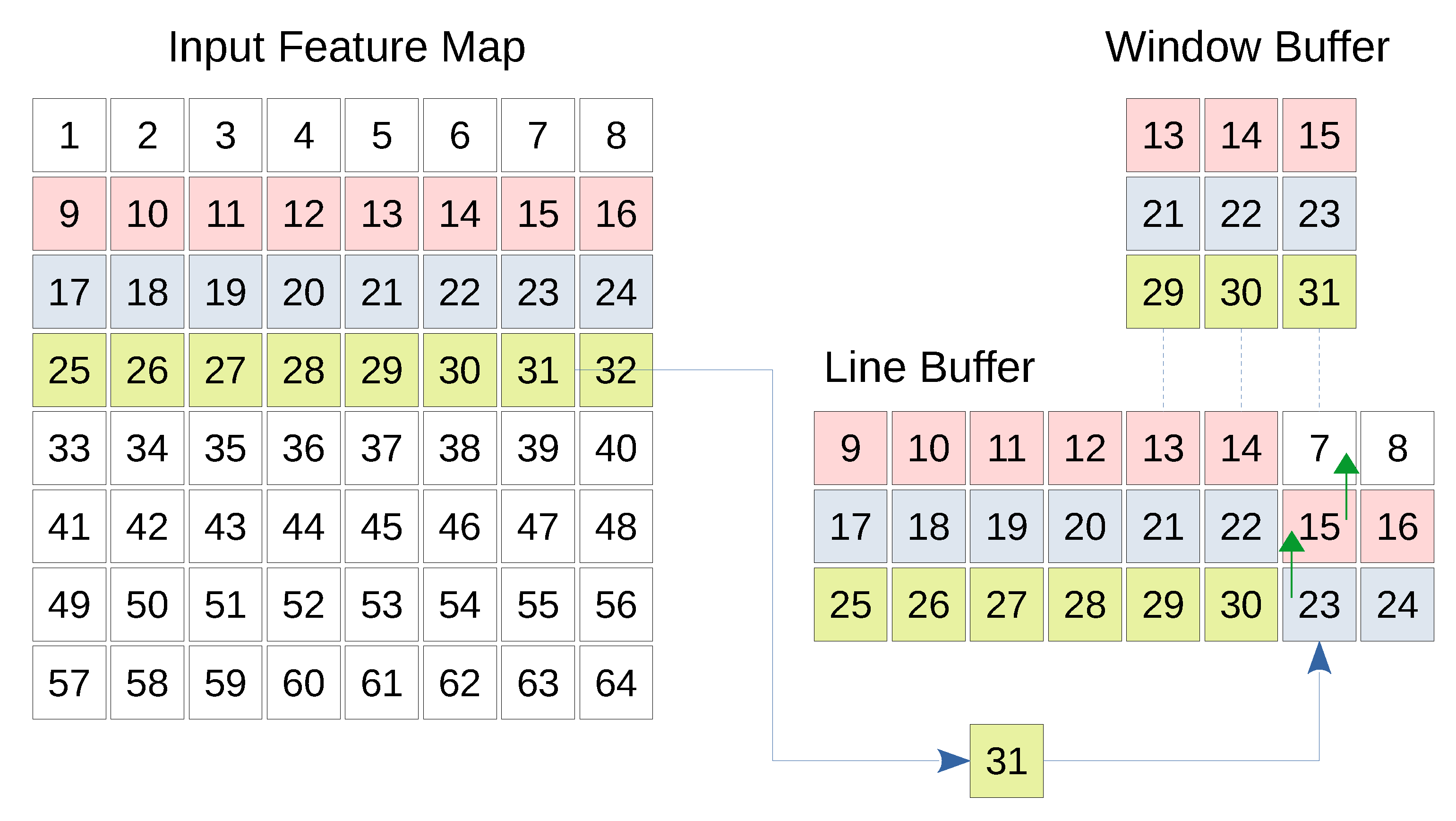
The convolutional layer as well as the pooling layer expect one or more feature maps as input and generate a number of output feature maps. Each feature map is scanned line by line, and each line is transferred to the next layer. This imposes that the first convolution or pooling operation cannot be completed until the appropriate number of lines are received by the CNN layer, which highlights the need to temporarily buffer the input lines. In case of convolutional layer, the kernel stride is less than its dimension. Therefore, the same input columns and/or rows are expected to be used by a later convolution operation using the same kernel. Instead of having to fetch the same set of input values from the previous feature maps repeatedly, local buffering saves the additional time and space needed by the previous layer. Therefore, a line buffer and a window buffer are needed. The line buffer is a special memory responsible for storing specific lines from previous feature maps locally. The dimensions of a line buffer depend on the kernel size as well as the size of the input feature map. The number of lines in a line buffer should be equal to the height of the kernel so that enough values can be covered by the kernel vertically. Furthermore, the number of columns in the line buffer should be the same number of columns in the input feature map(s). This is because a whole line should be stored before storing the next line [
28,
29]. To support parallelization, an array of line buffers, where each line buffer corresponds to an input feature map, is used. This could be thought of as a 3 dimensional line buffer. While the data is being buffered by the line buffer, the calculation of the concerned layer should take place. The window buffer is a small memory that has the same dimensions as the convolution or pooling kernel. This memory is responsible for preparing the data needed by the kernel to perform the convolution or the pooling.
The window buffer follows the same shifting pattern used by the kernel over the image. In fact, the window buffer copies the pixels required by the operation from the line buffer. These pixels are processed by the kernel, and the result is finally ready to be transferred to the next layer. Due to the hardware level parallelization in FPGA, 8 window buffers can sample the 8 line buffers that correspond to the 8 input channels, and 8 kernels can be applied on these window buffers in parallel. Resulting in 8 output values per clock cycle.
Figure 4 shows the basic structure of the line and window buffer where the fourth line of the input map is being buffered. Furthermore, the window buffer is highlighting a 3 × 3 region which will be treated by a kernel of the same size. Whenever a new input comes, the corresponding column is shifted up allowing the pixel to be inserted.
The idle time of a particular convolution or max pooling layer is the total number of input values that must be streamed to the line buffer in order for the convolution or max pooling computation engine to start or continue working. For example, in case of
convolution, the operation cannot be started until the first two lines and the first three values of the third line are already received by the line buffer. Furthermore, the computation engine is paused at the end of the third line because it has to wait for the first three values of the fourth line to be available. The same applies for the rest of the lines. This imposes additional waiting delays during which the computation engine is idle. In fact, every time the layer operation is executed, an output value is generated. Thus, we can consider the size of the output feature map as the number of times the layer operation was executed. This way, we can calculate idle time
of the layer as the difference between the total buffering time
calculated as the size of the input feature map, and the effective computation time
given as the output feature map size, as shown in Equation (
5).
where
,
and
are the number of input channels, the input height and the input width, respectively,
and
are the output height and width, respectively,
and
are the kernel height and width, respectively and finally
s and
d are the stride and dilation, respectively. It is noted that the idle time depends on the number of the input feature maps but irrelevant to the number of the output feature maps. The previous equation can be further simplified to Equation (
6) by assuming that the input feature maps and the kernels are all squares (
and
), which is our case (see
Figure 1).
The physical time interval equivalent to
can be calculated as
, where
is the number of clock cycles needed to transfer one input pixel to the line buffer. In the following paragraphs, we provide architectural details on how the stride and group convolution are handled and how they affect the idle time in a particular layer. Furthermore, we provide architectural information about the dilation and the skip/merge connections in
Section 7.
• Stride
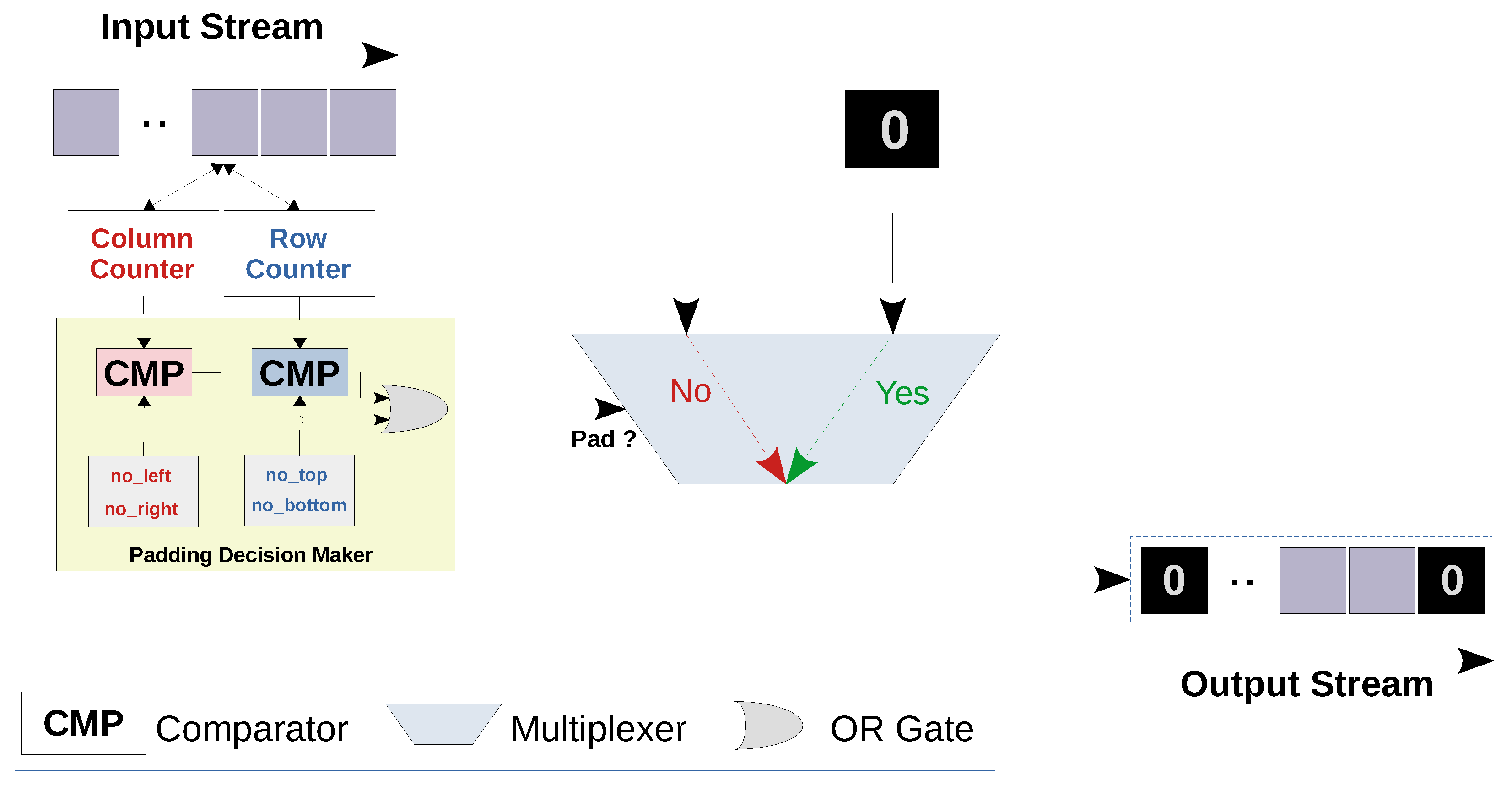
In case of the convolutional layers, the kernel is shifted by one pixel after each convolution operation horizontally or vertically (i.e., stride = 1). While in the first and the second max pooling layers, the stride is equal to the pooling filter sizes (i.e., stride = 4 and 2, respectively). In order to overcome the additional complexity imposed by the striding, we design a generic buffering engine that can be dynamically customized for different stride values. For this purpose, a row counter and a column counter are used to keep track of the row and the column to which the input value in the input feature map belongs. As the input values are streamed to the line buffer, the window buffer copies the chunk of values that are needed for the layer operation (i.e., convolution or max pooling) as illustrated in
Figure 4. However, the decision to start the layer operation is based on the values of the row and the column counters. Specifically, the operation is allowed to be performed only when the row and column counters are multiples of the vertical and horizontal strides respectively. Algorithm A1 in
Appendix A.1 shows how the stride operation is handled. In order to study the effect of the stride on the layer’s idle time, we differentiate the idle time with respect to the stride
s in Equation (
6):
This means that the higher the stride, the longer the waiting time within the layer.
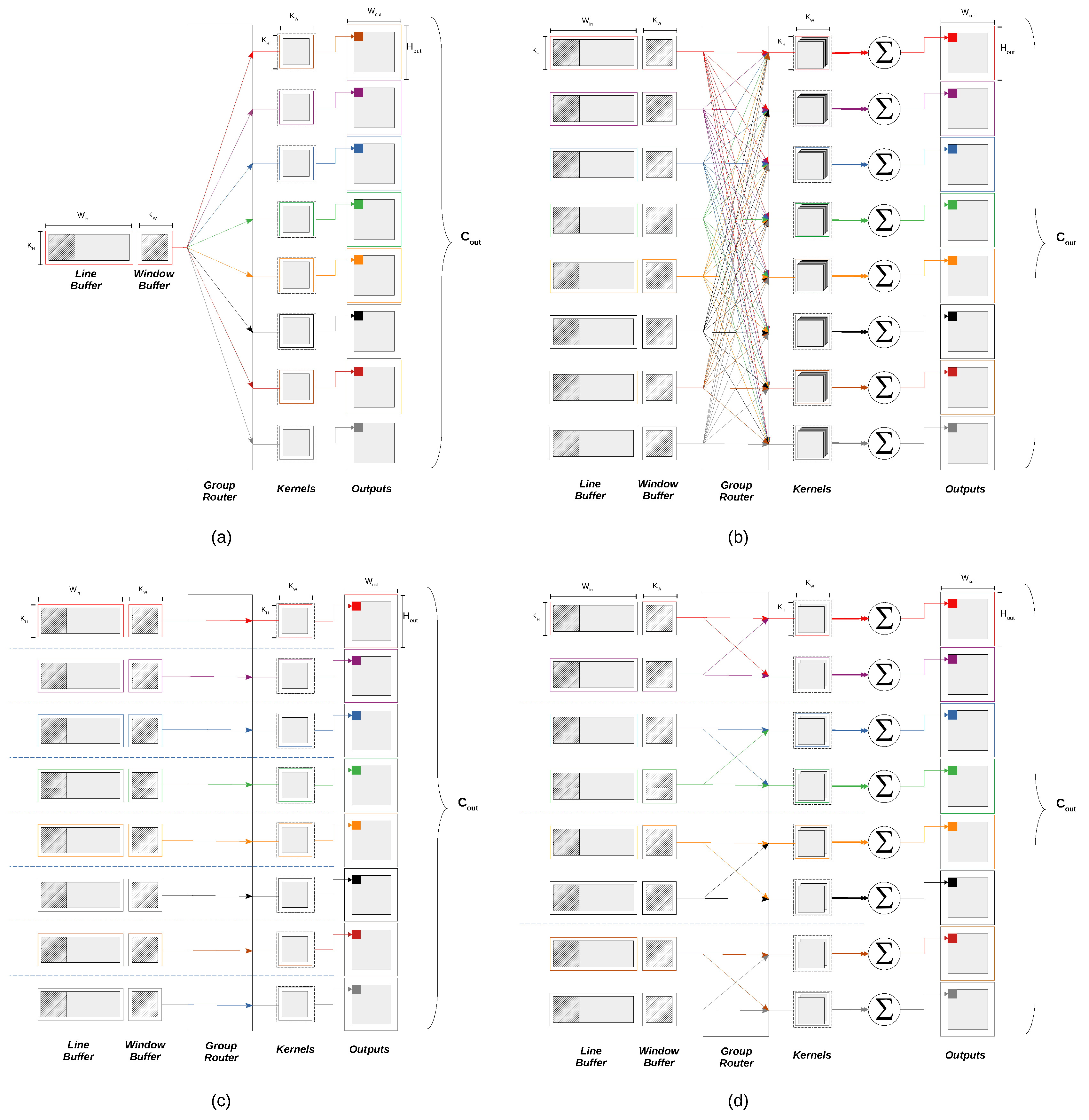
• Group Convolution
In group convolution, the input feature maps are arranged in groups, where each group is convoluted with its corresponding set of kernels. This way, each output feature map will be inferred from the input feature maps within the corresponding input group instead of being related to all input feature maps as in the standard convolution. No architectural modification for the line buffers or the window buffers is required, since the input still has to be buffered in the line buffers and then prepared in the window buffers for convolution. We introduce the “group router”, an array of demultiplexers that dynamically relate each window buffer to the correlative set of kernels. The routing decision inside the group router is based on the input group order as well as the input feature map order. In case of the first convolutional layer in our work, which produces 8 output channels from a single input channel, 8 convolutional kernels are used for the single input group. While in the second and the third convolutional layers, the standard convolution requires 64 kernels to produce 8 output channels. As mentioned in
Section 3.1, depthwise convolution is used to reduce the the number of kernels from 64 to 8, where each kernel is convoluted with a single input feature map. The group convolution has no effect on the idle time
of the layer since it does not effect the buffering scheme in the line buffer. Further details about the group convolution are available in
Appendix A.3.
5.1.4. Inter-Layer Packing
Once an output value of a layer is ready, it is streamed to the next layer for processing. Nevertheless, this limits the throughput between layers to one result value per clock cycle at most. In order to increase the throughput across the CNN (and consequently decrease the latency), we apply the pack/unpack technique. In this technique,
N output values of a layer (
) are concatenated together to form a single wider word, which is streamed within one clock cycle to the next layer (
). Consequently, the next layer (
) unpacks the concatenated word into its N values and performs the layer operation (e.g., convolution) in parallel. Theoretically, the inter-layer pipes have no bandwidth limit and any amount of data could be streamed from a layer to another. However, this is practically limited by the maximum achievable number of outputs at each clock cycle due to the limited hardware resources. As mentioned before, the first convolutional layer generates 8 output channels from a single input channel using 8 different convolutional kernels. If these 8 convolutions are done in parallel, the 8 output values can be concurrently streamed to the next layer within the same clock cycle. Along the rest of the CNN, the number of channels is fixed to 8 (
Figure 1). Therefore, we choose
so that the 8 output values can be packed together and transferred to the next layer, which in turn unpacks, performs layer operation and packs 8 output values. Each of these 8 values belong to a specific, single output channel of a layer i.e., to a single input channel of the next layer.
5.1.5. Activation Quantization
The output of the convolutional layers and the fully connected layers is normally obtained by applying an activation function on the result of the multiply and accumulate operations in each layer. For the representation of an activation output in a particular layer, the same amount of bits used for the weights in that layer might not necessarily be enough. Therefore, the sufficient number of bits () has to be determined for the input as well as the output of each activation layer:
Convolutional Layer 1 and Pooling Layer 1 data type.
Convolutional Layer 2 and Pooling Layer 2 data type.
Convolutional Layer 3 data type.
Fully connected Layer 1 data type.
Fully connected Layer 2 data type.
Fully connected Layer 3 data type.
In order to determine the integer part length (
) for the activation quantization, profiling each layer’s output range for the whole testset should be performed. This is achieved by using a profiling function which observes each calculation in every layer and keeps a copy of the maximum and minimum result. For instance, for each kernel convolution in the first convolutional layer, the maximum and minimum results of the multiplication and addition operation are saved. This applies for each input test image as well as other layers. Afterwards, the range needed for each layer (
i) in the worst case is calculated using Equation (
8).
where
and
are the maximum and minimum output values of the layer (
i), respectively. Eventually, the number of bits needed for the integer part is determined by applying Equation (
9).
Now that (
) is known, we need to determine (
). For this purpose, we follow an iterative process for bitwidth exploration. It should be noted that we follow two different approaches for parameter quantization and activation quantization. In case of input and parameter quantization, we only constrain the input, weights and biases (
already constrained) to certain bitwidths during training (QAT) and we use the quantization function mentioned in Equation (
2). While for the activations, we explore the needed bitwidth
by finding the needed
and
as mentioned.

 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}